Oxygen_Renderfarm2013_05_renderfarm
Chrome渲染分析之Rendering工具使用

Chrome渲染分析之Rendering工具使用页面的绘制时间(paint time)是每一个前端开发都需要关注的的重要指标,它决定了你的页面流畅程度。
而如何去观察页面的绘制时间,找到性能瓶颈,可以借助Chrome的开发者工具。
本文主要介绍Chrome渲染分析工具 Rendering。
如上图,按F12调出开发者工具,然后按“ESC”调出Rendering界面。
以上5个选项的意思如下:•1、Show paint rectangles 显示绘制矩形•2、Show composited layer borders 显示层的组合边界(注:蓝色的栅格表示的是分块)•3、Show FPS meter 显示FPS帧频•4、Enable continuous page repainting 开启持续绘制模式并检测页面绘制时间•5、Show potential scroll bottlenecks 显示潜在的滚动瓶颈。
1、Show paint rectangles开启显示绘制矩形这个选项,可以看到绿色的框(之前的版本都是红色的框,现在改绿色了,呵呵),这个绿色的框,表示页面正在绘制的区域,即是页面正在渲染,发生绘制操作的区域。
这是用来了解滚动时页面表现的第一个指示器。
鼠标移到图片上,可以发现css3动画的位移,而css3动画的位移导致页面重绘,重绘的区域即是绿色框住的部分。
细心的朋友可能会发现,这个绿色框住的部分,并不仅仅就是刚好那个div所在的区域,而涉及到周边的位置。
发生这种情况的原因,是页面的重绘是个连带反应,会影响周边元素。
开启这个选项之后,可以做一些常规的页面交互操作,如Slider 切换,拍拍网左侧导航mouse over时效果,可以看到页面效果所影响的范围。
再比如滚动页面,拍拍首页会出现一个返回顶部的按钮,滚动的时候,会发现返回顶部这个区域在不停的进行重绘,而返回顶部是position:fixed定位的。
android rendereffect 原理

android rendereffect 原理Android RenderEffect 是一种用于实现图形效果的功能。
它可以用来改变视图的外观和样式,从而增强用户界面的可视化效果。
本文将详细介绍 Android RenderEffect 的原理及其应用。
Android RenderEffect 是一个基于图形处理单元(GPU)的特效库。
它通过调用GPU 加速渲染任务,使得图形效果的处理更加高效和流畅。
RenderEffect 提供了一组内置的效果类,如模糊、光照、颜色滤镜等,开发者可以根据需要使用这些效果类来定制自己的图形效果。
Android RenderEffect 的原理主要涉及两个方面:GPU 加速和图形渲染。
首先,Android RenderEffect 使用 GPU 加速来提高图形效果的渲染速度。
普通的图形处理是在 CPU 上进行的,而 GPU 专门设计用于处理图形和图像相关的任务。
利用 GPU 加速可以大大提高图形处理的速度和性能。
Android RenderEffect 利用GPU 的并行处理能力,将图形效果的计算任务分解为多个并行处理的子任务,然后在 GPU 上同时执行这些子任务,从而加快图形效果的计算速度。
其次,Android RenderEffect 基于图形渲染来实现图形效果。
在 Android 中,图形渲染是通过绘制渲染树来完成的。
渲染树是一个结构化的图形对象树,包含了需要渲染的图形元素和各种渲染属性。
当需要绘制一个视图时,Android 会遍历该视图的渲染树,并根据渲染属性来执行相应的绘制操作。
Android RenderEffect 能够通过修改视图的渲染树来实现各种图形效果。
它可以在渲染树上添加或修改渲染属性,然后重新绘制视图,从而呈现出不同的图形效果。
Android RenderEffect 的使用方法相对简单。
首先,开发者需要在 XML 布局文件或代码中定义一个需要应用图形效果的视图。
Arnold渲染器用户指南说明书

Arnold featuresMemory-efficient, scalable raytracer rendering software helps artists render complex scenes quickly and easily.◆ See what's new (video: 2:31 min.)◆ Get feature details in the Arnold for Maya, Houdini, Cinema 4D, 3ds Max, or Katana user guidesSubsurface scatterHigh-performance ray-traced subsurface scattering eliminates the need to tune point clouds. Hair and furMemory-efficient ray-traced curve primitives help you create complex fur and hair renders.Motion blur3D motion blur interacts with shadows, volumes, indirect lighting, reflection, or refraction. Deformation motion blur and rotational motion are also supported. VolumesThe volumetric rendering system in Arnold can render effects such as smoke, clouds, fog, pyroclastic flow, and fire.InstancesArnold can more efficiently ray trace instances of many scene objects with transformation and material overrides. Subdivision and displacementArnold supports Catmull-Clark subdivision surfaces.OSL supportArnold now features support for Open Shading Language (OSL), an advanced shading language for Global Illumination renderers. Light Path ExpressionsLPEs give you power and flexibility to create Arbitrary Output Variables to help meet the needs of production.NEW|Adaptive samplingAdaptive sampling gives users another means of tuning images, allowing them to reduce render times without jeopardizing final image quality. NEW|Toon shaderAn advanced Toon shader is part of a non-photorealistic solution provided in combination with the Contour Filter.NEW|DenoisingTwo denoising solutions in Arnold offer flexibility by allowing users to use much lower-quality sampling settings. NEW|Material assignments and overrides Operators make it possible to override any part of a scene at render time and enable support for open standard framework such as MaterialX.NEW|Alembic proceduralA native Alembic procedural allows users to render Alembic files directly without any translation.NEW|Profiling API and structured statistics An extensive set of tools allow users to more easily identify performance issues and optimize rendering processes.Standard Surface shaderThis energy-saving, physically based uber shader helps produce a wide range of materials and looks. Standard Hair shaderThis physically based shader is built to render hair and fur, based on the d'Eon and Zinke models for specular and diffuse shading.Flexible and extensible APIIntegrate Arnold in external applications and create custom shaders, cameras, light filters, and output drivers. Stand-alone command-line rendererArnold has a native scene description format stored in human-readable text files. Easily edit, read, and write these files via the C/Python API.◆ See Arnold 5.1 release notesIntegrate Arnold into your pipeline•Free plug-ins provide a bridge to the Arnold renderer from within many popular 3D applications.•Arnold has supported plug-ins available for Maya, Houdini, Cinema 4D, 3ds Max, and Katana.•Arnold is fully customizable, with a powerful API to create custom rendering solutions.◆ See Arnold plug-ins。
kofnGA包用户指南说明书

Package‘kofnGA’October13,2022Title A Genetic Algorithm for Fixed-Size Subset SelectionVersion1.3Description Provides a function that uses a genetic algorithm to search for a subset of size k from the integers1:n,such that a user-supplied objective functionis minimized at that subset.The selection step is done by tournament selectionbased on ranks,and elitism may be used to retain a portion of the best solutionsfrom one generation to the next.Population objective function values mayoptionally be evaluated in parallel.License GPL-2Encoding UTF-8LazyData trueRoxygenNote6.1.0Imports bigmemoryNeedsCompilation noAuthor Mark A.Wolters[aut,cre]Maintainer Mark A.Wolters<*****************>Repository CRANDate/Publication2018-11-0206:10:03UTCR topics documented:kofnGA-package (2)kofnGA (2)plot.GAsearch (6)print.GAsearch (6)print.summary.GAsearch (7)summary.GAsearch (7)Index81kofnGA-package kofnGA:A genetic algorithm for selection offixed-size subsets.DescriptionA genetic algorithm(GA)to do subset selection:search for a subset of afixed size,k,from theintegers1:n,such that user-supplied function is minimized at that subset.DetailsThis package provides the function kofnGA,which implements a GA to perform subset selection;that is,choosing the best k elements from among n possibilities.We label the set of possibilities from which we are choosing by the integers1:n,and a solution is represented by an index vector,i.e.,a vector of integers in the range[1,n](with no duplicates)indicating which members of the setto choose.The objective function(defining which solution is“best”)is arbitrary and user-supplied;the only restriction on this function is that itsfirst argument must be an index vector encoding the solution.The search results output by kofnGA are a list object assigned to the S3class GAsearch.The package includes summary,print,and plot methods for this class to make it easier to inspect the results. kofnGA Search for the best subset of size k from n choices.DescriptionkofnGA implements a genetic algorithm for subset selection.The function searches for a subset of afixed size,k,from the integers1:n,such that user-supplied function OF is minimized at that subset.The selection step is done by tournament selection based on ranks,and elitism may be used to retain the best solutions from one generation to the next.Population objective function values can be evaluated in parallel.UsagekofnGA(n,k,OF,popsize=200,keepbest=floor(popsize/10),ngen=500,tourneysize=max(ceiling(popsize/10),2),mutprob=0.01,mutfrac=NULL,initpop=NULL,verbose=0,cluster=NULL,sharedmemory=FALSE,...)Argumentsn The maximum permissible index(i.e.,the size of the set we are doing subset selection from).The algorithm chooses a subset of integers from1to n.k The number of indices to choose(i.e.,the size of the subset).OF The objective function.Thefirst argument of OF should be an index vector of length k containing integers in the range[1,n].Additional arguments can bepassed to OF through....popsize The size of the population;equivalently,the number of offspring produced each generation.keepbest The keepbest leastfit offspring each generation are replaced by the keepbest mostfit members of the previous ed to implement elitism.ngen The number of generations to run.tourneysize The number of individuals involved in each tournament at the selection stage.mutprob The probability of mutation for each of the k chosen indices in each individual.An index chosen for mutation jumps to any other unused index,uniformly atrandom.This probability can be set indirectly through mutfrac.mutfrac The average fraction of offspring that will experience at least one mutation.Equivalent to setting mutprob to1-(1-mutfrac)^(1/k).Only used if mutprobis not supplied.This method of controlling mutation may be preferable if thealgorithm is being run at different values of k.initpop A popsize-by-k matrix of starting solutions.Thefinal populations from one GA search can be passed as the starting point of the next search.Possibly usefulif using this function in an adaptive,iterative,or parallel scheme(see examples).verbose An integer controlling the display of progress during search.If verbose takes positive value v,then the iteration number and best objective function value aredisplayed at the console every v generations.Otherwise nothing is displayed.Default is zero(no display).cluster If non-null,the objective function evaluations for each generation are done in parallel.cluster can be either a cluster as produced by makeCluster,or an in-teger number of parallel workers to use.If an integer,makeCluster(cluster)will be called to create a cluster,which will be stopped on function exit.sharedmemory If cluster is non-null and sharedmemory is TRUE,the parallel computation will employ shared-memory techniques to reduce the overhead of repeatedly passingthe population matrix to worker es code from the Rdsm package,which depends on bigmemory....Additional arguments passed to OF.Details•Tournament selection involves creating mating"tournaments"where two groups of tourneysize solutions are selected at random without regard tofitness.Within each tournament,victors arechosen by weighted sampling based on within-tournamentfitness ranks(larger ranks given tomorefit individuals).The two victors become parents of an offspring.This process is carriedout popsize times to produce the new population.•Crossover(reproduction)is carried out by combining the unique elements of both parents andkeeping k of them,chosen at random.•Increasing tourneysize will put more"selection pressure"on the choice of mating pairs,andwill speed up convergence(to a local optimum)accordingly.Smaller tourneysize valueswill conversely promote better searching of the solution space.•Increasing the size of the elite group(keepbest)also promotes more homogeneity in thepopulation,thereby speeding up convergence.ValueA list of S3class"GAsearch"with the following elements:bestsol A vector of length k holding the best solution found.bestobj The objective function value for the best solution found.pop A popsize-by-k matrix holding thefinal population,row-sorted in order of in-creasing objective function.Each row is an index vector representing one solu-tion.obj The objective function values corresponding to each row of pop.old A list holding information about the search progress.Its elements are:old$best The sequence of best solutions known over the course of the search(an(ngen+1)-by-k matrix)old$obj The sequence of objective function values corresponding to the solutions inold$bestold$avg The average population objective function value over the course of the search(a vector of length ngen+1).Useful to give a rough indication of populationdiversity over the search.If the averagefitness is close to the bestfitness in thepopulation,most individuals are likely quite similar to each other.Notes on parallel evaluationSpecifying a cluster allows OF to be evaluated over the population in parallel.The population of solutions will be distributed among the workers in cluster using static dispatching.Any cluster produced by makeCluster should work,though the sharedmemory option is only appropriate for a cluster of workers on the same multicore processor.Solutions must be sent to workers(and results gathered back)once per generation.This introduces communication overhead.Overhead can be reduced,but not eliminated,by setting sharedmemory=TRUE.The impact of parallelization on run time will depend on how the run time cost of evaluationg OF compares to the communication overhead.Test runs are recommended to determine if parallel execution is beneficial in a given situation.Note that only the objective function evaluations are distributed to the workers.Other parts of the al-gorithm(mutation,crossover)are computed serially.As long as OF is deterministic,reproducibility of the results from a given random seed should not be affected by the use of parallel computation.ReferencesMark A.Wolters(2015),“A Genetic Algorithm for Selection of Fixed-Size Subsets,with Appli-cation to Design Problems,”Journal of Statistical Software,volume68,Code Snippet1,available online.See Alsoplot.GAsearch plot method,print.GAsearch print method,and summary.GAsearch summary method.Examples#---Find the four smallest numbers in a random vector of100uniforms---#Generate the numbers and sort them so the best solution is(1,2,3,4).Numbers<-sort(runif(100))Numbers[1:6]#-View the smallest numbers.ObjFun<-function(v,some_numbers)sum(some_numbers[v])#-The objective function.ObjFun(1:4,Numbers)#-The global minimum.out<-kofnGA(n=100,k=4,OF=ObjFun,ngen=50,some_numbers=Numbers)#-Run the GA.summary(out)plot(out)##Not run:#Note:the following two examples take tens of seconds to run(on a2018laptop).#---Harder:find the50x50principal submatrix of a500x500matrix s.t.determinant is max---#Use eigenvalue decomposition and QR decomposition to make a matrix with known eigenvalues.n<-500#-Dimension of the matrix.k<-50#-Size of subset to sample.eigenvalues<-seq(10,1,length.out=n)#-Choose the eigenvalues(all positive).L<-diag(eigenvalues)RandMat<-matrix(rnorm(n^2),nrow=n)Q<-qr.Q(qr(RandMat))M<-Q%*%L%*%t(Q)M<-(M+t(M))/2#-Enusre symmetry(fix round-off errors).ObjFun<-function(v,Mat)-(determinant(Mat[v,v],log=TRUE)$modulus)out<-kofnGA(n=n,k=k,OF=ObjFun,Mat=M)print(out)summary(out)plot(out)#---For interest:run GA searches iteratively(use initpop argument to pass results)---#Alternate running with mutation probability0.05and0.005,50generations each time.#Use the same problem as just above(need to run that first).mutprob<-0.05result<-kofnGA(n=n,k=k,OF=ObjFun,ngen=50,mutprob=mutprob,Mat=M)#-First run(random start) allavg<-result$old$avg#-For holding population average OF valuesallbest<-result$old$obj#-For holding population best OF valuesfor(i in2:10){if(mutprob==0.05)mutprob<-0.005else mutprob<-0.05result<-kofnGA(n=n,k=k,OF=ObjFun,ngen=50,mutprob=mutprob,initpop=result$pop,Mat=M)allavg<-c(allavg,result$old$avg[2:51])allbest<-c(allbest,result$old$obj[2:51])}plot(0:500,allavg,type="l",col="blue",ylim=c(min(allbest),max(allavg)))lines(0:500,allbest,col="red")legend("topright",legend=c("Pop average","Pop best"),col=c("blue","red"),bty="n", lty=1,cex=0.8)summary(result)##End(Not run)6print.GAsearch plot.GAsearch Plot method for the GAsearch class output by kofnGA.DescriptionArguments type,lty,pch,col,lwd Can be supplied to change the appearance of the lines produced by the plot method.Each is a2-vector:thefirst element gives the parameter for the plot of average objective function value,and the second element gives the parameter for the plot of the minimum objective function value.See plot or matplot for description and possible values.Usage##S3method for class GAsearchplot(x,type=c("l","l"),lty=c(1,1),pch=c(-1,-1),col=c("blue","red"),lwd=c(1,1),...)Argumentsx An object of class GAsearch,as returned by kofnGA.type Controls series types.lty Controls line types.pch Controls point markers.col Controls colors.lwd Controls line widths.ed to pass other plot-control arguments.print.GAsearch Print method for the GAsearch class output by kofnGA.DescriptionPrint method for the GAsearch class output by kofnGA.Usage##S3method for class GAsearchprint(x,...)Argumentsx An object of class GAsearch,as returned by kofnGA....Included for consistency with generic functions.print.summary.GAsearch7 print.summary.GAsearchPrint method for the summary.GAsearch class used in kofnGA.DescriptionPrint method for the summary.GAsearch class used in kofnGA.Usage##S3method for class summary.GAsearchprint(x,...)Argumentsx An object of class summary.GAsearch....Included for consistency with generic functions.summary.GAsearch Summary method for the GAsearch class output by kofnGA.DescriptionSummary method for the GAsearch class output by kofnGA.Usage##S3method for class GAsearchsummary(object,...)Argumentsobject An object of class GAsearch,as returned by kofnGA....Included for consistency with generic functions.Index∗designkofnGA,2∗optimizekofnGA,2kofnGA,2,2,6,7kofnGA-package,2makeCluster,3,4plot.GAsearch,4,6print.GAsearch,4,6print.summary.GAsearch,7summary.GAsearch,4,78。
ae滤镜中英文对照文库

3D Channel (3D通道)3D Channel Extract-------------3D通道扩展Depth Matte--------------------深厚粗糙Depth of Field-----------------深层画面Fog 3D-------------------------3D 雾化ID Matte-----------------------ID 粗糙Adjust (调整)Brightness & Contrast----------亮度与对比度Channel Mixer------------------通道混合器Color Balance------------------色彩平衡Color Stabilizer---------------色彩稳压器Curves-------------------------曲线Hue/Saturation-----------------色饱和Levels-------------------------色阶Levels (Individual Controls)---色阶 (分色RGB的控制) posterize----------------------色调分离Threshold----------------------阈值Audio (音频)Backwards----------------------向后Bass & Treble------------------低音与高音Delay--------------------------延迟Flange & Chorus----------------边缘与合唱团 *High-Low Pass------------------高音/低音Modulator----------------------调幅器Parametric EQ------------------EQ参数Reverb-------------------------回音Stereo Mixer-------------------立体声混合器Tone---------------------------音调Blur & Sharpen (模糊与锐化)Clannel Blur-------------------通道模糊Compound Blur------------------复合的模糊Directional Blur---------------方向性的模糊Fast Blur----------------------快污模糊Gaussian Blur------------------高斯模糊Radial Blur--------------------径向模糊Sharpen------------------------锐化Unsharp Mask-------------------锐化掩膜 *Channel (通道)Alpha Levels-------------------ALPHA 层通道Arithmetic---------------------运算Bland--------------------------柔化Cineon Converter---------------间距转换器Compound Arithmetic------------复合运算Invert-------------------------反向Minimax------------------------像素化Remove Color Matting-----------去除粗颗粒颜色 *Set Channels-------------------调节通道Set Matte----------------------调节粗糙度Shift Channels-----------------转换通道Distort (变型)Bezier Warp--------------------Bezier 变型Bulge--------------------------鱼眼Displacement Map---------------画面偏移Mesh Warp----------------------网状变形Mirror-------------------------镜像Offset-------------------------偏移量Optics Compensation------------光学替换 (可制作球体滚动效果) Polar Coordinates--------------极坐标Reshape------------------------重塑Ripple-------------------------涟漪Smear--------------------------涂片Spherize-----------------------球型变形Transform----------------------变换Twirl--------------------------旋转变形Wave Warp----------------------波型变形Expression Controls (表达式控制)Angle Control------------------角度控制Checkbox Control---------------复选框控制Color Control------------------颜色控制Layer Control------------------图层控制Point Control------------------锐化控制Slider Control-----------------滑块控制Image Control (图像控制)Chaner Color-------------------改变颜色Color Balance (HLS)------------色彩平衡 (HLS)Colorama-----------------------着色剂Equalize-----------------------平衡Gamma/Pedestal/Gain------------GAMMA/电平/增益Median-------------------------中线PS Arbitrary MapPS-------------任意的映射Tint---------------------------去色Keying (键控制)Color Difference Key-----------差异的色键Color Key----------------------色键Color Range--------------------色键幅度Difference Matte---------------不同粗粗糙 (以粗颗粒渐变到下一张图) Extract------------------------扩展Inner Outer Key----------------内部、外部色键Linear Color Key---------------线性色键Luma Key-----------------------LUMA键Spill Suppressor---------------溢出抑制器Matte Tools (粗糙工具)Matte Cloker-------------------粗糙窒息物 *Simple Choker------------------简单的窒息物 *Paint (油漆)Vector Paint-------------------矢量油漆Perspective (透视)Basic 3D-----------------------基本的3DBevel Alpha--------------------倾斜 ALPHABevel Edges--------------------倾斜边Drop Shadow--------------------垂直阴影Render (渲染)4-Color Gradient---------------4色倾斜度Advanced Lightning-------------高级闪电Audio Spectrum-----------------音频光谱Audio Waveform-----------------音频波形Beam---------------------------射线Cell Pattern-------------------单元模式Ellipse------------------------椭圆Fill---------------------------填充Fractal------------------------分数维Fractal Noise------------------粗糙的分数维Grid---------------------------网格Lens Flare---------------------镜头光晕Lightning----------------------闪电Radio Waves--------------------音波Ramp---------------------------斜面Stroke-------------------------笔划 (与stylize-write on功能类似) Vegas--------------------------维加斯Simulation (模拟)Particle Playground------------粒子运动场Shatter------------------------粉碎Stylize (风格化)Brush Strokes------------------笔刷Color Emboss-------------------颜色浮雕Emboss-------------------------浮雕Find Edges---------------------查找边缘Glow---------------------------照亮边缘Leave Color--------------------离开颜色Mosaic-------------------------马赛克Motion Tile--------------------运动平铺Noise--------------------------噪音Roughen Edges------------------变粗糙边Scatter------------------------分散Strobe Light-------------------匣门光 *Texturize----------------------基底凸现Write-on-----------------------在.....上写 (与render-stroke功能类似)Text (文本)Basic Text---------------------基本的文本Numbers------------------------数字文本Path Text----------------------路径文本Time (时间)Echo---------------------------回响Posterize Time-----------------发布时间Time Difference----------------时间差别 *Time Displacement--------------时间偏移Transition (转场)Block Dissolve-----------------块溶解Gradient Wipe------------------斜角转场Iris Wipe----------------------爱丽斯转场 (三角形转场)Linear Wipe--------------------线性转场Radial Wipe--------------------半径转场Venetian Blinds----------------直贡呢的遮掩 (百叶窗式转场)Video (视频)Broadcast Colors---------------广播色Reduce Interlace Flicker-------降低频闪Timecode-----------------------时间码。
我的世界突变生物免费模组三个广告具体教程(一)

我的世界突变生物免费模组三个广告具体教程(一)我的世界突变生物免费模组三个广告具体教程介绍本教程将提供给您三个免费的突变生物模组广告教程,让您在我的世界中尽情享受突变生物的乐趣。
无需付费或下载第三方来源,您可以通过以下方式直接在游戏中获取和使用这些模组。
教程一:突变生物模组广告一1.打开我的世界游戏。
2.进入创造模式,并选择一个你喜欢的世界。
3.打开聊天框,输入命令:/give @p minecraft:spawn_egg 1 0{EntityTag:{id:“minecraft:chicken”}}4.按下回车键,你将收到一枚刷怪蛋。
5.将刷怪蛋放入你的物品栏中。
6.找到一个合适的位置,右键使用刷怪蛋,你将召唤出一只突变生物。
教程二:突变生物模组广告二1.打开我的世界游戏。
2.进入创造模式,并选择一个你喜欢的世界。
3.打开聊天框,输入命令:/summon Zombie ~ ~ ~ {IsVillager:1}4.按下回车键,你将召唤出一个突变的僵尸村民。
5.点击突变的僵尸村民,你将看到他们拥有突变体特征。
教程三:突变生物模组广告三1.打开我的世界游戏。
2.进入创造模式,并选择一个你喜欢的世界。
3.打开聊天框,输入命令:/give @p minecraft:spawn_egg 1 0{EntityTag:{id:“minecraft:cow”,CustomName:“MutationCow”}}4.按下回车键,你将收到一枚刷怪蛋。
5.将刷怪蛋放入你的物品栏中。
6.找到一个合适的位置,右键使用刷怪蛋,你将召唤出一只突变生物牛。
7.点击突变生物牛,你将看到它们具有突变的外观和自定义名称。
总结通过以上三个简单的教程,您可以轻松地在我的世界中体验突变生物模组的乐趣。
观察这些独特的生物外观和特征,为您的游戏体验增添一份新鲜感。
快去尝试吧!。
Stylized rendering techniques for scalable real-time 3d animation

“We’re searching here, trying to get away from the cut and dried handling of things all the way through—everything—and the only way to do it is to leave things open until we have completely explored every bit of it.”
CR Categories and Subject Descriptors: I.3.3 [Computer Graphics]: Picture/Image Generation; I.3.5 [Computer Graphics]: Three-Dimensional Graphics and Realism – Color, Shading, Shadowing, and Texture. Additional Key Words: real-time nonphotorealistic animation and rendering, silhouette edge detection, cartoon rendering, pencil sketch rendering, stylized rendering, cartoon effects.
1 Introduction
Recent advances in consumer-level graphics card performance are making a new domain of real-time 3D applications available for commodity platforms. Since the processor is no longer required to spend time rasterizing polygons, it can be utilized for other effects, such as the computation of subdivision surfaces, real-time physics, cloth modeling, realistic animation and inverse kinematics.
Acute3D_中文ppt_Mar2013_ForPrint

S3C ENGINE
JOB#3 JOB#2
S3C ENGINE
JOB#1
S3C ENGINE 三维模型及贴图修正OBJLeabharlann 量导出工作流程场景生成
瓦片化的三维场景模型
数据整合
原始影像采集
Ø 通过影像生成密集点云 Ø 基于点云构建三角网模型 Ø 优化/简化三角网模型 Ø 纹理信息生成
输出三维瓦片
3D GIS平台 3D 数据服务
smart3Dcapture : 法 国 巴 黎
法国巴黎 · 数据源 : · 数据处理 : · 面积 : 100+ km2 · 分辨率: 10cm / pixel
smart3Dcapture : 中 国 西 安
中国西安 · 数据源 : 194 张无人机正射影像 · 数据处理 : 6小时 1台运算引擎 · 面积 : 5 km2 · 分辨率: 6 - 8cm / pixel
影像导入
前处理工作站
任务序列
全自动模型运算
场景生成输出
S3C MASTER
JPEG / TIFF / RAW
S3C MASTER
Third party aerotriangulati on results
S3C MASTER OBJ导入
S3C ENGINE
JOB#N
S3C ENGINE
JOB#5 JOB#4
同一视角真实照片 与三维场景对比
smart3Dcapture
smart3Dcapture : 街 景 三 维
smart3Dcapture : 街 景 三 维
技术优势: 真 正 的 三 维
2.5D
3D
技术优势: 真 正 的 三 维
+ 建筑立面细节 + 建筑的悬挂镂空等结构 + 桥梁,立交桥等 +树
NVIDIA OptiX 2.5.1 光线追踪引擎与SDK说明书

Release Notes for theNVIDIA® OptiX™ ray tracing engineVersion 2.5.1 May 2012Welcome to the latest release of the NVIDIA OptiX ray tracing engine and SDK, with support for all CUDA-capable GPUs. This package contains the libraries required to experience the latest technology for programmable GPU ray tracing, plus pre-compiled samples (with source code) demonstrating a broad range of ray tracing techniques and highlighting basic functionality.Support:Please post comments or support questions on the new NVIDIA developer forum that can be found here:/devforum/categories/tagged/optix&catid=151 (use the optix tag for all OptiX related posts). Questions that require confidentiality can be e-mailed to ********************* and someone on the development team will respond. The OptiX download page is/optix.System Requirements (for running binaries referencing OptiX) Graphics Hardware:∙CUDA capable devices (G80 or later) are supported on GeForce, Quadro, or Tesla class products.Multiple devices/GPUs are onl y supported on “GT200” or “Fermi” class GPUs. Out-of-core raytracing of large datasets is only supported on Quadro and Tesla GPUs.Graphics Driver:∙The CUDA R275 or later driver is required. The latest drivers available are highly recommended (285.86 or later for Windows, 290.10 for Linux and the CUDA 4.0 driver extension for Mac). Forthe Mac, the driver extension module supplied with CUDA 4.0 or later will need to be installed.Driver versions beginning with 285.53 include very large speedup to OptiX compile times.∙Windows Vista and 7 use the Windows Display Driver Model (WDDM). This driver is suboptimal for GPU computation, so Nvidia has introduced the Tesla Compute Cluster (TCC) driver. Bydefault, Tesla products use the TCC driver, which does not support OpenGL or D3D, and does notsupport interoperating with WDDM cards in CUDA and OptiX. An OptiX context must use onlyWDDM devices or only TCC devices. This situation should be resolved later this year. In themeantime, placing your Tesla hardware into WDDM mode will allow it to work in a multi-GPUconfiguration with other WDDM devices such as Quadro brand parts.Operating System:∙Windows XP/Vista/7 32-bit or 64-bit; Linux RHEL 4.8 - 64-bit only, Ubuntu 10.10 - 64-bit; OSX10.6+ (universal binary with 32 and 64-bit x86).Development Environment Requirements (for compiling with OptiX) All Platforms (Windows, Linux, Mac OSX):∙CUDA Toolkit 2.3, 3.0, 3.1, 3.2, 4.0, 4.1, 4.2.OptiX 2.5 has been built with CUDA 4.0, but any specified toolkit should work when compiling PTX forOptiX. If an application links against both the OptiX library and the CUDA runtime on Mac and Linux, it is recommended to use CUDA 4.0. CUDA 4.1 and 4.2 are now supported. CUDA 4.1 and 4.2 code oftencontains a moderate performance penalty due to loads and stores not being vectorized anymore. Forthis reason CUDA 4.0 is generally preferred.∙C/C++ CompilerVisual Studio 2005, 2008 or 2010 is required on Windows systems. gcc 4.2 and 4.3 have been tested onLinux. The 3.2 Xcode development tools have been tested on Mac OSX 10.6.∙GLUTMost OptiX samples use the GLUT toolkit. Freeglut ships with the Windows OptiX distribution. GLUT isinstalled by default on Mac OSX. A GLUT installation is required to build samples on Linux.Fixes since OptiX 2.5.0 final release:∙CUDA 4.2 support.∙Linux distribution is now universal across 64-bit Linux distributions.∙Fixed slowdown with Lbvh builder in multi-GPU configurations.∙Optimized replacing a buffer with another of the same size, for faster stereo rendering∙Reduced overhead of kernel launches and recompiles when API state changes have occurred.∙Fixed texture unit assignment bug.∙Fixed optixpp issue where object->destroy() failed and checkError called object->getContext().∙Fixed bug in zoneplate sample.∙Fixed bug with BVH refit.∙Fixed matrix variable changes not being propagated to device.∙Fixed accesses to private variable in matrix class.∙Fixed CPUTraversal memory leak.∙Fix 32-bit kernel / 64-bit application paging problems.Fixes since OptiX 2.5.0 RC 3:∙User PTX code compiled for SM 2.0 using CUDA 4.1 now works correctly.∙Minor optimizations.∙Fixed bug with texture unit numbers.∙Fixed bug with transform node with null child.∙Fixed bug with BVHs that have no children.∙Fixed a debug assert with Lbvh and MedianBvh.Fixes since OptiX 2.5.0 RC 2:∙The environment v ariable “OPTIX_API_CAPTURE” may now be used in release builds to createa dump of all API calls. This is useful for sending bug reproducers to the OptiX developmentteam, and for diagnosing application behavior.∙Better load balancing across GPUs with diffe rent number of SM’s, for example a Quadro 2000 and a Tesla C2075.∙Multiple GPUs of differing minor SM version, such as SM 2.0 and SM 2.1, may now work together.∙Decreased host memory footprint during acceleration structure builds.∙Fixed serialization for “Lbvh” builder.∙Fixed ‘h’ key in Whirligig sample.∙Fixed bug with paging where some threads would execute some instructions multiple times on a page fault.∙Fixed bug with acceleration structure builds.Fixes since OptiX 2.5.0 RC 1:∙“-m” flag and “m” key in many samples now display whether paging is happening or not.∙Out of memory error bug fix. This bug happened while paging if a buffer was selected to be non-paged but still couldn't be allocated.∙Customer bug fix in OptiX compiler when exceptions and paging were turned on together.∙Customer bug fix regarding TextureSamplers.∙Fix for multiple rtIntersectChild calls in a loop.∙Fixed mcmc_sampler sample.Enhancements from OptiX 2.1.1:∙Out-of-Core Memory Paging– scene sizes can now exceed the amount of physical memory on professional GPUs (Quadro or Tesla) to the extent there is host RAM available. This support is automatic, but can be overridden. The resulting performance will vary according to the amount the scene is paging –which is a combination of how much is exceeding GPU memory, how much of the scene is visible to thecamera, and the extent of secondary rays in use. Some of the related changes include:o New BVH traverser –“BvhCompact” can compress data by up to a factor of four.o Added rtuCreateClusteredMesh() and rtuCreateClusteredMeshExt() for laying out data in a paging friendly manner.o Whether or not paging has been enabled can be queried with the rtContextGetAttribute() API call and specifying RT_CONTEXT_ATTRIBUTE_GPU_PAGING_ACTIVE.o Paging support can be disabled by calling the rtContextSetAttribute() API function with RT_CONTEXT_ATTRIBUTE_GPU_PAGING_FORCED_OFF.∙Unlimited Textures– when not using graphics interop textures, the first 127 textures will continue to take advantage of Texture Units, while any additional texture is now automatically stored in Global Memory ata minor performance cost.∙GPU BVH Builder– the original Lbvh builder has been replaced with the HLBVH2 algorithm to deliver far faster acceleration structure building than is possible via the CPU. The resulting traversal performance is comparable to CPU builders.∙Further optimizations for Fermi GPUs.∙Improved run time when using 64-bit PTX.∙Visual Studio 2010 support.∙Added RT_TIMEOUT_CALLBACK and rtContextSetTimeoutCallback(). OptiX can now periodically call a user provided function. This function can instruct OptiX to stop and return control to the caller withoutfinishing the call. See programming guide for more information.∙Added new RTcontext attributes that can be queried or set.o RT_CONTEXT_ATTRIBUTE_CPU_NUM_THREADS – for specifying the number of CPU threads OptiX can use for various tasks such as parallel CPU acceleration structure builds.o RT_CONTEXT_ATTRIBUTE_USED_HOST_MEMORY – Get the amount of host memory OptiX is consuming be tween API calls (note that this isn’t a high water mark).o RT_CONTEXT_ATTRIBUTE_GPU_PAGING_ACTIVE – Indicates if paging has been enabled. Once paging has been enabled it cannot be forced off.o RT_CONTEXT_ATTRIBUTE_GPU_PAGING_FORCED_OFF – Force paging to be off regardless of whether OptiX attempts to enable it.Enhancements from OptiX 2.1.1 (continued):∙Errors are now generated during compilation when calling an OptiX function in an illegal location (see table in Programming guide).∙Reduction in compile times for scenes with multiple ray types and programs only used by a single ray type.∙Added ability to throw an exception when rtIntersectChild() and rtReportIntersection() are called with an invalid index.∙Added rtContextSetAttribute().∙Added rtDeviceGetD3D9Device(), rtDeviceGetD3D10Device(), and rtDeviceGetD3D11Device().These functions return the OptiX device ordinal that corresponds to the given D3D device.∙Added support for VS2010 in RTU's rtuCUDACompileString() and rtuCUDACompileFile().∙For GCC targets, symbol exports are now controlled using visibility attributes. Thus, OptiX now only exports the same set of symbols that the windows version exports.∙Updates to optixu headerso Added Matrix3x3 make_matrix3x3(Matrix4x4) function.o Fixed variable liveness issues with optix::intersect_triangle() and optix::refract().o Added luminanceCIE(float3).o Added operator== and operator!= for (uint3,uint3).o Added ContextObj::getDeviceName(), ContextObj::getDeviceAttribute() andContextObj::getUsedHostMemory().o Added ContextObj::getCPUNumThreads(), ContextObj::getGPUPagingActive(),ContextObj::getGPUPagingForcedOff(), ContextObj::setCPUNumThreads() andContextObj::setGPUPagingForcedOff() to match new context properties.o OptixPP's destroy methods now set the underlying pointer to zero, so the container can be queried to determine if it is still valid.∙Samples and sample infrastructureo Added new sample that illustrates a method of doing displacement surfaces without having to pretessellate the surface. All tessellation happens during intersection.o Added sample_phong_lobe(), get_phong_lobe_pdf() and tonemap() to samples/cuda/helpers.h.o Refactored much of the code that made use of meshes in the samples into a MeshScene class.o The path_tracer sample now comes with a multiple importance sampling mode. Use the -mis flag to try it.∙CMakeo Look in paths that are installed by CUDA 4.0.o Added support for files with the same basename but different paths in the same target.o Working directory is now a subdirectory of CMakeFiles instead of the current binary directory.o Support for CUDA Toolkit installed in UNC paths.o Better support for flags and paths with spaces and quotes.Known limitations with version 2.5.0:∙Out-of-core dataset paging does not presently work with GeForce cards.∙The Lbvh builder has been completely replaced with the HLBVH2 algorithm. Note that specifying Lbvh as the builder in a 64-bit host application while using 32-bit PTX will cause the MedianBvh builder to beutilized. The internal format for Acceleration Structure data has changed. Previous cached data will not be usable with 2.5 and must be regenerated.∙Support for building host-based acceleration structures in parallel has been disabled on Linux in this version of OptiX.∙OptiX currently does not support running with NVIDIA Parallel Nsight. In addition, it is not recommended to compile PTX code using any -g (debug) flags to nvcc.∙Use of OpenGL and DirectX interop causes OptiX to crash when SLI is enabled. As noted below, SLI is not required to achieve scaling across multiple GPUs.∙All GPUs used by OptiX must be of the same MAJOR compute capability, such as compute capability 1.x or2.x. OptiX will automatically select the set of GPUs of the highest major compute capability and only usethose. For example, in a system with a GeForce GTX 460 (compute 2.1) and a GeForce GTX 480 (compute2.0), both will be used, but in a system with a Quadro 5800 (compute 1.3) and a Quadro 6000 (compute2.0) only the compute 2.0 device would only be selected. Applications may explicitly choose which GPUsto run, as is done in the progressive photon mapper sample, ppm.cpp, at the start of initScene(), but if the application requests a set of devices of different major compute capability an error will be returned.∙Texture arrays and MIP maps are not yet implemented.∙malloc(), free(), and printf() do not work in device code.∙Applications that use RT_BUFFER_INPUT_OUTPUT or RT_BUFFER_OUTPUT buffers on multi-GPU contexts must take care to ensure that the stride of memory accesses to that buffer is compatible with the PCIebus payload size. Using a buffer of type RT_FORMAT_FLOAT3, for example, will cause a massiveslowdown; use RT_FORMAT_FLOAT4 instead. Likewise, a group of parallel threads should present acontiguous span of 64 bytes for writing at once on an Intel chipset to avoid massive slowdowns, or 16bytes on NVIDIA chipsets to avoid moderate slowdowns.∙Linux only: due to a bug in GLUT on many Linux distributions, the SDK samples will not restore the original window size correctly after returning from full-screen mode. A newer version of freeglut may avoid thislimitation.∙The CUDA release notes recommend the use of -malign-double with GCC. However, on Mac OSX systems(10.5 with GCC 4.0.1 and 4.2.1 and 10.6 with GCC 4.2.1) this flag can produce miscompiles withstd::stream based classes in host code when compiling to 32 bits. If the structs are different sizes between device and host code, consider manually padding the structure rather than using this compiler flag.Performance Notes:∙OptiX performance tracks very closely to a GPU's CUDA core count and core clock speed for a given GPU generation.∙OptiX takes advantage of multiple GPUs without using SLI. It is not recommended to configure GPUs in SLI mode for OptiX applications. Multi-GPU scalability will vary with the workload being done, with longerand complex rendering (e.g., path tracing) scaling quite well with fast and simple rendering (e.g. Whitted or Cook) scaling much less.∙Mixing board types will reduce the memory size available to OptiX to that of the smallest GPU.∙Performance will be better when the entire scene fits within a single GPU’s memory. Adding additional GPUs increases performance, but does not increase the available memory beyond that of the smallestboard. If paging is disabled (see above), the entire scene must fit on the GPU.∙For compute-intensive rendering, performance is currently fairly linear in the number of pixels displayed/rendered. Reducing resolution can make development on entry level boards or laptops more practical.∙Performance on Windows Vista and 7 may be somewhat slower than Windows XP due to the architecture of the Windows Display Driver Model (WDDM).∙Uninitialized variables can increase register pressure and negatively impact performance.∙Pass arguments by reference instead of value whenever possible when calling local functions for optimal performance.Other Notes:∙CMake 2.8.6 (at least 2.6.3; 2.8.6 is the current version and also works.)/cmake/resources/software.htmlThe executable installer /files/v2.8/cmake-2.8.6-win32-x86.exe is recommended for Windows systems.。
渲染农场Vray动画渲染流程

正确的Vray动画渲染流程渲染农场流水线第一大类:仅仅是摄像机运动的静态场景动画的渲染type one: IRmap+BruteForce(QMC) 发光贴图+BF算法第一步(单帧调试阶段):调试好DMC sampler核心管理器的参数在单帧下已获得良好的质量第二步(动画前数据计算阶段,俗称跑光):1.保持次级引擎BruteForce(QMC)开启,勾选全局设置的Don't Render Final Image 以跳过不必要的渲染计算过程2.根据摄像机运动情况预估隔帧数量,使用MultiFrame increamental模式,计算完全部动画的IRmap3.打开IRmapViewer观察计算完成的IRmap采样点分布情况,将采样点不足的部分,缺失采样点的部分,通过手动补光方式叠加并补全,得到最终准备动画渲染的IRmap 文件(这一环节非常重要)第三步(渲染动画阶段)1.IRmap模式改为from file并读入之前准备好的最终IRmap文件2.将次级引擎关闭,即设置为none(因为所有计算结果已经存入在了IRmap的每个采样点中)3.将IRmap设置中的interplation sample设置为10-15 (最终渲染时插值采样不能过大,否则将导致闪烁)4.渲染!type two: IRmap+LightCache 发光贴图+灯光缓存第一步(单帧调试阶段):调试好DMC sampler核心管理器的参数在单帧下已获得良好的质量第二步(动画前数据计算阶段,俗称跑光):1.保持次级引擎LightCache开启,勾选全局设置的Don't Render Final Image以跳过不必要的渲染计算过程2.设置LightCache模式为SingleFrame方式,并在选项中去除勾选"Store direct light"这个选项(这点非常重要,去除这个选项将极大地避免Lightcache产生的GI闪烁)3.根据摄像机运动情况预估隔帧数量,使用MultiFrame increamental模式,计算完全部动画的IRmap4.打开IRmapViewer观察计算完成的IRmap采样点分布情况,将采样点不足的部分,缺失采样点的部分,通过手动补光方式叠加并补全,得到最终准备动画渲染的IRmap 文件(这一环节非常重要)第三步(渲染动画阶段)1.IRmap模式改为from file并读入之前准备好的最终IRmap文件2.这里分两种情况,如果场景中有大量模糊反折射需要利用lightcache来优化计算时间,可以保持次级引擎中LightCache仍旧开启,并且仍然为singleframe模式,如果不需要这样计算模糊反折射,将次级引擎关闭设置为none3.将IRmap设置中的interplation sample设置为10-15 (最终渲染时插值采样不能过大,否则将导致闪烁)4.渲染!第二大类:摄像机运动,物体和光源都在变化和运动type one: IRmap+BruteForce(QMC)第一步(单帧调试阶段):调试好DMC sampler核心管理器的参数在单帧下已获得良好的质量第二步(动画前数据计算阶段,俗称跑光):1.保持次级引擎BruteForce开启,勾选全局设置的Don't Render Image以跳过不必要的渲染计算过程2.设置IRmap模式为Animation-prepass方式(它将生成一个IRmap序列而不是单个IRmap以对应整个动画)3.计算全部的IRmap序列第三步(渲染动画阶段)1.IRmap模式改为Animation-render方式,并读入之前计算好的最终IRmap序列2.将次级引擎关闭,即设置为none(因为所有计算结果已经存入在了IRmap的每个采样点中)3.将IRmap设置中的interplation sample设置为10-15 (最终渲染时插值采样不能过大,否则将导致闪烁)并且将Interpolation frames设置为1(节省渲染时间)4.渲染!type two: IRmap+LightCache第一步(单帧调试阶段):调试好DMC sampler核心管理器的参数在单帧下已获得良好的质量第二步(动画前数据计算阶段,俗称跑光):1.保持次级引擎LightCache开启,勾选全局设置的Don't Render Image以跳过不必要的渲染计算过程2.设置LightCache模式为SingleFrame方式,并在选项中去除勾选"Store direct light"这个选项(这点非常重要,去除这个选项将极大地避免Lightcache产生的GI闪烁)3.设置IRmap模式为Animation-prepass方式(它将生成一个IRmap序列而不是单个IRmap以对应整个动画)4.计算全部的IRmap序列第三步(渲染动画阶段)1.IRmap模式改为Animation-render方式,并读入之前计算好的最终IRmap序列2.这里分两种情况,如果场景中有大量模糊反折射需要利用lightcache来优化计算时间,可以保持次级引擎中LightCache仍旧开启,并且仍然为singleframe模式,如果不需要这样计算模糊反折射,将次级引擎关闭设置为none3.将IRmap设置中的interplation sample设置为10-15 (最终渲染时插值采样不能过大,否则将导致闪烁)并且将Interpolation frames设置为1(节省渲染时间)4.渲染!另外,关于渲染中经常出现一些物体有奇怪白色亮点的问题,我在这里单独说明一下,这是由于模糊反射和深度反射产生的问题,原则上是物理正常的,不是bug,也很难免,这里提供两个方法:第一,将出现白点的材质,改为V rayMaterial,并在选项中将"treat glossy rays as GI“设置为"Always",并且确保关闭GI设置中的产生反射焦散的选项,即Reflection caustics保持关闭第二,将高亮物体(比如在反射中出现的很亮的物体,光源等)的反射深度降低,或者用OverrideMaterial将其反射通道给一个纯diffuse的材质最后提及几点很多朋友关注的问题:1.V ray渲染片树时到底该不该使用opacity通道,答案是尽量不要用opacity通道,因为V ray 的IRmap计算过程不能很好的支持这一通道,将导致渲染速度非常的慢。
unity代码创建草和模拟风的效果

unity代码创建草和模拟风的效果 void Start(){Test4();}//草private Vector3[] grassArray = new Vector3[7];private GameObject grassobj;void Test4(){GameObject obj = new GameObject(); = "grass";grassobj = obj;MeshFilter meshFilter = obj.AddComponent<MeshFilter>();//mesh的顶点,按照图的我们顺时针写就⾏Vector3[] newVertices ={new Vector3(0, 0, 0), new Vector3(0 ,1 ,0) , new Vector3(0, 2, 0), new Vector3(0, 3, 0),new Vector3(0.3f, 2 ,0 ), new Vector3(0.6f, 1 , 0), new Vector3(0.9f, 0 ,0)};grassArray = newVertices;//uV坐标,照抄上⾯的,去除zVector2[] newUV ={new Vector2(0, 0), new Vector2(0, 1), new Vector2(0, 2), new Vector2(0, 3),new Vector2(0.3f, 2), new Vector2(0.6f, 1), new Vector2(0.9f,0)};int[] newTriangles ={2,3,4,1,2,4,1,4,5,0,1,5,0,5,6,//顺时针渲染正⾯2,4,3,1,4,2,1,5,4,0,5,1,0,6,5//逆时针渲染背⾯};Mesh mesh = new Mesh();meshFilter.mesh = mesh;//顶点三⾓⾯ uvmesh.vertices = grassArray;mesh.uv = newUV;mesh.triangles = newTriangles;//渲染MeshRenderer renderer = obj.AddComponent<MeshRenderer>();Material mat = new Material (Shader.Find("Standard"));mat.color = Color.green;renderer.material = mat;}public float wind;Vector3[] baseVertices ={new Vector3(0, 0, 0), new Vector3(0 ,1 ,0) , new Vector3(0, 2, 0), new Vector3(0, 3, 0),new Vector3(0.3f, 2 ,0 ), new Vector3(0.6f, 1 , 0), new Vector3(0.9f, 0 ,0)};// Update is called once per framevoid Update(){//模拟草被风影响//顶点⾼度越⾼的草越容易被影响wind = Mathf.Sin(Time.time);//sin波for (int i = 0; i < grassArray.Length; i++){if (grassArray[i].y == 3){//⾼度为3的草grassArray[i].x = baseVertices[i].x + (wind * baseVertices[i].y * 0.2f);}else if (grassArray[i].y == 2){//⾼度为2的草grassArray[i].x = baseVertices[i].x + (wind * baseVertices[i].y * 0.15f);}else if (grassArray[i].y == 1){//⾼度为1的草grassArray[i].x = baseVertices[i].x + (wind * baseVertices[i].y * 0.1f);}}grassobj.GetComponent<MeshFilter>().mesh.vertices = grassArray;}通过代码创建的草的meshy轴单位是10到6的距离是0.9⼀棵草左右摇摆写法⽐较粗糙,后⾯再研究下更好的写法。
Renderbus渲染农场从入门到精通
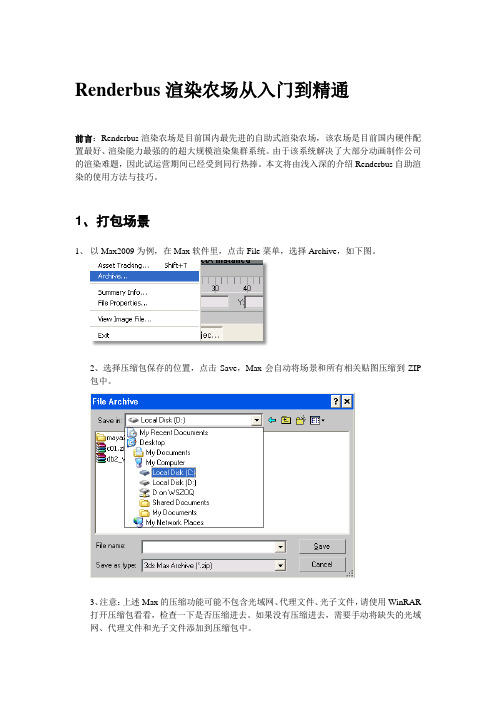
Renderbus渲染农场从入门到精通前言:Renderbus渲染农场是目前国内最先进的自助式渲染农场,该农场是目前国内硬件配置最好、渲染能力最强的的超大规模渲染集群系统。
由于该系统解决了大部分动画制作公司的渲染难题,因此试运营期间已经受到同行热捧。
本文将由浅入深的介绍Renderbus自助渲染的使用方法与技巧。
1、打包场景1、以Max2009为例,在Max软件里,点击File菜单,选择Archive,如下图。
2、选择压缩包保存的位置,点击Save,Max会自动将场景和所有相关贴图压缩到ZIP包中。
3、注意:上述Max的压缩功能可能不包含光域网、代理文件、光子文件,请使用WinRAR打开压缩包看看,检查一下是否压缩进去。
如果没有压缩进去,需要手动将缺失的光域网、代理文件和光子文件添加到压缩包中。
压缩包检查没问题之后,就可以上传到Renderbus的服务器啦2、F TP上传压缩包如何将文件上传到Renderbus服务器?可以通过如下两个途径:1、使用ftp软件上传。
此为推荐的上传方式,适用于上传大文件,稳定快速,如果中途网络突然中断,待网络恢复以后还能“断点续传”。
2、直接使用网页上传,此为备用的上传方式。
在提交渲染的时候,如果发现缺少了某个贴图,可以通过网页方式立即上传,无需启动ftp软件。
两个方式达到的目的都是一样,都是将本地电脑里的文件上传到renderbus服务器。
使用网页方式上传,不能上传超过20M的大文件。
在上传之前,先介绍一下Renderbus服务器的目录结构当您在Renderbus网站上注册成功以后,系统自动为你分配一个大小为20G的磁盘空间,里面有两个文件夹,名字分别为input和output。
(请放心,不同的注册id只能看到自己的文件,绝对不可能看到别人的文件)input目录:这个目录供您上传文件之用。
Renderbus建议您在input里面,为不同的场景创建单独的子目录,比如叫做Project001,Project002。
模拟真实草

图 21
8 最后我们要制作出草地被风 吹的感觉
先在菜单栏点击 hair>tools> brush ,此时如果鼠标移到观察窗 我 们会发现多了一个随鼠标移动的光 圈
接下来我们要先选中 hair 物 体 然后按住鼠标的左键 在上面慢 慢移动 如图 22 所示
图 22
图 23
在刷的过程中 我们会慢慢发现
移动的技巧 也会制作出各种各样自
5 接下来 我们要来修改一下草 的高度 使它适合我们的需求
点击 hair 下面会出现 hair 的对象窗口 然后点击属性菜单中的 guides 和 hairs 设置草的高度 length 为25 设置数量 count 为 20000 如图 18 所示
音 画 工 坊
我们先对渐变色的前一种颜色做 改变 设置 R red 为 0, G green 为 80,B(blue) 为 0,Brightness 为 100%
音 画 工 坊
决定了生长出来的草的样子 图上的 数据都根据需求设置好了 matrix extrude各数据也可以大家根据自己的 需求设置 可以使草长得高大点 或 者被风吹的方向不同 下面我来解释 一下各个数据的意义
* Move 中的 Z X Y 方向的值 取决于你想让草叶片往哪个方向弯曲 变形
* Scale 中的 Z X Y 方向的值 设置了每步将减少(或增加,如果你选 择了值超过 100%) 多边形的大小 比如 如果你原本的多边形为 10 米 Scale 值都设为 50%,那它将会第 2 步 减少为 5 米, 第 3 步减少为 2.5 米
音 画
工 坊
在 CINEMA 4D 中
用三种方法制作模拟草
浙江省海洋监测预报中心 蒋婵娟
C INEMA 4D 包括 Advanced Render MOCCA Thinking Particles Dynamics BodyPaint 3D NET Render Sketch and Toon Hair MoGraph 共九大模块 实现建模 实时 3D 纹理绘制 动画 渲染(卡通渲染 网络渲染) 角色 粒子 毛 发 动力系统以及运动图形的完美结合 被业界誉为 新一代的三维动画制作软件 广泛应用在各种行业里 在国外用 CINEMA 4D 的人非常多 因为它的效率非常高
3DMax流体插件FumeFX自带帮助教程中文翻译06_PostProcessing

Tutorial 06: Post Processing在这最后一个教程中,我们会学到如何使用Retimer去改变缓存重置并如何优化缓存。
In 3ds Max, select File->Open, and from your /Scenes/FumeFX/ Tutorials folder, select the file Tut_06_start.max.Retimer (重新定时)允许你更改已存在缓存的播放速度,当Optimizer 帮助你将存在大小设置为最低时。
在教程5中你已经学习到如何使用Wavelet Turbulence ,我们将在这一教程中同样使用它,但是我们不用在提高烟雾的细节上。
因为Wavelet Turbulence 和Retimer 使用它们各自的缓存用于输出,确保在FumeFX Preferences 中,Auto Synchronize Paths 是被激活的。
在FumeFX输出面板中,改变Output Path使其在你的机器上有效(现在的设置是C:\tut_06_start\FumeFX01_.fxd )。
由于我们已经激活了Auto Synchronize , Wavelet Turbulence 和Retimer Output 路径也同时改变了。
选择Sim 选项卡进入至U Extra Detail 面板并改变Mode 为Wavelet Turbulence注:要想成功地重新定时你的缓存,有一步一定不能忘。
在每次使用Retimer时Velocity通道都要输出。
另外,如果你在场景使用了fire, Temperature 通道也要输出。
没有这些通选择Gen选项卡进入到Output 面板点击Exporting Channels Set按钮并且添加道,重定时不能执行。
Temperature 和Velocity。
事实上当选择了Wavelet Turbulence Extra Detail Mode 后, Velocity就自动地被添加了,但是在这个案例中我们没有使用Wavelet Turbulence ,你注:这个教程会花长一些的时间去计算(在i7 920 CPU 机器上会花12分钟完成计算)必须手动地添加我们用mental ray 渲染创建一个全局光效果。
(整理)vr材质参数设置.

vr材质参数设置一、各种常用材质的调整1、亮光木材:漫射:贴图反射:35灰高光:0.8亚光木材:漫射:贴图反射:35灰高光:0.8 光泽(模糊):0.85 2、镜面不锈钢:漫射:黑色反射:255灰亚面不锈钢:漫射:黑色反射:200灰光泽(模糊):0.8拉丝不锈钢:漫射:黑色反射:衰减贴图(黑色部分贴图)光泽(模糊):0.83、陶器:漫射:白色反射:255 菲涅耳4、亚面石材:漫射:贴图反射:100灰高光:0.5 光泽(模糊):0.85 凹凸贴图5、抛光砖:漫射:平铺贴图反射:255 高光:0.8 光泽(模糊):0.98 菲涅耳要贴图坐标普通地砖:漫射:平铺贴图反射:255 高光:0.8 光泽(模糊):0.9 菲涅耳6、木地板:漫射:平铺贴图反射:70 贴图6x60 光泽(模糊):0.9 凹凸贴图7、清玻璃:漫射:灰色反射:255 折射255 折射率1.5磨砂玻璃:漫射:灰色反射:255 高光:0.8 光泽(模糊):0.9折射255 光泽(模糊):0.9 光折射率1.58、普通布料: 漫射:贴图凹凸贴图绒布: 漫射:衰减贴图置换给贴图降低置换参数要贴图坐标毛发地毯:先建一个平面 1500*2000 然后给澡啵 40 Z 140 然后给个VR毛发9、皮革:漫射:贴图反射:50 高光:0.6 光泽(模糊):0.8 凹凸贴图贴图坐标10、水材质:漫射:黑色反射:255 衰减菲*耳打勾折射:255 折射率1.33 烟雾颜色浅青色烟雾倍增 0.01凹凸贴图:澡波 350 凹凸 2011、纱窗:漫射:颜色白色折射:灰白贴图折射率1 接收GI:2草图阶段设置1、全局开关面板:关闭3D默认的灯光,关闭“反射/折射”和“光滑效果”2、图像采样器:“固定比率”,值为1。
3、关闭“抗锯齿过滤器”。
4、发光贴图:预设[非常低],模型细分30,插补采样105、灯光缓冲:细分1006、 RQMC采样器:适应数量0.95 噪波阈值:0.5 最小采样值8 全局细分倍增器:0.17、灯光和材质的细分值都降低5—8出图阶段设置1、全局开关面板:打开“反射/折射”和“光滑效果”2、图像采样器:“自适应准蒙特卡洛”。
unity的forwardrendering中光源的使用和light的rendermode

unity 的forward rendering 中光源的使用和light 的render
mode
在Unity 中的light 都有一个属性RenderMode ,可以设置light 的渲染模式为impotant 还是非important ,以前只是肤浅的认为important 对应的就是像素光,非important 就是顶点光,而auto 就按照graphic quality 里面的设置。
后来看了一下unity 的文档,其实不是这样,它完全的规则非常复杂:最亮的几个光源会被实现为完全的逐像素光照然后最多4 个光源会被实现为顶点光照剩下的光源会被实现为效率较高的球面调谐光照
( Spherical Harmonic )决定一个光源属于上面哪一类的规则:最亮的那盏方向光一定是第 1 类
render moder 是important 的光一定是第1 类如果前面两条加起来的像素光少于Quality Setting 里面的像素光数量,从剩下是所有光中找出这里面找出最亮的几盏变为第1 类最后剩下的光按照前面规则是第 2 或 3 类
也就是说我们在Quality Setting 里面设置的值并不能约束像素光的数量,它其实是像素光最少要保证的数量。
真正越苏像素光的使用一时要调节quality setting ,二还是要讲render mode 设为非important 这些光在渲染中的行为如下
base pass里面执行一盏像素光和所有定点光(包括球谐光照)其余的像素光每盏多一个pass,注意这些pass里面无阴影计算,所以unity 只计算最亮的那个方向光的阴影。
3dmax粒子系统详细介绍

粒子系统喷射( Spray )喷射模拟雨、喷泉、公园水龙带的喷水等水滴效果。
“粒子”组Particles group视口计数Viewport Count —在给定帧处,视口中显示的最大粒子数。
提示:将视口显示数量设置为少于渲染计数,可以提高视口的性能。
渲染计数Render Count —一个帧在渲染时可以显示的最大粒子数。
该选项与粒子系统的计时参数配合使用。
•如果粒子数达到“渲染计数”的值,粒子创建将暂停,直到有些粒子消亡。
•消亡了足够的粒子后,粒子创建将恢复,直到再次达到“渲染计数”的值。
水滴大小Drop Size —粒子的大小(以活动单位数计)。
速度Speed —每个粒子离开发射器时的初始速度。
粒子以此速度运动,除非受到粒子系统空间扭曲的影响。
变化Variation —改变粒子的初始速度和方向。
“变化”的值越大,喷射越强且范围越广。
水滴、圆点或十字叉Drops, Dots, or Ticks —选择粒子在视口中的显示方式。
显示设置不影响粒子的渲染方式。
水滴是一些类似雨滴的条纹,圆点是一些点,十字叉是一些小的加号。
“渲染”组Render group四面体Tetrahedron —粒子渲染为长四面体,长度由您在“水滴大小”参数中指定。
四面体是渲染的默认设置。
它提供水滴的基本模拟效果。
面Facing —粒子渲染为正方形面,其宽度和高度等于“水滴大小”。
面粒子始终面向摄影机(即用户的视角)。
这些粒子专门用于材质贴图。
请对气泡或雪花使用相应的不透明贴图。
注意:“面”只能在透视视图或摄影机视图中正常工作。
“计时”组Timing group计时参数控制发射的粒子的“出生和消亡”速率。
在“计时”组的底部是显示最大可持续速率的行。
此值基于“渲染计数”和每个粒子的寿命。
为了保证准确:最大可持续速率= 渲染计数/寿命因为一帧中的粒子数永远不会超过“渲染计数”的值,如果“出生速率”超过了最高速率,系统将用光所有粒子,并暂停生成粒子,直到有些粒子消亡,然后重新开始生成粒子,形成突发或喷射的粒子。
老玩家分享行星边际2最佳优化方案

老玩家分享行星边际2最佳优化方案此方案为玩家分享,非官方优化方案,只供参考。
感谢:PintoCat及人不蛋疼蛋自疼第一将你的所有驱动都升级到最新版本,去下一个驱动精灵就OK了~ 第二修改UserOptions.ini参数。
我希望官方能够出一个官方修改软件。
参考我的USER设置,出一款针对PS2国内用户进行优化~~ 修改UserOptions.ini之前,请在游戏内使用最低设置,然后再进行UserOptions.ini修改,修改好UserOptions.ini后,不要在游戏内重新设置视频选项。
附上我修改过的UserOptions.ini参数你们自行对照反正我设置过的画质不会太差,基本上能有06-08年DX9.0C主流游戏的高配置画质。
DISPLAY是窗口设定部分[Display]FullscreenRefresh=0 (这是全屏模式的XX 我不懂) Maximized=0 FullscreenWidth=1366 (这是全屏模式的分辨率1366X)FullscreenHeight=768 (这是全屏模式X768 上下合起来就是1366X768 16:9的标准分辨率) WindowedWidth=1024 (这个是窗口模式的下面的那个也是) WindowedHeight=768RenderQuality=1.000000 (这个一定要设定在0.800000到1.0000 低于这个数值,就是马赛克了这个就是渲染的精细度! 其实耗不了多少性能,画质差了还影响视觉~) Mode=Fullscreen (现在的模式是全屏模式) FullscreenMode=Fullscreen [Rendering] Graphi**Quality=2 (渲染等级一定2级) TextureQuality=4 (贴图等级 3 4都可以你放心,不会掉你的FPS 我推荐4) ShadowQuality=0 (阴影渲染,在卡马克写出新的阴影代码之前,现在的阴影都是最吃硬件的,果断关掉)RenderDistance=1500.000000 (渲染距离。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
强氧影视后期制作全流程
强氧简介
• 2001年成立。
致力于为国内图形图像用户提供专业解决方案
• 2003年成为美国超微SuperMicro中国独家总代理
• 2004年成为NVIDIA中国战略合作伙伴,并且建立强氧品牌专业图形工作站
• 2005年成为AMD中国区工作站唯一战略合作伙伴,同年强氧品牌工作站遍布全国
• 2005年7月,成为FranticFilms,PipelineFX代理,推出强氧品牌集群渲染系统,成为国内唯一能提供整合软硬件的高性能渲染系统
• 2006年成为BlackMagic Design中国独家总代 ,正式进军广电行业
• 2006年9月推出强氧品牌视频IO工作站。
• 2007年成为Ciprico中国独家总代理,同时推出强氧专业视频存储产品
强氧2009-2010
2008年成为APPLE国内专业级代理
2009年成为DigitalRapids国内代理,推出强氧新媒体编转码系统
2010年1月,成为PipelineFX中国唯一金品代理
2010年3月,成为Quantum Stornext FX中国独家总代理
2010年4月,成为The Foundry中国区代理
2010年8月,BirTV全国剪辑大赛视频工作站,指定强氧影视后期工作站产品2010年8月,强氧全系列影视后期工作站产品通过3C认证
2010年12月,强氧科技通过ISO9000国家质量体系认证
强氧财政走势
合作伙伴
强氧集群渲染系统
什么是Renderfarm
• 渲染农场(Renderfarm)其实就是“分布式并⾏行集群计算系统”,集群(cluster)指的是⼀一组计算机通过通信协议连接在⼀一起的计算机群,它们能够将⼯工作负载从⼀一个超载的计算机迁移到集群中的其他计算机上,这⼀一特性称为负载均衡(load balancing),这是⼀一种利⽤用现成的CPU、⺴⽹网络负载和操作系统构建的超级计算机,它使⽤用主流的商业计算机硬件设备达到或接近超级计算机的计算能⼒力。
为什么需要渲染集群
• 投资渲染集群的软硬件系统是花必要的钱,来保证投资(设备投资,⼈人员⼯工资等),赚取更⼤大的利润(通过将⽣生产流程并⾏行化,提⾼高单位⼯工作时间内设计⼈人员完成的⼯工作量,提⾼高⽣生产效率,满⾜足不断增⻓长的业务需求)。
在这⾥里很重要的是⼀一个改进就是将需要交互设计阶段,和⽆无需交互(或是只需要很少交互)的渲染计算阶段分开,通过购买额外的主机(计算资源)将实际⽣生产过程中这两个阶段并⾏行化,同时进⾏行,这⾥里看似投⼊入了⼀一些资⾦金,但带来的回报是巨⼤大的。
强氧集群渲染平台
RB1016
强氧集群渲染用户群
广电用户
中央电视台
北京电视台
吉林卫视
吉林省都市频道 北京朝阳电视台 上海文广都市频道
后期制作公司用户
• 北京银河长兴影视文化传播有限公司 • 北京万芳幸星有限公司
• 珠海火车头动漫影视制作公司
• 北京蓝月谷文化传媒有限公司
• 南京润和数码
• c gfish studio
• E clipse studio
• 武汉海豚传媒动画部
• 北京环球映画
• B aseFX
中国戏曲学院
北京工业大学软件学院
石家庄职业技术学院动画学院 电子科技大学中山学院
中山市职业技术学院
北京邮电大学世纪学院
华中科技大学
广州番禺农校
哈尔滨师范大学
长春职业技术学院 北京电子科技职业技术学院 东北师范大学美术学院
华侨学校
福建师范大学美术学院
吉林艺术学院
浙江艺术职业学院
北京实用技术学校
河北理工大学设计学部
云南师范大学
教育院校用户:
动漫基地用户
石景山数字艺术培训基地
齐鲁软件园公共服务平台
烟台动漫基地
中关村科技园区海淀园创业服务中心 郑州动漫基地
• 行业用户
• 北京天文馆
• 山东工业展览馆
• 航天工业部512 所多媒体中心 • 游戏公司用户 • 上海育碧软件公司
成功案例简析
中央电视台
特点:
应用软件环境相对单一
网络存储等硬件环境最复杂
我们的优势:
支持所有主流的三维和合成软件 可以完美支持SAN和NAS的存储环境 特有技术降低网络负载
BaseFX
特点:
应用软件环境相对复杂
网络存储等硬件环境比较复杂
我们的优势:
支持所有主流的三维和合成软件的不同版本 可以完美支持SAN和NAS的存储环境
特有技术降低网络负载
齐鲁软件园公共服务平台
特点:
应用软件环境最复杂
网络存储等硬件环境比较复杂
我们的优势:
完美所有主流的三维和合成软件的不同版本 可以完美支持SAN和NAS的存储环境
特有技术降低网络负载
独有的动态帧分配技术大幅提高利用率
特有的数据跟踪技术监控这个农场
河北理工大学设计学部
特点:
应用软件环境比较单一
网络存储等硬件环境最单一
我们的优势:
完美所有主流的三维和合成软件的不同版本 特有技术降低网络负载
领先的渲染农场管理系统
中国唯一的金牌代理
领先的渲染农场
管理系统
关于PipelineFX
• 成立于 2002年
• 风险投资背景
• 从SquareUSA购买知识产权
• 保留了SquareUSA的研发和维护
团队
• 在檀香山、旧金山、洛杉矶、
圣地亚哥和温哥华设有办事处
• 近600个客户遍及全球20多个
国家
拥有世界最广泛的客户
支持各种操作系统
支持几乎所有制作软件
功能特性
• 稳定
• 自由扩展
• 可自定义
• 灵活的授权方式 • 操作简单
• 技术领先
• 为数字媒体专门设计 • 世界级技术支持
稳定
• 自1999年便应用于实际制作 • 多线程管理器
• M ySQL数据库驱动
自由扩展
• 客户端-服务器模式 • 多线程管理器
• 集中配置管理
• 低网络流量
• 成功管理过运行数百万Job的数千台服务器
自定义
• 灵活的配置
– 定时加入桌面机
– 多重优先级设定
– 资源和属性
• 开放的平台
– C++、Perl和Python API
– 可用Python开发自定义GUI
– 命令行界面
– 自定义的命令行任务提交方式 • 可融入已有流程
灵活的授权方式
• 流动许可证,跨平台
– 所有服务器和桌面机都可获得授权
– 从网络的任何一点进行管理
• 每个主机1个License
– S upervisor License 包括MySQL数据库 (每个网络1个)
– W orker License
– 为一台主机指派多个任务 (多CPU)
智能渲染管理
智能数据跟踪
智能授权管理
智能最终帧检验
智能渲染进度管理
智能效率最大化(动态的帧分配)
智能视频转换(需要第三方插件)
智能流程资产管理(需要第三方插件)
专为艺术家设计的界⾯面Artistview
移动设备的Web⻚页⾯面MobileView
⼯工作站管理⼯工具QBLocker
iPad 或iPhone 终端的分析报告
这就是数字媒体的智能渲染流程管理。