Oracle插入数据时获取自增ID
oracle序列创建语句

oracle序列创建语句Oracle是一种关系型数据库管理系统,提供了多种创建序列的语句。
下面列举了10个常用的Oracle序列创建语句,以及对每个语句的详细解释。
1. CREATE SEQUENCE语句:CREATE SEQUENCE语句用于创建一个新的序列。
序列是一种自增的数字,可用于生成唯一的标识符或主键值。
以下是CREATE SEQUENCE语句的示例:```sqlCREATE SEQUENCE seq_id START WITH 1 INCREMENT BY 1; ```该语句创建了一个名为seq_id的序列,起始值为1,每次递增1。
2. CREATE SEQUENCE...MINVALUE语句:CREATE SEQUENCE...MINVALUE语句用于指定序列的最小值。
以下是CREATE SEQUENCE...MINVALUE语句的示例:```sqlCREATE SEQUENCE seq_id START WITH 1 INCREMENT BY 1 MINVALUE 1;```该语句创建了一个名为seq_id的序列,起始值为1,每次递增1,最小值为1。
3. CREATE SEQUENCE...MAXVALUE语句:CREATE SEQUENCE...MAXVALUE语句用于指定序列的最大值。
以下是CREATE SEQUENCE...MAXVALUE语句的示例:```sqlCREATE SEQUENCE seq_id START WITH 1 INCREMENT BY 1 MAXVALUE 100;```该语句创建了一个名为seq_id的序列,起始值为1,每次递增1,最大值为100。
4. CREATE SEQUENCE...CYCLE语句:CREATE SEQUENCE...CYCLE语句用于指定序列的循环方式。
当序列达到最大值后,会重新从最小值开始递增。
以下是CREATE SEQUENCE...CYCLE语句的示例:```sqlCREATE SEQUENCE seq_id START WITH 1 INCREMENT BY 1 MAXVALUE 10 CYCLE;```该语句创建了一个名为seq_id的序列,起始值为1,每次递增1,最大值为10,循环方式为循环。
oracle中的last_insert_id使用方法

oracle中的last_insert_id使用方法在Oracle数据库中,LAST_INSERT_ID是一个十分实用的功能,它可以返回最近一次插入操作生成的自增主键值。
以下将详细介绍LAST_INSERT_ID 的使用方法、应用场景及其实用性。
1.Oracle中LAST_INSERT_ID的作用LAST_INSERT_ID主要用于获取最近一次插入操作生成的自增主键值。
在Oracle数据库中,当执行插入操作时,系统会自动为插入的数据生成一个自增主键。
通过LAST_INSERT_ID,我们可以获取到这个自增主键值,以便于后续处理。
ST_INSERT_ID的用法示例在Oracle中,可以使用如下语法调用LAST_INSERT_ID:```SELECT LAST_INSERT_ID();```例如,假设我们有一个名为`test_table`的表,其中有一个自增主键`id`,我们可以通过以下语句插入一条数据并获取插入后的主键值:```sqlINSERT INTO test_table (name, age) VALUES ("张三", 25);SELECT LAST_INSERT_ID();```执行上述语句后,我们可以在后续查询中使用获取到的自增主键值:```sqlSELECT * FROM test_table WHERE id = (SELECT LAST_INSERT_ID());```3.与其他插入语句的区别在Oracle中,LAST_INSERT_ID与普通的插入语句有所不同。
普通的插入语句仅能插入数据,而不能直接获取插入操作生成的自增主键值。
使用LAST_INSERT_ID可以让我们在插入数据的同时,获取到对应的自增主键,提高了操作便利性。
4.应用场景及实用性LAST_INSERT_ID在以下场景中具有较高的实用性:- 当需要对插入的数据进行后续处理时,如插入数据后需要更新其他表或执行其他操作,可以使用LAST_INSERT_ID获取自增主键,便于后续处理。
oralce 表结构自增长列 autoincrement

oralce表结构自增长列autoincrement在Oracle中,实现自增长列(Auto Increment)的功能通常使用序列(Sequence)和触发器(Trigger)。
Oracle没有像某些数据库(如MySQL)中的AUTO_INCREMENT 关键字来直接定义自增长列,但可以通过序列和触发器来实现类似的功能。
以下是使用序列和触发器在Oracle中创建自增长列的基本步骤:1.创建序列(Sequence):CREATE SEQUENCE your_sequence_nameSTART WITH 1INCREMENT BY 1NOMAXVALUE;这将创建一个名为your_sequence_name的序列,起始值为1,每次递增1。
2.创建表并使用触发器(Trigger)关联序列:CREATE TABLE your_table_name(id NUMBER PRIMARY KEY,other_columns...--其他列);CREATE OR REPLACE TRIGGER your_trigger_nameBEFORE INSERT ON your_table_nameFOR EACH ROWBEGINSELECT your_sequence_name.NEXTVAL INTO:new.id FROM dual;END;这里创建了一个名为your_table_name的表,其中id列被定义为主键,并且在表中创建了一个名为your_trigger_name的触发器。
该触发器会在每次插入新行之前触发,并使用序列your_sequence_name的NEXTVAL值为id列赋予新值。
通过以上步骤,在向表中插入数据时,id列将自动从序列中获取下一个值作为自增长的主键值。
mysql 数据库自增id 的总结

mysql 数据库自增id 的总结有一个表StuInfo,里面只有两列StuID,StuName其中StuID是int型,主键,自增列。
现在我要插入数据,让他自动的向上增长,insert into StuInfo(StuID,StuName) values(????) 如何写?INSERT INTO StuInfo(StuID,StuName) V ALUES (NULL, `字符`)或者INSERT INTO StuInfo(StuName) V ALUES (`字符`)INSERT和REPLACE语句的功能都是向表中插入新的数据。
这两条语句的语法类似。
它们的主要区别是如何处理重复的数据。
1INSERT的一般用法MySQL中的INSERT语句和标准的INSERT不太一样,在标准的SQL语句中,一次插入一条记录的INSERT语句只有一种形式。
INSERT INTO tablename(列名…) V ALUES(列值);而在MySQL中还有另外一种形式。
INSERT INTO tablename SET column_name1 = value1, column_name2 = value2,…;第一种方法将列名和列值分开了,在使用时,列名必须和列值的数一致。
如下面的语句向users表中插入了一条记录:INSERT INTO users(id, name, age) V ALUES(123, '姚明', 25);第二种方法允许列名和列值成对出现和使用,如下面的语句将产生中样的效果。
INSERT INTO users SET id = 123, name = '姚明', age = 25;如果使用了SET方式,必须至少为一列赋值。
如果某一个字段使用了省缺值(如默认或自增值),这两种方法都可以省略这些字段。
如id字段上使用了自增值,上面两条语句可以写成如下形式:INSERT INTO users (name, age) V ALUES('姚明',25);INSERT INTO uses SET name = '姚明', age = 25;MySQL在V ALUES上也做了些变化。
oracle数据库ID自增长--序列

oracle数据库ID⾃增长--序列什么是序列?在mysql中有⼀个主键⾃动增长的id,例如:uid number primary key auto_increment;在oracle中序列就是类似于主键⾃动增长,两者功能是⼀样的,只是叫法不同⽽已。
在oracle中想要实现id⾃动增长只能⽤序列来实现。
在oracle中,是将序列装⼊内存,可以提⾼访问效率。
1.)序列的创建 create sequence 序列名称 increment by n 每次增长多少 //系统默认值为1. start with n从⼏开始 //系统默认值为1. [maxvalue n最⼤值|nomaxvalue] //NoMaxValue:是系统对序列设置的默认值. 即指定升序序列的最⼤值为10的27次⽅.降序序列的最⼤值为-1. [minvalue n最⼩值|nominvalue] //同上 [cycle |nocycle 是否循环] [cache n缓存的数量|nocache] //指定要保留在内存中整数的个数.默认缓存的格式为20个. 可以缓存的整数最少为2个. 可以缓存的整数个数最多为:Cell(maximum_num—minimum_num)/ABS(increment_num). 注:Cell(序列的最⼤上限值—最⼩下限值,)/ABS(每次⾃增的增量).例如:create sequence person_pid_seq increment by 1 start with 1 maxvalue 1000 nocycle nocache; 可以直接创建,其他的选项全部是默认值。
例如:create sequence person_pid_seq;2.)序列的操作序列创建完成之后,所有的⾃动增长就都是由我们⾃⼰操作了,那么如果操作呢?提供了两种⽅式。
2.1 nextval:取得序列的下⼀个值 2.2 currval:取得当前序列的内容注意:currval 需要再nextval调⽤之后才能使⽤3.)序列的使⽤ insert into person values(person_pid_seq.nextval,'name,'adress');//⼀般是利⽤nextval,让id保持⼀直递增。
Oracle创建表并设置主键自增
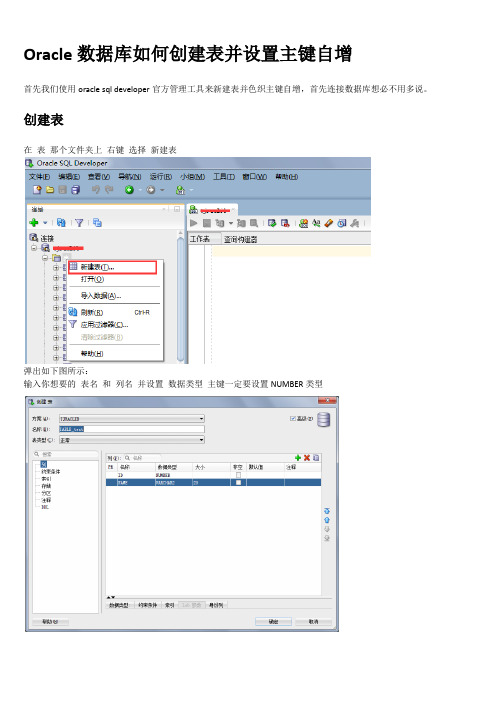
Oracle数据库如何创建表并设置主键自增
首先我们使用oracle sql developer官方管理工具来新建表并色织主键自增,首先连接数据库想必不用多说。
创建表
在表那个文件夹上右键选择新建表
弹出如下图所示:
输入你想要的表名和列名并设置数据类型主键一定要设置NUMBER类型
设置主键
只要在主键那一行单件一下最前面的小方块就行,产生如何所示的效果即可:
主键的标识就是那个小钥匙。
设置主键自增
下面我们设置主键自增,选中主键所在那一行,找到下面的身份列单击(如图所示):
如下图所示看到类型点击下拉菜单选择列序列:
此时系统自动生成触发器和序列不用做任何修改点击确定那个么一个主键自增的表就已经成功的生成了。
测试
下面我们测试一下数据插入是否成功,这里我们直插入name列不插入主键看看主键是否能够自增。
Select一下发现主键确实自动生成并且自增了,如果不放心可以多加几条测试数据,这里我就不多加描述了。
oracle 自动生成的主键索引规则

oracle 自动生成的主键索引规则
在Oracle数据库中,自动生成的主键索引通常遵循以下规则:
1.命名规则:主键索引的名称通常为主键列的名称加上"_PK"后缀。
例如,如果主键列
的名称是"id",则主键索引的名称将是"id_PK"。
2.创建规则:当在表上定义主键约束时,Oracle会自动创建一个唯一索引来确保主键
列的唯一性。
这个唯一索引就是主键索引。
3.存储规则:主键索引的存储方式与普通索引相同。
Oracle将根据表的存储参数和表
的存储类型(例如,表空间、区等)来决定主键索引的存储位置和存储方式。
需要注意的是,在Oracle数据库中,主键约束和主键索引是两个不同的概念。
主键约束用于确保主键列的唯一性,而主键索引则是为了支持主键约束而创建的索引。
尽管它们在功能上是相关的,但它们是不同的数据库对象。
数据库ID自增

数据库ID⾃增hibernate利⽤mysql的⾃增长id属性实现⾃增长id和⼿动赋值id并存 我们知道在中如果设置了表id为⾃增长属性的话,insert语句中如果对id赋值(值没有被⽤到过)了,则插⼊的数据的id会为⽤户设置的值,并且该表的id的最⼤值会重新计算,以插⼊后表的id最⼤值为⾃增值起点 但是如果使⽤,也想实现这个的特性的话,怎么做呢? ⾸先我们看下hibernate的id⽣成策略: hibernate⽂档写道 1、⾃动增长identity适⽤于MySQL、DB2、MS SQL Server,采⽤⽣成的主键,⽤于为long、short、int类型⽣成唯⼀标识使⽤SQL Server 和 MySQL 的⾃增字段,这个⽅法不能放到中,不⽀持⾃增字段,要设定sequence(MySQL 和 SQL Server 中很常⽤)数据库中的语法如下:MySQL:create table t_user(id int auto_increment primary key, name varchar(20));SQL Server:create table t_user(id int identity(1,1) primary key, name varchar(20));< id name="id" column="id" type="long">< generator class="identity" />< /id>2、sequenceDB2、Oracle均⽀持的序列,⽤于为long、short或int⽣成唯⼀标识数据库中的语法如下:Oracle:create sequence seq_name increment by 1 start with 1;需要主键值时可以调⽤seq_name.nextval或者seq_name.curval得到,数据库会帮助我们维护这个sequence序列,保证每次取到的值唯⼀,如:insert into tbl_name(id, name) values(seq_name.nextval, ‘Jimliu’);< id name="id" column="id" type="long">< generator class="sequence">< param name="sequence">seq_name</param>< /generator>< /id>如果我们没有指定sequence参数,则Hibernate会访问⼀个默认的sequence,是hibernate_sequence,我们也需要在数据库中建⽴这个sequence此外,sequence还可以有另外⼀个参数是paramters,可以查看Hibernate的API了解它的⽤法,见org.hibernate.id.SequenceGenerator调⽤数据库的sequence来⽣成主键,要设定序列名,不然hibernate⽆法找到:< param name="sequence">NAME_SEQ</param>(Oracle中很常⽤)3、hilo使⽤⼀个⾼/低位⽣成的long、short或int类型的标识符,给定⼀个表和字段作为⾼位值的来源,默认的表是hibernate_unique_key,默认的字段是next_hi。
详解mysql插入数据后返回自增ID的七种方法

详解mysql插⼊数据后返回⾃增ID的七种⽅法引⾔mysql 和 oracle 插⼊的时候有⼀个很⼤的区别是:oracle ⽀持序列做 id;mysql 本⾝有⼀个列可以做⾃增长字段。
mysql 在插⼊⼀条数据后,如何能获得到这个⾃增 id 的值呢?⼀:使⽤ last_insert_id()SELECT LAST_INSERT_ID();1. 每次 mysql 的 query 操作在 mysql 服务器上可以理解为⼀次“原⼦”操作, 写操作常常需要锁表,这⾥的锁表是 mysql 应⽤服务器锁表不是我们的应⽤程序锁表。
2. 因为 LAST_INSERT_ID 是基于 Connection 的,只要每个线程都使⽤独⽴的 Connection 对象,LAST_INSERT_ID 函数将返回该 Connection 对 AUTO_INCREMENT列最新的 insert or update* 作⽣成的第⼀个 record 的ID。
这个值不能被其它客户端(Connection)影响,保证了你能够找回⾃⼰的 ID ⽽不⽤担⼼其它客户端的活动,⽽且不需要加锁。
使⽤单INSERT 语句插⼊多条记录, LAST_INSERT_ID 返回⼀个列表。
3. LAST_INSERT_ID 是与 table ⽆关的,如果向表 a 插⼊数据后,再向表 b 插⼊数据,LAST_INSERT_ID 会改变。
⼆:使⽤ max(id)如果不是频繁的插⼊我们也可以使⽤这种⽅法来获取返回的id值select max(id) from user;这个⽅法的缺点是不适合⾼并发。
如果同时插⼊的时候返回的值可能不准确。
三:创建⼀个存储过程在存储过程中调⽤先插⼊再获取最⼤值的操作。
DELIMITER $$DROP PROCEDURE IF EXISTS `test` $$CREATE DEFINER=`root`@`localhost` PROCEDURE `test`(in name varchar(100),out oid int)BEGINinsert into user(loginname) values(name);select max(id) from user into oid;select oid;END $$DELIMITER ;call test('gg',@id);四:使⽤ @@identityselect @@IDENTITY@@identity 是表⽰的是最近⼀次向具有 identity 属性(即⾃增列)的表插⼊数据时对应的⾃增列的值,是系统定义的全局变量。
oracle 插入一条数据的rowid生成规则

oracle 插入一条数据的rowid生成规则Oracle 的 rowid 是唯一标识一行数据的一个非常重要的属性,它由以下部分构成:1. 数据对象编号(data object number,也叫文件标识符),用于唯一标识表,索引等对象。
2. 文件块编号(file block number),用于标识数据存储在表空间的哪个块中。
一个完整的 rowid 由 5 个字节组成,如下:AA BB CC DD EE其中,AA BB 是数据对象编号, CC DD 是文件块编号,EE 是行编号。
一般情况下,Oracle 不会把 rowid 暴露给用户,而是通过系统内部使用。
但是,在某些情况下,比如需要快速找到某一行数据的位置时,rowid 可以发挥很大的作用。
1. 如果表为空,直接分配地一个块(block),并将 rowid 设置为 0x0000.0001。
2. 如果表不为空,先在表空间中查找有没有未使用的块(free block),如果没有,就创建一个新的块。
然后,在块中找一个未使用的槽位(slot),作为新数据的存储位置。
3. 当新数据被存储到块中时,Oracle 会为它生成一个不重复并且唯一的行标识号,也就是 rowid。
rowid 的生成规则如下:1)由表的数据对象编号和块编号组成的部分已经确定,因此只需要确定行编号即可。
2)对于表中的第一行数据,Rowid 的偏移地址为(1,0),也就是第一个字节的第1 位(从 0 开始计数)。
4)Oracle 中的 rowid 存储在一块数据块的数据区中,而不是在跟该块相关的索引结构中。
因此,如果要查询一张表中的某个 rowid 所对应的数据行,需要全表扫描,这也是 rowid 不建议在查询过程中使用的原因之一。
总结:通过上述规则的描述,我们可以看出 rowid 具有唯一性,而且可以表明数据行所在的表、块以及行号,但是它只在 Oracle 系统内部使用,不应该直接使用。
oracle中中uuid的生成方法

一、概述在Oracle数据库中,UUID(Universally Unique Identifier)是一种用于识别信息实体的128位数字。
它是一种全局唯一的标识符,可以用来标识数据库中的每条记录,并且不会重复。
二、UUID的生成方法在Oracle中,可以通过以下方法来生成UUID:1. 使用SYS_GUID函数SYS_GUID函数是Oracle数据库提供的一种生成全局唯一标识符的方法。
它会返回一个RAW(16)数据类型的全局唯一标识符。
示例:```sqlSELECT SYS_GUID() FROM dual;```2. 使用UUID_GENERATE函数如果使用的是Oracle 12c及以上版本,可以使用UUID_GENERATE函数来生成UUID。
这个函数会返回一个VARCHAR2类型的全局唯一标识符。
示例:```sqlSELECT UUID_GENERATE() FROM dual;```3. 使用UUID()函数在Oracle 18c及以上版本,可以使用UUID()函数来生成UUID。
这个函数会返回一个VARCHAR2类型的全局唯一标识符。
示例:```sqlSELECT UUID() FROM dual;```三、UUID的用途生成的UUID可以应用在很多领域,比如:1. 数据库主键在数据库中,UUID可以作为主键来唯一标识每条记录,避免了主键冲突的问题。
2. 会话标识符在Web开发中,可以将UUID作为会话标识符来确保用户会话的唯一性。
3. 数据同步在分布式系统中,可以使用UUID来标识不同节点上的数据,实现数据的同步和一致性。
四、UUID的特点UUID具有以下几个特点:1. 全局唯一性生成的UUID是全局唯一的,极小概率会发生重复。
2. 无序性UUID是无序的,不同的UUID之间没有大小和顺序之分。
3. 长度固定UUID的长度是固定的,为128位,可以确保存储空间的高效利用。
五、总结通过以上介绍,我们了解了在Oracle数据库中生成UUID的方法以及UUID的用途和特点。
oracle的lpad函数

oracle的lpad函数在Oracle数据库中,LPAD函数用于将指定的字符串或字符重复添加到另一个字符串的开始位置,直到字符串达到指定的长度。
LPAD函数的语法如下:LPAD(string, length, [pad_string])其中:- string是要操作的字符串。
- length是要返回的字符串的长度。
- pad_string是可选的参数,用于指定要在字符串的开始位置添加的填充字符,默认值为空格。
下面是一些使用LPAD函数的示例:1.将字符串'ABC'的开始位置填充到长度为5的字符串:SELECT LPAD('ABC', 5) FROM dual;输出结果为:'ABC'2.将字符串'ABC'的开始位置填充到长度为5的字符串,填充字符为'Z':SELECT LPAD('ABC', 5, 'Z') FROM dual;输出结果为:'ZZABC'3.将数字123的开始位置填充到长度为5的字符串,填充字符为0:SELECT LPAD(123, 5, 0) FROM dual;4.批量处理数据表中的字符串字段,并将其开始位置填充到长度为10的字符串,填充字符为'*':UPDATE table_name SET column_name = LPAD(column_name, 10, '*');上述示例中,LPAD函数用于将字符串或数字的开始位置填充到指定的长度,以便在数据处理过程中保持一致的格式。
该函数在处理数据的对齐和格式化时非常有用。
oracle里面的rowid用法

oracle里面的rowid用法Rowid是Oracle数据库中的一个特殊数据类型,用于唯一标识数据库表中的每一行数据。
它可以被用于定位和操作特定的记录,尤其在处理大量数据时很有用。
本文将详细介绍Oracle中的rowid用法。
一、什么是rowid?Rowid是Oracle数据库中的一个伪列,它是一个唯一的标识符,用于唯一地标识数据库表中的每一行。
它由多个部分组成,包括文件号、块号、行号等信息,用于定位和访问存储在数据库中的数据。
二、rowid的结构Rowid由几个关键部分组成,包括数据对象号(data object number, DON)、文件号(file number)、块号(block number)、行号(row number)等。
其格式如下:CC.DDDDD其中,AAAA代表数据对象号,占4个字节;BBBB代表文件号,占4个字节;CCCC代表块号,占4个字节;DDDDD代表行号,占6个字节。
三、rowid的生成方式Oracle数据库会为每个数据块中的记录分配一个唯一的rowid。
rowid的生成方式主要有以下两种:1. 物理行标识符(Physical Row Identifier, Prid):物理行标识符是Oracle数据库生成的默认行标识符,它是唯一的,不可修改,且在记录被删除后,不会再被使用。
2. 逻辑行标识符(Logical Row Identifier, Lrid):逻辑行标识符是Oracle数据库在特定情况下生成的行标识符,例如在使用索引访问表时,数据库会生成逻辑行标识符来提高查询效率。
四、rowid的用法Rowid在Oracle数据库中有着广泛的应用,主要用于以下几个方面:1. 定位数据:通过rowid可以准确定位和访问数据库表中的某一行。
例如,可以使用rowid来快速定位特定的记录,或者将rowid作为查询条件来进行数据检索。
2. 数据修改:rowid也可以用于对数据库表进行数据修改。
liquibase createsequence参数

liquibase createsequence参数全文共四篇示例,供读者参考第一篇示例:Liquibase是一个开源的数据库变更管理工具,它允许开发人员对数据库结构进行版本控制,以便能够追踪并管理数据库的变更历史。
createsequence是Liquibase中一个常用的参数,用于创建数据库表中的序列。
在数据库中,序列是一种可以生成唯一整数值的对象,通常用于自动生成主键值。
在某些数据库管理系统中,如Oracle、PostgreSQL 等,序列在创建表时是必不可少的。
在Liquibase中,可以通过使用createsequence参数来创建数据库表中的序列。
使用createsequence参数创建序列非常简单,只需在Liquibase 的changelog文件中指定相应的标签和属性即可。
下面我们来看一个示例:```xml<changeSet id="1" author="user"><createSequence sequenceName="my_sequence" startValue="1" incrementBy="1" minValue="1" maxValue="100" ordered="true"/></changeSet>```在上面的示例中,我们使用createSequence标签创建了一个名为my_sequence的序列,起始值为1,递增值为1,最小值为1,最大值为100,ordered属性指定为true。
这样就成功创建了一个序列对象。
在实际使用中,除了上述示例中的属性外,createsequence参数还提供了一些其他可选属性,如cycle、cache、nocache、incrementBy等,可以根据实际需求对序列进行配置。
oracle查询表名以及表的列名

select column_name,data_type ,data_length,data_precision,data_scale from user_tab_columns [where table_name=表名];
其中:column_name:列名(varchar2(30)); data_type:列的数据类型(varchar2(106)); data_length:列的长度(number); eg:select column_name,data_type ,data_length,data_precision,data_scale from user_tab_columns where table_name='TEST_TEMP'; 结果:
-------------------------------------------------------------------------------column_name data_type data_length data_precision data_scale ID NUMBER 22 0 NAME NVARCHAR2 20 SEX CHAR 1 GRADE NVARCHAR2 10
--------------------------------------------------------------------------------
注:表名变量值必须大写。 另外,也可以通过 all_tab_columns来获取相关表的数据。 eg:select * from all_tab_columns where table_name='TEST_TEMP';
由于oracle中没有类似sqlserver中的自增字段所以我们如果想要通过设定类似id性质的唯一列的话需要借助oracle的sequence先建立一个序列然后在每次插入数据的时候通过前触发器来更新id值并将序列的序号加1这样的迂回方式来实现
sql执行insert插入一条记录同时获取刚插入的id
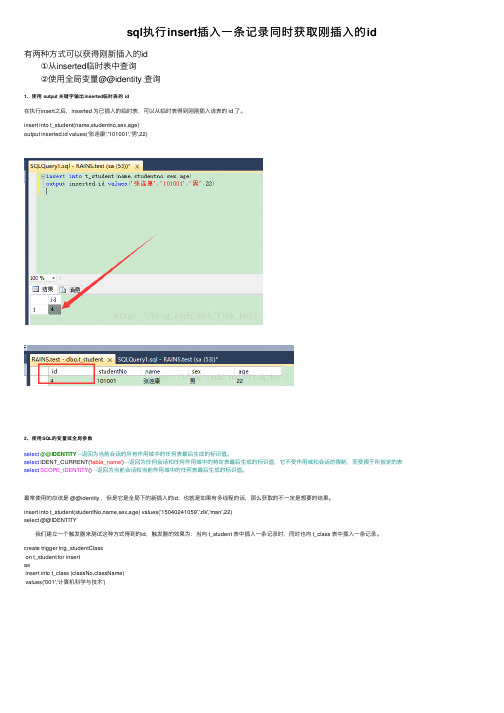
sql执⾏insert插⼊⼀条记录同时获取刚插⼊的id有两种⽅式可以获得刚新插⼊的id ①从inserted临时表中查询 ②使⽤全局变量@@identity 查询1、使⽤ output 关键字输出inserted临时表的 id在执⾏insert之后,inserted 为已插⼊的临时表,可以从临时表得到刚刚插⼊该表的 id 了。
insert into t_student(name,studentno,sex,age)output inserted.id values('张连康','101001','男',22)2、使⽤SQL的变量或全局参数select@@IDENTITY--返回为当前会话的所有作⽤域中的任何表最后⽣成的标识值。
select IDENT_CURRENT('table_name') --返回为任何会话和任何作⽤域中的特定表最后⽣成的标识值,它不受作⽤域和会话的限制,⽽受限于所指定的表select SCOPE_IDENTITY() --返回为当前会话和当前作⽤域中的任何表最后⽣成的标识值。
最常使⽤的应该是 @@identity ,但是它是全局下的新插⼊的id,也就是如果有多线程的话,那么获取的不⼀定是想要的结果。
insert into t_student(studentNo,name,sex,age) values('150********','zlk','man',22)select @@IDENTITY 我们建⽴⼀个触发器来测试这种⽅式得到的id,触发器的效果为:当向 t_student 表中插⼊⼀条记录时,同时也向 t_class 表中插⼊⼀条记录。
create trigger trig_studentClasson t_student for insertasinsert into t_class (classNo,className)values('001','计算机科学与技术')这三个的更多的使⽤说明,可以查看SQL联机帮助⼿册,⾥⾯有详细的说明。
oracle中字段递增的实现

999999999999999999999999999 with by 1
插入数据 insert 说明: 1>
: into student t values ( STUDENT_SEQ.nextval , 'name' , 'score' )
nocycle 是决定不循环,如果你设置了最大值那么你可以用 cycle 会使 seq 到最大之后循环.对于 nocache
5> 第一次 NEXTVAL 返回的是初始值;随后的 NEXTVAL 会自动增加你定义的 INCREMENTBY 值,然后返回增加后的值。 CURRVAL 总是返回当前 SEQUENCE 的值,但是在第一次 NEXTVAL 初始化之后才能使用 CURRVAL,否则会出错。一次 NEXTVAL 会增加一次 SEQUENCE 的值,所以如果你在同一个语句里面使用多个 NEXTVAL,其值就是不一样的。 6> 如果指定 CACHE 值,ORACLE 就可以预先在内存里面放置一些 sequence,这样存取的快些。cache 里面的取完后, oracle 自动再取一组到 cache。使用 cache 或许会跳号,比如数据库突然不正常 down 掉(shutdownabort),cache 中的 sequence 就会丢失.所以可以在 createsequence 的时候用 nocache 防止这种情况。 7> 影响 Sequence 的初始化参数: SEQUENCE_CACHE_ENTRIES = 设置能同时被 cache 的 sequence 数目。 可以很简单的 Drop Sequence DROP SEQUEN CEorder_seq; 在 Oracle 数据库中创建序列,在使用 sql 语句向数据库中写入数据的时候,利用序列产生的唯一值,实现表中主键 值自增。 例如: 》 》建表: * 表1: create table test( id int primary key not null, name varchar(10) ); commit; 表2: create table test2( id int primary key not null,
goldendb 自增列用法

goldendb 自增列用法GoldenDB 是一种数据库工具,它可以方便地管理和操作数据库中的数据。
自增列是一种特殊的列,它可以自动为每一条新插入的数据生成一个唯一的值,无需手动指定或输入。
在GoldenDB中,我们可以使用自增列来为表中的特定列设置自增属性,以便在插入新数据时自动生成唯一的值。
自增列的用法如下:1. 创建表时设置自增列:在创建表的时候,可以通过在列定义中使用AUTO_INCREMENT 关键字来指定该列为自增列。
例如:CREATE TABLE users (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50),age INT);在上述例子中,id 列被定义为自增列,并被设置为主键。
2. 插入数据时自动生成唯一值:当向包含自增列的表中插入新数据时,无需手动指定该列的值,系统会自动为该列生成一个唯一的值。
例如:INSERT INTO users (name, age) VALUES ('John', 25);在此例中,id 列的值将被自动分配,并且数据库将保证每次插入的值都是唯一的。
3. 获取自增列的值:在插入新数据后,我们可以通过LAST_INSERT_ID() 函数获取自增列的值。
例如:INSERT INTO users (name, age) VALUES ('Jane', 30);SELECT LAST_INSERT_ID();上述代码将插入一个新的行,并返回刚插入的行的自增列值。
4. 自增列的适用性:自增列通常用于作为主键,用来唯一标识表中的每一行。
由于自增列的值是由数据库系统自动生成的,因此可以保证唯一性,减少了手动分配的错误和冲突的可能性。
尽管自增列在很多情况下非常有用,但也有一些需要注意的地方:- 自增列的值不可修改:一旦自增列的值自动生成并插入到表中,就无法手动修改它。
如果需要修改该列的值,通常需要将该行删除并重新插入新的数据。
mysql uuid 在 oracle中的用法 -回复

mysql uuid 在oracle中的用法-回复MySQL和Oracle是两个流行的关系数据库管理系统(RDBMS),它们都被广泛应用于现代应用程序的数据存储和管理。
尽管它们有很多共同点,但在某些方面,它们的语法和功能略有不同。
本文将探讨MySQL中的UUID在Oracle中的用法。
UUID(通用唯一标识符)是一种唯一标识符,通常用于在数据库中标识行。
UUID由一个36个字符的字符串表示,其中包含32个十六进制数字和4个连字符。
MySQL和Oracle都支持UUID作为一种数据类型,但在使用和生成UUID时有一些语法和函数的差异。
让我们来看看在Oracle 中如何使用UUID。
一、UUID的生成在MySQL中,可以使用UUID()函数来生成一个新的UUID值,如下所示:SELECT UUID();但是在Oracle中,没有类似的内置函数来生成UUID。
然而,可以使用一些技巧来模拟生成UUID。
1. 使用SYS_GUID函数在Oracle中,可以使用SYS_GUID()函数来生成一个唯一的标识符。
SYS_GUID()函数返回一个RAW数据类型的十六进制值,相当于MySQL 的字节码。
然后,可以将其转换为字符串形式,并使用一些操作来模拟生成UUID,如下所示:SELECT REPLACE (LOWER (SYS_GUID()), '-', '') FROM DUAL;2. 利用SEQUENCE和TO_CHAR函数另一种方法是使用SEQUENCE和TO_CHAR函数来模拟生成UUID。
首先,需要创建一个SEQUENCE对象,用于生成递增的整数值。
然后,利用TO_CHAR函数将该整数值转换为十六进制,并添加连字符来模拟UUID的格式,如下所示:CREATE SEQUENCE my_seq START WITH 1;SELECT (TO_CHAR (my_seq.NEXTVAL, 'FMXXXXX') '-'TO_CHAR (my_seq.NEXTVAL, 'FMXXXX') '-'TO_CHAR (my_seq.NEXTVAL, 'FMXXXX') '-'TO_CHAR (my_seq.NEXTVAL, 'FMXXXX') '-'TO_CHAR (my_seq.NEXTVAL, 'FMXXXXXXXXXXXX')) FROM DUAL;二、UUID的存储在MySQL中,可以使用CHAR(36)或VARCHAR(36)数据类型来存储UUID值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
seq_atable.currval 的值只有在同一次会话中,发生seq_atable.nextval后有效:) 所以不会存在取错值的问题。
有二种方式使用自增字段:
使用序列+触发器实现自增,插入语句不需要管自增字段
如:create or replace trigger trg_atable before insert on atable for each row begin select seq_atable.nextval into :new.id from dual; end;
插入数据:insert into atable(a) values('test');
注:我创建了sequence 和trigger :,之后在procedure中插入数据,插入的时候没有管ID字段,在应用中,使用了hibernate,虽然hibernate在增加记录的时候也会处理ID,但是添加记录之后,查询记录发现,ID还是根据序列和触发器的规则设置的
Oracle插入数据时获取自增ID
自增字段:
表atable(id,a) id需要自增 首先建立一个序列:
create sequence seq_atable miபைடு நூலகம்value 1 maxvalue 999999999999999999 start with 1 increment by 1 nocache
首先要解决自增字段的问题,上面的二种方法哪种更适合这种用法呢? 建议使用第二种自增序列,否则处理起这个问题来比较麻烦。
使用自增字段的第二种方法,在插入一条记录后马上执行一下下面的语句即返回当前插入数据的ID。
$query="select seq_atable.currval from dual";
仅使用序列,需要在插入数据时,自增字段插入序列下一个值
如:insert into atable(id,a) values(seq_atable.nextval,'test');
三、返回刚插入记录的自增字段值
如上面的例子,我们插入一条记录后,我想马上返回刚插入的记录的ID号,我该怎么处理呢?