豆瓣图书爬虫使用教程
《2024年基于Python的豆瓣网站数据爬取与分析》范文

《基于Python的豆瓣网站数据爬取与分析》篇一一、引言随着互联网的快速发展,网络数据爬取与分析已成为一种重要的研究手段。
豆瓣网作为国内知名的社交网站,拥有丰富的用户数据和内容资源。
本文旨在介绍如何使用Python进行豆瓣网站的数据爬取与分析,并展示其应用价值。
二、数据爬取1. 确定爬取目标在豆瓣网站上,我们可以根据需求选择要爬取的数据类型,如电影、书籍、音乐等。
本文以电影为例,介绍如何进行数据爬取。
2. 编写爬虫程序使用Python语言,我们可以借助第三方库如requests、BeautifulSoup等来实现对豆瓣网站的爬取。
首先,需要发送请求获取网页源代码,然后通过解析源代码提取所需数据。
在编写爬虫程序时,需要注意遵守豆瓣网的爬虫协议,避免对网站造成过大负担。
同时,还需要注意反爬虫策略,如设置请求头、使用代理等。
3. 数据存储将爬取到的数据存储在合适的格式中,如CSV、JSON等。
便于后续的数据分析和处理。
三、数据分析1. 数据清洗对爬取到的数据进行清洗,去除重复、无效、错误的数据,保证数据的准确性。
2. 数据处理对清洗后的数据进行处理,如统计、分类、聚类等。
可以使用Python中的pandas、numpy等库进行数据处理。
3. 数据可视化将处理后的数据以图表的形式展示出来,便于观察和分析。
可以使用matplotlib、seaborn等库进行数据可视化。
四、应用价值1. 用户需求分析通过对豆瓣网站上的用户数据进行爬取和分析,可以了解用户的需求和兴趣爱好,为产品开发和改进提供参考。
2. 电影市场分析通过对豆瓣网上的电影数据进行爬取和分析,可以了解电影的市场表现、观众评价等信息,为电影投资和宣传提供参考。
3. 竞争情报分析通过对竞争对手在豆瓣网上的数据进行分析,可以了解其产品特点、优势和不足,为企业的竞争策略制定提供参考。
五、结论本文介绍了基于Python的豆瓣网站数据爬取与分析的方法和应用价值。
《2024年基于Python的豆瓣网站数据爬取与分析》范文

《基于Python的豆瓣网站数据爬取与分析》篇一一、引言在大数据时代,信息资源的获取和利用显得尤为重要。
豆瓣网作为国内知名的社交网站之一,拥有丰富的用户数据和资源。
本文将介绍如何使用Python进行豆瓣网站的数据爬取与分析,旨在为相关领域的研究提供参考。
二、数据爬取1. 确定爬取目标首先,我们需要明确要爬取的数据类型和目标。
例如,我们可以选择爬取豆瓣电影的评分、评论、用户评价等信息。
2. 选择合适的爬虫框架Python提供了多种爬虫框架,如BeautifulSoup、Selenium等。
根据实际需求,我们选择使用BeautifulSoup结合requests库进行数据爬取。
3. 编写爬虫程序(1)发送请求:使用requests库向豆瓣网站发送请求,获取HTML页面。
(2)解析页面:使用BeautifulSoup解析HTML页面,提取所需数据。
(3)保存数据:将提取的数据保存为CSV或JSON格式文件,以便后续分析。
三、数据分析1. 数据清洗对爬取的数据进行清洗,去除重复、无效、异常的数据,保证数据的准确性。
2. 数据统计与分析(1)对电影评分进行统计分析,了解用户对不同类型电影的喜好程度。
(2)对电影评论进行情感分析,了解用户对电影的情感倾向和评价内容。
(3)分析用户评价的关键词和主题,了解用户关注的重点和需求。
3. 可视化展示使用Python的数据可视化库(如Matplotlib、Seaborn等)将分析结果进行可视化展示,以便更好地理解数据和分析结果。
四、案例分析以某部电影为例,对其在豆瓣网上的评分、评论及用户评价进行详细分析。
通过数据分析和可视化展示,可以更直观地了解用户对该电影的评价和反馈,为电影制作方提供有价值的参考信息。
五、结论与展望通过对豆瓣网站数据的爬取与分析,我们可以获取大量有关用户行为、喜好、需求等方面的信息。
这些信息对于网站运营者、商家、研究机构等都具有重要的参考价值。
同时,随着技术的发展和大数据时代的到来,数据爬取与分析将越来越重要。
Python爬虫笔记:爬取豆瓣图书TOP250单页数据
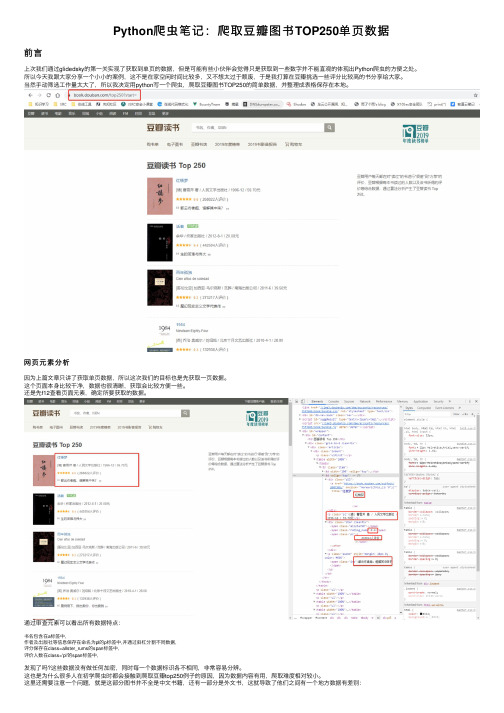
Python爬⾍笔记:爬取⾖瓣图书TOP250单页数据前⾔上次我们通过glidedsky的第⼀关实现了获取到单页的数据,但是可能有些⼩伙伴会觉得只是获取到⼀些数字并不能直观的体现出Python爬⾍的⽅便之处。
所以今天我跟⼤家分享⼀个⼩⼩的案例,这不是在家空闲时间⽐较多,⼜不想太过于颓废,于是我打算在⾖瓣挑选⼀些评分⽐较⾼的书分享给⼤家。
当然⼿动筛选⼯作量太⼤了,所以我决定⽤python写⼀个爬⾍,爬取⾖瓣图书TOP250的简单数据,并整理成表格保存在本地。
⽹页元素分析因为上篇⽂章只讲了获取单页数据,所以这次我们的⽬标也是先获取⼀页数据。
这个页⾯本⾝⽐较⼲净,数据也很清晰,获取会⽐较⽅便⼀些。
还是先f12查看页⾯元素,确定所要获取的数据。
通过审查元素可以看出所有数据特点:书名包含在a标签中,作者及出版社等信息保存在命名为pl的p标签中,并通过斜杠分割不同数据,评分保存在class=allster_rums的span标签中,评价⼈数在class='pl'的span标签中,发现了吗?这些数据没有做任何加密,同时每⼀个数据标识各不相同,⾮常容易分辨。
这也是为什么很多⼈在初学爬⾍时都会接触到爬取⾖瓣top250例⼦的原因,因为数据内容有⽤,爬取难度相对较⼩。
这⾥还需要注意⼀个问题,就是这部分图书并不全是中⽂书籍,还有⼀部分是外⽂书,这就导致了他们之间有⼀个地⽅数据有差别:外⽂书会多出⼀个译者名字,所以之后在保存数据到表格⽂件中时,需要特别注意。
代码实现在开始之前还是先明确⼀下程序执⾏流程:访问⽹页获取源代码提取数据分别保存到excel⽂件中⾸先解决访问⽹页和获取源代码的问题:import requestsfrom bs4 import BeautifulSoupurl = '/top250?start='headers = {'cookie':'你⾃⼰的cookie','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' }response = requests.get(url,headers=headers).textbs4 = BeautifulSoup(response,'html.parser')print(bs4)获取到之后当然就是对数据进⾏提取bookName = bs4.find_all('div',class_='pl2')for book in bookName:name = book.find('a')name = name.text.strip()name = name.replace(' ','')print(name)这段代码⾸先在获取到的html⽂本中寻找Class=pl2的div元素这是没有提取a标签中书名时的原始数据find_all()是BeautifulSoup模块提供的⼀个⽤来快速查询数据的⽅法,返回⼀个列表。
python豆瓣爬虫代码 -回复

python豆瓣爬虫代码-回复如何使用Python编写一个豆瓣爬虫?豆瓣是一个非常受欢迎的社交网站,它提供了各种各样的电影、图书、音乐和活动信息。
有时,我们可能需要获取豆瓣上的某些数据,比如电影的评分、图书的评论等。
为了方便获取这些数据,我们可以使用Python编写一个豆瓣爬虫。
那么,我们应该从哪些方面入手呢?下面将一步一步回答这个问题。
第一步:安装所需的库在开始编写豆瓣爬虫之前,我们需要安装两个库:requests和BeautifulSoup。
打开命令行窗口,并运行以下命令:pythonpip install requestspip install bs4这将会安装最新版本的requests和BeautifulSoup库。
requests库用于发送HTTP请求,而BeautifulSoup库用于解析HTML页面。
第二步:了解豆瓣网页结构在编写爬虫之前,我们需要了解豆瓣网页的结构,以便我们能够找到需要提取的数据。
我们可以打开豆瓣网站,然后使用浏览器的开发者工具(通常通过右键单击页面并选择“检查元素”打开)来查看HTML代码。
通过查看HTML代码,我们可以找到目标数据所在的位置。
例如,如果我们想要获取电影的评分,我们可以查看电影详情页面的HTML代码,找到包含评分的元素。
通常,评分信息是包含在一个具有特定类名或id的HTML元素中的。
第三步:发送HTTP请求有了目标数据的位置,我们现在可以开始编写代码了。
首先,我们需要发送一个HTTP请求来获取豆瓣页面的HTML代码。
我们可以使用requests 库中的get函数来实现这一点。
pythonimport requestsurl = "<豆瓣网页的URL>"response = requests.get(url)html = response.text在上面的代码中,我们先定义了豆瓣网页的URL。
然后,我们使用get函数向该URL发送一个HTTP请求,并将响应结果存储在response变量中。
Scrapy通过登录的方式爬取豆瓣影评数据

Scrapy通过登录的⽅式爬取⾖瓣影评数据Scrapy 通过登录的⽅式爬取⾖瓣影评数据爬⾍Scrapy⾖瓣Fly由于需要爬取影评数据在来做分析,就选择了⾖瓣影评来抓取数据,⼯具使⽤的是Scrapy⼯具来实现。
scrapy⼯具使⽤起来⽐较简单,主要分为以下⼏步:1、创建⼀个项⽬ ==scrapy startproject Douban得到⼀个项⽬⽬录如下:├── Douban│ ├── init.py │ ├── │ ├── │ ├── │ └── spiders │ └── init.py └── scrapy.cfg2 directories, 6 files然后定义⼀个Item项定义Item项,主要是为了⽅便得到爬取得内容。
(根据个⼈需要定义吧,不定义也可以。
)定义⼀个爬⾍类由上⾯的⽬录上,知道放在spider下⾯。
可以根据不同的需要继承 scrapy.Spider 或者是CrawlSpider。
然后定义url 以及parse⽅法当然也可以使⽤命令来⽣成模板scrapy genspider douban 抓取内容使⽤命令 scrapy crawl spidername具体可以参照通过scrapy 参考⼿册的程序定义之后,会发现在爬不到数据,这是因为⾖瓣使⽤了反爬⾍机制。
我们可以在内启动DOWNLOAD_DELAY=3 以及User-Agent代理:USER_AGENT = 'Douban (+)'这样就可以开启爬⾍了。
但是在爬取⾖瓣影评数据的时候,会发现,最多只能爬取10页,然后⾖瓣就需要你登录。
不然就只能爬取10页数据(从浏览去看,也是只能看到10页数据)。
这就需要我们登录之后再去爬取数据了。
然后在Scrapy⼿册的部分,发现了可以使⽤如下⽅式实现登录:1. class MySpider(scrapy.Spider):2. name = 'myspider'3.4. def start_requests(self):5. return [scrapy.FormRequest("/login",6. formdata={'user': 'john', 'pass': 'secret'},7. callback=self.logged_in)]8.9. def logged_in(self, response):10. # here you would extract links to follow and return Requests for11. # each of them, with another callback12. pass通过上⾯的⽅法,就可以实现登录⾖瓣爬取想要的数据了。
第一个爬虫——豆瓣新书信息爬取

第⼀个爬⾍——⾖瓣新书信息爬取本⽂记录了我学习的第⼀个爬⾍程序的过程。
根据《Python数据分析⼊门》⼀书中的提⽰和代码,对⾃⼰的知识进⾏查漏补缺。
在上爬⾍程序之前补充⼀个知识点:User-Agent。
它是Http协议中的⼀部分,属于头域的组成部分,User Agent也简称UA。
它是⼀个特殊字符串头,是⼀种向访问⽹站提供你所使⽤的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。
通过这个标识,⽤户所访问的⽹站可以显⽰不同的排版从⽽为⽤户提供更好的体验或者进⾏信息统计;例如⽤不同的设备访问同⼀个⽹页,它的排版就会不⼀样,这都是⽹页根据访问者的UA来判断的。
电脑浏览器上可以通过右击⽹页空⽩处——检查元素——Network——单击⼀个元素(如果没有就刷新⼀下⽹站页⾯)——下拉找到User-Agent。
例如本机的UA为:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.121 Safari/537.36⽹站服务器有时会通过识别UA的⽅式来阻⽌机器⼈(如requests)⼊侵,故我们需要在爬⾍程序⾥对⾃⼰的UA进⾏伪装。
伪装的具体步骤看下⽂。
这次爬⾍的⽬标是⾖瓣新书速递页⾯的信息,url为https:///latest。
可简单分为请求数据、解析数据、根据标签提取数据、进⼀步提取数据和“漂亮的”打印五个步骤。
⼀、请求数据import requestsfrom bs4 import BeautifulSoup#请求数据url = '/latest'headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.121 Safari/537.36"}data = requests.get(url,headers=headers)#暂不输⼊print(data.text)导⼊requests库和BeautifulSoup库。
Python基础之爬取豆瓣图书信息

Python基础之爬取⾖瓣图书信息概述所谓爬⾍,就是帮助我们从互联⽹上获取相关数据并提取有⽤的信息。
在⼤数据时代,爬⾍是数据采集⾮常重要的⼀种⼿段,⽐⼈⼯进⾏查询,采集数据更加⽅便,更加快捷。
刚开始学爬⾍时,⼀般从静态,结构⽐较规范的⽹页⼊⼿,然后逐步深⼊。
今天以爬取⾖瓣最受关注图书为例,简述Python在爬⾍⽅⾯的初步应⽤,仅供学习分享使⽤,如有不⾜之处,还请指正。
涉及知识点如果要实现爬⾍,需要掌握的Pyhton相关知识点如下所⽰:requests模块:requests是python实现的最简单易⽤的HTTP库,建议爬⾍使⽤requests。
关于requests模块的相关内容,可参考及简书上的BeautifulSoup模块:Beautiful Soup 是⼀个可以从HTML或XML⽂件中提取数据的Python库。
它能够通过你喜欢的转换器实现惯⽤的⽂档导航,查找,修改⽂档的⽅式。
关于BeautifulSoup的更多内容,可参考。
json模块:JSON(JavaScript Object Notation) 是⼀种轻量级的数据交换格式,易于⼈阅读和编写。
使⽤ JSON 函数需要导⼊ json 库。
关于json的更多内容,可参考。
re模块:re模块提供了与 Perl 语⾔类似的正则表达式匹配操作。
关于re模块的更多内容,可参考。
⽬标页⾯本例中爬取的信息为⾖瓣最受关注图书榜信息,共10本当前最受欢迎图书。
爬取页⾯截图,如下所⽰:爬取数据步骤1. 分析页⾯通过浏览器提供的开发⼈员⼯具(快捷键:F12),可以⽅便的对页⾯元素进⾏定位,经过定位分析,本次所要获取的内容,包括在UL【class=chart-dashed-list】标签内容,每⼀本书,都对应⼀个LI元素,是本次爬取的⽬标,如下所⽰:每⼀本书,对应⼀个Li【class=media clearfix】元素,书名为对应a【class=fleft】元素,描述为P【class=subject-abstract color-gray】标签元素内容,具体到每⼀本书的的详细内容,如下所⽰:2. 下载数据如果要分析数据,⾸先要进⾏下载,获取要爬取的数据信息,在Python中爬取数据,主要⽤requests模块,如下所⽰:1def get_data(url):2"""3获取数据4 :param url: 请求⽹址5 :return:返回请求的页⾯内容6"""7# 请求头,模拟浏览器,否则请求会返回4188 header = {9'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '10'Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'}11 resp = requests.get(url=url, headers=header) # 发送请求12if resp.status_code == 200:13# 如果返回成功,则返回内容14return resp.text15else:16# 否则,打印错误状态码,并返回空17print('返回状态码:', resp.status_code)18return''注意:在刚开始写爬⾍时,通常会遇到“HTTP Error 418”,请求⽹站的服务器端会进⾏检测此次访问是不是⼈为通过浏览器访问,如果不是,则返回418错误码。
python爬虫豆瓣代码

python爬虫豆瓣代码Python爬虫是一项非常基础和重要的技能,因为它可以让我们抓取各种网站的数据,从而方便我们进行数据分析和研究。
在这篇文章中,我们将介绍如何使用Python爬虫来抓取豆瓣网站的电影信息,来帮助读者更好地了解如何使用Python爬虫进行数据分析。
一、准备工作在开始编写Python爬虫之前,读者需要了解Python的基本语法知识,以及如何使用Python实现基本的数据处理功能。
此外,对于Python爬虫的技术细节,读者需要学习一些基本的库和框架,如requests, BeautifulSoup, pandas等等。
二、爬虫流程1.获取页面数据首先,我们需要使用requests库来获取豆瓣网页的HTML代码,定义好读取函数并传入我们要爬取的URL:```import requestsdef get_html(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64;x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/58.0.3029.110 Safari/537.3'}try:r = requests.get(url, headers=headers, timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return "Error"```2.解析页面数据获取到HTML代码后,我们需要使用BeautifulSoup库来解析HTML,以提取出页面中的电影信息。
首先需要引入BeautifulSoup库,然后使用BeautifulSoup导入HTML代码:```from bs4 import BeautifulSoupsoup = BeautifulSoup(html, 'html.parser')```3.提取数据我们的目标是从页面中提取电影的名称、导演、演员、评分等信息,所以可以使用BeautifulSoup的各种方法,例如find_all()查找标签,get()获取属性等等,来提取所需的信息。
基于Python的豆瓣网站数据爬取与分析

基于Python的豆瓣网站数据爬取与分析基于Python的豆瓣网站数据爬取与分析随着网络的普及和发展,豆瓣网站成为了一个知名的电影、图书、音乐等文化娱乐信息交流平台。
许多用户在该网站上分享自己对各种文化作品的评价和观点。
对这些数据进行爬取和分析,不仅可以了解用户的喜好和评价趋势,还可以帮助推荐个性化的文化产品。
本文介绍了一种基于Python的豆瓣网站数据爬取与分析方法,通过该方法可以获取豆瓣网站上的电影数据,并对该数据进行分析和可视化呈现。
首先,我们需要使用Python中的爬虫技术来获取豆瓣网站上的电影数据。
爬虫是一种自动化程序,它模拟人类操作浏览器获取网页中的数据。
Python提供了许多工具库,如BeautifulSoup和Requests,可以帮助我们实现网页数据的抓取。
我们可以使用Requests库向豆瓣网站发送HTTP请求,然后使用BeautifulSoup库来解析HTML页面,提取我们需要的电影数据。
通过分析豆瓣网站的页面结构,我们可以找到电影名称、评分和评论等关键信息。
在获取电影数据之后,我们可以使用Python中的数据分析工具来对数据进行处理和分析。
Python中有许多知名的科学计算和数据分析库,如NumPy、Pandas和Matplotlib。
这些库提供了丰富的数据处理和可视化功能,可以帮助我们快速分析和展示数据。
首先,我们可以使用Pandas库来加载抓取到的电影数据,并进行清洗和整理。
Pandas提供了强大的数据结构和数据处理函数,可以方便地对数据进行过滤、排序和聚合等操作。
我们可以使用Pandas来处理缺失数据和异常数据,保证数据的准确性和一致性。
此外,Pandas还提供了灵活的时间序列处理功能,可以帮助我们对电影数据进行按时间的分析。
然后,我们可以使用Matplotlib库来对电影数据进行可视化呈现。
Matplotlib是一个强大的绘图库,可以绘制各种类型的图表,如柱状图、折线图和散点图等。
python豆瓣爬虫代码

Python豆瓣爬虫代码一、引言豆瓣是一个非常受欢迎的社交网络平台,汇集了大量的书籍、电影、音乐等信息。
在豆瓣上,用户可以进行评分、评论和收藏等操作。
为了获取豆瓣上的信息,我们可以使用Python编写爬虫代码,实现自动化的数据抓取和分析。
本文将介绍Python豆瓣爬虫代码的编写,帮助读者了解如何使用Python获取豆瓣上的信息。
二、环境准备在编写豆瓣爬虫代码之前,我们需要准备一些必要的环境和工具。
首先,需要安装Python编程语言和相关的第三方库,如requests、BeautifulSoup等。
可以使用pip命令来安装这些库,确保版本兼容性。
pip install requestspip install BeautifulSoup其次,需要了解HTTP协议和HTML基础知识,这样才能理解爬虫代码的执行过程和数据的抓取方式。
同时,还需要学习一些基本的Python编程知识,如条件语句、循环语句、函数定义等。
三、获取豆瓣图书信息1. 导入库首先,我们需要导入必要的库和模块。
import requestsfrom bs4 import BeautifulSoup2. 发送HTTP请求接下来,我们使用requests库发送HTTP请求,获取豆瓣图书网页的内容。
url = ""response = requests.get(url)3. 解析HTML内容在得到网页的内容后,我们需要使用BeautifulSoup库解析HTML内容,提取出需要的信息。
soup = BeautifulSoup(response.text, 'html.parser')4. 提取图书信息通过分析豆瓣图书网页的HTML结构,我们可以找到要提取的图书信息所在的标签和属性。
利用BeautifulSoup库提供的方法,我们可以轻松地提取出这些信息。
books = soup.find_all('div', class_='pl2')for book in books:title = book.find('a')['title']author = book.find('p', class_='pl').text.strip().split('/')[0]rating = book.find('span', class_='rating_nums').textprint("书名:", title)print("作者:", author)print("评分:", rating)print("----------")5. 结果展示通过运行以上代码,我们可以获取豆瓣图书网页上前250本图书的信息,包括书名、作者和评分。
python7个爬虫小案例详解(附源码)

python7个爬虫小案例详解(附源码)Python 7个爬虫小案例详解(附源码)1. 爬取百度贴吧帖子使用Python的requests库和正则表达式爬取百度贴吧帖子内容,对网页进行解析,提取帖子内容和发帖时间等信息。
2. 爬取糗事百科段子使用Python的requests库和正则表达式爬取糗事百科段子内容,实现自动翻页功能,抓取全部内容并保存在本地。
3. 抓取当当网图书信息使用Python的requests库和XPath技术爬取当当网图书信息,包括书名、作者、出版社、价格等,存储在MySQL数据库中。
4. 爬取豆瓣电影排行榜使用Python的requests库和BeautifulSoup库爬取豆瓣电影排行榜,并对数据进行清洗和分析。
将电影的名称、评分、海报等信息保存到本地。
5. 爬取优酷视频链接使用Python的requests库和正则表达式爬取优酷视频链接,提取视频的URL地址和标题等信息。
6. 抓取小说网站章节内容使用Python的requests库爬取小说网站章节内容,实现自动翻页功能,不断抓取新的章节并保存在本地,并使用正则表达式提取章节内容。
7. 爬取新浪微博信息使用Python的requests库和正则表达式爬取新浪微博内容,获取微博的文本、图片、转发数、评论数等信息,并使用BeautifulSoup 库进行解析和分析。
这些爬虫小案例涵盖了网络爬虫的常见应用场景,对初学者来说是很好的入门教程。
通过学习这些案例,可以了解网络爬虫的基本原理和常见的爬取技术,并掌握Python的相关库的使用方法。
其次,这些案例也为后续的爬虫开发提供了很好的参考,可以在实际应用中进行模仿或者修改使用。
最后,这些案例的源码也为开发者提供了很好的学习资源,可以通过实战来提高Python编程水平。
爬虫---爬取豆瓣网评论内容

爬⾍---爬取⾖瓣⽹评论内容 这段时间肯定经常听到⼀句话“我命由我不由天”,没错,就是我们国产动漫---哪咤,今天我们通过python还有上次写的pyquery库来爬取⾖瓣⽹评论内容爬取⾖瓣⽹评论1、找到我们想要爬取的电影---⼩哪咤2、查看影⽚评论点击查看我们的影评,发现只能查看前200个影评,这⾥就需要登录了分析出来全部影评的接⼝地址好巧⽤到了上次写的通过requests登录⾖瓣⽹,然后通过session会话访问评论内容-----# coding:utf-8import requests# 登录请求地址s = requests.session()url = 'https:///j/mobile/login/basic'# 请求头headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" }# body数据data = {'name':"xxxxx", # 账号"password":"xxxx", # 密码"remember":"false"}# 发送请求r = s.post(url,headers=headers,data=data)# 全部评论内容url2 = 'https:///subject/26794435/comments?start=20&limit=20&sort=new_score&status=P'r2 = s.get(url2,headers=headers).content3、通过pyquery解析html导⼊pyquery解析html内容,分析html数据评论⼈的在 class =‘comment-info’下的a标签中;影评内容在class=‘short’中4、提取html上我们想要的内容已经分析出来我们想要的数据在哪⾥,那么接下来就是提取数据了# 解析htmldoc = pq(r2)items = doc('.comment-item').items()# 循环读取信息for i in items:# 评论昵称name = i('.comment-info a').text()print(name)# 评论内容content = i('.short').text()print(content)5、循环读取全部评论并且写⼊txt⽂件中这个地⽅⽤到的知识点写⼊应该不⽤在具体说了;循环读取全部评论就要查看分页情况了。
python爬虫:利用正则表达式爬取豆瓣读书首页的book

python爬⾍:利⽤正则表达式爬取⾖瓣读书⾸页的book 1、问题描述:爬取⾖瓣读书⾸页的图书的名称、链接、作者、出版⽇期,并将爬取的数据存储到Excel表格Douban_I.xlsx中2、思路分析:发送请求--获取数据--解析数据--存储数据1、⽬标⽹址:2、利⽤requests.get()⽅法向⾖瓣读书⾸页发送请求,获取⾸页的HTML源代码#⽬标⽹址targetUrl = "https:///"#发送请求,获取响应response = requests.get(targetUrl).text3、利⽤正则re.findall()解析出想要的信息: Name Url Author Date#编译成正则表达式对象,便于复⽤该匹配模式pattern = pile('<li.*?title="(.*?)".*?href="(.*?)".*?more-meta.*?author">(.*?)</span>.*?year">(.*?)</span>.*?</li>', re.S)results = re.findall(pattern, response)4、将数据存储到Excel表格中workBook = xlwt.Workbook(encoding='utf-8') #创建Excel表,并确定编码⽅式sheet = workBook.add_sheet("Douban_I")headData = ["书名", "链接", "作者", "出版⽇期"] #表头信息for colNum in range(len(headData)):sheet.write(0, colNum, headData[colNum])raw = 1for book in results: #书籍信息:名称、链接、作者、出版⽇期# name, url, author, date = bookfor column in range(len(book)):sheet.write(raw, column, book[column].strip())raw += 1workBook.save(".\Douban_I.xlsx")3、效果展⽰4、完整代码:# -* coding: utf-8 *-# author: wangshx6# date: 2018-11-04# description: 爬取⾖瓣读书⾸页的图书的名称、链接、作者、出版⽇期,并将爬取的数据存储到Excel表格Douban_I.xlsx中import requestsimport reimport xlwt#⽬标⽹址targetUrl = "https:///"#发送请求,获取响应response = requests.get(targetUrl).text''' 利⽤正则表达式解析出关键内容: Name Url Author Date '''#pile()是将正则字符串编译成正则表达式对象,便于复⽤该匹配模式#re.S 多⾏匹配(换⾏)pattern = pile('<li.*?title="(.*?)".*?href="(.*?)".*?more-meta.*?author">(.*?)</span>.*?year">(.*?)</span>.*?</li>', re.S)results = re.findall(pattern, response)#将数据列表存储到Excel表格Douban_I.xlsx中workBook = xlwt.Workbook(encoding='utf-8')sheet = workBook.add_sheet("Douban_I")headData = ["书名", "链接", "作者", "出版⽇期"] #表头for colNum in range(len(headData)):sheet.write(0, colNum, headData[colNum])raw = 1for book in results:# name, url, author, date = bookfor column in range(len(book)):sheet.write(raw, column, book[column].strip()) raw += 1workBook.save(".\Douban_I.xlsx")。
python豆瓣爬虫代码 -回复

python豆瓣爬虫代码-回复Python豆瓣爬虫代码前言互联网的普及和发展,使得我们每天都能获得海量的信息。
而随着信息的爆炸式增长,如何快速、准确地获取我们所需要的信息,成为了许多人面临的难题。
而豆瓣作为一款广受欢迎的社交网络平台,汇聚了大量的电影、书籍、音乐等信息,这为我们提供了一个绝佳的数据源。
本文将以Python豆瓣爬虫代码为主题,详细介绍如何利用Python编写一个简单的豆瓣爬虫。
第一步:导入所需库首先,我们需要导入所需的库。
Python提供了许多强大的第三方库来帮助我们进行网络爬取和数据处理。
在这个例子中,我们将使用`requests`库来发送HTTP请求,`beautifulsoup4`库来解析HTML页面。
pythonimport requestsfrom bs4 import BeautifulSoup第二步:发送HTTP请求要爬取豆瓣网页上的内容,我们首先需要发送HTTP请求来获取网页的HTML源码。
豆瓣的电影页面URL的格式通常是`python# 电影IDmovie_id = '27033637'# 构造URLurl = f'# 发送GET请求response = requests.get(url)第三步:解析HTML页面获取到网页的HTML源码后,我们需要使用`beautifulsoup4`库将HTML 源码解析成可以提取信息的数据结构。
我们可以按照HTML标签的层次结构来定位需要的信息。
python# 创建BeautifulSoup对象soup = BeautifulSoup(response.text, 'html.parser')# 使用select方法定位需要的标签title = soup.select_one('h1 span').text.strip()rating = soup.select_one('.rating_num').text.strip()第四步:提取所需信息在解析HTML页面后,我们可以通过选择合适的CSS选择器定位到需要的元素,并提取其中的信息。
python豆瓣爬虫代码

python豆瓣爬虫代码如何使用Python编写豆瓣爬虫代码?豆瓣是一个非常流行的影视、图书、音乐社交平台,用户可以在这里找到自己感兴趣的资源并与其他人分享。
而作为一名Python开发人员,我们可以通过编写豆瓣爬虫代码来获取豆瓣上的各种信息,并进行数据分析和应用开发。
那么接下来,我将一步一步地介绍如何使用Python编写豆瓣爬虫代码。
第一步:了解豆瓣网站的结构与规则在开始编写爬虫代码之前,我们需要了解豆瓣网站的结构与规则,以便能够准确地定位我们需要爬取的数据。
豆瓣网站的URL一般都遵循一定的规律,比如电影信息的URL通常是以"第二步:导入必要的库在Python中,我们可以使用第三方库来简化爬虫的编写。
在这个例子中,我们将使用两个非常常用的库,分别是requests和BeautifulSoup。
Requests库用于发送HTTP请求并获取网页内容,而BeautifulSoup库用于解析HTML代码,从而能够方便地提取我们需要的数据。
我们可以使用以下代码导入这两个库:import requestsfrom bs4 import BeautifulSoup第三步:发送HTTP请求并获取网页内容使用Requests库,我们可以发送HTTP请求,并通过获取到的网页内容进行下一步的解析。
在这个例子中,我们可以使用如下代码获取豆瓣电影页面的内容:url = "response = requests.get(url)html_content = response.text这里我们使用了requests库的get方法发送了一个GET请求,并将返回的response对象保存在response变量中。
然后,我们通过response对象的text属性获取到了网页的HTML代码,并将其保存在html_content中。
第四步:解析HTML代码并提取数据使用BeautifulSoup库,我们可以方便地解析HTML代码,并提取我们需要的数据。
Python爬虫-爬取豆瓣图书Top250
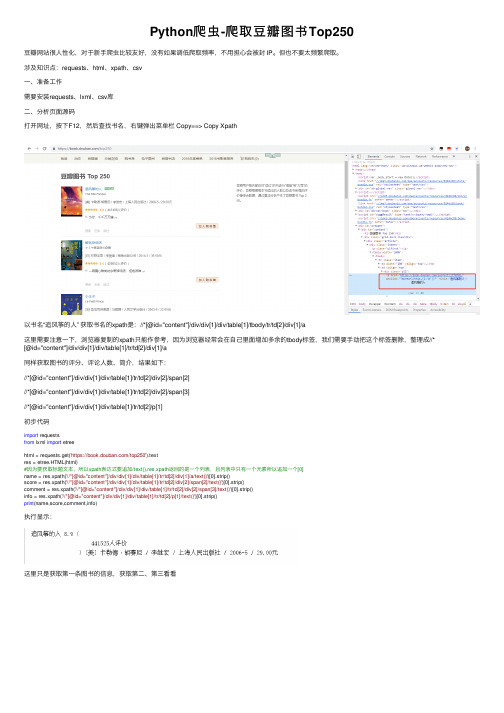
Python爬⾍-爬取⾖瓣图书Top250⾖瓣⽹站很⼈性化,对于新⼿爬⾍⽐较友好,没有如果调低爬取频率,不⽤担⼼会被封 IP。
但也不要太频繁爬取。
涉及知识点:requests、html、xpath、csv⼀、准备⼯作需要安装requests、lxml、csv库⼆、分析页⾯源码打开⽹址,按下F12,然后查找书名,右键弹出菜单栏 Copy==> Copy Xpath以书名“追风筝的⼈” 获取书名的xpath是://*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a这⾥需要注意⼀下,浏览器复制的xpath只能作参考,因为浏览器经常会在⾃⼰⾥⾯增加多余的tbody标签,我们需要⼿动把这个标签删除,整理成//* [@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a同样获取图书的评分、评论⼈数、简介,结果如下://*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[2]//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[3]//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/p[1]初步代码import requestsfrom lxml import etreehtml = requests.get('https:///top250').textres = etree.HTML(html)#因为要获取标题⽂本,所以xpath表达式要追加/text(),res.xpath返回的是⼀个列表,且列表中只有⼀个元素所以追加⼀个[0]name = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/text()')[0].strip()score = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[2]/text()')[0].strip()comment = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[3]/text()')[0].strip()info = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/p[1]/text()')[0].strip()print(name,score,comment,info)执⾏显⽰:这⾥只是获取第⼀条图书的信息,获取第⼆、第三看看得到xpath:import requestsfrom lxml import etreehtml = requests.get('https:///top250').textres = etree.HTML(html)name1 = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/text()')[0].strip()name2 = res.xpath('//*[@id="content"]/div/div[1]/div/table[2]/tr/td[2]/div[1]/a/text()')[0].strip()name3 = res.xpath('//*[@id="content"]/div/div[1]/div/table[3]/tr/td[2]/div[1]/a/text()')[0].strip()print(name1,name2,name3)执⾏显⽰:对⽐他们的xpath,发现只有table序号不⼀样,我们可以就去掉序号,得到全部关于书名的xpath信息:import requestsfrom lxml import etreehtml = requests.get('https:///top250').textres = etree.HTML(html)names = res.xpath('//*[@id="content"]/div/div[1]/div/table/tr/td[2]/div[1]/a/text()')for name in names:print(name.strip())执⾏结果:太多,这⾥只展⽰⼀部分对于其他评分、评论⼈数、简介也同样使⽤此⽅法来获取。
PYTHON极简主义爬虫——豆瓣图书爬取实战

PYTHON极简主义爬虫——豆瓣图书爬取实战展开全文文章已在CSDN首发。
本文以爬取豆瓣TOP250图书为例,但重点并不在案例本身,而在于梳理编写爬虫的逻辑和链路关键点,帮助感兴趣的童鞋逐渐形成自己编写爬虫的方法论(这个是最最最关键的),并在实战中体验requests+xpath绝妙的感觉。
没错,这一招requests+xpath(json)真的可以吃遍天。
马克思曾经没有说过——当你浏览网页时,看到的只是浏览器想让你看到的。
这句话道出了一个真谛——我们看到的网页只一个结果,而这个网页总是由众多小的“网页(或者说部分)”构成。
就像拼图,我们看到的网页其实是最终拼好的成品,当我们输入一个网址,浏览器会'自动'帮我们向远方的服务器发送构成这个大拼图的一众请求,服务器验证身份后,返回相关的小拼图(请求结果),而浏览器很智能的帮助我们把小拼图拼成大拼图。
我们需要的,就是找到网页中存储我们数据的那个小拼图的网址,并进一步解析相关内容。
以豆瓣TOP250图书为例,爬虫的第一步,就是“审查元素”,找到我们想要爬取的目标数据及其所在网址。
(豆瓣TOP250图书网址:https:///top250)1、审查元素,找到目标数据所在的URL审查元素,就是看构成网页的小拼图具体是怎么拼的,操作起来很简单,进入网页后,右键——审查元素,默认会自动定位到我们所需要的元素位置。
比如我们鼠标移动到“追风筝的人”标题上,右键后审查元素:其实,我们需要的数据(图书名称、评价人数、评分等等)都在一个个网页标签中。
爬虫这玩意儿就是刚开始看着绕但用起来很简单,极简主义友情提示,不要被复杂的结构迷惑。
在彻底定位目标数据之前,我们先简单明确两个概念:网页分为静态和动态;我们可以粗暴理解为,直接右键——查看源代码,这里显示的是静态网址的内容,如果里面包含我们需要的数据,那直接访问最初的网址(浏览器网址栏的网址)即可。
而有的数据是在我们浏览的过程中默默新加载(浏览过程中向服务器发送的请求)的,这部分网页的数据一般藏在JS/XHR模块里面。
爬取豆瓣书评的python代码

爬取豆瓣书评的python代码引言概述:在当今信息爆炸的时代,人们对于书籍的选择越来越依赖于他人的推荐和评价。
而豆瓣作为一个广受欢迎的图书评价平台,拥有大量的书评资源。
为了更好地挖掘这些宝贵的信息,我们可以利用Python编写一个爬虫程序,来自动爬取豆瓣书评。
本文将详细介绍如何编写这样一个爬虫程序。
正文内容:1. 爬取书籍基本信息1.1 确定目标书籍首先,我们需要确定要爬取的目标书籍。
可以通过书名、作者等信息来搜索目标书籍,并获得其豆瓣页面的URL。
1.2 解析HTML页面利用Python的第三方库,如BeautifulSoup或Scrapy,我们可以轻松地解析HTML页面,提取出需要的信息。
可以通过分析豆瓣书评页面的HTML结构,找到书籍的基本信息,如书名、作者、出版社等。
1.3 爬取书籍评分和评价人数除了基本信息外,评分和评价人数也是衡量一本书受欢迎程度的重要指标。
我们可以通过解析页面,提取出评分和评价人数的信息。
2. 爬取书评内容2.1 获取书评列表在豆瓣书籍的页面上,有一个书评列表,包含了用户对这本书的评价和评论。
我们可以通过解析页面,获取到这个书评列表的URL。
2.2 解析书评列表页面利用Python的爬虫库,我们可以发送HTTP请求,获取到书评列表页面的HTML内容。
然后,通过解析HTML,我们可以提取出每条书评的标题、评分、评论内容等信息。
2.3 翻页爬取豆瓣的书评列表通常是分页显示的,我们可以通过翻页的方式,获取到更多的书评内容。
可以通过分析页面的URL规律,来构造下一页的URL,并继续发送HTTP请求,获取到下一页的书评列表。
3. 数据存储与分析3.1 存储数据爬取到的书籍基本信息、评分、评价人数以及书评内容等数据,可以选择存储到数据库中,如MySQL或MongoDB。
也可以保存为文本文件或Excel表格,以便后续分析和使用。
3.2 数据分析爬取到的数据可以进行各种分析,如统计不同书籍的平均评分、评价人数分布等。
爬取豆瓣读书课设总结

爬取豆瓣读书课设总结
本文将介绍如何使用Python爬取豆瓣读书网站的书籍数据,以及如何将数据进行处理和分析。
具体内容如下:
1. 爬取豆瓣读书网站的数据
使用Python中的requests和BeautifulSoup库,可以轻松地爬取豆瓣读书网站的书籍数据。
具体步骤为:先发送HTTP请求获取网页内容,然后使用BeautifulSoup库对网页进行解析,从中提取出需要的数据。
2. 处理爬取到的数据
得到爬取到的书籍数据后,需要进行一些处理,例如去除空格和换行符,将字符串转换为数字等。
同时,还要处理一些异常情况,例如爬取到的数据缺失或者格式不正确。
3. 数据分析
得到处理后的数据后,可以使用Python中的Pandas库进行数据分析。
比如,可以计算出每个作者的平均评分、每种类型书籍的数量等等。
同时,还可以使用Matplotlib库对数据进行可视化,从而更直观地展示分析结果。
总之,使用Python爬取豆瓣读书网站的数据,可以轻松地获取大量的书籍数据,并进行分析和处理,为我们提供更全面的了解和参考。
- 1 -。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
采集网站:
https:///tag/%E5%B0%8F%E8%AF%B4?start=0&type =T
规则下载:
使用功能点:
●分页列表及详细信息提取
/tutorial/fylbxq7.aspx?t=1
●Xpath
/tutorialdetail-1/xpath1.html
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
2)将要采集的网址URL ,复制粘贴到网址输入框中,点击“保存网址”
豆瓣图书信息采集步骤2
1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
将页面下拉到底部,点击“后页>”按钮,在右侧的操作提示框中,选择“更多操作”
豆瓣图书信息采集步骤3
2)选择“循环点击单个链接”
豆瓣图书信息采集步骤4
步骤3:创建列表循环
1)移动鼠标,选中页面里的第一个图书链接。
选中后,系统会自动识别页面里的其他相似链接。
在右侧操作提示框中,选择“选中全部”
豆瓣图书信息采集步骤5
2)选择“循环点击每个链接”,以创建一个列表循环
豆瓣图书信息采集步骤6
1)在创建列表循环后,系统会自动点击第一个图书链接,进入图书详细信息页。
点击需要的字段信息,在右侧的操作提示框中,选择“采集该元素的文本”。
我们在这里,采集了图书名称、图书出版信息、内容简介、作者简介
豆瓣图书信息采集步骤7
2)字段信息选择完成后,选中相应的字段,可以进行字段的自定义命名,修改完成后,点击“确定”。
完成后,点击左上角的“保存并启动”,启动采集任务
豆瓣图书信息采集步骤8
3)选择“启动本地采集”
豆瓣图书信息采集步骤9
4)采集完成后,会跳出提示,选择“导出数据”。
选择“合适的导出方式”,将采集好的数据导出。
这里我们选择excel作为导出为格式,数据导出后如下图
豆瓣图书信息采集步骤10
步骤5:修改Xpath
通过上述导出的数据我们可以发现,部分图书的“内容简介”、“作者简介”没有采集下来(如:《解忧杂货店》图书详情页的“内容简介”采集下来了,但是《雪落香杉树》图书详情页的“内容简介”并未采集下来)。
这是因为,每个图书详情页的网页情况有所不同,系统自动生成的Xpath,不能完全正确定位到每个图书详情页的“内容简介”和“作者简介”。
以下将以“内容简介”这个字段为例,具体讲解xpath的修改。
“作者简介”字段修改同理,在此文中不做多讲。
1)选中“提取元素”步骤,点击“内容简介”字段,再点击如图所示的按钮
豆瓣图书信息采集步骤11
2)选择“自定义定位元素方式”
豆瓣图书信息采集步骤12
3)将八爪鱼系统自动生成的这条Xpath:
//DIV[@id='link-report']/DIV[1]/DIV[1]/P[1],复制粘贴到火狐浏览器中进行检测
豆瓣图书信息采集步骤13
4)将八爪鱼系统自动生成的此条Xpath,删减为
//DIV[@id='link-report']/DIV[1]/DIV[1](P[1]代表内容简介里的第一段,删掉即可定位到整个内容简介段落)。
我们发现:通过此条Xpath:
//DIV[@id='link-report']/DIV[1]/DIV[1],在《解忧杂货店》图书详情页,可以定位到“内容简介”字段,但是在《雪落香杉树》图书详情页,不能定位到“内容简介”字段
豆瓣图书信息采集步骤14
《解忧杂货店》图书详情页:可定位到“内容简介”字段
豆瓣图书信息采集步骤15
《雪落香杉树》图书详情页:不能定位到“内容简介”字段
5)观察网页源码发现,图书详情页“内容简介”字段,都具有相同的class属性,通过class属性,我们可写出一条能够定位所有图书详情页“内容简介”字段的Xpath:.//*[@id='link-report']//div[@class='intro']。
在火狐浏览器中检查发现,通过此条Xpath,确实能都定位到所有图书详情页的“内容简介”字段
豆瓣图书信息采集步骤16
6)将新写的此条Xpath:.//*[@id='link-report']//div[@class='intro'],复制粘贴到八爪鱼中的相应位置,并点击“确定”
豆瓣图书信息采集步骤17
7)重新“启动本地采集”并导出数据。
可以看到,所有图书详情页的“内容简介”字段均被抓取下来
豆瓣图书信息采集步骤18
注意:“作者简介”字段修改同理,需要修改Xpath,在此文中不做多讲。
相关采集教程:
新浪微博数据采集
豆瓣电影短评采集
搜狗微信文章采集
八爪鱼——70万用户选择的网页数据采集器。