3试验设计方法2
医院III期临床试验方案设计规程

医院III期临床试验方案设计规程---III期临床试验为扩大的多中心临床试验,技术要求和管理规范与II期相同,只是前者中参加试验的数量和规模更加扩大,并可有一部分非对照病例。
1. 题目:---包括试验药物名称,观察病例及临床试验的期别。
2. 前言:---扼要描述所进行试验药物的研制背景,进行试验的原因,或试验任务的来源,试验药物的组成、功能、主治、适应症,临床前药理、毒理的简况,研制单位、临床试验的负责单位和参加单位,进行临床试验的预期时间等。
3. 试验方案设计的依据:--《赫尔辛基宣言》--《新药审批办法》99.5.1--《药品临床试验管理规范》99.8--ICH-GCP---II期临床试验研究结果。
4. 试验目的---进一步评价试验药物的疗效和安全性。
5. 病例选择:--- 根据研究目的确定入选标准、排除标准和出组标准。
6. 试验方法---基本的试验方法为随机对照试验法,根据试验药物的具体情况可采用合适的盲法。
---对照试验:随机对照试验分为平行对照试验和交叉对照试验,根据对照药物的不同分为阳性对照(标准药物)和阴性对照(安慰剂)。
对照药物的选择要符合"同类""等效"的要求。
---随机化:对照试验中各组病例之分配必须实行随机化,并要明确随机化方法。
---盲法试验:随机对照试验中普遍采用盲法试验,要确立试验是单盲还是双盲。
明确双盲试验中,随机密码的管理、破盲的方法及时间、地点,以及受试者出现紧急情况时如何揭盲等问题。
7. 试验病例数:试验组例数>300例,另设对照组。
8. 治疗方法:---详细说明治疗药物、对照药物的给药途径、给药方法、给药次数、疗程等。
要明确规定除试验药物外,不得加用任何其它治疗同类疾病的药物或疗法。
9. 观察指标:---包括一般检查项目,安全性指标,诊断性指标和疗效性指标。
特殊实验检查项目,要说明试剂来源、仪器型号、类别、测试程序和方法等。
三期临床实验设计原则

三期临床实验设计原则随着医学技术的发展,临床实验在新药开发和治疗方案研究中扮演着重要的角色。
为了确保实验的准确性和可靠性,三期临床实验需要遵循一系列的设计原则。
本文将介绍三期临床实验的设计原则,包括样本选择、随机分组、盲法、安全监测以及数据分析等方面。
一、样本选择在进行三期临床实验时,样本选择是非常重要的。
研究者需要根据研究目的和疾病特点来确定合适的样本数量和样本特征。
为了保证实验结果的可靠性,样本的纳入应该符合特定的入选和排除标准。
同时,样本的代表性也需要被重视,以便将实验结果推广到更广泛的人群中。
二、随机分组随机分组是三期临床实验中常用的一种方法,它可以减少实验结果的偏倚。
在进行随机分组时,研究者需要将样本按照一定的规则(比如随机数字表或计算机随机数)分配到不同的治疗组和对照组中。
通过随机分组,可以避免个体差异对结果的影响,增加实验结果的可比性。
三、盲法为了减少主观因素对实验结果的干扰,三期临床实验通常采用盲法。
盲法分为单盲和双盲,其中单盲是指实验参与者不知道自己所接受的是治疗还是安慰剂,双盲还包括实验者不知道给予的是哪种处理。
通过盲法,可以减少实验结果的误差,提高实验结果的可信度。
四、安全监测在进行三期临床实验时,安全监测是必不可少的一环。
研究者需要密切关注参与者的安全情况,及时发现并处理不良反应。
为了确保参与者的权益和安全,实验过程中需要建立有效的监测机制和应急处理措施,及时采取适当的干预措施。
五、数据分析三期临床实验结束后,进行合理的数据分析可以得出准确的结论。
数据分析应该基于统计学原则,采用合适的统计方法进行数据处理和结果判断。
同时,数据分析过程应该遵循开放、透明、独立的原则,确保结果的客观性和科学性。
总结三期临床实验的设计原则涉及样本选择、随机分组、盲法、安全监测和数据分析等多个方面。
遵循这些原则可以确保实验的准确性和可靠性,为新药开发和治疗方案的制定提供有效的依据。
在未来的临床实验中,我们应该不断总结经验,提高实验设计的质量,为医学科研做出更大的贡献。
试验设计方法2篇

试验设计方法2篇试验设计方法第一篇:随机对照试验设计方法随机对照试验是一种用于比较药物治疗效果的常用方法,具有可靠性高,可重复性好的特点。
随机对照试验需要将病人随机分为治疗组和对照组,分别接受不同的治疗方式,然后通过对比两组病人的疗效和不良反应,来评价治疗效果的差异。
随机对照试验设计的步骤如下:1.研究问题的明确定义。
需要明确研究所涉及的人群、疾病类型、治疗方法等方面。
2.确定疗效评价指标。
评价指标应该与疾病的症状和治疗效果密切相关,具有客观性和可比性。
3.患者的随机分组。
将符合入选标准的病人随机分组,以消除非特异性因素的影响。
4.分组的盲法。
通过采用双盲设计或单盲设计,避免实验人员和参与病人对治疗组和对照组的不同预期,从而影响研究结果。
5.治疗方法的实施。
在两组病人中,分别按照研究设计所规定的治疗方案进行治疗,遵循研究方案中的药物剂量、疗程等要求。
6.结果的评价和统计分析。
采用合理的统计方法,对两组病人的疗效和不良反应进行比较分析,并对研究结果进行合理的解释和推广。
随机对照试验设计的优点在于:能够减少非特异性因素的干扰,使研究结果更可靠;可以评估不同治疗方法的优劣之间的差异;能够将病人的随机分组和盲法设计在实验中应用,充分保证了实验的可靠性和不偏颇性。
第二篇:交叉试验设计方法交叉试验是一种研究药物有效性和安全性的常用方法,可以有效地减少患者的个体差异对研究结果的影响。
具体来说,交叉试验将患者随机分为两个组别,并在相隔一定时间后互换治疗方案,以此来比较两种治疗方案的疗效和安全性。
交叉试验设计的步骤如下:1.研究问题的明确定义。
需要明确研究所涉及的人群、疾病类型、治疗方法等方面。
2.患者的入选标准和随机分组。
确定符合入选标准的患者,并通过随机分组来消除非特异性因素的影响。
3.治疗方法的实施。
在两个组别的患者中,分别按照研究设计所规定的治疗方案进行治疗,遵循研究方案中的药物剂量、疗程等要求。
4.交叉治疗组和交叉对照组的分配。
三交叉试验设计

三交叉试验设计
1. 试验因素
在三交叉试验设计中,主要的试验因素包括三个交叉点,分别是:处理交叉点、时间交叉点和个体交叉点。
处理交叉点指的是不同处理方式或条件之间的交叉,例如药物剂量、处理时间、处理方式等。
时间交叉点指的是不同时间点之间的交叉,例如实验开始和结束的时间点、观测时间间隔等。
个体交叉点指的是不同个体之间的交叉,例如不同年龄、性别、健康状况等个体之间的差异。
2. 试验指标
在三交叉试验设计中,试验指标是用来衡量试验效果或结果的变量,例如生理指标、生化指标、行为指标等。
这些指标应该能够客观地反映试验因素对受试对象的影响,并且应该具有可重复性和可量化性。
在试验过程中,需要对这些指标进行准确的测量和记录,以便后续的数据分析和结果解释。
3. 试验方法
在三交叉试验设计中,常用的试验方法包括完全随机化设计、随机区组设计、拉丁方设计
等。
这些设计方法能够有效地控制和处理各种试验因素和误差源,提高试验的准确性和可靠性。
在选择试验方法时,需要考虑试验的目的、受试对象的数量和特性、试验的复杂程度和成本等因素。
同时,还需要对试验过程进行详细的计划和安排,确保试验能够按照预定的方案顺利进行。
总之,三交叉试验设计是一种科学有效的实验设计方法,能够帮助研究者更好地控制和处理各种试验因素和误差源,提高实验的准确性和可靠性。
在实际应用中,需要根据具体情况选择合适的试验因素、试验指标和试验方法,并严格按照实验要求进行操作和记录数据,以便后续的数据分析和结果解释。
试验设计与分析2因子3因素因子设计

同理可得, 交互作用A×C的总平均效果AC:
对照AC AC
4n
对照AC ac abc l b a c ab bc
交互作用B×C的总平均效果BC:
BC
对照BC
4n
对照BC bc abc l a b c ab ac
定义2.2.1:若有线性组合 为对照,并记为(对照 ) Cr yr 满足约束条件 Cr 0,则称这样的线性组合 C Cr yr
r 1 r 1 r 1 m m m
4n
同理可得,
B的效果为:
(对照) B B 4n
(对照) B b ab bc abc l a c ac
对照ABC ABC
4n
对照ABC abc a b c ab ac bc l
现把23设计的线性组合对照的系数+、-号规则总结为下表2.2.5
表中所列 l,a , b , ab , c , ac , bc , abc 为标准顺序。 从此表很容易写出各个效果的线性组合表达式。对3个主要效果A, B,C线性组合中的系数符号有一个明显的规律:高水平时为 “+”,低水平时为“-”,其余各列的符号可以用乘法运算得到。 如AB列,由A列和B列同行的符号相乘得到AB列相应行的符号, ABC列的符合可由AB列和C列符号相乘。
0低
(3)当B在低水平,C在高水平时
1 ( ac c ) n
(4)当B、C在高水平时
2 3 设计的因子水平组合
1 (abc bc ) n
4项总平均效果为:
1 1 1 1 1 a l ab b ac c abc bc 4 n n n n 1 a ab ac abc l8 b c bc 上式中小括号内的部分是 项构成 4n A
第三章常用的几种实验设计方法

基本类型
1.完全随机设计 2.配对设计 3.配伍组设计 (随机区组设计) 4.自身比较设计 5.交叉设计 6.拉丁方设计
试验设计的步骤
1.根据试验的目的选择试验方案。 2.确定处理因素和处理水平。 3.确定试验类型。 4.根据实验效应的类型和处理因素的
情况选择统计方法。 5.确定样本量。 6.确定分组方案。
配伍组设计是先将若干个受试对 象按一定条件划分成若干个区组。每 一配伍组包含的受试对象,随机地分 别接受不同处理,每个配伍组的例数 等于处理组个数。
配伍的条件是影响实验效应的主要非 处理因素。可以按单一非处理因素分配伍 组,也可以按几个非处理因素的组合分配 伍组。
例如实验动物的种属、窝别、性别。年 龄、体重相同和相近的划人一个配伍组或 区组;临床试验根据具体要求可将性别、 体重、年龄、职业、病情和病程等条件相 同和相近的列入一个配伍组。分别将同一 配伍组内的受试对象随机地分别分配到各 处理组中去。
•2.双向误差控制,可以减少实验误差,比 配伍组设计优越。
(6) 缺点
• 1.要求各因素的水平数相等且无交互作 用,在实际应用中有一定的局限性;
• 2.重复数少,对差别的估计往往不够精 确,为了提高精确度,可将处理数相 同的几个拉丁方结合起来进行实验设 计。
例1.研究蛇毒的抑瘤作用,拟将四种瘤株匀浆接种小白 鼠;一天后分别用四种不同的蛇毒成份,各取四种不同 的剂量腹腔注射,每日一次.连续10天,停药一天,解 剖测瘤重。
交叉实验设计进行的实验所得数 据的统计处理可用方差分析,如果资 料的性质不适宜用方差分析则可用秩 和检验。
方差分析步骤:
秩和检验
1.处理间的比较(本例即A、B两种参数电针刺激 间的比较)
2因素3水平正交试验设计

2因素3水平正交试验设计
2因素3水平正交试验设计是一种经常用到的试验设计变体,它通常也被称为2因素
正交表法。
它是一种重要的机会控制试验,在一个实验中设计出2因素和3水平,从而尽
可能地排除变量间交互作用的可能性。
正交实验设计是一种个性化的实验设计,可以帮助
研究者收集有用结论,得出正确和正确的结果。
2因素3水平正交试验设计的一个主要原因是可以在简短的实验周期内最大程度地根
据实验目的给出一份可靠的结论。
实验期的长短取决于试验的完整性,即每个因素的水平
数量、每个水平上的重复观测次数和测量质量等。
正交实验常常要求一个因素以2水平或
3水平被研究,而另外一个因素以2水平或3水平被研究。
此外,每个水平要求至少两次
重复观测。
2因素3水平正交试验设计的另一个优势在于可以有效地消除实验中可能存在的偏差
因素,包括传统实验设计中不能有效控制的因素。
由于每一种情况在试验中只出现一次,
对每个因素的实验情况的影响都会被减少到最小。
此外,2因素3水平正交实验设计也可
以有效地使实验变量的不同干扰因素之间保持一致,从而减少偏见。
最后,2因素3水平正交实验设计可以提供有效的数据分析方法。
实验数据可以用来
检测实验中可能存在的水平之间的差异,使用这种分析方法可以很容易地得出有效的结论,而不需要考虑由于不同组之间交叉因素的影响而引起的干扰。
临床试验中随机分为三组实验设计方案举例

临床试验中随机分为三组实验设计方案举例一、引言在进行临床试验时,随机分组是一种常用的方法,可以减小实验结果的偏倚性,提高实验结果的可信度。
本文将介绍一种临床试验设计方案,其中将实验对象随机分为三组进行不同处理。
二、实验设计方案2.1 实验目的本实验的主要目的是探究一种新型药物对特定疾病的疗效,评估其安全性和有效性。
2.2 研究对象本实验拟纳入年龄在30-50岁、患有特定疾病的患者作为研究对象。
2.3 实验方法本实验采用随机分组法将研究对象分为三组,每组规模为50人。
根据随机分组结果,将研究对象分为A组、B组和C组。
2.4 实验组设置2.4.1 A组A组为对照组,接受传统治疗方法,作为对照参照组。
2.4.2 B组B组为实验组1,接受新型药物A进行治疗。
2.4.3 C组C组为实验组2,接受新型药物B进行治疗。
2.5 实验过程2.5.1 预实验期在正式实验开始前,需要进行预实验期,分别对A组、B组和C组的研究对象进行病情评估、基线数据收集等工作,以确保实验对象的统一性。
2.5.2 实验期在实验期间,按照实验组的设定,对A组、B组和C组的研究对象进行不同的治疗。
同时,进行随访、数据记录等工作,以便后续结果分析。
2.6 实验结果分析在实验结束后,对A组、B组和C组的治疗效果进行数据分析和比较,以确定新型药物的疗效和安全性。
常用的统计学方法和软件将被应用于结果的分析。
三、结论通过本实验设计方案,我们可以进行一项随机分为三组的临床试验,以评估一种新型药物的疗效和安全性。
该实验设计方案具有一定的科学性和严密性,可以得到较为可靠的试验结果。
参考文献1.Smith A, et al. Randomized controlled trial design: anintroduction. Journal of Clinical Research, 2010, 4(3): 76-81.2.Zhang B, et al. The importance of randomized controlled trial inclinical research. Modern Medicine, 2015, 35(2): 98-102.3.Wang C, et al. Statistical methods in clinical trial design andanalysis. Biomedical Statistics and Informatics, 2018, 13(4): 256-264.。
ⅡⅢ期临床试验设计与实施

ⅡⅢ期临床试验设计与实施Ⅱ期临床试验是在Ⅰ期临床试验之后进行的,主要目的是评估新药的安全性和有效性,并收集更多的证据来支持新药的推广和上市。
Ⅲ期临床试验是在Ⅱ期临床试验成功后进行,目的是进一步评估新药的安全性和有效性,并与现有治疗方法进行比较,以确定新药的优势和劣势。
本文将介绍Ⅱ、Ⅲ期临床试验的设计和实施过程。
一、Ⅱ期临床试验设计1.研究目标和假设:确定试验的主要目标和科学假设,例如评估新药的疗效、剂量反应关系等。
2.分组方法:将受试者随机分为实验组和对照组,实验组接受新药治疗,对照组接受常规治疗或安慰剂。
3.样本容量:通过统计学方法计算所需的样本容量,确保试验结果具有统计学意义。
4.入选标准:根据研究目标和受试者特征,确定入选标准,例如疾病类型、年龄、性别、病情严重程度等。
5.研究设计:确定试验的研究设计,例如前瞻性研究、随机对照试验等。
6.评估指标和测量方法:确定主要和次要评估指标,并确定测量方法,例如临床症状评估量表、生物标志物检测等。
7.数据收集和分析:设计数据收集表格,确定数据采集时间点,并确定数据分析方法。
8.质量控制:确保试验的可靠性和准确性,例如制定严格的试验操作规范、培训研究人员等。
二、Ⅱ期临床试验实施1.研究立项和伦理审查:提交研究计划和申请材料,经过伦理委员会的审查和批准。
2.中心选择和培训:选择合适的研究中心,培训研究人员,确保他们了解研究目标和研究方案,能够正确操作和记录数据。
3.受试者招募和入组:根据入选标准,招募适合的受试者,并进行初步筛选,确定他们是否符合试验要求。
4.随机分组和盲法:实施随机分组,将受试者随机分配到实验组和对照组,并实施盲法,保证结果的客观性和可靠性。
5.新药治疗和对照治疗:根据试验方案,实施新药治疗和对照治疗,确保治疗的一致性和准确性。
6.数据收集和管理:根据试验方案和数据收集表格,收集和记录受试者的相关数据,并进行数据管理和质量控制。
7.不良事件监测和报告:监测受试者的不良事件,及时报告和处理。
新药ⅡⅢ期临床试验的规范化设计

新药ⅡⅢ期临床试验的规范化设计新药Ⅱ、Ⅲ期临床试验的规范化设计是确保试验过程的科学性、严谨性和可靠性的重要步骤。
它包括从试验方案的设计到实施、数据采集和分析等各个环节,旨在对新药的疗效、安全性和适应证进行全面评价。
下面我将详细介绍新药Ⅱ、Ⅲ期临床试验的规范化设计的主要内容。
一、试验目标和假设的明确试验目标是指需要确认的主要研究问题,比如新药治疗效果是否优于现有治疗方法,新药是否具有安全性等。
在设计试验时,需要明确试验目标,以便根据目标进行样本容量的计算和详细的研究方案编写。
二、试验设计试验设计是指根据试验目标和研究问题,确定试验的类型和方法。
常见的试验设计包括随机对照试验、非随机对照试验、单盲试验、双盲试验等。
试验设计应遵循统计学原理,确保试验结果的可靠性。
三、样本容量计算样本容量计算是指根据试验设计和试验目标,计算需要纳入试验的患者或实验对象的数量。
样本容量的大小直接影响试验结果的精确性和可靠性。
在计算样本容量时,需要考虑试验的统计检验方法、显著性水平、效应大小、样本的方差等因素。
四、分组和随机化试验的分组和随机化是为了避免实验结果的偏倚和提高试验的可比性。
分组是将试验对象按照一定的规则分为不同的治疗组和对照组。
随机化是将试验对象随机分配到不同的治疗组和对照组,以消除个体差异和其他干预因素的影响。
五、数据采集和管理数据采集和管理是试验的重要环节,确保试验数据的准确、完整和可靠。
数据采集应遵循预先制定的数据采集表或CRF(Case Report Form),并进行严格的质量控制。
数据管理应建立合适的数据库,对数据进行完整性和逻辑性的检查。
六、试验的监督和安全性评估试验过程中应进行监督和安全性评估,以确保试验的合规性和保护试验对象的权益。
监督包括对试验中心、试验人员和试验数据的定期检查和复核。
安全性评估应随时监测试验对象的不良事件和不良反应,及时采取必要的措施保护试验对象的安全。
七、数据分析数据分析是根据试验目标和设计,对试验数据进行统计学分析,评估新药的疗效和安全性。
药物III期临床 试验设计

药物III期临床试验设计III期临床试验:III期临床试验治疗作用确证阶段。
其目的是进一步验证药物对目标适应症患者的治疗作用和安全性,评价利益与风险关系,最终为药物注册申请获得批准提供充分的依据。
试验一般应为具有足够样本量的随机盲法对照试验。
“对于预计长期服用的药物,药物的长期暴露试验通常在I期进行。
由于III期临床试验是以验证药物对目标适应症患者的治疗作用和安全性,评价利益与风险关系,因此强调试验必须有足够的样本量、进行与阳性药物对照的随机盲法的试验,使试验结果能够回答所提出的问题。
由于I、III期临床试验的目的不同,因此他们具有不同的特点为,III期临床试验的特点是在I期临床试验的基础上,此期试验为验证疗效的试验、其适应症相对固定、治疗方案相对确定、为验证疗效及观察安全性需要更广泛的足够的病例,对于预计长期服用的药物,药物的长期暴露试验通常在II期进行同时III期临床研究为完成药物的使用说明书提供了最后一份所需要的信息。
对于具体临床试验的设计来讲,在二期和三期其原则有多部分是相同的.其基本原则是随机、对照、盲法、前瞻。
随机是将单一样本人群随机分入试验组或对照组,能最好地确保两组的受试人群相似。
随机化可以避免那些可能影响结果的变量组间系统差异,也就是克服主客观偏因:即随机化是要求试验中二组病人的分配是均匀的、不随主观意志为转移的。
随机化是新药临床试验的基本原则。
虽然随机分配解决的主要是分配误差,由于随机对照双盲试验的实施,使主客观偏因都可因此得到排除,因而解决的不仅仅是分配误差,使试验的可信度明显提高。
双盲法是指受试者与研究者双方都不了解每个受试者接受的治疗,从而最大限度地减少由于受试者或研究人员了解治疗分配后引起的在管理、治疗或对病人的评价以及解释结果时出现的偏倚。
双盲的目的是为了确保主观评价及决定不会因了解治疗分配而受到影响。
对照:对照试验的目的是比较新药与对照药治疗结果的差别有无统计学显著意义由于临床治疗中所获得的疗效可能由药物引起,也可能由其他因素引起,因此要采用对照试验可以将其他因素的影响尽量减小。
Minitab DOE 操作说明 范例 全因子实验设计法3 因子2 水平实验设计
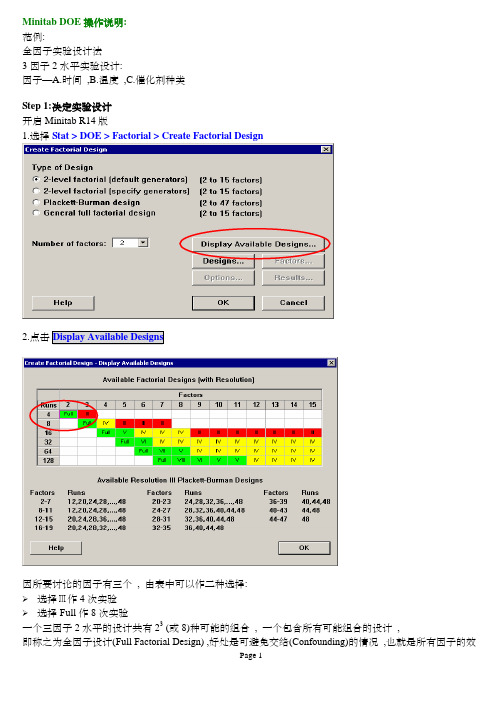
Minitab DOE操作说明:范例:全因子实验设计法3因子2水平实验设计:因子—A.时间 ,B.温度 ,C.催化剂种类Step 1:决定实验设计开启Minitab R14版1.选择Stat > DOE > Factorial > Create Factorial Design因所要讨论的因子有三个 , 由表中可以作二种选择:¾选择Ⅲ作4次实验¾选择Full作8次实验一个三因子2水平的设计共有23 (或8)种可能的组合 , 一个包含所有可能组合的设计 ,应无法与其它的效应明确分辨出来 ; 然而,使用较少的组合设计称之为部份因子设计(Fractional Factorial Design)此范例决定是全因子设计 , 因在化学工厂内 , 要控制这些因子(时间/压力/催化剂种类)并不耗费时间及成本 , 且实验可在非尖峰时间进行 , 避免打断生产线的进度 , 如果这实验所需成本很高或困难执行 , 你可能需做不同决定。
3.点击OK , 回到主对话框中4.选择2-level factorial (default generators), 在因子数选择35.点击Designs ,选取Full factorial6.在Number of replicates选项中选2 ,按OKStep 2:因子命名与因子水平的设定因子水平的设定可以是文字或数值¾若因子为连续性Æ使用数值水平设定,可为量测的任意值(ex.反应时间)¾若因子为类别变量Æ使用文字水平设定,为有限的可能值(ex.催化剂种类)就一个2水平的因子设计 , 因子水平设定为两个值 , 建议数值尽可能分开:Factor Low Setting High SettingTemperature 20° C 40° CPressure 1 atmosphere 4 atmospheresCatalyst A B1.点击Factors按钮2.输入因子名称及水平 , 完成后按OK回到Create Factorial Design主对话框Step 3:随机化与储存设计的内容1.按Options选项钮2.在Base for random data generator的字段 , 输入9 ,可控制随机化的结果,让每次 都可得到一致的模型3.确定有选取Store design in worksheet的选项后,并按OK4.回到Create Factorial Design主对话框按OK ,就会产生设计的内容并储存在工作窗体 中Step 4:¾若要切换工作窗体以RanOrder/StdOrder以及Coded/Uncoded 的呈现 ,可由菜单Stat ÆDOE ÆDisplay Design 来选择¾ 另外若要修改因子名称或设定 , 有两种方式: (1)可由菜单Stat ÆDOE ÆModify Design 来选择 (2)直接修改数据窗口中相对的因子列Step 5:数据收集与输入1.在数据窗口中C8的变量名称位置输入Yield2.可将此实验工作表打印出来并收集数据结果输入YieldStep 6:筛选实验目的是利用效应图来选取对于提高产能较大效应的因子¾配置一个模型(Fit a model)1.在菜单点选StatÆDOEÆFactorialÆAnalyze Factorial Design2.在Responses字段输入Yield3.点取Graphs选项钮4.绘制Normal(常态机率图)及Pareto(柏拉图) ,协助找到显著因子5.按OK 键 ,回到Analyze Factorial Design 主对话框 ,再按主对话框OK 键 ,即会将分析结果及绘图在窗口中 ¾ 效应图(Effect Plots)Normal(常态机率图) Pareto(柏拉图)¾确认重要的效应因使用为全因子设计,故包含3个单一之主效应、3个二次的(two-way)交互作用及1个三次的(three-way)交互作用Step 7:配置一个较简单的模型接下来,要由全因子模型所找到的重要因子再重新设定一个较简单的模型,也就是去除不显著之因子,评估适合度、图示解析及残差分析1.点选菜单选单StartÆDOEÆFactorialÆAnalyze Factorial Design2.选取Terms选项钮3.设定内容4.按OK键,回到Analyze Factorial Design主对话框6.勾选Four in one相关分析图,按OK键回主对话框7.按Analyze Factorial Design的主对话框OK键分析的结果会列在程序窗口中,残差分析图及相关图将可进一步评估¾主效应是否选取适当??¾设定的模型是否恰当??Step 8:评估调整后的模型而残差分析图的结果也是令人满意的Step 9:结论之描述¾因子图(Factorial Plots)以绘制主效应图(Main Effect Plot)及交互作用图(Interaction Plot)可以用目视的方法来决定效应分析1.点选菜单StatÆDOEÆFactorialÆFactorial Plots2.勾选Main Effects Plot ,再按下Setup3.在Response输入Yield4.将显著因子B(Pressure)及C(Catalyst)自Available字段到> Selected字段中2.勾选Interaction Plot ,再按下Setup,重复3与4步骤¾ 检视绘图内容在绘图窗口中会个别列出主效应图及交互作用图--主效应图(Main Effects Plot)分析压力图催化剂图(Catalyst Plot)Æ比较催化剂在两种类别的差异(1) 由图中显示 ,差异性比较:催化剂主效应>压力主效应 ,也就是说催化剂斜率的绝对值 大于压力斜率的绝对值 ,由于Yield 为望大值(越大越好) ,故压力在4大气压较1大气 压有较高的良率 ; 催化剂的种类使用A 较B 有较高的良率(2) 若因子之间没有交互作用存在 ,由主效应图即可找到使良率较高的最佳组合 ,此范例 有BC 交互作用显著差异存在 ,故接下来再由交互作用图来分析-- 分析交互作用图可看出因子间水平设定互相造成之冲击性 ,有加乘或抵消作用(1) 由图中显示 ,不论压力值在1大气压或4大气压 ,使用A 催化剂的Yield 皆大于B 催化剂 ;但是以A 催化剂而言 ,压力设定在4大气压比1大气压有明显Yield 变化(2)综合以上分析 ,使Yield 最大的最佳组合为压力4大气压与A 催化剂。
实验设计3-试验设计的类别及实施步骤

9、进行试验,确信每个试验单元均被对应于其试验条件 做好标识。 10、测量试验单元。 11、分析数据,标识主要影响因素。 12、确认取得最好输出结果的因素水平的组合。 13、在此优化组合的因素和水平值上进行重复试验以确 认效果。 14、通过标准作业程序固定优化的试验条件(因子和水 平),并进行应有的控制。 15、重新评估过程能力。
7因子以上
田口可靠设计法与传统试验设计方法的比较,如下表: 传统方法特点 田口可靠设计特点
1、如果存在许多输入因素, 1、确定产品或制造过程的 运行筛选DOE来确定关键 理想数学模型 的少数因素 2、在一组动态试验中同时 2、用因素试验、中心复合 研究大量的控制因子,以 试验或BOX—Behken试验 发现使理想模型中偏差最 设计完全研究关键的少数 小的因子和水平组合 因素
试验类型典型可控因素数试验类别1全因子试验所有因素和水平的组合1寻找最有利于输出的因子水平2建立可评估所有交互影响的数学模型4因子以内2部分因子试验所有组合的一个子集1寻找最有利于输出的因子水平2建立可评估部分交互影响的数学模型5因子以上3筛选试验1从大量因素中发现少数关键因素不评估因素间的交互作用7因子以上4中心复合设计1优化2建立非线性影响存在时的数学模型常用响应表面方法3因子以上5可靠设计1优化2在存在噪声因子变化的场合发现输出最小变异时对应的因子水平5因子以上6塔古奇动态可靠设计1优化7因子以上2优化产品或制造过程的函数3使输出对噪音因子敏感性最小对输入因子敏感最大田口可靠设计法与传统试验设计方法的比较如下表
试验类别
根据不同的目标和因素数,试验设计可分为下表所示6个种类。 试验类别 试验类型 目 标 典型可控因素数 4因子以内 1、全因子试 1、寻找最有利于输出的因 子水平 验(所有因素 2、建立可评估所有交互影 和水平的组合) 响的数学模型 2、部分因子 1、寻找最有利于输出的因子 试验(所有组 水平 合的一个子集)2、建立可评估部分交互影 响的数学模型 1、从大量因素中发现少数关 3、筛选试验 键因素(不评估因素间的交 互作用)
试验设计方法

对试验设计方法的一些探究试验设计概述:试验研究可分为试验设计、试验的实施、收集整理和分析试验数据等步骤。
而实验设计是影响研究成功与否最关键的一个环节,是提高试验质量的重要基础。
试验设计是在试验开始之前,根据某项研究的目的和要求,制定试验研究进程计划和具体的试验实施方案。
其主要内容是研究如何安排试验、取得数据,然后进行综合的科学分析,从而达到尽快获得最优方案的目的。
如果试验安排得合理,就能用较少的试验次数,在较短的时间内达到预期的试验目的;反之,试验次数既多,其结果还往往不能令人满意。
试验次数过多,不仅浪费大量的人力和物力,有时还会由于时间拖得太长,使试验条件发生变化而导致试验失败。
因此,如何合理安排试验方案是值得研究的一个重要课题。
目前,已建立起许多试验设计方法。
如我们大家比较熟悉的,常用单因素实验设计方法的有黄金分割法、分数法、交替法、等比法、对分法和随机法等,这些方法为多因素试验水平范围的选取提供了重要的依据,并在生产中取得了显著成效。
而多因素试验设计方法有正交试验设计、均匀实验设计、稳健试验设计、完全随机化设计、随机区组试验设计、回归正交试验设计、回归正交旋转试验设计等。
下面通过以下几种方法进行探究。
一、单因素试验设计在其他因素相对一致的条件下,只研究某一个因素效应的试验,就叫单因素试验。
常用的单因素试验设计方法有黄金分割法、分数法、交替法、等比法、对分法和随机法等。
单因素试验不仅简单易行,而且能对被试验因素作深入研究,是研究某个因素具体规律时常用而有效的手段。
同时还可结合生产中出现的问题随时布置试验,求得迅速解决。
单因素试验由于没有考虑各因素之间的相互关系,试验结果往往具有一定的局限性。
单因素试验只研究一个因素的效应,制定试验方案时,根据研究的目的要求及试验条件,把要研究的因素分成若干水平,每个水平就是一个处理,再加上对照(有时就是该因素的零水平)就可以了。
例如硫酸铵加量对微生物生长的影响试验,硫酸铵的用量分、、、四个水平。
试验设计与分析2因子3因素因子设计

对照A l a b ab c ac bc abc
4 1 1 5 1 3 2 11 24
(对照) A 24 A 3.00 4n 8
对照B l a b ab c ac bc abc
同理可得, 交互作用A×C的总平均效果AC:
对照AC AC
4n
对照AC
ac abc l b a c ab bc
交互作用B×C的总平均效果BC:
BC
对照BC
4n
对照BC
bc abc l a b c ab ac
交互作用A×B×C的总平均效果定义为 AB在C的两个水平下的平均值:
试验设计与分析之
3 设计 2
2.2.2
3设计 2
bc abc
23因子设计就是有三个因子 A、B、C,每个因子都是两 个水平。
高1
因子C
c b
ac ab
因 子
A、B、C为主要效果,AB、 AC、BC为两两交互作用的 效果,ABC为三个因子交互
作用的效果。为便于计算这 些效果,按照类似22设计的 原则和方法作一个立方体, 见图2.2.2。
S AC
22 0.25 16
S BC
42 1.00 16
S ABC
42 1.00 16
总离差平方和为
2 ST yijkl i 1 j 1 k 1 l 1 2 2 2 2
y2 2 2 2 2
16 2 2 2 3 1 6 2 52 78 .00 16
(2)C在高水平时,A效果在B的两个水平下的平均差,即
1 abc bc ac c 1 2n abc c ac bc 2 n n
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
试验结果如下: 蛋 鸡
主表
产 C1 B1 A2: 6.8 7.3 A1: 7.9 7.5 A3: 11.2 12.3 B2 A1:10.0 9.4 A3:10.8 11.5 A2: 7.3 7.6
组
B3 A3: 9.7 8.3 A2: 6.1 7.9 A1: 9.2 8.6
蛋
期
C2
C3
对此的分析,首先是建立辅表:
三、由于经费和试验条件的限制,可采用的试验单 元数较少,或不容易找到 满足以上三个条件的试验都可考虑采用拉丁方试验 设计
设计方法
以实际例子来说明拉丁方的设计方法
例:设计了3种饲料:A1、A2与A3,比较这3种饲料 对产蛋的影响;随机选取条件基本一致的3羽母鸡 (或3个鸡场、或3个家系)B1、B2及B3;选取3 个产蛋期C1、C2及C3
但k值如果很大,则在实际操作中不容易完成整个试 验,因此应当采取变通的办法
拉丁方的种类及其变换:第一行、第一列为顺序排列 的拉丁方称为标准方,随 k值的增加,每一 k2型的 标准方急速增加;每一标准方由于行与列的随机重 排而演化出不等的普通方 在作拉丁方设计时,一般总是随机选取一个标准方, 通过随机排列该方的行与列得到一个普通方而进行 实际试验 重复数与处理水平数的相互制约:在一个拉丁方中, 每一处理水平内的重复数=区组数=处理水平数= 横行数=纵列数
course
饲料间 蛋鸡组 产蛋阶段 误差项 T
SS
22.34 1.70 1.42 1.06 26.52
df
2 2 2 2 8
MS
11.17 0.85 0.71 0.53
F
21.08** 1.60 1.34
方差分析结果显示,饲料间差异显著,因此应对三 种饲料作多重比较:
SE 0.53 0.42 3
3
C 1.7
产蛋阶段平方和:
误差平方和:
SSC
26.5
2
.. 27.7 2
3
C 1.42
SSe SST SS A SSB SSC 1.06
各自由度为: dfT=3×3-1=8 dfA=dfB=dfC=dfe=3-1=2 列方差分析表:
方差分析表
拉丁方设计
在随机区组设计中,试验仅考虑一个区组,这个区 组可能是试验时期,也有可能是试验地域,如果 试验时期或试验地域同时出现并影响试验结果的 话,则随机区组设计将不合用
在交叉设计中,考虑了两个区组:B和C,B往往是 动物体,C往往是试验时期,但在统计分析时总 将B和C设计成效应相互抵消,因而在方差分析时 其作用反映不出来 在许多情况下,区组 B和区组 C的效应不可能这样 刚好相互抵消,它可能会产生系统误差,因而应 该从总误差中将其剔除,即在统计分析中应将这 种差异反映在方差分析表中,分析其显著性
r=2 C1 C2 C3 纵列和 B1 A2: 14.1 A1: 15.4 A3: 23.5 53.0 B2 A1: 19.4 A3: 22.3 A2: 14.9 56.6 B3 横行和 饲料和
x
A3: 18.0 51.5 A2: 14.0 51.7 A1: 17.8 56.2 49.8 159.4
A1: 52.6 8.77 A2: 43.0 7.17 A3: 63.8 10.63 159.4
统计分析:
第一步对主表进行解析: C = 159.42/18 = 1411.58
SST = 6.82 + 7.32 +…+ 8.62 – C = 52.84
SSr = (14.12 + 15.42 +…+ 17.82)/2 – C = 48.78
上页的拉丁方表是一个标准拉丁方,将其进行行变
换和列变换,得到普通方(这里的变换仅是表内的
A因子,B和C不动)
得: 蛋 鸡 组 B2 B3 A1:10.0 A3:9.7 A3:10.8 A2:6.1 A2: 7.3 A1:9.2 28.1 25.0
B1 产 C1 A2: 6.8 蛋 C2 A1: 7.9 期 C3 A3:11.2 纵列和: 25.9
也就是说,因子 A必须与因子 B均匀地搭配,同时 因子 A又必须与因子 C均匀地搭配,而因子 B与 因子 C已经均匀地搭配了,这就是说,3个因子必 须两两正交,这就是拉丁方设计的思想
事实上,观测指标随试验时间或试验阶段呈曲线变 化或不均匀变化的试验都可以采用拉丁方设计
拉丁方的基本概念
随机区组设计是将试验处理从一个方向排成区组或 重复,拉丁方设计是从两个方向排成区组或重复 并配置成两个区组因素和一个试验因素
查q表,得: q0.05,2,2 =6.09 q0.05,2,3 =8.28 q0.01,2,2 =14.0 q0.01,2,3 =19.0 则: LSR0.05,2,2 =2.56 LSR0.05,2,3 =3.48 LSR0.01,2,2 =5.88 LSR0.01,2,3 =7.98 饲料 0.05 0.01 A3 10.57 a A A1 9.03abA A1 9.03 ab A A2 6.73bA A2 6.73 b A A3 10.57aA
拉丁方的特点:
拉丁方的大小用 k表示,被试因子为 k个水平,因此 试验动物为 k个,试验时期为 k个,这样的拉丁方 称为 k2型拉丁方 K2型拉丁方的误差项自由度为 dfe=(k-1)(k-2),因此 22型拉丁方没有误差项自由度,32型拉丁方的误差 项自由度为 dfe=(3-1)(3-2)=2,42型拉丁方其自由 度为 dfe=(4-1)(4-2)=6等等 即 k值越大,其误差项自由度越大 这说明,拉丁方太小,误差项自由度很小,一方面 MSe变大了,另一方面 F理论值也变大了,因此主 效因子不易达到显著水平
将B和C搭配起来,形成3×3共9个组合,B和C是 正交的 将A因子3个水平随机地分配到这些组合中,使得B 因子的每一水平中都包含有A因子的所有水平,C 因子的每一水平中也都包含有A因子的所有水平
即A因子与B因子正交,A因子与C因子也正交
以B因子为列,C因子为行,A因子嵌入其中:
蛋鸡组
B1 B2 B3 产 C1 A1 A2 A3 蛋 C2 A2 A3 A1 期 C3 A3 A1 A2
在随机区组设计中,一整套试验,即因子 A的所有 水平都在每一个区组中得到反映,每一个区组都 是相互独立的
拉丁方有两个因子:B和 C,因此,因子 A的所有 水平都既要在 B因子的每一区组中得到反映,又 要在 C因子的每一区组中得到反映 上例中 A因子的3种饲料必须均匀、随机地分配到 奶牛的所有血统 B中,同时又必须均匀、随机地 分配到试验所有的泌乳阶段 C中
A B C D
B A D C
C D B A
D C A B
A B C D
B D A C
C A D B
D C B A
3×3拉丁方 A B C D E B A D C F C E A F B D C F E A E F B A D F D E B C 6×6拉丁方 F E D B C A
4×4拉丁方 A B C D E F G B C D E F G A C D E F G A B D E F G A B C E F G A B C D F G A B C D E
求校正值:
总平方和:
2 79.0 C
3 3
693.44
SST (6.82 ... 9.22 ) C 26.52
2 2 27.1 .. 28.7
饲料间平方和: SS A
3
C 22.34
蛋鸡组平方和:
SS B
25.9
2
.. 25.02
因此,区组 B(场、畜舍、家系)和区组 C(试验 时期)与主效应 A应同时得到考虑
但显然,在整个试验中,因子A是主效应,而因子B 和因子C的设置,其作用主要是为了消除系统误 差,其效应的显著性在试验中不是主要的
例如,设计了3种饲料,比较其对产奶量的影响, 由于牛的产奶量不仅受饲料的影响,而且还受牛 场(血统)和不同产犊时期的影响,因此要在牛 场里找到条件十分相似的母牛会很不容易;且泌 乳量是呈曲线变化的,单纯用交叉设计也不十分 理想
i
0
j
0
l
0
拉丁方设计的灵活运用
设置重复 使用 k的整数倍(设为 r)的供试动物进行试 验,即与完全随机设计相结合: 还以上一例为例:设3组产蛋母鸡,用3个试验期研究3 种饲料的优劣,每一组有2羽母鸡(根据需要,也可 以是3羽、4羽母鸡等),同一组中的两羽母鸡在相 同的试验期中所接受的A因子处理条件是一样的,需 要注意的是: 同一组中的2羽鸡应分开,处于独立状态,不能合在一 个笼子里或饲养在一个圈舍内; 同一组中的2羽母鸡其生理状态应尽可能一致
横行和 26.5 24.8 27.7 T=79.0
对A因子各水平进行累加,得: x1 = 9.03 A1:27.1 A2:20.2 x2 = 6.73 x3 =10.57 A3:31.7 T=79.0 上述数据为试验结束以后每一种饲料在每一个蛋鸡 组、每一试验期的产蛋量及各个和 对这一类数据一般可用三因子(无互作)的方差分 析法进行分析 作无效假设(A、B、C因子各水平其效应相同)
4×4
C B A D B D C A D A B C
5×5
C A E B D E B D A C D E A C B B D C E A A C B D E
以上经行和列的变换后的拉丁方称为普通方,在实 际使用中,一般不这样表示
随着k的变大,每一种k2的标准方急速增加,每一标 准方所能变换得到的普通方也随着增多:
即拉丁方中每一纵列、每一横行就是一个区组,就是 一个完整的处理;试验因子的每一水平在每一列、 每一行出现、且仅出现一次 即如需增加重复数,必须同时增加处理水平数;需减 少水平数,必然减少重复数;即重复与水平相互牵 制;因此拉丁方的规模不可能很大,一般在32~82之 间 交互作用与试验残效:使用拉丁方时,两区组因子与 被检验因子间必须无互作,因为拉丁方设计无法检 验这种互作