修改链表中的记录
c语言实现通讯录管理系统(用链表实现)
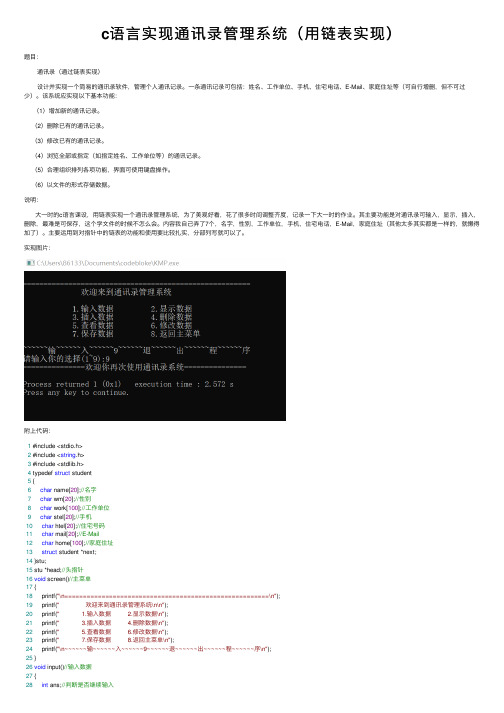
c语⾔实现通讯录管理系统(⽤链表实现)题⽬:通讯录(通过链表实现)设计并实现⼀个简易的通讯录软件,管理个⼈通讯记录。
⼀条通讯记录可包括:姓名、⼯作单位、⼿机、住宅电话、E-Mail、家庭住址等(可⾃⾏增删,但不可过少)。
该系统应实现以下基本功能:(1)增加新的通讯记录。
(2)删除已有的通讯记录。
(3)修改已有的通讯记录。
(4)浏览全部或指定(如指定姓名、⼯作单位等)的通讯记录。
(5)合理组织排列各项功能,界⾯可使⽤键盘操作。
(6)以⽂件的形式存储数据。
说明:⼤⼀时的c语⾔课设,⽤链表实现⼀个通讯录管理系统,为了美观好看,花了很多时间调整齐度,记录⼀下⼤⼀时的作业。
其主要功能是对通讯录可输⼊,显⽰,插⼊,删除,最难是可保存,这个学⽂件的时候不怎么会。
内容我⾃⼰弄了7个,名字,性别,⼯作单位,⼿机,住宅电话,E-Mail,家庭住址(其他太多其实都是⼀样的,就懒得加了)。
主要运⽤到对指针中的链表的功能和使⽤要⽐较扎实,分部列写就可以了。
实现图⽚:附上代码:1 #include <stdio.h>2 #include <string.h>3 #include <stdlib.h>4 typedef struct student5 {6char name[20];//名字7char wm[20];//性别8char work[100];//⼯作单位9char stel[20];//⼿机10char htel[20];//住宅号码11char mail[20];//E-Mail12char home[100];//家庭住址13struct student *next;14 }stu;15 stu *head;//头指针16void screen()//主菜单17 {18 printf("\n=======================================================\n");19 printf(" 欢迎来到通讯录管理系统\n\n");20 printf(" 1.输⼊数据 2.显⽰数据\n");21 printf(" 3.插⼊数据 4.删除数据\n");22 printf(" 5.查看数据 6.修改数据\n");23 printf(" 7.保存数据 8.返回主菜单\n");24 printf("\n~~~~~~输~~~~~~⼊~~~~~~9~~~~~~退~~~~~~出~~~~~~程~~~~~~序\n");25 }26void input()//输⼊数据27 {28int ans;//判断是否继续输⼊29 stu *p1,*p2;30 p1=(stu *)malloc(sizeof(stu));//申请内存来⽤31if(p1!=NULL)32 {33 printf("========输⼊数据========\n");34 head=p1;35while(1)36 {37 printf("名字:");38 scanf("%s",&p1->name);39 printf("性别:");40 scanf("%s",&p1->wm);41 printf("⼯作单位:");42 scanf("%s",&p1->work);43 printf("⼿机:");44 scanf("%s",&p1->stel);45 printf("住宅号码:");46 scanf("%s",&p1->htel);47 printf("E-Mail:");48 scanf("%s",&p1->mail);49 printf("家庭地址:");50 scanf("%s",&p1->home);51 printf("===================================\n");52 p2=p1;53 p1=(stu *)malloc(sizeof(stu));//申请下⼀个要⽤的空间54if(p1!=NULL)55 p2->next=p1;56 printf("请选择是否继续输⼊:1.继续 2.退出\n请选择:");//⽤户选择57 scanf("%d",&ans);58if(ans==1)//继续59continue;60else//退出61 {62 printf("========输⼊完毕========\n");63 p2->next=NULL;64free(p1);//将申请的的⽆⽤内存释放65break;66 }67 }68 }69 }70void look(stu *p1)//显⽰数据71 {72 printf("========显⽰数据========\n");73while(p1!=NULL)74 {75 printf("名字:%s\n",p1->name);76 printf("性别:%s\t",p1->wm);77 printf("⼯作单位:%s\t",p1->work);78 printf("⼿机:%s\t",p1->stel);79 printf("住宅号码:%s\t",p1->htel);80 printf("E-Mail:%s\t",p1->mail);81 printf("家庭住址:%s\n",p1->home);82 printf("=====================================\n");83 p1=p1->next;84 }85 printf("========显⽰完毕========\n");86 }87void insert()//插⼊数据88 {89int ans;//选择插⼊位置90char name[20];//插⼊者的名字91 printf("========插⼊数据========\n");92 stu *p1,*p2,*p3;93 p1=head;94 p3=(stu *)malloc(sizeof(stu));//申请内存95 p3->next=NULL;96 printf("请输⼊插⼊者的数据:\n");97 printf("名字:");98 scanf("%s",&p3->name);99 printf("性别:");100 scanf("%s",&p3->wm);101 printf("⼯作单位:");102 scanf("%s",&p3->work);103 printf("⼿机:");104 scanf("%s",&p3->stel);105 printf("住宅号码:");106 scanf("%s",&p3->htel);107 printf("E-Mail:");108 scanf("%s",&p3->mail);109 printf("家庭地址:");110 scanf("%s",&p3->home);111 printf("请选择插⼊位置:1.⾸位置插⼊ 2.尾部插⼊ 3.插到某⼈前⾯\n请选择:");112 scanf("%d",&ans);113switch(ans)114 {115case1://放到头指针116 p3->next=p1;117 head=p3;118break;119case2://放到尾部120while(p1->next!=NULL)121 p1=p1->next;122 p1->next=p3;123break;124case3://放到某⼈前⾯125 printf("请输⼊插到谁前⾯名字:");126 scanf("%s",name);127while(strcmp(name,p1->name)!=0)128 {129 p2=p1;130 p1=p1->next;131 }132 p2->next=p3;133 p3->next=p1;134break;135 }136 printf("========插⼊成功========\n");137 }138void deleted()//删除数据139 {140 stu *p1,*p2;141char name[20];//删除者名字142 printf("========删除数据========\n");143 printf("请输⼊要删除者的名字:");144 scanf("%s",name);145 p1=head;146if(head==NULL)//通讯录已经没数据了147 {148 printf("通讯录⾥什么也没有了。
sql update 链表语句

SQL update 链表语句一、概述在SQL 中,更新链表是一种常见的操作,它允许我们更新表中的记录。
在更新链表时,我们需要指定要更新的表,以及要更新的列和对应的新值。
我们还需要指定更新的条件,以确保只有符合条件的记录才会被更新。
二、更新链表的语法更新链表的基本语法如下:```sqlUPDATE 表名SET 列1 = 新值1, 列2 = 新值2, ...WHERE 条件;```其中,UPDATE 表名指定要更新的表,SET 列1 = 新值1, 列2 = 新值2, ... 指定要更新的列和对应的新值,WHERE 条件指定更新的条件。
假设我们有一个名为员工表的表,其中包含员工的ID、尊称和薪水信息,我们想要将ID为1001的员工的薪水增加500元,更新链表的语句如下:```sqlUPDATE 员工表SET 薪水 = 薪水 + 500WHERE ID = 1001;```三、更新链表的注意事项在更新链表时,需要注意以下几点:1. 更新的条件应该尽量精确。
如果更新条件过于宽泛,可能会导致不必要的记录被更新,这样会增加系统的负担,降低系统性能。
2. 在更新链表之前,最好先对更新语句进行测试。
可以通过在更新语句前添加 SELECT 语句来查看更新语句将影响哪些记录,从而确保更新操作的安全性和准确性。
3. 在更新链表时,应该尽量避免使用通配符。
通配符会导致更新条件过于宽泛,从而增加系统的负担。
四、更新链表的实例假设我们有一个名为订单表的表,其中包含订单编号、客户编号和订单金额信息,我们想要将客户编号为C001的客户的所有订单金额增加10,更新链表的语句如下:```sqlUPDATE 订单表SET 订单金额 = 订单金额 * 1.1WHERE 客户编号 = 'C001';```上述更新链表的语句中,我们使用了条件 `客户编号 = 'C001'` 来指定更新的条件,`订单金额 = 订单金额 * 1.1` 来指定需要更新的列和对应的新值。
计算机软件技术基础_实验指导书

《计算机软件技术基础》实验指导书编写:XXX适用专业:电器工程与自动化通讯工程电子信息工程安徽建筑工业学院电子与信息工程学院2007年9月实验一:线性链表的建立、查找、插入、删除实验实验学时:2实验类型:验证实验要求:必修一、实验目的通过本实验的学习,要求学生能够通过单链表的存储结构,掌握单链表的基本操作,包括单链表的建立、查找、插入、删除、输出等操作。
通过本实验可以巩固学生所学的线性表知识,提高编程能力,为后继课程的学习奠定基础。
二、实验内容1、为线性表{10,30,20,50,40,70,60,90,80,100}创建一个带头结点的单链表;2、在该链表上查找值为50,65的结点,并返回查找结果(找到:返回在县新链表中的位置);3、在该链表上值为50的结点后,插入一个值为120的结点;4、删除该链表上值为70的结点。
写出各操作的实现函数,并上机验证。
三、实验原理、方法和手段使用带头结点的单链表的表示线性表,通过实验,熟悉链表的创建、查找、插入、删除、输出等是链表的基本操作。
具体如下:(1)首先定义单链表的节点结构;(2)在单链表创建过程中,首先初始化一个带头结点的空链表,对线性表中的各元素依次通过键盘输入、建立该元素结点、插入到单链表中,实现单链表的创建过程;结点的插入有头插入和尾插入两种方法,采用不同方法时应注意元素的输入顺序。
(3)查找过程可以从头结点开始,将待查找的数据依次与每个结点的数据域比较,匹配及查找成功,弱链表访问完未找到匹配的元素,则查找不成功。
为能够返回查找成功的结点位置,在链表的搜索过程中,应设置一个计数器,记录搜索结点的序号;(4)插入结点时,首先要通过查找算法,找到带插入结点的前驱结点,然后为带插入元素建立结点,通过指针的修改,将结点插入。
(5)删除结点时,首先要通过查找算法,找到待删除结点的前驱,然后通过指针的修改,将待删除结点从链表中卸下,释放该结点。
(6)以上操作的正确性,均可以通过链表的输出结果来验证。
掌握数据结构中的链表和数组的应用场景

掌握数据结构中的链表和数组的应用场景链表和数组都是常用的数据结构,它们在不同的场景下有不同的应用。
一、链表的应用场景:1.链表适合动态插入和删除操作:链表的插入和删除操作非常高效,只需修改指针的指向,时间复杂度为O(1)。
因此,当需要频繁进行插入和删除操作时,链表是一个很好的选择。
-操作系统中的进程控制块(PCB):操作系统需要频繁地创建、停止、销毁进程,使用链表存储这些PCB,可以方便地插入、删除和管理进程。
-聊天记录:在聊天应用中,新的消息会动态插入到聊天记录中,使用链表存储聊天记录可以方便地插入新消息。
2.链表节省内存空间:每个节点只需存储当前元素和指向下一个节点的指针,不需要像数组一样预分配一块连续的内存空间,因此链表对内存空间的利用更加灵活。
-操作系统中的内存管理:操作系统使用链表来管理空闲内存块和已分配的内存块,可有效节省内存空间。
3.链表支持动态扩展:链表的长度可以随时变化,可以动态地扩容和缩容。
-缓存淘汰算法:在缓存中,如果链表已满,当有新数据需要加入缓存时,可以通过删除链表头部的节点来腾出空间。
4.链表可以快速合并和拆分:将两个链表合并成一个链表只要调整指针的指向即可,时间复杂度为O(1)。
-链表排序:在排序算法中,链表归并排序利用链表快速合并的特性,使得归并排序在链表上更高效。
二、数组的应用场景:1.随机访问:数组可以根据索引快速访问元素,时间复杂度为O(1)。
-图像处理:图像通常以像素点的形式存储在数组中,可以通过索引快速访问某个特定像素点的颜色信息。
2.内存连续存储:数组的元素在内存中是连续存储的,可以利用硬件缓存机制提高访问效率。
-矩阵运算:矩阵可以通过二维数组来表示,利用矩阵的连续存储特性,可以高效地进行矩阵运算。
3.大数据存储:数组可以预先分配一块连续的内存空间,非常适合存储大量的数据。
-数据库中的数据表:数据库中的数据表通常使用数组来实现,可以快速存取和处理大量的数据。
数据结构课程设计实验1_城市链表

数据结构课程设计实验报告实验一链表部分选题为:2.4.3—城市链表1、需求分析(1)创建一个带有头结点的单链表。
(2)结点中应包含城市名和城市的位置坐标。
(3)对城市链表能够利用城市名和位置坐标进行有关查找、插入、删除、更新等操作。
(4)能够对每次操作后的链表动态显示。
2、概要设计为了实现以上功能,可以从以下3个方面着手设计。
(1)主界面设计为了实现城市链表相关操作功能的管理,设计一个含有多个菜单项的主控菜单子程序以系统的各项子功能,方便用户使用本程序。
本系统主控菜单运行界面如下所示。
(2)存储结构设计本系统主要采用链表结构类型来表示存储在“城市链表”中的信息。
其中链表结点由4个分量组成:城市名name、城市的横坐标posx、城市的纵坐标posy、指向下一个结点的指针next。
(3)系统功能设计本程序设计了9个功能子菜单,其描述如下:①建立城市链表。
由函数creatLink()实现。
该功能实现城市结点的输入以及连接。
②插入链表记录。
由函数insert()实现。
该功能实现按坐标由小到大的顺序将结点插入到链表中。
③查询链表记录。
由searchName()函数和searchPos()函数实现。
其中searchName()实现按照城市名查询的操作,searchPos()实现按照城市坐标查询的操作。
④删除链表记录。
由delName()函数和delPos()函数实现。
其中delName()函数实现按照城市名删除的操作,delPos()函数实现按照城市坐标删除的操作。
⑤ 显示链表记录。
由printList ()函数实现。
该功能实现格式化的链表输出操作,可以显示修改后的链表状态。
⑥ 更新链表信息。
由update ()函数实现。
该功能实现按照城市名更新城市的坐标信息。
⑦ 返回城市坐标。
由getPos ()函数实现。
该功能实现给定一个已存储的城市,返回其坐标信息的操作。
⑧ 查看与坐标P 距离小于等于D 的城市。
由getCity ()函数实现。
数据结构程序填空题

数据结构程序填空题一、题目描述:编写一个程序,实现一个简单的链表数据结构,并完成以下操作:1. 初始化链表2. 在链表末尾插入节点3. 在链表指定位置插入节点4. 删除链表指定位置的节点5. 获取链表长度6. 打印链表中的所有节点二、解题思路:1. 定义链表节点结构体Node,包含一个数据域和一个指向下一个节点的指针域。
2. 定义链表结构体LinkedList,包含一个头节点指针和一个记录链表长度的变量。
3. 初始化链表时,将头节点指针置为空,链表长度置为0。
4. 在链表末尾插入节点时,先判断链表是否为空,若为空,则将新节点作为头节点;若不为空,则找到链表最后一个节点,将其指针指向新节点。
5. 在链表指定位置插入节点时,先判断插入位置的合法性,若位置超出链表长度范围,则插入失败;否则,找到插入位置的前一个节点,将新节点插入到其后面。
6. 删除链表指定位置的节点时,先判断删除位置的合法性,若位置超出链表长度范围,则删除失败;否则,找到删除位置的前一个节点,将其指针指向要删除节点的下一个节点,并释放要删除节点的内存空间。
7. 获取链表长度时,直接返回链表结构体中记录的长度变量。
8. 打印链表中的所有节点时,从头节点开始遍历链表,依次输出每个节点的数据域。
三、代码实现:```c#include <stdio.h>#include <stdlib.h>// 定义链表节点结构体typedef struct Node {int data; // 数据域struct Node* next; // 指针域} Node;// 定义链表结构体typedef struct LinkedList {Node* head; // 头节点指针int length; // 链表长度} LinkedList;// 初始化链表void initLinkedList(LinkedList* list) {list->head = NULL; // 头节点指针置为空list->length = 0; // 链表长度置为0}// 在链表末尾插入节点void insertAtEnd(LinkedList* list, int value) {Node* newNode = (Node*)malloc(sizeof(Node)); // 创建新节点newNode->data = value; // 设置新节点的数据域newNode->next = NULL; // 设置新节点的指针域为NULL if (list->head == NULL) {list->head = newNode; // 若链表为空,将新节点作为头节点} else {Node* current = list->head;while (current->next != NULL) {current = current->next; // 找到链表最后一个节点}current->next = newNode; // 将最后一个节点的指针指向新节点}list->length++; // 链表长度加1}// 在链表指定位置插入节点void insertAtPosition(LinkedList* list, int value, int position) {if (position < 0 || position > list->length) {printf("插入位置不合法!\n");return;}Node* newNode = (Node*)malloc(sizeof(Node)); // 创建新节点newNode->data = value; // 设置新节点的数据域if (position == 0) {newNode->next = list->head; // 若插入位置为0,将新节点作为头节点 list->head = newNode;} else {Node* current = list->head;for (int i = 0; i < position - 1; i++) {current = current->next; // 找到插入位置的前一个节点}newNode->next = current->next; // 将新节点的指针指向插入位置的节点 current->next = newNode; // 将插入位置的前一个节点的指针指向新节点}list->length++; // 链表长度加1}// 删除链表指定位置的节点void deleteAtPosition(LinkedList* list, int position) {if (position < 0 || position >= list->length) {printf("删除位置不合法!\n");return;}Node* temp;if (position == 0) {temp = list->head; // 记录要删除的节点list->head = list->head->next; // 将头节点指向下一个节点} else {Node* current = list->head;for (int i = 0; i < position - 1; i++) {current = current->next; // 找到删除位置的前一个节点}temp = current->next; // 记录要删除的节点current->next = current->next->next; // 将删除位置的前一个节点的指针指向删除位置的后一个节点}free(temp); // 释放要删除节点的内存空间list->length--; // 链表长度减1}// 获取链表长度int getLength(LinkedList* list) {return list->length;}// 打印链表中的所有节点void printLinkedList(LinkedList* list) { Node* current = list->head;while (current != NULL) {printf("%d ", current->data);current = current->next; // 遍历链表 }printf("\n");}int main() {LinkedList list;initLinkedList(&list);insertAtEnd(&list, 1);insertAtEnd(&list, 2);insertAtEnd(&list, 3);printf("链表中的节点:");printLinkedList(&list); // 链表中的节点:1 2 3insertAtPosition(&list, 4, 1);printf("链表中的节点:");printLinkedList(&list); // 链表中的节点:1 4 2 3deleteAtPosition(&list, 2);printf("链表中的节点:");printLinkedList(&list); // 链表中的节点:1 4 3int length = getLength(&list);printf("链表的长度:%d\n", length); // 链表的长度:3 return 0;}```四、测试结果:运行以上代码,输出结果为:```链表中的节点:1 2 3链表中的节点:1 4 2 3链表中的节点:1 4 3链表的长度:3```五、总结:通过以上程序的实现,我们成功地完成了一个简单的链表数据结构,并实现了初始化链表、在链表末尾插入节点、在链表指定位置插入节点、删除链表指定位置的节点、获取链表长度以及打印链表中的所有节点等操作。
c语言课程设计

课程设计任务书一、设计题目(一)学生成绩排名(二)根据条件进行学生成绩排名(三)链表的操作(链表的建立,访问,删除链表指定结点,增加结点)(四)学生成绩文件管理(五)一个综合系统(学生成绩管理系统)二、主要内容(一)学生成绩排名先采用选择法,将学生成绩从高到低进行排序,再输入一个学生的成绩,将此成绩按照排序规律插入已排好序的学生成绩数组,最后将排好序的成绩单进行反序存放。
(二)根据条件进行学生成绩排名在函数中进行10个学生成绩从高到低排名,再改进函数,进行n个学生成绩从高到低排名, 排名方式根据函数的style参数进行,如style为‘a'按升序排,style为' d ' 按降序排(a:ascending 升,d:descending 降)。
编写多个不同函数,使之能实现不同的排序算法(3种以上),再编写一个通用输出函数,(要求用函数指针做参数)能分别打印不同排序算法的结果。
(三)链表的操作(链表的建立,访问,删除链表指定结点,增加结点)建立一个动态链表,将学生数据(学号,成绩)存入链表结构中,实现链表的访问(求学生成绩的平均分,找到最高分,最低分,将其数据输出)。
删除指定学号的学生数据,对学生数据进行排序,分别在链表头部,中间,末尾插入学生数据。
(四)学生成绩文件管理定义一个结构体数组,存放10个学生的学号,姓名,三门课的成绩,输出单门课成绩最高的学生的学号、姓名、以及该门课程的成绩,输出三门课程的平均分数最高的学生的学号、姓名及其平均分,将10个学生的相关数据,存入文件中,再从文件中读出,按照平均分数从高到低进行排序,分别将结果输出到屏幕上和另一文件中,再从文件中读取第 1 ,3 , 5 ,7,9个学生的数据。
(五)学生成绩管理系统设计:数据库的数据项主要数据包括:学号、姓名、年级、专业、成绩1、成绩2、成绩3、平均成绩、总成绩。
要求具有以下功能:(1)添加、删除任意个记录。
区块链技术的数据结构解读

区块链技术的数据结构解读随着科技的不断进步,区块链技术逐渐成为了人们广泛关注的热点。
作为一种去中心化数字账本技术,它可以在无需信任的情况下实现数据的安全存储和传输。
而要想彻底理解区块链技术,必须了解其背后的数据结构。
本文将从数据结构的角度出发,介绍区块链技术的基本概念和相关数据结构。
一、区块链基础概念区块链是一种分布式的、去中心化的账本技术,其特点是将交易记录保存在由多个节点组成的网络中,而非由单一机构或个人拥有和控制。
在区块链中,所有的参与者都持有账本数据副本,这就保证了数据的可靠性、不可篡改和不可抵赖性。
同时,区块链技术还能够实现一种名为智能合约的自动化合约机制,可以令机器代替人类完成某些特定的业务操作。
区块是区块链中最基本的单位,每个区块中都有一批新的交易记录。
当交易发生时,它将被打包成一个块,并通过加密算法和数字签名的方式被验证和加密。
每个区块的构成包括起始区块的信息、时间戳、交易记录和一定数量的其他信息,这些信息组合在一起构成了一个不可改变的、有时间顺序的链,称为区块链。
二、区块链中的数据结构在区块链技术中,数据结构是至关重要的一部分,它承载着交易记录和账户信息。
区块链中的数据结构主要包括Merkle Tree(默克尔树)、哈希链表(Hashchain)和简单链表(Linked List)等。
下面将详细介绍这些数据结构的特点和应用。
1. 默克尔树Merkle Tree是一种由Ralph Merkle在1979年提出的哈希树结构,它可以有效的验证大量数据的完整性,并提高验证的速度。
在区块链中,Merkle Tree广泛应用于验证交易记录的完整性。
Merkle Tree的核心思想是将大量数据作为叶子节点,然后将它们配对组成一个个哈希值,再对这些哈希值再次配对构成更大的哈希值,一直进行下去,最终形成一棵根节点的哈希树。
在验证时,如果数据中任何一部分被篡改,它的哈希值将发生改变,从而导致整个哈希树的顶层节点发生变化,证明了数据被篡改的事实。
全国自考操作系统(存储管理)模拟试卷1(题后含答案及解析)

全国自考操作系统(存储管理)模拟试卷1(题后含答案及解析) 题型有:1. 单项选择题 3. 填空题 4. 简答题 6. 判断题单项选择题1.根据作业在本次分配到的内存起始地址将目标代码装到指定内存地址中,并修改所有有关地址部分的值的方法称为_______方式。
A.固定定位B.静态重定位C.动态重定位D.单一连续重定位正确答案:B 涉及知识点:存储管理2.静态地址重定位的对象是_______。
A.源程序B.编译程序C.目标程序D.执行程序正确答案:C 涉及知识点:存储管理3.使用_______,目标程序可以不经过任何改动而装入主存直接执行。
A.静态重定位B.动态重定位C.编译或汇编D.连接程序正确答案:B 涉及知识点:存储管理4.在可变式分区存储管理中,当释放和回收一个空闲区时,造成空闲表项区数减1的情况是_______。
A.无上邻空闲区,也无下邻空闲区B.有上邻空闲区,但无下邻空闲区C.无上邻空闲区,但有下邻空闲区D.有上邻空闲区,也有下邻空闲区正确答案:D解析:在有上邻空闲区也有下邻空闲区的情况下,释放区和上、下邻空闲区合并成一块空闲区,故原先记录上、下邻空闲区的两个表项就只需要合并为一个表项记录新的大空闲区。
知识模块:存储管理5.在下列存储管理算法中,内存的分配和释放平均时间之和为最大的是_______。
A.首次适应法B.循环首次适应法C.最佳适应法D.最差适应法正确答案:C解析:最佳适应算法的分配算法的速度比首次适应法、循环首次适应法和最差适应算法差得多,如用链表实现,释放算法要在链表中找上、下邻空闲区,修改过或新加入的空闲区还要有序地插入到链表中。
知识模块:存储管理6.早期采用交换技术的目的是_______。
A.能运行更多的程序B.能运行更大的程序C.实现分时系统D.实现虚拟存储技术正确答案:A 涉及知识点:存储管理7.虚拟存储器技术的目的是_______。
A.实现存储保护B.实现程序浮动C.可运行更大更多的程序D.扩充主存容量正确答案:C 涉及知识点:存储管理8.在以下存储管理方案中,不适用于多道程序设计系统的是_______。
太原理工数据结构实验答案

实验一线性表一.目的与要求本次实习的主要目的是为了使学生熟练掌握线性表的基本操作在顺序存储结构和链式存储结构上的实现,提高分析和解决问题的能力。
要求仔细阅读并理解下列例题,上机通过,并观察其结果,然后独立完成后面的实习题。
二.例题问题描述:用链表形式存储一个字符串,插入、删除某个字符,最后按正序、逆序两种方式输出字符串。
输入:初始字符串,插入位置,插入字符,删除字符。
输出:已建立链表(字符串),插入字符后链表,删除字符后链表,逆转后链表。
存储结构:采用链式存储结构算法的基本思想:建立链表当读入字符不是结束符时,给结点分配存储空间,写数据域,将新结点插到表尾;插入字符:根据读入的字符在链表中找插入位置,将新结点插入到该位置之前;删除字符:根据读入的删除字符在链表中找到被删结点后,将其从链表中删除;链表逆转:从链表的第一个结点开始对所有结点处理,将每个结点的前驱变为它的后继;打印链表:从链表的第一个结点开始,依次打印各[运行情况]Input a linktable(a string):abcde↙Build link is :abcdePlease input a char you want to insert after:b↙Please input a char you want to insert:c↙After p insert y,link is:abccdePlease input a char you want to delete:e↙after delete p,link is:abccdOpsite result is :dccba如图显示:实习题:问题描述:设顺序表A中的数据元素递增有序,试写一程序,将x插入到顺序表的适当位置上,使该表仍然有序。
输入:插入前的顺序表,插入的数,插入后的顺序表输出:插入前的顺序表,插入的数,插入后的顺序表存储结构:顺序表存储数据算法基本思想:其实这个题在学C语言时就已经写过了,这里采用顺序表来存储数据。
数据结构实验报告-实验一顺序表、单链表基本操作的实现

数据结构实验报告-实验⼀顺序表、单链表基本操作的实现实验⼀顺序表、单链表基本操作的实现l 实验⽬的1、顺序表(1)掌握线性表的基本运算。
(2)掌握顺序存储的概念,学会对顺序存储数据结构进⾏操作。
(3)加深对顺序存储数据结构的理解,逐步培养解决实际问题的编程能⼒。
l 实验内容1、顺序表1、编写线性表基本操作函数:(1)InitList(LIST *L,int ms)初始化线性表;(2)InsertList(LIST *L,int item,int rc)向线性表的指定位置插⼊元素;(3)DeleteList1(LIST *L,int item)删除指定元素值的线性表记录;(4)DeleteList2(LIST *L,int rc)删除指定位置的线性表记录;(5)FindList(LIST *L,int item)查找线性表的元素;(6)OutputList(LIST *L)输出线性表元素;2、调⽤上述函数实现下列操作:(1)初始化线性表;(2)调⽤插⼊函数建⽴⼀个线性表;(3)在线性表中寻找指定的元素;(4)在线性表中删除指定值的元素;(5)在线性表中删除指定位置的元素;(6)遍历并输出线性表;l 实验结果1、顺序表(1)流程图(2)程序运⾏主要结果截图(3)程序源代码#include<stdio.h>#include<stdlib.h>#include<malloc.h>struct LinearList/*定义线性表结构*/{int *list; /*存线性表元素*/int size; /*存线性表长度*/int Maxsize; /*存list数组元素的个数*/};typedef struct LinearList LIST;void InitList(LIST *L,int ms)/*初始化线性表*/{if((L->list=(int*)malloc(ms*sizeof(int)))==NULL){printf("内存申请错误");exit(1);}L->size=0;L->Maxsize=ms;}int InsertList(LIST *L,int item,int rc)/*item记录值;rc插⼊位置*/ {int i;if(L->size==L->Maxsize)/*线性表已满*/return -1;if(rc<0)rc=0;if(rc>L->size)rc=L->size;for(i=L->size-1;i>=rc;i--)/*将线性表元素后移*/L->list[i+=1]=L->list[i];L->list[rc]=item;L->size++;return0;}void OutputList(LIST *L)/*输出线性表元素*/{int i;printf("%d",L->list[i]);printf("\n");}int FindList(LIST *L,int item)/*查找线性元素,返回值>=0为元素的位置,返回-1为没找到*/ {int i;for(i=0;i<L->size;i++)if(item==L->list[i])return i;return -1;}int DeleteList1(LIST *L,int item)/*删除指定元素值得线性表记录,返回值为>=0为删除成功*/ {int i,n;for(i=0;i<L->size;i++)if(item==L->list[i])break;if(i<L->size){for(n=i;n<L->size-1;n++)L->list[n]=L->list[n+1];L->size--;return i;}return -1;}int DeleteList2(LIST *L,int rc)/*删除指定位置的线性表记录*/{int i,n;if(rc<0||rc>=L->size)return -1;for(n=rc;n<L->size-1;n++)L->list[n]=L->list[n+1];L->size--;return0;}int main(){LIST LL;int i,r;printf("list addr=%p\tsize=%d\tMaxsize=%d\n",LL.list,LL.size,LL.Maxsize);printf("list addr=%p\tsize=%d\tMaxsize=%d\n",LL.list,LL.list,LL.Maxsize);while(1){printf("请输⼊元素值,输⼊0结束插⼊操作:");fflush(stdin);/*清空标准输⼊缓冲区*/scanf("%d",&i);if(i==0)break;printf("请输⼊插⼊位置:");scanf("%d",&r);InsertList(&LL,i,r-1);printf("线性表为:");OutputList(&LL);}while(1){printf("请输⼊查找元素值,输⼊0结束查找操作:");fflush(stdin);/*清空标准输⼊缓冲区*/scanf("%d ",&i);if(i==0)break;r=FindList(&LL,i);if(r<0)printf("没有找到\n");elseprintf("有符合条件的元素,位置为:%d\n",r+1);}while(1){printf("请输⼊删除元素值,输⼊0结束查找操作:");fflush(stdin);/*清楚标准缓存区*/scanf("%d",&i);if(i==0)break;r=DeleteList1(&LL,i);if(i<0)printf("没有找到\n");else{printf("有符合条件的元素,位置为:%d\n线性表为:",r+1);OutputList(&LL);}while(1){printf("请输⼊删除元素位置,输⼊0结束查找操作:");fflush(stdin);/*清楚标准输⼊缓冲区*/scanf("%d",&r);if(r==0)break;i=DeleteList2(&LL,r-1);if(i<0)printf("位置越界\n");else{printf("线性表为:");OutputList(&LL);}}}链表基本操作l 实验⽬的2、链表(1)掌握链表的概念,学会对链表进⾏操作。
循环链表长度

循环链表长度介绍循环链表是一种特殊的链表结构,它与普通链表的区别在于尾节点指针不为null,而是指向链表的头节点,形成一个循环链表。
循环链表可以解决一些特定的问题,比如在某些场景下需要循环遍历链表或者需要快速访问链表的最后一个节点。
在这篇文章中,我们将重点讨论循环链表的长度计算方法,以及一些相关的问题和应用场景。
计算循环链表长度的方法计算循环链表的长度可以通过遍历链表的方式来实现,也可以通过记录链表的节点数来实现。
下面将介绍两种方法。
方法一:遍历链表遍历链表是一种直观的方法,通过从链表的头节点开始,依次遍历下一个节点,直到回到头节点。
在遍历的过程中,我们可以用一个计数器来记录遍历的节点数,最终的计数器值就是循环链表的长度。
具体的实现步骤如下: 1. 初始化计数器count为0; 2. 从链表的头节点开始,依次遍历下一个节点,每遍历一个节点,计数器count加1; 3. 当遍历到头节点时,停止遍历; 4. 返回计数器count的值,即为循环链表的长度。
遍历链表的代码示例:count = 0current = headwhile True:count += 1current = current.nextif current == head:breakreturn count方法二:记录节点数在循环链表中,每个节点都可以通过其下一个节点来访问到,因此可以通过每个节点的next指针来记录链表的节点数。
具体做法是,从链表的头节点开始,依次遍历下一个节点,每访问到一个节点,节点数加1,直到再次回到头节点为止。
具体的实现步骤如下: 1. 初始化节点数为1; 2. 从链表的头节点开始,依次遍历下一个节点,每访问到一个节点,节点数加1; 3. 当节点的next指针指向头节点时,停止遍历; 4. 返回节点数,即为循环链表的长度。
记录节点数的代码示例:count = 1current = head.nextwhile current != head:count += 1current = current.nextreturn count循环链表长度的应用场景循环链表长度的计算方法可以在一些特定的问题中得到应用。
数据结构代码题总结

以下是一些常见的数据结构代码题,以及相应的解决方案。
反转链表问题描述:给定一个链表,反转链表并返回新的头节点。
解决方案:使用迭代或递归方法反转链表。
迭代方法需要维护一个指向当前节点和前一个节点的指针,遍历链表并更新指针。
递归方法需要递归到链表的末尾,然后逐步返回并更新节点指针。
二叉树的最大深度问题描述:给定一个二叉树,找出其最大深度。
解决方案:使用递归或迭代方法遍历二叉树,并计算每个节点的深度。
递归方法在每个节点处递归计算左子树和右子树的最大深度,并返回它们的最大值加1。
迭代方法使用队列或栈来遍历二叉树,并记录每个节点的深度。
合并两个有序链表问题描述:将两个升序链表合并为一个新的升序链表并返回。
新链表是通过拼接给定的两个链表的所有节点组成的。
解决方案:使用迭代或递归方法合并两个有序链表。
迭代方法维护一个指向新链表的头节点和尾节点的指针,并使用两个指针分别遍历两个有序链表,将较小的节点添加到新链表中。
递归方法在每个节点处递归调用合并函数,并将较小的节点作为当前节点,较大的节点的子节点作为递归参数传递给下一层递归。
二叉搜索树的最小绝对差问题描述:给定一个所有节点值都是整数的二叉搜索树,返回一个节点,其值与该树中其他节点的值的最小绝对差最小。
解决方案:使用中序遍历遍历二叉搜索树,计算相邻节点之间的绝对差并找到最小值。
在遍历过程中,记录前一个节点的值和当前最小绝对差,比较当前节点与前一个节点之间的绝对差并更新最小绝对差和结果节点。
最长回文子串问题描述:给定一个字符串s,找到s 中最长的回文子串。
你可以假设s 的最大长度为1000。
解决方案:使用动态规划或中心扩展算法找到最长回文子串。
动态规划方法使用一个二维数组dp[i][j] 表示s[i:j+1] 是否是回文串,并使用递推关系dp[i][j] = dp[i+1][j-1] and s[i] == s[j] 计算dp 数组。
中心扩展算法从每个字符和字符间隙开始向两侧扩展,记录扩展的最大长度和起始位置。
链表的概念和应用

链表的概念和应用链表概念和应用链表是计算机科学中经常使用的数据结构,它可以用来管理大量数据,是非常重要的。
链表是一组有序的数据项的集合,每个数据项都包含了数据本身和一个指向下一个数据项的引用。
链表的数据项通过指针进行连接,形成一个链式结构。
链表可以用来存储和操作一组动态的数据集。
链表的结构和在内存中的存储方式,相对于其他线性数据结构(如数组),有一些优势。
最重要的是,在链表的结构中,可以实现动态的内存分配,提供了比其他数据结构更加灵活的数据组织方式。
当数据量很大时,链表的效率可能比数组低,但是当需要对数据进行频繁插入、删除等操作时,链表的效率、实用性会更高。
链表结构通常会包含两个重要的基本元素:头部(Head)和节点(Node)。
头部是链表的开始部分,其包含了链表的第一个节点的地址。
节点则包含了需要存储在链表中的数据和指向链表中下一个节点的地址。
链表可以根据头部地址遍历到所有的节点。
链表与数组的区别数组和链表都是用来存储数据的数据结构。
它们之间的区别主要在于数据存储的位置和内存分配方式。
数组数据会被连续存放在内存中,因此寻址非常快。
但是,由于内存块的大小通常会限制数组的大小。
当要插入或删除数据时,移动其他数据也会比较费时。
链表数据则以一种较为灵活的方式存储在内存中,每个数据项都被放置在完全不同的物理存储位置上。
每个节点都包含了指向下一个节点的引用,当需要插入或删除数据时,链表只需要修改指针,速度非常快。
链表的分类链表可分为单向链表、双向链表、循环链表和双向循环链表。
单向链表(Singly linked list):每个节点只有一个指针指向下一个节点,最后一个节点指向空。
双向链表(Doubly linked list):每个节点都有两个指针,一个指向上一个节点,另一个指向下一个节点。
双向链表可以在单向链表的基础上,增加在链表中向前(尾到头)遍历时的效率。
循环链表(Circular linked list):链表中最后一个节点与头节点连接成一个循环结构。
链表在现实世界中的应用

链表在现实世界中的应用链表是一种常用的数据结构,它由一系列节点组成,每个节点包含两个部分:数据和指向下一个节点的指针。
链表在计算机科学中被广泛应用于各种场景,而在现实生活中,我们也可以找到许多应用链表的例子:1. 文件系统:在计算机的文件系统中,目录的结构就是一个链表。
每个目录(文件夹)都包含多个文件和子目录。
子目录可以包含更多的文件和子目录,形成了一个层次结构。
这种结构可以用链表来表示,其中每个节点都代表一个目录,节点中的数据部分包含目录的名称,而指针部分指向下一个目录。
2. 网页浏览器的历史记录:当你在网页浏览器中浏览网页时,浏览器的历史记录功能使用链表来记录你访问过的网页。
新访问的网页会被添加到链表的头部,而链表的尾部是你最早访问的网页。
这样,你就可以方便地向前翻页,查看你之前访问过的网页。
3. 电话簿:在电话簿应用中,联系人信息被存储在一个链表中。
每个节点都代表一个联系人,节点中的数据部分包含联系人的姓名和电话号码,指针部分指向下一个联系人。
通过这种方式,你可以方便地按照字母顺序或其他方式浏览联系人列表。
4. 音乐播放器:在许多音乐播放器中,歌曲的播放列表使用链表来组织。
用户可以添加、删除和编辑播放列表,这些操作都可以在链表上方便地实现。
5. 操作系统:在操作系统的进程管理中,链表用于存储正在运行的进程。
每个节点代表一个进程,节点中的数据部分包含进程的状态和相关信息,指针部分指向下一个进程。
操作系统需要经常对链表进行操作,如创建新进程、删除进程和调度进程等。
以上只是链表在现实世界中的一些应用示例,实际上链表的应用非常广泛,它是一种非常有用的数据结构。
域名系统中的NSEC记录如何设置与管理(九)

域名系统中的NSEC记录如何设置与管理一、什么是NSEC记录?域名系统(Domain Name System,简称DNS)是互联网中用来将域名转换为IP地址的一种机制。
就像电话簿一样,DNS充当着将易于记忆的域名转换为计算机可处理的IP地址的角色。
在DNS中,NSEC记录(Next Secure)是一种用于验证域名存在性的记录类型。
它在区块链技术中起到了类似于链表的作用,记录了域名之间的有序关系,为域名查询提供了更高效的方式。
二、NSEC记录的作用和设置方法1. 作用NSEC记录的主要作用是告知查询者在该域名下是否存在下一个域名。
通过将域名按字母顺序排列,NSEC记录可以提供给没有匹配域名的查询者一个反馈信息,帮助其更高效地进行查询。
2. 设置方法首先,需要明确在哪里设置NSEC记录。
通常,这个工作交给域名的注册商或DNS解析商来完成。
在我们开始设置NSEC记录之前,需要先明白以下几个概念:(1)域名的授权服务器:负责提供与域名相关的DNS信息的服务器,可以理解为域名的“守门人”。
(2)域名的DNS解析商:负责将域名解析为相应的IP地址的服务商。
在设置NSEC记录之前,我们需要先登录到域名的授权服务器的管理面板。
然后,按照以下步骤进行设置:(1)找到域名列表并选择需要设置NSEC记录的域名。
(2)进入DNS管理选项,并找到“添加记录”或类似的选项。
(3)在记录类型中选择“NSEC”。
(4)填写NSEC记录的相关信息,包括域名、IP地址等。
(5)保存设置并等待生效。
三、NSEC记录的管理与维护NSEC记录的管理与维护主要包括监控、更新与删除。
1. 监控定期监控NSEC记录的有效性和完整性是保证域名系统运行正常的重要环节。
可以通过定期检查NSEC记录是否正常返回,是否能够正确指示下一个有效域名等方式进行监控。
2. 更新当域名发生变更或需要删除某个域名时,就需要更新NSEC记录。
更新NSEC记录可以通过登录授权服务器的管理面板,找到相应的域名并进入DNS管理选项,选择需要修改的NSEC记录进行更改。
六年级全一册信息技术课件-第19课测量射击速度——初识链表鄂教版

0 0 0
0
一、程序分析
分析以上脚本,程序只是记录最新的一次按键的产生 时间。但在程序运行过程中,用户按键的次数是未知的, 而且我们需要记录每一次按键按下的时间。仅仅使用变量 是不能到达程序功能要求的,需要使用“链表”来完成任 务。
0 0 0
0
二、基于链表的数据的过程记录 1.新建链表
0 0 0 0
测量射击速度——初识链表
0 0 0 0
射击类游戏中,按键的时间间隔越短越好,代表我 们射击的速度越快。我们可以尝试编写一个Scratch程 序来测量游戏中的时间间隔。
0 0 0 0
试一试 利用已学知识,尝试搭建如下脚本。思考该脚
本能否到达测量时间间隔的目的。
0 0 0 0
1
程序分析
2 基于链表的数据的过程记录
0 0 0
0
0 0 0
0
练一练 1.使用已学知识制作类似如下页图所示的“情 景对话”作品。
0 0 0 0
2.使用链表创建动画的建议脚本
0 0 0 0
3.使用链表的脚本有何不同? 使用链表的脚本,在修改角色对话“台词”时, 脚本是不需要修改的。这在软件开发中,是一项非 常关键的技术一程序与数据分离。
0 0 0
0
0 0 0
0
谢谢
Hale Waihona Puke 运行程序,计算机将 每一次接键的时间次按键 的时间进行了全程记录, 并逐一追加到链表中。就 好像有很多功能类似的存 储数据的“小盒子”。
0
0 0
0
做一做 程序在运行过程中记录了每一次按键产生的时间。
对于这些数据,我们可以将其导出,再使用“Excel 电子表格工具”处理,并计算出“平均按键时间间 隔”,“平均按键时间间隔”最小者将是我们的“射 击之王”。
aba问题

aba问题ABA 问题是指在进行 CAS 操作的时候,某个线程将一个变量的值从A 变成 B,再从 B 变成 A,其他线程会认为变量的值没有发生改变,于是正常进行 CAS 操作。
CAS(Compare And Swap):CAS 就是“比较并交换”,它有三个操作数:内存值 V、旧的预期值A、准备设置的新值 C。
CAS 最核心的思路就是,当且仅当预期值 A 和当前的内存值 V 相同时,才将内存值修改为 B。
例如,“变量”的初始值为 A,“线程1”、“线程2”对“变量”进行以下操作:“线程1”进行 CAS,记录“旧的预期值”为 A“线程1”被挂起,“线程2”执行“线程2”将“变量”的值改为 B“线程2”再次将“变量”的值改为 A“线程1”被唤醒,继续执行“线程1”准备将“变量”的值改为 B“线程1”进行 CAS,对比“变量”的“内存值”和“旧的预期值”都为 A“线程1”进行 CAS,将“变量”的值改为“准备设置的新值”:CABA 问题的影响例子中,“线程1”的 CAS 执行成功,但实际上“变量”被“线程2”改变过,经历了 A->B->A 的过程,然而“线程1”的 CAS 不能察觉到这个改变。
CAS 并不能检测出“变量”在此期间值是不是被修改过,只能检测出当前的值和最初的值是否一样。
看到这里,也许你会觉得这并没有什么问题,“变量”的值符合预期。
举个例子,有一个链表的初始状态为:A->B->C->D,“线程1”试图通过 CAS 将链表中的 A 改成 Z,进行以下操作:“线程1”进行 CAS,记录链表的首节点“旧的预期值”为 A (链表的状态:A->B->C->D)“线程1”被挂起,“线程2”执行(链表的状态:A->B->C->D)“线程2”将链表中的 B 删除(链表的状态:A->C->D)“线程1”被唤醒,继续执行(链表的状态:A->C->D)“线程1”准备将链表中的 A 改为 Z(链表的状态:A->C->D)“线程1”进行 CAS,对比链表首节点的“内存值”和“旧的预期值”都为 A(链表的状态:A->C->D)“线程1”进行 CAS,将链表中的 A 改为“准备设置的新值”:C (链表的状态:Z->C->D)在这个例子中,CAS 只能检测到链表的首节点的内存地址是否发生过改变,并不能检测到链表的结构是否改变。
undo日志

undo⽇志undo⽇志作⽤因⼀些原因(机器宕机/操作系统错误/⽤户主动rollback等)导致事务执⾏到⼀半,但这时事务的执⾏已经让很多信息修改了(提交前就会边执⾏边修改记录),但还有部分未执⾏,为了保证事务的⼀致性与原⼦性,要么全都执⾏成功,要么全都失败,所以就需要回滚,⽽rollback需要旧值依据,⽽这些旧值记录就存储在undo⽇志中。
redo⽇志记录记录时机InnoDB存储引擎在实际的进⾏增删改操作时,每操作⼀条记录都会先把对应的undo⽇志记录下来。
undo⽇志通⽤结构undo⽇志存储在类型为FIL_PAGE_UNDO_LOGO的页⾯中,⽽每条记录添加到数据页中时,都会隐式的⽣成两个列trix_id和roll_pointer,trix_id就是事务id,roll_pointer是指向记录对应的undo⽇志的⼀个指针end of record:本条undo⽇志在页中结束地址undo type:undo⽇志类型undo no:undo⽇志编号,事务没提交时,每⽣成⼀条undo⽇志就递增1table id:本条undo ⽇志对应记录所在table id(information_schema库中表innodb_sys_tables查看)主键各列信息列表:<len, value>关键列占⽤空间和真实值信息列表start of record:本条undo ⽇志在页中开始的地址各操作所对应的undo⽇志结构不同1. INSERT:回滚时,就是删除掉新增的这条记录。
暂时只考虑聚簇索引插⼊情况,因为⼆级索引也包含主键,所以删除时也会根据主键信息把⼆级索引中的内容也删除名称内容undo type TRX_UNDO_INSERT_REC2. DELETE:记录被删除时,该记录头部信息的delete_mask会置为1,且会根据头部信息中的next_record属性组成⼀个垃圾链表,⽽这个链表中各记录占⽤的空间可以被重⽤,数据页PAGE HEADER中有个PAGE_FREE属性记录了这个链表的头节点。
concurrentlinkedhashmap 原理

concurrentlinkedhashmap 原理ConcurrentLinkedHashMap原理ConcurrentLinkedHashMap是一种高效的并发哈希映射表,它提供了一个线程安全的哈希映射表,同时支持高并发的读写操作。
它是由Doug Lea在Java Concurrency in Practice一书中提出的。
ConcurrentLinkedHashMap的数据结构是一个双向链表加上散列表,主要用于解决高并发下的读写冲突和并发控制问题。
它的主要原理如下:1. 基于散列表的映射ConcurrentLinkedHashMap使用散列表来管理键值对。
当插入一个新的键值对时,先根据键的hashCode计算出在散列表中的位置,然后将键值对插入到该位置。
当需要查找某个键时,先根据hashCode计算出位置,然后再根据键进行比较来找到对应的值。
2. 双向链表记录访问顺序为了支持LRU(Least Recently Used)缓存策略和并发控制,ConcurrentLinkedHashMap中的散列表每个位置的元素都是一个双向链表的头节点。
每次插入一个新的键值对时,会将该节点插入到链表的头部。
这样,头部的节点就是最新访问的节点,尾部的节点就是最久未被访问的节点。
3. 并发控制为了保证ConcurrentLinkedHashMap的并发安全性,它使用了一种称为Striping 的技术,将整个散列表分成多个段(segment),每个段都有自己的锁。
不同的段可以同时进行读写操作,从而提高并发性能。
当进行读操作时,只需要获取对应段的锁,不需要获取整个散列表的锁。
这样即使在高并发的情况下,不同的读操作可以同时进行,不会出现争抢的情况,提高了读的并发能力。
当进行写操作时,需要先获取对应段的锁,然后进行插入、删除或修改操作。
这样保证了写操作的互斥性,避免了多个写操作同时进行导致的数据一致性问题。
4. LRU缓存策略ConcurrentLinkedHashMap还实现了LRU缓存策略,它通过双向链表记录访问顺序,并通过控制链表的长度来限制缓存的大小。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
printf("\t\t1.输入学生成绩\n");
printf("\t\t2.查询学生成绩\n");
printf("\t\t3.删除学生成绩\n");
printf("\t\t4.修改学生成绩\n");
printf("\t\t5.打印学生成绩\n");
}
if(p->sId==uSid)
{
printf("\n该生已经找到,具体信息如下:\n\n");
printf("姓名:%s\n语文:%.2f\n数学:%.2f\n英语:%.2f\n总分:%.2f\n平均:%.2f\n",p->name,p->sChinese,p->sMath,p->sEnglish,p->sScore,p->sAver);
New_Info=(STU *)malloc(sizeof(STU));
printf("\n学号:");
scanf("%ld",&New_Info->sId);
LIB: printf("姓名:");
scanf("%s",New_Info->name);
printf("语文:");
printf("语文:");
scanf("%f",&p->sChinese);
printf("数学:");
scanf("%f",&p->sMath);
printf("英语:");
scanf("%f",&p->sEnglish);
p->sScore=p->sChinese+p->sMath+p->sEnglish;//总分
case 2:
search_sId(head);break;
case 3:
head=del_stuInfo(head);break;
case 4:
head=modi_stuInfo(head);break;
case 5:
// output(head);break;
{
if(head==p)
{
head=p->next;
}
else
{
printf("记录已删除!\n");
q->next=p->next;
free(p);
}
}
else
{
printf("\t\t6.存盘并退出系统\n");
printf("\t\t__________________\n");
printf("\t\t请选择(1~6):");
scanf("%d",&x);
switch(x)
{
case 1:
head=insert(head);break;
printf("\n\n否则存储后:\n(1)p->sid=%ld,p->name=%s\n",p->sId,p->name);
printf("(2)New_Info->sid=%ld,New_Info->name=%s\n",New_Info->sId,New_Info->name);
}
}
else
{
p->next=New_Info;
New_Info->next=NULL;
}
}
return(head);
}
void search_sId(STU *head)//根据学号查询
{
STU *p;
long uSid;
printf("\n请输入要查询的学号:");
}
else
{
while(Biblioteka feof(fp)); if(fread(&per,sizeof(struct student),1,fp)==1)
{
p=(STU *)malloc(sizeof(STU));
p->sId=per.sId;
p->sChinese=per.score[0];
};
FILE *fp;
STU *load(char fileName[])//将文件中的数据放入链表
{
STU *p,*q,*head;
struct student per;
q=head=NULL;
if((fp=fopen(fileName,"rb"))==NULL)
{
return (head);
{
p=p->next;
}
if(p->sId==uSid)
{
printf("\n学号:");
scanf("%ld",&p->sId);
printf("姓名:");
scanf("%s",p->name);
p->sAver=0;
else
{
q->next=p;
q=p;
}
fclose(fp);
return (head);
}
}
}
STU *insert(STU *head)//插入记录,并算出平均分。
{
STU *New_Info,*p,*q;
New_Info->sAver=0;
p->sAver=p->sScore/3;//平均分
printf("总分:%.2f\n",p->sScore);
printf("平均分:%.2f",p->sAver);
}
else
{
printf("\n查无此人!\n");
}
}
return (head);
p=head;
if(head==NULL)//如果链表为空
{
printf("无任何学生信息!\n");
return (head);
}
else
{
while((p->next!=NULL)&&(p->sId!=uSid))//如果找到数据,则循环退出。此时,指针会自动定位到正确数据上。
New_Info->sAver=New_Info->sScore/3;//平均分
printf("总分:%.2f\n",New_Info->sScore);
printf("平均分:%.2f",New_Info->sAver);
p=head;
if(head==NULL)
{
head=New_Info;
float aver;
};
struct node
{
long sId;
char name[20];
float sChinese;
float sMath;
float sEnglish;
float sScore;
float sAver;
struct node *next;
New_Info->next=NULL;
}
else
{
while((p->next!=NULL)&&(p->sId<New_Info->sId))
{
q=p;
p=p->next;
}
if(p->sId>=New_Info->sId)
{
if(head==p)
scanf("%f",&New_Info->sChinese);
printf("数学:");
scanf("%f",&New_Info->sMath);
printf("英语:");
scanf("%f",&New_Info->sEnglish);
New_Info->sScore=New_Info->sChinese+New_Info->sMath+New_Info->sEnglish;//总分
}
void main()
{
int x;//菜单
STU *head;
char fname[20];
printf("请输入学生数据库文件名:");
scanf("%s",fname);
head=load(fname);
while(1)
{
printf("\n\n\t\t主菜单\n");
case 6:
// save(head,fname);