Review of Hardware Architectures for Advanced Encryption Standard Implementations Consideri
tep2

Hardware Abstraction ArchitectureTEP:2Group:Core Working GroupType:Best Current PracticeStatus:DraftTinyOS-Version: 2.0Author:Vlado Handziski,Joseph Polastre,Jan-Hinrich Hauer,Cory Sharp,Adam Wolisz,David Culler,David GayDraft-Created:14-Sep-2004Draft-Version: 1.6Draft-Modified:2007-02-28Draft-Discuss:TinyOS Developer List<tinyos-devel at>NoteThis document specifies a Best Current Practices for the TinyOS Community,and requests discus-sion and suggestions for improvements.The distribution of the memo is unlimited,provided thatthe header information and this note are preserved.Parts of this document are taken verbatimfrom the[HAA2005]paper that is under IEEE copyright and from the[T2TR]technical report.This memo is in full compliance with[TEP1].AbstractThis TEP documents a Hardware Abstraction Architecture(HAA)for TinyOS2.0that balances the con-flicting requirements of code reusability and portability on the one hand and efficiency and performance optimization on the other.Its three-layer design gradually adapts the capabilities of the underlying hardware platforms to the selected platform-independent hardware interface between the operating sys-tem core and the application code.At the same time,it allows the applications to utilize a platform’s full capabilities--exported at the second layer,when the performance requirements outweigh the need for cross-platform compatibility.1.IntroductionThe introduction of hardware abstraction in operating systems has proved valuable for increasing porta-bility and simplifying application development by hiding the hardware intricacies from the rest of the system.However,hardware abstractions come into conflict with the performance and energy-efficiency requirements of sensor network applications.This drives the need for a well-defined architecture of hardware abstractions that can strike a balance between these conflicting goals.The main challenge is to select appropriate levels of abstraction and to organize them in form of TinyOS components to support reusability while maintaining energy-efficiency through access to the full hardware capabilities when it is needed.1This TEP proposes a three-tier Hardware Abstraction Architecture(HAA)for TinyOS2.0that combines the strengths of the component model with an effective organization in form of three different levels of abstraction.The top level of abstraction fosters portability by providing a platform-independent hardware interface,the middle layer promotes efficiency through rich hardware-specific interfaces andthe lowest layer structures access to hardware registers and interrupts.The rest of this TEP specifies:•the details of the HAA and its three distinct layers(2.Architecture)•guidelines on selecting the“right”level of abstraction(bining different levels of abstraction)•how hardware abstractions can be shared among different TinyOS platforms(4.Horizontal de-composition)•the level of hardware abstraction for the processing units(5.CPU abstraction)•how some hardware abstractions may realize different degrees of alignment with the HAA toplayer(6.HIL alignment)The HAA is the architectural basis for many TinyOS2.0documentary TEPs, e.g.[TEP101], [TEP102],[TEP103]and so forth.Those TEPs focus on the hardware abstraction for a particular hardware module,and[TEP112]and[TEP115]explain how power management is realized.2.ArchitectureIn the proposed architecture(Fig.1),the hardware abstraction functionality is organized in three dis-tinct layers of components.Each layer has clearly defined responsibilities and is dependent on interfaces provided by lower layers.The capabilities of the underlying hardware are gradually adapted to the estab-lished platform-independent interface between the operating system and the applications.As we movefrom the hardware towards this top interface,the components become less and less hardware dependent, giving the developer more freedom in the design and the implementation of reusable applications.+-----------------------------+|||Cross-platform applications|||+--------------+--------------++-----------------+|+-----------------+|Platform-specific|||Platform-specific||applica-tions|||appli-cations|+--------+--------+Platform-independent|hardware interface+--------+--------+|+-----------------+--------+--------+-----------------+||||||||+-------+-------++-------+-------++-------+-------++-------+-------+|||.------+------.||.------+------.||.------+------.||.------+------.||2|||||||||||||||HIL4||||||HIL1||||HIL2||||HIL3|||‘------+------’||||||||‘------+------’||‘------+------’|||||||‘------+------’|||||||||+----+--++--+----+|||.------+------.|||||||||||||||||.------+------.||.------+--+---.||.---+--+------.|||||||||||||||||||HAL2||||||||||||||||||||HAL3||||HAL4||||HAL1|||‘------+------’||||||||||||||||||||||||||||||||‘------+------’||‘------+------’||‘------+------’||.------+------.|||||||||||||||.------+------.|||||.------+------.|||HPL2|||||||.------+------.|||HPL1||||||||HPL3||||HPL4|||‘------+------’||‘------+------’||‘------+------’||‘------+------’|+-------+-------++-------+-------++-------+-------++-------+-------+HW/SW||||bound-ary************************************************************************************ +------+------++------+------++------+------++------+------+|HW Platform1||HW Platform2||HW Plat-form3||HW Platform4|+-------------++-------------++-------------++-------------+Fig.1:The proposed Hardware Abstraction Architecture In contrast to the more traditional two step approach used in other embedded operating systemslike[WindowsCE],the three-level design results in increasedflexibility that arises from separating theplatform-specific abstractions and the adaptation wrappers that upgrade or downgrade them to thecurrent platform-independent interface.In this way,for maximum performance,the platform specific applications can circumvent the HIL components and directly tap to the HAL interfaces that provideaccess to the full capabilities of the hardware module.The rest of the section discusses the specific roles of each component layer in more detail.3Hardware Presentation Layer(HPL)The components belonging to the HPL are positioned directly over the HW/SW interface.As the name suggests,their major task is to“present”the capabilities of the hardware using the native concepts of the operating system.They access the hardware in the usual way,either by memory or by port mapped I/O.In the reverse direction,the hardware can request servicing by signaling an ing these communication channels internally,the HPL hides the hardware intricacies and exports a more readable interface(simple function calls)for the rest of the system.The HPL components SHOULD be stateless and expose an interface that is fully determined by the capabilities of the hardware module that is abstracted.This tight coupling with the hardware leaves little freedom in the design and the implementation of the components.Even though each HPL component will be as unique as the underlying hardware,all of them will have a similar general structure. For optimal integration with the rest of the architecture,each HPL component SHOULD have:•commands for initialization,starting,and stopping of the hardware module that are necessary for effective power management policy•“get”and“set”commands for the register(s)that control the operation of the hardware•separate commands with descriptive names for the most frequently usedflag-setting/testing op-erations•commands for enabling and disabling of the interrupts generated by the hardware module•service routines for the interrupts that are generated by the hardware moduleThe interrupt service routines in the HPL components perform only the most time critical operations (like copying a single value,clearing someflags,etc.),and delegate the rest of the processing to the higher level components that possess extended knowledge about the state of the system.The above HPL structure eases manipulation of the hardware.Instead of using cryptic macros and register names whose definitions are hidden deep in the headerfiles of compiler libraries,the programmer can now access hardware through a familiar interface.This HPL does not provide any substantial abstraction over the hardware beyond automating fre-quently used command sequences.Nonetheless,it hides the most hardware-dependent code and opens the way for developing higher-level abstraction components.These higher abstractions can be used with different HPL hardware-modules of the same class.For example,many of the microcontrollers used on the existing sensornet platforms have two USART modules for serial communication.They have the same functionality but are accessed using slightly different register names and generate different interrupt vectors.The HPL components can hide these small differences behind a consistent interface, making the higher-level abstractions resource independent.The programmer can then switch between the different USART modules by simple rewiring(not rewriting)the HPL components,without any changes to the implementation code.Hardware Adaptation Layer(HAL)The adaptation layer components represent the core of the architecture.They use the raw interfaces provided by the HPL components to build useful abstractions hiding the complexity naturally associated with the use of hardware resources.In contrast to the HPL components,they are allowed to maintain state that can be used for performing arbitration and resource control.Due to the efficiency requirements of sensor networks,abstractions at the HAL level are tailored to the concrete device class and platform.Instead of hiding the individual features of the hardware class behind generic models,HAL interfaces expose specific features and provide the“best”possible abstraction that streamlines application development while maintaining effective use of resources.For example,rather than using a single“file-like”abstraction for all devices,we propose domain spe-cific models like Alarm,ADC channel,EEPROM.According to the model,HAL components SHOULD4provide access to these abstractions via rich,customized interfaces,and not via standard narrow ones that hide all the functionality behind few overloaded commands.This also enables more efficient compile-time detection of abstraction interface usage errors.Hardware Interface Layer(HIL)Thefinal tier in the architecture is formed by the HIL components that take the platform-specific abstractions provided by the HAL and convert them to hardware-independent interfaces used by cross-platform applications.These interfaces provide a platform independent abstraction over the hardware that simplifies the development of the application software by hiding the hardware differences.To be successful,this API“contract”SHOULD reflect the typical hardware services that are required in a sensornet application.The complexity of the HIL components mainly depends on how advanced the capabilities of the abstracted hardware are with respect to the platform-independent interface.When the capabilities of the hardware exceed the current API contract,the HIL“downgrades”the platform-specific abstractions provided by the HAL until they are leveled-offwith the chosen standard interface.Consequently, when the underlying hardware is inferior,the HIL might have to resort to software simulation of the missing hardware capabilities.As newer and more capable platforms are introduced in the system, the pressure to break the current API contract will increase.When the performance requirements outweigh the benefits of the stable interface,a discrete jump will be made that realigns the API with the abstractions provided in the newer HAL.The evolution of the platform-independent interface will force a reimplementation of the affected HIL components.For newer platforms,the HIL will be much simpler because the API contract and their HAL abstractions are tightly related.On the other extreme, the cost of boosting up(in software)the capabilities of the old platforms will rise.Since we expect HIL interfaces to evolve as new platforms are designed,we must determine when the overhead of software emulation of hardware features can no longer be sustained.At this point, we introduce versioning of HIL interfaces.By assigning a version number to each iteration of an HIL interface,we can design applications using a legacy interface to be compatible with previously deployed devices.This is important for sensor networks since they execute long-running applications and may be deployed for years.An HIL MAY also branch,providing multiple different HIL interfaces with increasing levels of functionality.bining different levels of abstractionProviding two levels of abstraction to the application--the HIL and HAL--means that a hardware asset may be accessed at two levels in parallel,e.g.from different parts of the application and the OS libraries.The standard Oscilloscope application in TinyOS2.0,for example,may use the ADC to sample several values from a sensor,construct a message out of them and send it over the radio.For the sake of cross-platform compatibility,the application uses the standard Read interface provided by the ADC HIL and forwarded by the DemoSensorC component wired to,for example,the temperature sensor wrapper. When enough samples are collected in the message buffer,the application passes the message to the networking stack.The MAC protocol might use clear channel assessment to determine when it is safe to send the message,which could involve taking several ADC samples of an analog RSSI signal provided by the radio hardware.Since this is a very time critical operation in which the correlation between the consecutive samples has a significant influence,the programmer of the MAC might directly use the hardware specific interface of the HAL component as it provides muchfiner control over the conversion process.(Fig.2)depicts how the ADC hardware stack on the MSP430MCU on the level of HIL and HAL in parallel.+--------------------------------+|APP|+-+----------------------------+-+5||Read Send||||+---------+----------++-------+--------+|DemoSensorC/||||TemperatureC||ActiveMessageC|+---------+----------+|||+-------+--------+Read||||+-------+--------++---------+----------+|||HIL:AdcC|||+---------+----------+|TDA5250||||||Radio Stack|||||+-------+--------+|||+----------------------+||Msp430Adc12SingleChannel||||+---------+-----+----+|HAL:Msp430Adc12C|+--------------------+Fig.2:Accessing the MSP430ADC hardware abstractionvia*HIL*and*HAL*in parallelTo support this type of“vertical”flexibility the ADC HAL includes more complex arbitration and resource control functionality[TEP108]so that a safe shared access to the HPL exported resources can be guaranteed.4.Horizontal decompositionIn addition to the vertical decomposition of the HAA,a horizontal decomposition can promote reuse of the hardware resource abstractions that are common on different platforms.To this aim,TinyOS 2.0introduces the concept of chips,the self-contained abstraction of a given hardware chip:micro-controller,radio-chip,flash-chip,etc.Each chip decomposition follows the HAA model,providing HIL implementation(s)as the topmost component(s).Platforms are then built as compositions of different chip components with the help of“glue”components that perform the mapping(Fig.3)+----------------------------------------------------+|AppC||/Application Component/|+------+--------------------------------------+------+|||Millisecond Timer|Communication+------+------++---------+------+6|TimerMilliC||ActiveMessageC||||||/Platform||/Platform||Component/||Component/|+------+------++---------+------+||+------+------++------+------+||32kHz Timer||||+--------------+|||Atmega128||CC2420AlarmC||CC2420||+----++----+||Timer Stack||/Platform||Radio Stack||||Component/||||/Chip|+--------------+|/Chip||Component/||Component/|+-------------++-------------+Fig.3:The CC2420software depends on a physical and dedicatedtimer.The micaZ platform code maps this to a specific Atmega128timer.Some of the shared hardware modules are connected to the microcontroller using one of the standard bus interfaces:SPI,I2C,UART.To share hardware drivers across different platforms the issue of the abstraction of the interconnect has to be solved.Clearly,greatest portability and reuse would be achieved using a generic bus abstraction like in NetBSD[netBSD].This model abstracts the different bus protocols under one generic bus access scheme.In this way,it separates the abstraction of the chip from the abstraction of the interconnect,potentially allowing the same chip abstraction to be used with different connection protocols on different platforms.However,this generalization comes at high costs in performance.This may be affordable for desktop operating systems,but is highly sub-optimal for the application specific sensor network platforms.TinyOS2.0takes a less generic approach,providing HIL-level,microcontroller-independent abstrac-tions of the main bus protocols like I2C,SPI,UART and pin-I/O.This distinction enables protocol-specific optimizations,for example,the SPI abstraction does not have to deal with client addresses, where the I2C abstraction does.Furthermore,the programmer can choose to tap directly into the chip-specific HAL-level component,which could further improve the performance by allowingfine tuning using chip-specific configuration options.The TinyOS2.0bus abstractions,combined with the ones for low-level pin-I/O and pin-interrupts (see[TEP117]),enable a given chip abstraction to be reused on any platform that supports the required bus protocol.The CC2420radio,for example,can be used both on the Telos and on micaZ platforms, because the abstractions of the serial modules on the MSP430and Atmega128microcontrollers support the unified SPI bus abstraction,which is used by the same CC2420radio stack implementation.Sharing chips across platforms raises the issue of resource contention on the bus when multiple chips are connected to it.For example,on the micaZ the CC2420is connected to a dedicated SPI bus,while on the Telos platform one SPI bus is shared between the CC2420radio and theflash chip.To dissolve conflicts the resource reservation mechanism proposed in[TEP108]is applied:every chip abstraction that uses a bus protocol MUST use the Resource interface in order to gain access to the bus resource. In this way,the chip can be safely used both in dedicated scenarios,as well as in situations where multiple chips are connected to the same physical bus interconnect.75.CPU abstractionIn TinyOS most of the variability between the processing units is hidden from the OS simply by using a nesC/C based programming language with a common compiler suite(GCC).For example,the standard library distributed with the compiler creates the necessary start-up code for initializing the global variables,the stack pointer and the interrupt vector table,shielding the OS from these tasks.To unify things further,TinyOS provides common constructs for declaring reentrant and non-reentrant interrupt service routines and critical code-sections.The HAA is not currently used to abstract the features of the different CPUs.For the currently supported MCUs,the combination of the compiler suite support and the low-level I/O is sufficient. Nevertheless,if new cores with radically different architectures need to be supported by TinyOS in the future,this part of the hardware abstraction functionality will have to be explicitly addressed.6.HIL alignmentWhile the HAA requires that the HIL provides full hardware independence(Strong/Real HILs),some abstractions might only partially meet this goal(Weak HILs).This section introduces several terms describing different degrees of alignment with the concept of a HIL.It also uses the following differen-tiation:•platform-defined X:X is defined on all platforms,but the definition may be different•platform-specific X:X is defined on just one platformStrong/Real HILsStrong/Real HILs mean that“code using these abstractions can reasonably be expected to behave the same on all implementations”.This matches the original definition of the HIL level according to the HAA.Examples include the HIL for the Timer(TimerMilliC,[TEP102]),for LEDs(LedsC), active messages(ActiveMessageC,[TEP116],if not using any radio metadata at least),sensor wrappers (DemoSensorC,[TEP109])or storage([TEP103]).Strong HILs may use platform-defined types if they also provide operations to manipulate them(i.e.,they are platform-defined abstract data types),for example,the TinyOS2.x message buffer abstraction,message_t([TEP111]).Weak HILsWeak HILs mean that one“can write portable code over these abstractions,but any use of them involves platform-specific behavior”.Although such platform-specific behavior can--at least at a rudimentary syntactical level--be performed by a platform-independent application,the semantics require knowledge of the particular platform.For example,the ADC abstraction requires platform-specific configuration and the returned data must be interpreted in light of this configuration.The ADC configuration is exposed on all platforms through the“AdcConfigure”interface that takes a platform-defined type (adc config t)as a parameter.However,the returned ADC data may be processed in a platform-independent way,for example,by calculating the max/min or mean of multiple ADC readings.The benefit from weak HILs are that one can write portable utility code,e.g.,a repeated sampling for an ADC on top of the data path.While code using these abstractions may not be fully portable,it will still be easier to port than code built on top of HALs,because weak HILs involve some guidelines on how to expose some functionality,which should help programmers and provide guidance to platform developers.8Hardware Independent Interfaces(HII)Hardware Independent Interfaces(HII),is just an interface definition intended for use across multiple platforms.Examples include the SID interfaces,the pin interfaces from[TEP117],the Alarm/Counter/etc interfaces from[TEP102].Utility componentsUtility components are pieces of clearly portable code(typically generic components),which aren’t exposing a self-contained service.Examples include the components in tos/lib/timer and the Arbitrat-edRead*components.These provide and use HIIs.6.ConclusionThe proposed hardware abstraction architecture provides a set of core services that eliminate duplicated code and provide a coherent view of the system across different platforms.It supports the concurrent use of platform-independent and the platform-dependent interfaces in the same application.In this way,applications can localize their platform dependence to only the places where performance matters, while using standard cross-platform hardware interfaces for the remainder of the application. Author’s AddressVlado Handziski(handzisk at tkn.tu-berlin.de)1Joseph Polastre(polastre at )2Jan-Hinrich Hauer(hauer at tkn.tu-berlin.de)1Cory Sharp(cssharp at )2Adam Wolisz(awo at )1David Culler(culler at )2David Gay(david.e.gay at )3Citations1Technische Universitaet Berlin Telecommunication Networks Group Sekr.FT5,Einsteinufer2510587 Berlin,Germany2University of California,Berkeley Computer Science Department Berkeley,CA94720USA3Intel Research Berkeley2150Shattuck Ave,Suite1300CA94704[HAA2005]V.Handziski,J.Polastre,J.H.Hauer,C.Sharp,A.Wolisz and D.Culler,“Flexible Hardware Abstraction for Wireless Sensor Networks”,in Proceedings of the2nd European Workshop on Wireless Sensor Networks(EWSN2005),Istanbul,Turkey,2005.[T2TR]P.Levis,D.Gay,V.Handziski,J.-H.Hauer,B.Greenstein,M.Turon,J.Hui,K.Klues,C.Sharp, R.Szewczyk,J.Polastre,P.Buonadonna,L.Nachman,G.Tolle,D.Culler,and A.Wolisz,“T2:A Second Generation OS For Embedded Sensor Networks”,Technical Report TKN-05-007,Telecommunication Networks Group,Technische Universit¨a t Berlin,November2005.[WindowsCE]“The WindowsCE operating system home page”,Online, /embedded/windowsce9[NetBSD]“The NetBSD project home page”,Online,[TEP1]Philip Levis,“TEP structure and key words”[TEP101]Jan-Hinrich Hauer,Philip Levis,Vlado Handziski,David Gay“Analog-to-Digital Converters (ADCs)”[TEP102]Cory Sharp,Martin Turon,David Gay,“Timers”[TEP103]David Gay,Jonathan Hui,“Permanent Data Storage(Flash)”[TEP108]Kevin Klues,Philip Levis,David Gay,David Culler,Vlado Handziski,“Resource Arbitration”[TEP109]David Gay,Philip Levis,Wei Hong,Joe Polastre,and Gilman Tolle“Sensors and Sensor Boards”[TEP111]Philip Levis,“message t”[TEP112]Robert Szewczyk,Philip Levis,Martin Turon,Lama Nachman,Philip Buonadonna,Vlado Handziski,“Microcontroller Power Management”[TEP115]Kevin Klues,Vlado Handziski,Jan-Hinrich Hauer,Philip Levis,“Power Management of Non-Virtualised Devices”[TEP116]Philip Levis,“Packet Protocols”[TEP117]Phil Buonadonna,Jonathan Hui,“Low-Level I/O”10。
体系结构设计英语

体系结构设计英语Designing System ArchitecturesThe field of system architecture has become increasingly crucial in the modern technology landscape. As the complexity of software and hardware systems continues to grow, the need for robust and efficient architectural designs has become paramount. System architecture encompasses the fundamental organization and structure of a system, including its components, their interactions, and the principles that govern its design and evolution.One of the key aspects of system architecture is the ability to decompose a complex system into manageable and well-defined subsystems. This modular approach allows for better scalability, maintainability, and flexibility, as changes can be made to individual components without disrupting the entire system. By identifying the appropriate level of abstraction and defining clear interfaces between subsystems, system architects can create architectures that are easier to understand, develop, and evolve over time.Another crucial aspect of system architecture is the consideration of non-functional requirements such as performance, security, reliability,and scalability. These requirements often have a significant impact on the overall design and can influence the selection of specific architectural patterns and technologies. For example, a system designed for high-performance computing may prioritize parallel processing and distributed computing, while a system focused on secure data storage may emphasize encryption and access control mechanisms.The process of designing a system architecture typically involves several key steps. First, the system's requirements and goals must be clearly defined, taking into account both functional and non-functional requirements. This often involves a thorough analysis of the problem domain, stakeholder needs, and any existing constraints or limitations.Next, the system architect must identify the appropriate architectural styles and patterns that can effectively address the identified requirements. This may involve exploring various architectural approaches, such as client-server, microservices, event-driven, or n-tier architectures, and evaluating their suitability for the specific system being designed.Once the architectural style has been selected, the system architect must define the high-level components and their interactions. This may involve creating detailed component diagrams, data flowdiagrams, and other visual representations to ensure a clear understanding of the system's structure and behavior.As the design process progresses, the system architect must also consider the deployment and operational aspects of the system. This may include defining the infrastructure requirements, such as hardware, software, and network configurations, as well as the processes and tools needed for deployment, monitoring, and maintenance.Throughout the design process, the system architect must also engage in ongoing communication and collaboration with various stakeholders, including developers, project managers, and end-users. This ensures that the system architecture remains aligned with the evolving needs and constraints of the project, and that any changes or refinements can be effectively incorporated into the design.In conclusion, system architecture is a critical discipline that underpins the success of complex software and hardware systems. By leveraging modular design, considering non-functional requirements, and engaging in a structured design process, system architects can create architectures that are scalable, maintainable, and adaptable to the ever-changing technological landscape. As the demand for sophisticated and reliable systems continues to grow, the role of the system architect will become increasingly essential in drivinginnovation and ensuring the long-term success of technology-driven organizations.。
英语作文-集成电路设计行业的智能芯片与系统解决方案

英语作文-集成电路设计行业的智能芯片与系统解决方案The design and development of intelligent chips and system solutions in the integrated circuit design industry have revolutionized the way we interact with technology. These advancements have not only enhanced the performance and efficiency of electronic devices but have also opened up new possibilities for innovation in various fields.One of the key aspects of intelligent chip design is the integration of artificial intelligence (AI) algorithms. By incorporating AI into the chip architecture, designers are able to create systems that can learn and adapt to different situations, making them more efficient and versatile. This has led to the development of smart devices that can recognize speech, images, and patterns, enabling them to provide personalized experiences for users.Moreover, intelligent chips have also played a crucial role in the development of autonomous systems. By combining sensors, processors, and communication modules, designers have been able to create self-driving cars, drones, and robots that can navigate and interact with their environment without human intervention. These advancements have not only improved efficiency and safety but have also opened up new opportunities for automation in various industries.In addition to AI integration, intelligent chip design also focuses on energy efficiency and miniaturization. By optimizing the power consumption of chips and reducing their size, designers are able to create devices that are not only more environmentally friendly but also more portable and convenient for users. This has led to the development of wearable devices, smart home appliances, and IoT devices that can seamlessly integrate into our daily lives.Furthermore, intelligent chip design has also enabled the development of advanced security features. By incorporating encryption, authentication, and secure bootmechanisms into the chip architecture, designers are able to create systems that can protect sensitive data and prevent unauthorized access. This has become increasingly important in today's interconnected world, where cyber threats are becoming more sophisticated and prevalent.Overall, the integration of intelligent chips and system solutions in the integrated circuit design industry has transformed the way we interact with technology. From AI-powered devices to autonomous systems and energy-efficient gadgets, these advancements have not only improved the performance and efficiency of electronic devices but have also opened up new possibilities for innovation in various fields. As technology continues to evolve, intelligent chip design will play a crucial role in shaping the future of electronics and revolutionizing the way we live and work.。
出国访问留学的研修计划一例

High Performance Financial Computing using ReconfigurableSystem-on-Chip TechnologyThe aim of this project is to explore novel methods and tools for high performance financial computing using state-of-the-art programmable system-on-chip technology. In particular, the project will look at Monte Carlo simulation techniques of financial models, which are of paramount importance in financial applications such as bond pricing, risk analysis and market prediction. Our aim is to harness the high performance and flexibility of reconfigurable hardware platforms, or FPGAs, and assist financial experts with powerful computing resources which allow for real time financial computing. This includes the design of the necessary FPGA hardware but also of the corresponding Application Programming Interface (API) which allows financial experts, with little or no hardware knowledge, to program FPGAs seamlessly. The technical contributions of this project will include:1. The design of highly parameterised hardware architectures for financial computation using the concept of hardware skeletons2. Exploring the merits of both floating and fixed point arithmetic in such applications3. Exploring evolving hardware techniques such as run-time optimisation and reconfiguration to adapt to various environmental conditions e.g. performance, power etc.4. Development of a prototype working environment running on a commercial FPGA board.While this project deals with financial applications, its results will certainly be harnessed in other application areas and drive the development of architectures and tools for novel computations techniques.Mr Gu’s contribution to this project will be in the design of highly parameterised hardware architectures for three Monte-Carlo based financial simulations, namely: the Log-Normal Walk used to model the movements of financial instruments such as stocks and stock-market indices, the Dual Asset Value at Risk used in risk analysis of financial instruments, and the GARCH value at Risk particularly used to model the movements of volatile stocks. Mr Gu will use the Handel-C language to capture the above architectures using the concept of Hardware Skeletons which will allow them to be harnessed in different application areas. He will also implement these architectures on real hardware. The detailed work plan of the planned research visit is presented below.- 1 month: Familiarisation with the state-of-the-art of FPGAs, FPGA programming and financial computations. A training course on the Handel-C language will be arranged for the benefit of Mr Gu during this period.- 2 ½ months: Development of hardware architectures for random number generation- 3 ½ months: Development of hardware architectures for Monte-Carlo simulations.These will be harnessed for three financial computations, namely: Log-Normal Walk, Dual Asset Value at Risk, and the GARCH Value at Risk.- 4 months: Implementation of the above architecture on a real hardware platform.This will include the design of Input/Output data transfer mechanisms as well as a high level data and results manager- 1 month: Final report write-upMr Gu will be supervised by Dr. Khaled Benkrid who is a Lecturer in the Institute of Micro and Nano Systems, School of Engineering and Electronics, at the University of Edinburgh.。
计算机软硬件英语作文

计算机软硬件英语作文英文回答:Hardware.Computer hardware refers to the physical components of a computer system that can be touched and seen. These components work together to execute instructions and perform tasks. Key hardware components include:Processor (CPU): The brain of the computer, responsible for executing instructions and performing calculations.Memory (RAM): Stores data and instructions currently being processed by the CPU.Storage (HDD/SSD): Permanent storage devices that hold data and programs not actively being used by the CPU.Input devices: Peripherals used to input data into the computer, such as keyboards, mice, and scanners.Output devices: Peripherals used to display or output data from the computer, such as monitors and printers.Software.Computer software refers to the set of instructions and data that directs the operation of a computer system. It consists of two main types:System software: Manages the basic functions of the computer, such as the operating system (e.g., Windows, macOS), which provides an interface between the user and the hardware.Application software: Specific programs designed to perform particular tasks, such as word processors, spreadsheets, and web browsers.Hardware and Software Interaction.Hardware and software work together seamlessly to perform various tasks. The software provides instructions that the hardware executes, and the hardware provides the physical means to execute those instructions. For example, when you type a document in a word processor, the software converts your keystrokes into instructions that the processor executes, using the memory to store data and the storage to save the document.中文回答:硬件。
Declaration of Authorship

Efficient Hardware Architectures forModular MultiplicationbyDavid Narh AmanorA Thesissubmitted toThe University of Applied Sciences Offenburg, GermanyIn partial fulfillment of the requirements for theDegree of Master of ScienceinCommunication and Media EngineeringFebruary, 2005Approved:Prof. Dr. Angelika Erhardt Prof. Dr. Christof Paar Thesis Supervisor Thesis SupervisorDeclaration of Authorship“I declare in lieu of an oath that the Master thesis submitted has been produced by me without illegal help from other persons. I state that all passages which have been taken out of publications of all means or unpublished material either whole or in part, in words or ideas, have been marked as quotations in the relevant passage. I also confirm that the quotes included show the extent of the original quotes and are marked as such. I know that a false declaration willhave legal consequences.”David Narh AmanorFebruary, 2005iiPrefaceThis thesis describes the research which I conducted while completing my graduate work at the University of Applied Sciences Offenburg, Germany.The work produced scalable hardware implementations of existing and newly proposed algorithms for performing modular multiplication.The work presented can be instrumental in generating interest in the hardware implementation of emerging algorithms for doing faster modular multiplication, and can also be used in future research projects at the University of Applied Sciences Offenburg, Germany, and elsewhere.Of particular interest is the integration of the new architectures into existing public-key cryptosystems such as RSA, DSA, and ECC to speed up the arithmetic.I wish to thank the following people for their unselfish support throughout the entire duration of this thesis.I would like to thank my external advisor Prof. Christof Paar for providing me with all the tools and materials needed to conduct this research. I am particularly grateful to Dipl.-Ing. Jan Pelzl, who worked with me closely, and whose constant encouragement and advice gave me the energy to overcome several problems I encountered while working on this thesis.I wish to express my deepest gratitude to my supervisor Prof. Angelika Erhardt for being in constant touch with me and for all the help and advice she gave throughout all stages of the thesis. If it was not for Prof. Erhardt, I would not have had the opportunity of doing this thesis work and therefore, I would have missed out on a very rewarding experience.I am also grateful to Dipl.-Ing. Viktor Buminov and Prof. Manfred Schimmler, whose newly proposed algorithms and corresponding architectures form the basis of my thesis work and provide the necessary theoretical material for understanding the algorithms presented in this thesis.Finally, I would like to thank my brother, Mr. Samuel Kwesi Amanor, my friend and Pastor, Josiah Kwofie, Mr. Samuel Siaw Nartey and Mr. Csaba Karasz for their diverse support which enabled me to undertake my thesis work in Bochum.iiiAbstractModular multiplication is a core operation in many public-key cryptosystems, e.g., RSA, Diffie-Hellman key agreement (DH), ElGamal, and ECC. The Montgomery multiplication algorithm [2] is considered to be the fastest algorithm to compute X*Y mod M in computers when the values of X, Y and M are large.Recently, two new algorithms for modular multiplication and their corresponding architectures were proposed in [1]. These algorithms are optimizations of the Montgomery multiplication algorithm [2] and interleaved modular multiplication algorithm [3].In this thesis, software (Java) and hardware (VHDL) implementations of the existing and newly proposed algorithms and their corresponding architectures for performing modular multiplication have been done. In summary, three different multipliers for 32, 64, 128, 256, 512, and 1024 bits were implemented, simulated, and synthesized for a Xilinx FPGA.The implementations are scalable to any precision of the input variables X, Y and M.This thesis also evaluated the performance of the multipliers in [1] by a thorough comparison of the architectures on the basis of the area-time product.This thesis finally shows that the newly optimized algorithms and their corresponding architectures in [1] require minimum hardware resources and offer faster speed of computation compared to multipliers with the original Montgomery algorithm.ivTable of Contents1Introduction 91.1 Motivation 91.2 Thesis Outline 10 2Existing Architectures for Modular Multiplication 122.1 Carry Save Adders and Redundant Representation 122.2 Complexity Model 132.3 Montgomery Multiplication Algorithm 132.4 Interleaved Modular Multiplication 163 New Architectures for Modular Multiplication 193.1 Faster Montgomery Algorithm 193.2 Optimized Interleaved Algorithm 214 Software Implementation 264.1 Implementational Issues 264.2 Java Implementation of the Algorithms 264.2.1 Imported Libraries 274.2.2 Implementation Details of the Algorithms 284.2.3 1024 Bits Test of the Implemented Algorithms 30 5Hardware Implementation 345.1 Modeling Technique 345.2 Structural Elements of Multipliers 34vTable of Contents vi5.2.1 Carry Save Adder 355.2.2 Lookup Table 375.2.3 Register 395.2.4 One-Bit Shifter 405.3 VHDL Implementational Issues 415.4 Simulation of Architectures 435.5 Synthesis 456 Results and Analysis of the Architectures 476.1 Design Statistics 476.2 Area Analysis 506.3 Timing Analysis 516.4 Area – Time (AT) Analysis 536.5 RSA Encryption Time 557 Discussion 567.1 Summary and Conclusions 567.2 Further Research 577.2.1 RAM of FPGA 577.2.2 Word Wise Multiplication 57 References 58List of Figures2.3 Architecture of the loop of Algorithm 1b [1] 163.1 Architecture of Algorithm 3 [1] 21 3.2 Inner loop of modular multiplication using carry save addition [1] 233.2 Modular multiplication with one carry save adder [1] 254.2.2 Path through the loop of Algorithm 3 29 4.2.3 A 1024 bit test of Algorithm 1b 30 4.2.3 A 1024 bit test of Algorithm 3 314.2.3 A 1024 bit test of Algorithm 5 325.2 Block diagram showing components that wereimplemented for Faster Montgomery Architecture 35 5.2.1 VHDL implementation of carry save adder 36 5.2.2 VHDL implementation of lookup table 38 5.2.3 VHDL implementation of register 39 5.2.4 Implementation of ‘Shift Right’ unit 40 5.3 32 bit blocks of registers for storing input data bits 425.4 State diagram of implemented multipliers 436.2 Percentage of configurable logic blocks occupied 50 6.2 CLB Slices versus bitlength for Fast Montgomery Multiplier 51 6.3 Minimum clock periods for all implementations 52 6.3 Absolute times for all implementations 52 6.4 Area –time product analysis 54viiList of Tables6.1 Percentage of configurable logic block slices(out of 19200) occupied depending on bitlength 47 6.1 Number of gates 48 6.1 Minimum period and maximum frequency 48 6.1 Number of Dffs or Latches 48 6.1 Number of Function Generators 49 6.1 Number of MUX CARRYs 49 6.1 Total equivalent gate count for design 49 6.3 Absolute Time (ns) for all implementations 53 6.4 Area –Time Product Values 54 6.5 Time (ns) for 1024 bit RSA encryption 55viiiChapter 1Introduction1.1 MotivationThe rising growth of data communication and electronic transactions over the internet has made security to become the most important issue over the network. To provide modern security features, public-key cryptosystems are used. The widely used algorithms for public-key cryptosystems are RSA, Diffie-Hellman key agreement (DH), the digital signature algorithm (DSA) and systems based on elliptic curve cryptography (ECC). All these algorithms have one thing in common: they operate on very huge numbers (e.g. 160 to 2048 bits). Long word lengths are necessary to provide a sufficient amount of security, but also account for the computational cost of these algorithms.By far, the most popular public-key scheme in use today is RSA [9]. The core operation for data encryption processing in RSA is modular exponentiation, which is done by a series of modular multiplications (i.e., X*Y mod M). This accounts for most of the complexity in terms of time and resources needed. Unfortunately, the large word length (e.g. 1024 or 2048 bits) makes the RSA system slow and difficult to implement. This gives reason to search for dedicated hardware solutions which compute the modular multiplications efficiently with minimum resources.The Montgomery multiplication algorithm [2] is considered to be the fastest algorithm to compute X*Y mod M in computers when the values of X, Y and M are large. Another efficient algorithm for modular multiplication is the interleaved modular multiplication algorithm [4].In this thesis, two new algorithms for modular multiplication and their corresponding architectures which were proposed in [1] are implemented. TheseIntroduction 10 algorithms are optimisations of Montgomery multiplication and interleaved modular multiplication. They are optimised with respect to area and time complexity. In both algorithms the product of two n bit integers X and Y modulo M are computed by n iterations of a simple loop. Each loop consists of one single carry save addition, a comparison of constants, and a table lookup.These new algorithms have been proved in [1] to speed-up the modular multiplication operation by at least a factor of two in comparison with all methods previously known.The main advantages offered by these new algorithms are;•faster computation time, and•area requirements and resources for the implementation of their architectures in hardware are relatively small compared to theMontgomery multiplication algorithm presented in [1, Algorithm 1a and1b].1.2 Thesis OutlineChapter 2 provides an overview of the existing algorithms and their corresponding architectures for performing modular multiplication. The necessary background knowledge which is required for understanding the algorithms, architectures, and concepts presented in the subsequent chapters is also explained. This chapter also discusses the complexity model which was used to compare the existing architectures with the newly proposed ones.In Chapter 3, a description of the new algorithms for modular multiplication and their corresponding architectures are presented. The modifications that were applied to the existing algorithms to produce the new optimized versions are also explained in this chapter.Chapter 4 covers issues on the software implementation of the algorithms presented in Chapters 2 and 3. The special classes in Java which were used in the implementation of the algorithms are mentioned. The testing of the new optimized algorithms presented in Chapter 3 using random generated input variables is also discussed.The hardware modeling technique which was used in the implementation of the multipliers is explained in Chapter 5. In this chapter, the design capture of the architectures in VHDL is presented and the simulations of the VHDLIntroduction 11 implementations are also discussed. This chapter also discusses the target technology device and synthesis results. The state machine of the implemented multipliers is also presented in this chapter.In Chapter 6, analysis and comparison of the implemented multipliers is given. The vital design statistics which were generated after place and route were tabulated and graphically represented in this chapter. Of prime importance in this chapter is the area – time (AT) analysis of the multipliers which is the complexity metric used for the comparison.Chapter 7 concludes the thesis by setting out the facts and figures of the performance of the implemented multipliers. This chapter also itemizes a list of recommendations for further research.Chapter 2Existing Architectures for Modular Multiplication2.1 Carry Save Adders and Redundant RepresentationThe core operation of most algorithms for modular multiplication is addition. There are several different methods for addition in hardware: carry ripple addition, carry select addition, carry look ahead addition and others [8]. The disadvantage of these methods is the carry propagation, which is directly proportional to the length of the operands. This is not a big problem for operands of size 32 or 64 bits but the typical operand size in cryptographic applications range from 160 to 2048 bits. The resulting delay has a significant influence on the time complexity of these adders.The carry save adder seems to be the most cost effective adder for our application. Carry save addition is a method for an addition without carry propagation. It is simply a parallel ensemble of n full-adders without any horizontal connection. Its function is to add three n -bit integers X , Y , and Z to produce two integers C and S as results such thatC + S = X + Y + Z,where C represents the carry and S the sum.The i th bit s i of the sum S and the (i + 1)st bit c i+1 of carry C are calculated using the boolean equations,001=∨∨=⊕⊕=+c z y z x y x c z y x s ii i i i i i i i i iExisting Architectures for Modular Multiplication 13 When carry save adders are used in an algorithm one uses a notation of the form (S, C) = X + Y + Zto indicate that two results are produced by the addition.The results are now represented in two binary words, an n-bit word S and an (n+1) bit word C. Of course, this representation is redundant in the sense that we can represent one value in several different ways. This redundant representation has the advantage that the arithmetic operations are fast, because there is no carry propagation. On the other hand, it brings to the fore one basic disadvantage of the carry save adder:•It does not solve our problem of adding two integers to produce a single result. Rather, it adds three integers and produces two such that the sum of these two is equal to that of the three inputs. This method may not be suitable for applications which only require the normal addition.2.2 Complexity ModelFor comparison of different algorithms we need a complexity model that allows fora realistic evaluation of time and area requirements of the considered methods. In[1], the delay of a full adder (1 time unit) is taken as a reference for the time requirement and quantifies the delay of an access to a lookup table with the same time delay of 1 time unit. The area estimation is based on empirical studies in full-custom and semi-custom layouts for adders and storage elements: The area for 1 bit in a lookup table corresponds to 1 area unit. A register cell requires 4 area units per bit and a full adder requires 8 area units. These values provide a powerful and realistic model for evaluation of area and time for most algorithms for modular multiplication.In this thesis, the percentage of configurable logic block slices occupied and the absolute time for computation are used to evaluate the algorithms. Other hardware resources such as total number of gates and number of flip-flops or latches required were also documented to provide a more practical and realistic evaluation of the algorithms in [1].2.3 Montgomery Multiplication AlgorithmThe Montgomery algorithm [1, Algorithm 1a] computes P = (X*Y* (2n)-1) mod M. The idea of Montgomery [2] is to keep the lengths of the intermediate resultsExisting Architectures for Modular Multiplication14smaller than n +1 bits. This is achieved by interleaving the computations and additions of new partial products with divisions by 2; each of them reduces the bit-length of the intermediate result by one.For a detailed treatment of the Montgomery algorithm, the reader is referred to [2] and [1].The key concepts of the Montgomery algorithm [1, Algorithm 1b] are the following:• Adding a multiple of M to the intermediate result does not change the valueof the final result; because the result is computed modulo M . M is an odd number.• After each addition in the inner loop the least significant bit (LSB) of theintermediate result is inspected. If it is 1, i.e., the intermediate result is odd, we add M to make it even. This even number can be divided by 2 without remainder. This division by 2 reduces the intermediate result to n +1 bits again.• After n steps these divisions add up to one division by 2n .The Montgomery algorithm is very easy to implement since it operates least significant bit first and does not require any comparisons. A modification of Algorithm 1a with carry save adders is given in [1, Algorithm 1b]:Algorithm 1a: Montgomery multiplication [1]P-M;:M) then P ) if (P (; }P div ) P :(*M; p P ) P :(*Y; x P ) P :() {n; i ; i ) for (i (;) P :(;: LSB of P p bit of X;: i x X;in bits of n: number M ) ) (X*Y(Output: P MX, Y Y, M with Inputs: X,i th i -n =≥=+=+=++<===<≤625430201 mod 20001Existing Architectures for Modular Multiplication15Algorithm 1b: Fast Montgomery multiplication [1]P-M;:M) then P ) if (P (C;S ) P :(;} C div ; C :S div ) S :(*M; s C S :) S,C (*Y; x C S :) S,C () {n; i ; i ) for (i (; ; C : ) S :(;: LSB of S s bit of X;: i x X;of bits in n: number M ) ) (X*Y(Output: P M X, Y Y, M with Inputs: X,i th i -n =≥+===++=++=++<====<≤762254302001mod 20001In this algorithm the delay of one pass through the loop is reduced from O (n ) to O (1). This remarkable improvement of the propagation delay inside the loop of Algorithm 1b is due to the use of carry save adders to implement step (3) and (4) in Algorithm 1a.Step (3) and (4) in Algorithm 1b represent carry save adders. S and C denote the sum and carry of the three input operands respectively.Of course, the additions in step (6) and (7) are conventional additions. But since they are performed only once while the additions in the loop are performed n times this is subdominant with respect to the time complexity.Figure 1 shows the architecture for the implementation of the loop of Algorithm 1b. The layout comprises of two carry save adders (CSA) and registers for storing the intermediate results of the sum and carry. The carry save adders are the dominant occupiers of area in hardware especially for very large values of n (e.g. n 1024).In Chapter 3, we shall see the changes that were made in [1] to reduce the number of carry save adders in Figure1 from 2 to 1, thereby saving considerable hardware space. However, these changes also brought about other area consuming blocks such as lookup tables for storing precomputed values before the start of the loop.Existing Architectures for Modular Multiplication 16Fig. 1: Architecture of the loop of algorithm 1b [1].There are various modifications to the Montgomery algorithm in [5], [6] and [7]. All these algorithms aimed at decreasing the operating time for faster system performance and reducing the chip area for practical hardware implementation. 2.4 Interleaved Modular MultiplicationAnother well known algorithm for modular multiplication is the interleaved modular multiplication. The details of the method are sketched in [3, 4]. The idea is to interleave multiplication and reduction such that the intermediate results are kept as short as possible.As shown in [1, Algorithm 2], the computation of P requires n steps and at each step we perform the following operations:Existing Architectures for Modular Multiplication17• A left shift: 2*P• A partial product computation: x i * Y• An addition: 2*P+ x i * Y •At most 2 subtractions:If (P M) Then P := P – M; If (P M) Then P := P – M;The partial product computation and left shift operations are easily performed by using an array of AND gates and wiring respectively. The difficult task is the addition operation, which must be performed fast. This was done using carry save adders in [1, Algorithm 4], introducing only O (1) delay per step.Algorithm 2: Standard interleaved modulo multiplication [1]P-M; }:M) then P ) if (P (P-M; :M) then P ) if (P (I;P ) P :(*Y; x ) I :(*P; ) P :() {i ; i ; n ) for (i (;) P :( bit of X;: i x X;of bits in n: number M X*Y Output: P M X, Y Y, M with Inputs: X,i th i =≥=≥+===−−≥−===<≤765423 0 1201mod 0The main advantages of Algorithm 2 compared to the separated multiplication and division are the following:• Only one loop is required for the whole operation.• The intermediate results are never any longer than n +2 bits (thus reducingthe area for registers and full adders).But there are some disadvantages as well:Existing Architectures for Modular Multiplication 18 •The algorithm requires three additions with carry propagation in steps (5),(6) and (7).•In order to perform the comparisons in steps (4) and (5), the preceding additions have to be completed. This is important for the latency because the operands are large and, therefore, the carry propagation has a significant influence on the latency.•The comparison in step (6) and (7) also requires the inspection of the full bit lengths of the operands in the worst case. In contrast to addition, the comparison is performed MSB first. Therefore, these two operations cannot be pipelined without delay.Many researchers have tried to address these problems, but the only solution with a constant delay in the loop is the one of [8], which has an AT- complexity of 156n2.In [1], a different approach is presented which reduces the AT-complexity for modular multiplication considerably. In Chapter 3, this new optimized algorithm is presented and discussed.Chapter 3New Architectures for Modular Multiplication The detailed treatment of the new algorithms and their corresponding architectures presented in this chapter can be found in [1]. In this chapter, a summary of these algorithms and architectures is given. They have been designed to meet the core requirements of most modern devices: small chip area and low power consumption.3.1 Faster Montgomery AlgorithmIn Figure 1, the layout for the implementation of the loop of Algorithm 1b consists of two carry save adders. For large wordsizes (e.g. n = 1024 or higher), this would require considerable hardware resources to implement the architecture of Algorithm 1b. The motivation behind this optimized algorithm is that of reducing the chip area for practical hardware implementation of Algorithm 1b. This is possible if we can precompute the four possible values to be added to the intermediate result within the loop of Algorithm 1b, thereby reducing the number of carry save adders from 2 to 1. There are four possible scenarios:•if the sum of the old values of S and C is an even number, and if the actual bit x i of X is 0, then we add 0 before we perform the reduction of S and C by division by 2.•if the sum of the old values of S and C is an odd number, and if the actual bit x i of X is 0, then we must add M to make the intermediate result even.Afterwards, we divide S and C by 2.•if the sum of the old values of S and C is an even number, and if the actual bit x i of X is 1, but the increment x i *Y is even, too, then we do not need to add M to make the intermediate result even. Thus, in the loop we add Y before we perform the reduction of S and C by division by 2. The same action is necessary if the sum of S and C is odd, and if the actual bit x i of X is 1 and Y is odd as well. In this case, S+C+Y is an even number, too.New Architectures for Modular Multiplication20• if the sum of the old values of S and C is odd, the actual bit x i of X is 1, butthe increment x i *Y is even, then we must add Y and M to make the intermediate result even. Thus, in the loop we add Y +M before we perform the reduction of S and C by division by 2.The same action is necessary if the sum of S and C is even, and the actual bit x i of X is 1, and Y is odd. In this case, S +C +Y +M is an even number, too.The computation of Y +M can be done prior to the loop. This saves one of the two additions which are replaced by the choice of the right operand to be added to the old values of S and C . Algorithm 3 is a modification of Montgomery’s method which takes advantage of this idea.The advantage of Algorithm 3 in comparison to Algorithm 1 can be seen in the implementation of the loop of Algorithm 3 in Figure 2. The possible values of I are stored in a lookup-table, which is addressed by the actual values of x i , y 0, s 0 and c 0. The operations in the loop are now reduced to one table lookup and one carry save addition. Both these activities can be performed concurrently. Note that the shift right operations that implement the division by 2 can be done by routing.Algorithm 3: Faster Montgomery multiplication [1]P-M;:M) then P ) if (P (C;S ) P :(;} C div ; C :S div ) S :(I;C S :) S,C ( R;) then I :) and x y c ((s ) if ( Y;) then I :) and x y c (not(s ) if ( M;) then I :x ) and not c ((s ) if (; ) then I :x ) and not c ((s ) if () {n; i ; i ) for (i (; ; C : ) S :(M; of Y uted value R: precomp ;: LSB of Y , y : LSB of C , c : LSB of S s bit of X;: i x X;of bits in n: number M ) ) (X*Y(Output: P M X, Y Y, M with Inputs: X,i i i i th i -n =≥+===++==⊕⊕=⊕⊕=≠==++<===+=<≤10922876540302001mod 2000000000000001New Architectures for Modular Multiplication 21Fig. 2: Architecture of Algorithm 3 [1]In [1], the proof of Algorithm 3 is presented and the assumptions which were made in arriving at an Area-Time (AT) complexity of 96n2 are shown.3.2 Optimized Interleaved AlgorithmThe new algorithm [1, Algorithm 4] is an optimisation of the interleaved modular multiplication [1, Algorithm 2]. In [1], four details of Algorithm 2 were modified in order to overcome the problems mentioned in Chapter 2:•The intermediate results are no longer compared to M (as in steps (6) and(7) of Algorithm 2). Rather, a comparison to k*2n(k=0... 6) is performedwhich can be done in constant time. This comparison is done implicitly in the mod-operation in step (13) of Algorithm 4.New Architectures for Modular Multiplication22• Subtractions in steps (6), (7) of Algorithm 2 are replaced by one subtractionof k *2n which can be done in constant time by bit masking. • Next, the value of k *2n mod M is added in order to generate the correctintermediate result (step (12) of Algorithm 4).• Finally, carry save adders are used to perform the additions inside the loop,thereby reducing the latency to a constant. The intermediate results are in redundant form, coded in two words S and C instead of generated one word P .These changes made by the authors in [1] led to Algorithm 4, which looks more complicated than Algorithm 2. Its main advantage is the fact that all the computations in the loop can be performed in constant time. Hence, the time complexity of the whole algorithm is reduced to O(n ), provided the values of k *2n mod M are precomputed before execution of the loop.Algorithm 4: Modular multiplication using carry save addition [1]M;C) (S ) P :(M;})*C *C S *S () A :( A);CSA(S, C,) :) (S,C ( I); CSA(S, C,C) :) (S,(*Y;x ) I :(*A;) A :(*C;) C :(*S;) S :(; C ) C :(; S ) S :() {; i ; i n ) for (i (; ; A : ; C :) S :( bit of X;: i x X;of bits in n: number M X*Y Output: P MX, Y Y, M with Inputs: X,n n n n n i n n th i mod 12mod 2221110982726252mod 42mod 30120001mod 011+=+++=========−−≥−=====<≤++New Architectures for Modular Multiplication 23Fig. 3: Inner loop of modular multiplication using carry save addition [1]In [1], the authors specified some modifications that can be applied to Algorithm 2 in order simplify and significantly speed up the operations inside the loop. The mathematical proof which confirms the correctness of the Algorithm 4 can be referred to in [1].The architecture for the implementation of the loop of Algorithm 4 can be seen in the hardware layout in Figure 3.In [1], the authors showed how to reduce both area and time by further exploiting precalculation of values in a lookup-table and thus saving one carry save adder. The basic idea is:。
英语作文-探索集成电路设计中的新技术与应用前景

英语作文-探索集成电路设计中的新技术与应用前景As integrated circuit (IC) design continues to evolve, new technologies are constantly emerging, offering exciting possibilities for innovation and advancement. In this essay, we will explore some of the latest trends and applications in IC design, highlighting their potential impact on various industries and the future landscape of technology.One of the most significant advancements in IC design is the development of 3D integration technology. Unlike traditional 2D designs, which place all components on a single plane, 3D integration allows for stacking multiple layers of integrated circuits, thereby increasing functionality and performance while reducing footprint. This technology enables the creation of smaller, more power-efficient devices, making it ideal for applications in mobile devices, wearables, and IoT devices.Another area of innovation in IC design is the use of advanced materials such as graphene and carbon nanotubes. These materials offer unique electrical and mechanical properties that can greatly enhance the performance of integrated circuits. For example, graphene-based transistors have demonstrated higher electron mobility and faster switching speeds compared to traditional silicon transistors, paving the way for next-generation computing devices with unprecedented speed and efficiency.In addition to new materials, machine learning and artificial intelligence (AI) are playing an increasingly important role in IC design. By leveraging AI algorithms, designers can automate the process of optimizing chip architectures, reducing time-to-market and improving overall performance. AI-driven design tools can analyze vast amounts of data to identify the most efficient circuit layouts and power management strategies, leading to more reliable and cost-effective ICs.Moreover, the integration of photonics into IC design is opening up new possibilities for high-speed data communication and processing. Photonic integrated circuits (PICs)use light instead of electricity to transmit and manipulate data, offering significant advantages in terms of bandwidth and latency. PICs are already being used in data centers and telecommunications networks to improve the performance and scalability of optical communication systems.Furthermore, the emergence of quantum computing represents a paradigm shift in IC design, with the potential to solve complex problems that are currently intractable for classical computers. Quantum ICs, which exploit the principles of quantum mechanics to perform calculations, have the potential to revolutionize fields such as cryptography, materials science, and drug discovery. While quantum computing is still in its infancy, ongoing research and development efforts are rapidly advancing the state-of-the-art, bringing us closer to realizing the full potential of this transformative technology.In conclusion, the field of IC design is experiencing rapid innovation driven by advancements in materials science, machine learning, photonics, and quantum computing. These technologies hold the promise of delivering faster, more efficient, and more powerful integrated circuits, with profound implications for a wide range of industries and applications. As we continue to push the boundaries of what is possible, the future of IC design looks brighter than ever before.。
JVM for a Heterogeneous Shared Memory System

JVM for a Heterogeneous Shared Memory SystemDeQing Chen,Chunqiang Tang,Sandhya Dwarkadas,and Michael L.ScottComputer Science Department,University of Rochester AbstractInterWeave is a middleware system that supports the shar-ing of strongly typed data structures across heterogeneouslanguages and machine architectures.Java presents spe-cial challenges for InterWeave,including write detection,data translation,and the interface with the garbage col-lector.In this paper,we discuss our implementation ofJ-InterWeave,a JVM based on the Kaffe virtual machineand on our locally developed InterWeave client software.J-InterWeave uses bytecode instrumentation to detectwrites to shared objects,and leverages Kaffe’s class ob-jects to generate type information for correct transla-tion between the local object format and the machine-independent InterWeave wire format.Experiments in-dicate that our bytecode instrumentation imposes lessthan2%performance cost in Kaffe interpretation mode,and less than10%overhead in JIT mode.Moreover,J-InterWeave’s translation between local and wire format ismore than8times as fast as the implementation of ob-ject serialization in Sun JDK1.3.1for double arrays.Toillustrate theflexibility and efficiency of J-InterWeave inpractice,we discuss its use for remote visualization andsteering of a stellar dynamics simulation system writtenin C.1IntroductionMany recent projects have sought to support distributedshared memory in Java[3,16,24,32,38,41].Manyof these projects seek to enhance Java’s usefulness forlarge-scale parallel programs,and thus to compete withmore traditional languages such as C and Fortran in thearea of scientific computing.All assume that applicationcode will be written entirely in Java.Many—particularlythose based on existing software distributed shared mem-ory(S-DSM)systems—assume that all code will run oninstances of a common JVM.has yet to displace Fortran for scientific computing sug-gests that Java will be unlikely to do so soon.Even for systems written entirely in Java,it is appealing to be able to share objects across heterogeneous JVMs. This is possible,of course,using RMI and object serial-ization,but the resulting performance is poor[6].The ability to share state across different languages and heterogeneous platforms can also help build scalable dis-tributed services in general.Previous research on var-ious RPC(remote procedure call)systems[21,29]in-dicate that caching at the client side is an efficient way to improve service scalability.However,in those sys-tems,caching is mostly implemented in an ad-hoc man-ner,lacking a generalized translation semantics and co-herence model.Our on-going research project,InterWeave[9,37],aims to facilitate state sharing among distributed programs written in multiple languages(Java among them)and run-ning on heterogeneous machine architectures.InterWeave applications share strongly-typed data structures located in InterWeave segments.Data in a segment is defined using a machine and platform-independent interface de-scription language(IDL),and can be mapped into the ap-plication’s local memory assuming proper InterWeave li-brary calls.Once mapped,the data can be accessed as ordinary local objects.In this paper,we focus on the implementation of In-terWeave support in a Java Virtual Machine.We call our system J-InterWeave.The implementation is based on an existing implementation of InterWeave for C,and on the Kaffe virtual machine,version1.0.6[27].Our decision to implement InterWeave support directly in the JVM clearly reduces the generality of our work.A more portable approach would implement InterWeave support for segment management and wire-format trans-lation in Java libraries.This portability would come,how-ever,at what we consider an unacceptable price in perfor-mance.Because InterWeave employs a clearly defined internal wire format and communication protocol,it is at least possible in principle for support to be incorporated into other JVMs.We review related work in Java distributed shared state in Section2and provide a brief overview of the Inter-Weave system in Section3.A more detailed description is available elsewhere[8,37].Section4describes the J-InterWeave implementation.Section5presents the results of performance experiments,and describes the use of J-InterWeave for remote visualization and steering.Sec-tion6summarizes our results and suggests topics for fu-ture research.2Related WorkMany recent projects have sought to provide distributed data sharing in Java,either by building customized JVMs[2,3,24,38,41];by using pure Java implementa-tions(some of them with compiler support)[10,16,32]; or by using Java RMI[7,10,15,28].However,in all of these projects,sharing is limited to Java applications. To communicate with applications on heterogeneous plat-forms,today’s Java programmers can use network sock-ets,files,or RPC-like systems such as CORBA[39].What they lack is a general solution for distributed shared state. Breg and Polychronopoulos[6]have developed an al-ternative object serialization implementation in native code,which they show to be as much as eight times faster than the standard implementation.The direct compari-son between their results and ours is difficult.Our exper-iments suggest that J-Interweave is at least equally fast in the worst case scenario,in which an entire object is mod-ified.In cases where only part of an object is modified, InterWeave’s translation cost and communication band-width scale down proportionally,and can be expected to produce a significant performance advantage.Jaguar[40]modifies the JVM’s JIT(just-in-time com-piler)to map certain bytecode sequences directly to na-tive machine codes and shows that such bytecode rewrit-ing can improve the performance of object serialization. However the benefit is limited to certain types of objects and comes with an increasing price for accessing object fields.MOSS[12]facilitates the monitoring and steering of scientific applications with a CORBA-based distributed object system.InterWeave instead allows an application and its steerer to share their common state directly,and in-tegrates that sharing with the more tightly coupled sharing available in SMP clusters.Platform and language heterogeneity can be supported on virtual machine-based systems such as Sun JVM[23] and [25].The Common Language Run-time[20](CLR)under framework promises sup-port for multi-language application development.In com-parison to CLR,InterWeave’s goal is relatively modest: we map strongly typed state across languages.CLR seeks to map all high-level language features to a common type system and intermediate language,which in turn implies more semantic compromises for specific languages than are required with InterWeave.The transfer of abstract data structures wasfirst pro-posed by Herlihy and Liskov[17].Shasta[31]rewrites bi-nary code with instrumentation for access checks forfine-grained S-DSM.Midway[4]relies on compiler support to instrument writes to shared data items,much as we do in the J-InterWeave JVM.Various software shared memory systems[4,19,30]have been designed to explicitly asso-ciate synchronization operations with the shared data they protect in order to reduce coherence costs.Mermaid[42] and Agora[5]support data sharing across heterogeneous platforms,but only for restricted data types.3InterWeave OverviewIn this section,we provide a brief introduction to the design and implementation of InterWeave.A more de-tailed description can be found in an earlier paper[8]. For programs written in C,InterWeave is currently avail-able on a variety of Unix platforms and on Windows NT. J-InterWeave is a compatible implementation of the In-terWeave programming model,built on the Kaffe JVM. J-InterWeave allows a Java program to share data across heterogeneous architectures,and with programs in C and Fortran.The InterWeave programming model assumes a dis-tributed collection of servers and clients.Servers maintain persistent copies of InterWeave segments,and coordinate sharing of those segments by clients.To avail themselves of this support,clients must be linked with a special In-terWeave library,which serves to map a cached copy of needed segments into local memory.The servers are the same regardless of the programming language used by clients,but the client libraries may be different for differ-ent programming languages.In this paper we will focus on the client side.In the subsections below we describe the application programming interface for InterWeave programs written in Java.3.1Data Allocation and AddressingThe unit of sharing in InterWeave is a self-descriptive data segment within which programs allocate strongly typed blocks of memory.A block is a contiguous section of memory allocated in a segment.Every segment is specified by an Internet URL and managed by an InterWeave server running at the host indi-cated in the URL.Different segments may be managed by different servers.The blocks within a segment are num-bered and optionally named.By concatenating the seg-ment URL with a block number/name and offset(delim-ited by pound signs),we obtain a machine-independent pointer(MIP):“/path#block#offset”. To create and initialize a segment in Java,one can ex-ecute the following calls,each of which is elaborated on below or in the following subsections:IWSegment seg=new IWSegment(url);seg.wl_acquire();MyType myobj=new MyType(seg,blkname);myobj.field=......seg.wl_release();In Java,an InterWeave segment is captured as an IWSegment object.Assuming appropriate access rights, the new operation of the IWSegment object communi-cates with the appropriate server to initialize an empty segment.Blocks are allocated and modified after acquir-ing a write lock on the segment,described in more detail in Section3.3.The IWSegment object returned can be passed to the constructor of a particular block class to al-locate a block of that particular type in the segment. Once a segment is initialized,a process can convert be-tween the MIP of a particular data item in the segment and its local pointer by using mip ptr and ptr mip where appropriate.It should be emphasized that mip ptr is primar-ily a bootstrapping mechanism.Once a process has one pointer into a data structure(e.g.the root pointer in a lat-tice structure),any data reachable from that pointer can be directly accessed in the same way as local data,even if embedded pointers refer to data in other segments.In-terWeave’s pointer-swizzling and data-conversion mech-anisms ensure that such pointers will be valid local ma-chine addresses or references.It remains the program-mer’s responsibility to ensure that segments are accessed only under the protection of reader-writer locks.3.2HeterogeneityTo accommodate a variety of machine architectures,In-terWeave requires the programmer to use a language-and machine-independent notation(specifically,Sun’s XDR[36])to describe the data types inside an InterWeave segment.The InterWeave XDR compiler then translates this notation into type declarations and descriptors appro-priate to a particular programming language.When pro-gramming in C,the InterWeave XDR compiler generates twofiles:a.hfile containing type declarations and a.c file containing type descriptors.For Java,we generate a set of Java class declarationfiles.The type declarations generated by the XDR compiler are used by the programmer when writing the application. The type descriptors allow the InterWeave library to un-derstand the structure of types and to translate correctly between local and wire-format representations.The lo-cal representation is whatever the compiler normally em-ploys.In C,it takes the form of a pre-initialized data struc-ture;in Java,it is a class object.3.2.1Type Descriptors for JavaA special challenge in implementing Java for InterWeave is that the InterWeave XDR compiler needs to gener-ate correct type descriptors and ensure a one-to-one cor-respondence between the generated Java classes and C structures.In many cases mappings are straight forward: an XDR struct is mapped to a class in Java and a struct in C,primitivefields to primitivefields both in Java andC,pointersfields to object references in Java and pointers in C,and primitive arrays to primitive arrays. However,certain“semantics gaps”between Java and C force us to make some compromises.For example,a C pointer can point to any place inside a data block;while Java prohibits such liberties for any object reference. Thus,in our current design,we make the following compromises:An InterWeave block of a single primitive data item is translated into the corresponding wrapped class for the primitive type in Java(such as Integer,Float, etc.).Embedded structfields in an XDR struct definition areflattened out in Java and mapped asfields in its parent class.In C,they are translated naturally into embeddedfields.Array types are mapped into a wrapped IWObject(including the IWacquire,wl acquire, and rlpublic class IWSegment{public IWSegment(String URL,Boolean iscreate);public native staticint RegisterClass(Class type);public native staticObject mip_to_ptr(String mip);public native staticString ptr_to_mip(IWObject Ob-ject obj);......public native int wl_acquire();public native int wl_release();public native int rl_acquire();public native int rl_release();......}Figure2:IWSegment Class4.1.1JNI Library for IWSegment ClassThe native library for the IWSegment class serves as an intermediary between Kaffe and the C InterWeave library. Programmer-visible objects that reside within the IWSeg-ment library are managed in such a way that they look like ordinary Java objects.As in any JNI implementation,each native method has a corresponding C function that implements its function-ality.Most of these C functions simply translate their pa-rameters into C format and call corresponding functions in the C InterWeave API.However,the creation of an In-terWeave object and the method RegisterClass need special explanation.Mapping Blocks to Java Objects Like ordinary Java objects,InterWeave objects in Java are created by“new”operators.In Kaffe,the“new”operator is implemented directly by the bytecode execution engine.We modi-fied this implementation to call an internal function new-Block in the JNI library and newBlock calls the Inter-Weave C library to allocate an InterWeave block from the segment heap instead of the Kaffe object heap.Before returning the allocated block back to the“new”operator, newBlock initializes the block to be manipulated cor-rectly by Kaffe.In Kaffe,each Java object allocated from the Kaffe heap has an object header.This header contains a pointer to the object class and a pointer to its own monitor.Since C InterWeave already assumes that every block has a header (it makes no assumption about the contiguity of separate blocks),we put the Kaffe header at the beginning of what C InterWeave considers the body of the block.A correctly initialized J-InterWeave object is shown in Figure3.Figure3:Block structure in J-InterWeaveAfter returning from newBlock,the Kaffe engine calls the class constructor and executes any user cus-tomized operations.Java Class to C Type Descriptor Before any use of a class in a J-InterWeave segment,including the creation of an InterWeave object of the type,the class object must befirst registered with RegisterClass.Register-Class uses the reflection mechanism provided by the Java runtime system to determine the following informa-tion needed to generate the C type descriptor and passes it to the registration function in the C library.1.type of the block,whether it is a structure,array orpointer.2.total size of the block.3.for structures,the number offields,eachfield’s off-set in the structure,and a pointer to eachfield’s type descriptor.4.for arrays,the number of elements and a pointer tothe element’s type descriptor.5.for pointers,a type descriptor for the pointed-to data.The registered class objects and their corresponding C type descriptors are placed in a hashtable.The new-Block later uses this hashtable to convert a class object into the C type descriptor.The type descriptor is required by the C library to allocate an InterWeave block so that it has the information to translate back and forth between local and wire format(see Section3).4.2KaffeJ-InterWeave requires modifications to the byte code in-terpreter and the JIT compiler to implementfine-grained write detection via instrumentation.It also requires changes to the garbage collector to ensure that InterWeave blocks are not accidentally collected.Figure4:Extended Kaffe object header forfine-grained write detection4.2.1Write DetectionTo support diff-based transmission of InterWeave segment updates,we must identify changes made to InterWeave objects over a given span of time.The current C ver-sion of InterWeave,like most S-DSM systems,uses vir-tual memory traps to identify modified pages,for which it creates pristine copies(twins)that can be compared with the working copy later in order to create a diff.J-InterWeave could use this same technique,but only on machines that implement virtual memory.To enable our code to run on handheld and embedded devices,we pursue an alternative approach,in which we instrument the interpretation of store bytecodes in the JVM and JIT. In our implementation,only writes to InterWeave block objects need be monitored.In each Kaffe header,there is a pointer to the object method dispatch table.On most architectures,pointers are aligned on a word boundary so that the least significant bit is always zero.Thus,we use this bit as theflag for InterWeave objects.We also place two32-bit words just before the Kaffe object header,as shown in Figure4.The second word—modification status—records which parts of the object have been modified.A block’s body is logically divided into32parts,each of which corresponds to one bit in the modification status word.Thefirst extended word is pre-computed when initializing an object.It is the shift value used by the instrumented store bytecode code to quickly determine which bit in the modification status word to set(in other words,the granularity of the write detection).These two words are only needed for In-terWeave blocks,and cause no extra overhead for normal Kaffe objects.4.2.2Garbage CollectionLike distributedfile systems and databases(and unlike systems such as PerDiS[13])InterWeave requires man-ual deletion of data;there is no garbage collection.More-over the semantics of InterWeave segments ensure that an object reference(pointer)in an InterWeave object(block) can never point to a non-InterWeave object.As a result, InterWeave objects should never prevent the collection of unreachable Java objects.To prevent Kaffe from acci-dentally collecting InterWeave memory,we modify the garbage collector to traverse only the Kaffe heap.4.3InterWeave C libraryThe InterWeave C library needs little in the way of changes to be used by J-InterWeave.When an existing segment is mapped into local memory and its blocks are translated from wire format to local format,the library must call functions in the IWSegment native library to initialize the Kaffe object header for each block.When generating a description of modified data in the write lock release operation,the library must inspect the modifi-cation bits in Kaffe headers,rather than creating diffs from the pristine and working copies of the segment’s pages.4.4DiscussionAs Java is supposed to be“Write Once,Run Anywhere”, our design choice of implementing InterWeave support at the virtual machine level can pose the concern of the portability of Java InterWeave applications.Our current implementation requires direct JVM support for the fol-lowing requirements:1.Mapping from InterWeave type descriptors to Javaobject classes.2.Managing local segments and the translation be-tween InterWeave wire format and local Java objects.3.Supporting efficient write detection for objects in In-terWeave segments.We can use class reflection mechanisms along with pure Java libraries for InterWeave memory management and wire-format translation to meet thefirst two require-ments and implement J-InterWeave totally in pure Java. Write detection could be solved using bytecode rewrit-ing techniques as reported in BIT[22],but the resulting system would most likely incur significantly higher over-heads than our current implementation.We didn’t do this mainly because we wanted to leverage the existing C ver-sion of the code and pursue better performance.In J-InterWeave,accesses to mapped InterWeave blocks(objects)by different Java threads on a single VM need to be correctly synchronized via Java object monitors and appropriate InterWeave locks.Since J-InterWeave is not an S-DSM system for Java virtual machines,the Java memory model(JMM)[26]poses no particular problems. 5Performance EvaluationIn this section,we present performance results for the J-InterWeave implementation.All experiments employ a J-InterWeave client running on a1.7GHz Pentium-4Linux machine with768MB of RAM.In experiments involving20406080100120_201_co mp r e s s _202_j e s s _205_ra y t r a c e _209_db _213_j a va c _222_m p e g a u d i o _227_m t r t _228_j a c kJVM98 BenchmarksT i m e (s e c .)Figure 5:Overhead of write-detect instrumentation in Kaffe’s interpreter mode01234567_201_c o mp r e s s _202_j e s s _205_r a y t r a c e _209_d b _213_j a v a c _222_m p e g a u d i o _227_m t r t _228_j a c k JVM98 Benchmarks T i m e (s e c .)Figure 6:Overhead of write-detect instrumentation inKaffe’s JIT3modedata sharing,the InterWeave segment server is running on a 400MHz Sun Ultra-5workstation.5.1Cost of write detectionWe have used SPEC JVM98[33]to quantify the perfor-mance overhead of write detection via bytecode instru-mentation.Specifically,we compare the performance of benchmarks from JVM98(medium configuration)run-ning on top of the unmodified Kaffe system to the per-formance obtained when all objects are treated as if they resided in an InterWeave segment.The results appear in Figures 5and 6.Overall,the performance loss is small.In Kaffe’s inter-preter mode there is less than 2%performance degrada-tion;in JIT3mode,the performance loss is about 9.1%.The difference can be explained by the fact that in inter-preter mode,the per-bytecode execution time is already quite high,so extra checking time has much less impact than it does in JIT3mode.The Kaffe JIT3compiler does not incorporate more re-cent and sophisticated technologies to optimize the gener-ated code,such as those employed in IBM Jalepeno [35]and Jackal [38]to eliminate redundant object referenceand array boundary checks.By applying similar tech-niques in J-InterWeave to eliminate redundant instrumen-tation,we believe that the overhead could be further re-duced.5.2Translation costAs described in Sections 3,a J-InterWeave application must acquire a lock on a segment before reading or writ-ing it.The acquire operation will,if necessary,ob-tain a new version of the segment from the InterWeaveserver,and translate it from wire format into local Kaffeobject format.Similarly,after modifying an InterWeavesegment,a J-InterWeave application must invoke a write lock release operation,which translates modified por-tions of objects into wire format and sends the changes back to the server.From a high level point of view this translation re-sembles object serialization ,widely used to create per-sistent copies of objects,and to exchange objects between Java applications on heterogeneous machines.In this sub-section,we compare the performance of J-InterWeave’stranslation mechanism to that of object serialization in Sun’s JDK v.1.3.1.We compare against the Sun im-plementation because it is significantly faster than Kaffe v.1.0.6,and because Kaffe was unable to successfully se-rialize large arrays in our experiments.We first compare the cost of translating a large array of primitive double variables in both systems.Under Sun JDK we create a Java program to serialize double arrays into byte arrays and to de-serialize the byte arrays backagain.We measure the time for the serialization and de-serialization.Under J-InterWeave we create a programthat allocates double arrays of the same size,releases (un-maps)the segment,and exits.We measure the releasetime and subtract the time spent on communication with the server.We then run a program that acquires (maps)the segment,and measure the time to translate the byte arrays back into doubles in Kaffe.Results are shown in Figure 7,for arrays ranging in size from 25000to 250000elements.Overall,J-InterWeave is about twenty-three times faster than JDK 1.3.1in serialization,and 8times faster in dese-rialization.5.3Bandwidth reduction To evaluate the impact of InterWeave’s diff-based wire format,which transmits an encoding of only those bytes that have changed since the previous communication,we modify the previous experiment to modify between 10and 100%of a 200,000element double array.Results appear in Figures 8and 9.The former indicates translation time,the latter bytes transmitted.20406080100120140250005000075000100000125000150000175000200000225000250000Size of double array (in elements)T i m e (m s e c .)Figure 7:Comparison of double array translation betweenSun JDK 1.3.1and J-InterWeave102030405060708090100100908070605040302010Percentage of changesT i m e (m s e c .)Figure 8:Time needed to translate a partly modified dou-ble arrayIt is clear from the graph that as we reduce the per-centage of the array that is modified,both the translationtime and the required communication bandwidth go down by linear amounts.By comparison,object serialization is oblivious to the fraction of the data that has changed.5.4J-InterWeave Applications In this section,we describe the Astroflow application,developed by colleagues in the department of Physics andAstronomy,and modified by our group to take advan-tage of InterWeave’s ability to share data across hetero-geneous platforms.Other applications completed or cur-rently in development include interactive and incremental data mining,a distributed calendar system,and a multi-player game.Due to space limitations,we do not present these here.The Astroflow [11][14]application is a visualization tool for a hydrodynamics simulation actively used in the astrophysics domain.It is written in Java,but employs data from a series of binary files that are generated sepa-rately by a computational fluid dynamics simulation sys-00.20.40.60.811.21.41.61.8100908070605040302010Percentage of changesT r a n s mi s s i o n s i z e (M B )Figure 9:Bandwidth needed to transmit a partly modified double array2040608010012014012416Number of CPUsT i m e (s e c .)Figure 10:Simulator performance using InterWeave in-stead of file I/Otem.The simulator,in our case,is written in C,and runs on a cluster of 4AlphaServer 41005/600nodes under the Cashmere [34]S-DSM system.(Cashmere is a two-level system,exploiting hardware shared memory within SMP nodes and software shared memory among nodes.InterWeave provides a third level of sharing,based on dis-tributed versioned segments.We elaborate on this three-level structure in previous papers [8].)J-InterWeave makes it easy to connect the Astroflow vi-sualization front end directly to the simulator,to create an interactive system for visualization and steering.The ar-chitecture of the system is illustrated in Figure 1(page 1).Astroflow and the simulator share a segment with one header block specifying general configuration parameters and six arrays of doubles.The changes required to the two existing programs are small and limited.We wrote an XDR specification to describe the data structures we are sharing and replaced the original file operations with shared segment operations.No special care is re-quired to support multiple visualization clients or to con-trol the frequency of updates.While the simulation data。
classification of the evaluated hardware element

classification of the evaluatedhardware elementIn the field of hardware engineering, the evaluation of different hardware elements plays a crucial role in determining their functionality, reliability, and overall performance. These evaluations are carried out to assess the capabilities and limitations of the hardware components, ensuring that they meet specific criteria and standards. The classification of the evaluated hardware element helps to categorize and understand its characteristics, which aids in making informed decisions when selecting the appropriate hardware for a particular application. This article will delve into the classification of the evaluated hardware element and discuss the various categories that exist.1. Processing Units and MicroprocessorsOne of the most critical hardware components that are evaluated is the processing unit or microprocessor. These elements are responsible for executing instructions and performing calculations in a computer system. The evaluation of processing units involves assessing their clock speed, architecture, cache size, and power consumption. Based on these evaluations, processing units can be classified into various categories, such as low-end, mid-range, and high-end, based on their performance and capabilities.2. Memory ModulesMemory modules are another vital hardware element that is extensively evaluated. These modules store and retrieve data for quick access by the processor. The evaluationof memory modules involves testing their capacity, speed, type, and compatibility with the system. Classification of memory modules is typically done based on their capacity, type (e.g., RAM or ROM), and speed (e.g., DDR3 or DDR4). This classification helps in selecting the appropriate memory module that meets the requirements of the system in terms of storage and data transfer rates.3. Storage DevicesEvaluation of storage devices focuses on assessing their capacity, speed, reliability, and data transfer rates. Storage devices include hard disk drives (HDDs), solid-state drives (SSDs), and various other storage media. HDDs are evaluated based on parameters like rotational speed, data transfer rate, and storage capacity. SSDs are evaluated based on factors such as durability, transfer speed, and reliability. The classification of storage devices helps in selecting the appropriate storage medium based on the requirements of the system, whether it is for high-speed data access, larger storage capacity, or durability.4. Graphics Processing Units (GPUs)GPUs are hardware elements specifically designed to handle complex graphical computations and rendering tasks. The evaluation of GPUs involves assessing factors like CUDA core count, memory bandwidth, clock speed, and power consumption. GPUs are usually classified into different categories based on their performance levels, such as entry-level, mid-range, and high-end, to help users choose the appropriate GPU for their desired graphics-intensive applications.5. Networking DevicesEvaluating networking devices involves assessing their data transfer rates, compatibility with different network protocols, reliability, and security features. Networking devices include routers, switches, and wireless access points. Classification of networking devices is done based on their capabilities, such as gigabit routers, managed switches, or wireless routers. This classification helps in selecting the appropriate networking device that caters to the specific needs of the network infrastructure.6. Input and Output DevicesInput and output devices are evaluated based on factors like compatibility, data transfer rates, responsiveness, and durability. Input devices include keyboards, mice, and touchscreens, whereas output devices include monitors, printers, and speakers. These hardware elements are often classified based on their functionality, size, and connectivityoptions. This classification aids in selecting the appropriate input and output devices for seamless interaction with computer systems.In conclusion, the classification of the evaluated hardware element is essential for understanding and categorizing the characteristics and capabilities of different hardware components. Evaluating hardware elements such as processing units, memory modules, storage devices, GPUs, networking devices, and input/output devices allows for informed decision-making when selecting the appropriate hardware for specific applications. By considering the classification of the evaluated hardware element, individuals and organizations can ensure that their hardware choices align with their requirements and expectations.。
HardwareSoftware Synthesis and Verification using

Hardware/Software Synthesis and Verification usingEsterelSatnam SinghMicrosoftOne Microsoft WayRedmond, WA 98052, USAABSTRACTThe principal contribution of this paper is the demonstration of a promising technique for the synthesis of hardware and software from a single specification which is also amenable to formal analy-sis. We also demonstrate how the notion of synchronous observers may provide a way for engineers to express formal assertions about circuits which may be more accessible then the emerging grammar based approaches. We also report that the semantic basis for the system we evaluate pays dividends when formal static analysis is performed using model checking.1.INTRODUCTIONConventional approaches for the design and implementation of sys-tems that comprise hardware and software typically involve totally separate flows for the design and verification of the hardware and software components. The verification of the combined hardware/ software system still remains a significant challenge. The software design flow is based around imperative languages with semantics that model Von Neuman style architectures. The most popular soft-ware languages have semantics that can only be expressed in an operational way which is rather unsatisfactory from a formal verifi-cation and static analysis viewpoint. Conventional hardware description languages have semantics based on an event queue model which also lends itself to an operational style semantic description which is different from the semantic model typically used for software. This immediately poses a problem for any veri-fication techniques based on static analysis (e.g. formal verification) that need to analyse a system that comprises software and hardware. Is it possible to come up with a way of describing hardware and software based on the same semantic model or semantic models that can be easily related to each other?This paper explores a possible answer to this question by investigat-ing a formalism that has already proved itself as a mature technology for the static analysis of software. The formalism is cap-tured in the Esterel V7 programming language [2] and we report the result of experiments which evaluate this methodology for the syn-thesis of both hardware and software. We also report our experience of performing static analysis of hardware systems with properties expressed as synchronous observers which are checked using an embedded model checker.2.HARDWARE SOFTWARE TRADE-OFFS Given that Esterel has a semantic basis that is appropriate for syn-thesizing either hardware or software we attempted an experiment which uses Esterel to describe a system which is first implemented entirely in software and then entirely in hardware. If we can get such a flow to work then we would have achieved several desirable properties including the ability to produce corresponding hardware and software from the same specification and the ability to formally analyse the hardware or software. Furthermore, we would have a lot of flexibility to partition the system description so that some of it is realized in hardware and the rest is mapped to software.There are many useful applications for the ability to obtain either a hardware or software implementation from a single specification (or a hybrid of both). We are particularly interested in the case where dynamic reconfiguration [3] of programmable logic devices is used to swap in and out hardware blocks to perform space/time trade-offs. A hardware block may be swapped out to make way for a more important calculation in hardware or because it implements a calculation which can now be performed in software. In this case the function of the hardware block is replaced by a software thread on a processor (also on the reconfigurable logic device). This novel application requires the hardware and software components to have identical semantics. Conventional approaches involve designing both the hardware and software independently followed by an infor-mal verification process to establish their equivalence. The problem of trying to produce matching software and hardware blocks is one of the major impediments to the research efforts in the field of task-based dynamic reconfiguration. We avoid the duplication of imple-mentation effort, ensure that both resulting implantations have the same behaviour and we can also prove formal properties about our generated circuits.As an example of a quite simple hardware/software trade-off exper-iment we present the case of peripheral controller which can be implemented either in hardware or software. We chose a reconfig-urable fabric realized by Xilinx’s Virtex TM-II FPGA and it is on this device that we perform the hardware/software trade-offs. We use a specific development board manufactured by Xilinx called the MicroBlaze Multimedia Development Board, as shown in Figure 1 which contains a Virtex-II XC2V2000 FPGA.Figure 1. A Xilinx Virtex-II FPGA development board Software threads execute on a 32-bit soft processor called Micro-Blaze which is realized as a regular circuit on the Virtex-II FPGA. For the purpose of this experiment we need to choose an interface that runs at a speed which can be processed by a software thread running on a soft processor. We selected the RS232 interface on this board which has all its wires (RX, TX, CTS, RTS) connected directly to the FPGA (there is no dedicated UART chip on the board). Now we have the choice to read and write over the RS232 serial port either by creating a UART circuit on the FPGA fabric or by driving and reading the RX and TX wires from software.The send and receive portions of an RS232 interface were described graphically using Esterel’s safe state machine notation. The receive portion is illustrated in Figure 2. This version does not use hardwareflow control.Figure 2. The receive components of the RS232 interface. Figure 3. The send component of the RS232 interfaceThis state machine waits for a start bit and then assembles the par-allel character representation from the serial data from the RX wire and if a valid parity is produced it emits the consumed character. Not all the operations required to recognize a valid character on the RX serial line are convenient to describe using a graphical notation. For example, here we describe the notion if shifting in a new char-acter bit into an internal buffer using a text (in a textual macrostate). The send component is shown in Figure 3It is possible to hierarchically build layers on top of these descrip-tions to add additional features e.g. a FIFO for the read and send channels. Graphical and textual descriptions can be freely mixed with the graphical descriptions being automatically converted into their equivalent Esterel textual equivalents.Esterel has been used for some time for the synthesis of C software from either Esterel textual descriptions of the graphical state machine representations. Recently the ability to generate hardware from Esterel has become available with various hardware descrip-tions languages supported. We experimented with Esterel Technology’s implementation (called Esterel Studio) by generating VHDL netlists and pushing them through Xilinx’s flow which per-forms synthesis, mapping, placement and then produces a final implementation bitstream.The generated VHDL simulated without any problems using the commercial Modelsim simulator and produced the same wave-forms as the built-in simulator provided by Esterel Technolgoies (which can dump and display VCD files). The generated VHDL was also processed without complain by Xilinx’s implementation tools and required no adjustment for an implementation bitstream to be produced. The receive circuit is implemented using 21look-up tables which represents less than 1% of the capacity available on a XC2V2000 FPGA and is competitive with hand crafted implementations. We have experimented with the synthesis of several types and sizes of designs from Esterel. We noted that in all cases the generated VHDL results in implementations which are comparable to hand crafted behavioural descriptions or readily available IP-blocks. This is an important requirement since the inability to produce reasona-ble quality circuits would rule out this approach for making hardware/software trade-offs.We give below the interface for the VHDL generated in the case when only the receive component is synthesized.library IEEE;use IEEE.STD_LOGIC_1164.all;use IEEE.NUMERIC_STD.all;use work.receive_data_type_pkg.all;use work.receive_data_pkg.all;entity receive isport (clk: in std_logic;rst: in std_logic;rx: in std_logic;valid: out std_logic;chr: out std_logic;chr_data: out unsigned (7 downto 0) );end receive;One point to note is that the signal which is emitted by a character is recognized is represented in Esterel as a value signal. A value signal can be either present or absent (as represented by the value of the chr signal) and it also has a value which is represented by the bit-vector chr_data. In this case the chr signal can be used as aninterrupt or flag to some other circuit (e.g. a FIFO) or software proc-ess (e.g. an interrupt handler) which can capture the character that has just been read. The clk signal corresponds to the baud rate of the RX input.If this circuit were to be used as a peripheral on the OPB bus then an extra component is required to relate the clock frequency of the OPB bus to the baud rate of the peripheral. A clock divider circuit for performing this function is easily described in Esterel.We have tested the resulting circuit by executing it on the Micro-Blaze Multimedia board. Using an integrated logic analyser and by connecting an external terminal to the RS232 port we were able to observe the correct characters being recognized by the receive circuit.Next we configured the Esterel software to generate C rather than VHDL. This generated code which generates code to implement the UART functionality. Our target embedded system was still chosen to be the MicroBlaze Multimedia board and we instantiated a soft MicroBlaze processor on the FPGA. We also instantiated a timer circuit which generated interrupts at the same frequency as the baud rate. The interrupt handler code sampled the input of the RX input wire and used this value as an input to the Esterel generated state-machine. For each signal that can be emitted we define a call-back handler routine. In our case we defined a routine that simply wrote out the character that was read by the state-machine. We performed the same experiment as before and observed the embedded software correctly reading characters from a remote terminal. This demon-strated that for in this case the Esterel flow successfully yielded both a hardware and software implementation from the same spec-ification. In the software case the complete functionality of the UART was realised in code: the only input was the RX bit which was sampled at the baud rate. Now the developer can choose between a hard or soft implementation of a UART depending on constraints like area and speed. We successfully tested the UART at up to 19200 baud.3.ASSERTIONS USING SYNCHRNOUSOBERVORSGiven that we have the basic ability to synthesize either hardware of software from the same specification based on a clean semantic we next decided to see if we could stay within the Esterel method-ology to try and prove properties about our circuits.Emerging techniques for specifying assertions typically involve using an extra language which has suitable operators for taking about time (past, present and future) and logic relationships between signals. These languages are often concrete representa-tions of formal logics and assertion languages are really temporal logics which can be statically analysed. Can the graphical safe state machine notation provide an alternative way of specifying proper-ties about circuits which has the advantage of being cast in the same language as the specification notation? And can these circuit prop-erties be statically analysed to formally prove properties about circuits?The investigate these questions we performed another experiment where we design a peripheral for IBM’s OPB bus which forms part of IBM’s CoreConnect TM IP bus [1]. We chose the OPB bus because it is used by the MicroBlaze soft processor. This makes it easy for us to test and configure an implementation of this periph-eral from the soft processor implemented on an FPGA.An example of a common transaction on the OPB-bus is shown in Figure 4. The key feature of the protocol that we will verify with an example is that a read or write transaction should be acknowledged within 16 clock ticks. Unless a control signal is asserted to allow for more time if a peripheral does not respond within 16 ticks then an error occurs on the bus and this can cause the system to crash. Not shown is the OPB_RNW signal which determines whether a trans-action performs a read or a write.Figure 4. A sample OPB transactionWe considered the case of a memory mapped OPB slave peripheral which has two device registers that a master can write into and a third device register that a master can read from. The function per-formed by the peripheral is to simply add the contents of the two ‘write’ registers and make sure that the sum is communicated by the ‘read’ register. A safe state machine for such a peripheral is shown in Figure 5.This generated VHDL for this peripheral was incorporated into Xil-inx’s Embedded Developer Kit and it was then used as a building block of a system which also included a soft processor, an OPB system bus and various memory resources and interfaces. The suc-cessfully incorporation of the generated peripheral into the vendor tool flow is illustrated in Figure 6. We wrote test programs to check the operation of the peripheral with a 50MHz OPB system bus. Theperipheral always produced the correct answer.Figure 5. An OPB-slave peripheralFigure 6. OPB slave incorporated into vendor design flow Having successfully implemented an OPB peripheral from the Esterel specification we then attempted to prove an interesting property about this circuit. We choose to try and verify the property that this circuit will always emit an OPB transfer acknowledge signal two clock ticks after it gets either a read or a write request. If we can statically prove this property we know that this peripheral can never be the cause of a transfer acknowledge timeout event. We expressed this property as a regular Esterel safe state machine as shown in Figure 7.This synchronous observer tracks the signal emission behaviour in the implementation description and emits a signal if the system enters into a bad state i.e. a read or write request is not acknowl-edged in exactly two clock ticks.One way to try and check this property is to try and use it in simu-lations to see if an error case can be found. Esterel Studio supports this by either simulation directly within the Esterel framework or by the automatic generation of VHDL implementation files and test benches which can check properties specified as synchronousobservers.Figure 7. An assertion expressed as a synchronous observerHowever, the Esterel Studio system also incorporates a built-in model checker (Prover-SL from Prover Technology) which can be used to try and prove such properties. We use the latest V7 version of the Esterel language which allows us to reason about data as well as control which is an improvement from previous versions of the language. We configured the model check to see if the error signal corresponding to a bad state being entered is ever emitted i.e. might the circuit take longer than two clock ticks to acknowledge a trans-fer? It took Esterel Studio less than two seconds on a Sun Sparc Ultra-60 works tat ion to prove that this signal is never emitted.esverify -v OPB.eid -checkis0 XFERACK_MISSING--- esverify: Reading model from file "OPB.eid".--- esverify: Checking if output "XFERACK_MISSING" is 0 --- esverify: Start model-checking properties--- esverify: Verification complete for signal XFERACK_MISSING: --- esverify: ----- esverify: Model-Checking results summary--- esverify: --- esverify: Status of output "XFERACK_MISSING": Never emitted.We then produced a deliberately broken version of the peripheral which did not acknowledge read requests. Within two seconds the software was able to prove that there is a case when the acknowl-edge signal is not asserted after a transaction and provided a counter-model and VCD file.A conventional approach to catching such approach bugs involves either simulation (which has poor coverage) or the use of bus mon-itors which snoop the bus at execution time looking for protocol violations. A failure to acknowledge a transaction is one of the types of bugs that such systems can be configured to catch. How-ever, it is far more desirable to catch such problems with a static analysis. We are currently trying to convert a list of around 20 such bug checks used in a commercial OPB bus monitor into a collection of Esterel synchronous observers to allow us to check peripheral protocol conformance with static analyses.4.CONCLUSIONSThe approach of using Esterel to produce hardware and software seems to show some promise. Initial experiments show that service-able hardware and software can be produced and implemented on real hardware and embedded processors. The possibility to enter system specifications graphically makes this method much more accessible to regular engineers than competing formalisms which uses languages which are quite different to what engineers are used to. For any realistic system the developer still has to write some por-tions textually and become aware of the basic underlying principles of Esterel. It remains to be seen if the cost of learning this formalism is repaid by increased productivity, better static analysis and the ability to trade off hardware and software implementations. However, there are many refinements that need to be made to the Esterel language to properly support hardware description. Most of these requirements are easily met without upsetting the core design of the language. Examples include a much more flexible way of converting between integers and bit-vectors and to allow arbitrary precision bit-vectors. Currently performing an integer-based address decode for a 64-bit bus is possible in Esterel but one has to process the bus in chunks not larger than 31 bits.Another appealing aspect of this flow is the ability to write asser-tions in the same language as the system specification. This means that engineers do not need to learn yet another language and logic. Furthermore, the formal nature of Esterel’s semantics may help to make static analysis easier. Our initial experiments with using the integrated model checker are certainly encouraging. However, we need to design and verify more complex systems before we can come to a definitive conclusion about this promising technology for the design and verification of hardware and software from a single specification.A very useful application of this technology would be to task-based dynamic reconfiguration. This method would avoid the need to duplicate implementation effort and it would also allow important properties of dynamic reconfiguration to be statically analysed to ensure that reconfiguration does not break working circuits.“Virtex-II” is a trademark of Xilinx Inc. “CoreConnect” is atrademark of IBM.REFERENCES[1]IBM, “The CoreConnect TM Bus Architecture”, http:///product/coreconnect/docscrcon_wp.pdf, 1999.[2]Multiclock Esterel. Gérard Berry and Ellen Sentovich. Cor-rect Hardware Design and Verification Methods. CHARME 2001.[3]Markus Weinhardt and Wayne Luk. Task-Parallel Program-ming of Reconfigurable Systems. Field-Programmable Logic and Applications. Belfast, UK. Springer-Verlag. 200.。
五金工具英语作文

Hardware tools are an essential part of our daily lives,playing a crucial role in various activities,from home repairs to professional construction projects.In this essay, we will explore the significance of hardware tools,their types,and their applications.The Importance of Hardware ToolsHardware tools are indispensable for a multitude of tasks.They are used for assembling furniture,fixing household appliances,and constructing buildings.Without these tools, many tasks would be nearly impossible to complete efficiently.They save time,effort, and often,they are the only means to achieve a specific outcome.Types of Hardware Tools1.Hand Tools:These are the most basic and commonly used tools.They include hammers,screwdrivers,wrenches,pliers,and chisels.Hand tools are operated manually and are suitable for smallscale tasks.2.Power Tools:Power tools are designed to perform tasks more quickly and efficiently than hand tools.They require electricity or fuel to operate and include drills,saws, sanders,and grinders.3.Measuring Tools:Precision is key in many tasks,and measuring tools such as rulers, tape measures,and levels ensure accuracy in measurements.4.Cutting Tools:These tools are used for cutting various materials,including metal, wood,and plastic.Examples include hacksaws,jigsaws,and circular saws.5.Fastening Tools:These are used to secure materials together,such as nails,screws,and bolts.Tools like nail guns and power drills with screwdriver bits are used for fastening.6.Pneumatic Tools:Operated by compressed air,these tools are used in applications where high torque and power are needed,such as in the automotive industry.Applications of Hardware Tools1.Home Improvement:Hardware tools are essential for any DIY enthusiast.They are used for tasks such as painting,tiling,and assembling furniture.2.Automotive Repair:Mechanics rely on a wide range of hardware tools to service and repair vehicles,from wrenches to specialized diagnostic tools.3.Construction:The building industry heavily depends on hardware tools for tasks such as drilling,cutting,and assembling structures.4.Industrial Applications:In manufacturing and heavy industries,hardware tools are used for assembly,maintenance,and repair work.5.Agriculture:Farmers use hardware tools for various tasks,including the maintenance of machinery and the construction of agricultural structures.Safety and MaintenanceUsing hardware tools safely is paramount.This includes wearing appropriate protective gear,following the manufacturers instructions,and regularly maintaining the tools to ensure they remain in good working order.Proper maintenance prolongs the life of the tools and prevents accidents.ConclusionIn conclusion,hardware tools are a fundamental part of many industries and everyday tasks.Their versatility and necessity cannot be overstated.As technology advances,so too do the capabilities of hardware tools,making our lives easier and more efficient. Understanding the different types of hardware tools and their applications is crucial for anyone looking to undertake projects with confidence and success.。
演化硬件的实现方式

0 引言演化硬件(Evolvable Hardware),简称EHW或E-Hard。
它是一种硬件电路(现在是一种大规模集成电路),其能够像生物一样根据环境的变化而改变自身的结构以适应其生存环境,具有自组织、自适应、自修复功能。
演化硬件这一概念是在1992年由日本Hugo de Garis 和瑞士联邦工学院同时正式提出【1】,从而初步实现了早在20世纪50年代计算机之父John Von Neumann所提出的关于研制具有自繁殖与自修复能力的机器的设想【2】。
经过十几年的发展,随着对演化硬件的研究的不断深入,人们愈发地认识到演化硬件在未来科技发展中的重要性。
演化硬件的实现,建立在演化算法和可编程逻辑器件发展的基础之上。
可编程逻辑器件和演化算法的快速发展极大地推动和促进了演化硬件的实现进程。
演化算法为演化硬件提供了理论和方法学基础;可编程逻辑器件(Programmable Logic Device)为演化硬件提供了物质基础。
由于演化过程具有随机性,进化次数较多,从而要求相应的器件也要能够被反复配置,因此可以无穷次重复配置的现场可编程门阵列(Field Programmable Gate Array)也就成为当前比较理想的实现器件,目前FPGA器件为大多数的演化硬件所采用。
1主流演化算法(Evolvable Algorithm)在演化硬件中所使用的算法主要分为以下三类:遗传算法(GA),遗传规划(GP)和演化策略(ES)。
当前使用较多的演化算法主要有CGP【3】(Cartesian Genetic Programming)、*CGA【4】(A family of Compact Genetic Algorithms)、CoCGA【5】(Cooperative Compact Genetic Algorithms)和CCGA【6】(Cellular Compact Genetic Algorithms)。
毕业论文外文翻译----设计供应链以用来合理区分原始设备制造商的特点论文翻译-中英文论文对照翻译

中文3070字标题:Making supply chain design the rational differentiating characteristic of the OEMs原文:The ownership of the parts manufacturers was consequently fused together into new global companies with significant technological and innovation capabilities. At the same time,the OEMs divested their components and sub-systems divisionsin an effort to tap into the non-OEM a utomotive markets. These developments intensified the OEMs’ move t o outsource the bulk of the manufacturing and design of the subsystems andcomponents to their suppliers and, in effect, lost most of their manufacturing strength and bargaining power to them; thesuppliers currently account for 28% of the total automotiveindustry profits as opposed to only 24% for the OEMs. The outsourcing trend has thus resulted in OEMs relinquishing their historical strategic role and to position themselves more like original brand manufacturers (OBMs).These trends have contributed to an accelerated increaseof the supply uncertainty in addition to the already recognizeddemand uncertainty. Various supply uncertainty reductionstrategies have been designed in order to stabilize theplanning process among w hich the most significant is the design collaboration which includes the sharing of NPI plans and even a joint NPI plans design.As the components and sub-systems are being outsourced, and the suppliers are leveraging the innovation and technological costs across OEMs, i ndustry SC s tructure has also evolved into an extremely complex and intricate network in which allsuppliers tend to have short-term relations with multiple OEMs. The result: any difference in quality, performance, safety,fuel efficiency, and amenities has been reduced significantly.The OEMs, i n many w ays, have historically been treating SC design as a‘‘tactical’’ issue separate from concurrently designing the product and manufacturingprocess: after theconcept design phase, the Purchasing Department would start continuous quest for the lowest cost components by establishingan optimum between the capacity and production costs, locationof the supplier’s facility, and ransportation and logisticscosts (Financial Times 2005). Chain performance would thus bemeasured in oversimplified and sometimes counterproductive(cost reduction-based) terms.However, the performance measures that emphasize mainlycosts distort the way in which the chain members reach keydecisions concerning which customers are the most important and therefore the most profitable to serve. The fundamental problem of cost-centric measures is its focus on individual costsminimization rather than on the maximization of value to end customers (see e.g. Simaputang and Sridharan (2002) for details on the advantages of collaboration and cooperation in SCM).While the cost-centric measures might still be acceptable for components with low strategic importance, low customervisibility and low clock speed (e.g. nuts and bolts), they are far less appropriate for those with high clock speed.The lessons learned from fast moving industries (such asDell, Nike and Li & Fung) teach us that the companies that have successfully outsourced their manufacturing in order to lower their costs and increase their flexibility concomitantlycreated extremely valuable SC c ontrols that led them to remain the dominant player of the SC. This in turn has permitted these companies to further differentiate themselves from theircompetitors and has allowed them to maintain a sustainable competitive advantage. Not following the strategy ofimplementing SC controls, on the other hand, has severelylimited the ability of the OEMs to make the fundamental SCdesign and synchronization decision and has ultimately caused them to lose their role as integrators within the value chain.To maintain their role as value chain integrators, the OEMs should put more emphasis on the restructuring of their existing SC; the industry has to shift its differentiation focus intothe realm of SC design and synchronization. This implies thatthe supplier selection decisions should be guided not only by operational factorsbut also by strategic factors such asflexibility, the capacity to innovate, and the supplier’s business-technology alignment.When t he development of the SC b ecomes i ntegral to the NPI process, then the sup pliers’ responsibilities at differentstages of product and process designs could be clearlyacknowledged depending on the strategic importance and theclock speed of different components and sub-systems.In fact, in our opinion, the design of the SC links thatprecede the final assembly should be considered as the rationaldifferentiating characteristic of the OEMs from an operational point of view (agility, innovation, quality and reliability). Styling, an distribution channel design and management (thepost-OEM assembly operations)are the emotionaldifferentiating characteristics from a brand perspective.Classifying components based on their clock speed Thebarriers to clock speed, the dampeners, are the complexity ofthe product architecture and the organizational inertia of the OEMs. The up-stream rates of technological innovation, whichare dictated by the customer demands and the industry competitiveness, are accelerating as they cascade down thesupply chain. In order to capitalize on this down-streamacceleration, the OEMs have to modularize their products’ architecture.As mentioned, there are different clock speeds fordifferent auto sub-systems and components. To illustrate, wecan consider 10 of a vehicle’s most representative components. The sheet metal and the hardware (screws, bolts, nuts, rivets, etc.) have the lowest clock speed because these components’ rate of change and innovation is relatively low. Sheet metaland automotive hardware is produced in large-scalemanufacturing facilities with very little flexibility. Theengineering efforts are focused on efficiency and optimization of processes and not on new product design. At the conceptdesign stage all the product and process characteristics arewell known and can be easily planned for. To a lesser extent,the same is valid for glass and other automotive construction materials such as steel, aluminium, rubber and plasticThe non-functional structural components like the frames, sub-frames, rear axels, suspension components and the seats are located in the middle of the scale.These components are fabricated in large batches and the engineering efforts are focused both on improving efficiencyas well as product innovation and quality. Some productattributes need to be designed and developed after the concept design phase but in general the approach is conservative and incremental to current designs and processes.Exterior and interior ornamentation components and colors are closely related to the latest design trends and, as a result, they are associated with a higher clockspeed than the other components. During the concept phase the design fashion trends are still evolving but the core product attributes (plasticmoulds, pigments, etc.) are known, as are the basicmanufacturing processes. The batches are smaller than the ones used for the previous components in order to ensureflexibility.The electronic components and software have the highest clockspeed among the automotive sub-systems. During theconcept design phase only the performance specifications canbe determined. Even these specifications are subject to change pending technological advancement during the design phase as well as the social preferences of the customers.In the automotive industry the highest financial burden is created by the huge time gap between the capital investment and the moment of the first sale. This creates an acute need foraccurate sales volumes predictions and, even moreimportantly ,sales option mix. The base models volumes (withlower sticker prices and profitability) are easier to predictthan the high option content vehicles which bring in the mostprofits. In general, the higher the clockspeed the lesspredictable the demand becomes. The clockspeed of thecomponents and their associated clock speed scores areinstrumental in prioritizing the product design, processcapacity planning and SC c oordination activities during the NPI concept design phase.Classifying components based on their strategic importance From the government requirements and customer preferences point of view, the components and sub-systems could also have different strategic importance to the OEMs. I n fact, as we will show later, the ‘‘make or buy’’ decisions as well as the design of the SC during the concept phase of the NPI alsoreq uire a greaterunderstanding of the components’ strategic importance.How could we organize these strategic differences?Generally, the architecture of a product is considered aconstraint for the sourcing decisions. In the openarchitecture (the one whose specifications are public), as long as theperformance specifications of a product are met then the manufacturing process could be spread outside the boundariesof one corporation. One of the great advantages of an open architecture is that anyone can design add-on products for it. By making architecture public, however, a manufacturer allows others to duplicate its product. Bicycles and PCs a re excellentexamples of modular products with open architectures. Putting together standardized parts will result in the final product.Naturally, the extreme complexity of a vehicle(4,000–5,000 main components and up to 20,000 parts) and the inherited integral character of the system make it difficultto develop robust interfaces and performance specifications to serve as a development base for the individual sub-systems and components functional specifications. However, theapplicability of the open architecture concept to automanufacturing is a growing phenomenon. Today, the ‘‘Open Source’’ design and manufacturing of an entire vehicle maybe a concept of the future, but in the realm of low strategicimportance components it is very much a current event (see Blankmanet al. 2002 for details).In North America, although the OEMs are gradually openingup the architectural dimensions of their products to theirsuppliers, it is safe to argue that today the auto industry is more of a hybrid between open and closedponents with relatively low strategicimportance that do not contribute to the differentiation of theproducts (e.g. sheet metal, hardware and glass) are excellent candidates for open-source car designed manufacturing。
JUDGMENT METHOD FOR HARDWARE COMPATIBILITY
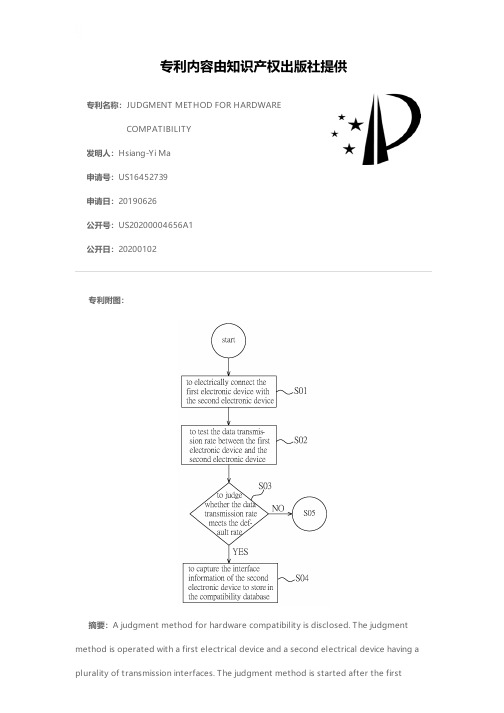
专利名称:JUDGMENT METHOD FOR HARDWARECOMPATIBILITY发明人:Hsiang-Yi Ma申请号:US16452739申请日:20190626公开号:US20200004656A1公开日:20200102专利内容由知识产权出版社提供专利附图:摘要:A judgment method for hardware compatibility is disclosed. The judgment method is operated with a first electrical device and a second electrical device having a plurality of transmission interfaces. The judgment method is started after the firstelectrical device electrically connected to one of the transmission interfaces of the second electrical device. The judgment method includes an interface information capturing process, a compatibility comparison process, a compatibility determination process and a recommendation execution process. In the interface information capturing process, the interface information of the transmission interface of the second electrical device connected to the first electrical device is captured. In the compatibility comparison process, the interface information is compared with a compatibility database to obtain a comparison result. In the compatibility determination process, the comparison result is compared with the interface information of another transmission interface of the second electrical device to obtain a determination result. In the recommendation execution process, a recommendation information is provided according to the determination result.申请人:AVerMedia Technologies, Inc.地址:New Taipei City TW国籍:TW更多信息请下载全文后查看。
你对集成电路工程的看法英语作文

你对集成电路工程的看法英语作文全文共3篇示例,供读者参考篇1My Perspective on Integrated Circuit EngineeringAs a student pursuing a degree in electrical engineering with a focus on integrated circuits, I have developed a deep fascination and respect for this intricate field. Integrated circuit (IC) engineering lies at the heart of the technological revolution that has transformed our world, enabling the creation of the incredibly complex yet compact devices that power our modern lives.At its core, IC engineering is the art of miniaturizing entire electronic circuits onto a single semiconductor chip, typically made of silicon. These chips, often no larger than a fingernail, can contain billions of microscopic transistors and other components, all meticulously arranged and interconnected to perform specific functions. It is a true testament to human ingenuity that such intricate systems can be designed, manufactured, and mass-produced with astonishing precision.One of the aspects of IC engineering that I find most captivating is the sheer scale of complexity involved. A modern microprocessor, for instance, can have billions of transistors etched onto its surface, each one a precisely engineered component that collectively enables the chip to perform intricate calculations and execute instructions at mind-boggling speeds. The design and manufacturing processes required to create these marvels of engineering are nothing short of awe-inspiring.Moreover, IC engineering is a field that demands a multidisciplinary approach, drawing upon principles from various domains such as physics, materials science, chemistry, and computer science. Understanding the behavior of electrons at the quantum level, the properties of semiconductor materials, and the intricate processes involved in fabrication and packaging are all essential components of this discipline.From a practical standpoint, the impact of IC engineering on our daily lives cannot be overstated. These tiny chips are the backbone of virtually every modern electronic device, from smartphones and computers to medical equipment and advanced scientific instruments. They enable us to process vast amounts of data, communicate instantly across the globe, and automate processes that were once unimaginable.Furthermore, the ongoing pursuit of miniaturization and increased performance in IC engineering has given rise to remarkable technological advancements. Moore's Law, the observation that the number of transistors on a chip doubles approximately every two years, has driven the industry forward at an astonishing pace. This relentless pursuit of smaller, faster, and more efficient chips has revolutionized sectors ranging from computing and telecommunications to transportation and energy management.Despite the immense progress made thus far, IC engineering still presents numerous challenges and opportunities for innovation. As transistors approach the limits of scaling dictated by the laws of physics, researchers are exploring novel materials, architectures, and manufacturing techniques to continue pushing the boundaries of what is possible. Concepts such as quantum computing, neuromorphic chips, andthree-dimensional integrated circuits hold the promise of unleashing entirely new realms of computational power and efficiency.From a personal perspective, what draws me most to IC engineering is the opportunity to be part of a field that is truly shaping the future. The devices and systems we create today willform the foundation for the technologies of tomorrow, enabling advancements in fields as diverse as artificial intelligence, renewable energy, and space exploration. The potential to contribute to such groundbreaking innovations is both humbling and exhilarating.Moreover, IC engineering offers a constantly evolving landscape of challenges and opportunities for learning. As new materials, tools, and techniques emerge, engineers must continually adapt and expand their knowledge, fostering a culture of lifelong learning and intellectual curiosity. This dynamic nature of the field ensures that every day brings new puzzles to solve and novel concepts to explore.Admittedly, the path to becoming a proficient IC engineer is not an easy one. It requires a solid grounding in mathematics, physics, and computer science, as well as a willingness to grapple with abstract concepts and complex systems. The design and manufacturing processes involved are incredibly intricate, demanding meticulous attention to detail and a deep understanding of the underlying principles.However, for those who embrace the challenge, the rewards are immense. IC engineering offers the opportunity to work at the cutting edge of technology, contributing to the developmentof devices and systems that have the potential to change the world. It is a field that fosters creativity, problem-solving, and collaboration, as engineers from diverse backgrounds come together to tackle complex challenges.As I look towards the future, I am filled with excitement and anticipation for the role I can play in the continued evolution of IC engineering. Whether it is developing more efficient and powerful processors, designing innovative sensor technologies, or exploring entirely new paradigms in computing, the possibilities are vast and limitless.In conclusion, integrated circuit engineering is a field that not only shapes the technological landscape but also pushes the boundaries of human ingenuity and innovation. It is a discipline that demands a deep understanding of fundamentals while fostering a spirit of curiosity and a drive for continuous learning. As a student immersed in this field, I am humbled by the achievements of those who have come before me and inspired by the potential to contribute to the next generation of groundbreaking technologies. IC engineering is not just a career path; it is a journey of discovery, a relentless pursuit of knowledge, and an opportunity to leave a lasting impact on the world.篇2My Views on Integrated Circuit EngineeringAs a student pursuing a degree in electrical engineering with a focus on integrated circuits, I have developed a profound appreciation for this intricate and fascinating field. Integrated circuits, or ICs, are the tiny marvels that power our modern world, enabling the technological advancements that have revolutionized nearly every aspect of our lives.At the heart of integrated circuit engineering lies a delicate dance between physics, materials science, and electrical engineering. These disciplines converge to create the miniature electronic circuits that serve as the building blocks of our digital age. From smartphones and computers to medical devices and aerospace technology, integrated circuits are ubiquitous, silently orchestrating the complex operations that make our world go round.One of the aspects that captivates me most about integrated circuit engineering is the sheer scale of its impact. These microscopic devices, smaller than the width of a human hair, have fundamentally transformed the way we communicate, work, and live. The ability to pack millions, or even billions, oftransistors onto a single chip has enabled the creation of incredibly powerful and compact electronic systems, reshaping industries and driving innovation across countless domains.The pursuit of ever-smaller and more efficient integrated circuits is a constant challenge that requires ingenuity, perseverance, and a deep understanding of the underlying scientific principles. As feature sizes continue to shrink, engineers must grapple with quantum mechanical effects, thermal challenges, and the inherent limitations of materials. This ongoing quest for miniaturization has spawned groundbreaking innovations in lithography, materials engineering, and circuit design techniques.Beyond the technical aspects, integrated circuit engineering also fascinates me from a societal perspective. The rapid advancement of this field has profound implications for our world, both positive and negative. On one hand, integrated circuits have enabled technological breakthroughs that have improved our quality of life, from life-saving medical devices to energy-efficient systems that help mitigate the effects of climate change. On the other hand, the proliferation of electronic devices and the ever-increasing demand for computing powerhave raised concerns about e-waste, energy consumption, and the environmental impact of manufacturing processes.As a student, I find myself grappling with these complex ethical considerations alongside the technical challenges of integrated circuit design. It is our responsibility as engineers to develop solutions that not only push the boundaries of what is possible but also prioritize sustainability, accessibility, and the greater good of society.One area that particularly excites me is the potential of integrated circuits in emerging fields like artificial intelligence, quantum computing, and biotechnology. The ability to design and fabricate specialized chips optimized for these cutting-edge applications could unlock new frontiers of scientific exploration and technological innovation. Imagine quantum computers capable of solving problems that would take classical computers billions of years, or neural networks that can process and analyze vast amounts of data with unprecedented speed and accuracy.However, as we venture into these uncharted territories, we must also remain vigilant and ethical in our approach. The potential for misuse or unintended consequences is ever-present, and it is our duty as engineers to ensure that our creations are developed and deployed with the utmost care and responsibility.Looking ahead, I am both awed and humbled by the possibilities that integrated circuit engineering holds. As we continue to push the boundaries of what is possible, we must also strive to maintain a delicate balance between technological progress and ethical considerations. It is a challenge that will require collaboration, critical thinking, and a deep commitment to the principles of responsible innovation.In the end, my fascination with integrated circuit engineering stems from its ability to merge seemingly disparate fields –physics, materials science, electrical engineering, and even philosophy – into a cohesive and transformative force. It is a field that demands not only technical expertise but also a deep understanding of the societal implications of our work. As I embark on my career in this field, I am excited to contribute to the ongoing quest for smaller, faster, and more efficient integrated circuits, while also striving to ensure that our creations serve the greater good of humanity.篇3My Views on Integrated Circuit EngineeringEver since I was a kid tinkering with electronics kits and building basic circuits, I've been fascinated by the world ofintegrated circuits and microchips. These tiny marvels of modern engineering have revolutionized virtually every aspect of our lives, from the smartphones in our pockets to the computers that power the internet and run complex simulations. As I've learned more about integrated circuit (IC) engineering through my coursework, my appreciation for this field has only grown deeper.At its core, IC engineering is the design and manufacturing of miniaturized electronic circuits onto semiconductor materials like silicon. What makes it so remarkable is the astounding level of complexity and miniaturization that can be achieved. A single modern microprocessor can contain billions of transistors, each one just a few nanometers wide, all etched onto a tiny chip just a few square centimeters in size. It's mind-boggling to think that something so small can perform such immense computational feats.The challenges of IC engineering are immense from both a theoretical and practical standpoint. On the design side, engineers must be masters of digital logic, computer architecture, semiconductor physics, electronic design automation tools, and much more. They need to be able to conceptualize and optimize massively complex circuits at boththe high level of chip architecture as well as the low-level implementation of individual logic gates.The manufacturing side introduces an entirely different set of difficulties. Fabricating integrated circuits requires construction of intricate 3D structures at the atomic scale using techniques like lithography, ion implantation, etching, and deposition. The fabrication plants (fabs) are incredibly expensive, easily running into the billions of dollars for a cutting-edge facility. The process is also highly sensitive, as even microscopic contamination can ruin an entire batch of wafers.Despite these immense challenges, the field continues to push forward at an incredible pace thanks to the principles of Moore's Law and semiconductor scaling. By making transistors smaller and packing more of them onto each chip, we've been able to increase performance and functionality by leaps and bounds every couple of years. This drive for perpetual miniaturization and optimization is what makes IC engineering such an exciting field to be a part of.From my perspective as a student, one of the most rewarding aspects of studying IC engineering is getting to apply knowledge from so many different disciplines. My coursework has required me to dive deep into topics like digital logic design,computer architecture, semiconductor device physics, electronic design automation, circuit analysis, and chip layout just to name a few. It's incredibly stimulating to see how all of these disparate areas intersect and combine to enable modern IC design.At the same time, the complexity of the subject matter is also one of the biggest challenges I've had to overcome. There's an immense amount of theoretical knowledge that needs to be synthesized and applied in order to design a functional IC. From the physical properties of semiconductors and quantum mechanics, to the abstractions of digital logic and computer architecture, to the pragmatic constraints of manufacturing processes, there is a staggering breadth of material to master.Hands-on experience with industry design tools and flows has been invaluable for really solidifying my understanding. Getting practice with hardware description languages like Verilog, logic synthesis, static timing analysis, floor planning, routing, and verification on real-world designs is where the theoretical concepts finally start clicking. While the learning curve for tools like these is extremely steep, there's no better way to prepare for a career in IC engineering.Looking ahead, I'm extremely excited about the future potential of integrated circuits and the innovations that willpower the next generations of technology. While traditional silicon CMOS scaling is facing fundamental limits, new materials, architectures, and integration strategies are emerging that could extend IC capabilities even further.For example, specialized hardware accelerators and domain-specific architectures, like Google's Tensor Processing Units for machine learning or Bitcoin mining ASICs, are enabling entirely new applications and levels of performance. Meanwhile, advances in semiconductor fabrication like 3D integration,gate-all-around FETs, and new materials like III-V compound semiconductors, could help ICs scale to even higher densities and efficiencies.On the flip side, as ICs become more ubiquitous in every domain, there are also a number of risks and challenges that the field will need to grapple with around topics like supply chain security, environmental impact, and ethical design of intelligent systems. As an engineer, it will be critical to carefully consider these broader implications.Ultimately though, what draws me to integrated circuit engineering above all else is the opportunity to work on technology that can truly change the world. From enabling next-generation computing systems that could help solvehumanity's greatest challenges, to bringing the benefits oflow-cost electronics to developing regions, to powering advancements we can't even yet imagine, ICs lie at the heart of so much potential innovation across every sector.Being able to play a role in designing and building the semiconductor brains that will drive future products and services is an incredibly exciting prospect. While the road ahead for IC engineering is sure to be arduous, full of mind-bending technical hurdles to overcome, I can't think of a more rewarding or important field to be contributing towards. The opportunity to invent revolutionary new capabilities and have a hand in shaping the future of technology is something that inspires me every day.。
关于硬件的英语作文加翻译

关于硬件的英语作文加翻译Title: The Evolution of Hardware: Past, Present, and Future。
In today's digital age, the evolution of hardware has been nothing short of remarkable. From the bulky mainframes of the past to the sleek and powerful devices of today, hardware technology has undergone rapid advancements, shaping the way we live, work, and communicate. In this essay, we will delve into the past, present, and future of hardware, exploring its transformation and the impact it has had on society.Past: The Roots of Hardware Evolution。
The journey of hardware evolution traces back to the earliest computing machines of the 20th century. These primitive devices, characterized by their large size and limited processing capabilities, laid the foundation for modern computing. One of the most significant milestoneswas the invention of the transistor in the late 1940s, which paved the way for smaller, more efficient electronic devices.During the 1970s and 1980s, the emergence of personal computers revolutionized the way individuals interacted with technology. Companies like IBM and Apple introduced innovative hardware designs that brought computing power directly into people's homes and offices. The evolution of microprocessors, such as the Intel 4004, further fueled the growth of the computing industry, enabling faster and more versatile machines.Present: The Era of Mobility and Connectivity。
Digital Signal Processing

Digital Signal Processing Digital Signal Processing (DSP) is a crucial aspect of modern technology, playing a significant role in various applications such as telecommunications, audio processing, image processing, radar, and many more. It involves the manipulation of signals in the digital domain, allowing for the extraction of valuable information, noise reduction, and signal enhancement. However, despiteits widespread use and importance, DSP also presents various challenges and complexities that need to be addressed. One of the primary problems in digital signal processing is the issue of signal distortion. When signals are processed digitally, there is a risk of introducing distortion due to quantization errors, finite word length effects, and other factors. This can result in a loss of signal quality and accuracy, impacting the overall performance of the system. Engineers and researchers are constantly working on developing techniques to mitigate these distortions, such as oversampling, dithering, and error correction algorithms. Another significant challenge in DSP is the management of computational complexity. As the demand for high-speed processing and real-time applications continues to grow, the need for efficient algorithms and hardware implementation becomes increasingly critical. Complex algorithms such as fast Fourier transforms (FFT), finite impulse response (FIR) filters, and adaptive signal processing require substantial computational resources. Therefore, optimizing these algorithms for speed and resource utilization is a constant area of research and development in the field of DSP. Furthermore, the design and implementation of DSP systems often require a deep understanding of both the theoretical and practical aspects ofsignal processing. Engineers and researchers need to have a strong grasp of mathematical concepts, such as linear algebra, probability theory, and complex analysis, to develop effective DSP algorithms. Additionally, they must beproficient in programming languages and have a thorough knowledge of hardware architectures to implement these algorithms in real-world systems. Moreover, the interdisciplinary nature of DSP poses a challenge in terms of collaboration and communication between professionals from different backgrounds. DSP involves elements of electrical engineering, computer science, mathematics, and physics, requiring individuals with diverse expertise to work together effectively. Thisnecessitates the development of interdisciplinary skills and a collaborative mindset to tackle the complex problems and drive innovation in the field ofdigital signal processing. In addition to technical challenges, ethical considerations also come into play in the realm of digital signal processing. The use of DSP in areas such as surveillance, data analysis, and communication raises concerns about privacy, security, and the potential misuse of technology. Engineers and researchers must be mindful of these ethical implications and work towards the responsible and ethical use of DSP to safeguard the rights and privacy of individuals. In conclusion, digital signal processing is a multifaceted field that presents various challenges, ranging from technical complexities to ethical considerations. Addressing these challenges requires a combination of technical expertise, interdisciplinary collaboration, and ethical awareness. As technology continues to advance, the field of DSP will undoubtedly evolve, bringing forth new challenges and opportunities for innovation. It is essential for professionals in this field to remain adaptable, creative, and ethically conscious as they navigate the complexities of digital signal processing.。
Memory Management in a combined VIASCI Hardware

Figure 1 shows bandwidth curves of MPI implementations for both an SCI and a native VIA implementation (GigaNet cLAN). The hardware is in both cases based on the PCI bus and the machines where the measurements were taken are comparable. The concrete values are based on ping{pong measurements and where taken from 7] in case of SCI, and from 10] (Linux case) for the cLAN hardware.
Memory Management in a combined VIA/SCI Hardware
Mario Trams, Wolfgang Rehm, Daniel Balkanski and Stanislav Simeonov ?
fmtr,rehmg@informatik.tu-chemnitz.de DaniBalkanski@, stan@bfu.bg
100 90 80 SCI MPI cLAN MPI
Bandwidth [0 10 0 256 1024 4096 16384 65536 262144 1048576
Message Size [Bytes]
Figure1. Comparison of MPI Implementations for Dolphins PCI{SCI Bridges and
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Review of Hardware Architectures for Advanced Encryption Standard Implementations ConsideringWireless Sensor NetworksPanu Hämäläinen1,Marko Hännikäinen2,and Timo D.Hämäläinen21Nokia Technology Platforms,WiWLAN SFVisiokatu3,FI-33720Tampere,Finlandpanu.hamalainen@2Tampere University of Technology,Institute of Digital and Computer SystemsP.O.Box553,FI-33101Tampere,Finlandmarko.hannikainen@tut.fi,timo.d.hamalainen@tut.fit.cs.tut.fi/research/daciAbstract.Wireless Sensor Networks(WSN)are seen as attractive solutions forvarious monitoring and controlling applications,a large part of which requirecryptographic protection.Due to the strict cost and power consumption require-ments,their cryptographic implementations should be compact and energy-effi-cient.In this paper,we survey hardware architectures proposed for AdvancedEncryption Standard(AES)implementations in low-cost and low-power devices.The survey considers both dedicated hardware and specialized processor designs.According to our review,currently8-bit dedicated hardware designs seem to bethe most feasible solutions for embedded,low-power WSN nodes.Alternatively,compact special functional units can be used for extending the instruction sets ofWSN node processors for efficient AES execution.1IntroductionCryptographic algorithms are utilized for security services in various environments in which low cost and low power consumption are key requirements.Wireless Sensor Net-works(WSN)[1]constructed of embedded,low-cost,and low-power wireless nodes fall into the class of such technologies[2],ZigBee[3]and TUTWSN[4]as examples. Nodes themselves are independent of each other but they collaborate to serve the ap-plication tasks of WSNs by sensing,processing,and exchanging data as well as acting according to the data content[1].WSNs are envisioned as cost-effective and intelligent solutions for various applications in automation,health care,environmental monitor-ing,safety,and security.A large part of the applications require protection for the data transfer as well as for the WSN nodes themselves[5].Even though WSNs can contain devices with varying capabilities,in this paper the term node refers to an embedded, highly resource-constrained,low-cost,and low-power WSN device.Compared to software,significantly higher performance and lower power consump-tion can be achieved with dedicated hardware and specialized processor architectures S.Vassiliadis et al.(Eds.):SAMOS2007,LNCS4599,pp.443–453,2007.c Springer-Verlag Berlin Heidelberg2007444P.Hämäläinen,M.Hännikäinen,and T.D.Hämäläinentuned for the execution of security procedures in WSN nodes.A software implementa-tion on a general-purpose processor always contains overhead due to instruction fetch and decode,memory access,and possibly due to an unsuitable instruction set and word size.As Advanced Encryption Standard(AES)[6]is a standardized encryption algo-rithm and considered secure,it has become the default choice in numerous applications, including the standard WSN technologies IEEE802.15.4[7]and ZigBee[3].In this paper,we review and compare hardware architectures that are potentially suit-able for AES implementations in WSN nodes.We have selected the architectures from more than150examined research papers,including both dedicated hardware as well as specialized cryptographic processor designs.We believe that the paper is comprehen-sive as well as valuable for designers evaluating and developing AES implementations for embedded,low-cost,and low-power WSN nodes.The survey focuses on academic research papers as publicly available information on commercial implementations is typically very limited.However,we believe that the reviewed designs comprehensively cover the utilized design choices and trade-offs suited for WSN node implementations.The paper is organized as follows.Section2presents an overview of the AES algo-rithm,discusses high-level architectural alternatives for its hardware implementation, and argues their suitability for WSN nodes.In Section3,we survey existing low-cost and potentially low-power AES hardware designs.Section4reviews specialized pro-cessor architectures proposed for efficient AES implementations in low-cost wireless devices.In this paper,a specialized processor architecture refers to a design that in-cludes support for AES but the design can be capable of executing other tasks as well.A dedicated hardware implementation can only be used for executing AES.2Overview of AES AlgorithmAES[6]is a symmetric cipher that processes data in128-bit blocks.It supports key sizes of128,192,and256bits and consists of10,12,or14iteration rounds,respectively. Each round mixes the data with a roundkey,which is generated from the encryption key.The encryption round operations are presented in Fig.1.The cipher maintains an internal,4-by-4matrix of bytes,called State,on which the operations are performed. Initially State isfilled with the input data block and XOR-ed with the encryption key. Regular rounds consist of operations called SubBytes,ShiftRows,MixColumns,and Ad-dRoundKey.The last round bypasses MixColumns.Decryption requires inverting these operations.SubBytes is an invertible,nonlinear transformation.It uses16identical256-byte sub-stitution tables(S-box)for independently mapping each byte of State into another byte. S-box entries are generated by computing multiplicative inverses in Galois Field GF(28) and applying an affine transformation.SubBytes can be implemented either by com-puting the substitution[8,9,10,11,12]or using table lookups[10,13,14].ShiftRows is a cyclic left shift of the second,third,and fourth row of State by one,two,and three bytes, respectively.MixColumns performs a modular polynomial multiplication in GF(28)on each column.Instead of computing separately,SubBytes and MixColumns can also be combined into large Look-Up-Tables(LUT),called T-boxes[9,15].During each round,Review of Hardware Architectures for AES Implementations445Fig.1.Round operations of AES encryptionAddRoundKey performs XOR with State and the roundkey.Roundkey generation(key expansion)includes S-box substitutions,word rotations,and XOR operations performed on the encryption key.For more details on the AES algorithm and its inversion,we refer to[6].2.1Design Choices for AES Support in HardwareThe basic techniques for implementing a block cipher with rounds,such as AES,are iterated,pipelined,and loop-unrolled architectures[16].The more advanced structures include partial pipelining and sub-pipelining combined with these basic techniques.The architectures are illustrated in Fig.2.The iterated architecture leads to the smallest implementations as it consists of one round component which is fed with its own output until the required number of rounds has been performed.The pipelined architecture contains all the rounds as separate com-ponents with registers in between.As a result,it is the fastest(in terms of throughput) and the largest of the basic structures.The loop-unrolled architectures perform two or more rounds per clock cycle and the execution of the cipher is iterated.In a pipelined architecture,unrolling can only decrease the latency of outputting thefirst block.In sub-pipelining,registers are placed inside the round component in order to increase the maximum clock frequency.In the partial pipelining scheme,the pipeline contains e.g. the half of the rounds with registers in between.Although pipelined and loop-unrolled architectures enable very high-speed AES im-plementations,they also imply large area and high power consumption,which makes them unattractive for WSN nodes.Furthermore,they cannot be fully exploited in feed-back modes of operation[9,14].Feedback modes are often used for security reasons in encryption and for Message Authentication Code(MAC)generation,e.g.as in the446P.Hämäläinen,M.Hännikäinen,and T.D.Hämäläinen(a)(b)(c)(d)Fig.2.Hardware architectures for round-based block cipher implementations:(a)iterated,(b) pipelined,(c)loop-unrolled,and(d)the combination of partial pipelining and sub-pipelining. The exemplar full cipher consists of four rounds.security schemes of the standard WSN technologies[7,3].Iterative architectures enable low-resource implementations with full-speed utilization also in feedback modes.The width of the AES data path can be further reduced to decrease logic area and power [8,9,10,11,12,13,14].Hence,the review of this paper focuses on AES designs utilizing iterated structures.In addition to the architectural choices,the design of AES enables a large number of algorithm-specific hardware trade-offs.The trade-offs consist of choosing between memory-based LUTs and combinatorial logic,decreasing the amount of parallelism, transferring the GF computations into another arithmetic domain,choosing between precomputed and on-the-fly key expansion,and sharing resources between encryption, decryption,and key expansion data paths.These aspects and their effects are discussed in the review of the following sections.3Hardware Implementations of AESSince the ratification of AES in2001,a large number of its hardware implementations has appeared.We surveyed more than100papers for the review of this section.Ac-cording to the survey,most AES designs have been targeted at and implemented in Field Programmable Gate Array(FPGA)technologies.Whereas earlier AES designs mainly focused on intensively pipelined,high-speed implementations,the more recent work has concentrated on compactness and lower power consumption.Of all the de-signs,Table1lists the proposals which we have considered to have achieved the most significant results and which are possibly suitable for highly resource-constrained WSN nodes.The table is organized according to the time of publication of the designs,in or-der to reflect also the evolution in thefield.A more comprehensive table,containing theReview of Hardware Architectures for AES Implementations447 pact hardware implementations of AESDesign Tech.Data E/D Mode Keys S-box Cells Mem Lat Clk Tpwidth(1)(2)(3)(4)(5)(6)(7)[MHz][Mbit/s] Ref.[16]Xilinx128E ECB n/a logic352801125294Xilinx128E ECB n/a logic306102140492 Ref.[18]Altera16E ECB n/a ROM1693380n/a32Altera16ED ECB n/a ROM3324380n/a24 Ref.[19]Altera32E ECB n/a ROM8241044n/a115Altera32ED ECB n/a ROM12131044n/a115 Ref.[8].11µm32ED ECB128logic5400054131311.11µm32ED ECB128logic6300044138400.11µm64ED ECB128logic8000032137549.11µm128ED ECB128logic125000111451691 Ref.[13]Xilinx32ED ECB128ROM22234660166Ref.[15]Xilinx32ED ECB128ROM146346123358Ref.[10].60µm32ED CBC all logic85000925070Xilinx mix ED CBC all ROM11250n/a161215 Ref.[11].35µm8E ECB128logic36000101610013Ref.[14]Altera32E ECB128ROM512755116270Altera32ED CCM128ROM1434111127890 Ref.[9]Xilinx8ED ECB128logic1242n/a672Ref.[12].35µm8ED ECB128logic3400010328010Ref.[20].13µm8E ECB128logic31000160152121(1)Encryption(E)or decryption(D)or both(ED)supported for the mode in(2).(2)Supported mode of operation by the design.(3)’n/a’means no key expansion included,a value refers to the supported keys sizes.(4)Specifies the technique used for the SybBytes implementation.’ROM’means memory-based table-lookups and’logic’combinatorial logic.(5)Resource consumption of the design.ASICs in gate-equivalents and FPGAs as general-purpose programmable resources:Xilinx slices or Altera Logic Elements(LE).(6)Dedicated memory components used from the specific FPGA of the reference.(7)The number of clock cycles for encrypting a block of tencies caused by precomputed key expansion not included.’Tp’refers to the encryption throughput in the mode of(2).Latencies caused by precomputed key expansion not included.highest-speed pipelined implementations as well,can be found in[17].For the details of Xilinx and Altera FPGA devices,the readers are referred to their specific data sheets.The references[16,18,19]are included in the table mainly for historical reasons as AES implementations that are better suited for WSNs have appeared later.However, those references were thefirst most comprehensive implementation studies that pro-posed compact AES designs as well.Ref.[16]presents a thorough study of AES en-cryption data path implementations with the different architectural choices described in Section2.1but lacks decryption and key expansion logic.The functionalities are also lacking from[18,19].Nevertheless,[18,19]have been thefirst to propose folded AES448P.Hämäläinen,M.Hännikäinen,and T.D.Hämäläinendesigns[13],in which the data path width has been decreased from its native width (128bits).Later on,folding has successfully been utilized in the most compact and low-power AES implementations discussed below.Direct comparison between[16]and [18,19]is not possible as different FPGA and SubBytes implementation technologies have been used(logic vs.ROM).A Xilinx slice roughly equals to two Altera LEs.As [16]uses the native data width,its latency is lower and throughput higher than in[18,19]. Since[19]utilizes the T-box method,its LE count is lower than that of[18],despite of the wider data path.On the other hand,the method requires larger amount of memory for the LUTs.The folding factor increases the latency as more clock cycles are needed for processing a128-bit block of data.A number of iterative Application Specific Integrated Circuit(ASIC)designs with varying data path widths have been reported in[8].The designs are based on an efficient S-box architecture and include en/decryption for128-bit keys.Roundkeys are generated on-the-fly,either by sharing S-boxes with the main data path or by dedicating separate S-boxes for key expansion.The smallest version is a32-bit AES architecture with four shared S-boxes.The results of[8]are still currently relevant:even though the gate counts are not the lowest,according to our knowledge the implementations offer the best area-throughput ratios of existing compact AES implementations.A32-bit AES architecture with a precomputed key expansion is developed for FP-GAs in[13].The design takes advantage of the dedicated memory blocks of FPGAs by implementing S-box as a LUT.The paper proposes a method for arranging the bytes of State so that it can efficiently be stored into memory components or shift registers.The arrangement allows performing ShiftRows with addressing logic.The same method is proposed again in[10].For decreasing the amount of storage space as well as support-ing various data path widths,we have developed the idea further in[21]without an implementation.In[14],we removed the decryption functionality of[13]and used the core for implementing the security processing of IEEE802.15.4[7]and ZigBee[3]in a low-cost FPGA.Ref.[15]improves the FPGA resource consumption of[13]with the T-box method.The design requires equal amount of memory components in the FPGA but uses them more efficiently.A resource-efficient ASIC design supporting en/decryption is presented in[10].The on-the-fly roundkey generation shares S-boxes with the main data path.The design is based on a regular architecture that can be scaled for different speed and area require-ments.The smallest ASIC version contains a32-bit data path.The FPGA design uses varying data widths for different phases of the algorithm.Support for the Cipher Block Chaining(CBC)encryption mode is also pared to the32-bit implementa-tions of[8],the throughput of the ASIC implementation is lower and area larger.Ref.[10] also uses an older ASIC technology which prevents absolute area comparisons.However, the latencies of[8]are lower,which indicates that its designs are more efficient.A low-power and compact ASIC core for128-bit-key AES encryption is reported in[11].The8-bit data path is used for the round operations as well as for the on-the-fly key expansion.The data path contains one S-box implemented as combinatorial logic. State and the current roundkey are stored in a32×8-bit RAM,which has been imple-mented with registers and multiplexers.The memory is intensively used by cycling each intermediate result through the RAM,increasing the total cycle count of the design.ForReview of Hardware Architectures for AES Implementations449 MixColumns,the design uses a shift-register-based approach,which is capable of com-puting the operation in28cycles.Decryption functionality is added to the design in [12],which also reports results from a manufactured chip.As stated,an increase in the folding factor increases latency and thus decreases throughput from the designs with wider data paths.A8-bit AES processor for FPGAs is designed in[9],capable of128-bit-key encryp-tion and decryption.The data path consists of an S-box and a GF multiplier/accumu-lator.The execution is controlled with a program stored in ROM.RAM is used as data memory.The design is fairly inefficient as the cycle count is significantly higher than e.g.in[15]with not much lower FPGA resource consumption.According to our knowledge,our encryption-only core presented in[20]is the most efficient one of reported8-bit AES implementations in terms of area-throughput ratio. This is due to the novel data path architecture that is based on the8-bit permutation structure proposed in[21].In[9,11,12],the AES round operations as well as the round-key generation operations are performed sequentially.In our design,the operations are performed in parallel(for different8-bit pieces of data/key),which considerably de-creases the total cycle count and increases the throughput.Still,we succeeded in main-taining the hardware area and the power consumption low.The gate area is at the same level with[11,12].The achieved cycle count of160can be seen as the minimum for an iterated8-bit AES implementation.We have estimated that including the decryption functionality would add about25%to the total area.Only[12,20]of the ASIC references include power consumption measures.For[12] the power consumption is45µW/MHz and for the area-optimized implementation of [20]37µW/MHz.In[12],the power has been measured from a manufactured chip. However,the higher throughput of[20]potentially results in considerably lower energy consumption per processed block.For achieving equal throughputs,[20]can be run at considerably lower clock frequency.3.1WSN Suitability of Dedicated Hardware ImplementationsAccording to the survey,the best suited approaches for the hardware implementation of AES in WSN nodes seem to be the8-bit designs[12,20].They result in the lowest hardware area(i.e.cost).Their power consumptions are presumably also among the lowest even though power has not been reported for the other designs.Even though [20]includes only encryption functionality,it is still usable in real WSNs:decryption functionality of the AES core itself is not often required in commonly used security processing schemes.For example,this is the case in the standardized WSN technologies [7,3].In addition to these two8-bit designs,the32-bit implementations of[8]can also be suitable for WSN nodes.The hardware areas are low and the area-throughput ratios high.The32-bit cores can be combined with the encryption-mode wrapper of[14]for efficient security processing in the standard WSN technologies.Considering FPGAs, the T-box method of[13]seems to be the best approach for resource-efficient imple-mentations.However,FPGA technologies are currently not feasible solutions for WSN nodes due to their high power consumption.450P.Hämäläinen,M.Hännikäinen,and T.D.Hämäläinen4Specialized Processor Architectures for AESAn effective performance-area trade-off between dedicated hardware implementations and general-purpose processors can be achieved with programmable specialized proces-sors.Such Application Specific Instruction set Processors(ASIP)are typically general-purpose but they have also been tailored to support a specific application domain or task.A large part of the proposals in the cryptographic domain have concentrated on maximizing performance and programmability[17],which often results in high power consumption and cost and thus makes the proposals unsuited for WSN nodes.In this section we review processor architectures proposed for efficient AES execution in low-cost devices,shown in Table2.The ASIP implementation reported in[22]uses the Xtensa configurable processor architecture from Tensilica.In the paper,the execution of cryptographic algorithms, including AES,is accelerated by extending the instruction set of the processor with algorithm-specific instructions.As a result,the performance is improved by several ten-folds from the original(however,the original implementations are poor).The achieved throughput for AES is17Mbit/s at188MHz in a0.18µm ASIC technology.Area or powerfigures have not been reported.An ASIP architecture based on the32-bit MIPS processor architecture has been pub-lished in[23].A special unit supporting fast LUT functionality is included for accel-erating the RC4and AES algorithms.The unit consists of two1024×32-bit RAMs implying large area.For accelerating Data Encryption Standard(DES),[23]proposes a very large configurable permutation unit consisting of51232×1-bit multiplexers.The achieved throughput for AES is around64Mbit/s at100MHz.The size of the processor core is6.25mm2in a0.18µm ASIC technology.The power is approximately90mW.In[26],an instruction set extension has been developed for accelerating AES in32-bit processors.The custom instruction performs the SubBytes(or its inverse)operation using a special functional unit.The unit has been integrated into a LEON-2processor prototyped in an FPGA.The resulting encryption speedup is up to1.43and the code size reduction30–40%.The area of the unit is400gates in a0.35µm ASIC technology. The absolute value for the throughput and the complete processor size in the ASIC technology have not been reported.We have utilized a processor architecture called Transport Triggered Architecture (TTA)to develop an area-efficient ASIP design for accelerating the execution of RC4 and AES in[24].In addition to the standard functional units,the processor includes four 256×8-bit RAM-based LUT units,a32-bit unit for converting between byte and word Table2.Specialized processor architectures for AES executionDesign Technology Area Clock Throughput Power[MHz][Mbit/s][mW/MHz]Ref.[22].18µm n/a18817n/aRef.[23].18µm 6.25mm2100640.90Ref.[24].13µm70kgates10068n/aRef.[25].18µm 2.25mm214 1.8 1.2Review of Hardware Architectures for AES Implementations451 representations of the AES State,and a unit for performing a combined32-bit Mix-Columns and AddRoundKey operation in a single clock cycle.The LUT units eliminate main memory accesses in the same way as the custom instruction of[26].The size of our TTA processor that supports AES and RC4is69.4kgates in a0.13µm ASIC tech-nology.The throughput is68.5Mbit/s for AES using precomputed roundkeys at100 MHz.Power consumption was not evaluated in this study.A microcoded cryptoprocessor designed for executing DES,AES,and Elliptic Curve Cryptography(ECC)has been published in[25].The data path contains an expan-sion/permutation unit,a shifter,four memory-based LUTs,two logic units,and a regis-terfile consisting of sixteen256-bit registers.The processor can be reconfigured by modifying the microcoded program and the contents of the LUTs.The encryption throughput for AES is1.83Mbit/s at13.56MHz with on-the-fly key expansion.The hardware area in a0.18µm technology is2.25mm2and the power consumption for AES is16.3mW.4.1WSN Suitability of Specialized Processor ArchitecturesCompared to the most compact AES hardware implementations of Section3,the re-viewed specialized processor architectures result in significantly larger areas,lower performances,and higher power consumptions.Their benefits are in programmabil-ity and/or reconfigurability compared to dedicated hardware and in performance when compared to general-purpose processors of the same application domain.The cost of the processor presented in[23]is high and thus it is poorly suited for WSN nodes.On the contrary,the special operation units presented in[24,26]can be used for increasing the performances of the main processors in WSN nodes.Whereas [26]dedicates its unit for AES only,the LUT unit of[24]is suited for other tasks as well. The performance results in these two papers are considerably better than in[22].If a 32-bit general-purpose processor is considered to be used in a WSN node,the complete processor design of[24]with its special support for AES is a feasible solution.Even though the AES performance of[25]is lower than e.g.in[24],the processor can be suitable for WSN nodes which frequently need to perform also ECC computations.5ConclusionsA large part of WSN applications require cryptographic protection.Due to the con-straints of WSN nodes,their cryptographic implementations should be low-cost and energy-efficient.In this paper,we reviewed hardware architectures proposed for AES implementations in such environments.The survey considered both dedicated hardware and specialized processor designs.According to our survey,currently8-bit dedicated hardware designs seem to be the most feasible solutions for WSN nodes.Alternatively, compact special functional units can be used for extending the instruction sets of WSN node processors for efficient AES execution.The reviewed designs often offer signifi-cantly higher throughput at their maximum clock speed than what is actually required for WSN communications.Hence,considerable power savings can be achieved by de-creasing the clock speed from its maximum without affecting the wireless data rates452P.Hämäläinen,M.Hännikäinen,and T.D.Hämäläinenof nodes.We believe that the review presented in this paper is valuable for designers evaluating and developing AES implementations for environments in which low cost and low power consumption are key requirements,beyond WSNs as well. References1.Stankovic,J.A.,Abdelzaher,T.F.,Lu,C.,Sha,L.,Hou,J.C.:Real-time communicationand coordination in embedded sensor networks.Proceedings of the IEEE91(7),1002–1022 (2003)2.Hämäläinen,P.,Kuorilehto,M.,Alho,T.,Hännikäinen,M.,Hämäläinen,T.D.:Security inwireless sensor networks:Considerations and experiments.In:Proc.Embedded Computer Systems:Architectures,Modelling,and Simulation(SAMOS VI)Workshop–Special Session on Wireless Sensor Networks,Samos,Greece,pp.167–177(July17-20,2006)3.ZigBee Alliance:ZigBee Specification Version1.0(December2004)4.Suhonen,J.,Kohvakka,M.,Hännikäinen,M.,Hämäläinen,T.D.:Design,implementation,and experiments on outdoor deployment of wireless sensor network for environmental mon-itoring.In:Proc.Embedded Computer Systems:Architectures,Modelling,and Simulation (SAMOS VI)Workshop–Special Session on Wireless Sensor Networks,Samos,Greece,pp.109–121(July17-20,2006)5.Avancha,S.,Undercoffer,J.,Joshi,A.,Pinkston,J.:Security for Wireless Sensor Networks.In:Wireless Sensor Networks,1st edn.pp.253–275.Springer,Heidelberg(2004)6.National Institute of Standards and Technology(NIST):Advanced Encryption Standard(AES),FIPS-197(2001)7.IEEE:IEEE Standard for Local and Metropolitan Area Networks—Part15.4:WirelessMedium Access Control(MAC)and Physical Layer(PHY)Specifications for Low-Rate Wireless Personal Area Networks(LR-WPAN),IEEE Std802.15.4(2003)8.Satoh,A.,Morioka,S.,Takano,K.,Munetoh,S.:A compact Rijndael hardware architecturewith S-box optimization.In:Boyd,C.(ed.)ASIACRYPT2001.LNCS,vol.2248,pp.239–254.Springer,Heidelberg(2001)9.Good,T.,Benaissa,M.:AES on FPGA from the fastest to the smallest.In:Rao,J.R.,Sunar,B.(eds.)CHES2005.LNCS,vol.3659,pp.427–440.Springer,Heidelberg(2005)10.Pramstaller,N.,Mangard,S.,Dominikus,S.,Wolkerstorfer,J.:Efficient AES implementa-tions on ASICs and FPGAs.In:Proc.4th Conf.on the Advanced Encryption Standard(AES 2004),Bonn,Germany,May10-12,2005,pp.98–112(2005)11.Feldhofer,M.,Dominikus,S.,Wolkerstorfer,J.:Strong authentication for RFID systemsusing the AES algorithm.In:Joye,M.,Quisquater,J.-J.(eds.)CHES2004.LNCS,vol.3156, pp.357–370.Springer,Heidelberg(2004)12.Feldhofer,M.,Wolkerstorfer,J.,Rijmen,V.:AES implementation on a grain of sand.IEEProc.Inf.Secur.152(1),13–20(2005)13.Chodowiec,P.,Gaj,K.:Very compact FPGA implementation of the AES algorithm.In:D.Walter,C.,Koç,Ç.K.,Paar,C.(eds.)CHES2003.LNCS,vol.2779,pp.319–333.Springer,Heidelberg(2003)14.Hämäläinen,P.,Hännikäinen,M.,Hämäläinen,T.:Efficient hardware implementation of se-curity processing for IEEE802.15.4wireless networks.In:Proc.48th IEEE Int.Midwest Symp.on Circuits and Systems(MWSCAS2005),Cincinnati,OH,USA,August7-10,2005, pp.484–487(2005)15.Rouvroy,G.,Standaert,F.X.,Quisquater,J.J.,Legat,J.D.:Compact and efficient encryp-tion/decryption module for FPGA implementation of the AES Rijndael very well suited for small embedded applications.In:Proc.IEEE Int.Conf.on Inf.Tech.:Coding and Computing (ITCC2004),Las Vegas,NV,USA,April4-6,2004,vol.2,pp.583–587(2004)。