Stata 图形示例及代码
Stata代码解释(配合demo1代码)

Stata代码解释(配合demo1代码)在stata代码第二行的(有铅笔在纸上写字)的图标打开代码文件在打开的DO-file中open-file,点击.do结尾的文件(demo.do)红色:路径绿色:注释蓝色:代码1-8行:相当于表头11-14行,是每一个stata代码中都有的clear all——清空STATA所有文件中的数据,重新开始cap log close——关闭之前打开的log文件(后面会说是什么)set more off——跑一个特别长的回归,STATA会显示一个more,要一直点才会不断出现,如果一开始就这么写的话就不会出现这个情况cd "C:/课件/17秋计量/Stata_0923" ——固定stata的工作目录,打开数据、存储数据、打开log、存储log文件、输出表格的操作就都不用输这个路径了,直接输文件的名字就好!把STATA的工作目录调到一个工作路径上,打开数据时,要找到数据所在路径并复制粘贴到这个部分就行,.dta前面的部分选定所想运行的代码,点do_file里最上面的第二行小图标里面的Do就可以了然后返回输出界面看,如果有红色字体就是报错Log文件:Log就是日志的意思相当于就将所有操作过程、代码、执行情况都记录在一个.txt的文件中,防止写代码的时候忘记保存code.突然停电等情况,Help:执行help log文件就会自动跳出stata的帮助文件,这个文件中就会系统的介绍log的用法Help+一个指令,运行时就会自动跳出stata关于该指令的帮助文件,系统介绍这个指令的用法如何导入数据:如果数据时一个.dta文件,就直接在操作界面中打开数据就好use 文件名称.dta, clear(clear的作用是如果现在你正在使用另一个数据,如果没有clear那么就会报错,相当于先关掉你之前正在处理的数据,重新打开一个新的数据,如果你之前处理的数据没有保存的话,那么stata会直接关闭不保存,所以一定要先保存再打开)运行一下,到操作页面看,右边就是出现的所有变量,下面就是变量的描述这一个数据集是在古德里奇里面所附的,助教已经发到论坛上了操作页面上面的小图标里:在dofile的右边有data editor, data editor browse,Data editor browse 打开以后就是整个样本集的全貌,几个变量,几个样本点,可以浏览数据(不能编辑)Data editor点开以后,和browse的页面一样,但是可以对数据进行编辑所以不鼓励用data editorExcel 也可以直接打开默认将第一行作为变量名剩下的都是数据import excel using (excel文件名).xlsx, first clear不输入first的话,会把所有的格都当做数据,如果输入first clear 的话,stata会将第一行作为变量名而非数据Stata识别命令的时候会以行为单位的,相当于会先执行一行的,再执行下一行,所以如果一行命令很长的时候,可以换行,否则会一直从左边写到右边去换行的时候先打一个空格,再接三条从右上向左下的斜线///,stata自动将这种代码当做一行处理38.39行执行browse指令,就相当于刚刚点开了放大镜的那个小图标执行edit也一样,相当于点开刚刚的小图标如何保存处理过后的数据46行save (取一个你想命名的名字)_1.dta,replace注意要有_1,要不然之前原始的文件就会被换成新的文件Replace必须写,相当于把之前的文件替换掉,不然会报错Describe:变量的基本信息,是数值型的还是字符型的,先给你展示一下第一列就是变量的类型:整数、小数型的第二列是腐烂了美团第三列是label:我们存变量的时候,之后会有很多的操作,所以变量名不会很长,所以取名会比较精简,但是为了防止之后不知道所写的是什么,就会加一个label,解释一下这个变量名如果describe之后没有加任何东西的话,就是默认展示所有变量如果describe之后加上一个变量例如wage,就只会展示wage的变量名Describe可以缩写为d之前的browse 也可以写为bro哪些变量可以缩写,可以点击help进行查看Codebook展示一些具体的描述性统计例如61行codebook,可以看出取值范围,非重复的值是多少,标准差,均值,最大最小值等Summary(缩写为sum)和codebook一样Sum wage, detail则会更详细一些,会告诉你很多分位数上的值是多少如果想调用其中的一个数值,一个就是复制下来粘贴,但是不美观也容易出错另一个就是生成一个数值变量——scalar,例如把工资的平均值赋成一个数值变量(插一句:stata的变量分为两种,一种是wage这种相当于一个项量,另一个是stata自己生成的一个相当于标量)赋成数值变量的方式就是scalar (你所取的名字,例如wage_average)=r(mean)(你所调取的stata内部给这个量所取的名字)如何知道stata对这个量的内部名字呢?就是在sum wage 之后执行一个return list,就可以看到stata内部对某一个值的内部标定,想赋哪一个值就可以将前面的标定引用Scalar 生成之后,stata就会自动保存下来,之后每一次想用的时候就输自己取的这个名字就好,例如你想让stata展示一下这个值的大小,就写display(缩写为dis)wage_avg就可以了Tabstat,就是把变量的信息以表格的形式呈现出来(助教说这个和tabulate说反了,是看描述进行统计的)Tab educ, stat( mean min max) by (urban)他就会具体的呈现出来by (urban)就涉及两个变量了,就是在农村住的人,平均受教育年份是13.21,城市里住的人的受教育年份是14.56tabulate feduc 是看具体的值,出现了几次tabulate father education(指令打做tabulate feduc) 就是这个值出现了多少次都呈现出来,父亲的受教育程度0是文盲,有受过1年教育,一直到18年教育的phd,右边的frequent就是出现过多少次,再右边一列就是百分比,再右边一列就是累计的百分比,相当于统计当中的F的值tab feduc, miss(也可以写作tab feduc, m)相当于把缺失的数据也展出出来这个是用来看数据的分布和缺失程度的,非常重要可以看变量之间二维的分布就是在tab之后输入两个变量(例如tab south urban)south也是一个零变量,1代表来自南方,0代表来自北方,urban1则是1代表来自城里,0代表来自农村之后以行出现south,以列出现urbantab south urban,row就是以行为单位出现百分比,表现出在所有的北方人里面大概75%是南方人,在所有的列里面大概65%是城里人tab south urban,chi2 就是做一个卡方检验,看这两个变量的分布上有没有显著性的y依赖于x的分布关系94行tab south urban, summ(wage) means看工资的平均值分为南方的城里农村以及北方的城里农村95-97一样的意思Correlation(简写做corr)就是看协方差和相关系数Correduc wage就是得到两个的相关系数(正值就是正相关,负值就是负相关)correduc wage, cov就是得到两个变量的协方差矩阵,左上角是教育程度的方差,右下角是工资的方差,左下角就是协方差同样可以用return list 调取代数,并用scalar赋值变量correducmeducfeduc 的话,涉及三个变量,最后就会反应他们之间的两两关系list就是可以把brouse当中的几行数据调取出来sort这个指令很重要,相当于excel当中的排序,sort hours就是把所有数据按照工作时长排序,(先执行之后再brouse一下看看)order feducmeduc就是将这个变量放在最前面,后面再跟什么工作时长、教育年限之类的其他变量scalar pi = 3.1415926,这是你取的名字,之后你再想用的时候就可以直接打pi就好但这是一个数值变量,你如何生成一个变量、即一个项量呢?就是用generate这个指令,简写做gen,比如你想将每个人都算一个年龄的平方,例子见133行另外例子:取工资的对数:generatelnwage = log(wage)生成一个新的变量之后就要养成贴标签的习惯,label varage_sq "age square"因为标签是文本,所以要加上双引号另外一种标签是数据标签——label define urbanlabel 1 "Urban"0 "Rural"是先生成一个数值标签(urbanlabel也是自己取的名字)相当于做衣服,label values就是将urbanlabel这个标签穿做一些数值模拟的时候会用到gen random1 = runiform()在(0.1)上生成随机分布的随机数,random1就是自己命的名gen random2 = rnormal(0)(这个没有解释)gen wage_k = wage/1000就是新生成一个单位,原来的单位是美元,现在自己新生成一个单位叫做千美元label varwage_k "wage (:1000yuan)"gen obsID = _n 按照顺序生成了一个编号(_n在stata当中就是自动生成1.2.3….)只有每一个人都有了一个相应的编号,就可以把不同的数据集相互合并egen比gen可以执行更为复杂的操作egenIQ_rank = rank(IQ)就是按照IQ进行排序bysorteduc: egenwage_byeduc = mean(wage)就是按照受教育程度来求工资的平均值,bysort 就是同时也按education从小到大排序对变量重新命名——见165行变量的类型也可以调换。
空间计量模型stata代码

空间计量模型stata代码本文将介绍如何使用Stata软件进行空间计量模型分析,并提供相应的代码示例。
空间计量模型是一种考虑空间依赖关系的统计模型,常用于研究城市、区域发展、环境污染等问题。
以下是具体的步骤和代码:1. 加载数据首先使用命令“use”加载数据文件。
假设我们的数据文件名为“data.dta”,则代码如下:use 'data.dta', clear2. 空间权重矩阵的构建空间权重矩阵是空间计量模型的重要组成部分,用于描述地理空间上的邻近关系。
常见的权重矩阵类型包括邻接矩阵、距离矩阵、K近邻法等。
这里以邻接矩阵为例,假设我们的邻接矩阵文件名为“w.gal”,则代码如下:spmat wspset w, clearspset w using 'w.gal', idvar(id) coordvar(x y) 其中,“spmat”命令用于创建一个新的空间权重矩阵对象,“spset”命令用于设置权重矩阵对象的属性。
3. 空间计量模型的估计以空间自回归模型为例,假设我们的因变量为“y”,自变量为“x1”、“x2”,则模型的代码如下:spreg y x1 x2, wmatrix(w) robust其中,“spreg”命令用于进行空间自回归模型的估计,“wmatrix”选项用于指定权重矩阵对象,“robust”选项用于进行异方差性处理。
4. 结果输出和解释最后,使用“estimates”命令输出模型的估计结果,并进行解释。
例如,下面的代码将输出估计结果的标准误、t值和p值:estimates store model1estimates table model1, b(se) t(p) star(0.1 0.05 0.01) 其中,“estimates store”命令用于将估计结果存储到模型对象中,“estimates table”命令用于输出估计结果的表格形式。
解释结果时,需要注意权重矩阵的特征值和特征向量,以及空间自相关性的类型和程度。
Stata中的图形制作绝对自己总结

第三章S t a t a中的图形制作1.菜单操作2.直方图:用矩形的面积(即长度和宽度)来表示频数分布的图形。
3.散点图:反映两个或多个变量之间的关系。
通常用纵轴来表示因变量,用横轴来表示自变量。
量foreign分成两个图形进行绘制。
Twoway scatter mpg weight||lfit mpg weight,title(mpg与weight散点图) subtitle(1978年美国汽车数据图) legend(position(6))||表示多个图形在一个坐标轴中显示;lfit mpg weight绘制拟合曲线进一步设置:Msymbol(T) mcolor(black) mlabel(make) mlabpositon(9) by(foreign)散点形状:实心大三角,颜色:黑色,标签内容:make,位置为9点钟处;按foreign绘制4.曲线标绘图用线段的升降趋势来说明现象变化或变量之间关系的一种图形。
它与散点图类似,实际上它就是将连续型的数值变量点连接起来的一种图形,但由于它还可以用于回归曲线的绘制。
基本命令[twoway] line y x一定注意x变量要放置在y变量之后连接样式的设定connect(样式代码)线条样式的设定clpattern(样式代码)案例:运用consumption_china.dta数据绘制曲线标绘图。
利用文件中的数据绘制人均消费c和人均国内生产总值y随时间变化的曲线标绘图。
(1)将图例分成两行设计,图例内容“人均消费“和”人均GDP”,并让图例在图形内部十一点钟的位置;(2)线条一条为实线连接,一条为虚线连接;5.条形图:是用矩形的长度来表示相互独立的变量大小取值的统计图形。
横向的条形图hbar,纵向条形图bar。
在绘制条形图的过程中,需要指明所要展示的统计量,如果不指明统计量,则会默认显示均值(mean)统计量。
6.饼图:用圆形及圆内扇形的大小表示总体中各部分所占比例的统计图,通常用来表示各部分在总体中所占份额。
Stata中的图形制作(绝对自己总结)

第三章 Stata 中的图形制作1.菜单操作2.直方图:用矩形的面积(即长度和宽度)来表示频数分布的图形。
D e n s i t y3.散点图:反映两个或多个变量之间的关系。
通常用纵轴来表示因变量,用横轴来表示自变量。
基本[twoway] scatter y x因变量在前数据标记的设定数据标记形状的设定、颜色的设定、大小的设定、散点标签的设定msymbol(散点形状代码);mcolor(red)散点为红色;msize(5)散点大小为5号散点标签:mlabel (标签容的变量名)和mlabposition(代表钟表点数的数字)例如设定散点的容为变量city,位置在3点钟处:mlabel (city) mlabposition(3) 群组划分:by(foreign)案例:运用usaauto数据文件中的数据绘制mpg和weight关系的散点图。
(1)为图形添加标题“mpg 与weight散点图”和副标题“1978年美国汽车数据图”;(2)为图形添加图例,位置在钟表2点钟处;(3)绘制一条拟合的趋势曲线;(4)将散点的形状设置为实心大三角,颜色为黑色;(5)为每个散点添加标签,容为汽车的品牌(make),位置为9点钟处,颜色为黑色;(6)按照变量foreign 分成两个图形进行绘制。
Twoway scatter mpg weight||lfit mpg weight,title(mpg与weight散点图) subtitle(1978年美国汽车数据图) legend(position(6))||表示多个图形在一个坐标轴中显示;lfit mpg weight绘制拟合曲线进一步设置:Msymbol(T) mcolor(black) mlabel(make) mlabpositon(9) by(foreign)散点形状:实心大三角,颜色:黑色,标签容:make,位置为9点钟处;按foreign绘制12342,0003,0004,0005,000Weight (lbs.)Mileage (mpg)Fitted values1978年美国汽车数据图mpg与weight散点图AMC ConcordAMC PacerAMC SpiritBuick CenturyBuick ElectraBuick LeSabreBuick OpelBuick RegalBuick RivieraBuick SkylarkCad. DevilleCad. EldoradoCad. SevilleChev. ChevetteChev. ImpalaChev. MalibuChev. Monte CarloChev. MonzaChev. NovaDodge ColtDodge DiplomatDodge MagnumDodge St. RegisFord FiestaFord MustangLinc. ContinentalLinc. Mark VLinc. VersaillesMerc. BobcatMerc. CougarMerc. MarquisMerc. MonarchMerc. XR-7Merc. ZephyrOlds 98Olds Cutl SuprOlds CutlassOlds Delta 88Olds OmegaOlds StarfireOlds ToronadoPlym. ArrowPlym. ChampPlym. HorizonPlym. SapporoPlym. VolarePont. CatalinaPont. FirebirdPont. Grand PrixPont. Le MansPont. PhoenixPont. SunbirdAudi 5000Audi FoxBMW 320iDatsun 200Datsun 210Datsun 510Datsun 810Fiat StradaHonda AccordHonda CivicMazda GLCPeugeot 604Renault Le CarSubaruToyota CelicaToyota CorollaToyota CoronaVW DasherVW DieselVW RabbitVW SciroccoVolvo 26012342,0003,0004,0005,0002,0003,0004,0005,0001978年美国汽车数据图1978年美国汽车数据图mpg与weight散点图mpg与weight散点图Mileage(mpg)Weight (lbs.)Graphs by Car type4.曲线标绘图用线段的升降趋势来说明现象变化或变量之间关系的一种图形。
stata画图和线性回归基础

test exper 或者 test exper =0 3。检验 educ和 tenure的联合显著性
test educ tenure 或者 test (educ=0) (tenure=0)
a
21
例三:生产函数production use production,clear reg lny lnl lnk
a
10
1。要求方程省略常数项
reg price mpg weight foreign, nocons 2。稳健性估计(一般用于大样本OLS)
reg price mpg weight foreign, vce(robust) 或者:reg price mpg weight foreign, r
3。设置置信区间(默认95%)
a
2
作图时命令方式比较复杂,建议多用菜单方式。 一起来做下列图形: 打开wage2.dta 1。 男性和女性工资均值的条形图 2。 白人和其他人的工资的冰饼图 3。 wage的直方图,并检验是否服从正态分布。
a
3
组合图形:
画出price与weight的散点图,并画出其拟 合线。
图形界面设计:
图形标题,X轴标志,Y轴标志,样式选择, 图例,分组标志。
Coef:回归系数 Std.Err:标准误差 方差协方差矩阵的对角线元素的开方(vce) 95%下限=估计值-t临界值下限*标准误差 95%下限=估计值+t临界值上限*标准误差
a
14
模型常用的其他形式:
对数 半对数 平方项 n次方 指数 交乘项
虽然对函数形式和自变量的选取有选择和检 验的方法,但最好还是从“经济意义”角度 确定。
第7讲 stata作图

坐标轴刻度及刻度标签 坐标轴刻度(tick)与刻度标签(label) sysuse auto,clear scatter mpg weight, xlabel(#10) scatter mpg weight, /// ylabel(10(5)45) /// xlabel(1500 2000 3000 4000 4500 5000) scatter mpg weight, ymlabel(##5) xmtick(##10)
第七讲 stata作图
Stata中的图形种类 graph twoway 二维图 scatter 散点图 line 折线图 area 区域图 lfit 线性拟合图 qfit 非线性拟合图 histogram 直方图 kdensity 密度函数图 function 函数图 graph matrix 矩阵图 graph box 箱型图 graph dot 点图 graph bar 条形图 graph pie 饼图
参数设定规则 #4 ##10 10(5)45 设定4个最佳值 10-1=9个子刻度列印于住刻度之间 在10到45范围内,每隔5列印一个子刻度
坐标轴标题 ytitle(),xtitle() scatter mpg weight, ytitle(“汽车里数”,place(top)) /// xtitle(“汽车重量”,place(right)) scatter mpg weight,xtitle(“汽车里数” “(mpg)”)
双坐标系 共用X轴 sysuse sp500,clear twoway line close change date twoway (line close date, yaxis(1))/// (line change date,yaxis(2)) twoway (line close date,yaxis(1))/// (line change date,yaxis(2)),/// ylabel(-50(10)40) 单独的y轴和x轴 twoway (line close date, yaxis(1) xaxis(1)) (line change date,yaxis(2) xaxis(2))
Stata中的图形制作(绝对自己总结)

第三章Stata中的图形制作
4.曲线标绘图
用线段的升降趋势来说明现象变化或变量之间关系的一种图形。
它与散点图类似,实际上它就是将连续型的数值变量点连接起来的一种图形,但由于它还可以用于回归曲线的绘制。
clpattern(样式代码)
consumption_china.dta数据绘制曲线标绘图。
利用文件中的数据绘制人均消费
随时间变化的曲线标绘图。
(1)将图例分成两行设计,图例内容
5.条形图:是用矩形的长度来表示相互独立的变量大小取值的统计图形。
横向的条形图hbar,纵
向条形图bar。
在绘制条形图的过程中,需要指明所要展示的统计量,如果不指明统计量,则会默认显示均值
6.饼图:用圆形及圆内扇形的大小表示总体中各部分所占比例的统计图,通常用来表示各部分。
Stata中的图形制作(绝对自己总结)

第三章 Stata 中的图形制作1.菜单操作2.直方图:用矩形的面积(即长度和宽度)来表示频数分布的图形。
D e n s i t y3.散点图:反映两个或多个变量之间的关系。
通常用纵轴来表示因变量,用横轴来表示自变量。
基本[twoway] scatter y x因变量在前数据标记的设定数据标记形状的设定、颜色的设定、大小的设定、散点标签的设定msymbol(散点形状代码);mcolor(red)散点为红色;msize(5)散点大小为5号散点标签:mlabel (标签内容的变量名)和mlabposition(代表钟表点数的数字)例如设定散点的内容为变量city,位置在3点钟处:mlabel (city) mlabposition(3)群组划分:by(foreign)案例:运用usaauto数据文件中的数据绘制mpg和weight关系的散点图。
(1)为图形添加标题“mpg与weight散点图”和副标题“1978年美国汽车数据图”;(2)为图形添加图例,位置在钟表2点钟处;(3)绘制一条拟合的趋势曲线;(4)将散点的形状设置为实心大三角,颜色为黑色;(5)为每个散点添加标签,内容为汽车的品牌(make),位置为9点钟处,颜色为黑色;(6)按照变量foreign分成两个图形进行绘制。
Twoway scatter mpg weight||lfit mpg weight,title(mpg与weight散点图) subtitle(1978年美国汽车数据图) legend(position(6))||表示多个图形在一个坐标轴中显示;lfit mpg weight绘制拟合曲线进一步设置:Msymbol(T) mcolor(black) mlabel(make) mlabpositon(9) by(foreign)4.曲线标绘图用线段的升降趋势来说明现象变化或变量之间关系的一种图形。
它与散点图类似,实际上它就是将连续型的数值变量点连接起来的一种图形,但由于它还可以用于回归曲线的绘制。
Stata 作图

#delimit ; twoway function y=normden(x), range(-4 -1.96) bcolor(gs12) recast(area) || function y=normden(x), range(1.96 4) bcolor(gs12) recast(area) || function y=normden(x), range(-4 4) ||, plotregion(style(none)) yscale(off) xscale(noline) legend(off) xlabel(-4 "-4 sd" -3 "-3 sd" -2 "-2 sd" -1 "-1 sd" 0 "mean" 1 "1 sd" 2 "2 sd" 3 "3 sd" 4 "4 sd", grid gmin gmax) xtitle("") ; #delimit cr
sysuse educ99gdp, clear graph hbar (asis) public private, over(country) sysuse citytemp graph bar (mean) tempjuly tempjan,over(region) stack sysuse educ99gdp, clear graph hbar (asis) public private, over(country) stack
茎叶图 sysuse auto, clear stem weight
矩阵图 graph matrix graph matrix price length weight mpg
Stata中的图形制作绝对自己总结

plabel(_allpercent,gap(9)):显示所有标签,相对位置为9
pie(1,explodecolor(yellow)):对第一个图例变量,突出显示,颜色设定为黄色
legend(position(11)row(1)ring(0))方向为11点,一排显示,内部显示
3.散点图:反映两个或多个变量之间的关系。通常用纵轴来表示因变量,用横轴来表示自变量。
基本
[twoway]scatteryx因变量在前
数据标记的设定
数据标记形状的设定、颜色的设定、大小的设定、散点标签的设定
graphbar/hbarcurrentsolidgross,over(year)blabel(bar,position(outside)yline(30000))stack
blabel(bar,position(outside)):以条柱的高度数值给条柱添加标签,位置在条柱的右;yline(300000):标识线的绘制,注意的是:该函数在blabel的括号内
5.条形图:是用矩形的长度来表示相互独立的变量大小取值的统计图形。横向的条形图hbar,纵向条形图bar。
在绘制条形图的过程中,需要指明所要展示的统计量,如果不指明统计量,则会默认显示均值(mean)统计量。
stack选项
将具有多个y变量的统计量上下堆积,可以了解内部的比例结构
blabel选项
增添条柱的数值标签;改变bar的名称和组合
第三章Stata中的图形制作
1.菜单操作
Plots
二,Stata实用命令之图形绘制
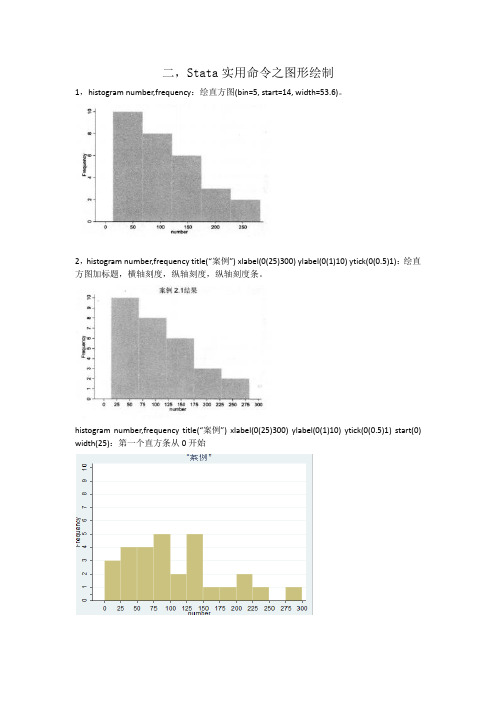
二,Stata实用命令之图形绘制1,histogram number,frequency:绘直方图(bin=5, start=14, width=53.6)。
2,histogram number,frequency title(“案例”) xlabel(0(25)300) ylabel(0(1)10) ytick(0(0.5)1):绘直方图加标题,横轴刻度,纵轴刻度,纵轴刻度条。
histogram number,frequency title(“案例”) xlabel(0(25)300) ylabel(0(1)10) ytick(0(0.5)1) start(0) width(25):第一个直方条从0开始3,graph twoway scatter SG TZ:散点图。
graph twoway scatter SG TZ,title("1234") xlabel(56(2)80) ylabel(150(10)190) ytick(150(5)190):散点图增加标题/坐标数据/刻度。
graph twoway scatter SG TZ,title("1234") xlabel(56(2)80) ylabel(150(10)190) ytick(150(5)190) msymbol(D) mcolor(yellow):散点图增加标题/坐标数据/刻度/散点形状/散点颜色。
提示:help colorstyle4,graph twoway line total first year:曲线图。
graph twoway line total first year,title(“案列”) xlabel(1997(2)2012) ylabel(0(10)80) xtick(1997(1)2012) legend(label(1 “总进球数”) label(2 ”第一射手进球数”))graph twoway line total first year,title(“案列”) xlabel(1997(2)2012) ylabel(0(10)80) xtick(1997(1)2012) legend(label(1 “总进球数”) label(2 ”第一射手进球数”)) clpattern(solid dash):solid实线——代表第一个自变量,dash虚线——第二个自变量。
topsis的stata代码

topsis的stata代码以下是使用Stata进行TOPSIS(Technique for Order of Preference by Similarity to Ideal Solution)分析的示例代码:首先,假设我们有n个样本和m个评价指标。
假设数据集的变量名为x1、x2、...、xm,其中x1到xm为评价指标的值。
1. 导入数据集:use "数据集文件名.dta", clear.2. 计算标准化矩阵:gen x1_std = (x1 mean(x1)) / sd(x1)。
gen x2_std = (x2 mean(x2)) / sd(x2)。
...gen xm_std = (xm mean(xm)) / sd(xm)。
3. 确定正理想解和负理想解:egen x1_pos = max(x1_std)。
egen x2_pos = max(x2_std)。
...egen xm_pos = max(xm_std)。
egen x1_neg = min(x1_std)。
egen x2_neg = min(x2_std)。
...egen xm_neg = min(xm_std)。
4. 计算与正理想解的距离:gen x1_dist_pos = sqrt((x1_std x1_pos)^2)。
gen x2_dist_pos = sqrt((x2_std x2_pos)^2)。
...gen xm_dist_pos = sqrt((xm_std xm_pos)^2)。
5. 计算与负理想解的距离:gen x1_dist_neg = sqrt((x1_std x1_neg)^2)。
gen x2_dist_neg = sqrt((x2_std x2_neg)^2)。
...gen xm_dist_neg = sqrt((xm_std xm_neg)^2)。
6. 计算正理想解的距离和负理想解的距离之比:gen x1_ratio = x1_dist_neg / (x1_dist_pos + x1_dist_neg)。
stata代码解读 -回复

stata代码解读-回复[stata代码解读]Stata是一种广泛应用于统计分析和数据管理的软件,常用于社会科学研究领域。
本文将逐步解读一段Stata代码,帮助读者理解代码背后的逻辑和实现功能。
首先,让我们来看一段示例代码:clear 清空数据集import delimited "data.csv", clear 从CSV文件导入数据describe 显示数据集的变量概要egen total_income = total(income) 计算总收入变量regress y total_income x1 x2 进行回归分析predict y_hat 预测因变量的值,并存储在新变量y_hat中以上代码包含了Stata中常用的一些命令和函数,让我们逐步解读:1. `clear`:该命令清空当前的数据集,确保从一张空的数据表开始读取新的数据。
2. `import delimited`:该命令用于从CSV文件中导入数据。
在代码中,我们从名为"data.csv"的文件中导入数据,并使用`clear`选项来确保导入数据前先清空数据表。
3. `describe`:该命令用于显示数据集的变量概要。
它将输出数据集中包含的变量列表和每个变量的类型、标签和摘要统计信息。
4. `egen total_income = total(income)`:该命令使用`egen`函数计算总收入变量。
`egen`函数是Stata中的一个强大工具,用于生成新的派生变量或汇总统计量。
在这个例子中,我们使用`total`函数将变量"income"中所有观察值的和保存到新的变量"total_income"中。
5. `regress y total_income x1 x2`:该命令进行回归分析。
它将因变量"y"和自变量"total_income"、"x1"和"x2"输入模型,并估计回归方程的系数。
Stata图形示例及代码

Stata8图形示例及代码一、带标注的散点图sysuse lifeexp, clearkeep if region==2 | region==3replace gnppc = gnppc / 1000label var gnppc "GNP per capita (thousands of dollars)"gen lgnp = log(gnp)qui reg lexp lgnppredict hatlabel var hat "Linear prediction"replace country = "Trinidad" if country=="Trinidad and Tobago" replace country = "Para" if country == "Paraguay"gen pos = 3replace pos = 9 if lexp > hatreplace pos = 3 if country == "Colombia"replace pos = 3 if country == "Para"replace pos = 3 if country == "Trinidad"replace pos = 9 if country == "United States"#delimit ;twoway(scatter lexp gnppc, mlabel(country) mlabv(pos))(line hat gnppc, sort), xsca(log) xlabel(.5 5 10 15 20 25 30, grid) legend(off)title("Life expectancy vs. GNP per capita")subtitle("North, Central, and South America")note("Data source: World bank, 1998")ytitle("Life expectancy at birth (years)");#delimit cr二、对数坐标散点图sysuse lifeexp, cleargen gnp000 = gnppc/1000label var gnp000 "GNP per capita, thousands of dollars" scatter lexp gnp000, xsca(log) ///xlabel(.5 2.5 10(10)40, grid)三、加权散点图sysuse census, cleargen drate = divorce / pop18plabel var drate "Divorce rate"scatter drate medage [w=pop18p] if state!="Nevada", msymbol(Oh) /// note("State data excluding Nevada" ///"Area of symbol proportional to state's population aged 18+")四、带置信区间的直线回归图sysuse auto, clearquietly regress mpg weightpredict hatpredict stf, stdfgen lo = hat - 1.96*stfgen hi = hat + 1.96*stfscatter mpg weight || line hat lo hi weight, pstyle(p2 p3 p3) sort五、期望寿命折线图sysuse uslifeexp, cleargen diff = le_wm - le_bmlabel var diff "Difference"#delimit ;line le_wm year, yaxis(1 2) xaxis(1 2)|| line le_bm year|| line diff year|| lfit diff year||,ylabel(0(5)20, axis(2) gmin angle(horizontal))ylabel(0 20(10)80, gmax angle(horizontal))ytitle("", axis(2))xlabel(1918, axis(2)) xtitle("", axis(2))ytitle("Life expectancy at birth (years)")title("White and black life expectancy")subtitle("USA, 1900-1999")note("Source: National Vital Statistics, Vol 50, No. 6" "(1918 dip caused by 1918 Influenza Pandemic)")legend(label(1 "White males") label(2 "Black males"))legend(col(1) pos(3));#delimit cr六、带置信区间的散点图sysuse auto, clearquietly regress mpg weightpredict hatpredict s, stdfgen low = hat - 1.96*sgen hi = hat + 1.96*s#delimit ;twowayrarea low hi weight, sort bcolor(gs14) || scatter mpg weight;#delimit cr七、折线、散点复合图sysuse sp500, clear#delimit ;twowayline close date, yaxis(1)||bar change date, yaxis(2)||in 1/52,ysca(axis(1) r(1000 1400)) ylab(1200(50)1400, axis(1)) ysca(axis(2) r(-50 300)) ylab(-50 0 50, axis(2))ytick(-50(25)50, axis(2) grid)legend(off)title("S&P 500")subtitle("January - March 2001")note("Source: Yahoo!Finance and Commodity Systems, Inc.") yline(1150, axis(1) lstyle(foreground));#delimit cr八、人口金字塔sysuse pop2000, clearreplace maletotal = -maletotal/1e+6replace femtotal = femtotal/1e+6gen zero = 0#delimit ;twowaybar maletotal agegrp, horizontal xvarlab(Males)||bar femtotal agegrp, horizontal xvarlab(Females)||sc agegrp zero , mlabel(agegrp) mlabcolor(black) msymbol(i) ||,xtitle("Population in millions") ytitle("")plotregion(style(none))ysca(noline) ylabel(none)xsca(noline titlegap(-3.5))xlabel(-12 "12" -10 "10" -8 "8" -6 "6" -4 "4" 4(2)12 , tlength(0) grid gmin gmax)legend(label(1 Males) label(2 Females)) legend(order(1 2))title("US Male and Female Population by Age, 2000")note("Source: U.S. Census Bureau, Census 2000, Tables 1, 2 and 3");#delimit cr九、折线穗式图sysuse sp500, clear#delimit ;twoway line close date, yaxis(1) || spike change date, yaxis(2) ||, yscale(axis(1) r(700 1400)) ylabel(1000(100)1400, axis(1))yscale(axis(2) r(-50 300)) ylabel(-50 0 50, axis(2))ytick(-50(25)50, axis(2) grid)legend(off)title("S&P 500")subtitle("January - December 2001")note("Source: Yahoo!Finance and Commodity Systems, Inc.")yline(950, axis(1) lstyle(foreground));#delimit cr十、针式图sysuse lifeexp, clearkeep if region==3gen lngnp = ln(gnppc)quietly regress le lngnppredict r, residtwoway dropline r gnp, ///yline(0, lstyle(foreground)) mlabel(country) mlabpos(9) ///ylab(-6(1)6) ///subtitle("Regression of life expectancy on ln(gnp)" "Residuals:" " ", pos(11)) ///note("Residuals in years; positive values indicate" "longer than predicted life expectancy")十一、直方图sysuse sp500, clear#delimit ;histogram volume, freqxaxis(1 2)ylabel(0(10)60, grid)xlabel(12321 "mean"9735 "-1 s.d."14907 "+1 s.d."7149 "-2 s.d."17493 "+2 s.d."20078 "+3 s.d."22664 "+4 s.d.", axis(2) grid gmax)xtitle("", axis(2))subtitle("S&P 500, January 2001 - December 2001")note("Source: Yahoo!Finance and Commodity Systems, Inc.") ;#delimit cr十二、带拟合分布曲线的直方图sysuse sp500, clear#delimit ;histogram volume, freq normalxaxis(1 2)ylabel(0(10)60, grid)xlabel(12321 "mean"9735 "-1 s.d."14907 "+1 s.d."7149 "-2 s.d."17493 "+2 s.d."20078 "+3 s.d."22664 "+4 s.d.", axis(2) grid gmax)xtitle("", axis(2))subtitle("S&P 500, January 2001 - December 2001")note("Source: Yahoo!Finance and Commodity Systems, Inc.") ;#delimit cr十三、折线穗式条形复合图sysuse sp500, clearreplace volume = volume/1000#delimit ;twowayrspike hi low date ||line close date ||bar volume date, barw(.25) yaxis(2) ||in 1/57, ysca(axis(1) r(900 1400))ysca(axis(2) r( 9 45))ylabel(, axis(2) grid)ytitle(" Price -- High, Low, Close") ytitle(" Volume (millions)", axis(2) bexpand just(left)) legend(off)subtitle("S&P 500", margin(b+2.5))note("Source: Yahoo!Finance and Commodity Systems, Inc.");#delimit cr十四、区间图sysuse sp500, cleargen month = month(date)sort monthby month: egen lo = min(volume)by month: egen hi = max(volume)format lo hi %10.0gcby month: keep if _n==_N#delimit ;twoway rcap lo hi month,xlabel(1 "J" 2 "F" 3 "M" 4 "A" 5 "M" 6 "J"7 "J" 8 "A" 9 "S" 10 "O" 11 "N" 12 "D") xtitle("Month of 2001")ytitle("High and Low Volume")yaxis(1 2) ylabel(12321 "12,321 (mean)", axis(2) angle(0)) ytitle("", axis(2))yline(12321, lstyle(foreground))msize(*2)title("Volume of the S&P 500", margin(b+2.5))note("Source: Yahoo!Finance and Commodity Systems Inc.") ;#delimit cr十五、区域图sysuse gnp96, clear#delimit ;twoway area d.gnp96 date, xlabel(36(8)164, angle(90))ylabel(-100(50)200, angle(0))ytitle("Billions of 1996 Dollars")xtitle("")subtitle("Change in U.S. GNP", position(11))note("Source: U.S. Department of Commerce, Bureau of Economic Analysis") ;#delimit cr十六、根据函数制作的曲线图#delimit ;twoway function y=exp(-x/6)*sin(x), range(0 12.57)yline(0, lstyle(foreground))xlabel(0 3.14 "pi" 6.28 "2 pi" 9.42 "3 pi" 12.57 "4 pi") plotregion(style(none))xscale(noline);#delimit cr十七、正态曲线下的面积图#delimit ;twowayfunction y=normden(x), range(-4 -1.96) bcolor(gs12) recast(area) || function y=normden(x), range(1.96 4) bcolor(gs12) recast(area) ||function y=normden(x), range(-4 4) clstyle(foreground) ||,plotregion(style(none))yscale(off) xscale(noline)legend(off)xlabel(-4 "-4 sd" -3 "-3 sd" -2 "-2 sd" -1 "-1 sd" 0 "mean"1 "1 sd"2 "2 sd"3 "3 sd"4 "4 sd", grid gmin gmax)xtitle("");#delimit cr十八、期望寿命曲线图sysuse uslifeexp, clear#delimit ;twoway line le year || fpfit le year ||,ytitle("Life Expectancy, years")xlabel(1900 1918 1940(20)2000)title("Life Expectancy at Birth")subtitle("U.S., 1900-1999")note("Source: National Vital Statistics Report, Vol. 50 No. 6")legend(off)text(48.5 1923"The 1918 Influenza Pandemic was the worst epidemic""known in the U.S.""More citizens died than in all combat deaths of the""20th century.", box place(se) just(left) margin(l+4 t+1 b+1) width(85)) ;#delimit cr十九、矩阵图sysuse lifeexp, cleargen lgnppc = ln(gnppc)gr matrix popgr lexp lgnp safe二十、半对角矩阵图sysuse lifeexp, cleargenerate lgnppc = ln(gnppc)graph matrix popgr lgnp safe lexp, half二十一、带网格线的矩阵图sysuse lifeexp, cleargenerate lgnppc = ln(gnppc)graph matrix popgr lgnp safe lexp, maxes(ylab(#4, grid) xlab(#4, grid))二十二、带上标题、标注、网格线的矩阵图sysuse lifeexp, cleargenerate lgnppc = ln(gnppc)label var lgnppc "ln GNP per capita"#delimit ;graph matrix popgr lgnp safe lexp,maxes(ylab(#4, grid) xlab(#4, grid))subtitle("Summary of 1998 life-expectancy data") note("Source: The World Bank Group");#delimit cr二十三、横向组合折线图sysuse uslifeexp, clearline le_male year, saving(male)line le_female year, saving(female)graph combine male.gph female.gph, ycommon二十四、纵向组合折线图sysuse uslifeexp, clearline le_male year, ylab(,grid) saving(male) line le_female year, ylab(,grid) saving(female) gr combine male.gph female.gph, col(1) scale(1)二十五、复合矩阵图sysuse lifeexp, cleargen loggnp = log10(gnppc)label var loggnp "Log base 10 of GNP per capita"#delimit ;scatter lexp loggnp, yscale(alt) xscale(alt) xlabel(, grid gmax) saving(yx) twoway histogram lexp, fraction xscale(alt reverse) horiz saving(hy)twoway histogram loggnp, fraction yscale(alt reverse)ylabel(,nogrid) xlabel(,grid gmax) saving(hx);graph combine hy.gph yx.gph hx.gph, hole(3)imargin(0 0 0 0) graphregion(margin(l=22 r=22))title("Life expectancy at birth vs. GNP per capita")note("Source: 1998 data from The World Bank Group");#delimit cr二十六、面积不等的复合矩阵图sysuse lifeexp, cleargen loggnp = log10(gnppc)label var loggnp "Log base 10 of GNP per capita"#delimit ;scatter lexp loggnp, yscale(alt) xscale(alt) xlabel(, grid gmax) saving(yx) twoway histogram lexp, fraction xscale(alt reverse) horiz fxsize(25) saving(hy)twoway histogram loggnp, fractionyscale(alt reverse) ylabel(0(.1).2, nogrid)xlabel(,grid gmax) fysize(25)saving(hx) ;graph combine hy.gph yx.gph hx.gph, hole(3)imargin(0 0 0 0) graphregion(margin(l=22 r=22))title("Life expectancy at birth vs. GNP per capita")note("Source: 1998 data from The World Bank Group") ;#delimit cr二十七、生存曲线sysuse cancer, clearstset studytime, fail(died) streg, distribution(exponential) predict S, survsts graph, plot(line S _t, sort)二十八、复式条图sysuse citytemp, clear#delimit ;graph bar tempjuly tempjan, over(region) bargap(-30)legend( label(1 "July") label(2 "January") )ytitle("Degrees Fahrenheit")title("Average July and January temperatures")subtitle("by regions of the United States")note("Source: U.S. Census Bureau, U.S. Dept. of Commerce") ; #delimit cr二十九、带标注的复式条图sysuse citytemp, clear#delimit ;graph bar tempjuly tempjan, over(region) bargap(-30)legend( label(1 "July") label(2 "January") )ytitle("Degrees Fahrenheit")title("Average July and January temperatures")subtitle("by regions of the United States")note("Source: U.S. Census Bureau, U.S. Dept. of Commerce") blabel(bar, position(inside) format(%9.1f) color(white)) ; #delimit cr三十、分组复式条图sysuse citytemp, clear#delimit ;graph bar (mean) tempjuly tempjan,over(division, label(labsize(*.75)))over(region)bargap(-30) nofillytitle("Degrees Fahrenheit")legend( label(1 "July") label(2 "January") )title("Average July and January temperatures")subtitle("by region and division of the United States")note("Source: U.S. Census Bureau, U.S. Dept. of Commerce") ; #delimit cr三十一、水平分组复式条图sysuse citytemp, clear#delimit ;graph hbar tempjan, over(division) over(region) nofillytitle("Degrees Fahrenheit")title("Average January temperature")subtitle("by region and division of the United States")note("Source: U.S. Census Bureau, U.S. Dept. of Commerce") ; #delimit cr三十二、分组复式条图sysuse nlsw88, clear#delimit ;graph bar wage, over(smsa, descend gap(-30)) over(married)over(collgrad, relabel(1 "Not college graduate" 2 "College graduate"))ytitle("")title("Average Hourly Wage, 1988, Women Aged 34-46")subtitle("by College Graduation, Marital Status, and SMSA residence")note("Source: 1988 data from NLS, U.S. Dept. of Labor, Bureau of Labor Statistics") ;#delimit cr三十三、水平堆积条图sysuse educ99gdp, cleargenerate total = private + public#delimit ;graph hbar (asis) public private,over(country, sort(total) descending) stacktitle("Spending on tertiary education as % of GDP, 1999", span pos(11))subtitle(" ")note("Source: OECD, Education at a Glance 2002", span) ; #delimit cr三十四、水平条图sysuse nlsw88, clear#delimit ;graph hbar wage, over(ind, sort(1)) over(collgrad)title("Average hourly wage, 1988, women aged 34-46", span)subtitle(" ")note("Source: 1988 data from NLS, U.S. Dept. of Labor, Bureau of Labor Statistics", span)ysize(7) ;#delimit cr三十五、带标注的横向组合条图sysuse nlsw88, clear#delimit ;graph hbar wage, over( occ, axis(off) sort(1) ) blabel( group, pos(base) color(bg) )ytitle( "" )by( union,title("Average Hourly Wage, 1988, Women Aged 34-46")note("Source: 1988 data from NLS, U.S. Dept. of Labor, Bureau of Labor Statistics") ) ;#delimit cr三十六、带参考线的分类散点图sysuse nlsw88, clear#delimit ;graph dot wage, over(occ, sort(1))ytitle("")title("Average hourly wage, 1988, women aged 34-46", span)subtitle(" ")note("Source: 1988 data from NLS, U.S. Dept. of Labor, Bureau of Labor Statistics", span) ;#delimit cr三十七、带参考线的分类散点图sysuse nlsw88, clear#delimit ;graph dot (p10) p10=wage (p90) p90=wage,over(occ, sort(2))legend(label(1 "10th percentile") label(2 "90th percentile"))title("10th and 90th percentiles of hourly wage", span)subtitle("Women aged 34-46, 1988" " ", span)note("Source: 1988 data from NLS, U.S. Dept. of Labor, Bureau of Labor Statistics", span) ;#delimit cr三十八、带参考线横向组合的分类散点图sysuse nlsw88, clear#delimit ;graph dot wage,over(occ, sort(1))by(collgrad,title("Average hourly wage, 1988, women aged 34-46", span)subtitle(" ")note("Source: 1988 data from NLS, U.S. Dept. of Labor, Bureau of Labor Statistics", span) );#delimit cr三十九、箱式图(须髯图)sysuse bplong, clear#delimit ;graph box bp,over(when) over(sex)ytitle("Systolic blood pressure")title("Response to treatment, by Sex")subtitle("(120 Preoperative Patients)" " ")note("Source: Fictional Drug Trial, Stata Corporation, 2003") ; #delimit cr四十、水平箱式图(须髯图)sysuse nlsw88, clear#delimit ;graph hbox wage,over(ind, sort(1)) nooutsideytitle("")title("Hourly wage, 1988, woman aged 34-46", span)subtitle(" ")note("Source: 1988 data from NLS, U.S. Dept. of Labor, Bureau of Labor Statistics", span) ;#delimit cr四十一、横向组合水平箱式图(须髯图)sysuse nlsw88, clear#delimit ;graph hbox wage,over(ind, sort(1)) nooutsideytitle("")by(union,title("Hourly wage, 1988, woman aged 34-46", span)subtitle(" ")note("Source: 1988 data from NLS, U.S. Dept. of Labor, Bureau of Labor Statistics", span) );#delimit cr。
第三章 Stata中的图形制作(绝对自己总结)
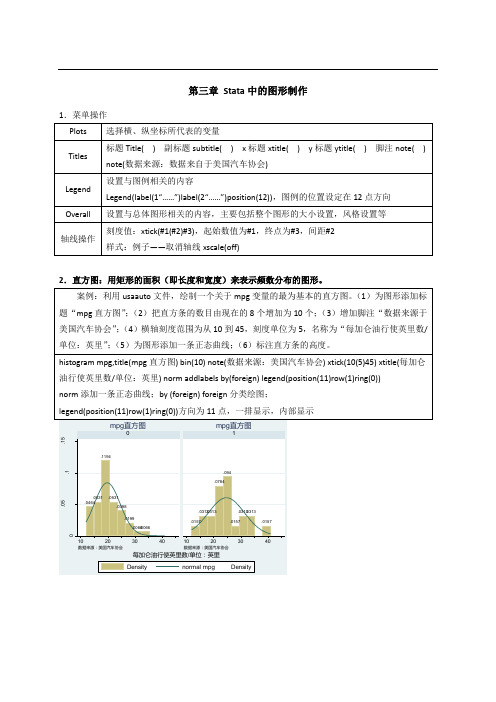
第三章 Stata 中的图形制作1.菜单操作2.直方图:用矩形的面积(即长度和宽度)来表示频数分布的图形。
D e n s i t y3.散点图:反映两个或多个变量之间的关系。
通常用纵轴来表示因变量,用横轴来表示自变量。
基本[twoway] scatter y x因变量在前数据标记的设定数据标记形状的设定、颜色的设定、大小的设定、散点标签的设定msymbol(散点形状代码);mcolor(red)散点为红色;msize(5)散点大小为5号散点标签:mlabel (标签内容的变量名)和mlabposition(代表钟表点数的数字)例如设定散点的内容为变量city,位置在3点钟处:mlabel (city) mlabposition(3) 群组划分:by(foreign)案例:运用usaauto数据文件中的数据绘制mpg和weight关系的散点图。
(1)为图形添加标题“mpg 与weight散点图”和副标题“1978年美国汽车数据图”;(2)为图形添加图例,位置在钟表2点钟处;(3)绘制一条拟合的趋势曲线;(4)将散点的形状设置为实心大三角,颜色为黑色;(5)为每个散点添加标签,内容为汽车的品牌(make),位置为9点钟处,颜色为黑色;(6)按照变量foreign分成两个图形进行绘制。
Twoway scatter mpg weight||lfit mpg weight,title(mpg与weight散点图) subtitle(1978年美国汽车数据图) legend(position(6))||表示多个图形在一个坐标轴中显示;lfit mpg weight 绘制拟合曲线 进一步设置:Msymbol(T) mcolor(black) mlabel(make) mlabpositon(9) by(foreign)散点形状:实心大三角,颜色:黑色,标签内容:make ,位置为9点钟处;按foreign 绘制4.曲线标绘图用线段的升降趋势来说明现象变化或变量之间关系的一种图形。
Stata绘图学习手册

Stata绘图学习⼿册转载请联系本⽂主要包括常见绘图的散点图、直⽅图、条形图、饼图等相关操作命令以及图⽰。
⼀.Stata图形汇总介绍graph twoway ⼆维图scatter 散点图histogram 直⽅图line 折线图area 区域图lfit 线性拟合图qfit ⾮线性拟合图kdensity 密度函数图function 函数图graph matrix 矩阵图graph bar 条形图graph dot 点图graph box 箱形图graph pie 饼图ac 相关系数图pac 偏相关系数图irf 脉冲相应函数图⼆.Stata 图形制作命令结构命令结构graph-command (plot-command, plot-options) (plot-command , plot-options) , graph-options或者graph-command plot-command,plot-options || plot-command , plot-options || , graph-options * graph-command定义图的类型,plot-command 定义曲线类型,同⼀个图中如果有多条曲线可以⽤括号分开,也可以⽤“| *”分开,曲线有其⾃⾝的选项,plot-command 定义曲线类型,同⼀个图中如果有多条曲线可以⽤括号分开,也可以⽤“| *”分开,曲线有其⾃⾝的选项,⽽整个图也有其选项。
例如twoway为graph-command中的命令之⼀,⽽scatter为plot-command *中的命令之⼀。
曲线选项和图选项,例如 * twoway (scatter mpg weight) , title("美国汽车") //图选项:标题 * twoway (scatter mpg weight , msymbol(Oh)) //曲线选项,点的类型上述命令没反应了直接敲 * twoway (scatter mpg weight , msymbol(Oh)) , title("美国汽车") //同时⽤图与曲线选项命令可以简写,如下列命令等价*sysuse auto, cleargraph twoway scatter mpg weighttwoway scatter mpg weight三.散点图散点图在各个绘图中占有重要作⽤,散点图具有表明变量之间关系的作⽤,因此在统计分析中得到⼴泛应⽤散点图的功能与意义:对数据进⾏预处理的重要图形之⼀,散点图深受专家学者的喜爱,散点图主要作⽤在于描绘某变量随着另⼀个变量变化的⼤致趋势,进⾏对变量之间的相关关系进⾏研究help twoway scattersysuse uslifeexp2, clearscatter le year, title("Scatterplot") subtitle("Life expectancy at birth, U.S.") note("1") caption("Source: National Vital Statistics Report, Vol. 50 No. 6") scheme(economist)四.直⽅图直⽅图⼜称为柱状图,是⼀种统计报告图,⼀般⽤横轴表⽰数据类型,纵轴表⽰分布状况,直⽅图可以表⽰分布状况变化,例如分别有⼀组数据,分别为地区,31个省份,然后分别为有⾼校的个数,分别字母region和number表⽰直⽅图命令为histogram number, frequency sysuse sp500histogram volumehistogram volume, frequency分组绘制直⽅图sysuse auto, clearhistogram mpg, percent discrete///by(foreign, col(1) note(分组指标:汽车产地)///title("图3:不同产地汽车⾥数")///subtitle("直⽅图") ///) ///ytitle(百分⽐) xtitle(汽车⾥数)五.折线图或者曲线标绘图折线图或者曲线标绘图是双向关系图中的⼀种,⽤线条的升降来表⽰变量或者现象之间的关系,与散点图的区别在于⽤线连接,可以看出整体趋势,但是弱化了每⼀个具体点上⾯的数值⼤⼩sysuse uslifeexp, cleargenerate diff = le_wm - le_bmlabel var diff "Difference"line le_wm year, yaxis(1 2) xaxis(1 2)|| line le_bm year|| line diff year|| lfit diff year|| lfit diff year||,ylabel(0(5)20, axis(2) gmin angle(horizontal)) ylabel(0 20(10)80, gmax angle(horizontal))ytitle("", axis(2))xlabel(1918, axis(2)) xtitle("", axis(2))ylabel(, axis(2) grid)ytitle("Life expectancy at birth (years)")title("White and black life expectancy")subtitle("USA, 1900-1999")note("Source: National Vital Statistics, Vol 50, No. 6" "(1918 dip caused by 1918 Influenza Pandemic)")六.条形图矩形的长度来表⽰相互独⽴的变量⼤⼩help graph bar命令格式1:graph bar yvars [if] [in] [weight] [, options]graph bar yvars [if] [in] [weight] [, options]graph hbar yvars [if] [in] [weight] [, options]基本⽤法: graph bar yvars ...sysuse nlsw88, cleargraph bar wage, over(race)累加柱体或者横向条形图sysuse educ99gdp, cleargraph hbar (mean) public private, over(country)重叠柱体sysuse nlsw88, cleargraph bar (mean) hours wage, over(race) over(married)七.饼图百分⽐图⽤圆形或者扇形内⼤⼩来表⽰总体中各部分所占⽐例的⼤⼩命令为帮助⽂件为help graph pie菜单式操作为Menu>raphics > Pie chartSyntaxSlices as totals or percentages of each variablegraph pie varlist [if] [in] [weight] [, options]Slices as totals or percentages within over() categories graph pie varname [if] [in] [weight], over(varname) [options] Slices as frequencies within over() categoriesgraph pie [if] [in] [weight], over(varname) [options]input sales marketing research developmentsales marketing research develop~t1. 12 14 2 82. end. label var sales "Sales". label var market "Marketing". label var research "Research". label var develop "Development". graph pie sales marketing research development, plabel(_all name, size(*1.5) color(white)) (Note 1) legend(off) (Note 2)plotregion(lstyle(none)) (Note 3)title("Expenditures, XYZ Corp.")subtitle("2002")note("Source: 2002 Financial Report (fictional data)")。
Stata中的图形制作(绝对自己总结)-精选.pdf

第三章Stata 中的图形制作1.菜单操作Plots 选择横、纵坐标所代表的变量Titles标题Title() 副标题subtitle() x 标题xtitle() y 标题ytitle() 脚注note()note(数据来源:数据来自于美国汽车协会)Legend设置与图例相关的内容Legend(label(1“……”)label(2“……”)position(12)),图例的位置设定在12点方向Overall 设置与总体图形相关的内容,主要包括整个图形的大小设置,风格设置等轴线操作刻度值:xtick(#1(#2)#3),起始数值为#1,终点为#3,间距#2 样式:例子——取消轴线xscale(off)2.直方图:用矩形的面积(即长度和宽度)来表示频数分布的图形。
案例:利用usaauto 文件,绘制一个关于mpg 变量的最为基本的直方图。
(1)为图形添加标题“mpg 直方图”;(2)把直方条的数目由现在的8个增加为10个;(3)增加脚注“数据来源于美国汽车协会”;(4)横轴刻度范围为从10到45,刻度单位为5,名称为“每加仑油行使英里数/单位:英里”;(5)为图形添加一条正态曲线;(6)标注直方条的高度。
histogram mpg,title(mpg 直方图) bin(10) note(数据来源:美国汽车协会) xtick(10(5)45) xtitle(每加仑油行使英里数/单位:英里) norm addlabels by(foreign) legend(position(11)row(1)ring(0)) norm 添加一条正态曲线;by (foreign) foreign 分类绘图;legend(position(11)row(1)ring(0))方向为11点,一排显示,内部显示.0464.0531.1194.0531.0398.0199.0066.0066.0157.0313.0313.0784.094.0157.0313.0313.0157.05.1.151020304010203040数据来源:美国汽车协会数据来源:美国汽车协会1mpg 直方图mpg 直方图Densitynormal mpg DensityDe n si t y 每加仑油行使英里数/单位:英里Graphs by Car type3.散点图:反映两个或多个变量之间的关系。
Stata_画图专题(2):基础绘图命令汇编

1.1 twoway function:函数图
命令格式
[[ ] ]
[ ][ ][
]
twoway function y = f(x) if in , options
其中下划线为命令的最简写形式,即 twoway 可简写为 tw;方括号内的部分均可省略,即可省 略 “y =” 这个部分;f (x) 是这个命令的主体,可以是一般数学函数式,也可以是 Stata 内已有
[ ][ ][
][
]
graph hbar yvars if in weight , options
其中 yvars 是变量列表,值的大小由 y 轴来刻画;而条形图中 x 轴代表的是类别,其宽度都是 一样的。比如有两组数据:男生人数 45 人和女生人数 50 人,那么条形图的主要用途是对比两 组人的数量(y 轴值)。在命令中,yvars 除了要填多个变量,而且在变量列表前还需加上需对 比的统计量2。表 3 中列举了常用的一些。若想如实反映3,则命令为 (axis)。注意:这些统计 量需放置于变量列表 yvars 之前,且需要用英文括号括起来。
stata中常用图形twowayfunctiontwowayhistogram绘制普通的数学统计函数图形与数据库数据无关用两组数据构成多个坐标点考察坐标点的分布由一系列高度不等的纵向条纹或线段表示某一组数据分布情况b对数据集做简单的总结又因形状如箱子而得名1112131415161718图形名称函数图散点图直方图条形图点统计图箱线图饼图矩阵图graphgraphgraphgraphgraphbardotboxpiematrix一般用于判断两变量之间是否存在某种关联或总结坐标点的分布模式
可选参数 [options] 需要讲两个:
• “分组”。前面说的画条形图需要先分组,那么分组的命令是 over(varname[, over_subopts]), 即按某一变量 varname 来分组;[over_subopts] 是次可选项,比如 sort(#) 表示 “按第 # 组的值排序后绘图”。最简单的形式4可以参看表 4;
第7讲 stata作图
坐标轴刻度及刻度标签 刻度及标签 主刻度及标签:ylabel(),xlabel() 主刻度: ytick(),xtick() 子刻度及标签:ymlabel(),xmlabel() 子刻度: ymtick(),xmtick()
图形管理 图形保存 第一种方式 sysuse sp500,clear twoway line high date graph save fig1.gph,replace graph use fig1.gph 第二种方式 twoway line high date,saving(price.gph,replace) 手动方式 右键->save graph.. 图形调用 graph use fig1.gpraph twoway 二维图 scatter 散点图 line 折线图 area 区域图 lfit 线性拟合图 qfit 非线性拟合图 histogram 直方图 kdensity 密度函数图 function 函数图 graph matrix 矩阵图 graph box 箱型图 graph dot 点图 graph bar 条形图 graph pie 饼图
双坐标系 共用X轴 sysuse sp500,clear twoway line close change date twoway (line close date, yaxis(1))/// (line change date,yaxis(2)) twoway (line close date,yaxis(1))/// (line change date,yaxis(2)),/// ylabel(-50(10)40) 单独的y轴和x轴 twoway (line close date, yaxis(1) xaxis(1)) (line change date,yaxis(2) xaxis(2))
如何用Stata作漂亮的图?来看超详细教程!

如何用Stata作漂亮的图?来看超详细教程!概要本文涉及到的内容包括,在拿到一个数据集后:如何使用list、describe命令,初步了解数据集;如何使用codebook、summarize命令了解某一个变量x的缺失值、统计量,并使用stem、graph box、histogram命令画出茎叶图、箱式图以及柱状图;如何使用twoway graphs来展示数值型变量x和y之间的关系,并画出散点图(scatter plot)、折线图(line plot)、带数据标记的直线图(connected plot)等多种图像;如何使图像变得更加美观。
下面,我们通过例子来了解这些命令。
本次使用的是1900-1999年美国期望寿命的数据,这是Stata 14.0自带的一个数据库。
提醒(1) 使用Stata时,尽量不用命令框,而最好使用do file编写命令。
这样可以保证操作的可重复性。
(2) 本文中,所有命令以黄色背景、粗体、蓝色字体显示。
(3) do file中命令末尾的双斜线//表示添加注释(例如,图0.1.1第6行set linesize 255后为注释),三斜线///表示换行(例如,图0.1.1从第8行到16行为一个完整的命令,其中使用///换行)。
图0.1.11. 导入数据并观察图1.1.1 Stata 14.2自带的数据库. sysuse uslifeexp这一步的目的是导入该系统自带数据。
屏幕显示的结果如下。
. list in 1/10通过这个命令,我们可以查看该数据库第1到第10个数据,对数据有一个初步的了解。
屏幕显示的结果如下。
. describe通过这个命令,我们可以查看这个数据集的简要介绍,包括了样本数量(obs:100)、变量数量(vars:10)、大小(size:3800)、以及每个标量的简要介绍。
屏幕显示的结果如下。
2. 单变量探索以及作图在这一小节中,我们一起来对某一个变量进行探索。