A neural network model of attention-modulated neurodynamics
利用神经网络进行网络流量识别——特征提取的方法是(1)直接原始报文提取前24字节,24个报。。。

利⽤神经⽹络进⾏⽹络流量识别——特征提取的⽅法是(1)直接原始报⽂提取前24字节,24个报。
国外的⽂献汇总:《Network Traffic Classification via Neural Networks》使⽤的是全连接⽹络,传统机器学习特征⼯程的技术。
top10特征如下:List of AttributesPort number server Minimum segment size client→server First quartile of number of control bytes in each packet client→server Maximum number of bytes in IP packets server→client Maximum number of bytes in Ethernet package server→client Maximum segment sizeserver→client Mean segment size server→client Median number of control bytes in each packet bidirectional Number of bytes sent in initial window client→server Minimum segment size server→clientTable 7: Top 10 attributes as determined by connection weights《Deep Learning for Encrypted Traffic Classification: An Overview》2018年⽂章,⾥⾯提到流量分类技术的发展历程:案例:流量识别流量识别任务(Skype, WeChat, BT等类别)1. 最简单的⽅法是使⽤端⼝号。
但是,它的准确性⼀直在下降,因为较新的应⽤程序要么使⽤众所周知的端⼝号来掩盖其流量,要么不使⽤标准的注册端⼝号。
基于多注意力机制的维吾尔语人称代词指代消解

的先行语, 因为文本中 “
(布葛热汗)” 与
“ (他)” 距离更近. 但是, 候选先行语 “
(吾
斯英)” 才是照应语 “ (他)” 正确的先行语. 所以,
人称代词指代消解应该充分考虑候选先行语距离特
征和更深层次的语境信息.
针对以上问题, 本文提出基于多注意力机制的
深度学习模型应用于维吾尔语人称代词指代消解任
2. Key Laboratory of software engineering technology, Xinjiang University, Urumqi 830046 3. Key Laboratory of Signal and Information Processing, Xinjiang University, Urumqi 830046 4. Network Center, Xinjiang University, Urumqi 830046 5. College of formation Science and Technology, Xinjiang University, Urumqi 830046
指代消解作为自然语言处理一个重要子任务, 深度学习模型在指代消解中得到广泛的研究. 这些 研究关注照应语和候选先行语的语义信息, 应用大 量的神经网络模型进行候选先行语预测[6−8]. 目前 的研究主要针对中文和英文等具有充足语料库的语 种, 对维吾尔语等小语种的研究不够深入, 针对小语 种的研究无论是语料标注还是实体识别都需要掌握 多级语法知识、语义知识, 甚至相应语言领域知识, 在当前自然语言处理的研究阶段, 要获取和学习研 究中所需知识仍比较困难. 人称代词指代消解作为 指代消解任务更细粒度的一个分支, 不仅依赖照应 语和候选先行语特征信息, 还要关注距离特征和上 下文语境信息. 例如句子:
结合注意力机制的长文本分类方法

结合注意力机制的长文本分类方法卢玲;杨武;王远伦;雷子鉴;李莹【摘要】News text usually consists of tens to hundreds of sentences,which has a large number of characters and contains more information that is not relevant to the topic,affecting the classification performance.In view of the problem,a long text classification method combined with attention mechanism was proposed.Firstly,a sentence was represented by a paragraph vector,and then a neural network attention model of paragraph vectors and text categories was constructed to calculate the sentence's attention.Then the sentence was filtered according to its contribution to the category,which value was mean square error of sentence attention vector.Finally,a classifier base on Convolutional Neural Network (CNN) was constructed.The filtered text and the attention matrix were respectively taken as the network input.Max pooling was used for featurefiltering.Random dropout was used to reduce over-fitting.Experiments were conducted on data set of Chinese news text classification task,which was one of the shared tasks in Natural Language Processing and Chinese Computing (NLP&CC) 2014.The proposed method achieved 80.39% in terms of accuracy for the filtered text,which length was 82.74% of the text before filtering,yielded an accuracy improvement of considerable 2.1%compared to text before filtering.The emperimental results show that combining with attention mechanism,the proposed method can improve accuracy of long text classification while achieving sentence levelinformation filtering.%新闻文本常包含几十至几百条句子,因字符数多、包含较多与主题无关信息,影响分类性能.对此,提出了结合注意力机制的长文本分类方法.首先将文本的句子表示为段落向量,再构建段落向量与文本类别的神经网络注意力模型,用于计算句子的注意力,将句子注意力的均方差作为其对类别的贡献度,进行句子过滤,然后构建卷积神经网络(CNN)分类模型,分别将过滤后的文本及其注意力矩阵作为网络输入.模型用max pooling进行特征过滤,用随机dropout防止过拟合.实验在自然语言处理与中文计算(NLP&CC)评测2014的新闻分类数据集上进行.当过滤文本长度为过滤前文本的82.74%时,19类新闻的分类正确率为80.39%,比过滤前文本的分类正确率超出2.1%,表明结合注意力机制的句子过滤方法及分类模型,可在句子级信息过滤的同时提高长文本分类正确率.【期刊名称】《计算机应用》【年(卷),期】2018(038)005【总页数】6页(P1272-1277)【关键词】注意力机制;卷积神经网络;段落向量;信息过滤;文本分类【作者】卢玲;杨武;王远伦;雷子鉴;李莹【作者单位】重庆理工大学计算机科学与工程学院,重庆400050;重庆理工大学计算机科学与工程学院,重庆400050;重庆理工大学计算机科学与工程学院,重庆400050;重庆理工大学计算机科学与工程学院,重庆400050;重庆理工大学计算机科学与工程学院,重庆400050【正文语种】中文【中图分类】TP391.1对海量文本进行自动分类,在信息检索、网络舆情发现等领域具有广泛应用价值。
融合知识图谱与注意力机制的短文本分类模型

第47卷第1期Vol.47No.1计算机工程Computer Engineering2021年1月January2021融合知识图谱与注意力机制的短文本分类模型丁辰晖1,夏鸿斌1,2,刘渊1,2(1.江南大学数字媒体学院,江苏无锡214122;2.江苏省媒体设计与软件技术重点实验室,江苏无锡214122)摘要:针对短文本缺乏上下文信息导致的语义模糊问题,构建一种融合知识图谱和注意力机制的神经网络模型。
借助现有知识库获取短文本相关的概念集,以获得短文本相关先验知识,弥补短文本缺乏上下文信息的不足。
将字符向量、词向量以及短文本的概念集作为模型的输入,运用编码器-解码器模型对短文本与概念集进行编码,利用注意力机制计算每个概念权重值,减小无关噪声概念对短文本分类的影响,在此基础上通过双向门控循环单元编码短文本输入序列,获取短文本分类特征,从而更准确地进行短文本分类。
实验结果表明,该模型在AGNews、Ohsumed 和TagMyNews短文本数据集上的准确率分别达到73.95%、40.69%和63.10%,具有较好的分类能力。
关键词:短文本分类;知识图谱;自然语言处理;注意力机制;双向门控循环单元开放科学(资源服务)标志码(OSID):中文引用格式:丁辰晖,夏鸿斌,刘渊.融合知识图谱与注意力机制的短文本分类模型[J].计算机工程,2021,47(1):94-100.英文引用格式:DING Chenhui,XIA Hongbin,LIU Yuan.Short text classification model combining knowledge graph and attention mechanism[J].Computer Engineering,2021,47(1):94-100.Short Text Classification Model Combining Knowledge Graph and Attention MechanismDING Chenhui1,XIA Hongbin1,2,LIU Yuan1,2(1.School of Digital Media,Jiangnan University,Wuxi,Jiangsu214122,China;2.Jiangsu Key Laboratory of Media Design andSoftware Technology,Wuxi,Jiangsu214122,China)【Abstract】Concerning the semantic ambiguity caused by the lack of context information,this paper proposes a neural network model,which combines knowledge graph and attention mechanism.By using the existing knowledge base to obtain the concept set related to the short text,the prior knowledge related to the short text is obtained to address the lack of context information in the short text.The character vector,word vector,and concept set of the short text are taken as the input of the model.Then the encoder-decoder model is used to encode the short text and concept set,and the attention mechanism is used to calculate the weight value of each concept to reduce the influence of unrelated noise concepts on short text classification.On this basis,a Bi-directional-Gated Recurrent Unit(Bi-GRU)is used to encode the input sequences of the short text to obtain short text classification features,so as to perform short text classification more effectively.Experimental results show that the accuracy of the model on AGNews,Ohsumed and TagMyNews short text data sets is73.95%,40.69%and63.10%,respectively,showing a good classification ability.【Key words】short text classification;knowledge graph;Natural Language Processing(NLP);attention mechanism;Bi-directional-Gated Recurrent Unit(Bi-GRU)DOI:10.19678/j.issn.1000-3428.00567340概述近年来,随着Twitter、微博等社交网络的出现,人们可以轻松便捷地在社交平台上发布文本、图片、视频等多样化的信息,社交网络已超越传统媒体成为新的信息聚集地,并以极快的速度影响着社会的信息传播格局[1]。
浙江省强基联盟2023-2024学年高三上学期12月联考英语试题

浙江省强基联盟2023-2024学年高三上学期12月联考英语试题学校:___________姓名:___________班级:___________考号:___________一、短对话1.What will the man do next?A.Collect some information.B.Discuss with some students.C.Get the woman’s opinion.2.Why is the woman in a hurry?A.To answer a call.B.To search for a store.C.To look for a washroom. 3.What happened to Larry last night?A.He fell into water.B.He couldn’t find his hotel.C.He was caught in the rain.4.Where will the woman go tomorrow night?A.To the man’s house.B.To a cinema.C.To a restaurant. 5.What does the woman think of the man?A.Bad-tempered.B.Warm-hearted.C.Absent-minded.二、长对话听下面一段较长对话,回答以下小题。
6.What is the man worried about?A.His friend’s visit.B.Loss of his friend.C.His poor cooking. 7.What does the woman suggest the man do?A.Download an app.B.Cook unique cuisines.C.Go out with his friend.听下面一段较长对话,回答以下小题。
基于CNN-LSTM-Attention组合模型对我国货运量时序预测对比
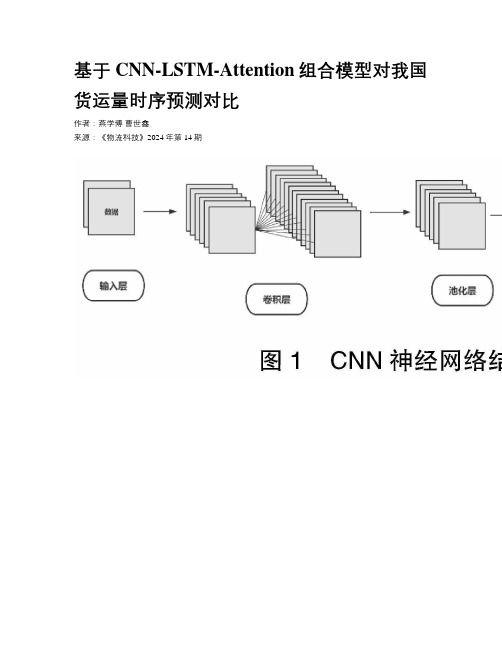
基于CNN-LSTM-Attention组合模型对我国货运量时序预测对比作者:燕学博曹世鑫来源:《物流科技》2024年第14期摘要:為了进一步提高我国货运量的预测准确性,文章基于卷积神经网络和长短期记忆网络模型,引入注意力机制(Attention Mechanism)的组合预测模型,以对我国货运量进行时序预测。
首先,利用卷积神经网络提取货运量数据变化特征。
其次,将所提取的特征构成时间序列作为长短期记忆网络的输入。
最后,通过注意力集中捕捉预测模型中经LSTM层输出的信息特征,划分权重比例,提取关键信息,实现货运量预测。
结合全国月度货运量历史数据进行时序预测,然后与其他神经网络预测的各种评价指标进行对比,结果显示,CNN-LSTM-Attention模型预测误差小于其他模型,预测准确性相对较好。
关键词:货运量;预测;CNN;LSTM;注意力机制中图分类号:F259.22 文献标志码:A DOI:10.13714/ki.1002-3100.2024.14.002文章编号:1002-3100(2024)14-0005-05Comparison of Time-Series Prediction of Freight Transportation Volume in China Based on CNN-LSTM-Attention Combination ModelYAN Xuebo1,CAO Shixin2 (1. School of Management, Fujian University of Technology,Fuzhou 350118, China; 2. School of Transportation, Fujian University of Technology, Fuzhou 350118, China)Abstract: In order to further improve the prediction accuracy of China's high freight volume,this paper introduces a combined prediction model of Attention Mechanism based on convolutional neural network and long and short-term memory network model to forecast China's freight volume in time series. First of all, the convolutional neural network is used to extract the features of the freight volume data changes, and then the extracted features are used to constitute a time series as the input of the long and short-term memory network, and finally, the attention is focused on capturing the features of the information output from the LSTM layer in the prediction model, dividing the weight ratio, extracting the key information, and realizing the prediction of the freight volume. Combined with the national monthly freight volume historical data for time series prediction, and then compared with other neural network prediction of various evaluation indexes, the results show that the CNN-LSTM-Attention model prediction error is smaller than other models, and the prediction accuracy is relatively good.Key words: freight volume; prediction; CNN; LSTM; attention mechanism0 引言近年来,我国的货物运输总量持续增长,但增速整体上呈现出逐渐减缓的趋势,这主要是因为我们的货运量预测不够准确和合理,导致了资源的浪费[1]。
rnn的基本原理

rnn的基本原理RNN, short for Recurrent Neural Network, is a type of artificial neural network designed to capture sequential data patterns. RNN is based on the idea of looping through the same set of neurons multiple times, allowing information to persist. RNN is commonly used in natural language processing, speech recognition, and other tasks that involve sequential data processing.RNN,即循环神经网络,是一种设计用于捕捉序列数据模式的人工神经网络。
RNN基于多次循环通过相同一组神经元的想法,从而允许信息保留。
RNN通常用于自然语言处理,语音识别和其他涉及顺序数据处理的任务。
One key feature of RNN is its ability to maintain a hidden state that serves as memory for the network. This hidden state allows the network to retain information about previous inputs and use it to make predictions about future inputs. The ability to remember past information is crucial for tasks that involve sequences, as it enables the network to learn long-term dependencies.RNN的一个关键功能是其能够保持作为网络记忆的隐藏状态。
深度神经网络知识蒸馏综述

Computer Science and Application 计算机科学与应用, 2020, 10(9), 1625-1630Published Online September 2020 in Hans. /journal/csahttps:///10.12677/csa.2020.109171深度神经网络知识蒸馏综述韩宇中国公安部第一研究所,北京收稿日期:2020年9月3日;录用日期:2020年9月17日;发布日期:2020年9月24日摘要深度神经网络在计算机视觉、自然语言处理、语音识别等多个领域取得了巨大成功,但是随着网络结构的复杂化,神经网络模型需要消耗大量的计算资源和存储空间,严重制约了深度神经网络在资源有限的应用环境和实时在线处理的应用上的发展。
因此,需要在尽量不损失模型性能的前提下,对深度神经网络进行压缩。
本文介绍了基于知识蒸馏的神经网络模型压缩方法,对深度神经网络知识蒸馏领域的相关代表性工作进行了详细的梳理与总结,并对知识蒸馏未来发展趋势进行展望。
关键词神经网络,深度学习,知识蒸馏A Review of Knowledge Distillationin Deep Neural NetworksYu HanThe First Research Institute, The Ministry of Public Security of PRC, BeijingReceived: Sep. 3rd, 2020; accepted: Sep. 17th, 2020; published: Sep. 24th, 2020AbstractDeep neural networks have achieved great success in computer vision, natural language processing, speech recognition and other fields. However, with the complexity of network structure, the neural network model needs to consume a lot of computing resources and storage space, which seriously restricts the development of deep neural network in the resource limited application environment and real-time online processing application. Therefore, it is necessary to compress the deep neural network without losing the performance of the model as much as possible. This article introduces韩宇the neural network model compression method based on knowledge distillation, combs and sum-marizes the relevant representative works in the field of deep neural network knowledge distilla-tion in detail, and prospects the future development trend of knowledge distillation. KeywordsNeural Network, Deep Learning, Knowledge DistillationCopyright © 2020 by author(s) and Hans Publishers Inc. This work is licensed under the Creative Commons Attribution International License (CC BY 4.0)./licenses/by/4.0/1. 引言近年来,随着人工智能的不断兴起,深度神经网络已经被广泛应用在计算机视觉、自然语言处理、语音识别等多个领域,并取得了巨大的成功。
卷积神经网络结构的改进及其在语音识别中的应用研究

卷积神经网络结构的改进及其在语音识别中的应用研究随着人工智能技术的不断发展,深度学习作为其中的一种重要方法,已经得到广泛应用。
其中,卷积神经网络(Convolutional Neural Networks, CNN)作为一种特殊的神经网络模型,拥有许多优秀的特性,在语音识别等领域的应用也取得了一系列的成功。
本文将介绍卷积神经网络结构的改进及其在语音识别中的应用研究。
一、卷积神经网络结构的改进1.1 基础卷积神经网络结构卷积神经网络是一种高效的深度前馈神经网络,由输入层,卷积层,激活层,池化层,全连接层和输出层组成。
其中,卷积层是卷积神经网络的重要组成部分,卷积核负责对输入数据进行卷积运算,提取出它们之间的特征。
池化层可以减小特征映射的大小和数量。
为了增强模型的鲁棒性,常常会对网络结构进行一些改进。
1.2 递归卷积神经网络结构递归卷积神经网络(Recurrent Convolutional Neural Network, RCNN)是在传统卷积神经网络的基础上进行改进的。
在语音识别领域,往往需要序列建模,而传统卷积神经网络在处理时序数据时不能直接处理变长的序列。
递归卷积神经网络引入了循环神经网络(RNN)的概念,并通过共享卷积核的方式,建立对于当前时刻输入和前一个时刻参数的依赖关系,使网络可以捕捉到序列的上下文信息。
1.3 带注意力机制卷积神经网络结构带注意力机制的卷积神经网络(Attention-based Convolutional Neural Networks, ACNN)是在RCNN的基础上进一步改进的,它引入了注意力机制,可以集中注意力在网络的某些部分上,从而提高特定信息的重要性并抑制其他的信息。
在语音识别领域,ACNN可以通过注意输入音频的重要部分,进而提高模型在噪声等复杂环境下的识别能力。
二、卷积神经网络在语音识别中的应用研究针对语音合成、语音识别等语音信号领域的特点,有很多研究者将卷积神经网络应用于这些任务中,并取得了不错的效果。
2020届上海市建平中学高三下学期英语3月月考试卷( Word版 )

建平中学高三下3月月考2020.3Ⅱ. Grammar and VocabularySection ADirections: Read the following passage. Fill in the blanks to make the passage coherent and grammatically correct. For the blanks with a given word, fill in each blank with the proper form of the given word. For the other blanks, use one word that best fits each blank.Cruz Genet, 11, and Anthony Skopick, 10, couldn’t agree. Were the birds out on the ice ducks or geese? There was only one way to find out.So on a chilly January evening last year, the two friends ventured(冒险)onto the frozen pond near their homes in Frankfort, Illinois, ___21___(get)a better look. First they cast a rock onto the ice to test it, then they stepped on it. ___22___(convince)the ice would hold their weight, Ant hony took a few steps, then… FOOMP. He crashed through the seemingly frozen surface. There was no sound, he just fell instantly.Cruz rushed to help his terrified friend. FOOMP—the pond swallowed him too. Cruz managed to lift ___23___ out of the frozen water and onto a more solid section. He then cautiously worked his way toward Anthony. But the ice ___24___(not hold),a nd he fell in again. This time, he couldn’t get out. The boys were up to their necks in icy water and quickly losing feeling in their limbs. There was not much chance ___25___ they could free themselves from the trouble. Cruz was sure he was going to die.Anthony’s older sister had seen the boys ___26___(fall)into the pond and started screaming for help. John Lavin, a neighbor driving nearby on his way to the grocery store, heard her. He quickly pulled over. Seeing the boys, he grabbed a nearby buoy(浮标),kicked off his shoes, and ran into the water, ___27___(chop)his way through the ice with free fist. Lavin made his way ___28___ Cruz and Anthony and pull them back to land. They were taken to the hospital, where doctors discovered that their five-minute stay in the water ___29___(lower)their body temperature nearly ten degrees.Fortunately, the boys have fully recovered, ___30___ they are still a little awestruck(惊叹的)by their fearless neighbor.“Just to think,”says Cruz,“I f he hadn’t been there, I would have died.”Section BDirections:Complete the following passage by using the words in the box. Each word can only be used once.American fashion from the ___31___ of Parisian design. Independence came in tying, wrapping, storing, and rationalizing that wardrobe. These designers established the modem dress code, letting playsuits and other active outfits suit casual clothing, allowing pants to enter the wardrobe, and prizing rationalism and utility in dress, in contradiction to dressing for an occasion. Fashion in America was logical and ___32___ to the will of the women who wore it. American fashion addressed a democracy, whereas traditional Paris-based fashion was prescriptive and imposed on women, willing or not.In an earlier time, American fashion had also followed the dictates of Paris, or even ___33___ specific French designs. Designer sportswear was not modeled on that of Europe, as “modem art” would later be; it was ___34___ invented and developed in America. Its designers were not high-end with supplementary lines. The design objective and the business commitment were targeted to sportswear, and the distinctive traits were problem-solving ingenuity(独创性)and realistic lifestyle applications. Ease of care was most important: summerdresses and outfits, in particular, were ___35___ cotton, readily capable of being washed and pressed at home. Closings were simple, practical, and ___36___, as the modem woman depended on no personal maid to dress her. American designers ___37___ the freedom of women who wore the clothing.Many have argued that the women designers of that time ___38___ their own clothing values into a new style. Of course, much of this argument in the 1930s-40s was advanced because there was little or no experience in designing clothes on the basis of utility. But could utility alone ___39___ the new ideas of the American designers? Fashion is often regarded as a pursuit of beauty, and some cherished fashion’s relationship to the fine arts. What the designers of the American sportswear proved was that fashion is a design art, answering to the demanding needs of service. Of course these practical, ___40___ designers have determined the course of late twentieth-century fashion. They were the pioneers of gender equity, in their useful, adaptable clothing, which was both made for the masses and capable of self-expression.Ⅲ. Reading comprehensionSection ADirections:For each blank in the following passages there are four words or phrases marked A, B, C, and D. Fill in each blank with the word or phrase that best fits the context.Face shape lets AI spot rare disordersPeople with genetic syndromes(综合症)sometimes have revealing facial features, but using them to make a quick and cheap diagnosis an be ___41___ given there are hundreds of possible conditions they may have. A new neural network that analyses photographs of faces can help doctors ___42___ the possibilities.Yaron Gurovich at biotechnology firm FDNA in Boston and his team built a neural network to look at the overall impression of faces and ___43___ a list of the 10 genetic syndromes a person is most likely to have.They ___44___ the neural network, called DeepGestalt, on 17,000 images correctly labelled to match more than 200 genetic syndromes. The team then asked the AI to ___45___ potential genetic disorders from a further 502 photos of people with such conditions. It included the correct answer among its list of 10 responses 91 per cent of the time.Gurovich and his team also ___46___ the neural network’s ability to distinguish between the different genetic mutations(变异)that can lead to the same syndrome. They used photographs of people with Noonan syndrome, which can result from mutations in any one of five genes. DeepGestalt correctly identified the genetic source of the physical appearance 64 per cent of the time. It’s clearly not ___47___, but it’s still much better than humans are at trying to do this.As the system makes its assessments, the facial regions that were most helpful in the determination are ___48___ and made available for doctors to view. This helps them to understand the relationships between genetic make-up and physical appearance.The fact that the diagnosis is based on a simple photograph raises questions about ___49___. If faces can reveal details about genetics, then employers and insurance providers could, in principle, ___50___ use such techniques to ___51___ against people who have a high probability of having certain disorders. ___52___, Gurovich says the tool will only be ___53___ for use by clinicians.This technique could bring significant ___54___ for those who have genetic syndromes. The real value here is that for some of these ultra-rare diseases, the process of diagnosis can be many, many years. This kind of technology can help narrow down the search space and then be confirmed through checking genetic markers. For some diseases, it will cut down the time to diagnosis dramatically. For others, it could perhaps add means of finding other people with the disease and, ___55___, help find new treatments or cures.41. A. convincing B. tricky C. reliable D. feasible42. A. bring about B. result from C. narrow down D. rule out43. A. return B. input C. top D. feed44. A. based B. imposed C. focused D. trained45. A. identify B. distinguish C. shift D. cure46. A. tested B. demonstrated C. recognized D. acquired47. A. acceptable B. perfect C. reliable D. workable48. A. covered B. excluded C. highlighted D. supervised49. A. objectivity B. accuracy C. credibility D. privacy50. A. legally B. habitually C. efficiently D. secretly51. A. discriminate B. fight C. argue D. vote52. A. Furthermore B. Therefore C. Otherwise D. However53. A. impossible B. available C. ready D. rare54. A. challenges B. benefits C. damages D. concerns55. A. by contrast B. in turn C. in addition D. on the contrarySection BDirections:Read the following three passages. Each passage is followed by several questions or unfinished statements. For each of them there are four choices marked A, B, C, and D. Choose the one that fits best according to the information given in the passage you have just read.(A)The two roadsIt was New Year’s night. An aged man was standing at a window. He raised his mournful eyes towards the deep blue sky, where the stars were floating like white lilies on the surface of a clear calm lake. When he cast them on the earth, where a few more hopeless people besides himself now moved towards their certain goal—the tomb. He had already passed sixty of the stages leading to it, and he had brought from his journey nothing but errors and regret. Now his health was poor, his mind vacant, his heart sorrowful, and his old age short of comforts.The days of his youth appeared like dreams before him, and he recalled the serious moment when his father placed him at the entrance of the two roads—one leading to a peaceful, sunny place, covered with flowers, fruits and resounding with soft, sweet songs; the other leading to a deep, dark cave, which was endless, where poison flowed instead of water and where devils and poisonous snakes hissed and crawled.He looked towards the sky and cried painfully, "Oh youth, return! Oh my father, place me once more at the entrance to life, and I'll choose the better way!" But both his father and the days of his youth had passed away.He saw the lights flowing away in the darkness. These were the days of his wasted life; he saw a star fall from the sky and disappeared, and this was the symbol of himself. His regret, which was like a sharp arrow, struck deeply into his heart. Then he remembered his friends in his childhood, who entered on life together with him. But they had made their way to success and were now honored and happy on this New Year's night.The clock in the high church tower struck and the sound made him remember his parents' early love for him. They had taught him and prayed to God for his good. But he chose the wrong way. With shame and grief he dared no longer look towards that heaven where his father lived. His darkened eyes were full of tears, and with a despairing effort, he burst out a cry: "Come back, my early days! Come back!"And his youth did return, for all this was only a dream, which he had on New Year's Night. He was still young though his faults were real; he had not yet entered the deep, dark cave, and he was still free to walk on the roadwhich leads to the peaceful and sunny land.Those who still linger on the entrance of life, hesitating to choose the bright road, remember that when years are passed and your feet stumble on the dark mountains, you will cry bitterly, but in vain. "O youth, return! Oh give me back my early days!"56. In the 3rd paragraph, the man cried painfully because ___.A. all the hopeless people were moving towards deathB. he had lost forever the chance to take the right roadC. His parents and the happy days of his youth were goneD. he refused to take the toad leading to a deep dark cave57. What happened to the man before his sudden realization?A. He was at his father’s fune ral farewell.B. He was enjoying the New Year’s eve.C. He was wandering at the entrance to life.D. He was having a dream of his life in old age.58. We can infer from the story that ___.A. the man’s childhood friends led a joyful life like himB. the man still had the opportunity to chose the right wayC. both the man’s parents passed away when he was youngD. the man’s father was quite strict with his son before death59. The passage is mainly written for ____.A. a new driver getting lost on a detourB. a concerned mother with two children to raiseC. an experienced teacher with a good reputationD. a hesitating young adult facing a tough life choice(B)“Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo”is a real sentence.How?Let’s break it down, starting with a simple phrase:Monkeys from Pisa bully deer from London.OK, admittedly it’s an implausible scenario, but it’s a grammatically fine sentence. In English we can use place names as adjectives, so let’s shorten the sentence a little.Pisa monkeys bully London deer.Now we’ll throw in some giraffes from Paris to even the score with those mean monkeys.Pisa monkeys, whom Paris giraffes intimidate, bully London deer.English is peculiar in that you can omit relative pronouns, e.g.,“the person whom I love”can be expressed as “the person I love.”L et’s do that to this sentence.Pisa monkeys Paris giraffes intimidate bully London deer.This kind of pronoun removal can be a little more difficult to grasp when written than when spoken. Saying the above sentences with pauses after monkeys and intimidate can help. Now we need to replace both of the verbs, intimidate and bully, with their(admittedly uncommon)synonym, buffalo.Pisa monkeys Paris giraffes buffalo buffalo London deer.A gain, pauses help keep the meaning in mind: Put a pause after monkeys and the first buffalo. Now we’ll replace all the worldwide place names with the second-largest city in New York State, Buffalo.(T hat’s Buffalo’s tallest building, One Seneca Tower, below.)Buffalo monkeys Buffalo giraffes buffalo buffalo Buffalo deer.You can probably guess what the next step is. But before we replace all the animals with the common name for the American bison, note how the capital letters in the above sentence help you keep the place names separate from the other usages of the word. OK, here goes:Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.One last thing to note: This exceptional sentence is possible because the plural of the animal buffalo is buffalo, not buffalos, otherwise all the words wouldn’t be identical.English is strange and wonderful!60. How should we read the following sentence with proper pauses?A. Buffalo buffalo Buffalo / buffalo buffalo / buffalo Buffalo buffalo.B. Buffalo buffalo / Buffalo buffalo buffalo / buffalo Buffalo buffalo.C. Buffalo buffalo Buffalo / buffalo buffalo buffalo / Buffalo buffalo.D. Buffalo buffalo / Buffalo buffalo / buffalo buffalo Buffalo buffalo.61. What is the key element to make this sentence possible?A. The relative pronouns in English can be omitted.B. In English, place names can be used as adjectives.C. The city has the same name with a kind of American bison.D. The word buffalo has the same form of singular and plural.62. Where can you probably find this article?A. Wandering the EarthB. Linguistics Around UsC. Popular Animal ScienceD. Collins English Grammar(C)The idea that richer countries are happier may seem intuitively obvious. However, in 1974, research by economist Richard Easterlin found otherwise. He discovered that while individuals with higher incomes were more likely to be happy, this did not hold at a national level. In the United States, for example, average income per person rose steadily between 1946 and 1970, but reported happiness levels showed no positive long-term trend; in fact, they declined between 1060 and 1970. These differences between nation-level and individual results gave rise to the term“Easterlin paradox”: the idea that a higher rate of economic growth does not result in higher average long-term happiness.Having access to additional income seems to only provide a temporary surge in happiness. Since a certain minimum income is needed for basic necessities, it’s possible that the happiness boost from extra cash isn’t that great once you rise above the poverty line. This would explain Easterlin’s findings in the United States and other developed countries. He argued that life satisfaction does rise with average incomes—but only in the short term. Recent research has challenged the Eastern paradox, however. In 2013, sociologists Ruut Veenhoven and Floris Vergunst conducted a study using statistics from the World Database of Happiness. Their analysis revealed a positive correlation between economic growth and happiness. Another study by the University of Michigan found that there is no maximum wealth threshold at which more money ceases to contribute to your happiness:“If there is a satiation point, we are yet to reach it.”T he study’s findin gs suggested that every extra dollar you earn makes you happier. With so much debate about the relationship between money and happiness, it’s clear that happiness itself is a complex concept and depends on many factors.According to psychologists Selin Kesebir and Shigehiro Oishi, happiness also depends on how your income compares to the people around you. They argue that a country’s economic growth only makes its citizens happier if wealth is evenly distributed. In emerging countries with high income inequality—where the rich get richer and the poor get poorer—average happiness tends to drop because only relatively few people benefit from the economic prosperity. This suggests that governments should consider implementing policies to ensure more equal distribution of wealth. The happier people are, the more productive they are likely to become, thus leading to improved economic outcomes at the individual and national levels.There is continuing debate about the link between wealth and happiness, with arguments both for and against the notion that richer countries are happier. However, it is clear that wealth alone isn’t enough to make us happy. The effect of income inequality on happiness shows that happiness is a societal responsibility. We need to remember the positive effects of generosity, altruism, and building social connections. Perhaps our focus should be less on how much money we have, and more on how we use it.63. According to the passage, Easterlin Paradox refers to ____.A. the fact that the more money, the happier people will feelB. the suggestion that money should be given the top priorityC. the question how economic outcomes are distributed nationwideD. the opinion that higher income doesn’t necessarily generate happiness64. The word“satiation”in paragraph 3 is closest in meaning to“__”.A. satisfactionB. controversialC. centralD. sensitive65. What is the major reason for people’s unhappiness related to money?A. Money not enoughB. Money not fairly distributedC. Rich people richerD. Unequal money paid for equal work66. Which of the following might be best title of this passage?A. It’s all relativeB. Easterlin paradoxC. The economics of happinessD. Rising income, rising happinessSection CDirections:Read the passage carefully. Fill in each blank with a proper sentence given in the box. Each sentenceTrue intelligenceTaking charge of yourself involves putting to test some very popular myths. At the top of the list is the notion that intelligence is measured by your ability to solve complex problems; to read, write and compute at certain levels; and to resolve abstract equations quickly. ___67___ It encourages a kind of intellectual prejudice that has brought with it some discouraging results. We have come to believe that someone who has more educational merit badges, who is very good at some form of school discipline is "intelligent. " Yet mental hospitals are filled with patients who have all of the properly lettered certificates. A truer indicator of intelligence is an effective, happy life lived each day and each present moment of every day. ___68___Problem solving is a useful help to your happiness, but if you know that given your inability to resolve a particular concern you can still choose happiness for yourself, or at a minimum refuse to choose unhappiness, then you are intelligent. You are intelligent because you have the ultimate weapon against the big N.B.D.—Nervous Break Down.“Intelligent”do not have N. B. D. ’s because they are in charge of themselves. ___69___You can begin to think of yourself as truly intelligent on the basis of how you choose to feel in the face of trying circumstances. The life struggles are pretty much the same for each of us. Everyone who is involved with other human beings in any social context has similar difficulties. Disagreements, conflicts and compromises are a part of what it means to be human. ___70___ But some people are able to make it, to avoid immobilizing depression and unhappiness despite such occurrences, while others collapse or have an N. B. D. Those who recognize problems as a human condition and don’t measure happiness by an absence of problems are the most intelligent kind of humans we know; also, the most rare.Ⅳ. Summary writingDirections:Read the following passage. Summarize the main idea and the main point(s) of the passage in no more than 60 words. Use your own words as far as possible.Blowing a Few TopsEver stopped to consider the upside of volcanic eruptions? It’s not all death, destruction and hot liquidrock—scientists have a plan to cool the planet by simulating one such eruption.Solar geoengineering involves simulating a volcano by spraying aerosols(气溶胶)into the atmosphere. When they combine with oxygen, droplets of sulfuric acid(硫酸)form. These droplets reflect sunlight away from Earth, cooling the planet. All good in theory, but the consequences are largely unknown and a few could be disastrous. In a study recently published in Nature Communications, researchers led by Anthony Jones, a climate scientist from the University of Exeter, found that using this technology in the Northern Hemisphere could reduce the number of tropical winds hitting the U.S. and Caribbean. But there’s an annoying exchang e: more winds in the Southern Hemisphere and a drought across the Sahel region of Africa. That’s because the entire climate system is linked—disrupting one region will invariably affect another. How would a nation react if another was causing its weather to get much worse? Would that be an act of war?There is, however, a case for using solar geoengineering on a global scale. Jones says it could be used to“take the edge off”the temperature increases scientists are predicting. It could be used while the world searches for more effective strategies.The study also highlights a far bigger problem with solar geoengineering: its complete lack of regulation.“T here’s nothing that could stop one country just doing it,”Jones says.“You only need about 100 aircraft with three flights per day. It would cost $1 billion to $10 billion per year.”He adds,“I t’s deeply disturbing that we have this technology that could have such a massive influence on the climate, yet there’s just no regulation to stop countries or even organizations from doing it.”Jones cautions that there is much about the climate system we do not understand, as well as far more that will need to be done before solar geoengineering is considered safe—or too dangerous to even discuss.V. TranslationsDirections:Translate the following sentences into English, using the words given in the brackets.72. 建议老年人晚上不要喝浓茶,以免睡不着。
注意力机制(AttentionMechanism)在自然语言处理中的应用

注意⼒机制(AttentionMechanism)在⾃然语⾔处理中的应⽤注意⼒机制(Attention Mechanism)在⾃然语⾔处理中的应⽤近年来,深度学习的研究越来越深⼊,在各个领域也都获得了不少突破性的进展。
基于注意⼒(attention)机制的神经⽹络成为了最近神经⽹络研究的⼀个热点,本⼈最近也学习了⼀些基于attention机制的神经⽹络在⾃然语⾔处理(NLP)领域的论⽂,现在来对attention在NLP中的应⽤进⾏⼀个总结,和⼤家⼀起分享。
1 Attention研究进展Attention机制最早是在视觉图像领域提出来的,应该是在九⼏年思想就提出来了,但是真正⽕起来应该算是google mind团队的这篇论⽂《Recurrent Models of Visual Attention》[14],他们在RNN模型上使⽤了attention机制来进⾏图像分类。
随后,Bahdanau等⼈在论⽂《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使⽤类似attention的机制在机器翻译任务上将翻译和对齐同时进⾏,他们的⼯作算是是第⼀个提出attention机制应⽤到NLP领域中。
接着类似的基于attention机制的RNN模型扩展开始应⽤到各种NLP任务中。
最近,如何在CNN中使⽤attention机制也成为了⼤家的研究热点。
下图表⽰了attention研究进展的⼤概趋势。
2 Recurrent Models of Visual Attention在介绍NLP中的Attention之前,我想⼤致说⼀下图像中使⽤attention的思想。
就具代表性的这篇论⽂《Recurrent Models of Visual Attention》 [14],他们研究的动机其实也是受到⼈类注意⼒机制的启发。
annotated transformer结构

Annotated Transformer: A Comprehensive Guide to theTransformer ArchitectureThe Transformer model has revolutionized natural language processing (NLP) tasks since its introduction in a 2017 paper by Vaswani et al. named “Attention is All You Need”. This architecture has replaced the recurrent neural networks (RNNs) as the state-of-the-art approach in many NLP applications, including machine translation, sentiment analysis, and language generation. In this article, we provide an in-depth understanding of the Transformer model, exploring its architecture and key components.Introduction to the Transformer ArchitectureThe Transformer architecture is a neural network model that operates on sequences of data, such as sentences or words. Unlike traditional approaches, the Transformer does not rely on recurrent or convolutional layers. Instead, it introduces the concept of self-attention mechanism, enabling the model to weigh the importance of different words or positions within the input sequence.Transformer Components1. Self-Attention MechanismThe self-attention mechanism is the foundation of the Transformer architecture. It allows the model to compute the representation of each word in a sequence by considering the importance of other words in that sequence. This mechanism enables the Transformer to capture dependencies beyond the context window size and handle long-range dependencies more effectively.2. EncoderThe encoder in the Transformer is responsible for processing the input sequence and creating a representation that captures the contextual information of each word. It consists of multiple layers, where each layer contains a multi-head self-attention mechanism and a feed-forward neural network. The self-attention mechanism captures interactions between different words in the input sequence, while the feed-forward network provides non-linear transformations to enhance the encoding capability.3. DecoderThe decoder in the Transformer takes the encoded input representation and generates the output sequence. Similar to the encoder, the decoder comprises multiple layers with self-attention and feed-forward mechanisms. However, the decoder also includes an additional attention mechanism called masked self-attention, which helps the model attend only to previously generated tokens during the decoding process.4. Multi-Head AttentionMulti-head attention is a vital component of both the encoder and decoder. It allows the model to focus on different parts of the input sequence simultaneously by performing multiple parallel self-attention operations. This mechanism helps the Transformer to capture different types of information and improve its representation power.5. Positional EncodingPositional encoding is used in the Transformer to provide the model with information about the order of words in the input sequence. By adding positional encodings to the word embeddings, the model can differentiate between words with the same meaning but different positions. Various positional encoding schemes, including sine and cosine functions, are employed to achieve this goal effectively.6. Residual Connections and Layer NormalizationThe Transformer extensively utilizes residual connections and layer normalization techniques to stabilize the training process. Residual connections enable the model to preserve information from earlier layers, ensuring a smooth flow of gradients during training. Layer normalization helps in reducing the internal covariate shift, preventing the model from becoming overly sensitive to changes in input distribution.7. MaskingMasking plays a crucial role in the Transformer architecture, particularly in the decoder. During the training of the model, certain tokens in the input are masked to prevent the model from cheating by directly using the answers during the generation process. Masking helps the model learn to generate the correct output based solely on the input sequence.ConclusionThe Transformer architecture has significantly contributed to the field of NLP and has become the de facto standard for many sequence-based tasks. Its self-attention mechanism, along with other key components like the encoder, decoder, multi-head attention, and positional encoding, enables the model to effectively capture dependencies and generate accurate outputs. By understanding the inner workings of the Transformer, researchers and practitioners can leverage its power to develop innovative NLP applications in the future.。
一种基于改进Attention U-net的联合视杯视盘分割方法

第38卷第3期 计算机应用与软件Vol 38No.32021年3月 ComputerApplicationsandSoftwareMar.2021一种基于改进AttentionU net的联合视杯视盘分割方法秦运输 王行甫(中国科学技术大学计算机科学与技术学院 安徽合肥230031)收稿日期:2019-09-13。
秦运输,硕士生,主研领域:医学图像处理。
王行甫,副教授。
摘 要 青光眼是当前世界范围内致盲的主要病因之一,其发病过程没有明显的特征。
视杯盘比是青光眼诊断中最主要的评估指标之一,这使得视杯视盘的分割成为了目前青光眼诊断的关键。
已有的视杯视盘分割方法大多基于手工提取的特征,低效且精度不高。
提出一种名为MAR2U net的深度神经网络架构用于青光眼视杯视盘的联合分割。
它是基于AttentionU net的一种改进架构,通过在AttentionU net的基础之上引入递归残差卷积模块来提取更加深层次的特征,并结合多尺度的输入和多标签的FocalTversky损失函数来提升模型的联合分割性能。
实验结果表明,该方法在REFUGE数据集上的分割效果较已有方法取得了显著提升,为实现大规模的青光眼诊断筛查提供了基础。
关键词 青光眼检测 视杯与视盘 分割 AttentionU net中图分类号 TP3 文献标志码 A DOI:10.3969/j.issn.1000 386x.2021.03.028AJOINTSEGMENTATIONMETHODFOROPTICDISCANDOPTICCUPBASEDONMODIFIEDATTENTIONU NETQinYunshu WangXingfu(SchoolofComputerScienceandTechnology,UniversityofScienceandTechnologyofChina,Hefei230031,Anhui,China)Abstract Glaucomaisoneofthemaincausesofblindnessintheworld,andthepathogenesishasnoobviouscharacteristics.Asoneofthemostimportantevaluationindexesinthediagnosisofglaucoma,opticdiscandcupratioisthekeytothediagnosisofglaucoma.Mostoftheexistingopticdiscandcupsegmentationmethodsarebasedonthemanuallyextractedfeatures,whichareinefficientandhavelowaccuracy.ThispaperproposesadeepneuralnetworknamedMAR2U netforthejointsegmentationofopticdiscandopticcup.ItisanimprovedarchitecturebasedonAttentionU net.OnthebasisofAttentionU net,recursiveresidualconvolutionmodulewasintroducedtoextractdeeperfeatures,andthejointsegmentationperformanceofthemodelwasimprovedbycombiningmulti scaleinputsandmulti labelFocalTverskylossfunction.TheexperimentalresultsshowthatthesegmentationeffectofproposedmethodonREFUGEdatasethasbeensignificantlyimprovedcomparedwiththeexistingmethods,whichprovidesafoundationforlarge scaleglaucomadiagnosis.Keywords Glaucomadetection Opticdiscandcup Segmentation AttentionU net0 引 言青光眼是一种慢性的眼底疾病,也是当前世界范围导致视力损伤的主要原因之一[1]。
上海市南模中学2022-2023学年高三上学期开学考英语试题(含答案)

2022年南模中学高三上初态考II. Grammar and VocabularySection ADirections: After reading the passage below, fill in the blanks to make the passages coherent and grammatically correct. For the blanks with a given word, fill in each blank with the proper form of the given word; for the other blanks, use one word that best fits each blank.Quantum computer chips demonstrated at the highest temperatures ever Quantum computing is heating up. For the first time, quantum computer chips (21) ________ (operate) at a temperature above -272℃, or 1 kelvin. That may still seem frigid, but it is just warm enough to potentially enable a huge leap in the capabilities.Quantum computers are made of quantum bits, or qubits(量子比特), (22) ________ can be made in several different ways. One that (23) ________ (receive) attention from some of the field's big players consists of electrons on a silicon chip.These systems only function at extremely low temperatures-below 100 millikelvin, or -273.05℃-so the qubits have to be stored in powerful refrigerators. The electronics that power them won't run at such low temperatures, and also emit heat that could disrupt the qubits, so (24) ________ are generally stored outside the refrigerators with each qubit is connected by a wire to its electronic controller.“Eventually, for useful quantum computing, we will need to go to something like a million qubits, and this sort of brute force method, with one wire per qubit, won't work any more,” says Menno Veldhorst at QuTech in the Netherlands. “It works for two qubits, but not for a million.”Veldhorst and his colleagues, (25) ________ another team led by researchers at the University of New South Wales in Australia, have how demonstrated that these qubits can be operated at (26) ________ (high) temperatures. The latter team showed they were able to control the state of two qubits on a chip at temperatures up to 1.5 kelvin, and Veldhorst's group used two qubits at 1. I kelvin in (27) ________ is called a logic gate, which performs the basic operations that make up more complex calculations.(28) ________ we know the qubits themselves can function at higher temperatures, the next step is incorporating the electronics onto the same chip. “I hope that (29) ________ we have that circuit, it won't be too hard to scale to something with practical applications,” says Veldhorst.Those quantum circuits will be similar in many ways to the circuits we use of traditional computers, so they can be scaled up relatively easily (30) ________ (compare) with other kinds of quantum computers, he says.Section BDirections: Fill in each blank with a proper word chosen from the box. Each word can only be used once. Note that there is one word more than you need.Wildfires rage as China's Chongqing suffers unrelenting record heat waveFrom: CNN August 23, 2022Thousands of emergency responders are battling to (31) ________ fast-spreading wildfires in China's southwestern city of Chongqing amid a weeks-long, record heat wave in the region.The fires, which have been visible at night from parts of the downtown area, have (32) ________ forests and mountains around the mega city in recent days. On social media, residents in downtown Chongqing complained of smelling smoke inside their apartments, while others posted pictures of burning embers from the fires reaching their balconies.Municipal authorities have not yet reported any casualties and said the fires are being kept under control, according to an update on Tuesday morning. More than 1,500 residents have been (33) ________ to safe zones, while 5,000 firefighters, police, local officers and volunteers, and seen firefighting helicopters have been dispatched to help combat the blazes, state-run Xinhua news agency reported.The fires in Chongqing were the result of “spontaneous combustion” mainly caused by (34) ________ high temperatures, Bai Ye, a professor at China's Forest and Grassland Fire Prevention and Extinguishing Research Center told state-run Beijing Daily.The wildfires are another knock-on effect of a crippling heat wave China's worst since 1961 -that has swept through southwestern, central and eastern parts of the country in recent weeks, with temperatures crossing 40 degrees Celsius (104 degrees Fahrenheit) in more than 100 cities.They are also part of a global trend of wildfires that have ravaged areas from Australia to California, with scientists saying (35) ________ global temperatures due to human-driven climate change increase the risk of these events.China's heat wave has also brought (36) ________ demand for air conditioning and reductions in hydropower capacity due to drought conditions that have (37) ________ the country's (38) ________ critical Yangtze River and connected waterways.Earlier this week, Sichuan province, neighboring Chongqing, extended temporary power outages at factories in 19 of the region's 21 cities. The power cuts will now run until at least Thursday, in a move the local government says will ensure residential power supplies. Last week, the province's capital city Chengdu began (39) ________ lights in subway stations in a bid to save electricity. Chongqing enacted an order for factories to suspend operations for seven days starting last Wednesday, according to state media.On Tuesday morning, China issued a red alert heat warning, the highest of four color-coded levels, to at least 165 cities and counties across the country. Chinese authorities have (40) ________ said more than 900 million people across the country have been affected by the heat wave this summer.III. Reading ComprehensionsSection ADirections: For each blank in the following passage, there are four words or phrases marked A, B, C and D. Fill in each blank with the word or phrase that best fits the context.Mind-reading AI turns thoughts into words using a brain implantAn artificial intelligence can accurately translate thoughts into sentences, at least for a limited vocabulary of 250 words. The system may bring us a step closer to (41) ________ speech to people who have lost the ability because of paralysis.Joseph Makin at the University of California, San Francisco, and his colleagues used deep learning algorithms tostudy the brain (42) ________ of four women as they spoke. The women, who all have epilepsy, already had electrodes attached to their brains to (43) ________ seizures. Each woman was asked to read aloud from a set of sentences as the team measured brain activity. The largest group of sentences (44) ________ 250 unique words.The team fed this brain activity to a neural network algorithm, training it to identify regularly (45) ________ patterns that could be linked to repeated aspects of speech, such as vowels or consonants. These patterns were then fed to a second neural network, which tried to turn them into words to (46) ________ a sentence.Each woman repeated the sentences at least twice, and the final repetition didn't form part of the training data, (47) ________ the researchers to test the system. Each time a person speaks the same sentence, the brain activity associated will be similar but not identical. “Memorising the brain activity of the these sentences wouldn't help, so the network instead has to learn what's similar about them so that it can generalise to this final example,” says Makin. Across the four women, the AI's best (48) ________ was an average translation error rate of 3 per cent.Makin says that using a small number of sentences made it easier for the AI to learn which words tend to follow others. For example, the AI was able to decode that the word “Turner” was always likely to follow the word “Tina” in this set of sentences, from brain (49) ________ alone.The team tried decoding the brain signal data into (50) ________ words at time, rather than whole sentences, but this increased the error rate to 38 per cent even for the best performance. “So the network clearly is learning facts about which words go together, and not just which neural activity (51) ________ to which words,” says Makin. This will make it hard to (52) ________ the system to a larger vocabulary because each new word increases the number of possible sentences, reducing (53) ________.Making says 250 words could still be useful for people who can't talk. “We want to deploy this in a patient with an actual speech disability,” he says, although it is possible their brain activity may be different from that of the women in this study, making this more (54) ________.Sophie Scott at University College London says we are a long way from being able to translate brain signal data comprehensively. “You probably know around 250, 000 words, so it's still an incredibly (55) ________ set of speech that they're using,” she says.41. A. inspecting B. restoring C. admiring D. inspiring42. A. emotion B. attractiveness C. awareness D. signals43. A. monitor B. master C. control D. expect44. A. concluded B. excluded C. contained D. increased45. A. extended B. occurring C. ignored D. concerned46. A. form B. handle C. hand D. force47. A. issuing B. producing C. allowing D. acquiring48. A. behavior B. comment C. preparation D. performance49. A. possibility B. activity C. capacity D. responsibility50. A. individual B. financial C. social D. technical51. A. serves B. finishes C. maps D. competes52. A. switch up B. put up C. rise up D. scale up53. A. privacy B. accuracy C. currency D. fluency54. A. critical B. specific C. proper D. difficult55. A. committed B. oppressed C. restricted D. dominatedSection BDirections: Read the following two passage. Each passage is followed by several questions or unfinished statements. For each of them there are four choices marked A, B, C and D. Choose the one that fits best according to the information given in the passage you have just read.(A)Of all the components of a good night's sleep, dreams seem to be least within our control. In dreams, a window opens into a world where logic is suspended and dead people speak. A century ago, Freud formulated his revolutionary theory that dreams were the disguised shadows of our unconscious desires and fears; by the late 1970s, neurologists had switched to thinking of them as just “mental noise”-the random byproducts of the neural repair work that goes on during sleep. Now researchers suspect that dreams are part of the mind's emotional thermostat, regulating moods while the brain is “off line.” And one leading authority says that these intensely powerful mental events can be not only harnessed but actually brought under conscious control, to help us sleep and feel better. “It's your dream,” says Rosalind Cartwright, chair of psychology at Chicago's Medical Center, “if you don't like it, change it.”The link between dreams and emotions shows up among the patients in Cartwright's clinic. Most people seem to have more bad dreams early in the night, progressing toward happier ones before awakening, suggesting that they are working through negative feelings generated during the day. Because our conscious mind is occupied with daily life we don't always think about the emotional significance of the day's events-until, it appears, we begin to dream.And this process need not be left to the unconscious. Cartwright believes one can exercise conscious control over recurring bad dreams. As soon as you awaken, identify what is upsetting about the dream. Visualize how you would like it to end instead; the next time it occurs, try to wake up just enough to control its course. With much practice people can learn to, literally, do it in their sleep.At the end of the day, there's probably little reason to pay attention to our dreams at all unless they keep up from sleeping or “we wake up in panic,” Cartwright says. Terrorism, economic uncertainties and general feelings of insecurity have increased people's anxiety. Those suffering from persistent nightmares should seek help from a therapist. For the rest of us, the brain has its ways of working through bad feelings. Sleep-or rather dream-on it and you'll feel better in the morning.56. By saying that “dreams are part of the mind's emotional thermostat.” (Para. 1) the researchers mean that ________.A. we can think logically in the dreams tooB. dreams can be brought under conscious controlC. dreams represent our unconscious desires and fearsD. dreams can help us keep our mood comparatively stable57. What did Cartwright find in her clinic?A. Most bad dreams were followed by happier ones.B. Divorced couples usually have more bad dreams.C. One's dreaming process is related to his emotion.D. People having negative feelings dream more often.58. That author points out that a person who has constant bad dreams should ________.A. learn to control his dreamsB. consult a doctorC. sleep and dream on itD. get rid of anxiety first(B)People have been painting pictures for at least 30, 000 years. The earliest pictures were painted by people who hunted animals. They used to paint pictures of the animals they wanted to catch and kill. Pictures of this kind have been found on the walls of caves in France and Spain. No one knows why they were painted there. Perhaps the painters thought that their pictures would help them to catch these animals. Or perhaps human beings have always wanted to tell stories in pictures.About 5,000 years ago, the Egyptians and other people in the Near East began to use pictures as kind of writing. They drew simple pictures or signs to represent things and ideas, and also to represent the sounds of their language. The signs these people used became a kind of alphabet. The Egyptians used to record information and to tell stories by putting picture writing and pictures together. When an important person died, scenes and stories from his life were painted and carved on the walls of the place where he was buried. Some of these pictures are like modern comic strip stories. It has been said that Egypt is the home of the comic strip. But, for the Egyptians, pictures still had magic power. So they did not try to make their way of writing simple. The ordinary people could not understand it.By the year 1,000 BC, people who lived in the area around the Mediterranean Sea had developed a simpler system of writing. The signs they used were very easy to write, and there were fewer of them than in the Egyptian system. This was because each sign, or letter, represented only one sound in their language. The Greeks developed this system and formed the letters of the Greek alphabet. The Romans copied the idea, and the Roman alphabet is now used all over the world.These days, we can write down a story, or record information, without using pictures. But we still need pictures of all kinds: drawing, photographs, signs and diagrams. We find them everywhere: in books and newspapers, in the street, and on the walls of the places where we live and work. Pictures help us to understand and remember things more easily, and they can make a story much more interesting.59. Pictures of animals were painted on the walls of caves in France and Spain because ________.A. the hunters wanted to see the picturesB. the painters were animal loversC. the painters wanted to show imaginationD. the pictures were thought to be helpful60. The Greek alphabet was simpler than the Egyptian system for all the following reasons EXCEPT that ________.A. the former was easy to writeB. there were fewer signs in the formerC. the former was easy to pronounceD. each sign stood for only one sound61. Which of the following statements is TRUE?A. The Egyptian signs later became a particular alphabet.B. The Egyptians liked to write comic strip stories.C. The Roman alphabet was developed from the Egyptian one.D. The Greeks copied their writing system from the Egyptians.62. In the last paragraph, the author thinks that pictures ________.A. should be made comprehensibleB. should be made interestingC. are of much use in our lifeD. have disappeared from our life(C)I live in the land of Disney, Hollywood and year-round sun. You may think people in such a glamorous, fun-filled place are happier than others. If so, you have some mistaken ideas about the nature of happiness.Many intelligent people still equate happiness with fun. The truth is that fun and happiness have little or nothing in common. Fun is what we experience during an act. Happiness is what we experience after an act. It is a deeper, more abiding emotion.Going to an amusement park or ball game, watching a movie or television, are fun activities that help us relax, temporarily forget our problems and maybe even laugh. But they do not bring happiness, because their positive effects end when the fun ends.I have often thought that if Hollywood stars have a role to play, it is to teach us that happiness has nothing to do with fun. These rich, beautiful individuals have constant access to glamorous parties, fancy cars, expensive homes, everything that spells "happiness". But in memoir after memoir, celebrities reveal the unhappiness hidden beneath all their fun: depression, alcoholism, drug addiction, broken marriages, troubled children and profound loneliness.Ask a bachelor why he resists marriage even though he finds dating to be less and less satisfying. If he's honest, he will tell you that he is afraid of making a commitment. For commitment is in fact quite painful. The single life is filled with fun, adventure and excitement. Marriage has such moments, but they are not its most distinguishing features.Similarly, couples that choose not to have children are deciding in favor of painless fun over painful happiness. They can dine out ever they want and sleep as late as they want. Couples with infant children are lucky to get a whole night's sleep or a three-day vacation. I don't know any parent who would choose the word fun to describe raising children.Understanding and accepting that true happiness has nothing to do with fun is one of the most liberating realizations we can ever come to. It liberates time: now we can devote more hours to activities that can genuinely increase our happiness. It liberates money: buying that new car or those fancy clothes that will do nothing to increase our happiness now seems pointless. And it liberates us from envy: we now understand that all those rich and glamorous people we were so sure are happy because they are always having so much fun actually may not be happy at all.63. Which of the following is true?A. Fun creates long-lasting satisfaction.B. Fun provides enjoyment while pain leads to happiness.C. Happiness is enduring whereas fun is short-lived.D. Fun that is long-standing may lead to happiness.64. To the author, Hollywood stars all have an important role to play that is to ________.A. write memoir after memoir about their happinessB. tell the public that happiness has nothing to do with funC. teach people how to enjoy their livesD. bring happiness to the public instead of going to glamorous parties65. Having infant children ________.A. are lucky since they can have a whole night's sleepB. find fun in tucking them into bed at nightC. find more time to play and joke with themD. derive happiness from their endeavor66. If one gets the meaning of the true sense of happiness, he will ________.A. stop playing games and joking with othersB. make the best use of his time increasing happinessC. give a free hand to moneyD. keep himself with his familySection CDirections: Read the passage carefully. Fill in each blank with a proper sentence given in the box. Each sentence can be used only once. Note that there are two more sentences than you need.Swarm ImmunityHoneybees run vaccination programmes, too. An old saw has it that there is nothing new under the sun. ___67___ Work just published in the Journal of Experimental Biology by Gyan Harwood of the University of Illinois, Urbana-Champaign, confirms that honeybees got there first. It also suggest that they run what look like the equivalent of prime-boost childhood vaccination programmes.Being gregarious, honeybees are at constant risk of diseases sweeping through their hives. Most animals which live in crowded conditions have particularly robust immune systems, so it long puzzled entomologists that honeybees do not. __68__Part of the answer, discovered in 2015, is that queen bees vaccinate their eggs by transferring into them, before they are laid, fragments of proteins from disease-causing pathogens. __69__ But that observation raise the question of how the queen receives her antigen supply in the first place, for she subsists purely on royal jelly, a substance secreted by worked bees which are at the stage of their lives (which precedes the period that they spend flying around foragingfor nectar and pollen) when they act as nurses to larvae. Dr Harwood therefore wondered if the nurses were incorporating into the royal jelly they were producing, fragments from pathogens they had consumed while eating the victuals brought to the hive by the foragers.To test this idea, he teamed up with a group at the University of Helsinki, in Finland, led by Heli Salmela. __70__ Instead of nectar, they fed the nurses on sugar-water, and for these of the hives they laced this syrup with Paenibacillus larvae, a bacterium that causes a hive-killing disease called American foulbrood.IV. Summary WritingDirections: Read the following three passages. Summarize the main idea and the main point(s) of the passage in no more than 60 words. Use your own words as far as possible.71.Why Mindset Mastery Is Vital to Your SuccessThe single most important factor influencing a person's success, whether personal or professional, is mindset. What you think about has a direct impact on your behavior, and not the other way around. A seemingly small thing that makes a huge difference, mindset accounts for the primary distinction between those who succeed and those who do not. And, if you are serious about achieving success in any area of your life, you must learn to master yours.To successfully accomplish any worthwhile feat, a person must first feel capable of achieving it. It doesn't matter what anyone else thinks. Mindset is essential to developing healthy self-esteem. It is an important tool that affects our daily self-dialogue and strengthen our beliefs, attitudes and feelings about ourselves. So, become the gatekeeper of your mind and plant seeds of positivity rather than criticism and doubt.Besides, mindset is critical to drive. Drive is the constant determination to achieve an important objective. It includes the process of developing a vision for success and engaging in sustained effort over time. Without drive, achieving most goals would be difficult at best. With the power to direct focus and encourage commitment to higher purpose, mindset can easily urge someone to push past comfort zones. People with drive are self-motivated and strive to accomplish more.No matter what goal you seek to achieve, the path to your success is sure to include some challenges. When facing an extreme hardship, a person may feel justified in bowing to defeat. For them, it can feel like an easy road. If you want to get through them, however, you will need to develop thick skin and learn to face each challenge head on. Yet, this is where mindset plays a critical role. The capacity to move through the fire, to get knocked down and not knocked out, is the proof to the power of a strong mindset.Are you ready to command your results? If so, make a conscious decision to master your mindset and reach for greater success in the new year and beyond.V. TranslationDirections: Translate the following sentences into English, using the words given in the brackets.l.博物馆展览的展品见证了埃及的农业文明. (witness n.)2.和人们认为的不一样的是,很多发达国家也搞应试教育. (contrary)3.与其说他是个诗人,不如说是个画家,给读者呈现了唐朝的繁荣、开放和包容的景象. (as)4.这些创意、暖心的视频让我们明白:即使病毒的爆发要求我们隔离,我们仍然有一种惺惺相惜的感觉. (reminder) VI. Guided WritingDirections: Write an English composition in 120-150 words according to the instructions given below in Chinese.假设你是李华,你要竞选学校模拟联合国社团主席,请写一篇竞选演讲稿,内容包括:1.你认为自己具备什么条件2.如果当选,你会为大家做什么语法填空21. have been operated22. which23. is receiving24. they25. with 26. higher27. what28. As29. after30. compared 选词填空31. F 32. A 33. C 34. K 35. J 36. D 37. G 38. I 39. H 40. B完形填空41-45 BDACB46-50 ACDBA51-55 CDBDC阅读理解56. D. 57. C. 58. B59. D. 60. C. 61. A. 62. C63. C 64. B 65. D 66. B67. F 68. C 69. E 70. B。
《人工智能英语》试卷(含答案)

参考试卷一、写出以下单词的中文意思(每小题0.5分,共10分)1 accuracy 11 customize2 actuator 12 definition3 adjust 13 defuzzification4 agent 14 deployment5 algorithm 15 effector6 analogy 16 entity7 attribute 17 extract8 backtrack 18 feedback9 blockchain 19 finite10 cluster 20 framework二、根据给出的中文意思,写出英文单词(每小题0.5分,共10分)1 v.收集,搜集11 n.神经元;神经细胞2 adj.嵌入的,内置的12 n.节点3 n.指示器;指标13 v.运转;操作4 n.基础设施,基础架构14 n.模式5 v.合并;集成15 v.察觉,发觉6 n.解释器,解释程序16 n.前提7 n.迭代;循环17 adj.程序的;过程的8 n.库18 n.回归9n.元数据19 adj.健壮的,强健的;结实的10 v.监视;控制;监测20 v.筛选三、根据给出的短语,写出中文意思(每小题1分,共10分)1 data object2 cyber security3 smart manufacturing4 clustered system5 data visualization6 open source7 analyze text8 cloud computing9 computation power10 object recognition四、根据给出的中文意思,写出英文短语(每小题1分,共10分)1 数据结构2 决策树3 演绎推理4 贪婪最佳优先搜索5 隐藏模式,隐含模式6 知识挖掘7 逻辑推理8 预测性维护9 搜索引擎10 文本挖掘技术五、写出以下缩略语的完整形式和中文意思(每小题1分,共10分)缩略语完整形式中文意思1 ANN2 AR3 BFS4 CV5 DFS6 ES7 IA8 KNN9 NLP10 VR六、阅读短文,回答问题(每小题2分,共10分)Artificial Neural Network (ANN)An artificial neural network (ANN) is the piece of a computing system designed to simulate the way the human brain analyzes and processes information. It is the foundation of artificial intelligence (AI) and solves problems that would prove impossible or difficult by human or statistical standards. ANNs have self-learning capabilities that enable them to produce better results as more data becomes available.Artificial neural networks are built like the human brain, with neuron nodes interconnected like a web. The human brain has hundreds of billions of cells called neurons. Each neuron is made up of a cell body that is responsible for processing information by carrying information towards (inputs) and away (outputs) from the brain.An ANN has hundreds or thousands of artificial neurons called processing units, which are interconnected by nodes. These processing units are made up of input and output units. The input units receive various forms and structures of information based on an internal weighting system, and the neural network attempts to learn about the information presented to produce one output report. Just like humans need rules and guidelines to come up with a result or output, ANNs alsouse a set of learning rules called backpropagation, an abbreviation for backward propagation of error, to perfect their output results.An ANN initially goes through a training phase where it learns to recognize patterns in data, whether visually, aurally, or textually. During this supervised phase, the network compares its actual output produced with what it was meant to produce — the desired output. The difference between both outcomes is adjusted using backpropagation. This means that the network works backward, going from the output unit to the input units to adjust the weight of its connections between the units until the difference between the actual and desired outcome produces the lowest possible error.A neural network may contain the following 3 layers:Input layer – The activity of the input units represents the raw information that can feed into the network.Hidden layer – To determine the activity of each hidden unit. The activities of the input units and the weights on the connections between the input and the hidden units. There may be one or more hidden layers.Output layer – The behavior of the output units depends on the activity of the hidden units and the weights between the hidden and output units.1. What is an artificial neural network (ANN)?2.What is each neuron made up of?3.Wha do the input units do?4.What does an ANN initially go through?5.How many layers may a neural network contain? What are they?七、将下列词填入适当的位置(每词只用一次)。
基于深度强化学习的文本相似语义计算模型

㊀第52卷第3期郑州大学学报(理学版)Vol.52No.3㊀2020年9月J.Zhengzhou Univ.(Nat.Sci.Ed.)Sep.2020收稿日期:2020-02-17基金项目:国家自然科学基金项目(71303215);浙江省科技计划项目(2020C03091,2017C31110)㊂作者简介:陈观林(1978 ),男,浙江台州人,教授,主要从事大数据及人工智能研究,E-mail:chenguanlin @;通信作者:周梁(1982 ),男,浙江杭州人,高级工程师,主要从事大数据研究,E-mail:zl@㊂基于深度强化学习的文本相似语义计算模型陈观林1,2,㊀侍晓龙1,2,㊀周㊀梁3,㊀翁文勇1(1.浙大城市学院计算机与计算科学学院㊀浙江杭州310015;2.浙江大学计算机学院㊀浙江杭州310027;3.杭州市大数据管理服务中心㊀浙江杭州310020)摘要:语义相似计算是自然语言处理领域一个常见问题,现有的基于深度学习的语义相似计算模型大多数是通过卷积网络或者长短时记忆模型来提取语义特征,但是这种语义特征的提取方式存在语义信息丢失的问题㊂提出两点改进传统深度学习模型在提取语义特征时的语义丢失现象㊂首先是改进注意力相互加权模型㊂基于相互加权方式做出改进,使用多个加权权重矩阵加权语义,同时提出新的正则项计算方法㊂其次在语义相似计算模型中引入强化学习的方法对文本进行自动分组处理,在语义相似计算领域最常用的Siamese Network 模型上使用强化学习算法,改善长短时记忆模型在提取句子的语义时所面临的语义丢失现象㊂通过实验验证,改进的方法处理中文句子有不错的效果㊂关键词:深度学习;语义相似计算;强化学习中图分类号:TP319㊀㊀㊀㊀㊀文献标志码:A㊀㊀㊀㊀㊀文章编号:1671-6841(2020)03-0001-08DOI :10.13705/j.issn.1671-6841.20200380㊀引言语义相似计算是机器进行语义理解的一种手段[1-2],通过相似类比从而让机器能间接地理解问题㊂语义相似计算应用十分广泛,比如百度问答系统㊁新闻推荐领域等㊂相比于传统的基于统计的语义相似计算模型,基于机器学习和深度学习的语义相似计算模型能更加细致地表达句子的语义特征和结构特征,比如词向量[3]㊁长短时记忆网络(long short-term memory,LSTM)模型[4]㊂这些语义特征模型存在一些深度学习模型的通病,比如长短时记忆模型虽然是专门用来处理时序模型的,这种模型可以较好地表达句子的结构信息,但是它在处理长句子过程中会因为反向传播算法而带来梯度消失问题,从而丧失很多语义信息,尤其是句子靠前部分的词语信息,因为梯度很难传到靠近前面词语的位置㊂深度学习的快速发展促进了词义㊁语义理解方面很大的进展,比如Word2vec [5]㊁LSTM 等对语义特征提取有很好的表达方式㊂词向量模型的出现很好解决了词义级别上的表达,通过收集大量语料库可以很好训练出词与词之间的关系表达,词义关系通常体现在其词向量的空间距离上的关系㊂LSTM 模型主要是循环神经网络的改进模型,用来解决具有时序相关性的问题㊂通过使用LSTM 模型提取句子语义信息,可以很好地表达句子结构上的信息,然后映射到固定向量特征中,通过计算向量的距离来表示相似程度,这是比较主流的处理方式㊂卷积神经网络(convolutional neural networks,CNN)在图像处理领域取得了巨大成功,很多研究人员把CNN 当作语义特征抽取的一种方式,将句子的词向量拼接成句子矩阵,使用CNN 网络卷积转化为语义矩阵,通过池化等方法从语义矩阵抽象出语义向量,计算向量的余弦距离或者欧氏距离等㊂注意力模型对图像和自然语言处理的深度学习模型有重要的影响,注意力模型可以用于LSTM 等模型当中,缓解模型的语义丢失现象㊂深度学习的语义计算模型一般是基于Siamese [6]模型,Siamese 网络本质上也是解决降维问题,将句子的2郑州大学学报(理学版)第52卷语义映射到一个低维的向量空间㊂LSTM Siamese Network网络[7]是Siamese网络的一个实例框架,以单个字符作为输入单元,用LSTM网络来代替Siamese网络的函数,通过LSTM来提取特征得到一个固定长度向量,然后通过全连接层后抽取两个样本的最终特征作为计算距离的向量,采用余弦距离表示语义相似程度㊂Si-amese LSTM模型[8]最大的亮点是使用了曼哈顿距离来衡量句子语义相似程度㊂最近在斯坦福数据集中表现较好的是DRCN[9]模型,该模型将前层的特征拼接到下一层,从而可以长时间保留前层的信息㊂Information distilled LSTM(ID-LSTM)[10]模型将强化学习算法和LSTM结合用于文本分类任务,通过训练一个蒸馏网络将句子中非重要词蒸馏出去㊂为了判断蒸馏网络模型好坏,引入强化学习的策略梯度算法, LSTM抽取后的语义特征输入到分类网络当中进行文本分类,并且使用分类网络输出的结果作为回报值来更新蒸馏网络模型㊂本文基于Siamese Network模型,加入强化学习的方法,通过一系列句子词语蒸馏的方法,将句子中不重要的词语蒸馏出去,从而可以改善LSTM进行语义提取过程中对重要的词语学习不到的问题,实验结果表明该方法对中文句子有不错的效果㊂1㊀DDPG算法深度确定性策略梯度算法(deep deterministic policy gradient,DDPG)[11]是一种强化学习算法,使用策略梯度方法[12-13]来更新神经网络的参数㊂DDPG算法有策略网络Actor和估值网络Critic两个部分组成:Actor 是动作执行者,输入的是环境特征,输出的是动作;Critic输入的是环境特征以及策略网络输出的动作,而输出的是评判该Actor最终能获得总回报值的期望㊂同时为了解决策略更新过程中神经网络收敛不稳定情况,DDPG算法在更新梯度的时候使用了软更新的策略,在训练过程中定义在线网络和目标网络,并不是直接将在线网络复制给目标,而是以微小的更新量更新给目标网络,这样可以使训练过程更加稳定㊂DDPG网络算法步骤如下㊂1)初始化Actor和Critic的在线网络和目标网络㊂2)将在线网络参数拷贝给目标网络㊂3)循环以下步骤:①在线的Actor会根据传入的环境s t执行动作a t;②执行动作以后获得一个回报值r t,并且更新新的状态s t+1;③将这个过程中的s t㊁a t㊁r t㊁s t+1存储到一个缓冲区中;④互动多个过程后,从缓冲区采样然后训练Critic网络,采用传统Back Propagation的更新方式;⑤采用策略更新的方式更新Actor;⑥采用软更新的方式将在线的参数更新到目标网络当中㊂2㊀算法设计2.1㊀模型总体结构本文将强化学习算法和Siamese LSTM模型进行融合,训练出具有一定自动蒸馏句子能力的语义相似计算模型,模型的整体结构如图1所示㊂模型的整体结构是一个强化学习的模型,类似于DDPG算法模型,有两个组成部分,最外围的策略网络是句子蒸馏网络模块,该网络使用多层深度神经网络模型,可以看成是一个Actor网络㊂内层的整体架构是一个Siamese LSTM模型,可以看成是一个Critic网络,Multi-LSTM使用了两层的LSTM模型叠加,并且在第二层LSTM模型的隐藏层输出加入Attention模型来加权语义,最终将提取的语义向量用曼哈顿距离来表示语义相似度㊂模型的训练模式也和DDPG算法相似,Actor网络部分和Critic网络部分分别训练,内部的环境模型通过反向传播算法(back propagatio,BP)[14]来更新,外部的策略网络根据环境的损失值使用策略梯度来更新㊂㊀第3期陈观林,等:基于深度强化学习的文本相似语义计算模型图1㊀模型整体结构Figure 1㊀The overall architecture of the model2.2㊀句子蒸馏网络模型句子蒸馏网络是由策略网络和Multi-LSTM 网络组成的结构,Multi-LSTM 是环境模型的一个组成部分,用于句子的语义抽取,是环境和Actor 交互的唯一接口㊂Policy Network 模型就是Actor 网络,模型的详细表述如图2所示㊂图2㊀句子蒸馏网络模型Figure 2㊀The network model of sentence distillation图2(a)是Multi-LSTM 模型,包含两层的LSTM 网络,图2(b)是Policy Network 模型,是一个两层的神经网络模型,其中{w 1,w 2, ,w t , ,w e }表示每个时刻输入句子的词向量,{S 1,S 2, ,S t , ,S e }表示每个时刻细胞的状态,初始时刻将LSTM 细胞初始化为0,{h 1,h 2, ,h t , ,h e }表示每个时刻LSTM 的隐藏层输出,{a 1,a 2,a t -1,a n }表示每个时刻Policy Network 的输出动作值,当词向量输入到LSTM 模型当中的时候,都会先将LSTM 细胞当前的状态和隐藏层的输出以及词向量合并成状态S t ,S t =S t -1 h t -1 w t ㊂将第一层LSTM 细胞当前状态和隐藏层输出以及词向量合并成状态S t 后,将状态传入句子蒸馏网络判断当前传入词是否应该被保留,如果判断保留就将词向量传入第一层LSTM 模型当中进行计算,如果判断不保留则跳过当前词㊂同时将采用两层的LSTM 模型来进行语义特征提取,通过句子蒸馏网络可以将一个长句子中的非关键词去掉,从而保留句子的核心词语,使得语义相似判断效果更好㊂2.3㊀协同注意力加权模型协同注意力是一种相互加权的机制,是一种软注意力的加权方式㊂LSTM 的第二层输出每个时刻的语义信息㊂将这些语义信息进行相互加权,其中两个多层的LSTM 模型的权重可以根据输入的文本类型来决定是否共享参数㊂模型的结构如图3所示㊂第二层的{H 1,H 2, ,H t , ,H e }输出状态传入加权模型当中进行加权㊂协同注意力模型的内部加权方式有很多种,比如可以直接将两个多层LSTM 模型的最高层生成的每个时刻语义矩阵直接进行相乘,然后经过Softmax 函数来生成权重信息,也可以用额外的语义矩阵进行加权,如图4所示的加权方式,其中H 1和H 2表示LSTM 的第二层隐藏层输出拼接成的语义矩阵,W s 是一个L ˑL 加权矩阵,H 1是一个L ˑn 形状的矩阵,H 2是一个L ˑm 形状的矩阵,进行矩阵操作运算:3郑州大学学报(理学版)第52卷W 1=softmax(sum(H T 1W s H 2)),W 2=softmax(sum(H T 1W s H 2)T )㊂图3㊀Co-Attention 加权模型Figure 3㊀The Co-Attention weightedmodel 图4㊀Co-attention 加权方式Figure 4㊀The Co-attention weighted method㊀㊀经过运算可以获得一个n ˑm 的权重矩阵,然后将每行的参数同样相加,并将每列的参数相加,经过Soft-max 函数进行归一化后,可以分别获得H 1语义矩阵和H 2语义矩阵的每个时刻分别对应的语义权重向量,最后将各自的权重向量和语义矩阵相乘可以获取最后句子的语义向量㊂单个的加权矩阵往往会加权语义矩阵中的某一个方面,我们为了获取语句更丰富的语义信息,使用多个加权矩阵来对LSTM 每个时刻输出的语义进行加权,生成多个权重向量㊂为了避免多个权重矩阵最终生成的权重矩阵相同从而失去丰富性,在最终的函数当中会定义一个正则项,正则项的推导如下㊂假设我们定义了n 个加权矩阵W s 1,W s 2, ,W sn ,用这n 个加权矩阵来对语义矩阵H 1和H 2进行语义加权,按照相互加权的矩阵运算公式W t =softmax(sum(H T 1W s H 2)),最终我们可以获得n 个权重矩阵W t 1,W t 2, ,W tn ,为了使得这n 个加权矩阵能够加权语义矩阵不同方面的语义特征,我们希望这n 个权重矩阵能够尽可能不相同,因此我们对这n 个权重矩阵进行加和求平均值,记作W t ,为了保证任意两个权重矩阵之间的距离尽可能大,从而引用降维线性判别分析算法(linear discriminant analysis,LDA)中的类间散度思想来对这个问题进行求解,将W t 看作是一个中心的权重矩阵,则我们的原问题可以化为任意一个权重矩阵距离中心权重矩阵的距离尽可能的大,因此可以定义正则项L =ðn i =1W ti -W t ,通过最大化这个正则项,也就是最小化倒数保证每个权重矩阵尽可能的不相同,从而可以保证每个权重矩阵都能够抽取不同层次的语义信息㊂2.4㊀损失函数设计首先采用曼哈顿距离来衡量两个语义向量之间的距离,公式为d =exp(- h a -h b ),d ɪ[0,1],其中4㊀第3期陈观林,等:基于深度强化学习的文本相似语义计算模型h a 和h b 表示最终的语义向量㊂同时本文将采用对比损失函数作为最终损失函数,对比损失函数的公式为l =12N ðN n =1yd 2+(1-y )max(margin -d ,0)2,其中:y 代表输入到模型的样本标签语义是否相似,取值为{0,1};margin 表示一个设置的阈值㊂对比损失函数可以很好表达成对样本的匹配程度,当样本标签为1时,也就是样本相似时候,对比损失函数只有加号前面的一项,当原本相似的样本在抽象成语义向量的空间距离比较大的时候,损失函数会变大㊂当样本标签为0时,对比损失函数只有加号的后面一项,当样本不相似,而抽象出来的距离很小则损失函数变大㊂2.5㊀模型训练设计算法整体的流程和DDPG 算法流程类似,有在线和目标网络两个部分,依据策略更新的方式更新网络㊂模型在训练过程中不容易收敛,会因为参数大小或者参数的递减策略设置不正确等原因使整个模型达不到理想的效果㊂为了使训练过程更加稳定,我们将使用高策略的更新方式来更新网络㊂高策略更新方式定义在线和目标两组网络,两组网络的结构完全相同,但是更新时间不同㊂在每个批量训练之前要将目标网络的参数赋值给在线网络,然后用在线网络作为训练网络来参与整体的训练,并且在一个批量当中进行每个样本的更新,当一个批量训练完毕后,要将在线网络当中的参数更新到目标网络上,更新方式使用的是软方式,即设置一个参数β,则最终更新到目标网络上的参数为Target θ=(1-β)T arg et θ+βOnline θ㊂最后在下个批量训练开始之前,将目标网络的参数再次赋值给在线网络进行下一轮的训练,同时本文将采用曼哈顿距离来表示句子之间相似性,损失函数采用对比损失值作为训练㊂在训练过程中还用到一些训练技巧,比如在强化学习训练过程中,当要学习的环境很复杂的情况下,开始训练收敛过程会很慢,或者很可能不会收敛,因此会有一个预训练的过程㊂预训练过程可以认为是模型学习环境的一个初始的合理参数的设置过程㊂对于句子蒸馏网络的预训练部分,由于本文后续实验采用数据的中文词汇特殊性(句子的前几个词非常重要),一般将句子的前几个词组保留,后面的词组以一定的概率随机蒸馏出去㊂3㊀数据与实验分析3.1㊀实验数据本论文的实验数据使用的是网络爬取的数据,包括一整套汽车名称数据㊁汽车的配件信息以及售后信息等,用户同样会提供他们收集的汽车信息的数据库,我们要将这两个数据库的信息进行整合,使得相同型号的汽车信息能被整合到一起㊂但是用户提供的汽车名称和本文数据库中的汽车名称不完全相同,如表1所示,该表是部分本文标注好的数据,右边是本文数据的命名标准,左边是用户的数据库㊂可能会有型号上的描述不一样,通过语义相似计算的方法将用户提供的名称和数据库中的车辆名称做一个相似性匹配,从而确定是我们数据库当中的哪个型号的车,然后将所有的数据进行整合㊂实验数据有6万多对已经标注的配对的数据,训练和测试数据集比例为5ʒ1㊂在生成训练数据过程中要1ʒ2随机生成负样本,对于每一对标注的语句对,随机从样本数据中选择非配对的句子作为负样本㊂表1㊀数据命名标准Table 1㊀The standard of naming data用户数据库汽车描述信息本文数据库汽车描述信息东风大力神EQ4186L 半挂牵引汽车东风EQ4186L 半挂牵引汽车东风天龙DFL5250GJBA 混凝土搅拌运输车东风DFL5250GJBAX1混凝土搅拌运输车进口奔驰BENZ SLK200K 1.8AT(04-11)奔驰BENZ SLK200K 跑车奔驰SLK 2010款SLK 200K 进口宝马BMW E46323Ci 2.5AT 宝马BMW 323Ci 轿车一汽大众速腾FV72062.0MT(200604-201203)速腾2.0L MT 舒适型速腾FV7206E 轿车速腾2.0L 手动挡舒适型东风雪铁龙世嘉DC7205DB 2.0L MT 两厢夺冠版(200904)世嘉2009款两厢2.0L 手动夺冠版东风雪铁龙DC7205DB 轿车世嘉2009款两厢2.0L 手动夺冠版56郑州大学学报(理学版)第52卷3.2㊀词向量训练本文使用gensim工具来训练Word2vec的词向量,gensim是一个python库,能实现很多常用自然语言处理的算法,比如latent semantic analysis(LSA)㊁latent dirichlet allocation(LDA)等,首先使用数据库当中的所有汽车作为语料库来训练词向量,总量大概有1000多万条数据㊂对数据库当中的词进行一些特殊符号及格式除杂后,使用jieba分词工具对汽车描述名称进行分词,然后使用gensim工具进行中文的词向量训练㊂3.3㊀多加权模型实验与结果分析3.3.1㊀模型的训练㊀本次实验是验证多加权协同注意力模型有效性,该模型主要在Siamese LSTM上实现,加权方式会定义额外的加权矩阵进行语义的加权,具体结构参考2.3节㊂首先是3个Co-attention模型,3个模型的不同点是加权矩阵的数量不同㊂训练的两个模型的参数如表2所示㊂两个模型都使用Siamese LSTM架构和两层的LSTM来计算输入句子的语义信息㊂输入句子长度大于30的句子将被采用截断处理㊂输入句子的长度小于30的句子使用特殊字符填充㊂每次输入一个Batch进行训练㊂句子之间的相似度采用曼哈顿距离来表示,损失函数使用对比损失函数来计算㊂最后使用Adam 优化算法[15]来调整参数㊂3.3.2㊀实验结果分析㊀本次实验主要是验证多加权的注意力模型效果㊂试验结果表明:当加权矩阵从1个矩阵变成3个矩阵,并且使用一定正则项来训练以后,准确率有明显提升,从0.85提升到0.87;但是从3个加权矩阵上升到10个加权矩阵的时候,实验效果提升的幅度明显小很多㊂由此我们可以看出,多加权的注意力模型相比于单个加权模型来说有一定的提升效果,但是当加权矩阵过多的时候,提升就很小,同时也会增加很多计算量㊂表2㊀Co-attention模型参数Table2㊀The parameters of the Co-attention model参数名称参数含义参数数值Batch_size每次训练获取的语句对数20对Seq_length模型输入句子的最大长度30Embedding_dim输入词向量的维数200Dropout_keep_prob Dropout概率 1.0Hidden_units LSTM隐藏层维度100Att_matrix_num加权矩阵的数量1/3/10个Margin对比损失函数参数 1.0Lr初始学习率0.01Optimizer优化函数Adam3.4㊀基于句子蒸馏语义计算模型实验分析本次实验选取测试数据中用户数据库命名的数据作为原始数据,设置阈值为0.5,对于每个用户的汽车名称,和我们数据库的汽车名称作相似性计算,大于0.5的作为相同车名备选项,然后把相似值排序后选出最相似的一个作为最终的相似车型名称㊂本次实验使用Siamese LSTM模型作为对比模型,最终试验结果在测试数据集下,我们提出的基于强化学习的模型相较于Siamese LSTM模型准确率从91%上升到95.7%㊂由于训练数据不够充分,所以训练出来的蒸馏模型对于部分句子蒸馏出的信息比较多,比如必要的汽车名称或者一些车型的具体型号被蒸馏出去,导致相同车型的车名称计算相似性时值会很小,从而被丢弃,所以召回率会有一些损失,从100%下降到96%㊂但是蒸馏模型能够蒸馏出去一些非必要的词语,比如像 商务型 等修饰词,可以使得语义抽取更加简练,能够突出重点信息㊂而非蒸馏的模型,可能会受汽车名称中过多的无效或者是错误的修饰性词语的干扰,比如我们用户数据库有一个汽车为 骏捷SY7182UZ1.8T AT (200603)骏捷1.8T AT舒适型轿车 ,我们的车型库的数据里有 中华SY7182UZ轿车骏捷1.8T自动挡尊贵型 和 中华SY7182US轿车骏捷1.8T手动挡舒适型 ,在Siamese LSTM模型计算下后一个会比前一个相似性还高,这样的情况在样本数据中大量存在㊂但是判断是不是同一辆车一般只需要车名和紧接着车名后面的车型号就能唯一识别出来,因此蒸馏模型可以一定程度地将后面修饰的蒸馏出去,因此会增加模型判断的准确率㊂㊀第3期陈观林,等:基于深度强化学习的文本相似语义计算模型表3为句子蒸馏前后的效果,其中第1列是原来的汽车名称,第2列是经过分词工具分词后去除特殊符号后的模型输入数据,第3列的是蒸馏后的效果㊂虽然训练数据不足,但是可以看出句子蒸馏模型会对句子中一些不太重要的修饰性词语蒸馏出去,基本上会保留主要的汽车名称以及必要的汽车统一型号名称,这些信息是识别汽车唯一性的充要条件㊂但也会导致比如排量㊁年份等信息丢失,这与具体的训练数据不足有关㊂表3㊀句子蒸馏效果Table 3㊀The sentence distillation results原语句分词后句子蒸馏后句子上汽通用雪佛兰乐骋SGM7160AT 1.6L AT 豪华型(200801)乐骋2008款1.6L SX 自动上汽通用雪佛兰乐骋SGM7160AT 1.6L AT 豪华型200801乐骋2008款1.6L SX 自动上汽通用雪佛兰乐骋SGM7160AT 乐骋2008款自动一汽大众速腾FV72062.0MT (200604-201203)速腾2.0L MT 舒适型一汽大众速腾FV7206 2.0MT 200604-201203速腾2.0L MT 舒适型一汽大众速腾FV7206速腾MT 进口宝马BMW E46323Ci 2.5AT 进口宝马BMW E46323Ci 2.5AT进口宝马BMW 进口奔驰BENZ SLK200K 1.8AT(04-11)进口奔驰BENZ SLK200K 1.8AT 04-11进口奔驰BENZ 广汽本田奥德赛HG6482BAC4A 2.4L CVT 尊享版(201408)奥德赛2015款2.4L 尊享版广汽本田奥德赛HG6482BAC4A 2.4LCVT 尊享版201408奥德赛2015款2.4L 尊享版广汽本田奥德赛HG6482BAC4A 奥德赛2015款尊享4㊀总结本文将深度学习算法和强化学习算法结合起来研究,通过使用强化学习算法来改善LSTM 模型提取语义时可能的语义丢失现象,在语义相似计算模型Siamese Network 上取得了很好的效果㊂但是本文的模型仍然存在一些问题:由于模型是采用强化学习方式训练,LSTM 提取的语义很复杂,模型要想收敛比较好就需要大量的采样,从而大大增加训练的时间,否则很容易陷入局部最优;另外,测试使用的场景和数据有限,只是在比较小的项目数据集上测试,对于很多其他场景的应用没有测试㊂参考文献:[1]㊀许飞翔,叶霞,李琳琳,等.基于SA-BP 算法的本体概念语义相似度综合计算[J].计算机科学,2020,47(1):199-204.XU F X,YE X,LI L L,et prehensive calculation of semantic similarity of ontology concept based on SA-BP[J].Com-puter science,2020,47(1):199-204.[2]㊀张克亮,李芊芊.基于本体的语义相似度计算研究[J].郑州大学学报(理学版),2019,51(2):52-59.ZHANG K L,LI Q Q.A survey of ontology-based semantic similarity measurement[J].Journal of Zhengzhou university(natural science edition),2019,51(2):52-59.[3]㊀MIKOLOV T,CHEN K,CORRADO G,et al.Efficient estimation of word representations in vector space[C]ʊThe 1st Interna-tional Conference on Learning Representations.Scottsdale,2013:1-12.[4]㊀HOCHREITER S,SCHMIDHUBER J.Long short-term memory[J].Neural computation,1997,9(8):1735-80.[5]㊀MIKOLOV T,SUTSEVER I,CHEN K,et al.Distributed representations of words and phrases and their compositionality[J].Advances in neural information processing systems,2013,26:3111-3119.[6]㊀CHOPRA S,HADSELL R,LECUN Y.Learning a similarity metric discriminatively,with application to face verification[C]ʊThe IEEE Computer Society Conference on Computer Vision and Pattern Recognition.San Diego,2005:539-546.[7]㊀NECULOIU P,VERSTEEGH M,ROTARU M.Learning text similarity with Siamese recurrent networks[C]ʊProceedings of the 1st Workshop on Representation Learning for NLP,Berlin,2016:148-157.[8]㊀MUELLER J,THYAGARAJAN A.Siamese recurrent architectures for learning sentence similarity[C]ʊThe 30th AAAI Confer-78郑州大学学报(理学版)第52卷ence on Artificial Intelligence.Phoenix,2016:2786-2792.[9]㊀KIM S,KANG I,KWAK N.Semantic sentence matching with densely-connected recurrent and co-attentive information[C]ʊThe33th AAAI Conference on Artificial Intelligence.Honolulu,2019:6586-6593.[10]ZHANG T Y,HUANG M L,LI Z.Learning structured representation for text classification via reinforcement learning[C]ʊThe32th AAAI Conference on Artificial Intelligence.New Orleans,2018:1-8.[11]LILLICRAP T P,HUNT J J,PRITZEL A,et al.Continuous control with deep reinforcement learning[J].Computer science,2015,8(6):A187.[12]SUTTON R,MCALLESTER S,SINGH D A,et al.Policy gradient methods for reinforcement learning with function approxima-tion[J].Advances in neural information processing systems,2000,12:1057-1063.[13]MNIH V,BADIA A P,MIRZA M,et al.Asynchronous methods for deep reinforcement learning[C]ʊInternational Conferenceon Machine Learning.New York,2016:1-8.[14]RUMELHART D E,HINTON G E,WILLIAMS R J.Learning representations by back-propagating errors[J].Nature,1986,323(6088):533-536.[15]KINGMA D P,BA J.Adam:a method for stochastic optimization[C]ʊThe3rd International Conference on Learning Represen-tations.San Diego,2015:1-15.A Text Similarity Semantic Computing Model Based on DeepReinforcement LearningCHEN Guanlin1,2,SHI Xiaolong1,2,ZHOU Liang3,WENG Wenyong1(1.School of Computer and Computing Science,Zhejiang University City College,Hangzhou310015,China;2.College of Computer Science,Zhejiang University,Hangzhou310027,China;3.Hangzhou Big Data Management Service Center,Hangzhou310020,China) Abstract:Semantic similarity computing was a common problem in the field of natural language process-ing.Most of the existing semantic similarity computing models extracted semantic features based on CNN or LSTM.There was semantic information loss problem with this way of extracting semantic features.Two points were proposed to improve traditional deep learning models.Firstly attention weight model using multiple weighted matrices was improved to weight semantics.And a new method was proposed to calcu-late weight.Secondly reinforcement learning method in the semantic similarity calculation model was used to improve the semantic loss phenomenon.The reinforcement learning algorithms were studied in the most commonly Siamese Network model,which could improve the semantic loss of LSTM models when extrac-ting the semantics of sentences.The experiments showed that the improved method had a good effect in processing Chinese sentences.Key words:deep learning;semantic similarity;reinforcement learning(责任编辑:方惠敏)。
昆虫也具有一定智力

昆虫也具有一定智力人们普遍认为昆虫是没有思维活动的低等动物。
然而,别看昆虫的大脑小如针尖,它们的智力却一点不逊于体形庞大的高等动物。
英国科学家最新研究发现,昆虫不仅有思维活动、会数数、懂得分门别类,甚至可以识别人脸。
来自英国玛丽女王学院、伦敦大学和剑桥大学的科学家用计算机模拟昆虫大脑开展实验。
实验结果显示,昆虫的大脑容量足以使它们拥有思维活动。
实际上,数百个神经细胞就可以支持动物数数;数千个神经细胞就可以使动物拥有思维活动。
蜜蜂的大脑重量约为1毫克,包含近100万个神经细胞。
这些神经细胞足可以使蜜蜂拥有思维活动和数数能力。
此外,它们可以区分出各种动物,判断图形是否对称。
美国西弗吉尼亚大学神经生物学家萨拉·法里斯说,蝗虫、蚂蚁、蜜蜂等脑容量较小的昆虫实际上都比人们想像中聪明得多,能够根据外部环境改变自己的行为习惯。
众所周知,蚂蚁、蜜蜂等昆虫拥有复杂的社会系统;蜜蜂可以通过特殊的舞姿与同伴展开交流。
这些小昆虫的行为甚至比一些脊椎动物还复杂。
希特卡说:“它们聪明绝顶。
或许,我们只是不敢相信如此微小的大脑竟能完成如此复杂的行为。
它们的大脑虽然小,但做这些事情已经足够。
”“问题是,既然这些昆虫凭借如此微小的大脑就可以做这些事情,那么对脑容量大的动物而言,体积大的大脑又有什么用处呢,”希特卡提出并解决了这个问题,“更大并不意味着更好。
有时候事实与人们想像的恰恰相反。
”他解释说:“我们知道,身材决定动物的脑容量,但脑容量并不决定动物可以做出哪些行为。
体积大的大脑并不一定复杂,可能只是相同神经元的无限重复。
它能记住更多图像和声音,但并没有增加功能的复杂性。
在计算机模拟实验中,体积大的大脑意味着更大的硬盘驱动器,而不是更好的处理器。
”鲸鱼大脑可重达9千克,包含约2000亿个神经细胞;人类大脑重量通常在1.25千克至1.45千克之间,包含约850亿个神经细胞;蜜蜂大脑重量约为1毫克,包含近100万个神经细胞。
ChatGPT在机器翻译和跨语言通讯中的应用和发展(英文中文双语版优质文档)

ChatGPT在机器翻译和跨语言通讯中的应用和发展(英文中文双语版优质文档)Machine translation and cross-language communication have always been important research directions in the field of artificial intelligence. ChatGPT, as a natural language processing model, has been widely used and developed in these two fields. Next, I will explain the application and development of ChatGPT from two aspects of machine translation and cross-language communication.1. Machine translationMachine translation is the process of automatically translating text from one language into another, and it has a wide range of applications in cross-language communication, cross-cultural communication, and information acquisition. ChatGPT, as a language generation model based on natural language processing, can play an important role in machine translation.1. Neural machine translation based on ChatGPTNeural machine translation is a neural network-based machine translation method that uses neural networks to establish a mapping relationship between a source language and a target language. ChatGPT, as a neural network-based language generation model, can be used for neural machine translation.In neural machine translation, ChatGPT can be used to generate translation results in the target language. ChatGPT can generate sentences in the target language based on the source language sentences and context information. The advantage of ChatGPT is that it can generate natural and fluent language, but the disadvantage is that there may be lexical and grammatical errors.2. Improvement of Neural Machine Translation Based on ChatGPTIn order to improve the translation quality of ChatGPT in neural machine translation, the researchers proposed a series of improvement methods. The more important one is the Transformer-based neural machine translation model.Transformer is a neural network model based on self-attention mechanism, which can learn the mapping relationship between source language and target language. In the Transformer-based neural machine translation model, ChatGPT can be used to generate sentences in the target language, while using the self-attention mechanism to establish the mapping relationship between the source language and the target language. This approach can improve the quality and speed of machine translation.2. Cross-language communicationCross-language communication refers to the exchange and communication between people or devices using different languages, and it has a wide range of applications in international trade, tourism, education, etc. As a natural language processing model, ChatGPT also has important applications and developments in cross-language communication.1. ChatGPT-based machine translation toolChatGPT can be used to develop cross-language machine translation tools, enabling people to communicate and communicate in their native language. This tool enables cross-language communication by translating people's voice or text input into voice or text output in other languages.ChatGPT can take advantage of its powerful natural language processing capabilities and play an important role in cross-language machine translation. It can generate natural and smooth language translation results based on information such as context, context, and grammatical rules, thereby improving the quality and accuracy of machine translation.2. Cross-language dialogue system based on ChatGPTChatGPT can also be used to develop a cross-language dialogue system, enabling people of different languages to conduct real-time dialogue and communication. This kind of system can realize cross-language dialogue by translating the input speech or text, and then output the translation result to the other party of the dialogue.In a cross-language dialogue system, ChatGPT can generate responses related to the dialogue content based on information such as context and context. Such a system can improve the quality of its translations and responses through continuous learning and optimization to better meet the needs of users.3. Cross-lingual information retrieval based on ChatGPTIn addition to cross-language translation and dialogue, ChatGPT can also be used for cross-language information retrieval. This application can help people find and obtain the required information in texts in different languages, and improve the efficiency and accuracy of information retrieval.In cross-language information retrieval, ChatGPT can translate the query content into other languages according to the user's query content and context information, then find the corresponding information in the target language, and translate it into the language output required by the user. Such applications can play an important role in cross-language information retrieval, making it easier for people to obtain the information they need.In general, ChatGPT, as a language generation model based on natural language processing, has a wide range of applications and developments in machine translation and cross-language communication. With the continuous development of technology in the future, the application of ChatGPT in these two fields will become more and more extensive, so that people can communicate and communicate across languages more conveniently.机器翻译和跨语言通讯一直是人工智能领域的重要研究方向,ChatGPT作为一种自然语言处理模型,在这两个领域也有着广泛的应用和发展。
深度学习之AttentionModel(注意力模型)

深度学习之AttentionModel(注意⼒模型)1、Attention Model 概述 深度学习⾥的Attention model其实模拟的是⼈脑的注意⼒模型,举个例⼦来说,当我们观赏⼀幅画时,虽然我们可以看到整幅画的全貌,但是在我们深⼊仔细地观察时,其实眼睛聚焦的就只有很⼩的⼀块,这个时候⼈的⼤脑主要关注在这⼀⼩块图案上,也就是说这个时候⼈脑对整幅图的关注并不是均衡的,是有⼀定的权重区分的。
这就是深度学习⾥的Attention Model的核⼼思想。
⼈脑的注意⼒模型,说到底是⼀种资源分配模型,在某个特定时刻,你的注意⼒总是集中在画⾯中的某个焦点部分,⽽对其它部分视⽽不见。
2、Encoder-Decoder框架 所谓encoder-decoder模型,⼜叫做编码-解码模型。
这是⼀种应⽤于seq2seq问题的模型。
seq2seq问题简单的说,就是根据⼀个输⼊序列x,来⽣成另⼀个输出序列y。
常见的应⽤有机器翻译,⽂档提取,问答系统等。
Encoder-Decoder模型中的编码,就是将输⼊序列转化成⼀个固定长度的向量;解码,就是将之前⽣成的固定向量再转化成输出序列。
Encoder-Decoder(编码-解码)是深度学习中⾮常常见的⼀个模型框架,⽐如⽆监督算法的auto-encoding就是⽤编码-解码的结构设计并训练的;⽐如这两年⽐较热的image caption的应⽤,就是CNN-RNN的编码-解码框架;再⽐如神经⽹络机器翻译NMT模型,往往就是LSTM-LSTM的编码-解码框架。
因此,准确的说,Encoder-Decoder并不是⼀个具体的模型,⽽是⼀类框架。
Encoder和Decoder部分可以是任意的⽂字,语⾳,图像,视频数据,模型可以采⽤CNN,RNN,BiRNN、LSTM、GRU等等。
所以基于Encoder-Decoder,我们可以设计出各种各样的应⽤算法。
Encoder-Decoder框架可以看作是⼀种⽂本处理领域的研究模式,应⽤场景异常⼴泛,下图是⽂本处理领域⾥常⽤的Encoder-Decoder 框架最抽象的⼀种表⽰: 对于句⼦对<X,Y>,我们的⽬标是给定输⼊句⼦X,期待通过Encoder-Decoder框架来⽣成⽬标句⼦Y。
基础大模型 英语

基础大模型英语Here is an English essay on the topic of "Foundational Large Language Models" with a word count of over 1000 words:The Transformative Power of Foundational Large Language ModelsThe rapid progress in artificial intelligence (AI) and machine learning (ML) has been truly remarkable in recent years. One of the most significant advancements in this field is the development of foundational large language models (LLMs). These powerful AI systems have demonstrated an unprecedented ability to understand and generate human-like text, revolutionizing various applications and pushing the boundaries of what was previously thought possible.At the heart of these foundational LLMs lies a deep neural network architecture known as the transformer. This architecture, first introduced in the seminal paper "Attention is All You Need" by Vaswani et al. in 2017, has proven to be a game-changer in the field of natural language processing (NLP). Unlike traditional language models that relied on recurrent neural networks or convolutional neural networks, the transformer architecture is built on the concept of attention, which allows the model to efficiently capture long-range dependencies in the input text.One of the key features of foundational LLMs is their ability to learn from vast amounts of text data, often in the range of billions of words. This massive amount of training data, combined with the power of the transformer architecture, enables these models to develop a deep understanding of language, including its syntax, semantics, and contextual nuances. This understanding is then reflected in their ability to perform a wide range of language-related tasks with remarkable accuracy and fluency.Perhaps the most impressive aspect of foundational LLMs is their versatility. These models can be fine-tuned or adapted to various specific tasks, such as text generation, question answering, sentiment analysis, and even code generation. This versatility has made them invaluable tools in fields as diverse as natural language processing, content creation, customer service, and even software development.One of the most prominent examples of a foundational LLM is GPT-3, developed by OpenAI. GPT-3, which stands for Generative Pre-trained Transformer 3, has been hailed as a breakthrough in natural language processing, demonstrating an uncanny ability to generate human-like text on a wide range of topics. From creative writing to language translation, GPT-3 has shown that it can adapt to various tasks with remarkable proficiency.However, GPT-3 is not the only foundational LLM that has made a significant impact. Other notable examples include BERT (Bidirectional Encoder Representations from Transformers) developed by Google, and T5 (Text-to-Text Transfer Transformer) developed by researchers at Google Brain. Each of these models has its own unique strengths and capabilities, and the field of foundational LLMs is continuously evolving, with new and improved models constantly being developed.One of the key drivers behind the success of foundational LLMs is the availability of large-scale computing power and vast datasets. The ability to train these models on massive amounts of text data has been crucial in enabling them to develop a deep understanding of language. Additionally, the advancements in hardware, such as the development of powerful graphics processing units (GPUs) and tensor processing units (TPUs), have made it possible to train these models efficiently and effectively.Despite their impressive capabilities, foundational LLMs are not without their challenges and limitations. One of the primary concerns is the potential for these models to perpetuate or amplify biases present in the training data, leading to biased or discriminatory outputs. Researchers and developers are actively working on addressing these issues, exploring techniques such as data curation,model fine-tuning, and the development of ethical AI principles.Another challenge is the computational and energy-intensive nature of training these models. The sheer scale of the datasets and the complexity of the architectures involved require significant resources, both in terms of hardware and energy consumption. This has led to concerns about the environmental impact of AI development and the need for more sustainable approaches to training and deploying these models.Despite these challenges, the potential of foundational LLMs is undeniable. As these models continue to evolve and improve, they are poised to revolutionize a wide range of industries and applications. From natural language processing to content creation, from customer service to software development, the impact of foundational LLMs is likely to be far-reaching and profound.In conclusion, the development of foundational large language models represents a significant milestone in the field of artificial intelligence. These powerful AI systems have demonstrated an unprecedented ability to understand and generate human-like text, paving the way for a wide range of transformative applications. As the field of foundational LLMs continues to evolve, we can expect to see even more remarkable advancements in the years to come,pushing the boundaries of what is possible in the world of artificial intelligence.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
RESEARCH ARTICLEA neural network model of attention-modulated neurodynamicsYuqiao Gu ÆHans Liljenstro¨m Received:15July 2006/Accepted:7September 2007/Published online:2October 2007ÓSpringer Science+Business Media B.V.2007Abstract Visual attention appears to modulate cortical neurodynamics and synchronization through various cho-linergic mechanisms.In order to study these mechanisms,we have developed a neural network model of visual cortex area V4,based on psychophysical,anatomical and physi-ological data.With this model,we want to link selective visual information processing to neural circuits within V4,bottom-up sensory input pathways,top-down attention input pathways,and to cholinergic modulation from the prefrontal lobe.We investigate cellular and network mechanisms underlying some recent analytical results from visual attention experimental data.Our model can repro-duce the experimental findings that attention to a stimulus causes increased gamma-frequency synchronization in the superficial puter simulations and STA power analysis also demonstrate different effects of the different cholinergic attention modulation action mechanisms.Keywords Attention ÁNeural network model ÁHodgkin–Huxley neurons ÁVisual cortex ÁV4ÁNeuromodulationIntroductionAttention is known to play a key role in perception,including action selection,object recognition and memory(Hamker 2004a,b ).The main effect of attentional selection appears to be a modulation of the underlying competitive interaction between the stimuli in the visual field.Studies of cortical areas V2and V4indicate that attention serves to modulate the suppressive interaction between two or more stimuli presented simultaneously within the receptive field (Corchs and Deco 2002).Intermodular competition and mutual biasing result from the interaction between modules corresponding to different visual areas (Deco and Rolls 2004).Analysis of in vivo visual attention experimental data has revealed that visual attention has several effects in modulating cortical oscillations,in terms of changes in firing rate (McAdams and Maunsell 1999),and gamma and beta coherence (Fries et al.2001).In selective attention tasks,after the cue onset and before the stimulus onset,there is a delay period during which the monkey’s attention was directed to the place where the stimulus would appear (Fries et al.2001).Data analysis showed that during the delay,the power spectra were dominated by frequencies around 17Hz.With attention,this low-frequency syn-chronization was reduced.During the stimulus period,there were two distinct bands in the power spectrum,one below 10Hz and another at 35–60Hz.With attention,the reduction in low-frequency synchronization was main-tained and,conversely,gamma-frequency synchronization was increased.Visual attention is clearly associated with the visual cortex.This cortical structure is composed of a multi-scale network system and is apparently involved in many higher level information processing tasks,including cognition and consciousness.At a macro-scale,visual cortex is organized as a hierarchy of cortical areas.Cognitive tasks in a simple environment,or perception of novel unexpected stimuli,seems to involve a pure bottom-up processing,driven by external stimuli through a cascade from lower to higherY.Gu ÁH.Liljenstro¨m (&)Department of Biometry and Engineering,SLU,Uppsala,Swedene-mail:hans.liljenstrom@bt.slu.seY.GuSchool of Automation and Energy Engineering,Tianjin University of Technology,Tianjin,P.R.ChinaCogn Neurodyn (2007)1:275–285DOI 10.1007/s11571-007-9028-7areas.However,when the environment is cluttered,or there is internal expectancy,attention,or a behavioral goal, experimental evidence indicates a more complex interac-tion between top-down and bottom-up signals.Such top-down information from higher areas,driven by internal signals,and bottom-up signals from lower areas,driven by external stimuli,seems involved in complex cognition and conscious awareness tasks(Desimone and Duncan1995; Hupe´et al.2001;Fries et al.2001;Angelucci and Bullier 2003;Kranczioch et al.2005).Results in Hupe´et al. (2001)indicate that higher area top-down feedback acts on the earliest part of the response in lower areas,and can last throughout the whole duration of the stimulus response. Angelucci and Bullier(2003)suggest that top-down feed-back projections from higher areas contact both pyramidal and inhibitory neurons in the lower area,and spread much further laterally than the local lateral connections within the lower area.At a meso-scale,each area of the visual cortex is conventionally divided into six layers,some of which can be further divided into several sub-layers,based on their detailed functional roles in visual information processing(such as orientation and retinotopic position).According to the basic signal transferring and process-ing functions,the six layers can be roughly regarded as three layers:layer2/3,layer4and layer5/6.A major part of bottom-up inter-areal connections terminate in the granular layer(layer4),another,smaller part of bottom-up inter-areal connections terminate in layer 6.Top-down inter-areal connections terminate in the supra-(layer2/3) and infra-granular layers(layer5/6).Using techniques of microinjections of D-3H-Asp and injections of horseradish peroxidase,very detailed intra-areal connections,including intra-laminar and lateral excitatory projections have been experimentally investigated(Fitzpatrick et al.1985;Blas-del et al.1985and Kisvarday et al.1989).The inter-scale network interactions of various excit-atory and inhibitory neurons in the visual cortex generate oscillatory signals with complex patterns of frequencies associated with particular states of the brain.Synchronous activity at an intermediate and lower-frequency range (theta,delta and alpha)between distant areas was observed during perception of stimuli with varying behavioral sig-nificance(von Stein et al.2000;Siegel et al.2000). Particularly,von Stein et al.(2000)found that intermediate (4–12Hz,theta/alpha)frequency interactions were related to stimulus expectancy,and suggest that intermediate-fre-quency interaction might mediate top-down processes. Rhythms in the beta(12–30Hz)and the gamma(30–80Hz)ranges are also found in visual cortex,and are often associated with attention,perception,cognition and con-scious awareness(Fries et al.2001).Data suggest that gamma rhythms are associated with relatively local com-putations,whereas beta rhythms are associated with higher level interactions.Generally,it is believed that lower fre-quency bands are generated by global circuits,while higher frequency bands are derived from local connections.Previously,Wright and Liley(1995)have developed a global scale model of electrocortical activity,using cortico-cortical and intracortical synaptic coupling densities and localfield potentials.The simulated spectra of their model show realistic peaks of power occurring at theta,alpha,beta and gamma ranges.With increasing cortical activation parameter,there is a‘shift to the right’of spectral density, imitating the effect of increasing cortical arousal.Kopell and her colleagues have demonstrated,with a small network composed of two pyramidal neurons and two inhibitory Hodgkin–Huxley neurons,that oscillations may shift from gamma to beta,when increasing the strength of recurrent excitatory synapses and the amplitude of one or more slow K conductances(Kopell and Ermentrout2000).They also developed a cortical local circuit model in which cholinergic modulation,acting on adaptation currents in principal cells, induces a transition between asynchronous spontaneous activity and a‘‘background’’gamma rhythm(Bo¨rgers et al. 2005).In earlier work of our own group,we have studied oscillations of this kind in olfactory information processing, using neural population models of the olfactory cortex (Liljenstro¨m1991;Wu and Liljenstro¨m1994;Liljenstro¨m and Hasselmo1995;Basu and Liljenstro¨m2001).For example,in Liljenstro¨m and Hasselmo(1995)we demon-strated cholinergic modulation shifts in olfactory network oscillations.Recently,we have developed neural network models with realistic anatomical circuits and physiological parameters of neocortex to simulate and analyze EEG-like signals and investigate how the dynamics are affected by the internal local and global connection topology,and different types of external stimuli and signals(Gu et al.2004,2006). In the present work,we further develop and generalize our experiences and ideas from previous neural network mod-eling for visual cortex.We construct a model of the visual cortex area V4,based on anatomical and physiological data. Using our model of the visual cortex,we simulate some data analysis results from selective visual attention tasks,carried out on macaque monkeys attended to behaviorally relevant stimuli and ignored distracters(Fries et al.2001).We also discuss hypotheses about various cholinergic action mech-anisms involved in top-down attention modulation. MethodsNeuron types and equations describing the dynamicsof neuronsOur model is composed of three functional layers including layer2/3,layer4and layer5/6.Each layer contains20·20excitatory neurons(pyramidal neurons in layer2/3 and layer5/6,and spiny stellate neurons in layer4)in a quadratic lattice with lattice distance0.2mm,and10·10 inhibitory neurons in a quadratic lattice with lattice dis-tance0.4mm.Thus,there are20%inhibitory neurons, which roughly corresponds to the cortical distribution.The pyramidal neurons in layer2/3and layer5/6,and the spiny stellate neurons in layer4satisfy Hodgkin–Huxley equa-tions of the following form(which are essentially the same as in Kopell et al.2000):CV0¼Àg LðVþ67ÞÀg Na m3hðVÀ50ÞÀg K n4ðVþ100ÞÀg AHP wðVþ100ÞÀI synþI applð1Þwhere V is the membrane potential and C=1l F is the membrane capacitance.g L=0.1mS is the leak conductance,g Na=20mS and g K=10mS are the maximal sodium and potassium conductances, respectively,g AHP the maximal slow potassium conductance of the afterhyperpolarization(AHP)current, which varies from0mS to 1.0mS,depending on the attention state:in idle state,g AHP=1.0mS,with attention, g AHP£1.0mS.The variables m,h,n and w satisfym0¼0:32ð54þVÞ1ÀexpðÀðVþ54Þ=4Þð1ÀmÞÀ0:28ðVþ27ÞexpððVþ27Þ=5ÞÀ1m;ð2Þh0¼0:128expðÀð50þVÞ=18Þð1ÀhÞÀ41þexpðÀðVþ27Þ=5Þh;ð3Þn0¼0:032ðVþ52Þ1ÀexpððVþ52Þ=5Þð1ÀnÞÀ0:5expðÀð57þVÞ=40Þn;ð4Þw0¼w1ðVÞÀws wðVÞ;ð5Þwherew1ðVÞ¼11þexpðÀðVþ35Þ=10Þð6Þands wðVÞ¼4003:3expððVþ35Þ=20ÞþexpðÀðVþ35Þ=20Þ:ð7ÞThe inhibitory neurons have identical equations,except there is no AHP current.The synaptic input current I syn and the applied current I appl of pyramidal,stellate,and inhibitory neurons will be described in section‘‘Network architecture and equations’’. Network architecture and equationsFigure1shows the schematic diagram of the network topology,in which we take into account different types of spiking neurons and the detailed connection circuitry based on anatomical and physiologicalfindings.Three different types of signalflows are included in our model:one type is the local interaction signals within each layer and between different layers;another type is the bottom-up input signals from the lower area;the other type is the top-down input signals from the higher area.The inhibitory neurons in each layer have interactions within their own layer only, while excitatory neurons have interactions within their own layer,as well as between layers and areas.The connections between excitatory and inhibitory neurons within each layer form a‘‘Mexican hat’’shape with an on-center and an off-surround lateral synaptic input for each neuron,as shown in Fig.2and described in detail below.The bottom-up sensory inputs from lower areas,which constitute the strongest signalflow in the network,activate the local area network via two routes.The major stream of the bottom-up signal inputs to spiny stellate neurons in layer 4.The minor stream of the bottom-up signal inputs to pyramidal neurons in layer5/yer4spiny stellate neu-rons excite the layer2/3pyramidal neurons with laterally spread connections,which constitute the strongest interac-tions between yer5/6pyramidal neurons activate the spiny stellate neurons in layer4with laterally spread connections,which constitute the second strongest connec-tions between yer2/3pyramidal neurons send feedback signals to layer6pyramidal neurons with laterally distributed yer4spiny stellate neurons send descending signals to layer5/6pyramidal neurons with spread yer5/6pyramidal neurons send ascending small focus signals to layer2/3pyramidal neurons yer2/3pyramidal neurons send descending focus signals to layer4stellate neurons below.Attention-activated cholinergic modulation signals from higher area pass down into layer5/6and layer2/3.These signals spread laterally with a radius which is larger than the lateral excitatory connection radius,but smaller than the lateral inhibitory connection radius in these two layers.The reason for this top-down input structure is that the higher areas have larger receptivefields than the lower areas.In each layer j(where j=2/3,4,and4/6)of the local area network,there are four types of interactions:(1)lateral excitatory–excitatory,(2)excitatory–inhibitory,(3)inhib-itory–excitatory,and(4)inhibitory–inhibitory,withcorresponding connection strengths,C j ,kl ee ,C j ,kl ie ,C j ,kl ei ,andC j ,kl ii,which vary with distance between neurons k and l .We construct our lateral connections based on the experimental findings that the lateral interaction can be described by a Mexican hat shape,i.e.the total lateral synaptic inputs to a neuron are,in general,excitatory at a short distance,and inhibitory at a long distance.The excitatory–excitatory connections apparently activate neighboring excitatory neurons,whereas the excitatory–inhibitory connections activate neighboring inhibitory neurons,which subsequently could inhibit dis-tant excitatory neurons.Therefore,in our model,the lateral excitatory connection strength from neuron l to neuron k is strongest between close neighbors,and decreasing with distance as,C ee j ;kl ¼g ee jðR ee j Àd kl ÞR ee j;if d kl R ee j0;otherwise (ð8ÞC ie j ;kl ¼g ie j ðR iej Àd kl Þie j;if d kl R ie j 0;otherwise(ð9ÞThe lateral inhibitory–inhibitory connections could inhibit distant inhibitory neurons,thus weakening the inhibitory effect of distant inhibitory neurons.Hence,in our model,the inhibitory connection strength is weakest for neighboring neurons,and increasing with distance.The lateral inhibitory connection strength reaches a maximal value when the distance between neurons is half of the inhibitory interaction radius,then decreases with distance between neurons.Inhibitory connection strength from neuron l to neuron k is described byC ei j ;kl¼g ei j 2d klR ei j;if d kl R ei j =2g ei j 2ðR eij Àd kl ÞR ei j;if R ei j =2\d kl R eij0;if d kl [R ei j 8>><>>:ð10ÞC ii j ;kl ¼g ii j 2d klii j;if d kl R ii j =2g ii j 2ðR iij Àd kl ÞR ii j;if R ii j =2\d kl R iij0;ifd kl [R ii j8>><>>:ð11Þwhere g j ee ,g j ie ,g j ei and g j iiare conductances,representing the maximum excitatory—excitatory,excitatory—inhibitory,inhibitory—excitatory,and inhibitory—inhibitory couplingstrengths in layer j ,respectively.R j ee ,R j ie ,R j ei and R j iiaretheFig.1A schematic diagram of the model architecture.The small triangles in layer 2/3and layer 5/6represent pyramidal neurons,the small open circles in layer 4are spiny stellate neurons,and the small solid circles in each layer are inhibitory neurons.The arrows show the connection patterns between different layers and the signal flows coming from the other areas.The large solid open circle in each layer represents the lateral excitatory connection radius,the large dashed open circle in each layer represents inhibitory connection radius.The dotted open circles in layer 2/3and layer 5/6denote the top-down attention modulation radius R moduFig.2The lateral connection strength to an excitatory neuron (a )andthat to an inhibitory neurons (b )as function of distance in each layer.In this graph,the parameter values of various synaptic strengths andvarious connection rediuses are:g ee =0.25mS,g ie =0.5mS,g ei =0.3mS,g ii =0.3mS,R ee =0.5mm,R ie =0.5mm,R ei =1.0mm,R ii =1.0mmcorresponding lateral connection radiuses,and d kl is the distance between neuron k and l.From Eqs.(8)and(10),we can obtain that the total connection strength to an excitatory neuron,as a function of distance,has a Mexican hat shape,as shown in Fig.2A. Similarly,Eqs.(9)and(11)give a Mexican hat shape for the total connection strength to an inhibitory neuron as a function of distance,as shown in Fig.2B.In our model,the connection strength from the excit-atory neuron l in layer j to the excitatory neuron k in layer i is given byC ee ij;kl ¼geeijðR eejÀd klÞR eeij;if d kl R ee ij0;otherwise(ð12Þwhere d kl is the lateral distance between neuron l and k.The synaptic input currents,I syn,for each one of the excitatory(pyramidal)and inhibitory neurons are defined below.The synaptic input current,I2/3p,ksyn(t)of the k th pyramidal neuron in layer2/3at time t is composed of lateral excitatory inputs from neighboring pyramidal neurons and lateral inhibitory inputs from neighboring inhibitory neurons in layer2/3,feedforward inputs from the stellate neurons in layer4,and from the pyramidal neurons in layer5/6:I syn 2=3p;k ðtÞ¼ðV2=3p;kðtÞÀV EÞXlC eeð2=3Þ4;kls e4;lðtÞþXlC ee2=3;kls e2=3;lðtÞþXlC eeð2=3Þð5=6Þ;kls e5=6;lðtÞ!þðV2=3p;kðtÞÀV IÞXlC ei2=3;kls i2=3;lðtÞð13Þwhere V2/3p,k(t)is the membrane potential of pyramidal neuron k in layer2/3at time t.V E=0mV is the reversal potential for excitatory synaptic currents,V I=–80mV is the reversal potential for inhibitory synaptic currents.s j,l x is the presynaptic output signal from neuron l in layer j,with x=e for excitatory,or x=i for inhibitory signals, respectively,and defined by Eqs.(19)and(20).The synaptic input current,I2/3i,ksyn of the k th inhibitory neuron in layer2/3is composed of the lateral excitatory inputs from neighboring pyramidal neurons,and lateral inhibitory inputs from neighboring inhibitory neurons:I syn 2=3i;k ðtÞ¼ðV2=3i;kðtÞÀV EÞXlC ie2=3;kls e2=3;lðtÞþðV2=3i;kðtÞÀV IÞXlC ii2=3;kl s i2=3;lðtÞð14ÞThe synaptic input current,I4s,ksyn(t)of the k th stellate neuron in layer4at time t is composed of the ascending input from the pyramidal neurons in layer6,descending input from the pyramidal neurons in layer2/3,and lateral excitatory inputs from the on-center neighboring stellate neurons in layer4,and lateral inhibitory inputs from the off-surround neighboring inhibitory neurons in the same layer:I syn4s;kðtÞ¼ðV4s;kðtÞÀV EÞXlC ee4ð5=6Þ;kls e5=6;lðtÞþXlC ee4ð2=3Þ;kls e2=3;lðtÞþXlC ee4;kls e4;lðtÞ!þðV4s;kðtÞÀV IÞXlC ei4;kls i4;lðtÞð15ÞThe synaptic input current,I4i,ksyn of the k th inhibitory neuron in layer4is composed of the lateral excitatory inputs from neighboring stellate neurons and lateral inhibitory inputs from neighboring inhibitory neurons:I syn4i;kðtÞ¼ðV4i;kðtÞÀV EÞXlC ie4;kls e4;lðtÞþðV4i;kðtÞÀV IÞXlC ii4;kls i4;lðtÞð16ÞThe synaptic input current I5/6p,ksyn(t)of the k th pyramidal neuron in layer5/6at time t is composed of the feedback inputs from pyramidal neurons in layer2/3,descending inputs from stellate neurons in layer4,and lateral excitatory inputs from neighboring pyramidal neurons and lateral inhibitory inputs from neighboring inhibitory neurons:I syn5=6p;kðtÞ¼ðV5=6p;kðtÞÀV EÞXlC eeð5=6Þð2=3Þ;kls e2=3;lðtÞþXlC eeð5=6Þ4;kls e4;lðtÞþXlC ee5=6;kls e5=6;lðtÞ!þðV5=6p;kðtÞÀV IÞXlC ei5=6;kls i5=6;lðtÞð17ÞFinally,the synaptic input current,I6i,ksyn of the k th inhibitory neuron in layer6is composed of lateral excitatory inputs from neighboring pyramidal neurons and lateral inhibitory inputs from neighboring inhibitory neurons:I syn5=6i;kðtÞ¼ðV5=6i;kðtÞÀV EÞXlC ie5=6;kl s e5=6;lðtÞþðV5=6i;kðtÞÀV IÞXlC ii5=6;kls i5=6;lðtÞð18ÞThe excitatory and inhibitory presynaptic outputs in Eqs.(13–18)satisfyfirst order Eqs.of(19)and(20), respectively:s e 0j ;l ¼5ð1þtanh ðV j ;l =4ÞÞð1Às e j ;l ÞÀs ej ;l =2;ð19Þs i 0j ;l ¼2ð1þtanh ðV j ;l =4ÞÞð1Às i j ;l ÞÀs i j ;l =15:ð20Þwhere j refers to the layer,and l to the presynaptic neuron.V j ,l corresponds to the membrane potential of presynaptic neuron l in layer j .Computer simulation,result analysis and comparison with experimental resultsComputer simulations of the model are carried out in Visual C++ 6.0environment.The values of network parameters in an idle state are given in Tables 1and 2.In our simulations,the top-down modulation radius R modu is taken as 0.6mm,which is larger than the lateral excitatory connection radius of 0.5mm,in each layer.In addition,each neuron of the network receives an internal back-ground noise input current.The background current to each excitatory neuron is given by a random number between 0and 10(l A),and the corresponding background current to each inhibitory neuron is given by a random number between 0and 3(l A).The differential equations given in section ‘‘Methods’’are solved by a forward Euler method,with time step 0.1ms.In each case,the total simulation time is 1s.To mimic the situation in the visual attention experiment in Fries et al.(2001),in each layer,we have groups of ‘‘attended-in’’neurons (where attention is directed to a stimulus location inside the receptive field (RF)of these neurons)and groups of ‘‘attended-out’’neurons (where attention is directed to a stimulus location outside the RF these neurons),as shown in Fig.3.During a stimulus period,two identical stimuli are presented;one appears at a location inside the RF of the attended-in group and the other appears at a location inside the RF of the attended-out group.To analyze the simulation results of spike trains,and compare with experimental results (Fries et al.2001),we calculate power spectra of spike triggered averages (STAs)of the local field potential (LFP),representing the oscilla-tory synchronization between spikes and LFP.Since the initial stage for each simulation is unstable,the first 0.1s of the simulation results are discarded before analysis.Theanalysis is performed in a Matlab 7.1environment.The LFP for each excitatory neuron in the attended-in and attended-out groups is estimated as the sum of excitatory inputs to this neuron,including the inputs from neighboring neurons in the same layer,and from neurons in the other layers.The LFP is filtered by a Butterworth filter of order 2with a cutoff at 200Hz.The spike time of a neuron is calculated as the time when the membrane potential crosses –20mV from below.STA of a neuron is computed as the sum of the 241ms LFP centered in each spike time,divided by the number of spikes of that neuron.The STAs of the attended-in group or attended-out group are com-puted as the sum of the STAs of all the neurons in that group,divided by the number of neurons (in that group).The STAs are first detrended before the power spectra are computed.We investigate the dynamics and the effects ofTable 1Parameters of network connection structure and strength in layersg j ee (mS)g j ie (mS)g j ei (mS)g j ii (mS)R j ee (mm)R j ie (mm)R j ei (mm)R j ii (mm)Layer 2/30.25 1.00.30.150.50.5 1.0 1.0Layer 40.25 1.00.30.150.50.5 1.0 1.0Layer 60.251.00.30.150.50.51.01.0Table 2Parameters of feedforward and feedback connectionstrength between layersg ij ee (mS)R j ee (mm)Layer 4to layer 2/30.30.5Layer 5/6to layer 2/30.150Layer 2/3to layer 40.150Layer 5/6to layer 40.20.5Layer 2/3to layer 5/60.150.5Layer 4to layer 5/60.150.5attention(cholinergic modulation)in an idle state,during a delay period,and during stimulation,as described in more detail in the following sub-sections.Network dynamics in an idle stateThe results of our model simulations in an idle state,only using background random inputs to the neurons,are shown in Fig.4.In Fig.4A,a raster graph shows the spiking activities of5·5pyramidal neurons(out of20·20total) in layer2/3.Fig.4B shows the corresponding STA power spectra of the attended-in and attended-out groups in the superficial layer2/3during the idle period,when no attention modulation is applied.Figure4implies that low frequencies in16*22Hz of the beta band are the domi-nant frequencies of the network neurons.Fig.4B indicates that the oscillatory synchronization in this band is also quite strong.These results agree with the experimental findings that power spectra are dominated by frequencies around17Hz in idle states(Fries et al.2001). Attention effects during a delay periodWhen attention is directed to a certain place,the prefrontal lobe sends top-down cholinergic input signals via top-down pathways to layers2/3and5/6of the visual cortex,as shown in Fig.1.To test various experimental hypotheses about the mechanisms of attention modulation on individ-ual neurons and network connections,we assume that the top-down signals may have three different effects on the pyramidal neurons and on the local and global network connections in our simulations.One effect is to facilitate extracortical top-down excitatory synaptic inputs to the pyramidal neurons(global connections).Another effect is to inhibit certain intracortical excitatory and inhibitory synaptic conductances(local connections),as discussed in Kuczewski et al.(2005)and in Korchounov et al.(2005).A third effect is to modulate the slow AHP current by decreasing the K conductance,g AHP,thus increasing the excitability,as discussed by Bo¨rgers et al.(2005).We simulated the cholinergic modulation effect of inhibiting the intracortical excitatory and inhibitory syn-aptic inputs,by decreasing the lateral excitatory and inhibitory conductances to zero(i.e.g j ee=0mS and g j ei= 0mS)for the pyramidal neurons in the attended-in group, within R mod u in layers2/3and5/6.The background random input currents to each excitatory and inhibitory neuron are the same as in section‘‘Network dynamics in an idle state’’.The spikes of one pyramidal neuron in the attended-in group and of one pyramidal neuron in the attended-out group are shown in the second row of Fig.5A.The com-puted LFP,STA and STA power of attended-in and attended-out neurons in layer2/3are also illustrated in paring Fig.4B with the bottom panel of Fig.5A,one can see that the dominant frequency of the oscillatory synchronization and its STA power in the attended-in group decreased by inhibition of the intracor-tical synaptic inputs.This result agrees qualitatively with experimentalfindings that low-frequency synchronization is reduced during attention.In Fig.5B,we present simulation results of the cholin-ergic effect of facilitating the extracortical top-down excitatory synaptic inputs,and of decreasing the K con-ductance,g AHP,as well as different combinations of these effects.The STA power spectra are calculated for attended-in and attended-out groups in the superficial layer2/3.In all the frames(a)to(l)in Fig.5B,the attention top-down modulations are applied to the pyramidal neurons,or to connections to the pyramidal neurons in the attended-in group and around this group within radius R mod u inlayers。