第四章 多重共线性和虚拟变量的应用
虚拟变量实验报告感想

通过本次虚拟变量实验,我对虚拟变量有了更加深入的理解和认识,感受到了其在计量经济学中的重要作用。
以下是我对本次实验的一些感想。
一、虚拟变量的重要性虚拟变量在计量经济学中具有举足轻重的地位。
它可以将定性变量转化为定量变量,使模型更加全面地反映经济现象。
在现实生活中,许多因素都是定性因素,如性别、民族、地区等,这些因素无法直接用数值表示,但它们对经济现象的影响却是客观存在的。
虚拟变量恰好能够将这些定性因素纳入模型,使模型更加准确、全面地反映经济现象。
二、虚拟变量的设定在本次实验中,我们学习了如何设定虚拟变量。
首先,要明确虚拟变量的含义和作用,然后根据研究目的和实际数据情况,确定虚拟变量的个数。
需要注意的是,当定性变量含有m个类别时,应引入m-1个虚拟变量,以避免多重共线性问题。
此外,虚拟变量的取值应遵循互斥和完备的原则,即每个样本只能属于一个类别。
三、虚拟变量的估计与检验在本次实验中,我们运用Eviews软件对虚拟变量模型进行了估计和检验。
通过观察模型的回归结果,我们可以了解虚拟变量对因变量的影响程度。
此外,我们还可以通过t检验、F检验等方法对虚拟变量的显著性进行检验。
在检验过程中,要注意控制其他变量的影响,以确保检验结果的可靠性。
四、虚拟变量的应用虚拟变量在实际应用中非常广泛。
以下是一些常见的应用场景:1. 时间序列分析:在时间序列分析中,虚拟变量可以用来表示季节性、节假日等因素对经济现象的影响。
2. 州际差异分析:在分析不同地区经济现象时,可以引入地区虚拟变量,以反映地区间的差异。
3. 政策效应分析:在分析政策对经济现象的影响时,可以引入政策虚拟变量,以观察政策实施前后经济现象的变化。
4. 模型设定:在构建计量经济模型时,可以引入虚拟变量来表示定性因素,使模型更加全面。
五、实验收获通过本次虚拟变量实验,我收获颇丰。
首先,我掌握了虚拟变量的基本原理和操作方法,为今后的研究奠定了基础。
其次,我学会了如何设定虚拟变量、估计模型和检验结果,提高了自己的实践能力。
计量经济学复习知识点重点难点

计量经济学复习知识点重点难点计量经济学知识点第一章导论1、计量经济学的研究步骤:模型设定、估计参数、模型检验、模型应用。
2、计量经济学是统计学、经济学和数学的结合。
3、计量经济学作为经济学的一门独立学科被正式确立的标志:1930年12月国际计量经济学会的成立。
4、计量经济学是经济学的一个分支学科。
第二章简单线性回归模型1、在总体回归函数中引进随机扰动项的原因:①作为未知影响因素的代表;②作为无法取得数据的已知因素的代表;③作为众多细小影响因素的综合代表;④模型的设定误差;⑤变量的观测误差;⑥经济现象的内在随机性。
2、简单线性回归模型的基本假定:①零均值假定;②同方差假定;③随机扰动项和解释变量不相关假定;④无自相关假定;⑤正态性假定。
3、OLS回归线的性质:①样本回归线通过样本均值;②估计值的均值等于实际值的均值;③剩余项ei的均值为零;④被解释变量的估计值与剩余项不相关;⑤解释变量与剩余项不相关。
4、参数估计量的评价标准:无偏性、有效性、一致性。
5、OLS估计量的统计特征:线性特性、无偏性、有效性。
6、可决系数R2的特点:①可决系数是非负的统计量;②可决系数的取值范围为[0,1];③可决系数是样本观测值的函数,可决系数是随抽样而变动的随机变量。
第三章多元线性回归模型1、多元线性回归模型的古典假定:①零均值假定;②同方差和无自相关假定;③随机扰动项和解释变量不相关假定;④无多重共线性假定;⑤正态性假定。
2、估计多元线性回归模型参数的方法:最小二乘估计、极大似然估计、矩估计、广义矩估计。
3、参数最小二乘估计的性质:线性性质、无偏性、有效性。
4、可决系数必定非负,但是根据公式计算的修正的可决系数可能为负值,这时规定为0。
5、可决系数只是对模型拟合优度的度量,可决系数越大,只是说明列入模型中的解释变量对被解释变量的联合影响程度越大,并非说明模型中各个解释变量对被解释变量的影响程度也大。
6、当R2=0时,F=0;当R2越大时,F值也越大;当R2=1时,F→∞。
虚拟变量回归

数据收集
收集不同市场细分群体的基本信息和 产品需求数据,如年龄、性别、收入、 消费习惯等。
变量设置
将市场细分变量转换为虚拟变量,并 引入到回归模型中。
结果分析
分析虚拟变量的系数和显著性,解释 其对产品需求的影响,为市场定位提 供依据。
案例三:教育程度与收入水平的关系研究
目的
研究教育程度对收入水平的影响,以及 不同教育程度对收入水平的差异。
虚拟变量可能依赖于某些自变量,需 要谨慎处理以避免多重共线性问题。
REPORT
CATALOG
DATE
ANALYSIS
SUMMAR Y
03
虚拟变量回归的模型构 建
线性回归模型
线性回归模型是最常用的回归分析方法之一,用 于探索自变量与因变量之间的线性关系。
在线性回归模型中,虚拟变量可以作为自变量引 入,以解释和预测因变量的变化。
变量设置
将教育程度转换为虚拟变量,并引入 到回归模型中。
数据收集
收集受访者的教育程度和收入水平数 据。
结果分析
分析虚拟变量的系数和显著性,解释 其对收入水平的影响,为职业规划和 教育投资提供参考。
案例四:健康状况与生活习惯的关系研究
目的
数据收集
研究生活习惯对健康状况的影响,以及不 同生活习惯对健康状况的差异。
虚拟变量回归的应用场景
1 2
社会科学研究
在社会科学研究中,经常需要研究分类变量对连 续变量的影响。例如,研究不同教育程度或不同 职业对收入的影响。
生物统计学
在生物统计学中,虚拟变量回归可用于研究基因 型、物种或地理区域等因素对连续变量的影响。
3
市场分析
在市场分析中,虚拟变量回归可用于研究不同产 品类别、品牌或市场细分对销售或其他连续变量 的影响。
虚拟变量 实验报告

虚拟变量实验报告引言虚拟变量(dummy variable)是在统计学中常用的一种技术,用于表示分类变量。
通过将分类变量转换为二进制数值变量,虚拟变量可以在回归分析、方差分析以及其他统计模型中发挥重要作用。
本实验报告旨在介绍虚拟变量的概念、用法以及在实际应用中的一些注意事项。
虚拟变量的定义虚拟变量是一种二元变量,用于表示某个特征是否存在。
通常情况下,虚拟变量的取值为0或1。
虚拟变量可以用于将分类变量转换为数值变量,使其适用于各种统计模型。
虚拟变量的应用虚拟变量主要用于以下两个方面的统计模型:1. 回归分析在回归分析中,虚拟变量被用于表示一个分类变量的不同水平。
例如,在研究某产品的销售量时,可以引入虚拟变量表示该产品是否进行了促销活动。
这样,回归模型就可以分析促销活动对销售量的影响。
2. 方差分析方差分析是一种用于比较不同组之间差异的统计方法。
虚拟变量可以用于表示不同组的存在与否。
例如,在研究不同药物对某种疾病治疗效果时,可以引入虚拟变量表示不同药物的使用与否,进而进行方差分析。
如何创建虚拟变量创建虚拟变量的方法通常有两种:1. 单变量编码单变量编码是最常见的创建虚拟变量的方法。
对于具有k个水平的分类变量,单变量编码将该变量转换为k-1个虚拟变量。
其中,k-1个虚拟变量分别表示k个水平的存在与否。
例如,在研究不同颜色对产品销售量的影响时,可以使用单变量编码将颜色变量转换为两个虚拟变量,分别表示是否为蓝色和是否为红色。
2. 二进制编码二进制编码是一种使用更少虚拟变量的方法。
对于具有k个水平的分类变量,二进制编码将该变量转换为log2(k)个虚拟变量。
其中,每个虚拟变量都表示一个水平的存在与否。
例如,在研究不同国家对某项政策的支持时,可以使用二进制编码将国家变量转换为几个虚拟变量,每个虚拟变量表示一个国家的存在与否。
虚拟变量的注意事项在使用虚拟变量时需要注意以下几点:1.避免虚拟变量陷阱:虚拟变量陷阱是指多个虚拟变量之间存在完全共线性的情况,这会导致回归模型的多重共线性。
虚拟变量(哑变量)回归

Di = 1 ,是女性
= 0 ,不是女性
例2:大学生年级变量具有四个类别,如何构造?
Yi
b0
b1D1i
b2D2ib3D3i Nhomakorabeab4D4i
ui
“虚拟变量 陷阱”
其中,
D1=1,是大一,否则为0; D2=1,是大二,否则为0;
D3=1,是大三,否则为0; D4=1,是大三,否则为0。
虚拟变量的建立
状况对妇女曾生子女数(CEB)的影响。
其中,文化程度分为文盲或半文盲(1)、小学(2)、初中(3)、 高中(4)和大学(5)共五类 居住地分为城市(1)和农村(2)共两类。
读书破万卷,下笔如有神--杜甫
精品文档 欢迎下载
虚拟变量回归只能做其他类和参照类的比较
直接对任意两个回归系数之差进行检验的方法:
1、建立无差异假设:H0:Bi=Bj; H1:Bi≠Bj
2、构造t统计量:
t
bi bj S(bi bj )
~ tnk 1
3、检验其显著性
S 其中
(bi bj )
vii v jj 2vij
补充问题
参照类的选择
根据研究者的选择偏好,无实质性影响
(0)
虚拟变量回归系数的意义
参照类:大一男生(所有虚拟变量均取0)
^
Y b0 b1INCOME
(1)
变式1:大二男生(DG2=1,虚拟变量均取0)
^
Y b0 b1INCOME b2
(2)
变式2:大一女生(DS=1,虚拟变量均取0)
^
Y b0 b1INCOME b4
(3)
参照类中,b0为直线的截距,b1为直线斜率,即 INCOME 的回归系数
计量经济学复习要点

计量经济学复习要点第一篇:计量经济学复习要点计量经济学复习要点第一章、概率论基础1.随机事件的概念P22.古典概行例题P5例1.1P2例1.2利用第一章的知识说明抽签的合理性如何利用第一章的知识估计一个池塘有多少鱼还有一个关于晚上紧急集合穿错鞋的题目,记不太清楚了3.期望与方差的概念,切比雪夫不等式,看例题1.4-例题1.8,不要求求出数4.变异系数的概念P175.大数定律和中心极限定律(具有独立同分布的随机变量序列的有限和近似地服从正态分布)的概念P24、P25第二章、矩阵代数1.矩阵的定义,加(page29)、减(page29)、乘(page30)、转置(page30)、逆(page31)知道怎么回事2.最小二乘法P39-P41(定义最小二乘解)3.第三节没有听,求听课学霸补充第三章、数据的分析方法和参数的统计推断1.数据的分析方法(算数平均、加权算数平均、几何平均、移动平均)(1)几种分析方法的定义(2)几中分析方法的不同(3)每种分析方法的具体作用(4)移动平均法中k的选择(5)指数平滑法的意义,α的选择,P552.t分布的概率密度函数3.矩估计法定义4.几大似然估计法P65,例题3.7例题3.85.贝叶斯估计和极大极小估计(应该是只看一下概念就可以了)6.假设检验(1)基本思想P75(2)双边假设检验(3)单边假设检验(4)参数检验P807.方差分析的思想、作用和模型第四章、一元线性回归(计算题)回归方程的求法,显著性检验,经济解释(各参数的解释),不显著的解释第六章、虚拟变量的回归模型1.虚拟变量的作用及模型2.应用虚拟变量改变回归直线的截距、斜率3.对稳定性的检验第二篇:2007计量经济学复习要点2007年计量经济学课程要点归纳1.十大经典假设的证明(关于两变量模型的性质检验)2.BLUE估计量的证明3.自相关检验方法(检验方法一定要记住)4.异方差检验方法(至少三种)5.孙老师讲过的附录要留意6.异方差与自相关的补救措施7.违反十大经典假设情况下的问题怎么解决(如多重共线性,异方差,自相关问题,虚拟变量的估计)注:以上重点均是提供参考,不做考试说明计量考察的重点是对计量模型的建立与估算,结果评价与补救思路的考察,没有大量的数学计算,请同学们放心!建议大家根据参考要点确定进度,并根据孙老师上课的重点决定自己的复习范围!希望同学们认真复习,考出好成绩!王琳第三篇:计量经济学复习笔记计量经济学复习笔记CH1导论1、计量经济学:以经济理论和经济数据的事实为依据,运用数学、统计学的方法,通过建立数学模型来研究经济数量关系和规律的一门经济学科。
计量经济学(共33张PPT)

假定3>2,其几何意义:
问题:
虚拟变量为何只选“0”, ‘1“,选择0,1,2 等 可以吗
同一种属性,两个变量能够表示几种状态? 思考,如果在模型中引入季节效应?月份效应?
(3)多个虚拟变量的引入——多种因素
例:研究学历(本科及以上,本科以下),性别(男、女)对员工工资的 影响。
在例1基础上,再引入代表学历的虚拟变量D2:
离散选择模型(离散被解释变量)
D (2)多个虚拟变量的设定和引入 0 女职工本科以上学历的平均薪金:
本科以下
当回归模型有截距项时,只能引入 m-1 个虚拟变量
注意:加法方式引入虚拟变量,考察了截距的不同。
交互作用的引入方法:在模型中引入相关变量的乘积。
反映性别的虚拟变量可取为: 女职工本科以下学历的平均薪金:
几何意义:
•两个函数有相同的斜率,说明男女职工平均薪金对工龄的变 化率是一样的。
•如果2>0,表明两个函数截距不相同,且男职工平均薪金比 女职工高,两者平均薪金水平相差2。 •如果2<0,表明两个函数截距不相同,且男职工平均薪金比女 职工低,两者平均薪金水平相差2。 •如果2=0,表明两个函数截距相同,即男职工,女职工的平
均薪金没有显著差异。
可以通过传统的回归检验,对2的统计显著性进行 检验,以判断企业男女职工的平均薪金水平是否有 显著差异。
2
0
(2)多个虚拟变量的设定和引入
——一种因素多种状态(水平):
例:研究收入和教育水平(分为高,中,低三类)对个人保健支出的影响。
教育水平考虑三个层次:
低学历:高中以下,
中等学历:高中,及大中专 高学历:大学及其以上。
2、基本概念
定量因素——可直接测度,数值性的因素 定性因素——属性因素,表征某种属性存在
虚拟变量
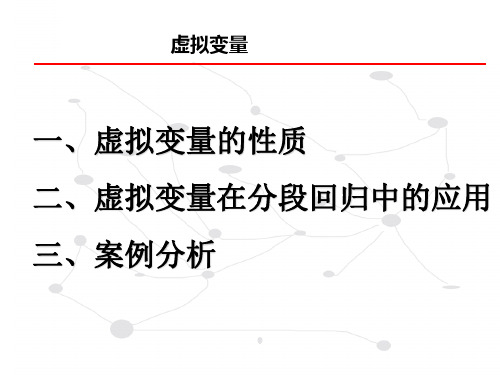
加法+乘法类型:反映相异回归
• 以乘法形式引入虚拟解释变量,是在设定的计量经济模 型中,将 虚拟解释变量与其他解释变量相乘作为解释变 量,以表示模型中斜率系数的差异。 • 以乘法形式引入虚拟解释变量的主要作用是:
第一:分析因素间的交互影响;
第二:分段线性回归,提高模型对现实经济现象的 描述精度 。
分段回归的实际应用
公司是如何酬劳其销售代表的? 其支付佣金的方式取决于销售量的一个目标或
临界水平X *
销售佣金在临界值X *之前随销售量线性增加, 在这个临界值之后仍线性增加,只是斜率更大。 于是得到由两段构成的分段线性回归
销售佣金是在临界值处改变斜率的。
类似的例子 税金的缴纳,产出与成本之间的关系
* * *
R 2 0.882 R 2 0.866 F 54.78
用虚拟变量表示不同斜率的回归 ---乘法类型:分段线性回归
根据以上分析,可以推导出两个时期的
储蓄-收入回归方程:
平均储蓄函数:1970-1981年 ˆ 1.02 0.0803 X Y
t
平均储蓄函数:1982-1995年 ˆ Y ( 1.02 152.48) (0.0803 0.0655)X
用虚拟变量表示不同斜率的回归 ---乘法类型:分段线性回归
储蓄—收入的回归方程:
Yt 1 2 Dt 1 Xt 2 Dt Xt ut
Y—个人储蓄, X—个人可支配收入
1, 观察值从1982年开始 Dt 0, 其他(观察值到1982年)
Y 1 1 X 2 X X D ut
回归的类型
虚拟变量模型的性质
根据加入的途径,可以将虚拟变量模型分成两种类型:
研究生经济学计量经济学知识点归纳总结

研究生经济学计量经济学知识点归纳总结经济学是一门研究人类社会经济活动的学科,而计量经济学则是经济学中一个重要的分支,它运用数理统计和计量方法来研究经济现象和经济关系。
作为研究生学习经济学的学生,对计量经济学的知识点归纳总结是非常重要的。
本文将就研究生经济学计量经济学的主要知识点进行系统梳理和总结。
1. 计量经济学简介1.1 计量经济学的定义与发展- 计量经济学的定义及其在经济学中的地位- 计量经济学的发展历程及其与经济学的关系1.2 计量经济学的基本原理与方法- 建立与检验经济模型的方法- 如何进行数据的采集和处理- 计量经济学常用的工具与技术2. 单变量回归模型2.1 单变量回归模型的基本概念- 自变量、因变量、误差项的含义和关系- 回归分析的基本思想和目标2.2 单变量回归模型的估计与检验 - 最小二乘法估计- 各类假设检验- 回归模型的拟合度与解释度2.3 单变量回归模型的应用与扩展 - 异常值与多重共线性的处理- 非线性回归模型的建立与分析 - 面板数据模型的应用3. 多元回归模型3.1 多元回归模型的基本概念- 多个自变量与一个因变量的关系 - 多元回归模型的形式和假设3.2 多元回归模型的估计与检验- 最小二乘法估计与系数解释- 多元回归模型常见检验方法3.3 多元回归模型的应用与扩展- 多重共线性与变量选择- 面板数据模型的建立与应用- 虚拟变量与交互项的使用4. 时间序列分析4.1 时间序列分析的基本概念- 时间序列数据的特点与类型- 时间序列分析的目标和方法4.2 时间序列模型的建立与估计- AR、MA、ARMA模型的定义和性质 - 时间序列模型的参数估计方法4.3 时间序列模型的诊断与预测- 残差序列的诊断方法- 时间序列的预测与模型选择5. 面板数据分析5.1 面板数据的概念和分类- 面板数据的含义和特点- 面板数据的分类及其应用领域5.2 面板数据模型的估计与检验- 固定效应模型与随机效应模型的概念- 面板数据模型的估计方法和效果评估5.3 面板数据模型的应用与扩展- 异质性与端点问题的处理- 面板数据模型的非线性建模方法- 面板数据模型的动态分析框架通过对以上内容的整理和总结,我们可以对研究生经济学计量经济学的主要知识点有一个全面的了解和掌握,为今后的学习和研究提供良好的基础。
计量经济学4.3多重共线性

对数据进行清洗,处理缺失值和异常 值,进行描述性统计分析和可视化, 以初步了解数据分布和特征。
模型构建与求解过程
变量选择
模型设定
模型求解
根据研究目的和理论基础,选 择与被解释变量(贷款违约风 险)相关的解释变量(如年龄 、收入、负债比等),并控制 其他可能影响结果的变量(如 性别、教育程度等)。
诊断工具
相关系数矩阵
通过观察解释变量之间的相关系数,可以初步判断是否存在多重 共线性。当相关系数较高时,可能存在多重共线性问题。
散点图与回归分析
通过绘制散点图并进行回归分析,可以直观地观察解释变量之间的 线性关系,从而判断是否存在多重共线性。
方差分解与主成分分析
利用方差分解和主成分分析方法,可以诊断多重共线性的来源和影 响程度。
采用多元线性回归模型,以贷 款违约风险为被解释变量,以 上述解释变量为自变量,构建 计量经济学模型。
运用最小二乘法(OLS)对模型 进行求解,得到各解释变量的系 数估计值、标准误、t统计量和p 值等。
结果展示与解读
结果展示
将模型求解结果以表格形式展示,包括各解释变量的系数估计值、标准误、t统计量、p值和置信区间等。
检验方法
方差膨胀因子(VIF)检验
通过计算解释变量的方差膨胀因子,判断是否存在多重共线性。当VIF值远大于1时,表明存在严 重的多重共线性。
条件指数(CI)检验
利用条件指数的大小来判断多重共线性的程度。条件指数越大,多重共线性问题越严重。
特征根与条件数检验
通过计算特征根和条件数来判断多重共线性的存在。当特征根接近于0或条件数较大时,表明存 在多重共线性。
案例分析
案例一
通过收集某地区房价、人口、收入等变量的数据,建立计量经济学模型进行实证分析。在模型检验过 程中,发现房价与人口、收入之间存在较高的相关系数,且VIF值较大,表明存在多重共线性问题。 经过进一步诊断和处理,最终得到合理的模型结果。
计量经济学重点内容

第一章导论计量经济学定义:计量经济学(Econometrics)是一门应用数学、统计学和经济理论来分析、估计和检验经济现象与理论的科学。
通过使用统计数据和经济模型,计量经济学试图量化经济关系,以更好地理解经济变量之间的相互作用。
研究的问题(相关关系):计量经济学的目的是研究经济变量之间的关系,例如:1. 消费与收入的关系。
2. 教育与工资的关系。
3. 利率与投资的关系。
第二章 OLS (普通最小二乘法):OLS 是一种用于估计线性回归模型中未知参数的方法。
它通过最小化误差平方和来找到回归线。
在一元线性回归中,我们通常使用普通最小二乘法(OLS)来估计模型参数。
对于模型 Y = α + βX + ε,我们可以使用以下公式来计算α和β:β= Σ( (X - mean(X)) (Y - mean(Y)) ) / Σ( (X - mean(X))^2 ) α̂ = mean(Y) - β̂ * mean(X)这里,mea n(X) 是 X 变量的平均值(即ΣX/n),mean(Y) 是 Y 变量的平均值(即ΣY/n)。
在这些公式中,mean 表示求平均值。
Σ 表示对所有数据点求和,n 是样本大小。
这里α_hat 是截距的估计值,β_hat 是斜率的估计值。
结论及推论:1. 在高斯马尔可夫假设下,OLS 估计量是最佳线性无偏估计量(BLUE)。
2. 当误差项的方差是常数时,OLS 估计量是有效的。
3. 如果模型是正确规范的,并且误差项是独立且同分布的,那么 OLS 估计量是一致的。
4. 如果误差项与解释变量相关,或者存在遗漏变量,那么 OLS 估计量可能是有偏的。
5. OLS 提供了估计的标准误差、t 统计量和其他统计量,这些可以用于进行假设检验和构建置信区间。
第三章一元回归:(1)总函、样函:总函数和样本函数是线性回归模型的两种表现形式。
总函数(总体函数)表示整体样本的关系,一般形式为Y = β0 + β1X + ε。
计量经济学第四章完整课件

并举例说明它们在多元线性回归模型中
的应用。
3
三元及以上的模型形式
介绍三元甚至更高元线性回归模型的形 式和特点,以及如何使用OLS方法对其进 行参数估计。
虚拟变量的提出及其意义
介绍虚拟变量的提出及其意义,比如如 何解决分类变量无法进行直接运算的问 题。
OLS的代数性质
算术型和几何型
介绍OLS方法多元线性回归模型 中的代数性质,以及如何理解 算术型和几何型模型。
2 决定系数
介绍决定系数的概念、计算方法和意义,在实际问题中它常用来度量模型的拟合优度。
3 调整后的决定系数
介绍调整后的决定系数的概念、计算方法和意义,在实际问题中它比决定系数更加准确 地度量了模型的拟合优度。
多元线性回归模型的精确定义
1
解释变量和控制变量的区别
2
介绍解释变量和控制变量的概念和区别,
OLS估计量的性质
介绍OLS估计量的无偏性、一致 性、有效性和正态性等性质,以 及它们在实际问题中的影响。
OLS的假设条件
介绍OLS估计方法的假设条件, 包括线性和可加性、无自相关性、 零均值和同方差性等。
模型拟合优度的度量
1 相关系数
介绍相关系数的概念、计算方法和意义,在实际问题中它常用来度量两个变量之间的线 性关系。
OLS系数估计量的可加性 和线性性
介绍OLS估计量的可加性和线性 性在多元线性回归模型中的应 用。
方差和协方差的估计
介绍如何利用OLS方法对方差和 协方差进行估计,以及估计量 的属性和应用。
经济变量的分类
将经济变量按照性质、应用领域、研究对象等多个维度进行分类,帮助您更好地理解和分析 变量。
经济变量的测度
介绍经济变量的测度方法,包括定量测度和定性测度,以及各自的优劣势。
计量经济学(庞皓)课后思考题答案解析

思考题答案第一章 绪论思考题1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用?答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。
计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。
经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。
我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。
1.2理论计量经济学和应用计量经济学的区别和联系是什么?答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。
理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。
所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。
应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。
1.3怎样理解计量经济学与理论经济学、经济统计学的关系?答:1、计量经济学与经济学的关系。
联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。
区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。
2、计量经济学与经济统计学的关系。
联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。
逻辑回归的变量类型的处理方法-概述说明以及解释

逻辑回归的变量类型的处理方法-概述说明以及解释1.引言1.1 概述逻辑回归是一种常用的分类算法,可以用于预测二分类问题。
在应用逻辑回归之前,针对不同类型的变量,我们需要对其进行处理,以确保模型的准确性和可靠性。
本文将详细介绍逻辑回归中变量类型的处理方法。
在进行逻辑回归之前,我们首先需要了解不同变量类型的分类。
变量可以分为两大类:连续变量和离散变量。
连续变量是在一个范围内有无限多个可能值的变量,例如年龄、身高等。
而离散变量则是只有有限个可能值的变量,例如性别、学历等。
针对连续变量,我们通常采取的处理方法是进行归一化或者标准化。
归一化可以将变量的取值范围缩放到0-1之间,而标准化则是将变量的取值转化为均值为0,标准差为1的正态分布。
通过这些处理方法,可以消除不同变量之间的量纲差异,使得模型更加准确。
对于离散变量,我们可以采用编码的方式进行处理。
常见的编码方法有哑变量编码和标签编码。
哑变量编码将原始的离散变量转化为多个二进制变量,用于表示每个可能取值的存在与否。
而标签编码则是将每个取值映射为一个数字。
通过这些编码方法,可以将离散变量转化为模型可以处理的数值。
在本文的接下来的部分,我们将详细介绍连续变量和离散变量的处理方法,并给出具体的示例和实践经验。
同时,我们也会讨论处理不平衡数据和缺失值的相关策略,以提高模型的准确性和稳定性。
总的来说,逻辑回归的变量类型的处理方法对于建立准确可靠的模型至关重要。
通过合理的处理方法,我们可以充分利用各个变量的信息,提高模型的预测能力,为实际问题的解决提供有力的支持。
在接下来的章节中,我们将一一介绍并深入讨论这些处理方法及其应用。
1.2文章结构文章结构部分的内容编写如下:1.2 文章结构本文主要围绕逻辑回归的变量类型展开讨论,在以下章节中将详细介绍不同变量类型的处理方法。
首先,我们将在第2.1节对变量类型进行分类,包括连续变量和离散变量。
随后,在第2.2节中,我们将重点介绍连续变量的处理方法,包括数据标准化、离群值处理和多项式特征构造等。
计量经济学知识点

计量经济学知识点计量经济学是一门融合了经济学、统计学和数学的交叉学科,它运用数学和统计方法来分析经济数据,从而揭示经济现象之间的数量关系和规律。
以下将为您介绍一些计量经济学的重要知识点。
一、回归分析回归分析是计量经济学的核心方法之一。
简单线性回归模型是最基础的形式,它假设因变量(Y)与一个自变量(X)之间存在线性关系,可以用方程 Y =β₀+β₁X +ε 来表示。
其中,β₀是截距,β₁是斜率,ε 是随机误差项。
在进行回归分析时,我们需要估计参数β₀和β₁。
常用的估计方法是最小二乘法,其目标是使残差平方和最小。
通过计算得到的回归系数可以解释自变量对因变量的影响程度。
多元线性回归则是将简单线性回归扩展到多个自变量的情况,模型变为 Y =β₀+β₁X₁+β₂X₂+… +βₖXₖ +ε。
回归分析还需要进行一系列的检验,包括模型的拟合优度检验(如R²统计量)、变量的显著性检验(t 检验)和整体模型的显著性检验(F 检验)等。
二、异方差性异方差性是指误差项的方差不是恒定的,而是随着自变量的取值不同而变化。
这会导致最小二乘法估计的有效性受到影响。
为了检测异方差性,可以使用图形法(如绘制残差图)或统计检验方法(如怀特检验)。
如果发现存在异方差性,可以采用加权最小二乘法等方法进行修正。
三、自相关性自相关性指的是误差项在不同观测值之间存在相关性。
常见的自相关形式有正自相关和负自相关。
自相关性会使估计的标准误差产生偏差,影响参数估计的有效性和假设检验的结果。
常用的检测方法有杜宾瓦特森检验。
解决自相关问题可以采用广义差分法等方法。
四、多重共线性多重共线性是指自变量之间存在较强的线性关系。
这会导致回归系数估计值不稳定,难以准确解释变量的影响。
可以通过计算方差膨胀因子(VIF)来判断是否存在多重共线性。
解决多重共线性的方法包括删除相关变量、增大样本容量或使用岭回归等方法。
五、虚拟变量虚拟变量常用于表示定性的因素,例如性别、季节、地区等。
设计虚拟变量方法

设计虚拟变量方法虚拟变量方法(Dummy Variable Method),也称为哑变量方法或指示变量法,是一种常用的统计方法,主要用于处理分类变量在数值分析中的应用问题。
本文将详细讨论虚拟变量方法的原理、应用及优缺点,并举例说明其具体操作步骤。
1. 虚拟变量方法原理虚拟变量方法的核心思想是将分类变量转换为二值的虚拟变量(dummy variable),以便在数值分析中使用。
对于具有n个类别的分类变量,虚拟变量方法将其转化为n个二值变量,每个二值变量代表一个类别。
如果样本属于某个类别,则对应的二值变量取1,否则为0。
2. 虚拟变量方法的应用虚拟变量方法主要应用于以下两个方面:2.1. 处理分类变量: 在回归分析中,通常只能处理数值型变量。
使用虚拟变量方法,我们可以将分类变量转化为虚拟变量,然后应用回归模型进行分析。
虚拟变量方法在社会科学和经济学等领域有广泛的应用,比如研究不同性别对工资的影响,通过将性别变量转化为虚拟变量,可以确定性别对工资的影响是否显著。
2.2. 建立交互作用: 虚拟变量方法还可以用于研究多个变量之间的关系及其交互作用。
通过将多个分类变量转化为虚拟变量,并进行交叉乘积运算,可以获取不同类别组合的效应差异,进而分析各个变量之间的关系。
3. 虚拟变量方法的步骤虚拟变量方法的操作步骤如下:3.1. 选择分类变量: 首先需要确定需要转化为虚拟变量的分类变量。
3.2. 创建虚拟变量: 对于n个类别的分类变量,创建n-1个虚拟变量。
其中,一个类别作为基准类别(reference category),在计算逻辑回归模型时作为参照。
3.3. 赋值: 对于样本中的每一个观测值,根据其所属类别,为相应的虚拟变量赋值。
如果某一样本属于某个类别,则对应的虚拟变量取1,否则为0。
3.4. 分析: 根据创建的虚拟变量,应用适当的统计方法进行分析。
可以使用回归模型、方差分析或卡方检验等方法。
4. 虚拟变量方法的优缺点虚拟变量方法具有以下优点:4.1. 解决了分类变量在数值分析中的应用问题: 虚拟变量方法允许我们在回归分析中使用分类变量,可以更全面地考虑分类变量对结果的影响。
第四章多重共线性和虚拟变量的应用

2 2 2 y x x x x y x y x x y x x 0 i 1i 2i 1i 2i i 2i i 2i 2i i 2i 2i ˆ 1 x1i 2 x2i 2 ( x1i x2i )2 2 ( x 2 2 i ) 2 2 ( x 2 2 i ) 2 0
p1、p2、p3 2、指数增长率方法 例如研究三种指数 p 1t= 1+ 2 p 2t+ 3 p 3t+vt 关系时,可用如下模型:
(pit-pi,t-1) pit p it= log( ) log(pit)-log(pi,t-1) pi,t-1 pi,t-1
15
3、以比率代替高度相关的变量 若模型中存在高度
在对数据调整后,我们建立如下的模型:
logYt= 0+ 1X1t+ 2X2t+ 3X3t+ 4logX4t+ 5logX5t+ 6logX6t+ 7logX7t
+ 8logX8t+ 9X9t+ 10logX10t+ 11logX11t+ut
利用普通最小二乘法回归方程,得到如下的结果:
16
多重共线性的修正
三、补充新数据。 由于多重共线性是一样本特征,故有可能在关于 同样变量的另一样本中共线性没有第一个样本那 么严重。Christ(1966)认为:解释变量之间的相 关程度与样本容量成反比,即样本容量越小,相 关程度越高;样本容量越大,相关程度越小。因 此,收集更多观测值,增加样本容量,就可以避 免或减轻多重共线性的危害。
v 2 x2i 2
ˆ 的方差也是无限大的。因此,当存在完 同理, 2 全多重共线性时,我们将不能求得参数估计值, 参数估计值的方差无限大。 当存在近似多重共线性时,尽管可以求得参数估 计值,但它们是不稳定的,同时参数估计值的方 差将变大,变大的程度取决于多重共线性的严重 程度。
第四节 虚拟变量

其中:Yi为企业职工的薪金,Xi为工龄, Di=1,若是男性,Di=0,若是女性。
二、虚拟变量的引入
❖ 虚拟变量做为解释变量引入模型有两种基本 方式:加法方式和乘法方式。
1、加法方式
上述企业职工薪金模型中性别虚拟变量的引入采 取了加法方式。
yˆi 924.7058 0.6327xi 61.1917Di 0.0080XDi
根据t检验,D、XD的回归系数均不显著,即认为α=a2-a1=0, β=b2b1=0;这表明1998年、1999年我国城镇居民消费函数并没有显著 差异。因此,可以将两年的样本数据合并成一个样本,估计城镇
居民的消费函数。
估计以下模型:
+εi
D
1 0
样本2 样本1
Yi= a1 +b1xi+ (a2 - a1 )Di+(b2-b1)XDi +εi 其中,XDi=xi*Di。
第(1)种情况下模型结构是稳定的,其余情
利用t检验判断况D都、表X明D模系型数结的构不显稳著定性。,可以得到四种 检验结果: (1)两个系数均等于零,即a2=a1,b2=b1,表明两个回 归模型之间没有显著差异,称之为“重合回归” 。
GENR XD=X*D1
生成变量XD
LS Y C X D1 XD 估计需求函数
结果如下图所示:
对应的t统 计量值
R2的值 调整的R2值 SE的值
我国城镇居民彩电需求函数的估计结果为:
yˆi 57.61 0.0119xi 31.8731Di 0.0088XDi
α、β的t检验都是显著的,表明我国城镇居民低收入家 庭与中高收入家庭对彩电的消费需求,在截距和斜率上 都存在着明显差异,各自的需求函数为:
虚拟变量的分析
虚拟变量(dummy variable )在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。
例如需要考虑性别、民族、不同历史时期、季节差异、企业所有制性质不同等因素的影响。
这些因素也应该包括在模型中。
由于定性变量通常表示的是某种特征的有和无,所以量化方法可采用取值为1或0。
这种变量称作虚拟变量,用D 表示。
虚拟变量应用于模型中,对其回归系数的估计与检验方法与定量变量相同。
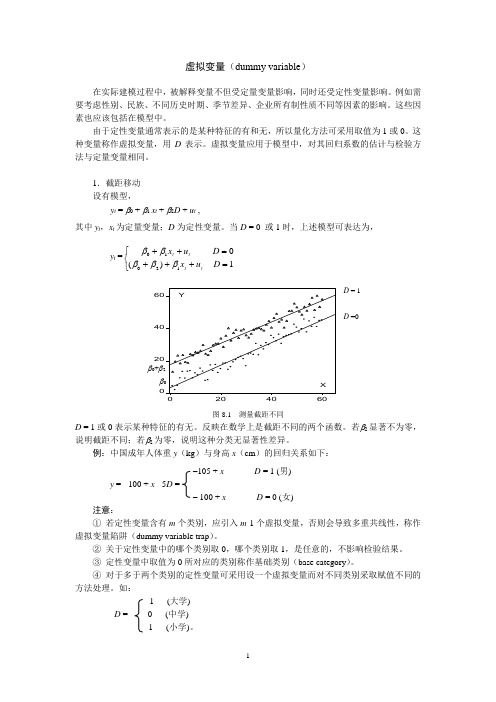
1.截距移动 设有模型,y t = β0 + β1 x t + β2D + u t ,其中y t ,x t 为定量变量;D 为定性变量。
当D = 0 或1时,上述模型可表达为,y t =⎩⎨⎧=+++=++1)(012010D u x D u x tt t t βββββ0204060204060X Y图8.1 测量截距不同D = 1或0表示某种特征的有无。
反映在数学上是截距不同的两个函数。
若β2显著不为零,说明截距不同;若β2为零,说明这种分类无显著性差异。
例:中国成年人体重y (kg )与身高x (cm )的回归关系如下: –105 + x D = 1 (男)y = - 100 + x - 5D =– 100 + x D = 0 (女) 注意:① 若定性变量含有m 个类别,应引入m -1个虚拟变量,否则会导致多重共线性,称作虚拟变量陷阱(dummy variable trap )。
② 关于定性变量中的哪个类别取0,哪个类别取1,是任意的,不影响检验结果。
③ 定性变量中取值为0所对应的类别称作基础类别(base category )。
④ 对于多于两个类别的定性变量可采用设一个虚拟变量而对不同类别采取赋值不同的方法处理。
如:1 (大学) D = 0 (中学) -1 (小学)。
β0β0+β2D = 1 D =0例1:市场用煤销售量模型(file: Dummy1) 我国市场用煤销量的季节性数据(1982-1988,《中国统计年鉴》1987,1989)见下图与表。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
... 如果存在一组不完全为零的常数 λ 1、 λ 2、 λ n ,满 足 λ 1X1+λ 2X2+...+λ nXn=0,即任一变量都可以由其 它变量的线性组合推出,则这组变量满足完全多重共 线性。
若变量组 X 1、 X2、...Xn 满足如下关系 式:λ 1X1+λ 2X2+...+λ nXn+u=0 ,其中u表示随机误差 项,即某一变量不仅取决于其它变量的线性组合,也 取决于随机误差项,此时变量组之间存在非严格但近 似的线性关系,解释变量之间高度相关,也即变量组 存在近似多重共线性关系。
检验多重共线性问题是否严重
若回归模型的 R 2 值高(如 R 2>0.8),或F检验值显著, 但单个解释变量系数估计值却不显著;或从金融理论 知某个解释变量对因变量有重要影响,但其估计值却 不显著,则可以认为存在严重的多重共线性问题。 若两个解释变量之间的相关系数高,比如说大于0.8, 则可以认为存在严重的多重共线性。
(p it-p i,t-1 ) p it p it= = log( ) = log(p it)-log(p i,t-1 ) p i,t-1 p i,t-1
•
3、以比率代替高度相关的变量。若模型中存在高度 相关的变量,在不违反金融理论的前提下,可以求得 两者之间的比率,并以此比率代替相应变量出现在模 型中。例如对于模型 Y t= α 0+ α 1X 1t+ α 2X 2t+ α 3X 3t+ut , 若 X2t与 X3t之间高度相关,且模型的目的是用于预测, X2t 则可令 ,则 。 Yt=β 0+β 1X1t+β 2Rt+vt R t= X3t 此外,当模型中有较多解释变量的滞后值,并存在严 重多重共线性时,可以考虑用被解释变量的滞后值代 替解释变量的滞后值;以人均形式的变量代替总体变 量在某些状况下也可以在一定程度上降低多重共线性 的程度。
多重共线性产生的原因
多重共线性问题在金融数据中是普遍存在的,不仅存 在于时间序列数据中,也存在于横截面数据中。具体 而言,多重共线性产生的原因主要有以下几点: (1)数据收集及计算方法。 (2)模型或从中取样的总体受到限制。 (3)模型设定偏误。 此外,在观测值个数较少,以至于小于解释变量个数 时,也会产生多重共线性;时间序列数据中,若同时 使用解释变量的当期值和滞后值,由于当期值和滞后 值之间往往高度相关,也容易产生多重共线性。
判断多重共线性的存在范围
要确定多重共线性是由哪些主要变量引起的,可以采 用辅助回归法(auxiliary regression method)。所 谓辅助回归是指某一解释变量对其余解释变量的回归, 区别于因变量对所有解释变量回归的主回归(main regression)。 辅助回归法构造的检验统计量定义如下:
一.删除不必要的变量。 如果在产生多重共线性的因素中有相对不重要的变量, 则可试着将其删除,这是解决多重共线性最简单的方 法,但删除变量也可能会导致新问题的产生: 1、被删除变量对因变量的影响将被其它解释变量和 随机误差项所吸收,这可能一方面解决了一部分变量 的多重共线性问题,但另一方面却又同时增强了另一 部分变量的多重共线性问题,而且,还可能使随机误 差项的自相关程度增强。 2、删除某个变量可能会导致模型设定误差 (specification error)。所谓模型设定误差,指的是 在建立回归模型的过程中,因为错误设定模型结构而 产生的误差。错误的删除解释变量将会导致最小二乘 估计值是有偏的。
利用普通最小二乘法回归方程,得到如下的结果:
logY t=619.88 − 0.062X 1t+0.006X 2t+0.053X 3t+0.078logX 4t+0.067logX 5t-0.357logX 6t
+0.061logX 7t-0.001logX 8t-72.596X 9t-0.789logX 10t-0.186即不能求得参数估计值。
而对于参数估计值的方差,有
σ v 2 ∑ x2i 2 ˆ var( β1 ) = = 2 =∞ 2 2 2 2 2 2 2 2 ∑ x1i ∑ x2i − (∑ x1i x2i ) λ (∑ x 2i ) − λ (∑ x 2i )
ˆ 同理,β 2的方差也是无限大的。因此,当存在完全多 重共线性时,我们将不能求得参数估计值,参数估计 值的方差无限大。 当存在近似多重共线性时,尽管可以求得参数估计值, 但它们是不稳定的,同时参数估计值的方差将变大, 变大的程度取决于多重共线性的严重程度。
去掉不显著的变量,对模型重新回归得到:
logY t=739.37 − 0.055X 1t+0.05X 3t-0.257 logX 6t+0.056 logX 7t-86.951X 9t-0.91 logX 10t
在10%的显著性水平下,变量系数估计值的t值都是 显著的,模型的 R 2 =0.78,R 2 =0.75,总体上看模 型是不错的。尽管估计值的t值是显著的,我们仍来 检验该模型解释变量之间是否存在多重共线性,因为 若两个变量之间存在高度相关并且符号相反,他们的 作用就会相互抵消,从而有可能两个变量都是显著的。 首先,根据 2和t值,我们无法发现多重共线性,因 R 此我们将利用变量之间的相关系数来判断。
第四章 多重共线性和虚拟变量的应用
多重共线性的概念
多重共线性(multicollinearity)一词最早由挪威经济 学家弗瑞希(R.Frisch)于1934年提出。 其原义是 指回归模型中的一些或全部解释变量中存在的一种完 全(perfect)或准确(exact)的线性关系。而现在所说的 多重共线性,除指上述提到的完全多重共线性 (perfect multicollinearity),也包括近似多重共线性 (near multicollinearity).为对上述两概念加以区别, 我们以一组解释变量 为例: X 1、 X2、...X n
σ v 2 ∑ x2i 2
在实际金融数据中,完全多重共线性只是一种极端 情况,各种解释变量之间存在的往往是近似多重共 线性,因此通常所说多重共线性造成的后果是指近 似多重共线性造成的后果,具体而言,它将造成如 下的后果: 1.回归方程参数估计值将变得不精确,因为较大的 方差将会导致置信区间变宽。 2.由于参数估计值的标准差变大,t值将缩小,使得t 检验有可能得出错误的结论 。 3.将无法区分单个变量对被解释变量的影响作用。
∑ yi x1i ∑ x2i 2 − ∑ x1i x2i ∑ yi x2i λ ∑ yi x2i ∑ x2i 2 − λ ∑ yi x2i ∑ x2i 2 0 ˆ = = β1 = 2 2 2 2 2 2 2 2 2 λ (∑ x 2i ) − λ (∑ x 2i ) ∑ x1i ∑ x2i − (∑ x1i x2i ) 0
多重共线性的后果
多重共线性不会改变最小二乘估计的无偏性,但在解 释变量之间存在严重的多重共线性而被忽略时,会对 模型的估计、检验与预测产生严重的不良后果。以某 一离差形式(即 xt = Xt − X )表示的二元线性回归模 型完全共线性 yi = β1 x1i + β 2 x2 i + vi 为例 : 假设存在关系 x1i = λ x2i ,常数 λ ≠ 0 。则 β1 的估计
Ri 2 /(k − 1) Fi= ,服从自由度为k-1与n-k的F分布。 2 (1 − Ri ) /(n − k)
其中 Ri 2(i=1,2,…k)为第i个解释变量 X i 关于其余解 释变量的辅助回归的拟和优度,k为解释变量的个数, n代表样本容量。
检验多重共线性的表现形式
当确定多重共线性是由哪些主要变量引起后,若要找 出与主要变量有共线性的解释变量,即确定多重共线 性的表现形式,可采用偏相关系数法。解释变量与的 偏相关系数即是在其它的解释变量固定的情况下它们 之间的相关系数。 偏相关系数法构造的检验统计量定义如下: ρ ij ,服从自由度为T-p-1的t分布。 ti = n − k − 1
在对数据调整后,我们建立如下的模型:
logY t= α 0 + α 1X 1t+ α 2X 2t+ α 3 X 3t+ α 4 logX 4t+ α 5 logX 5t+ α 6 logX 6t+ α 7logX 7t
+ α 8 logX 8t + α 9 X 9t + α 10 logX 10t + α 11 logX 11t + u t
二、改变解释变量的形式。 1、差分法。对于时间序列数据而言,若原始变量存 在严重的多重共线性,则可以考虑对变量取差分形式, 可在一定程度上降低多重共线性的程度。例如对于模 Y t= α 0+ α 1X 1t+ α 2X 2t+u t 型 ,可把变量变换为参数 形式: 。 ∆Yt=α 0+α 1∆X1t+α 2∆X2t+∆ut 2、指数增长率方法。例如研究三种指数 p1、p2、p3 • • • 关系时,可用如下模型:p 1t=β 1+β 2 p 2t+β 3 p 3t+vt
ρ 其中n为样本容量,k为解释变量的个数, ij 为 Xi与 Xj 的偏相关系数。若 ti 显著不为零,则认为Xi 、Xj 是引
起多重共线性的原因,否则不是。
1 − ρ ij2
多重共线性的修正
如前所述,多重共线性在金融数据中是普遍存在的, 是否对多重共线性采取修正措施取决于多重共线性的 严重程度。若多重共线性程度较轻微,并不严重影响 系数估计值(符号正确,t值显著),则可以忽略多 重共线性问题。若多重共线性对重要因素的系数估计 值有严重的影响,则必须进行补救。而采取何种补救 措施,则取决于多重共线性因素的重要性、其它数据 来源的可用性、所估计模型的目的以及其它需要考虑 的事项。以下将介绍几种补救措施。