nagios常见错误排查
故障排查中的常用工具介绍

故障排查中的常用工具介绍故障排查是维护和管理各种系统运行的重要环节。
在故障排查过程中,使用适当的工具可以帮助我们准确地定位和解决问题。
本文将介绍一些常用的故障排查工具,帮助读者更好地了解和运用它们。
一、监控工具监控工具是故障排查中不可或缺的一部分。
它们可以实时监测系统的性能指标和运行状态,提供有关系统资源利用率、服务可用性等方面的信息。
常见的监控工具包括Zabbix、Nagios和Prometheus等。
这些工具提供了可视化的仪表盘和报警功能,帮助管理员及时发现并解决潜在问题。
二、日志分析工具日志记录系统的运行状态和事件是故障排查的重要依据。
对于大型系统而言,日志文件往往非常庞大,难以手工分析。
因此,使用专业的日志分析工具可以快速定位故障。
常见的日志分析工具有ELK (Elasticsearch、Logstash和Kibana),它们提供了强大的搜索、过滤和可视化功能,帮助我们追踪错误和异常。
三、网络分析工具故障排查中,网络问题是一个常见的挑战。
网络分析工具可以帮助我们诊断网络故障,并找出关键的瓶颈。
Wireshark是一个流行的网络协议分析器,它可以捕获和分析网络流量。
通过Wireshark,我们可以查看报文的详细信息、检测网络延迟和丢包情况等。
四、性能测试工具性能问题通常是系统故障的一个主要原因。
为了评估系统的性能,并及时发现性能瓶颈和异常情况,使用性能测试工具是必要的。
JMeter 是一个开源的性能测试工具,可以模拟多个用户同时访问系统,从而测试系统的负载和响应时间。
通过JMeter,我们可以在实际部署之前发现潜在的性能问题。
五、远程管理工具远程管理工具可以帮助管理员迅速定位和解决故障,而不必亲身到达故障现场。
例如,SecureCRT提供了强大的远程终端访问功能,可以远程登录服务器进行故障排查和管理操作。
类似的工具还有TeamViewer、Remote Desktop等,它们可以实现远程桌面控制,便于进行故障定位和解决。
nagios流程分析

nagios流程分析在大部分环境中,nagios是不需要优化的,一来监控这个东西大家都不觉得很重要,二来n agios本身已经是个很轻量级的软件,架构比较合理,三来现在的机器配置都很恐怖,一台普通的pc机撑起上千台host,上三四千service的监控那是小菜一碟,实际环境中有这么大量监控需求的地方本来就不多,就算有这么大量监控需求的公司,用nagios的并不多数吧!但是某些情况下,还是偶尔碰到需要优化的情况。
我需要监控的机器数量就超过了1000台,而且用的nagios,用了被动检查的架构以后,撑起这么多的监控本来是没有问题,但是上周的时候,做nagios和ndotuils的集成就出现了性能瓶颈,凌晨5点左右,把ndotuils架到两台nagios上之后,应用启动什么的都正常,但是到了上午8点就发现了问题,看到检查结果的last_check时间从7:20到8:20不等,而且是均匀分布,没有办法,只好把ndo mod关掉,到了上午10点左右,就恢复正常了。
既然nagios出现了瓶颈,就不妨拿源码来看一下,配置文件的选项优化,在nagios的文档里说了很多,但是还是感觉不是很直观,分析源码,只是属于个人兴趣,这里把流程跟大家分享一下,至于优化方案,还是需要大家多多指点了。
一、nagios在启动以后,载入成daemon,整个的步骤如下:1、读入配置文件(read_main_config_file)2、初始化event_broker3、载入所有broker_mod(ndomod包括在这里面)4、读入object信息(包括service,host,servicegroup,hostgroup,contact,contactgr oup等等)5、告诉broker,我启动了6、初始化daemon(例行工作,fork进程,修改根目录,设置信号量等等)7、打开cmd文件(nagios.cmd)8、初始化status数据(status.dat)9、读取保存数据(retention.dat)10、读取注释数据11、读取downtime数据12、读取性能数据13、初始化event_timing循环14、初始化check_stats15、生成status.dat(空的,不写数据)16、传输event_loop_start信息到broker(ndo:获取scheduling_info中数据)17、开始event_execution_loop,检查数据,直到捕获重启或者关闭信号如果接到了重启或者关闭的信号,则继续往下执行18、通知broker_mod,我要关闭了,或者我要重启了19、保存retention文件20、清理性能数据21、清理downtime数据22、清理注释数据23、如果是关闭信号,清理status.dat24、如果是关闭信号,删除cmd文件步骤比较简单,其中比较重要的有两个,一个是13,初始化循环,另一个就是17,nagios 在作为daemon运行的过程中,就是在不断的执行这个循环。
服务器维护工具

服务器维护工具服务器的稳定运行对于任何企业或组织来说都至关重要。
为了确保服务器的顺利运行并及时解决潜在的问题,可靠且高效的服务器维护工具是必不可少的。
本文将介绍一些常用的服务器维护工具,帮助您选择适合您需求的工具。
一、监控工具服务器监控工具是用于监视服务器性能和资源利用率的软件。
下面是三种常用的监控工具:1. NagiosNagios是一款开源的监控工具,它可以实时监控服务器的各种指标,如CPU使用率、内存利用率、网络流量等。
当服务器出现故障或资源超载时,Nagios会及时发出警报,帮助管理员快速响应和解决问题。
2. ZabbixZabbix是一款功能强大的网络监控工具,可以对多个服务器进行集中监控。
它支持多种监控方式,如SNMP、ICMP、JMX等,还可以生成报告和图表用于性能分析和趋势预测。
3. SolarWinds Server & Application MonitorSolarWinds Server & Application Monitor是一套全面的服务器监控解决方案,可提供对服务器硬件、操作系统和应用程序的实时监控。
它可以自动发现并监控服务器上的各种组件,提供预警和故障排查功能,帮助管理员及时识别和解决问题。
二、配置管理工具配置管理工具用于管理服务器配置和软件部署,确保服务器环境的一致性和可维护性。
1. PuppetPuppet是一款自动化服务器配置管理工具,可用于管理大规模服务器环境。
它可以定义服务器配置的状态,自动进行配置更改和软件部署,实现一键化管理和自动化运维。
2. AnsibleAnsible是一款用于服务器配置管理和应用部署的开源工具。
它使用SSH协议进行通信,无需在目标服务器上安装客户端,具有简单易用、可扩展性强的特点。
3. ChefChef是一款基于Ruby语言的自动化配置管理工具,它可以管理服务器的配置和软件部署。
Chef使用"副本"的概念来管理目标服务器的状态,并通过"食谱"来定义配置规则和操作流程。
监控系统Nagios系列(八) 抖动(falpping)检测和处理

监控系统Nagios系列(八) 抖动(falpping)检测和处理所谓抖动,是指状态在一定时间内变化过于频繁。
如果某个对象处于抖动状态,那么这时候的状态变化也是无意义的。
Nagios提供了抖动状态的检查以及针对抖动状态的处理。
1.判定抖动状态抖动是由于状态变化过于频繁导致,但是该如何定义“频繁”?每次检查得到的状态都与上次不一样?还是一定时间内状态变化达到某个阈值?这个确实很难有统一的标准。
Nagios通过统计状态变化的频度,与用户配置的阈值比对,来判定是进入还是退出抖动状态。
Nagios在其对象配置定义中,提供了Host和Service进入、退出抖动的阈值。
Nagios的全局配置项low_host_flap_threshold,high_host_flap_threshold,low_service_flap_threshold,high_service_flap_threshold 分别定义Host和Service的退出和进入抖动状态的阈值。
具体的Host和Service的配置项是low_flap_threshold,high_flap_threshold。
Nagios统计状态变化频度的方法大概描述为:存储Host或Service的21检查结果分析21次检查结果种状态变化次数统计状态变化的频率比对变化频率与抖动阈值,确定是进入还是退出Nagios计算抖动频率的方法就是:(状态变化次数/状态可能的变化次数)*100 。
但是Nagios对状态变化次数有一个权重,21次检查结果中,近期的状态变化权重比远期的高。
(关于权重这点实际上意义不大,如果需要更接近当前状态,可以把21次缩短,然后增加retry,类似soft和hard状态变化,这样更准确)。
2.判定抖动的例子下面图中有21次检查,OK状态的是绿色,WARNING状态的是黄色,CRITICAL状态的是红色。
image图中总共有20次可能状态发生变化,也就是最大只有20次状态变化,实际上有7次状态变化,那么理论上状态变化的频度为:(7/20)*100 = 35%。
Nagios安装与配置详解

Nagios学习笔记之(一)最初搭建2012-07-17 13:05:08标签:linux监控nagios cacti声明:原创作品,如需,请与作者联系。
否则将追究法律责任。
Nagios学习笔记之一最初搭建一、简介:Nagios是一款开源的免费网络监视工具,能有效监控Windows、Linux和Unix的主机状态,交换机路由器等网络设置,打印机等。
在系统或服务状态异常时发出或短信报警第一时间通知运维人员,在状态恢复后发出正常的或短信通知。
二、搭建过程:OS:CentOS 5.5 x86_64(最小化即可)Nagios主程序:nagios-cn-3.4.1Nagios插件:nagios-plugins-1.4.15.tar.gz2.1安装前:2.1.1安装依赖包,下载源程序包1.#cd/etc/yum.repos.d/2.#rm-fr./*3.#wget wget mirrors.163./.help/CentOS-Base-163.repo4.#yum makecache#删除系统自带的yum源,下载网易的网络源并更新缓存1.#yum-y install gcc glibc glibc-common gd gd-devel httpd#安装必须的依赖包1.#wget /sourceforge/nagios/nagios-3.4.1.tar.gz2.#wget /sourceforge/nagiosplug/nagios-plugins-1.4.15.tar.gz#下载nagios主程序以及插件程序2.1.2正式安装:1.#groupadd nagcmd2.#useradd-G nagcmd nagios3.#usermod-G nagcmd apache#创建一个用户组名为nagcmd用于从Web接口执行外部命令。
将nagios用户和apache用户都加到这个组中。
1.#tar zxf nagios-3.4.1.tar.gz2.#cd nagios3.#./configure--prefix=/usr/local/nagios --with-command-group=nagcmd4.#解压程序包,并进行预编译前的配置(默认用户就是nagios,所以只需指定组)5.#make all#编译Nagios程序包源码6.#make install#安装二进制运行程序7.#make install-init#初始化脚本8.#make install-config#配置文件样本9.#make install-commandmode#设置运行目录权限10.#make install-webconf#安装Nagios的WEB配置文件到Apache的conf.d目录下#htpasswd -c /usr/local/nagios/etc/ers nagiosadmin#创建一个nagiosadmin的用户用于登录Nagios的web界面。
cognos错误整理

Cognos错误总结文档文档信息版本记录Cognos问题1、UDA-SQL-0458问题描述:UDA-SQL-0458 PREPARE failed because the query requires local processing of the data. The option to allow local processing has not been enabled. UDA-SQL-0580 The use of call statements as derived tables is not supported by the database and requires local processing of the data. RSV-SRV-0042解决办法:open your FM model, select the data source, check properties, Query Processing should be "Limited Local"2、jre冲突问题描述:解决办法:把\cognos\c8\bin\jre\1.4.2\lib\ext \bcprov-jdk13-125.jar这个文件拷贝到java_home的jdk下的jre目录下的\lib\ext目录3、ANS-MES-0005错误问题描述:解决办法:这个问题最终也没得到更好根据一直以来的总结:主要分析可能原因和相应的解决办法,但是有的人用这种办法好用,但我们的客户还是没好用,现写下来做参考。
1、原因是对报表快速的进行拖拽、点击,移动等操作时,有可能会发生这类错误(我自己猜想,这个可能是因为当前的这张报表比较大,cognos的BS报表程序反应不过来,程序内部出现了异常,这个好像是cognos analysis studio自身的BUG。
)当出现这类错误时,不管后面进行何种操作都会报错,关掉后重新打开就不会报错了。
网络优化的网络监测与故障排查

网络优化的网络监测与故障排查网络优化是指通过对网络进行综合分析和调整,以提高网络性能和用户体验的过程。
在网络优化的过程中,网络监测和故障排查是至关重要的环节。
本文将介绍网络监测与故障排查的基本概念及其在网络优化中的作用。
一、网络监测的基本概念及作用网络监测是指对网络性能和运行状态进行实时监测和分析的过程。
通过网络监测,可以及时发现并解决网络中的问题,确保网络正常运行。
网络监测的作用主要体现在以下几个方面:1. 实时监控网络性能:通过监测网络的带宽利用率、延迟、丢包率等指标,及时发现网络潜在问题,确保网络的稳定和高效运行。
2. 发现网络故障:网络监测可以帮助管理员及时发现并定位网络故障,减少网络停机时间,提高网络的可用性。
3. 优化网络资源配置:通过对网络性能进行监测和分析,管理员可以了解网络资源的使用情况,从而进行合理的资源配置,提高网络的利用率。
二、故障排查的基本概念及步骤故障排查是指通过一系列的步骤和方法,对网络故障进行定位和解决的过程。
网络故障可能涉及网络设备故障、网络配置错误、线路故障等多个方面。
以下是故障排查的基本步骤:1. 收集故障信息:在排查故障之前,首先要收集故障的相关信息,包括故障现象、故障发生的时间及持续时间等,有助于后续的故障分析和定位。
2. 分析故障现象:根据故障信息,对故障现象进行分析,确定故障的范围和可能的原因。
3. 排查故障原因:根据故障现象的分析,逐步缩小故障范围,并进行相应的排查工作,例如检查网络设备配置、检测网络线路是否正常等。
4. 解决故障并验证:根据故障排查过程中的发现,针对可能的原因进行相应的修复工作,并进行验证,确保故障得到解决。
5. 故障记录和总结:在故障解决后,需要对故障过程进行记录和总结,以便日后参考和避免类似故障的再次发生。
三、常用的网络监测与故障排查工具网络监测和故障排查离不开一些专用的工具和软件。
以下是常用的网络监测与故障排查工具的简介:1. Ping命令:通过发送ICMP报文并接收响应,来测试主机之间的连通性和网络性能。
nagios pnp 安装与错误解决方案

Rrdtool是一个绘制图表工具,我们安装rrdtool的用途就是将nagios监控的数据传送到rrdtool,然后由rrdtool绘制出图表呈现出来;例如:各个时间点cpu使用情况、磁盘使用情况(能看到近1年的任何监控信息),都会由它绘制成图表呈现出来,方便我们分析系统运行情况。
1、所需要的安装包(1)zlib-1.2.3.tar.gz(2)libpng-1.2.8-config.tar.gz(3)freetype-2.1.10.tar.gz(4)libart_lgpl-2.3.17.tar.gz(5)cgilib-0.5.tar.gz(6)rrdtool-1.2.12.tar.gz(7)pnp-0[1].4.13.tar.gz2、Rrdtool安装2.1环境变量添加,因为后面编译会持续用到。
BUILD_DIR=/tmp/rrdbuildINSTALL_DIR=/usr/local/rrdtool2.2创建安装目录mkdir -p $BUILD_DIRmkdir $BUILD_DIR/lb2.3安装rrdtool需要支持的库,最主要的就是编译。
(1)zlib-1.2.3.tar.gztar zxvf zlib-1.2.3.tar.gz解压安装包,进入安装目录编译-env CFLAGS="-O3 -fPIC" ./configure --prefix=$BUILD_DIR/lbnake && make install(2)libpng-1.2.8-config.tar.gztar zxvf libpng-1.2.8-config.tar.gz编译-env CPPFLAGS="-I$BUILD_DIR/lb/include"LDFLAGS="-L$BUILD_DIR/lb/l ib" CFLAGS="-O3 -fPIC" ./configure --disable-shared--prefix=$BUILD_DIR/lb(3)freetype-2.1.10.tar.gztar zxvf freetype-2.1.10.tar.gz编译-env CPPFLAGS="-I$BUILD_DIR/lb/include"LDFLAGS="-L$BUILD_DIR/lb/l ib" CFLAGS="-O3 -fPIC"./configure --disable-shared --prefix=$BUILD_DI R/lbnake && make install(4)libart_lgpl-2.3.17.tar.gztar zxvf libart_lgpl-2.3.17.tar.gz编译-env CFLAGS="-O3 -fPIC" ./configure --disable-shared--prefix=$BUI LD_DIR/lbnake && make install(5)cgilib-0.5.tar.gzmake CC=gcc CFLAGS="-O3 -fPIC-I."mkdir -p $BUILD_DIR/lb/includecp *.h $BUILD_DIR/lb/includemkdir -p $BUILD_DIR/lb/libcp libcgi* $BUILD_DIR/lb/lib(6)rrdtool-1.2.12.tar.gztar zxvf rrdtool-1.2.12.tar.gz编译-./configure --prefix=$INSTALL_DIR --disable-python --disable-tclmake && make install3、安装pnptar –zxvf pnp-0.4.13.tar.gzcd pnp-0.4.13./configure--with-nagios-user=nagios--with-nagios-group-nagios--with-rrdtool=/usr/local/rrdtool/bin/rrdtool--with-perfdata-dir=/usr/local/ nagios/share/perfdataMake allMake installMake install-configMake install-init4、配置PNP在PNP安装完成后,默认安装目录下自带了模板配置文件,因此,只需要将模板文件复制一份作为PNP配置文件即可。
nagios端口机制 -回复

nagios端口机制-回复问题:什么是Nagios端口机制?Nagios是一款非常流行的开源网络监控工具,它能够帮助系统管理员监控各种网络设备和服务的状态。
在Nagios中,端口机制是一项关键功能,用于检测和监控网络上各个设备和服务的运行状态。
本文将逐步解释Nagios的端口机制是如何工作的,并介绍其使用和设置。
第一步:理解端口和监控在开始讨论Nagios的端口机制之前,我们需要了解一些关于端口和监控的基础知识。
在计算机网络中,端口是用于在不同的进程之间进行通信的特定数字标识。
通常情况下,每个网络服务都使用特定的端口来接收和发送数据。
监控是指对网络设备和服务进行持续的跟踪和评估,以确保它们正常运行。
监控结果可用于识别和解决潜在的故障和问题。
第二步:Nagios的基本工作原理Nagios通过周期性地向设备发送指定的请求,并检查响应来监控网络设备和服务。
这些请求通常是基于不同协议的数据包,而Nagios则负责收集和分析这些响应。
对于端口监控,Nagios使用的是TCP和UDP协议。
TCP(Transmission Control Protocol)是一种面向连接的协议,为数据传输提供可靠性和有序性。
UDP(User Datagram Protocol)则是一种无连接的协议,适用于时间敏感的应用。
第三步:Nagios端口机制的使用Nagios的端口机制允许管理员指定要监控的设备和服务的端口号,并设置监控的方法和频率。
以下是一些常见的使用方法:1. 端口存活性检查:管理员可以设置Nagios定期检查设备上特定端口的存活性。
如果端口处于打开状态,Nagios会发出警报。
这是一种常用的监控方法,可以帮助管理员及时发现网络设备和服务的故障。
2. 端口数据收集:Nagios还可以通过检查特定端口的响应来收集数据。
例如,管理员可以设置Nagios检查Web服务器的80端口,以确保服务器正常运行,并记录每次检查的响应时间和内容。
容器编排错误排查与故障处理技巧

容器编排错误排查与故障处理技巧随着容器技术的日益成熟,容器编排已成为现代云计算领域中不可或缺的一环。
容器编排平台如Kubernetes等为开发者提供了高效的容器集群管理和调度能力,然而在实际应用中,难免会遇到一些问题和故障。
本文将探讨容器编排中的错误排查与故障处理技巧,帮助读者更好地解决这些问题。
一、错误排查技巧1.日志分析在面对故障时,首先要做的是分析容器运行时的日志。
通过观察日志信息,可以了解容器内部的运行情况和错误提示。
容器编排平台通常会为每个容器提供标准输出和错误输出。
使用命令kubectl logs可以查看容器的运行日志,并通过分析日志内容来定位问题。
2.监控在容器编排平台中,监控是非常重要的一环。
通过监控系统可以实时监测容器集群的运行状态和指标,如CPU、内存、网络等。
当出现异常时,监控系统可以及时报警,帮助管理员寻找故障原因。
常见的容器监控系统有Prometheus和Grafana等。
3.事件追踪当容器编排系统出现问题时,常常需要追踪事件的发生和处理过程。
容器编排平台一般会记录事件日志,如Node添加、Pod创建、容器重启等。
通过查看事件日志,可以了解容器编排系统的操作历史,从而找到可能的问题根源。
4.调试工具除了日志分析和监控系统外,还可以使用一些调试工具来辅助问题排查。
例如,kubectl exec命令可以进入正在运行的容器内部,以执行命令和查看文件。
还可以使用网络抓包工具如Wireshark来对容器之间的通信进行监控,以诊断网络问题。
二、故障处理技巧1.容器重启当一个容器出现故障时,可以尝试重新启动容器,来解决可能的临时问题。
容器编排平台提供了kubectl restart命令来重新启动容器。
此外,还可以调整容器的资源限制,如调整内存和CPU等,以适应容器的需求。
2.节点迁移当一个节点出现故障或超过资源限制时,可以考虑将容器迁移至其他节点。
通过kubectl drain命令可以将一个节点上的所有Pod迁移至其他节点,以实现高可用和负载均衡。
nagios全攻略
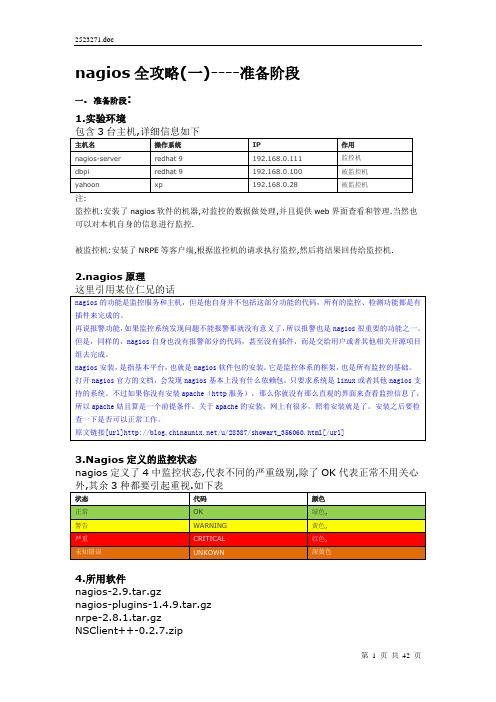
nagios全攻略(一)----准备阶段一. 准备阶段:1.实验环境注:监控机:安装了nagios软件的机器,对监控的数据做处理,并且提供web界面查看和管理.当然也可以对本机自身的信息进行监控.被监控机:安装了NRPE等客户端,根据监控机的请求执行监控,然后将结果回传给监控机.2.nagios原理3.Nagios定义的监控状态nagios定义了4中监控状态,代表不同的严重级别,除了OK代表正常不用关心4.所用软件nagios-2.9.tar.gznagios-plugins-1.4.9.tar.gznrpe-2.8.1.tar.gzNSClient++-0.2.7.zip注:前三个的下载地址:[url][/url],后一个的[url]/projects/nscplus[/url] 5.总体目标学习嘛,总要有个目标,很简单,就是看到下面这张图主机名要监控的服务nagios-server 是否活动是否开启ftp磁盘使用情况dbpi 是否活动是否开启ssh磁盘使用情况cpu负载swap分区使用情况其中蓝色字体的服务是外部服务,也就是说不需要登陆被监控机,直接在外部就可以进行检查.例如我们需要检查被监控机是否打开80端口,就可以在别的一台机器上telnet被监控机的80端口即可.绿色字体表示是内部服务,意思是必须登陆到被监控机上才能查看.因为它们属于”本地信息”(nagios将之称为LOCAL).很容易理解,你不登陆到被监控机上,如何知道当前磁盘的使用情况呢?nagios是不是很强大,基本上对监控对象的任何信息都可以一手掌握了.而且不用登陆到目的机就可以看到那台机器私密的”本地信息”,比木马还厉害啊.但是别误会,这可不是什么木马.nagios有着十分安全的措施.这确实是一个庞大的工程,你想想这还只是三台机器而已都已经监控这么多服务了,那要是多个几十台怎么办,不用紧张,从现在开始,跟我动手吧.家庭作业,将所用的软件下载好,配置好监控机192.168.0.111上的apache.敬请期待nagios全攻略(二)----基本安装和配置(上)二. 基本安装和配置本部分主要参考官方文档和田逸的文章<<看我出招之:我用Nagios(技术细节)>>来修改完成.最后达到如下的功能监控机自身的信息,包括主机信息以及对外提供的服务被监控机对外提供的服务如下所有的操作都在监控机192.168.0.111上进行1.安装nagios主程序解压缩tar -zxvf nagios-2.9.tar.gzcd nagios-2.9编译,指定安装目录为/usr/local/nagios./configure --prefix=/usr/local/nagiosmake all输出如下信息求救,而实际上输出的内容包含很多有价值的信息,例如安装路径,版本,每一步做什么,接下来的步骤等.尤其是输出的最后一屏信息,我个人建议好好的读一下.例如上面就列出了很多有价值的信息,我们只需要按照他说的做就行了.安装make install[root@localhost nagios-2.9]#useradd nagios[root@localhost nagios-2.9]#mkdir /usr/local/nagios[root@localhost nagios-2.9]# chown nagios.nagios /usr/local/ nagios查看目录权限[root@localhost nagios-2.9]# ll /usr/localdrwxr-sr-x 2 nagios nagios 4096 Jul 10 11:14 nagios 看到nagios目录的权限已经被正确修改了执行如下命令来安装脚本make install-init执行make install-commandmode执行make install-config验证程序是否被正确安装。
nagios报警触发机制

Nagios报警触发机制简介之前我曾经学过zabbix,以为他们的机制差不多,但是实际操作测试以来,才发现差别很大,而且网上很多教程都很坑人,比如说nagios里面涉及到抖动、以及模板的调用,跟zabbix 区别很大,接下来我就在下文里进行一个详细的介绍。
Cfg文件的调用Nagios一般监控的话分为服务监控和主机监控,然后对应的配置也文件也需要定义每一个主机和每一个服务的一些相关的功能,我们可以在模板文件里有所看到模板里面就定义了几种,然后呢,网上经常就是直接调用他们,比如说nagios自带的localhost 的模板里面,语法如下它就引用了模板里面的local-service服务然后从local-service里面又引用了generic-service也就是说,这个服务的配置参数引用了所有以上的参数,然后嵌套调用,这样可以省很多东西,不过作为初学者的我来说,刚开始还以为就只有那么几个东西,结果报警触发的时候死活不发邮件,或者隔了好一会儿才发送,所以一定要明白这一点,甚至可以说自己创造一个服务的定义,然后自己引用自己的,我就是这样做的,至于以上参数,有几个重要的在后期的报警上面我会多写一点。
Nagios的报警触发机制Nagios的报警触发默认状态下所定义的服务并不是一监测到问题就报警,而是当发现问题之后,继续监测问题,如果问题仍然持续,才进行报警。
监测单位时间字面意思,上面是服务的时间,下面是主机的时间,这个的话定义一个单位时间为60秒,默认也是60秒,你可以根据自己的需要进行修改,比如说你可以改成30秒,那么两个时间单位就是一分钟,这一点一定要明确。
监测的“软态”和“硬态”首先要清楚几个字段的意思啊retry_check_interval 重试时间max_check_attempts 这个是出现故障的连接次数,达到这个次数之后就报警然后来介绍一下软态硬态是什么意思,以下就直接摘网上的了,反正我已经通过测试了一、软态:被监控项处于retry_check检测周期内的非正常状态;二、硬态:被监控项达到max_check_attempts最大次数后的非正常状态;除此之外的状态,我们估且称之为“常态”。
服务器故障排除如何快速定位和解决常见的服务器故障问题

服务器故障排除如何快速定位和解决常见的服务器故障问题概述:服务器作为网络通信的核心设备,扮演着数据存储、资源共享和应用支持等重要角色。
然而,服务器常常会遭遇各种故障,导致服务中断和数据丢失。
本文将介绍如何快速定位和解决常见的服务器故障问题,帮助管理员们更好地维护和管理服务器。
1. 监控系统1.1 安装监控软件:使用专业的监控软件对服务器进行实时监控,例如Zabbix、Nagios等。
1.2 设置告警规则:根据服务器的性能特点,设置合理的告警规则,以便在故障发生时及时收到通知。
1.3 实时监测:定期检查监控系统的运行情况,确保它能够正常工作并及时反馈服务器运行状态。
2. 硬件故障2.1 电源问题:检查电源线是否插好,确认电源插座是否正常供电。
2.2 硬盘故障:使用磁盘健康检测工具,如Smartmontools,观察硬盘的状态和SMART属性。
2.3 内存问题:通过内存测试工具,如Memtest86+,对服务器的内存进行全面的检测。
2.4 CPU故障:使用专业的CPU压力测试软件,如Prime95,对CPU进行稳定性测试。
3. 网络故障3.1 链路故障:检查网络线缆的链接状态,确保线缆连接牢固且无损坏。
3.2 IP地址冲突:使用IP扫描工具,如Angry IP Scanner,扫描局域网是否存在IP地址冲突问题。
3.3 配置错误:确认服务器的网络配置是否正确,包括网关、子网掩码、DNS等参数的设置。
4. 操作系统故障4.1 日志分析:通过查看服务器操作系统的系统日志,如/var/log/messages,以及应用程序日志,来定位故障原因。
4.2 进程监控:使用工具如top命令,监控服务器进程的运行情况,检查是否有异常进程或进程占用过高的情况。
4.3 更新和补丁:及时更新操作系统和应用程序的补丁,提高服务器的安全性和稳定性。
5. 安全问题5.1 防火墙:检查服务器的防火墙配置,确保正确设置了入站和出站规则,防止未经授权的访问。
nagios监控系统手册详细操作

nagios网络监控Nagios是什么:Nagios是一款开源的免费网络监视工具,能有效监控Windows、Linux和Unix的主机状态,交换机路由器等网络设置,打印机等。
在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知。
nagios是功能强大的监控软件,主要用来监控网络设备的状态(比如:主机的资源状态);适合于:对大量的服务器进行监控,判断其负载或服务是否正常,发生异常能通过邮件、短信报警。
特别注意:流量监控不是他的强项,流量监控建议使用cacti.可以绘制非常直观的图形nagios能监视什么:nagios可以监控:1、主机是否宕机(通过ping命令,如果ping不通会认为主机属于宕机状态,但不影响所监控的其他服务);2、服务器资源(cpu使用率、硬盘剩余空间等);3、网络服务(smtp\pop3\http\);4、监控网络设备(路由器、交换机等。
)一、RHEL系统上部署Nagios:(禁用selinux功能)系统环境:RHEL,在nagios主机上监控mysql服务器nagios 主机:192.168.10.100mysql 主机: 192.168.10.101操作步骤:1、安装编译所需的软件包:如下图所示:# yum –y install httpd php-* gd-* mysql-devel(若mysql-devel包不安装,会没有check_mysql插件。
)2、创建运行nagios服务的用户注:useradd nagios #创建运行nagios服务的用户usermod -G nagios apache #使apache用户对nagios目录具有写权限,不然web页面操作失败.3、nagios软件安装释放nagios源码包,进行编译前的预备置:编译并安装nagios及相关操作,如下图所示:注:make install //安装主程序,CGI和HTML文件make install-init //在/etc/rc.d/init.d安装启动脚本make install-commandmode //配置目录权限make install-config //安装示例配置文件make install-webconf //安装nagios的web接口,会在/etc/httpd/conf.d目录中创建nagios.conf文件。
1.视觉系统故障排查,编程bug排查方法

1.视觉系统故障排查,编程bug排查方法(实用版3篇)篇1 目录1.视觉系统故障的基本概念2.视觉系统故障排查的一般步骤3.编程 bug 排查的一般方法4.视觉系统故障排查和编程 bug 排查的实践案例篇1正文视觉系统故障排查,通常是指在计算机视觉系统中出现故障时,通过一系列的步骤和方法来定位和解决故障的过程。
在这个过程中,需要先了解视觉系统故障的基本概念。
视觉系统故障可以分为硬件故障和软件故障两种类型。
硬件故障指的是摄像头、传感器等硬件设备出现问题,而软件故障则是指程序代码、算法等方面出现问题。
在排查视觉系统故障时,需要先确定故障的类型,然后采取相应的排查方法。
一般来说,视觉系统故障排查的一般步骤包括:确定故障现象、分析故障原因、定位故障位置、解决故障问题等。
在这个过程中,需要运用一些常见的排查方法,例如:检查硬件设备是否正常工作、检查程序代码是否存在 bug、检查算法参数是否设置正确等。
与视觉系统故障排查类似,编程 bug 排查也需要通过一系列的步骤和方法来定位和解决故障。
一般来说,编程 bug 排查的一般方法包括:阅读代码、调试程序、复现故障、分析原因等。
在这个过程中,需要运用一些常见的排查工具,例如:调试器、日志、断言等。
视觉系统故障排查和编程 bug 排查的实践案例可以帮助我们更好地理解这些方法的应用。
例如,在视觉系统中,当出现无法识别物体的情况时,可以通过检查硬件设备、调整算法参数等方式来排查故障。
在编程中,当出现程序崩溃的情况时,可以通过调试程序、分析日志等方式来定位bug。
视觉系统故障排查和编程 bug 排查都需要我们具备一定的专业知识和实践经验。
篇2 目录1.视觉系统故障排查的重要性2.编程 bug 排查的一般方法3.视觉系统故障排查的特殊方法4.总结篇2正文视觉系统故障排查是计算机技术领域中的一个重要分支。
当视觉系统出现故障时,我们需要对其进行排查以找出故障原因并进行修复。
与其他类型的故障排查相比,视觉系统故障排查有其特殊之处,需要运用特殊的方法进行。
问题排查解决方案

问题排查解决方案问题排查是在面对各种技术、操作、功能等问题时,通过对问题进行分析、调查和验证来找出问题根源并加以解决的过程。
在现代社会中,问题排查解决方案对于各行各业来说都非常重要,它不仅可以提高工作效率,还可以避免或减少由问题引起的损失和风险。
本文将介绍问题排查解决方案的基本步骤和常用工具,帮助读者更好地应对问题。
一、问题排查的基本步骤1.收集信息在开始问题排查之前,首先需要收集相关的信息。
信息的来源可以包括用户反馈、系统日志、监控数据等。
收集的信息应该尽可能全面和准确,以便更好地分析问题。
2.分析问题在收集到足够的信息之后,接下来需要对问题进行分析。
分析问题时可以采用自顶向下或自底向上的方法。
自顶向下的方法是从问题的外围开始逐步缩小范围,直到找到问题的根源;自底向上的方法是从问题的具体表象逐步向上追溯,直到找到问题的根源。
根据具体情况选择合适的分析方法。
3.制定假设在分析问题的基础上,可以制定一些假设来帮助进一步的排查。
假设可以根据分析的结果和经验来确定,需要合理可行并且有针对性。
4.验证假设制定了假设之后,就需要通过验证来确定问题的根源。
验证可以采用实验、测试、演示等方法,具体根据问题的性质和解决方案的可行性来确定。
5.解决问题通过验证假设,可以获得问题的根源,然后就可以制定解决方案并加以实施。
解决方案应该具备可行性和可持续性,能够解决问题并避免类似问题再次发生。
6.评估效果解决问题后,需要进行效果评估,以确保问题得到了解决。
评估方法可以包括对系统性能、用户满意度等进行检测和比较。
二、常用问题排查工具1.日志分析工具日志是问题排查中非常重要的信息来源,通过对日志进行分析可以了解系统的运行状态和发生问题的原因。
常用的日志分析工具有ELK Stack、Splunk等。
2.监控工具监控工具可以实时监测系统的状态和性能指标,并在出现异常时提供警报。
常用的监控工具有Zabbix、Nagios等。
3.性能分析工具性能分析工具可以对系统进行性能测量和分析,找出系统性能瓶颈,并提供相关的解决方案。
列出常用的故障检测方法。

列出常用的故障检测方法。
故障检测是指在系统运行过程中,通过一系列手段和方法来发现和诊断系统中存在的故障,以便及时修复和恢复系统正常运行。
下面将介绍一些常用的故障检测方法。
1. 日志分析日志是系统运行时产生的记录信息,通过对系统日志的分析可以帮助发现系统中存在的故障。
通过分析日志,可以了解系统的运行状态、异常行为和错误信息。
常用的日志分析工具有ELK、Splunk等,可以实时监控和分析系统日志,及时发现故障。
2. 心跳检测心跳检测是指通过定时发送心跳信号来检测系统是否正常运行。
在分布式系统中,不同节点之间可以通过发送心跳信号来互相检测对方的状态。
一旦发现某个节点没有响应心跳信号,就可以判定该节点发生故障。
3. 健康检查健康检查是指通过检测系统的各个组件和功能是否正常运行来判断系统是否存在故障。
例如,可以通过检查数据库连接是否正常、网络是否可达、硬件设备是否正常工作等来进行健康检查。
常用的健康检查工具有Nagios、Zabbix等。
4. 异常监测异常监测是指通过监控系统的各种指标和参数来判断系统是否存在异常。
例如,可以监测系统的CPU利用率、内存使用率、磁盘空间等指标,一旦超过阈值就可以判定系统存在异常。
常用的异常监测工具有Prometheus、Grafana等。
5. 性能测试性能测试是指通过模拟系统负载和压力来测试系统的性能,以寻找系统存在的瓶颈和故障。
通过性能测试可以了解系统的各项指标和性能数据,发现系统性能下降和异常的原因。
常用的性能测试工具有JMeter、LoadRunner等。
6. 代码审查代码审查是指通过对系统代码的静态分析和检查来发现代码中的潜在问题和错误。
通过代码审查可以发现代码中的逻辑错误、安全漏洞和性能问题,及时修复和优化代码,提高系统的稳定性和可靠性。
7. 单元测试单元测试是指对系统的各个模块和组件进行独立测试,以验证其功能的正确性和健壮性。
通过单元测试可以发现代码中的逻辑错误和边界情况,提高系统的可靠性和稳定性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
无权查看任何主机的信息。
请检查HTTP服务器关于该CGI的访问权限设置。
解决办法:
vi /usr/local/nagios/etc/cgi.cfg
将use_authentication的值改为0.
use_authentication=0
然后重启os服务
service nagios restart
还有可能:
配置文件中的hostname和service_description使用了中文。
建议hostname和service_description 不要使用中文
三、访问时出现乱码
一般是apache 配置文件的编码问题
解决方法:
确定安装gd-devel包
然后回到解压目录,
#make clean
重新编译安装一下
# ./configure --with-gd-lib=/usr/lib --with-gd-inc=/usr/include
接下来
#./configure --with-command-group=nagcmd
nagios常见错误排查
一、启动时报错
“Starting nagios:This account is currently not available”
解决方法:
修改/etc/passwd
将/sbin/nologin改成/bin/bash
二、nagios安装好后,网页访问出现如下错误:
ndo2db_group=nagcmd
注意第二个,ndo2db的所属组,是nagcmd.因为前面系统加的用户nagios是nagcmd组的.
解决方法:
vim /usr/local/apache2/conf/
最后添加AddDefaultCharset utf-8
四、出现 The requested URL /nagios/cgi-bin/statusmap.cgi was not found on this server错误
ndomod: Could not open data sink! I'll keep trying, but some output may get lost...
解决思路:
# vim /usr/local/nagios/etc/ndo2db.cfg
ndo2db_user=nagios
#make all;
make install;
make install-init;
make install-config;
make install-commandmode;
makeinstall-webconf
五、查看nagios.log日志出现如下错误: