seeds-evs-candidates-questionnaire
tpo32三篇托福阅读TOEFL原文译文题目答案译文背景知识

tpo32三篇托福阅读TOEFL原文译文题目答案译文背景知识阅读-1 (2)原文 (2)译文 (5)题目 (7)答案 (16)背景知识 (16)阅读-2 (25)原文 (25)译文 (28)题目 (31)答案 (40)背景知识 (41)阅读-3 (49)原文 (49)译文 (53)题目 (55)答案 (63)背景知识 (64)阅读-1原文Plant Colonization①Colonization is one way in which plants can change the ecology of a site. Colonization is a process with two components: invasion and survival. The rate at which a site is colonized by plants depends on both the rate at which individual organisms (seeds, spores, immature or mature individuals) arrive at the site and their success at becoming established and surviving. Success in colonization depends to a great extent on there being a site available for colonization – a safe site where disturbance by fire or by cutting down of trees has either removed competing species or reduced levels of competition and other negative interactions to a level at which the invading species can become established. For a given rate of invasion, colonization of a moist, fertile site is likely to be much more rapid than that of a dry, infertile site because of poor survival on the latter. A fertile, plowed field is rapidly invaded by a large variety of weeds, whereas a neighboring construction site from which the soil has been compacted or removed to expose a coarse, infertile parent material may remain virtually free of vegetation for many months or even years despite receiving the same input of seeds as the plowed field.②Both the rate of invasion and the rate of extinction vary greatly among different plant species. Pioneer species - those that occur only in the earliest stages of colonization -tend to have high rates of invasion because they produce very large numbers of reproductive propagules (seeds, spores, and so on) and because they have an efficient means of dispersal (normally, wind).③If colonizers produce short-lived reproductive propagules, they must produce very large numbers unless they have an efficient means of dispersal to suitable new habitats. Many plants depend on wind for dispersal and produce abundant quantities of small, relatively short-lived seeds to compensate for the fact that wind is not always a reliable means If reaching the appropriate type of habitat. Alternative strategies have evolved in some plants, such as those that produce fewer but larger seeds that are dispersed to suitable sites by birds or small mammals or those that produce long-lived seeds. Many forest plants seem to exhibit the latter adaptation, and viable seeds of pioneer species can be found in large numbers on some forest floors. For example, as many as 1,125 viable seeds per square meter were found in a 100-year-old Douglas fir/western hemlock forest in coastal British Columbia. Nearly all the seeds that had germinated from this seed bank were from pioneer species. The rapid colonization of such sites after disturbance is undoubtedly in part a reflection of the largeseed band on the forest floor.④An adaptation that is well developed in colonizing species is a high degree of variation in germination (the beginning of a seed’s growth). Seeds of a given species exhibit a wide range of germination dates, increasing the probability that at least some of the seeds will germinate during a period of favorable environmental conditions. This is particularly important for species that colonize an environment where there is no existing vegetation to ameliorate climatic extremes and in which there may be great climatic diversity.⑤Species succession in plant communities, i.e., the temporal sequence of appearance and disappearance of species is dependent on events occurring at different stages in the life history of a species. Variation in rates of invasion and growth plays an important role in determining patterns of succession, especially secondary succession. The species that are first to colonize a site are those that produce abundant seed that is distributed successfully to new sites. Such species generally grow rapidly and quickly dominate new sites, excluding other species with lower invasion and growth rates. The first community that occupies a disturbed area therefore may be composed of specie with the highest rate of invasion, whereas the community of the subsequent stage may consist of plants with similar survival ratesbut lower invasion rates.译文植物定居①定居是植物改变一个地点生态环境的一种方式。
Introduction to Artificial Intelli智慧树知到课后章节答案2023年

Introduction to Artificial Intelligence智慧树知到课后章节答案2023年下哈尔滨工程大学哈尔滨工程大学第一章测试1.All life has intelligence The following statements about intelligence arewrong()A:All life has intelligence B:Bacteria do not have intelligence C:At present,human intelligence is the highest level of nature D:From the perspective of life, intelligence is the basic ability of life to adapt to the natural world答案:Bacteria do not have intelligence2.Which of the following techniques is unsupervised learning in artificialintelligence?()A:Neural network B:Support vector machine C:Decision tree D:Clustering答案:Clustering3.To which period can the history of the development of artificial intelligencebe traced back?()A:1970s B:Late 19th century C:Early 21st century D:1950s答案:Late 19th century4.Which of the following fields does not belong to the scope of artificialintelligence application?()A:Aviation B:Medical C:Agriculture D:Finance答案:Aviation5.The first artificial neuron model in human history was the MP model,proposed by Hebb.()A:对 B:错答案:错6.Big data will bring considerable value in government public services, medicalservices, retail, manufacturing, and personal location services. ()A:错 B:对答案:对第二章测试1.Which of the following options is not human reason:()A:Value rationality B:Intellectual rationality C:Methodological rationalityD:Cognitive rationality答案:Intellectual rationality2.When did life begin? ()A:Between 10 billion and 4.5 billion years B:Between 13.8 billion years and10 billion years C:Between 4.5 billion and 3.5 billion years D:Before 13.8billion years答案:Between 4.5 billion and 3.5 billion years3.Which of the following statements is true regarding the philosophicalthinking about artificial intelligence?()A:Philosophical thinking has hindered the progress of artificial intelligence.B:Philosophical thinking has contributed to the development of artificialintelligence. C:Philosophical thinking is only concerned with the ethicalimplications of artificial intelligence. D:Philosophical thinking has no impact on the development of artificial intelligence.答案:Philosophical thinking has contributed to the development ofartificial intelligence.4.What is the rational nature of artificial intelligence?()A:The ability to communicate effectively with humans. B:The ability to feel emotions and express creativity. C:The ability to reason and make logicaldeductions. D:The ability to learn from experience and adapt to newsituations.答案:The ability to reason and make logical deductions.5.Which of the following statements is true regarding the rational nature ofartificial intelligence?()A:The rational nature of artificial intelligence includes emotional intelligence.B:The rational nature of artificial intelligence is limited to logical reasoning.C:The rational nature of artificial intelligence is not important for itsdevelopment. D:The rational nature of artificial intelligence is only concerned with mathematical calculations.答案:The rational nature of artificial intelligence is limited to logicalreasoning.6.Connectionism believes that the basic element of human thinking is symbol,not neuron; Human's cognitive process is a self-organization process ofsymbol operation rather than weight. ()A:对 B:错答案:错第三章测试1.The brain of all organisms can be divided into three primitive parts:forebrain, midbrain and hindbrain. Specifically, the human brain is composed of brainstem, cerebellum and brain (forebrain). ()A:错 B:对答案:对2.The neural connections in the brain are chaotic. ()A:对 B:错答案:错3.The following statement about the left and right half of the brain and itsfunction is wrong ().A:When dictating questions, the left brain is responsible for logical thinking,and the right brain is responsible for language description. B:The left brain is like a scientist, good at abstract thinking and complex calculation, but lacking rich emotion. C:The right brain is like an artist, creative in music, art andother artistic activities, and rich in emotion D:The left and right hemispheres of the brain have the same shape, but their functions are quite different. They are generally called the left brain and the right brain respectively.答案:When dictating questions, the left brain is responsible for logicalthinking, and the right brain is responsible for language description.4.What is the basic unit of the nervous system?()A:Neuron B:Gene C:Atom D:Molecule答案:Neuron5.What is the role of the prefrontal cortex in cognitive functions?()A:It is responsible for sensory processing. B:It is involved in emotionalprocessing. C:It is responsible for higher-level cognitive functions. D:It isinvolved in motor control.答案:It is responsible for higher-level cognitive functions.6.What is the definition of intelligence?()A:The ability to communicate effectively. B:The ability to perform physicaltasks. C:The ability to acquire and apply knowledge and skills. D:The abilityto regulate emotions.答案:The ability to acquire and apply knowledge and skills.第四章测试1.The forward propagation neural network is based on the mathematicalmodel of neurons and is composed of neurons connected together by specific connection methods. Different artificial neural networks generally havedifferent structures, but the basis is still the mathematical model of neurons.()A:对 B:错答案:对2.In the perceptron, the weights are adjusted by learning so that the networkcan get the desired output for any input. ()A:对 B:错答案:对3.Convolution neural network is a feedforward neural network, which hasmany advantages and has excellent performance for large image processing.Among the following options, the advantage of convolution neural network is().A:Implicit learning avoids explicit feature extraction B:Weight sharingC:Translation invariance D:Strong robustness答案:Implicit learning avoids explicit feature extraction;Weightsharing;Strong robustness4.In a feedforward neural network, information travels in which direction?()A:Forward B:Both A and B C:None of the above D:Backward答案:Forward5.What is the main feature of a convolutional neural network?()A:They are used for speech recognition. B:They are used for natural languageprocessing. C:They are used for reinforcement learning. D:They are used forimage recognition.答案:They are used for image recognition.6.Which of the following is a characteristic of deep neural networks?()A:They require less training data than shallow neural networks. B:They havefewer hidden layers than shallow neural networks. C:They have loweraccuracy than shallow neural networks. D:They are more computationallyexpensive than shallow neural networks.答案:They are more computationally expensive than shallow neuralnetworks.第五章测试1.Machine learning refers to how the computer simulates or realizes humanlearning behavior to obtain new knowledge or skills, and reorganizes the existing knowledge structure to continuously improve its own performance.()A:对 B:错答案:对2.The best decision sequence of Markov decision process is solved by Bellmanequation, and the value of each state is determined not only by the current state but also by the later state.()A:对 B:错答案:对3.Alex Net's contributions to this work include: ().A:Use GPUNVIDIAGTX580 to reduce the training time B:Use the modified linear unit (Re LU) as the nonlinear activation function C:Cover the larger pool to avoid the average effect of average pool D:Use the Dropouttechnology to selectively ignore the single neuron during training to avoid over-fitting the model答案:Use GPUNVIDIAGTX580 to reduce the training time;Use themodified linear unit (Re LU) as the nonlinear activation function;Cover the larger pool to avoid the average effect of average pool;Use theDropout technology to selectively ignore the single neuron duringtraining to avoid over-fitting the model4.In supervised learning, what is the role of the labeled data?()A:To evaluate the model B:To train the model C:None of the above D:To test the model答案:To train the model5.In reinforcement learning, what is the goal of the agent?()A:To identify patterns in input data B:To minimize the error between thepredicted and actual output C:To maximize the reward obtained from theenvironment D:To classify input data into different categories答案:To maximize the reward obtained from the environment6.Which of the following is a characteristic of transfer learning?()A:It can only be used for supervised learning tasks B:It requires a largeamount of labeled data C:It involves transferring knowledge from onedomain to another D:It is only applicable to small-scale problems答案:It involves transferring knowledge from one domain to another第六章测试1.Image segmentation is the technology and process of dividing an image intoseveral specific regions with unique properties and proposing objects ofinterest. In the following statement about image segmentation algorithm, the error is ().A:Region growth method is to complete the segmentation by calculating the mean vector of the offset. B:Watershed algorithm, MeanShift segmentation,region growth and Ostu threshold segmentation can complete imagesegmentation. C:Watershed algorithm is often used to segment the objectsconnected in the image. D:Otsu threshold segmentation, also known as themaximum between-class difference method, realizes the automatic selection of global threshold T by counting the histogram characteristics of the entire image答案:Region growth method is to complete the segmentation bycalculating the mean vector of the offset.2.Camera calibration is a key step when using machine vision to measureobjects. Its calibration accuracy will directly affect the measurementaccuracy. Among them, camera calibration generally involves the mutualconversion of object point coordinates in several coordinate systems. So,what coordinate systems do you mean by "several coordinate systems" here?()A:Image coordinate system B:Image plane coordinate system C:Cameracoordinate system D:World coordinate system答案:Image coordinate system;Image plane coordinate system;Camera coordinate system;World coordinate systemmonly used digital image filtering methods:().A:bilateral filtering B:median filter C:mean filtering D:Gaussian filter答案:bilateral filtering;median filter;mean filtering;Gaussian filter4.Application areas of digital image processing include:()A:Industrial inspection B:Biomedical Science C:Scenario simulation D:remote sensing答案:Industrial inspection;Biomedical Science5.Image segmentation is the technology and process of dividing an image intoseveral specific regions with unique properties and proposing objects ofinterest. In the following statement about image segmentation algorithm, the error is ( ).A:Otsu threshold segmentation, also known as the maximum between-class difference method, realizes the automatic selection of global threshold T by counting the histogram characteristics of the entire imageB: Watershed algorithm is often used to segment the objects connected in the image. C:Region growth method is to complete the segmentation bycalculating the mean vector of the offset. D:Watershed algorithm, MeanShift segmentation, region growth and Ostu threshold segmentation can complete image segmentation.答案:Region growth method is to complete the segmentation bycalculating the mean vector of the offset.第七章测试1.Blind search can be applied to many different search problems, but it has notbeen widely used due to its low efficiency.()A:错 B:对答案:对2.Which of the following search methods uses a FIFO queue ().A:width-first search B:random search C:depth-first search D:generation-test method答案:width-first search3.What causes the complexity of the semantic network ().A:There is no recognized formal representation system B:The quantifiernetwork is inadequate C:The means of knowledge representation are diverse D:The relationship between nodes can be linear, nonlinear, or even recursive 答案:The means of knowledge representation are diverse;Therelationship between nodes can be linear, nonlinear, or even recursive4.In the knowledge graph taking Leonardo da Vinci as an example, the entity ofthe character represents a node, and the relationship between the artist and the character represents an edge. Search is the process of finding the actionsequence of an intelligent system.()A:对 B:错答案:对5.Which of the following statements about common methods of path search iswrong()A:When using the artificial potential field method, when there are someobstacles in any distance around the target point, it is easy to cause the path to be unreachable B:The A* algorithm occupies too much memory during the search, the search efficiency is reduced, and the optimal result cannot beguaranteed C:The artificial potential field method can quickly search for acollision-free path with strong flexibility D:A* algorithm can solve theshortest path of state space search答案:When using the artificial potential field method, when there aresome obstacles in any distance around the target point, it is easy tocause the path to be unreachable第八章测试1.The language, spoken language, written language, sign language and Pythonlanguage of human communication are all natural languages.()A:对 B:错答案:错2.The following statement about machine translation is wrong ().A:The analysis stage of machine translation is mainly lexical analysis andpragmatic analysis B:The essence of machine translation is the discovery and application of bilingual translation laws. C:The four stages of machinetranslation are retrieval, analysis, conversion and generation. D:At present,natural language machine translation generally takes sentences as thetranslation unit.答案:The analysis stage of machine translation is mainly lexical analysis and pragmatic analysis3.Which of the following fields does machine translation belong to? ()A:Expert system B:Machine learning C:Human sensory simulation D:Natural language system答案:Natural language system4.The following statements about language are wrong: ()。
工业机器人的路径规划算法考核试卷

A. A*算法
B. D*算法
C. Floyd算法
D. Bresenham算法
16.在路径规划中,以下哪种数据结构用于存储已访问的节点?()
A.开放列表
B.关闭列表
C.路径列表
D.邻接矩阵
17.关于工业机器人的路径规划,以下哪个描述是错误的?()
B. Dijkstra算法
C. D*算法
D. RRT算法
13.关于路径规划中的碰撞检测,以下哪种方法计算量相对较小?()
A.精确碰撞检测
B.粗略碰撞检测
C.迭代最近点法(ICP)
D.点到线段距离计算
14.以下哪项不是路径平滑处理的目的?()
A.降低路径长度
B.减少运动时间
C.减少能量消耗
D.增加路径上的拐点
3.用于评估路径规划算法性能的指标通常包括路径长度、规划时间和______。
4.在路径规划中,为了减少计算量,常用的空间划分技术有四叉树和______。
5.机器人路径规划中的碰撞检测可以通过______和基于几何的碰撞检测两种方法实现。
6.路径平滑处理的目的是为了减少路径的拐点,提高路径的______和可执行性。
A. A*算法
B. Dijkstra算法
C. Floyd算法
D. Bresenham算法
2.下列哪种算法不属于路径规划中的启发式搜索算法?()
A. A*算法
B. D*算法
C. IDA*算法
D. Breadth First Search算法
3.在A*算法中,H(n)代表什么?()
A.从起始点到当前点的代价
4.在工业机器人路径规划中,如何处理动态障碍物?请提出一种算法或策略,并解释其工作原理和有效性。
专题05 阅读理解D篇(2024年新课标I卷) (专家评价+三年真题+满分策略+多维变式) 原卷版

《2024年高考英语新课标卷真题深度解析与考后提升》专题05阅读理解D篇(新课标I卷)原卷版(专家评价+全文翻译+三年真题+词汇变式+满分策略+话题变式)目录一、原题呈现P2二、答案解析P3三、专家评价P3四、全文翻译P3五、词汇变式P4(一)考纲词汇词形转换P4(二)考纲词汇识词知意P4(三)高频短语积少成多P5(四)阅读理解单句填空变式P5(五)长难句分析P6六、三年真题P7(一)2023年新课标I卷阅读理解D篇P7(二)2022年新课标I卷阅读理解D篇P8(三)2021年新课标I卷阅读理解D篇P9七、满分策略(阅读理解说明文)P10八、阅读理解变式P12 变式一:生物多样性研究、发现、进展6篇P12变式二:阅读理解D篇35题变式(科普研究建议类)6篇P20一原题呈现阅读理解D篇关键词: 说明文;人与社会;社会科学研究方法研究;生物多样性; 科学探究精神;科学素养In the race to document the species on Earth before they go extinct, researchers and citizen scientists have collected billions of records. Today, most records of biodiversity are often in the form of photos, videos, and other digital records. Though they are useful for detecting shifts in the number and variety of species in an area, a new Stanford study has found that this type of record is not perfect.“With the rise of technology it is easy for people to make observation s of different species with the aid of a mobile application,” said Barnabas Daru, who is lead author of the study and assistant professor of biology in the Stanford School of Humanities and Sciences. “These observations now outnumber the primary data that comes from physical specimens(标本), and since we are increasingly using observational data to investigate how species are responding to global change, I wanted to know: Are they usable?”Using a global dataset of 1.9 billion records of plants, insects, birds, and animals, Daru and his team tested how well these data represent actual global biodiversity patterns.“We were particularly interested in exploring the aspects of sampling that tend to bias (使有偏差) data, like the greater likelihood of a citizen scientist to take a picture of a flowering plant instead of the grass right next to it,” said Daru.Their study revealed that the large number of observation-only records did not lead to better global coverage. Moreover, these data are biased and favor certain regions, time periods, and species. This makes sense because the people who get observational biodiversity data on mobile devices are often citizen scientists recording their encounters with species in areas nearby. These data are also biased toward certain species with attractive or eye-catching features.What can we do with the imperfect datasets of biodiversity?“Quite a lot,” Daru explained. “Biodiversity apps can use our study results to inform users of oversampled areas and lead them to places – and even species – that are not w ell-sampled. To improve the quality of observational data, biodiversity apps can also encourage users to have an expert confirm the identification of their uploaded image.”32. What do we know about the records of species collected now?A. They are becoming outdated.B. They are mostly in electronic form.C. They are limited in number.D. They are used for public exhibition.33. What does Daru’s study focus on?A. Threatened species.B. Physical specimens.C. Observational data.D. Mobile applications.34. What has led to the biases according to the study?A. Mistakes in data analysis.B. Poor quality of uploaded pictures.C. Improper way of sampling.D. Unreliable data collection devices.35. What is Daru’s suggestion for biodiversity apps?A. Review data from certain areas.B. Hire experts to check the records.C. Confirm the identity of the users.D. Give guidance to citizen scientists.二答案解析三专家评价考查关键能力,促进思维品质发展2024年高考英语全国卷继续加强内容和形式创新,优化试题设问角度和方式,增强试题的开放性和灵活性,引导学生进行独立思考和判断,培养逻辑思维能力、批判思维能力和创新思维能力。
精品解析:2024年新课标全国Ⅰ卷英语高考真题解析(参考版)-A4答案卷尾

B.To sell home-grown vegetables.
C.To motivate her fellow gardeners.
15.Why does Marie recommend beginners to grow strawberries?
Help restore and protect Marin's natural areas from the Marin Headlands to Bolinas Ridge. We'll explore beautiful park sites while conducting invasive (侵入的) plant removal, winter planting, and seed collection. Habitat Restoration Team volunteers play a vital role in restoring sensitive resources and protecting endangered species across the ridges and valleys.GROUPS
A.To discover mineral resources.B.To develop new wildlife parks.
C.To protect the local ecosystem.D.To conduct biological research.
22.What is the lower age limit for joining the Habitat Restoration Team?
A.A pop star.B.An old song.C.A radio program.
东师2022考研英语教学法真题

东师2022考研英语教学法真题【第一部分:单项填空】1. However, some actors _____ us with the deep feelings they can inspire in us for a character they are playing. [单选题] *A.astonishedB. astonishingC. astonish(正确答案)D. is astonished2. He was a _____ figure in the French film industry. [单选题] *A. dominantlyB. dominant(正确答案)C. dominanceD. dominants3. The morning after your arrival, you meet with the _____ physician for a private consultation. [单选题] *A. residentsB. resident(正确答案)C. residenceD. residences4._____a reply, he decided to write again. [单选题] *A. Not receivingB. ReceivingC. Not having received(正确答案)D. Having not received5.With lots of trees and flowers _____here and there, the city looks very beautiful. [单选题] *A. having plantedB. planted(正确答案)C. have been plantedD. to be planted6. I have bought two ball-pens, _______ writes well. [单选题] *A. none of themB. neither of themC. neither of which(正确答案)D. none of which7.Great changes have taken place since then in the factory _______we are working. [单选题] *A.where(正确答案)B.hatC.whichD.there8.The engineer ______my father works is about 50 years old. [单选题] *A. to whomB. on whomC. with whichD. with whom(正确答案)9.The reason ______he didn't come was ______he was ill. [单选题] *A. why; that(正确答案)B.that;whyC. for that;thatD.for which;what10. Is _______ some German friends visited last week? [单选题] *A. this schoolB. this the schoolC. this school oneD. this school where(正确答案)11. They are not very good, but we like_______. [单选题] *A. anyway to play basketball with themB. to play basketball with them anyway(正确答案)C. to play with them basketball anywayD. with them to play basketball anyway12. He sent me an e-mail, _______to get further information. [单选题] *A. hopedB hoping(正确答案)C. to hopeD. hope13._____in 1636, Harvard is one of the most famous universities in the United States. [单选题] *A. Being roundedB it was foundedC. Founded(正确答案)D. Founding14.The ____boy was last seen ______near the East Lake. [单选题] *A. Missing, playing(正确答案)B. missing, playC missed, playedD missed, to play15. Tony was very unhappy for _______ to the party. [单选题] *A. having not been invitedB. not having invitedC. having not invitedD not having been invited(正确答案)【第二部分:完形填空】A new study found that inner-city kids living in neighborhoods with more green spacegained about 13% less weight over a two-year period than kids living amid more concrete and fewer trees. Such __62__ tell a powerful story. The obesity epidemic began in the 1980s, and many people __63__ it to increased portion sizes and inactivity, but that can't be everything. Fast foods and TVs have been __64__ us for a long time. "Most experts agree that the changes were __65__ to something in the environment," says social epidemiologist Thomas Glass of The Johns Hopkins Bloomberg School of Public Health. That something could be a __66__ of the green.The new research, __67__ in the American Journal of Preventive Medicine, isn't the first to associate greenery with better health, but it does get us closer __68__ identifying what works and why. At its most straightforward, a green neighborhood __69__ means more places for kids to play – which is __70__ since time spent outdoors is one of the strongest correlates of children's activity levels. But green space is good for the mind__71__: research by environmental psychologists has shown that it has cognitive __72__ for children with attention-deficit disorder. In one study, just reading __73__ in a green setting improved kids' symptoms.__74__ to grassy areas has also been linked to __75__ stress and a lower body mass index (体重指数) among adults. And an __76__ of 3,000 Tokyo residents associated walkable green spaces with greater longevity (长寿) among senior citizens.Glass cautions that most studies don't __77__ prove a causal link between greenness and health, but they're nonetheless helping spur action. In September the U. S. House of Representatives __78__ the delightfully named No Child Left Inside Act to encourage public initiatives aimed at exposing kids to the outdoors.Finding green space is not __79__ easy, and you may have to work a bit to get your family a little grass and trees. If you live in a suburb or a city with good parks, take__80__ of what's there. Your children in particular will love it – and their bodies and minds will be __81__ to you.16. [单选题] *A) findings(正确答案)B) thesesC) hypothesesD) abstracts17. [单选题] *A) adaptB) attribute(正确答案)C) allocateD) alternate18. [单选题] *A) amongstB) alongC) besideD) with(正确答案)19. [单选题] *A) gluedB) related(正确答案)C) trackedD) appointed20. [单选题] *A) scrapingB) denyingC) depressingD) shrinking(正确答案)21. [单选题] *A) published(正确答案)B) simulatedC) illuminatedD) circulated22. [单选题] *A)atB)to(正确答案)C)forD)over23. [单选题] *A) fullyB) simply(正确答案)C) seriouslyD) uniquely24. [单选题] *A)vital(正确答案)B)casualC)fatalD)subtle25. [单选题] *A) stillB) alreadyC) too(正确答案)D) yet26. [单选题] *A) benefits(正确答案)B) profitsC) revenuesD) awards27. [单选题] *A) outwardB) apartC) asideD) outside(正确答案)28. [单选题] *A) ImmunityB) ReactionC) Exposure(正确答案)D) Addiction29. [单选题] *A)muchB)less(正确答案)C)moreD)little30. [单选题] *A) installmentB) expeditionC) analysis(正确答案)D) option31. [单选题] *A) curiouslyB) negativelyC) necessarily(正确答案)D) comfortably32. [单选题] *A) relievedB) delegatedC) approved(正确答案)D) performed33. [单选题] *A)merelyB)always(正确答案)C)mainlyD)almost34. [单选题] *A) advantage(正确答案)B) exceptionC) measureD) charge35. [单选题] *A) elevatedB) mercifulC) contentedD) grateful(正确答案)【第三部分:阅读理解】Passage 1Will there ever be another Einstein? This is the undercurrent of conversation at Einstein memorial meetings throughout the year. A new Einstein will emerge, scientists say. But it may take a long time. After all, more than 200 years separated Einstein from his nearest rival, Isaac Newton.Many physicists say the next Einstein hasn’t been born yet, or is a baby now. That’s because the quest for a unified theory that would account for all the forces of nature has pushed current mathematics to its limits. New math must be created before the problem can be solved.But researchers say there are many other factors working against another Einsteinemerging anytime soon.For one thing, physics is a much different field today. In Einstein’s day, there were only a few thousand physicists worldwide, and the theoreticians who could intellectually rival Einstein probably would fit into a streetcar with seats to spare.Education is different, too. One crucial aspect of Einstein’s training that is overlooked is the years of philosophy he read as a teenager—Kant, Schopenhauer and Spinoza, among others. It taught him how to think independently and abstractly about space and time, and it wasn’t long before he became a philosopher himself.“The independence created by philosophical insight is—in my opinion—the mark of distinction between a mere artisan (工匠) or specialist and a real seeker after truth,”Einstein wrote in 1944.And he was an accomplished musician. The interplay between music and math is well known. Einstein would furiously play his violin as a way to think through a knotty physics problem.Today, universities have produced millions of physicists. There aren’t many jobs in science for them, so they go to Wall Street and Silicon Valley to apply their analytical skills to more practical—and rewarding—efforts.“Maybe there is an Einstein out there today,” said Columbia University physicist Brian Greene, “but it would be a lot harder for him to be heard.”Especially considering what Einstein was proposing.“The actual fabric of space and time curving? My God, what an idea!” Greene said at a recent gathering at the Aspen Institute. “It takes a certain type of person who will bang his head against the wall because you believe you’ll find the solution.”Perhaps the best examples are the five scientific papers Einstein wrote in his “miracle year” of 1905. These “thought experiments” were pages of calculations signed and submitted to the prestigious journal Annalen der Physik by a virtual unknown. There were no footnotes or citations.What might happen to such a submission today?“We all get papers like those in the mail,” Greene said. “We put them in the junk file.”36. What do scientists seem to agree upon, judging from the first two paragraphs? [单选题] *[A] Einstein pushed mathematics almost to its limits.[B] It will take another Einstein to build a unified theory.[C] No physicist is likely to surpass Einstein in the next 200 years.[D] It will be some time before a new Einstein emerges.(正确答案)37. What was critical to Einstein’s success? [单选题] *[A] His talent as an accomplished musician.[B] His independent and abstract thinking.(正确答案)[C] His untiring effort to fulfill his potential.[D] His solid foundation in math theory.38. What does the author tell us about physicists today? [单选题] *[A] They tend to neglect training in analytical skills.[B] They are very good at solving practical problems.[C] They attach great importance to publishing academic papers.[D] They often go into fields yielding greater financial benefits.(正确答案)39. What does Brian Greene imply by saying “... it would be a lot harder for him to be heard” (Lines 1-2, Para. 9)? [单选题] *[A] People have to compete in order to get their papers published.[B] It is hard for a scientist to have his papers published today.[C] Papers like Einstein’s would unlikely get published today.[D] Nobody will read papers on apparently ridiculous theories.(正确答案)40. When he submitted his papers in 1905, Einstein _______. [单选题] *[A] forgot to make footnotes and citations[B] was little known in academic circles(正确答案)[C] was known as a young genius in math calculations[D] knew nothing about the format of academic papersPassage 2The relationship between formal education and economic growth in poorcountries is widely misunderstood by economists and politicians alike. Progress in both areas is undoubtedly necessary for the social, political, and intellectual development of these and all other societies; however, the conventional view that education should be one of the very highest priorities for promoting rapid economic development in poor countries is wrong. We are fortunate that it is, because building new educational systems there and putting enough people through them to improve economic performance would require two or three generations. The findings of a research institution have consistently shown that workers in all countries can be trained on the job to achieve radically higher productivity and, as a result, radically higher standards ofliving.Ironically, the first evidence for this idea appeared in the United States. Not long ago, with the country entering a recession and Japan at its pre-bubble peak, the U.S. workforce was derided as poorly educated and one of the primary causes of the poor U.S. economic performance. Japan was, and remains, the global leader in automotive-assembly productivity. Yet the research revealed that the U.S. factories of Honda, Nissan, and Toyota achieved about 95 percent of the productivity of their Japanese counterparts - a result of the training that U.S. workers received on the job.More recently, while examining housing construction, the researchers discoveredthat illiterate, non-English-speaking Mexican workers in Houston, Texas, consistently met best-practice labor productivity standards despite the complexity of the building industry's work.What is the real relationship between education and economic development? Wehave to suspect that continuing economic growth promotes the development of education even when governments don't force it. After all, that's how education got started. When our ancestors were hunters and gatherers 10, 000 years ago, they didn't have time to wonder much about anything besides finding food. Only when humanity began to get its food in a more productive way was there time for other things.As education improved, humanity's productivity potential increased as well.When the competitive environment pushed our ancestors to achieve that potential,they could in tum afford more education. This increasingly high level of education is probably a necessary, but not a sufficient, condition for the complex political systems required by advanced economic performance. Thus poor countries might not be ableto escape their poverty traps without political changes that may be possible only with broader formal education. A lack of formal education, however, doesn't constrain the ability of the developing world's workforce to substantially improve productivity forthe foreseeable future. On the contrary, constraints on improving productivity explain why education isn't developing more quickly there than it is.41. The author holds in Paragraph 1 that the importance of education in poor [单选题] * countries[A] is subject to groundless doubts.[B] has fallen victim of bias.[C] is conventionally downgraded.[D] has been overestimated.(正确答案)42. It is stated in Paragraph 1 that the construction of a new educational system [单选题] *[A] challenges economists and politicians.[B] takes efforts of generations.(正确答案)[C] demands priority from the government.[D] requires sufficient labor force.43. A major difference between the Japanese and U.S. workforces is that [单选题] *[A] the Japanese workforce is better disciplined.[B] the Japanese workforce is more productive.(正确答案)[C] the U.S. workforce has a better education.[D] the U.S. workforce is more organized.44. The author quotes the example of our ancestors to show that education emerged [单选题] *[A] when people had enough time.[B] prior to better ways of finding food.[C] when people no longer went hungry.(正确答案)[D] as a result of pressure on government.45. According to the last paragraph, development of education [单选题] *[A] results directly from competitive environments.[B] does not depend on economic performance.[C] follows improved productivity.(正确答案)[D] cannot afford political changes.Passage 3A symbiotic relationship is an interaction between two or more species in which one species lives in or on another species. There are three main types of symbiotic relationships: parasitism, commensalism, and mutualism. The first and the third can be key factors in the structure of a biological community; that is, all the populations oforganisms living together and potentially interacting in a particular area.Parasitism is a kind of predator-prey relationship in which one organism, the parasite, derives its food at the expense of its symbiotic associate, the host. Parasites are usually smaller than their hosts. An example of a parasite is a tapeworm that lives inside the intestines of a larger animal and absorbs nutrients from its host. Natural selection favors the parasites that are best able to find and feed on hosts. At the same time, defensive abilities of hosts are also selected for. As an example, plants make chemicals toxic to fungal and bacterial parasites, along with ones toxic to predatory animals (sometimes they are the same chemicals). In vertebrates, the immune system provides a multiple defense against internal parasites.At times, it is actually possible to watch the effects of natural selection in host-parasite relationships. For example, Australia during the 1940 s was overrun by hundreds of millions of European rabbits. The rabbits destroyed huge expanses of Australia and threatened the sheep and cattle industries. In 1950, myxoma virus, a parasite that affects rabbits, was deliberately introduced into Australia to control the rabbit population. Spread rapidly by mosquitoes, the virus devastated the rabbit population. The virus was less deadly to the offspring of surviving rabbits, however, and it caused less and less harm over the years. Apparently, genotypes (the genetic make-up of an organism) in the rabbit population were selected that were better able to resist the parasite. Meanwhile, the deadliest strains of the virus perished with their hosts as natural selection favored strains that could infect hosts but not kill them. Thus, natural selection stabilized this host-parasite relationship.In contrast to parasitism, in commensalism, one partner benefits without significantly affecting the other. Few cases of absolute commensalism probably exist, because it is unlikely that one of the partners will be completely unaffected. Commensal associations sometimes involve one species' obtaining food that is inadvertently exposed by another. For instance, several kinds of birds feed on insects flushed out of the grass by grazing cattle. It is difficult to imagine how this could affect the cattle, but the relationship may help or hinder them in some way not yet recognized.The third type of symbiosis, mutualism, benefits both partners in the relationship Legume plants and their nitrogen-fixing bacteria, and the interactions between flowering plantsand their pollinators, are examples of mutualistic association. In the first case, the plants provide the bacteria with carbohydrates and other organic compounds, and the bacteria have enzymes that act as catalysts that eventually add nitrogen to the soil, enriching it. In the second case, pollinators (insects, birds) obtain food from the flowering plant, and the plant has its pollen distributed and seeds dispersed much more efficiently than they would be if they were carried by the wind only. Another example of mutualism would be the bull's horn acacia tree, which grows in Central and South America. The tree provides a place to live for ants of the genus Pseudomyrmex. The ants live in large, hollow thorns and eat sugar secreted by the tree. The ants also eat yellow structures at the tip of leaflets: these are protein rich and seem to have no function for the tree except to attract ants. The ants benefit the host tree by attacking virtually anything that touches it. They sting other insects and large herbivores (animals that eat only plants) and even clip surrounding vegetation that grows near the tree. When the ants are removed, the trees usually die, probably because herbivores damage them so much that they are unable to compete with surrounding vegetation for light and growing space.The complex interplay of species in symbiotic relationships highlights an important point about communities: Their structure depends on a web of diverse connections among organisms.46.Which of the following statements about commensalism can be inferred from paragraph 1? [单选题] *[A]It excludes interactions between more than two species.[B]It makes it less likely for species within a community to survive.[C]Its significance to the organization of biological communities is small.(正确答案)[D]Its role in the structure of biological populations is a disruptive one.47.According to paragraph 2. which of the following is true of the action of natural selection on hosts and parasites? [单选题] *[A]Hosts benefit more from natural selection than parasites do.[B]Both aggression in predators and defensive capacities in hosts are favored for species survival.(正确答案)[C]The ability to make toxic chemicals enables a parasite to find and isolate its host.[D]Larger size equips a parasite to prey on smaller host organisms.48.Which of the following can be concluded from the discussion in paragraph 3 about theAustralian rabbit population? [单选题] *[A]Human intervention may alter the host, the parasite. and the relationship between them.(正确答案)[B]The risks of introducing outside organisms into a biological community are not worth the benefits.[C]Humans should not interfere in host-parasite relationships.[D]Organisms that survive a parasitic attack do so in spite of the natural selection process.49.According to paragraph 3, all of the following characterize the way natural selectionstabilized the Australian rabbit population EXCEPT: [单选题] *[A]The most toxic viruses died with their hosts.[B]The surviving rabbits were increasingly immune to the virus.[C]The decline of the mosquito population caused the spread of the virus to decline.(正确答案)[D]Rabbits with specific genetic make-ups were favored.50.According to paragraph 5. which of the following is NOT true of the relationshipbetween the bull's horn acacia tree and the Pseudomyrmex ants? [单选题] *[A]Ants defend the host trees against the predatory actions of insects and animals.[B]The acacia trees are a valuable source of nutrition for the ants.[C]The ants enable the acacia tree to produce its own chemical defenses.(正确答案)[D]The ants protect the acacia from having to compete with surrounding vegetation.。
Dynamic Transcriptome Landscape of Maize Embryo and

Dynamic Transcriptome Landscape of Maize Embryo and Endosperm Development1[W][OPEN]Jian Chen2,Biao Zeng2,Mei Zhang,Shaojun Xie,Gaokui Wang,Andrew Hauck,and Jinsheng Lai*State Key Laboratory of Agro-biotechnology and National Maize Improvement Center,Department of Plant Genetics and Breeding,China Agricultural University,Beijing100193,People’s Republic of ChinaMaize(Zea mays)is an excellent cereal model for research on seed development because of its relatively large size for both embryo and endosperm.Despite the importance of seed in agriculture,the genome-wide transcriptome pattern throughout seed development has not been well ing high-throughput RNA sequencing,we developed a spatio-temporal transcriptome atlas of B73maize seed development based on53samples from fertilization to maturity for embryo, endosperm,and whole seed tissues.A total of26,105genes were found to be involved in programming seed development,in-cluding1,614transcription factors.Global comparisons of gene expression highlighted the fundamental transcriptomic repro-gramming and the phases of development.Coexpression analysis provided further insight into the dynamic reprogramming of the transcriptome by revealing functional transitions during bined with the published nonseed high-throughput RNA sequencing data,we identified91transcription factors and1,167other seed-specific genes,which should help elucidate key mechanisms and regulatory networks that underlie seed development.In addition,correlation of gene expression with the pattern of DNA methylation revealed that hypomethylation of the gene body region should be an important factor for the expressional activation of seed-specific genes,especially for extremely highly expressed genes such as zeins.This study provides a valuable resource for understanding the genetic control of seed development of monocotyledon plants.Maize(Zea mays)is one of the most important crops and provides resources for food,feed,and biofuel (Godfray et al.,2010).It has also been used as a model system to study diverse biological phenomena,such as transposons,heterosis,imprinting,and genetic diversity (Bennetzen and Hake,2009).The seed is a key organ of maize that consists of the embryo,endosperm,and seed coat.Maize seed development initiates from a double fertilization event in which two pollen sperm fuse with the egg and central cells of the female gametophyte to produce the progenitors of the embryo and endosperm, respectively(Dumas and Mogensen,1993;Chaudhury et al.,2001).The mature embryo inherits the genetic information for the next plant generation(Scanlon and Takacs,2009),whereas the endosperm,which is storage tissue for the embryo,persists throughout seed devel-opment and functions as the site of starch and protein synthesis(Sabelli and Larkins,2009).Elucidation of the genetic regulatory mechanisms involved in maize seed development will facilitate the design of strategies to improve yield and quality,and provide insight that is applicable to other monocotyledon plants.A key means to explore the mechanisms of seed de-velopment is to identify gene activities and functions. Genetic studies have uncovered a number of genes that play major roles in governing embryogenesis and ac-cumulation of endosperm storage compounds,such as Viviparous1,KNOTTED1,Indeterminate gametophyte1, Shrunken1(Sh1),Opaque2(O2),and Defective kernel1 (Chourey and Nelson,1976;McCarty et al.,1991;Smith et al.,1995;Vicente-Carbajosa et al.,1997;Lid et al., 2002;Evans,2007).Furthermore,the activity of some genes has also been extensively studied.Typical exam-ples are zein genes that encode primary storage proteins in endosperm.Woo et al.(2001)examined zein gene expression and showed that they were the most highly expressed genes in endosperm based on EST data,where-as their dynamic expression patterns were revealed in a later study(Feng et al.,2009).Nevertheless,informa-tion on the global gene expression network throughout seed development is still very limited.The transcriptome is the overall set of transcripts, which varies based on cell or tissue type,develop-mental stage,and physiological condition.Analysis of transcriptome dynamics aids in implying the function of unannotated genes,identifying genes that act as critical network hubs,and interpreting the cellular pro-cesses associated with development.In Arabidopsis (Arabidopsis thaliana),the genes expressed in devel-oping seed and its subregions at several develop-ment stages have been analyzed with Affymetrix GeneChips(Le et al.,2010;Belmonte et al.,2013).In1This work was supported by the National High Technology Re-search and Development Program of China(863Project,grant no. 2012AA10A305to J.L.)and the National Natural Science Foundation of China(grant no.31225020to J.L.).2These authors contributed equally to the article.*Address correspondence to jlai@.The author responsible for distribution of materials integral to the findings presented in this article in accordance with the policy de-scribed in the Instructions for Authors()is: Jinsheng Lai(jlai@).[W]The online version of this article contains Web-only data.[OPEN]Articles can be viewed online without a subscription./cgi/doi/10.1104/pp.114.240689maize,microarray-based atlases of global transcription have provided insight into the programs controlling development of different organ systems (Sekhon et al.,2011).Compared with microarray,high-throughput RNA sequencing (RNA-seq)is a powerful tool to com-prehensively investigate the transcriptome at a much lower cost,but with higher sensitivity and accuracy (Wang et al.,2009b).Several studies have taken ad-vantage of the RNA-seq strategy to interpret the dy-namic reprogramming of the transcriptome during leaf,shoot apical meristem,and embryonic leaf develop-ment in maize (Li et al.,2010;Takacs et al.,2012;Liu et al.,2013).To date,only two studies have focused on identi-fying important regulators and processes required for embryo,endosperm,and/or whole seed development in maize based on a genome-wide transcriptional pro-file produced by RNA-seq (Liu et al.,2008;Teoh et al.,2013).However,these studies were limited by the low number of samples used and they did not provide an extensive,global view of transcriptome dynamics over the majority of seed development stages.Here,we pres-ent a comprehensive transcriptome study of maize em-bryo,endosperm,and whole seed tissue from fertilization to maturity using RNA-seq,which serves as a valu-able resource for analyzing gene function on a global scale and elucidating the developmental processes of maize seed.RESULTSGeneration and Analysis of the RNA-seq Data SetTo systematically investigate the dynamics of the maize seed transcriptome over development,we generated RNA-seq libraries of B73seed tissues from different developmental stages,including 15embryo,17endo-sperm,and 21whole seed samples (Fig.1).Utilizing paired-end Illumina sequencing technology,we gen-erated around 1.9billion high-quality reads,80.2%of which could be uniquely mapped to the B73referencegenome (Schnable et al.,2009;Supplemental Table S1).The genic distribution of reads was 66.6%exonic,25.6%splice junction,and 2.6%intronic,leaving about 5%from unannotated genomic regions,demonstrating that most of the detected genes have been annotated.Uniquely mapped reads were used to estimate nor-malized transcription level as reads per kilobase per million (RPKM).To reduce the in fluence of transcrip-tion noise,genes from the B73filtered gene set (FGS)were included for analysis only if their RPKM values were $1.Considering that our purpose was not to identify minor differential expression of genes between two time points of development,but to provide an atlas of gene expression pro file across tissues using time se-ries biological samples,we only randomly selected 12samples to have a biological replicate (Supplemental Fig.S1)to assess our data parisons of bio-logical replicates showed that their expression values were highly correlated (average R 2=0.96).For the samples with biological replicates,we took the average RPKM as the expression quantity.To further evaluate the quality of our expression data,we compared the transcript abundance patterns of a number of selected genes with previously measured expression pro files (Supplemental Fig.S2).For example,LEAFY COTYLE-DON1(LEC1),which functions in embryogenesis,was mainly expressed in the early stage of the embryo (Lotan et al.,1998).Globulin2(Glb2)had high expres-sion late in embryogenesis,in accordance with its func-tion as an important storage protein in the embryo (Kriz,1989).Similarly,O2,a transcription factor (TF)that regulates zein synthesis (Vicente-Carbajosa et al.,1997),and Fertilization independent endosperm1(Fie1),a repressor of endosperm development in the absence of fertilization (Danilevskaya et al.,2003),were almost ex-clusively expressed in the endosperm.Expression pat-terns of these selected genes were identi fied exclusively in their known tissue of activity,indicating that the embryo and endosperm samples were processed well.In total,we detected 26,105genes expressed in at least 1of the 53samples (Supplemental Data Set S1).The distribution of these genes is revealed by aVennFigure 1.Overview of the time series maize seed samples used for RNA-seq analysis.The photographs show the changes in maize embryo,endosperm,and whole seed during development.The 53samples shown here were used to generate RNA-seq libraries.Bar =5mm.Transcriptome Dynamics of Maize Seeddiagram (Fig.2A),which shows that 20,360genes were common among all three tissue types.The number of genes detected in endosperm tissue during the devel-opmental stages was lower and much more variable compared with embryo or whole seed tissue,and a greater number of genes were expressed in the tissue during the early and late phases.Several thousand fewer expressed genes were detected 14d after polli-nation (DAP)in the endosperm compared with 6or 8DAP (Fig.2B;Supplemental Data Set S2).In addition,the median expression level in the embryo was roughly 2-fold greater than that of the endosperm from 10to 30DAP (Fig.2C).Of the 1,506genes unique to the whole seed samples,451were present in RNA-seq data of 14and/or 25DAP pericarp tissue (Morohashi et al.,2012).Considering that the maternal tissue is the vast majority of the content of the early seed (Márton et al.,2005;Pennington et al.,2008),we inferred that most of these genes might be expressed exclusively in maternal tissue such as the pericarp or nucellus.Moreover,1,062genes in the embryo and endosperm with low expression were not detected in whole seed samples (Fig.2C).Division of Development Phases by Global Gene Expression PatternsTo gain insight into the relationships among the dif-ferent transcriptomes,we performed principal compo-nent analysis (PCA)on the complete data set,which can graphically display the transcriptional signatures and developmental similarity.The first component(40.7%variance explained)separated samples based on tissue identity and clearly distinguished embryo from endosperm samples,with whole seed samples located in between (Fig.3A).The second component (24.4%variance explained)discriminated early,mid-dle,and late stages of development for all three tissues (Fig.3A).The wider area occupied by endosperm sam-ples than embryo demonstrates stronger transcriptome reprogramming in developing endosperm,which is mainly attributable to drastic changes in the early and late stages.Moreover,whole seed samples of 0to 8DAP and 30to 38DAP clustered closely to the embryo,but 10to 28DAP samples were close to the endosperm.Cluster analysis of the time series data for the tissues grouped samples well along the axis of developmental time (Fig.3,B –D).Embryo samples from 10to 20DAP and 22to 38DAP were the primary clusters,which correspond to morphogenesis and maturation phases of development (Fig.3B).This is consistent with the embryo undergoing active DNA synthesis,cell division,and differentiation,and then switching to synthesis of storage reserve and desiccation (Vernoud et al.,2005).Expression differences in endosperm samples resulted in three primary clusters,which correspond to early,middle,and late phases of development (Fig.3C).The earliest time point (6and 8DAP)is an active period of cell division and cell elongation that terminates at about 20to 25DAP (Duvick,1961).The samples of 10to 24DAP formed one subgroup and 26to 34DAP formed another subgroup,suggesting that they mark the period forming the main cell types and maturation of endo-sperm,respectively (Fig.3C).The two subgroupsformFigure 2.Analysis of global gene expres-sion among different samples.A,Venn diagram of the 26,105genes detected among embryo,endosperm,and whole seed.B,Number of genes expressed in each of the samples.C,Comparison of expression levels of genes detected in embryo and endosperm tissues.Chen et al.a larger cluster for active accumulation of storage com-pounds during 10to 34DAP.The distinct cluster of 36and 38DAP is in accordance with the end of storage compound accumulation in the endosperm and the ac-tivation of biological processes involved in dormancy and dehydration.In whole seed tissue,a primary clus-ter was formed from the earliest time points with 0to 4DAP and 6to 8DAP samples as subgroups,separating the nucellus degradation as well as endosperm syncy-tial and cellularization phases from the rapid expansion of the endosperm and development of embryonic tissues (Fig.3D).After 10DAP,the embryo and endosperm dominate the formation of seed,as shown in Figure 1and morphological observation (Pennington et al.,2008).As effected by both embryo and endosperm,10to 28DAP whole seed samples clustered together and 30to 38DAP formed another group (Fig.3D).These results con firmthat the expression data successfully captured the char-acteristic seed development phases and should there-fore contain valuable insights about corresponding changes in the transcriptome.Integration of Gene Activity and Cellular Function across Development PhasesThe PCA and hierarchical clustering analysis graph-ically display the relationship among different sam-ples,but do not indicate the detailed cellular ing the k-means clustering algorithm,we classi fied the detected genes into 16,14,and 10coexpression modules for embryo,endosperm,and whole seed,re-spectively,each of which contains genes that harbor similar expression patterns (Fig.4).We then used Map-Man annotation to assign genes to functionalcategoriesFigure 3.Global transcriptome relationships among different stages and tissues.A,PCA of the RNA-seq data for the 53seed samples shows five distinct groups:I for embryo (light red),II for endosperm (light blue),and III to V for early (III),middle (IV),and late (V)whole seed (light purple).B to D,Cluster dendrogram showing global transcriptome relationships among time series samples of embryo (B),endosperm (C),and whole seed (D).The y axis measures the degree of variance (see the “Materials and Methods”).The bottom row indicates the developmental phases according to the cluster dendrogram of the time series data.au,Approximately unbiased.Transcriptome Dynamics of Maize Seed(Supplemental Fig.S3).Thus,we can aggregate genes over continuous time points and obtain a view of func-tional transitions along seed development.According to the cluster analysis results,most mod-ules of the embryo can be divided into middle (10–20DAP)and late (22–38DAP)stages (Fig.4A).The middle stage,best represented by modules C1to C7,is typi fied by the overrepresentation of glycolysis,tri-carboxylic acid cycle,mitochondrial electron transport,redox,RNA regulation,DNA and protein synthesis,cell organization,and division-related genes.This is consis-tent with the high requirement of energy during em-bryo formation.The late stage represented by C8to C12exhibited up-regulation of the cell wall,hormone me-tabolism (ethylene and jasmonate),stress,storage pro-teins,and transport-related genes,which coincides with the maturation of the embryo.The modules C13to C16included genes that were broadly expressed across the time points sampled and were related to hormone me-tabolism (brassinosteroid),cold stress,RNA process-ing and regulation,amino acid activation,and protein targeting.All of the 14coexpression modules of endosperm can be roughly divided into early (6–8DAP),middle (10–34DAP),and late (36–38DAP)stages (Fig.4B).The early stage (represented by modules C1to C4)isexempli fied by high expression of hormone metabo-lism (gibberellin),cell wall,cell organization and cycle,amino acid metabolism,DNA,and protein synthesis –related genes,which is consistent with differentiation,mitosis,and endoreduplication.Genes in the tricar-boxylic acid cycle and mitochondrial electron transport are also overrepresented and related to energy de-mands at that time.The middle stage (best represented by C5to C8,in which different modules have distinct pro files)is the active storage accumulation phase and exhibits high expression of carbohydrate metabolism genes,as expected.Increased expression of protein degradation-related genes around 26to 34DAP in C7and C8coincides with the process of endosperm matu-ration.Genes involved in protein degradation,second-ary metabolism,oxidative pentose phosphate,receptor kinase signaling,and transport were up-regulated in the late stage in modules C9to C14during the con-cluding phase of endosperm maturation.Ten DAP and later time points of whole seed sam-ples re flect the additive combination of embryo and endosperm expression.Genes that are active early in development (0–8DAP)in clusters C1to C4are ex-pected to be related to maternal tissue,which is the bulk of the seed at that time.A group of genes are highly expressed in C1at 0DAP,but theirexpressionFigure 4.Coexpression modules.A to C,Expression patterns of coexpression modules of embryo (A),endosperm (B),and whole seed (C),ordered according to the sample time points of their peak expression.For each gene,the RPKM value normalized by the maximum value of all RPKM values of the gene over all time points is shown.Chen et al.drops rapidly by2DAP,suggesting that they have functional roles that precede pollination.This group includes photosynthesis light reaction members and some TFs involved in RNA regulation.Genes related to cell wall and protein degradation,signaling,nucle-otide metabolism,DNA synthesis,cell organization, and mitochondrial electron transport are overrepre-sented in C2to C4,which has increased expression after pollination,in accordance with the degradation of nucellus tissue and development of embryonic tissues. The expression patterns and functional categories of the1,506genes detected only in whole seed samples are shown in Supplemental Figure S4.Because these genes tend to be expressed at high levels mainly before 8DAP,they are presumed to have functions in early seed development.Together,these data show that the transition of major biochemical processes along the developmental time axis of the seed is produced partly by highly coordi-nated transcript dynamics.TF Expression during Seed DevelopmentOf the2,297identified maize TFs(Zhang et al.,2011), 1,614(70%)are included in our analysis(Supplemental Data Set S3),which accounts for6.18%of the total number of genes detected in seed tissue.The num-ber of TFs detected in the different samples is shown in Supplemental Figure S5A.Their proportion to the total genes expressed in each tissue time point was always greater in embryo than endosperm samples (Supplemental Fig.S5B).Shannon entropy has been used to determine the specificity of gene expression, with lower values indicating a more time-specific pro-file(Makarevitch et al.,2013).The Shannon entropy of TFs was significantly lower than all other genes in both embryo(P=2.3310210)and endosperm(P,1.53 1023),indicating that TFs tended to be expressed more time specifically than other genes(Supplemental Fig.S5, C and D).The number of TFs from each family used in the seed development program,along with the proportion of members present in the coexpression modules rel-ative to the total members of the family expressed in the tissue,is shown in Supplemental Figure S6. Enrichment of these TF families in the coexpression modules based on observed numbers was evaluated with Fisher’s exact test.Significant TF family enrich-ment was identified for specific coexpression modules. For example,12auxin-response factor TFs(38.7%) were expressed in embryo module C2during mor-phogenesis and one-half of the detected members of the WRKY family were active in endosperm module C12late in endosperm development.The WRKY family has been reported to be mainly involved in the physiological programs of pathogen defense and se-nescence(Eulgem et al.,2000;Pandey and Somssich, 2009).Twenty-one MIKC family TFs(56.8%)were pres-ent in whole seed module C2,implying an important role in regulating genes involved in response to fertil-ization.The developmental specificity of the detected TFs makes them excellent candidates for reverse ge-netics approaches to investigate their role in grain production.Tissue-Specific Genes of SeedIdentification of uncharacterized tissue-specific genes can help to explain their function and understand the underlying control of tissue or organ identity.To gen-erate a comprehensive catalog of seed-specific genes, results from this study were compared with25pub-lished nonseed RNA-seq data sets(Jia et al.,2009;Wang et al.,2009a;Li et al.,2010;Davidson et al.,2011;Bolduc et al.,2012),including root,shoot,shoot apical meristem, leaf,cob,tassel,and immature ear(Supplemental Table S2).In total,we identified1,258seed-specific genes,in-cluding91TFs from a variety of families(Supplemental Data Set S4).To gain further insight into the spatial expression trend in the developing seed,we divided these genes into four groups:embryo specific,endo-sperm specific,expressed in both embryo and endo-sperm,and other as only expressed in whole seed (Table I).The dynamic expression patterns of these genes reflect their roles in corresponding development stages(Supplemental Fig.S7).The largest numbers of seed-specific genes were observed in the endosperm, consistent with a study in maize using microarrays (Sekhon et al.,2011),perhaps reflecting the specific function of endosperm.We compared the distribution of tissue-specific genes and TFs in embryo and endosperm coexpression mod-ules to identify important phases in the underlying transcription network.Coexpression modules with an enrichment of tissue-specific genes or TFs may provide insight about uncharacterized genes and preparation for subsequent developmental processes.A feature of gene activity is shown in Figure5.Fisher’s exact test (P,0.05)was used to determine modules with sig-nificant enrichment of tissue-specific genes and TFs in the embryo and endosperm.In the embryo,TFs and tissue-specific genes were significantly enriched in the late phase,suggesting a specific process during matu-ration.In the endosperm,we observed that TFs and tissue-specific genes were overrepresented in the mid-dle phase,which conforms to the role of endosperm inTable I.Total number of detected seed-specific genes and TFsData are presented as n.Tissue Type Specific Genes Specific TFs Embryo24923Endosperm74259Embryo and endosperm2196Other a483Total1,25891a These genes only detected expression in whole seeds.Transcriptome Dynamics of Maize Seedstorage compound accumulation and to speci fic pro-gress at this phase.To gain further insight into the functional signi fi-cance of tissue-speci fic genes,overrepresented gene ontology (GO)terms were examined using the WEGO online tool (Ye et al.,2006;Supplemental Fig.S8).All overrepresented GO terms were observed for themiddle embryo development phase,including the bio-synthetic process,cellular metabolic process,macro-molecule,and nitrogen compound metabolic process.Similarly,overrepresented GO terms for the endosperm were mostly observed in the early phase,including the macromolecule,nitrogen compound metabolic pro-cess,DNA binding,and transcription regulator.GenesFigure 5.Distribution and enrichment of genes,tissue-specific genes,TFs,and tissue-specific TFs in coexpression modules of embryo and endosperm.A and B,Bars indicate the percentage of all detected genes (green),tissue-specific genes (blue),TFs (red),and tissue-specific TFs (purple)observed in a coexpression module (C)or in the development phase (Total)relative to the total number of each group detected across samples for embryo (A)and endosperm (B).The number of genes represented by the percentage is shown on the right y axis.Enrichment for tissue-specific genes and TFs was evaluated with Fisher’s exact test based on the number of genes observed in each coexpression module,whereas enrichment for tissue-specific TFs was evaluated based on the number of TFs observed in each coexpression module.Asterisks represent significant enrichment at a false dis-covery rate #0.05.Chen et al.involved in the nutrient reservoir class were enriched in the middle phase.The oxidoreductase class was overrepresented in late phase,and is known to be in-volved in maturation (Zhu and Scandalios,1994).The Expression of Zein Genes in EndospermZeins are the most important storage proteins in maize endosperm and are an important factor in seed quality.According to Xu and Messing (2008),there are 41a ,1b ,3g ,and 2d zein genes.In order to explore their expression pattern,we first con firmed the gene models by mapping publicly available full-length com-plementary DNAs of zein subfamily genes to B73bac-terial arti ficial chromosomes,and then mapped these back to the reference genome.Because some of these zein genes were not assembled in the current B73ref-erence genome or were only annotated in the working gene set,we con firmed a final set of 35zein genes in the FGS of the B73annotation,including 30a ,1b ,3g ,and 1d zein genes (Supplemental Table S3).About three-quarters (26)of these were in the list of the 100most highly expressed genes in the endosperm,based on mean expression across all endosperm samples (Supplemental Table S4).The distribution of these most highly expressed genes clearly showed that the 26zeins and 4starch synthesis genes were actively expressed in the middle phase of endosperm devel-opment,characteristic of storage compound accumu-lation (Fig.6A).Previous research has shown that the zein genes con-stitute approximately 40%to 50%of the total tran-scripts in the endosperm (Marks et al.,1985;Woo et al.,2001),but these results are based on EST data from a single tissue or pooled tissues and only a few zein genes were assessed.Thus,we reevaluated the transcriptomic contribution of zein genes across endosperm develop-ment using our RNA-seq data,which is able to overcome the high structural similarity among them,especially in the a family (Xu and Messing,2008).Zein genes stably accounted for about 65%of transcripts from 10to 34DAP,with 19-kD a zeins (approximately 42%),22-kD a zeins (approximately 8%),and g zeins (approximately 10%)representing the most abundant transcripts (Fig.6B).The expression of different members within agivenFigure 6.Analysis of highly expressed genes in the endosperm.A,The distribution of the 100most highly expressed genes in the endosperm ordered by mean expression in different modules.B,The dynamic transcript levels of different zein gene family members in the endosperm as reflected by their percentage among all detected gene transcript levels.C,Heat map showing RPKM values of 35zein genes in the different development stages of the endosperm.+,Having intact coding regions;2,with premature_stop;N,no;Y ,yes.Transcriptome Dynamics of Maize Seed。
时空极差熵权法 英文

时空极差熵权法英文The Time-Space Extreme Difference Entropy Weighting Method (TSWEDEM) is a multi-criteria decision-making method that is used to evaluate the performance of a set of alternatives concerning multiple criteria. The technique employs a top-down approach that aims to identify the most advantageous alternative that satisfies the preferences and constraints of the decision-maker. This paper provides a comprehensive review of the TSWEDEM, including its theoretical background, algorithm, and practical applications.The TSWEDEM is based on two core concepts: entropy and weighting. Entropy is a measure of the uncertainty or unpredictability of a system, while weighting is a technique used to assign relative importance to different criteria or factors. In the context of the TSWEDEM, entropy is used to measure the degree of difference between the performance of alternatives with respect to each criterion, while weighting is used to incorporate the decision-maker's preferences for each criterion.The algorithm of the TSWEDEM can be divided into three steps: normalization of the decision matrix, determination of the weighting coefficient and calculation of the fuzzy comprehensive appraisal. The first step involves standardizing the decision matrix to avoid dominance by any single criterion. The second step involves determining the weighting coefficient for each criterion through the use of expert judgment or other methods. The final step involves calculating the fuzzy comprehensive appraisal for each alternative, which is a weighted sum of the normalized scores for each criterion.The advantages of the TSWEDEM include its ability to handle both quantitative and qualitative criteria, its ability to incorporate expert judgment, and its ability to provide a comprehensive evaluation of alternatives. The technique has been successfully applied in avariety of fields, including environmental management, transportation planning, and energy systems analysis.In environmental management, the TSWEDEM has been used to evaluate the performance of different waste management strategies. In transportation planning, it has been used to select the best transportation mode for a given route. In energy systems analysis, it has been used to evaluate the performance of different renewable energy technologies.However, the TSWEDEM has several limitations, including the subjectivity of the weighting process, the potential for inconsistency in expert judgment, and the lack of a clear theoretical foundation. Additionally, the technique can betime-consuming and computationally intensive, particularly when dealing with large and complex decision matrices.In conclusion, the TSWEDEM is a valuable multi-criteria decision-making method that can help decision-makers evaluate the performance of alternatives concerning multiple criteria. Its theoretical foundation, algorithm, and practical applications have been discussed in detail. Thetechnique has several advantages, but it also has some limitations, which need to be considered when applying it in practice.。
c4.5算法的基本原理 -回复

c4.5算法的基本原理-回复什么是C4.5算法?C4.5算法是机器学习领域中的一种决策树算法,是ID3算法的改进版本。
它由Ross Quinlan于1993年提出,是一种用于分类问题的监督学习算法。
C4.5算法的基本原理是通过对数据集进行划分来构建决策树,以实现对新样本进行分类。
下面将详细介绍C4.5算法的基本原理和步骤。
C4.5算法的基本原理是基于信息增益来选择最优特征进行划分。
在构建决策树的过程中,C4.5算法通过计算每个特征的信息增益比来选择最优特征,从而实现对数据集的划分。
信息增益是指在得知某个特征的取值后,对分类结果的不确定性减少的程度。
C4.5算法的步骤如下:1. 选择最优特征:计算每个特征的信息增益比,选择具有最大信息增益比的特征作为当前节点的划分特征。
2. 划分数据集:根据划分特征将数据集划分为多个子数据集,每个子数据集包含具有相同特征值的样本。
3. 递归构建子树:对每个子数据集递归地应用步骤1和步骤2,构建子树。
4. 停止划分:当数据集的所有属性都已经被使用或者数据集中的样本都属于同一类别时,停止划分,将当前节点标记为叶节点,并将叶节点标记为数据集中样本数最多的类别。
5. 构建决策树:将步骤3中得到的子树连接到当前节点,构成完整的决策树。
具体来说,C4.5算法的核心步骤是选择最优特征和划分数据集。
在选择最优特征时,C4.5算法通过计算每个特征的信息增益比来选择最优特征。
信息增益比是信息增益除以划分数据集的熵,熵是度量数据集的纯度的指标。
信息增益比能够避免特征取值较多而导致的信息增益偏大的问题,从而更加准确地选择最优特征。
划分数据集是将数据集根据划分特征的取值划分为多个子数据集,每个子数据集包含具有相同特征值的样本。
划分后的子数据集可以分别作为子树的训练数据,递归地构建子树。
每个子树的构建过程都是通过选择最优特征和划分数据集来实现的。
当数据集的所有属性都已经被使用或者数据集中的样本都属于同一类别时,停止划分,将当前节点标记为叶节点,并将叶节点标记为数据集中样本数最多的类别。
人工智能训练师(3级)理论知识复习题
输入层
输出层
激活函数
22
在知识图谱中,用于表示实体间关系的边通常具有什么类型?
有向边
无向边
加权边
线性边
23
类脑计算的主要目标是:
模拟人类的大脑功能 b) 创建一个全新的智能
创建一个全新的智能生物
提高计算机的运算速度
优化网络安全性
24
在模式识别中,特征选择的目标是:
降低维度
增加噪声
增强数据
数据预处理
任务目标
项目预算
数据来源
项目截止时间
11
在评估人工智能系统时,下列哪个因素是最重要的评估指标?
a) 系统的准确性
系统的准确性
系统的响应速度
系统的外观设计
系统的品牌知名度
12
评估人工智能系统时,下列哪个因素可以衡量系统的可靠性和鲁棒性?
系统的安全性
系统的用户友好性
系统的社会影响
系统的数据处理能力
13
当模型在验证集上不能达到理想的评估指标时,( )。
加强与行业人员的联系
提高技术实施效率
提升数据分析准确性
减少团队协作难度
4
人工智能是通过什么来呈现人类智能的技术?
计算机程序
机械装置
化学合成物
电子设备
5
人工智能的研究内容主要包括什么?
计算机实现智能的原理
网络安全技术
建筑设计原理
动物行为研究方法
6
人工智能科学是一门研究、开发和应用智能体的( )。
跨学科领域
57
VMAF是用于评估视频质量的指标,它基于以下哪个原理进行评估?
人眼感知模型
编码效率
数据压缩算法
庞皓版计量经济学课后习题答案
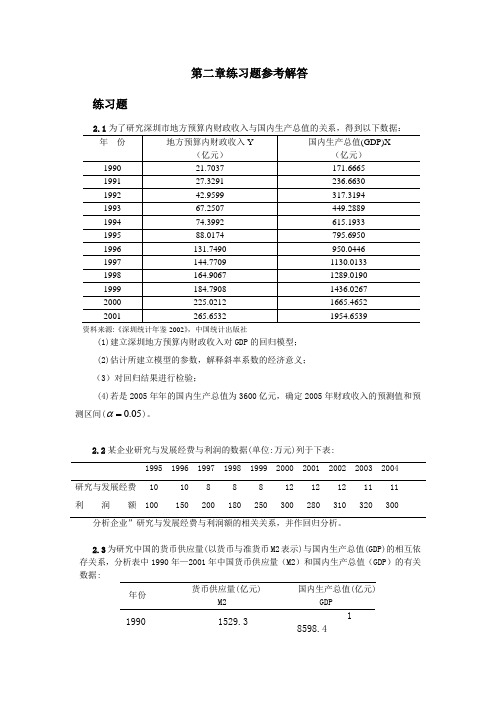
第二章练习题参考解答练习题资料来源:《深圳统计年鉴2002》,中国统计出版社(1)建立深圳地方预算内财政收入对GDP的回归模型;(2)估计所建立模型的参数,解释斜率系数的经济意义;(3)对回归结果进行检验;(4)若是2005年年的国内生产总值为3600亿元,确定2005年财政收入的预测值和预测区间(0.05α=)。
2.2某企业研究与发展经费与利润的数据(单位:万元)列于下表:1995 1996 1997 1998 1999 2000 2001 2002 2003 2004研究与发展经费 10 10 8 8 8 12 12 12 11 11利润额 100 150 200 180 250 300 280 310 320 300 分析企业”研究与发展经费与利润额的相关关系,并作回归分析。
2.3为研究中国的货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相互依存关系,分析表中1990年—2001年中国货币供应量(M2)和国内生产总值(GDP)的有关数据:年份货币供应量(亿元)M2国内生产总值(亿元)GDP1990 1529.31 8598.41991 19349.92 1662.51992 25402.22 6651.91993 34879.83 4560.51994 46923.54 6670.01995 60750.55 7494.91996 76094.96 6850.51997 90995.37 3142.71998 104498.57 6967.21999 119897.98 0579.42000 134610.38 8228.12001 158301.99 4346.4资料来源:《中国统计年鉴2002》,第51页、第662页,中国统计出版社对货币供应量与国内生产总值作相关分析,并说明分析结果的经济意义。
2.4表中是16支公益股票某年的每股帐面价值和当年红利:根据上表资料:(1)建立每股帐面价值和当年红利的回归方程;(2)解释回归系数的经济意义;(3)若序号为6的公司的股票每股帐面价值增加1元,估计当年红利可能为多少?2.5美国各航空公司业绩的统计数据公布在《华尔街日报1999年年鉴》(The Wall Street1。
贝叶斯决策理论(英文)--非常经典!
What is Bayesian classification?
Bayesian classification is based on Bayes theorem
Bayesian classifiers have exhibited high accuracy and fast speed when applied to large databases
贝叶斯决策理论英文非常经典
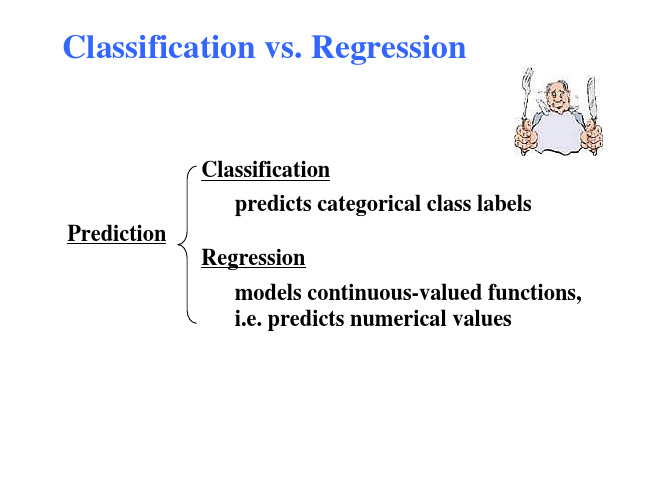
Classification vs. Regression
Classification predicts categorical class labels Prediction Regression models continuous-valued functions, i.e. predicts numerical values
Two step process of prediction (I)
Step 1: Construct a model to describe a training set
• the set of tuples used for model construction is called training set • the set of tuples can be called as a sample (a tuple can also be called as a sample) • a tuple is usually called an example (usually with the label) or an instance (usually without the label) • the attribute to be predicted is called label Training algorithm
孟德尔随机化extract clump access代码 -回复

孟德尔随机化extract clump access代码-回复[孟德尔随机化extract clump access代码]孟德尔随机化(或称为Fisher-互换)是一种用于实验证据收集和分析的方法,旨在消除由于无法控制某些参数而引起的偏见。
这种方法被广泛用于生物学、医学和社会科学研究中。
其中一个常见的应用领域是评估新药的疗效。
在这篇文章中,我们将研究如何使用孟德尔随机化方法来提取类群访问数据。
假设我们正在进行一个实验,想要比较两种不同访问方式下网站用户的行为。
我们将采用孟德尔随机化方法来确保我们的实验结果是可靠的并且没有偏见。
首先,我们需要准备我们的实验数据。
我们将创建一个包含用户ID、访问方式和用户行为的数据集。
对于这个示例,我们将假设我们有1000个用户参与了实验,其中500个使用A方式访问,500个使用B方式访问。
接下来,我们需要实现孟德尔随机化方法的代码来提取类群访问数据。
以下是一个例子:pythonimport randomdef extract_clump_access(data, clump_size):clump_a = []clump_b = []for user in data:access_type = user['access_type']if access_type == 'A':clump_a.append(user)elif access_type == 'B':clump_b.append(user)random.shuffle(clump_a)random.shuffle(clump_b)clump_a = clump_a[:clump_size]clump_b = clump_b[:clump_size]return clump_a, clump_b# Usage exampledata = [{'user_id': 1, 'access_type': 'A', 'behavior': 'click'},{'user_id': 2, 'access_type': 'A', 'behavior': 'browse'},{'user_id': 3, 'access_type': 'B', 'behavior': 'purchase'},{'user_id': 4, 'access_type': 'B', 'behavior': 'click'}]clump_a, clump_b = extract_clump_access(data, 100)在上述代码中,我们首先创建了两个空的列表来存储根据访问方式提取的类群数据。
ACM-GIS%202006-A%20Peer-to-Peer%20Spatial%20Cloaking%20Algorithm%20for%20Anonymous%20Location-based%

A Peer-to-Peer Spatial Cloaking Algorithm for AnonymousLocation-based Services∗Chi-Yin Chow Department of Computer Science and Engineering University of Minnesota Minneapolis,MN cchow@ Mohamed F.MokbelDepartment of ComputerScience and EngineeringUniversity of MinnesotaMinneapolis,MNmokbel@Xuan LiuIBM Thomas J.WatsonResearch CenterHawthorne,NYxuanliu@ABSTRACTThis paper tackles a major privacy threat in current location-based services where users have to report their ex-act locations to the database server in order to obtain their desired services.For example,a mobile user asking about her nearest restaurant has to report her exact location.With untrusted service providers,reporting private location in-formation may lead to several privacy threats.In this pa-per,we present a peer-to-peer(P2P)spatial cloaking algo-rithm in which mobile and stationary users can entertain location-based services without revealing their exact loca-tion information.The main idea is that before requesting any location-based service,the mobile user will form a group from her peers via single-hop communication and/or multi-hop routing.Then,the spatial cloaked area is computed as the region that covers the entire group of peers.Two modes of operations are supported within the proposed P2P spa-tial cloaking algorithm,namely,the on-demand mode and the proactive mode.Experimental results show that the P2P spatial cloaking algorithm operated in the on-demand mode has lower communication cost and better quality of services than the proactive mode,but the on-demand incurs longer response time.Categories and Subject Descriptors:H.2.8[Database Applications]:Spatial databases and GISGeneral Terms:Algorithms and Experimentation. Keywords:Mobile computing,location-based services,lo-cation privacy and spatial cloaking.1.INTRODUCTIONThe emergence of state-of-the-art location-detection de-vices,e.g.,cellular phones,global positioning system(GPS) devices,and radio-frequency identification(RFID)chips re-sults in a location-dependent information access paradigm,∗This work is supported in part by the Grants-in-Aid of Re-search,Artistry,and Scholarship,University of Minnesota. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on thefirst page.To copy otherwise,to republish,to post on servers or to redistribute to lists,requires prior specific permission and/or a fee.ACM-GIS’06,November10-11,2006,Arlington,Virginia,USA. Copyright2006ACM1-59593-529-0/06/0011...$5.00.known as location-based services(LBS)[30].In LBS,mobile users have the ability to issue location-based queries to the location-based database server.Examples of such queries include“where is my nearest gas station”,“what are the restaurants within one mile of my location”,and“what is the traffic condition within ten minutes of my route”.To get the precise answer of these queries,the user has to pro-vide her exact location information to the database server. With untrustworthy servers,adversaries may access sensi-tive information about specific individuals based on their location information and issued queries.For example,an adversary may check a user’s habit and interest by knowing the places she visits and the time of each visit,or someone can track the locations of his ex-friends.In fact,in many cases,GPS devices have been used in stalking personal lo-cations[12,39].To tackle this major privacy concern,three centralized privacy-preserving frameworks are proposed for LBS[13,14,31],in which a trusted third party is used as a middleware to blur user locations into spatial regions to achieve k-anonymity,i.e.,a user is indistinguishable among other k−1users.The centralized privacy-preserving frame-work possesses the following shortcomings:1)The central-ized trusted third party could be the system bottleneck or single point of failure.2)Since the centralized third party has the complete knowledge of the location information and queries of all users,it may pose a serious privacy threat when the third party is attacked by adversaries.In this paper,we propose a peer-to-peer(P2P)spatial cloaking algorithm.Mobile users adopting the P2P spatial cloaking algorithm can protect their privacy without seeking help from any centralized third party.Other than the short-comings of the centralized approach,our work is also moti-vated by the following facts:1)The computation power and storage capacity of most mobile devices have been improv-ing at a fast pace.2)P2P communication technologies,such as IEEE802.11and Bluetooth,have been widely deployed.3)Many new applications based on P2P information shar-ing have rapidly taken shape,e.g.,cooperative information access[9,32]and P2P spatio-temporal query processing[20, 24].Figure1gives an illustrative example of P2P spatial cloak-ing.The mobile user A wants tofind her nearest gas station while beingfive anonymous,i.e.,the user is indistinguish-able amongfive users.Thus,the mobile user A has to look around andfind other four peers to collaborate as a group. In this example,the four peers are B,C,D,and E.Then, the mobile user A cloaks her exact location into a spatialA B CDEBase Stationregion that covers the entire group of mobile users A ,B ,C ,D ,and E .The mobile user A randomly selects one of the mobile users within the group as an agent .In the ex-ample given in Figure 1,the mobile user D is selected as an agent.Then,the mobile user A sends her query (i.e.,what is the nearest gas station)along with her cloaked spa-tial region to the agent.The agent forwards the query to the location-based database server through a base station.Since the location-based database server processes the query based on the cloaked spatial region,it can only give a list of candidate answers that includes the actual answers and some false positives.After the agent receives the candidate answers,it forwards the candidate answers to the mobile user A .Finally,the mobile user A gets the actual answer by filtering out all the false positives.The proposed P2P spatial cloaking algorithm can operate in two modes:on-demand and proactive .In the on-demand mode,mobile clients execute the cloaking algorithm when they need to access information from the location-based database server.On the other side,in the proactive mode,mobile clients periodically look around to find the desired number of peers.Thus,they can cloak their exact locations into spatial regions whenever they want to retrieve informa-tion from the location-based database server.In general,the contributions of this paper can be summarized as follows:1.We introduce a distributed system architecture for pro-viding anonymous location-based services (LBS)for mobile users.2.We propose the first P2P spatial cloaking algorithm for mobile users to entertain high quality location-based services without compromising their privacy.3.We provide experimental evidence that our proposed algorithm is efficient in terms of the response time,is scalable to large numbers of mobile clients,and is effective as it provides high-quality services for mobile clients without the need of exact location information.The rest of this paper is organized as follows.Section 2highlights the related work.The system model of the P2P spatial cloaking algorithm is presented in Section 3.The P2P spatial cloaking algorithm is described in Section 4.Section 5discusses the integration of the P2P spatial cloak-ing algorithm with privacy-aware location-based database servers.Section 6depicts the experimental evaluation of the P2P spatial cloaking algorithm.Finally,Section 7con-cludes this paper.2.RELATED WORKThe k -anonymity model [37,38]has been widely used in maintaining privacy in databases [5,26,27,28].The main idea is to have each tuple in the table as k -anonymous,i.e.,indistinguishable among other k −1tuples.Although we aim for the similar k -anonymity model for the P2P spatial cloaking algorithm,none of these techniques can be applied to protect user privacy for LBS,mainly for the following four reasons:1)These techniques preserve the privacy of the stored data.In our model,we aim not to store the data at all.Instead,we store perturbed versions of the data.Thus,data privacy is managed before storing the data.2)These approaches protect the data not the queries.In anonymous LBS,we aim to protect the user who issues the query to the location-based database server.For example,a mobile user who wants to ask about her nearest gas station needs to pro-tect her location while the location information of the gas station is not protected.3)These approaches guarantee the k -anonymity for a snapshot of the database.In LBS,the user location is continuously changing.Such dynamic be-havior calls for continuous maintenance of the k -anonymity model.(4)These approaches assume a unified k -anonymity requirement for all the stored records.In our P2P spatial cloaking algorithm,k -anonymity is a user-specified privacy requirement which may have a different value for each user.Motivated by the privacy threats of location-detection de-vices [1,4,6,40],several research efforts are dedicated to protect the locations of mobile users (e.g.,false dummies [23],landmark objects [18],and location perturbation [10,13,14]).The most closed approaches to ours are two centralized spatial cloaking algorithms,namely,the spatio-temporal cloaking [14]and the CliqueCloak algorithm [13],and one decentralized privacy-preserving algorithm [23].The spatio-temporal cloaking algorithm [14]assumes that all users have the same k -anonymity requirements.Furthermore,it lacks the scalability because it deals with each single request of each user individually.The CliqueCloak algorithm [13]as-sumes a different k -anonymity requirement for each user.However,since it has large computation overhead,it is lim-ited to a small k -anonymity requirement,i.e.,k is from 5to 10.A decentralized privacy-preserving algorithm is proposed for LBS [23].The main idea is that the mobile client sends a set of false locations,called dummies ,along with its true location to the location-based database server.However,the disadvantages of using dummies are threefold.First,the user has to generate realistic dummies to pre-vent the adversary from guessing its true location.Second,the location-based database server wastes a lot of resources to process the dummies.Finally,the adversary may esti-mate the user location by using cellular positioning tech-niques [34],e.g.,the time-of-arrival (TOA),the time differ-ence of arrival (TDOA)and the direction of arrival (DOA).Although several existing distributed group formation al-gorithms can be used to find peers in a mobile environment,they are not designed for privacy preserving in LBS.Some algorithms are limited to only finding the neighboring peers,e.g.,lowest-ID [11],largest-connectivity (degree)[33]and mobility-based clustering algorithms [2,25].When a mo-bile user with a strict privacy requirement,i.e.,the value of k −1is larger than the number of neighboring peers,it has to enlist other peers for help via multi-hop routing.Other algorithms do not have this limitation,but they are designed for grouping stable mobile clients together to facil-Location-based Database ServerDatabase ServerDatabase ServerFigure 2:The system architectureitate efficient data replica allocation,e.g.,dynamic connec-tivity based group algorithm [16]and mobility-based clus-tering algorithm,called DRAM [19].Our work is different from these approaches in that we propose a P2P spatial cloaking algorithm that is dedicated for mobile users to dis-cover other k −1peers via single-hop communication and/or via multi-hop routing,in order to preserve user privacy in LBS.3.SYSTEM MODELFigure 2depicts the system architecture for the pro-posed P2P spatial cloaking algorithm which contains two main components:mobile clients and location-based data-base server .Each mobile client has its own privacy profile that specifies its desired level of privacy.A privacy profile includes two parameters,k and A min ,k indicates that the user wants to be k -anonymous,i.e.,indistinguishable among k users,while A min specifies the minimum resolution of the cloaked spatial region.The larger the value of k and A min ,the more strict privacy requirements a user needs.Mobile users have the ability to change their privacy profile at any time.Our employed privacy profile matches the privacy re-quirements of mobiles users as depicted by several social science studies (e.g.,see [4,15,17,22,29]).In this architecture,each mobile user is equipped with two wireless network interface cards;one of them is dedicated to communicate with the location-based database server through the base station,while the other one is devoted to the communication with other peers.A similar multi-interface technique has been used to implement IP multi-homing for stream control transmission protocol (SCTP),in which a machine is installed with multiple network in-terface cards,and each assigned a different IP address [36].Similarly,in mobile P2P cooperation environment,mobile users have a network connection to access information from the server,e.g.,through a wireless modem or a base station,and the mobile users also have the ability to communicate with other peers via a wireless LAN,e.g.,IEEE 802.11or Bluetooth [9,24,32].Furthermore,each mobile client is equipped with a positioning device, e.g.,GPS or sensor-based local positioning systems,to determine its current lo-cation information.4.P2P SPATIAL CLOAKINGIn this section,we present the data structure and the P2P spatial cloaking algorithm.Then,we describe two operation modes of the algorithm:on-demand and proactive .4.1Data StructureThe entire system area is divided into grid.The mobile client communicates with each other to discover other k −1peers,in order to achieve the k -anonymity requirement.TheAlgorithm 1P2P Spatial Cloaking:Request Originator m 1:Function P2PCloaking-Originator (h ,k )2://Phase 1:Peer searching phase 3:The hop distance h is set to h4:The set of discovered peers T is set to {∅},and the number ofdiscovered peers k =|T |=05:while k <k −1do6:Broadcast a FORM GROUP request with the parameter h (Al-gorithm 2gives the response of each peer p that receives this request)7:T is the set of peers that respond back to m by executingAlgorithm 28:k =|T |;9:if k <k −1then 10:if T =T then 11:Suspend the request 12:end if 13:h ←h +1;14:T ←T ;15:end if 16:end while17://Phase 2:Location adjustment phase 18:for all T i ∈T do19:|mT i .p |←the greatest possible distance between m and T i .pby considering the timestamp of T i .p ’s reply and maximum speed20:end for21://Phase 3:Spatial cloaking phase22:Form a group with k −1peers having the smallest |mp |23:h ←the largest hop distance h p of the selected k −1peers 24:Determine a grid area A that covers the entire group 25:if A <A min then26:Extend the area of A till it covers A min 27:end if28:Randomly select a mobile client of the group as an agent 29:Forward the query and A to the agentmobile client can thus blur its exact location into a cloaked spatial region that is the minimum grid area covering the k −1peers and itself,and satisfies A min as well.The grid area is represented by the ID of the left-bottom and right-top cells,i.e.,(l,b )and (r,t ).In addition,each mobile client maintains a parameter h that is the required hop distance of the last peer searching.The initial value of h is equal to one.4.2AlgorithmFigure 3gives a running example for the P2P spatial cloaking algorithm.There are 15mobile clients,m 1to m 15,represented as solid circles.m 8is the request originator,other black circles represent the mobile clients received the request from m 8.The dotted circles represent the commu-nication range of the mobile client,and the arrow represents the movement direction.Algorithms 1and 2give the pseudo code for the request originator (denoted as m )and the re-quest receivers (denoted as p ),respectively.In general,the algorithm consists of the following three phases:Phase 1:Peer searching phase .The request origina-tor m wants to retrieve information from the location-based database server.m first sets h to h ,a set of discovered peers T to {∅}and the number of discovered peers k to zero,i.e.,|T |.(Lines 3to 4in Algorithm 1).Then,m broadcasts a FORM GROUP request along with a message sequence ID and the hop distance h to its neighboring peers (Line 6in Algorithm 1).m listens to the network and waits for the reply from its neighboring peers.Algorithm 2describes how a peer p responds to the FORM GROUP request along with a hop distance h and aFigure3:P2P spatial cloaking algorithm.Algorithm2P2P Spatial Cloaking:Request Receiver p1:Function P2PCloaking-Receiver(h)2://Let r be the request forwarder3:if the request is duplicate then4:Reply r with an ACK message5:return;6:end if7:h p←1;8:if h=1then9:Send the tuple T=<p,(x p,y p),v maxp ,t p,h p>to r10:else11:h←h−1;12:Broadcast a FORM GROUP request with the parameter h 13:T p is the set of peers that respond back to p14:for all T i∈T p do15:T i.h p←T i.h p+1;16:end for17:T p←T p∪{<p,(x p,y p),v maxp ,t p,h p>};18:Send T p back to r19:end ifmessage sequence ID from another peer(denoted as r)that is either the request originator or the forwarder of the re-quest.First,p checks if it is a duplicate request based on the message sequence ID.If it is a duplicate request,it sim-ply replies r with an ACK message without processing the request.Otherwise,p processes the request based on the value of h:Case1:h= 1.p turns in a tuple that contains its ID,current location,maximum movement speed,a timestamp and a hop distance(it is set to one),i.e.,< p,(x p,y p),v max p,t p,h p>,to r(Line9in Algorithm2). Case2:h> 1.p decrements h and broadcasts the FORM GROUP request with the updated h and the origi-nal message sequence ID to its neighboring peers.p keeps listening to the network,until it collects the replies from all its neighboring peers.After that,p increments the h p of each collected tuple,and then it appends its own tuple to the collected tuples T p.Finally,it sends T p back to r (Lines11to18in Algorithm2).After m collects the tuples T from its neighboring peers, if m cannotfind other k−1peers with a hop distance of h,it increments h and re-broadcasts the FORM GROUP request along with a new message sequence ID and h.m repeatedly increments h till itfinds other k−1peers(Lines6to14in Algorithm1).However,if mfinds the same set of peers in two consecutive broadcasts,i.e.,with hop distances h and h+1,there are not enough connected peers for m.Thus, m has to relax its privacy profile,i.e.,use a smaller value of k,or to be suspended for a period of time(Line11in Algorithm1).Figures3(a)and3(b)depict single-hop and multi-hop peer searching in our running example,respectively.In Fig-ure3(a),the request originator,m8,(e.g.,k=5)canfind k−1peers via single-hop communication,so m8sets h=1. Since h=1,its neighboring peers,m5,m6,m7,m9,m10, and m11,will not further broadcast the FORM GROUP re-quest.On the other hand,in Figure3(b),m8does not connect to k−1peers directly,so it has to set h>1.Thus, its neighboring peers,m7,m10,and m11,will broadcast the FORM GROUP request along with a decremented hop dis-tance,i.e.,h=h−1,and the original message sequence ID to their neighboring peers.Phase2:Location adjustment phase.Since the peer keeps moving,we have to capture the movement between the time when the peer sends its tuple and the current time. For each received tuple from a peer p,the request originator, m,determines the greatest possible distance between them by an equation,|mp |=|mp|+(t c−t p)×v max p,where |mp|is the Euclidean distance between m and p at time t p,i.e.,|mp|=(x m−x p)2+(y m−y p)2,t c is the currenttime,t p is the timestamp of the tuple and v maxpis the maximum speed of p(Lines18to20in Algorithm1).In this paper,a conservative approach is used to determine the distance,because we assume that the peer will move with the maximum speed in any direction.If p gives its movement direction,m has the ability to determine a more precise distance between them.Figure3(c)illustrates that,for each discovered peer,the circle represents the largest region where the peer can lo-cate at time t c.The greatest possible distance between the request originator m8and its discovered peer,m5,m6,m7, m9,m10,or m11is represented by a dotted line.For exam-ple,the distance of the line m8m 11is the greatest possible distance between m8and m11at time t c,i.e.,|m8m 11|. Phase3:Spatial cloaking phase.In this phase,the request originator,m,forms a virtual group with the k−1 nearest peers,based on the greatest possible distance be-tween them(Line22in Algorithm1).To adapt to the dynamic network topology and k-anonymity requirement, m sets h to the largest value of h p of the selected k−1 peers(Line15in Algorithm1).Then,m determines the minimum grid area A covering the entire group(Line24in Algorithm1).If the area of A is less than A min,m extends A,until it satisfies A min(Lines25to27in Algorithm1). Figure3(c)gives the k−1nearest peers,m6,m7,m10,and m11to the request originator,m8.For example,the privacy profile of m8is(k=5,A min=20cells),and the required cloaked spatial region of m8is represented by a bold rectan-gle,as depicted in Figure3(d).To issue the query to the location-based database server anonymously,m randomly selects a mobile client in the group as an agent(Line28in Algorithm1).Then,m sendsthe query along with the cloaked spatial region,i.e.,A,to the agent(Line29in Algorithm1).The agent forwards thequery to the location-based database server.After the serverprocesses the query with respect to the cloaked spatial re-gion,it sends a list of candidate answers back to the agent.The agent forwards the candidate answer to m,and then mfilters out the false positives from the candidate answers. 4.3Modes of OperationsThe P2P spatial cloaking algorithm can operate in twomodes,on-demand and proactive.The on-demand mode:The mobile client only executesthe algorithm when it needs to retrieve information from the location-based database server.The algorithm operatedin the on-demand mode generally incurs less communica-tion overhead than the proactive mode,because the mobileclient only executes the algorithm when necessary.However,it suffers from a longer response time than the algorithm op-erated in the proactive mode.The proactive mode:The mobile client adopting theproactive mode periodically executes the algorithm in back-ground.The mobile client can cloak its location into a spa-tial region immediately,once it wants to communicate withthe location-based database server.The proactive mode pro-vides a better response time than the on-demand mode,but it generally incurs higher communication overhead and giveslower quality of service than the on-demand mode.5.ANONYMOUS LOCATION-BASEDSERVICESHaving the spatial cloaked region as an output form Algo-rithm1,the mobile user m sends her request to the location-based server through an agent p that is randomly selected.Existing location-based database servers can support onlyexact point locations rather than cloaked regions.In or-der to be able to work with a spatial region,location-basedservers need to be equipped with a privacy-aware queryprocessor(e.g.,see[29,31]).The main idea of the privacy-aware query processor is to return a list of candidate answerrather than the exact query answer.Then,the mobile user m willfilter the candidate list to eliminate its false positives andfind its exact answer.The tighter the spatial cloaked re-gion,the lower is the size of the candidate answer,and hencethe better is the performance of the privacy-aware query processor.However,tight cloaked regions may represent re-laxed privacy constrained.Thus,a trade-offbetween the user privacy and the quality of service can be achieved[31]. Figure4(a)depicts such scenario by showing the data stored at the server side.There are32target objects,i.e., gas stations,T1to T32represented as black circles,the shaded area represents the spatial cloaked area of the mo-bile client who issued the query.For clarification,the actual mobile client location is plotted in Figure4(a)as a black square inside the cloaked area.However,such information is neither stored at the server side nor revealed to the server. The privacy-aware query processor determines a range that includes all target objects that are possibly contributing to the answer given that the actual location of the mobile client could be anywhere within the shaded area.The range is rep-resented as a bold rectangle,as depicted in Figure4(b).The server sends a list of candidate answers,i.e.,T8,T12,T13, T16,T17,T21,and T22,back to the agent.The agent next for-(a)Server Side(b)Client SideFigure4:Anonymous location-based services wards the candidate answers to the requesting mobile client either through single-hop communication or through multi-hop routing.Finally,the mobile client can get the actualanswer,i.e.,T13,byfiltering out the false positives from thecandidate answers.The algorithmic details of the privacy-aware query proces-sor is beyond the scope of this paper.Interested readers are referred to[31]for more details.6.EXPERIMENTAL RESULTSIn this section,we evaluate and compare the scalabilityand efficiency of the P2P spatial cloaking algorithm in boththe on-demand and proactive modes with respect to the av-erage response time per query,the average number of mes-sages per query,and the size of the returned candidate an-swers from the location-based database server.The queryresponse time in the on-demand mode is defined as the timeelapsed between a mobile client starting to search k−1peersand receiving the candidate answers from the agent.On theother hand,the query response time in the proactive mode is defined as the time elapsed between a mobile client startingto forward its query along with the cloaked spatial regionto the agent and receiving the candidate answers from theagent.The simulation model is implemented in C++usingCSIM[35].In all the experiments in this section,we consider an in-dividual random walk model that is based on“random way-point”model[7,8].At the beginning,the mobile clientsare randomly distributed in a spatial space of1,000×1,000square meters,in which a uniform grid structure of100×100cells is constructed.Each mobile client randomly chooses itsown destination in the space with a randomly determined speed s from a uniform distribution U(v min,v max).When the mobile client reaches the destination,it comes to a stand-still for one second to determine its next destination.Afterthat,the mobile client moves towards its new destinationwith another speed.All the mobile clients repeat this move-ment behavior during the simulation.The time interval be-tween two consecutive queries generated by a mobile client follows an exponential distribution with a mean of ten sec-onds.All the experiments consider one half-duplex wirelesschannel for a mobile client to communicate with its peers with a total bandwidth of2Mbps and a transmission range of250meters.When a mobile client wants to communicate with other peers or the location-based database server,it has to wait if the requested channel is busy.In the simulated mobile environment,there is a centralized location-based database server,and one wireless communication channel between the location-based database server and the mobile。
无选择策略的改进蜜蜂群算法

能策 略搜 索 问题 解 空 间 的 算 法 。 常 见 的启 发 式 算
法 包括 微 粒 群 算 法 4 、 群 算 法 刮 和 蜜 蜂 群 算 。蚁 法 等 。
目前 , 由于 蜜蜂 群 体智 能行 为 的高 效 性 及 采 用 蜜 蜂各 种 行 为 的智 能 搜 索 策 略搜 索 问 题 解 空 间 的 算 法研 究 还 处 于 初 级 阶段 , 此 , 于 蜜 蜂 群 算 法 因 对
的研 究 已经 被越来 越 多 的学者 所关 注 。
式 )提 出 了新 的蜂 群 算 法 ( B ) 。 后 , ayn , A C¨ 随 H ia Q a ] A C算法 进行 了 四点 改进 : 1 u n1 对 B 3 ( )改 进 了
更新 公式 t f = ,
,
f
,
({ — , ( 中 .随机 , f 其 f ) 、 j } 的 随机 产 生 区 间变 到
其受工蜂分工 的不 同将搜索空间的解分为引领蜂 ,
侦察 蜂 、 随 蜂 。算 法 初 始 时 , 侦 察 蜂 随 机 搜 索 跟 让
收 稿 日期 :0 1 3 7 21- - 00
进使得所有解快速收敛 于一点 。 文献 [4 1 ]对 A C B
算法 做 了新 的改进 : 1 ( )改 进 了初 始解 的生 成方 法 。
文献 [ ] 据 蜜 蜂 的交 配行 为 , 用 类 似 于遗 8根 采 传算 法 中个 体 间 的作 用 方 式 ( 制 、 叉 和 变 异 算 复 交 子) 设计 个体 之 间 的作 用 关 系 。文 献 [-O 对其 进 9l ]
行 了改进 。而 很 多 学 者 发 现 蜜 蜂 的觅 食 行 为 具 有
field crops research 校稿 -回复

field crops research 校稿-回复以下是一篇关于田间作物研究的1500-2000字文章:田间作物研究[Field Crops Research]导言[Introduction]:田间作物研究是农业科学的一个重要分支,旨在提高农作物的产量和质量,以满足日益增长的人口需求和粮食安全的挑战。
通过对不同农作物、品种和种植技术的研究,农业科学家们致力于实现农作物的优化生长、适应环境变化和抗逆性,以及降低农药使用和提高耐旱能力,从而推动农业的可持续发展。
主体[Body]:1.农作物选择和品种选育[Crop Selection and Breeding]:田间作物研究的首要任务之一是选择适合特定地区的农作物和品种。
不同地理和气候条件下,不同的作物和品种可能具有不同的适应性。
通过研究,科学家们可以了解各种作物和品种对于光照、温度、土壤pH、水分和营养需求的差异,并确定最佳的种植条件。
此外,农作物品种选育也是田间作物研究的重要方面。
通过研究和改良,科学家们努力培育出具有高产、抗虫、抗病、耐旱或适应低温的农作物新品种。
这样的品种可以在不同的环境条件下获得较高的产量,减少农药使用并提高作物抗逆性。
2.土壤改良和营养管理[Soil Improvement and Nutrient Management]:为了提高农作物的产量和质量,农业科学家们必须研究如何改良土壤质量,并有效管理土壤中的营养素。
一种方法是对土壤进行分析,了解其物理、化学和生物特性。
改善土壤的方法包括施加有机肥料、使用土壤改良剂和实施轮作。
有机肥料可以增加土壤有机质含量,提高土壤保水能力和保持性。
同时,适当使用土壤改良剂可以改善土壤结构,增加通气性和及时排水能力。
轮作可以帮助减少土壤退化,增加微生物生物多样性,并减少病虫害的发生。
营养素管理是另一个重要的研究领域,在保证农作物的正常生长发育过程中极为关键。
通过研究植物对不同营养元素的需求,科学家可以制定最佳的施肥方案,以确保作物获得足够的营养。
deb-abc算法公式

deb-abc算法公式
ABC算法是一种基于蜜蜂的觅食行为的优化算法。
其名称ABC来自于英文单词"artificial bee colony",意味着"人工蜂群"。
ABC算法模拟了蜜蜂在觅食过程中的三种角色,即雇佣蜂(employed bee),侦察蜂(onlooker bee)和侦察蜂(scout bee)。
ABC算法的公式可以概括为以下几个步骤:
1.初始化蜜蜂种群和目标函数:随机生成一定数量的候选解(蜜蜂个体)以及对应的目标函数值。
2.雇佣蜂阶段:每个雇佣蜂根据自己当前位置计算一个新的解,并通过比较新解和旧解的目标函数值来选择更优的解。
3.侦察蜂阶段:对于那些经过一定次数的迭代后目标函数值没有更新的蜜蜂,将其位置重新随机设定,以搜索更广阔的解空间。
4.侦察蜂选择最佳解:侦察蜂根据雇佣蜂的结果以概率的方式选择最佳的解,并在下一轮迭代中继续进行搜索。
5.更新最佳解:将找到的最佳解与当前最佳解进行比较,如果新解更优,则更新最佳解。
6.结束判断:当满足终止条件时,停止迭代,否则返回步骤2。
ABC算法具有全局搜索能力和较好的收敛性,并且不需要对目标函数进行求导。
它适用于解决各种优化问题,如函数优化、组合优化和参数优化等。
同时,由于其简单有效的原理,ABC算法也可以进行拓展和改进,例如加入自适应策略、动态调整参数、引入启发式信息等,以提高算法的性能和收敛速度。
seedv 实验室 范式 -回复

seedv 实验室范式-回复实验室范式作为科学研究的基石,对推动科学和技术进步起着重要作用。
在本文中,我们将从实验室范式的定义和特征开始讨论,然后探讨其在科学研究中的重要性和必要性,最后介绍一些实验室范式的应用和发展趋势。
实验室范式可以定义为科学研究中的基本理论和实践模式。
它涵盖了一系列实验设计、数据收集和分析等方法,以及科学研究中广泛认可的标准和规范。
这些标准和规范旨在确保科学研究的结果可靠性、可重复性和可验证性。
实验室范式的特征之一是实验设计的重要性。
科学研究往往需要通过实验来验证和检验假设。
而实验设计是确保实验过程符合科学原则的关键。
合理的实验设计应该能够控制和操纵研究变量,最大程度地排除其他干扰因素的影响,从而得到可靠的实验结果。
另一个特征是数据的收集和分析。
科学研究需要通过收集和记录实验数据,然后通过统计分析等方法对数据进行解读和推理。
科学研究中广泛应用的数据分析方法包括描述统计、推断统计和回归分析等。
这些方法的应用可以帮助研究人员得出合理的结论,并对科学理论进行验证和修正。
实验室范式的重要性不言而喻。
首先,实验室范式确保了科学研究的结果的可靠性和可重复性。
通过遵循一定的实验标准和规范,科学家们能够确保其实验结果的准确性,并使其他研究人员能够在相同的实验条件下复制和验证这些结果。
这一特性是科学发展的基础,也是确保科学研究质量的关键。
其次,实验室范式对于科学研究的发展和创新至关重要。
在实验室范式的指导下,科学家们能够系统地进行科学探索,从中发现新的事实和现象,推动科学知识的积累和创新。
只有通过遵循科学实践的规范和标准,科学研究才能够保持其独特和独立性,并为科学家们提供一个共同的平台来交流和合作。
实验室范式在现代科学研究中有多种应用。
在物理学、化学、生物学等基础科学领域,实验室范式的应用非常广泛。
例如,物理学中的实验室范式包括设计实验、收集数据和分析结果等;在化学实验室中,实验室范式用于确保化学反应的安全性和有效性;生物学研究中的实验室范式则包括对生物样本的处理和分析等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
www.seeds.isevs@Phone: +354-8456178 _____________________________________________________________________________________________EVS – European Voluntary Service at SEEDS in Iceland.We, at SEEDS, are looking for motivated and enthusiastic young people. Your answers to the following questions will help us to have an idea about you, your motivations, your expectations, your needs and your future projects.Please answer all the following questions in English (do not worry about mistakes –they won’t count against you!), be short and precise, answers do not need to be long and extensive.Feel free to add any other information you may find relevant to be taken into account during our selection process, while reviewing your candidature:Biographical dataFamily name:First Name:Address:Phone numbers (landline and mobile please):E-mail:Birth Date:Gender:Place of birth:Nationality:Emergency contact person/people (name, address, phone number & e-mail):Special needs (if so, please specify, eg. Dietary requirements, allergies, medical conditions, etc.): Living situation: Are you currently:Studying:working:unemployed:Sending organisation:Name:Address:Phone:E-mail:Webpage:Contact person (name, position, phone number, e-mail):www.seeds.isevs@Phone: +354-8456178 _____________________________________________________________________________________________ Project(s) applying for? Note that SEEDS hosts and/or coordinates more than one EVS project:1.2.3.Which dates are you available? From? To?1.Please give a short description of yourself, your background, your life at the moment, yourhobbies, past experiences and future plans:2.What is voluntary service for you? What does volunteer mean to you?3.Have you already participated in any voluntary or associative activities? If « yes » where,when, for how long, what type of activity and with which organisations?4.Why would you like to take part in EVS? Why now?5.Do you have any worries or fears about becoming an EVS volunteer? What challenges doyou think you will face?6.Why did you choose Iceland? Why do you want to volunteer in Iceland and not at home?7.Have you already travelled or lived abroad? If « yes » where, when, for what reason and forhow long?8.What kind of difficulties do you think you will face or encounter while living for a longerperiod of time in Iceland as a foreign country to you, with a different culture as yours?www.seeds.isevs@Phone: +354-8456178 _____________________________________________________________________________________________9.What kind of knowledge, strengths or skills you believe you posses that may be usefulduring your voluntary service in Iceland? Where, during the project you are applying for, do you see they will be very useful?10.What kind of knowledge or skills would you like to gain? What would you like to learnwhile volunteering in Iceland?11.Which part of the project(s) you are applying for; you consider could be the mostchallenging one? Why?12.What do you think your contribution will be to the hosting organisation and the project(s)you are applying for?13.Do you have any objection to sharing a room? (If your answer is Yes, please explain why).What do you consider to be the rights and responsibilities of those sharing a house or bedroom?14.Please put in order of preference:Daily contact with the publicHeavy manual workIntellectual workLight manual workTeam workWorking aloneWorking outdoors15. Please put in order of preference your location of accommodation:In a city or large townIn an isolated rural situationIn a small town or villageIn a suburban areawww.seeds.isevs@Phone: +354-8456178 _____________________________________________________________________________________________16.Why do you think you should be selected?17.Do you have a driving licence? If « yes » do you drive a car regularly?18.And finally… How would you describe yourself?We have listed some key words that may help you to describe yourself. Please underline the words which seem to describe you the best and add other words if you wish. You may like to ask a friend to help you.Extroverted introspective fun-loving adventurous noisy untidy studiousmusical artistic leader easy-to-please shy organisedmoody patient dancer reader follower listenertalkative independent quiet tidy early-to-bed flexiblereligious athletic forthright worrier confident prudentcaring stubborn party-goer emotional lacking confidencePlease feel free to include additional information you may find relevant to be taken into account during our selection process, while reviewing your candidature.。