文档处理系统的随机模型(IJIEEB-V8-N5-7)
文本处理中的向量空间模型

向量空间模型在文本处理中的应用引言在信息检索和自然语言处理领域,向量空间模型是一种常用的文本表示方法。
它将文本转换为向量形式,通过计算向量之间的相似度来实现文本分类、聚类和检索等任务。
本文将详细介绍向量空间模型在文本处理中的原理、应用和优化方法。
1. 向量空间模型的原理向量空间模型基于词袋模型,将文本表示为一个高维向量。
每个维度代表一个词语,而向量中的值表示该词语在文本中出现的次数或权重。
通过这种方式,可以捕捉到不同词语在文本中的重要性和关联性。
具体而言,向量空间模型包括以下步骤:1.文本预处理:去除停用词、标点符号等无关信息,并进行词干化或词形还原等操作。
2.构建词典:将所有文档中出现过的词语构建成一个词典。
3.文档表示:对每个文档进行向量化表示,常见的方法有计算词频(TermFrequency)或使用TF-IDF(Term Frequency-Inverse DocumentFrequency)对词频进行加权。
4.向量相似度计算:通过计算向量之间的余弦相似度或欧氏距离等指标,来度量文本之间的相似性。
2. 向量空间模型的应用向量空间模型在文本处理中有广泛的应用,包括但不限于以下几个方面:2.1 文本分类文本分类是将文本分为不同类别的任务。
向量空间模型可以将每个文档表示为一个向量,并使用分类算法(如朴素贝叶斯、支持向量机等)进行分类。
通过对训练集进行学习,可以构建一个分类器,用于对新文档进行分类。
2.2 文本聚类文本聚类是将相似的文档分到同一类别的任务。
向量空间模型可以通过计算向量之间的相似度,将相似的文档聚在一起。
常见的聚类算法有K-means、层次聚类等。
2.3 文本检索文本检索是根据用户输入的查询词,在大规模文本库中找到相关文档的任务。
向量空间模型可以将用户查询和每个文档表示为向量,并计算它们之间的相似度。
通过排序相似度得分,可以返回与查询最相关的前几个结果。
2.4 信息抽取信息抽取是从文本中提取结构化信息的任务。
数学建模四大模型总结

四类基本模型1 优化模型1.1 数学规划模型线性规划、整数线性规划、非线性规划、多目标规划、动态规划。
1.2 微分方程组模型阻滞增长模型、SARS 传播模型。
1.3 图论与网络优化问题最短路径问题、网络最大流问题、最小费用最大流问题、最小生成树问题(MST)、旅行商问题(TSP)、图的着色问题。
1.4 概率模型决策模型、随机存储模型、随机人口模型、报童问题、Marko v 链模型。
1.5 组合优化经典问题● 多维背包问题(MKP)背包问题:n 个物品,对物品i ,体积为i w ,背包容量为W 。
如何将尽可能多的物品装入背包。
多维背包问题:n 个物品,对物品i ,价值为i p ,体积为i w ,背包容量为W 。
如何选取物品装入背包,是背包中物品的总价值最大。
多维背包问题在实际中的应用有:资源分配、货物装载和存储分配等问题。
该问题属于NP 难问题。
● 二维指派问题(QAP)工作指派问题:n 个工作可以由个工人分n 别完成。
工人完成工i 作的时间为j ij d 。
如何安排使总工作时间最小。
二维指派问题(常以机器布局问题为例):n 台机器要布置在个地方n ,机器与之间i k 的物流量为ik f ,位置与之间j l 的距离为jl d ,如何布置使费用最小。
二维指派问题在实际中的应用有:校园建筑物的布局、医院科室的安排、成组技术中加工中心的组成问题等。
● 旅行商问题(TSP)旅行商问题:有n 个城市,城市与之间i j 的距离为ij d ,找一条经过n 个城市的巡回(每个城市经过且只经过一次,最后回到出发点),使得总路程最小。
● 车辆路径问题(VRP)车辆路径问题(也称车辆计划):已知个客户n 的位置坐标和货物需求,在可供使用车辆数量及运载能力条件的约束下,每辆车都从起点出发,完成若干客户点的运送任务后再回到起点,要求以最少的车辆数、最小的车辆总行程完成货物的派送任务。
软件工程的十大模型

软件工程的十大模型软件工程是涉及规划、设计、开发、测试和维护软件系统的学科领域。
在软件开发过程中,存在多种模型用于组织和管理项目的不同阶段。
以下是十大常见的软件工程模型:1.瀑布模型(Waterfall Model):这是最传统的软件开发模型,依序执行阶段(需求、设计、实现、测试、部署和维护)。
每个阶段按顺序进行,前一阶段完成后才开始下一阶段。
2.原型模型(Prototyping Model):原型模型通过迭代构建原型来理解和确认用户需求。
在反复的原型构建和用户反馈中,逐步完善系统需求。
3.迭代模型(Iterative Model):迭代模型将软件开发过程分成多个迭代周期,每个迭代周期包括需求、设计、开发和测试等阶段。
每次迭代都会增加新功能或修复问题。
4.增量模型(Incremental Model):增量模型将系统功能分成多个增量,在每个增量中逐步构建、测试和交付部分功能。
5.螺旋模型(Spiral Model):螺旋模型以风险管理为核心,通过不断迭代的螺旋来完成软件的开发。
每个螺旋圈代表一个迭代周期,包括计划、风险评估、工程和评审等阶段。
6.敏捷开发模型(Agile Model):敏捷开发是一种迭代和增量开发方法,强调团队合作、快速交付、持续反馈和灵活响应变化。
7.V模型(V-Model):V模型将软件开发的各个阶段与对应的测试阶段相对应。
每个开发阶段都有对应的验证和确认测试阶段,形成V形状的结构。
8.喷泉模型(Fountain Model):喷泉模型强调软件开发过程中的知识管理和复用,鼓励团队在开发中积累并共享知识。
9.融合模型(Hybrid Model):融合模型是将多种软件工程模型和方法结合使用,根据项目的需求和特点来灵活选择和应用不同的模型元素。
10.脚手架模型(Scaffold Model):脚手架模型强调在软件开发中使用现有的、可复用的组件或结构,以加速和简化开发过程。
每种模型都有其独特的优点和局限性,选择最合适的模型取决于项目的特点、需求和团队的工作方式。
nlp模型发展史

nlp模型发展史
自然语言处理(NLP)模型的发展历经了多个阶段和技术革新,包括
规则驱动模型、基于统计模型、深度学习模型等。
1.规则驱动模型(1950s-1990s)。
早期的自然语言处理模型是基于规则的,即由人类专家手动编写语法
规则和词汇表来解决自然语言处理问题,例如语法分析、机器翻译和信息
检索等。
但由于语言的复杂性和准确性的限制,这些规则驱动的模型变得
难以维护和扩展,无法处理自然语言的多义性和歧义性。
2.基于统计模型(1990s-2010s)。
随着计算机技术的快速发展和数据量的大幅增加,基于统计建模的方
法在自然语言处理中变得越来越流行。
这种模型使用预先收集的语言数据
集来学习语言规律,然后使用这些规则来处理新的语言数据。
常见的算法
包括隐马尔可夫模型(HMM)、条件随机场(CRF)、最大熵模型(MaxEnt)等。
这些模型在许多自然语言处理任务中都取得了有限的成功,包括语音
识别、词性标注、实体识别、情感分析等。
3.深度学习模型(2010s至今)。
深度学习模型是一种利用人工神经网络解决自然语言处理问题的方法。
这种模型使用深度神经网络来自动学习语言的特征,并能够处理大量的语
言数据和复杂的语言规律。
在自然语言处理中,深度学习模型已经被广泛
应用于文本分类、机器翻译、问答系统、语义分析等任务中,其中最著名
的包括卷积神经网络(CNN)、递归神经网络(RNN)、长短期记忆网络(LSTM)和Transformer等。
通过使用这些深度学习模型,自然语言处理
系统已经取得了很大的进展,并成为当前研究的热点领域之一。
2025年软件资格考试软件评测师(中级)(基础知识、应用技术)合卷试题与参考答案

2025年软件资格考试软件评测师(基础知识、应用技术)合卷(中级)模拟试题(答案在后面)一、基础知识(客观选择题,75题,每题1分,共75分)1、以下关于软件生存周期模型的描述中,正确的是()A. 螺旋模型适用于大规模、复杂和风险高的项目B. 水晶模型强调在软件开发过程中快速迭代和适应变化C. 精益软件开发模型适用于小型、快速开发的项目D. 瀑布模型强调软件开发的阶段性和顺序性2、在软件工程中,以下哪个概念不属于软件质量特性()A. 可靠性B. 可维护性C. 可用性D. 可移植性3、题干:以下关于软件架构的定义中,不正确的是:A. 软件架构是指软件系统整体的结构和组成部分之间的关系B. 软件架构描述了软件系统的组件和组件之间的关系C. 软件架构主要关注软件系统的功能需求D. 软件架构定义了软件系统的可维护性和可扩展性4、题干:在软件架构设计过程中,以下哪种设计原则可以帮助降低系统的复杂度?A. 开放封闭原则B. 单一职责原则C. 迪米特法则D. 里氏替换原则5、在软件工程中,下列哪个阶段通常被称为“需求分析”阶段?A. 软件设计阶段B. 软件编码阶段C. 软件测试阶段D. 软件需求分析阶段6、以下哪种软件测试方法属于静态测试?A. 单元测试B. 灰盒测试C. 漏洞扫描D. 系统测试7、在软件工程中,以下哪个不是软件生命周期模型?A. 水晶模型B. 瀑布模型C. 螺旋模型D. 快速原型模型8、下列关于软件需求规格说明书(SRS)的说法中,错误的是:A. SRS应具有可验证性B. SRS应具有无歧义性C. SRS应具有一致性D. SRS不应包含用户界面设计9、在软件生存周期中,以下哪个阶段负责确定软件的需求和功能?A. 软件设计阶段B. 软件需求分析阶段C. 软件编码阶段D. 软件测试阶段 10、以下哪项不属于软件质量模型中的“外部质量”?A. 性能B. 可维护性C. 可用性D. 可移植性11、在软件开发过程中,以下哪一项不属于软件测试的范畴?()A. 单元测试B. 集成测试C. 需求分析D. 系统测试12、以下关于软件维护的说法,不正确的是()。
我国高校创新创业教育生态构建模型:基于扎根理论的质性探索

2024年第8期现代商贸工业Modern Business Trade Industry基金项目:河南省高等教育教学改革研究与实践项目(就业创业指导类)(2021SJGLX1038);2021年度河南省高等教育教学改革研究与实践立项项目子项目(jg2252)㊂作者简介:王丽萍(1980-),女,山东禹城人,教育学硕士,郑州经贸学院副教授㊂我国高校创新创业教育生态构建模型:基于扎根理论的质性探索王丽萍(郑州经贸学院创新创业学院,河南郑州451191)摘㊀要:借助NVivo12软件,按时间序列对2018-2021年关于创业教育生态系统的49份文本资料进行词频分析,并运用扎根理论对相关文本资料进行编码分析,构建了高校创新创业教育生态系统理论模型㊂扎根结果分析,创业教育生态系统包括创业主体㊁高校㊁社会和政府四大要素,其中创业主体是中心角色,通过 内部支持 协同合作 外部保障 形成体系㊂目前高校创新创业生态系统研究已经取得了坚实的成果,但还存在成长的空间,比如在专创融合㊁家庭因素㊁创业主体的 反哺 作用等方面均需要继续探索㊂关键词:创新创业教育;生态系统;高校;扎根理论中图分类号:F2㊀㊀㊀㊀㊀文献标识码:A㊀㊀㊀㊀㊀㊀doi:10.19311/ki.1672-3198.2024.08.0080㊀引言‘中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要“中提到 优化创新创业创造生态 ㊂充分说明创新创业教育仅仅依靠高校远远不够,需要将校内㊁校外资源进行有机整合,构建以高校为主导的创新创业教育生态系统㊂当前,我国高校创业教育已经发展到生态化阶段,建立高校创业教育生态系统 是解决高校创业教育发展的 最后一公里 问题㊂本文采用扎根理论,构建我国高校创新创业教育生态系统理论模型,以期对我国高校双创教育高质量发展具有借鉴意义㊂1㊀文献回顾目前,关于创新创业教育生态系统的构建研究主要集中在生态文化培育㊁生态因子协作以及生态机制等方面㊂1.1㊀生态文化培育研究生态文化培育的研究多借鉴美国㊁以色列等高校的做法,再融入国内 立德树人 的思政元素㊂王志强(2020)认为从多个维度培育校内的创新创业文化,从而构建起所在区域内成熟的创新创业教育网络和生态系统㊂1.2㊀生态因子协作研究目前,高校创业教育生态系统已初具雏形,但要素与要素之间尚未形成良好循环㊂鲍明旭(2020)认为在数字经济背景下建设完善的创新创业教育生态系统,需要政府㊁高校和产业同心协力,合理运用数字技术和数字平台㊂1.3㊀生态机制研究现阶段,学者们倾向于思考创业生态系统如何高效运作,研究重点多集中于生态机制研究㊂陈元媛(2021)指出要完善高校创新创业教育的统筹机制㊂政府要发挥好 中介 作用,做好创新成果转化的服务工作㊂综上,研究成果多集中在生态文化培育㊁生态因子协作以及生态机制等问题上,其中以生态因子协作研究为最多,分为内部要素和外部要素,内部要素以高校为主体,外部要素包括政府㊁企业㊁社会等,但各生态要素之间如何良性协作尚未形成系统,还有待进一步研究构建我国高校创新创业教育生态系统运作模型㊂2㊀研究设计2.1㊀研究方法本文对国内颁布的双创政策文件㊁学术期刊文章等文本进行逐步编码,并在编码的过程中运用NVivo12的词频检索功能对范畴内容进行时间序列上的比较分析,进而找出现阶段双创教育的重心领域㊂2.2㊀数据收集本文的数据来源于两个部分㊂一是,收集2015-2021年间的官方文件㊂中华人民共和国中央人民政府㊁中华人民共和国教育部等官方网站公布的关于 创新创业 的相关政策文件,共收集到9份;二是,收集知网数据库2018-2021年间的期刊论文㊂以 创业教育生态系统 为主题词,检索到121篇北大核心㊁CSSCI 等期刊论文,从中随机选取40篇㊂㊃32㊃现代商贸工业Modern Business Trade Industry2024年第8期3㊀范畴提炼与模型构建3.1㊀开放式编码提炼概念与范畴将文本材料进行编码,主要包括开放性编码(OpenCoding)㊁主轴编码(Axial Coding)和选择性编码(Selec-tive Coding)㊂(1)开放式编码㊂将49份文本资料随机选取28份导入NVivo12软件中,并进行编号和命名,对原始文本和范畴的确定进行不断理解㊁整合㊁筛选和比较,同时根据概念间的重复度和出现的频次进行反复推敲,最后形成了60个初始概念编码和18个范畴㊂(2)主轴编码㊂通过主轴编码后对创新创业教育生态系统进一步形成了4个主范畴㊂如表1所示㊂表1㊀三级编码过程主范畴副范畴初始范畴内涵解释创业主体B1创业主体A1个人创业主体校内参与创业的个人A2组织创业主体组织创业主体主要涉及高校㊁地方政府和企业高校社会B2领导体系B3课程建设B4师资建设B5制度建设B6文化建设B7校外合作A3专项工作领导机构主要任务有两项,一是总体推进校内创新创业工作开展;二是统筹协调与社会㊁企业㊁政府等各方的合作A4创业教育专门机构主要任务是推进高校创新创业学科建设,成立创新创业教育专家委员会和教学团队A5理论基础课程包括通识教育课程㊁专创融合课程㊁在线课程等的建设,以及双创教材㊁教学方法改革等研究A6课外实践活动包括非正规课程㊁专业社团㊁第二课堂㊁实践平台等实践活动A7校内师资校内师资包括专职教师和实践教师A8校外师资校外师资包括专家学者㊁企业人士㊁政府人员等A9师资制度包括师资培养㊁激励政策㊁考核评价等制度建设A10学生制度包括创业支持㊁学分认定㊁弹性学制等制度建设A11校内机制主要指保障机制㊁评价机制㊁创新人才培养机制等A12校内文化建设包括创造高校创新创业的氛围营造和人文环境建设A13校外文化建设包括社交文化和创业文化的打造 营造独立㊁自由㊁创业㊁实干的创新创业氛围A14资源体系高校与社会㊁企业合作,争取创业所需人力㊁技术㊁信息㊁场地㊁资金等资源A15对外合作高校可与名校㊁创业孵化器㊁企业㊁政府㊁公众等进行合作和交流政府B8保障服务A16政府支持政府通过多方来源可从资金㊁场地㊁政策㊁立法㊁科技㊁管理等方面给予支持A17创业指导服务高校㊁政府和企业可以提供信息㊁培训㊁商机等多方面服务㊀㊀(3)选择性编码与模型构建㊂经过选择性编码,将高校创新创业教育生态系统梳理出一条 故事线 :高校为创业主体提供 内部支持 ,社会通过 协同合作 为创业主体营造适宜创业的社会文化和资源体系,政府通过 外部保障 为创业主体提供资金㊁场地㊁政策等保障性支持和创业指导服务,创业主体向政府㊁社会和高校反哺科研成果和创新产品与工艺等㊂构建出高校创新创业教育生态系统理论模型,如图1所示㊂图1㊀高校创新创业教育生态系统构建理论模型(4)饱和度检验㊂本研究对剩余的21份文本资料进行了理论饱和度检验,对其进行三级编码后,所得结果基本包括在以上所得范畴中,未发现新的范畴关系结构㊂由此得出,本文基于扎根理论构建的理论模型是饱和的㊂除此之外,还向本领域两位专家㊁学者请教了编码结果和理论模型,得到了他们肯定,说明图1所示的理论模型通过了理论饱和度检验㊂4㊀模型阐释及扎根结果分析下面将阐释模型中的4个主范畴 创业主体㊁高校㊁社会和政府之间的逻辑关系㊂4.1㊀内部支持在创新创业过程中,高校可以从领导体系㊁课程㊁师资㊁制度㊁校园文化等方面为创业主体提供内部支持㊂ 高校 在创新创业教育生态体系中作为创业主体的 土壤 ,向大学生供给大量 养分 ㊂ 领导体系 通过建设合理的 课程体系 ㊁搭建全面的 师资队伍 ㊁设置科学的 制度体系 ㊂ 高校 为创新创业教育生态系统不断提供 物质基础 , 课程体系 和 师资队伍 为创新创业教育生态系统生产 知识能量 , 制度体系 保证 知识能量 在创业教育生态系统中的流通和循环㊂4.2㊀协同合作协同合作,包括校外文化建设和校外合作㊂校外文化建设指的是社会文化氛围的营造;校外合作,包括资源体系和对外合作㊂一个社会创新创业文化的建立,需要国家㊁企业㊁媒体㊁高校㊁家庭等多种要素共同协作㊂4.3㊀外部保障外部保障,主要指的是政府的支持和创业指导服㊃42㊃2024年第8期现代商贸工业Modern Business Trade Industry务㊂政府需要从资金㊁场地㊁政策㊁立法㊁智力㊁管理㊁资源等方面对创业主体给予支持㊂创业指导服务也需要政府从信息㊁培训和项目等方面予以提供㊂如果将高校比作是 根 ,那么政府则更像是 土壤 ,只有肥沃的土壤才能源源不断向根系输送足够的养分㊂综上所述,创新创业教育生态系统是一个有机的整体,高校为创业主体提供 内部支持 ,与社会 协同合作 为创业主体营造社会文化和资源体系,政府为创业主体提供 外部保障 ,它们之间相互联动共同推进高校创新创业教育的发展,需要内外部各种要素的协同作用,最终达到提升创新创业教育质量和效率的目的㊂5㊀研究结论与展望5.1㊀研究结论本文采用扎根理论的方法,对2018-2021年有关 创业教育生态系统 的49份文本资料进行了逐步编码和系统分析,并按年份对文本资料进行NVivo12词频检索分析,发现目前高校创新创业生态系统研究已经取得了坚实的成果,但还存在成长的空间,比如在家庭因素㊁专创融合㊁创业主体的 反哺 作用㊁ 协同协作 和 外部保障 等方面均需要继续探索㊂(1)生态系统的主体中,缺少 家庭 这一重要主体㊂忽视了 家庭 在大学生创新创业教育中的重要作用㊂习近平总书记曾指出 家风是社会风气的重要组成部分 ,想要培育良好的创新创业社会风气和文化, 家庭 的作用不可小觑,但我国自古崇尚中庸之道,想要在短时间内改变确实有一定难度,需要政府㊁社会㊁媒体等持续宣传,为家庭树立创新创业风气奠定基础㊂(2)专业课程与创业课程存在 两张皮 现象,需要基于生态系统理论构建真正的专创融合课程体系㊂传统的专业课程注重培养学生的归纳推理(是什么)和演绎推理(应该是什么)的能力,而创业思维更注重培养溯因推理(可能是什么)能力,在面对当今高度不确定的环境,更需要学生的溯因推理能力㊂除此以外,双创课程是一个随着时代发展而不断变化的课程,无论是教学内容㊁教学形式㊁方法和手段都需要与时俱进㊁不断创新㊂(3)忽视了创业主体(大学生)的 反哺 作用㊂从当前研究来看,创新创业生态系统的建设过于注重自上而下的能量输送,即高校㊁社会和政府向创业主体(大学生),而对创业主体(大学生)的主观能动性和 反哺 能力较为忽视㊂高校㊁社会或政府可以建设更多的平台和渠道,让创业主体(大学生)的创新创业成果,比如科研成果㊁产品㊁工艺等赋能高校㊁企业和政府,从而形成 能量 闭环㊂5.2㊀研究贡献(1)研究方法创新㊂首次运用扎根理论对高校创新创业教育生态系统进行了系统地总结和梳理,阐述现阶段高校创新创业教育的进展,为今后的理论研究和教育实践提供参考借鉴㊂在研究的过程中,发现现今创新创业教育生态系统的成果丰硕,但也存在薄弱点,比如:生态系统的主体中,缺少 家庭 这一重要主体;专业课程与创业课程存在 两张皮 现象;忽视了创业主体(大学生)的 反哺 作用;针对 内部支持 的研究明显多于协同协作 和 外部保障 等,希望在高校建构创新创业教育生态系统时予以重点补充和考虑㊂(2)研究理论创新㊂以 故事线 (StoryLine)的形式描绘和构建出高校创新创业教育生态系统理论模型㊂当前关于创新创业教育生态系统的研究主要集中于对生态系统中各因子之间的协作研究㊂本文从整体上通过对已有研究的总结和分析,抽象出高校创新创业教育生态系统的模型,为我国高校创新创业教育系统的发展一个可供参考的理论框架㊂5.3㊀研究不足与展望(1)研究不足㊂本文以扎根理论的质性研究方法为基础,构建了高校创新创业教育生态系统构建理论模型㊂但是,仍然存在一定的不足㊂比如,对数据的收集可能仍存在一定的不足,由于疫情期间,去高校做访谈的条件有限,未能收集到一手资料,因此,本文收集数据是选取一定量相关政策文件和期刊论文,导致最终的模型构建有可能针对性不强㊂(2)未来展望㊂首先,在选取数据方面,未来的研究可偏重一手资料㊂比如,选择入选全国创新创业典型经验的高校㊂其次,在研究方法上,可以更加多样化㊂比如,采用实地访谈法和案例分析法,在注重进行结构化或半结构化访谈的基础上,可同时采用焦点小组访谈的方式,深入挖掘数据现象,由表及里,探索出更内在的本质,此方式更有利于被访谈者之间进行更深层次的互动交流,因此,所得到的信息也往往比个别访谈更加深入和全面㊂参考文献[1]杨晓慧.高校创业教育生态系统建设的国际比较和中国特色[J].中国高教研究,2018,(1):48-52.[2]王志强,朱黎雨.以色列创新创业教育生态系统的构建及其启示[J].河北师范大学学报,2020,(1):67-74. [3]鲍明旭.数字时代创新创业教育生态系统研究 基于三螺旋理论[J].技术经济与管理研究,2020,(10): 31-35.[4]陈元媛.基于生态系统理论的高校创新创业教育研究[J].学校党建与思想教育,2021,(7):94-96.㊃52㊃。
2022年哈尔滨商业大学软件工程专业《计算机系统结构》科目期末试卷A(有答案)

2022年哈尔滨商业大学软件工程专业《计算机系统结构》科目期末试卷A(有答案)一、选择题1、若输入流水线的指令既无局部性相关,也不存在全局性相关,则()。
A.可获得高的吞吐率和效率B.流水线的效率和吞吐率恶化C.出现瓶颈D.可靠性提高2、推出系列机的新机器,不能更改的是()。
A.原有指令的寻址方式和操作码B.系统总线的组成C.数据通路宽度D.存储芯片的集成度3、多处理机的各自独立型操作系统()。
A.要求管理程序不必是可再入的B.适合于紧耦合多处理机C.工作负荷较平衡D.有较高的可靠性4、对汇编语言程序员透明的是()A.I/O方式中的DMA访问B.浮点数据表示C.访问方式保护D.程序性中断5、以下说法不正确的是( )A.线性流水线是单功能流水线B.动态流水线是多功能流水线C.静态流水线是多功能流水线D.动态流水线只能是单功能流水线6、汇编语言程序经()的()成机器语言程序。
A.编译程序,翻译B.汇编程序,翻译C.汇编程序,解释D.编译程序,解释7、在流水机器中,全局性相关是指( )。
A.先写后读相关B.先读后写相关C.指令相关D.由转移指令引起的相关8、浮点数尾数基值rm=8,尾数数值部分长6位,可表示的规格化最小正尾数为( )A.0.5B.0.25C.0.125D.1/649、计算机系统多级层次中,从下层到上层,各级相对顺序正确的应当是()。
A.汇编语言机器级,操作系统机器级,高级语言机器级B.微程序机器级,传统机器语言机器级,汇编语言机器级C.传统机器语言机器级,高级语言机器级,汇编语言机器级D.汇编语言机器级,应用语言机器级,高级语言机器级10、下列说法中不正确的是( )A.软件设计费用比软件重复生产费用高B.硬件功能只需实现一次,而软件功能可能要多次重复实现C.硬件的生产费用比软件的生产费用高D.硬件的设计费用比软件的设计费用低二、填空题11、多计算机互连网络中的通信模式有________和________12、基于存储器-存储器的向量指令是指________来自________,两种结或把而且把操作后的结果直接写入存储器。
随机系统建模与仿真.pptx

2.自相关域特性 自相关函数是对随机过程在相关域上的特
性描述。它表征随机过程在一个时刻和另一时 刻采样值之间的相互依赖程度,即表征信号随 机变化的程度。
对于平稳随机过程,有自相关函数
Rx
(
)
lim
T
1 T
T
x(t)x(t )dt
0
(6.21)
第21页/共88页
6.1 随机系统基本知识(续)
则 X称在区间 (上a,b服) 从均匀分布,记作
。
X ~ U (a,b)
第9页/共88页
6.1 随机系统基本知识(续)
均匀分布的概率密度函数和分布函数可 用图6-2的曲线表示。
图6-2 均匀分布的分布曲线
第10页/共88页
6.1 随机系统基本知识(续)
(2)正态分布 正态分布又称为高斯分布,是最常用的一种连续分
布。若连续型随机变量 X的概率密度函数为
f (x)
1
x 2
e 2 2
2
(6.12)
其中 为大于零的常数,则 称X 服从参数 的,正
态分布,记作 X ~ (。, 2 )
第11页/共88页
6.1 随机系统基本知识(续)
(3)泊松分布
若离散型随机变量 X的概率分布为
Fk
F(xk )
k e
k!
k 0,1, 2,
E(
xK
(t
))
E(
X
(t))
lim
T
1 T
T
0 xK (t)dt
(2)方差
2 xK
2X
lim 1 T T
T 0
xK (t) E
xK (t) 2
dt
重庆大学本科学生毕业设计(论文)

1绪论 (1)2 Logisim仿真软件 (3)3 计算机组成原理实验 (5)3.1 实验简介 (5)1.1.1运算器实验 (5)1.1.2 静态随机存储器实验 (6)1.1.3微程序控制器实验 (6)1.1.4 简单模型机实验 (8)1.1.5复杂模型机实验 (9)3.2 指令系统 (9)1.2.1 简单模型机指令 (9)1.2.2 复杂模型机指令 (10)3.3 微指令设计 (12)3.4 时序单元 (13)4 仿真实现 (15)4.1 运算器实验 (15)4.2 存储器实验 (18)4.3 微程序控制器实验 (19)4.4 模型机实验 (24)4.4.1简单模型机 (24)4.4.2 复杂模型机 (27)5 结论 (32)5.1 体会 (32)5.2 总结 (32)附录A:实验微程序 (35)1 绪论《计算机组成原理》是计算机科学与技术及其相关专业的一门非常重要的专业基础课程,课程配套的实验对该课程内容的掌握至关重要。
教学反映,该课程对初学者难度较大,它要求学生熟练掌握计算机各子系统的组成原理、设计方法、相互关系以及各子系统互相连接构成整机系统的技术。
受到总学时、实验场所和实验设备的限制,实验课上同学们要在实验中观察得到正确的结果,必须具有扎实的基础、清晰的概念、正确的逻辑设计以及合理的操作步骤。
目前国内大部分高校采用的实验方式主要是利用一些现有的计算机组成原理实验箱来完成实验[1]。
我院采用的是TD-CMX计算机体系结构与计算机系统设计平台,此平台由一个教学实验箱、FPGA开发板和动态图形调试软件组成。
实验箱已将计算机的各个逻辑组成部件芯片全部做好并焊接在实验板上,学生只需按实验指导书中的要求进行连线并拨动相应开关,然后观察实验结果就能完成实验[1]。
这种实验过程简单死板,仅有验证没有设计,并且实验箱的费用高,淘汰快,易损坏且难维护,学生对实验设备利用率低,实验效果也不太理想。
同时,这种实验方式离不开实验箱,所以学生只能在指定的实验室中完成实验,在短暂的实验时间内,学生第一次接触实验箱就要完成连线和操作,难度较大,如果实验前没有预习,实验效果将大打折扣。
经典的自然语言处理模型

经典的自然语言处理模型自然语言处理(NLP)是计算机科学中一个重要领域,它涉及计算机对人类语言的理解和生成。
在现代社会,人们越来越依赖自然语言处理技术,例如智能语音助手、机器翻译和情感分析等。
本文将介绍一些经典的自然语言处理模型。
1. 词袋模型词袋模型是自然语言处理中最简单的模型之一,它把文本中的所有单词或词组看作一个袋子,忽略它们在文本中的顺序,然后根据它们出现的频率建立模型。
基于该模型,在文本分类,情感分析,特征提取等任务中,可以直接使用基于统计的方法,例如朴素贝叶斯和支持向量机。
虽然词袋模型简单易于实现,但它仅仅依赖于单个单词的频率,缺少对上下文信息的考虑,容易产生歧义和误解。
2. 循环神经网络(RNN)循环神经网络是一种能够处理序列数据的神经网络,它的主要优势在于可以捕捉到单词在序列中的位置和其上下文信息。
RNN中有一个隐藏状态,用户表示当前单词的上下文信息,与前一个单词的隐藏状态和当前的输入共同更新。
RNN广泛用于文本生成,语言模型,机器翻译和情感分析等任务中。
在NLP中,基于RNN的LSTM(Long Short-Term Memory)模型是相当流行的,它能够解决梯度消失和梯度爆炸等问题,并且能够记忆除当前状态以外的许多步骤中间的信息。
3. 卷积神经网络(CNN)卷积神经网络是一种设计用于处理图像、音频和文本等数据的深度学习模型。
在NLP中,CNN主要用于文本分类和情感分析等任务,其基本思想是将文本看作二维矩阵,然后使用卷积核进行卷积,提取特征。
CNN通过卷积层提取n-gram信息,然后使用池化层压缩这些信息。
在某些情况下,CNN在性能上甚至能够超越RNN。
4. 递归神经网络(Tree-RNN)递归神经网络是一种能够处理树形结构数据的网络。
在NLP 中,它主要用于处理句法分析和语义角色标注等任务,因为语言表达具有层次结构,例如短语作为句子的一部分。
Tree-RNN通过遍历句子中的语法树建立模型,可以捕捉到短语之间的关系及其上下文信息。
2024年4月《软件工程》全国自考考题含解析

2024年4月《软件工程》全国自考考题一、单项选择题1、CMMI组织过程改善的成熟度等级中的2级是______。
A.已执行级B.已定义级C.已管理级D.已定量管理级2、软件工程在20世纪60年代末到80年代初获得的主要成果有______。
A.CASE产品B.面向对象语言C.瀑布模型D.软件生存周期过程3、软件结构化设计中,支持“自顶向下逐步求精”的详细设计,并且能够以一种结构化方式严格地控制从一个处理到另一个处理的转移,这个详细设计工具是______。
A.PAD图B.程序流程图C.DFD图D.N-S图4、RUP的迭代、增量式开发过程中,需要估算成本、进度,并能够减少次要的错误风险,至少需要完成______。
A.初始阶段B.精化阶段C.构造阶段D.移交阶段5、下列不属于软件危机的主要表现是______。
A.软件生产效率低B.软件开发没有工具支持C.软件生产质量低D.软件开发缺乏可遵循的原理、原则、方法体系以及有效的管理6、在教师科研方案中规定对教授、副教授和讲师分别计算分数,做相应的处理,则根据黑盒测试中的等价类划分技术,下列划分正确的是______。
A.3个有效等价类,3个无效等价类B.3个有效等价类,1个无效等价类C.1个有效等价类,1个无效等价类D.1个有效等价类,3个无效等价类7、结构化分析方法给出了一种能表达功能模型的工具是______。
A.HIPO图B.PAD图C.N-S图D.DFD图8、有效性测试的目标是发现软件实现的功能与下列哪个选项不一致,正确的是______。
A.需求规格说明书B.概要设计说明书C.详细设计说明书D.测试计划9、下列不属于创建一个系统的类图步骤是______。
A.模型化待建系统中的概念,形成类图中基本元素B.模型化待建系统中的各种关系,形成该系统的初始关系C.模型化系统中的接口,不需给出该系统的最终类图D.模型化逻辑数据库模式10、下列可用于概念模型和软件模型的动态结构的是______。
一个简单文件处理的随机模型(IJITCS-V11-N7-6)

I.J. Information Technology and Computer Science, 2019, 7, 43-53Published Online July 2019 in MECS (/)DOI: 10.5815/ijitcs.2019.07.06A Stochastic Model for Simple DocumentProcessingPierre MOUKELI MBINDZOUKOUInstitut Supérieur de Tectonolgie (IST), LAIMA –Institut Africain d’Informatique (IAI), Libreville – GABONE-mail: pierre.moukeli@Arsène Roland MOUKOUKOUUniversité des Sciences et Techniques de Masuku – GABONE-mail: arsenem@Pr. David NACCACHEENS Paris - FRANCEE-mail: david.naccache@Nino TSKHOVREBASHVILICentre de Recherche en Informatique, Université Paris 1 Panthéon-Sorbonne, Paris - FranceE-mail: ntskhovrebashvili@Received: 17 April 2019; Accepted: 23 May 2019; Published: 08 July 2019 Abstract—This work focuses on the stationary behaviorof a simple document processing system. We mean by simple document, any document whose processing, at each stage of its progression in its graph of processing, is assured by a single person. Our simple document processing system derives from the general model described by MOUKELI and NEMBE. It is about an adaptation of the said general model to determine in terms of metrics and performance, its behavior in the particular case of simple document processing. By way of illustration, data relating to a station of a central administration of a ministry, observed over six (6) years, were presented. The need to study this specific case comes from the fact that the processing of simple documents is based on a hierarchical organization and the use of priority queues. As in the general model proposed by MOUKELI and NEMBE, our model has a static component and a dynamic component. The static component is a tree that represents the hierarchical organization of the processing stations. The dynamic component consists of a Markov process and a network of priority queues which model all waiting lines at each processing unit. Key performance indicators were defined and studied point by point and on average. As well as issues specific to the hierarchical model associated with priority queues have been analyzed and solutions proposed; it is mainly infinite loops.Index Terms—Document processing, workflow, hierarchic chart, counting processes, stochastic models, waiting lines, Markov processes priority queues.I.I NTRODUCTIONWith the Internet development, e-Government [1-6] is experiencing a huge expansion particularly characterized by a massive document exchange and consequently a large increase in the workload related to the processing of documents [7-8]. As MOUKELI and NEMBE raised in [9], the management of documents flow in both public and private administrations ‘‘is of both deterministic and random nature and becomes a problem of great scientific, technologic and economic interest’’. The nature and specificity of these documents being varied, in this paper we focused on simple documents that represent, according to our estimates, over 70% of the mass of documents processed.We mean by simple document, a document whose processing is provided at all times by one person at a time. We have adapted MOUKELI and NEMBE model [9] to the simple document processing case, by proposing a mathematical formalization adapted to this problem and performance analysis based on realistic assumptions.Our choice to study simple documents workflow, as a specific model from the general model described by MOUKELI and NEMBE [9], is motivated by the particular nature of the processing graph of simple documents and by the dynamic data structure presents at each node of the said graph. Indeed, the traffic of simple documents is organized according to a graph which is generally a tree reflecting the hierarchical organization of the administration in charge of handling such documents.Moreover, at each workstation or node receiving simple documents to be processed, these are stored in a priority queue [11-12]. So, we found it useful to study the behavior of a simple document processing system by examining the properties of the processing graph and the behavior of a priority queue associated with each node of the tree. This system (graph of priority queues) is susceptible to saturate and loops can appear in the document processing cycle. Our model finely analyzes these situations in order to identify or predict them. One of the main objectives was stated by MOUKELI and NEMBE [9], namely "when a document is inserted into the system, the path it follows should benefit from a priori knowledge on how the system behaves for similar documents’’. Hence the need to define necessary metrics to improve the decision-making process, by using, as suggested by Van der Aalst [13], stochastic models, and especially queues [11] to lead this analysis at the strategic level. Finally, it should also be noted that document processing is part of the workflow domain, for which a great amount of research has been devoted [14-23].The second part of this article presents related works. The third part supplements the definitions proposed by MOUKELI and NEMBE [9]. The fourth part sets out in more detail the problem briefly described in the preceding paragraph; this problem is illustrated by a practical case presenting data from an observation of an administrative workstation for six years. The fifth part is devoted to the description of our simple document processing model; starting with general considerations, we describe our mathematical model with its static and dynamic components. The sixth part is devoted to the study of the performances of the system; in particular, it presents the main performance indicators of static and dynamic models, as well as those relating to system saturation and infinite loop detection.II.R ELATED W ORKSMOUKELI and NEMBE [9] described a general model for document processing. Remember that document processing is a process close to the production management, or more generally, the workflow [20-23], with one fundamental difference: in the case of a document processing system, outputs can become system inputs, as in sequential systems. This justifies the use of Markov processes in the general model proposed by MOUKELI and NEMBE [9].Our contribution, which is a continuation of the work of MOUKELI and NEMBE, focuses on the workflow of simple documents, as a specific model. Indeed, the processing of simple documents is organized according to a hierarchical tree graph. We were therefore interested in studying the adaptation of the general model to this specific case, in particular by examining the properties of the processing graph and the behavior of the priority queue associated with each node of the processing chart.III.D EFINITIONSIn a previous article [9], concepts related to document processing were defined. These include, as a reminder, the following concepts: managerial unit, document, processing, processing time, service time, waiting time, station or processing unit, document transmission, document processing graph, organization chart, document tracking. In addition, the five definitions below. Definition 1:Simple document. A simple document is any document whose treatment, at each stage of its progression in its processing graph, is provided by a single person. No copy or part of the document can be processed at the same time in another workstation. In the remainder of this article, unless otherwise specified, the term document will refer to a simple document. Definition 2: Mail. According to Wikipedia, "mail refers to written correspondence between people, usually two: a sender who sends it and a recipient who receives it". In the field of our study, these are handwritten or typed letters, on paper or dematerialized, exchanged along a hierarchical line.Definition 3:hierarchical organization chart. This is a tree representing a vertical organization. The upstream nodes, whose roots represent the chiefs or hierarchical superiors, while the nodes in front, whose leaves correspond to the subordinates or collaborators. An example of a flowchart is given in Fig. 1. A hierarchical organization chart can be represented by a tree with the highest hierarchical root; it can also represent the entry point into the system.Definition 4: Hierarchical level. This is the position of a person in a hierarchical organization chart relative to the highest hierarchical leader. Formally: let (,,)G V E R= be a tree modeling a hierarchical organization chart, of which V is the set of nodes; E all the edges; and R V∈, the root. The hierarchical level of a node x V∈ is the length of the path [],R x; that is, the number of edges constituting the path from the root R to the node x. It is in fact a function h defined as follows::[,]Vhx R x→⎧⎨⎩(1) In this formula, [,]R x is the length of the path [,]R x, provided that ()0.h R=Definition 5: Hierarchical line. It is a path from a hierarchical superior to his subordinate in a hierarchical organization chart. The hierarchical line is the path that follows information from a superior to his subordinate orvice versa. For example, in Fig. 1, the axis "Minister - Secretary General - Director General of SMEs - Director of Studies - Head of Service Approval" is a hierarchical line. Formally: let (,,)G V E R =be a tree modeling a hierarchical organization chart, V is the set of nodes; E all the edges; and R V ∈, the root. A hierarchical line is a tuple 12(...)n x x x defined as follows:1121(,)(...)/,1:()()i i nn i i x x E x x x V i i n and h x h x ++∈∈∀≤<<⎧⎪⎨⎪⎩ (2)IV. T HE PROBLEM OF S IMPLE D OCUMENT P ROCESSING The general problem of the treatment of documents was raised by MOUKELI and NEMBE [9]. In short, document processing occupies a central place in the everyday life of public and private administrations at the level of all jobs; sustainable development and preservation of nature require. The control of this flow (more and more digital) escapes human operator overtimes, which are responsible for monitoring and processing information without adequate tools. This is why the analysis and the follow-up of this flow are necessary for better processing of the documents. For example, one could better identify the points of inertia or bottlenecks, master the capabilities of the system and predict its behavior under certain conditions.To facilitate the analysis of this data flow, MOUKELI and NEMBE [9] have proposed a general mathematical model to represent it and predict its behavior. They deduced properties that could lead to performance metrics for document processing systems. The purpose of the present study is to adapt this general model to the particular case of simple documents. This study is motivated by the following observation: in both public and private administrations, more than 70% of thedocuments processed are simple documents, the most emblematic of which is mail. According to the noticed practices, the hierarchical leader does not often have tools allowing him to know the performances of the system [24] when new simple documents are introduced there. In addition, 10% of these documents get lost in the line of processing, for lack of traceability.To illustrate this problem, we will present the practical case of a processing station of a Gabonese administration, namely, the General-Secretariat of a ministry, observed by us during the period 2004 - 2009, that is six years. Fig. 1 below places this station in the Ministry's organizational chart.Fig.1. Functional organization chart of the Gabonese Ministry of SMEs,2004-2009, (Pavers in bold: non-detailed organizationof two trust bodies).Table 1. Classification of documents processed by the Secretary General 2004-2009 (Pavers in bold: non-detailed organization of two trust bodies)We have classified the documents processed by the Secretary-General into several types ranging from speeches to legislative and regulatory texts (Table 1). The origins (applicants) of the documents are the hierarchical superior who is the Minister, the subordinates of the Secretary-General (SG), who are the Director Generals and other collaborators, as well as the Secretary-General himself and the external natural or legal persons to the Ministry.The recipients of the documents are the Secretary-General himself for working documents, the Minister, the subordinates, and persons outside the Ministry. Certain documents intended for external persons are transmitted by the Secretary-General's Office to the Minister for signature before being sent to the final recipient. Only the 1776 documents whose content was produced by the station over a period of six years are listed here.A much bigger crowd of documents is not covered, including documents in simple transit for visas, documents examined in working sessions, documents for signature or countersignature, as well as documents seized or formatted by secretaries from the Cabinet of the Secretary-General. We note that 1344 (or 76%) of the 1776 documents are classified as Simple Documents (orange lines).The Table 2 shows, for each type of document, the priority level and the mean service time (MST). This time covers the design, control, and validation (signature, countersignature or visa) of the document. This service time is measured in hours of work.Table 2. Document priority level and mean service time (MST).With regard to Table 2, we notice that the time taken to serve Simple Documents (orange lines) is 2057 hours, represents 34% of the total service time (TST) which is of 6021 hours. We remind you that it is about average time, because in practice the service time of some documents can be very short (copy-paste with minimal adaptations in the case of the administrative documents) or lengthened in particular by the numerous external requests of the Ministry (for example the reception of a telephone call during the service).V.M ODELING A S YSTEM OF S IMPLE D OCUMENTP ROCESSINGIn the previous section, we presented the problem of simple document processing. In this part, we now detail the general model for describing the behavior of a simple document processing system. Beginning with an overview of the general considerations of the model, we will describe our mathematical model with its static and dynamic componentsA. General considerations on the modelThe graph is the most appropriate mathematical tool for modeling the interactions generated by the exchange of documents between processing stations. In the case of a hierarchical organization, this graph is reduced to a tree:(,,)T V E R=; where V is the set of summits or work stations; E is the set of edges, that is, pairs of vertices 2(,)a b V∈such that a is the hierarchical leader of b; which also means that documents can be exchanged by a and b for processing; finally, the node R V∈is the root of the tree.This tree results from the hierarchical organization of the administration. Since the processing stations are interconnected by a computer network, this tree is, in fact, a sub-graph of the said computer network. Therefore, without losing the generality, we will consider in the rest of this article, that the network is reduced to this tree. Simple documents are processed by a station according to their priority, and with equal priority, according to the order of arrival. These documents are therefore placed in a queue [12] according to their priority and their order of arrival; that is to say in a FIFO with priority. Formally, if x V∈ is a processing station, then we write W x, the priority queue associated with x. Each station x processes the document d of highest priority, first come, which is at the front of the queue. The processing is done in a random time. A document can be put on hold for information provided by other stations outside the hierarchical line; which only impacts the waiting time; when this information is available, the document is put back in the queue according to its priority. Besides, the hierarchical leader may send back a document to his subordinate for correction or for further information. The number of these superior-subordinate roundtrips is not limited, and the priority of a document may change during this journey according to the instructions of the hierarchical leader.In the present article, we disregard the type of processing performed on a document. After processing, the station can:∙close the document (e.g. classification),∙send the document outside,he (she) exists,∙send the document to a collaborator with processing instructions,∙send the document to a collaborator with annotations or corrections,∙put the document on hold for information from stations outside the hierarchy line,∙put the document back to his (her) hierarchical boss for additional instructions.In addition, each document is labeled with the total processing time (i.e., waiting time and service time).A previous study [9] identified three problems resulting from the modeling of document processing by a static graph, namely:∙How to determine the variables for measuring system performance?∙The static graph does not account for the dynamic behavior of the system;∙The inputs in the system depend on the outputs.MOUKELI and NEMBE [9] have proposed a model that addresses (answers) these concerns. In the specific case of simple documents managed in a priority queue, three new problems arise:∙How does the general model behave when applied to the specific case of simple documents,especially in terms of indicators and performancemeasures?∙ A non-priority document can remain indefinitely in the queue if higher priority documents alwaysarrive in said queue;∙ A document can turn indefinitely in the hierarchical line due to incessant back and forthcaused by the consequent changes. This problemarises acutely when the hierarchical line isreorganized (appointment of new people), ordisorganized (case of restructuring).B. Mathematical modelThe mathematical model we propose aims to describe the static and dynamic behavior of our system made up of workstations dedicated to the processing of simple documents. This system consists of a static component modeled by a tree reflecting the hierarchical organization of the administration in charge of document processing. The nodes of this tree form the states of a Markov chain, and the edges represent the probabilities of transitions between these states. The properties of the static component are described through states and the matrix of transition probabilities. These probabilities depend on the nature of the simple documents and the processing capacity of the stations.The dynamic component consists of a network of queues each formed by a priority queue associated with each node. The formal system is a quadruplet (,,,)V E R F; queues. The next two sections formally describe these two components (static and dynamic).a. Static model of the systemThe static component of our system is materialized by a network of workstations dedicated to simple document processing [8]. It is modeled by a tree reflecting the hierarchical organization of the administration in charge of document processing. The remainder of this subsection describes the generalities of this model and the document priority management; it also analyzes the constraints related to priority queues.a) General descriptionLet (,,)T V E R= be a tree such that V is the set of vertices or workstations; E is the set of edges, that is to say pairs of vertices 2(,)a b V∈such that a is the hierarchical leader of b ; finally; R V∈is the root node of the tree. The nodes are workstations and the edges represent the hierarchical relationship between these stations. Each edge (,)a b E∈can be labeled by the cost of transition crossing from node a to node b or vice versa; which gives us a vector of valuations. On this tree, each node x is associated with a priority queue denoted W x . This queue contains all simple documents waiting for processing at station x, in order of priority; and with equal priority, in order of arrival. In this queue, based on the model of MOUKELI and NEMBE [9], the waiting time of a document corresponds to the processing time of the documents that will have preceded it in said queue. From this definition, MOUKELI and NEMBE deduced the processing time of a document d:()()()P W ST d T d T d=+; (3)WherePT, T W and T S respectively denote the processing, waiting and service times of the document d; understood that the service time is the time actually spent by the station to look at the document d.b) Document priority ModelWhen a document is received, the station assigns it a priority. The notion of priority, although subjective, is the importance or urgency of a document, which will cause it to be processed before other documents already waiting in the queue associated with the station. Inserting a document into this queue means implicitly associating with it a priority. As an indication, Table 2 gives an example of prioritization of documents (column in red), for example, speeches are the highest priority documents, followed by memos and correspondences. We ignore the motivations of the station in its assessment of the priority of one document over another. The only certainty on which we base ourselves is that upon receipt of a document to be processed, either the station processes it immediately, which forces it to stop processing the current document and to put it on hold (return to head ofdocuments (insertion in the queue) for further processing; which in reality means giving it a priority.Concretely we suppose that the queue is logically organized according to a partial order noted π defined as follows:2:/(,'),',()(') and ' can be processed in any order ()(') absolutely must be processed before 'D d d D d d d d d d d d d d πππππ→∀∈≠⎧⎨⎩=⇔<⇔ (4)In the above formula (4), D is the set of documents processed at a given stationand is the set of natural numbers.Implementing priority queues: heaps. Priority queues associated with document processing stations can be effectively implemented with heaps; data structures whose performances in terms of costs are known. Thus for the removal of the root, the insertion of an element and the creation of the heap, we have respectively costs of the order, for the first two, of O (n ) and for the last, of (())O nLog n ; where n is the number of documents contained in the heap.In addition, two priority queues can be merged; what is necessary in case one station transfers its records to another (retirement, vacation, permanent or temporary departure), because the documents are replaced according to their priority in the merged system. As well as we can divide a heap into two heaps of the same size up to one element, even if it is necessary to rebalance the sub-trees obtained. This last operation turns out to be necessary when a station is duplicated to be unloaded. c) Constraints related to priority queuesThe dynamic behavior of our document processing model shows that the outputs of the system (processed documents) can become entries in the system (documents to be processed). This dynamic behavior imposes constraints on our system, in particular those that follows:∙ A document waiting in a queue can remain thereindefinitely because higher priority documents are systematically received by the station. This means that the waiting time of a document depends not only on the length of the queue, but also on the frequency with which the documents are received and the service time of the station. Now, these three variables (queue length, entries frequency in the queue and service time) are random and therefore depend on the laws of probability that govern them ;∙ There is a non-zero probability that a documentwill loop in the system due to an incessant back and forth in the hierarchical line of processing. Conceptually, the model admits a possibility of infinite loop in the processing line of a document, and it must, therefore, make it possible to phenomenon and to be able to detect it.Solution to the problem of infinite waiting: incremental priority . Holding documents in a priority queue causes a non-zero probability that a non-priority document will remain in the queue indefinitely because higher priority documents are always inserted before it. One solution to this problem is to implement the incremental priority mechanism. For this purpose, when a document has exceeded a certain time in the queue at a given priority, its priority is increased (incremented) by one rank, in order to move it to the next higher priority.As the lower priority documents, which are overdue, have their priority incremented, the queue tends gradually to a FIFO because all the documents will tend towards the highest priority. This situation actually reflects the case of a station saturated or over-solicited. In such a situation, we suggest either to unload this station for the benefit of other stations or to duplicate this station whenever possible. The system must be able to detect the occurrence of these FIFOs.Infinite loop solution: dealing with the problem at the organic level . In practice, this infinite loop occurs only in the presence of a real organizational problem: either one of the stations does not have enough skills to properly process the document, or there is a misunderstanding between some actors in the hierarchical line. In other words, the problem is upstream from the mathematical model; it should, therefore, be treated upstream. In the case of proven incompetence, we recommend redirecting the document to a more competent collaborator; where applicable, it is the responsibility of one of the line managers to process the document. In the case of incomprehension, it is recommended to the highest hierarchical leader in the hierarchical processing line to solve the dispute or to process the document. b. Dynamic model of the systemThe dynamic model is used to describe the temporal behavior (evolution) of the system, which is modeled as N priority queues, and K document classes or document priority levels; given that Class 1 documents are the highest priority. Each queue, noted M K /M K /1 is modeled by a Markov process [25]. Any document that has spent in a class C i for more than T units of time (with 0T >) becomes a document of class 1i C -. Formally:1,();1.i w i d C T d T d C i K -∀∈>⇒∈<≤ (5)The remainder of this subsection formally describes the priority service discipline queue model, as well as service discipline and the M K / M K /1 queue.a) Description of a priority service discipline queue A network consisting of N priority service discipline queues is considered. The documents belong to K distinct classes (or types). Documents of class C i ,Poisson process with arrival rate .j λThe service time of a document of class C i is a random variable that follows an exponential law of parameter ,i μ (1).i K ≤≤ We will assume that the service times of the documents of the class C i are independent and identically distributed (i.i.d). In addition, the document arrival processes are independent of one another and independent of service times. Finally, each queue, assumed to have unlimited capacity, is associated with a single processing unit, that is to say, a single server, also called service station. b) Description of the service disciplineThe documents of class C i are priority with regard to those of the class 1,i C + (1)i K ≤<. In each class, processing takes place on a first-come, first-served (FIFO) basis, because documents of the same class have the same importance (equal priority). During the processing of a document d by a station, if a document d’ of higher class (higher priority) appears, it is processed immediately (preemption of service), and the document d is put back at the head of the line; the processing of document d , of lower class, will resume at the point where it ceased, as soon as all the documents of higher classes have been processed, and this, until completion or further interruption of service. Any document leaves the station (queue) only when the service request has been fully satisfied.In this service discipline, documents with the lowest priority could wait quite a long time. To alleviate this problem, the service discipline is relaxed by introducing the possibility of raising the priority of a document that has waited too long in a class. Formally:1,()i wi i d C T d T d C -∀∈>⇒∈; (6)In formula (6), 1i K <≤, T is the maximum waiting time in a class, and T wi (d ) the waiting time of the document d in the class C i . This is the incremental priority, stated previously.The priority queue thus defined is a Markovian system, noted M K /M K /1; that is a multiclass Markovian queue with Poisson arrival processes and exponentially distributed service times; there are K classes of documents and a single server. We consider that our document processing system is a tree consisting of N M K /M K /1 queues; knowing that we have one queue per node of this tree. A graphical representation of this tree is given in Fig. 2.c) Description of a M K /M K/1 queueAn //1KKM M queue is the standard //1M M queue with K document classes and priority service discipline. A classic monograph on priority queues is Jaiswal [10]. In our system, an //1K K M M queue will be modeled by a birth and death process taking values in ...⨯⨯⨯, where is the set of natural integers.Let us denote by t X the state of a //1K K M M queue at time t . The state space is described by K-tuples ()1,...,K n n ∈; where i n is the number of class i documents in the queue, 1i K ≤≤. We Note t X the size of the queue at time t . We are interested in the stationary behavior of the process (),0t X t ≥.Fig.2. Example of tree with 8 queuesd) Description of the multiclass queuing network Our document processing system is represented by a network of M K /M K /1 queues; it is a tree reflecting the hierarchical relationship between the service stations (nodes).Each M K /M K /1 queue is represented by a node in the tree (example Fig. 2). We consider a tree with N nodes, noted (,,),V E R where V is the set of vertices or workstations; E is the set of edges, that is, pairs of vertices 2(,),a b V ∈such that a is the hierarchical leader of b ; finally, R V ∈is the root node of the tree.The system is described with the following parameters (see [25]):∙ :K The number of document types in the network;it is the number of priority levels or the number of document classes;∙ :N the number of queues (nodes) within thenetwork;∙ :ij n the number of documents of class j , in thequeue i , 1i N ≤≤ and 1;j K ≤≤1;Nj ij i n n ==∑ (7)The number of documents of class j in the network,1;j K ≤≤()1...;K n n η= (8)。
电子档案单套制管理实施模型
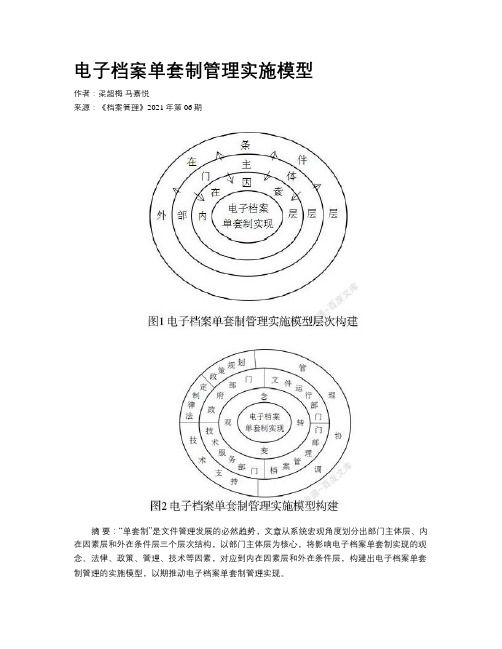
电子档案单套制管理实施模型作者:梁超梅马嘉悦来源:《档案管理》2021年第06期摘要:“单套制”是文件管理发展的必然趋势,文章从系统宏观角度划分出部门主体层、内在因素层和外在条件层三个层次结构,以部门主体层为核心,将影响电子档案单套制实现的观念、法律、政策、管理、技术等因素,对应到内在因素层和外在条件层,构建出电子档案单套制管理的实施模型,以期推动电子档案单套制管理实现。
关键词:电子档案;单套制;实施模型;内在因素层;外在条件层Abstract: 'Single set system' is the inevitable trend of the development of document management. From the perspective of macro system, it can be divided into three levels:Department main body layer, internal factor layer and external condition layer. Taking the Department main body level as the core, the concept, law, policy, management, technology and other factors that affect the realization of single set system of electronic Archives are corresponding to the internal factor layer and external condition layer, so as to construct the single set system of electronic Archives The implementation model of management is expected to promote the realization of single set management of electronic Archives.Keywords: Electronic archives; Single set system; Implementation model; Inner factor layer; Outer condition layer近年来,学术界关于“单套制”概念的研究有很多,笔者仍沿用此前在《基于单轨制、单套制、双轨制和双套制概念辨析之文件管理模式探讨》文章中的观点,认为“单套制”是归档后以一种文件形式保存和利用,“双套制”是归档后以两种文件形式保存和利用,“单轨制”“双轨制”分别指归档前以一种或两种文件形式运行的模式。
人机交互式机器翻译中的随机响应模型

人机交互式机器翻译中的随机响应模型人机交互式机器翻译(Human-Computer Interactive Machine Translation, HCIMT)是目前机器翻译领域的一个热门研究方向。
在传统的机器翻译系统中,机器翻译引擎通常是通过对预先构建的双语语料进行训练而得到的,翻译质量和准确性常常受到语料质量和翻译算法的限制。
然而,在人机交互式机器翻译中,用户可以与系统进行实时交互,通过反馈和指导来改进翻译结果,从而提高翻译质量和用户满意度。
在人机交互式机器翻译系统中,随机响应模型(Random Response Model, RRM)是一种常用的理论框架,用于描述用户在交互过程中的反馈和行为。
RRM基于概率模型,假设用户的反馈行为是随机的,并且反映了用户在面对不确定性和复杂性时的决策过程。
通过分析RRM在人机交互式机器翻译中的应用,可以深入解析用户对翻译质量和系统性能的认知和反馈机制,为改进翻译系统提供理论基础和方法参考。
涉及到多个方面的研究内容,包括用户交互行为建模、反馈分析和系统性能评估等。
首先,用户交互行为建模是研究RRM在人机交互过程中的应用,通过分析用户的语言习惯、翻译需求和反馈偏好等因素,揭示用户在选择和修正翻译结果时的心理和行为模式。
其次,反馈分析是指对用户反馈信息的处理和利用,包括翻译错误标注、翻译建议生成和用户满意度评估等,用于指导系统改进和优化翻译结果。
最后,系统性能评估是通过定量和定性方法对人机交互式机器翻译系统的翻译效果和用户体验进行评价,根据RRM的理论来解释和预测系统的性能表现。
在用户交互行为建模方面,研究人员可以通过观察和分析用户在实际翻译任务中的操作记录和反馈数据,获取用户的偏好和行为模式。
基于这些数据,可以建立用户交互行为模型,包括用户反馈概率分布、错误修正策略和翻译选择偏好等。
例如,一些用户可能更倾向于直接修改不准确的翻译结果,而另一些用户则更喜欢提出独立的翻译建议;一些用户可能更关注翻译的语法正确性,而另一些用户更注重翻译的语义一致性。
xjdp4系统模型IIss 共74页

y(t) = max [ x1(t),x(t) ]– min [ x2(t),x(t) ] 由于系统在t以前的历史可由两个变量x1(t)
和x2(t)的值完全描述,所以要决定时刻t的输出 值不必知道所有过去的输入值,只需在每个时 刻修正x1(t) 和x2(t) 即可,也就是说,在每个 t+1 时刻:
• X1(t),X2(t)就是描述飞机的飞行状态和状态变 量。
第三节 系统定量分析模型
第4章节系统模型与模型化
一、系统的状态和状态变量
在状态空间方法中,动态系统在时刻t0的输出 与之前时刻t0,t0–1,t0–2,…的输入值以及一定数量 的状态变量的数值有关。这些在t0的数值总结了系统 的过去历史对时刻t0时输出的影响。
– 机理法:定性+定量
图解法
• 图解法:经济学中的需求曲线D与供给曲线 S之间的关系。略。。
• S=f(p), • D=g(p)
拟合法
• 建模者根据某种假设选择一种模型,用以 解释观察的行为,如果收集到的数据说明 建模者的假设基本合理,则进一步按照某 种法则去选择模型的参数。
• 定量为主,以历史数据为依据建模及量化, 建模根据某种假设,选择一种理论模型和 模式,用以解释所观察行为。如果所收集 到的数据说明建模者的假设基本合理,则 进一步按照某种法则去选择模型参数
(1)Logistic曲线
• 该曲线由德国数学—生物学家P.F.Verhust
于1837年首先提出,之后由美国生物学家、
人口统计学家皮尔(Pearl)用它对生物繁
, 殖和生长过程进行了大量研究,故又称皮
利用UML建模设计EJB应用系统

利用UML建模设计EJB应用系统
陶隽;赵文耘;杨俊
【期刊名称】《计算机工程》
【年(卷),期】2002(028)003
【摘要】从EJB构件模型出发,分析了EJB应用系统建模的特殊性.以开发一个网上书店的EJB系统为例,结合EJB构件模型特点,使用统一建模语言(UML)来建模和设计,展示了UML在开发EJB应用系统中的运用.
【总页数】3页(P253-255)
【作者】陶隽;赵文耘;杨俊
【作者单位】复旦大学计算机系软件工程实验室,上海,200433;复旦大学计算机系软件工程实验室,上海,200433;复旦大学计算机系软件工程实验室,上海,200433【正文语种】中文
【中图分类】TP311.51
【相关文献】
1.利用UML模型设计EJB组件 [J], 易嵩杰;李陶深
2.利用UML建模设计指挥自动化软件系统 [J], 唐朝京;鲜明;肖顺平;张义荣;赵志超;李华胜
3.使用UML进行基于EJB的应用系统开发研究 [J], 翁鸣;梁俊斌;林原;苏德富
4.餐饮收银子系统的UML建模设计与实现 [J], 张斌
5.UML在B/S模式应用系统建模设计中的应用 [J], 明海波
因版权原因,仅展示原文概要,查看原文内容请购买。
文档向量模型

文本分类的定义及关键技术1.1文本分类的定义文本分类系统的任务是:在给定的分类体系下,根据文本的内容或属性,将大量的文本归到一个或多个类别中。
从数学角度来看,文本分类是一个映射的过程,它将未标明类别的文本映射到已有的类别中,该映射可以是一一映射,也可以是一对多的映射,因为通常一篇文本可以同多个类别相关联。
用数学公式表示如下:f:A→B其中,A为待分类的文本集合,B为分类体系中的类别集合文本分类的映射规则是系统根据已经掌握的每类若干样本的数据信息,总结出分类的规律性而建立的判别公式和判别规则。
然后在遇到新文本时,根据总结出的判别规则,确定文本相关的类别。
1.2特征项类型的确定中文文本信息处理和欧洲语言信息处理的一个最大的区别就在于中文被写成连续的字串,词与词之间没有显式的界限,而欧洲语言句子的词与词之间有空格。
所以我们必须对文本进行预处理,确定好特征项类型,即基于什么类型的特征去分类,常见的特征项类型有字、字串、词、短语等。
现有的研究认为以词为单位来进行处理比较合理,所有我们就以词为特征单位的类型。
另外,由于文本中有很多语法词(例如“的”、“和”等)以及一些虚词、感叹词、连词等,所有这些词不能表达文本的内容,更不能描述文本类别的特征;还有一些词汇在所有文本中出现的频率都基本相同,区分性差,也不能作为文本类别的特征,可以考虑把它们作为停用词滤除掉。
1.3特征抽取与选择特征抽取一般是通过构造一个特征评分函数,把测量空间的数据投影到特征空间,得到在特征空间的值,然后根据特征空间中的值对每个特征进行评估,它可以看作是从测量空间到特征空间的一种映射或变换。
特征选择就是根据特征评估结果从中选出最优的且最有代表性的特征子集作为该类的类别特征。
因此,特征提取与选择是文本集共性与规则的归纳过程,是文本分类中最关键的问题,它可以降低特征空间的维数,从而达到降低计算复杂度和提高分类准确率的目的。
常用的特征评分函数有:互信息、信息增益、期望交叉熵和文本证据权等等,其中信息增益算法结合特征项出现与不出现的情况,进行特征项的度量,实际应用中效果较好,它的计算公式如下:其中t为特征项,m为文本类别数,针对工程需求,我们将文本分为(地理特征、岩石学特征、化学特征、微量元素、其他)五类。
基于大语言模型的竞品车型配置问答系统设计与应用研究

基于大语言模型的竞品车型配置问答系统设计与应用研究雷天凤;张永;龚春忠;周伟明
【期刊名称】《汽车科技》
【年(卷),期】2024()3
【摘要】本研究致力于优化汽车研发工程师对大量车型配置信息的研究和分析过程。
通过设计一款基于大语言模型的智能问答系统,工程师能够以自然语言形式获取车型配置信息的统计和可视化结果,避免了逐步筛选或使用数据分析工具的繁琐步骤,提高了竞品数据分析的效率。
考虑到目前大语言模型在汽车预研工作中的限制,我们采用案例分析法,以已构建的车型配置表为基础,制定了六步骤的研究过程,包括系统设计、大语言模型选择、数据库构建、自然语言解析、SQL执行与可视化,以及最终结果的封装。
成功实现了基于大语言模型的智能问答系统,为汽车工程师提供了一个便捷的竞品问题解答平台,填补了在汽车领域对车型配置信息利用方面的不足,使工程师能够更迅速地获取他们所需的关键问题答案。
【总页数】8页(P73-80)
【作者】雷天凤;张永;龚春忠;周伟明
【作者单位】合众新能源汽车股份有限公司;浙江工业大学
【正文语种】中文
【中图分类】U462.1;TP319
【相关文献】
1.基于道路试验的轿车动力性提升研究r——以两款竞品车型为例
2.即将上市的重点车型及竞品车型突出特点对比报告
3.基于大语言模型的教育问答系统研究
4.基于句粒度提示的大语言模型时序知识问答方法
5.基于大语言模型的BIM正向设计问答系统研究
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Published Online September 2016 in MECS (/) DOI: 10.5815/ijieeb.2016.05.07
A Stochastic Model for Document Processing Systems
Pierre Moukeli MbinAI, B.P. 2263 Libreville, Gabon Email: pierre.moukeli@, jnembe@ Abstract—This work is focused on the stationary behavior of a document processing system. This problem can be handled using workflow models; knowing that the techniques used in workflow modeling heavily rely on constrained Petri nets. When using a document processing system, one wishes to know how the system behaves when a new document enters in order to give precise support to the manager’s decision. This requires a good analysis of the system’s performances. But according to many authors, stochastic models, specifically waiting lines should be used instead of Petri nets at a strategic level in order to lead such analysis. The need to study a new model comes from the fact that we wish to provide tools for a decision maker to lead accurate performance analysis in a document processing system. In this paper, amodel for document management systems in an organization is studied. The model has a static and a dynamic component. The static one is a graph which represents transitions between processing units. The dynamic component is composed of a Markov processes and a network of queues which model the set of waiting-lines at each processing unit. Key performance indicators are defined and studied point-wise and on the average. Formulas are given for some example models. Index Terms—Document processing, workflow, counting processes; stochastic models, waiting lines, Markov processes. I. INTRODUCTION With the development of Internet, e-commerce and egovernment, the workflow of complex documents processing in an organization become a problem of great scientific, technical and economic interest. The purpose of this work is to propose a mathematical formalization of the problem and analyze the key performances of systems for which the basic assumptions we make here can be matched. A great amount of research has been devoted to workflow technologies (see for instance [6], [2], [3], [18], and the many references contained there). This activity has produced numerous tools available in the software industry. However, this work was essentially focused on workflow modeling using Petri nets with constraints. From our knowledge, very few attention has been given to performance measures of modeled systems. These measures become even more important when human Copyright © 2016 MECS beings play a key role in the workflow process. The performance analysis is indeed necessary when the workflow is related to a document processing system in public and private administrations because the system load has a huge impact on the processing speed (see [8], [19]). Indeed in such a system, there might be many actors with enough skills to process a given document. The system should thus be able to choose the right resource by taking in account its load and its processing time. Similarly, when a document is introduced in the system the path it follows should benefit from apriori knowledge about how the system behaved for similar documents. System metrics are thus necessary in order to enhance the decision-making process. Van der Aalst ([3]) suggests the use of stochastic models and especially waiting-lines to carry out this analysis on the tactical level. This paper shows how stochastic methods can be used to represent a system and forecast its behavior using the analysis of exchanged data flows. It should also be noticed that Petri nets cannot capture all the information related to time. Time is involved locally and globally in a document processing system. The service time at each node will affect the waiting line on the next node. In a few well-documented cases, the performances of networks of queues are well studied. These metrics can thus be used to quantify the quality of a document processing system. The context will be clearly defined in the next section. This will lead to a formal model described in section 3. It has a static component which can be seen as a graph and contains all the information about the transition logic, and a dynamic component which can be seen as a network of queues. Useful measures to assess the system quality are derived from this double representation. Basic and more advanced material about Petri nets can be found in [1], [2], [3], [4], [5] for instance. Networks of queues are treated for instance in [7], [12], [13]. II. DEFINITIONS AND PRELIMINARY RESULTS In this section, we shall first state the basic definitions used in the field of document processing systems. Then the main problem linked to document processing will be stated and pictured using a basic example. Eventually, our basic model enabling the analysis of system’s performances will be described and the problems raised by this model will be underlined. This model has two