自然语言处理_Dataset Used in the Co-training Experiments for COLT 98(COLT98联合训练实验数据集)
人工智能自然语言技术练习(习题卷9)

人工智能自然语言技术练习(习题卷9)第1部分:单项选择题,共45题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]如何理解NNLM这个模型,它是一个什么样的模型A)基于统计的语言模型B)基于神经网络的语言模型C)预训练模型D)编解码模型答案:C解析:2.[单选题]文本文件中存储的其实并不是我们在编辑器里看到的一个个的字符,而是字符的()。
A)内码B)外码C)反码D)补码答案:A解析:3.[单选题]数据可视化data visualization,导入_哪个包?A)A: sklearn.linear_modelB)B: sklearn.model_selectionC)C: matplotlib.pylabD)D: sklearn.metrics答案:D解析:4.[单选题]dropout作为常用的函数,它能起到什么作用A)没有激活函数功能B)一种正则化方式C)一种图像特征处理算法D)一种语音处理算法答案:B解析:5.[单选题]以下四个描述中,哪个选项正确的描述了XGBoost的基本核心思想A)训练出来一个一次函数图像去描述数据B)训练出来一个二次函数图像去描述数据C)不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数f(x),去拟合上次预测的残差。
D)不确定答案:C解析:C)LSTM 神经网络模型使用门结构实现了对序列数据中的遗忘与记忆D)使用大量的文本序列数据对 LSTM 模型训练后,可以捕捉到文本间的依赖关系,训练好的模型就可以根据指定的文本生成后序的内容答案:B解析:7.[单选题]relu函数的作用是可以将小于()的数输出为0A)-1B)0C)1D)x答案:B解析:8.[单选题]以下不是语料库的三点基本认识的是A)语料库中存放的是在语言的实际使用中真实出现出的语言材料。
B)语料库是以电子计算机为载体承载语言知识的基本资源,并不等于语言知识。
C)真实语料需要经过加工(分析和处理),才能成为有用的资源。
基于迁移学习的自然语言处理研究

基于迁移学习的自然语言处理研究自然语言处理(Natural Language Processing, NLP)是人工智能(AI)领域中的一个重要分支。
它致力于让计算机理解、处理和生成人类语言,尤其是语言中的意义。
然而,NLP的复杂性却导致了其研究的挑战性和困难度。
随着近年来深度学习和人工智能技术的快速发展,基于迁移学习的NLP研究已经成为了一个备受关注的领域。
本文将介绍什么是迁移学习、迁移学习在NLP中的应用和取得的成果。
一、什么是迁移学习迁移学习是一种机器学习方法,它通过将已训练好的模型迁移到新任务上,以提高新任务的性能。
通俗地讲,迁移学习就是将一个模型从一个问题上"迁移"到另一个问题上。
比如,在降低交通事故风险的问题中,我们可以通过将已有的关于人的驾驶行为的数据"迁移"到车辆自动驾驶系统中,提高自动驾驶系统的性能。
迁移学习的核心就是,通过利用源领域的知识,来更好地完成目标领域中的任务。
在迁移学习中,源领域和目标领域可以是不同的,但在理论和实际应用中,选择适当的源领域和适当的迁移方式是非常重要的。
二、迁移学习在NLP中的应用NLP是一个非常复杂的领域。
它涉及许多不同的子任务,如文本分类、命名实体识别、情感分析、机器翻译等。
对于每一个子任务,需要从人类语言中抽象出相应的特征或规则来,然后用这些特征或规则来解决各种各样的问题。
对于不同的子任务,提取的特征或规则是不同的。
因此,每一个子任务都需要从头开始训练模型,这对于计算机资源和时间都是一个巨大的浪费。
迁移学习的思想为我们提供了一个解决方案。
NLP中的迁移学习主要基于两个方面:一方面是语言模型,也称为词向量模型;另一方面是预训练模型。
1. 语言模型语言模型是NLP中的一个重要概念。
它提供了一种方法来计算出一个句子序列的概率。
比如,对于一个句子"我喜欢吃苹果",语言模型就可以计算出这个句子的概率。
人工智能导论-第四课自然语言处理
研究表示,在大脑皮层中局部回路的基本连接 可以通过一系列的互联规则所捕获,而且这些 规则在大脑皮层中处于不断循环之中。
模拟人脑利用历史信息来做决策
两种不同神经网络的缩写。
时间递归神经网络(recurrent neural network) 结构递归神经网络(recursive neural network)
无法对词向量做比较,任意两个词之间都是孤立的
34
自然语言处理
词向量
使用上下文来表示单词
使用共现矩阵(Cooccurrence matrix) 一个基于窗口的共现矩阵例子
窗口长度是1(一般是5-10) 语料样例
▪ I like deep learning. ▪ I like NLP. ▪ I enjoy flying
7
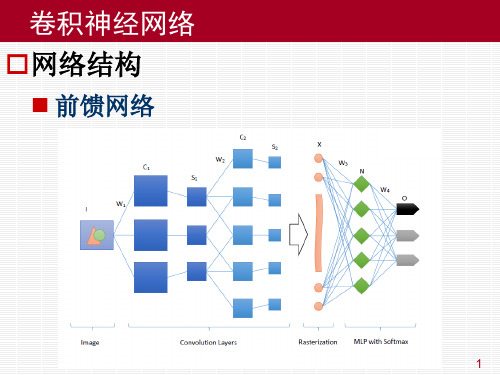
卷积神经网络 卷积网络训练过程
反向传播过程
从高层到底层,逐层进行分析
光栅化层 ▪ 从上一层传过来的残差为
▪ 重新整理成为一系列矩阵即可,若上一层 Q 有 q 个 池化核,则传播到池化层的残差为
8
卷积神经网络 卷积网络训练过程
反向传播过程
从高层到底层,逐层进行分析
池化层 ▪ 应池化过程中常用的两种池化方案,反传残差的时 候也有两种上采样方案 ▪ 最大池化:将1个点的残差直接拷贝到4个点。 ▪ 均值池化:将1个点的残差平均到4个点。 ▪ 传播到卷积层的残差为
9
卷积神经网络 卷积网络训练过程
反向传播过程
从高层到底层,逐层进行分析
卷积层 ▪ 卷积层有参数,所以卷积层的反传过程需要更新权 值,并反传残差。 ▪ 先考虑权值更新,考虑卷积层某个“神经中枢”中 的第一个神经元 ▪ 多层感知器的梯度公式
自然语言处理_Question-AnswerDataset(试题答案数据集)

⾃然语⾔处理_Question-AnswerDataset(试题答案数据集)Question-Answer Dataset(试题答案数据集)数据摘要:This page provides a link to a corpus of Wikipedia articles, manually-generated factoid questions from them, and manually-generated answers to these questions, for use in academic research. These data were collected by Noah Smith, Michael Heilman, Rebecca Hwa, Shay Cohen, Kevin Gimpel, and many students at Carnegie Mellon University and the University of Pittsburgh between 2008 and 2010.中⽂关键词:问题,答案,数据集,语料库,⼿⼯⽣成,英⽂关键词:questions,answers,Dataset,corpus,questions,manually-generated,数据格式:TEXT数据⽤途:Information Processing,Academic Research数据详细介绍:Question-Answer DatasetThis page provides a link to a corpus of Wikipedia articles, manually-generated factoid questions from them, and manually-generated answers to these questions, for use in academic research. These data were collected by Noah Smith, Michael Heilman, Rebecca Hwa, Shay Cohen, Kevin Gimpel, and many students at Carnegie Mellon University and the University of Pittsburgh between 2008 and 2010.DownloadManually-generated factoid question/answer pairs with difficulty ratings from Wikipedia articles. Dataset includes articles, questions, and answers.Version 1.1 released August 6, 2010README.v1.1; Question_Answer_Dataset_v1.1.tar.gzArchived ReleasesVersion 1.0 released February 18, 2010README.v1.0; Question_Answer_Dataset_v1.0.tar.gzFurther ReadingPlease cite this paper if you write any papers involving the use of the data above: Question Generation as a Competitive Undergraduate Course ProjectNoah A. Smith, Michael Heilman, and Rebecca HwaIn Proceedings of the NSF Workshop on the Question Generation Shared Task and Evaluation Challenge, Arlington, VA, September 2008.AcknowledgmentsThis research project was supported by NSF IIS-0713265 (to Smith), an NSF Graduate Research Fellowship (to Heilman), NSF IIS-0712810 and IIS-0745914 (to Hwa), and Institute of Education Sciences, U.S. Department of Education R305B040063 (to Carnegie Mellon).数据预览:点此下载完整数据集。
抽取式机器阅读理解研究综述

20215712机器阅读理解(Machine Reading Comprehension,MRC)是自然语言处理(Natural Language Processing,NLP)领域的热门研究方向,利用机器对数据集中的文本内容进行理解和分析,回答提出的问题,能够最大程度地评估机器理解语言的能力。
目前,MRC任务一般分为填空式、选择式、抽取式、生成式和多跳推理式5类[1]。
在过去的数十年中,涌现出许多在限定领域的MRC应用,例如智慧城市、智能客服、智能司法系统以及智能教育系统。
抽取式机器阅读理解是MRC任务中重要的一类,其主要利用给定的文本内容和相关问题,通过对文本内容的分析和理解,给出正确的答案。
该任务需要预测出答案的起止位置从而选出答案片段,通常也被称为跨距预测或者片段预测[2]。
抽取式MRC任务中的问题一般抽取式机器阅读理解研究综述包玥,李艳玲,林民内蒙古师范大学计算机科学技术学院,呼和浩特010022摘要:机器阅读理解要求机器能够理解自然语言文本并回答相关问题,是自然语言处理领域的核心技术,也是自然语言处理领域最具挑战性的任务之一。
抽取式机器阅读理解是机器阅读理解任务中一个重要的分支,因其更贴合实际情况,更能够反映机器的理解能力,成为当前学术界和工业界的研究热点。
对抽取式机器阅读理解从以下四个方面进行了全面地综述:介绍了机器阅读理解任务及其发展历程;介绍了抽取式机器阅读理解任务以及其现阶段存在的难点;对抽取式机器阅读理解任务的主要数据集及方法进行了梳理总结;讨论了抽取式机器阅读理解的未来发展方向。
关键词:抽取式机器阅读理解;自然语言处理;深度学习;迁移学习;注意力机制文献标志码:A中图分类号:TP391.1doi:10.3778/j.issn.1002-8331.2102-0038Review of Extractive Machine Reading ComprehensionBAO Yue,LI Yanling,LIN MinCollege of Computer Science and Technology,Inner Mongolia Normal University,Hohhot010022,ChinaAbstract:Machine reading comprehension requires machines to understand natural language texts and answer related questions,which is the core technology in the field of natural language processing and one of the most challenging tasksin the field of natural language processing.Extractive machine reading comprehension is an important branch of machine reading comprehension task.Because it is more suitable for the actual situation and can reflect the understanding ability of the machine,it has become a research hotspot in the current academic and industrial circles.This paper makes a compre-hensive review of extractive machine reading comprehension from four aspects,first of all,the paper introduces the task of machine reading comprehension and its development process.Secondly,it describes the task of extractive machine reading comprehension and its difficulties at present.Then,the main data sets and methods of the extractive machine read-ing comprehension task are summarized.Finally,the future development direction of extractive machine reading compre-hension is discussed.Key words:extractive machine reading comprehension;natural language processing;deep learning;transfer learning; attention mechanism基金项目:国家自然科学基金(61806103,61562068);内蒙古纪检监察大数据实验室开放课题(IMDBD2020013);内蒙古自治区“草原英才”工程青年创新创业人才项目;内蒙古师范大学研究生创新基金(CXJJS20127);内蒙古自治区科技计划(JH20180175);内蒙古自治区高等学校科学技术研究项目(NJZY21578,NJZY21551)。
cog一级功能和二级功能分类

cog一级功能和二级功能分类Cog一级功能和二级功能分类一、Cog一级功能分类1. 自然语言处理(Natural Language Processing, NLP)- 文本识别与解析(Text Recognition and Parsing):能够识别和解析输入的文本,提取其中的关键信息。
- 文本生成与合成(Text Generation and Synthesis):能够根据输入的要求和条件生成符合语法规则且意义明确的文本。
- 语义理解与推理(Semantic Understanding and Reasoning):能够理解文本的语义,并进行推理和逻辑分析。
2. 计算机视觉(Computer Vision)- 图像识别与分类(Image Recognition and Classification):能够识别和分类输入的图像,识别其中的对象、场景或特征。
- 目标检测与跟踪(Object Detection and Tracking):能够检测和跟踪图像或视频中的目标,并标注其位置和轨迹。
- 图像生成与合成(Image Generation and Synthesis):能够根据输入的条件和要求生成新的图像,具有一定的创造性。
3. 机器学习与深度学习(Machine Learning and Deep Learning) - 模型训练与调优(Model Training and Tuning):能够根据给定的数据集训练模型,并通过调优提高模型的性能。
- 特征提取与降维(Feature Extraction and Dimensionality Reduction):能够从原始数据中提取有用的特征,并降低数据的维度。
- 模型评估与预测(Model Evaluation and Prediction):能够评估模型的性能,对新的数据进行预测并给出相应的概率或置信度。
4. 自动化与控制(Automation and Control)- 过程监测与控制(Process Monitoring and Control):能够监测和控制系统或过程的状态和行为,实现自动化的控制和优化。
DS501数据科学家直通车【第九版】2018年7月

DS501数据科学家直通车课程大纲(第九版)数据科学家直通车项目旨在帮助学员全面提升能力,斩获心仪的数据科学offer课时安排【第一节课】(课程主页免费注册)2018年7月28日 7:00 pm (PST ) 2018年7月28日 10:00 pm (EST )2018年7月29日 10:00 am (北京时间)【课程安排】课程长度: 3 个月 开课时间: 8/3/2018 - 10/24/2018 (美国时间) 课程时长: 6 小时/周 授课语言:中文课程名称美西时间美东时间北京时间理论串讲 周五 7:00 pm - 9:00 pm 周五 10:00 pm - 12:00 am 周六 10:00 am - 12:00 pm 项目面试实战周六 7:00 pm - 9:00 pm 周六 10:00 pm - 12:00 am 周日 10:00 am - 12:00 pm面试解析和项目拓展答疑 周二 7:00 pm - 9:00 pm 周二 10:00 pm - 12:00 am 周三 10:00 am - 12:00 pm课程负责人课程组老师:J ack❏Career Consultation 指导老师 ❏BitTiger 课程负责人❏帮助上百学员制定目标和计划 ❏擅长背景分析、战略定位联系方式微信账号: techisawesome 电子邮件: jack@bittiger.io学习路径课前准备: 基础课程数据科学家直通车要求学员具备一定的数理统计知识以及基础编程能力。
为了保证学员在直播课程中的学习质量,BitTiger提供以下基础学习资源,请学员在课前提前学习。
课程内容课程要点数据科学理论基础●Matrix Basics矩阵基础●Statistics and Probability统计概率基础●Machine Learning理论基础数据分析工具●Python语言基础与应用●R语言基础与应用●SQL基础与应用●数据可视化Tableau的使用●大数据分析工具MapReduce、Hadoop、Hive●Spark for Data Science with Python数据分析常见应用及技术介绍●广告搜索内部原理●深度学习及无人车●推荐系统●Airbnb大数据预测Phase 1: Lending Club风险评估项目(R)及项目面试实战【项目介绍】随着Fintech行业以及P2P网贷产业的快速发展,风险分析(Loan Risk Analysis)成为了网贷平台避免投资损失,实现投资回报的重要指标之一。
自然语言处理实验—文本分类

自然语言处理实验—文本分类
实验目的:
文本分类是自然语言处理中的重要任务之一,旨在将文本按照预定义的类别进行分类。
本实验旨在使用自然语言处理技术,对给定的文本数据集进行分类。
实验步骤:
1. 数据集准备:选择合适的文本数据集作为实验数据,确保数据集包含已经标注好的类别信息。
2. 数据预处理:对文本数据进行预处理,包括去除特殊字符、分词、停用词处理、词形还原等步骤。
3. 特征提取:选择合适的特征提取方法,将文本转化为向量表示。
常用的特征提取方法包括词袋模型、TF-IDF等。
4. 模型选择:选择合适的分类模型,如朴素贝叶斯、支持向量机、深度学习模型等。
5. 模型训练:使用训练集对选择的分类模型进行训练。
6. 模型评估:使用测试集对训练好的分类模型进行评估,计算分类准确率、精确率、召回率等指标。
7. 结果分析:分析实验结果,对分类结果进行调整和改进。
注意事项:
1. 数据集的选择应该符合实验目的,且包含足够的样本和类别信息。
2. 在预处理和特征提取过程中,需要根据实验需求进行适当的调整
和优化。
3. 模型选择应根据实验数据的特点和要求进行选择,可以尝试多种模型进行比较。
4. 在模型训练和评估过程中,需要注意模型的调参和过拟合问题,并及时进行调整。
5. 结果分析过程可以包括对错分类样本的分析,以及对模型的改进和优化思路的探讨。
实验结果:
实验结果包括模型的分类准确率、精确率、召回率等指标,以及对实验结果的分析和改进思路。
根据实验结果,可以对文本分类问题进行更深入的研究和探讨。
与人工智能相关的英语单词

与人工智能相关的英语单词1. Artificial Intelligence (AI): 人工智能,它是计算机科学的分支,旨在模拟人类的智能和思维。
AI包括机器学习、自然语言处理、计算机视觉等技术,这些技术可以用于创建智能机器人、智能助理、自动驾驶汽车等。
举例:Google's AI language model can answer complex questions and translate text between languages.2. Machine Learning (ML): 机器学习是AI的一个分支,它是指通过计算机程序从数据中学习并做出决策。
ML使用算法来分析大量数据并自动识别模式和趋势,从而进行预测和分类。
举例:Amazon's ML algorithm can predict which products a customer might be interested in based on their previous purchases and browsing history.3. Natural Language Processing (NLP): 自然语言处理是AI的一个分支,它是指将人类语言转化为计算机可理解的形式。
NLP包括文本分析、情感分析、语音识别等技术,这些技术可以用于创建聊天机器人、语音助手、自动翻译等。
举例:Apple's Siri can understand and respond to human speech through NLP technology.4. Computer Vision (CV): 计算机视觉是AI的一个分支,它是指将图像转化为计算机可理解的形式。
CV包括图像识别、目标检测、人脸识别等技术,这些技术可以用于创建智能监控系统、自动驾驶汽车、智能家居等。
举例:Facebook's CV technology can identify and tag friends in photos posted on the social network.5. Deep Learning (DL): 深度学习是机器学习的一个分支,它是指使用深度神经网络进行学习。
自然语言处理 文字 型号提取 训练

自然语言处理文字型号提取训练自然语言处理(Natural Language Processing,NLP)是人工智能领域中的一个重要研究方向,它致力于使机器能够处理和理解人类语言。
在NLP的研究中,文字型号提取是一个关键的任务,它涉及从文本中抽取出具有特定意义的信息。
文字型号提取是指从文本中识别和提取出特定的型号信息。
这些型号可以是日期、时间、地址、电话号码、电子邮件地址等。
在许多实际应用中,需要从大量文本中提取出这些型号信息,以便进行后续的分析和处理。
例如,在信息抽取、舆情分析、智能客服等领域,文字型号提取都发挥着重要作用。
为了进行文字型号提取,一般需要使用机器学习的方法进行训练。
首先,需要构建一个合适的训练数据集,其中包含了标注了型号信息的文本样本。
然后,可以使用各种机器学习算法进行模型训练,以学习从文本中提取出型号信息的规律和模式。
常用的机器学习算法包括支持向量机(Support Vector Machine,SVM)、决策树(Decision Tree)、随机森林(Random Forest)等。
这些算法在文字型号提取任务中具有较好的效果,可以根据具体的应用场景选择合适的算法进行训练。
除了传统的机器学习算法,近年来深度学习技术在文字型号提取任务中也取得了很大的进展。
深度学习模型如循环神经网络(Recurrent Neural Network,RNN)和长短时记忆网络(Long Short-Term Memory,LSTM)等在处理自然语言时能够更好地捕捉上下文信息,从而提升文字型号提取的准确性。
在进行文字型号提取任务时,还需要考虑到一些实际问题。
首先,文本数据的质量对型号提取的准确性有着重要影响,因此需要进行文本清洗和预处理,去除一些无关的信息和噪声。
其次,对于一些复杂的型号,可能需要结合领域知识进行特定的规则设计,以提高型号提取的效果。
此外,对于不同语种的文本,需要使用相应的语言模型进行处理,以确保准确性和鲁棒性。
自然语言处理实验报告

自然语言处理实验报告一、实验背景自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,旨在使计算机能够理解、解释和生成人类语言。
在本次实验中,我们将探讨NLP在文本分类任务上的应用。
二、实验数据我们选取了一个包含新闻文本的数据集作为实验数据,共包括数千条新闻文本样本,每个样本均有对应的类别标签,如政治、经济、体育等。
三、实验步骤1. 数据预处理:首先对文本数据进行清洗,如去除标点符号、停用词和数字等干扰项,然后对文本进行分词处理。
2. 特征提取:选取TF-IDF(Term Frequency-Inverse Document Frequency)作为特征提取方法,将文本表示为向量形式。
3. 模型选择:本次实验中我们选择了朴素贝叶斯分类器作为文本分类的基本模型。
4. 模型训练:将数据集按照8:2的比例划分为训练集和测试集,用训练集对模型进行训练。
5. 模型评估:使用测试集对训练好的模型进行评估,计算准确率、召回率和F1值等指标。
四、实验结果经过多次实验和调优,我们最终得到了一个在文本分类任务上表现良好的模型。
在测试集上,我们的模型达到了90%以上的准确率,表现优异。
五、实验总结通过本次实验,我们深入了解了自然语言处理在文本分类任务上的应用。
同时,我们也发现了一些问题和改进空间,如模型泛化能力不足、特征选择不合适等,这些将是我们未来研究的重点方向。
六、展望未来在未来的研究中,我们将进一步探索不同的特征提取方法和模型结构,以提升文本分类的准确率和效率。
同时,我们还将探索深度学习等新领域的应用,以更好地解决自然语言处理中的挑战和问题。
七、参考文献1. Jurafsky, D., & Martin, J. H. (2019). Speech and Language Processing (3rd ed.). Pearson.2. Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press.以上为自然语言处理实验报告的内容,希望对您有所帮助。
如何在Python中进行自然语言处理和文本挖掘

如何在Python中进行自然语言处理和文本挖掘自然语言处理(Natural Language Processing,简称NLP)是计算机科学和人工智能领域中一门研究人类语言和计算机之间互动的学科。
它旨在使计算机能够理解、解释和生成人类语言的信息。
文本挖掘(Text Mining)是NLP的一个分支,着重于从大量文本数据中发现并提取有价值的知识和信息。
在Python中,有许多流行的库和工具可用于进行自然语言处理和文本挖掘。
下面将介绍一些常用的库和一般的处理流程。
1. NLTK (Natural Language Toolkit):这是一个广泛使用的自然语言处理库,提供了丰富的功能和数据集。
可以使用NLTK进行分词、词性标注、句法分析、语义分析等常见任务。
2. spaCy:这是一个高度优化的自然语言处理库,特点是速度快且易于使用。
它提供了一些先进的功能,如实体识别、命名实体识别和依存句法分析。
3. TextBlob:这是一个易于使用的库,建立在NLTK之上,提供了简洁的API和一些常见的自然语言处理任务的功能,如情感分析和文本分类。
4. Gensim:这是一个用于主题建模和文本相似度分析的库。
它提供了一些算法和工具,包括TF-IDF、LSI(Latent Semantic Indexing)和LDA(Latent Dirichlet Allocation)等。
5. Scikit-learn:这是一个广泛使用的机器学习库,可以用于文本分类、聚类、特征提取等任务。
它提供了一些常用的文本预处理步骤,如向量化和标准化等。
下面是一个处理文本数据的一般流程:1.数据预处理:首先,需要对文本数据进行一些基本的清洗和处理。
这包括去除特殊字符、标点符号和停用词(如"的"、"在"等常见词),对英文进行大小写转换等。
2.分词:将文本分割成独立的词语或单词。
可以使用NLTK、spaCy 或自定义的规则进行分词。
使用机器学习技术进行自然语言处理的技巧

使用机器学习技术进行自然语言处理的技巧自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支,它致力于使计算机能够理解、处理和生成人类语言。
机器学习技术在NLP中起着至关重要的作用,通过分析大量的语言数据,机器学习算法能够从中学习规律,从而实现对自然语言的处理和应用。
在本文中,我们将探讨使用机器学习技术进行自然语言处理的一些技巧和方法。
1. 数据预处理:在进行自然语言处理之前,首先需要对数据进行预处理。
数据预处理的目标是将原始的文本数据转化为机器可以理解的形式。
常见的数据预处理技术包括分词、去除停用词、词性标注、lemmatization等。
分词将原始文本按照词语进行切分,去除停用词是指去除那些在给定语境中没有实际含义的常见词汇,词性标注是为每个词语标注其词性,lemmatization是将词语转化为其原型。
2. 特征选择:在机器学习模型中,特征是指输入到模型中的数据的某些属性。
在NLP中,文本的特征可以是单词、短语、句子等。
然而,不是所有的特征都对模型的性能有贡献。
因此,在使用机器学习进行自然语言处理时,我们需要选择合适的特征。
常见的特征选择方法包括TF-IDF、词嵌入和n-gram模型等。
TF-IDF通过计算词语在文档中的频率和在整个语料库中的逆文档频率来评估词语的重要性。
词嵌入是一种将词语映射到连续向量空间的方法,它能够捕捉到词语之间的语义关系。
n-gram模型可以考虑到连续n个词语的出现情况。
3. 模型选择:在使用机器学习进行自然语言处理时,选择合适的模型是非常关键的。
根据任务的不同,可以选择不同的机器学习模型,如朴素贝叶斯分类器、支持向量机、神经网络等。
朴素贝叶斯分类器是一种基于贝叶斯定理和特征条件独立性假设的分类器,它在文本分类等任务中表现良好。
支持向量机是一种通过在特征空间中找到最优边界来进行分类的方法,它在文本分类和命名实体识别等任务中具有较好的性能。
自然语言处理在大数据分析中的应用

自然语言处理在大数据分析中的应用IntroductionWith the rising volume of data available to organizations, automated data analysis processes are increasingly important. One of the key challenges in processing this data is understanding and extracting meaning from large amounts of unstructured text data. Natural Language Processing (NLP) is a set of technologies, techniques, and algorithms used to analyze and interpret unstructured human language data. NLP can be applied to a variety of use cases such as sentiment analysis, chatbots, document classification, language translation, and more. This article will explore the application of NLPin Big Data analysis with a focus on its benefits and challenges.Benefits of NLP in Big Data analysis1. Enhanced accuracy in data analysisBy applying NLP techniques to data analysis, organizations can reduce the chances of errors and inaccuracies. A properly configured NLP model can identify more complex patterns and subtle nuances in text data compared to human analysis.2. Increased speed of data analysisAnalyzing vast amounts of data can be time-consuming, and NLP can significantly reduce the time needed for data analysis. For instance, a sentiment analysis tool can read through thousands of customerreviews or social media posts within a short time and provide insights on the overall opinion of the customers.3. Deepened understanding of human interactionsBy analyzing data generated from human interactions, organizations can gain a deeper understanding of customer preferences, opinions, and behaviors. Instead of relying on surveys or market research, NLP can analyze the vast amounts of data that customers generate and provide real insights for decision-making.4. Improved customer support with chatbotsNLP can be used to train chatbots to understand and respond to customers' queries. Chatbots can analyze customer messages and respond with relevant and helpful information, which can improve customer satisfaction and reduce support staff's workload.Challenges of NLP in Big Data analysis1. Data qualityLow-quality data can hinder the accuracy of NLP analysis. Data cleaning and preprocessing are essential to ensure accurate insights. Organizations must ensure the data they collect is well-structured and that any noise or irrelevant data is removed before analysis.2. Language barriersNLP is highly language-dependent, and the accuracy of analysis depends on the model's training data and the language being analyzed. Therefore, multi-lingual data analysis requires the development of models that understand different languages and dialects.3. Algorithm selectionDifferent NLP algorithms are designed to address specific challenges, such as machine translation or sentiment analysis. However, no single algorithm is perfect, and it may be challenging to determine which algorithm is best suited for a specific task or dataset.4. Ethical concernsNLP can expose sensitive and confidential information, and the ethical use of NLP remains a concern. Organizations must pay close attention to data governance and ensure that the data they collect is used ethically and responsibly.Application of NLP in Big Data analysis1. Sentiment analysisSentiment analysis is the process of determining the emotional tone or attitude expressed in text, such as tweets or comments. NLP techniques can help organizations analyze and classify user sentiments as either positive, negative, or neutral.2. Entity recognitionEntity recognition involves analyzing text to identify specific entities such as people, organizations, or locations. NLP models can be trained to identify such entities automatically and provide rich insights for organizations.3. Topic modelingTopic modeling involves identifying the underlying topics within a document or a corpus of documents. By analyzing data using topic modeling, organizations can identify themes, trends, and patterns in text data.4. Machine translationMachine translation involves translating text from one language to another. NLP algorithms can analyze text and translate it from one language to another while retaining the original message's meaning.ConclusionNLP is a rapidly growing field, and its application in Big Data analysis is only beginning to scratch the surface of its potential. NLP's accuracy and speed of analysis have significant implications for organizations looking for deeper insights into customer behavior, sentiment, and preferences. However, organizations must be mindful of the challenges of NLP and ensure that the data they collect is high-quality, the algorithms used are appropriate, and their use of NLP is ethical and responsible.。
自然语言处理的工具库和模型训练步骤详解

自然语言处理的工具库和模型训练步骤详解自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支,它致力于研究如何使计算机能够理解、理解和处理人类语言。
在NLP的发展过程中,工具库和模型训练是不可或缺的两个环节。
本文将详细介绍自然语言处理的工具库和模型训练的步骤。
在自然语言处理中,工具库是指提供了一系列功能和算法的软件包,用于处理文本数据。
常见的自然语言处理工具库包括NLTK、Spacy和Gensim等。
NLTK(Natural Language Toolkit)是一个Python库,提供了丰富的自然语言处理功能,包括文本处理、词性标注、命名实体识别、词干提取等。
通过NLTK,可以方便地对文本进行分词、清洗和预处理,为模型训练做准备。
Spacy是一个流行的现代自然语言处理库,它具有高性能和易用性,并提供了多种自然语言处理任务的功能。
Spacy的特点之一是其快速和高效的分词器,能够很好地处理各种复杂的语言结构。
此外,Spacy还提供了词性标注、依存句法分析、命名实体识别等功能,可以帮助开发者快速构建自然语言处理模型。
Gensim是一个用于主题建模和文本相似度计算的Python库。
它提供了一系列高效的算法,如LSA(Latent Semantic Analysis)、LDA(Latent Dirichlet Allocation)和Word2Vec,可用于处理大规模的文本数据。
Gensim的主要优点是速度快、内存效率高,适用于各种自然语言处理任务。
在进行自然语言处理任务之前,首先需要准备训练数据和测试数据。
训练数据是指用于训练模型的大规模文本语料库,可以是从互联网上收集的文本数据,也可以是从已有的语料库中提取的数据。
测试数据是用于评估模型性能的数据集,一般包括一些标注好的样本和未标注的样本。
在模型训练之前,需要对原始文本数据进行预处理。
预处理步骤包括分词、清洗、去除停用词和构建词表等。
自然语言处理中常见的语言模型训练性能测试(八)

自然语言处理(NLP)是人工智能领域中一个重要的分支,旨在使计算机能够理解、解释和使用人类语言。
在NLP中,语言模型是一个重要的概念,它是一种用于生成文本或预测下一个单词的统计模型。
在NLP应用中,语言模型训练的性能测试是至关重要的,它可以帮助开发者评估模型的准确性、效率和稳定性。
本文将介绍自然语言处理中常见的语言模型训练性能测试,以及一些常用的评估指标和测试方法。
一、语言模型训练的性能测试概述在自然语言处理中,语言模型训练的性能测试是指评估语言模型在不同任务中的表现,包括生成文本、语音识别、机器翻译等。
常见的性能测试指标包括准确性、速度、内存占用、模型大小等。
在进行性能测试时,开发者需要考虑模型的训练时间、数据集大小、模型架构等因素,以确保模型在实际应用中能够表现良好。
二、常用的性能测试指标1. 准确性:准确性是评估语言模型性能的重要指标,通常使用困惑度(perplexity)来衡量模型生成文本的准确性。
困惑度越低,表示模型生成的文本越准确。
2. 速度:语言模型在实际应用中需要能够快速生成文本或进行预测,因此速度是一个重要的测试指标。
通常使用每秒生成的单词数或预测的响应时间来衡量模型的速度。
3. 内存占用:语言模型通常需要大量的内存来存储模型参数和计算中间结果。
评估模型的内存占用可以帮助开发者选择适合实际应用的模型。
4. 模型大小:模型大小也是一个重要的性能测试指标,通常使用模型的参数数量或存储空间大小来衡量模型的大小。
三、性能测试方法1. 基准测试(Benchmarking):基准测试是一种常用的性能测试方法,它通过在标准数据集上比较不同模型的表现来评估模型的性能。
开发者可以使用一些公开的基准数据集,如PTB、WikiText等,来评估语言模型的准确性和速度。
2. 负载测试(Load testing):负载测试是一种测试方法,通过模拟多用户同时访问系统来评估系统的性能。
在语言模型训练中,开发者可以使用大规模数据集来模拟实际应用中的负载,评估模型的训练时间和内存占用。
机器学习中的自然语言处理方法详述

机器学习中的自然语言处理方法详述机器学习,尤其是在自然语言处理领域,取得了令人瞩目的进展。
自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支,旨在使计算机能够理解、处理和生成人类语言。
本文将详述机器学习中的自然语言处理方法,涵盖了常见的技术和算法。
首先,文本预处理是自然语言处理中的一项重要工作。
由于自然语言的复杂性和多样性,需要对文本进行一系列的处理步骤,以准备好用于机器学习算法的输入数据。
常见的预处理技术包括分词、停用词过滤、词性标注和词干提取等。
分词是将文本划分成独立的单词或标记的过程,可以使用规则模型或统计模型来实现。
停用词过滤是去除常见的无实义的词语,如"a"、"the"等。
词性标注是为每个词语标注其词性,以便后续处理。
词干提取是将词语还原为其基本形式,如将"running"还原为"run"。
其次,词嵌入(Word Embedding)是自然语言处理中的一项关键技术。
词嵌入将一个词语映射到一个低维向量,捕捉到词语之间的语义关系。
常见的词嵌入模型有Word2Vec、GloVe和FastText等。
Word2Vec模型基于神经网络,通过预测目标词语的上下文来学习词向量。
GloVe模型则是基于全局词共现矩阵进行训练,旨在捕捉到词语之间的全局关系。
而FastText模型不仅学习了词向量,还将词语表示为字符级 n-gram 的向量,以捕捉词语内的更详细关系。
第三,文本分类是自然语言处理中的一个重要任务。
文本分类旨在将文本划分为预定义的类别,如垃圾邮件识别、情感分析等。
常见的文本分类算法有朴素贝叶斯、支持向量机(SVM)和深度学习模型等。
朴素贝叶斯是一种基于贝叶斯定理的概率模型,通过计算文本在每个类别下的概率来进行分类。
SVM则是基于样本的特征向量和类别信息来构建一个最优的超平面,以将不同类别的文本分开。
机器学习在自然语言处理中的应用案例

机器学习在自然语言处理中的应用案例自然语言处理(Natural Language Processing, NLP)是人工智能领域的重要分支,通过使用机器学习算法和模型,实现对人类语言进行理解和处理。
机器学习在NLP中发挥了关键作用,为我们提供了许多强大的自然语言处理工具和应用。
本文将介绍几个机器学习在自然语言处理中的应用案例。
一、情感分析(Sentiment Analysis)情感分析是一种通过机器学习算法对文本进行分析,从中提取出对应的情感倾向。
它在广告营销、舆情分析等领域具有重要意义。
例如,在社交媒体上对用户发布的评论进行情感分析,可以帮助企业了解用户对产品或服务的评价,为市场推广决策提供参考。
机器学习模型可以通过训练大量的带有标签的文本数据,学习文本中的情感表达。
一种常用的模型是基于词袋模型(Bag-of-Words)和朴素贝叶斯分类器的方法。
该模型将文本表示为词汇的向量,并根据先验概率对情感进行分类。
二、文本分类(Text Classification)文本分类是将文本按照预先定义的类别进行分类的任务,常用于新闻分类、垃圾邮件过滤等场景。
机器学习可以通过训练数据集,学习不同类别之间的区别,从而对未知文本进行分类。
常用的文本分类模型包括支持向量机(Support Vector Machines, SVM)和卷积神经网络(Convolutional Neural Networks, CNN)等。
这些模型可以学习词语之间的语义关系和上下文信息,提取特征并进行分类。
三、命名实体识别(Named Entity Recognition)命名实体识别是一种识别文本中实体(如人名、地名、组织机构名等)的任务。
该任务在信息抽取、问答系统等领域有着广泛的应用。
机器学习可以通过训练数据集,学习实体的特征,并通过分类算法进行识别。
常用的算法包括条件随机场(Conditional Random Fields, CRF)和递归神经网络(Recurrent Neural Networks, RNN)等。
自然语言处理中的文本分类算法优化

自然语言处理中的文本分类算法优化自然语言处理(Natural Language Processing,简称NLP)中的文本分类算法一直是研究人员和工程师们关注的焦点之一。
文本分类的目标是将文本数据按照一定的类别进行分类,以便更好地理解、分析和利用文本。
然而,由于不同文本分类任务的特点和需求不同,如何优化文本分类算法成为一个挑战。
在NLP中,文本分类常常被应用于垃圾邮件过滤、情感分析、新闻分类等任务中。
传统的文本分类方法主要依赖于手工设计的特征和统计机器学习算法。
通过提取一些关键的特征信息,如词袋模型、TF-IDF及n-gram等,并采用支持向量机(Support Vector Machine,SVM)或朴素贝叶斯分类器(Naive Bayes Classifier)等算法进行训练和分类。
这种方法在一些任务上可以取得较好的效果,但是在处理复杂文本语义和语境时则存在一定的局限性。
随着深度学习的兴起,特别是语言模型的发展,基于神经网络的文本分类算法也逐渐成为主流。
其中,卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)是两个常用的模型结构。
CNN 能够有效地捕捉文本中的局部特征,通过卷积和池化操作实现特征的提取与压缩,从而实现分类。
而RNN则通过建立一个循环的状态来建模文本的时序信息,能够处理长距离的依赖关系,并在文本分类任务中表现出色。
然而,为了进一步优化文本分类算法,研究者们提出了许多改进的方法。
一方面,一些学者将深度学习与传统机器学习方法相结合,提出了混合模型。
这样的模型能够综合利用深度学习和传统方法的优势,例如将CNN和SVM相结合,既能够自动学习文本特征,又能够获得更好的分类性能。
另一方面,一些学者则聚焦于提取更丰富的特征信息,例如引入预训练的词向量(Word Embeddings),如Word2Vec和GloVe等。
机器学习技术中的自然语言处理方法调优策略

机器学习技术中的自然语言处理方法调优策略在机器学习技术中,自然语言处理(Natural Language Processing,NLP)方法的调优策略是提高模型性能和效果的关键。
NLP是一门研究如何使计算机能够理解和利用自然语言的学科,包括文本分类、情感分析、句法分析等多个任务。
本文将介绍几种常用的NLP方法调优策略,包括数据预处理、特征工程、模型选择和超参数调优。
首先,在进行NLP任务前,数据预处理是必不可少的一步。
首先需要进行数据清洗,包括去除噪声数据、删除冗余信息和处理缺失值等。
其次,需要进行文本分词和词干提取,将句子拆分成单词,并将单词归一化为其原始形式以减少特征空间的维度。
此外,还需要处理停用词,这些常见的无意义词语可以被过滤掉,从而减少噪声对模型性能的影响。
其次,特征工程在NLP中也具有重要的作用。
选择合适的特征对于提高模型的准确性至关重要。
在NLP中,常用的特征包括词频(Term Frequency,TF)、逆文档频率(Inverse Document Frequency,IDF)和词嵌入(Word Embedding)等。
TF表示一个词在文档中出现的频率,IDF表示一个词的重要性,词嵌入将单词映射到一个高维向量空间中,能够捕捉到单词之间的语义关系。
此外,还可以考虑使用N-gram模型来获取更多上下文信息,或者使用词袋模型来表示文本特征。
在选择模型时,需要根据具体的NLP任务和数据情况做出合适的选择。
常见的NLP模型包括朴素贝叶斯分类器、支持向量机、决策树和深度学习模型如循环神经网络(Recurrent Neural Networks,RNN)和卷积神经网络(Convolutional Neural Networks,CNN)。
不同的模型有不同的特点和适用场景,应根据任务需求选择最合适的模型。
最后,超参数调优是提高NLP模型性能的必要步骤。
超参数是控制模型训练过程中的参数,如学习率、正则化参数、批量大小等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Dataset Used in the Co-training Experiments for COLT 98(COLT98联合训练实验数据集)
数据摘要:
This data set contains a subset of the WWW-pages collected from computer science departments of various universities in January 1997 by the World Wide Knowledge Base (Web->Kb) project of the CMU text learning group. The 1051 pages were manually classified into the following categories:
Course (230)
Non-Course (821)
中文关键词:
COLT98,数据集,联合训练实验,课程,非课程,
英文关键词:
COLT98,Dataset,Co-training Experiments,Course,Non-Course,
数据格式:
TEXT
数据用途:
Classification,information processing
数据详细介绍:
Dataset Used in the Co-training Experiments for COLT 98
This data set contains a subset of the WWW-pages collected from computer science departments of various universities in January 1997 by the World Wide Knowledge Base (Web->Kb) project of the CMU text learning group. The 1051 pages were manually classified into the following categories:
Course (230)
Non-Course (821)
The data is available from
/afs//project/theo-51/www/co-training/data/course-cotra in-data.tar.gz
(GNU tar'ed and gzip'ped).
The files are organized into a directory structure with two directories at the top level
Fulltext - This directory contains the text on the web pages
Inlinks - This directory contains the anchor text on the hyperlinks pointing to the page. Under each of the two directories, there is one directory for each class (course,
non-course). These directories in turn contain the Web-pages. The file name of each page corresponds to its URL, where '/' was replaced with '^'. Note that the pages start with a MIME-header.
If you have any questions about this dataset, send mail to Rayid Ghani
(rayid@)
last update: November 24, 1999 (Rayid)
created: November 24, 1999 (Rayid)
数据预览:
点此下载完整数据集。