南京大学张莉用python玩转数据
91018-Python语言教学-14-张莉-基于数据处理与分析的Python案例展示

南京大学
基于数据处理与分析的Python案例展示
18
道指 成分 股数 据投 资组 合
南京大学
1.选股
如
何
2.计算不同证券的均值、协方差
构
3.给不同资产随机分配初始权重
建
(fileid, len(w)) for fileid in inaugural.fileids() for w in inaugural.words(fileid) if fileid > '1950') print(cfd.items()) cfd.plot()
南京大学
基于数据处理与分析的Python案例展示
南京大学
基于数据处理与分析的Python案例展示
8
古滕堡项目
Source
>>> from nltk.corpus import gutenberg >>> allwords = gutenberg.words('shakespeare-hamlet.txt') >>> len(allwords) 37360 >>> len(set(allwords)) 5447 >>> all_words.count('Hamlet') 99 >>> A = set(allwords) >>> longwords = [w for w in A if len(w) > 12] >>> print(sorted(longwords))
使用Python进行大数据分析和处理

使用Python进行大数据分析和处理一、引言随着大数据时代的到来,数据分析和处理技术愈发重要。
Python作为一种简单易学、功能强大的编程语言,被广泛应用于数据科学领域。
本文将介绍如何使用Python进行大数据分析和处理,并分为以下几个部分:数据获取、数据清洗、数据分析、数据可视化和模型建立。
二、数据获取在进行大数据分析和处理之前,我们需要从各种数据源中获取数据。
Python提供了丰富的库和工具,可以轻松地从数据库、API、Web页面以及本地文件中获取数据。
比如,我们可以使用pandas库中的read_sql()函数从数据库中读取数据,使用requests库从API获取数据,使用beautifulsoup库从Web页面获取数据,使用csv库从本地CSV文件中获取数据。
三、数据清洗获取到原始数据之后,通常需要进行数据清洗。
数据清洗是指对数据进行预处理,包括处理缺失值、处理异常值、处理重复值、数据格式转换等。
Python提供了丰富的库和函数来帮助我们进行数据清洗,如pandas库中的dropna()函数用于处理缺失值,使用numpy库中的where()函数用于处理异常值,使用pandas库中的duplicated()函数用于处理重复值。
四、数据分析数据分析是大数据处理的核心环节之一。
Python提供了强大的库和工具来进行数据分析,如pandas库和numpy库。
使用这些库,我们可以进行数据聚合、数据筛选、数据排序、数据计算等。
例如,我们可以使用pandas库中的groupby()函数进行数据聚合,使用pandas库中的query()函数进行数据筛选,使用pandas库中的sort_values()函数进行数据排序,使用numpy库中的mean()函数进行数据计算。
五、数据可视化数据可视化是将数据以图形化的方式展现出来,帮助我们更好地理解数据的分布和趋势。
Python提供了多种库和工具来进行数据可视化,如matplotlib库和seaborn库。
基于Python的混合式英语教学数据融合实施方案

基于Python的混合式英语教学数据融合实施方案王劼华(南京大学金陵学院江苏南京210089)摘要:“互联网+””时代,为提高高校英语教学效果,开拓大学英语课程线上线下混合式教学模式创新研究的思路,该文将着重关注如何有效地挖掘多个互联网教学平台的数据,与外语教学的特殊性结合,做针对性研究,从而制订有效的混合式精准教学实施方案,并通过数据融合方案全面地了解和指导学生的英语学习。
该文介绍了方案实施工具Python与Anaconda,以及方案实施策略,其中包括数据的读取与保存、数据的筛选处理、分析结果的可视化展示和相关性分析4个部分,并通过示例呈现了如何利用Python来实施混合式英语教学数据融合。
关键词:数据融合Python英语教学混合式精准教学实施方案中图分类号:H319.3;G434文献标识码:A文章编号:1672-3791(2022)06(b)-0189-04Implementation Scheme of Data Fusion in Hybrid EnglishTeaching Based on PythonWANG Jiehua(Nanjing University Jinling College,Nanjing,Jiangsu Province,210089China)Abstract:In the"Internet+"era,in order to enhance the teaching efficiency of college English courses,and explore a new innovative approach for the online-offline blended teaching mode,the paper emphasizes how to effectively utilize the data from multiple online teaching platforms,and carries out a corresponding study by combining data mining with the particularity of language teaching,and thereby formulates an implementation program for the ef‐fective blended precision teaching,through which teachers can comprehensively understand and instruct English learning of college students.This paper introduces Python and Anaconda as the development tools,and the imple‐mentation strategies including data reading and saving,data filter and processing,visualization display and relativity analysis,and demonstrates how to implement data fusion in blended English teaching based on Python by way of illustration.Key Words:Data fusion;Python;English teaching;Blended;Precision teaching;Implementation大数据与多元智能的融合,可以更为准确地判断学生的个性、学习程度、学习特长等,从而为学生提供精准教学、个性化学习,提高教学质量和效率[1]。
序列常用函数和方法简介

1.序列
(1) 序列的标准类型运算
<、>、<=、>=、==、!=
值比较
is、is not
对象身份比较
and、or、not
逻辑运算
(2) 通用序列类型操作
seq[start: end]
切片操作
*
重复组合序列数据
+
连接 2 个序列
in、not in
l.insert(index, obj)
l.pop(index)
l.remove(obj) l.reverse() l.sort(key=None, reverse=False)
引位置,索引从 0 开始 将对象 obj 插入列表 l 中索引为 index 的元 素前 移除列表 l 中索引为 index 的一个元素(默 认为最后一个元素),并且返回该元素的值 移除列表 l 中某个值的第一个匹配项 将列表 l 中的元素反转 对原列表 l 进行排序,可通过参数 key 指定 排序依据,通过参数 reverse 指定顺序(默 认方式)或逆序排列
1) s.endswith(suffix[, start[,
end]]) s.startswith(prefix[,
start[, end]])
描述 返回字符串 s 首字母大写其余小写的形式 返回字符串 s 的小写形式 返回字符串 s 的大写形式 返回字符串 s 的标题形式即单词首字母大写形式 格式化字符串操作 返回指定字符在[指定位置的]字符串 s 中出现的次数 返回指定字符在[指定位置的]字符串 s 中出现的索引 号,找不到则返回-1 与 find() 类 似 , 不 同 的 是 如 果 找 不 到 会 引 发 ValueError 异常 把字符串 s 中的 old(旧字符串)替换成 new(新字符 串)。如果指定第三个参数 count,则仅仅替换前 count 次出现的子串 移除字符串 s 左边的指定字符(默认为空格),返回移 除字符串 s 左边指定字符后生成的新字符串 移除字符串 s 末尾的指定字符(默认为空格),返回移 除字符串 s 末尾指定字符后生成的新字符串 移除字符串 s 头尾指定的字符(默认为空格),返回移 除字符串 s 头尾指定字符后生成的新字符串 用指定的字符串 s 连接元素为字符串的可迭代对象 以指定的字符作为分隔符(默认为空格)分割字符串 s,maxsplit 指分割次数(默认为不限制次数) 判断字符串 s[的指定位置]是否以后缀 suffix 结尾
python处理数据的方法

Python是一种广泛使用的编程语言,特别适合于数据处理和分析。
下面是处理数据的一些常用方法:1. 数据导入:Python提供了多种方式来导入数据,包括从文本文件、CSV文件、Excel文件、数据库等导入数据。
常用的库有pandas、numpy、csv等。
示例代码:使用pandas库导入CSV文件import pandas as pddata = pd.read_csv('data.csv')2. 数据清洗:数据清洗是指对数据进行标准化和规范化处理,以确保数据的准确性和一致性。
可以使用Python中的字符串处理和数据类型转换函数来完成数据清洗。
示例代码:将数据转换为浮点数类型data['column_name'] = data['column_name'].astype(float)3. 数据筛选:根据需要选择数据集中的特定数据。
可以使用Python中的条件语句和循环结构来实现数据筛选。
示例代码:筛选年龄大于等于18岁的用户数据users = data[data['age'] >= 18]4. 数据可视化:使用Python中的matplotlib、seaborn等库,可以将数据处理结果以图表形式展示出来。
示例代码:使用matplotlib库绘制柱状图import matplotlib.pyplot as pltplt.bar(users['age'].unique(), users['count'])plt.show()5. 数据分析:使用Python中的pandas库,可以对数据进行统计分析和挖掘。
可以使用各种统计函数和算法来分析数据,如求和、平均值、中位数、方差等。
示例代码:计算销售额的平均值和标准差mean_sales = data['sales'].mean()std_sales = data['sales'].std()print(f"平均销售额: {mean_sales:.2f}")print(f"标准差: {std_sales:.2f}")以上是Python处理数据的一些常用方法,具体应用时需要根据数据的特点和需求选择合适的方法和技术。
Python财经数据接口TuShare研究和数据处理分析实例

《用Python玩转数据》之利用免费财经数据接口TuShare获取和分析数据by Dazhuang@NJU1.安装在Anaconda Prompt窗口中输入如下命令安装:> pip install tushare2. 介绍"TuShare是一个免费、开源的python财经数据接口包。
主要实现对股票等金融数据从数据采集、清洗加工到数据存储的过程,能够为金融分析人员提供快速、整洁、和多样的便于分析的数据,为他们在数据获取方面极大地减轻工作量,使他们更加专注于策略和模型的研究与实现上。
考虑到Python pandas包在金融量化分析中体现出的优势,TuShare 返回的绝大部分的数据格式都是pandas DataFrame类型,非常便于用pandas/NumPy/Matplotlib进行数据分析和可视化。
当然,如果您习惯了用Excel或者关系型数据库做分析,您也可以通过TuShare的数据存储功能,将数据全部保存到本地后进行分析。
"这是TuShare官网(/index.html)上对于TuShare的描述,它提供了便捷的各类财经数据和新闻等的接口。
3. 简单示例例如要想获取股票代码是600848的股票在2018年3月1日至3月10日间的基本历史数据,只要使用如下代码即可:>>> import tushare as ts>>> ts.get_hist_data('600848',start='2018-03-01',end='2018-03-08')open high close low volumedate2018-03-08 23.82 24.10 23.99 23.71 34416.472018-03-07 24.06 24.28 23.90 23.89 43007.212018-03-06 24.20 24.28 24.03 23.82 48066.022018-03-05 24.48 24.48 24.13 23.91 37519.752018-03-02 23.90 24.39 24.33 23.63 61194.212018-03-01 23.69 24.48 24.18 23.56 46819.00…get_hist_data()函数可以获取三年内A股历史行情,其他Tushare中功能相似的函数还有get_h_data()和get_k_data()。
如何利用Python进行大数据处理与分析

如何利用Python进行大数据处理与分析Python是一种功能强大且易于学习的编程语言,在大数据处理和分析方面有着广泛的应用。
本文将介绍如何使用Python进行大数据处理和分析的基本技巧和工具,以帮助读者更好地应用Python进行数据处理和分析。
一、数据处理与准备在进行大数据处理和分析之前,首先需要对数据进行处理和准备。
Python提供了一些强大的库和工具,可以用于数据清洗、转换和整理,例如NumPy、Pandas和Eaxcel等。
下面将介绍其中几个常用的库和工具。
1. NumPyNumPy是Python中用于科学计算和数值分析的重要库。
它提供了一个强大的多维数组对象,以及用于操作数组的数学函数。
使用NumPy可以进行数据清洗、转换和整理,以满足后续的分析需求。
2. PandasPandas是一个开源的Python库,提供了丰富的数据结构和数据分析工具。
它是基于NumPy开发的,常用于数据整理、数据清洗、数据分析和数据可视化等任务。
Pandas中的DataFrame对象是进行数据处理和分析的核心数据结构。
3. EaxcelEaxcel是一个用于数据处理和分析的强大工具。
它可以读取和写入Excel文件,进行数据转换和整理,以及执行各种数据操作。
Eaxcel的使用简单且功能丰富,适用于处理小到大规模的数据。
二、数据分析与建模完成数据处理和准备后,接下来可以进行数据分析和建模。
Python提供了一些优秀的库和工具,可以用于数据分析和建模,例如Pandas、Matplotlib、Seaborn和Scikit-learn等。
下面将介绍其中几个常用的库和工具。
1. Pandas在数据分析和建模中,Pandas是一个非常有用的工具。
它提供了丰富的数据结构和数据操作函数,可以用于数据探索、数据聚合、数据统计和数据可视化等任务。
通过Pandas,可以轻松地对数据进行各种分析和建模操作。
2. MatplotlibMatplotlib是Python中用于绘制各种静态、交互式和动态图形的重要库。
91036-Python语言教学-4-张莉-多样化可扩展的Python教学模式探索与实践-4月22日上午

理工类 数据显示、选择、筛 选、统计等 聚类/分类 NumPy(常用函数,声 音,图像等处理应 用) SciPy
Matplotlib
pandas
scikit-learn csv,excel等数据处理 多样化可扩展的Python教学模式探索与实践
商学院 数据显示、选择、筛选、 统计 聚类 NumPy(专业相关函数) Matplotlib(专业相关) pandas(专业相关)
• 以法律为准绳不断强调国家的统一 • 认为由各州组成的联邦是永久性的
南京大学
多样化可扩展的Python教学模式探索与实践
15
课程多样化实施方案
课程多样化实施(内容维度)
项目开发(理工类)
所用模块 Urllib Webdriver pandas Pylab BeautifulSoup Jieba Wordcloud
for i in range(30):
quotes[i] = quotes_historical_yahoo_ochl(listDji[i], start, end)
listTemp[i][j] = 1.0 or -1.0 data = vstack(listTemp)
第0类 AXP,CVX,DIS,JNJ,MCD,UTX,WMT,XOM
南京大学
多样化可扩展的Python教学模式探索与实践
12
课程多样化实施方案
课程多样化实施(内容维度)
# Filename: kmeansStu.py
import numpy as np from sklearn.cluster import KMeans list1 = [88.0,74.0,96.0,85.0] list2 = [92.0,99.0,95.0,94.0] list3 = [91.0,87.0,99.0,95.0] list4 = [78.0,99.0,97.0,81.0] list5 = [88.0,78.0,98.0,84.0] list6 = [100.0,95.0,100.0,92.0] X = np.array([list1,list2,list3,list4,list5,list6])
Python数据处理技巧分享

Python数据处理技巧分享第一章:数据读取与导入在数据处理过程中,首先需要将数据从外部文件中读取并导入到Python编程环境中。
Python提供了多种方法来实现数据的读取与导入,常用的包括pandas和csv等。
1.1 使用pandas读取Excel数据Pandas是一个强大的数据处理库,可以有效地读取和处理Excel数据。
使用pandas读取Excel数据可以通过以下步骤实现:- 导入pandas库:import pandas as pd- 使用pd.read_excel()函数读取Excel文件:data =pd.read_excel('data.xlsx')- 查看读取到的数据:print(data)1.2 使用csv库读取CSV数据如果数据以CSV格式存储,可以使用Python内置的csv库进行读取。
以下是读取CSV数据的基本步骤:- 导入csv库:import csv- 打开CSV文件:with open('data.csv', 'r') as file:- 创建csv.reader对象:reader = csv.reader(file)- 读取数据:for row in reader: print(row)第二章:数据清洗与预处理在数据处理过程中,往往需要进行数据清洗与预处理,以确保数据的质量和一致性。
以下是一些常用的数据清洗与预处理技巧。
2.1 缺失值处理在实际数据中,常常会存在缺失值的情况。
处理缺失值的一种常用方法是将缺失值替换为均值或中位数。
可以使用pandas库中的fillna()函数实现缺失值的替换。
2.2 异常值处理异常值可能会对数据的分析和建模产生干扰。
较常用的异常值处理方法包括删除异常值和替换异常值。
删除异常值可以使用pandas库中的drop()函数实现,而替换异常值可以使用fillna()函数。
第三章:数据转换与计算当数据成功导入Python环境后,接下来需要进行数据转换与计算,以满足具体的分析需求。
Python中的大规模数据处理技巧

Python中的大规模数据处理技巧随着数据时代的到来,数据处理变得越来越重要。
对于大规模数据的处理,Python具有很强的优势,下面我们就来介绍一些Python中的大规模数据处理技巧。
一、利用Pandas进行数据处理Pandas是Python中非常常用的数据处理库,可以用来处理各种类型的数据。
对于大规模数据的处理,Pandas有很多技巧可以用来提高处理效率。
比如可以利用Pandas中的groupby函数进行分组处理,将相同的数据聚合在一起,从而减少计算量。
二、使用Numpy处理超大型数组数据当数据量非常大时,我们需要使用Numpy来处理超大型数组数据。
Numpy是Python中高性能科学计算库,因为其对数组进行了优化,所以处理数据的速度非常快。
对于大型的多维数组数据,Numpy更是表现出了强大的计算能力,可以大大提高数据处理的速度。
三、使用Dask处理大数据量Dask是一个优秀的Python分布式计算框架,可以用于处理大型数据。
Dask可以自动将大型数据集分成块,然后并行处理这些块,以保证处理效率。
使用Dask,数据处理人员可以轻松地处理大规模数据。
四、利用Spark进行分布式数据处理对于大规模数据处理,Spark成为了一个很受欢迎的分布式计算框架。
Spark能够将数据分成多个块,同时在多个节点上进行计算,从而大大提高处理效率。
Spark还拥有很多优秀的机器学习算法,可以用于特征提取、分类、聚类等任务,大大提高了数据处理的效率。
五、使用机器学习技术处理数据机器学习技术是当前处理大数据的热门趋势。
机器学习技术可以通过学习大量数据的规律和特征,从而建立一个有效的模型。
机器学习技术可以大大提高数据处理的效率,为数据处理带来了全新的发展方向。
总结:Python拥有非常强的数据处理能力,可以用来处理大规模数据。
利用Pandas、Numpy、Dask和Spark等库和框架,可以让数据处理变得更加容易和高效。
如何使用Python进行数据科学实践

如何使用Python进行数据科学实践在当今信息化的时代,数据正变得越来越重要。
对于数据科学家而言,掌握有效的数据处理工具是必不可少的。
Python作为一种高级编程语言,因其丰富的数据科学库和简洁易读的语法成为广大数据科学家的首选。
本文将介绍如何使用Python进行数据科学实践。
一、数据收集与整理数据科学的第一步是收集和整理数据。
Python提供了许多工具和库来帮助我们完成这个任务。
首先,我们可以使用Python的requests库来获取互联网上的数据。
通过简单的代码,我们就能够从web页面上获取所需的数据。
一旦我们获得了数据,接下来就是进行数据整理。
Python的Pandas库是一个非常强大的数据处理工具,它提供了DataFrame对象,方便我们对数据进行操作和分析。
我们可以通过Pandas来清洗、筛选和重塑我们的数据,为后续的数据科学工作做好准备。
二、数据探索与可视化数据科学的核心工作之一是数据探索。
Python的Matplotlib库和Seaborn库是两个强大的可视化工具,它们可以帮助我们更清晰地了解我们的数据。
使用Matplotlib和Seaborn,我们可以绘制各种统计图表,如直方图、折线图、散点图等,从而直观地观察数据的分布情况和相关性。
此外,这些库还提供了自定义功能,使我们能够创建美观而有创意的图表,更好地传达数据的含义。
三、数据分析与建模有了干净整洁的数据和可视化工具之后,我们可以进一步进行数据分析和建模。
Python的NumPy和SciPy库为我们提供了丰富的数学和统计函数,使我们能够进行各种数值计算和统计分析。
当我们需要进行机器学习和深度学习时,Python的Scikit-learn和TensorFlow库是我们的好帮手。
Scikit-learn提供了各种机器学习算法的实现,TensorFlow则是一个强大的深度学习框架。
通过使用这些库,我们可以构建复杂的模型,并对它们进行训练和评估。
使用Python进行大数据分析和处理

使用Python进行大数据分析和处理随着互联网的快速发展和技术的进步,大数据已经成为了当今社会的一个热门话题。
大数据的处理和分析对于企业和组织来说至关重要,它们可以通过分析大数据来获取有价值的信息和洞察力,从而做出更明智的决策。
而Python作为一种功能强大且易于使用的编程语言,成为了大数据分析和处理的首选工具。
首先,Python拥有丰富的数据处理和分析库。
其中最著名的就是Pandas库。
Pandas提供了快速、灵活和易于使用的数据结构,使得我们可以轻松地处理和分析大规模的数据集。
它提供了各种功能,包括数据清洗、数据转换、数据合并和数据分组等。
此外,Pandas还提供了强大的数据可视化功能,可以帮助我们更好地理解和展示数据。
除了Pandas,Python还有其他一些重要的数据处理和分析库,如NumPy、SciPy和Matplotlib等,它们都为大数据分析和处理提供了丰富的功能和工具。
其次,Python具有良好的扩展性和灵活性。
Python是一种开源的编程语言,拥有庞大的社区支持和活跃的开发者社区。
这意味着我们可以轻松地找到各种各样的第三方库和工具,以满足不同的需求。
例如,如果我们需要进行机器学习和深度学习方面的大数据分析,可以使用TensorFlow、PyTorch和Scikit-learn等库来实现。
而如果我们需要进行自然语言处理方面的大数据分析,可以使用NLTK和SpaCy等库来实现。
Python的扩展性和灵活性使得我们可以根据自己的需求选择最适合的工具和库,从而更好地进行大数据分析和处理。
此外,Python还具有易学易用的特点。
相比于其他编程语言,Python的语法简洁明了,易于理解和学习。
这使得即使没有编程经验的人也能够迅速上手。
此外,Python还有丰富的文档和教程资源,可以帮助我们更好地学习和使用Python进行大数据分析和处理。
而且,Python还有一个强大的交互式解释器,可以帮助我们快速测试和调试代码。
Python大数据处理使用Python处理大规模数据集

Python大数据处理使用Python处理大规模数据集Python大数据处理随着大数据时代的到来,大规模的数据集日益普遍。
为了高效地处理这些海量数据,Python作为一种简洁且强大的编程语言,受到了广泛的应用。
本文将介绍使用Python处理大规模数据集的方法和技巧。
一、Python与大数据处理的优势Python作为一种高级编程语言,具有许多处理大数据集的优势。
首先,Python具有丰富的第三方库和工具,如NumPy、Pandas和Dask等,使得处理大规模数据变得更加简单和高效。
其次,Python语法简洁明了,易于理解和学习,降低了处理大数据集的门槛。
此外,Python 还支持多线程和多进程,能够充分利用多核处理器的性能,进一步加速数据处理过程。
二、数据读取与加载在处理大规模数据集之前,首先需要将数据读取和加载到Python中。
对于结构化数据,可以使用Pandas库提供的read_csv()函数直接读取CSV文件。
如果数据存储在数据库中,可以使用Python的数据库连接库,如psycopg2或sqlite3,通过SQL查询获取数据。
对于非结构化数据,可以使用Python的文件读取函数,如open()和readlines(),逐行读取数据。
三、数据清洗与预处理在处理大规模数据集之前,通常需要进行数据清洗和预处理,以确保数据的质量和准确性。
Python提供了丰富的数据处理函数和方法,如缺失值处理、异常值处理、数据标准化和数据归一化等。
可以使用Pandas库的fillna()函数填充缺失值,使用drop_duplicates()函数删除重复值,使用apply()函数对数据进行批量处理。
四、数据分析与统计Python提供了各种用于数据分析和统计的库和工具,使得对大规模数据集进行分析和统计变得更加简单和高效。
Pandas库提供了丰富的数据处理和分析函数,如groupby()、pivot_table()和describe()等,可以对数据进行分组、聚合和统计。
917380-Python教学-张莉-分层系统思想在Python数据处理教学实践中的应用(2018.4.15)

分层系统思想在Python数据处理教学实践中的应用张莉南京大学大学计算机基础教学部zhl@4/15/2018Python是一种怎样的程序设计语言?强大明确 优雅简洁 集大成>>> import thisThe Zen of Python, by Tim PetersBeautiful is better than ugly. Explicit is better than implicit. Simple is better than complex.Complex is better than complicated.Flat is better than nested. Sparse is better than dense. Readability counts.Special cases aren't special enough to break the rules.Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced.In the face of ambiguity, refuse the temptation to guess.There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never.Although never is often better than *right* now.If the implementation is hard to explain, it's a bad idea.If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!为什么在Python教学中,我们似乎常常会更容易被学生惊艳到?Python—适合终生学习的程序设计语言1 2345系统分层广度深度Python 数据处理之系统思想 Python 数据处理之分层思想 Python 数据处理之示例大纲12 3Python数据处理之系统思想局部与全局简单的数据处理与分析过程数据展现4数据 分析3数据 处理数据 采集12采集处理分析展现采集自己收集班级数据,教务处等官方部门获取处理缺失值填充分析计算相关性,做某些成绩的预测展现预测结果图>>> data = pd.read_excel(r'scores.xlsx',index_col = '学号', encoding='utf-8')>>> print(data['数学'].corr(data['物理'])0.802418346861>>> regr = linear_model.LinearRegression()>>> regr.fit(data['数学'].values.reshape(-1, 1), data['Python'])>>> math = 77>>> print(regr.predict(math))>>> plt.scatter(data['数学'], data['Python'])>>> plt.plot(data['数学'], regr.predict(data['数学'].values.reshape(-1,1)), color='red')采集处理分析展现采集爬虫抓取单个页面并解析内容,发现url规律抓取和解析多个页面处理去停用词,取某一种词性的词如名词分析统计词频展现绘制词云# segment words line by lineword_list = pseg.cut(subject)for word, flag in word_list:if not word in stop_words and flag == 'n': newslist.append(word)Python数据处理之分层思想层层递进数据集/语料库Actus Primus. Scoena Prima.Enter Barnardo and Francisco two Centinels. Barnardo. Who's there? Fran. Nay answer me: Stand & vnfoldyour selfeIt/pps excuses/vbz these/dts actions/nns as/cs being/beg the/at chain/nn reaction/nn to/in basic/jj errors/nns made/vbn in/in the/at previous/jj administration/nn ./.speaker phone[+2],radio[+2],infrared[+2]##my favorite features , although there are many , are the speaker phone , the radio andthe infrared .网络爬虫Web APIpattern =pile(‘<td>…</td>',flags= re.M)数据采集中的分层思想传达:采集正好需要的数据往往非常困难,一般需要做进一步的处理其他要说的调用库的阶段读/写文档的重要性Python数据处理之示例无基础学生学期课程设计Python—适合终生学习的程序设计语言THANKS 谢谢聆听。
慕课-用Python玩转数据-2编程题答案

慕课-⽤Python玩转数据-2编程题答案1、对于两个不同的整数A和B,如果整数A的全部因⼦(包括1,不包括A本⾝)之和等于B;且整数B的全部因⼦(包括1,不包括B本⾝)之和等于A,则将A和B称为亲密数。
⾃定义函数fac(x)计算x包括1但不包括本⾝的所有因⼦和并返回。
从键盘输⼊整数n,调⽤fac()函数寻找n以内的亲密数并输出。
注意每个亲密数对只输出⼀次,⼩的在前⼤的在后,例如220-284。
def fac(num):for j in range(2,num+1):a = 0b = 0for i in range(1,j):if j % i == 0:a = a + ifor c in range(1,a):if a % c == 0:b += cif j == b and b != a:if j < a:print("{0}-{1}".format(j,a))2、找第n个默尼森数。
P是素数且M也是素数,并且满⾜等式M=2^P-1,则称M为默尼森数。
例如,P=5,M=2^P-1=31,5和31都是素数,因此31是默尼森数def prime(num):if num == 1:print(num)else:for i in range(2,num):if num % i == 0:breakelse:return 1def monisen(no):a = 2b = 1while b <= no:if prime(a):c = 2 ** a - 1if prime(c):b += 1a += 1print(c)。
Pyhon数据分析项目——男女电影评分差异比较

《用Python玩转数据》数据分析项目一、程序功能基于MovieLens 100k数据集中男性女性对电影的评分来判断男性还是女性电影评分的差异性更大。
二、数据来源数据集下载:/datasets/movielens/ml-100k.zip数据含义:u.data 表示100k条评分记录,每一列的数值含义是:user id | item id | rating | timestamper表示用户的信息,每一列的数值含义是:user id | age | gender | occupation | zip codeu.item文件表示电影的相关信息,每一列的数值含义是:movie/item id | movie title | release date | video release date |IMDb URL | unknown | Action | Adventure | Animation | Children's | Comedy | Crime | Documentary | Drama | Fantasy |Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi |Thriller | War | Western |# API文档请参考/pandas-docs/stable/三、分析和参考代码基于本数据集可以进行很多分析,例如简单的可基于男生和女生评分均值统计男女各自最喜爱的10部电影,结果如下:>>> mean_ratings[:10]gender F Mtitle'Til There Was You (1997) 2.200000 2.5000001-900 (1994) 1.000000 3.000000101 Dalmatians (1996) 3.116279 2.77272712 Angry Men (1957) 4.269231 4.363636187 (1997) 3.500000 2.8709682 Days in the Valley (1996) 3.235294 3.22368420,000 Leagues Under the Sea (1954) 3.214286 3.568966 2001: A Space Odyssey (1968) 3.491228 4.1039603 Ninjas: High Noon At Mega Mountain (1998) 1.000000 1.00000039 Steps, The (1935) 4.000000 4.060000而要判断男性还是女性电影评分的差异性大小则可以利用标准差,标准差越大表示评分离散程度大,即差异性大,反之表示数据越聚集,差异性小。
PythonDataFrame修改操作综合

《用Python玩转数据》课程资料-DataFrame修改操作综合by Dazhuang@NJUDataFrame对象(或Series对象)创建好以后常常需要修改包括添加、删除和直接修改行和列数据等,假设数据框aDF的值如下所示:>>> aDFname pay0 Mayue 30001 Lilin 45002 Wuyun 8000(1)添加列添加列可直接赋值,例如给aDF中添加tax列的方法如下:>>> aDF['tax'] = [0.05, 0.05, 0.1]>>> aDFname pay tax0 Mayue 3000 0.051 Lilin 4500 0.052 Wuyun 8000 0.1(2)添加行添加行可用对象的标签(loc)和位置(iloc)索引,也可通过append()方法或concat()函数等进行处理,以loc为例,例如要给aDF添加一个新行,可用如下方法:>>> aDF.loc[5] = {'name': 'Liuxi', 'pay': 5000, 'tax': 0.05}>>> aDFname pay tax0 Mayue 3000 0.051 Lilin 4500 0.052 Wuyun 8000 0.15 Liuxi 5000 0.05其中5为行标签。
(3)删除对象元素删除数据可直接用“del 数据”的方式进行,但这种方式是直接对原始数据操作,不是很安全,pandas中可利用drop()方法删除指定轴上的数据,drop()方法返回一个新的对象,不会直接修改原始数据。
例如:删除行标签为5的行(aDF没有变):>>> aDF.drop(5)name pay tax0 Mayue 3000 0.051 Lilin 4500 0.052 Wuyun 8000 0.1删除tax列:>>> aDF.drop('tax', axis = 1)name pay0 Mayue 30001 Lilin 45002 Wuyun 80005 Liuxi 5000可通过循环或类似“aDF.drop(['pay', 'tax'], axis = 1)”这样的方式删除多行或多列数据。
1将Python和pip加入环境变量中的方法
4. 在命令提示符下输入“python”命令即可打开 Python 环境
5. 同样可以将 pip 命令加入环境变量中
《用 Python 玩转数据》MOOC பைடு நூலகம்程资料
双击path行打开编辑用户变量窗口在其中加入你自己的python本机安装路径一般在本地用户下后确定4
《用 Python 玩转数据》MOOC 课程资料
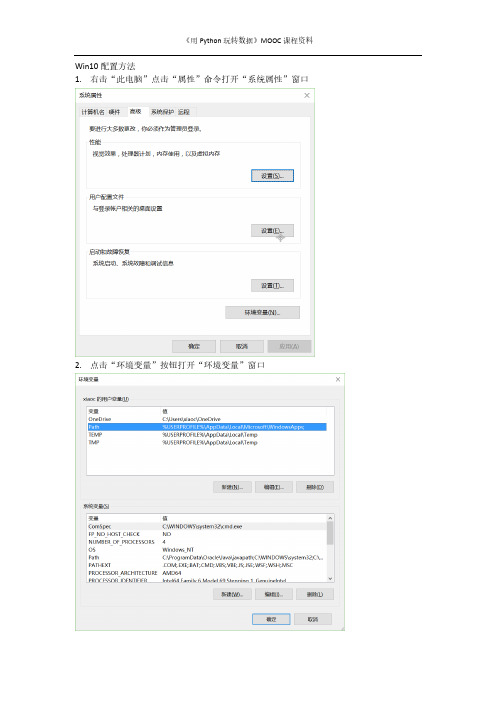
Win10 配置方法 1. 右击“此电脑”点击“属性”命令打开“系统属性”窗口
2. 点击“环境变量”按钮打开“环境变量”窗口
《用 Python 玩转数据》MOOC 课程资料
Python玩转数据分析——T检验概念适用条件单样本t检验两独立样本t检验两配对样本t检验

Python玩转数据分析——T检验概念适⽤条件单样本t检验两独⽴样本t检验两配对样本t检验# 概念T检验,也称 student t 检验 ( Student’s t test ) ,⽤来⽐较两个样本的均值差异是否显著,通常⽤于样本含量较⼩ ( n <30 ) 的样本。
分为单样本 t 检验、两独⽴样本 t 检验和两配对样本 t 检验。
# 适⽤条件1. 已知⼀个总体均数;2. 可得到⼀个样本均数及该样本标准差;3. 样本来⾃正态或近似正态总体。
# 单样本 t 检验假设现在有10个男⽣的体重数据(单位:千克),问这些男⽣体重的均值与70千克是否有显著差异(显著性⽔平为0.05)?代码如下:```codeweight=[53,75,69,67,58,64,70,72,65,74]def t_1samp(list_c,u):lst=list_c.copy()n=len(lst)s=np.std(lst)*(n**0.5)/(n-1)**0.5t=(np.mean(lst)-u)/(s/(n)**0.5)sig=2*stats.t.sf(abs(t),n-1)dic_res=[{'t值':t,'⾃由度':n-1,'Sig.':sig,'平均值差值':np.mean(lst)-u}]df_res=pd.DataFrame(dic_res,columns=['t值','⾃由度','Sig.','平均值差值'])return df_rest_1samp(weight,70)```# 两独⽴样本 t 检验假设现在还有另外10个⼥⽣的体重数据,问上⼀组男⽣的体重和这⼀组⼥⽣的体重有⽆明显差异(显著性⽔平为0.05)。
代码如下:```codeweight_f=[42,44,54,62,58,57,63,55,57,48]def t_2samp(list_c1,list_c2):lst1,lst2=list_c1.copy(),list_c2.copy()n1,n2=len(lst1),len(lst2)sig_homovar=stats.levene(lst1,lst2)[1]var1,var2=np.var(lst1)*n1/(n1-1),np.var(lst2)*n2/(n2-1)var12=((n1-1)*var1+(n2-1)*var2)/(n1+n2-2)t_homo=(np.mean(lst1)-np.mean(lst2))/(var12*(1/n1+1/n2))**0.5df_homo=n1+n2-2sig_homo=2*stats.t.sf(abs(t_homo),df_homo)t_nothomo=(np.mean(lst1)-np.mean(lst2))/(var1/n1+var2/n2)**0.5df_nothomo=(var1/n1+var2/n2)**2/((var1/n1)**2/n1+(var2/n2)**2/n2)sig_nothomo=2*stats.t.sf(abs(t_nothomo),df_nothomo)df_res=pd.DataFrame(index=['假定等⽅差','不假定等⽅差'],columns=['显著性','t值','⾃由度','Sig.'])df_res['显著性']=[sig_homovar,'-']df_res['t值']=[t_homo,t_nothomo]df_res['⾃由度']=[df_homo,df_nothomo]df_res['Sig.']=[sig_homo,sig_nothomo]return df_rest_2samp(weight,weight_f)```# 两配对样本 t 检验假设现在这组男⽣开始⽤某种减肥⽅法减肥,⼀个星期后测得各⾃体重,问这种减肥⽅法效果是否显著(显著性⽔平为0.05)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Python 面面 Multi-dimensional View of Python观Department of Computer Science and Technology Department of University Basic Computer Teaching2用Python玩转数据条件if 语句# Filename: ifpro.py sd1 = 3 sd2 = 3if sd1 == sd2:print "the square's area is:%d" % (sd1*sd2)Fileif expression : expr_true_suite语 法条件表达式: •比较运算符 •成员运算符 •逻辑运算符expression•expression 条件为True 时执行的代码块 •代码块必须缩进(通常为4个空格)expr_true_suite3# Filename: elsepro.pysd1 = int (raw_input ('the first side:')) sd2 = int (raw_input ('the second side:')) if sd1 == sd2:print "the square's area is:%d" %(sd1*sd2) else :print "the rectangle's area is:%d" %(sd1*sd2)Fileif expression : expr_true_suiteelse:expr_false_suite 语 法•expression 条件为False 时执行的代码块•代码块必须缩进 •else 语句不缩进expr_false_suitethe first side:4 the second side:4 the square's area is:16Input andOutputif expression :expr_true_suite elif expression2: expr2_true_suite : :elif expressionN : exprN_true_suite else:none_of_the_above_suite语 法•expression2为True 时执行的代码块expr2_true_suite•expressionN 为True 时执行的代码块exprN_true_suite•none_of_the_above_s uite 是以上所有条件都不满足时执行的代码块else# Filename: elifpro.pyk = raw_input ('input the index of shape:') if k == '1':print 'circle' elif k == '2': print 'oval' elif k == '3':print 'rectangle' elif k == '4':print 'triangle' else :print 'you input the invalid number'Fileinput the index of shape:3 rectangleI nput andOutputinput the index of shape:8 you input the invalid numberI nput and Output条件嵌套•同等缩进为同一条件结构# Filename: ifnestpro.pyk = raw_input ('input the index of shape:') if k == '1':print 'circle' elif k == '2': print 'oval' elif k == '3':sd1 = int (raw_input ('the first side:')) sd2 = int (raw_input (:'the second side')) if sd1 == sd2:print "the square's area is:%d" %(sd1*sd2) else :print "the rectangle's area is:%d" %(sd1*sd2) print 'rectangle' elif k == '4':print 'triangle' else :print 'you input the invalid number'Fileinput the index of shape:3 the first side:3 the second side:4the rectangle's area is:12I nput andOutputinput the index of shape:2 ovalI nput and Output7猜数字游戏•程序随机产生一个0~300间的整数,玩家竞猜,系统给出“猜中”、“太大了”或“太小了”的提示。
# Filename: guessnum1.pyfrom random import randintx = randint(0, 300)print'Please input a number between 0~300:' digit = input()if digit == x :print'Bingo!'elif digit > x:print'Too large,please try again.'else:print 'Too small,please try again.'F ile89用Python玩转数据RANGE 和XRANGErange()10range (start, end, step=1) range (start, end) range (end)语 法•起始值(包含)start•终值(不包含)end•步长(不能为0)step•生成一个真实的列表•不包含end 的值range (start, end, step=1)•缺省step 值为1range (start, end)•缺省了start 值为0,step 为1range (end)>>> range (3,11,2) [3, 5, 7, 9]>>> range (3,11)[3, 4, 5, 6, 7, 8, 9, 10] >>> range (11)[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]Sourcexrange()异同range() xrange()语法一样返回列表生成器生成真实列表用多少生成多少>>> xrange(3,11,2)xrange(3, 11, 2)>>> print xrange(3,11,2)xrange(3, 11, 2)>>> for i in xrange(3,11,2):print iS ource11Output:3579在Python 3.x中不支持xrange()函数,都使用range()函数,其返回值为range对象,并且需要显式调用,常用list(range(10))形式12用Python玩转数据循环while 循环>>> sumA = 0 >>> j = 1>>> while j < 10: sumA += j j += 1 >>> sumA 45 >>> j 10Source13while expression: suite_to_repeat语法•条件表达式•当expression 值为True 时执行suite_to_repeat 代码块expressionfor iter_var in iterable_object: suite_to_repeat语 法•遍历一个数据集内的成员 •在列表解析中使用 •生成器表达式中使用可以明确循环的次数•String •List•Tuple •Dictionary •Fileiterable_object•字符串就是一个iterable_object•range()返回的也是iterable_object >>> s = 'python'>>> for c in s:print cpython>>> for i in range(3,11,2):print i,3 5 7 9S ourcePython 3.x中print函数用法与Python 2.x中的语句用法也有所改变,例如此处变成print( i, end = ' ')猜数字游戏16 •程序随机产生一个0~300间的整数,玩家竞猜,允许猜多次,系统给出“猜中”、“太大了”或“太小了”的提示。
# Filename: guessnum2.pyfrom random import randintx = randint(0, 300)for count in range(0,5):print'Please input a number between 0~300:' digit = input()if digit == x :print'Bingo!'elif digit > x:print'Too large,please try again.'else:print'Too small,please try again.'F ile17用Python玩转数据循环中的BREAK,CONTINUE和ELSEbreak 语句•break 语句终止当前循环,转而执行循环之后的语句# Filename: breakpro.pysumA = 0 i = 1while True : sumA += i i += 1if sumA > 10: breakprint 'i=%d,sum=%d' % (i,sumA)File18Output:i=6,sumA=15•输出2-100之间的素数# Filename: prime.pyfrom math import sqrt j=2while j <=100: i = 2 k= sqrt(j)while ( i <= k ):if j%i == 0: break i = i+1 if ( i > k): print j, j += 1FileOutput:2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97# Filename: prime.pyfrom math import sqrt for i in range (2,101): k = int (sqrt(i))for j in range (2,k+1): if i%j == 0: break if ( ): print i,File•输出2-100之间的素数Output:2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97flag = 1flag = 0 flag•在while和for循环中,continue语句的作用:–停止当前循环,重新进入循环–while循环则判断循环条件是否满足–for循环则判断迭代是否已经结束•循环中的break :# Filename: breakpro.py sumA = 0 i = 1while i <= 5: sumA += i if i == 3: breakprint 'i=%d,sum=%d' % (i,sumA) i += 1 F ile •循环中的continue :# Filename: continuepro.pysumA = 0 i = 1while i <= 5: sumA += i i += 1 if i == 3: continueprint 'i=%d,sum=%d' % (i,sumA)File猜数字游戏(想停就停,非固定次数)23 •程序随机产生一个0~300间的整数,玩家竞猜,允许玩家自己控制游戏次数,如果猜中系统给出提示并退出程序,如果猜错给出“太大了”或“太小了”的提示,如果不想继续玩可以退出。