二叉树的存储与遍历
洛谷题解P4913【【深基16.例3】二叉树深度】

洛⾕题解P4913【【深基16.例3】⼆叉树深度】这是⼀道关于⼆叉树的⼊门题。
这题主要考察⼆叉树的存储以及⼆叉树的遍历。
那么我就来分这两部分来讲。
Part 1 存储考虑⼀个⼆叉树的每个节点都有两个⼦节点,所以我们可以考虑⽤⼀个结构体来存储:其中,和分别代表节点的左节点编号和右节点编号。
当读⼊时,就⾮常⽅便了,直接读⼊即可:Part 2 遍历这道题要我们求⼆叉树的深度,就⼀定要遍历这棵树。
⾸先明确⼀点题⽬中未提到的,编号为1的节点是⼆叉树的根节点。
于是我们可以从根节点出发,先递归遍历该节点的左节点,再递归遍历该节点的右节点。
其中还要记录该节点的深度,出发时深度为1每到⼀个节点时更新⼀下深度:到达叶⼦节点时,就总体上就这么多吧。
因为每个节点遍历⼀次,所以总时间复杂度为O (n )AC Codestruct node { int left, right;};node tree[MAXN];left right _for (i, 1, n) cin >> tree[i].left >> tree[i].right;dfs(tree[id].left, deep+1);dfs(tree[id].right, deep+1);ans = max(ans, deep);return if (id == 0) return ;#include <iostream>#define _for(i, a, b) for (int i=(a); i<=(b); i++)using namespace std;const int MAXN = 1e6 + 10;struct node {int left, right;};node tree[MAXN];//存储结构定义int n, ans;void dfs(int id, int deep) {if (id == 0) return ;//到达叶⼦节点时返回ans = max(ans, deep);//更新答案dfs(tree[id].left, deep+1);//向左遍历dfs(tree[id].right, deep+1);//向右遍历}int main() {cin >> n;_for (i, 1, n) cin >> tree[i].left >> tree[i].right;//读⼊+建树dfs(1, 1);//从1号节点出发,当前深度为1cout << ans << endl;//输出答案return 0;//完结撒花!}Processing math: 100%。
实验报告:二叉树

实验报告:二叉树第一篇:实验报告:二叉树实验报告二叉树一实验目的1、进一步掌握指针变量,动态变量的含义;2、掌握二叉树的结构特性以及各种存储结构的特点及适用范围。
3、掌握用指针类型描述、访问和处理二叉树的运算。
4、熟悉各种存储结构的特征以及如何应用树结构解决具体问题。
二实验原理树形结构是一种应用十分广泛和重要的非线性数据结构,是一种以分支关系定义的层次结构。
在这种结构中,每个数据元素至多只有一个前驱,但可以有多个后继;数据元素之间的关系是一对多的层次关系。
树形结构主要用于描述客观世界中具有层次结构的数据关系,它在客观世界中大量存在。
遍历二叉树的实质是将非线性结构转为线性结构。
三使用仪器,材料计算机 2 Wndows xp 3 VC6.0四实验步骤【问题描述】建立一个二叉树,请分别按前序,中序和后序遍历该二叉树。
【基本要求】从键盘接受输入(按前序顺序),以二叉链表作为存储结构,建立二叉树(以前序来建立),并采用递归算法对其进行前序,中序和后序遍历,将结果输出。
【实现提示】按前序次序输入二叉树中结点的值(一个整数),0表示空树,叶子结点的特征是其左右孩子指针为空。
五实验过程原始记录基本数据结构描述; 2 函数间的调用关系;用类C语言描述各个子函数的算法;附录:源程序。
六试验结果分析将实验结果分析、实验中遇到的问题和解决问题的方法以及关于本实验项目的心得体会,写在实验报告上。
第二篇:数据结构-二叉树的遍历实验报告实验报告课程名:数据结构(C语言版)实验名:二叉树的遍历姓名:班级:学号:时间:2014.11.03一实验目的与要求1.掌握二叉树的存储方法2.掌握二叉树的三种遍历方法3.实现二叉树的三种遍历方法中的一种二实验内容• 接受用户输入一株二叉树• 输出这株二叉树的前根, 中根, 后根遍历中任意一种的顺序三实验结果与分析//*********************************************************** //头文件#include #include //*********************************************************** //宏定义#define OK 1 #define ERROR 0 #define OVERFLOW 0//*********************************************************** typedef struct BiTNode { //二叉树二叉链表存储结构char data;struct BiTNode *lChild,*rChild;}BiTNode,*BiTree;//******************************** *************************** int CreateBiTree(BiTree &T){ //按先序次序输入二叉中树结点的值,空格表示空树//构造二叉链表表示的二叉树T char ch;fflush(stdin);scanf(“%c”,&ch);if(ch==' ')T=NULL;else{ if(!(T=(BiTNode *)malloc(sizeof(BiTNode))))return(OVERFLOW);T->data=ch;Creat eBiTree(T->lChild);CreateBiTree(T->rChild);} return(OK);} //********************************************************* void PreOrderTraverse(BiTree T){ //采用二叉链表存储结构,先序遍历二叉树的递归算法if(T){ printf(“%c”,T->data);PreOrderTraverse(T->lChild);PreOrd erTraverse(T->rChild);} } /***********************************************************/ void InOrderTraverse(BiTree T){ //采用二叉链表存储结构,中序遍历二叉树的递归算法if(T){ InOrderTraverse(T->lChild);printf(“%c”,T->data);InOrderT raverse(T->rChild);} }//*********************************************************** void PostOrderTraverse(BiTree T){ //采用二叉链表存储结构,后序遍历二叉树的递归算法if(T){ PostOrderTraverse(T->lChild);PostOrderTraverse(T->rChild) ;printf(“%c”,T->data);} }//*********************************************************** void main(){ //主函数分别实现建立并输出先、中、后序遍历二叉树printf(“please input your tree follow the PreOrder:n”);BiTNode *Tree;CreateBiTree(Tree);printf(“n先序遍历二叉树:”);PreOrderTraverse(Tree);printf(“n中序遍历二叉树:”);InOrderTraverse(Tree);printf(“n后序遍历二叉树:”);PostOrderTraverse(Tree);}图1:二叉树的遍历运行结果第三篇:数据结构二叉树操作验证实验报告班级:计算机11-2 学号:40 姓名:朱报龙成绩:_________实验七二叉树操作验证一、实验目的⑴ 掌握二叉树的逻辑结构;⑵ 掌握二叉树的二叉链表存储结构;⑶ 掌握基于二叉链表存储的二叉树的遍历操作的实现。
数据结构之二叉树(BinaryTree)

数据结构之⼆叉树(BinaryTree)⽬录导读 ⼆叉树是⼀种很常见的数据结构,但要注意的是,⼆叉树并不是树的特殊情况,⼆叉树与树是两种不⼀样的数据结构。
⽬录 ⼀、⼆叉树的定义 ⼆、⼆叉树为何不是特殊的树 三、⼆叉树的五种基本形态 四、⼆叉树相关术语 五、⼆叉树的主要性质(6个) 六、⼆叉树的存储结构(2种) 七、⼆叉树的遍历算法(4种) ⼋、⼆叉树的基本应⽤:⼆叉排序树、平衡⼆叉树、赫夫曼树及赫夫曼编码⼀、⼆叉树的定义 如果你知道树的定义(有限个结点组成的具有层次关系的集合),那么就很好理解⼆叉树了。
定义:⼆叉树是n(n≥0)个结点的有限集,⼆叉树是每个结点最多有两个⼦树的树结构,它由⼀个根结点及左⼦树和右⼦树组成。
(这⾥的左⼦树和右⼦树也是⼆叉树)。
值得注意的是,⼆叉树和“度⾄多为2的有序树”⼏乎⼀样,但,⼆叉树不是树的特殊情形。
具体分析如下⼆、⼆叉树为何不是特殊的树 1、⼆叉树与⽆序树不同 ⼆叉树的⼦树有左右之分,不能颠倒。
⽆序树的⼦树⽆左右之分。
2、⼆叉树与有序树也不同(关键) 当有序树有两个⼦树时,确实可以看做⼀颗⼆叉树,但当只有⼀个⼦树时,就没有了左右之分,如图所⽰:三、⼆叉树的五种基本状态四、⼆叉树相关术语是满⼆叉树;⽽国际定义为,不存在度为1的结点,即结点的度要么为2要么为0,这样的⼆叉树就称为满⼆叉树。
这两种概念完全不同,既然在国内,我们就默认第⼀种定义就好)。
完全⼆叉树:如果将⼀颗深度为K的⼆叉树按从上到下、从左到右的顺序进⾏编号,如果各结点的编号与深度为K的满⼆叉树相同位置的编号完全对应,那么这就是⼀颗完全⼆叉树。
如图所⽰:五、⼆叉树的主要性质 ⼆叉树的性质是基于它的结构⽽得来的,这些性质不必死记,使⽤到再查询或者⾃⼰根据⼆叉树结构进⾏推理即可。
性质1:⾮空⼆叉树的叶⼦结点数等于双分⽀结点数加1。
证明:设⼆叉树的叶⼦结点数为X,单分⽀结点数为Y,双分⽀结点数为Z。
数据结构-二叉树的存储结构和遍历

return(p); }
建立二叉树
以字符串的形式“根左子树右子树”定义 一棵二叉树
1)空树 2)只含一个根 结点的二叉树 A 3)
B C
A
以空白字符“ ”表示
以字符串“A ”表示
D
以下列字符串表示 AB C D
建立二叉树 A B C C
T
A ^ B ^ C^ ^ D^
D
建立二叉树
Status CreateBiTree(BiTree &T) {
1 if (!T) return;
2 Inorder(T->lchild, visit); // 遍历左子树 3 visit(T->data); } // 访问结点 4 Inorder(T->rchild, visit); // 遍历右子树
后序(根)遍历
若二叉树为空树,则空操
根
左 子树
右 子树
作;否则, (1)后序遍历左子树; (2)后序遍历右子树; (3)访问根结点。
统计二叉树中结点的个数
遍历访问了每个结点一次且仅一次
设置一个全局变量count=0
将visit改为:count++
统计二叉树中结点的个数
void PreOrder (BiTree T){ if (! T ) return; count++; Preorder( T->lchild); Preorder( T->rchild); } void Preorder (BiTree T,void( *visit)(TElemType& e)) { // 先序遍历二叉树 1 if (!T) return; 2 visit(T->data); // 访问结点 3 Preorder(T->lchild, visit); // 遍历左子树 4 Preorder(T->rchild, visit);// 遍历右子树 }
计算机二级公共基础专题探究——二叉树

公共基础专题探究——二叉树1.6 树与二叉树树是一种简单的非线性结构,所有元素之间具有明显的层次特性。
在树结构中,没有前件的结点只有一个,称为树的根结点,简称树的根。
每一个结点可以有多个后件,称为该结点的子结点。
没有后件的结点称为叶子结点。
在树结构中,一个结点所拥有的后件的个数称为该结点的度,所有结点中最大的度称为树的度。
为该结点的左子树与右子树。
二叉树的基本性质:必考的题目(1)在二叉树的第k层上,最多有2k-1(k≥1)个结点;(2)深度为m的二叉树最多有2m-1个结点;(3)度为0的结点(即叶子结点)总是比度为2的结点多一个;(4)二叉树中 n = n0 +n1 +n2k层上有2k-1个结点深度为m的满二叉树有2m-1个结点。
若干结点。
二叉树的遍历:(一般画个图要你把顺序写出来)后序遍历(访问根结点在访问左子树和访问右子树之后)重点题型:二叉树的遍历例1:某二叉树的前序序列为ABCD,中序序列为DCBA,则后序序列为(DCBA )。
【解析】前序序列为ABCD,可知A为根结点。
根据中序序列为DCBA可知DCB是A的左子树。
根据前序序列可知B是CD的根结点。
再根据中序序列可知DC是结点B的左子树。
根据前序序列可知,C是D的根结点,故后序序列为DCBA例2:对下列二叉树进行前序遍历的结果为 ABDYECFXZ例3:设二叉树如下,则后序序列为 DGEBHFCA【解析】本题中前序遍历为ABDEGCFH,中序遍历为DBGEAFHC,后序遍历为DGEBHFCA完全二叉树指除最后一层外,每一层上的结点数均达到最大值,在最后堆排序问题:例1:已知前序序列与中序序列均为ABCDEFGH,求后序序列【解析】设根节点为D≠0,左子树为L,右子树为R,有遍历顺序为:前:D-L-R 已知ABCDEFGH中:L-D-R 已知ABCDEFGH后:L-R-D 待求由此可知,L=0,D-R= ABCDEFGH故R-D=HGFEDCBA,即后序序列= HGFEDCBA变式训练1:已知后序序列与中序序列均为ABCDEFGH,求前序序列答案:HGFEDCBA,(这次R=0)结论:若前序序列与中序序列均为某序列,则后序序列为该序列的倒序,且为折线;同样地,若后序序列与中序序列均为某序列,则前序序列为该序列的倒序,且为折线例2:已知前序序列=ABCD,中序序列=DCBA,求后序序列【解析】设根节点为D≠0,左子树为L,右子树为R,有遍历顺序为:前:D-L-R 已知ABCD中:L-D-R 已知DCBA后:L-R-D 待求因为ABCD与DCBA正好相反,由此可知,R=0所以D-L=ABCD,即L-D=DCBA所以后序序列= DCBA变式训练2-1:中序序列=BDCA,后序序列=DCBA,求前序序列【解析】设根节点为D≠0,左子树为L,右子树为R,有遍历顺序为:前:D-L-R 待求中:L-D-R 已知BDC,A后:L-R-D 已知DCB,A通过观察可知,R=0,L={B,D,C},D=A中、后变换时,{B,D,C}发生了变化,说明左子树结构特殊,进一步令中’:L’-D’-R’已知B,DC后’:L’-R’-D’已知DC,B可知L’=0,即D’=B,R’= DC可以画出二叉树示意图为:Array所以前序序列= ABCD变式训练2-2:中序序列=ABC,后序序列=CBA,求前序序列【解析】设根节点为D≠0,左子树为L,右子树为R,有遍历顺序为:前:D-L-R 待求中:L-D-R 已知ABC后:L-R-D 已知通过观察可知,L=0,D-R=ABC,R-D=CBA所以前序序列=D-L-R= D-R=ABC变式训练2-3:前序序列=ABC,中序序列=CBA,求后序序列【解析】设根节点为D≠0,左子树为L,右子树为R,有遍历顺序为:前:D-L-R 已知A,BC中:L-D-R 已知CB,A后:L-R-D 待求通过观察可知,D=A ,L={B,C},R=0所以后序序列=CBA (一边偏)题型二:求二叉树的深度。
数据结构——- 二叉树

证明: 5.1 二叉树的概念
(1)总结点数为 ●二叉树的主要性质 n=n0+n1+n2 (2)除根结点外,每个 ●性质3: 结点都有一个边e进入 任何一棵二叉树,若其终端结点数为n0, n=e+1 度为2的结点数为n2,则n0=n2+1 (3)边e又是由度为1或2 A 的点射出,因此 e=n1+2n2 G B (4)由(2)(3) F C D n=n1+2n2+1 (5)由(4)-(1)可得 G n0=n2+1
《数据结构与算法》
★★★★★
第五章 二叉树
廊坊师范学院 数学与信息科学学院
树型结构--实例:五子棋
A
B
D
E
F
C
…...........
…...........
第五章 二叉树
本章重点难点
重点: 二叉树的定义,性质,存储结 构以及相关的应用——遍历,二叉搜 索树,堆优先 队列,Huffman树等 难点: 二叉树的遍历算法及相关应用
证明: 5.1 二叉树的概念
(1)总结点数为 ●二叉树的主要性质 n=n0+n1+n2 (2)除根结点外,每个 ●性质3: 结点都有一个边e进入 任何一棵二叉树,若其终端结点数为n0, n=e+1 度为2的结点数为n2,则n0=n2+1 (3)边e又是由度为1或2 A 的点射出,因此 e=n1+2n2 G B (4)由(2)(3) F C D n=n1+2n2+1 (5)由(4)-(1)可得 G n0=n2+1
A B C E D F G
证明: 由性质4可推出
由性质2(深度为k的 二叉树,至多有2k+1-1 个结点)可知,高度 为h(k+1)的二叉树,其 有n (n>0)个结点的完全二叉树的高度为 结点个数n满足: 「log2(n+1) ,深度为「log2(n+1) -1 2h-1-1<n<=2h-1 高度:二叉树中最大叶结点的层数+1 2h-1<n+1<=2h 取对数得到: 0层 1 h-1<log2(n+1)<=h 3 1层 2 因为h是整数,所以 h= log2(n+1) 5 2层 4
二叉树的各种基本运算的实现实验报告

二叉树的各种基本运算的实现实验报告
一、实验目的
实验目的为了深入学习二叉树的各种基本运算,通过操作实现二叉树的建立、存储、查找、删除、遍历等各种基本运算操作。
二、实验内容
1、构造一个二叉树。
我们首先用一定的节点来构建一棵二叉树,包括节点的左子节点和右子节点。
2、实现查找二叉树中的节点。
在查找二叉树中的节点时,我们根据二叉树的特点,从根节点开始查找,根据要查找的节点的值与根节点的值的大小的关系,来决定接下来查找的方向,直到找到要查找的节点为止。
3、实现删除二叉树中的节点。
在删除二叉树节点时,我们要做的是找到要删除节点的父节点,然后让父节点的链接指向要删除节点的子节点,有可能要删除节点有一个子节点,有可能有两个极点,有可能没有子节点,我们要根据每种情况进行处理,来保持二叉树的结构不变。
4、对二叉树进行遍历操作。
二叉树的遍历有多种方法,本实验使用的是先序遍历。
首先从根节点出发,根据先序遍历的顺序,先访问左子树,然后再访问右子树,最后访问根节点。
三、实验步骤
1、构建二叉树:
我们用一个数组代表要构建的二叉树,第一项为根节点,第二项和第三项是根节点的子节点。
树的存储结构、遍历;二叉树的定义、性质、存储结构、遍历以及树、森林、二叉树的转换

树和二叉树树与二叉树是本书的重点内容之一,知识点多且比较零碎。
其中二叉树又是本章的重点。
在本章中我们要了解树的定义、熟悉树的存储结构、遍历;二叉树的定义、性质、存储结构、遍历以及树、森林、二叉树的转换。
哈夫曼树及哈夫曼编码等内容。
算法的重点是二叉树的遍历及其应用。
6.1 树的定义一、树的定义树:树是n(n>0)个结点的有限集合T。
一棵树满足下列条件:(1)有且仅有一个称为根的结点;(2)其余结点可分为m(m>=0)棵互不相交的有限集合T1,T2,T3,…Tm,其中每个集合又是一棵树,并称之为根的子树。
有关树的一些基本概念:1)结点的度:树中每个结点具有的子树数目或后继结点数。
如图中结点A的度为2,B的度为32) 树的度:所有结点的度的最大值为树的度。
(图中树的度为3)3) 分支结点:即:树中所有度大于0的结点。
4) 叶子结点:即:树中度为零的结点,也称为终端结点。
5) 孩子结点:一个结点的后续结点称为该结点的孩子结点。
6) 双亲结点:一个结点为其后继结点的双亲结点。
7) 子孙结点:一个结点的所有子树中的结点为该结点的子孙结点。
8) 祖先结点:从根结点到一个结点的路径上所有结点(除自己外)称为该结点的祖先结点。
(如A和B为D结点的祖先结点)9) 兄弟结点:具有同一父亲的结点互相为兄弟结点。
(如B和C为兄弟结点)10) 结点的层数:从根结点到该结点的路径上的结点总数称为该结点的层数(包括该结点)。
11) 树的深度(高度):树中结点的最大层数为树的深度。
(图中树的深度为4)12) 森林:0个或多个互不相交的树的集合。
上图中:树的度为3,树的深度为4。
结点A,B,C,D,E,F,G,H,I,J的度分别为:2, 3, 2, 0 ,2 , 0, 0, 0, 0, 0叶结点有:D, F, G, H, I, JB,C为兄弟,D, E, F为兄弟,F, G为兄弟。
I,J为兄弟。
二、树的表示1. 树的逻辑结构描述Tree=(D,R)其中:D为具有相同性质的数据元素的集合。
实现二叉链表存储结构下二叉树的先序遍历的非递归算法

实现二叉链表存储结构下二叉树的先序遍历的非递归算法要实现二叉链表存储结构下二叉树的先序遍历的非递归算法,可以使用栈来辅助存储节点。
首先,创建一个空栈,并将树的根节点压入栈中。
然后,循环执行以下步骤,直到栈为空:1. 弹出栈顶的节点,并访问该节点。
2. 若该节点存在右子节点,则将右子节点压入栈中。
3. 若该节点存在左子节点,则将左子节点压入栈中。
注:先将右子节点压入栈中,再将左子节点压入栈中的原因是,出栈操作时会先访问左子节点。
下面是使用Python语言实现的例子:```pythonclass TreeNode:def __init__(self, value):self.val = valueself.left = Noneself.right = Nonedef preorderTraversal(root):if root is None:return []stack = []result = []node = rootwhile stack or node:while node:result.append(node.val)stack.append(node)node = node.leftnode = stack.pop()node = node.rightreturn result```这里的树节点类为`TreeNode`,其中包含节点的值属性`val`,以及左子节点和右子节点属性`left`和`right`。
`preorderTraversal`函数为非递归的先序遍历实现,输入参数为二叉树的根节点。
函数中使用了一个栈`stack`来存储节点,以及一个列表`result`来存储遍历结果。
在函数中,先判断根节点是否为None。
如果是,则直接返回空列表。
然后,创建一个空栈和结果列表。
接下来,用一个`while`循环来执行上述的遍历过程。
循环的条件是栈`stack`不为空或者当前节点`node`不为None。
设计以先序遍历的顺序建立二叉树的二叉链表存储结构的算法

设计以先序遍历的顺序建立二叉树的二叉链表存储结构的算法一、算法简介二叉树是一种重要的树形结构,它的建立方式有多种,其中一种是按照先序遍历的顺序建立二叉树。
这种方式需要将先序遍历序列和二叉树的存储结构相结合,采用二叉链表存储结构。
具体流程是按照先序遍历序列的顺序依次创建二叉树的各个节点,同时使用二叉链表结构保存每个节点的数据和指针信息。
二、算法实现算法的实现主要包括初始化二叉树、创建节点、建立二叉树等步骤,下面对这些步骤进行详细描述。
1. 初始化二叉树初始化二叉树需要创建一个根节点,同时将根节点的左右指针指向NULL,表示二叉树为空。
2. 创建节点创建节点需要通过输入元素数据来创建,同时节点的左右指针也需要初始化为NULL。
3. 建立二叉树建立二叉树是按照先序遍历序列来实现的,具体流程如下:(1)读入当前节点的元素数据,创建节点,并将其作为当前节点。
(2)判断当前节点的元素数据是否为结束符号(这里结束符号可以指定),如果是,则返回NULL。
(3)递归创建当前节点的左子树,将左子树的根节点赋值给当前节点的左指针。
(4)递归创建当前节点的右子树,将右子树的根节点赋值给当前节点的右指针。
(5)返回当前节点。
三、算法优化虽然上述算法实现简单明了,但它有一个缺点,即无法处理空节点的情况,如果输入的先序遍历序列中存在空节点,那么该算法就无法建立正确的二叉树了。
因此,可以在输入的先序遍历序列中使用一个特殊的符号(如#)表示空节点,在建立节点时,如果遇到该符号,则将该节点的指针设置为NULL即可。
四、算法总结按照先序遍历的顺序建立二叉树是一种基于二叉链表存储结构的建树方式。
它通过递归的方式构建整个二叉树,同时为了处理空节点的情况,还需要对输入的先序遍历序列进行特殊处理。
该算法的效率较高,适用于对先序遍历序列已知的情况下建立二叉树。
二叉树的遍历PPT-课件

4 、二叉树的创建算法
利用二叉树前序遍历的结果可以非常方便地生成给定的
二叉树,具体做法是:将第一个输入的结点作为二叉树的 根结点,后继输入的结点序列是二叉树左子树前序遍历的 结果,由它们生成二叉树的左子树;再接下来输入的结点 序列为二叉树右子树前序遍历的结果,应该由它们生成二 叉树的右子树;而由二叉树左子树前序遍历的结果生成二 叉树的左子树和由二叉树右子树前序遍历的结果生成二叉 树的右子树的过程均与由整棵二叉树的前序遍历结果生成 该二叉树的过程完全相同,只是所处理的对象范围不同, 于是完全可以使用递归方式加以实现。
void createbintree(bintree *t) { char ch; if ((ch=getchar())==' ') *t=NULL; else { *t=(bintnode *)malloc(sizeof(bintnode)); /*生成二叉树的根结点*/ (*t)->data=ch; createbintree(&(*t)->lchild); /*递归实现左子树的建立*/ createbintree(&(*t)->rchild); /*递归实现右子树的建立*/ }
if (s.top>-1) { t=s.data[s.top]; s.tag[s.top]=1; t=t->rchild; }
else t=NULL; }
}
7.5 二叉树其它运算的实现
由于二叉树本身的定义是递归的,因此关于二叉树的许多 问题或运算采用递归方式实现非常地简单和自然。 1、二叉树的查找locate(t,x)
(1)对一棵二叉树中序遍历时,若我们将二叉树严
格地按左子树的所有结点位于根结点的左侧,右子树的所
《算法导论》读书笔记之第10章 基本数据结构之二叉树

《算法导论》读书笔记之第10章基本数据结构之二叉树摘要书中第10章10.4小节介绍了有根树,简单介绍了二叉树和分支数目无限制的有根树的存储结构,而没有关于二叉树的遍历过程。
为此对二叉树做个简单的总结,介绍一下二叉树基本概念、性质、二叉树的存储结构和遍历过程,主要包括先根遍历、中根遍历、后根遍历和层次遍历。
1、二叉树的定义二叉树(Binary Tree)是一种特殊的树型结构,每个节点至多有两棵子树,且二叉树的子树有左右之分,次序不能颠倒。
由定义可知,二叉树中不存在度(结点拥有的子树数目)大于2的节点。
二叉树形状如下下图所示:2、二叉树的性质(1)在二叉树中的第i层上至多有2^(i-1)个结点(i>=1)。
备注:^表示此方(2)深度为k的二叉树至多有2^k-1个节点(k>=1)。
(3)对任何一棵二叉树T,如果其终端结点数目为n0,度为2的节点数目为n2,则n0=n2+1。
满二叉树:深度为k且具有2^k-1个结点的二叉树。
即满二叉树中的每一层上的结点数都是最大的结点数。
完全二叉树:深度为k具有n个结点的二叉树,当且仅当每一个结点与深度为k的满二叉树中的编号从1至n的结点一一对应。
可以得到一般结论:满二叉树和完全二叉树是两种特殊形态的二叉树,满二叉树肯定是完全二叉树,但完全二叉树不不一定是满二叉树。
举例如下图是所示:(4)具有n个节点的完全二叉树的深度为log2n + 1。
3、二叉树的存储结构可以采用顺序存储数组和链式存储二叉链表两种方法来存储二叉树。
经常使用的二叉链表方法,因为其非常灵活,方便二叉树的操作。
二叉树的二叉链表存储结构如下所示:1 typedef struct binary_tree_node2 {3 int elem;4 struct binary_tree_node *left;5 struct binary_tree_node *right;6 }binary_tree_node,*binary_tree;举例说明二叉链表存储过程,如下图所示:从图中可以看出:在还有n个结点的二叉链表中有n+1个空链域。
二叉树

6-2-2 二叉树的基本操作与存储实现
1、二叉树的基本操作 Initiate(bt)
Create(x, lbt, rbt)
InsertL(bt, x, parent) InsertR(bt, x, parent) DeleteL(bt,parent) DeleteR(bt,parent)
Search(bt,x)
BiTree DeleteL(BiTree bt, BiTree parent){ BiTree p; if(parent==NULL||parent->lchild==NULL){ cout<<“删除出错”<<endl; return NULL; } p=parent->lchild; parent->lchild =NULL; delete p; return bt ; }
a b c e 0 1 2 3 4 5 a b c d e ^ 6 7 8 9 10 ^ ^ ^ f g
d
f
g
特点:结点间关系蕴含在其存储位置中。浪费空间, 适于存满二叉树和完全二叉树。
二、链式存储结构 1、二叉链表存储法
A
B C E G D B A ^
lchild data rchild
F
^ C ^ typedef struct BiTNode { DataType data; struct BiTNode *lchild, *rchild; }BiTNode, *BiTree; ^ E
二叉树的五种基本形态
A
A
A B
A
B 空二叉树
B
C 左、右子树 均非空
只有根结点 的二叉树
右子树为空
左子树为空
05二叉树

}
if (Parent->Lchild == NULL) /* Parent所指结点左子树为空 */ Parent->Lchild = ptr;
else
{
/* Parent所指结点左子树非空 */
ptr->Lchild = Parent->Lchild;
Parent->Lchild = ptr;
}
二叉树可以是空的,空二叉树没有任何结 点; 二叉树上的每个结点最多可以有两棵子树, 这两棵子树是不相交的; 二叉树上一个结点的两棵子树有左、右之 分,次序是不能颠倒的。
图5-2 两棵不同的二叉树
从二叉树中的一个结点往下,到达它的 某个子、孙结点时所经由的路线,称为一条 “路径”。对于路径来说,从开始结点到终 止结点,中间经过的结点个数,称为路径的 “长度”。从根结点开始、到某个结点的路 径长度,称为该结点的“深度”。
一棵一般的二叉树,是由如下的3类结点组成的: 根结点——二叉树的起始结点; 分支(或内部结点)——至少有一个非空子树 (即度为1或2)的结点 叶结点——没有非空子树(即度为0)的结点。 有两种特殊的二叉树:满二叉树和完全二叉树。
所谓“满二叉树”,是指该二叉树的每 一个结点,或是有两个非空子树的结点,或 是叶结点,且每层都必须含有最多的结点个 数。
性质5-2 树高为k(k≥0)的二叉树, 最多有2k+1−1个结点。 【证明】由性质5-1可知,在树高为k的 二叉树里,第0层有20个结点,第1层有21个 结点,第2层有22个结点,„„,第k层有2k 个结点。因此,要求出树高为k的二叉树的 结点个数,就是求和:
20 + 21 + 22 +„+ 2k
第六章树与二叉树教案 二叉树的类型定义 存储结构 遍历 哈夫曼树与哈夫曼编码

即 k-1 ≤ log2 n < k
因为 k 只能是整数,因此, k =log2n + 1
问题:
一棵含有n个结点的二叉树,可能达 到的最大深度和最小深度各是多少?
1
答:最大n,
2
最小[log2n] + 1
第六章 树和二叉树教案
二叉树的类型定义 存储结构 遍历 哈夫曼树与哈夫曼编码
树是常用的数据结构
•家族 •各种组织结构 •操作系统中的文件管理 •编译原理中的源程序语法结构 •信息系统管理 •。。。。
2
6.1 树的类型定义 6.2 二叉树的类型定义
6.2.3 二叉树的存储结构 6.3 二叉树的遍历
二叉树上每个结点至多有两棵子树, 则第 i 层的结点数 = 2i-2 2 = 2i-1 。
性质 2 :
深度为 k 的二叉树上至多含 2k-1 个 结点(k≥1)。
证明:
基于上一条性质,深度为 k 的二叉
树上的结点数至多为
20+21+ +2k-1 = 2k-1 。
(等比数列求和)
k
k
(第i层的最大结点数) 2i1 2k
i 1
i 1
性质 3 :
对任何一棵二叉树,若它含有n0 个叶 子结点(0度节点)、n2 个度为 2 的结 点,则必存在关系式:n0 = n2+1。
证明:
设 二叉树上结点总数 n = n0 + n1 + n2 又 二叉树上分支总数 b = n1+2n2
而 b = n-1 = n0 + n1 + n2 - 1 由此, n0 = n2 + 1 。
第六章 树与二叉树

森林的遍历
(4) 广度优先遍历(层次序 遍历) :
数据结构
若森林F为空,返回; 否则 依次遍历各棵树的根 结点; 依次遍历各棵树根结 点的所有子女; 依次遍历这些子女结 森林的二叉树表示 点的子女结点。
45
二叉树的计数 由二叉树的前序序列和中序序列可唯 一地确定一棵二叉树。例, 前序序列 { ABHFDECKG } 和中序序列 { HBDFAEKCG }, 构造二叉树过程如 下:
三个结点构成的不同的二叉树
8
用二 叉 树 表达实际问题
例2 双人比赛的所有可能的结局
开始
甲
开局连赢两局 或五局三胜
乙
甲
甲 甲 乙
乙
乙 甲 乙 甲 甲 乙
甲
乙 甲
乙
乙
甲
乙甲
乙
甲
乙 甲 乙
二叉树的性质
数据结构
性质1 若二叉树的层次从1开始, 则在二叉树的 第 i 层最多有 2i -1个结点。(i 1) [证明用数学归纳法] 性质2 高度为k的二叉树最多有 2k-1个结点。 (k 0) [证明用求等比级数前k项和的公式]
前序遍历二叉树算法的框架是 若二叉树为空,则空操作; 否则 – 访问根结点 (V); – 前序遍历左子树 (L); – 前序遍历右子树 (R)。
遍历结果 -+a*b-cd/ef
27
数据结构
后序遍历 (Postorder Traversal)
后序遍历二叉树算法的框架是 若二叉树为空,则空操作; 否则 – 后序遍历左子树 (L); – 后序遍历右子树 (R); – 访问根结点 (V)。
数据结构
36
左子女-右兄弟表示法 第一种解决方案
理论基础 —— 二叉树
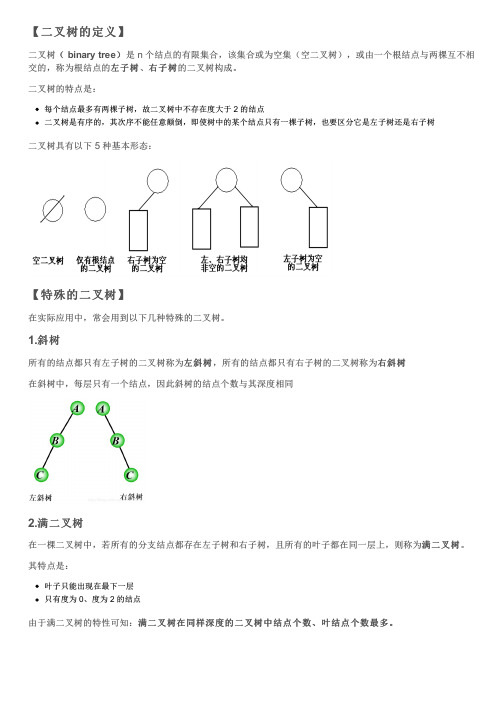
【二叉树的定义】( binary tree)是 n 个结点的有限集合,该集合或为空集(空二叉树),或由一个根结点与两棵互不相二叉树(右子树的二叉树构成。
交的,称为根结点的左子树左子树、右子树二叉树的特点是:每个结点最多有两棵子树,故二叉树中不存在度大于 2 的结点二叉树是有序的,其次序不能任意颠倒,即使树中的某个结点只有一棵子树,也要区分它是左子树还是右子树二叉树具有以下 5 种基本形态:【特殊的二叉树】在实际应用中,常会用到以下几种特殊的二叉树。
1.斜树右斜树左斜树,所有的结点都只有右子树的二叉树称为右斜树所有的结点都只有左子树的二叉树称为左斜树在斜树中,每层只有一个结点,因此斜树的结点个数与其深度相同2.满二叉树满二叉树。
在一棵二叉树中,若所有的分支结点都存在左子树和右子树,且所有的叶子都在同一层上,则称为满二叉树其特点是:叶子只能出现在最下一层只有度为 0、度为 2 的结点满二叉树在同样深度的二叉树中结点个数、叶结点个数最多。
由于满二叉树的特性可知:满二叉树在同样深度的二叉树中结点个数、叶结点个数最多。
3.完全二叉树对一棵具 n 个结点的二叉树按层序编号,若编号为 i 的结点与同样深度的满二叉树中编号 i 的结点在二叉树中的满二叉树是完全二叉树位置完全相同,则称为完全二叉树完全二叉树,那么显然有:满二叉树是完全二叉树其特点是:叶结点只能出现在最下两层,且最下层的叶结点都集中在二叉树左侧连续的位置若有度为 1 的结点,只可能有一个,且其只有左孩子深度为 k 的完全二叉树在 k -1 层上行一定是满二叉树简单来说,在满二叉树中,从最后一个结点开始,连续去掉任意个的结点,即是一棵完全二叉树【二叉树的性质】1.二叉树二叉树的第 i 层上行最多有个结点2.二叉树中,最多有个结点,最少有 k 个结点在一棵深度为 k 的二叉树推论:深度为 k 且具个结点的二叉树一定是满二叉树,但深度为 k 具有 k 个结点的二叉树不一定是斜树3.具有 n 个结点的二叉树二叉树,其分支数:B=n-1,对于任意一个结点,每度贡献一个分支,即:度为 0 的结点贡献 0 个分支,度为 1 的结点贡献 1 个分支,度为 2 的结点贡献 2 个分支。
二叉树的定义

二叉树的定义、定义、存储二叉树的定义二叉树是每个节点最多有两个子树的树结构。
通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。
二叉树常被用于实现二叉查找树和二叉堆。
二叉树的每个结点至多只有二棵子树(不存在度大于2的结点),二叉树的子树有左右之分,次序不能颠倒。
特殊二叉树1. 斜树所有结点都只有左子树的二叉树叫左斜树,所有结点都只有右子树的二叉树叫右斜树。
斜树的每一层都只有一个结点,结点的个数与斜树的深度相同。
2. 满二叉树在一棵二叉树中,如果所有分支结点都存在左子树和右子树,并且所有叶子结点都在同一层上,这样的二叉树称为满二叉树。
(上图中所示的二叉树,就是一棵满二叉树)3. 完全二叉树对一棵具有n个结点的二叉树按层序编号,如果编号为i(1≤i≤n)的结点与同样深度的满二叉树中的编号为i的结点在二叉树中的位置完全相同,则这棵二叉树称为完全二叉树。
二叉树的性质性质1:在二叉树的第i层上至多有2i-1个结点(i≥1)。
(数学归纳法可证)性质2:深度为k的二叉树最多有2k-1个结点(k≥1)。
(由性质1,通过等比数列求和可证)性质3:一棵二叉树的叶子结点数为n0,度为2的结点数为n2,则n0 = n2 + 1。
证:结点总数n = n0 + n1 + n2。
设B为分支总数,因为除根节点外,其余结点都有一个分支进入,所以n = B + 1。
又因为分支是由度为1或2的结点射出,所以B = n1 + 2n2。
综上:n = n0 + n1 + n2 = B + 1 = n1 + 2n2 + 1,得出:n0 = n2 + 1。
性质4:具有n个结点的完全二叉树的深度为floor(log2n) + 1 。
性质5:如果对一棵有n个结点的完全二叉树(其深度为floor(log2n) + 1 )的结点按层序编号,则对任一结点i(1≤i≤n)有:(1)如果i = 1,则结点i是二叉树的根,无双亲;如果i > 1,则其双亲PARENT(i)是结点 floor((i)/2)。
二叉树的顺序存储结构代码

二叉树的顺序存储结构代码介绍二叉树是一种常用的数据结构,它由节点组成,每个节点最多有两个子节点。
在计算机中,我们通常使用顺序存储结构来表示二叉树。
顺序存储结构是将二叉树的节点按照从上到下、从左到右的顺序依次存储在一个数组中。
本文将详细介绍二叉树的顺序存储结构代码,包括初始化、插入节点、删除节点以及遍历等操作。
二叉树的顺序存储结构代码实现初始化二叉树首先,我们需要定义一个数组来存储二叉树的节点。
假设数组的大小为n,则二叉树的最大节点数量为n-1。
# 初始化二叉树,将数组中所有元素置为空def init_binary_tree(n):binary_tree = [None] * nreturn binary_tree插入节点在二叉树的顺序存储结构中,节点的插入操作需要保持二叉树的特性,即左子节点小于父节点,右子节点大于父节点。
插入节点的算法如下:1.找到待插入位置的父节点索引parent_index。
2.如果待插入节点小于父节点,将其插入到父节点的左子节点位置,即数组索引2*parent_index+1处。
3.如果待插入节点大于父节点,将其插入到父节点的右子节点位置,即数组索引2*parent_index+2处。
# 插入节点def insert_node(binary_tree, node):index = 0 # 当前节点的索引值,初始值为根节点的索引值while binary_tree[index] is not None:if node < binary_tree[index]:index = 2 * index + 1 # 插入到左子节点else:index = 2 * index + 2 # 插入到右子节点binary_tree[index] = node删除节点删除节点需要保持二叉树的特性,即在删除节点后,仍然满足左子节点小于父节点,右子节点大于父节点的条件。
删除节点的算法如下:1.找到待删除节点的索引delete_index。
二叉树的遍历
T->rchild= CreatBiTree(); /*构造右子树*/ 扩展先序遍历序列
}
2021/2/21
return (T) ;}
A B Φ D Φ Φ C Φ 17Φ
T
T
T
ch=B
ch=Φ
Λ
T
T= Λ, Creat(T)
ch=A T
A
B creat(T L)
ΛB 返回
creat(T L)
creat(T R)
A
p=p->RChild;
}
2021/2/21
}
top
A
B
C
D
top
B
top
A
A
top
D
A
top
A
top
C
13
top
中序遍历二叉树的非递归算法:
A
void InOrder(BiTree T)
{ InitStack(&S); 相当于top=-1;
p=T;
B
C
while(p!=NULL | | !IsEmpty(S)) 相当于top==-1;
}
后序遍历二叉树的递归算法:
void PostOrder (BiTree T)
{ if(T!=NULL)
{ PostOrder (T->lchild);
PostOrder (T->rchild);
printf(T->data); }
2021/2/21
15
}
先序遍历二叉树的递归算法: void PreOder (BiTree T) { if(T! =NULL){ printf (T->data); PreOrder (T->lchild); PreOrder (T->rchild); } }
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
{ if ( T )
{ //如果二叉树不为空
Inorder ( T -> lchild ) ; //中序遍历左子树
printf( T -> data) ;
//输出根结点
Inorder ( T -> rchild ) ; //中序遍历右子树
// 左右孩子指针
} BiTNode, *BiTree;
2)三叉链表
例2:对例1
root
lchild
结点结构 data parent rchild
A
B
D
C
E
F
类型定义
typedef struct TriTNode { // 结点结构 TElemType data; struct TriTNode *lchild, *rchild;
Preorder ( T -> rchild ) ; //先序遍历右子树
}
}
2)中序遍历算法
若二叉树为空,则空操作;
否则,
中序遍历左子树; 访问根结点;
D
L
RБайду номын сангаас
中序遍历右子树。
例3: 中序遍历
L
D
R
A
A
B
C
LD R
L DR
□
D
□
□
□
□
B
C
L DR
中序遍历序列:B D A C
D
递归算法描述
void Inorder ( BiTree T )
// 左右孩子指针
struct TriTNode *parent; //双亲指针 } TriTNode, *TriTree;
例3: 链式存储结构示例
A
B
C
DE A
F A∧
B
∧C
B
∧C
∧ D ∧ ∧ E ∧ ∧ F ∧ ∧ D ∧ ∧∧ E ∧∧ ∧∧ F ∧∧
二叉链表
三叉链表
注意:对于一棵二叉树,若采用二叉链表
例1: 完全二叉树存储
1
2
3
4
5
6
7
8
9 10
1 2 3 4 5 6 7 8 9 10
例2: 非完全二叉树存储
1
A
2
B
5C
3
D
7
E
14
F
1 2 3 4 5 6 7 8 9 10 11 12 13 14
AB D 0 C 0 E 0 0 0 0 0 0F
注意:1)对于一棵二叉树,若采用顺序存储
时,对完全二叉树,比较方便;对非完全二 叉树,将会浪费大量存储单元。
存储时,当二叉树为非完全二叉树时,比较 方便,若为完全二叉树时,将会占用较多存 储单元(存放地址的指针)。
若一棵二叉树有n个结点,采用二叉链表作 存储结构时,共有2n个指针域,其中只有n1个?指针指向左右孩子,其余n+1个指? 针为 空。
在二叉链表结构中的操作
查询元素? 查询元素的后继? 查询元素的前驱?
【重点难点】
遍历二叉树的递归算法及其应用 ,二叉树线索化
【教学内容】
§6.2.3 二叉树的存储结构 §6.3.1 遍历二叉树 §6.3.2 线索二叉树
【内容回顾】
6.1 树的定义和基本术语 6.2 二叉树
-6.2.1 二叉树的定义 -6.2.2 二叉树的性质
【课题导入】
回顾线性表的存储方法? 顺序存储 链式存储
§6.2.3 二叉树的存储结构
1. 顺序存储结构
约定用一组地址连续的存储单元依次自上而 下,自左至右存储完全二叉树上的结点元素。
#define MAX_TREE_SIZE 100 // 二叉树的最大结点数 typedef TElemType SqBiTree[MAX_TREE_SIZE];
// 0号单元存储根结点 SqBiTree bt;
根据二叉树的结构,分为三部分:
L 左子树
D 根结点 R 右子树
遍历二叉树的方法:
D
L
R
先序遍历 DLR 中序遍历 LDR 后序遍历 LRD
由于其中的左右子树也是二叉树,属于递归
结构,所以常常借助递归算法实现。
1)先序遍历算法
若二叉树为空,则空操作;
否则,
访问根结点; 先序遍历左子树;
对“二叉树”而言,可以有两 条搜索路径:
➢ 先上后下的按层次遍历; ➢ 先左(子树)后右(子树)
的遍历;
2、先上后下的按层次遍历
从第一层开始,同一层从左到右。
例1:如右图 按层次遍历序列为: ABFCGDEH
A B
C DE
F G
H
特点:先被遍历的结点的孩子先于后遍历 的结点的孩子遍历。
3、先左后右的遍历算法
2)最坏的非完全二叉树是只有右分支,设 高度为K,则需占用2K?-1个存储单元,而实 际只有k个元素,实际只需k个存储单元。
因此,对于非完全二叉树,不宜采用顺 序存储结构。
顺序结构存储二叉树的优点
1)存储时,元素的位置(下标+1)对应 其在完全二叉树中的序号。
2)可快速方便地访问元素的双亲和左 右孩子。
【学习目标】
1.熟练掌握二叉链表存储结构; 2.熟练掌握遍历二叉树的递归算法,并能够实现二叉树的其它 操作; 3.了解按层次遍历二叉树的算法,能够熟练写出给定二叉树的 各种遍历序列,会根据给定的遍历序列画出二叉树。 4. 理解二叉树线索化的实质是建立结点与其在相应序列中的前 驱或后继之间的直接联系。了解二叉树的线索化过程以及在中 序线索化树上找给定结点的前驱和后继的方法。能够熟练地画 出给定二叉树的各种线索。
2、链式存储表示
1)二叉链表 2)三叉链表
1) 二叉链表
例1:
A
root
结点结构 lchild data rchild
A
B
D
C
E
F
B C
D E
F
类型定义
typedef struct BiTNode { // 结点结构 TElemType data; struct BiTNode *lchild, *rchild;
D
L
R
先序遍历右子树。
例2: 先序遍历
A
B
C
D
L
R
A D LR
D LR
□
D
□
□
B
□
□
先序遍历序列:A B D C
C D LR
D
递归算法描述
void Preorder ( BiTree T )
{ if ( T )
{ //如果二叉树不为空
printf( T -> data) ;
//输出根结点
Preorder ( T -> lchild ) ; //先序遍历左子树
这种存储结构的特点是: 寻找孩子结点容易,双亲比较困难。
§6.3.1 遍历二叉树
1、导入 2、先上后下的按层次遍历 3、先左后右的遍历算法 4、遍历二叉树的应用
1、导入
问题:怎样在二叉树中查找具有某种特征的结点? 怎样对二叉树中全部结点逐一进行某种处理?
遍历二叉树:即如何按照某条搜索路径巡访二叉树 中每个结点,使得每个结点均被访问一次,而且仅 被访问一次。 “访问”的含义可以很广,如:输出结点的信息, 对结点进行统一的操作等。