Data distribution and loop parallelization for shared-memory multiprocessors
TOEFL分类词汇5页精简版

1地理GEOGRAPHY geography 地理geographer地理学家hemisphere半球meridian 子午线,经线parallel 平行圈,纬线latitude 经度longitude 纬度elevation 海拔altitude 高度horizon 地平线equator 赤道Arctic 北极Antarctic(An tarctica) 南极expedition 探险navigation航海topography地形,地形学continent 大陆continental shelf 大陆架continental drift 大陆漂移说plain 平原plateau (highland) 高地lowland 低地basin 盆地cavern (cave)洞穴oasis (沙漠)绿洲cleft (flaw) 裂缝crevice (rift;slit) 裂缝summit 山顶range (山)脉valley 峡谷gorge峡谷canyon 峡谷channel (strait) 海峡marine(maritime;oceanic)海的tide 潮汐ebb(away) 退潮sea-floor spreading海床扩展ocean bottom 海床coastland 沿海地区contour 轮廓;海岸线continental island 大陆岛volcanic island 火山岛coral island珊瑚岛insular 海岛的islet 小岛peninsular半岛ledge 暗礁remote-sensing 遥感的terrain 地域terrestrial 地球的,陆地的terrestrial heat (geothermal) 地热terrestrial magnetism(geomagnetism) 地磁subterranean ( underground) 地底下evaporation蒸发salinity 含盐度sediment 沉淀物,沉积物tropics 热带地区tropical 热带的temperate 温带的temperate latitudes 温带地区frigid 寒带的frost heaving 冻胀现象2地质geology 地质学geologist 地质学家crust 地壳mantle 地幔core 地核continental c rust 大陆地壳oceanic crus t 海洋地壳layer (stratu m,复strata) 地层plate 板块fault 断层fault plane 断层面fault zone 断层带rift (crack; split) 断裂fossil 化石petrify 石化,硬化igneous rock火成岩sedimentaryrock 沉积岩metamorphicrock 变质岩quartz 石英limestone 石灰岩marble 大理石granite 花岗岩lithogenous岩成的lithosphere岩石圈mineral 矿物ore 矿石deposit 矿床platinum 白金,铂silver 银copper 黄铜aluminum 铝tin 锡lead 铅zinc 锌nickel 镍mercury 汞,水银sodium 钠fieldstone 卵石gem 宝石diamond 钻石emerald 绿宝石ruby 红宝石crystal 水晶glacier 冰川glacial 冰川的glacial epoch( age, period) 冰川期glacial drift冰渍iceberg 冰山volcano 火山active volcano 活火山extinct volcano 死火山dormant volcano 休眠火山eruption 火山喷发crater 火山口lava (magma)火山岩浆magma 岩浆volcanic 火山的volcanic dust 火山尘volcanic ash火山灰earthquake (quake; tremor;seism) 地震seismic 地震的seismology地震学magnitude震级seismic wave地震波cataclysm 灾变3天文ASTRONOM Y 天文学astronomy 天文学astronomical 天文的巨大的astronomical observatory 天文台astronomer 天文学家astrophysics 天文物理学astrology 占星学pseudoscien ce 伪科学infinite 无限的vacuum 真空cosmos(universe) 宇宙cosmology 宇宙学cosmic(universal)宇宙的cosmic radiation 宇宙辐射radiation 辐射emission 发射,散发cosmic rays宇宙射线infrared ray红外线celestial 天的天体的celestial body(heavenly body)天体celestialmap/sky atlas天体图celestial sphere 天球space 空间planeroid 位面constellation星座cluster 星团nebula 星云galaxy星系,银河intergalactic星系间的Milky Way银河系dwarf (dwarfstar) 白矮星quasar 类星体,类星射电源star 恒星stellar 恒星的interstellar恒星间的solar system太阳系solar radiation 太阳辐射solar corona日冕chromosphere 色球photosphere光球convection zone 对流层radiativezone 辐射层thermonuclear energycoresolar eclipse日食planet 行星planetoid (asteroid) 小行星interplanetary 行星间的satellite 卫星lunar 月球的meteor 流星meteor shower流星雨meteoroid 流星体meteorite 陨石chondrite 球粒状陨石comet 彗星revolve 旋转,绕转spin 旋转orbit 轨道twinkle 闪烁naked eye 肉眼Mercury 水星Venus 金星Earth 地球Mars 火星Jupiter 木星Saturn 土星Uranus 天王星Neptune 海王星Pluto 冥王星space (outer space) 太空,外层空间spacecraft sp aceship宇宙飞船spaceman/a stronaut宇航员,航天员space suit 宇航服,航天服space shuttle 航天飞机space telescope空间望远镜astronaut 宇航员space debris太空垃圾ammonia 氨absolute magnitude绝对量级high-resolution 高清晰度interferometer 干扰仪4气象Meteorology气象meteorology气象meteorologist 气象学家forecast (predict) 预报barometer/indicator气压计climate 气候balmy(moderate)温与的tepid(lukewarm)微温的chilly 寒冷的frigid 严寒的serene 晴朗的atmosphere大气层troposphere对流层current (气)流vapor 蒸汽evaporate 蒸发damp (wet;dank;moist;humid) 潮湿的humidity 湿度moisture 潮湿;水分saturate 饱与dew 露frost 霜fog (mist) 雾smog 烟雾droplet 小水珠condense 浓缩crystal 水晶体结晶状的downpour/torrential rain大雨tempest (storm) 暴风雨drizzle 细雨shower 阵雨hail 冰雹blizzard (snowstorm) 暴风雪avalanche (snowslide) 雪崩precipitation(雨、露、雪等)降水breeze 微风blast/gust一阵gale 大风whirlwind 旋风typhoon 台风hurricane 飓风tornado (twis ter, cyclone) 龙卷风funnel 漏斗,漏斗云disaster, cal amity, catast rophe 灾难devastation 破坏submerge 淹没drought 旱灾arid 干旱的5化学chemistry 化学biochemistry生化chemical property 化学特性,化学性质chemical composition (makeup ) 化学成分constitute 构成组成constituent/component成分chemical agent 化学试剂chemical reaction 化学反应chemical change 化学变化chemical bond 化学键chemical apparatus 化学器械substance (matter; material) 物质element 元素periodic table 周期表ammonia 氨氨水hydrogen 氢oxygen 氧nitrogen 氮helium 氦carbon 碳calcium 钙silicon 硅silica 硅土sulfur 硫iodine 碘blend 混合neutralize 中与combination化合组合compound化合物hydrocarbon碳氢化合物hydronic液体循环加热/冷却derivative 衍生物alchemy 炼金术petroleum (oil) 石油petroleum products 石油产品crude oil 原油refine 提炼,精炼impurity 杂质gasoline 汽油methane 甲烷disintegration(decomposition)分解erosion 腐蚀hackneyed陈腐的caustic 腐蚀性的corrode 腐蚀stale 陈腐的rust 生锈solution 溶液dissolve 溶解solvent 溶剂solubility 可溶性cohesive 聚合力cohesion 附着力adhesive 粘合力molecule 分子atom 原子nuclear 原子的nucleus 原子核electron 电子neutron 中子proton 质子molecule 分子ion 离子particle 粒子particle accel erator粒子加速器explosive 爆炸的;炸药explode (使)爆炸blast 爆破kindle(ignite)燃起sear 烧灼intermediary媒介物catalysis(复catalyses)催化作用catalyst 催化剂artificial 人造的synthetic 合成的synthetic fiber 人造纤维plastic 塑料polymer 聚合物polymerization 聚合作用dye (pigment)染料染色tint 上色scorch 使褪色bleach 漂白cosmetics 化妆品6物理PHYSICS物理学physics 物理mechanics力学thermodynamics 热力学acoustics 声学electromagnetism 电磁学optics 光学dynamics 动力学statics 静力学relativity 相对性相关性相对论dimension尺度维boundary 边界brim/edge/rim/brink 边缘force 力pressure 压力impetus 推动力velocity 速度expedite 加速acceleration加速度accelerate 加速decelerate 减速horizontal 水平declivity 下倾的斜面precipitate向下投掷motion 运动inertia 惯性gravity 地心引力gravitation引力引力作用relativity 相对friction 摩擦attrition 磨损chafe/scrape 擦热equilibrium 平衡equilibrium 平衡状态temperature 温度thermometer 温度计centigrade 摄氏的fusion 溶合thaw (使)溶化融解sublimate 使升华distillation 蒸馏colt (使)凝块foam 泡沫density 密度liquid 液体dilute 稀释冲淡dehydrate(使)脱水evaporate 蒸发evaporation蒸发作用ventilation通风release 释放discharge 释放diffuse 传播扩散emit/eject发出放射radiate 射出transpire 发散排出medium (media) 媒质frequency 频率band 波段wavelength波长pitch 音高intensity 强度echo 回声resonance 回声,反响acoustic 音响的sonar 声纳ultrasonics超声学electricity 电static electricity 静电magnetism磁性磁力磁学magnet 磁体electromagnet 电磁magnetic field 磁场electric current 电流direct current (DC) 直流电alternating current AC交流电electric circuit 电路electric charge 电荷electric voltage 电压electric shock 触电electric appliance 电器conductor 导体insulator 绝缘体semiconductor 半导体battery (cell)电池dry battery干电池storage battery 蓄电池electronics电子学electronic 电子的electronic component (part) 电子零件integrated circuit 集成电路chip 集成电器片,集成块electron tube 电子管vacuum tube 真空管transistor 晶体管shrink 收缩amplification (名词)放大amplify (动词)放大amplifier 放大器,扬声器quiver/jar 震动vibration 震动oscillation 震荡optical 光(学)的optical fiber光学纤维lens 透镜,镜片convex 凸透镜concave 凹透镜microscope显微镜telescope 望远镜magnifier 放大镜spectrum 光谱wavelength波长ultraviolet 紫外线X rays X射线Gamma raysγ射线infrared rays红外线microwaves微波dispersion 色散transparent透明translucent半透明opaque 不透明的compatible兼容的elasticity 弹性chaos/disorder 混乱clutter 混乱(使)混乱7数学MATHEMATICSmathematics数学mathematician 数学家arithmetic 算术calculate(count)计算calculation计算calculator 计算器calculus 微积分differential calculus 微分学integral calculus 积分学abacus 算盘numeral 数字digit 数字,数位enumerate/numerate 计数even 偶数odd 奇数sum 与total 总与,总数aggregate 总计fraction 分数,小数percentage百分比quarter 四分之一decimal 十进位,(十进)小数addition 加法plus 加上正的subtraction 减法minus 减去负的subtract/de duct 减去multiplicatio n 乘法multiplicatio n table 乘法表multiply 乘以times乘以power 乘方square 平方division 除法divide 除以algebra 代数equation 方程式,等式formula 公式root 根function 函数probability概率statistics 统计ratio/proportion 比率estimate/gauge 估计evaluate 估计评价variant/variable 变量discrete 不连续的离散的dispersion离差差量symmetry 对称(性)匀称quantity 表示量的数或符号quantitative量的,数量的qualitative 质的,质量的deduction (inference) 推论,演绎induction 归纳rank 排序排行等级sequence 序列dual 二重的两层的diagram 图表geometry 几何geometric 几何的figure 图形形状parallel adj.平行n. 平行线intersect 相交dimension 维area 面积facet 平面quadrilateral四边形vertical/plumb/upright/perpendicular 垂直的square 正方形rectangle 长方形,矩形polygon 多边形loop 圈,环circle 圆形circular 循环的,圆的circulation循环circumference 圆周circuitous 迂回的ellipse (oval)椭圆形volume 体积bulk 容积cube 立方形cubic 立方体的sphere 球形cone 圆锥形column 圆柱柱状物caliber 口径diameter 直径radius 半径triangle 三角形angle 角degree (角) 度8生态环境ECOLOGY 生态学ecologist 生态学家ecosystem 生态系统balance (of n ature) 自然界生态平衡scenic 景色优美的scenery 景色puddle 小水洼creek/brook 小溪trickle 滴crystal/limpid 清澈的niche 小生态环境habitat 栖息地rain forest 雨林food chain 食物链acid rain 酸雨greenhouse effect 温室效应infrared radiation红外线辐射ozone layer (ozonosphere)臭氧层ultraviolet radiation紫外辐射contaminate(defile)污染pollution control 污染控制air pollution空气污染water pollution 水污染noise pollution 噪音污染soil pollution土壤污染pollution-free 无污染pollutant 污染物noxious (toxic) 有毒的fume/fumes(有毒)废气solid waste固体垃圾sewage (wastewater) 污水sewage purification污水净化sewage disposal 污水处理decibel (噪音)分贝9农林畜牧agriculture (farming) 农业agricultural农业的agrarian 土地的,农业的land (soil) 土壤;土地soil conservation 土壤保护soil erosion泥土流失silt 粉砂,泥沙clay 黏土,湿土clod 土块barren 贫瘠prolific/luxuriant 多产的fertile 肥沃的arable 适于耕种的indigenous土产的当地的pilot(experimental)试验性的harrow( rake) 耙,耙土ridge 田埂furrow 犁沟plot (patch)小块地ranch 农场,牧场plantation 种植园人造林ranch 大农场经营农场orchard 果园nursery 苗圃seedbed 苗床sickle 镰刀spade 铲,锹shovel (平头) 铲pick 稿tractor 拖拉机cultivate (till)耕作husbandry 耕种管理animal husbandry畜牧业sow(seed) 播种harvest 收割weed 除草irrigate 灌溉manure(fertilizer) 肥料spray 喷洒(农药)insecticide(pesticide)杀虫剂pest 害虫rust 锈病weed 杂草除草grain (cereal)谷物,谷粒granary(grain store) 粮仓barn 谷仓畜棚mill 碾,磨wheat 小麦corn 玉米rice 大米barley 大麦sorghum 高粱oats燕麦rye 黑麦millet 粟,小米fermentation发酵vegetable 蔬菜horticulture园艺学hydroponics水栽法,营养液栽培法greenhouse(glasshouse,hotbed) 温室conservatory温室cabbage 洋白菜lettuce 生菜mustard 芥菜spinach 菠菜broccoli 花椰菜cucumber 黄瓜eggplant 茄子pepper 辣椒pumpkin (squash)南瓜tomato 西红柿beet 甜菜carrot 胡萝卜radish 小红萝卜pea 豌豆soybean 大豆celery 芹菜garlic 大蒜leek 韭菜onion 洋葱头potato 土豆peanut 花生sesame 芝麻cotton 棉花animal husbandry畜牧业pasture 牧场graze 放牧livestock 家畜fowl (poultry)家禽cattle 牛,家畜buffalo 野牛dairy (dairy c attle) 奶牛dairy farm 乳牛场trot (马)小跑hay (作饲料用)干草haystack 干草堆fodder (feed) 饲料trough 饲料槽barn(shed) 牲口槽stable 厩,马厩cowshed 牛棚pigpen(hog pen, pigsty)猪圈sheepfold (sheep pen) 羊栏roost (hen house) 鸡舍fish farm 养鱼场aquaculture水产养殖10生物Darwinism达尔文学说进化论natural selection 自然选择evolve (使)进化发展evolutionary进化的creature 生物organism 生物有机物microbe 微生物scavenger 食腐动物rot 腐烂decay (使)腐败respiration呼吸metabolism新陈代谢secrete 分泌secretion 分泌物assimilate 吸收vital 活的活体的anatomy 解剖学microscope显微镜organ 器官vestige 退化器官,遗迹spleen 脾脏calorie 卡路里fat (grease)脂肪carbohydrate(starch) 碳水化合物(淀粉),糖类glucose 葡萄糖starch 淀粉fat 脂肪protein 蛋白质vitamin 维他命malnourished 营养不良的class 纲order 目family 科genus 属suborder 亚目species 种species 物种subsist/exist生存extinct 灭绝morphology形态学fauna 动物群flora 植物群植物界breed n.品种v.繁殖multiply(reproduce)繁殖proliferate 繁衍propagate 繁殖传播posterity 后代ripe 植物成熟mature 动物成熟symbiotic 共生的immune 免除的,免疫的immunity 免疫hygiene 卫生sanitation 卫生parasite 寄生虫necrosis 坏死futile 无用的11动植物动物strain(动物昆虫)种血统homotherm恒温动物poikilotherm变温动物invertebrate无脊椎动物vertebrate 脊椎动物spine 脊骨spineless 无脊椎的aquatic( life)水生动物reptile 爬行动物amphibian (amphibiousanimal) 两栖动物rodent 啮齿动物(如松鼠)primate 灵长动物plankton 浮游生物mollusk 软体动物coelenterate腔肠动物(珊瑚)monogamous 一夫一妻的,一雄一雌的polygamous一夫多妻的,一雄多雌的polyandrous一妻多夫的,一雌多雄的appetite 食欲stodgy 难消化的herbivorous食草的carnal 肉体的carnivorous食肉的omnivorous杂食的predatory/carnivorous食肉的predator 捕食者prey v.捕食 n.被捕食的动物trapper 诱捕动物者community动物群落或人的部落gregarious群居的horde (昆虫等)群swarm(昆虫等)群flock (鸟,羊等)群herd 兽群bunch (花等)束,捧dinosaur 恐龙extinction 灭绝mammal 哺乳动物hump 驼峰dolphin 海豚porpoise 海豚whale 鲸鱼rhinoceros犀牛bat 蝙蝠beaver 海狸sloth 树懒slothful 懒惰的primates 灵长目动物gorilla 大猩猩chimpanzee 黑猩猩baboon 狒狒insect 昆虫antenna (复antennae) 触须tentacle 触角larva 幼虫,幼体larvae (复)幼虫pest 害虫worm 虫,蠕虫caterpillar 毛虫moth 蛾lizard 蜥蜴chameleon变色蜥蜴turtle 龟shrimp 小虾prawn 对虾lobster 对虾crab 螃蟹clam 蛤蜊sponge 海绵coral 珊瑚starfish 海星jellyfish 水母oyster 牡蛎蚝clam 蛤scale 鳞片beast 野兽fertilize 使…受精hatch 孵spawn (鱼、虾、蛙)孵(产卵)pregnant 怀孕的offspring (young) 子孙后代regeneration再生domesticate驯养camouflage伪装mimicry 拟态hibernate 冬眠dormant 休眠的migrate 迁移fluffy 绒毛的fuzzy 有绒毛的,绒毛状wing 翅膀,翼bill (鸟)嘴beak (鹰等的)嘴nest 筑巢canary 金丝雀chirp (鸟,虫的叫声)唧唧squeak (老鼠等)吱吱植物botany 植物学botanist 植物学家botanical (botanic) 植物的plant 植物aquatic plant 水生植物parasite plant 寄生植物fern 蕨类植物shade 树荫canopy 树冠层,顶棚foliage (leaf)叶leaflet 小叶rosette (叶的)丛生stem 茎stalk 杆leafstalk 叶柄seeds 种子everlasting永久的pollen 花粉授粉给pollinate 授粉crossbreed 杂交shoot (sprou t ) 嫩芽,抽枝germinate 发芽bud 芽发芽花蕾flower 花petal 花瓣column 花柱peel(skin) 果皮shell (硬) 果壳去壳husk(干)果壳(玉米)苞叶timber 木材木料log 圆木trunk 树干branch 树枝bough 大或者粗的树枝twig 小树枝bark 树皮peel 剥削剥落herb 香草药草lawn 草坪meadow 草地,牧场prairie 大草原jungle 丛林shrub (bush)灌木shrub 灌木cluster 一簇(灌木)丛生bunch 串束photosynthesis 光合作用symbiotic 共生的symbiosis 共生wither (shrivel, fade) 凋谢pollen 花粉pollinate 传授花粉pollination授粉cell 细胞tissue 组织organ 器官system 系统root pressure 根压cohesion-tension 凝聚压力bore 腔,肠rosette 玫瑰形饰物orchid 兰花淡紫色sequoia 红杉美洲杉laurel 月桂树12人类社会archaeology考古学archeologist考古学家anthropology人类学ethnology人种学,人类文化学anthropologist 人类学家paleoanthropologist古人类学家ecological anthropologist生态人类学家psychological anthropologist 心理人类学家unearth 发掘发现scoop 汲取挖掘exhume 掘出excavation挖掘excavate (unearth) 挖掘ruins 遗迹,废墟relic 遗物,文物remnant 残余;遗迹artifact 手工艺品porcelain 瓷器archaic 古的antique 古物,古董antiquity 古代,古老primitive 原始的最初的Stone Age 石器时代Bronze Age (青)铜器时代Iron Age 铁器时代Paleolithic 旧石器时代的Mesolithic 中石器时代的Neolithic 新石器时代的chronologica l 按年代顺序的skull 颅骨cranial 颅骨的,头盖的origin 起源originate 起源于aboriginal 土著,原来的ascend 追溯ancestor 祖先forerunner(predecessor)先驱descent(ancestry) 血统hybrid 杂种,混血hominid 原始人类homogeneous 同一种族(种类)的ethnic 种族的ethics 伦理学human 人类的;人性的juvenile 青少年的adult 成人,成人的(mature)patriarchal家长的族长的marital 婚姻的household家庭家族status 地位genteel 上流社会的convention传统taboo 禁忌禁止institutionalize 使制度化tribe 部落;clan 氏族community社区社会公社urban 城市的rustic 乡村的metropolitan首都/大城市的exotic 外来的异国风味的13政治POLITICS 政治constitution宪法legislation 立法Democrats民主党Republicans共与党Amendment修正案Congress 美国国会Senate 参议院House of Representatives众议院monarchy 君主制anarchism无政府主义federal system 联邦制presidentialsystem 总统制municipal 市的,市政的metropolitan 大都市的centralized 中央集权的ideology 意识形态maneuver 擦略tariff 关税immigrant 移民institutionali ze 机构化election 选举vote 投票office holding 任职veto 否决American Re volution 美国革命/独立战争Independenc e War 美国独立战争Civil War美国内战radical 激进的,根本的overturning颠覆性的independent独立的breathtaking激动人心的military 军事的colonize 拓殖,殖民per capita 人均treason 叛国conspiracy阴谋imprisonment 监禁release 释放pardon 特赦accusation谴责,指控welfare 福利patronage 资助,赞助unionization联合,结合14 音乐euphonious悦耳的harsh 刺耳的musical instrument 乐器orchestra 管弦乐队string 弦乐wind 管乐chorus 合唱团band 乐队concert 音乐会shook rattle摇拨浪鼓pound drum击鼓footbeat 点脚,跺脚percussion震荡,打击乐器note 音符movement 乐章score 乐谱lyric 歌词fanatical 狂热的jazz 爵士乐hillbilly music 乡村音乐folk music 民间音乐pop music 流行音乐classical music 古典音乐conservatory音乐学校15心理PSYCHOLOGY 心理mental 心理的physical 身体的,物质物理的spiritual 心灵的conformity从众majority 多数人minority 少数人threshold judgment (心理学)初始性判断subject 受实验对象15教育higher educa tion 高等教育moral charac ter 道德品质domain 领域faculty 全体教员alumni 校友treasurer生活委员,财务大臣elective syste m 选课制度curriculum 课程(总称)discipline 学科,管理didactic 教诲的说教的sermon 说教edify 陶冶教化instill(infuse,impact)灌输initiate 启蒙enlighten 启发,开导learn by rote死记硬背17人物choreographer 舞蹈编排家critic 批评家satirist 讽刺作家inventor 发明家biographer自传作家sculptor 雕塑家feminist 女权主义者humanitarian 人道主义者imagist 意象派诗人philanthropist 慈善家proprietor 业主mortal 犯人precursor 先驱figurehead名誉领袖disciple 学徒apprentice学徒mechanic 机械工minimalist简单抽象派艺术avant-garde前卫派territory 领域genre 风格,体裁eccentric 古怪的odd 怪诞的,奇数的erratic 奇怪的weird 怪异的,不可思议的unique 独一无二的romantic 浪漫的innocent 天真的,无罪的lovelorn 相思病苦的emotional 情绪的,情感的sentimental感伤,多愁善感cheerless 无精打采无生命力patriarchal家长的,族长的rigid 僵化的spare 简朴的clumsy 笨拙的nervous 紧张的contemporary 当代的acclaimed 受欢迎的preeminent 杰出的outstanding 杰出的versatile (人)多才多艺的,(物体)多功能的household 家庭的,家喻户晓genuine 真正的authentic 逼真的symbolic 象征性的immortal 不朽的,神nostalgia 怀旧主义,思乡emotive 感人的prodigious 巨大的posthumous 死后的。
综合布线术语
布线施工专用术语和词汇在局域网布线与施工过程中,通常会涉及到一些专用术语和词汇。
为了理解这些术语和词汇,本节先对有关的术语和词汇进行必要的解释和说明。
1、综合布线系统(PDS,Premises Distribution System):也称开放式布线系统(Open Cabling System),是一种在建筑物和建筑群中综合布线的网络系统。
它把建筑物内部的语音交换设备、智能数据处理设备及其他数据通信设施相互连结起来,并通过必要的设备同建筑物外部数据网络或电话线路相连,是由通信电缆、光缆和各种连接设备等构成的,用以支持数据、图像、语音、视频信号通信的布线系统。
综合布线系统包括3个子系统:水平布线于系统、垂直布线子系统和建筑群布线子系统。
通常也称作网络的水平干线、垂直干线和主干线。
2、建筑物与建筑群智能化系统:由通信系统、办公自动化系统、楼宇自动化系统(空调控制、给排水控制、照明控制等)、消防控制系统、综合布线系统等构成的弱电系统称作建筑物与建筑群智能化系统。
3、建筑群布线子系统:由建筑群配线架以及连接建筑群配线架和各建筑物配线架的电缆、光缆等组成的布线系统。
4、水平布线子系统:由楼层配线架,信息端口以及连接楼层配线架和信息端口的网络电缆、光缆等组成的布线系统。
5、垂直布线子系统:由建筑物配线架以及连接建筑物配线架和各楼层配线架的电缆,光缆等组成的布线系统。
6、工作区和信息点:工作区是用户使用终端设备的地方,也就是客户机所在的房间,信息点是客户机与网络的连接点。
7、区域电缆:建筑上的一个概念。
这个概念将平面电缆分为两个部分。
在移动、添加和更换时无需变动整个平面电缆。
8、集合点:一种互连设备,可将平面电缆分为两部分。
用于区域电缆连接。
9、转接点:因型号或规格的不同或布线环境的要求进行电缆、光缆转接的地点。
10、配线架:一种机架固定的面板(通常19英寸宽),内含连接硬件。
用于电缆组与设备之间的接插连接。
高维时空数据的建模与统计推断, 英文

高维时空数据的建模与统计推断, 英文In the realm of data science, the modeling and statistical inference of high-dimensional spatiotemporal data present unique challenges and opportunities. This type of data, which encapsulates information across multiple dimensions and over time, offers a rich source of insights but also poses computational and analytical complexities. The key lies in developing effective techniques that can capture the intricate relationships and patterns inherent in these data, while also accounting for their inherent noise and uncertainty.在数据科学领域,高维时空数据的建模与统计推断既带来了独特的挑战,也提供了丰富的机遇。
这类数据涵盖了多个维度和时间的信息,提供了深入洞察的丰富资源,但同时也带来了计算和分析的复杂性。
关键在于开发有效的技术,这些技术既要能够捕捉数据中固有的复杂关系和模式,又要考虑其固有的噪声和不确定性。
To address these challenges, a multifaceted approach is necessary. On the modeling front, techniques such as dimensionality reduction and sparse modeling can help identify the most relevant features and reduce the computational burden. Machine learning algorithms, especially those designed for handling high-dimensional data, can also be leveraged to capture complex relationships and patterns.为了应对这些挑战,需要采取多方面的方法。
parallel_computing_toolbox

Parallel Computing Toolbox 4.3Perform parallel computations on multicore computers and computer clustersParallel Computing Toolbox™ lets you solve computationally and data-intensive problems using MATLAB® andSimulink® on multicore and multiprocessor computers. Parallel processing constructs such as parallel for-loops,distributed arrays, parallel numerical algorithms, and message-passing functions let you implement task- anddata-parallel algorithms in MATLAB at a high level without programming for specific hardware and networkarchitectures. As a result,converting serial MATLAB applications to parallel MATLAB applications requires fewcode modifications and no programming in a low-level language. You can run your applications interactively oroffline, in batch environments.Key Features▪Support for data-parallel and task-parallel application development▪Ability to annotate code segments with parfor(parallel for-loops) and spmd(single program multiple data) forimplementing task- and data-parallel algorithms▪High-level constructs such as distributed arrays, parallel algorithms, and message-passing functions for processinglarge data sets on multiple processors▪Ability to run eight workers locally on a multicore desktop▪Integration with MATLAB Distributed Computing Server for cluster- and grid-based applications that use anyscheduler or any number of workers▪Interactive and batch execution modesDeveloping parallel applications with Parallel Computing Toolbox. The toolbox enables application prototyping on thedesktop with up to eight local workers (left), and, with MATLAB Distributed Computing Server (right), applications canbe scaled to multiple computers on a cluster or a grid or cloud computing service.You can use the toolbox to execute applications on a single multicore or multiprocessor desktop. Without changing the code, you can run the same application on a computer cluster or a grid or cloud computing service (using MATLAB Distributed Computing Server™). Parallel MATLAB applications can be distributed as executables or shared libraries (built using MATLAB Compiler™) that can access MATLAB Distributed Computing Server.Programming Parallel Applications in MATLABParallel Computing Toolbox provides several high-level programming constructs that let you convert your serial MATLAB code to run in parallel on several workers(MATLAB computational engines that run independently of MATLAB clients).Constructs such as parallel for-loops (parfor) and distributed arrays simplify parallel code development by abstracting away the complexity of managing coordination and distribution of computations and data between a MATLAB client and workers, as well as between workers. These constructs function even in the absence of workers, letting you maintain a single version of your code for both serial and parallel execution.You can run an application that uses up to eight workers on your multicore desktop. Using MATLAB Distributed Computing Server, you can run the same application without modification on large resources such as computer clusters or grid and cloud computing services.Taking Advantage of Built-in Parallel Computing Support in MathWorks ProductsKey functions in a growing number of products in the MATLAB and Simulink product families, such as Statistics Toolbox™ and Simulink Design Optimization™, provide built-in support for parallel computing. In the presence of Parallel Computing Toolbox, these functions exploit parallel computing resources by distributing computations across available workers, enabling you to take advantage of parallel computing resources without additional programming effort.Implementing Task-Parallel AlgorithmsYou can parallelize Monte Carlo simulations and other coarse-grained or embarrassingly parallel problems by organizing them into independent tasks(units of work). Parallel for-loops in the toolbox offer one way to distribute tasks across multiple MATLAB workers. Using these loops, you can automatically distribute independent loop iterations to multiple MATLAB workers. The parfor construct manages data and code transfer between the MATLAB client session and the workers. It automatically detects the presence of workers and reverts to serial behavior if none are present.Using parallel for-loops for a task-parallel application. You can use parallel for-loops in MATLAB scripts and functions and execute them both interactively and offline.You can also explicitly program tasks either as MATLAB functions or as MATLAB scripts. You execute the tasks, when specified as functions, by manipulating task and job objects in the toolbox or, when specified as scripts, by using the batch function.Implementing Data-Parallel AlgorithmsFor MATLAB algorithms that require large data set processing, Parallel Computing Toolbox provides distributed arrays and parallel functions that can operate on these arrays. Distributed arrays let you process significantly larger data sets than you could in a single MATLAB session by distributing data across multiple workers and using parallel functions to perform operations on the distributed data. The toolbox also provides functions for moving distributed data to and from MAT-files.You can work with distributed arrays interactively from your MATLAB session as you would with MATLAB arrays. Working with distributed arrays and their associated parallel functions does not require knowledge oflow-level programming tools, such as MPI. The toolbox provides more than 150 parallel functions for operating on distributed arrays, including linear algebra routines based on ScaLAPACK. You can use the familiar operatorsfor arrays in MATLAB to perform indexing, matrix multiplication, and transforms directly on distributed arrays.Programming with distributed arrays. Distributed arrays and parallel algorithms let you create data-parallel MATLAB programs with minimal changes to your code and without programming in MPI.The toolbox also provides the spmd(single program multiple data) construct, which you can use to designate sections of your code to run concurrently across workers participating in a parallel computation. During program execution,spmd automatically transfers data and code used within its body to the workers and, once the execution is complete, brings results back to the MATLAB client session.For explicit, fine-grained control over your parallelization scheme, which also requires explicitly managing interworker coordination, Parallel Computing Toolbox functions provide access to message-passing routines based on the MPI standard (MPICH2), including functions for send, receive, broadcast, barrier, and probe operations.Working in an Interactive Parallel EnvironmentParallel Computing Toolbox extends the MATLAB interactive environment, letting you prototype and develop task- and data- parallel applications in your familiar environment. The matlabpool command allocates a set of dedicated computational resources for you, connecting your MATLAB session to a pool of MATLAB workers that can run either locally on your desktop or on a computer cluster. The command sets up an interactive parallel execution environment in which you can execute your parallel MATLAB code from the command prompt and retrieve results immediately as computations finish.In this environment, parallel for-loops and distributed arrays automatically detect the presence of workers and distribute computations and data between your MATLAB session and the workers. Commands can be collected into MATLAB functions or scripts and submitted for offline execution.Working in Batch EnvironmentsParallel Computing Toolbox lets you use batch environments for offline execution, enabling you to free your MATLAB client session for other activities while you execute large MATLAB and Simulink applications. You can also shut down your MATLAB client session while your application executes and retrieve results later.The batch function lets you execute MATLAB scripts offline. It provides a mechanism for data transfer betweenMATLAB client and worker workspaces, which frees you from explicitly managing data in multiple workspaces.The toolbox also provides job and task objects. These objects provide a lower-level but more general mechanism to execute parallel MATLAB applications in batch environments. Both the batch function and the job and task objects can be used to offload the execution of serial MATLAB programs from a desktop MATLAB session to a worker.Executing MATLAB scripts offline. With the Configurations Manager, you can direct program execution to your workstation using eight local workers or to a cluster using any scheduler and any number of workers.Scaling Up to Clusters, Grids, and Clouds Using MATLAB Distributed Computing ServerParallel Computing Toolbox provides the ability to use up to eight local workers on a multicore or multiprocessor computer using a single toolbox license. When used with MATLAB Distributed Computing Server, you can run an application using any number of workers on large-scale resources such as computer clusters or grid and cloud computing services. The server also supports both interactive and batch workflows.Using MATLAB Compiler, you can build MATLAB applications that use toolbox functions into standalone executables or shared software components and distribute them royalty-free. These executables and libraries can connect to MATLAB Distributed Computing Server workers and perform MATLAB computations on large computing resources.Product Details, Demos, and System Requirements/products/parallel-computingTrial Software/trialrequestSales/contactsalesTechnical Support/support Running a gene regulation model on a cluster using MATLAB Distributed Computing Server. The server enablesapplications developed using Parallel Computing Toolbox to harness computer clusters for large problems. Compiled parallel MATLAB applications can also use the server.Integrating Products into Your Computing EnvironmentMATLAB Distributed Computing Server provides a job manager and directly supports several third-partyschedulers such as Platform LSF®, Microsoft® Windows® HPC Server, Altair PBS Pro®, and TORQUE. Using the Configurations Manager in the toolbox, you can maintain named settings such as scheduler type, path settings,and cluster usage policies. Switching between clusters or schedulers typically requires changing the configuration name only.MATLAB Distributed Computing Server dynamically enables the required product licenses when an application runs on the cluster, based on the user’s profile. As a result, administrators need to manage only the server license on the cluster rather than separate toolbox and blockset licenses for every cluster user.ResourcesOnline User Community /matlabcentral Training Services /training Third-Party Products and Services /connections Worldwide Contacts /contact© 2010 The MathWorks, Inc. MATLAB and Simulink are registered trademarks of The MathWorks, Inc. See /trademarks for a list of additional trademarks. Other product or brand names may be trademarks or registered trademarks of their respective holders.。
综合布线术语

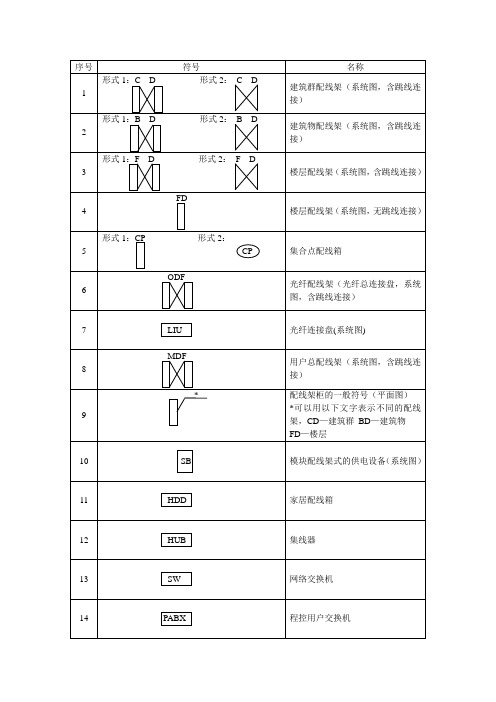
序号符号名称形式1:C D 形式2: C D建筑群配线架(系统图,含跳线连1接)形式1:B D 形式2:B D建筑物配线架(系统图,含跳线连2接)形式1:F D 形式2: F D楼层配线架(系统图,含跳线连3接)FD楼层配线架(系统图,无跳线连4接)形式1:CP 形式2:5 CP 集合点配线箱ODF光纤配线架(光纤总连接盘,系统6图,含跳线连接)7 LIU 光纤连接盘(系统图)MDF用户总配线架(系统图,含跳线连8接)* 配线架柜的一般符号(平面图)9 *可以用以下文字表示不同的配线架,CD—建筑群BD—建筑物FD—楼层10 SB 模块配线架式的供电设备(系统图)11 HDD 家居配线箱12 HUB 集线器13 SW 网络交换机14 PABX 程控用户交换机15 IP 网络电话16 AP 无线接入点TO17 信息点(插座)形式1:nTO 形式2:nTO 信息插座,n 为信息孔数(n≤4)18 例如:TO,2TO,4TO 分别为单孔、双孔、四孔信息插座形式1:* 形式2:* 信息插座的一般符号,*可以用以19 下的文字符号区别不同插座TP—电话TD—计算机(数据)MUTO20 多用户信息插座形式1:TV 形式2:TV21 电视插座22 光纤或光缆23 线槽24 CD 建筑群配线设备25 BD 建筑物配线设备26 FD 楼层配线设备27 CP 集合点28 ODF 用户配线架29 MDF 用户总配线架30 RJ45 8 位模块通用插座31 IDC 卡接式配线模块32 OF 光纤33 ST 卡口式锁紧连接器(光纤连接器)34 SC 直插式连接器(光纤连接器)35 SFF 小型连接器(光纤连接器)36 TE 终端设备37 HDD 家居配线箱序号表达内容英文代号汉字代号1 沿钢索敷设SR S2 沿屋架或楼层下弦敷设BE LM3 沿柱子敷设CLE ZM4 沿墙敷设WE QM5 沿天棚敷设CE PM6 在能进人的吊顶内敷设ACE PNM7 暗敷在梁内BC LA8 暗敷在柱子内CLC ZA9 暗敷在屋面顶板内CC PA10 暗敷在地面地板内FC DA11 暗敷在不能进人的吊顶内AC PNA12 暗敷在墙内WC QA13 线吊式敷设CP14 链吊式敷设CH L15 管吊式敷设P G16 吸顶式或直附式敷设S D17 嵌入式(不可上人的顶棚)敷设R R18 顶棚内安装(可进人的顶棚)CR DR19 墙壁内安装WR BR20 台上安装T T21 用硬质塑料管敷设PC VG22 用半硬质塑料管敷设FEC ZVG23 用薄壁电线管敷设TC DG24 用水煤气钢管敷设SC G25 用金属线槽敷设SR GC26 用电缆桥架托盘敷设CT27 用瓷夹头敷设PL CJ28 用塑料夹子敷设PCL VT29 用蛇皮管敷设CP30 用瓷瓶瓷柱敷设K CP术语或符号英文名中文名或解释ACR Attenuation to Crosstalk Ratio 衷减—串音衰减比率ADU Asynchronous Data Unit 异步数据单元ATM Asynchronous Transfer Mode 异步传输模式BA Building Automatization 楼宇自动化BD Building Distributor 建筑物配线设备B-ISDN Broadband ISDN 宽带ISDN10BASE-T 10ABASE-T 10Mbit/s 基于2 对线应用的以太网100BASE-TX 100BASE-TX 100Mbit/s 基于2 对线应用的以太网100BASE-T4 100BASE-T4 100Mbit/s 基于4 对线应用的以太网100BASE-T2 100BASE-T2 100Mbit/s 基于2 对线全双工应用的以太网1000BASE-T 1000BASE-T 1000Mbit/s 基于4 对线全双工应用的以太网100BASE-VG 100BASE-VG 100Mbit/s 基于4 对线应用的需求优先级网络CA Communication Automatization 通信自动化64CAP 64-Carrierless Amplitude Phase 8*8 无载波幅度和相位调制(也有16、4、2 的)CD Campus Distrbutor 建筑群配线设备CP Consolidation Point 集合点CSMA/CD Carrier Sense Multiple Access with Collision用碰撞检测方式的载波监听多路1BASE5 Detection 1BASE5 访问1Mbit/s 基于粗电缆CSMA/CD CSMA/CD 10BASE-F CSMA/CD 10Mbit/s 基于光纤10BASE-FCSMA/CD CSMA/CD Fibre Optic Inter-Repeater Link CSMA/CD 中继器之间的光纤链路FOIRLCISPR Commission Internationale Speciale des国际无线电干革命扰特别委员会Perturbations RadiodB dB 电信传输单位:分贝dBm dBm 取1mW 作基准值,以分贝表示的绝对功率电平dB mo dB mo 取1mW 作基准值,相对于零相对电平点,以分贝表示的信号绝对功率电平DCE Data Circuit Equipment 数据电路设备DDN Digital Data Network 数字数据网DSP Digital Signal Processing 数字信号处理DTE Date Terminal Equipment 数据终端设备ELA Electronic Industries Association 美国电子工业协会ELFEXT Equal Level Far End Crosstalk 等电平远端串音EMC Electro Magnetic Compatibility 电磁兼容性EMI Electro Magnetic Interference 电磁干扰ER Equipment Room 设备间FC Fiber Channel 光纤信道FD Floor Distributor 楼层配线设备FDDI Fiber Distributed Data Interface 光纤分布数据接口FEP [(CF(CF)-CF)(CF-CF)] FEP 氟塑料树脂FEXT Far End Crosstalk 远端串音f.f.s For further study 进一步研究FR Frame Relay 帧中继FTP Foil Twisted Pair 金属箔对绞线FTTB Fiber To The Building 光纤到大楼FTTD Fiber To The Desk 光纤到桌面FTTH Fiber To The Home 光纤到家庭FWHM Full Width Half Maximum 谱线最大宽度GCS Generic Cabling System 综合布线系统HIPPI High Perform Parallel Interface 高性能并行接口HUB HUB 集线器ISDN Integrated Building Distribution Network 建筑物综合分布网络IBS Intelligent Building System 智能大楼系统IDC Insulation Displacement Connection 绝缘压穿连接IEC International Electrotechnical Commission 国际电工技术委员会IEEE The Institute of Electrical and Electronice美国电气及电子工程师学会EngineersIP Internet Protocol 因特网协议ISDN Integrated Services Digital Network 综合业务数字网ISO Integrated Organization for Standardizafion 国际标准化组织ITU-T International Telecommunication Union- 国际电信联盟-电信(前称Telecommunications(formerly CCITT) CCITT)LAN Local Area Network 局域网LCF FDDI Low Cost Fiber FDDI 低费用光纤FDDILSHF-FR Low Smoke Halogen Free-Flame Retardant 低烟无卤阻燃LSLC Low Smoke Limited Combustible 低烟阻燃LSCN Low Smoke Non-Combustible 低烟非燃LSOH Low Smoke Zero Halogen 低烟无卤MDNEXT Multiple Disturb NEXT 多个干扰的近端串音MLT-3 Multi-Level Transmission-3 3 电平传输码MUTO Multi-User Telecommunications Outlet 多用户信息插座N/A Not Applicable 不适用的NEXT Near End Crosstalk 近端串音N-ISDN Narrow ISDN 窄带ISDNNRZ-I No Return Zero-Inverse 非归零反转码OA Office Automatization 办公自动化PAM5 Pulse Amplitude Modulation 5 5 级脉幅调制PBX Private Branch exchange 用户电话交换机PDS Premises Distribution System 建筑物布线系统PFA [(CF(OR)-CF)(CF-CF)] PFA 氟塑料树脂PMD Physical Layer Medium Dependent 依赖于物理层模式PSELFEXT POWER Sum ELFEXT 等电平远端串扰功率和PSNEXT Power Sum NEXT 近端串扰功率和PSPDN Packet Switched Public Data Network 公众分组交换数据网RF Radio Frequency 射频SC Subscriber Connector(Optical Fiber) 用户连接器(光纤)SC-D Subscriber Connector-Dual(Optical Fiber) 双联用户连接器(光纤)SCS Structured Cabling System 结构化布线系统SDU Synchronous Data Unit 同步数据单元SM FDDI Single- Mode FDDI 单模FDDISFTP Shielded Foil Twisted Pair 屏蔽金属箔对绞线STP Shielded Twisted Pair 屏蔽对绞线TIA Telecommunications Industry Association 美国电信工业协会TO Telecommunications Outlet 信息插座(电信引出端)Token Ring Token Ring 4Mbit/s 令牌环路4Mbit/s4Mbit/sToken Ring Token Ring 16Mbit/s 令牌环路16Mbit.s16Mbit/sTP Transition Point 转接点TP-PMD/CDDI Twisted Pair-Physical Layer Medium 依赖对绞线介质的传送模式/或称Dependent/cable Distributed Data Interface铜缆分布数据接口UL Underwriters Laboratories 美国保险商实验所安全标准UNI User Network Interface 用户网络侧接口UPS Uninterrupted Power System 不间断电源系统UTP Unshielded Twisted Pair 非屏蔽对绞线VOD Video on Demand 视像点播Vr.m.s Vroot.mean.square 电压有效值WAN Wide Area Network 广域网布线施工专用术语和词汇在局域网布线与施工过程中,通常会涉及到一些专用术语和词汇。
Modeling the Spatial Dynamics of Regional Land Use_The CLUE-S Model

Modeling the Spatial Dynamics of Regional Land Use:The CLUE-S ModelPETER H.VERBURG*Department of Environmental Sciences Wageningen UniversityP.O.Box376700AA Wageningen,The NetherlandsandFaculty of Geographical SciencesUtrecht UniversityP.O.Box801153508TC Utrecht,The NetherlandsWELMOED SOEPBOERA.VELDKAMPDepartment of Environmental Sciences Wageningen UniversityP.O.Box376700AA Wageningen,The NetherlandsRAMIL LIMPIADAVICTORIA ESPALDONSchool of Environmental Science and Management University of the Philippines Los Ban˜osCollege,Laguna4031,Philippines SHARIFAH S.A.MASTURADepartment of GeographyUniversiti Kebangsaan Malaysia43600BangiSelangor,MalaysiaABSTRACT/Land-use change models are important tools for integrated environmental management.Through scenario analysis they can help to identify near-future critical locations in the face of environmental change.A dynamic,spatially ex-plicit,land-use change model is presented for the regional scale:CLUE-S.The model is specifically developed for the analysis of land use in small regions(e.g.,a watershed or province)at afine spatial resolution.The model structure is based on systems theory to allow the integrated analysis of land-use change in relation to socio-economic and biophysi-cal driving factors.The model explicitly addresses the hierar-chical organization of land use systems,spatial connectivity between locations and stability.Stability is incorporated by a set of variables that define the relative elasticity of the actual land-use type to conversion.The user can specify these set-tings based on expert knowledge or survey data.Two appli-cations of the model in the Philippines and Malaysia are used to illustrate the functioning of the model and its validation.Land-use change is central to environmental man-agement through its influence on biodiversity,water and radiation budgets,trace gas emissions,carbon cy-cling,and livelihoods(Lambin and others2000a, Turner1994).Land-use planning attempts to influence the land-use change dynamics so that land-use config-urations are achieved that balance environmental and stakeholder needs.Environmental management and land-use planning therefore need information about the dynamics of land use.Models can help to understand these dynamics and project near future land-use trajectories in order to target management decisions(Schoonenboom1995).Environmental management,and land-use planning specifically,take place at different spatial and organisa-tional levels,often corresponding with either eco-re-gional or administrative units,such as the national or provincial level.The information needed and the man-agement decisions made are different for the different levels of analysis.At the national level it is often suffi-cient to identify regions that qualify as“hot-spots”of land-use change,i.e.,areas that are likely to be faced with rapid land use conversions.Once these hot-spots are identified a more detailed land use change analysis is often needed at the regional level.At the regional level,the effects of land-use change on natural resources can be determined by a combina-tion of land use change analysis and specific models to assess the impact on natural resources.Examples of this type of model are water balance models(Schulze 2000),nutrient balance models(Priess and Koning 2001,Smaling and Fresco1993)and erosion/sedimen-tation models(Schoorl and Veldkamp2000).Most of-KEY WORDS:Land-use change;Modeling;Systems approach;Sce-nario analysis;Natural resources management*Author to whom correspondence should be addressed;email:pverburg@gissrv.iend.wau.nlDOI:10.1007/s00267-002-2630-x Environmental Management Vol.30,No.3,pp.391–405©2002Springer-Verlag New York Inc.ten these models need high-resolution data for land use to appropriately simulate the processes involved.Land-Use Change ModelsThe rising awareness of the need for spatially-ex-plicit land-use models within the Land-Use and Land-Cover Change research community(LUCC;Lambin and others2000a,Turner and others1995)has led to the development of a wide range of land-use change models.Whereas most models were originally devel-oped for deforestation(reviews by Kaimowitz and An-gelsen1998,Lambin1997)more recent efforts also address other land use conversions such as urbaniza-tion and agricultural intensification(Brown and others 2000,Engelen and others1995,Hilferink and Rietveld 1999,Lambin and others2000b).Spatially explicit ap-proaches are often based on cellular automata that simulate land use change as a function of land use in the neighborhood and a set of user-specified relations with driving factors(Balzter and others1998,Candau 2000,Engelen and others1995,Wu1998).The speci-fication of the neighborhood functions and transition rules is done either based on the user’s expert knowl-edge,which can be a problematic process due to a lack of quantitative understanding,or on empirical rela-tions between land use and driving factors(e.g.,Pi-janowski and others2000,Pontius and others2000).A probability surface,based on either logistic regression or neural network analysis of historic conversions,is made for future conversions.Projections of change are based on applying a cut-off value to this probability sur-face.Although appropriate for short-term projections,if the trend in land-use change continues,this methodology is incapable of projecting changes when the demands for different land-use types change,leading to a discontinua-tion of the trends.Moreover,these models are usually capable of simulating the conversion of one land-use type only(e.g.deforestation)because they do not address competition between land-use types explicitly.The CLUE Modeling FrameworkThe Conversion of Land Use and its Effects(CLUE) modeling framework(Veldkamp and Fresco1996,Ver-burg and others1999a)was developed to simulate land-use change using empirically quantified relations be-tween land use and its driving factors in combination with dynamic modeling.In contrast to most empirical models,it is possible to simulate multiple land-use types simultaneously through the dynamic simulation of competition between land-use types.This model was developed for the national and con-tinental level,applications are available for Central America(Kok and Winograd2001),Ecuador(de Kon-ing and others1999),China(Verburg and others 2000),and Java,Indonesia(Verburg and others 1999b).For study areas with such a large extent the spatial resolution of analysis was coarse(pixel size vary-ing between7ϫ7and32ϫ32km).This is a conse-quence of the impossibility to acquire data for land use and all driving factors atfiner spatial resolutions.A coarse spatial resolution requires a different data rep-resentation than the common representation for data with afine spatial resolution.Infine resolution grid-based approaches land use is defined by the most dom-inant land-use type within the pixel.However,such a data representation would lead to large biases in the land-use distribution as some class proportions will di-minish and other will increase with scale depending on the spatial and probability distributions of the cover types(Moody and Woodcock1994).In the applications of the CLUE model at the national or continental level we have,therefore,represented land use by designating the relative cover of each land-use type in each pixel, e.g.a pixel can contain30%cultivated land,40%grass-land,and30%forest.This data representation is di-rectly related to the information contained in the cen-sus data that underlie the applications.For each administrative unit,census data denote the number of hectares devoted to different land-use types.When studying areas with a relatively small spatial ex-tent,we often base our land-use data on land-use maps or remote sensing images that denote land-use types respec-tively by homogeneous polygons or classified pixels. When converted to a raster format this results in only one, dominant,land-use type occupying one unit of analysis. The validity of this data representation depends on the patchiness of the landscape and the pixel size chosen. Most sub-national land use studies use this representation of land use with pixel sizes varying between a few meters up to about1ϫ1km.The two different data represen-tations are shown in Figure1.Because of the differences in data representation and other features that are typical for regional appli-cations,the CLUE model can not directly be applied at the regional scale.This paper describes the mod-ified modeling approach for regional applications of the model,now called CLUE-S(the Conversion of Land Use and its Effects at Small regional extent). The next section describes the theories underlying the development of the model after which it is de-scribed how these concepts are incorporated in the simulation model.The functioning of the model is illustrated for two case-studies and is followed by a general discussion.392P.H.Verburg and othersCharacteristics of Land-Use SystemsThis section lists the main concepts and theories that are prevalent for describing the dynamics of land-use change being relevant for the development of land-use change models.Land-use systems are complex and operate at the interface of multiple social and ecological systems.The similarities between land use,social,and ecological systems allow us to use concepts that have proven to be useful for studying and simulating ecological systems in our analysis of land-use change (Loucks 1977,Adger 1999,Holling and Sanderson 1996).Among those con-cepts,connectivity is important.The concept of con-nectivity acknowledges that locations that are at a cer-tain distance are related to each other (Green 1994).Connectivity can be a direct result of biophysical pro-cesses,e.g.,sedimentation in the lowlands is a direct result of erosion in the uplands,but more often it is due to the movement of species or humans through the nd degradation at a certain location will trigger farmers to clear land at a new location.Thus,changes in land use at this new location are related to the land-use conditions in the other location.In other instances more complex relations exist that are rooted in the social and economic organization of the system.The hierarchical structure of social organization causes some lower level processes to be constrained by higher level dynamics,e.g.,the establishments of a new fruit-tree plantation in an area near to the market might in fluence prices in such a way that it is no longer pro fitable for farmers to produce fruits in more distant areas.For studying this situation an-other concept from ecology,hierarchy theory,is use-ful (Allen and Starr 1982,O ’Neill and others 1986).This theory states that higher level processes con-strain lower level processes whereas the higher level processes might emerge from lower level dynamics.This makes the analysis of the land-use system at different levels of analysis necessary.Connectivity implies that we cannot understand land use at a certain location by solely studying the site characteristics of that location.The situation atneigh-Figure 1.Data representation and land-use model used for respectively case-studies with a national/continental extent and local/regional extent.Modeling Regional Land-Use Change393boring or even more distant locations can be as impor-tant as the conditions at the location itself.Land-use and land-cover change are the result of many interacting processes.Each of these processes operates over a range of scales in space and time.These processes are driven by one or more of these variables that influence the actions of the agents of land-use and cover change involved.These variables are often re-ferred to as underlying driving forces which underpin the proximate causes of land-use change,such as wood extraction or agricultural expansion(Geist and Lambin 2001).These driving factors include demographic fac-tors(e.g.,population pressure),economic factors(e.g., economic growth),technological factors,policy and institutional factors,cultural factors,and biophysical factors(Turner and others1995,Kaimowitz and An-gelsen1998).These factors influence land-use change in different ways.Some of these factors directly influ-ence the rate and quantity of land-use change,e.g.the amount of forest cleared by new incoming migrants. Other factors determine the location of land-use change,e.g.the suitability of the soils for agricultural land use.Especially the biophysical factors do pose constraints to land-use change at certain locations, leading to spatially differentiated pathways of change.It is not possible to classify all factors in groups that either influence the rate or location of land-use change.In some cases the same driving factor has both an influ-ence on the quantity of land-use change as well as on the location of land-use change.Population pressure is often an important driving factor of land-use conver-sions(Rudel and Roper1997).At the same time it is the relative population pressure that determines which land-use changes are taking place at a certain location. Intensively cultivated arable lands are commonly situ-ated at a limited distance from the villages while more extensively managed grasslands are often found at a larger distance from population concentrations,a rela-tion that can be explained by labor intensity,transport costs,and the quality of the products(Von Thu¨nen 1966).The determination of the driving factors of land use changes is often problematic and an issue of dis-cussion(Lambin and others2001).There is no unify-ing theory that includes all processes relevant to land-use change.Reviews of case studies show that it is not possible to simply relate land-use change to population growth,poverty,and infrastructure.Rather,the inter-play of several proximate as well as underlying factors drive land-use change in a synergetic way with large variations caused by location specific conditions (Lambin and others2001,Geist and Lambin2001).In regional modeling we often need to rely on poor data describing this complexity.Instead of using the under-lying driving factors it is needed to use proximate vari-ables that can represent the underlying driving factors. Especially for factors that are important in determining the location of change it is essential that the factor can be mapped quantitatively,representing its spatial vari-ation.The causality between the underlying driving factors and the(proximate)factors used in modeling (in this paper,also referred to as“driving factors”) should be certified.Other system properties that are relevant for land-use systems are stability and resilience,concepts often used to describe ecological systems and,to some extent, social systems(Adger2000,Holling1973,Levin and others1998).Resilience refers to the buffer capacity or the ability of the ecosystem or society to absorb pertur-bations,or the magnitude of disturbance that can be absorbed before a system changes its structure by changing the variables and processes that control be-havior(Holling1992).Stability and resilience are con-cepts that can also be used to describe the dynamics of land-use systems,that inherit these characteristics from both ecological and social systems.Due to stability and resilience of the system disturbances and external in-fluences will,mostly,not directly change the landscape structure(Conway1985).After a natural disaster lands might be abandoned and the population might tempo-rally migrate.However,people will in most cases return after some time and continue land-use management practices as before,recovering the land-use structure (Kok and others2002).Stability in the land-use struc-ture is also a result of the social,economic,and insti-tutional structure.Instead of a direct change in the land-use structure upon a fall in prices of a certain product,farmers will wait a few years,depending on the investments made,before they change their cropping system.These characteristics of land-use systems provide a number requirements for the modelling of land-use change that have been used in the development of the CLUE-S model,including:●Models should not analyze land use at a single scale,but rather include multiple,interconnected spatial scales because of the hierarchical organization of land-use systems.●Special attention should be given to the drivingfactors of land-use change,distinguishing drivers that determine the quantity of change from drivers of the location of change.●Sudden changes in driving factors should not di-rectly change the structure of the land-use system asa consequence of the resilience and stability of theland-use system.394P.H.Verburg and others●The model structure should allow spatial interac-tions between locations and feedbacks from higher levels of organization.Model DescriptionModel StructureThe model is sub-divided into two distinct modules,namely a non-spatial demand module and a spatially explicit allocation procedure (Figure 2).The non-spa-tial module calculates the area change for all land-use types at the aggregate level.Within the second part of the model these demands are translated into land-use changes at different locations within the study region using a raster-based system.For the land-use demand module,different alterna-tive model speci fications are possible,ranging from simple trend extrapolations to complex economic mod-els.The choice for a speci fic model is very much de-pendent on the nature of the most important land-use conversions taking place within the study area and the scenarios that need to be considered.Therefore,the demand calculations will differ between applications and scenarios and need to be decided by the user for the speci fic situation.The results from the demandmodule need to specify,on a yearly basis,the area covered by the different land-use types,which is a direct input for the allocation module.The rest of this paper focuses on the procedure to allocate these demands to land-use conversions at speci fic locations within the study area.The allocation is based upon a combination of em-pirical,spatial analysis,and dynamic modelling.Figure 3gives an overview of the procedure.The empirical analysis unravels the relations between the spatial dis-tribution of land use and a series of factors that are drivers and constraints of land use.The results of this empirical analysis are used within the model when sim-ulating the competition between land-use types for a speci fic location.In addition,a set of decision rules is speci fied by the user to restrict the conversions that can take place based on the actual land-use pattern.The different components of the procedure are now dis-cussed in more detail.Spatial AnalysisThe pattern of land use,as it can be observed from an airplane window or through remotely sensed im-ages,reveals the spatial organization of land use in relation to the underlying biophysical andsocio-eco-Figure 2.Overview of the modelingprocedure.Figure 3.Schematic represen-tation of the procedure to allo-cate changes in land use to a raster based map.Modeling Regional Land-Use Change395nomic conditions.These observations can be formal-ized by overlaying this land-use pattern with maps de-picting the variability in biophysical and socio-economic conditions.Geographical Information Systems(GIS)are used to process all spatial data and convert these into a regular grid.Apart from land use, data are gathered that represent the assumed driving forces of land use in the study area.The list of assumed driving forces is based on prevalent theories on driving factors of land-use change(Lambin and others2001, Kaimowitz and Angelsen1998,Turner and others 1993)and knowledge of the conditions in the study area.Data can originate from remote sensing(e.g., land use),secondary statistics(e.g.,population distri-bution),maps(e.g.,soil),and other sources.To allow a straightforward analysis,the data are converted into a grid based system with a cell size that depends on the resolution of the available data.This often involves the aggregation of one or more layers of thematic data,e.g. it does not make sense to use a30-m resolution if that is available for land-use data only,while the digital elevation model has a resolution of500m.Therefore, all data are aggregated to the same resolution that best represents the quality and resolution of the data.The relations between land use and its driving fac-tors are thereafter evaluated using stepwise logistic re-gression.Logistic regression is an often used method-ology in land-use change research(Geoghegan and others2001,Serneels and Lambin2001).In this study we use logistic regression to indicate the probability of a certain grid cell to be devoted to a land-use type given a set of driving factors following:LogͩP i1ϪP i ͪϭ0ϩ1X1,iϩ2X2,i......ϩn X n,iwhere P i is the probability of a grid cell for the occur-rence of the considered land-use type and the X’s are the driving factors.The stepwise procedure is used to help us select the relevant driving factors from a larger set of factors that are assumed to influence the land-use pattern.Variables that have no significant contribution to the explanation of the land-use pattern are excluded from thefinal regression equation.Where in ordinal least squares regression the R2 gives a measure of modelfit,there is no equivalent for logistic regression.Instead,the goodness offit can be evaluated with the ROC method(Pontius and Schnei-der2000,Swets1986)which evaluates the predicted probabilities by comparing them with the observed val-ues over the whole domain of predicted probabilities instead of only evaluating the percentage of correctly classified observations at afixed cut-off value.This is an appropriate methodology for our application,because we will use a wide range of probabilities within the model calculations.The influence of spatial autocorrelation on the re-gression results can be minimized by only performing the regression on a random sample of pixels at a certain minimum distance from one another.Such a selection method is adopted in order to maximize the distance between the selected pixels to attenuate the problem associated with spatial autocorrelation.For case-studies where autocorrelation has an important influence on the land-use structure it is possible to further exploit it by incorporating an autoregressive term in the regres-sion equation(Overmars and others2002).Based upon the regression results a probability map can be calculated for each land-use type.A new probabil-ity map is calculated every year with updated values for the driving factors that are projected to change in time,such as the population distribution or accessibility.Decision RulesLand-use type or location specific decision rules can be specified by the user.Location specific decision rules include the delineation of protected areas such as nature reserves.If a protected area is specified,no changes are allowed within this area.For each land-use type decision rules determine the conditions under which the land-use type is allowed to change in the next time step.These decision rules are implemented to give certain land-use types a certain resistance to change in order to generate the stability in the land-use structure that is typical for many landscapes.Three different situations can be distinguished and for each land-use type the user should specify which situation is most relevant for that land-use type:1.For some land-use types it is very unlikely that theyare converted into another land-use type after their first conversion;as soon as an agricultural area is urbanized it is not expected to return to agriculture or to be converted into forest cover.Unless a de-crease in area demand for this land-use type occurs the locations covered by this land use are no longer evaluated for potential land-use changes.If this situation is selected it also holds that if the demand for this land-use type decreases,there is no possi-bility for expansion in other areas.In other words, when this setting is applied to forest cover and deforestation needs to be allocated,it is impossible to reforest other areas at the same time.2.Other land-use types are converted more easily.Aswidden agriculture system is most likely to be con-verted into another land-use type soon after its396P.H.Verburg and othersinitial conversion.When this situation is selected for a land-use type no restrictions to change are considered in the allocation module.3.There is also a number of land-use types that oper-ate in between these two extremes.Permanent ag-riculture and plantations require an investment for their establishment.It is therefore not very likely that they will be converted very soon after into another land-use type.However,in the end,when another land-use type becomes more pro fitable,a conversion is possible.This situation is dealt with by de fining the relative elasticity for change (ELAS u )for the land-use type into any other land use type.The relative elasticity ranges between 0(similar to Situation 2)and 1(similar to Situation 1).The higher the de fined elasticity,the more dif ficult it gets to convert this land-use type.The elasticity should be de fined based on the user ’s knowledge of the situation,but can also be tuned during the calibration of the petition and Actual Allocation of Change Allocation of land-use change is made in an iterative procedure given the probability maps,the decision rules in combination with the actual land-use map,and the demand for the different land-use types (Figure 4).The following steps are followed in the calculation:1.The first step includes the determination of all grid cells that are allowed to change.Grid cells that are either part of a protected area or under a land-use type that is not allowed to change (Situation 1,above)are excluded from further calculation.2.For each grid cell i the total probability (TPROP i,u )is calculated for each of the land-use types u accord-ing to:TPROP i,u ϭP i,u ϩELAS u ϩITER u ,where ITER u is an iteration variable that is speci fic to the land use.ELAS u is the relative elasticity for change speci fied in the decision rules (Situation 3de-scribed above)and is only given a value if grid-cell i is already under land use type u in the year considered.ELAS u equals zero if all changes are allowed (Situation 2).3.A preliminary allocation is made with an equalvalue of the iteration variable (ITER u )for all land-use types by allocating the land-use type with the highest total probability for the considered grid cell.This will cause a number of grid cells to change land use.4.The total allocated area of each land use is nowcompared to the demand.For land-use types where the allocated area is smaller than the demanded area the value of the iteration variable is increased.For land-use types for which too much is allocated the value is decreased.5.Steps 2to 4are repeated as long as the demandsare not correctly allocated.When allocation equals demand the final map is saved and the calculations can continue for the next yearly timestep.Figure 5shows the development of the iteration parameter ITER u for different land-use types during asimulation.Figure 4.Representation of the iterative procedure for land-use changeallocation.Figure 5.Change in the iteration parameter (ITER u )during the simulation within one time-step.The different lines rep-resent the iteration parameter for different land-use types.The parameter is changed for all land-use types synchronously until the allocated land use equals the demand.Modeling Regional Land-Use Change397Multi-Scale CharacteristicsOne of the requirements for land-use change mod-els are multi-scale characteristics.The above described model structure incorporates different types of scale interactions.Within the iterative procedure there is a continuous interaction between macro-scale demands and local land-use suitability as determined by the re-gression equations.When the demand changes,the iterative procedure will cause the land-use types for which demand increased to have a higher competitive capacity (higher value for ITER u )to ensure enough allocation of this land-use type.Instead of only being determined by the local conditions,captured by the logistic regressions,it is also the regional demand that affects the actually allocated changes.This allows the model to “overrule ”the local suitability,it is not always the land-use type with the highest probability according to the logistic regression equation (P i,u )that the grid cell is allocated to.Apart from these two distinct levels of analysis there are also driving forces that operate over a certain dis-tance instead of being locally important.Applying a neighborhood function that is able to represent the regional in fluence of the data incorporates this type of variable.Population pressure is an example of such a variable:often the in fluence of population acts over a certain distance.Therefore,it is not the exact location of peoples houses that determines the land-use pattern.The average population density over a larger area is often a more appropriate variable.Such a population density surface can be created by a neighborhood func-tion using detailed spatial data.The data generated this way can be included in the spatial analysis as anotherindependent factor.In the application of the model in the Philippines,described hereafter,we applied a 5ϫ5focal filter to the population map to generate a map representing the general population pressure.Instead of using these variables,generated by neighborhood analysis,it is also possible to use the more advanced technique of multi-level statistics (Goldstein 1995),which enable a model to include higher-level variables in a straightforward manner within the regression equa-tion (Polsky and Easterling 2001).Application of the ModelIn this paper,two examples of applications of the model are provided to illustrate its function.TheseTable nd-use classes and driving factors evaluated for Sibuyan IslandLand-use classes Driving factors (location)Forest Altitude (m)GrasslandSlope Coconut plantation AspectRice fieldsDistance to town Others (incl.mangrove and settlements)Distance to stream Distance to road Distance to coast Distance to port Erosion vulnerability GeologyPopulation density(neighborhood 5ϫ5)Figure 6.Location of the case-study areas.398P.H.Verburg and others。
纯化水系统性能确认方案中英文对照

XXX LTD.标题:WS-01纯化水系统性能确认方案TITLE: PROTOCAL FOR PERFORMANCE QUALIFICATION OF PURIFIEDWATERGENERATION,STORAGE ANDDISTRIBUTION SYSTEM 011.0 目的PURPOSE:方案编码Protocol No.:生效日期Effective Date: 页码:1 / 17此验证方案旨在为原料药二车间和制剂〔II〕车间的纯化水系统供给性能确认程序。
The purpose of this protocol is to provide the procedure for the performance qualification of Purified water generation ,storage and distribution system for workshop 2 and workshop 10 as described in the change control.证明纯化水制水系统,存储系统和输送系统能够连续稳定的供给符合标准要求的纯化水并确定它的牢靠性,同时供给证明文件。
To provide documented evidence that the Purified water generation system, Storage and Distribution System is capable to continuously supply the Purified Water with the specified quality attributes in consistent manner and thereby establishing its dependability.在如期完成纯化水系统WS-01 的安装确认和运行确认后,供给纯化水系统存储系统和输送系统性能确认的原理机制。
ddp训练的device参数

一、什么是DDP训练?分布式数据并行(DDP)训练是一种用于训练深度学习模型的并行计算技术。
在传统的模型训练中,数据被分配到单个设备上,并且计算是在该设备上进行的。
而在DDP训练中,数据被分布到多个设备上,并且计算也是在多个设备上同时进行的。
DDP训练的主要目的是加快模型训练的速度,提高训练过程的效率。
二、DDP训练中的device参数在进行DDP训练时,需要使用device参数来指定每个设备的编号。
设备参数是指定每个设备在并行计算中所使用的编号,以及设备之间的通信和同步方式。
在PyTorch中,可以使用torch.device来指定设备参数,并且可以使用torch.distributed包中的函数来进行设备之间的通信和同步操作。
三、设备参数的使用方法在PyTorch中,可以通过以下方式来指定设备参数:1. 使用torch.device函数来指定设备参数,例如:device1 = torch.device('cuda:0')device2 = torch.device('cuda:1')这样就分别指定了两个设备的参数,其中'cuda:0'表示第一个GPU设备,'cuda:1'表示第二个GPU设备。
2. 使用torch.distributed包中的函数来进行设备之间的通信和同步操作,例如:torch.distributed.broadcast(tensor, src, group)torch.distributed.reduce(tensor, dst, op, group)使用这些函数可以在并行计算中对不同设备之间的数据进行传输和处理。
四、设备参数的设置注意事项在使用设备参数进行DDP训练时,需要注意以下几点:1. 确保设备参数的编号是唯一的,并且设备的数量不超过系统的硬件限制。
2. 确保设备参数的通信和同步方式是正确的,以避免数据丢失或计算错误。
数字孪生网络(DTN)概念、架构及关键技术

数字孪生网络(DTN): 概念、架构及关键技术孙 滔 1周 铖 1段晓东 1陆 璐 1陈丹阳 1杨红伟 1朱艳宏 1刘 超 1李 琴 1 王 晓 2 沈 震 2 瞿逢重 3 蒋怀光 4 王飞跃2摘 要 随着5G 商用规模部署、下一代互联网IPv6的深化应用, 新一代网络技术的发展引发产业界的关注. 网络的智能化被认为是新一代网络发展的趋势. 网络为数字化社会的信息传输提供了基础, 而网络本身的数字化是智能化发展的先决条件. 面向数字化、智能化的新一代网络发展目标, 本文首次系统化提出了 “数字孪生网络(DTN: Digital twin network)”的概念, 给出了系统架构设计, 分析了DTN 的关键技术. 通过对DTN 发展挑战的分析, 本文指出了未来 “数字孪生网络”的发展方向.关键词 数字孪生网络, 网络自动化, 网络闭环控制, 全生命周期运维引用格式 孙滔, 周铖, 段晓东, 陆璐, 陈丹阳, 杨红伟, 朱艳宏, 刘超, 李琴, 王晓, 沈震, 瞿逢重, 蒋怀光, 王飞跃. 数字孪生网络(DTN): 概念、架构及关键技术. 自动化学报, 2021, 47(3): 569−582DOI 10.16383/j.aas.c210097Digital Twin Network (DTN): Concepts, Architecture, and Key TechnologiesSUN Tao 1 ZHOU Cheng 1 DUAN Xiao-Dong 1 LU Lu 1 CHEN Dan-Yang 1 YANG Hong-Wei 1ZHU Yan-Hong 1 LIU Chao 1 LI Qin 1 WANG Xiao 2 SHEN Zhen 2QU Feng-Zhong 3 JIANG Huai-Guang 4 WANG Fei-Yue 2Abstract With the commercial deployment of 5G and the migration of internet from IPv4 to IPv6, the new devel-opment of the network technology has highly attracted the attention of the industry. The intelligentization of net-work is believed as the trend of the new generation of network development. The network provides the foundation for the information transmission in the digital society, and the digitalization of the network itself is the prerequisite for the intelligent development. Facing the goal of the new generation of digital and intelligent network, this paper introduces the new concept of “digital twin network (DTN)”, designs the system architecture, and analyzes the key technologies of DTN. By investigating the challenges of DTN, this paper points out the future development direc-tion of digital twin network.Key words Digital twin network (DTN), network automation, network closed-loop control, full life cycle operation Citation Sun Tao, Zhou Cheng, Duan Xiao-Dong, Lu Lu, Chen Dan-Yang, Yang Hong-Wei, Zhu Yan-Hong, Liu Chao, Li Qin, Wang Xiao, Shen Zhen, Qu Feng-Zhong, Jiang Huai-Guang, Wang Fei-Yue. Digital twin network (DTN): concepts, architecture, and key technologies. Acta Automatica Sinica , 2021, 47(3): 569−582随着5G 、物联网和云计算技术的发展以及层出不穷的网络新业务涌现, 网络负载不断增加, 网络规模持续扩大. 由此带来的网络复杂性, 使得网络的运行和维护变得越来越复杂[1−2]. 同时, 由于网络运营的高可靠性要求, 网络故障的高代价以及昂贵的试验成本, 网络的变动往往牵一发而动全身,新技术的部署愈发困难. 具体来说, 超大规模网络发展面临的典型挑战总结如下.1) 网络灵活性不足. 伴随物联网技术的兴起,网络通信由最初的人与人通信, 发展至人与物通信,并进一步发展至物与物通信. 通信模式不断更新,网络承载的业务类型、网络所服务的对象、连接到网络的设备类型等呈现出多样化发展的态势, 均对网络本身提出了更高的要求, 网络需具备更高的灵活性与可扩展性.收稿日期 2021-01-29 录用日期 2021-03-08Manuscript received January 29, 2021; accepted March 8, 2021国家重点研发计划(2020YFB1806801, 2020YFB1806800), 国家自然科学基金资助(61773382)Supported by National Key Research and Development Pro-gram of China (2020YFB1806801, 2020YFB1806800) and Nation-al Natural Science Foundation of China (61773382)本文责任编委 魏庆来Recommended by Associate Editor WEI Qing-Lai1. 中国移动通信有限公司研究院 北京 100053 中国2. 中国科学院自动化研究所复杂系统管理与控制国家重点实验室 北京100190 中国3. 浙江大学浙江省海洋观测—成像区重点实验室舟山 316021 中国4. 美国国家可再生能源实验室 科罗拉多州 戈尔登 80401 美国1. China Mobile Research Institute, Beijing 100053, China2. Sta-te Key Laboratory for Management and Control of Complex Sys-tems, Institute of Automation, Chinese Academy of Sciences,Beijing 100190, China3. Key Laboratory of Ocean Observation-Imaging Testbed of Zhejiang Province, Zhejiang University,Zhoushan 316021, China4. National Renewable Energy Labor-atory, Golden, Colorado 80401, USA第 47 卷 第 3 期自 动 化 学 报Vol. 47, No. 32021 年 3 月ACTA AUTOMATICA SINICAMarch, 20212) 网络新技术研发周期长、部署难度大. 作为基础设施, 网络具有高可靠性要求, 网络运营商的现网环境很难直接用于科研人员的网络创新技术研究. 仅仅基于线下仿真平台的研究会大大影响结果的有效性, 从而降低网络创新技术的发展速度. 此外, 新技术的失败风险和失败代价会阻碍对网络创新应用的尝试.3) 网络管理运维复杂. 随着云计算、虚拟化技术的发展, 传统网络已经开始向软件化、可编程转变, 呈现了许多新的特点, 如资源的云化、业务的按需设计、资源的编排等, 这使得网络的运行和维护面临着前所未有的压力. 由于缺乏有效的统一仿真、分析和预测平台, 很难从现有的预防性运维转向理想的预测性运维.4) 网络优化成本高、风险大. 由于缺乏有效的虚拟验证平台, 网络优化操作不得不直接作用在现网基础设施中, 造成较长的时间消耗以及较高的现网运行业务风险, 从而加大网络的运营成本.为解决上述困难, 网络智能化越来越为产业界所重视. “基于意图的网络”[3−4], “自动驾驶网络”[5−6],“零接触(Zero-Touch)网络”[7]等概念和技术相继被业界提出和推广, 希望借助网络智能化技术, 实现网络自动化和自主化运行的愿景. 数字孪生网络构建物理网络的实时镜像, 可增强物理网络所缺少的系统性仿真、优化、验证和控制能力, 助力上述网络新技术的部署, 更加高效地应对网络问题和挑战.将数字孪生技术应用于网络, 创建物理网络设施的虚拟镜像, 即可搭建数字孪生网络平台. 通过物理网络和孪生网络实时交互, 相互影响, 数字孪生网络平台能够助力网络实现低成本试错、智能化决策和高效率创新. 数字孪生网络的研究和应用在产业和学术界还处于起步阶段. 本文结构如下: 第1节介绍数字孪生的研究与应用现状, 第2节描述数字孪生网络的定义和架构并给出应用示例, 第3节描述数字孪生网络的关键技术, 第4节描述数字孪生网络的目标价值, 最后是总结和展望.1 数字孪生技术研究和应用现状1.1 数字孪生及相关技术概述数字孪生的概念最早由美国学者M. Grieves 教授提出[8], 并定义为三维模型, 包括实体产品、虚拟产品以及二者间的连接. 2012年, 美国空军研究实验室和美国国家航空航天局 (National Aero-nautics and Space Administration, NASA)合作提出构建未来飞行器的数字孪生体[9], 并定义数字孪生为高度集成的多物理场、多尺度、多概率的仿真模型. 近年来, 随着多学科建模与仿真技术的飞速发展, 数字孪生技术研究成为热点, 并在虚拟样机、数字孪生车间、数字孪生卫星、能源交通、医疗健康等诸多领域得到成功运用[10−12]. 面向未来网络, 伴随着云计算、大数据、人工智能等技术的不断发展以及信息的泛在化, 数字孪生技术也将更广泛地运用于人体活动监控与管理、家居生活和科学研究等领域, 使得整个社会走向虚拟与现实结合的 “数字孪生” 世界. 国际电信联盟电信标准化部 (Interna-tional Telecommunication Union — Telecommuni-cation Standardization Sector, ITU-T)面向未来网络的Network2030焦点组的技术报告[13−14]也将数字孪生作为未来网络12个代表性用例之一.数字孪生模型框架目前尚无统一定义. 商业公司、科研机构和标准组织都在尝试定义通用或者专用的模型框架. Gartner在其物联网(Internet of things, IoT)数字孪生技术报告[15]中提出构建一个物理实体的数字孪生体需要4个关键要素: 模型、数据、监控和唯一性. 文献[10]提出了数字孪生的五维模型 {PE, VE, Ss, DD, CN}, 其中, PE表示物理实体, VE表示虚拟实体, Ss表示服务, DD表示孪生数据, CN表示各部分之间的连接. 国际标准化组织(International Organization for Standardiza-tion, ISO)发布了面向制造的数字孪生系统框架标准草案[16−17], 提出包含数据采集域、设备控制域、数字孪生域和用户域的参考框架, 该草案即将成为数字孪生领域第一个国际标准.与数字孪生观念紧密相关的理论, 是由中国科学院自动化研究所王飞跃研究员于2004年提出的平行系统理论[18−19]. 平行系统理论同数字孪生理论在虚实映射、动态仿真等方面有相似性. 但是, 两者在研究对象、核心思想、实现方法、功能等方面均有所区别[20]. 数字孪生主要研究由信息空间和物理空间组成的空间物理系统 (Cyber physical system, CPS)[21], 而平行系统主要研究社会网络、信息资源和物理空间深度融合的社会物理信息系统 (Cyber physical social system, CPSS)[22], 包含社会活动的部分, 考虑社会的反映和影响. 平行系统相对于数字孪生的 “形似”, 更注重 “神似”. 数字孪生通过数字化空间构建物理空间的镜像, 而平行系统更强调计算实验和外在行为的干预, 基于人工系统生成场景. 平行系统理论在平行医疗[23−24]、平行自动驾驶[25]、平行军事[26]等领域同样有较多应用. 类似于数字孪生及平行系统理论, 文献[27]提出了智能空间设想,探讨了基于智能交通空间, 实现智能化车辆和交通基础设施控制的可行性.1.2 数字孪生网络相关探索与工作随着数字孪生技术的发展及其在生产制造等多570自 动 化 学 报47 卷个产业的应用, 数字孪生技术理念在通信网络领域的应用也逐渐被业界研究和关注. 华为公司提出在意图驱动网络的网络云化引擎(Network cloud en-gine, NCE)中[28], 在物理网络和商业意图之间构建数字孪生, 将过去离散的数据进行关联并转为在线共享, 构建全生命周期的数字化运维能力. Aria 公司的产品 STEP-T (Strategic traffic engineer-ing and planning tool) [29]在运营商客户的骨干网上建立数字孪生体, 运用人工智能 (Artificial intel-ligence, AI)技术在大规模复杂骨干网上完成了路由优化和故障仿真. 文献[30−31]提出基于赛博孪生(Cybertwin)的下一代网络架构, 通过人和物在虚拟世界的数字表示, 提供通信助理、日志记录和数字资产等功能, 适于未来网络从端到端连接至云到端连接的演进. 文献[32]建立了5G移动边缘计算(Mobile edge computing, MEC)网络的数字孪生体, 利用孪生体离线训练基于强化学习的资源分配优化和归一化节能算法, 然后将方案更新至MEC网络. 文献[33]提出一种工业互联网对应的数字孪生网络集成框架, 利用强化学习算法在此框架下寻求最优随机计算卸载和资源分配策略. 文献[34]建立了面向6G移动边缘计算系统的数字孪生边缘网络, 其中边缘服务器的孪生体评估实体服务器的状态, 移动边缘计算系统的孪生体提供数据用于训练卸载策略, 方案在降低卸载延时的同时减少了系统开销. 此外, 数字孪生技术在无线频谱等方面的感知与管理也有了相关的探索.中国科学院自动化所王飞跃研究员将平行系统理论用于网络系统, 提出 “平行网络(Parallel net-works)” 网络架构[35−37], 通过建立相应的人工网络系统, 开展相关计算实验, 对网络进行全面、准确和及时的评估. 数字孪生网络与平行网络在概念和目标上有一定的相似性, 主要设计思想都是类似于状态观测器的设计思路, 通过构造出类似原系统的衍生系统, 再针对所构造的人工网络系统或者孪生系统间接的修正实际系统的状态, 从而调整网络优化资源管理, 达到网络性能优化的目的. 同时, 二者在架构和实现方法上有所区别: 平行网络中的人工网络并非总是实际网络的完全映射; 数字孪生网络的孪生体强调物理网络的实时镜像. 平行网络中的人工网络基于软件定义网络(Software defined net-work, SDN)[38−39]技术和理念, 实现集中控制、整体优化和决策的功能; 数字孪生网络的孪生层不依赖SDN技术进行构建, 而是根据物理网络中网元和拓扑的实际形态进行抽象建模. 在实现方法上, 平行网络可基于有限数据进行计算实验和平行执行, 不依赖于全面、准确的数据即可建模; 数字孪生网络强调基于全面且准确的数据, 进行精准建模, 达成虚实网络实时交互.数字孪生网络技术的相关研究目前还处于初级阶段. 尽管数字孪生技术在网络中的应用已经起步,但目前的应用侧重于特定的物理网络中、特定的场景(如网络运维)中, 或者将网络数字孪生平台作为网络仿真工具. 结合数字孪生技术的特点以及在其他行业的应用, 本文认为数字孪生网络可以作为网络系统的一个有机整体, 成为未来涉及物理网络的全生命周期的通用架构, 服务于网络规划、建设、维护、优化, 以及网络自动驾驶、意图网络等网络创新技术的应用, 提升网络的自动化和智能化水平.2 数字孪生网络定义和架构2.1 数字孪生网络定义数字孪生网络业界尚无统一的定义, 本文将 “数字孪生网络” 定义为: 一个具有物理网络实体及虚拟孪生体, 且二者可进行实时交互映射的网络系统.在此系统中, 各种网络管理和应用可利用数字孪生技术构建的网络虚拟孪生体, 基于数据和模型对物理网络进行高效的分析、诊断、仿真和控制. 基于此定义, 数字孪生网络应当具备4个核心要素:数据、模型、映射和交互, 如图1所示.交互分析、诊断模型网络孪生体数据仿真、控制映射图 1 数字孪生网络的核心要素Fig. 1 The core elements of digital twin networks1) 数据是构建数字孪生网络的基石, 通过构建统一的数据共享仓库作为数字孪生网络的单一事实源, 高效存储物理网络的配置、拓扑、状态、日志、用户业务等历史和实时数据, 为网络孪生体提供数据支撑.2) 模型是数字孪生网络的能力源, 功能丰富的数据模型可通过灵活组合的方式创建多种模型实例, 服务于各种网络应用.3) 映射是物理网络实体通过网络孪生体的高保真可视化呈现, 是数字孪生网络区别于网络仿真系统的最典型特征.3 期孙滔等: 数字孪生网络(DTN): 概念、架构及关键技术5714) 交互是达成虚实同步的关键, 网络孪生体通过标准化的接口连接网络服务应用和物理网络实体, 完成对于物理网络的实时信息采集和控制, 并提供及时诊断和分析.基于四要素构建的网络孪生体可借助优化算法、管理方法、专家知识等对物理网络进行全生命周期的分析、诊断、仿真和控制, 实现物理网络与孪生网络的实时交互映射, 帮助网络以更低成本、更高效率、更小的现网影响部署各种网络应用, 助力网络实现极简化和智慧化运维.2.2 数字孪生网络架构根据数字孪生网络的定义和四个核心要素, 数字孪生网络可以设计为如图2所示的 “三层三域双闭环” 架构: 三层指构成数字孪生网络系统的物理网络层、孪生网络层和网络应用层; 三域指孪生网络层数据域、模型域和管理域, 分别对应数据共享仓库、服务映射模型和网络孪生体管理三个子系统;“双闭环” 是指孪生网络层内基于服务映射模型的“内闭环” 仿真和优化, 以及基于三层架构的 “外闭环” 对网络应用的控制、反馈和优化.1) 物理网络层. 物理实体网络中的各种网元通过孪生南向接口同网络孪生体交互网络数据和网络控制信息. 作为网络孪生体的实体对象, 物理网络既可以是蜂窝接入网、蜂窝核心网, 也可以是数据中心网络、园区企业网、工业物联网等; 既可以是单一网络域(例如, 无线或有线接入网、传输网、核心网、承载网等)子网, 也可以是端到端的跨域网络.既可以是网络域内所有的基础设施, 也可以是网络域内特定的基础设施(例如, 无线频谱资源、核心网用户面网元等).2) 孪生网络层. 孪生网络层是数字孪生网络系统的标志, 包含数据共享仓库、服务映射模型和网络孪生体管理三个关键子系统. 数据共享仓库子系统负责采集和存储各种网络数据, 并向数据映射模型子系统提供数据服务和统一接口; 服务映射模型子系统完成基于数据的建模, 为各种网络应用提供数据模型实例, 最大化网络业务的敏捷性和可编程性; 网络孪生体管理子系统负责网络孪生体的全生命周期管理以及可视化呈现.3) 网络应用层. 网络应用通过孪生北向接口向孪生网络层输入需求, 并通过模型化实例在孪生网络层进行业务的部署. 充分验证后, 孪生网络层通过南向接口将控制更新下发至物理实体网络. 网络运维和优化、网络可视化、意图验证、网络自动驾驶等网络创新技术及各种应用能够以更低的成本、更数据共享仓库迭代优化仿真验证网络孪生体管理网络应用层网络创新技术验证网络可视化意图验证网络管理网络维护和优化能力调用意图翻译数据管理数据服务功能模型数据存储用户业务运行状态网络配置基础模型数据采集数据采集服务映射模型网络规划流量建模安全建模故障诊断调度优化质量保障网元模型拓扑模型孪生网络层模型管理安全管理拓扑管理控制下发物理网络层规划建设维护优化运营...图 2 数字孪生网络架构Fig. 2 Digital twin network architecture572自 动 化 学 报47 卷高的效率和更小的现网业务影响实现快速部署.从数字孪生网络的架构可以看出, 数字孪生网络不局限于软件定义网络SDN的架构; 同平行网络相似, 数字孪生网络能够基于虚拟层的仿真, 实现SDN管理和控制层无法实现的复杂网络动态控制和优化. 表1进一步对比了数字孪生网络、软件定义网络和平行网络在物理对象、架构层次、虚实映射和分析方法等方面的区别.2.3 孪生网络层三大子系统2.3.1 数据共享仓库数据共享仓库通过南向接口采集并存储网络实体的各种配置和运行数据, 形成数字孪生网络的单一事实源, 为各种服务于应用的网络模型提供准确完备的数据, 包括但不限于网络配置信息、网络运行状态和用户业务数据等. 数据共享仓库主要有以下四项职责.1)数据采集. 完成网络数据的抽取、转换、加载, 以及清洗和加工, 便于大规模的数据实现高效分布式存储.2)数据存储. 结合网络数据的多样化特性, 利用多种数据存储技术, 完成海量网络数据的高效存储.3)数据服务. 为服务映射模型子系统提供包括快速检索、并发冲突、批量服务、统一接口等多种数据服务.4)数据管理. 完成数据的资产管理、安全管理、质量管理和元数据管理.作为数字孪生网络的基石, 数据共享仓库中的数据越完备越准确, 数据模型的丰富性和准确性就越高.2.3.2 服务映射模型服务映射模型包括基础模型和功能模型两部分.基础模型是指基于网元基本配置、环境信息、运行状态、链路拓扑等信息, 建立的对应于物理实体网络的网元模型和拓扑模型, 实现对物理网络的实时精确描述.功能模型是指针对特定的应用场景, 充分利用数据仓库中的网络数据, 建立的网络分析、仿真、诊断、预测、保障等各种数据模型. 功能模型可以通过多个维度构建和扩展: 按照网络类型构建, 可以有服务于单网络域(如移动接入网、传输网、核心网、承载网等)的模型或者服务于多网络域的模型; 按照功能类型划分, 可分为状态监测、流量分析、安全演练、故障诊断、质量保障等模型; 按照适用范围划分, 可以划分为通用模型和专用模型; 按照网络生命周期管理划分, 可分为规划、建设、维护、优化和运营等模型. 将多个维度结合在一起, 可以创建面向更为具体应用场景的数据模型, 例如, 可以建立园区网络核心交换机上的流量均衡优化模型, 通过模型实例服务于相应的网络应用.基础模型和功能模型通过实例或者实例的组合向上层网络应用提供服务, 最大化网络业务的敏捷性和可编程性. 同时, 模型实例需要通过程序驱动在虚拟孪生网元或网络拓扑中对预测、调度、配置、优化等目标完成充分的仿真和验证, 保证变更控制下发到物理网络时的有效性和可靠性.2.3.3 网络孪生体管理网络孪生体管理完成数字孪生网络的管理功能, 全生命周期记录, 可视化呈现和管控网络孪生体的各种元素, 包括拓扑管理、模型管理和安全管理.1)拓扑管理基于基础模型, 生成物理网络对应的虚拟拓扑, 并对拓扑进行多维度、多层次的可视化展现.2)模型管理服务于各种数据模型实例的创建、存储、更新以及模型组合、应用关联的管理. 同时,可视化地呈现模型实例的数据加载、模型仿真验证过程和结果.3)安全管理与共享数据仓库中的数据管理一起, 负责数字孪生网络数据和模型安全保障相关的鉴权、认证、授权、加密和完整性保护.表 1 DTN、SDN和平行网络对比Table 1 Comparison of DTN, SDN and parallel networks维度数字孪生网络 DTN软件定义网络 SDN平行网络物理对象各种类型的物理网元具备 SDN 特性的物理网元各种类型的物理网元架构层次物理层、孪生层和网络应用层物理层、控制层和管理层物理层、人工网络 + 计算实验层虚拟网络物理网络的孪生镜像, 孪生层通过统一数据建模构建N/A基于人工系统生成物理网络对应的人工网络;人工网络基于 SDN 架构构建虚实映射通过功能映射模型对网络应用进行仿真和迭代优化; 注重虚实映射的实时性和精确性N/A通过人工网络逼近物理网络; 更加强调计算实验和外在行为的干预分析方法基于孪生层的共享数据仓库, 充分利用大数据分析、人工智能技术, 通过模型化实例的迭代仿真, 实现网络的全局动态实时控制和优化只具备基本的网络控制和管理能力, 缺乏对于复杂网络的动态控制和优化能力通过对人工网络(以及人工数据)进行各种实验, 对网络行为进行分析和预测, 进而平行执行至物理网络并根据反馈迭代优化3 期孙滔等: 数字孪生网络(DTN): 概念、架构及关键技术5732.4 应用示例: 基于DTN实现意图网络意图网络[3]是可以使用 “用户意图” 进行管理的网络, 它能够识别和接收操作员或用户的意图,并根据用户意图自主地配置和调整自己, 从而实现预期的结果, 而无需用户指定用于如何实现结果的详细技术步骤. 图3所示为一种基于数字孪生网络架构实现意图网络的参考框架. 其中意图网络的基础设施对应于DTN架构中的物理网络层, 意图网络的配置验证、意图保障和自动修复等关键功能可基于孪生网络层的多种服务映射模型实现, 实时保障来自网络应用层的用户意图.意图输入网络应用层孪生网络层服务映射模型意图翻译自动修复调度优化故障诊断流量分析拓扑模型仿真验证配置验证共享数据仓库意图保障配置下发数据采集物理网络层网络基础设施图 3 基于DTN的意图网络框架Fig. 3 Intent network architecture1) 基于服务映射模型的配置验证. 用户意图经过意图翻译后, 生成大量物理网络能执行的网络配置, 如果将这些配置直接下发到物理网络上可能影响其他业务正常处理, 所产生的影响无法预估. 利用数字孪生网络的服务映射模型, 提前校验和模拟配置下发, 提前发现配置中的一些异常问题, 例如地址冲突、路由环路、路由不可达等. 验证配置既能满足用户业务意图, 又对其他已有业务没有影响后,再将配置下发到物理网络.2) 基于服务映射模型的意图保障和自动修复.通过数据采集将物理网络运行状态传递到孪生网络层的数据共享仓库, 服务映射模型不断验证用户意图是否被满足. 当发现网络偏离了用户业务意图,可利用AI等智能化技术做根因分析, 生成修复策略. 因为当前AI技术还不能保证修复策略完全可靠且能解决问题, 所以一般需要人工确认无误后再下发到物理网络, 拉低了故障修复效率. 利用数字孪生网络的服务映射模型先验证修复策略, 保证正确无误后, 再通过自动化配置模块下发到物理网络,既提高了运维效率, 又推动了AI技术的应用落地.综上, 意图网络可基于数字孪生网络架构, 实现网络配置的提前验证和用户业务意图的实时保障等关键功能, 这将有助于意图网络的有效落地部署.3 数字孪生网络的关键技术3.1 问题和挑战构建数字孪生网络系统面临以下主要问题和挑战:1) 兼容性问题. 网络中不同厂商设备的技术实现和支持的功能不一致, 因此建立面向全网络域的数据共享仓库, 设计适配异厂家设备的接口以进行统一数据采集和处理的难度较高.2) 建模难度大. 基于大规模网络数据, 数据建模既要保证模型功能的丰富性, 也需考虑模型的灵活性和可扩展性, 这些需求进一步加大了构建高效的、层次化的基础模型和功能模型的难度.3) 实时性挑战. 对于实时性要求较高的业务,模型仿真和验证在数字孪生网络上的处理会增加延迟, 所以模型的功能和流程需要增加多种网络应用场景下的处理机制; 同时, 实时性要求也会进一步增加系统的软硬件性能需求.4) 规模性难题. 通信网络通常网元数量多、覆盖地域广、服务时间长, 因此网络数字孪生体必将是一个规模庞大的复杂巨系统, 这会显著增加数据的采集和存储、模型的设计和运用等方面的复杂度,对系统的软硬件要求也会非常高.为了解决以上问题和挑战, 本文将基于第2.2节提出数字孪生网络参考架构, 拟采用目标驱动的网络数据采集、多元网络数据存储和服务、多维全生命周期网络建模、交互式可视化呈现、以及接口协议体系五大关键使能技术, 完成数字孪生网络系统的构建.3.2 目标驱动的网络数据采集数据采集是构建数据仓库的基础, 作为物理网络的数字镜像, 数据越全面、准确, 数字孪生网络越能高保真的还原物理网络. 数据采集应当采用目标驱动模式, 数据采集的类型、频率和方法以满足数字孪生网络的应用为目标, 兼具全面、高效的特征.当对特定网络应用进行数据建模时, 所需的数据均可以从网络孪生层的数据共享仓库中高效获取. 以目标应用为驱动, 只有全面、高效地采集模型所需数据, 才能构建精准数据模型, 为目标应用提供良好服务.网络数据采集方式有很多, 例如技术成熟、应用广泛的SNMP (Simple network management protocol)、Netconf, 可采集原始码流的NetFlow、sFlow, 支持数据源端推送模式的网络遥测(Net-work telemetry)等; 不同的数据采集方案具备不同574自 动 化 学 报47 卷。
电力英语专业词汇中英文

AA.B.C极密度继电器(第二报警值)A.B.C极密度继电器(第一报警值)A.B.C极主储压器漏氮指示器Indicator for N2安(培) ampere (A)安全边界 safety boundaries安全标志 safety mark安全标准 safety standard安全操作规程safety operation specifications安全措施 safety measure / safety action安全电压 safety voltage安全阀 relief valve / safety valve 安全阀打开 Safety valve opening安全防护技术要求 safeguarding specifications 安全分析报告 safety analysis report安全工程(学) safety engineering安全工作压力 safe working pressure 安全管理 safety management安全技术措施 safety technical steps (measurement))安全技术规程 safety technical regulation安全距离 safe distance安全可靠运行safe and reliable operation安全认证 safety certification安全色 safety color安全设[措]施 maintenance prevention安全生产 safety in production安全特低电压safety extra-low voltage安全限度 safe limit安全性 safety安全要求 safety requirement安全裕度 safety margin安全运行safe and reliable operation / safe operation安全责任制system of safety responsibility安全注意事项 safety precautions安匝 ampere-turns安装 erection / mounting / installation安装垫 mounting pad安装费用 installation cost安装和使用条件 condition of installation and use安装和维护erection and maintenance 安装结构 mounting structure安装结构或间距 mounting structure or spacing安装竣工检验 final installation inspection安装孔 fixing hole安装面 mounting face安装平面 mounting plane安装使用说明书 instructions for installation & operation安装说明 mounting instruction安装条件 mounting conditions安装图 assembly drawing安装有…… be installed / be fitted with氨气检漏 ammonia sniffing鞍型端子 saddle terminal按钮 push-button按钮开关 push button actuator按生产要素分配 distribution based on production factors按照 in accordance with (to) / according to按指数衰减的直流恢复电压exponentially decaying d.c.recovery voltage盎斯-英寸 ounce-inch凹坑 pit奥氏体 austeniteB八小时工作制 8-hour duty巴(表压) bar (gauge pressure)扒钉 anti-cheking iron扒渣 dross trap拔模斜度 draft把...拆开 take apart 把M安装在N上 fit M on N把M套在N上 fit M over N把M装(插)进N fit M into N把手 handle坝址 dam site白班 dayshift白点 fish eye / flake白金 white gold白金电极 platinum electrode白口铁 white cast iron白口铸铁 white cast iron白铁皮 white iron白噪声 white noise百分比抽样检验percent sampling inspection and test百分数 percentage百分数导电率 percent conductivity百分阻抗 percentage impedance摆动 wobble摆动焊 welding with weaving; weave bead welding摆动振动 wagging vibration摆脱电流 let-go current扳手 wrench / spanner斑点 spot搬运 handling板材 sheets板规(靠模) plate gauge (shaping plate)板坯 slab板条箱(包装用) crate板牙 screw plate / die-block半波 half-wave / half-cycle / loop 半波持续时间 loop duration 半成品 semi-finished product半打(六个) half a dozen半导体 semiconductor半导体层 semiconducting layer半干法 semi-dry method半个正弦波 a half sine wave半个周波 one-half cycle半极 half a pole半控 half control半年度检验 semiannual inspection and test半衰期 half-life半小时 half an hour半硬钢 half-hard steel半圆棒 half round bar半自动 semi-automatic半自动的 semi-automatic半自动焊 semi-automatic welding 伴随 accompany棒料 billet棒形绝缘子 rod insulator包封 encapsulating包封胶 encapsulating compound包覆导体 clad conductor包含体 inclusion body包括 include / comprise / contain 包络线 envelope curve包铅金属 lead coated metal包税区 bonded area包装 package / packing包装标志 packing mark包装标准 packing standard包装箱 packing box / packaging case 饱和saturation饱和磁化强度saturation magnetization饱和度 degree of saturation饱和效应 saturation effect饱和因数 saturation factor保持 hold保持继电器keep relay保持经济适度快速增长 maintain an appropriate rapid economic growth 保持在合闸位置 be held in closed position保持至少5分钟 at least maintain for 5 min保护电抗器 protective reactor保护电力间隙 protection power gap 保护电路 protective circuit保护断路器 back-up circuit breaker/ protection circuit breaker保护范围 protective range保护火花间隙 protective spark gap 保护继电器 protective relay保护开关back-up switch / protection switch保护水平 protection level保护用互感器protective transformer保护装置protective equipment (device)保护装置的保护水平protection level of a protective device保护装置的保护因数protection factor of a protective device保留垫板 fusible (permanent) backing保留指数 retention index保税区 bonded area 保温材料adiabator / thermal insulation material保温层 lagging / thermal insulation 保温加热器 temperature-keeping heater保温冒口 insulated feeder保温温度 holding temperature保险 insurance保险阀 lock valve保险公司 insurance company保险丝 fuse / fuse wire保证 ensure / assure / guarantee保证国家的长治久安guarantee China’s long-term stability保证社会公共需要 guarantee social needs报废 riscard / refuse / scrap报废品 scrapped product报告 report报告编号 reference of report number 报警 alarm报批for approval爆裂 rupture爆破片 bursting disks爆破片的误爆破unintentional rupture of bursting disk爆破压力 rupture pressure爆炸性气体 explosive gases杯状纵磁结构cup-shaped axial magnetic structure备份 backup备件 spare parts备料场charging area / charge make-up area备忘录 memorandum (-book)备用 prepared for use 备用的辅助开关spare auxiliary switch备用面板 blank panel备有…… be fitted with… / be equipped with …备注 Remarks背板 sheet backing背点 ant-apex背对背电容器组back-to-back capacitor bank背景情况 background背景噪声 background noise背景噪声水平 background noise level背砂 backing sand背压力 back pressure背压式汽轮机 back-pressure turbine 倍频器 frequency doubler被覆层coating layer / coat /coating被覆线 coated wire被审核方 auditee被试断路器 the test circuit breaker 焙烧baking本图 This drawing本图对应断路器处于下列状态 This diagram corresponds to the following conditions:本图供用户作液压柜-断路器本体(密度继电器、储压器漏氮指示器、接线盒)之间电缆联接参考用。
【国标】综合布线规范GB2000

建筑与建筑群综合布线工程系统设计规范Code for engineering design of generic cabling system for building and campusGBT/T 50311-2000主编部门:中华人民共和国信息产业部批准部门:中华人民共和国建设部施行日期:2000年8月1日中国计划出版社2000北京目次1.总则2.术语和符号3.系统设计4.系统指标5.工作区6.配线子系统7.干线子系统8.设备间9.管理10.建筑群子系统11.电气防护、接地及防火12.安装工艺要求本规范用词说明附:条文说明总则1.0.1为了适应经济建设高速发展和改革开放的社会需求,配合现代化城市建设和信息通信网向数字化、综合化、智能化方向发展,搞好建筑与建筑群的电话、数据、图文、图像等多媒体综合网络建设,制定本规范。
1.0.2本规范适用于新建、扩建、改建建筑与建筑群的综合布线系统工程设计。
1.0.3综合布线系统的设施及管线的建设,应纳入建筑与建筑群相应的规划之中。
1.0.4综合布线系统应与大楼办公自动化(OA)、通信自动化(CA)、楼宇自动化(BA)等系统统筹规划,按照各种信息的传输要求做到合理使用,并应符合相关的标准。
1.0.5工程设计时,应根据工程项目的性质、功能、环境条件和近、远用户要求、进行综合布线系统设施和管线的设计。
工程设计施工必须保证综合布线系统的质量和安全,考虑施工和维护方便,做到技术先进,经济合理。
1.0.6工程设计中必须选用符合国家有关技术标准的定型产品。
未经国家认可的产品质量监督检验机构鉴定合格的设备及主要材料,不得在工程中使用。
1.0.7综合布线系统的工程设计。
除应符合本规范外,尚应符合国家现行的相关强制性标准的规定。
术语和符号2.1术语2.1.1建筑与建筑群综合布线系统generic cabling system for building and campus建筑物或建筑群内的传输网络。
综合布线术语
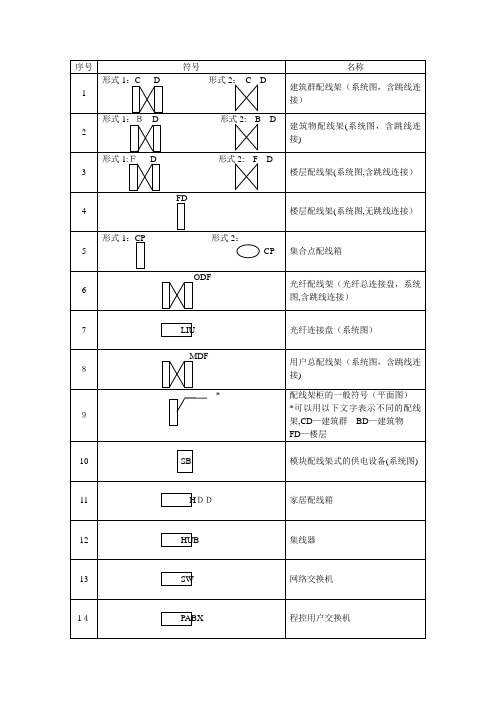
布线施工专用术语和词汇在局域网布线与施工过程中,通常会涉及到一些专用术语和词汇。
为了理解这些术语和词汇,本节先对有关的术语和词汇进行必要的解释和说明。
1、综合布线系统(PDS,Premises Distribution System):也称开放式布线系统(Ope nCabling System),是一种在建筑物和建筑群中综合布线的网络系统。
它把建筑物内部的语音交换设备、智能数据处理设备及其他数据通信设施相互连结起来,并通过必要的设备同建筑物外部数据网络或电话线路相连,是由通信电缆、光缆和各种连接设备等构成的,用以支持数据、图像、语音、视频信号通信的布线系统.综合布线系统包括3个子系统:水平布线于系统、垂直布线子系统和建筑群布线子系统。
通常也称作网络的水平干线、垂直干线和主干线。
2、建筑物与建筑群智能化系统:由通信系统、办公自动化系统、楼宇自动化系统(空调控制、给排水控制、照明控制等)、消防控制系统、综合布线系统等构成的弱电系统称作建筑物与3、建筑群布线子系统: 由建筑群配线架以及连接建筑群配线架和各建筑群智能化系统。
ﻫ建筑物配线架的电缆、光缆等组成的布线系统。
4、水平布线子系统:由楼层配线架,信息端口以及连接楼层配线架和信息端口的网络电缆、光缆等组成的布线系统.5、垂直布线子系统: 由建筑物配线架以及连接建筑物配线架和各楼层配线架的电缆,光缆等组成的布线系统.6、工作区和信息点:工作区是用户使用终端设备的地方,也就是客户机所在的房间,信息点是客户机与网络的连接点。
7、区域电缆:建筑上的一个概念。
这个概念将平面电缆分为两个部分。
在移动、添加和更换时无需变动整个平面电缆。
ﻫ8、集合点:一种互连设备,可将平面电缆分为两部分。
用于区域电缆连接。
9、转接点: 因型号或规格的不同或布线环境的要求进行电缆、光缆转接的地点。
ﻫ10、配线架:一种机架固定的面板(通常19英寸宽),内含连接硬件。
用于电缆组与设备之间的接插连接.11、楼层配线间:放置楼层配线架和通信设备的空间.12、建筑物配线间:放置建筑物配线架.通信设备和应用设备的空间。
建筑与建筑群综合布线工程系统设计规范

建造与建造群综合布线工程系统设计规范编号:GBT/T 50311-2000主编部门:中华人民共和国信息产业部批准部门:中华人民共和国建设部施行日期:2000 年8 月1 日1. 总则2. 术语和符号3. 系统设计4. 系统指标5. 工作区6. 配线子系统7. 干线子系统8. 设备间9. 管理10. 建造群子系统11. 电气防护、接地及防火12. 安装工艺要求本规范用词说明附:条文说明11.0.1 为了适应经济建设高速发展和改革开放的社会需求,配合现代化城市建设和信息通信网向数字化、综合化、智能化方向发展,搞好建造与建造群的电话、数据、图文、图象等多媒体综合网络建设,制定本规范。
1.0.2 本规范合用于新建、扩建、改建建造与建造群的综合布线系统工程设计。
1.0.3 综合布线系统的设施及管线的建设,应纳入建造与建造群相应的规划之中。
1.0.4 综合布线系统应与大楼办公自动化 (OA) 、通信自动化 (CA) 、楼宇自动化 (BA) 等系统统筹规划,按照各种信息的传输要求做到合理使用,并应符合相关的标准。
1.0.5 工程设计时,应根据工程项目的性质、功能、环境条件和近、远用户要求、进行综合布线系统设施和管线的设计。
工程设计施工必须保证综合布线系统的质量和安全,考虑施工和维护方便,做到技术先进,经济合理。
1.0.6 工程设计中必须选用符合国家有关技术标准的定型产品。
未经国家认可的产品质量监督检验机构鉴定合格的设备及主要材料,不得在工程中使用。
1.0.7 综合布线系统的工程设计。
除应符合本规范外,尚应符合国家现行的相关强制性标准的规定。
2.1.1 建造与建造群综合布线系统generic cabling system for building and campus建造物或者建造群内的传输网络。
它既使话音和数据通信设备、交换设备和其他信息管理系统彼此相连,又使这些设备与外部通信网络相连接。
它包括建造物到外部网络或者电话局线路上的连线点与工作区的话音或者数据终端之间的所有电缆及相关联的布线部件。
电信术语

术语或符号英文名中文名或解释ACR Attenuation to Crosstalk Ratio衷减—串音衰减比率ADU Asynchronous Data Unit异步数据单元ATM Asynchronous Transfer Mode异步传输模式BA Building Automatization楼宇自动化BD Building Distributor建筑物配线设备B-ISDN Broadband ISDN宽带ISDN10BASE-T10ABASE-T10Mbit/s基于2对线应用的以太网100BASE-TX100BASE-TX100Mbit/s基于2对线应用的以太网100BASE-T4100BASE-T4100Mbit/s基于4对线应用的以太网100BASE-T2100BASE-T2100Mbit/s基于2对线全双工应用的以太网1000BASE-T1000BASE-T1000Mbit/s基于4对线全双工应用的以太网100BASE-VG100BASE-VG100Mbit/s基于4对线应用的需求优先级网络CA Communication Automatization通信自动化64CAP64-Carrierless Amplitude Phase8*8无载波幅度和相位调制(也有16、4、2的)CD Campus Distrbutor建筑群配线设备CP Consolidation Point集合点CSMA/CD 1BASE5Carrier Sense Multiple Access withCollision Detection 1BASE5用碰撞检测方式的载波监听多路访问1Mbit/s基于粗电缆CSMA/CD10BASE-FCSMA/CD 10BASE-F CSMA/CD 10Mbit/s基于光纤CSMA/CDFOIRLCSMA/CD Fibre Optic Inter-Repeater Link CSMA/CD中继器之间的光纤链路CISPR Commission Internationale Speciale desPerturbations Radio国际无线电干革命扰特别委员会dB dB电信传输单位:分贝dBm dBm取1mW作基准值,以分贝表示的绝对功率电平dB mo dB mo取1mW作基准值,相对于零相对电平点,以分贝表示的信号绝对功率电平DCE Data Circuit Equipment数据电路设备DDN Digital Data Network数字数据网DSP Digital Signal Processing数字信号处理DTE Date Terminal Equipment数据终端设备ELA Electronic Industries Association美国电子工业协会ELFEXT Equal Level Far End Crosstalk等电平远端串音EMC Electro Magnetic Compatibility电磁兼容性EMI Electro Magnetic Interference电磁干扰ER Equipment Room设备间FC Fiber Channel光纤信道FD Floor Distributor楼层配线设备FDDI Fiber Distributed Data Interface光纤分布数据接口FEP[(CF(CF)-CF)(CF-CF)]FEP氟塑料树脂FEXT Far End Crosstalk远端串音f.f.s For further study进一步研究FR Frame Relay帧中继FTP Foil Twisted Pair金属箔对绞线FTTB Fiber To The Building光纤到大楼FTTD Fiber To The Desk光纤到桌面FTTH Fiber To The Home光纤到家庭FWHM Full Width Half Maximum谱线最大宽度GCS Generic Cabling System综合布线系统HIPPI High Perform Parallel Interface高性能并行接口HUB HUB集线器ISDN Integrated Building Distribution Network建筑物综合分布网络IBS Intelligent Building System智能大楼系统IDC Insulation Displacement Connection绝缘压穿连接IEC International Electrotechnical Commission国际电工技术委员会美国电气及电子工程师学会IEEE The Institute of Electrical and ElectroniceEngineersIP Internet Protocol因特网协议ISDN Integrated Services Digital Network综合业务数字网ISO Integrated Organization for Standardizafion国际标准化组织ITU-T International Telecommunication国际电信联盟-电信(前称CCITT)Union-Telecommunications(formerlyCCITT)LAN Local Area Network局域网LCF FDDI Low Cost Fiber FDDI低费用光纤FDDILSHF-FR Low Smoke Halogen Free-Flame Retardant低烟无卤阻燃LSLC Low Smoke Limited Combustible低烟阻燃LSCN Low Smoke Non-Combustible低烟非燃LSOH Low Smoke Zero Halogen低烟无卤MDNEXT Multiple Disturb NEXT多个干扰的近端串音MLT-3Multi-Level Transmission-33电平传输码MUTO Multi-User Telecommunications Outlet多用户信息插座N/A Not Applicable不适用的NEXT Near End Crosstalk近端串音N-ISDN Narrow ISDN窄带ISDNNRZ-I No Return Zero-Inverse非归零反转码OA Office Automatization办公自动化PAM5Pulse Amplitude Modulation 55级脉幅调制PBX Private Branch exchange用户电话交换机PDS Premises Distribution System建筑物布线系统PFA[(CF(OR)-CF)(CF-CF)]PFA氟塑料树脂PMD Physical Layer Medium Dependent依赖于物理层模式PSELFEXT POWER Sum ELFEXT等电平远端串扰功率和PSNEXT Power Sum NEXT近端串扰功率和PSPDN Packet Switched Public Data Network公众分组交换数据网RF Radio Frequency射频SC Subscriber Connector(Optical Fiber)用户连接器(光纤)SC-D Subscriber Connector-Dual(Optical Fiber)双联用户连接器(光纤)SCS Structured Cabling System结构化布线系统SDU Synchronous Data Unit同步数据单元SM FDDI Single- Mode FDDI单模FDDISFTP Shielded Foil Twisted Pair屏蔽金属箔对绞线STP Shielded Twisted Pair屏蔽对绞线TIA Telecommunications Industry Association美国电信工业协会TO Telecommunications Outlet信息插座(电信引出端)Token Ring4Mbit/sToken Ring 4Mbit/s令牌环路4Mbit/sToken Ring16Mbit/sToken Ring 16Mbit/s令牌环路16Mbit.sTP Transition Point转接点TP-PMD/C DDI Twisted Pair-Physical Layer MediumDependent/cable Distributed Data Interface依赖对绞线介质的传送模式/或称铜缆分布数据接口UL Underwriters Laboratories美国保险商实验所安全标准UNI User Network Interface用户网络侧接口UPS Uninterrupted Power System不间断电源系统UTP Unshielded Twisted Pair非屏蔽对绞线VOD Video on Demand视像点播Vr.m.s Vroot.mean.square电压有效值WAN Wide Area Network广域网电信业相关术语2008-11-07 11:03增值业务运营中心Value-added Business Operations Center 注意operation需用复数运营总监Director of OperationChief Operation Director 是首席运营官,习惯上中文的“总监”相当于Director,而不是首席XX 官。
数学专有名词英文

数学专业英语词汇英汉对照1 概率论与数理统计词汇英汉对照表Aabsolute value 绝对值accept 接受acceptable region 接受域additivity 可加性adjusted 调整的alternative hypothesis 对立假设analysis 分析analysis of covariance 协方差分析analysis of variance 方差分析arithmetic mean 算术平均值association 相关性assumption 假设assumption checking 假设检验availability 有效度average 均值Bbalanced 平衡的band 带宽bar chart 条形图beta-distribution 贝塔分布between groups 组间的bias 偏倚binomial distribution 二项分布binomial test 二项检验Ccalculate 计算case 个案category 类别center of gravity 重心central tendency 中心趋势chi-square distribution 卡方分布chi-square test 卡方检验classify 分类cluster analysis 聚类分析coefficient 系数coefficient of correlation 相关系数collinearity 共线性column 列compare 比较comparison 对照components 构成,分量compound 复合的confidence interval 置信区间consistency 一致性constant 常数continuous variable 连续变量control charts 控制图correlation 相关covariance 协方差covariance matrix 协方差矩阵critical point 临界点critical value 临界值crosstab 列联表cubic 三次的,立方的cubic term 三次项cumulative distribution function 累加分布函数curve estimation 曲线估计Ddata 数据default 默认的definition 定义deleted residual 剔除残差density function 密度函数dependent variable 因变量description 描述design of experiment 试验设计deviations 差异df.(degree of freedom) 自由度diagnostic 诊断dimension 维discrete variable 离散变量discriminant function 判别函数discriminatory analysis 判别分析distance 距离distribution 分布D-optimal design D-优化设计Eeaqual 相等effects of interaction 交互效应efficiency 有效性eigenvalue 特征值equal size 等含量equation 方程error 误差estimate 估计estimation of parameters 参数估计estimations 估计量evaluate 衡量exact value 精确值expectation 期望expected value 期望值exponential 指数的exponential distributon 指数分布extreme value 极值Ffactor 因素,因子factor analysis 因子分析factor score 因子得分factorial designs 析因设计factorial experiment 析因试验fit 拟合fitted line 拟合线fitted value 拟合值fixed model 固定模型fixed variable 固定变量fractional factorial design 部分析因设计frequency 频数F-test F检验full factorial design 完全析因设计function 函数Ggamma distribution 伽玛分布geometric mean 几何均值group 组Hharmomic mean 调和均值heterogeneity 不齐性histogram 直方图homogeneity 齐性homogeneity of variance 方差齐性hypothesis 假设hypothesis test 假设检验Iindependence 独立independent variable 自变量independent-samples 独立样本index 指数index of correlation 相关指数interaction 交互作用interclass correlation 组内相关interval estimate 区间估计intraclass correlation 组间相关inverse 倒数的iterate 迭代Kkernal 核Kolmogorov-Smirnov test 柯尔莫哥洛夫-斯米诺夫检验kurtosis 峰度Llarge sample problem 大样本问题layer 层least-significant difference 最小显著差数least-square estimation 最小二乘估计least-square method 最小二乘法level 水平level of significance 显著性水平leverage value 中心化杠杆值life 寿命life test 寿命试验likelihood function 似然函数likelihood ratio test 似然比检验linear 线性的linear estimator 线性估计linear model 线性模型linear regression 线性回归linear relation 线性关系linear term 线性项logarithmic 对数的logarithms 对数logistic 逻辑的lost function 损失函数Mmain effect 主效应matrix 矩阵maximum 最大值maximum likelihood estimation 极大似然估计mean squared deviation(MSD) 均方差mean sum of square 均方和measure 衡量media 中位数M-estimator M估计minimum 最小值missing values 缺失值mixed model 混合模型mode 众数model 模型Monte Carle method 蒙特卡罗法moving average 移动平均值multicollinearity 多元共线性multiple comparison 多重比较multiple correlation 多重相关multiple correlation coefficient 复相关系数multiple correlation coefficient 多元相关系数multiple regression analysis 多元回归分析multiple regression equation 多元回归方程multiple response 多响应multivariate analysis 多元分析Nnegative relationship 负相关nonadditively 不可加性nonlinear 非线性nonlinear regression 非线性回归noparametric tests 非参数检验normal distribution 正态分布null hypothesis 零假设number of cases 个案数Oone-sample 单样本one-tailed test 单侧检验one-way ANOVA 单向方差分析one-way classification 单向分类optimal 优化的optimum allocation 最优配制order 排序order statistics 次序统计量origin 原点orthogonal 正交的outliers 异常值Ppaired observations 成对观测数据paired-sample 成对样本parameter 参数parameter estimation 参数估计partial correlation 偏相关partial correlation coefficient 偏相关系数partial regression coefficient 偏回归系数percent 百分数percentiles 百分位数pie chart 饼图point estimate 点估计poisson distribution 泊松分布polynomial curve 多项式曲线polynomial regression 多项式回归polynomials 多项式positive relationship 正相关power 幂P-P plot P-P概率图predict 预测predicted value 预测值prediction intervals 预测区间principal component analysis 主成分分析proability 概率probability density function 概率密度函数probit analysis 概率分析proportion 比例Qqadratic 二次的Q-Q plot Q-Q概率图quadratic term 二次项quality control 质量控制quantitative 数量的,度量的quartiles 四分位数Rrandom 随机的random number 随机数random number 随机数random sampling 随机取样random seed 随机数种子random variable 随机变量randomization 随机化range 极差rank 秩rank correlation 秩相关rank statistic 秩统计量regression analysis 回归分析regression coefficient 回归系数regression line 回归线reject 拒绝rejection region 拒绝域relationship 关系reliability 可靠性repeated 重复的report 报告,报表residual 残差residual sum of squares 剩余平方和response 响应risk function 风险函数robustness 稳健性root mean square 标准差row 行run 游程run test 游程检验Ssample 样本sample size 样本容量sample space 样本空间sampling 取样sampling inspection 抽样检验scatter chart 散点图S-curve S形曲线separately 单独地sets 集合sign test 符号检验significance 显著性significance level 显著性水平significance testing 显著性检验significant 显著的,有效的significant digits 有效数字skewed distribution 偏态分布skewness 偏度small sample problem 小样本问题smooth 平滑sort 排序soruces of variation 方差来源space 空间spread 扩展square 平方standard deviation 标准离差standard error of mean 均值的标准误差standardization 标准化standardize 标准化statistic 统计量statistical quality control 统计质量控制std. residual 标准残差stepwise regression analysis 逐步回归stimulus 刺激strong assumption 强假设stud. deleted residual 学生化剔除残差stud. residual 学生化残差subsamples 次级样本sufficient statistic 充分统计量sum 和sum of squares 平方和summary 概括,综述Ttable 表t-distribution t分布test 检验test criterion 检验判据test for linearity 线性检验test of goodness of fit 拟合优度检验test of homogeneity 齐性检验test of independence 独立性检验test rules 检验法则test statistics 检验统计量testing function 检验函数time series 时间序列tolerance limits 容许限total 总共,和transformation 转换treatment 处理trimmed mean 截尾均值true value 真值t-test t检验two-tailed test 双侧检验Uunbalanced 不平衡的unbiased estimation 无偏估计unbiasedness 无偏性uniform distribution 均匀分布Vvalue of estimator 估计值variable 变量variance 方差variance components 方差分量variance ratio 方差比various 不同的vector 向量Wweight 加权,权重weighted average 加权平均值within groups 组内的ZZ score Z分数2. 最优化方法词汇英汉对照表Aactive constraint 活动约束active set method 活动集法analytic gradient 解析梯度approximate 近似arbitrary 强制性的argument 变量attainment factor 达到因子Bbandwidth 带宽be equivalent to 等价于best-fit 最佳拟合bound 边界Ccoefficient 系数complex-value 复数值component 分量constant 常数constrained 有约束的constraint 约束constraint function 约束函数continuous 连续的converge 收敛cubic polynomial interpolation method 三次多项式插值法curve-fitting 曲线拟合Ddata-fitting 数据拟合default 默认的,默认的define 定义diagonal 对角的direct search method 直接搜索法direction of search 搜索方向discontinuous 不连续Eeigenvalue 特征值empty matrix 空矩阵equality 等式exceeded 溢出的Ffeasible 可行的feasible solution 可行解finite-difference 有限差分first-order 一阶GGauss-Newton method 高斯-牛顿法goal attainment problem 目标达到问题gradient 梯度gradient method 梯度法Hhandle 句柄Hessian matrix 海色矩阵Iindependent variables 独立变量inequality 不等式infeasibility 不可行性infeasible 不可行的initial feasible solution 初始可行解initialize 初始化inverse 逆invoke 激活iteration 迭代iteration 迭代JJacobian 雅可比矩阵LLagrange multiplier 拉格朗日乘子large-scale 大型的least square 最小二乘least squares sense 最小二乘意义上的Levenberg-Marquardt method 列文伯格-马夸尔特法line search 一维搜索linear 线性的linear equality constraints 线性等式约束linear programming problem 线性规划问题local solution 局部解Mmedium-scale 中型的minimize 最小化mixed quadratic and cubic polynomial interpolation and extrapolation method 混合二次、三次多项式内插、外插法multiobjective 多目标的Nnonlinear 非线性的norm 范数Oobjective function 目标函数observed data 测量数据optimization routine 优化过程optimize 优化optimizer 求解器over-determined system 超定系统Pparameter 参数partial derivatives 偏导数polynomial interpolation method 多项式插值法Qquadratic 二次的quadratic interpolation method 二次内插法quadratic programming 二次规划Rreal-value 实数值residuals 残差robust 稳健的robustness 稳健性,鲁棒性Sscalar 标量semi-infinitely problem 半无限问题Sequential Quadratic Programming method 序列二次规划法simplex search method 单纯形法solution 解sparse matrix 稀疏矩阵sparsity pattern 稀疏模式sparsity structure 稀疏结构starting point 初始点stationary point 驻点step length 步长subspace trust region method 子空间置信域法sum-of-squares 平方和symmetric matrix 对称矩阵Ttermination message 终止信息termination tolerance 终止容限the exit condition 退出条件the method of steepest descent 最速下降法transpose 转置Uunconstrained 无约束的under-determined system 负定系统Vvariable 变量vector 矢量Wweighting matrix 加权矩阵3 样条词汇英汉对照表Aapproximation 逼近array 数组a spline in b-form/b-spline b样条a spline of polynomial piece /ppform spline 分段多项式样条Bbivariate spline function 二元样条函数break/breaks 断点Ccoefficient/coefficients 系数cubic interpolation 三次插值/三次内插cubic polynomial 三次多项式cubic smoothing spline 三次平滑样条cubic spline 三次样条cubic spline interpolation 三次样条插值/三次样条内插curve 曲线Ddegree of freedom 自由度dimension 维数end conditions 约束条件Iinput argument 输入参数interpolation 插值/内插interval 取值区间Kknot/knots 节点Lleast-squares approximation 最小二乘拟合Mmultiplicity 重次multivariate function 多元函数Ooptional argument 可选参数order 阶次output argument 输出参数Ppoint/points 数据点rational spline 有理样条rounding error 舍入误差(相对误差)Sscalar 标量sequence 数列(数组)spline 样条spline approximation 样条逼近/样条拟合spline function 样条函数spline curve 样条曲线spline interpolation 样条插值/样条内插spline surface 样条曲面smoothing spline 平滑样条Ttolerance 允许精度Uunivariate function 一元函数Vvector 向量weight/weights 权重4 偏微分方程数值解词汇英汉对照表Aabsolute error 绝对误差absolute tolerance 绝对容限adaptive mesh 适应性网格Bboundary condition 边界条件Ccontour plot 等值线图converge 收敛coordinate 坐标系Ddecomposed 分解的decomposed geometry matrix 分解几何矩阵diagonal matrix 对角矩阵Dirichlet boundary conditionsDirichlet边界条件eigenvalue 特征值elliptic 椭圆形的error estimate 误差估计exact solution 精确解Ggeneralized Neumann boundary condition 推广的Neumann边界条件geometry 几何形状geometry description matrix 几何描述矩阵geometry matrix 几何矩阵graphical user interface(GUI)图形用户界面Hhyperbolic 双曲线的Iinitial mesh 初始网格Jjiggle 微调LLagrange multipliers 拉格朗日乘子Laplace equation 拉普拉斯方程linear interpolation 线性插值loop 循环Mmachine precision 机器精度mixed boundary condition 混合边界条件NNeuman boundary condition Neuman边界条件node point 节点nonlinear solver 非线性求解器normal vector 法向量PParabolic 抛物线型的partial differential equation 偏微分方程plane strain 平面应变plane stress 平面应力Poisson’s equation 泊松方程polygon 多边形positive definite 正定Qquality 质量Rrefined triangular mesh 加密的三角形网格relative tolerance 相对容限relative tolerance 相对容限residual 残差residual norm 残差范数Ssingular 奇异的。
PARALLEL AND DISTRIBUTED SIMULATION SYSTEMS

Proceedings of the 2001 Winter Simulation ConferenceB. A. Peters, J. S. Smith, D. J. Medeiros, and M. W. Rohrer, eds.ABSTRACTOriginating from basic research conducted in the 1970’s and 1980’s, the parallel and distributed simulation field has ma-tured over the last few decades. Today, operational systems have been fielded for applications such as military training, analysis of communication networks, and air traffic control systems, to mention a few. This tutorial gives an overview of technologies to distribute the execution of simulation pro-grams over multiple computer systems. Particular emphasis is placed on synchronization (also called time management) algorithms as well as data distribution techniques.1 INTRODUCTIONParallel and distributed simulation is concerned with issues introduced by distributing the execution of a discrete event simulation program over multiple computers. Parallel dis-crete event simulation is concerned with execution on mul-tiprocessor computing platforms containing multiple cen-tral processing units (CPUs) that interact frequently, e.g., thousands of times per second. Distributed simulation is concerned with the execution of simulations on loosely coupled systems where interactions take much more time, e.g., milliseconds or more, and occur less often. It includes execution on geographically distributed computers inter-connected via a wide area network such as the Internet. In both cases the execution of a single simulation model, per-haps composed of several simulation programs, is distrib-uted over multiple computers.There are two principal categories of simulations of concern here. The first are simulations primarily used for analysis, e.g., to evaluate alternate designs or control poli-cies of a complex system, e.g., an air traffic network. Here the principal goal is to compute results of the simulation as quickly as possible in order to improve the effectiveness of the simulation tool. A related application is to use simula-tions to evaluate alternate courses of action, e.g., to evaluate different control actions imposed on an air traffic network in order to reduce delays induced by inclement weather in one portion of the air space. Use of simulations to manage on-going processes is referred to as on-line simulation.The second type of simulation of interest here are those used to create virtual environments into which hu-mans and/or hardware devices are embedded. Such envi-ronments are widely used for training, entertainment (e.g., video games), and test of evaluation of devices. Virtual environments have been used extensively to train military personnel because they provide a much safer, more cost effective, and environmentally friendlier approach to train-ing than field exercises.Parallel and distributed simulation systems can provide substantial benefit to these applications in several ways: • Execution times of analytic simulations can be re-duced by subdividing a large simulation computa-tion into many sub-computations that can executeconcurrently. One can reduce the execution timeby up to a factor equal to the number of proces-sors that are used. This may be important simplybecause the simulation takes a long time to exe-cute, e.g., simulations of communication networkscontaining tens of thousands of nodes may requiredays or weeks for a single run.• Very fast executions are needed for on-line simu-lations because there is often very little timeavailable to make important decisions. In manycases, simulation results must be produced in sec-onds in order for simulation results to be useful.Again, parallel simulation provides a means to re-duce execution time.• Simulations used for virtual environments must execute in real time, i.e., the simulator must beable to simulate a second of activity in a second ofwallclock time so that the virtual environment ap-pears realistic in that it evolves as rapidly as theactual system. Distributing the execution of thesimulation across multiple processors can help toachieve this property. Ideally, scalable executioncan be obtained whereby the distributed simula-tion continues to run in real time as the system be-PARALLEL AND DISTRIBUTED SIMULATION SYSTEMSRichard M. FujimotoCollege of ComputingGeorgia Institute of TechnologyAtlanta, GA 30332-0280, U.S.A.ing simulated and the number of processors areincreased in proportion.• Distributed simulation techniques can be used to create virtual environments that are geographi-cally distributed, enabling one to allow humansand/or devices to interact as if they were co-located. Such distributed virtual environmentshave obvious benefits in terms of convenienceand reduced travel costs.• Distributed simulation can simplify integrating simulators that execute on machines from differentmanufacturers. For example, flight simulators fordifferent types of aircraft may have been developedon different architectures. Rather than porting theseprograms to a single computer, it may be more costeffective to “hook together” the existing simulators,each executing on a different computer, to create anew virtual environment.• Another potential benefit of utilizing multiple processors is increased tolerance to failures. If oneprocessor fails, it may be possible for other proc-essors to continue the simulation provided criticalelements do not reside on the failed processors.Work in parallel and distributed simulation systems has taken place in three, largely separate research communities. The first is the high performance computing community which was concerned primarily with speeding up the execu-tion of simulation programs by distributing their execution over multiple CPUs. Early work in synchronization algo-rithms dates back to the late 1970’s with seminal work by Chandy and Misra (1978), and Bryant (1977) (among oth-ers) who are credited with first formulating the synchroniza-tion problem and developing the first algorithms to solve it. These algorithms are among a class of algorithms that are today referred to as conservative synchronization algo-rithms. A few years later, seminal work by Jefferson devel-oped the Time Warp algorithm (Jefferson 1985). Time Warp is important because it defined fundamental constructs widely used in a class of algorithms termed optimistic syn-chronization. Conservative and optimistic synchronization techniques form the core of a large body of work concerning parallel discrete event simulation techniques.The second community involved in the development of distributed simulation technology is the defense com-munity. While the high performance computing commu-nity was largely concerned with reducing execution time, the defense community was concerned with integrating separate training simulations in order to facilitate interop-erability and software reuse. The SIMNET (SIMulator NETworking) project (1983 to 1990) demonstrated the vi-ability of using distributed simulations to create virtual worlds for training soldiers in military engagements (Miller and Thorpe 1995). This lead to the development of a set of standards for interconnecting simulators known as the Distributed Interactive Simulation (DIS) standards (IEEE Std 1278.1-1995 1995). The 1990’s also saw the development of the Aggregate Level Simulation Protocol (ALSP) that applied the SIMNET concept of interoperabil-ity and model reuse to wargame simulations. ALSP and DIS have since been replaced by the High Level Architec-ture whose scope spans the broad range of defense simula-tions, including simulations for training, analysis, and test and evaluation of hardware components.A third track of research and development efforts arose from the Internet and computer gaming community. Work in this area can be traced back to a role-playing game called dungeons and dragons and a textual fantasy computer game called Adventure developed in the 1970’s. These soon gave way to MultiUser Dungeon (MUD) games in the 1980’s. Important additions such as sophisti-cated computer graphics helped created the video game in-dustry that is flourishing today.This paper is organized as follows. The next section is concerned with the execution of analytic simulations on parallel computers, with the principal goal of reducing execution time. Synchronization is a key problem that must be addressed. Section 3 is concerned with an ap-proach to parallel simulation known as time decomposi-tion. Section 4 is concerned with distributed virtual envi-ronments and issues such as data distribution that arise in that domain. This paper is an updated version of a previ-ous tutorial presented at this conference in (Fujimoto 1999b). A much more detailed treatment of this subject is presented in (Fujimoto 2000).2 TIME MANAGEMENTTime management is concerned with ensuring that the exe-cution of the parallel/distributed simulation is properly synchronized. This is particularly important in analytic simulations. Time management not only ensures that events are processed in a correct order, but also helps to ensure that repeated executions of a simulation with the same inputs produce exactly the same results. Currently, time management techniques such as those described here are typically not used in training simulations, where incor-rect event orderings and non-repeatable simulation execu-tions can usually be tolerated.Time management algorithms usually assume the simulation consists of a collection of logical processes (LPs) that communicate by exchanging timestamped mes-sages or events. The goal of the synchronization mecha-nism is to ensure that each LP processes events in time-stamp order; this requirement is referred to as the local causality constraint. It can be shown that if each LP ad-heres to the local causality constraint, execution of the simulation program on a parallel computer will produce exactly the same results as an execution on a sequential computer. An important side effect of this property is thatit is straightforward to ensure that the execution of the simulation is repeatable.Each LP can be viewed as a sequential discrete event simulation. This means each LP maintains some local state and a list of time stamped events that have been scheduled for this LP (including local events within the LP that it has scheduled for itself), but have not yet been processed. This pending event list must also include events sent to this LP from other LPs. The main processing loop of the LP repeat-edly removes the smallest time stamped event and processes it. Thus, the computation performed by an LP can be viewed as a sequence of event computations. Processing an event means zero or more state variables within the LP may be modified, and the LP may schedule additional events for itself or other LPs. Each LP maintains a simulation time clock that indicates the time stamp of the most recent event processed by the LP. Any event scheduled by an LP must have a time stamp at least as large as the LP’s simulation time clock when the event was scheduled.Time management algorithms can be classified as be-ing either conservative or optimistic. Each of these are de-scribed next.2.1 Conservative SynchronizationThe first synchronization algorithms were based on conser-vative approaches. This means the synchronization algo-rithm takes precautions to avoid violating the local causality constraint. For example, suppose an LP is at simulation time 10, and it is ready to process its next event with time stamp 15. But how does the LP know it won’t later receive an event from another LP with time stamp (say) 12? The synchronization algorithm must ensure no event with time stamp less than 15 can be later received before it can allow the time stamp 15 event to be processed.Thus, the principal task of any conservative protocol is to determine when it is “safe” to process an event, i.e., when can one guarantee no event containing a smaller time stamp will be later received by this LP. An LP cannot process an event until it has been guaranteed to be safe.2.1.1 First Generation AlgorithmsThe algorithms described in (Bryant 1977, Chandy and Misra 1978) were perhaps the first synchronization algo-rithms to be developed. They assume the topology indicat-ing which LPs send messages to which others is fixed and known prior to execution. It is assumed each LP sends messages with non-decreasing time stamps, and the com-munication network ensures that messages are received in the same order that they were sent. This guarantees that messages arriving on each incoming link of an LP arrive in timestamp order. This implies that the timestamp of the last message received on a link is a lower bound on the timestamp of any subsequent message that will later be re-ceived on that link.Messages arriving on each incoming link are stored in first-in-first-out order, which is also timestamp order be-cause of the above restriction. Local events scheduled within the LP can be handled by having a queue within each LP that holds messages sent by an LP to itself. Each link has a clock that is equal to the timestamp of the mes-sage at the front of that link’s queue if the queue contains a message, or the timestamp of the last received message if the queue is empty. The process repeatedly selects the link with the smallest clock and, if there is a message in that link’s queue, processes it. If the selected queue is empty, the process blocks. The LP never blocks on the queue con-taining messages it schedules for itself, however. This pro-tocol guarantees that each process will only process events in non-decreasing timestamp order.Although this approach ensures the local causality constraint is never violated, it is prone to deadlock. A cycle of empty links with small link clock values (e.g., smaller than any unprocessed message in the simulator) can occur, resulting in each process waiting for the next process in the cycle. If there are relatively few unproc-essed event messages compared to the number of links in the network, or if the unprocessed events become clus-tered in one portion of the network, deadlock may occur very frequently.Null messages are used to avoid deadlock. A null message with timestamp T null sent from LP A to LP B is a promise by LP A that it will not later send a message to LP B carrying a timestamp smaller than T null. Null messages do not correspond to any activity in the simulated system; they are defined purely for avoiding deadlock situations. Processes send null messages on each outgoing link after processing each event. A null message provides the re-ceiver with additional information that may be used to de-termine that other events are safe to process.Null messages are processed by each LP just like ordi-nary non-null messages, except no activity is simulated by the processing of a null message. In particular, processing a null message advances the simulation clock of the LP to the time stamp of the null message. However, no state variables are modified and no non-null messages are sent as the result of processing a null message.How does a process determine the timestamps of the null messages it sends? The clock value of each incoming link provides a lower bound on the timestamp of the next event that will be removed from that link’s buffer. When coupled with knowledge of the simulation performed by the process, this bound can be used to determine a lower bound on the timestamp of the next outgoing message on each out-put link. For example, if a queue server has a minimum ser-vice time of T, then the timestamp of any future departure event must be at least T units of simulated time larger than any arrival event that will be received in the future.Whenever a process finishes processing a null or non-null message, it sends a new null message on each outgo-ing link. The receiver of the null message can then com-pute new bounds on its outgoing links, send this informa-tion on to its neighbors, and so on. It can be shown that this algorithm avoids deadlock (Chandy and Misra 1978).The null message algorithm introduced a key property utilized by virtually all conservative synchronization algo-rithms: lookahead. If an LP is at simulation time T, and it can guarantee that any message it will send in the future will have a time stamp of at least T+L regardless of what mes-sages it may later receive, the LP is said to have a lookahead of L. As we just saw, lookahead is used to generate the time stamps of null messages. One constraint of the null message algorithm is it requires that no cycle among LPs exist con-taining zero lookahead, i.e., it is impossible for a sequence of messages to traverse the cycle, with each message sched-uling a new message with the same time stamp.2.1.2 Second Generation AlgorithmsThe main drawback with the null message algorithm is it may generate an excessive number of null messages. Con-sider a simulation containing two LPs. Suppose both are blocked, each has reached simulation time 100, and each has a lookahead equal to 1. Suppose the next unprocessed event in the simulation has a time stamp of 200. The null message algorithm will result in null messages exchanged between the LPs with time stamp 101, 102, 103, and so on. This will continue until the LPs advance to simulation time 200, when the event with time stamp 200 can now be proc-essed. A hundred null messages must be sent and proc-essed between the two LPs before the non-null message can be processed. This is clearly very inefficient. The problem becomes even more severe if there are many LPs.The principal problem is the algorithm uses only the current simulation time of each LP and lookahead to pre-dict the minimum time stamp of messages it could generate in the future. To solve this problem, we observe that the key piece of information that is required is the time stamp of the next unprocessed event within each LP. If the LPs could collectively recognize that this event has time stamp 200, all of the LPs could immediately advance from simu-lation time 100 to time 200. Thus, the time of the next event across the entire simulation provides critical information that avoids the “time creeping” problem in the null message algorithm. This idea is exploited in more ad-vanced synchronization algorithms.Another problem with the null message algorithm concerns the case where each LP can send messages to many other LPs. In the worst case, the LP topology is fully connected meaning each LP could send a message to any other. In this case, each LP must broadcast a null mes-sage to every other LP after processing each event. This also results in an excessive number of null messages.One early approach to solving these problems is an al-ternate algorithm that allows the computation to deadlock, but then detects and breaks it (Chandy and Misra 1981). The deadlock can be broken by observing that the mes-sage(s) containing the smallest timestamp is (are) always safe to process. Alternatively, one may use a distributed computation to compute lower bound information (not unlike the distributed computation using null messages de-scribed above) to enlarge the set of safe messages.Many other approaches have been developed. Some protocols use a synchronous execution where the computa-tion cycles between (i) determining which events are “safe’” to process, and (ii) processing those events. It is clear that the key step is determining the events that are safe to process each cycle. Each LP must determine a lower bound on the time stamp (LBTS) of messages it might later receive from other LPs. This can be deter-mined from a snapshot of the distributed computation as the minimum among:• the simulation time of the next event within each LP if the LP is blocked, or the current time of theLP if it is not blocked, plus the LP’s lookaheadand• the time stamp of any transient messages, i.e., any message that has been sent but has not yet beenreceived at its destination.A barrier synchronization can be used to obtain the snapshot. Transient messages can be “flushed” out of the system in order to account for their time stamps. If first-in-first-out communication channels are used, null messages can be sent through the channels to flush the channels, though as noted earlier, this may result in many null mes-sages. Alternatively, each LP can maintain a counter of the number of messages it has sent, and the number if has re-ceived. When the sum of the send and receive counters across all of the LPs are the same, and each LP has reached the barrier point, it is guaranteed that there are no more transient messages in the system. In practice, summing the counters can be combined with the computation for com-puting the global minimum value.To determine which events are safe, the distance be-tween LPs is sometimes used. This “distance” is the minimum amount of simulation time that must elapse for an event in one LP to directly or indirectly affect another LP, and can be used by an LP to determine bounds on the timestamp of future events it might receive from other LPs. This assumes it is known which LPs send messages to which other LPs. Full elaboration this technique is beyond the scope of the present discussion, however, these tech-niques and others are described in (Fujimoto 2000).Another thread of research in synchronization algo-rithms concerns relaxing ordering constraints in order to improve performance. Some approaches amount to simplyignoring out of order event processing (Sokol and Stucky 1990, Rao, et al. 1998). Use of time intervals, rather than precise time stamps, to encode uncertainty of temporal in-formation in order to improve the performance of time management algorithms have also been proposed (Fujimoto 1999a) (Beraldi and Nigro 2000). Use of causal order rather than time stamp order for distributed simula-tion applications has also been studied (Lee, et al. 2001).2.2 Optimistic SynchronizationIn contrast to conservative approaches that avoid violations of the local causality constraint, optimistic methods allow violations to occur, but are able to detect and recover from them. Optimistic approaches offer two important advan-tages over conservative techniques. First, they can exploit greater degrees of parallelism. If two events might affect each other, but the computations are such that they actually don’t, optimistic mechanisms can process the events con-currently, while conservative methods must sequentialize execution. Second, conservative mechanism generally rely on application specific information (e.g., distance between objects) in order to determine which events are safe to process. While optimistic mechanisms can execute more efficiently if they exploit such information, they are less reliant on such information for correct execution. This al-lows the synchronization mechanism to be more transpar-ent to the application program than conservative ap-proaches, simplifying software development. On the other hand, optimistic methods may require more overhead com-putations than conservative approaches, leading to certain performance degradations.The Time Warp mechanism (Jefferson 1985) is the most well known optimistic method. When an LP receives an event with timestamp smaller than one or more events it has already processed, it rolls back and reprocesses those events in timestamp order. Rolling back an event involves restoring the state of the LP to that which existed prior to processing the event (checkpoints are taken for this pur-pose), and “unsending” messages sent by the rolled back events. An elegant mechanism called anti-messages is provided to “unsend” messages.An anti-message is a duplicate copy of a previously sent message. Whenever an anti-message and its matching (positive) message are both stored in the same queue, the two are deleted (annihilated). To “unsend” a message, a process need only send the corresponding anti-message. If the matching positive message has already been processed, the receiver process is rolled back, possibly producing ad-ditional anti-messages. Using this recursive procedure all effects of the erroneous message will eventually be erased.Two problems remain to be solved before the above ap-proach can be viewed as a viable synchronization mecha-nism. First, certain computations, e.g., I/O operations, can-not be rolled back. Second, the computation will continually consume more and more memory resources because a his-tory (e.g., checkpoints) must be retained, even if no roll-backs occur; some mechanism is required to reclaim the memory used for this history information. Both problems are solved by global virtual time(GVT). GVT is a lower bound on the timestamp of any future rollback. GVT is computed by observing that rollbacks are caused by mes-sages arriving “in the past.” Therefore, the smallest time-stamp among unprocessed and partially processed messages gives a value for GVT. Once GVT has been computed, I/O operations occurring at simulated times older than GVT can be committed, and storage older than GVT (except one state vector for each LP) can be reclaimed.GVT computations are essentially the same as LBTS computations used in conservative algorithms. This is be-cause rollbacks result from receiving a message or anti-message in the LP’s past. Thus, GVT amounts to comput-ing a lower bound on the time stamp of future messages (or anti-messages) that may later be received.A pure Time Warp system can suffer from overly op-timistic execution, i.e., some LPs may advance too far ahead of others leading to excessive memory utilization and long rollbacks. Many other optimistic algorithms have been proposed to address these problems. Most attempt to limit the amount of optimism. An early technique involves using a sliding window of simulated time (Sokol and Stucky 1990). The window is defined as [GVT, GVT+W] where W is a user defined parameter. Only events with time stamp within this interval are eligible for processing. Another approach delays message sends until it is guaran-teed that the send will not be later rolled back, i.e., until GVT advances to the simulation time at which the event was scheduled. This eliminates the need for anti-messages and avoids cascaded rollbacks, i.e., a rollback resulting in the generation of additional rollbacks (Dickens and Rey-nolds 1990). A technique called direct cancellation is sometimes used to rapidly cancel incorrect messages, thereby helping to reduce overly optimistic execution (Fujimoto 1989, Zhang and Tropper 2001).Another problem with optimistic synchronization con-cerns the amount of memory that may be required to store history information. Several techniques have been devel-oped to address this problem. For example, one can roll back computations to reclaim memory resources (Jefferson 1990, Lin and Preiss 1991). State saving can be performed infrequently rather than after each event (Lin, et al. 1993, Palaniswamy and Wilsey 1993). The memory used by some state vectors can be reclaimed even though their time stamp is larger than GVT (Preiss and Loucks 1995).Early approaches to controlling Time Warp execution used user-defined parameters that had to be tuned to opti-mize performance. Later work has focused on adaptive approaches where the simulation executive automatically monitors the execution and adjusts control parameters to maximize performance. Examples of such adaptive controlmechanisms are described in (Ferscha 1995, Das and Fu-jimoto 1997), among others.Practical implementation of optimistic algorithms re-quires that one must be able to roll back all operations, or be able to postpone them until GVT advances past the simulation time of the operation. Care must be taken to ensure operations such as memory allocation and dealloca-tion are handled properly, e.g., one must be able to roll back these operations. Also, one must be able to roll back execution errors. This can be problematic in certain situa-tions, e.g., if an optimistic execution causes portions of the internal state of the Time Warp executive to be overwritten (Nicol and Liu 1997).Another approach to optimistic execution involves the use of reverse computation techniques rather than rollback (Carothers, et al. 1999). Undoing an event computation is accomplished by executing the inverse computation, e.g., to undo incrementing a state variable, the variable is in-stead decremented. The advantage of this technique is it avoids state saving, which may be both time consuming and require a large amount of memory. In (Carothers, et al. 1999) a reverse compiler is described to automatically generate inverse computations.2.3 Current State-of-the-ArtSynchronization is a well-studied area of research in the par-allel discrete event simulation field. There is no clear con-sensus concerning whether optimistic or conservative syn-chronization perform better; indeed, the optimal approach usually depends on the application. In general, if the appli-cation has good lookahead characteristics and programming the application to exploit this lookahead is not overly bur-densome, conservative approaches are the method of choice. Indeed, much research has been devoted to improving the lookahead of simulation applications, e.g., see (Deelman, et al. 2001). Otherwise, optimistic synchronization offers greater promise. Disadvantages of optimistic synchroniza-tion include the potentially large amount of memory that may be required, and the complexity of optimistic simula-tion executives. Techniques to reduce memory utilization further aggravate the complexity issue.Recently, synchronization algorithms have assumed an increased importance because of their use in the DoD High Level Architecture (HLA). Because the HLA is driven by the desire to reuse existing simulations, an important dis-advantage of optimistic synchronization in this context is the effort required to add state saving and other mechanism to enable the simulation to be rolled back.3 TIME PARALLEL SIMULATIONTime-parallel simulation methods have been developed for attacking specific simulation problems with well-defined objectives, e.g., measuring the loss rate of a finite capacity queue of an ATM multiplexer. Time-parallel algorithms divide the simulated time axis into intervals, and assign each interval to a different processor. This allows for mas-sively parallel execution because simulations often span long periods of simulated time.A central question that must be addressed by time-parallel simulators is ensuring the states computed at the “boundaries” of the time intervals match. Specifically, it is clear that the state computed at the end of the interval [T i-1,T i] must match the state at the beginning of interval [T i,T i+1]. Thus, this approach relies on being able to per-form the simulation corresponding to the ith interval with-out first completing the simulations of the preceding (i-1, i-2, ... 1) intervals.Because of the “state-matching” problem, time-parallel simulation is really more of a methodology for developing massively parallel algorithms for specific simulation prob-lems than a general approach for executing arbitrary dis-crete-event simulation models on parallel computers. Time-parallel algorithms are currently not as robust as space-parallel approaches because they rely on specific properties of the system being modeled, e.g., specification of the sys-tem’s behavior as recurrence equations and/or a relatively simple state descriptor. This approach is currently limited to a handful of applications, e.g., queuing networks, Petri nets, cache memories, and multiplexers in communication net-works. Space-parallel simulations offer greater flexibility and wider applicability, but concurrency is limited to the number of logical processes. In some cases, both time and space-parallelism can be used.One approach to solving the state matching problem is to have each processor guess the initial state of its simula-tion, and then simulate the system based on this guessed initial state (Lin and Lazowska 1991). In general, the initial state will not match the final state of the previous interval. After the interval simulators have completed, a “fix-up” computation is performed to account for the fact that the wrong initial state was used. This might be performed, for instance, by simply repeating the simulation, using the fi-nal state computed in the previous interval as the new ini-tial state. This “fix-up” process is repeated until the initial state of each interval matches the final state of the previous interval. In the worst case, N such iterations are required when there are N simulators. However, if the final state of each interval simulator is seldom dependent on the initial state, far fewer iterations will be needed.In (Heidelberger and Stone 1990) the above approach is proposed to simulate cache memories using a least-recently-used replacement policy. This approach is effec-tive for this application because the final state of the cache is not heavily dependent on the cache’s initial state. A variation on this approach devised in the context of simu-lating statistical multiplexers for asynchronous transfer mode (ATM) switches precomputes certain points in time where one can guarantee that a buffer overflow (full。
Fault-tolerant systems

we have applied several improvement: we
ideas. First, we use an algorithmic rent number of particles.
recombination of most particles. To study the kinetics of these large numbers of interacting particles, a full Monte Carlo simulation of their movements is needed. One of the main points of interest is computing the number of ions that escape from the high-energy electron tracks. To be able to simulate the movements of the positive ions and the thermalized initial spatial distribution obtain information by comparing electrons, an of these particles must be and
b Department of Physics and Astronomy, Vrije Universiteit, De Boelelaan 1081, 1081 HV Amsterdam, Netherlands
Abstract
Ion recombination in nonpolar liquids is an important problem in radiation chemistry. We have designed and implemented a parallel Monte Carlo simulation for this computationally intensive task on a network of workstations. The main problem with parallelizing this application is that the amount of work performed by each process decreases during execution, resulting in high communication overhead and load imbalances. We address this problem by dynamically adjusting the number of processors that are used. We have evaluated the performance of the parallel program on two systems, one using Ethernet and the other using Myrinet. On Ethernet, the program suffers from a large communication overhead. Using the Myrinet
DATA DISTRIBUTION SYSTEM AND DATA DISTRIBUTION MET

专利名称:DATA DISTRIBUTION SYSTEM AND DATADISTRIBUTION METHOD发明人:KAWABE KAZUHIDE,河邉 一秀申请号:JP特願平10-47496申请日:19980227公开号:JP特開平11-249984A公开日:19990917专利内容由知识产权出版社提供专利附图:摘要:PROBLEM TO BE SOLVED: To enable the configurational simplicity of the entire system, to reduce costs and to make a data storage hard disk small by receiving the data broadcasting of ground waves/satellite waves by a server PC and distributing it to eachclient PC. SOLUTION: In this data distribution system and this data distributing method which receive data broadcasting from ground waves and satellite waves, the system comprises a server PC 6 that receives the data broadcasting, a storage medium connected to the PC 6 and plural client PCs 10 to 13 which constitute a network together with the PC 6 and transmit and receive data of the data broadcasting and the PCs 10 to 13 activate receiving software and receive the data of the data broadcasting through the network.申请人:NEC CORP,日本電気株式会社地址:東京都港区芝五丁目7番1号国籍:JP代理人:山下 穣平更多信息请下载全文后查看。
RAID

RAID 1
RAID 1 is essentially a solution in which write operations mirror onto primary and secondary drives.
RAID 2
RAID 2 is no longer used. RAID 2 computes ECC (error correction code) information across stripes, but modern disk drives already store and compute ECC information across disk stripes.
RAID 30
RAID 30 combines RAID 0 and RAID 3 features. With RAID 30, data stripes across different disks (RAID 0) and a dedicated parity disk. This is also referred to as striping of dedicated parity arrays. RAID 30 requires a minimum of six disks to implement and can tolerate the loss of two disks, one per array. RAID 30 is typically used when the data consists of large files that are accessed sequentially, for example, in video streaming.
RAID 0
RAID 0 consists of simply striping data across multiple disk drives. Thus, RAID 0 can provide some performance advantages, but it does not provide redundancy or data protection.
自动向量化中基于数据依赖分析的循环分布算法

自动向量化中基于数据依赖分析的循环分布算法黄磊;姚远;侯永生;杨明【期刊名称】《计算机科学》【年(卷),期】2011(038)009【摘要】循环分布是开发向量化程序的一个有效的方法.但是由于程序中的数据相关性,当前的自动向量化编译器实现完全的循环分布非常困难.因此,当前的自动向量化编译器一般采用简单的循环分布方法.以数据依赖关系分析为基础,从有无依赖环的角度分析了程序中语句的向量化能力,提出了基于语句向量化识别的循环分布算法,并在自动向量化中加以实现.通过此方法,可以充分地分析语句或依赖环的向量化能力,最终采用循环分布,将可向量化的语句与不可向量化的语句分布在不同的循环中.该方法可以处理当前的自动向量化编译器无法向量化的循环,对一些语句间有依赖关系的循环可达到较好的效果.%Loop distribution is a useful method to vectorization programs;but because of the data dependence;it's very hard to completely achieve loop distribution in auto-vectorizatioa So;it's usually used easily loop distribution in current auto-vectorization compiler. Here;discussed a new loop distribution method based on identify the statement vectoriza tion;from the data dependence view;and achieved in current auto-vectorization compiler. By this method;we can com pletely analyse which statement can vectorize;which dependence cycle can vectorize;finally using loop distribution;the vectorization statements can and no-vector statements be distributed in different loops. This method can handle these loops which can't be vectorized by other auto-vectorization compilers;and have good effect for some loops which have complex dependence.【总页数】6页(P288-293)【作者】黄磊;姚远;侯永生;杨明【作者单位】解放军信息工程大学信息工程学院郑州450002;解放军信息工程大学信息工程学院郑州450002;解放军信息工程大学信息工程学院郑州450002;解放军信息工程大学信息工程学院郑州450002【正文语种】中文【中图分类】TP311【相关文献】1.传感器网络中基于域的分布式自动成簇算法研究 [J], 谢志军;钱江波2.基于龙芯3B的循环规约算法向量化研究 [J], 吴淅;黄章进;顾乃杰3.基于自动分析直方图灰度分布的数字图像阈值化算法 [J], 高春鸣;兰秋军4.α稳定分布下基于SSCA算法的低阶循环谱算法 [J],5.基于遗传算法和学习向量化网络的基因表达数据的阈值分析 [J], 刘珑龙;周西龙;刘雪峰因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1 Introduction
Parallelization and data distribution are two topics closely related when parallelizing loops for cache-coherent shared-memory parallel systems. In these systems, cache miss penalties can be signi cantly large and false sharing, invalidations and excessive data replication can have negative e ects in performance. In some cases, these e ects can easily o set any gain due to parallel execution. Most current shared-memory compilers choose a loop in each nest for parallelization, and it is interchanged as far out as data dependence analysis allows. Inner loops are strip-mined and blocked to exploit all possible data reuse in the processor cache. Iterations in each parallel loop are distributed across the parallel threads according to a xed scheme. Some compilers also ensure that each major data structure in the program is aligned on a cache line boundary and make the contiguous dimension of an array (i.e., the rst dimension in Fortran) an integer multiple of a cache line. This is useful to avoid false sharing of cache lines so that each processor works with complete cache lines.
Some researchers AL93] have focussed on better determining which loop to parallelize with the purpose of obtaining maximum parallelism while minimizing sharing of cache lines (true sharing). They analyze data and computation decomposition without regard to the original layout of the data structures. A more recent work AAL95] proposes to enhance spatial locality, reduce false sharing (access to di erent data items co-located on the same cache line) and con ict misses among accesses to the set of data assigned to each processor. This is done by applying some data transformations making data accessed by each processor contiguous in the shared address space. JE95] have also proposed algorithms to transform data layouts to improve memory performance; they analyze perprocess shared data accesses in parallel programs, identify data structures that are susceptible to false sharing and choose an appropriate layout transformation to reduce the number of false sharing misses. These data layout transformations require that all accesses to the arrays in the entire program use the new layout; programming languages (such as Fortran) can make these transformations difcult and the compiler has to guarantee that all possible accesses are updated accordingly and optimized. In the past years, other researchers have targeted their e orts to automatic data distribution for distributed-memory multiprocessors BCG+ 95, AGG+ 95, KK95, SSGC95], according to the array access patterns and parallel execution of operations within computationally intensive phases. The objective is to specify the mapping for the arrays used in these computational phases, and it can be either static or dynamic. In a static mapping, the layout of the arrays does not change during the execution of the program; in a dynamic mapping, remapping operations are performed in order to change the layout of arrays in di erent computational phases. A basic observation of this paper is that this technology developed for distributed memory compilers is useful for shared memory architectures in which each processor has access to a high-capacity private cache (for instance, 4 Mbyte in each processor of a R8000 SGI Power Challenge or between 512 Kbyte and 16 Mbyte in each processor of a R10000 SGI Power Challenge architecture SGI96]). In these systems, the cache behaves as an attraction local memory that stores data referenced by the processor. Trying to minimize true and false sharing reduces data motion through the interconnection network. The techniques we have developed represent the application of the owner computes rule, frequently used in distributed-memory systems, to shared-memory machines. In a parallel loop, a chuck of iterations is assigned to each processor. The execution of this chunk will bring any remote data to its cache. Notice that data remapping is implicitly done by the caching mechanism itself. We propose to parallelize loops taking into account the data that is stored in the private cache of each processor, either because it has been previously computed or fetched in other loops, or that needs to be stored in the cache because it will be useful in the following loops. PDDT keeps track of the array sections that are accessed during the execution of the di erent computational phases in an application in order to decide, with a global view, the parallelization strategy for each loop. This is done