Virtual Memory on Data Diffusion Architectures
operating system《操作系统》ch09-virtual memory-70

Example of a page table snapshot:
Frame #
….
valid-invalid bit
v v v v i
i i
page table
During address translation, if valid–invalid bit in page table entry is I page fault
Copy-on-Write (COW) allows both parent and child processes to initially share the same pages in memory If either process modifies a shared page, only then is the page copied COW allows more efficient process creation as only modified pages are copied Free pages are allocated from a pool of zeroed-out pages
9.22
Need For Page Replacement
9.23
Basic Page Replacement
1. Find the location of the desired page on disk
2. Find a free frame:
- If there is a free frame, use it
page fault 1. Operating system looks at another table to decide:
第4章习题答案

(2)SRAM 芯片和 DRAM 芯片各有哪些特点?各自用在哪些场合?
(3)CPU 和主存之间有哪两种通信方式?SDRAM 芯片采用什么方式和 CPU 交换信息?
(4)为什么在 CPU 和主存之间引入 Cache 能提高 CPU 访存效率?
(5)为什么说 Cache 对程序员来说是透明的?
(6)什么是 Cache 映射的关联度?关联度与命中率、命中时间的关系各是什么?
EEPROM (Electrically EPROM) 多模块存储器(Multi-Module Memory) 双口 RAM (Dual Port RAM) 程序访问的局部化
空间局部性(Spatial Locality) 命中时间(Hit Time) 失靶损失(Miss Penalty) Cache 槽或 Cache 行 (Slot / Line) 全相联 Cache(Fully Associative Cache) 多级 Cache(Multilevel Cache) 代码 Cache(指令 Cache) 先进先出 (First-In-First-Out,FIFO) Write Through(写直达、通过式写、直写) Write Back (写回、回写) 物理存储器(Physical Memory) 虚页号(Virtual Page number ) 物理地址(Physical address) 物理页号(Page frame) 重定位(Relocation) 页表基址寄存器(Page table base register) 修改位(Modify bit / Dirty bit) 访问方式位(Access bit) 交换(swapping) / 页面调度(paging) LRU 页(Least Recently Used Page) 分页式虚拟存储器(Paging VM) 段页式虚拟存储器(Paged Segmentation VM)
微虚拟化技术将虚拟机效率再提升30%

微虚拟化技术将虚拟机效率再提升30%作者:郭涛来源:《中国计算机报》2012年第15期大多数用户已经认同,使用VMware、Citrix、微软的服务器虚拟化软件,可以大幅提升服务器的效率。
如果有厂商说,它不仅可以将物理服务器的效率提升60%~80%,而且可以将虚拟环境中服务器的效率再提升30%,你相信吗?Virtustream公司高级副总裁Reuven Cohen坚定地表示,Virtustream可以做到这一点。
Virtustream是一家云计算软件和服务提供商,其产品的核心技术之一就是Reuven Cohen 津津乐道的微虚拟化技术。
Reuven Cohen将VMware、Citrix、微软等提供的虚拟化技术称为第一代虚拟化技术。
这些技术都是以虚拟机(VM)为最小单位进行部署和调整的,每个VM 配备多少CUP、内存等都是相对固定的。
Virtustream的微虚拟化技术则不同,它可以深入到VM之下,实现更细粒度的虚拟化资源调配。
比如,它可以对每个VM之下的CPU、内存进行调整、管理和优化,因此才能将虚拟环境中的服务器效率再提升30%。
Virtustream不仅可以实现更细粒度的虚拟化,而且其计费也不是以VM为单位,而是细化到I/O层面。
“微虚拟化技术在VM的基础上实现了更细粒度的虚拟化。
”Reuven Cohen表示,“微虚拟化技术与第一代虚拟化技术之间并不是相互替代的关系,而是实现了进一步优化。
”作为一个云基础架构方案提供商,Virtustream主要为世界2000强这样的大型企业服务。
因此,Virtustream的云平台除了具有高性能以外,还必须在可扩展性以及安全性上优于其他为中小企业或个人提供服务的云平台。
很多人习惯将Virtustream云平台与Amazon进行比较。
Reuven Cohen表示,Virtustream与Amazon的不同主要体现在两方面:第一,Virtustream的可扩展性更强;第二,Virtustream是为大型企业服务的,而Amazon主要是为中小企业服务的。
存储异构虚拟化技术简介
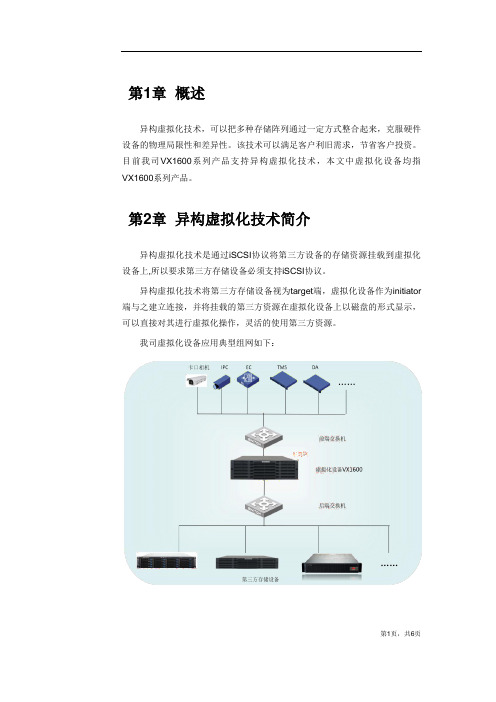
第1章概述异构虚拟化技术,可以把多种存储阵列通过一定方式整合起来,克服硬件设备的物理局限性和差异性。
该技术可以满足客户利旧需求,节省客户投资。
目前我司VX1600系列产品支持异构虚拟化技术,本文中虚拟化设备均指VX1600系列产品。
第2章异构虚拟化技术简介异构虚拟化技术是通过iSCSI协议将第三方设备的存储资源挂载到虚拟化设备上,所以要求第三方存储设备必须支持iSCSI协议。
异构虚拟化技术将第三方存储设备视为target端,虚拟化设备作为initiator 端与之建立连接,并将挂载的第三方资源在虚拟化设备上以磁盘的形式显示,可以直接对其进行虚拟化操作,灵活的使用第三方资源。
我司虚拟化设备应用典型组网如下:第1页,共6页第3章异构虚拟化技术优点异构虚拟化技术优点如下:➢强大的兼容性:第三方存储支持iSCSI协议均可被虚拟化(目前测试了多个厂商的存储设备,包括华为、netAPP、群晖、海康等);➢友好操作界面:识别的所有第三方资源标示为SCSI设备,并以磁盘的形式显示,磁盘属性包括厂商、资源容量、挂载的IP及target等信息,方便及时定位具体的第三方存储;➢一键式操作:对上报的第三方资源执行“虚拟化”操作后,即可使用异构资源;➢虚拟化性能低损耗:第三方存储在被虚拟化后,支持的监控性能未受影响(目前测试我司设备的监控应用业务模型,在虚拟化后,监控性能并没有受影响);➢安全性高:支持chap认证,包括discovery chap和logon chap双重安全性验证;➢高可靠性:可以同时虚拟化多种第三方存储设备,且下发业务流量正常,虚拟化设备运行稳定。
第4章虚拟化设备配置指导虚拟化第三方存储时,需要在第三方存储及虚拟化设备上配置。
在第三方存储端将虚拟化设备看作Linux客户端,并对其提供相应的资源。
4.1 第三方存储上配置将虚拟化设备看作Linux客户端,第三方存储上的配置即是将资源分配给该Linux客户端(虚拟设备的initiator名称可根据“4.2.1 查看initiator名称”中方法获取)。
虚拟化基础知识-内存

虚拟化基础知识:内存虚拟化(转)分类: 虚拟化作者: 刘苏平内存虚拟化基本知识在管理内存资源之前,应当了解ESX/ESXi 是如何虚拟化和使用这些内存资源的。
VMkernel 管理所有的计算机内存。
(一种例外情况是在ESX 中分配给服务控制台的内存。
)VMkernel 会将这种受管计算机内存的一部分拿来自己使用。
剩余的内存可供虚拟机使用。
虚拟机将计算机内存用于两个用途:每个虚拟机均需要有自己的内存,且VMM 需要一些内存和动态开销内存用于其代码和数据。
虚拟内存空间划分为块,每个块通常为4 KB,块也称为页。
物理内存也划分为块,每个块通常也是 4 KB。
当物理内存占满时,不在物理内存中的虚拟页的数据将存储到磁盘上。
ESX/ESXi 还提供对大页(2 MB) 的支持。
虚拟机内存每个虚拟机均会根据其配置大小消耗内存,还会消耗额外开销内存以用于虚拟化。
内存过载对于每个正在运行的虚拟机,系统会为虚拟机的预留(如果有)和虚拟化开销预留物理内存。
由于ESX/ESXi 主机使用内存管理技术,因此虚拟机可以使用的内存大于物理机(主机)可用的内存。
例如,您有一个内存为2 GB 的主机,其上运行四个虚拟机,每个虚拟机的内存为1 GB。
这种情况下,内存会过载。
过载有一定的意义,因为通常情况下有些虚拟机负载较轻,而有些虚拟机负载较重,相对活动水平会随着时间的推移而有所差异。
为了改善内存利用率,ESX/ESXi 主机将闲置虚拟机的内存转移给需要更多内存的虚拟机。
使用“预留”或“份额”参数可优先向重要的虚拟机分配内存。
如果这部分内存未使用,可以用于其他虚拟机。
内存共享许多工作负载存在跨虚拟机共享内存的机会。
例如,几个虚拟机可能正在运行同一客户机操作系统的多个实例,加载了相同的应用程序或组件,或包含公用数据。
ESX/ESXi 系统使用专用的分页共享技术安全地消除了内存页的冗余副本。
采用内存共享,由多个虚拟机组成的工作负载消耗的内存通常要少于其在物理机上运行时所需的内存。
MIPS科技和Virage Logic合作提供优化嵌入式内存IP

化 袭 击 后 无 需 派 遣 人 员 即 可 快 速 获 取 爆 炸 现 场 精 确 的 探
测 数 据 , 而 避 免 核 反 应 部 队探 测 数 据 时 直 接暴 露 在 核 辐 从 射 的 环 境 中 而 受 到 核 辐 射 的威 胁 。
结 语
本 文应 用 时 间 触 发模 式 设 计 了液 压式 制动 能 量 再 生 系 统 的 电子 控 制 系统 混 合 调 度 器 , 现 了 HB S的基 本 功 能 。 实 R
通 过功 能 模 块划 分 、 务 划 分 和 时 间 序 列 的 设 计 可 以 方 便 任
地 设 计 时 问触 发 模 式 调 度 器 。 时间 触 发模 式设 计 的 电子 控
V rg o i 的 AS P 9 m R i eL gc a A 0 n S AM 内 存 实 体 ( mo y isa c ) 以 及 S Wa e me r n tn e , i rTM 5 6 GP 高 密 度 S AM 编 译 器 ( R R S AM c mpl )系列 产 品 专 为 MI S 2处 理 器而 优 化 , 协 助 客 户加 速 为 蓝 光 D o ir e P3 以 VD、 T I TV、 顶 盒 和 宽 带 客 户 端 设 备 ( P ) HD V、P 机 C E 开
在 核 生 化 战争 中 , 爆 炸 中心 附 近 及 时 、 确 的 数 据 对 准
采 集 工 作 非 常 重 要 。 能 否 在 最 短 的 时 间 内监 测 到 爆 炸 中
心 的相 关 参 数 , 断 爆 炸 类 型 , 对 产 生 的 破 坏 情 况 进 行 判 并 估 算 , 快 速 采 取 应 对 措 施 的 关 键 , 些 工 作 常 常 需 要 专 是 这
计算机英语组成原理

计算机组成原理中英对照COMPUTER HARDWARE 计算机硬件Computer systems consist of hardware and software. Hardware is the physical part of the system. Once designed,hardware is difficult and expensive to change. Software is the set of programs that instruct the hardware and is easier to modify than hardware.计算机系统由硬件和软件组成。
硬件是系统的物理部分。
硬件一旦设计完毕,要修改是困难的,并且花费也大。
软件是指挥硬件的程序集合,比硬件容易修改。
Every computer has four basic hardware components:每台计算机都有如下4种基本硬件部件:•Input devices.输入设备•Output devices.输出设备•Main memory.主存储器•Central processing unit(CPU).中央处理器A PROCESSOR 处理器A processor is composed of two functional units—a control unit and an arithmetic/logic unit—and a set of special workspaces called registers.处理器由两个功能部件(控制部件和算术逻辑部件)与一组称为寄存器的特殊工作空间组成。
The Control Unit控制部件The Arithmetic and Logic Unit算术逻辑部件Registers寄存器MEMORY SYSTEMS 存储系统Memory Devices存储器RANDOM-ACCESS MEMORY随机存储器READ-ONLY MEMORY只读存储器MAGNETIC DISKS磁盘CD-ROMS只读光盘MAGNETIC TAPE磁带INPUT/OUTPUT SYSTEM 输入输出(I/O系统)Programmed I/O(程序控制I/O)Programmed I/O,also known as direct I/O,is accomplished by a program executing on the processor itself to control the I/O operations and transfer the data.程序控制I/O,又称直接I/O,由在处理器上执行的程序去控制I/O操作和传送数据。
内存延迟 对有限元计算的影响

内存延迟对有限元计算的影响内存延迟对有限元计算的影响有限元计算是一种常见的数值模拟方法,广泛应用于结构分析、流体力学、热传导等领域。
在进行有限元计算时,计算机需要读取和处理大量的数据,其中包括模型的几何信息、材料参数、边界条件等。
而这些数据通常存储在计算机的内存中,因此内存的性能对有限元计算的效率和精度有着重要的影响。
内存延迟是指计算机访问内存时所需的时间延迟。
内存延迟取决于计算机硬件的设计和内存的性能。
通常,内存延迟由内存时钟速度、总线宽度和内存类型等因素决定。
较低的内存延迟意味着计算机可以更快地读取和写入数据,从而提高计算效率。
内存延迟对有限元计算的影响主要体现在两个方面:计算速度和计算精度。
内存延迟会影响计算速度。
在有限元计算中,计算机需要频繁地读取和写入内存中的数据。
当内存延迟较高时,计算机需要等待更长的时间才能获取所需的数据,从而导致计算速度的下降。
特别是在处理大规模模型或复杂计算任务时,内存延迟可能成为性能瓶颈,限制计算机的运算速度。
因此,提高内存的读写速度和降低内存延迟对于提高有限元计算的效率至关重要。
内存延迟还会对计算精度产生影响。
在有限元计算中,精确的数据读取和写入是保证计算精度的基础。
当内存延迟较高时,计算机读取和写入数据的准确性可能受到影响,从而导致计算结果的误差。
尤其是在进行高精度的数值模拟时,内存延迟可能导致计算结果的偏差,影响对结构或系统行为的准确预测。
因此,降低内存延迟有助于提高有限元计算的精度和可靠性。
为了减小内存延迟对有限元计算的影响,可以采取一些措施:1.选择高性能的内存模块。
不同型号的内存模块具有不同的性能指标,包括时钟速度、延迟和带宽等。
选择具有较低延迟和较高带宽的内存模块可以提高计算机的读写速度,从而减小内存延迟对有限元计算的影响。
2.合理设计计算任务。
在进行有限元计算时,可以通过合理的计算任务划分和并行计算技术来减小内存延迟的影响。
将大规模模型划分为多个子域,分别进行计算,并利用并行计算技术将计算任务分配给多个处理器或计算节点,可以减小计算机对内存的读写需求,从而降低内存延迟对计算的影响。
相变存储器的突破点,以低功耗手机

伊利诺伊大学的工程师已经开发出一种超低功耗非易失性存储器,可能有一天会为消费者提供与手持设备,由一个团队的工程师数周或数个月,研究结果甚至不用充电,导致由助理教授埃里克流行,上周晚些时候发表在科学快讯,职位选择在提前出版的论文在印刷版科学magazine.The团队成立至今,一直能够存储几百位数据,但他们希望扩展生产以创建阵列的存储位,可以一起操作。他们还需要创建多比特内存,不像当今的多级单元(MLC)NAND闪存的固态硬盘(SSD),以实现更大的数据密度。相变memoryThe研究是根据现有的技术,被称为相变随机存取存储器,或只是相变存储器(PCM)。然而,而不是用金属线作为电阻,研究小组利用碳纳米管,比人的头发细10,000倍,需要少得多的功率正在制造比标准PCM.PCM产品的今天由极少数公司,尚未赶上作为主流技术。在公司工作的PCM是英特尔,意法半导体和Numonyx Omneo 128-Mbit的NOR兼容PCM产品线,运去年。三星去年宣布一个512Mbit的PCM内存芯片为在移动handsets.PCM使用使用硫族化合物,含有银色的半导体,如硫,硒或碲的玻璃状物质。半导体有一个属性,允许他们的身体状态,它们的原子的排列,要改变从结晶,无定形的小ZAP通过应用电力。这两个国家有非常不同的电气性能,可以很容易地测量,硫系理想的数据存储。伊利诺伊大学的工程师说,为了创建一个位数据使用他们的新技术,他们将少量的PCM在纳米间隙中形成的碳纳米管的中间,这是10纳米宽。他们可以切换位“开”和“关”小电流通过nanotube.They,通过说,他们的技术是速度比典型的PCM,并使用100倍的能源,它提供了便携式设备电池寿命更长。工程师说,他们正在努力进一步降低功耗,进一步提高能源利用效率。“尽管我们已经采取了一种技术,表明它可以提高100倍,我们还没有达成什么是身体可能。甚至还没有测试的限制,我认为我们可以降低能耗,至少10的另一个因素,“的流行said.Smartphone staminaThe碳纳米管,PCM可以提高移动设备的能源效率,智能手机可以运行更长的时间点较小的电池,甚至没有收获自己的热,机械或太阳能电池通过简单的地步,它可以供电,流行说:“我认为任何人谁处理了很多充电器和堵塞的东西在每晚上可以涉及到手机或笔记本电脑的电池可以持续数周或数月,流行,说:“谁也隶属于贝克曼研究所高级科学和技术在伊利诺伊州。登录|注册Twitter上关注我们获取的Widget订阅Techworld的newslettersThe研究员指出,虽然今天大多电池功率显示的智能手机或超便携笔记本电脑,是专门为内存的比例不断提高。“任何时候你要运行的应用程序,或者存储MP3音乐,或流式视频,它耗尽电池,说:“研究生伟业辽,即将提交的报告的合著者。 “内存和处理器都在努力的检索数据。随着人们使用自己的手机拨打电话和更多的计算,提高了数据存储和检索操作是很重要的。”该小组说,碳纳米管的PCM也可用于降低功耗在任何设备上运行的电池,包括卫星,远程通讯设备,以及一些科学和军事应用。
人工智能驱动内存互连进化

人工智能驱动内存互连进化人工智能(AI)、车用芯片的复杂程度逐步递增,边缘处理比重也在增加,存储的选择、设计、使用模式及配置将会面临更大的挑战。
因此,为了满足AI 和机器学习应用程序的需要,位置(Location)越来越多地应用于数据需要驻留的地方和存储数据的内存。
在芯片、元件和系统之间移动以及处理优先处理顺序不明确的情况下,设计团队只能在合并和共享存储之间取得平衡以降低成本,或增加更多不同类型的存储来提升效能、降低功耗。
但这个问题不仅仅是内存供应商面临的挑战;其他AI利益相关者也在发挥作用,解决方案最关键的一部分是内存互联,即内存离计算越来越近。
在人工智能硬件峰会内存互联的挑战和解决方案圆桌讨论上Rambus研究员Steve Woo 表示:“我们都在人工智能的不同方面工作。
”从目前来看,内建SRAM和DRAM存储仍是当前主推技术。
DRAM密度高、使用电容储存结构相对简单,又具有低延迟、高效能和接近无限次存取的耐用度,功耗也比较低。
SRAM速度非常快,但较为昂贵且密度有限。
这些不同的需求会影响存储的类型、数量以及内建或外接存储的选择。
Marvell ASIC业务部门的CTO Igor Arsovski在SRAM方面有着丰富的经验,他表示,用啤酒来比喻内存互连并不坏。
“SRAM就好比一瓶啤酒。
它很容易使用,使用它的能耗很低,它只提供你所需的。
“但如果内存不够,你就会走得更远,而且需要消耗更多的能量,就像需要走得更远才能买到啤酒一样。
”HBM vs LPDDR外接存储的竞赛,基本上以DRAM-GDDR和HBM为主。
从工程和制造角度来看,GDDR比较像DDR和LPDDR等其他类型的DRAM,可以放在一个标准的印刷电路板上并使用类似的制程。
HBM是比较新的技术,牵涉到堆叠和矽中介层,每个HBM堆叠都有上千个连接,因此需要高密度的互连,这远远超过PCB的处理能力。
HBM追求最高效能和优质的电源效率,但成本更高,需要更多的工程时间和技术。
avm算法流程 -回复

avm算法流程-回复AVM算法(Adaptive Virtual Memory Algorithm)是一种用于管理计算机虚拟内存的算法。
它通过将物理内存和辅助存储(通常是硬盘)结合起来,实现了虚拟内存的扩展。
本文将详细介绍AVM算法的流程,并逐步回答与该主题相关的问题。
一、什么是AVM算法?AVM算法是一种实现虚拟内存管理的算法。
虚拟内存是计算机系统中的一种技术,它允许程序使用比物理内存更大的地址空间,将不常用的数据或程序代码交换到辅助存储器中,从而提高系统性能和资源利用率。
AVM算法通过智能地管理虚拟内存页表,使得虚拟内存与物理内存之间的数据交换更加高效和灵活。
二、AVM算法的流程是怎样的?1. 初始化:AVM算法的第一步是初始化。
在系统启动时,操作系统会初始化虚拟内存管理模块,并设置一些关键参数,如页大小、页表大小等。
2. 地址转换:当程序访问虚拟内存时,AVM算法需要进行地址转换。
首先,它通过页表将虚拟地址转换为物理地址,确定所需数据在物理内存中的位置。
如果数据不在物理内存中,则会发生缺页中断。
3. 缺页处理:当发生缺页中断时,AVM算法会触发缺页处理流程。
操作系统会从辅助存储器中选择一个页进行淘汰,将其替换出物理内存,然后将所需数据加载到物理内存中的空闲页中,并更新页表。
这个过程涉及到淘汰策略的选择,如LRU(最近最少使用)算法。
4. 页面替换:当物理内存不足时,AVM算法需要选择合适的页进行替换。
常见的页面替换算法有FIFO(先进先出)算法、LRU(最近最少使用)算法等。
5. 写回策略:AVM算法还需要考虑写回策略。
当虚拟内存中的数据被修改时,是否及时写回到辅助存储器中取决于写回策略。
常见的写回策略有写回缓存和写直达。
6. 统计与优化:最后,AVM算法会对虚拟内存的使用情况进行统计与优化。
它会根据程序的访问模式和数据访问频率,动态地调整页表和淘汰策略,提高系统性能和资源利用率。
三、AVM算法的优势和应用场景是什么?AVM算法有以下几个优势:1. 资源利用率高:AVM可以将物理内存和辅助存储结合起来,实现虚拟内存的扩展,充分利用系统资源。
微处理器结构10虚拟存储器

1:
Virtual
Physical
Addresses
0:
Addresses
1:
CPU
P-1:
N-1:
Disk
Address Translation: Hardware converts virtual addresses to physical addresses via an OS-managed lookup table (page table)
虚拟存储器 (Virtual Memory)
为什么要使用虚拟存储器
程序所需要的存储器比计算机实际具有的内 存大
DOS应用程序曾采用overlay技术来执行大程序
多个程序需要同时共享物理内存
程序需要在内存中可重定位(relocatable) 程序之间需要隔离保护
虚拟存储器使每个程序运行在独立的、足够 大的虚拟地址空间!
Processor Signals Controller
(1) Initiate Block Read
Read block of length P starting at disk address X and store starting at memory address Y
页表(page table)
页在物理内存中采用全相联组织 全相联组织使得操作系统能使用复杂的
替换策略,从而提高命中率 虚拟地址到物理地址之间的映射由页表
来实现 页表在物理内存中连续存放 页表的位置由专用寄存器—页表寄存器
来指明
页缺失
Page Faults ( “Cache Misses”)
Physical Addresses
Memory
0: 1:
N-1:
VIRTUAL MEMORY MANAGEMENT METHOD AND PROCESSOR

专利名称:VIRTUAL MEMORY MANAGEMENT METHODAND PROCESSOR发明人:Wei ZHU,Chao LI,Bo LIN申请号:US17231133申请日:20210415公开号:US20220075522A1公开日:20220310专利内容由知识产权出版社提供专利附图:摘要:A virtual memory management method applied to an intelligent processor including an operation accelerator includes: determining m storage units from a physical memory, the m storage units forming a virtual memory; dividing the m storage units inton storage groups; determining an address mapping relationship for each storage group to obtain n address mapping relationships, the n address mapping relationship being correspondence of between n virtual addresses of the virtual memory and physical addresses of the m storage units, where m and n are dynamically updated according to requirements of the operation accelerator. In the method, the number of the storage units in each storage group can be configured according to requirements of the operation accelerator, and a data storage bit width and a data storage depth of the virtual memory are dynamically updated to thereby improve data access efficiency.申请人:Xiamen SigmaStar Technology Ltd.地址:Fujian CN国籍:CN更多信息请下载全文后查看。
忆阻器存算一体架构的科学意义与学术价值

忆阻器存算一体架构的科学意义与学术价值“基于忆阻器的新型存算一体架构,可以打破算力瓶颈,满足人工智能等复杂任务对计算硬件的高需求。
”清华大学未来芯片技术高精尖创新中心教授吴华强说。
随着摩尔定律趋近极限,通过集成电路工艺微缩的方式获得算力提升越来越难;而计算与存储在不同电路单元中完成,会造成大量数据搬运功耗增加和额外延迟。
如何提高算力,突破技术瓶颈?26日,记者从清华大学获悉,该校微电子所、未来芯片技术高精尖创新中心钱鹤、吴华强教授团队,与合作者共同研发出一款基于多个忆阻器阵列的存算一体系统,在处理卷积神经网络时的能效比图形处理器芯片高两个数量级,大幅提升计算设备的算力,且比传统芯片的功耗降低100倍。
相关成果近日发表于《自然》杂志上。
如何彻底解决VDI存储性能瓶颈

IOPS
病毒扫描+补丁
Writes Reads
日常工作
9:00 AM
6:00 PM
10:00 PM
注意:存储性能不足会严重影响用户体验甚至导致服务中断!
VDI存储性能估算
以1000个50GB桌面作为性能估算基准: • 单一用户耗时120秒登录,IOPS= (25000/120) = 208IOPS 每用户。分五批每批200个用户同时登 录,需要40,800 IOPS,该性能压力持续十分钟; • 单一用户耗时30秒登录,IOPS= (2,400/30) = 80 IOPS 每用户。1000个用户同时登录,需要80 , 000 IOPS,该性能压力持续30秒; • 正常工作状态IOPS为20~30 IOPS,则1000用户 系统正常IOPS需求至少为20,000~30,000 IOPS, 该性能必须同时保证; • 按照容量需满足至少50TB可用容量。
✔ ✔ ✔
容量性价比
顺序I/O性价比
✗ ✗
容量性价比
(纯闪存储产品扩展容量十分昂贵)
写入稳定性
单盘性能受限,通过增加磁 盘数量可提升性能,但此方 案采购成本高,同时需要占 用更多机架空间,空调和电 力成本,性价比低
写入稳定性有带检验
闪存擦写次数,温度敏感程序 ,写入放大效应都会对数据安 全产生不利影响
2015.10.28 | 北京, 中国
如何彻底解决VDI存储性能瓶颈?
薛友逢 NimbleStorage 存储架构师
Agenda
1 2 3
NimbleStorage公司简介 虚拟桌面存储性能分析 虚拟桌面高性能解决方案
CONFIDENTIAL
2
公司简介
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Virtual Memory on Data Diffusion ArchitecturesJorge Buenabad-Ch´a vezA thesis submitted to the University of Bristol in accordance with the requirements for the degree of Doctor of Philosophy in the Faculty of Engineering,Department of ComputerScience.July1998A b s t r a c tData diffusion architectures(also known as COMA machines)are scalable multiprocessors that provide a shared address space on top of distributed main memory.Their distinctive feature is that data “diffuses”,or migrates and replicates,in main memory according to whichever processors are using the data;thus effective access time tends to be local access time.This property is possible due to the associative organisation of main memory,which in effect decouples each address and its data item from any physical location.A data item can thus be placed and replicated where it is needed.Also, the physical address space does not have to be afixed and contiguous address range.It can be any set of addresses within the address range of the processors,possibly varying over time,provided it is smaller than the size of main memory.Thisflexibility,which is similar to that of an address space under virtual memory management,offers new possibilities to organise virtual memory in order to support a general purpose multiprogramming environment.This thesis presents an analysis of possible ways to organise virtual memory on such machines, and proposes two main alternatives:traditional virtual memory(TVM)is organised around afixed and contiguous physical address space using a traditional mapping;associative memory virtual memory (AMVM)is organised around a varying and non-contiguous physical address space using a simpler mapping.Our analysis suggests that AMVM has performance advantages over TVM.The KSR-1, thefirst commercial data diffusion architecture,has a virtual memory which is similar to AMVM,but is partly integrated with the data diffusing hardware.AMVM is more hardware independent,and has potentially improved performance.For data to diffuse,a fraction of main memory must be reserved as diffusion space to ensure reasonable performance.This thesis presents an analysis of diffusion space requirements that suggests that,on set-associative memory,the adequate provision of diffusion space should start with a base size diffusion space across all memory sets,and that it be adjusted on demand.To evaluate TVM and AMVM,and to gain insight into the provision of diffusion space,a multi-processor emulation of a data diffusion architecture has been extended to include the emulation of part of the Mach operating system virtual memory.This extension implements TVM;a slightly modified version implements AMVM.On applications tested,AMVM shows a marginal performance gain over TVM.We argue that AMVM will offer greater advantages on applications with higher degrees of parallelism or larger data sets.For the provision of diffusion space to be adequate,our results on set-associative memory suggest the need for a simple interaction between virtual memory software and the data diffusing hardware.iAcknowledgementsIt is a pleasure to thank the people who made possible the completion of this work.The British Council,CINVESTA V,CONACyT and SEP provided the necessary funds.PACT and the University of Bristol provided a much suitable environment.Dr.Sergio Chapa was particularly supportive at CINVESTA V,ensuring that funds were available all the way through.I had very useful discussions and nice talks with Catherine Barnaby,Andy Jones,Hendrik-Jan Agterkamp,Julio Peralta and Oscar Olmedo.Graham Riley was very helpful during my visit to the Centre for Novel Computing at Manchester University,where I studied the operation of virtual memory management on the KSR-1multiprocessor.Mike Brown,manager of PACT,was extremely patient and supportive in giving me as much time as possible for the completion of the experimental work and writing up of the thesis.He also took care of“migrating”the experimental platform to M´e xico for this research to be continued at the CINVESTA V.Professor David May was very supportive in the last stage of the writing up of the thesis.Henk Muller and Paul Stallard were a source of support and inspiration.The emulator of the HORN DDM,on which the experimental work was carried out,is a piece of art.This work would not have been possible without it.I also had lots of much useful discussions with them.Thank you very much Henk and Paul—just alphabetical order.I feel very lucky to have worked with my adviser,Professor David H.D.Warren.His patience, encouragement,and both technical and administrative support made possible the completion of this thesis.Above all,from working with him I had all the way through such an experience as that described below.“It is quite obvious that in order to be sensitive to oneself,one has to have an image of complete, healthy human functioning—and how is one to acquire such an experience if one has not had it in one’s own childhood,or later in life?...In previous epochs of our own culture,or in China and India,...the teacher was not only,or even primarily,a source of information,but his function was to convey certain human attitudes.”Thank you David.A Paty de Albamis hermanos Paty,Ra´u l y el G¨u eromi pap´a Jorgey mi mam´a Maria Luisa “Termina lo que empiezas y luego te vas a jugar”.ivDECLARATIONvviContentsAbstract i Acknowledgements ii DECLARATION v 1Introduction11.1Summary and Thesis Layout11 2Virtual Memory132.1Introduction132.2Virtual Address Space Management162.2.1Address Translation172.2.2Paging or Segmentation?192.2.3Combining Paging and Segmentation202.2.4Multiple,Single,or Global Address Space Virtual Memory?212.3Page Table Organisation Alternatives242.4Translation Lookaside Buffer262.4.1TLB Coherency272.4.2TLB Organisation and Management292.4.3TLB Performance312.5Main Memory Management332.5.1Page Replacement Policies332.5.2Allocation Policies352.6Swap Space Management362.7Summary37 3Virtual memory on shared memory multiprocessors393.1Shared Memory Multiprocessors393.1.1Data Coherence403.1.2Memory Consistency413.2Virtual Address Space Management423.3TLB Management443.3.1Hardware Solutions453.3.2Software Solutions453.4Scalability47vii3.5Mach:a Portable Uniprocessor and Multiprocessor Operating System483.5.1Virtual Address Space Management493.5.2Main Memory Management503.6Summary51 4Data diffusion architectures554.1Background and Related Work564.1.1A Software Approach:Shared Virtual Memory564.1.2A Hardware-software Approach:Shared Virtual Memory II574.1.3A Hardware Approach:Virtual Shared Memory574.1.4A CC-NUMA Example:the DASH Multiprocessor594.2Data Diffusion Architectures–Design Issues614.2.1Data Coherency Protocol644.2.2Associative Main Memory Organisation674.3Data Diffusion Architectures–Examples694.3.1The HORN DDM704.3.2The KSR-1724.4Summary74 5Design Issues for Virtual Memory on Data Diffusion Architectures775.1Introduction775.2Supporting New Views of Memory805.3Supporting a Traditional View of Memory835.4Design Goals875.5Summary88 6The KSR-1Virtual Memory916.1Introduction916.2Virtual Address Space Management926.3Main Memory Management966.4Discussion1006.4.1Efficient Address Translation1006.4.2Advantages of a Large Main Memory Allocation Unit1026.4.3Disadvantages1036.5Summary104 7Our Proposals for Virtual Memory on Data Diffusion Architectures1077.1Traditional Virtual Memory:TVM1087.2Associative Memory Virtual Memory:AMVM1127.2.1Using TLB Support for Superpages under AMVM1147.3Discussion1157.4Performance Evaluation—Experimental Goal1187.5Provision of Diffusion Space–Experimental Goal1217.5.1Informal analysis of diffusion space requirements121viii7.5.2Providing diffusion space1247.6Summary125 8Experimental methodology1298.1Multiprocessor emulation1298.2The HORN DDM emulator1318.2.1Calibration1328.2.2Emulation of the HORN DDM1328.3Emulation of virtual memory1368.3.1Emulation of TLB1368.3.2Emulation of Traditional Virtual Memory1388.3.3Some comments on the port1408.3.4Emulation of Associative Memory Virtual Memory1418.3.5Base experimental configuration1428.4Validation of virtual memory emulation1438.4.1Method1448.4.2Results1458.4.3Conclusions1468.5Applications1478.6Summary150 9Performance Evaluation of Two Approaches1539.1Method1549.2Results1569.2.1Wave Virtual Memory Overhead1589.2.2Aurora Virtual Memory Overhead1609.2.3Mp3d Virtual Memory Overhead1609.3Discussion1619.4Summary162 10Evaluation of Diffusion Space Requirements16510.1Method16610.1.1Comments on our experimental methodology16910.2Results17110.2.1Diffusion Space Requirement of Wave17110.2.2Diffusion Space Requirements of Aurora18010.2.3Diffusion Space Requirements of Mp3d18110.3Discussion18410.3.1Adjusting Diffusion Space18610.3.2Other Results18810.3.3Generalising our Results18910.3.4Further Work19110.4Summary191ix11Conclusions and Further Work19311.1Limitations and Further work200 Glossary213xList of Figures2.1Virtual memory organisation.Each virtual address used by an application is dynami-cally translated into a physical address using mapping tables.142.2A virtual address space(shaded)is logically divided into pages all of the same size,into segments of variable size,or into segments themselves divided into pages.162.3Virtual-to-physical address translation at page granularity.182.4Address translation in the GE645processor under segmentation and paging.212.5Global address space virtual memory,above.The segments of each application aremapped to the paged global virtual address space.Below,private-to-global virtualaddress translation in the IBM RT PC architecture.233.1Shared memory multiprocessors:bus-based(left)and cross-bar-based.404.1The DASH architecture.594.2The Data Diffusion Machine with buses as interconnect medium.624.3The Bristol DDM.704.4The HORN DDM.714.5The HORN DDM with a general interconnect and collapsed hierarchy.724.6The KSR-1architecture for1088processors.735.1In data diffusion architectures the physical address space can be any set of addresses,possibly varying over time,within a physical address range which is limited by theaddressing capability of the processors or the associative organisation of main memory.796.1Mapping of virtual addresses into global virtual addresses in the KSR-1.936.2Global address space virtual memory in the KSR-1.The global virtual address spaceis mapped with the identity function to the physical address range of the associativemain memory.946.3Memory layout in each memory node in the KSR-1.976.4OSF-1memory lists for each machine-wide memory set in the KSR-1.997.1Alternatives to organise virtual memory around afixed and contiguous physical ad-dress space and a traditional mapping with commodity hardware.1117.2Traditional virtual memory(TVM).1127.3Associative memory virtual memory(AMVM).113xi8.1Increasing the fanout of directory nodes in the HORN DDM emulator on a networkof T800transputers.133 8.2Transputer processes in the HORN DDM emulator.134 8.3Transputer address space layout under the HORN DDM emulator.135 8.4Superpage and partial subblock TLB entries.137 8.5Transputer address space layout under TVM.138 8.6Transputer address space layout under single address space AMVM.141 8.7Our version of Rosenburg’s program on the HORN DDM emulator.1468.8The speedup of our applications on the HORN DDM emulator without virtual memory.1479.1Wave virtual memory overhead.158 9.2Aurora virtual memory overhead.1599.3Mp3d virtual memory overhead.16110.1The effect of varying the size of diffusion space on Wave-TVM.172 10.2Grid data partitioning of Wave into each processor.173 10.3The effect of varying the size of diffusion space on Aurora-TVM.180 10.4The effect of varying the size of diffusion space on Mp3d-TVM.182xiiList of Tables4.1Access times in the memory hierarchy of the KSR-1multiprocessor.748.1Calibration example.1328.2Our experimental HORN DDM hardware configuration.1438.3Shared references made by our applications without virtual memory.1489.1Total TLB miss count over all processors.15710.1The effect of varying the number of computation steps and associativity offirst-leveldirectories on the execution time of Wave-TVM on32processors.Main memoryis of size64Mega bytes(5124-K-byte pages for each memory node),and16-wayset-associative.Diffusion space is3004-K-byte pages for each memory node.17610.2The effect of varying the number of computation steps and associativity offirst-leveldirectories on the execution time of Wave-TVM on32processors,under the FIFO withsecond chance replacement for memory sets.Main memory is of size64Mega bytes(5124-K-byte pages for each memory node),and16-way set-associative.Diffusionspace is3004-K-byte pages for each memory node.17810.3The effect of varying the number of computation steps and associativity offirst-leveldirectories on the execution time of Wave-TVM on32processors,under the standardreplacement policy for memory sets and modifying the array that it in the originalversion is only read.Main memory is of size64Mega bytes(5124-K-byte pagesfor each memory node),and16-way set-associative.Diffusion space is3004-K-bytepages for each memory node.179xiiixivChapter1IntroductionMultiprocessors are general purpose machines capable of exploiting parallelism,and thus are a means to improve application performance.To this end,the computation of the application has to be divided among several processors,which need to communicate with each other in order to coordinate their task and to share data and code.Dividing the computation and specifying processor communication are the responsibility of the application programmer,system software,or both[4,pp.223–287]. However,the way processor communication actually takes place depends on the underlying hardware organisation.In early designs of multiprocessors,memory is either shared by all processors through a common interconnect medium,such as a bus,or distributed among the processors,each processor using privately a portion of memory.These configurations are classified as shared memory and distributed memory multiprocessors,respectively.Processor communication in shared memory multiprocessors takes place via shared variables. There is thus no need to specify communication for processors to share data and code,only to coordinate their tasks.This aspect simplifies parallel programming,and also offers more portability to software developed for uniprocessor systems.Also,the common interconnect simplifies maintaining data coherence(guaranteeing that each processor uses the last value written to a data item).Coherence becomes an issue as a result of each processor using a cache.When multiple caches hold a copy of a data item that is subsequently written by a processor,all other copies must be invalidated or updated.A common interconnect also provides uniform memory access(UMA)time to each processor,which simplifies migrating a computation from one processor to another in order to balance the system1workload.Unfortunately,shared memory multiprocessors are not scalable,as the memory bandwidth of a common interconnect does not increase as more processors are added.In contrast,distributed memory multiprocessors tend to be scalable because memory bandwidth increases with the number of processors.They are also simpler to build than shared memory mul-tiprocessors because data coherence is not an issue for the hardware.However,programmers have to specify communication for processors to coordinate the task,and also to share data and code,via messages explicitly sent and received by each processor.Message-passing communication requires more involvement from the programmer,and renders software less portable.More recently,the design of some multiprocessors has been seeking to combine the ease of programming of shared memory multiprocessors with the scalability of distributed memory multi-processors.The approach has been to provide a shared address space on top of memory distributed among the processors.Memory bandwidth thus increases as more processors are added.In these systems,a reference by a processor can be local(to the nearest memory portion)or remote.However, this is transparent to software;the underlying hardware is responsible to fetch local or remote data to each processor.Multiprocessors with this organisation have variously been referred to as virtual shared memory machines,distributed shared memory machines,or scalable shared memory ma-chines.These systems are attractive because in principle they can offer as much processing power as vector or array processors at a more reasonable cost,and because they are software compatible with shared memory multiprocessors.A few early designs have already been implemented.The RP3[15], the Stanford DASH[64]and the MIT Alewife[17,2]are research prototypes.The KSR-1was a commercial product during1991-95[44].Non-uniform memory access(NUMA)architectures were thefirstly proposed class of virtual shared memory multiprocessors.The term NUMA emphasises the difference in time to access different data due to the distributed organisation of memory.The design of NUMAs was mainly addressed to the system interconnect and the mapping of the shared address space onto memory nodes.However,data coherence at the level of caches,if available and used,was the programmer’s responsibility[15].The design of cache-coherent(CC-)NUMA architectures then built on that early work to support by hardware data coherence at cache line granularity of typically16to128bytes.In NUMAs and CC-NUMAs,a key factor to achieve scalable performance is that most of the data2used by each processor should be resident either in its cache or in its local memory.If a processor mostly incurs remote references,performance may degrade significantly.The placement of data upon memory nodes is thus an issue in these architectures,although it can be avoided in CC-NUMAs if caches are large enough to hold most of the local and remote data used by each processor.Yet to improve the local to remote access ratio(hence performance),methods have been suggested that include modifying application code and data structures[41],or modifying system software to migrate and replicate data among memory nodes as needed[18,113].Both alternatives are not simple to implement:software for(UMA)shared memory multiprocessors has to be modified to deal with the distributed organisation of main memory.Also,both alternatives cannot guarantee improving the local to remote access ratio due to the dynamic access pattern of each application.Balancing the system workload by migrating a computation from one processor to another is clearly difficult too.The RP3 is a NUMA;the Dash and MIT Alewife are both CC-NUMAs.Data diffusion architectures are another class of virtual shared memory multiprocessors.Their distinctive feature is that data diffuses,or migrates and replicates,in main memoryFor this reason,we think the term“cache only memory architecture”is somewhat misleading,and prefer the term“data diffusion architecture”.An associative main memory will be somewhat more expensive than traditional main memory. However,hardware components are becoming cheaper,and represent a cost to be made only once.In contrast,the cost of software development has increased,and tuning applications to improve the local to remote access ratio has to be made for each application and for each processor-count and memory configuration.Data diffusion architectures were introduced with the proposal of the Data Diffusion Machine (DDM)[114].The KSR-1was thefirst commercial architecture of this class.Both the DDM and the KSR-1use a hierarchical organisation where software runs at the leave nodes only,and nodes above the leaves keep track of the data items in the nodes below.The DDM wasfirst proposed with a hierarchy of buses,but has since been investigated for point-to-pointlinks as interconnect medium[86,83,85,115]. The KSR-1uses a hierarchy of A-F is a more recent proposal of aflat(non-hierarchical) data diffusion architecture[48,111].This thesis investigates the design issues for virtual memory on data diffusion architectures.As is well known,virtual memory is a memory management scheme that makes main memory appear much larger than it actually is.This illusion simplifies the programming task,as applications larger than the available main memory can run partially loaded in main memory in a way transparent to the programmer.Virtual memory also efficiently supports multiprogramming,since the more applications partially loaded in main memory there are,the easier it is for the scheduler tofind an application ready to run when others block for I/O or synchronisation.These benefits of virtual memory are possible by considering each address used by an application only a means to identify(code and)data[32], and not a description of where in main memory data is.The addresses used by an application are virtual addresses which are dynamically translated into physical addresses using mapping tables. When the mapping of a virtual address is invalid,the data is initialised or swapped into main memory from secondary storage,and the mapping tables updated accordingly.The virtual address space an application can use is thus not limited to the size of main memory;it can be as large as the addressing capability of the processor.Virtual memory makes possible aflexible and general purpose multiprogramming environment,4which is desirable for a data diffusion architecture.Yet the design of virtual memory for these architectures is interesting in itself.Virtual memory was conceived with traditional main memory underneath,where physical addresses are bound to storage locations.Hence the physical address space isfixed and in effect contiguous.In data diffusion architectures,the associative organisation of main memory in effect decouples each(physical)address and its data item from any storage location. Physical addresses are only means to identify data in main memory.They are like virtual addresses. Hence in principle,the physical address space can be any set of addresses within the address range of the processor.Software can choose the configuration of the physical address space.Moreover,the set of addresses composing the physical address space can vary over time.The set of all possible physical addresses that can be represented in main memory,or physical address range,is only limited by the addressing capability of the processors.Theflexibility of the physical address space of data diffusion architectures is similar to that of a virtual address space,and offers new possibilities to organise virtual memory.This thesis presents an analysis of possible ways to organise virtual memory in these architectures.The thesis describes how virtual memory can support novel views of memory in which the use of address space is sparse: only items actually used come to exist.Although this is also possible on traditional main memory,the virtual-to-physical address mapping would have to be organised at item granularity:with a mapping table entry for each item.However,for efficiency in main memory use and swapping operations, the mapping in most systems is organised atfixed-size page granularity of typically4K-bytes;the mapping of a virtual address into a physical address is:,where is the virtual page number(the most significant bits)of,is the offset(least significant bits)of,and gives the initial address of the physical page which is the image of the virtual page being accessed.In data diffusion architectures,address translation can proceed at page granularity,yet only items actually allocated come to exist.The thesis also describes how virtual memory can provide a traditional view of memory,where address space is allocated in contiguous chunks,but take a novel view of the physical memory. Virtual memory can be organised in several different ways to provide a traditional view of memory. Here,however,we only describe briefly our proposals to organise virtual memory on data diffusion architectures,which were chosen based on the criteria of low implementation cost and performance.5The motivating factor of ourfirst proposal is low implementation cost:maximum portability. Hence we ignore theflexibility of the physical address space,and choose afixed and contiguous physical address space as in traditional main memory.Hence commodity hardware and software can be used to implement the virtual memory system.A virtual memory for(UMA)shared memory multiprocessor should require little change to make it immediately usable in a data diffusion architec-ture.Most virtual memory systems today support what is referred to as multiple address space virtual memory:a private virtual address space is handled for each application,and each virtual address space is logically divided into pages.Hence ourfirst proposal is a paged multiple address virtual memory, which we will refer to as traditional virtual memory,or TVM,because the view of main memory as afixed and contiguous physical address space is traditional.Address translation under TVM will proceed at page granularity,which has been found to incur a somewhat significant overhead for some applications(on uniprocessors),up to50%of the execution time[105,88].This overhead corresponds to what is referred to as translation lookaside buffer (TLB)miss overhead.The TLB is a small and fast associative memory near the processor which caches the more recently used page mapping table entries,and is an essential component to achieve reasonable performance under virtual memory.Only on a TLB miss,when the TLB does not hold the required mapping table entry,are page tables in main memory actually accessed.Even so,for large applications the TLB may not hold the mapping for all the pages continuously used.And unfortunately,it is not only a matter of increasing the size of the TLB;larger TLBs are slower and thus address translation and accessing data are also slower[107].Address translation overhead can be reduced if the virtual address space of each application is divided into variable-size segments,which can be of size up to Giga bytes.Since most applications have a code segment,a data segment and for each processor a stack segment,each processor only requires three or so TLB entries.Hence TLB miss overhead is negligible.However,handling variable-size segments makes the management of main memory a difficult task.Swapping segments of variable size in and out tends to fragment main memory into small,non-contiguous portions that cannot be used even though they are not allocated to any application;and a segment can only be swapped into main memory if a large enough contiguous portion of physical address space is available.In contrast, handling pages all of the same size simplifies main memory management because any virtual page6can be placed into any physical page.Another alternative to reduce TLB miss overhead is to use TLB support for variable-size pages[105, 88].Pages larger than the base-size page are referred to as superpages,and can be up to tens,hundreds or a even a few thousand Mega-bytes.The use of TLB support for superpages tends to reduce the TLB miss count and consequently TLB miss overhead.But it is optional because superpages are like segments only restricted to have a size and alignment in powers of two:using superpages requires to map a virtual superpage into a physical superpage.If swapping and main memory management are to proceed at base-size page granularity,which is desirable for efficiency,then physical superpages must be dynamically promoted by virtual memory software.Base-size physical pages must be copied around,possibly deallocating and reallocating some of them and this entails invalidating mapping information in TLBs for processors not to access erroneous data.And while superpage promotion is taking place the processors must wait.The motivating factor of our second proposal is performance.In our second proposal,a private virtual address space is used for each application,and is mapped at segment granularity into a paged global virtual address space.Applications can easily share data in the global virtual address space by mapping private segments to the same global segment.The mapping from private virtual address into global addresses is efficient because each processor only needs a few segmented TLB entries or segment registers.Yet swapping and main memory management are efficient because the global virtual address space is paged.The mapping of global virtual addresses into physical addresses is simply the identity function: the global virtual address space is mapped with the identity function to the physical address range of the associative main memory.However,since the physical address range cannot all be represented in main memory,as neither can the data it may identify,physical address creation and destruction must be supported by the data diffusing hardware.Hence the physical address space will be varying and non-contiguous at page granularity.Because using a varying physical address space is only possible if main memory is associative,we refer to our second proposal as associative memory virtual memory, or AMVM.The rationale behind AMVM is to use TLB support for superpages without incurring the overhead of superpage promotion.Since the global virtual addresses of each segment are mapped into physical7。