实验8查找与排序算法的实现和应用
数据结构中查找和排序算法实验报告

for(i=ST.length; !EQ(ST.elem[i].key,key); --i);
return i;
}
3.归并排序算法描述如下:
merge(ListType r,int l,int m,int n,ListType &r2)
{
i=l;j=m+1;k=l-1;
sift(ListType &r,int k,int m)
{
i=k;j=2*i;x=r[k].key;finished=FALSE;
t=r[k];
while((j<=m)&&(!finished))
{
if ((j<m)&&(r[j].key>r[j+1].key)) j++;
if (x<=r[j].key)
将两个或两个以上的有序表组合成一个新的有序表的方法叫归并。
假设初始序列含有n个记录,则可看成是n个有序的子序列,每个子序列的长度为1,然后两两归并,得到n/2个长度为2或1的有序子序列;再两两归并,如此重复。
4.堆排序分析:
只需要一个记录大小的辅助空间,每个待排序的记录仅占有一个存储空间。
什么是堆?n个元素的序列{k1,k2,...,kn}当且仅当满足下列关系时,称之为堆。关系一:ki<=k2i关系二:ki<=k2i+1(i=1,2,...,n/2)
静态查找表的顺序存储结构:
typedef struct {ElemType *e源自em;int length;
}SSTable;
顺序查找:从表中最后一个记录开始,逐个进行记录的关键字和给定值的比较,若某个记录的关键字和给定值比较相等,则查找成功,找到所查记录;反之,查找不成功。
数据结构实验七、八 查找排序及其应用

实验七、八查找排序应用问题实现一、实验目的1.理解掌握动态查找表在计算机中的各种实现方法。
2.熟练掌握顺序查找、折半查找在顺序表上的实现及解决简单的应用问题。
3.熟练掌握常用排序算法在顺序表上的实现,能解决简单的应用问题。
二、实验内容⏹题目:从键盘上输入n个学生的基本信息(学号、姓名、班级、年龄等),建立其顺存储结构,然后执行如下操作:1、分别按学号、姓名、班级、年龄进行插入排序、交换排序和选择排序并显示排序结果(排序算法任选,但必须保证每种算法至少使用一次);2、可按学号、姓名、班级或其组合查找某一学生,若查找成功,则输出其基本信息,否则提示出错。
试设计程序完成上述功能。
提示:上述操作可用菜单方式实现,字符数据类型可用字符串比较函数strcmp (const char *, const char *) ,在string.h 头文件中测试数据:自定⏹设计要求:1、上机前,认真学习教材,理解掌握各种查找算法、排序算法的特点及在计算机中的实现方法2、上机前,认真独立地写出本次程序清单,流程图,该程序包括数据类型以及每一种操作的具体的函数定义和主函数。
有关算法分别参阅讲义和参考教材事例。
⏹头文件中数据结构设计及相关函数声明:#include<iostream.h>#include<string.h>#define MAXSIZE 20 //设记录不超过20个typedef struct { //学生数据结构体定义int Snumber; //学号char Name[10]; //姓名char Class[20]; //班级int Age; //年龄char Sex[10]; //性别}RecordType;typedef struct { //定义顺序表的结构RecordType r [ MAXSIZE +1 ]; //存储顺序表的向量int length ; //顺序表的长度}SqList ;void DataInput(SqList &L); //数据输入void DataPrint(SqList &L); //数据输出void InsertSort(SqList &L); //直接插入排序void QuickSort(SqList &L); //快速排序void SelectSort(SqList &L); //直接选择排序三、实验步骤(一)、数据结构与核心算法的设计描述根据实验题目及要求,宜采用顺序表的线性结构,实验中最重要的是三种排序算法的理解和实现,只有真正理解算法的内涵,才能熟练地应用,并解决相应的问题。
查找排序实验报告

查找排序实验报告一、实验目的本次实验的主要目的是深入理解和比较不同的查找和排序算法在性能和效率方面的差异。
通过实际编程实现和测试,掌握常见查找排序算法的原理和应用场景,为今后在实际编程中能够选择合适的算法解决问题提供实践经验。
二、实验环境本次实验使用的编程语言为 Python,开发环境为 PyCharm。
计算机配置为:处理器_____,内存_____,操作系统_____。
三、实验内容1、查找算法顺序查找二分查找2、排序算法冒泡排序插入排序选择排序快速排序四、算法原理1、顺序查找顺序查找是一种最简单的查找算法。
它从数组的一端开始,依次比较每个元素,直到找到目标元素或者遍历完整个数组。
其时间复杂度为 O(n),在最坏情况下需要遍历整个数组。
2、二分查找二分查找适用于已排序的数组。
它通过不断将数组中间的元素与目标元素进行比较,将查找范围缩小为原来的一半,直到找到目标元素或者确定目标元素不存在。
其时间复杂度为 O(log n),效率较高。
3、冒泡排序冒泡排序通过反复比较相邻的两个元素并交换它们的位置,将最大的元素逐步“浮”到数组的末尾。
每次遍历都能确定一个最大的元素,经过 n-1 次遍历完成排序。
其时间复杂度为 O(n^2)。
4、插入排序插入排序将数组分为已排序和未排序两部分,每次从未排序部分取出一个元素,插入到已排序部分的合适位置。
其时间复杂度在最坏情况下为 O(n^2),但在接近有序的情况下性能较好。
5、选择排序选择排序每次从待排序数组中选择最小的元素,与当前位置的元素交换。
经过 n-1 次选择完成排序。
其时间复杂度为 O(n^2)。
6、快速排序快速排序采用分治的思想,选择一个基准元素,将数组分为小于基准和大于基准两部分,然后对这两部分分别递归排序。
其平均时间复杂度为 O(n log n),在大多数情况下性能优异。
五、实验步骤1、算法实现使用Python 语言实现上述六种查找排序算法,并分别封装成函数,以便后续调用和测试。
排序和查找的实验报告

排序和查找的实验报告实验报告:排序和查找引言排序和查找是计算机科学中非常重要的基本算法。
排序算法用于将一组数据按照一定的顺序排列,而查找算法则用于在已排序的数据中寻找特定的元素。
本实验旨在比较不同排序和查找算法的性能,并分析它们的优缺点。
实验设计为了比较不同排序算法的性能,我们选择了常见的几种排序算法,包括冒泡排序、插入排序、选择排序、快速排序和归并排序。
我们使用相同的随机数据集对这些算法进行了测试,并记录了它们的执行时间和占用空间。
在查找算法的比较实验中,我们选择了顺序查找和二分查找两种常见的算法。
同样地,我们使用相同的随机数据集对这些算法进行了测试,并记录了它们的执行时间和占用空间。
实验结果在排序算法的比较实验中,我们发现快速排序和归并排序在大多数情况下表现最好,它们的平均执行时间和空间占用都要优于其他排序算法。
而冒泡排序和插入排序则表现较差,它们的执行时间和空间占用相对较高。
在查找算法的比较实验中,二分查找明显优于顺序查找,尤其是在数据规模较大时。
二分查找的平均执行时间远远小于顺序查找,并且占用的空间也更少。
结论通过本实验的比较,我们得出了一些结论。
首先,快速排序和归并排序是较优的排序算法,可以在大多数情况下获得较好的性能。
其次,二分查找是一种高效的查找算法,特别适用于已排序的数据集。
最后,我们也发现了一些排序和查找算法的局限性,比如冒泡排序和插入排序在大数据规模下性能较差。
总的来说,本实验为我们提供了对排序和查找算法性能的深入了解,同时也为我们在实际应用中选择合适的算法提供了一定的参考。
希望我们的实验结果能够对相关领域的研究和应用有所帮助。
查找、排序的应用实验

淮海工学院计算机科学系实验报告书课程名:《数据结构》题目:查找、排序的应用实验班级:软件112学号:2011122635姓名:排序、查找的应用实验报告要求1目的与要求:1)查找、排序是日常数据处理过程中经常要进行的操作和运算,掌握其算法与应用对于提高学生数据处理能力和综合应用能力显得十分重要。
2)本次实验前,要求同学完整理解有关排序和查找的相关算法和基本思想以及种算法使用的数据存储结构;3)利用C或C++语言独立完成本次实验内容或题目,程序具有良好的交互性(以菜单形式列出实验排序和显示命令,并可进行交互操作)和实用性;4)本次实验为实验成绩评定主要验收内容之一,希望同学们认真对待,并按时完成实验任务;5)本次实验为综合性实验,请于2012年12月23日按时提交实验报告(纸质报告每班10份);6)下周开始数据结构课程设计,务必按时提交实验报告,任何同学不得拖延。
2 实验内容或题目题目:对记录序列(查找表):{287,109,063,930,589,184,505,269,008,083}分别实现如下操作:1)分别使用直接插入排序、冒泡排序、快速排序、简单选择排序、堆排序(可选)、链式基数排序算法对纪录序列进行排序,并显示排序结果;2)对上述纪录列表排好序,然后对其进行折半查找或顺序查找;3 实验步骤与源程序#include "stdio.h"#include "stdlib.h"#define LIST_SIZE 20#define TRUE 1#define FALSE 0typedef int KeyType;typedef struct{KeyType key;}RecordType;typedef struct{RecordType r[LIST_SIZE+1];int length;}RecordList;void seqSearch(RecordList *l){KeyType k; int i;printf("请输出要查询的元素k:");fflush(stdin);scanf("%d",&k);i=l->length;while (i>=0&&l->r[i].key!=k)i--;printf("该元素的位置是");printf("%d",i+1);//cout<<"该元素在图中第"<<i<<"个位置"<<endl; printf("\n");}void BinSrch(RecordList *l){KeyType q;int mid;printf("请输入要查询的元素k:");fflush(stdin);scanf("%d",&q);int low=1;int high=l->length;while(low<=high){mid=(low+high)/2;if(q==l->r[mid].key){printf("该元素的位置为:");printf("%d",mid+1);//注意不能随便使用&printf("\n");break;}else if(q<l->r[mid].key)high=mid-1;elselow=mid+1;}}void inputkey(RecordList *l){int i;printf("请输入线性表长度:");//遇到错误:1.print用法scanf("%d",&(l->length));//&将变量的地址赋值,而不是变量的值for(i=1;i<=l->length ;i++){printf("请输入第%d个元素的值:",i);fflush(stdin);scanf("%d",&(l->r[i].key));}}void InsSort(RecordList *l){for(int i=2;i<=l->length;i++){l->r[0].key=l->r[i].key;int j=i-1;while(l->r[0].key<l->r[j].key){l->r[j+1].key=l->r[j].key;j=j-1;}l->r[j+1].key=l->r[0].key;}}//直接插入排序void BubbleSort(RecordList *l){int x,i,n,change,j;n=l->length;change=TRUE;for(i=1;i<=n-1&&change;++i){change=FALSE;for(j=1;j<=n-i;++j)if(l->r[j].key>l->r[j+1].key){x=l->r[j].key;l->r[j].key=l->r[j+1].key ;l->r[j+1].key=x;change=TRUE;}}}//冒泡排序法int QKPass(RecordList *l,int left,int right) {int x;x=l->r[left].key ;int low=left;int high=right;while(low<high){while(low<high&&l->r[high].key>=x)high--;if(low<high){l->r[low].key=l->r[high].key;low++;}while(low<high&&l->r[low].key<=x)low++;if(low<high){l->r[high].key=l->r[low].key;high--;}}l->r[low].key=x;return(low);}void QKSort(RecordList *l,int low,int high){int pos;if(low<high){pos=QKPass(l,low,high);QKSort(l,low,pos-1);QKSort(l,pos+1,high);}}//快速排序void SelectSort(RecordList *l){int n,i,k,j,x;n=l->length;for(i=1;i<=n-1;++i){k=i;for(j=i+1;j<=n;++j)if(l->r[j].key<l->r[k].key) k=j;if(k!=i){x=l->r[i].key;l->r[i].key=l->r[k].key;l->r[k].key=x;} }}void output(RecordList *l){for(int i=1;i<=l->length;i++){printf("%d",l->r[i].key);printf("\n");}}void main(){RecordList *l,*t,*m,*n;l=(RecordList *)malloc(sizeof(RecordList));int low;int high;int flag=1;int xuanze;while(flag!=0){printf("####################################################\n");printf("###### 请选择你要进行的操作! #########\n");printf("###### 1.直接插入排序; #########\n");printf("###### 2.冒泡排序; #########\n");printf("###### 3.快速排序; #########\n");printf("###### 4.简单选择排序; #########\n");printf("###### 5.顺序查找; #########\n");printf("###### 6.折半查找; #########\n");printf("###### 7.退出! #########\n");printf("####################################################\n");scanf("%d",&xuanze);switch(xuanze){case 1:inputkey(l);InsSort(l);printf("直接插入排序结果是:\n");output(l);break;case 2:inputkey(l);BubbleSort(l);printf("冒泡排序结果是:\n");output(l);break;case 3:inputkey(l);low=1;high=l->length;QKSort(l,low,high);printf("快速排序结果是:\n");output(l);break;case 4:inputkey(l);SelectSort(l);printf("简单选择排序结果是:\n");output(l);break;case 5:inputkey(l);InsSort(l);printf("排序结果是:\n");output(l);seqSearch(l);break;case 6:inputkey(l);InsSort(l);printf("排序结果是:\n");output(l);break;BinSrch(l);case 7:flag=0;break;}}}4 测试数据与实验结果(可以抓图粘贴)《数据结构》实验报告- 10 -5 结果分析与实验体会1.编程时要细心,避免不必要的错误;2.要先熟悉书本上的内容,否则编译会有困难;3.不能太过死板,要灵活运用所学知识。
查找和排序实验报告

查找和排序实验报告
本实验主要针对以查找、排序算法为主要实现目标的软件开发,进行实验室研究。
实
验包括:冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、基数排序,
以及折半查找算法。
实验采用C语言编写,在完成以上排序以及查找方法的基础上,针对实验的工程要求,进行了性能分析,分析了算法空间复杂度以及时间复杂度。
通过首先采用循环方式,构建未排序数组,在此基础上,调用算法实现查找和排序。
也对不同算法进行对比分析,将数据量在100个至30000个之间进行测试。
结果表明:快速排序与希尔排序在时间复杂度方面具有最好的表现,而冒泡排序和选
择排序时间复杂度较高。
在空间复杂度方面,基数排序表现最佳,折半查找的空间复杂度
则比较可观。
在工程应用中,根据对不同排序算法的研究,可以更准确、有效地选择正确的算法实现,有效应用C语言搭建软件系统,提高软件应用效率。
(建议加入算法图)
本实验结束前,可以得出结论:
另外,也可以从这些研究中发现,在使用C语言实现软件系统时,应该重视算法支持
能力,以提高软件应用效率。
由于查找和排序算法在软件应用中占有重要地位,此次实验
对此有贡献,可为未来开发提供支持。
数据结构实验查找和排序

查找、排序算法的应用班级学号姓名一、实验目的1 掌握查找的不同方法,并能用高级语言实现查找算法。
2 熟练掌握顺序表和有序表的顺序查找和二分查找方法。
3 掌握排序的不同方法,并能用高级语言实现排序算法。
4 熟练掌握顺序表的选择排序、冒泡排序和直接插入排序算法的实现。
二、实验内容1 创建给定的顺序表。
表中共包含八条学生信息,信息如下:学号姓名班级C++ 数据结构1 王立03511 85 762 张秋03511 78 883 刘丽03511 90 794 王通03511 75 865 赵阳03511 60 716 李艳03511 58 687 钱娜03511 95 898 孙胜03511 45 602 使用顺序查找方法,从查找表中查找姓名为赵阳和王夏的学生。
如果查找成功,则显示该生的相关信息;如果查找不成功,则给出相应的提示信息。
3 使用二分查找方法,从查找表中查找学号为7和12的学生。
如果查找成功,则显示该生的相关信息;如果查找不成功,则给出相应的提示信息。
(注意:创建静态查找表时必须按学号的从小到大排列!)4 使用直接插入排序方法,对学生信息中的姓名进行排序。
输出排序前和排序后的学生信息表,验证排序结果。
5 使用直接选择排序方法,对学生信息中的C成绩进行排序。
输出排序前和排序后的学生信息表,验证排序结果。
6 使用冒泡排序方法,对学生信息中的数据结构成绩进行排序。
输出排序前和排序后的学生信息表,验证排序结果。
7 编写一个主函数,将上面函数连在一起,构成一个完整程序。
8 将实验源程序调试并运行。
三、实验结果#include<iostream>#include<string>using namespace std;# define size 10struct student{string num;string name;string classnum;int cscore;int datascore;};struct seqlist{student stu[size];int len;};//创建顺序表void create_seq(seqlist &L){int n;cout<<"请输入学生的人数:";cin>>n;L.len=n;cout<<endl;cout<<"请输入学生信息:"<<endl;cout<<"学号"<<" "<<"姓名"<<" "<<"班级"<<" "<<"C++成绩"<<" "<<"数据结构成绩"<<endl;for(int i=1;i<=L.len;i++ ){cin>>L.stu [i].num >>L.stu [i].name >>L.stu[i].classnum >>L.stu[i].cscore >>L.stu [i].datascore ;}}//输出顺序表的信息void display(seqlist L){cout<<"学号"<<" "<<"姓名"<<" "<<"班级"<<" "<<"C++成绩"<<" "<<"数据结构成绩"<<endl;for(int i=1;i<=L.len;i++){cout<<L.stu [i].num<<" "<<L.stu [i].name<<" "<<L.stu [i].classnum <<" "<<L.stu [i].cscore <<" "<<L.stu [i].datascore <<endl;}cout<<endl;}//顺序查找void seq_search(seqlist L,string n){int i=1;while(i<=L.len &&L.stu [i].name !=n){ i++;}if(i>L.len ){cout<<"该生不存在"<<endl;return;}cout<<L.stu [i].num<<" "<<L.stu [i].name<<" "<<L.stu [i].classnum <<" "<<L.stu [i].cscore <<" "<<L.stu [i].datascore <<endl;}//折半查找void bin_search(seqlist L,string n){int low,high,mid;low=1;high=L.len ;while(low<=high){mid=(low+high)/2;if(L.stu[mid].num==n){cout<<L.stu [mid].num<<" "<<L.stu [mid].name<<" "<<L.stu [mid].classnum <<" "<<L.stu [mid].cscore <<" "<<L.stu [mid].datascore <<endl; return;}else if(n<L.stu [mid].num){high=mid-1;}else{low=mid+1;}}cout<<"该学生不存在"<<endl;}//直接选择排序void selectsort(seqlist L){int k;student temp;for(int i=1;i<=L.len -1;i++){k=i;for(int j=i+1;j<=L.len;j++){if(L.stu[j].cscore<L.stu[k].cscore)k=j;}if(k!=i){temp=L.stu [i] ;L.stu [i] =L.stu [k] ;L.stu [k] =temp;}}display(L);}void bubblesort(seqlist L){int i,j,flag=1;student w;for(i=1;(i<=L.len -1)&&(flag);i++){flag=0;for(j=L.len ;j>=i+1;j--)if(L.stu [j].datascore <L.stu [j-1].datascore ){w=L.stu [j];L.stu [j]=L.stu [j-1];L.stu [j-1]=w;flag=1;}}display(L);}void insertsort2(seqlist L){int i, j;for( i=2; i<=L.len; i++ )if (L.stu[i].name< L.stu[i-1].name){L.stu[0]=L.stu[i]; // 复制为哨兵for(j=i-1; L.stu[0].name<L.stu[j].name; j-- )L.stu[j+1]=L.stu[j]; // 记录后移L.stu[j+1]=L.stu[0]; // 插入到正确位置}cout<<"排序后学生的信息如下:"<<endl;display(L);}void main(){seqlist L;cout<<"创建顺序表"<<endl;create_seq(L);cout<<"输出顺序表"<<endl;display(L);cout<<"顺序查找"<<endl;seq_search(L,"赵阳");seq_search(L,"王夏");cout<<"折半查找"<<endl;bin_search(L,"7");bin_search(L,"12");cout<<"直接插入排序"<<endl;insertsort2(L);cout<<"直接选择排序"<<endl;selectsort(L);cout<<"冒泡排序"<<endl;bubblesort(L);}执行结果如下:四、实验总结1.对于String 类的应用时要用using namespace std; 而不能直接用<Sting.h>,那样总是说前面少一个分号。
查找排序实验报告总结

一、实验目的本次实验旨在通过编写程序实现查找和排序算法,掌握基本的查找和排序方法,了解不同算法的优缺点,提高编程能力和数据处理能力。
二、实验内容1. 查找算法本次实验涉及以下查找算法:顺序查找、二分查找、插值查找。
(1)顺序查找顺序查找算法的基本思想是从线性表的第一个元素开始,依次将线性表中的元素与要查找的元素进行比较,若找到相等的元素,则查找成功;若线性表中所有的元素都与要查找的元素进行了比较但都不相等,则查找失败。
(2)二分查找二分查找算法的基本思想是将待查找的元素与线性表中间位置的元素进行比较,若中间位置的元素正好是要查找的元素,则查找成功;若要查找的元素比中间位置的元素小,则在线性表的前半部分继续查找;若要查找的元素比中间位置的元素大,则在线性表的后半部分继续查找。
重复以上步骤,直到找到要查找的元素或查找失败。
(3)插值查找插值查找算法的基本思想是根据要查找的元素与线性表中元素的大小关系,估算出要查找的元素应该在大致的位置,然后从这个位置开始进行查找。
2. 排序算法本次实验涉及以下排序算法:冒泡排序、选择排序、插入排序、快速排序。
(1)冒泡排序冒泡排序算法的基本思想是通过比较相邻的元素,将较大的元素交换到后面,较小的元素交换到前面,直到整个线性表有序。
(2)选择排序选择排序算法的基本思想是在未排序的序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
以此类推,直到所有元素均排序完毕。
(3)插入排序插入排序算法的基本思想是将一个记录插入到已排好序的有序表中,从而得到一个新的、记录数增加1的有序表。
(4)快速排序快速排序算法的基本思想是选择一个元素作为基准元素,将线性表分为两个子表,一个子表中所有元素均小于基准元素,另一个子表中所有元素均大于基准元素,然后递归地对两个子表进行快速排序。
三、实验结果与分析1. 查找算法通过实验,我们发现:(1)顺序查找算法的时间复杂度为O(n),适用于数据量较小的线性表。
排序查找实验报告

排序查找实验报告排序查找实验报告一、引言排序和查找是计算机科学中非常重要的基础算法。
排序算法可以将一组无序的数据按照某种规则重新排列,而查找算法则可以在大量数据中快速找到目标元素。
本实验旨在通过实际操作和观察,对比不同的排序和查找算法的性能和效果,以便更好地理解和应用这些算法。
二、实验目的本实验的主要目的有以下几点:1. 理解不同排序算法的原理和特点;2. 掌握不同排序算法的实现方法;3. 比较不同排序算法之间的性能差异;4. 理解不同查找算法的原理和特点;5. 掌握不同查找算法的实现方法;6. 比较不同查找算法之间的性能差异。
三、实验过程1. 排序算法实验在排序算法实验中,我们选择了冒泡排序、选择排序和快速排序三种常见的排序算法进行比较。
首先,我们编写了一个随机生成一组无序数据的函数,并将其作为排序算法的输入。
然后,分别使用冒泡排序、选择排序和快速排序对这组数据进行排序,并记录下每种算法的执行时间。
最后,我们比较了三种算法的执行效率和排序结果的准确性。
2. 查找算法实验在查找算法实验中,我们选择了顺序查找、二分查找和哈希查找三种常见的查找算法进行比较。
首先,我们编写了一个生成有序数据的函数,并将其作为查找算法的输入。
然后,分别使用顺序查找、二分查找和哈希查找对这组数据进行查找,并记录下每种算法的执行时间。
最后,我们比较了三种算法的执行效率和查找结果的准确性。
四、实验结果1. 排序算法实验结果经过实验比较,我们发现快速排序算法在大多数情况下具有最好的性能表现,其平均时间复杂度为O(nlogn)。
冒泡排序算法虽然简单,但其时间复杂度为O(n^2),在数据量较大时效率较低。
选择排序算法的时间复杂度也为O(n^2),但相对于冒泡排序,其交换次数较少,因此效率稍高。
2. 查找算法实验结果顺序查找算法是最简单的一种查找算法,其时间复杂度为O(n),适用于小规模数据的查找。
二分查找算法的时间复杂度为O(logn),适用于有序数据的查找。
查找和排序 实验报告

查找和排序实验报告查找和排序实验报告一、引言查找和排序是计算机科学中非常重要的基础算法之一。
查找(Search)是指在一组数据中寻找目标元素的过程,而排序(Sort)则是将一组数据按照特定的规则进行排列的过程。
本实验旨在通过实际操作和实验验证,深入理解查找和排序算法的原理和应用。
二、查找算法实验1. 顺序查找顺序查找是最简单的查找算法之一,它的基本思想是逐个比较待查找元素与数据集合中的元素,直到找到目标元素或遍历完整个数据集合。
在本实验中,我们设计了一个包含1000个随机整数的数据集合,并使用顺序查找算法查找指定的目标元素。
实验结果显示,顺序查找的时间复杂度为O(n)。
2. 二分查找二分查找是一种高效的查找算法,它要求待查找的数据集合必须是有序的。
二分查找的基本思想是通过不断缩小查找范围,将待查找元素与中间元素进行比较,从而确定目标元素的位置。
在本实验中,我们首先对数据集合进行排序,然后使用二分查找算法查找指定的目标元素。
实验结果显示,二分查找的时间复杂度为O(log n)。
三、排序算法实验1. 冒泡排序冒泡排序是一种简单但低效的排序算法,它的基本思想是通过相邻元素的比较和交换,将较大(或较小)的元素逐渐“冒泡”到数列的一端。
在本实验中,我们设计了一个包含1000个随机整数的数据集合,并使用冒泡排序算法对其进行排序。
实验结果显示,冒泡排序的时间复杂度为O(n^2)。
2. 插入排序插入排序是一种简单且高效的排序算法,它的基本思想是将数据集合分为已排序和未排序两部分,每次从未排序部分选择一个元素插入到已排序部分的适当位置。
在本实验中,我们使用插入排序算法对包含1000个随机整数的数据集合进行排序。
实验结果显示,插入排序的时间复杂度为O(n^2)。
3. 快速排序快速排序是一种高效的排序算法,它的基本思想是通过递归地将数据集合划分为较小和较大的两个子集合,然后对子集合进行排序,最后将排序好的子集合合并起来。
实验8查找与排序算法的实现和应用

陕西科技大学实验报告班级学号姓名实验组别实验日期室温报告日期成绩报告内容:(目的和要求、原理、步骤、数据、计算、小结等)实验名称:查找与排序算法的实现和应用实验目的:1.掌握顺序表中查找的实现及监视哨的作用。
2.掌握折半查找所需的条件、折半查找的过程和实现方法。
3.掌握二叉排序树的创建过程,掌握二叉排序树查找过程的实现。
4.掌握哈希表的基本概念,熟悉哈希函数的选择方法,掌握使用线性探测法和链地址法进行冲突解决的方法。
5.掌握直接插入排序、希尔排序、快速排序算法的实现。
实验环境(硬/软件要求):Windows 2000,Visual C++ 6.0实验内容:通过具体算法程序,进一步加深对各种查找算法的掌握,以及对实际应用中问题解决方法的掌握。
各查找算法的输入序列为:26 5 37 1 61 11 59 15 48 19 输出要求:查找关键字37,给出查找结果。
对于给定的某无序序列,分别用直接插入排序、希尔排序、快速排序等方法进行排序,并输出每种排序下的各趟排序结果。
各排序算法输入的无序序列为:26 5 37 1 61 11 59 15 48 19。
实验要求:一、查找法1.顺序查找首先从键盘输入一个数据序列生成一个顺序表,然后从键盘上任意输入一个值,在顺序表中进行查找。
2.折半查找任意输入一组数据作为个数据元素的键值,首先将此序列进行排序,然后再改有序表上使用折半查找算法进一对给定值key的查找。
3.二叉树查找任意输入一组数据作为二叉排序树中节点的键值,首先创建一颗二叉排序树,然后再次二叉排序树上实现对一定k的查找过程。
4.哈希表查找任意输入一组数值作为个元素的键值,哈希函数为Hash(key)=key%11,用线性探测再散列法解决冲突问题。
二、排序算法编程实现直接插入排序、希尔排序、快速排序各算法函数;并编写主函数对各排序函数进行测试。
实验原理:1.顺序查找:在一个已知无(或有序)序队列中找出与给定关键字相同的数的具体位置。
查找排序算法实验报告(3篇)

第1篇一、实验目的1. 熟悉常见的查找和排序算法。
2. 分析不同查找和排序算法的时间复杂度和空间复杂度。
3. 比较不同算法在处理大数据量时的性能差异。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.73. 开发工具:PyCharm三、实验内容1. 实现以下查找和排序算法:(1)查找算法:顺序查找、二分查找(2)排序算法:冒泡排序、选择排序、插入排序、快速排序、归并排序2. 分析算法的时间复杂度和空间复杂度。
3. 对不同算法进行性能测试,比较其处理大数据量时的性能差异。
四、实验步骤1. 实现查找和排序算法。
2. 分析算法的时间复杂度和空间复杂度。
3. 创建测试数据,包括小数据量和大数据量。
4. 对每种算法进行测试,记录运行时间。
5. 分析测试结果,比较不同算法的性能。
五、实验结果与分析1. 算法实现(1)顺序查找def sequential_search(arr, target): for i in range(len(arr)):if arr[i] == target:return ireturn -1(2)二分查找def binary_search(arr, target):low, high = 0, len(arr) - 1while low <= high:mid = (low + high) // 2if arr[mid] == target:return midelif arr[mid] < target:low = mid + 1else:high = mid - 1return -1(3)冒泡排序def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j](4)选择排序def selection_sort(arr):n = len(arr)for i in range(n):min_idx = ifor j in range(i+1, n):if arr[min_idx] > arr[j]:min_idx = jarr[i], arr[min_idx] = arr[min_idx], arr[i](5)插入排序def insertion_sort(arr):for i in range(1, len(arr)):key = arr[i]j = i-1while j >=0 and key < arr[j]:arr[j+1] = arr[j]j -= 1arr[j+1] = key(6)快速排序def quick_sort(arr):if len(arr) <= 1:pivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)(7)归并排序def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])return merge(left, right)def merge(left, right):result = []i = j = 0while i < len(left) and j < len(right):if left[i] < right[j]:result.append(left[i])i += 1else:result.append(right[j])result.extend(left[i:])result.extend(right[j:])return result2. 算法时间复杂度和空间复杂度分析(1)顺序查找:时间复杂度为O(n),空间复杂度为O(1)。
实验8_9查找和排序应用

实验8、9 查找、排序算法的应用班级: B155A6 学号: 2015405A607 姓名:武俊其成绩:一、实验目的1.掌握查找的不同方法,并能用高级语言实现查找算法。
2.熟练掌握顺序表和有序表的顺序查找和二分查找方法。
3.掌握排序的不同方法,并能用高级语言实现排序算法。
4.熟练掌握顺序表的选择排序、冒泡排序和直接插入排序算法的实现。
二、实验内容1.学生信息如下:学号姓名数据结构程序设计1 王立76 882 张秋88 773 刘丽79 654 王通86 855 赵阳71 906 李艳68 707 钱娜89 958 孙胜60 762.创建顺序查找表,输入学生信息。
【选做:也可以将学生信息存入文件,直接从文件读取学生信息】3.使用顺序查找方法按姓名查找学生。
如果查找成功,则显示该生的相关信息;如果查找不成功,则给出相应的提示信息。
4.使用二分查找方法,查找学生学号信息。
如果查找成功,则显示该生的相关信息;如果查找不成功,则给出相应的提示信息。
5.使用直接插入排序方法,对学生信息中的姓名进行排序。
输出排序前和排序后的学生信息表,验证排序结果。
6.使用直接选择排序方法,对学生信息中的数据结构成绩进行排序。
输出排序前和排序后的学生信息表,验证排序结果。
7.使用冒泡排序方法,对学生信息中的程序设计成绩进行排序。
输出排序前和排序后的学生信息表,验证排序结果。
8.编写一个菜单,来实现各项功能的选择。
*******************学生成绩管理系统****************** 1.信息初始化2.顺序查找** 3.二分查找4.直接插入排序** 5.冒泡排序6.直接选择排序** 0.退出*****************************************************9.利用工程完成本次实验任务,各个功能分别放到一个函数中。
三、实验结果给出源程序及输入、输出结果。
#include<iostream>using namespace std;#include<stdlib.h>#include<string.h>#define N 10000define OK 1#define ERROR 0#define MAXSIZE 30typedef int Status;typedef struct information{int num;char name[30];int score1;int score2;}xinxi;typedef struct{xinxi *elem;int studentnum;}Stu;void Input(Stu &stu ,int n) //输入学生信息{for(int i=0;i<n;i++){cout<<"请输入第"<<"i+1"<<"个学生的学号:";fflush(stdin);cin>>stu.elem[i].num ;cout<<"请输入第"<<"i+1"<<"个学生的姓名:";cin>>stu.elem[i].name ;cout<<"请输入第"<<"i+1"<<"个的数据结构成绩(0-100):";cin>>stu.elem[i].score1 ;while (stu.elem[i].score1<0||stu.elem[i].score1>100){cout<<"输入不合法,请重新输入。
查找与排序实验报告

查找与排序实验报告《查找与排序实验报告》摘要:本实验旨在通过不同的查找与排序算法对比分析它们的效率和性能。
我们使用了常见的查找算法包括线性查找、二分查找和哈希查找,以及排序算法包括冒泡排序、快速排序和归并排序。
通过实验数据的对比分析,我们得出了每种算法的优缺点和适用场景,为实际应用提供了参考依据。
1. 实验目的通过实验对比不同查找与排序算法的性能,分析它们的优缺点和适用场景。
2. 实验方法(1)查找算法实验:分别使用线性查找、二分查找和哈希查找算法,对含有一定数量元素的数组进行查找操作,并记录比较次数和查找时间。
(2)排序算法实验:分别使用冒泡排序、快速排序和归并排序算法,对含有一定数量元素的数组进行排序操作,并记录比较次数和排序时间。
3. 实验结果(1)查找算法实验结果表明,二分查找在有序数组中的查找效率最高,哈希查找在大规模数据中的查找效率最高。
(2)排序算法实验结果表明,快速排序在平均情况下的排序效率最高,归并排序在最坏情况下的排序效率最高。
4. 实验分析通过实验数据的对比分析,我们得出了以下结论:(1)查找算法:二分查找适用于有序数组的查找,哈希查找适用于大规模数据的查找。
(2)排序算法:快速排序适用于平均情况下的排序,归并排序适用于最坏情况下的排序。
5. 结论不同的查找与排序算法在不同的场景下有着不同的性能表现,选择合适的算法可以提高程序的效率和性能。
本实验为实际应用提供了参考依据,对算法的选择和优化具有一定的指导意义。
通过本次实验,我们深入了解了不同查找与排序算法的原理和性能,为今后的算法设计和优化工作提供了宝贵的经验和参考。
实验八-查找、排序

实验8:查找、排序一、实验目的深入了解各种内部排序方法及效率分析。
二、问题描述各种内部排序算法的时间复杂度分析,试通过随机数据比较算法的关键字比较次数和关键字移动次数。
三、实验要求1、对起泡排序、直接插入排序、简单选择排序、快速排序、希尔排序、堆排序这六种常用排序算法进行比较。
2、待排序表的表长不超过100;其中数据用伪随机数产生程序产生。
3、至少要用6组不同的输入数据做比较。
4、要对实验结果做简单分析。
四、实验环境PC微机DOS操作系统或 Windows 操作系统Turbo C 程序集成环境或 Visual C++ 程序集成环境五、实验步骤1、根据问题描述写出基本算法。
2、设计六种排序算法并用适当语言实现。
3、输入几组随机数据,并对其关键字比较次数和关键字移动次数的比较。
4、对结果进行分析。
5、进行总结。
六种实验算法的基本思想:(1)直接插入排序的基本思想是:当插入第i个数据元素k时,由前i-1个数据元素组成已排序的数据元素序列,将k的关键字与序列中各数据元素的关键字依次进行比较后,找到该插入位置j,并将第j以及后面的数据元素顺序后移一个位置,然后将k插入到位置j,使得插入后的数据元素序列仍是排序的。
(2)希尔排序的基本思想是:先将整个待排序记录序列按给定的下标增量进行分组,并对组内的记录采用直接插入排序,再减小下标增量,即每组包含的记录增多,再继续对每组组内的记录采用直接插入排序;以此类推,当下标增量减小到1时,整个待排序记录已成为一组,再对全体待排序记录进行一次直接插入排序即可完成排序工作。
(3)冒泡排序的基本思想是:将相邻的两个数据元素按关键字进行比较,如果反序,则交换。
对于一个待排序的数据元素序列,经一趟排序后最大值数据元素移到最大位置,其它值较大的数据元素向也最终位置移动,此过程为一次起泡。
然后对下面的记录重复上述过程直到过程中没有交换为止,则已完成对记录的排序。
(4)选择排序的基本思想是:设有N个数据元素的序列,第一趟排序,比较N个数据元素,选择关键字最小的数据元素,将其交换到序列的第1个位置上;第2趟排序,在余下的N-1个数据元素中,再选取关键字最小的数据元素,交换到序列的第2个位置上;继续进行,经过N-1趟排序,N个数据元素则按递增次序排列完成。
数据结构的排序与查找算法

数据结构的排序与查找算法数据结构是计算机科学中一门重要的基础课程,它研究了数据的组织、存储和管理方式。
对于大规模数据的处理,排序和查找算法是数据结构中的两个核心问题。
本文将介绍常见的排序和查找算法,包括其原理、实现方法以及应用场景。
一、排序算法排序算法是将一组无序的数据按照特定的规则进行排列的过程。
常见的排序算法包括冒泡排序、插入排序、选择排序、快速排序、归并排序等。
1. 冒泡排序冒泡排序是一种简单的排序算法,它重复地遍历要排序的数列,每次比较相邻的两个元素,如果顺序错误就交换它们,直到没有再需要交换的元素为止。
2. 插入排序插入排序是一种简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序的数据,在已排序序列中从后向前扫描,找到相应位置插入。
3. 选择排序选择排序是一种简单直观的排序算法,它的工作原理是每次从待排序的数据中选择最小(或最大)的一个元素,与待排序数据的第一个元素交换,直到所有待排序数据排序完成。
4. 快速排序快速排序是一种分治的排序算法,它使用了递归的思想。
快速排序首先选择一个基准元素,将小于基准的元素放在左边,大于基准的元素放在右边,然后对左右两个子序列进行递归排序。
5. 归并排序归并排序是一种分治的排序算法,它的核心思想是将待排序序列拆分成若干个子序列,分别对子序列进行排序,最后将排好序的子序列合并成最终的排序结果。
二、查找算法查找算法是在一组数据中寻找特定元素的过程。
常见的查找算法包括线性查找、二分查找、哈希查找等。
1. 线性查找线性查找是一种简单直观的查找算法,它从数据的起始位置开始,依次比较每个元素,直到找到目标元素或遍历完整个数据。
2. 二分查找二分查找是一种高效的查找算法,它要求待查找的数据必须是有序的。
二分查找从有序数据的中间元素开始比较,根据比较结果可以确定目标元素在左半部分还是右半部分,然后递归地在相应半部分继续查找,直到找到目标元素或确定不存在。
3. 哈希查找哈希查找是一种利用哈希表进行查找的算法,它通过将关键字映射到哈希表中的位置,将查找的时间复杂度降低到常数级。
排序与查找算法

排序与查找算法排序与查找算法是计算机科学中常见的问题解决技巧。
排序算法主要用于将一组数据按照特定规则进行排列,方便后续的查找和操作。
而查找算法则用于在已排序的数据中快速定位所需的元素。
本文将介绍几种常见的排序与查找算法,并对它们的原理和应用进行详细阐述。
一、排序算法1. 冒泡排序冒泡排序是一种简单但效率较低的排序算法。
其基本思想是重复地遍历待排序序列,每次比较相邻的两个元素,如果顺序不符合要求,则交换位置,直到整个序列有序为止。
2. 插入排序插入排序采用逐步构建有序序列的思想。
首先将序列的第一个元素看作是已排序序列,然后从第二个元素开始逐个插入到已排序序列中的合适位置。
插入排序具有稳定性和原地排序的特点。
3. 快速排序快速排序是一种常用的排序算法,其核心思想是选择一个基准元素,将序列分成小于等于基准元素和大于基准元素的两个子序列,然后对子序列进行递归排序。
快速排序具有高效性能和不占用额外的存储空间的优点。
4. 归并排序归并排序是一种分治思想的排序算法,它将待排序序列不断地二分并递归排序,最后再将排序好的子序列合并为一个有序序列。
归并排序具有稳定性和稳定的时间复杂度,适用于大规模数据的排序。
二、查找算法1. 顺序查找顺序查找是一种简单但效率较低的查找算法。
它从序列的第一个元素开始逐个比较,直到找到匹配的元素或者遍历完整个序列。
顺序查找适用于无序序列或者数据规模较小的情况。
2. 二分查找二分查找是一种高效的查找算法,前提是待查找的序列已经排序。
它通过不断缩小查找范围,将待查找序列分为两部分,并逐步逼近目标元素。
二分查找的时间复杂度为O(log n),适用于大规模有序序列的查找。
3. 哈希查找哈希查找利用哈希函数将元素与存储位置建立映射关系,从而实现快速的查找。
它将元素存储在哈希表中,通过计算哈希值直接定位元素的存储位置,从而提高查找效率。
哈希查找适用于需要频繁查找的场景。
总结:排序与查找算法是计算机科学中重要的基础知识,应用广泛。
实验八 查找和排序

注意事项:在磁盘上创建一个目录,专门用于存储数据结构实验的程序。
因为机房机器有还原卡,请同学们将文件夹建立在最后一个盘中,以学号为文件夹名。
实验八查找和排序一、实验目的掌握运用数据结构两种基本运算查找和排序,并能通过其能解决应用问题。
二、实验要求1.掌握本实验的算法。
2.上机将本算法实现。
三、实验内容为宿舍管理人员编写一个宿舍管理查询软件, 程序采用交互工作方式,其流程如下:建立数据文件,数据结构采用线性表,存储方式任选(建议用顺序存储结构),数据元素是结构类型(学号,姓名,性别,房号),元素的值可从键盘上输入,可以在程序中直接初始化。
数据文件按关键字(学号、姓名、房号)进行排序(排序方法任选一种),打印排序结果。
(注意字符串的比较应该用strcmp(str1,str2)函数)查询菜单: (查找方法任选一种)1. 按学号查询2. 按姓名查询3. 按房号查询打印任一查询结果(可以连续操作)。
参考:typedef struct {char sno[10];char sname[2];int sex; //以0表示女,1表示男int roomno;}DataType;struct SeqList{DataType *elem;int length;};void init(SeqList &L){L.elem=(DataType *)malloc(MAXSIZE*sizeof(DataType));L.length=0;}void printlist(SeqList L){ int i;cout<<" sno name sex roomno\n";for(i=0;i<L.length;i++)cout<<setw(7)<<L.elem[i].sno<<setw(10)<<L.elem[i].sname<<setw(3)<<L.elem[i].sex<<setw(6) <<L.elem[i].roomno<<endl;}。
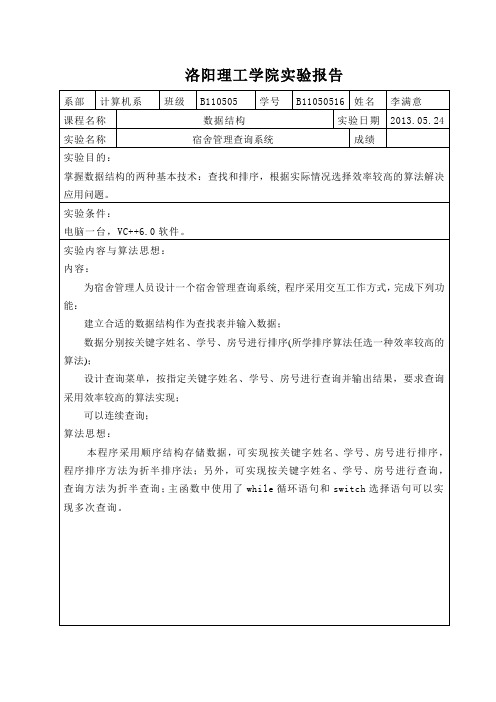
实验目的:查找和排序,根据实际情况选择效率较高的算法解决应用问题。
洛阳理工学院实验报告附:源程序:#include<stdio.h>#include<stdlib.h>struct student{char name[20];char num[20];char room[20];};struct student stu[20];int a;int shuru(){int i=1,flag=1;printf("请输入宿舍成员并以“*”作为输入结束标记:\n");while(flag){scanf("%s",stu[i].name);if(strcmp(stu[i].name,"*")==0)break;scanf("%s%s",stu[i].num,stu[i].room);a=i;i++;}}void shuchu(){int i;char name[20]="name",num[20]="num",room[20]="room";printf("%-15s%15s%15s\n",name,num,room);for(i=1;i<=a;i++){printf("%-15s%15s%15s\n",stu[i].name,stu[i].num,stu[i].room);}printf("\n");}void binsortname(struct student stu[],int a){struct student x;int low,high,mid,i,j;for(i=2;i<=a;++i){x=stu[i];low=1;high=i-1;while(low<=high){mid=(low+high)/2;if(strcmp(,stu[mid].name)<0)high=mid-1;else low=mid+1;}for(j=i-1;j>=low;--j)stu[j+1]=stu[j];stu[low]=x;}}void binsrchname(struct student stu[]){int low,high,mid;char k[20];low=1;high=a;/*置区间初值*/printf("请输入需要查找的姓名:");scanf("%s",k);while( low <= high){mid=(low+high) / 2;if(strcmp(k,stu[mid].name)==0){printf("%15s%15s%15s\n",stu[mid].name,stu[mid].num,stu[mid].room);break;}/*找到待查元素*/elseif(strcmp(k,stu[mid].name)<0)high=mid-1;/*未找到,则继续在前半区间进行查找*/elselow=mid+1;/*继续在后半区间进行查找*/}}void binsortnum(struct student stu[],int a){struct student x;int low,high,mid,i,j;for(i=2;i<=a;++i){x=stu[i];low=1;high=i-1;while(low<=high){mid=(low+high)/2;if(strcmp(x.num,stu[mid].num)<0)high=mid-1;else low=mid+1;}for(j=i-1;j>=low;--j)stu[j+1]=stu[j];stu[low]=x;}}void binsrchnum(struct student stu[]){int low,high,mid;char k[20];low=1;high=a;/*置区间初值*/printf("请输入需要查找的学号:");scanf("%s",k);while( low <= high){mid=(low+high) / 2;if(strcmp(k,stu[mid].num)==0){printf("%15s%15s%15s\n",stu[mid].name,stu[mid].num,stu[mid].room);break;}/*找到待查元素*/elseif(strcmp(k,stu[mid].num)<0)high=mid-1;/*未找到,则继续在前半区间进行查找*/elselow=mid+1;/*继续在后半区间进行查找*/}}void binsortroom(struct student stu[],int a){struct student x;int low,high,mid,i,j;for(i=2;i<=a;++i){x=stu[i];low=1;high=i-1;while(low<=high){mid=(low+high)/2;if(strcmp(x.room,stu[mid].room)<0)high=mid-1;else low=mid+1;}for(j=i-1;j>=low;--j)stu[j+1]=stu[j];stu[low]=x;}}void binsrchroom(struct student stu[]){int low,high,mid;char k[20];low=1;high=a;/*置区间初值*/printf("请输入需要查找的房间号:");scanf("%s",k);while( low <= high){mid=(low+high) / 2;if(strcmp(k,stu[mid].room)==0){printf("%15s%15s%15s\n",stu[mid].name,stu[mid].num,stu[mid].room);break;}/*找到待查元素*/elseif(strcmp(k,stu[mid].room)<0)high=mid-1;/*未找到,则继续在前半区间进行查找*/elselow=mid+1;/*继续在后半区间进行查找*/}}void main(){int flag=1,choice;shuru();binsortname(stu,a);printf("您输入的宿舍人员数据为:\n");shuchu();printf("***********************************************\n"); printf("* 请选择所需要的操作:*\n"); printf("* 1,按姓名排序:*\n"); printf("* 2,按学号排序:*\n"); printf("* 3,按房间号排序:*\n"); printf("* 4,按姓名查找:*\n"); printf("* 5,按学号查找:*\n"); printf("* 6,按房间号查找:*\n"); printf("* 7,退出。
查找、排序的应用实验报告

实验七查找、排序的应用一、实验目的1、本实验可以使学生更进一步巩固各种查找和排序的基本知识。
2、学会比较各种排序与查找算法的优劣。
3、学会针对所给问题选用最适合的算法。
4、掌握利用常用的排序与选择算法的思想来解决一般问题的方法和技巧。
二、实验内容[ 问题描述]对学生的基本信息进行管理。
[ 基本要求]设计一个学生信息管理系统,学生对象至少要包含:学号、姓名、性别、成绩1、成绩2、总成绩等信息。
要求实现以下功能:1.总成绩要求自动计算;2.查询:分别给定学生学号、姓名、性别,能够查找到学生的基本信息(要求至少用两种查找算法实现);3.排序:分别按学生的学号、成绩1、成绩2、总成绩进行排序(要求至少用两种排序算法实现)。
[ 测试数据]由学生依据软件工程的测试技术自己确定。
三、实验前的准备工作1、掌握哈希表的定义,哈希函数的构造方法。
2、掌握一些常用的查找方法。
1、掌握几种常用的排序方法。
2、掌握直接排序方法。
折半查找算法:for(i nt i=1;i<ST.le ngth;i++)〃使学号变为有序for(i nt j=i ;j>=1;j--)if(ST.r[j].xuehao<ST.r[j-1].xuehao) {LI=ST.r[j]; ST.r[j]=ST.r[j-1];ST.r[j-1]=LI;四、实验报告要求1、 实验报告要按照实验报告格式规范书写。
2、 实验上要写出多批测试数据的运行结果。
3、 结合运行结果,对程序进行分析。
五、算法设计a 、折半查找设表长为n , low 、high 和mid 分别指向待查元素所在区间的下界、上界和 中点,key 为给定值。
初始时,令low=1,high=n,mid=与mid 指向的记录比较,key==r[mid].keykey<r[mid].key key>r[mid].key key 若 若 若 重复上述操作,直至 ,查找成功,贝V high=mid-1 ,贝V low=mid+1low>high 时,查找失败(low+high)/2 ,让b 、顺序查找从表的一端开始逐个进行记录的关键字和给定值的比较。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
陕西科技大学实验报告班级学号姓名实验组别实验日期室温报告日期成绩报告内容:(目的和要求、原理、步骤、数据、计算、小结等)实验名称:查找与排序算法的实现和应用实验目的:1. 掌握顺序表中查找的实现及监视哨的作用。
2. 掌握折半查找所需的条件、折半查找的过程和实现方法。
3. 掌握二叉排序树的创建过程,掌握二叉排序树查找过程的实现。
4. 掌握哈希表的基本概念,熟悉哈希函数的选择方法,掌握使用线性探测法和链地址法进行冲突解决的方法。
5. 掌握直接插入排序、希尔排序、快速排序算法的实现。
实验环境(硬/软件要求):Windows 2000,Visual C++ 6.0实验内容:通过具体算法程序,进一步加深对各种查找算法的掌握,以及对实际应用中问题解决方法的掌握。
各查找算法的输入序列为:26 5 37 1 61 11 59 15 48 19输出要求:查找关键字37,给出查找结果。
对于给定的某无序序列,分别用直接插入排序、希尔排序、快速排序等方法进行排序,并输出每种排序下的各趟排序结果。
各排序算法输入的无序序列为:26 5 37 1 61 11 59 15 48 19。
实验要求:一、查找法1. 顺序查找首先从键盘输入一个数据序列生成一个顺序表,然后从键盘上任意输入一个值,在顺序表中进行查找。
2. 折半查找任意输入一组数据作为个数据元素的键值,首先将此序列进行排序,然后再改有序表上使用折半查找算法进对给定值key 的查找。
3. 二叉树查找任意输入一组数据作为二叉排序树中节点的键值,首先创建一颗二叉排序树,然后再次二叉排序树上实现对一定k的查找过程。
4. 哈希表查找任意输入一组数值作为个元素的键值,哈希函数为Hash (key )=key%11, 用线性探测再散列法解决冲突问题。
二、排序算法编程实现直接插入排序、希尔排序、快速排序各算法函数;并编写主函数对各排序函数进行测试。
实验原理:1. 顺序查找:在一个已知无(或有序)序队列中找出与给定关键字相同的数的具体位置。
原理是让关键字与队列中的数从最后一个开始逐个比较,直到找出与给定关键字相同的数为止,它的缺点是效率低下。
二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,且插入删除困难。
因此,折半查找方法适用于不经常变动而查找频繁的有序列表。
首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。
重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
2•哈希查找:哈希查找的操作步骤:⑴用给定的哈希函数构造哈希表;⑵根据选择的冲突处理方法解决地址冲突;⑶在哈希表的基础上执行哈希查找。
哈希查找的本质是先将数据映射成它的哈希值。
哈希查找的核心是构造一个哈希函数,它将原来直观、整洁的数据映射为看上去似乎是随机的一些整数。
哈希查找的产生有这样一种背景一一有些数据本身是无法排序的(如图像),有些数据是很难比较的(如图像)。
如果数据本身是无法排序的,就不能对它们进行比较查找。
如果数据是很难比较的,即使采用折半查找,要比较的次数也是非常多的。
因此,哈希查找并不查找数据本身,而是先将数据映射为一个整数(它的哈希值),并将哈希值相同的数据存放在同一个位置一即以哈希值为索引构造一个数组。
在哈希查找的过程中,只需先将要查找的数据映射为它的哈希值,然后查找具有这个哈希值的数据,这就大大减少了查找次数。
如果构造哈希函数的参数经过精心设计,内存空间也足以存放哈希表,查找一个数据元素所需的比较次数基本上就接近于一次。
3.排序算法:排序(Sorting)是计算机程序设计中的一种重要操作,它的功能是将一个数据元素(或流程图:输入查找条件用户输入输出结果记录)的任意序列,重新排列成一个关键字有序的序列。
排序创建二叉树是否继续中序遍历实验代码:一、查找法1、顺序查找#i nclude <stdio.h>#defi ne MAX 100typedef int keytype;typedef struct{ keytype key;}elemtype;typedef struct{ elemtype elem[MAX+1];int len gth;}SStable;void create_seq(SStable*list);int seq_search(SStable*list,keytype k);void mai n(){ SStable *list,table;keytype key;int i;list=& table;printf("请输入顺序表的长度:"); scan f("%d",&list->le ngth); create_seq(list);printf("创建的顺序表内容:\n");for(i=0;i<list->length;i++) printf("list.elem[%d].key=%d\n",i+1,list->elem[i].key);printf("输入查找关键字:");scanf("%d",&key);seq_search(list,key);}void create_seq(SStable *list){ int i;printf("请输入顺序表的内容:\n"); for(i=0;i<list->length;i++){ printf("list.elem[%d].key=",i+1);scanf("%d",&list->elem[i].key);}}int seq_search(SStable*list,keytype k){ int i=0,flag=0;while(i<list->length){ if(list->elem[i].key==k){ printf("查找成功.\n");flag=1; printf("list.elem[%d].key=%d\n",i+1,k);}i++;}if(flag==0)printf("没有找到数据%d!\n",k);return(flag);}2、折半查找#include<stdio.h>#define MAX 100typedef struct{ int elem[MAX+1];int length;}Stable;void creat_seq(Stable*list);int sort_seq(Stable*list);int bin_search(Stable*list,int k,int low,int higt);void main(){ Stable *list,table;int i,key;list=&table;printf("请输入线性表的长度:"); scanf("%d",&list->length);creat_seq(list);sort_seq(list);printf("排列后的数据\n"); for(i=1;i<=list->length;i++)printf("list.elem[%d].key=%d\n",i,list->elem[i]); printf("\n 请输入查找的值:");scanf("%d",&key); bin_search(list,key,1,list->length);}void creat_seq(Stable*list){ int i;printf("请输入顺序表的内容:\n"); for(i=1;i<=list->length;i++){printf("list.elem[%d].key=",i);scanf("%d",&list->elem[i]);}}int sort_seq(Stable*list){ int i,j,flag;for(i=1;i<list->length;i++){flag=0;for( j=1;j<list->length-i+1;j++)if (list->elem[j]>list->elem[j+1]) {list->elem[0]=list->elem[ j+1];list->elem[j+1]=list->elem[j]; list->elem[j]=list->elem[0];flag=1;}if(flag==0)return 1;}}int bin_search(Stable*list,int k,int low,int high) { int mid;if(low>high){ printf("没有找到要查找的值\n");return(0);}mid=(low+high)/2;if(list->elem[mid]==k){ printf("查找成功\n"); printf("list[%d]=%d\n",mid,k);return(mid);}elseif(list->elem[mid]<k)return(bin_search(list,k,mid+1,high));else return(bin_search(list,k,low,mid-1));}3、二叉树查找#include <stdio.h>#include <stdlib.h>typedef struct bitnode{int key;struct bitnode *lchild;struct bitnode *rchild;}bnode;void ins_bitree(bnode *p,int k){bnode *q;if(p->key >k&&p->lchild)ins_bitree(p->lchild,k);elseif(p->key<=k&&p->rchild)ins_bitree(p->rchild,k);else{q=(bnode *)malloc(sizeof(bnode)); q->key=k;q->lchild=NULL;q->rchild=NULL;if(p->key>k)p->lchild=q;elsep->rchild=q;}}void bit_search(bnode *p,int k){if(p->key>k&&p->lchild) bit_search(p->lchild,k);elseif(p->key<k&&p->rchild)bit_search(p->rchild,k);else if(p->key ==k) printf("查找成功!\n");else printf("%d 不存在!\n");}void inorder(bnode *p){if(p){inorder(p->lchild); printf("%4d",p->key); inorder(p->rchild);}}void main (){ int k;bnode *p;0 结束 :\n");p=NULL;printf("请输入二叉树结点的值,输入 scanf("%d",&k);p=(bnode *)malloc(sizeof(bnode)); p->key=k; p->lchild=NULL; p->rchild=NULL; scanf("%d",&k); while (k>0){ins_bitree(p,k); scanf("%d",&k);}printf("\n");printf("二叉树排序的结果 :"); inorder(p);printf("\n 请输入查找的值 :\n"); scanf("%d",&k); bit_search(p,k);}4 、哈希表查找#include <stdio.h> #define MAX 11 void ins_hash(int hash[],int key)infkKk N kukey%MA><=h (h a s h -k ll H O )宀hash-kHkey八recrn八e-se宁」H k +rwh=e(ldA M A X QO QO h a s h_l d 70)k」++=h (k」A M A X )宀hash-klHkey八recrn八k2uaw h i _e (k 2A kQO QO h a s h -k 270)k 2++=h(k 2A k )hash-k2llkey 八recrn八voidouflhash(infhash=)宀5'二f o r (ll'o xM A X _.++)=h(hash三)prinff(=hash-%dll%2n=Lhashe-voidhashlsearch(infhash-Linfkey)宀infk-kl>2J-aguo八kukey%MA>< if(hash-kHukey)宀prinff(=hash-%dH%d=Kkey)八f_agun,凹>#嬴潯■\n");else{k1=k+1;while(k1<MAX&&hash[k1]!=key) k1++; if(k1<MAX){printf("hash[%d]=%d",k1,key); flag=1;} k2=0; if(!flag){while(k2<k&&hash[k2]!=key) k2++; if(k2<k){printf("hash[%d]=%d",k2,key); flag=1;}}if(flag){printf("查找成功! \n"); return; }else{printf("查找失败! \n"); return;}} }void main(){int i,key,k,sum=0;int hash[MAX]; for(i=0;i<MAX;i++) hash[i]=0;printf("请输入数据,以 0 结束: scanf("%d",&key); sum++;while(key&&sum<MAX) {ins_hash(hash,key); scanf("%d",&key); sum++;}printf("\n"); out_hash(hash); printf("\n");printf("请输入查找的值: "); scanf("%d",&k); hash_search(hash,k);printf("\n");}二、排序算法#include<stdio.h> #include<time.h> #define size 11 typedef char datatype;typedef struct{int key;datatype others;}rectype;void INSERTSORT(rectype R[]){ int i,j;for (i=2;i<=size;i++){ R[0]=R[i];j=i-1;while (R[0].key<R[j].key){ R[ j+1]=R[j];j--;}R[ j+1]=R[0];}}void SHELLSORT(rectype R[],int n) {int i,j,h;rectype temp; h=n/2;while(h>0) {for(j=h;j<=n-1;j++) {temp=R[ j]; i=j-h;while ((i>=0)&&temp.key<R[i].key) {R[i+h]=R[i];i=i-h;}R[i+h]=temp;} h=h/2;} } int PARTITION(rectype R[],int l,int h) {int i,j;rectype temp; i=1;j=h;temp=R[i]; do{while ((R[j].key>=temp.key)&&(i<j)) j--;if(i<j)R[i++]=R[j];while ((R[i].key<=temp.key)&&(i<j)) i++;if(i<j) R[ j--]=R[i];}while(i!=j);R[i]=temp;return i;}void QUICKSORT(rectype R[],int s1,int t1){ int i;if(s1<t1){ i=PARTITION(R,s1,t1);QUICKSORT(R,s1,i-1);QUICKSORT(R,i+1,t1);}}void main(){ rectype R[size];int i;printf("请输入使用插入算法排序的10 个数据\n");for(i=1;i<size;i++) scanf("%d",&R[i].key);printf("\n 插入排序之前\n");for(i=1;i<size;i++)printf("%d\t",R[i].key) ;INSERTSORT(R);printf("\n 插入排序之后\n"); for(i=1;i<size;i++) printf("%d\t",R[i].key); printf("\n 请输入使用希尔顿算法排序的10 个数据\n"); for(i=0;i<size-1;i++)scanf("%d",&R[i].key);printf("\n 希尔排序之前\n");for(i=0;i<size-1;i++) printf("%d\t",R[i].key);SHELLSORT(R,10);printf("\n 希尔排序之后\n"); for(i=0;i<size-1;i++) printf("%d\t",R[i].key); printf("请输入使用快速算法排序的10 个数据\n"); for(i=1;i<size;i++)scanf("%d",&R[i].key);printf("\n 快速排序之前\n");for(i=1;i<size;i++) printf("%d\t",R[i].key);QUICKSORT(R,1,10);printf("\n 快速排序之后\n");for(i=1;i<size;i++) printf("%d\t",R[i].key);}实验结果顺序查找:折半查找: 二叉树查找: 哈希表查找:通过本次实验,我实验小结:此次操作证明可以用编程实现查找与排序,实验结果正确。