sqoop从hive到mysql,mysql到hive
林子雨大数据技术原理与应用第二章课后题答案

大数据第二章课后题答案黎狸1.试述Hadoop和谷歌的MapReduce、GFS等技术之间的关系。
Hadoop是Apache软件基金会旗下的一-个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。
①Hadoop 的核心是分布式文件系统( Hadoop Ditributed FileSystem,HDFS )和MapReduce。
②HDFS是对谷歌文件系统( Google File System, GFS )的开源实现,是面向普通硬件环境的分布式文件系统,具有较高的读写速度、很好的容错性和可伸缩性,支持大规模数据的分布式存储,其冗余数据存储的方式很好地保证了数据的安全性。
③MapReduce 是针对谷歌MapReduce的开源实现,允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,采用MapReduce 来整合分布式文件系统上的数据,可保证分析和处理数据的高效性。
2.试述Hadoop具有哪些特性。
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性。
①高可靠性。
采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外提供服务。
②高效性。
作为并行分布式计算平台,Hadoop采用分布式存储和分布式处理两大核心技术,能够高效地处理PB级数据。
③高可扩展性。
Hadoop的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点。
④高容错性。
采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
⑤成本低。
Hadoop采用廉价的计算机集群,成本比较低,普通用户也很容易用自己的PC搭建Hadoop运行环境。
⑥运行在Linux平台上。
Hadoop是基于Java语言开发的,可以较好地运行在Linux平台上。
⑦支持多种编程语言。
Hadoop 上的应用程序也可以使用其他语言编写,如C++。
林子雨大数据技术原理与应用第二章课后题答案

大数据第二章课后题答案黎狸1. 试述Hadoop 和谷歌的MapReduce 、GFS 等技术之间的关系。
Hadoop 是Apache 软件基金会旗下的一-个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。
①Hadoop 的核心是分布式文件系统( Hadoop Ditributed FileSystem,HDFS ) 和MapReduce 。
②HDFS是对谷歌文件系统( Google File System, GFS ) 的开源实现,是面向普通硬件环境的分布式文件系统,具有较高的读写速度、很好的容错性和可伸缩性,支持大规模数据的分布式存储,其冗余数据存储的方式很好地保证了数据的安全性。
③MapReduce 是针对谷歌MapReduce 的开源实现,允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,采用MapReduce 来整合分布式文件系统上的数据,可保证分析和处理数据的高效性。
2. 试述Hadoop 具有哪些特性。
Hadoop 是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性。
①高可靠性。
采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外提供服务。
②高效性。
作为并行分布式计算平台,Hadoop 采用分布式存储和分布式处理两大核心技术,能够高效地处理PB 级数据。
③高可扩展性。
Hadoop 的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点。
④高容错性。
采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
⑤成本低。
Hadoop 采用廉价的计算机集群,成本比较低,普通用户也很容易用自己的PC 搭建Hadoop 运行环境。
⑥运行在Linux 平台上。
Hadoop 是基于Java 语言开发的,可以较好地运行在Linux 平台上。
sqoop 从 hive 导到mysql遇到的问题

环境hive 版本hive-0.11.0sqoop 版本sqoop-1.4.4.bin__hadoop-1.0.0从hive导到mysqlmysql 表:mysql> desc cps_activation;+————+————-+——+—–+———+—————-+| Field | Type | Null | Key | Default | Extra |+————+————-+——+—–+———+—————-+| id | int(11) | NO | PRI | NULL | auto_increment || day | date | NO | MUL | NULL | || pkgname | varchar(50) | YES | | NULL | || cid | varchar(50) | YES | | NULL | || pid | varchar(50) | YES | | NULL | || activation | int(11) | YES | | NULL | |+————+————-+——+—–+———+—————-+6 rows in set (0.01 sec)hive表hive> desc active;OKid int Noneday string Nonepkgname string Nonecid string Nonepid string Noneactivation int None测试链接成功[hadoop@hs11 ~]sqoop list-databases –connect jdbc:mysql://localhost:3306/ –username root –password adminWarning: /usr/lib/hcatalog does not exist! HCatalog jobs will fail.Please set $HCAT_HOME to the root of your HCatalog installation.13/08/20 16:42:26 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 13/08/20 16:42:26 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.information_schemaeasyhadoopmysqltest[hadoop@hs11 ~]$ sqoop list-databases –connect jdbc:mysql://localhost:3306/test –username root –password adminWarning: /usr/lib/hcatalog does not exist! HCatalog jobs will fail.Please set $HCAT_HOME to the root of your HCatalog installation.13/08/20 16:42:40 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.13/08/20 16:42:40 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.information_schemaeasyhadoopmysqltest[hadoop@hs11 ~]$ sqoop list-tables –connect jdbc:mysql://localhost:3306/test –username root –password adminWarning: /usr/lib/hcatalog does not exist! HCatalog jobs will fail.Please set $HCAT_HOME to the root of your HCatalog installation.13/08/20 16:42:54 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.13/08/20 16:42:54 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.active[hadoop@hs11 ~]$ sqoop create-hive-table –connect jdbc:mysql://localhost:3306/test –table active –username root –password admin –h ive-table testWarning: /usr/lib/hcatalog does not exist! HCatalog jobs will fail.Please set $HCAT_HOME to the root of your HCatalog installation.13/08/20 16:57:04 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.13/08/20 16:57:04 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override13/08/20 16:57:04 INFO tool.BaseSqoopTool: delimiters with –fields-terminated-by, etc.13/08/20 16:57:04 WARN tool.BaseSqoopTool: It seems that you’ve specified at least one of following:13/08/20 16:57:04 WARN tool.BaseSqoopTool: –hive-home13/08/20 16:57:04 WARN tool.BaseSqoopTool: –hive-overwrite13/08/20 16:57:04 WARN tool.BaseSqoopTool: –create-hive-table13/08/20 16:57:04 WARN tool.BaseSqoopTool: –hive-table13/08/20 16:57:04 WARN tool.BaseSqoopTool: –hive-partition-key13/08/20 16:57:04 WARN tool.BaseSqoopTool: –hive-partition-value13/08/20 16:57:04 WARN tool.BaseSqoopTool: –map-column-hive13/08/20 16:57:04 WARN tool.BaseSqoopTool: Without specifying parameter –hive-import. Please note that13/08/20 16:57:04 WARN tool.BaseSqoopTool: those arguments will not be used in this session. Either13/08/20 16:57:04 WARN tool.BaseSqoopTool: specify –hive-import to apply them correctly or remove them13/08/20 16:57:04 WARN tool.BaseSqoopTool: from command line to remove this warning.13/08/20 16:57:04 INFO tool.BaseSqoopTool: Please note that –hive-home, –hive-partition-key,13/08/20 16:57:04 INFO tool.BaseSqoopTool: hive-partition-value and –map-column-hive options are13/08/20 16:57:04 INFO tool.BaseSqoopTool: are also valid for HCatalog imports and exports13/08/20 16:57:04 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.13/08/20 16:57:05 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `active` AS t LIMIT 113/08/20 16:57:05 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `active` AS t LIMIT 113/08/20 16:57:05 WARN hive.TableDefWriter: Column day had to be cast to a less precise type in Hive13/08/20 16:57:05 INFO hive.HiveImport: Loading uploaded data into Hive1、拒绝连接[hadoop@hs11 ~]$ sqoop export –connect jdbc:mysql://localhost/test –username root –password admin –table test –export-dir /user/h ive/warehouse/actmpWarning: /usr/lib/hcatalog does not exist! HCatalog jobs will fail.Please set $HCAT_HOME to the root of your HCatalog installation.13/08/21 09:14:07 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.13/08/21 09:14:07 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.13/08/21 09:14:07 INFO tool.CodeGenTool: Beginning code generation13/08/21 09:14:07 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `test` AS t LIMIT 113/08/21 09:14:07 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `test` AS t LIMIT 113/08/21 09:14:07 INFO pilationManager: HADOOP_MAPRED_HOME is /home/hadoop/hadoop-1.1.2Note: /tmp/sqoop-hadoop/compile/0b5cae714a00b3940fb793c3694408ac/test.java uses or overrides a deprecated API.Note: Recompile with -Xlint:deprecation for details.13/08/21 09:14:08 INFO pilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/0b5cae714a00b3940fb793c3694408ac/test.ja r13/08/21 09:14:08 INFO mapreduce.ExportJobBase: Beginning export of test13/08/21 09:14:09 INFO input.FileInputFormat: Total input paths to process : 113/08/21 09:14:09 INFO input.FileInputFormat: Total input paths to process : 113/08/21 09:14:09 INFO util.NativeCodeLoader: Loaded the native-hadoop library13/08/21 09:14:09 WARN snappy.LoadSnappy: Snappy native library not loaded13/08/21 09:14:10 INFO mapred.JobClient: Running job: job_201307251523_005913/08/21 09:14:11 INFO mapred.JobClient: map 0% reduce 0%13/08/21 09:14:20 INFO mapred.JobClient: Task Id : attempt_201307251523_0059_m_000000_0, Status : FAILEDjava.io.IOException: municationsException: Communications link failure due to underlying exception:** BEGIN NESTED EXCEPTION **.ConnectExceptionMESSAGE: Connection refusedSTACKTRACE:.ConnectException: Connection refusedat .PlainSocketImpl.socketConnect(Native Method)at .PlainSocketImpl.doConnect(PlainSocketImpl.java:351)at .PlainSocketImpl.connectToAddress(PlainSocketImpl.java:213)at .PlainSocketImpl.connect(PlainSocketImpl.java:200)at .SocksSocketImpl.connect(SocksSocketImpl.java:366)at .Socket.connect(Socket.java:529)at .Socket.connect(Socket.java:478)at .Socket.<init>(Socket.java:375)at .Socket.<init>(Socket.java:218)at com.mysql.jdbc.StandardSocketFactory.connect(StandardSocketFactory.java:256)at com.mysql.jdbc.MysqlIO.<init>(MysqlIO.java:271)at com.mysql.jdbc.Connection.createNewIO(Connection.java:2771)at com.mysql.jdbc.Connection.<init>(Connection.java:1555)at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:285)at java.sql.DriverManager.getConnection(DriverManager.java:582)at java.sql.DriverManager.getConnection(DriverManager.java:185)at org.apache.sqoop.mapreduce.db.DBConfiguration.getConnection(DBConfiguration.java:294)at org.apache.sqoop.mapreduce.AsyncSqlRecordWriter.<init>(AsyncSqlRecordWriter.java:76)at org.apache.sqoop.mapreduce.ExportOutputFormat$ExportRecordWriter.<init>(ExportOutputFormat.java:95)at org.apache.sqoop.mapreduce.ExportOutputFormat.getRecordWriter(ExportOutputFormat.java:77)at org.apache.hadoop.mapred.MapTask$NewDirectOutputCollector.<init>(MapTask.java:628)at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:753)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:370)at org.apache.hadoop.mapred.Child$4.run(Child.java:255)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:396)at erGroupInformation.doAs(UserGroupInformation.java:1149)at org.apache.hadoop.mapred.Child.main(Child.java:249)** END NESTED EXCEPTION **Last packet sent to the server was 1 ms ago.at org.apache.sqoop.mapreduce.ExportOutputFormat.getRecordWriter(ExportOutputFormat.java:79)at org.apache.hadoop.mapred.MapTask$NewDirectOutputCollector.<init>(MapTask.java:628)at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:753)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:370)at org.apache.hadoop.mapred.Child$4.run(Child.java:255)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:396)at erGroupInformation.doAs(UserGroupInformation.java:1149)at org.apache.hadoop.mapred.Child.main(Child.java:249)Caused by: municationsException: Communications link failure due to underlying exception: ** BEGIN NESTED EXCEPTION **.ConnectExceptionMESSAGE: Connection refusedmysql 用户权限问题mysql> show grants;mysql> GRANT ALL PRIVILEGES ON *.* TO ‘root’@'%’ IDENTIFIED BY PASSWORD ‘*4ACFE3202A5FF5CF467898FC58AAB1D615029441′ WITH GRANT OPTI ON;mysql> FLUSH PRIVILEGES;mysql> create table test (mkey varchar(30),pkg varchar(50),cid varchar(20),pid varchar(50),count int,primary key(mkey,pkg,cid,pid) );alter ignore table cps_activation add unique index_day_pkgname_cid_pid (`day`,`pkgname`,`cid`,`pid`);Query OK, 0 rows affected (0.03 sec)2. 表不存在===========[hadoop@hs11 ~]$ sqoop export –connect jdbc:mysql://10.10.20.11/test –username root –password admin –table test –export-dir /user/ hive/warehouse/actmpWarning: /usr/lib/hcatalog does not exist! HCatalog jobs will fail.Please set $HCAT_HOME to the root of your HCatalog installation.13/08/21 09:16:26 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.13/08/21 09:16:26 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.13/08/21 09:16:26 INFO tool.CodeGenTool: Beginning code generation13/08/21 09:16:27 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `test` AS t LIMIT 113/08/21 09:16:27 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `test` AS t LIMIT 113/08/21 09:16:27 INFO pilationManager: HADOOP_MAPRED_HOME is /home/hadoop/hadoop-1.1.2Note: /tmp/sqoop-hadoop/compile/74d18a91ec141f2feb777dc698bf7eb4/test.java uses or overrides a deprecated API.Note: Recompile with -Xlint:deprecation for details.13/08/21 09:16:28 INFO pilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/74d18a91ec141f2feb777dc698bf7eb4/test.ja r13/08/21 09:16:28 INFO mapreduce.ExportJobBase: Beginning export of test13/08/21 09:16:29 INFO input.FileInputFormat: Total input paths to process : 113/08/21 09:16:29 INFO input.FileInputFormat: Total input paths to process : 113/08/21 09:16:29 INFO util.NativeCodeLoader: Loaded the native-hadoop library13/08/21 09:16:29 WARN snappy.LoadSnappy: Snappy native library not loaded13/08/21 09:16:29 INFO mapred.JobClient: Running job: job_201307251523_006013/08/21 09:16:30 INFO mapred.JobClient: map 0% reduce 0%13/08/21 09:16:38 INFO mapred.JobClient: Task Id : attempt_201307251523_0060_m_000000_0, Status : FAILEDjava.io.IOException: Can’t export data, please check task tracker logsat org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:112)at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39)at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144)at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64)at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:370)at org.apache.hadoop.mapred.Child$4.run(Child.java:255)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:396)at erGroupInformation.doAs(UserGroupInformation.java:1149)at org.apache.hadoop.mapred.Child.main(Child.java:249)Caused by: java.util.NoSuchElementExceptionat java.util.AbstractList$Itr.next(AbstractList.java:350)at test.__loadFromFields(test.java:252)at test.parse(test.java:201)at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83)… 10 more导出数据到MySQL,当然数据库表要先存在,否则会报错此错误的原因为sqoop解析文件的字段与MySql数据库的表的字段对应不上造成的。
SQOOP的使用方法

SQOOP的使⽤⽅法Sqoop是个命令⾏⼯具,⽤来在Hadoop和rdbms之间传输数据。
以Hadoop的⾓度看待数据流向,从rdbms往Hadoop是导⼊⽤sqoop import命令,反之从hadoop往rdbms下发数据⽤sqoop export命令以oracle hive为例⼦,命令举例:sqoop import -D oraoop.jdbc.url.verbatim=true --hive-import --hive-overwrite --connect jdbc:oracle:thin:@192.168.1.10:1521:orcl --username usernamexx --password passwdxx --table WH_PRG.TB_JSQ_PRD_GRID_MDF -sqoop export -D oraoop.jdbc.url.verbatim=true --connect "jdbc:oracle:thin:@192.168.1.10:1521:orcl" --username usernamexx --password passwdxx --table ORACLETABLE --export-dir /user/hive/warehouse/test.db/tablena 注意:oracle表名⼤写,hive表名保持和创建表时候的⼤⼩写,建表是⼤写,这⼉就⼤写,建表时候⼩写,这⼉就⼩写-m 1表⽰并⾏度,根据oracle库的性能⾃⾏决定导⼊的时候是默认覆盖,如果hive中有同名表,会⾃动删除重建导出的时候是追加,要先在oracle测建好空表,⽽且再次导⼊时候要把原来的内容清空,否则因为是追加数据会产⽣重复数据,字段顺序要对齐,否则可能产⽣列的错位附1:Sqoop导⼊常规参数意思参数参数名称others 插件命令附加参数target-dir 导⼊HDFS的⽬标路径delete-target-dir 如果指定⽬录存在,则先删除掉fetch-size 从数据库中批量读取记录数split-by 按照指定列去分割数据columns 从表中导出指定的⼀组列的数据null-string 字符串类型null时转义为null-non-string ⾮字符串类型null时转义为query 查询语句where 查询条件direct 使⽤直接导出模式(优化速度)warehouse-dir HDFS存放表的根路径append 将数据追加到HDFS上⼀个已存在的数据集上as-avrodatafile 将数据导⼊到Avroas-sequencefile 将数据导⼊到SequenceFileas-textfile 将数据导⼊到普通⽂本⽂件(默认)boundary-query 边界查询,⽤于创建分⽚(InputSplit)direct-split-size 分割输⼊stream的字节⼤⼩(在直接导⼊模式下)inline-lob-limit 设置内联的LOB对象的⼤⼩compress 启⽤压缩compression-codec 指定Hadoop的codec⽅式(默认gzip)incremental mode模式last-value 指定⾃从上次导⼊后列的最⼤值connect 指定JDBC连接字符串connection-manager 指定要使⽤的连接管理器类driver 指定要使⽤的JDBC驱动类username 设置认证⽤户名password 设置认证密码verbose 打印详细的运⾏信息connection-param-file 可选,指定存储数据库连接参数的属性⽂件hadoop-home hadoop-home的路径enclosed-by 字段值前后加上指定的字符escaped-by 双引号作转义处理fields-terminated-by 字段分隔符lines-terminated-by ⾏分隔符optionally-enclosed-by 强制给字段值前后都加上指定符号mysql-delimiters Mysql默认的分隔符input-enclosed-by 对字段值前后指定的字符进⾏解析input-escaped-by 对含有转义双引号的字段值作转义处理input-escaped-by 导⼊使⽤的字段分隔符input-lines-terminated-by 导⼊使⽤的⾏分隔符input-optionally-enclosed-by 导⼊时强制给字段值前后都加上指定符号bindir ⽣成的java⽂件、class⽂件及打包为JAR的JAR包⽂件输出路径class-name ⽣成的Java⽂件指定的名称jar-file 合并时引⼊的jar包outdir ⽣成的java⽂件存放路径package-name 包名map-column-java 映射的数据类型table 关系数据库表名num-mappers 启动map的数量,默认是4个附2:Sqoop的import⼯具抽数的⼏种情况1. Hive表⽆分区,全量从Oracle中抽取数据到Hive的表中sqoop import -D =root.myqueue \–connect jdbc:oracle:thin:@192.168.1.128:1521:mydatabase \–username jsz \–password 123456 \–table mys.test \–columns ID,NAME,AGE,SALARY,DATA_DATE \-m 1 \–hive-table default.test \–create-hive-table \–hive-drop-import-delims \–verbose \–fetch-size 5000 \–target-dir /apps/testdata/default/test \–delete-target-dir \–hive-overwrite \–null-string ‘\\N’ \–null-non-string ‘\\N’ \–hive-import;2. Hive表有分区,增量从Oracle中抽取数据到Hive表中:sqoop import -D =root.myqueue \–connect jdbc:oracle:thin:@192.168.1.128:1521:mydatabase \–username jsz \–password 123456 \–table mys.test \–columns ID,NAME,AGE,SALARY,LCD \-m 1 \–hive-partition-key op_day \–hive-partition-value 20160525 \–where “lcd >= trunc(TO_DATE(‘20160525′,’YYYY-MM-DD’),’dd’) and lcd < trunc(TO_DATE(‘20160526′,’YYYY-MM-DD’),’dd’)” \–hive-table default.test_partition \–create-hive-table \–hive-drop-import-delims \–verbose \–fetch-size 5000 \–target-dir /apps/testdata/default/test_partition \–delete-target-dir \–hive-overwrite \–null-string ‘\\N’ \–null-non-string ‘\\N’ \–hive-import;3.使⽤select语句:sqoop import \-D =root.myqueue \-D oracle.sessionTimeZone=America/Los_Angeles \–connect jdbc:oracle:thin:@192.168.1.128:1521:mydatabase \–username jsz \–password 123456 \–query “select ID,NAME,AGE,SALARY,DATA_DATE from mys.test WHERE ID = ‘10086’ and $CONDITIONS” \–verbose \–fetch-size 5000 \–hive-table default.test \–target-dir /apps/testdata/default/test \–delete-target-dir \–fields-terminated-by ‘\001’ \–lines-terminated-by ‘\n’ \-m 1 \–hive-import \–hive-overwrite \–null-string ‘\\N’ \–null-non-string ‘\\N’ \–hive-drop-import-delimsSqoop的export⼯具导数的情况:将Hive的数据导⼊Oracle,整个过程分为三步:1) 删除Oracle表的历史数据sqoop eval -D =root.myqueue \–connect jdbc:oracle:thin:@192.168.1.128:1521:mydatabase \–username jsz \–password 123456 \–verbose \–e “delete from mys.test”2) Hive导出到HDFS指定路径hive -e “use default;set =root.myqueue;set hive.insert.into.multilevel.dirs=true;insert overwrite directory ‘/apps/testdata/default/test’ select id,name,age,salary,data_date from default.test;”3) 将HDFS的数据导⼊到Oracle中sqoop export \-D =root.myqueue \-D mapred.task.timeout=0 \–connect jdbc:oracle:thin:@192.168.1.128:1521:mydatabase \–username jsz \–password 123456 \–table mys.test \–columns ID,NAME,AGE,SALARY,DATA_DATE \–export-dir /apps/testdata/default/test \–verbose \–input-null-string ‘\\N’ \–input-null-non-string ‘\\N’ \–input-fields-terminated-by ‘\001’ \–input-lines-terminated-by ‘\n’ \-m 1。
用Sqoop进行Hive和MySQL之间的数据互导

⽤Sqoop进⾏Hive和MySQL之间的数据互导Hive导数据⼊MySQL创建mysql表use anticheat;create table anticheat_blacklist(userid varchar(30) primary key ,dt int,update_time timestamp,delete_flag int,operator varchar(30));全量导出⽤sqoop export全量导出hive表数据⼊mysql,具体命令如下:sqoop export -D =datacenter--connect jdbc:mysql://localhost:3306/anticheat?tinyInt1isBit=false--username root--password ^qn9DFYPm--table anticheat_blacklist--input-fields-terminated-by '\t'--input-null-string '\\N'--input-null-non-string '\\N'--num-mappers 10--export-dir hdfs://dc5/user/test/hive/online/anticheat_blacklist_mysql增量导出sqoop export -D =datacenter--connect jdbc:mysql://localhost:3306/anticheat?tinyInt1isBit=false--username root--password ^qn9DFYPm--table anticheat_blacklist2--input-fields-terminated-by '\t'--input-null-string '\\N'--input-null-non-string '\\N'--num-mappers 10--update-key update_time--update-mode allowinsert--export-dir hdfs://dc5/user/test/hive/online/anticheat_blacklist_mysql2MySQL导数据⼊Hive创建Hive表创建同步mysql表的hive表CREATE TABLE test.anticheat_blacklist_mysql(key string,dt int,update_time timestamp,delete_flag int,operator string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS TEXTFILELOCATION 'hdfs://dc5/user/test/hive/online/anticheat_blacklist_mysql';全量导⼊⽤sqoop import全量导出mysql表数据⼊hive表,具体命令如下:sqoop import -D =datacenter--connect jdbc:mysql://localhost:3306/anticheat?tinyInt1isBit=false--username root--password ^qn9DFYPm--table anticheat_blacklist--delete-target-dir--beeline "jdbc:hive2://:10000/test;principal=hive/@;"--hive-import --fields-terminated-by '\t'--hive-database test--hive-table anticheat_blacklist_mysql--null-string '\\N'--null-non-string '\\N'--hive-overwrite--num-mappers 1--outdir /home/test/data/anticheat/mysql2hivenull字符串转为NULL,添加下⾯两条参数可以实现:–null-string 如果指定列为字符串类型,使⽤指定字符串替换值为null的该类列的值–null-non-string 如果指定列为⾮字符串类型,使⽤指定字符串替换值为null的该类列的值增量导⼊增量导⼊:(根据时间来导⼊,如果表中没有时间属性,可以增加⼀列时间簇)核⼼参数:–check-column ⽤来指定⼀些列,这些列在增量导⼊时⽤来检查这些数据是否作为增量数据进⾏导⼊,和关系型数据库中的⾃增字段及时间戳类似. 注意:这些被指定的列的类型不能使任意字符类型(在关系数据库中),如char、varchar等类型都是不可以的,同时–check-column可以去指定多个列–incremental ⽤来指定增量导⼊的模式,两种模式分别为Append和Lastmodified–last-value 指定上⼀次导⼊中检查列指定字段最⼤值,即会导⼊⽐lastvalue指定值⼤的数据记录注意:上⾯三个参数都必须添加!执⾏语句:sqoop import -D =datacenter--connect jdbc:mysql://localhost:3306/anticheat?tinyInt1isBit=false--username root--password ^qn9DFYPm--table anticheat_blacklist--delete-target-dir--hive-import --fields-terminated-by '\t'--beeline "jdbc:hive2://:10000/test;principal=hive/@;"--hive-database test--hive-table anticheat_blacklist_mysql--null-string '\\N'--hive-overwrite--num-mappers 1--check-column update_time--incremental lastmodified--last-value "2019-04-12 14:31:34"--outdir /home/test/data/anticheat/mysql2hive以上语句使⽤ lastmodified 模式进⾏增量导⼊,结果报错:错误信息:--incremental lastmodified option for hive imports is not supported. Please remove the parameter --incremental lastmodified错误原因:Sqoop 不⽀持 mysql转hive时使⽤ lastmodified 模式进⾏增量导⼊,但mysql转HDFS时可以⽀持该⽅式!我们使⽤append⽅式导⼊:sqoop import -D =datacenter--connect jdbc:mysql://localhost:3306/anticheat?tinyInt1isBit=false--username root--password ^qn9DFYPm--table anticheat_blacklist--delete-target-dir--hive-import --fields-terminated-by '\t'--hive-database test--hive-table anticheat_blacklist_mysql--null-string '\\N'--null-non-string '\\N'--num-mappers 1--check-column update_time--incremental append--last-value "2019-04-12 14:31:34"--outdir /home/test/data/anticheat/mysql2hive增量导⼊成功!。
2023上半年 大数据分析师(中级)考前冲刺题A1卷

2023上半年 大数据分析师(中级)考前冲刺题A1卷1.【单选题】HBase的三层结构不包括()。
A:Zookeeper文件B:ROOT表C:.META.表D:Region正确答案:D答案解析:HBase的三层结构分别是Zookeeper文件,ROOT表,.META.表2.【单选题】HBase与Hadoop生态系统其他组件的关系描述不正确的是()。
A:利用HDFS进行数据存储B:利用Zookeeper进行协同服务管理C:利用Spark进行并行计算D:利用Sqoop进行数据导入与导出正确答案:C答案解析:HBase的并行计算不使用Spark3.【单选题】Hive中having子句通常会和()子句一起出现。
A:selectB:fromC:whereD:group by正确答案:D答案解析:having是分组后进行筛选,需要和group by一起使用4.【单选题】Hive中把弧度转换为角度的函数是()。
A:degreesB:radiansC:todegreesD:toradians正确答案:A5.【单选题】Hive中的函数last_day的作用是()。
A:得到参数所指定时间的后一天B:得到参数所指定时间所在月份的最后一天C:得到参数所指定时间所在年份的最后一天D:得到参数所指定时间的前一天正确答案:B6.【单选题】Hive中加载数据到表中,指定文件路径的关键字是()。
A:pathB:inpathC:directoryD:local正确答案:B答案解析:inpath指定要导入的文件7.【单选题】MySQL中,()不是查询语句中的关键字。
A:group byB:havingC:limitD:update正确答案:D8.【单选题】MySQL中,select ascii('A');的查询结果是()。
A:'A'C:65D:64正确答案:C答案解析:A的编码是659.【单选题】MySQL中,查询所有学生的sno和name的SQL语句是()。
Sqoop命令

sqoop import --verbose --fields-terminated-by ',' --connect jdbc:mysql://IP:PORT/database --username root --password PASSWD --table tablename --target-dir /dfsdir/dfsdir --split-by 'SPLIT BREAK'
Warning: $HADOOP_HOME is deprecated.
13/09/07 11:24:09 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
13/09/07 11:24:09 INFO hive.HiveImport: Loading uploaded data into Hive
13/09/07 11:24:10 INFO manager.MySQLManager: Executing SQL statement: SELECT t.* FROM `sqooptable` AS t LIMIT 1
5)将关系型数据库的表结构复制到hive中,只是复制表的结构,表中的内容没有复制
[hduser@master ~]$ sqoop create-hive-table --connect jdbc:mysql://slave1.hadoop:3306/sqooptest --table sqooptable --username root --password 123456 --hive-table hivetest1
sqoop用法

sqoop用法Sqoop是一个用于在Apache Hadoop和结构化数据存储之间传输数据的工具。
它支持从关系型数据库(如MySQL、Oracle、PostgreSQL等)中导入数据到Hadoop的HDFS(Hadoop分布式文件系统)中,并且可以将Hadoop中的数据导出到关系型数据库中。
Sqoop是一个开源的工具,它可以帮助用户更轻松地将数据从传统的关系型数据库中导入到Hadoop中,从而实现更高效的数据处理和分析。
Sqoop的使用方法非常简单,只需要按照以下步骤进行操作即可:1. 安装Sqoop首先需要安装Sqoop,可以从官方网站上下载最新版本的Sqoop,并按照官方文档进行安装。
2. 连接数据库在使用Sqoop之前,需要先连接到要导入数据的数据库。
可以使用以下命令连接到MySQL数据库:sqoop import --connect jdbc:mysql://localhost/test --username root --password root其中,--connect参数指定要连接的数据库的URL,--username和--password参数指定要使用的用户名和密码。
3. 导入数据连接到数据库之后,就可以使用Sqoop将数据导入到Hadoop中了。
可以使用以下命令将MySQL中的数据导入到Hadoop的HDFS中:sqoop import --connect jdbc:mysql://localhost/test --username root --password root --table employee --target-dir/user/hadoop/employee其中,--table参数指定要导入的表名,--target-dir参数指定导入数据的目标目录。
4. 导出数据除了将数据从关系型数据库中导入到Hadoop中,Sqoop还支持将Hadoop中的数据导出到关系型数据库中。
用Sqoop导入mysql到hive遇到的坑

坑1:同步数据后所有字段的值都为null经过分析发现,导致所有字段值为null的原因是在建立Hive表时设置的分隔符不正确。
与MySQL中的数据导入时的分隔符不一样,导致Hive无法正确切分数据,从而查询结果为空。
需要注意的是,这个过程并不属于导入失败,因此导入命令没有报错。
实际上,使用sqoop import将数据存储到了对应的HDFS路径上,而不是直接导入表中。
查询时,Hive会从HDFS 路径上提取数据,并根据Hive表的结构和定义展示类似表格的形式。
因此,导入过程并不会报错,但由于Hive定义的分隔符与存放在HDFS上的数据的分隔符不一致,所以查询结果全部为null。
您可以查看自己的Hive建表语句,如下所示:CREATE TABLE IF NOT EXISTS ods.test1 (id BIGINT,type_id INT,parent_id INT,name STRING,note_state INT)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;可以看到,分隔符为FIELDS TERMINATED BY ‘\t’,然而从PostgreSQL或者MySQL导入的数据分隔符应该是FIELDS TERMINATED BY ‘\u0001’。
因此,我们只需要将分隔符修改回来,就可以正常导入数据了。
您可以按照如下步骤删除表并重新建表,指定分隔符为FIELDS TERMINATED BY ‘\u0001’:DROP TABLE IF EXISTS ods.test1;CREATE TABLE IF NOT EXISTS ods.test1 (id BIGINT,type_id INT,parent_id INT,name STRING,note_state INT)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\u0001' STORED AS TEXTFILE;坑2:tinyint类型的字段值都为null在运行sqoop完成后,发现所有tinyint类型的字段始终为null。
《大数据技术原理与操作应用》第9章习题答案

第9章课后习题答案一、选择题1.下列语句中,描述错误的是( ) 。
A.可以通过 CLI 方式、Java Api 方式调用 Sqoop。
B.Sqoop 底层会将 Sqoop 命令转换为 MapReduce 任务,并通过 Sqoop 连接器进行数据的导入导出操作。
C.Sqoop 是独立的数据迁移工具,可以在任何系统上执行。
D.如果在Hadoop 分布式集群环境下,连接MySQL 服务器参数不能是“ localhost” 或“127. 0. 0. 1” 。
参考答案:C2.下列选项中,属于 Sqoop 命令的参数有() 。
A. importB. outputC. inputD. export参考答案:AD二、判断题1.Sqoop 工具的使用,依赖 Java 环境和 Hadoop 环境。
( )参考答案:对2.Sqoop 从 Hive 表导出 MySQL 表时,首先需要在 MySQL 中创建表结构。
( )参考答案:对3.如果没有指定“ --num-mappers 1”( 或“ -m 1”,即 Map 任务个数为“1”),那么在命令中必须还要添加“ --split-by” 参数。
( )参考答案:对4.如果指定了“ \n” 为 Sqoop 导入的换行符,当 MySQL 的某个 string 字段的值如果包含了“ \n”, 则会导致 Sqoop 导入多出一行记录。
( )参考答案:对5.在导入开始之前,Sqoop 使用 JDBC 来检查将要导入的表,检索出表中所有的列以及列的SQL 数据类型。
( )参考答案:对6.merge 是将两个数据集合并的工具,对于相同的 value 会覆盖新值。
( )参考答案:错7.metastore 文件的存储位置可以通过“conf / sqoop-site. xml” 配置文件修改。
()参考答案:对8.$CONDITIONS相当于一个动态占位符,动态的接收传过滤后的子集数据,然后让每个Map 任务执行查询的结果并进行数据导入。
基于大数据的高校学生画像系统探究与设计
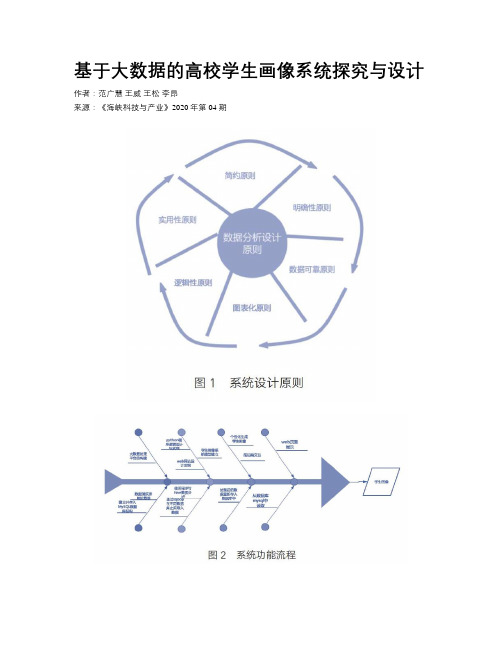
基于大数据的高校学生画像系统探究与设计作者:范广慧王威王松李昂来源:《海峡科技与产业》2020年第04期摘要:近年来,我国大数据技术发展迅速,并在很多方面得到应用,数据的价值越来越受到重视。
高校在教学过程中积累了大量的学生数据,该进一步思考,如何让这些数据转变为提高学生水平的宝贵资源。
本文在搭建Hadoop大数据平台基础上,对学生的生活数据、图书借阅数据、成绩数据等在内的多种数据,从多个角度去分析,刻画学生的行为和偏好习惯等,为学生进行画像,有助于学生对自己有一个全面客观的定位,也有助于学生管理部门精确管理和帮助学生,提高学生管理水平。
关键词:大数据;Hadoop;学生画像;数据分析中图分类号:TP311.5 文獻标识码:A随着互联网、大数据和人工智能技术的飞速发展,各行各业积累的数据被看作宝贵的矿藏,可从中挖掘出宝贵的信息资源,高校的学生数据也不例外,学生的各种生活数据(如餐饮、购物、上网时长、宿舍卫生分数等)、图书借阅数据、成绩数据等在内的多种数据,从多个角度去分析,刻画学生的行为和偏好习惯等,为学生进行画像,有助于学生对自己有一个全面客观的定位,也有助于学生管理部门精确管理和帮助学生,提高学生培养水平。
1 基于大数据的学生画像系统设计1.1 学生画像系统功能需求基于大数据的学生画像系统通过网络在Web网页上进行访问,架构分为三层:客户机—服务器—数据库模式,学生通过Web网页登录到自己的系统中,通过辨别每位同学的信息,程序自动从数据库中读取数据并实时通过程序设计生成该学生的各项数据如消费、学习、生活等,并根据该学生的数据生成年度或学期总结报告并且给予建议和意见,例如学生在借阅图书方面非常勤奋,就会对其进行鼓励和激励,若是学生在学业成绩上有多门挂科,就会对其进行学业警示并给予学习建议[1]。
通过本系统希望可以为学生们提供一个集学业统计、信息查询和年终总结等多功能于一体的学生画像系统。
1.2 学生画像系统性能需求1.2.1 海量数据的存储空间需求因为需要满足大量的存储需求和调用分析处理,所以选择使用MySQL数据库对数据进行存储,MySQL是当今市面上比较流行的关系型数据库,用python程序对MySQL进行调用较为方便快捷。
sqoop命令参数中文手册

Sqoop中文手册1.概述本文档主要对SQOOP的使用进行了说明,参考内容主要来自于Cloudera SQOOP的官方文档。
为了用中文更清楚明白地描述各参数的使用含义,本文档几乎所有参数使用说明都经过了我的实际验证而得到。
2.codegen将关系数据库表映射为一个Java文件、Java class类、以及相关的jar包,作用主要是两方面:1、将数据库表映射为一个Java文件,在该Java文件中对应有表的各个字段。
2、生成的Jar和class文件在metastore功能使用时会用到。
基础语句:sqoop codegen –connect jdbc:MySQL://localhost:3306/hive –usernameroot –password 123456 –table TBLS2参数说明–bindir <dir> 指定生成的java文件、编译成的class文件及将生成文件打包为JAR的JAR包文件输出路径–class-name <name> 设定生成的Java文件指定的名称–outdir <dir> 生成的java文件存放路径–package-name<name> 包名,如nic,则会生成cn和cnnic两级目录,生成的文件(如java文件)就存放在cnnic目录里–input-null-non-string<null-str> 在生成的java文件中,可以将null字符串设为想要设定的值(比如空字符串’’)–input-null-string<null-str> 同上,设定时,最好与上面的属性一起设置,且设置同样的值(比如空字符串等等)。
–map-column-java<arg> 数据库字段在生成的java文件中会映射为各种属性,且默认的数据类型与数据库类型保持对应,比如数据库中某字段的类型为bigint,则在Java文件中的数据类型为long型,通过这个属性,可以改变数据库字段在java中映射的数据类型,格式如:–map-column-java DB_ID=String,id=Integer–null-non-string<null-str> 在生成的java文件中,比如TBL_ID==null?”null”:””,通过这个属性设置可以将null字符串设置为其它值如ddd,TBL_ID==null?”ddd”:””–null-string<null-str> 同上,使用的时候最好和上面的属性一起用,且设置为相同的值–table <table-name> 对应关系数据库的表名,生成的java文件中的各属性与该表的各字段一一对应。
Hadoop大数据技术与项目实战知到章节答案智慧树2023年山西职业技术学院

Hadoop大数据技术与项目实战知到章节测试答案智慧树2023年最新山西职业技术学院绪论单元测试1.下列对大数据的特点描述不正确的是()参考答案:价值密度高第一章测试1.云主机和物理机的寿命都是永久性的。
()参考答案:错2.对于实时性要求高的应用,需要应用实时处理架构。
()参考答案:对3.数据仓库是用来存储数据的而不是分析数据的。
()参考答案:错4.在DWS层中,用户行为日志数据分为公共字段和事件字段。
()参考答案:对5.项目实施流程中没有哪一步()参考答案:下载数据6.数据分析在企业中的作用()参考答案:直接的获取经营的利润7.数据结构中哪项不是页面入口的来源()参考答案:登录页8.Hadoop的三大发行版本是()参考答案:HDP;CDH;Apache9.流量分析常见指标有哪些方面()参考答案:转化路径分析;来源分析;访客分析;受访分析10.网站流量数据分析的意义有哪些()参考答案:帮助提高网站流量;帮助网站运营人员获取网站流量信息;提升网站用户体验;从多方面提供网站分析的数据依据第二章测试1.Hadoop是一种分布式系统基础架构,主要解决海量数据存储和海量数据计算两大问题。
()参考答案:对2.在HDFS配置文件中,主要配置的就是hdfs-site.xml配置文件。
()参考答案:对3.在Hadoop分布式集群中,不需要对集群中的每一个节点都进行ip规划。
()参考答案:错4.利用HDFS操作命令可以将数据文件从本地上传到HDFS上,也可以将数据文件从HDFS下载到本地。
()参考答案:对5.在HDFS API操作中, closeFileSystem方法的功能是释放文件系统对象的资源。
()参考答案:对6.MapReduce词频统计案例中,执行map任务的最后阶段,会将缓冲区的数据全部写入到磁盘。
()参考答案:对7.Flume是Cloudera公司提供的一款高可用、高可靠、分布式的系统,可用于海量日志采集、聚合和传输。
Sqoop安装与使用(sqoop-1.4.5 on hadoop 1.0.4)

Sqoop安装与使用(sqoop-1.4.5 on hadoop 1.0.4) 1.什么是SqoopSqoop即SQL to Hadoop ,是一款方便的在传统型数据库与Hadoop之间进行数据迁移的工具,充分利用MapReduce并行特点以批处理的方式加快数据传输,发展至今主要演化了二大版本,Sqoop1和Sqoop2。
Sqoop工具是hadoop下连接关系型数据库和Hadoop的桥梁,支持关系型数据库和hive、hdfs,hbase之间数据的相互导入,可以使用全表导入和增量导入。
那么为什么选择Sqoop呢?高效可控的利用资源,任务并行度,超时时间。
数据类型映射与转化,可自动进行,用户也可自定义支持多种主流数据库,MySQL,Oracle,SQL Server,DB2等等2.Sqoop1和Sqoop2对比的异同之处两个不同的版本,完全不兼容版本号划分区别,Apache版本:1.4.x(Sqoop1);1.99.x(Sqoop2) CDH版本: Sqoop-1.4.3-cdh4(Sqoop1) ; Sqoop2-1.99.2-cdh4.5.0(Sqoop2) Sqoop2比Sqoop1的改进引入Sqoop server,集中化管理connector等多种访问方式:CLI,Web UI,REST API 引入基于角色的安全机制3.Sqoop1与Sqoop2的架构图Sqoop架构图1Sqoop架构图25.Sqoop的安装部署5.0 安装环境hadoop:hadoop-1.0.4sqoop:sqoop-1.4.5.bin__hadoop-1.0.05.1 下载安装包及解压tar -zxvf sqoop-1.4.5.bin__hadoop-1.0.0.tar.gzln -s ./package/sqoop-1.4.5.bin__hadoop-1.0.0/ sqoop 5.2 配置环境变量和配置文件cd sqoop/conf/mv sqoop-env-template.sh sqoop-env.shvi sqoop-env.sh在sqoop-env.sh中添加如下代码#Set path to where bin/hadoop is available#export HADOOP_COMMON_HOME=export HADOOP_COMMON_HOME=/home/hadoop/hadoop-2.2.0#Set path to where hadoop-*-core.jar is available#export HADOOP_MAPRED_HOME=export HADOOP_MAPRED_HOME=/home/hadoop/hadoop-2.2.0#set the path to where bin/hbase is available#export HBASE_HOME=export HBASE_HOME=/home/hadoop/hbase-0.96.2-hadoop2#Set the path to where bin/hive is available#export HIVE_HOME=export HIVE_HOME=/home/hadoop/apache-hive-0.13.1-bin#Set the path for where zookeper config dir is#export ZOOCFGDIR=export ZOOCFGDIR=/home/hadoop/zookeeper-3.4.5(如果数据读取不设计hbase和hive,那么相关hbase和hive的配置可以不加,如果集群有独立的zookeeper集群,那么配置zookeeper,反之,不用配置)。
1+x大数据试题+参考答案

1+x大数据试题+参考答案一、单选题(共80题,每题1分,共80分)1、关于Sqoop数据的导入导出描述不正确的是?()A、实现从MySQL到Hive的导入导出B、实现从MySQL到Oracle的导入导出C、实现从HDFS到Oracle的导入导出D、实现从HDFS到MySQL的导入导出正确答案:B2、关于ZooKeeper临时节点的说法正确的是?()A、创建临时节点的命令为:create -s /tmp myvalueB、临时节点允许有子节点C、一旦会话结束,临时节点将被自动删除D、临时节点不能手动删除正确答案:C3、下列关于调度器的描述不正确的是?()A、先进先出调度器可以是多队列B、容器调度器其实是多个FIFO队列C、公平调度器不允许管理员为每个队列单独设置调度策略D、先进先出调度器以集群资源独占的方式运行作业正确答案:A4、Hive 适合()环境A、Hive 适合关系型数据环境B、Hive 适合用于联机(online)事务处理C、适合应用在大量不可变数据的批处理作业D、提供实时查询功能正确答案:C5、下列哪些不是 ZooKeeper 的特点()A、可靠性B、顺序一致性C、多样系统映像D、原子性正确答案:C6、tar 命令用于对文件进行打包压缩或解压,-t 参数含义()A、查看压缩包内有哪些文件B、创建压缩文件C、向压缩归档末尾追加文件D、解开压缩文件正确答案:A7、下列哪些不是 HBase 的特点()A、高可靠性B、高性能C、面向列D、紧密性正确答案:D8、把公钥追加到授权文件的命令是?()A、ssh-addB、ssh-copy-idC、ssh-keygenD、ssh正确答案:B9、HDFS有一个gzip文件大小75MB,客户端设置Block大小为64MB。
当运行mapreduce任务读取该文件时input split大小为?A、64MBB、75MBC、一个map读取64MB,另外一个map读取11MB正确答案:B10、大数据平台实施方案流程中,建议整个项目过程顺序是()。
2022-3 大数据分析师(初级)考前冲刺题A1卷

信息素养培训平台2022.3 大数据分析师(初级)考前冲刺题A1卷1.【单选题】下面关于MapReduce任务描述不正确的是()。
A:不同的Map任务之间不会进行通信B:不同的Reduce任务之间也不会发生任何信息交换C:Map需要考虑数据全局性D:用户不能显式地从一台机器向另一台机器发送消息正确答案:C答案解析:在MapReduce工作工作中: 不同的Map任务之间不会进行通信。
不同的Reduce任务之间也不会发生任何信息交换。
Map需要考虑数据局部性,Reduce无需考虑数据局部性。
用户不能显式地从一台机器向另一台机器发送消息。
所有的数据交换都是通过MapReduce框架自身去实现的。
2.【单选题】下列不适用于大数据图计算的产品是()。
A:GraphXB:PregelC:FlumeD:PowerGraph正确答案:C答案解析:Flume是实时采集工具。
3.【单选题】利用Sqoop进行数据同步描述错误的是()。
A:将关系数据库数据导入HDFSB:将关系数据库数据导入HiveC:将关系数据库数据导入HBaseD:将HDFS数据导入Hive正确答案:D答案解析:Sqoop是一款开源的工具,主要用于在Hadoop与传统的关系数据库间进行数据的传递4.【单选题】散点图用于展示数据的相关性和分布关系,由X轴和Y轴两个变量组成。
通过因变量(Y轴数值)随自变量(X轴数值)变化的呈现数据的大致趋势,同时支持从类别和颜色两个维度观察数据的分布情况。
散点图支持()坐标系。
A:一维B:二维C:三维D:四维正确答案:B答案解析:散点图用于描述二维数据之间的关系。
5.【单选题】下列属于图形数据库的是()。
A:HBaseB:MongoDBC:Neo4JD:Oracle正确答案:C答案解析:图数据库的相关产品包括:Neo4J、OrientDB、InfoGrid、GraphDB等。
6.【单选题】哪种图形用于表示三维数据()。
1+x大数据试题库及答案

1+x大数据试题库及答案一、单选题(共90题,每题1分,共90分)1、名称节点(NameNode)是HDFS的管理者,它的职责有3个方面,下面哪个选项不是NamdeNode的职责?()A、负责保存数据块B、负责管理和维护HDFS的命名空间(NameSpace)C、接收客户端的请求D、管理DataNode上的数据块(Block)正确答案:A2、Sqoop的底层实现是()?A、HDFSB、HbaseC、MapReduceD、Hadoop正确答案:C3、下面哪个程序负责 HDFS 数据存储?()A、tasktrackerB、NameNodeC、JobtrackerD、secondaryNameNodeE、Datanode正确答案:E4、对于HDFS文件读取过程,描述不正确的是?()A、通过对数据流反复调用read(.方法,把数据从数据节点传输到客户端B、HDFS客户端通过Configuration对象的open(.方法打开要读取的文件C、当客户端读取完数据时,调用FSDataInputStream对象的close(.方法关闭输入流D、DistributedFileSystem负责向远程的名称节点(NameNode)发起RPC调用,得到文件的数据块信息,返回数据块列表正确答案:B5、大数据分析平台的实施流程顺序是()。
A与甲方确定总体计划B组建项目团队C部署环境准备D应用集成及数据集成E 系统安装和调试A、BACEDB、DABCEC、CABEDD、ADCBE正确答案:A6、HDfS中的block默认保存几份?A、3份B、2份C、1份D、不确定正确答案:A7、以下选项哪个是 YARN 中动态创建的资源容器()A、ApplicationMasterB、NodeManagerC、ResourceManagerD、Container正确答案:D8、以下对数据节点理解错误的是 ( .A、数据节点的数据保存在磁盘中B、数据节点通常只有一个C、数据节点在名称节点的统一调度下进行数据块的创建、删除和复制等操作D、数据节点用来存储具体的文件内容正确答案:B9、2003年,Google公司发表了主要讲解海量数据的可靠存储方法的论文是?()A、“The Google File System”B、“MapReduce: Simplified Data Processing on Large Clusters”C、“The Hadoop File System”D、“Bigtable: A Distributed Storage System for Structured Data”正确答案:A10、列出mysql数据库中的所有数据库sqoop命令是?()A、sqoop create-hive-table –connectB、sqoop list-databases –connectC、sqoop list-tables –connectD、sqoop import –connect正确答案:B11、Hadoop完全分布模式配置免密登录是要?()A、实现主节点到其他节点免密登录B、以上都不是C、实现从节点到主节点的免密登录D、主节点和从节点任意两个节点之间免密登录正确答案:D12、列出mysql数据库中的所有数据库sqoop命令是?A、sqoop list-tables –connectB、sqoop import –connectC、sqoop list-databases –connectD、sqoop create-hive-table –connect正确答案:C13、典型的 NoSQL 数据库是()A、HbaseB、OracleC、MySQLD、Hive正确答案:A14、在 HDFS 分布式文件系统中,一般采用冗余存储,冗余因子通常设置为()A、4B、2C、3D、1正确答案:C15、关于ZooKeeper顺序节点的说法正确的是?()A、通过顺序节点,可以创建分布式系统唯一IDB、创建顺序节点的命令为:create /test value1C、创建顺序节点时不能连续执行创建命令,否者报错节点已存在D、顺序节点的序号能无限增加正确答案:A16、把公钥追加到授权文件的命令是?()A、ssh-copy-idB、ssh-keygenC、sshD、ssh-add正确答案:A17、下列哪些不是 ZooKeeper 的特点()A、可靠性B、顺序一致性C、多样系统映像D、原子性正确答案:C18、下面就Zookeeper的配置文件zoo.cfg的一部分,请问initLimit 表示的含义是?()TickTime=2000InitLimit=10SyncLimit=5A、Leader-Follower初始通信时限B、Client-Server初始通信时限C、Leader-Follower同步通信时限D、Client-Server通信心跳时间正确答案:A19、在确认客户需求,进行确认需求调研的时候,以下说法正确的是()。
10_尚硅谷大数据之Sqoop

第10章Sqoop10.1 Sqoop概述Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如:MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache 项目。
最新的稳定版本是1.4.7。
Sqoop2的最新版本是1.99.7。
请注意,1.99.7与1.4.7不兼容,且没有特征不完整,它并不打算用于生产部署。
10.2 Sqoop下载与安装10.2.1 Sqoop安装地址1)Sqoop官网地址:/2)文档查看地址:/docs/1.4.7/index.html3)下载地址:https:///apache/sqoop/1.4.7/10.2.2 Sqoop安装部署1) 把sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz上传到linux的/opt/software目录下2) 解压sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz到/opt/module/目录下[atguigu@hadoop102 software]$ tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/module/3) 修改sqoop-1.4.7.bin__hadoop-2.6.0的名称为sqoop[atguigu@hadoop102 software]$ mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop4) 修改/opt/module/sqoop/conf目录下的sqoop-env-template.sh名称为sqoop-env.sh[atguigu@hadoop102 software]$ mv sqoop-env-template.sh sqoop-env.sh[atguigu@hadoop102 software]$ mv sqoop-site-template.xml sqoop-site.xml5)配置sqoop-env.sh文件export HADOOP_COMMON_HOME=/opt/module/hadoop-2.7.2export HADOOP_MAPRED_HOME=/opt/module/hadoop-2.7.2export HIVE_HOME=/opt/module/hiveexport ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10export ZOOCFGDIR=/opt/module/zookeeper-3.4.1010.2.3 添加JDBC驱动拷贝/opt/software/mysql-libs/mysql-connector-java-5.1.27目录下的mysql-connector-java-5.1.27-bin.jar到/opt/module/sqoop/lib/[atguigu@hadoop102 mysql-connector-java-5.1.27]$ cp mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop/lib/10.2.4验证Sqoop我们可以通过某一个command来验证sqoop配置是否正确:10.2.5测试Sqoop是否能够成功连接数据库10.3 导入数据在Sqoop中,“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,HIVE,HBASE)中传输数据,叫做:导入,即使用import关键字。
sqoop面试题

sqoop⾯试题1.1 Sqoop 在⼯作中的定位是会⽤就⾏1.1.1 Sqoop导⼊数据到hdfs中的参数1. /opt/module/sqoop/bin/sqoop import \2. --connect \ # 特殊的jdbc连接的字符串3. --username \4. --password \5. --target-dir \ # hdfs⽬标的⽬录6. --delete-target-dir \ # 导⼊的⽬标⽬录如果存在则删除那个⽬录7. --num-mappers \ #相当于 -m ,并⾏导⼊时map task的个数8. --fields-terminated-by \9. --query "$2" ' and $CONDITIONS;' # 指定满⾜sql和条件的数据导⼊1.1.2 Sqoop导⼊hive时的参数⼀步将表结构和数据都导⼊到hive中1. bin/sqoop import \2. --connect jdbc的url字符串 \3. --table mysql中的表名\4. --username 账号 \5. --password 密码\6. --hive-import \7. --m mapTask的个数\8. --hive-database hive中的数据库名;1.1.3 Rdbms中的增量数据如何导⼊?1. --check-column 字段名 \ #指定判断检查的依据字段2. --incremental 导⼊模式\ # ⽤来指定增量导⼊的模式(Mode),append和lastmodified3. --last-value 上⼀次导⼊结束的时间\4. --m mapTask的个数 \5. --merge-key 主键补充:·如果使⽤merge-key合并模式如果是新增的数据则增加,因为incremental是lastmodified模式,那么当有数据更新了,⽽主键没有变,则会进⾏合并。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3. 创建与mysql中指定表结构相同的hive表
sqoop create-hive-table --connect jdbc:mysql://192.168.1.10/testdb --username chroot --password chcloud --table channel --fields-terminated-by '\t'
4. 用SQL的语句形式将MySQL数据库表中数据导入到HDFS中
sql语句中必须有where $CONDITIONS
sqoop import --connect jdbc:mysql://192.168.1.10/testdb --username chroot --password chcloud --query 'select distinct username, channel from user_test where $CONDITIONS' --split-by username --target-dir /user/query/ -m 1
stored as textfile
location'/user/root/timeslot_hour';
mysql -h 192.168.1.10 -uchiq_voice -pchiq_voice --default-character-set=gb2312 -B -e 'select * from bd_chiq.bd_chiq_appstore_activation;' > /opt/tnn/data/bd_chiq_appstore_activation.xls
-------------
-------------hive表不能是“stored as RCFile” textfile应该可以。。。。RCFile导入数据会导不进去,直接进入默认hdfs路径下
1. mysql————>hdfs
(hdfs目录存在的话会报错)
sqoop import --connect jdbc:mysql://192.168.1.10/testdb --username chroot --password chcloud --table user_test --target-dir /warehouse/test_tn.db/test -m 1
2. mysql————>hive
---HDFS默认路径下:/user/当前用户名/表名; hive表也默认,不在任何数据库里:
sqoop import --connect jdbc:mysql://172.168.234.31/bd_chiq --username etl --password etl --table whole_active_data_hive --hive-import -m 1
---指定具体数据库及表名,并覆盖 (mysql表和hive表结构相同)
sqoop import --connect jdbc:mysql://172.168.234.31/bd_chiq --username etl --password etl --table whole_active_data_hive --fields-terminated-by '\t' --hive-import --hive-table black_goods_data.whole_active_data --hive-overwrite -m 1
5. 用SQL的语句形式将MySQL数据库表中数据导入到hive中
也要指明路径
sqoop import --connect jdbc:mysql://118.123.227.19:3306/wggetl --username wggetl --password wggetl -e'select * from x where $CONDITIONS' --target-dir /warehouse/tag_system.db/mid_fridge_food_management --hive-import --hive-table tag_system.mid_fridge_food_management --fields-terminated-by '\t' --hive-overwrite -m 1
hadoop fs -put record1.txt /warehouse/test_tn.db/tnn/record
create table timeslot_hour(timeslot string, hour int)
row format delimited fields terminated by ','
hadoop fs -rm /warehouse/test_tn.db/tnn/test.txt
hadoop fs -put record1.txt /warehouse/test_tn.db/tnn/record1
hadoop fs -copyFromLocal usercount.txt hdfs://localhost/root/us--------
--------------
select 'global' as cid, 'barcode' as idtype, devsn as id, GROUP_CONCAT(type) as food_management, replace(date_sub(CURRENT_DATE(),interval 1 day),'-','') as updatetime, date_sub(CURRENT_DATE(),interval 1 day) as p_log_date from (select distinct devsn, case when type='剩菜' then '剩菜剩饭' when type='Vegetables' then '蔬菜' when type='1' then '蔬菜' when type='Others' then '其他' else type end as type from ingredients_history where CAST(savetime AS date)>=date_sub(CURRENT_DATE(),interval 30 day)) w group by devsn
6. hive-->mysql:
sqoop export --connect jdbc:mysql://172.168.234.31/bd_chiq --username etl --password etl --table whole_active_data_hive --input-fields-terminated-by '\t' --export-dir /warehouse/black_goods_data.db/whole_active_data