Kettle基础操作及相关步骤
Kettle用户操作手册1

Kettle用户操作手册1.kettle介绍1.1 什么是kettleKettle是“Kettle E.T.T.L. Envirnonment”只取首字母的缩写,这意味着它被设计用来帮助你实现你的ETTL 需要:抽取、转换、装入和加载数据;它的名字起源正如该项目的主程序员MATT所说:希望把各种数据放到一个壶里然后以一种指定的格式流出。
Spoon是一个图形用户界面,它允许你运行转换或者任务。
1.2 Kettle 的安装要运行此工具你必须安装 Sun 公司的JAVA 运行环境1.4 或者更高版本,相关资源你可以到网络上搜索JDK 进行下载,Kettle 的下载可以到/取得最新版本。
1.3运行SPOON下面是在不同的平台上运行Spoon 所支持的脚本:Spoon.bat: 在windows 平台运行Spoon。
Spoon.sh: 在Linux、Apple OSX、Solaris 平台运行Spoon。
1.4 资源库一个Kettle资源库可以包含那些转换信息,这意味着为了从数据库资源中加载一个转换就必须连接相应的资源库。
在启动SPOON的时候,可以在资源库中定义一个数据库连接,利用启动spoon时弹出的资源库对话框来定义,如图所示:单击加号便可新增;关于资源库的信息存储在文件“reposityries.xml”中,它位于你的缺省home 目录的隐藏目录“.kettle”中。
如果是windows 系统,这个路径就是c:\Documents andSettings\<username>\.kettle。
如果你不想每次在Spoon 启动的时候都显示这个对话框,你可以在“编辑/选项”菜单下面禁用它。
admin 用户的缺省密码也是admin。
如果你创建了资源库,你可以在“资源库/编辑用户”菜单下面修改缺省密码。
1.5 定义1.5.1 转换主要用来完成数据的转换处理。
转换步骤,可以理解为将一个或者多个不同的数据源组装成一条数据流水线。
Kettle入门教程

Kettle入门教程最近做的项目用到了ETL工具Kettle,这个工具相当好用,可以将各种类型数据作为数据流,经过处理后再生成各种类型的数据。
正如其名“水壶”,将各个地方的水倒进水壶里,再用水壶倒入不同的容器。
不过一来初学乍用,二来对此任务不是很感兴趣,研究的不是很深入,可能是以一种不科学的方法使用的,但观教程,常用的内容似乎也涉及到了,并且Y大说过,要善于总结,于是有了这篇,作为入门说明吧。
一、下载与安装官网地址大概700~800M,下载好解压缩即可。
当然,要求JDK环境(似乎有自带)二、任务(.kjb)与转换(.ktr)Kettle工具的主界面-作业简单地说,一个转换就是一个ETL的过程,而作业则是多个转换、作业的集合,在作业中可以对转换或作业进行调度、定时任务等(据说定时不好用,可以通过其他方式,比如linux的crontab命令,不过实际使用中,这个指令也不大好使,有待查看日志探明原因。
)我在实际过程中,写的流程不是很复杂,当数据抽取需要多步骤时,分成多个转换,在集合到一个作业里顺序摆放,然后执行即可,不放到作业里的话,要对多个转换依次执行命令,比较麻烦。
三、煎锅、勺子、厨房是不是莫名其妙,以为走错了片场?然而这是几个重要的工具名称。
1)勺子-Spoon.bat/spoon.sh图形界面工具,就是启动上图主界面的命令行。
这个界面应该是JavaFX做的。
这个用来在有图形界面的系统下写任务(如何通过命令行写我不知道,并且我怀疑没有这个可能……),如Windows,写好后,也可以通过该工具进行执行,调试。
这个工具最大的问题是启动很慢,并且如果修改了数据库连接的配置,只有重新启动才能生效了。
这时候就体现了命令行的优越性。
转换窗口简单的转换示例左边有很多控件可供选择,上图展示了我在使用中经常用到的几个控件。
•执行SQL脚本:可以直接在控件里写SQL,并指定执行的库。
•表输入:通过查询数据库的表来获取输入数据流。
kettle的作业和转换

kettle的作业和转换Kettle的作业和转换一、介绍KettleKettle是一款功能强大的开源ETL工具,ETL是指数据的抽取(Extract)、转换(Transform)和加载(Load)的过程。
Kettle 能够帮助用户在不同数据源之间进行数据的传输、转换和处理,以满足各种数据集成和数据处理的需求。
二、Kettle的作业1. 什么是Kettle作业?Kettle作业是由一系列定义好的转换和任务(Job)组成的工作流程。
它可以根据预定义的顺序和条件来执行各种任务,实现数据的抽取、转换和加载等操作。
2. 如何创建Kettle作业?创建Kettle作业非常简单,只需要打开Kettle工作台,选择新建作业,然后在作业设计界面中拖拽和配置各种任务和转换组件即可。
用户可以根据实际需求,自由组合各种任务和转换,构建出自己所需的作业流程。
3. Kettle作业的执行顺序和条件Kettle作业中的任务执行顺序和条件可以通过连接线和控制节点来定义。
连接线表示任务间的依赖关系,控制节点则用于设置任务的执行条件。
通过合理设置连接线和控制节点,可以实现灵活的作业流程控制。
4. Kettle作业的调度和监控Kettle提供了丰富的调度和监控功能,用户可以根据需要设置作业的执行时间和频率,也可以通过日志和警报功能实时监控作业的执行情况。
这些功能可以帮助用户更好地管理和控制数据处理过程。
三、Kettle的转换1. 什么是Kettle转换?Kettle转换是Kettle中最基本的数据处理单元,它由一系列的步骤(Step)和连接(Hop)组成。
每个步骤负责不同的数据处理任务,如数据抽取、数据转换、数据加载等。
2. 如何创建Kettle转换?创建Kettle转换同样很简单,只需要在Kettle工作台中选择新建转换,然后在转换设计界面中拖拽和配置各种步骤和连接即可。
用户可以根据实际需求,自由组合各种步骤和连接,构建出自己所需的转换流程。
自-kettle使用说明(简版)

Kettl e使用说明简版1、文档说明本文档主要介绍我们实际应用中使用Kettle工具来开发ETL过程的相关说明,内部文档,仅供参考.2、ETL流程图3、关键操作介绍3.1创建资源库[对象位置]:登陆界面[实现功能]:配置存储相关转换、任务及相关附属信息的数据库[操作说明]:1)进入登陆界面:2)点击新建按钮,进入配置界面,填写相关信息3)填写完毕,可测试是否成功,成功后,进入如下界面,点创建或更新4)创建完毕可用资源库用户登录Kettle,默认用户名,密码:admin/admin[备注]:我们一般建立一个独立的数据库用户,专门存储Kettle相关信息,资源库就连接在这个数据库用户上3.2创建转换[对象位置]:文件〉〉新建〉〉转换[实现功能]:将库A的表A1中的数据经过一定转换,插入到库B的表B1[操作说明]:1)新建一个转换2)将“核心对象〉〉输入〉〉表输入”拖到转换设置面板3)双击“表输入”,进入脚本编辑界面:本界面可以设置数据库连接,点“新建”可以创建一个新的数据库连接,点“编辑”更改数据库连接,然后编辑好相关提取语句:4)将“核心对象〉〉输出〉〉表输出”拖到转换设置面板5)双击“表输出”,进入脚本编辑界面:本界面需要选择数据转入目标表的数据库连接,以及目标表的表名称,如果数据量比较大的话,可以设置每次提交的数据量6)将表输入和表输出连接:按住shift,鼠标从“表输入”拖到“表输出”,如图:7)该转换编辑成功,可以保存并执行测试[保存]:[执行]:8)执行成功后便可以编辑其它转换,过程类似[备注]:1)编写的SQL语句的字段别名要与数据转入的目标表的字段名称一致;2)语句最后不能有标点;3)若SQL中有参数的话,需要将“替换SQL语句中的变量”选中;4)转换前可以执行一些脚本比如:将“脚本〉〉执行SQL脚本”拖入,并连接即可,双击可编辑SQL(需要有分号,若更新库则需要提交)3.3创建任务[对象位置]:文件〉〉新建〉〉任务[实现功能]:将多个操作串行合并,形成一个整体任务,其中的操作可以是转换、任务、脚本等等[使用说明]:1)新建一个任务2)拖入几个任务对象,可以是转换、任务、脚本等,并连接,如图:3)双击相关对象进行编辑,需要选择已经建立好的转换(任务名称)名称4)所有中间步骤的对象都已设定好以后,保存任务,执行测试任务[备注]:任务中各对象执行,以前一对象成功执行为前提,若任务里,包含多个子任务,如果各任务之间相互独立,可以在子任务中拖入“success”对象,否则当母任务中某一对象执行失败,则任务停止。
kettle工具用法

kettle工具用法关于"kettle工具用法"的1500-2000字文章:Kettle工具是一款功能强大的开源数据集成工具,旨在简化和自动化数据导入、转换和输出的过程。
它拥有直观而强大的用户界面,可让用户通过图形化界面创建和管理数据管道。
本文将逐步回答Kettle工具的用法,涵盖安装、界面介绍、数据导入和转换、数据输出等方面。
一、安装Kettle工具首先,访问Kettle官方网站并下载最新版本的Kettle工具。
下载完成后,运行安装程序,并按照提示进行安装。
安装完成后,打开Kettle工具。
二、界面介绍打开Kettle工具后,你将看到一个主界面,其中包含了工具栏、转换面板和作业面板等。
工具栏上有各种按钮,用于打开、保存和运行数据转换和作业。
转换面板用于创建、编辑和管理数据转换,而作业面板用于创建和管理作业。
你可以通过拖放组件和连接器来建立转换和作业的流程。
三、数据导入数据导入是Kettle工具的一个重要功能,它允许将数据从各种来源导入到目标数据库或文件中。
在Kettle中,你可以通过以下步骤导入数据:1. 创建新的数据转换:在转换面板上右键单击,选择“新建转换”来创建一个新的数据转换。
2. 添加数据输入组件:在工具栏上选择“输入”,然后拖放数据源到转换面板上。
根据需要选择适当的输入类型,如CSV文件、数据库、Excel文件等。
3. 配置数据输入组件:选择添加到转换面板的数据输入组件,右键单击并选择“编辑”。
在配置窗口中,设置数据源的连接信息、查询语句和字段映射等。
4. 添加目标组件:与添加数据输入组件类似,选择“输出”按钮并拖放目标数据库或文件组件到转换面板上。
5. 配置目标组件:选择添加到转换面板的目标组件,右键单击并选择“编辑”。
在配置窗口中,设置目标数据库的连接信息、目标表或文件的格式等。
6. 连接输入和目标组件:在转换面板上,拖动鼠标从数据输入组件的输出连接器到目标组件的输入连接器上,建立数据流。
2024年史上最强Kettle培训教程

配置环境变量
将Kettle的bin目录添加到 系统环境变量PATH中
2024/2/29
启动服务
在命令行中输入kettle.bat (Windows)或kettle.sh (Linux/MacOS)启动服 务
服务端口
默认端口为8080,可通过 配置文件进行修改
6
常见问题解决方案
问题1
无法启动服务
解决方案
作有很大的帮助。
2024/2/29
30
行业发展趋势分析
2024/2/29
大数据时代下的数据处理需求
随着大数据时代的到来,数据处理需求越来越大,Kettle作为一种高效的数据处理工具, 将会得到更广泛的应用。
Kettle在数据仓库建设中的地位和作用
数据仓库是企业级数据集成和存储的重要平台,Kettle在数据仓库建设中扮演着重要的角 色,能够实现数据的快速集成和转换。
2024/2/29
27
06
总结回顾与未来展望
2024/2/29
28
关键知识点总结回顾
Kettle工具介绍和使用场景:包括Kettle的基本概 念、特点、使用场景等,让学员对Kettle有一个 全面的了解。
Kettle组件和功能介绍:介绍了Kettle中的各种组 件和功能,如输入/输出组件、转换组件、脚本组 件等,以及如何使用这些组件完成复杂的数据处 理任务。
2024/2/29
数据抽取、转换和加载(ETL)过程详解:详细讲 解了ETL过程中的各个环节,包括数据抽取、清洗 、转换、加载等,以及如何使用Kettle实现这些 操作。
Kettle性能优化技巧:分享了在使用Kettle过程中 如何优化性能,提高数据处理效率的方法和技巧 。
kettle 转换、作业和步骤

Kettle是一款开源的ETL工具,专门用来处理数据转换、加载和作业调度。
通过Kettle,用户可以轻松地创建复杂的数据转换和作业流程,从而实现数据的抽取、转换和加载。
Kettle的核心概念主要包括转换(Transformation)、作业(Job)和步骤(Step)。
下面将分别介绍这三个概念的基本含义和使用方法。
一、转换(Transformation)1. 转换是Kettle中最基本的概念,它代表了一组数据处理步骤,通常用来实现数据的抽取、转换和加载(ETL)。
用户可以通过Kettle的图形化界面设计转换流程,将各种数据处理步骤以图形节点的方式连接起来,形成一个完整的数据处理流程。
2. 转换的主要组成部分包括输入步骤、输出步骤、转换步骤和作业调度步骤。
用户可以通过这些步骤实现数据的输入和输出,数据的转换处理,以及转换流程的调度和控制。
3. 在设计转换时,用户需要考虑数据来源、数据格式、数据处理逻辑和数据目的地等方面的问题,通过合理地使用Kettle内置的各种步骤和插件,可以实现复杂的数据处理流程,满足不同的业务需求。
二、作业(Job)1. 作业是Kettle中用来实现作业调度和流程控制的概念,它代表了一组数据处理和转换流程的调度和控制逻辑。
用户可以通过Kettle的图形化界面设计作业流程,将各种数据处理和转换流程以图形节点的方式连接起来,形成一个完整的作业调度流程。
2. 作业的主要组成部分包括作业入口、作业步骤和作业输出。
用户可以通过这些部分实现作业的启动条件、作业步骤的调度和控制,以及作业的执行结果输出。
3. 在设计作业时,用户需要考虑作业流程、作业调度和作业控制逻辑等方面的问题,通过合理地使用Kettle内置的各种作业步骤和插件,可以实现复杂的作业调度流程,实现灵活的作业调度和控制。
三、步骤(Step)1. 步骤是Kettle中最基本的数据处理单元,它代表了数据处理和转换流程中的最小操作单元。
史上最强Kettle培训教程资料

流程调试与优化
对整个处理流程进行调试和优化,确保数据处 理的正确性和高效性。
总结与拓展思考
Kettle是一款功能强大的ETL工具, 可以高效地处理大量数据。
Kettle支持多种数据库和文件格式的 输出,可以满足不同的需求场景。
在实际使用中,需要根据具体需求和 数据特点,设计合理的处理流程和方 案。
Kettle支持多种快捷键操 作,用户可以在工具栏中 查看并设置相关快捷键。
视图切换与展示
设计视图
用于可视化设计ETL转换流程和作业调度流程,支持拖拽组件并进行 连线,方便用户进行流程设计。
预览视图
用于预览当前转换/作业的执行结果,帮助用户及时发现并解决问题 。
日志视图
展示当前转换/作业的执行日志信息,包括执行步骤、耗时、错误信 息等,方便用户进行问题定位和排查。
数据抽取策略及实现
抽取策略
根据业务需求和数据特点 ,制定合适的数据抽取策 略,如全量抽取、增量抽 取等。
抽取实现方式
介绍如何通过Kettle实现 数据抽取,包括使用不同 的抽取组件、设置抽取参 数等。
性能优化技巧
分享在数据抽取过程中进 行性能优化的技巧,如并 行抽取、分批抽取等。
数据转换技巧分享
启动Kettle
将下载的压缩包解压到指定目录 ,如C:kettle或
/home/user/kettle。
解压安装包
将Kettle的可执行文件路径添加 到系统的环境变量中,以便在命 令行或终端中直接运行Kettle。
配置环境变量
双击Kettle的可执行文件或在命 令行中输入kettle命令,即可启 动Kettle软件。
错误代码
ERROR: Database connection failed
2024版kettle教程学习

kettle教程学习目录•kettle概述与安装•kettle基础操作•数据抽取、清洗与加载•转换设计高级功能•作业设计高级功能•kettle实战案例分享PART01kettle概述与安装kettle简介01Kettle是一款开源的ETL工具,全称为Kettle Extraction,Transformation and Loading。
02Kettle提供了一个图形化的界面来设计ETL过程,支持多种数据源和数据目标。
03Kettle是纯Java编写,可以在Windows、Linux和Mac OS等操作系统上运行。
强大的数据转换能力Kettle 提供了丰富的数据转换组件,支持数据清洗、转换、聚合等操作。
Kettle 支持多种数据源,如关系型数据库、文件、API 等,方便用户进行数据整合。
开源性Kettle 是一款开源软件,用户可以自由使用和修改,降低了成本。
图形化界面Kettle 提供了直观的图形化界面,方便用户进行ETL 任务的设计和开发。
跨平台性Kettle 可以在多种操作系统上运行,具有良好的跨平台性。
kettle 特点与优势0102下载Kettle安装包从官方网站或开源社区下载Kettle安装包。
安装Java环境确保计算机上已经安装了Java运行环境(JRE)或Java开发工具包(JDK)。
解压安装包将下载的Kettle安装包解压到指定目录。
配置环境变量(可选)将Kettle的安装目录添加到系统的环境变量中,方便在命令行中启动Kettle。
启动Kettle双击解压后的目录中的Spoon.bat(Windows)或Spoon.sh(Linux/Mac OS)文件,启动Kettle图形化界面。
030405安装步骤与配置PART02kettle基础操作界面介绍与功能导航主界面布局菜单栏、工具栏、设计面板、属性窗口等功能导航通过菜单栏和工具栏快速访问常用功能视图切换在设计面板中切换不同视图,如设计视图、数据视图等1 2 3支持多种数据库类型,如MySQL、Oracle、SQL Server等数据源类型配置数据库连接信息,如主机名、端口号、数据库名、用户名和密码等数据源配置添加、编辑和删除数据源,方便在转换和作业中引用数据源管理数据源配置与管理转换与作业设计拖放组件在设计面板中拖放输入、输出和处理组件连接组件通过箭头连接组件,定义数据流向•配置组件属性:设置组件的特定属性,如查询语句、目标表等添加作业项在设计面板中添加作业项,如开始、结束、邮件通知等连接作业项通过箭头连接作业项,定义作业执行流程调试模式在调试模式下运行转换或作业,查看详细执行过程和结果运行模式在正常模式下运行转换或作业,进行实际数据处理PART03数据抽取、清洗与加载数据抽取方法与技巧使用Kettle的“表输入”步骤从数据库中抽取数据配置数据库连接,编写SQL查询语句,实现数据的抽取。
kettle数据库连接的用法

Kettle数据库连接的用法一、Kettle概述Kettle是一款开源的ETL工具,由Pentaho公司开发,是业界公认的ETL工具之一。
Kettle具有可视化的操作界面,基于元数据实现数据抽取、转换和装载的功能,同时支持多种数据库和文件格式的数据源。
在Kettle中,连接数据库是进行数据处理的基础操作之一,本文将从Kettle数据库连接的使用方法进行详细介绍。
二、Kettle数据库连接的配置步骤1. 打开Kettle打开Kettle软件,在左侧的导航栏中选择“数据库连接”,进入数据库连接配置界面。
2. 新建数据库连接在数据库连接界面,点击“新建”按钮,弹出新建数据库连接对话框。
3. 填写连接信息在新建数据库连接对话框中,填写数据库连接的相关信息,包括连接名称、数据库类型、数据库主机、端口号、数据库名称、用户名、密码等。
4. 测试连接填写完数据库连接信息后,点击“测试连接”按钮,测试连接是否成功。
如果连接成功,则会提示“连接成功”;如果连接失败,则会提示“连接失败”,需要重新检查连接信息。
5. 保存数据库连接测试连接成功后,点击“确定”按钮,保存数据库连接信息。
此时,就可以在数据库连接界面看到新建的数据库连接。
6. 修改和删除数据库连接在数据库连接界面,可以对已有的数据库连接进行修改和删除操作。
点击“编辑”按钮可以修改数据库连接信息,点击“删除”按钮可以删除数据库连接。
三、Kettle数据库连接的常见问题及解决方法1. 连接超时在使用Kettle连接数据库时,有时会遇到连接超时的问题,导致无法正常连接到数据库。
这时可以尝试以下解决方法:- 检查数据库连接信息是否填写正确,包括主机名、端口号、用户名和密码等;- 检查网络是否畅通,确保可以正常访问数据库服务器;- 增加连接超时时间,可以在数据库连接配置界面中设置连接超时时间。
2. 数据库版本不兼容在使用Kettle连接数据库时,有时会因为数据库版本不兼容而无法连接到数据库,这时可以尝试以下解决方法:- 更新Kettle版本,确保支持当前数据库的最新版本;- 更新数据库驱动程序,Kettle连接数据库需要使用相应数据库的驱动程序,确保使用的驱动程序与数据库版本兼容。
2024年史上最强Kettle培训教程

史上最强Kettle培训教程一、引言Kettle是一款开源的ETL工具,具有简单易用、功能强大、扩展性强等特点。
本教程旨在帮助读者全面了解Kettle的基础知识、高级应用以及最佳实践,从而掌握这款强大的ETL工具。
二、Kettle简介1.1Kettle概述Kettle是一款基于Java开发的ETL工具,主要用于数据抽取、转换和加载。
它由Pentaho公司开发,并在2006年开源。
Kettle支持多种数据源,如关系型数据库、文本文件、Excel文件等,并且提供了丰富的转换组件,可以满足各种复杂的数据处理需求。
1.2Kettle主要组件Kettle主要包括两个组件:Spoon和Pan。
Spoon是Kettle的图形界面设计工具,用于创建和编辑ETL转换;Pan是Kettle的命令行执行工具,用于执行Spoon中创建的转换。
三、Kettle基础教程2.1环境搭建2.2Spoon界面介绍启动Spoon,看到的是欢迎界面。
“新建”按钮,创建一个转换或作业。
在转换编辑界面,左侧为组件面板,右侧为画布。
在画布上,我们可以通过拖拽组件来创建ETL流程。
2.3创建转换在本节中,我们将学习如何创建一个简单的ETL转换。
从组件面板中拖拽一个“表输入”组件到画布上,双击该组件,设置数据库连接和SQL查询。
然后,拖拽一个“表输出”组件到画布上,双击该组件,设置目标数据库连接和表名。
将“表输入”和“表输出”组件连接起来,保存并运行转换。
2.4执行转换pan.sh-file=/path/to/your/transformation.ktr其中,`/path/to/your/transformation.ktr`为转换文件的路径。
四、Kettle高级教程3.1数据类型转换在ETL过程中,我们经常需要对数据进行类型转换。
Kettle提供了丰富的类型转换组件,如“复制记录”、“字段选择”等。
在本节中,我们将学习如何使用这些组件进行数据类型转换。
2024版kettle使用教程(超详细)

分布式计算原理
阐述Kettle分布式计算的原理, 如何利用集群资源进行并行处理 和任务调度。
01 02 03 04
集群配置与部署
详细讲解Kettle集群的配置步骤, 包括环境准备、节点配置、网络 设置等。
集群监控与管理
介绍Kettle提供的集群监控和管 理工具,方便用户实时了解集群 状态和作业执行情况。
03
实战演练
以一个具体的实时数据处理任务为例, 介绍如何使用Kettle设计实时数据处理 流程。
案例四:Kettle在数据挖掘中应用
数据挖掘概念介绍
01
数据挖掘是指从大量数据中提取出有用的信息和知识的
过程,包括分类、聚类、关联规则挖掘等任务。
Kettle在数据挖掘中的应用
02
Kettle提供了丰富的数据处理和转换功能,可以方便地
Chapter
案例一:ETL过程自动化实现
ETL概念介绍
ETL即Extract, Transform, Load,是数据仓 库技术中重要环节,包括数据抽取、清洗、转 换和加载等步骤。
Kettle实现ETL过程
通过Kettle的图形化界面,可以方便地设计ETL流程, 实现数据的自动化抽取、转换和加载。
作业项配置
对作业项进行详细配置,包括数据源、目标库、 字段映射等。
作业项管理
支持作业项的复制、粘贴、删除等操作,方便快速构建作业。
定时任务设置与执行
定时任务设置
支持基于Cron表达式的定时任务设置,实现 周期性自动执行。
立即执行
支持手动触发作业执行,满足即时数据处理 需求。
执行日志查看
2024版搞定Kettle详细教程

学员心得体会分享
学员A
通过本次学习,我深入了解了Kettle工具的使用方法和技巧,掌握了ETL流程中的各个环节, 对数据处理有了更深入的理解。
学员B
本次课程让我对Kettle有了全新的认识,之前在使用过程中遇到的一些问题也得到了很好的 解决,感谢老师的耐心讲解。
编辑ETL流程。
布局调整
用户可自由调整各面板的大小 和位置,以满足个性化需求。
折叠与展开
支持折叠或展开组件面板和属 性面板,以节省屏幕空间。
快捷键设置及运用场景
01
快捷键设置
用户可在Kettle中进行自定义快捷键设置,提高操作效率。
02
常用快捷键
如Ctrl+S保存、Ctrl+R运行、Ctrl+Z撤销等,方便用户快速执行常用操
资源隔离与限制
对任务进行资源隔离和限制,防止某 个任务占用过多资源导致其他任务无 法执行。
监控指标设置及报警机制构建
监控指标
设置关键监控指标,如任务执行状态、执行时长、数据质量等,以 实时掌握任务运行情况。
报警机制
构建完善的报警机制,当监控指标异常时及时发出报警通知,以便 相关人员第一时间介入处理。
问题2
Kettle界面显示异常或操作不流畅。
解决方案
调整系统分辨率或缩放设置;关闭其 他占用资源较多的程序;升级电脑硬 件配置。
问题3
在使用Kettle进行数据转换时出现错 误。
解决方案
检查数据源连接是否正常;检查转换 步骤是否正确配置;查看Kettle日志, 定位错误原因并进行修复。
etl工具kettle用户手册及kettle.x使用步骤带案例超详细版

E T L工具K e t t l e用户手册之Spoon 2.5.0用户手册Spoon 2.5.0用户手册 (1)1、Spoon介绍 (14)1、1 什么是Spoon (14)1、2 安装 (14)1、3 运行Spoon (14)1、4 资源库 (14)1、5 资源库自动登录 (15)1、6 定义 (15)1、6、1 转换 (15)1、6、2 任务 (16)1、7 工具栏 (17)1、8 选项 (17)1、8、1 General标签 (18)1、8、2 Look Feel标签 (19)1、9 搜索元数据 (19)1、10设置环境变量 (20)2、创建一个转换或任务(Creating a Transformation or Job) (21)3、数据库连接(Database Connections) (21)3、1 描述 (21)3、2 设置窗口 (22)3、3 选项 (22)3、4 数据库用法 (22)4、SQL编辑器(SQL Editor) (23)4、1 描述 (23)4、2 屏幕截图 (23)4、3 局限性 (24)5、数据库浏览器(Database Explorer) (24)5、1 屏幕截图 (24)5、2 描述 (24)6、节点连接(Hops) (25)6、1 描述 (25)6、1、1 转换连接 (25)6、2 屏幕截图 (25)6、3 创建一个连接 (26)6、4 拆分一个连接 (26)6、5 转换连接颜色 (26)7、变量(Variables) (27)7、1 变量使用 (27)7、2 变量范围 (27)7、2、1 环境变量 (27)7、2、2 Kettle变量 (27)7、2、3 内部变量 (27)8、转换设置(Transformation Settings) (28)8、1 描述 (28)8、2 屏幕截图 (29)8、3 选项 (32)8、4 其它 (33)9、转换步骤(Transformation steps) (33)9、1 描述 (33)9、2 运行步骤的多个副本 (33)9、3 分发或者复制 (35)9、4 常用错误处理 (35)9、5 Apache虚拟文件系统(VFS)支持 (37)9、6 转换步骤类型 (39)9、6、1 文本文件输入(Text Input) (39)9、6、1、1 屏幕截图 (39)9、6、1、2 图标 (41)9、6、1、3 常用描述 (42)9、6、1、4 选项 (42)9、6、1、5 格式化 (47)9、6、1、6 其它 (48)9、6、2 表输入(Table Input) (49)9、6、2、1 屏幕截图 (49)9、6、2、2 图标 (49)9、6、2、3 常用描述 (49)9、6、2、4 选项 (50)9、6、2、5 示例 (50)9、6、2、6 其它 (51)9、6、3 获取系统信息(Get System Info) (51)9、6、3、1 屏幕截图 (51)9、6、3、2 图标 (52)9、6、3、3 常用描述 (52)9、6、3、4 选项 (53)9、6、3、5 用法 (53)9、6、4 生成行(Generate Rows) (54)9、6、4、2 图标 (54)9、6、4、3 常用描述 (55)9、6、4、4 选项 (55)9、6、5 文件反序列化(De-serialize from file)(原来名称为Cube Input) (55)9、6、5、1 屏幕截图 (55)9、6、5、2 图标 (55)9、6、5、3 常用描述 (55)9、6、6 XBase输入(XBase input) (56)9、6、6、1 屏幕截图 (56)9、6、6、2 图标 (56)9、6、6、3 常用描述 (56)9、6、6、4 选项 (56)9、6、7 Excel输入(Excel Input) (57)9、6、7、1 屏幕截图 (57)9、6、7、2 图标 (59)9、6、7、3 常用描述 (59)9、6、7、4 选项 (59)9、6、8 XML输入(XML input) (60)9、6、8、1 屏幕截图 (60)9、6、8、2 图标 (61)9、6、8、3 常用描述 (61)9、6、8、4 选项 (62)9、6、9 获取文件名(Get File Names) (63)9、6、9、1 屏幕截图 (63)9、6、9、2 图标 (63)9、6、9、3 常用描述 (63)9、6、10 文本文件输出(Text File Output) (64)9、6、10、1 屏幕截图 (64)9、6、10、2 图标 (65)9、6、10、3 常用描述 (65)9、6、11 表输出(Table output) (67)9、6、11、1 屏幕截图 (67)9、6、11、2 图标 (67)9、6、11、3 常用描述 (67)9、6、11、4 选项 (68)9、6、11、5 其它 (68)9、6、12 插入/更新(Insert/Update) (69)9、6、12、1 屏幕截图 (69)9、6、12、2 图标 (69)9、6、12、3 常用描述 (69)9、6、12、4 选项 (70)9、6、12、5 其它 (70)9、6、13 更新(Update) (71)9、6、13、2 图标 (71)9、6、13、3 常用描述 (71)9、6、14 删除(Delete) (72)9、6、14、1 屏幕截图 (72)9、6、14、2 图标 (72)9、6、14、3 常用描述 (72)9、6、15 序列化到文件(Serialize to file)(以前是Cube Output) (73)9、6、15、1 屏幕截图 (73)9、6、15、2 图标 (73)9、6、15、3 常用描述 (73)9、6、16 XML输出(XML output) (74)9、6、16、1 屏幕截图 (74)9、6、16、2 图标 (75)9、6、16、3 常用描述 (75)9、6、16、4 选项 (75)9、6、17 Excel输出(Excel Output) (76)9、6、17、1 屏幕截图 (76)9、6、17、2 图标 (78)9、6、17、3 常用描述 (78)9、6、17、4 选项 (78)9、6、18 Access输出(Microsoft Access Output) (79)9、6、18、1 屏幕截图 (79)9、6、18、2 图标 (79)9、6、18、3 常用描述 (79)9、6、18、4 选项 (79)9、6、19 数据库查询(Database lookup) (80)9、6、19、1 屏幕截图 (80)9、6、19、2 图标 (80)9、6、19、3 常用描述 (80)9、6、19、4 选项 (81)9、6、20 流查询(Stream lookup) (81)9、6、20、1 屏幕截图 (81)9、6、20、2 图标 (81)9、6、20、3 常用描述 (82)9、6、20、4 选项 (82)9、6、20、5 其它 (82)9、6、21 调用数据库存储过程(Call DB Procedure) (83)9、6、21、1 屏幕截图 (83)9、6、21、2 图标 (83)9、6、21、3 常用描述 (83)9、6、21、4 选项 (83)9、6、21、5 其它 (84)9、6、22 HTTP客户端(HTTP Cient) (84)9、6、22、2 图标 (84)9、6、22、3 常用描述 (84)9、6、22、4 选项 (85)9、6、23 字段选择(Select values) (85)9、6、23、1 屏幕截图 (85)9、6、23、2 图标 (87)9、6、23、3 常用描述 (87)9、6、23、4 选项 (87)9、6、24 过滤行(Filter rows) (88)9、6、24、1 屏幕截图 (88)9、6、24、2 图标 (88)9、6、24、3 常用描述 (88)9、6、24、4 选项 (88)9、6、25 行排序(Sort rows) (89)9、6、25、1 屏幕截图 (89)9、6、25、2 图标 (89)9、6、25、3 常用描述 (89)9、6、25、4 选项 (89)9、6、25、5 其它 (90)9、6、26 添加序列(Add sequence) (90)9、6、26、1 屏幕截图 (90)9、6、26、2 图标 (90)9、6、26、3 常用描述 (90)9、6、26、4 选项 (91)9、6、27 空操作-什么都不做(Dummy-do nothing) (91)9、6、27、1 屏幕截图 (91)9、6、27、2 图标 (91)9、6、27、3 常用描述 (91)9、6、27、4 选项 (92)9、6、28 行转列(Row Normaliser) (93)9、6、28、1 屏幕截图 (93)9、6、28、2 图标 (93)9、6、28、3 常用描述 (93)9、6、28、4 选项 (94)9、6、28、5 其它 (94)9、6、29 拆分字段(Split Fields) (95)9、6、29、1 屏幕截图 (95)9、6、29、2 图标 (95)9、6、29、3 常用描述 (95)9、6、29、4 选项 (95)9、6、30 去除重复记录(Unique rows) (96)9、6、30、1 屏幕截图 (96)9、6、30、2 图标 (96)9、6、30、4 选项 (97)9、6、30、5 其它 (97)9、6、31 分组(Group By) (98)9、6、31、1 屏幕截图 (98)9、6、31、2 图标 (98)9、6、31、3 常用描述 (98)9、6、31、4 选项 (99)9、6、32 设置为空值(Null if) (99)9、6、32、1 屏幕截图 (99)9、6、32、2 图标 (99)9、6、32、3 常用描述 (100)9、6、33 计算器(Calculator) (100)9、6、33、1 屏幕截图 (100)9、6、33、2 图标 (100)9、6、33、3 常用描述 (101)9、6、33、4 功能列表 (101)9、6、34增加XML(XML Add) (102)9、6、34、1 屏幕截图 (102)9、6、34、2 图标 (102)9、6、34、3 常用描述 (102)9、6、34、4 选项 (103)9、6、35增加常量(Add constants) (103)9、6、35、1 屏幕截图 (103)9、6、35、2 图标 (103)9、6、35、3 常用描述和使用 (104)9、6、36行转列(Row Denormaliser) (104)9、6、36、1 屏幕截图 (104)9、6、36、2 图标 (104)9、6、36、3 常用描述 (105)9、6、36、4 选项 (105)9、6、37行扁平化(Flattener) (105)9、6、37、1 屏幕截图 (105)9、6、37、2 图标 (105)9、6、37、3 常用描述 (105)9、6、37、4 选项 (106)9、6、37、5 示例 (106)9、6、38值映射(Value Mapper) (107)9、6、38、1 屏幕截图 (107)9、6、38、2 图标 (107)9、6、38、3 常用描述 (107)9、6、39被冻结的步骤(Blocking step) (108)9、6、39、1 屏幕截图 (108)9、6、39、2 图标 (108)9、6、40记录关联(笛卡尔输出)(Join Rows-Cartesian Product) (109)9、6、40、1 屏幕截图 (109)9、6、40、2 图标 (109)9、6、40、3 常用描述 (109)9、6、40、4 选项 (110)9、6、41数据库连接(Database Join) (110)9、6、41、1 屏幕截图 (110)9、6、41、2 图标 (111)9、6、41、3 常用描述 (111)9、6、41、4 选项 (111)9、6、42合并记录(Merge rows) (112)9、6、42、1 屏幕截图 (112)9、6、42、2 图标 (112)9、6、42、3 常用描述 (112)9、6、43 存储合并(Stored Merge) (113)9、6、43、1 屏幕截图 (113)9、6、43、2 图标 (113)9、6、43、3 常用描述 (113)9、6、44 合并连接(Merge Join) (114)9、6、44、1 屏幕截图 (114)9、6、44、2 图标 (114)9、6、44、3 常用描述和使用 (114)9、6、44、4 选项 (114)9、6、45 Java Script值(Java Script Value) (115)9、6、45、1 屏幕截图 (115)9、6、45、2 图标 (115)9、6、45、3 常用描述 (115)9、6、45、4 选项 (115)9、6、45、5 其它 (116)9、6、45、6 值函数 (116)9、6、45、7 JavaScript示例 (120)9、6、45、7、1 回忆先前的行 (120)9、6、45、7、2 设置地址名称到大写 (120)9、6、45、7、3 从日期字段提取信息 (120)9、6、46改进的Java Script值(Modified Java Script Value) (121)9、6、46、1 屏幕截图 (121)9、6、46、2 图标 (121)9、6、46、3 常用描述 (121)9、6、46、4 Java Script函数 (121)9、6、46、5 Java Script (122)9、6、46、6 字段 (122)9、6、46、7 其它 (122)9、6、47执行SQL语句(Execute SQL script) (123)9、6、47、2 图标 (123)9、6、47、3 常用描述 (123)9、6、48 维度更新/查询(Dimension lookup/update) (126)9、6、48、1 屏幕截图 (126)9、6、48、2 图标 (126)9、6、49 联合更新/查询(Combination lookup/update) (127)9、6、49、1 屏幕截图 (127)9、6、49、2 图标 (127)9、6、49、3 常用描述 (127)9、6、50 映射(Mapping) (128)9、6、50、1 屏幕截图 (128)9、6、50、2 图标 (128)9、6、50、3 常用描述和使用 (128)9、6、51 从结果获取记录(Get rows from result) (129)9、6、51、1 屏幕截图 (129)9、6、51、2 图标 (129)9、6、51、3 常用描述 (129)9、6、52 复制记录到结果(Copy rows to result) (129)9、6、52、1 屏幕截图 (129)9、6、52、2 图标 (130)9、6、52、3 常用描述 (130)9、6、53 设置变量(Set Variable) (130)9、6、53、1 屏幕截图 (130)9、6、53、2 图标 (130)9、6、53、3 常用描述 (131)9、6、53、4 变量使用 (131)9、6、54 获取变量(Get Variable) (131)9、6、54、1 屏幕截图 (131)9、6、54、2 图标 (132)9、6、54、3 常用描述 (132)9、6、55 从以前的结果获取文件(Get files from result) (132)9、6、55、1 屏幕截图 (132)9、6、55、2 图标 (132)9、6、55、3 常用描述 (132)9、6、56 复制文件名到结果(Set files in result) (133)9、6、56、1 屏幕截图 (133)9、6、56、2 图标 (133)9、6、56、3 常用描述 (133)9、6、57 记录注射器(Injector) (134)9、6、57、1 屏幕截图 (134)9、6、57、2 图标 (134)9、6、57、3 常用描述 (134)9、6、58 套接字读入器(Socket Reader) (135)9、6、58、2 图标 (135)9、6、58、3 常用描述和使用 (135)9、6、59 套接字输写器(Socket Writer) (135)9、6、59、1 屏幕截图 (135)9、6、59、2 图标 (136)9、6、59、3 常用描述和使用 (136)9、6、60聚合行(Aggregate Rows) (136)9、6、60、1 屏幕截图 (136)9、6、60、2 图标 (136)9、6、60、3 常用描述 (136)9、6、60、4 选项 (137)9、6、61流XML输入(Streaming XML Input) (137)9、6、61、1 屏幕截图 (137)9、6、61、2 图标 (138)9、6、61、3 常用描述 (139)9、6、61、4 选项 (139)9、6、61、5 完整的示例 (140)9、6、62中止(Abort) (142)9、6、62、1 屏幕截图 (142)9、6、62、2 图标 (142)9、6、62、3 常用描述 (143)9、6、62、4 选项 (143)9、6、63Oracle批量装载(Oracle bulk loader) (144)9、6、63、1 屏幕截图 (144)9、6、63、2 图标 (144)9、6、63、3 常用描述 (145)9、6、63、4 选项 (145)10、任务设置(Job Settings) (145)10、1 描述 (145)10、2 屏幕截图 (146)10、3 选项 (146)10、4 其它 (146)11、任务条目(Job Entries) (147)11、1 描述 (147)11、2 任务条目类型 (147)11、2、1特殊的任务条目 (147)11、2、1、1 屏幕截图 (147)11、2、1、2 图标 (147)11、2、1、3 常用描述 (148)11、2、1、3、1 启动 (148)11、2、1、3、2 Dummy (148)11、2、1、3、3 OK (148)11、2、1、3、4 ERROR (148)11、2、2、1 屏幕截图 (149)11、2、2、2 图标 (149)11、2、2、3 常用描述 (149)11、2、2、4 选项 (149)11、2、3 任务 (151)11、2、3、1 屏幕截图 (151)11、2、3、2 图标 (151)11、2、3、3 常用描述 (151)11、2、3、4 选项 (151)11、2、4 Shell (152)11、2、4、1 屏幕截图 (152)11、2、4、2 图标 (153)11、2、4、3 常用描述 (153)11、2、4、4 选项 (153)11、2、5 Mail (154)11、2、5、1 屏幕截图 (154)11、2、5、2 图标 (154)11、2、5、3 常用描述 (155)11、2、5、4 选项 (155)11、2、6 SQL (156)11、2、6、1 屏幕截图 (156)11、2、6、2 图标 (156)11、2、6、3 常用描述 (156)11、2、6、4 选项 (156)11、2、7 FTP (157)11、2、7、1 屏幕截图 (157)11、2、7、2 图标 (157)11、2、7、3 常用描述 (157)11、2、7、4 选项 (157)11、2、8 Table Exists (158)11、2、8、1 屏幕截图 (158)11、2、8、2 图标 (159)11、2、8、3 常用描述 (159)11、2、8、4 选项 (159)11、2、9 File Exists (159)11、2、9、1 屏幕截图 (159)11、2、9、2 图标 (159)11、2、9、3 常用描述 (159)11、2、9、4 选项 (160)11、2、10 Evaluation(javascript) (160)11、2、10、1 屏幕截图 (160)11、2、10、2 图标 (160)11、2、10、3 常用描述 (160)11、2、11 SFTP (161)11、2、11、1 屏幕截图 (161)11、2、11、2 图标 (161)11、2、11、3 常用描述 (162)11、2、11、4 选项 (162)11、2、12 HTTP (163)11、2、12、1 屏幕截图 (163)11、2、12、2 图标 (163)11、2、12、3 常用描述 (163)11、2、12、4 选项 (163)11、2、13 Create a file (164)11、2、13、1 屏幕截图 (164)11、2、13、2 图标 (165)11、2、13、3 常用描述 (165)11、2、13、4 选项 (165)11、2、13、5 其它 (165)11、2、14 Delete a file (165)11、2、14、1 屏幕截图 (165)11、2、14、2 图标 (165)11、2、14、3 常用描述 (166)11、2、14、4 选项 (166)11、2、14、5 其它 (166)11、2、15 Wait a file (166)11、2、15、1 屏幕截图 (166)11、2、15、2 图标 (166)11、2、15、3 常用描述 (167)11、2、15、4 选项 (167)11、2、15、5 其它 (167)11、2、16 File compare (167)11、2、16、1 屏幕截图 (167)11、2、16、2 图标 (168)11、2、16、3 常用描述 (168)11、2、16、4 选项 (168)11、2、16、5 其它 (168)11、2、17 Put files with secureFTP (169)11、2、17、1 屏幕截图 (169)11、2、17、2 图标 (169)11、2、17、3 常用描述 (169)11、2、17、4 选项 (169)11、2、18 Ping a host (170)11、2、18、1 屏幕截图 (170)11、2、18、2 图标 (170)11、2、18、3 常用描述 (170)11、2、19 Wait for (171)11、2、19、1 屏幕截图 (171)11、2、19、2 图标 (171)11、2、19、3 常用描述 (171)11、2、19、4 选项 (171)11、2、20 Display Msgbox info (172)11、2、20、1 屏幕截图 (172)11、2、20、2 图标 (172)11、2、20、3 常用描述 (172)11、2、20、4 选项 (172)11、2、21 Abort job (173)11、2、21、1 屏幕截图 (173)11、2、21、2 图标 (173)11、2、21、3 常用描述 (173)11、2、21、4 选项 (173)11、2、22 XSL transformation (174)11、2、22、1 屏幕截图 (174)11、2、22、2 图标 (174)11、2、22、3 常用描述 (174)11、2、22、4 选项 (174)11、2、23 Zip files (175)11、2、23、1 屏幕截图 (175)11、2、23、2 图标 (175)11、2、23、3 常用描述 (175)11、2、23、4 选项 (175)12、图形界面(Graphical View) (176)12、1 描述 (176)12、2 添加步骤或者任务条目 (176)12、2、1 拖放创建步骤 (176)12、2、2 从步骤类型树创建步骤 (177)12、2、3 在你想要的位置创建步骤 (177)12、3 隐藏步骤 (177)12、4 转换步骤选项(右键上下文菜单) (177)12、4、1 编辑步骤 (177)12、4、2 编辑步骤描述 (177)12、4、3 数据迁移 (177)12、4、4 复制 (177)12、4、5 复制步骤 (178)12、4、6 删除步骤 (178)12、4、7 显示输入字段 (178)12、4、8 显示输出字段 (178)12、5 任务条目选项(右键上下文菜单) (178)12、5、1 打开转换/任务 (178)12、5、3 编辑任务入口描述 (178)12、5、4 复制任务入口 (178)12、5、5 复制选择的任务入口到剪贴板 (178)12、5、6 排列/分布 (179)12、5、7 拆开节点 (179)12、5、8 删除所有任务入口的副本 (179)12、6 添加节点连接 (179)12、7 运行转换 (179)12、8 屏幕截图 (179)12、9 执行选项 (180)12、9、1 在哪里执行 (180)12、9、2 预览 (180)12、9、3 使用安全模式 (180)12、9、4 日志级别 (180)12、9、5 重放日期 (180)12、9、6 参数 (180)12、9、7 变量 (180)12、10 设置远程或者从属服务器 (181)12、10、1 概述 (181)12、10、2 屏幕截图 (181)13、日志(Logging) (181)13、1 日志描述 (181)13、2 屏幕截图 (182)13、3 日志网格 (182)13、3、1 转换日志网格 (182)13、3、2 任务日志网格 (183)13、4 按钮 (183)13、4、1 转换按钮 (183)13、4、1、1 开始转换 (183)13、4、1、2 预览 (183)13、4、1、3 显示错误行 (183)13、4、1、4 清除日志 (184)13、4、1、5 日志设置 (184)13、4、1、6 仅仅显示活动的步骤 (184)13、4、2 任务按钮 (184)13、4、2、1 启动任务 (184)13、4、2、2 停止任务 (185)13、4、2、3 刷新日志 (185)13、4、2、4 清除日志 (185)13、4、2、5 日志设置 (185)13、4、2、6 自动刷新 (186)14、网格(Grids) (186)14、1 描述 (186)14、2 功能 (186)14、3 导航 (186)15、资源库浏览器(Repository Explorer) (187)15、1 描述 (187)15、2 屏幕截图 (187)15、3 右键单击功能 (187)15、4 备份/资源库 (188)16、共享对象(Share objects) (188)1、Spoon介绍1、1 什么是SpoonKettle是”Kettle E.T.T.L. Envirnonment”只取首字母的缩写。
Kettle使用+说明

2014/10/06
设置和坑[1]
• 需要配置pentaho-big-data-plugin 目录中的plugin.properties文件
▫ 把active.hadoop.configuration = 的值改成 hadp20
• mysql貌似连不上,需要把mysql-connector-java-***-bin.jar 放到lib目录中
Transformation举例二:支持hive表操作
• 支持Hive的表操作,结合使用hadoop file output 可以支持从关系型 数据库向hive表中导入数据
Transformation举例三:数据同步
Hyperbase 外表
改表的列的 顺序和类型
• 支持数据更新和同步
▫ 两张表的列的顺序和数据格式必须一模一样 ▫ 注意hyperbase id 为字典序,但RDB id则不一定
combined with transactions: This status table holds for all jobs/transformations all tables that need to be in a consistent state. For all tables the last processed keys (source/target) and the status is saved. Some tables might need compound keys depending on the ER-design. It is also possible to combine this approach with the own Kettle transformation log tables and the Dates and Dependencies functionality. There is an extended example in the Pentaho Data Integration for Database Developers (PDI2000C) course in module ETL patterns (Patterns: Batching, Transaction V - Status Table) • Snapshot-Based CDC • When no suitable time stamps or IDs are available or when some records might have been updated, you need the snapshot-based approach. Store a copy of the loaded data (in a table or even a file) and compare record by record. It is possible to create a SQL statement that queries the delta or use a transformation. Kettle supports this very comfortable by the Merge rows (diff) step. There is an extended example in the Pentaho Data Integration for Database Developers (PDI2000C) course in module ETL patterns (Pattern: Change Data Capture) • Trigger-Based CDC • Kettle does not create triggers in a database system and some (or most?) people don't like the trigger-based CDC approach because it introduces a further layer of complexity into another system. Over time it is hard to maintain and keep in sync with the overall architecture. But at the end, it depends on the use case and might be needed in some projects. There are two main options: • Create a trigger and write the changed data to a separate table • This table has a time stamp or sequenced ID that can be used to select the changed data rows. • Create a trigger and call Kettle directly via the Kettle API • This scenario might be needed in real-time CDC needs, so a Kettle transformation might be called directly from the trigger. Some databases support Java calls from a trigger (e.g. PL/Java for PostgreSQL or Oracle, see References below). • If you are using Hibernate to communicate with the database, you can use Hibernate event listeners as triggers (package summary). That way it would work with every database when you use standard SQL queries or HQL queries in the triggers. • Database Log-Based CDC • Some databases allow own CDC logs that can be analyzed. • Real-time CDC • So in case you need Real-time CDC, some of the above solutions will solve this need. Depending on the timing (how real-time or near-time) your needs are, you may choose the best suitable option. The trigger based call of Kettle is the most real-time solution. It is also possible to combine all of the above solutions with a continuously executed transformation (e.g. every 15 minutes) that collects the changed data.
kettle使用手册
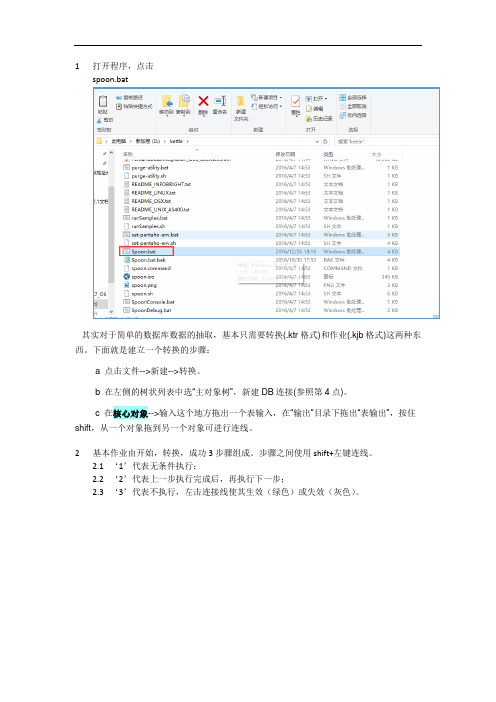
1打开程序,点击spoon.bat其实对于简单的数据库数据的抽取,基本只需要转换(.ktr格式)和作业(.kjb格式)这两种东西。
下面就是建立一个转换的步骤:a 点击文件-->新建-->转换。
b 在左侧的树状列表中选“主对象树”,新建DB连接(参照第4点)。
c 在核心对象-->输入这个地方拖出一个表输入,在“输出”目录下拖出“表输出”,按住shift,从一个对象拖到另一个对象可进行连线。
2基本作业由开始,转换,成功3步骤组成。
步骤之间使用shift+左键连线。
2.1‘1’代表无条件执行;2.2‘2’代表上一步执行完成后,再执行下一步;2.3‘3’代表不执行,左击连接线使其生效(绿色)或失效(灰色)。
3打开具体步骤中的转换流程,点击‘Transformation’跳转至相应具体转换流程,编辑此转换具体路径,双击转换,弹出窗口,‘1’为相对路径,点击‘2’选择具体Visit.ktr 转换,为绝对路径。
4建立数据库连接,输入相应信息测试,成功即可图45转换具体设置,如图4,‘表输出’至‘文本文件输出’流程跳接线为错误处理步骤,当输出格式不能满足表输出的目的表结构类型时,将会将记录输出到‘文本文件输出’中的记录中。
5.1双击‘表输入’,输入相应的SSQL语句,选择配置数据库连接,或新增,预览查询生成的结果(如果数据库配置中使用变量获取,此处预览生成错误)。
5.2双击‘表输出’,选择数据库连接,‘浏览’选择相应目标表,(此处‘使用批量插入’勾选去除,目的是在错误处理步骤中无法使用批量处理,可能是插件兼容问题)6表输出插件定义a) Target Schema:目标模式。
要写数据的表的Schema的名称。
允许表明中包含“。
”对数据源来说是很重要的b) 目标表:要写数据的表名。
c) 提交记录数量:在数据表中用事物插入行。
如果n比0大,每n行提交一次连接。
否则不使用事务,速度会慢一些。
d) 裁剪表:在第一行数据插入之前裁剪表。
KETTLE使用说明(中文版)

5.4 输出:插入/更新
插入/更新:若流里的数据在目标表中不存在,执行插入,否则执行更新, 数据量不大的情况下,一般采用插入/更新操作。
5.5 输出:更新
这个步骤类似于插入/更新步骤,除了对数据不作插入操作之外。它仅仅 执行更新操作。
5.6 输出:删除
这个步骤类似于更新步骤,除了不更新操作之外,其他的行均被删除。
选择表输入, excel 输出,建立节点 连接。右击连接线,可编辑连线属 性。
5.1常用输入:
表输入 Excel 输入 文本文件输入 XML 文件输入 CUBE 输入(多维数据集) 获取系统信息
5.2输入:表输入
选择表输入,点击鼠标右键,选择编辑步骤。 步骤名称可以更改,一般更改为和输入表相关的名称。 数据库连接 : 选择一个已建好的数据库连接,也可以新建一个。 点击”获取SQL查询语句”,可弹出数据库浏览器,选择自己需要的表或视图。 选择好表或视图后,SQL 区域会显示相应的SQL,如选择在SQL里包含字段名,你 所选择的表的所有字段均会显示. 在SQL区域用户可手动修改SQL语句。
7.3 Flow :Blocking Step(被冻结的步骤)
这是一个非常简单的步骤,它冻结所有的输出,直到从上一个步骤来的最后一行 数据到达,最后 一行数据将发送到下一步。 你可以使用这个步骤触发常用插件、 存储过程和js等等。
8.0 连接 :Merge Join(合并排序)
这个步骤将来自两个不同的步骤输 入的数据执行一个高效的合并。合 并选项包括INNER ,LEFT OUTER , RIGHT OUTER, FULL OUTER. 这个步骤将输入的行按照指定的字 段存储 被合并的两个步骤,必须按照相同 的段进行排序。
Kettle使用手册及测试案例

一、【kettle】window安装与配置1、下载kettle包,并解压2、安装jdk,并配置java环境a).打开我的电脑--属性--高级--环境变量b).新建系统变量JA V A_HOME和CLASSPATH变量名:JA V A_HOME变量值:C:\Program Files\Java\jdk1.7.0[具体路径以自己本机安装目录为准]变量名:CLASSPATH变量值:.;%JA V A_HOME%\lib\dt.jar;%JA V A_HOME%\lib\tools.jar;c). 选择“系统变量”中变量名为“Path”的环境变量,双击该变量,把JDK安装路径中bin目录的绝对路径,添加到Path变量的值中,并使用半角的分号和已有的路径进行分隔。
变量名:Path变量值:%JA V A_HOME%\bin;%JA V A_HOME%\jre\bin;3、配置kettle环境在系统的环境变量中添加KETTLE_HOME变量,目录指向kettle的安装目录:D:\kettle\data-integration4、启动spoonWindows直接双击批处理文件Spoon.bat具体路径为:kettle\data-integration\Spoon.batLinux 则是执行spoon.sh,具体路径为:~/kettle/data-integration/spoon.sh二、使用Kettle同步数据同步数据常见的应用场景包括以下4个种类型:➢ 只增加、无更新、无删除➢ 只更新、无增加、无删除➢ 增加+更新、无删除➢ 增加+更新+删除只增加、无更新、无删除对于这种只增加数据的情况,可细分为以下2种类型:1) 基表存在更新字段。
通过获取目标表上最大的更新时间或最大ID,在“表输入”步骤中加入条件限制只读取新增的数据。
2) 基表不存在更新字段。
通过“插入/更新”步骤进行插入。
插入/更新步骤选项:只更新、无增加、无删除通过“更新”步骤进行更新。
kettle 公式 处理

kettle 公式处理Kettle是一款功能强大的开源ETL工具,它可以帮助用户快速高效地进行数据抽取、转换和加载。
本文将介绍Kettle的基本原理和使用方法。
一、Kettle的基本原理Kettle采用了一种基于元数据的可视化设计思路,用户可以通过图形界面进行ETL任务的设计和配置。
Kettle将ETL任务分为三个主要步骤:数据抽取(Extract)、数据转换(Transform)和数据加载(Load)。
在数据抽取阶段,Kettle可以从各种数据源(如关系型数据库、文件、Web服务等)中提取数据;在数据转换阶段,Kettle可以对数据进行清洗、过滤、转换等操作;最后,在数据加载阶段,Kettle可以将处理后的数据加载到目标数据仓库或数据库中。
二、Kettle的使用方法1. 安装和配置Kettle:首先,用户需要下载并安装Kettle软件。
安装完成后,可以通过修改配置文件来配置Kettle的运行环境,如设置JVM参数、数据库连接等。
2. 创建一个新的ETL任务:在Kettle中,每个ETL任务被称为一个转换(Transformation)。
用户可以通过菜单或快捷键创建一个新的转换。
创建完成后,用户可以为转换设置名称和描述。
3. 设计转换的输入步骤:在转换中,用户需要定义输入数据的来源。
可以通过拖拽和连接各种输入步骤(如数据库输入、文本文件输入等)来完成数据抽取。
4. 设计转换的转换步骤:在转换步骤中,用户可以进行各种数据转换操作,如字段映射、条件过滤、数据清洗等。
Kettle提供了丰富的转换步骤和函数,用户可以根据需要选择和配置。
5. 设计转换的输出步骤:在转换的最后,用户需要定义输出数据的目标。
可以通过拖拽和连接各种输出步骤(如数据库输出、文本文件输出等)来完成数据加载。
6. 运行转换:转换设计完成后,用户可以通过点击运行按钮来执行转换。
在转换运行过程中,Kettle会显示详细的日志信息,以便用户进行调试和监控。