语音编码算法AMR NB , AMR WB 和AMR WB+的区别
Volte-VoLTE语音质量优化案例精编个

VoLTE语音质量优化案例1:VoLTE窄带与宽带语音质量对比【问题现象】在3GPPLTE中,VoLTE业务编码有AMR-NB窄带和AMR-WB宽带两种编码,两种编码速率具有不同的话音质量,所以又分别称为VoLTE标清语音(或VoLTE12.2kbps)和VoLTE高清语音(或VoLTE23.85kbps)。
【问题分析】AMR-NB和AMR-WB这2种编码具有如下特点:●每20ms产生一个语音包,包括了RTP/UDP/RLC-Security压缩头;●每160ms生成一个SID语音静默包。
●帧长20ms;AMR-NB编码特点为:● 4.75kbps到12.2kbps共8个码率,分别为:4.75、5.15、5.9、6.7、7.4、7.95、10.2、12.2kbps;●采样率为8kHz。
AMR-WB编码特点为:● 6.6kbps到23.85kbps共8个码率,分别为:6.6、8.85、12.65、14.25、15.85、18.25、19.85、23.05、23.85kbps;●采样率为16kHz。
可见两者显着的差异是采样速率不一样,窄带一个语音帧是160个点,宽带一个语音帧采样320个点。
AMRNB的语音带宽范围:300-3400Hz,8KHz采样。
AMRWB 的语音带宽范围:?50-7000Hz,16KHz采样。
用户可主观感受到话音比以前更加自然、舒适和易于分辨。
AMRWB与AMRNB不同之处在于AMRWB按16kHz采样,分别按频率带50~6400Hz?和6400~7000Hz进行编码。
用来降低复杂度,AMRWB将位算法集中到更重要的频率区。
低频带使用ACELP算法进行编码。
添加几个特征来达到一个高的主观质量。
线性预测(LP)算法是在每隔20ms的帧要进行一次线性预测算法,每5ms搜索一次自适应码本,这个过程是在12.8Kbs速率下进行。
高频带是在解码器端使用低带和随机激励的参数重建的,目的是调整与在声音基础上的低频有关的高频带.高频带的声频通过使用由低带LP过滤器产生的LP滤波器进行重建。
自适应多码率(AMR)宽带语音编码

自适应多码率(AMR)宽带语音编码1.AMR-WB的应用需求1.1 AMR-WB需求目前在GSM和WCDMA系统中使用AMR声码器为窄带AMR声码器。
在窄带AMR声码器中,语音信号的带宽最高限制在3.4kHz,采样频率为8kHz。
窄带AMR语音编码器在语音信号质量和抗干扰方面已经取得了较好的性能,并被广泛的商用。
然而窄带语音编解码器由于带宽的限制,在语音的自然度、音乐处理、以及在一些特殊音处理等方面还不尽人意。
宽带AMR语音声码器其音频带宽扩展到7kHz,采样频率扩展到16kHz,由于带宽的扩展,该声码器在语音的自然度、音乐,特别是在免提电话(手机)方面较窄带语音编解码器有较大的改善。
可以预见,由于宽带服务提供了一个比较丰富的话音音质的改善,因此宽带AMR 将在3G网络应用中有广泛的市场。
由于AMR-WB的最高编码速率高达23.85kbps,因此宽带AMR只在较低或中等误码的信道中提供较好的性能(载噪比大于13dB),其信号质量超过G.711PCM有线信号质量。
对于误码或干扰比较严重的信道,需要使用窄带AMR,因为窄带AMR具有较低的编码速率,传输信道能够提供较多的纠错比特用于信道编码。
因此窄带AMR和宽带AMR是两种不同类型的服务选择,适应于不同的用户需求,不能相互取代。
AMR-WB属于WCDMA的语音编解码算法标准之一,目前已经有正式的协议和定点C代码。
1.2 ALC功能预研通信系统中,由于终端、传输线路的变化,话音信号电平可能出现过大或过小的情况,这都影响了人们的正常通话,有调查表明,如果能把话音电平保持在适合的范围,可以延长人们在通信系统中的平均通话时间,最终提高系统运营商的经济效益。
独立的ALC设备应该遵循协议ITU-T G.169的指标要求,功能较全。
嵌入式的ALC可以作为一个TC或EC的附加功能,应该具有较小的计算量,在自动调整话音信号电平的同时不能其它话音失真的副作用。
1.3 SMV算法需求SMV(Selectable mode vocoder)算法属于CDMA2000系统中的语音编解码算法标准之一.3、技术要求3.1 技术需求及预期成果3.1.1 AMR-WB需求及预期成果根据功能来进行划分,要求在以下几个方面进行预研1、对AMR-WB语音编解码功能的研究预期成果:《AMR-WB语音编解码功能分析报告》要求:对AMR-WB语音编解码处理方案进行详细分析,对一些理论上的难点和要点以及实现方法进行详细的说明,对一些公式进行必要的推导。
VoLTE维护优化丛书

第1章VoLTE网络配置篇无线测试涉及的网络参数如下表所示:第2章厂家个性VoLTE质量问题篇问题1:IMS无法注册的可能原因?答:手机附着LTE网络并成功建立QCI9承载后PDN connectivity reject,无法建立QCI5默认承载,将导致无法成功注册IMS。
如下图所示:手机attach request -attach complete过程已经建立QCI=9的信令承载,UE会在PDN Connectivity Request消息中包含APN信息,从HSS取得的订阅信息中,Service-Selection="wildcard",所以MME接受UE请求的APN。
根据新的APN,分配一个Bearer ID给default EPS,并且发送Create Session Bearer Request 到S-GW。
S-GW会在它的EPS Bearer 表中创建一个新的实体,并且发送Create Session Request到P-GW中。
S-GW会为Control Plane和User Plane创建新的DL S-GW TEID并且把他们发送到P-GW,创建QCI5默认承载。
因此PDN CONECTIVITY REJECT会导致无法建立QCI5的默认承载,直接导致IMS无法注册。
1)如果是ESM过程导致的拒绝(比如默认承载建立失败),才会带PDN CONNECTIVITY REJECT消息,EMM层拒绝,只有ATTACH REJECT消息。
2)如果拒绝原因值是"unknown EPS bearer context",UE会本地去激活存在的默认承载或专用承载3)常见的拒绝原因有:IMSI中的MNC与核心网配置的不一致。
以下为可能的解决方法:1:检查核心网和eNB侧是否存在相关告警并及时处理2:查看拒绝原因,核查相应参数是否配置正确(IMSI中的MNC与核心网配置的不一致, APN的设置不当等问题)3:是否存在SIM问题及核心网对SIM卡实行限制相应功能及接入等级4:SIM卡和核心网HSS记录信息不一致导致无法注册5:PDN请求拒绝大部分是核心网问题,可以通过抓取信令分析问题2: VoLTE中呼叫前转、呼入限制等补充业务由哪个网元提供数据配置?答: Ut AS是提供业务逻辑和业务执行的应用服务器,VoLTE中使用其进行UE 到业务AS的业务数据管理配置,提供设置、取消业务数据,激活、去激活业务等功能。
编码算法AMR NB , AMR WB 和AMR WB+的区别

自适应语音编码1.AMR-WB的应用需求1.1 AMR-WB需求目前在GSM和WCDMA系统中使用AMR声码器为窄带AMR声码器。
在窄带AMR声码器中,语音信号的带宽最高限制在3.4kHz,采样频率为8kHz。
窄带AMR语音编码器在语音信号质量和抗干扰方面已经取得了较好的性能,并被广泛的商用。
然而窄带语音编解码器由于带宽的限制,在语音的自然度、音乐处理、以及在一些特殊音处理等方面还不尽人意。
宽带AMR语音声码器其音频带宽扩展到7kHz,采样频率扩展到16kHz,由于带宽的扩展,该声码器在语音的自然度、音乐,特别是在免提电话(手机)方面较窄带语音编解码器有较大的改善。
可以预见,由于宽带服务提供了一个比较丰富的话音音质的改善,因此宽带AMR 将在3G网络应用中有广泛的市场。
由于AMR-WB的最高编码速率高达23.85kbps,因此宽带AMR只在较低或中等误码的信道中提供较好的性能(载噪比大于13dB),其信号质量超过G.711PCM有线信号质量。
对于误码或干扰比较严重的信道,需要使用窄带AMR,因为窄带AMR具有较低的编码速率,传输信道能够提供较多的纠错比特用于信道编码。
因此窄带AMR和宽带AMR是两种不同类型的服务选择,适应于不同的用户需求,不能相互取代。
AMR-WB属于WCDMA的语音编解码算法标准之一,目前已经有正式的协议和定点C代码。
1.2 ALC功能预研通信系统中,由于终端、传输线路的变化,话音信号电平可能出现过大或过小的情况,这都影响了人们的正常通话,有调查表明,如果能把话音电平保持在适合的范围,可以延长人们在通信系统中的平均通话时间,最终提高系统运营商的经济效益。
独立的ALC设备应该遵循协议ITU-T G.169的指标要求,功能较全。
嵌入式的ALC可以作为一个TC或EC的附加功能,应该具有较小的计算量,在自动调整话音信号电平的同时不能其它话音失真的副作用。
3.1.1 AMR-WB需求及预期成果根据功能来进行划分,要求在以下几个方面进行预研1、对AMR-WB语音编解码功能的研究预期成果:《AMR-WB语音编解码功能分析报告》要求:对AMR-WB语音编解码处理方案进行详细分析,对一些理论上的难点和要点以及实现方法进行详细的说明,对一些公式进行必要的推导。
VoLTE语音质量优化案例(14个)

VoLTE语音质量优化案例1:VoLTE窄带与宽带语音质量对比【问题现象】在3GPP LTE中,VoLTE业务编码有AMR-NB窄带和AMR-WB宽带两种编码,两种编码速率具有不同的话音质量,所以又分别称为VoLTE标清语音(或VoLTE 12.2kbps)和VoLTE 高清语音(或VoLTE 23.85kbps)。
【问题分析】AMR-NB和AMR-WB这2种编码具有如下特点:●每20ms产生一个语音包,包括了RTP/UDP/RLC-Security压缩头;●每160ms生成一个SID语音静默包。
●帧长20ms;AMR-NB编码特点为:● 4.75kbps到12.2kbps共8个码率,分别为:4.75、5.15、5.9、6.7、7.4、7.95、10.2、12.2kbps;●采样率为8kHz。
AMR-WB编码特点为:● 6.6kbps到23.85kbps共8个码率,分别为:6.6、8.85、12.65、14.25、15.85、18.25、19.85、23.05、23.85kbps;●采样率为16kHz。
可见两者显著的差异是采样速率不一样,窄带一个语音帧是160个点,宽带一个语音帧采样320个点。
AMR NB的语音带宽范围:300-3400Hz,8KHz采样。
AMR WB的语音带宽范围:50-7000Hz,16KHz采样。
用户可主观感受到话音比以前更加自然、舒适和易于分辨。
AMR WB与AMR NB不同之处在于AMR WB按16kHz采样,分别按频率带50~6400Hz 和6400~7000Hz 进行编码。
用来降低复杂度,AMR WB将位算法集中到更重要的频率区。
低频带使用ACELP算法进行编码。
添加几个特征来达到一个高的主观质量。
线性预测(LP)算法是在每隔20ms 的帧要进行一次线性预测算法,每5ms搜索一次自适应码本,这个过程是在12.8Kbs 速率下进行。
高频带是在解码器端使用低带和随机激励的参数重建的, 目的是调整与在声音基础上的低频有关的高频带. 高频带的声频通过使用由低带LP 过滤器产生的LP 滤波器进行重建。
简述欧美及我国常用的语音编码技术

语音编码技术是指将语音信号转换成数字信号的过程,以便于数字通信和存储。
欧美及我国常用的语音编码技术有很多种,每种技术都有其特点和适用场景。
在本文中,我将对欧美及我国常用的语音编码技术进行简要描述,并分析它们的优缺点和应用范围。
1. PCM(Pulse Code Modulation,脉冲编码调制)PCM是一种最基本的编码技术,它将模拟语音信号按照一定的采样频率和量化位数转换成数字信号。
PCM具有简单、成本低廉的优点,适用于通信和存储。
然而,PCM需要较高的带宽和存储空间,而且在传输过程中容易受到噪声和失真的影响。
2. ADPCM(Adaptive Differential Pulse Code Modulation,自适应差分脉冲编码调制)ADPCM是一种改进型的PCM技术,它通过差分编码和自适应量化实现了更高的压缩比和更好的抗噪能力。
ADPCM适用于语音通信和数字语音存储领域,可以有效地降低带宽和存储需求,提高语音质量。
3. CELP(Code Excited Linear Prediction,编码激励线性预测)CELP是一种基于语音产生模型的编码技术,它通过对语音信号的激励和线性预测参数进行编码,实现了更高的压缩比和更好的语音质量。
CELP适用于数字语音通信和存储,已经成为了现代语音编码的主流技术之一。
4. G.729G.729是一种窄带语音编码标准,它采用了多种高效的压缩算法和声学模型,实现了良好的语音质量和低码率。
G.729被广泛应用于IP通信方式和语音会议系统,能够在有限的带宽下实现优秀的语音通信效果。
5. AMR(Adaptive Multi-Rate,自适应多速率)AMR是一种自适应多速率语音编码技术,它可以根据网络条件和通信需求动态调整编码速率,实现了灵活的语音通信和存储。
AMR适用于移动通信和语音在线服务领域,能够提供高质量的语音体验。
以上是欧美及我国常用的几种语音编码技术,每种技术都有自己的特点和应用场景。
VoLTE测试终端使用指导
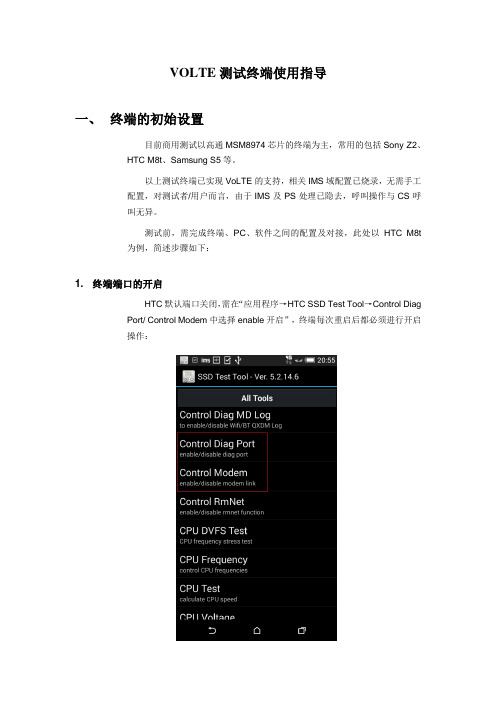
VOLTE测试终端使用指导一、终端的初始设置目前商用测试以高通MSM8974芯片的终端为主,常用的包括Sony Z2、HTC M8t、Samsung S5等。
以上测试终端已实现VoLTE的支持,相关IMS域配置已烧录,无需手工配置,对测试者/用户而言,由于IMS及PS处理已隐去,呼叫操作与CS呼叫无异。
测试前,需完成终端、PC、软件之间的配置及对接,此处以HTC M8t 为例,简述步骤如下:1. 终端端口的开启HTC默认端口关闭,需在“应用程序→HTC SSD Test Tool→Control Diag Port/ Control Modem中选择enable开启”,终端每次重启后都必须进行开启操作:2. 终端驱动安装终端通过USB连接PC后,设备管理器将检测到多个未知端口,右键选择更新驱动,并选择驱动存放路径即可,需注意每个未知端口都要完成更新。
1、终端连接PC后,设备管理器显示未知端口:2、驱动安装后,Diag Port及Modem已识别:3. 关停终端的LOG采集终端与CDS、鼎利、QXDM等软件对接时,需关停终端内部的Log采集,否则软件无法抓取终端信令,可在“应用程序→HTC SSD Test Tool→QXDMLogger”中关停(终端每次重启后都必须进行如下操作):点击Disable DQ:去掉图中红圈内的小勾:4. 网络类型选择根据测试需要,可以在“应用程序→HTC SSD Test Tool→Network Type Switch”中选择锁定LTE、2G/3G/4G自动等方式,一般VoLTE基本语音测试选择锁定LTE,而eSRVCC、CSFB等选择2G/3G/4G自动。
二、终端常用操作1. VoLTE语音编码标准VoLTE使用两种语音编码标准:AMR(或AMR-NB)、AMR-WB。
每种编码标准又都包含多种码率,中移的测试用例中包含不同编码方式及不同码率之间的对比测试,终端侧可在QXDM的NV Browser中对编码方式及码率进行修改,方法如下:码率及对应NV Value1、在QXDM中打开NV Browser(View→New→Common→NV Browser),找到“65964 QIPCall HD Voice Enabled”,Value为0代表标清AMR-NB ,Value为1代表高清AMR-WB。
语音编码技术的分类

语音编码技术的分类语音编码技术概述语音编码技术是指将语音信号转换成数字信号的技术,是现代通信系统中不可或缺的一部分。
语音编码技术能够有效地压缩语音数据,减小传输带宽,提高通信质量。
分类1.无损编码–PCM编码:将模拟语音信号进行采样和量化,并使用脉冲编码调制(PCM)进行数字化,保留了所有原始信息。
–ADPCM编码:利用自适应差分脉冲编码调制(ADPCM)对采样值进行编码,以减小数据量。
–LPC编码:根据语音信号的模型参数,利用线性预测编码(LPC)对信号进行编码,适用于高压缩比的应用。
2.有损编码–CELP编码:采用声道模型和码字搜索算法,通过对语音信号进行向量量化,实现高压缩比的语音编码。
–MP3编码:基于MDCT变换和感知模型,通过分析人耳对声音敏感度,实现高质量音频的压缩。
–AMR编码:适用于移动通信系统的编码标准,通过对语音信号进行截断和窄带限制,达到低比特率的编码效果。
无损编码无损编码技术旨在将语音信号以无失真的方式进行压缩,并能够还原原始信号。
其中,PCM编码是一种最简单的无损编码方式,它通过对语音信号进行时域采样和量化,将连续的模拟信号转换为离散的数字信号。
由于PCM编码保留了全部语音信息,因此文件体积较大,不适合传输和存储。
为了减小数据量,ADPCM编码在PCM编码的基础上引入了差分脉冲编码调制技术。
ADPCM编码根据每个采样值和前一个采样值之间的差异进行编码,以便用更少的位数表示信号。
LPC编码则通过语音信号的线性预测,利用模型参数的编码表示来实现信号的压缩。
有损编码有损编码技术能够更高效地压缩语音信号,但在压缩的过程中会存在一定的信号失真。
有损编码主要应用于高压缩比的语音传输和存储场景。
CELP编码是一种基于声道模型的语音编码技术,它利用矢量量化和码字搜索算法对语音信号进行编码。
通过分析语音信号在频域和时间域的特性,CELP编码能够以较低的比特率实现较高的语音质量。
MP3编码是广泛应用于音频压缩的技术,它基于MDCT变换和感知模型。
AMR编解码格式介绍

每一帧的数据有分为三个部分:Class A/B/C
Class A:一帧中最敏感、最重要的数据。一旦这一部份数据有损坏,整个帧就无法解码,就损坏了。所以,一般在无线传输的时候要使用各种冗余的方式对这部分数据加以保护。
-
-
二、AMR帧格式:
AMR有两种类型的帧格式:AMR IF1和AMR IF2
1. AMR IF1:
IF1的帧格式如下图所示:
FrameType, Mode Indication, Mode Request对应上面两个表格里的数。从上面的表格里我们可以看出,这三个域的值是相同的。所以在IF2中省略了Mode Indication, Mode Request两个域。
图3列举了AMR-NB 5.9Kbit的一个帧的格式,
对于5.9kbit一帧的有118bit的数据,15*8=120=118+2,所以在最后有2个bit的填充位。
参考文献:
RFC3267 RTP Payload Format for AMR and AMR-WB
3GPP TS 26.201 V6.0.0
4
1
253
6
33
3
AMR-WB 14.25 kbit/s
4
1
285
6
37
4
AMR-WB 15.85 kbit/s
4
1
317
6
41
5
AMR-WB 18.25 kbit/s
4
1
365
6
47
6
AMR-WB 19.85 kbit/s
AMR音频编码器概述及文件格式分析

AMR音频编码器概述及文件格式分析全称Adaptive Multi-Rate,自适应多速率编码,主要用于移动设备的音频,压缩比比较大,但相对其他的压缩格式质量比较差,由于多用于人声,通话,效果还是很不错的。
AMR-WB应用于EDGE、3G可充分体现其优势。
足够的传输带宽保证AMR-WB可采用从6.6kb/s到23.85kb/s共九种编一、分类1. AMR: 又称为AMR-NB,相对于下面的WB而言,语音带宽范围:300-3400Hz,8KHz抽样2. AMR-WB:AMR Wide Band,语音带宽范围: 50-7000Hz , 16KHz 抽样“AMR-WB”全称为“Adaptive Multi-rate - Wideband”,即“自适应多速率宽带编码”,采样频率为16kHz,是一种同时被国际标准化组织ITU-T和3GPP采用的宽带语音编码标准,也称为G722.2标准。
AMR-WB提供语音带宽范围达到50~7000Hz,用户可主观感受到话音比以前更加自然、舒适和易于分辨。
与之作比较,现在GSM用的EFR(Enhanced Full Rate,增强型全速率编码)采样频率为8kHz,语音带宽为200~3400Hz。
AMR-WB应用于窄带GSM(全速信道16k,GMSK)的优势在于其可采用从6.6kb/s,8.85kb/s和12.65kb/s三种编码,当网络繁忙时C/I恶化,编码器可以自动调整编码模式,从而增强QoS。
在这种应用中,AMR-WB抗扰度优于AMR-NB。
AMR-WB应用于EDGE、3G可充分体现其优势。
足够的传输带宽保证AMR-WB可采用从6.6kb/s到23.85kb/s共九种编码,语音质量超越PSTN固定电话。
二、编码方式1. AMR-NB:10 - - TDMA-EFR SID11 - - PDC-EFR SID12-14 - - For future use15 - - No Data (No transmission/No reception) 2. AMR-WB:Frame Type Index ModeIndicationModeRequestFrame content (AMR-WB mode,comfort noise, or other)0 0 0 AMR-WB 6.60 kbit/s1 1 1 AMR-WB 8.85 kbit/s2 2 2 AMR-WB 12.65 kbit/s3 3 3 AMR-WB 14.25 kbit/s4 4 4 AMR-WB 15.85 kbit/s5 5 5 AMR-WB 18.25 kbit/s6 6 6 AMR-WB 19.85 kbit/s7 7 7 AMR-WB 23.05 kbit/s8 8 8 AMR-WB 23.85 kbit/s9 - - AMR-WB SID (Comfort Noise Frame)10-13 - - For future use14 - - speech lost15 - - No Data (No transmission/Noreception)- -二、AMR 帧格式:AMR 有两种类型的帧格式:AMR IF1 和 AMR IF21. AMR IF1:IF1 的帧格式如下图所示:FrameType, Mode Indication, Mode Request 对应上面两个表格里的数。
中国移动VoLTE无线网络优化“金种子”考试试题

简答题:1、语音采用CSFB还是VOLTE是如何决定?VoLTE在开机驻留阶段的策略:支持VoLTE的UE无线侧驻留策略不变,核心网基于Attach Request消息中UE能力信息,确定注册为VoLTE或CSFB;(((选网流程:终端一般选网的优先级如下:LTE(高):满足LTE最小接入电平要求即驻留,否则尝试驻留UMTS,LTE内驻留策略:1)初次驻留搜索支持的所有频段,选择信号最强的小区接入;2)非初次开机优选上一次驻留频段;UMTS(中):若支持UMTS且满足UMTS网络最小接入电平要求即驻留,否则选择GMS驻留;GMS(低):若满足GSM网络最小接入电平即驻留,否则脱网;)))终端能力在附着阶段会通知网络,CSFB和eSRVCC在无线侧由单独的参数控制,互不影响;注册流程:CS Voice only : SGs联合注册成功,语音业务采用CSFB方式,驻留LTE;SGs联合注册失败且UE为语音优先,返回3G/2G注册;IMS PS Voice only:IMS注册成功,语音业务采用VoLTE方式;IMS注册失败且UE为语音优先,返回3G/2G注册;CS voice preferred,IMS PS Voice as secondary:SGs联合注册成功,语音业务采用CSFB方式;SGs联合注册失败,发起IMS注册且成功,语音业务采用VoLTE方式;两种注册均失败,UE为语音优先,返回3G/2G注册;IMS PS Voice preferred,CS Voice as secondary:同时完成SGs联合注册和IMS注册,语音采用VoLTE方式;IMS注册失败,语音方式采用CSFB方式,按照协议,UE每10分钟尝试一次IMS注册;IMS注册成功,SGs联合注册失败,UE驻留在LTE,语音业务采用VoLTE;IMS注册和SGs注册都失败,UE为语音优先,返回3G/2G注册;2、VoLTE通话结束QCI5是否会和QCI1承载一起释放,并说明原因?不会,对于支持VoLTE的UE,无论是否有VoLTE会话,如果IMS域注册成功,则QCI5+QCI9始终存在,当有VoLTE会话时,会再建立QCI1,如果是视频会话,还会有QCI2;VoLTE通话结束后,只有QCI1专用承载会释放,QCI5默认承载不会释放;3、支持VoLTE功能的UE在RRC连接态只有QCI9承载,可能的原因是什么?1、QCI5的默认承载建立失败;2、UE 没有打开VoLTE开关;3、EPC不支持VoLTE,导致无法建立QCI5;4、UE建立QCI9后发起PDN Connectivily Request ,EPC反馈PDN Connectivily Reject导致未建立QCI54、在视频通话时,UE会有哪几个QCI?并说明每个QCI具体作用?在视频通话过程中,UE会建立QCI 9 + QCI 5 + QCI 1 + QCI2 ;UE在attach时,与default APN建立数据默认承载QCI 9;Attach完成后,UE与IMS APN建立QCI5的默认承载,用于传输SIP信令;VoLTE语音建立QCI1的专用承载,用于传输语音;可视电话(视频)建立QCI1和QCI2的专用承载,分布传输语音和视频;5、SRVCC测试中,如果eNodeB没有发起向MME的handover required消息,可能的原因是什么?应该观察哪些信令消息予以分析确认?1、eNB没有收到UE上报的measurement reports:快衰场景下,UE未能上报measurementreports,导致eNodeB没有发起向MME的handover required消息。
amr编码格式

AMR编码格式1. 简介AMR(Adaptive Multi-Rate)是一种用于语音编码和解码的格式。
它是一种有损压缩算法,旨在将语音信号转化为尽可能小的数据量,同时保持较高的音频质量。
AMR编码格式广泛应用于手机通信、语音识别、语音合成等领域。
2. AMR编码原理AMR编码原理基于对人耳听觉特性的研究,通过对语音信号进行预处理、分帧、声道判别、参数提取和压缩等步骤来实现。
2.1 预处理预处理阶段主要包括降噪、回声消除等操作。
这些操作旨在减少背景噪声和混响对语音质量的影响,并提升后续处理的准确性。
2.2 分帧分帧将连续的语音信号分成若干个短时段的帧,通常每帧持续时间为20毫秒。
这样做可以使得后续处理更加精确,并方便对每个时间段内的特征进行提取。
2.3 声道判别声道判别是为了确定使用合适的模型来描述语音信号。
不同的声道条件下,语音信号的特征参数具有差异,因此需要根据实际情况进行判别。
2.4 参数提取参数提取是AMR编码的关键步骤之一。
它通过对每帧语音信号进行分析,提取出一系列特征参数,如基频、线性预测编码系数等。
2.5 压缩压缩阶段将参数进行进一步处理和压缩,以减少数据量。
AMR采用了多种压缩算法,如矢量量化、编码器预测等。
这些算法可以在保持较高音质的同时,有效地降低数据存储和传输所需的带宽。
3. AMR编码格式AMR编码格式是一种二进制格式,用于存储经过压缩的语音数据。
它由多个帧组成,并包含了每个帧的相关参数信息。
3.1 帧结构AMR编码格式中的每个帧由多个子帧组成。
每个子帧包含了一个固定长度的字节序列,表示该子帧的语音数据。
3.2 参数信息除了语音数据外,AMR编码格式还包含了每个子帧所使用的声道模型、采样率、帧类型等参数信息。
这些参数信息可以帮助解码器正确地进行解码操作。
3.3 帧类型AMR编码格式定义了多种帧类型,用于表示不同的语音信号特性。
常见的帧类型包括语音帧、静音帧、SID(Silence Insertion Descriptor)帧等。
amr编码格式

amr编码格式AMR(Adaptive Multi-Rate)是一种音频编码格式,广泛应用于移动通信领域。
它是一种自适应多速率编码技术,旨在提供高质量的语音通信,同时尽可能减少数据传输的带宽占用。
AMR编码格式的设计目标是在保证语音质量的前提下,尽量减小数据传输的开销。
为了实现这一目标,AMR采用了多速率编码的策略。
它根据语音信号的特点,动态地调整编码速率,以适应不同的网络条件和带宽限制。
这种自适应的编码方式,使得AMR在不同网络环境下都能提供稳定的语音通信质量。
AMR编码格式采用了窄带语音编码技术,将语音信号的频带限制在300Hz到3400Hz之间。
这样做的好处是可以减小数据传输的开销,同时保证语音的可理解性。
AMR编码格式还采用了多种编码速率,包括4.75kbps、5.15kbps、5.9kbps、6.7kbps、7.4kbps、7.95kbps、10.2kbps和12.2kbps等。
不同的编码速率对应着不同的语音质量,用户可以根据实际需求选择合适的编码速率。
AMR编码格式的核心是一种称为自适应多速率编码的算法。
该算法根据语音信号的特点,动态地调整编码速率。
当网络条件较好时,AMR会选择较高的编码速率,以提供更高质量的语音通信。
而当网络条件较差时,AMR会自动降低编码速率,以减小数据传输的开销。
这种自适应的编码方式,使得AMR在不同网络环境下都能提供稳定的语音通信质量。
AMR编码格式在移动通信领域有着广泛的应用。
它被广泛应用于GSM、UMTS、CDMA2000等移动通信标准中,成为语音通信的重要组成部分。
AMR编码格式不仅可以提供高质量的语音通信,还可以减小数据传输的开销,提高网络的利用率。
这使得AMR成为了移动通信领域的重要技术之一。
总之,AMR编码格式是一种自适应多速率编码技术,旨在提供高质量的语音通信,同时尽可能减少数据传输的带宽占用。
它采用了窄带语音编码技术,动态地调整编码速率,以适应不同的网络条件和带宽限制。
语音编码算法AMR NB , AMR WB 和AMR WB+的区别

AMR NB的语音带宽范围:300-3400Hz,8KHz采样 AMR WB的语音带宽范围: 50-7000Hz,16KHz采样AMR-WB+的采样速率是在16~48 kHz之间。
这使得它的语音带宽更宽(24 kHz) AMR WB 与AMR NB的不同之处在于AMR WB在16k取样率的运作,两个频率带50~6400Hz 和6400~7000Hz 进行编码,用来降低复杂度,将位算法集中到更重要的频率区。
低频带使用ACELP算法进行编码。
添加几个特征来达到一个高的主观质量。
线性预测(LP)算法是在每隔20ms 的帧要进行一次线性预测算法,每5ms搜索一次自适应码本。
这个过程是在12.8Kbs 速率下进行的.高频带是在解码器端使用低带和随机激励的参数重建的, 目的是调整与在声音基础上的低频有关的高频带. 高频带的声频通过使用由低带LP 过滤器产生的LP 滤波器进行重建.下面来看看AMR WB+,AMR WB+不像现有编码器仅采用单一算法,而是对处理语音和音效分别采用ACELP(Algebraic Code Excited Linear Prediction)编码技术和变换码激励(TCX)编码技术,这种混合模式能提供比AMR WB同更好的音频质量。
对于单声道编码, AMR WB+采用混合的ACELP/TCX编码模型。
AMR WB+编解码器能接受单声道或立体声的输入信号,采样频率在16~48 kHz之间。
单声道信号可分解成2个频带:一个是低频信号,采样率低至12.8 kHz,即AMR WB的内部频率;另一个则是高频信号,含有6.4 kHz以上的所有频率。
混合的ACELP/ TCX编码模型应用于低频信号,并利用一种频宽延伸(BWE)法对高频信号进行编码,撷取出能代表频谱封包与增益的参数,信号经过量化后再传送至解码器。
解码器会使用外推法求算出高频信号的结构。
每个子帧都进行增益校正与运算,然后再进行传输,藉此确保低频带与高频带之间6.4 kHz衔接处的连续性。
VoLTE语音AMR-NB AMR-WB 资源占有情况有何区别?

VoLTE语音AMR-NB AMR-WB 资源占有情况有何区别?AMR全称Adaptive Multi-Rate,自适应多速率编码,主要用于移动设备的音频,压缩比比较大,但相对其他的压缩格式质量比较差,由于多用于人声,通话。
其中AMR分为AMR-NB 和AMR-WB两种,对于VoLTE而言,AMR-NB则为12.2k语音编码制式,AMR-WB则为23.85k语音编码制式。
AMR-NB和AMR-WB的本质区别在于其语音带宽和抽样频率有所区别,NB的语音带宽范围为:300~3400khz,抽样频率为8khz;而WB的语音带宽为50~7000khz,抽样频率为16khz。
以下为相关的AMR-NB的编码方式,共分为16种,其中0~7对应不同编码方式,8~15用于噪音或者保留用,VoLTE里的AMR-NB采用的编码方案7;而AMR-WB的编码方式同样也有16种,其中0~8对应不同编码方式,9~15保留用,当前VoLTE语音的WB编码制式采用的编码方式8。
以下为VoLTE相关测试中的高标清占用资源对比情况:从趋势图来看,在SINR大于5的时候,整体MOS值比较平稳,其中高清MOS值稳定在3.5以上,标清语音MOS值稳定在3.2左右,而在SINR值小于5之后,高清和标清语音的MOS值均呈现波动且整体均值下降的趋势。
另外由于在SINR差点打点数较少的原因,其MOS均值会出现随着SINR均值下降而抬升的异常情况。
在下行PDCP速率里对比中标清语音在7kb左右,在SINR小于0之后开始出现明显的波动情况,直至掉0。
高清语音PDCP速率则在15kbps左右,同样在SINR小于0后开始出现剧烈的波动情况。
从高清和标清的下行PRB数对比情况来看,整体占用的RB数差距不明显,另外下行PRB 个数随着SINR值恶化逐级抬升。
从高标清的指标和资源对比来看,本身AMR-NB和AMR-WB对于网络资源的利用程度来看差距不大(PRB上占用差不多),但AMR-WB对于网络资源的利用率会相对高些(高清的码率更高),且AMR-WB的用户体验更好(MOS值高于AMR-NB一截),且抗干扰性上并没有明显差别,因此在VoLTE将来部署中,更推荐采用AMR-WB编码制式。
移动通信中的语音编码技术

移动通信中的语音编码技术在当今高度互联的时代,移动通信已经成为我们生活中不可或缺的一部分。
无论是与亲朋好友保持联系,还是进行商务沟通,清晰流畅的语音通话质量始终是用户关注的重点。
而在这背后,语音编码技术发挥着至关重要的作用。
语音编码技术的主要任务是在尽可能保证语音质量的前提下,降低语音信号的数据量,以便更高效地在移动通信网络中传输和存储。
这就好比我们要把大量的物品装进一个有限空间的箱子里,需要巧妙地压缩和整理,同时还要确保物品的完整性和可用性。
要理解语音编码技术,首先得了解语音信号的特点。
语音信号实际上是一种时变的模拟信号,包含了丰富的信息,如音高、音强、音色等。
传统的模拟通信方式直接传输这样的模拟信号,不仅占用带宽大,而且容易受到干扰。
而数字通信则将模拟语音信号转换为数字信号进行传输,这就需要对语音进行编码。
在移动通信中,常用的语音编码技术可以大致分为三类:波形编码、参数编码和混合编码。
波形编码是一种尽可能保留原始语音信号波形的编码方式。
它的优点是语音质量高,能够接近原始语音,但缺点也很明显,就是编码速率较高,需要较大的带宽资源。
常见的波形编码技术有脉冲编码调制(PCM)和自适应差分脉冲编码调制(ADPCM)。
PCM 是最基本的编码方式,通过对模拟语音信号进行均匀采样和量化,将其转换为数字信号。
ADPCM 则是在 PCM 的基础上,根据语音信号的特点自适应地调整量化步长,从而在一定程度上降低了编码速率。
参数编码则是完全不同的思路。
它不是直接对语音波形进行编码,而是通过分析语音信号的产生模型,提取语音的特征参数进行编码传输。
这种方式编码速率很低,但语音质量相对较差,容易产生失真。
常见的参数编码技术有线性预测编码(LPC)。
LPC 基于语音信号的线性预测模型,通过计算预测系数来描述语音的特征。
混合编码则是结合了波形编码和参数编码的优点。
它在保留一定语音波形信息的同时,也对语音的参数进行建模和编码,从而在较低的编码速率下获得较好的语音质量。
AMR_WB_语音编码中模式选择算法的研究

通过对参数进行比较, 可以将每一帧模 闭环方式的模式选择是基于分段信噪比准则的,分段信噪比 在对这些参数进行计算后,
Σ Σ Σ Σ Σ Σ Σ Σ Σ Σ Σ Σ Σ
segSNRi =20log10
n = 0
Σx(n)
2 w
第二阶段 ECR 是在开环 LTP (Long Term Prediction ) 分析之后 segSNR = 1 NSF NG-1
(作者单位
湖南省湘西自治州民族广播电视大学 )
图2
数据库关系模型
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
AMR-WB+语音编码中模式选择算法的研究
文/李平安 刘 锰 罗 坚 邓知辉 AMR-WB+是 3GPP 选定的语音编码标准, 它较以往的语音编码算法的主要区别是增加了对立体声 摘 要: 在第三代移动通信系统中, 信号的支持, 并采用了 ACELP/TCX 的混合编码模式。针对这种混合编码模式选择算法进行了研究, 讨论了闭环和开环两种情况下的模式选 择, 并进行了实验比较。 关键词: 增强自适应多速率宽带; 模式选择; 性能测试 中图分类号: TP393 文献标识码: A Abstract: 3GPP has standardized the Extended Adaptive Multi-Rate-Wideband codec in 3rd generation mobile communication systems. Compared to the before audio codec algorithm, the main discrimination of AMR-WB+ is that it supports for stereophonic signal and adopts the ACELP/TCX hybrid codec mode. The paper studys alternative algorithm aiming to ACELP/TCX hybrid codec mode, and discusses the mode selection under the circumstances of closed loop and open loop. Furthermore, the experiment comparison has been executed. Keywords: AMR-WB+ (Extended Adaptive Multi-Rate-Wideband ) ; mode selection; Performance Testing 一、 引言 (20ms); TCX 的帧长则有 256, 512, 1024 样点三种情况,根据模式
AMR录音碎片重组与格式解析恢复

AMR录音碎片重组与格式解析恢复目前手机数据恢复已成主流因为存在删除清零等问题导致大家恢复手机完全变成了拼运气,看人品。
手机恢复经常碰到手机需要恢复录音的且需求量较大,之前一直没对AMR 研究过,经常有同行反馈所以最近做了些测试以及研究。
因为手机录音的格式较多,3GP.AMR.OGG.WMA. WAV等格式,,目前只针对AMR 进行了研究并且成功开发出了AMR碎片的提取工具。
先看一下AMR的音频结构与编码:1.amr codec种类amr一般是指amr-nb,即8kHz采样,有8种比特率的编解码算法。
另外有amr-wb,即16kHz采样,9种比特率的编码算法。
由于amr-wb采样率高,所以复杂度大概是amr 的两倍。
amr和amr-wb都属于speech codec,对audio的编码效果并不好,为了提高对audio的编码效果,出现了amr-wb+。
amr-wb+可以支持更高的采样率,对speech 和audio采用不同的编码算法,对speech采用ACELP编码,对audio采用变换编码。
amr-wb+在低比特率上对audio的编码效果与he aac+相当。
amr-wb+包含amr-wb,但复杂度更高。
2.amr-nbThe AMR codec is a multi-mode codec that supports 8 narrow band speech encoding modes with bit rates between 4.75 and 12.2 kbps. The sampling frequency used in AMR is 8000 Hz and the speech encoding is performed on 20 ms speech frames. Therefore, each encoded AMR speech frame represents 160 samples of the original speech.amr-nb支持8种比特率,分别是4.75,5.15,5.9,6.7,7.4,7.95,10.2,12.2kbps。
【4G+(VOLTE)知识】_VOLTE实战经验-

1参数与定时器配置(建议)1.1VoLTE互操作类参数1.2VoLTE功能类参数1.3定时器参数1.3.1接入类定时器参数英文名:T300功能描述:该参数表示UE侧控制RRC connection establishment过程的定时器。
在UE 发送RRCConnectionRequest后启动。
在超时前如果:1.UE收到RRCConnectionSetup或RRCConnectionReject;2.触发Cell-reselection过程;3.NAS层终止RRC connection establishment 过程。
则定时器停止。
如定时器超时,则UE重置MAC层、释放MAC层配置、重置所有已建立RBs (Radio Bears)的RLC实体。
并通知NAS层RRC connection establishment 失败对网络质量的影响:增加该参数的取值,可以提高UE的RRC connection establishment过程中随机接入的成功率。
但是,当UE选择的小区信道质量较差或负载较大时,可能增加UE的无谓随机接入尝试次数。
减少该参数的取值,当UE选择的小区信道质量较差或负载较大时,可能减少UE的无谓随机接入尝试次数。
但是,可能降低UE的RRC connection establishment过程中随机接入的成功率1.3.2切换类定时器参数英文名:T304For Intra-Lte功能描述:在“E-UTRAN内切换”和“切换入E-UTRAN的系统间切换”的情况下,UE 在收到带有“mobilityControlInfo”的RRC连接重配置消息时启动定时器,在完成新小区的随机接入后停止定时器;定时器超时后UE需恢复原小区配置并发起RRC重建请求对网络质量的影响:用于系统内切换,该值设置过大会导致切换失败无法及时回退并发起RRC连接重建过程1.3.3重建类定时器1)参数英文名:T311功能描述:T311用于UE的RRC连接重建过程,T311控制UE开始RRC连接重建到UE 选择一个小区过程所需的时间,期间UE执行cell-selection过程。
TD-SCDMA的AMR编码

在语音编码领域中,随着传输、处理、存储等各种信息量的巨增,信息的压缩处理已成为迫切的要求,基于新的网络和新的要求,无论是从节省传输频带资源,还是保持线路通信的高效率等方面来看,研究采用各种可变速率语音编码技术的系统都有重要意义。
目前为了适应此需要提出了AMR(Adaptivemulti-Rate)概念,即自适应话音编码器。
基于带宽的考虑可分为AMR- NB(AMR-Narrowband)和AMR-WB(AMR-Wideband)。
对于AMR-NB,语音通道带宽限制为3.7 MHz,采样频率为8 kHz,而AMR-WB为7 MHz的带宽,采样频率为16 kHz,但考虑语音的短时相关性,每帧长度均为20 ms。
这2种编码器根据带宽的要求虽然选用了不同的速率,但有异曲同工之处,以下着重介绍在TD-SCDMA 中AMR-NB的实现。
此编码器运用了代数码本线性预测(ACELP)混合编码方式,也就是数字语音信号中既包括若干语音特征参数又包括部分波形编码信息,再运用这些特征信息重新合成语音信号的过程。
控制这些参数的提取数目,根据速率要求对信息进行取舍而得到了以下8种速率,混合组成如表1所示的自适应语音编码器。
表1中模式AMR-12.20就提取出244比特的参数信息,而模式AMR-4.70却只提取了95比特信息。
根据这些比特所含的信息量可以将其分为3类比特class 0,1,2。
在信道编码时class0和1都将会使用循环冗余校验码进行差错检验,对于class 2则根据上一帧进行恢复。
语音编码或语音压缩编码研究的基本问题,就是在给定编码速率的条件下,如何能得到尽量好的重建语音质量。
主观评定方法符合人类听话时对语音质量的感觉得到了广泛应用。
常用的方法有平均得分意见(mean opinion score,简称MOS)判定法,表2说明了AMR话音编码器各模式的话音质量。
1AMR模式选择的自适应机制自适应的基本概念是以更加智能的方式解决信源和信道编码的速率分配问题,使得无线资源的配置和利用更加灵活和高效。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
不过我感觉这些对比都是对比的表面现象,没有对比AMR NB和AMR WB的本质不同,AMR NB和AMR WB语音编解码都是使用的是多码率宽带代数码激励线性预测ACELP(Algebraic Code Excitation Linear Prediction)。
AMR NB的语音带宽范围:300-3400Hz,8KHz采样
AMR WB的语音带宽范围: 50-7000Hz,16KHz采样
AMR-WB+的采样速率是在16~48 kHz之间。
这使得它的语音带宽更宽(24 kHz) AMR WB与AMR NB的不同之处在于AMR WB在16k取样率的运作,两个频率带
50~6400Hz 和6400~7000Hz 进行编码,用来降低复杂度,将位算法集中到更重要的频率区。
低频带使用ACELP算法进行编码。
添加几个特征来达到一个高的主观质量。
线性预测(LP)算法是在每隔20ms 的帧要进行一次线性预测算法,每5ms搜索一次自适应码本。
这个过程是在12.8Kbs 速率下进行的.高频带是在解码器端使用低带和随机激励的参数重建的, 目的是调整与在声音基础上的低频有关的高
频带. 高频带的声频通过使用由低带LP 过滤器产生的LP 滤波器进行重建.
下面来看看AMR WB+,AMR WB+不像现有编码器仅采用单一算法,而是对处理语音和音效分别采用ACELP(Algebraic Code Excited Linear Prediction)编码技术和变换码激励(TCX)编码技术,这种混合模式能提供比AMR WB同更好的音频质量。
对于单声道编码, AMR WB+采用混合的ACELP/TCX编码模型。
AMR WB+编解码器能接受单声道或立体声的输入信号,采样频率在16~48 kHz之间。
单声道信号可分解成2个频带:一个是低频信号,采样率低至12.8 kHz,即AMR WB的内部频率;另一个则是高频信号,含有6.4 kHz以上的所有频率。
混合的ACELP/ TCX编码模型应用于低频信号,并利用一种频宽延伸(BWE)法对高频信号进行编码,撷取出能代表频谱封包与增益的参数,信号经过量化后再传送至解码器。
解码器会使用外推法求算出高频信号的结构。
每个子帧都进行增益校正与运算,然后再进行传输,藉此确保低频带与高频带之间6.4 kHz 衔接处的连续性。
由于只传输少量的参数,因此BWE总比特率仅有0.8 Kb/s。
对于立体声编码,AMR WB+立体声编码和单声道编码一样会分割频带。
低频带立体声信号编码采用一套新的半参数技术。
两个声道经过压缩混合后形成一个单声道信号,再用上述的AMR—WB+核心编解码器进行编码。
高频带部分(6.4 kHz以上)则在两个立体声声道上运用参数型BWE进行编码,这与对单声道信号的高频部分进行编码是一样的。
编解码器能在6~48 Kb/s的比特率下运作,并能在更高的频率中支援所有可听的频谱。
有别于在7 kHz频带下运作的AMR WB,AMR WB+能将编码频宽延伸至19 kHz。
因此即使在语音信号上亦能发挥超越AMR WB的效能(AMR WB频宽14 kHz)。