一种迁移成本可感知的虚拟机整合算法
OpenStack迁移虚拟机流程分析
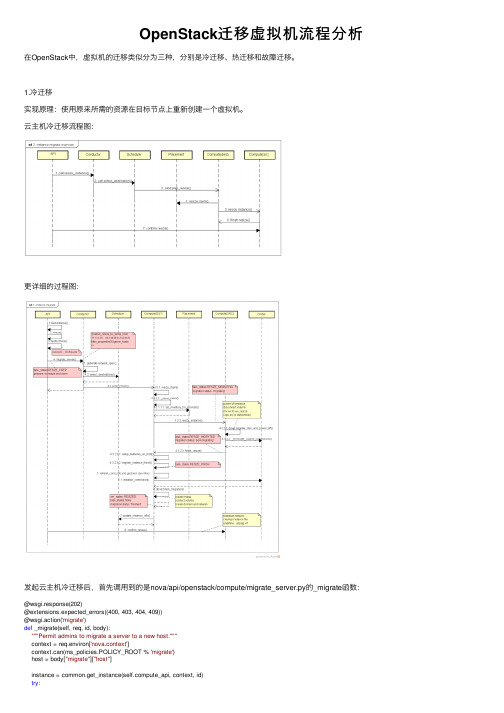
OpenStack迁移虚拟机流程分析在OpenStack中,虚拟机的迁移类似分为三种,分别是冷迁移、热迁移和故障迁移。
1.冷迁移实现原理:使⽤原来所需的资源在⽬标节点上重新创建⼀个虚拟机。
云主机冷迁移流程图:更详细的过程图:发起云主机冷迁移后,⾸先调⽤到的是nova/api/openstack/compute/migrate_server.py的_migrate函数:@wsgi.response(202)@extensions.expected_errors((400, 403, 404, 409))@wsgi.action('migrate')def _migrate(self, req, id, body):"""Permit admins to migrate a server to a new host."""context = req.environ['nova.context']context.can(ms_policies.POLICY_ROOT % 'migrate')host = body["migrate"]["host"]instance = common.get_instance(pute_api, context, id)try:pute_api.resize(req.environ['nova.context'], instance, host=host)........这⾥的核⼼代码是调⽤到了resize函数,openstack本⾝还有个resize功能,它的作⽤是对云主机的配置进⾏升级,但只能往上升,冷迁移的流程跟resize⼯作流程⼀样,只不过是flavor没有发⽣改变。
实现代码是在nova/compute/api.py:@check_instance_lock@check_instance_cell@check_instance_state(vm_state=[vm_states.ACTIVE, vm_states.STOPPED])def resize(self, context, instance, flavor_id=None, clean_shutdown=True,host=None,**extra_instance_updates):# 检查flavor是否是新flavor,如果是resize则进⾏配额预留分配、修改虚拟机的状态、# 提交迁移记录和⽣成⽬的宿主机需满⾜的条件对象specrequest........pute_task_api.resize_instance(context, instance,extra_instance_updates, scheduler_hint=scheduler_hint,flavor=new_instance_type,reservations=quotas.reservations or [],clean_shutdown=clean_shutdown,request_spec=request_spec,host=host)这⾥的核⼼是调⽤resize_instance函数进⾏处理,该函数实现在nova/conductor/api.py,该函数再调⽤了nova/conductor/rpcapi.py⽂件中的migrate_server函数:def migrate_server(self, context, instance, scheduler_hint, live, rebuild,flavor, block_migration, disk_over_commit,reservations=None, clean_shutdown=True, request_spec=None, host=None):# 根据版本号构建kw参数return cctxt.call(context, 'migrate_server', **kw)通过远程调⽤conductor进程的migrate_server函数,此时进⼊nova/conductor/manage.py⽂件中的migrate_server函数:def migrate_server(self, context, instance, scheduler_hint, live, rebuild,flavor, block_migration, disk_over_commit, reservations=None,clean_shutdown=True, request_spec=None, host=None):# ⼀些条件判断,判断是进⾏冷迁移还是热迁移if not live and not rebuild and flavor:# 冷迁移⾛这个逻辑instance_uuid = instance.uuidwith compute_utils.EventReporter(context, 'cold_migrate',instance_uuid):self._cold_migrate(context, instance, flavor,scheduler_hint['filter_properties'],reservations, clean_shutdown, request_spec,host=host)else:raise NotImplementedError()核⼼代码是调⽤了_cold_migrate函数:@wrap_instance_event(prefix='conductor')def _cold_migrate(self, context, instance, flavor, filter_properties,reservations, clean_shutdown, request_spec, host=None):image = utils.get_image_from_system_metadata(instance.system_metadata)task = self._build_cold_migrate_task(context, instance, flavor,request_spec,reservations, clean_shutdown, host=host)task.execute()构建迁移任务,然后执⾏任务:def _build_cold_migrate_task(self, context, instance, flavor,request_spec, reservations,clean_shutdown, host=None):# nova/conductor/tasks/migrate.pyreturn migrate.MigrationTask(context, instance, flavor,request_spec,reservations, clean_shutdown,pute_rpcapi,self.scheduler_client,host=host)这⾥是返回了MigrationTask类实例,该类继承的TaskBase基类的execute函数会调⽤_execute函数,所以我们直接看该MigrationTask类的execute函数实现即可:def _execute(self): # 选择⼀个宿主机 pute_rpcapi.prep_resize(self.context, self.instance, legacy_spec['image'],self.flavor, host, self.reservations,request_spec=legacy_spec, filter_properties=legacy_props,node=node, clean_shutdown=self.clean_shutdown)这⾥调⽤到了nova/compute/rpcapi.py中的prep_resize函数:def prep_resize(self, ctxt, instance, image, instance_type, host,reservations=None, request_spec=None,filter_properties=None, node=None,clean_shutdown=True):image_p = jsonutils.to_primitive(image)msg_args = {'instance': instance,'instance_type': instance_type,'image': image_p,'reservations': reservations,'request_spec': request_spec,'filter_properties': filter_properties,'node': node,'clean_shutdown': clean_shutdown}version = '4.1'client = self.router.by_host(ctxt, host)if not client.can_send_version(version):version = '4.0'msg_args['instance_type'] = objects_base.obj_to_primitive(instance_type)cctxt = client.prepare(server=host, version=version)# 远程调⽤到宿主机上让其准备将要迁移过去的虚拟机的资源cctxt.cast(ctxt, 'prep_resize', **msg_args)这⾥远程调⽤到了nova/compute/manager.py中的prep_resize函数,该函数的核⼼代码是调⽤了_prep_resize:def _prep_resize(self, context, image, instance, instance_type,quotas, request_spec, filter_properties, node,clean_shutdown=True):.........rt = self._get_resource_tracker()# 这⾥进⾏了资源的检查和预留分配并更新数据库宿主机更新后的资源with rt.resize_claim(context, instance, instance_type, node,image_meta=image, limits=limits) as claim:(_LI('Migrating'), instance=instance)pute_rpcapi.resize_instance(context, instance, claim.migration, image,instance_type, quotas.reservations,clean_shutdown)分配好资源后调⽤pute_rpcapi.resize_instance函数:def resize_instance(self, ctxt, instance, migration, image, instance_type,reservations=None, clean_shutdown=True):msg_args = {'instance': instance, 'migration': migration,'image': image, 'reservations': reservations,'instance_type': instance_type,'clean_shutdown': clean_shutdown,}version = '4.1'client = self.router.by_instance(ctxt, instance)if not client.can_send_version(version):msg_args['instance_type'] = objects_base.obj_to_primitive(instance_type)version = '4.0'cctxt = client.prepare(server=_compute_host(None, instance),version=version)# 到源主机的nova/compute/manager.py中执⾏resize_instance函数cctxt.cast(ctxt, 'resize_instance', **msg_args)进⼊源主机的resize_instance函数中:def resize_instance(self, context, instance, image,reservations, migration, instance_type,clean_shutdown):# 获取要迁移的云主机⽹卡信息# 修改数据库云主机状态# 迁移事件通知# 关机并进⾏磁盘迁移disk_info = self.driver.migrate_disk_and_power_off(context, instance, migration.dest_host,instance_type, network_info,block_device_info,timeout, retry_interval)# 开始为虚拟机迁移⽹络work_api.migrate_instance_start(context,instance,migration_p)pute_rpcapi.finish_resize(context, instance,migration, image, disk_info,migration.dest_compute, reservations=quotas.reservations)此时远程调⽤⽬的主机的finish_resize函数:def finish_resize(self, context, disk_info, image, instance,reservations, migration):# 提交配额.....self._finish_resize(context, instance, migration,disk_info, image_meta)def _finish_resize(self, context, instance, migration, disk_info,image_meta):# 初始化⽹络work_api.setup_networks_on_host(context, instance,migration['dest_compute'])migration_p = obj_base.obj_to_primitive(migration)work_api.migrate_instance_finish(context,instance,migration_p)# 获取当前云主机的⽹络信息network_info = work_api.get_instance_nw_info(context, instance)# 更新数据库状态instance.task_state = task_states.RESIZE_FINISHinstance.save(expected_task_state=task_states.RESIZE_MIGRATED)# nova/virt/libvirt/driver.pyself.driver.finish_migration(context, migration, instance,disk_info,network_info,image_meta, resize_instance,block_device_info, power_on)最后还要再出发⼀次confirm resize函数完成整个冷迁移过程,该函数是确认在源主机上删除云主机的数据和⽹络数据等,函数⽂件在nova/api/openstack/compute/servers.py:@wsgi.action('confirmResize')def _action_confirm_resize(self, req, id, body):pute_api.confirm_resize(context, instance)def confirm_resize(self, context, instance, migration=None):"""Confirms a migration/resize and deletes the 'old' instance."""# 修改迁移状态和更新配额......pute_rpcapi.confirm_resize(context,instance,migration,migration.source_compute,quotas.reservations or [])@wsgi.action('confirmResize')def _action_confirm_resize(self, req, id, body):pute_api.confirm_resize(context, instance)def confirm_resize(self, context, instance, migration=None):"""Confirms a migration/resize and deletes the 'old' instance."""# 修改迁移状态和更新配额......pute_rpcapi.confirm_resize(context,instance,migration,migration.source_compute,quotas.reservations or [])通过rpc调⽤到源宿主机上进⾏confirm_resize,这函数中⽐较核⼼的部分是调⽤了_confirm_resize函数:def _confirm_resize(self, context, instance, quotas,migration=None):"""Destroys the source instance."""self._notify_about_instance_usage(context, instance,"resize.confirm.start")# NOTE(tr3buchet): tear down networks on source host# 断掉⽹络work_api.setup_networks_on_host(context, instance,migration.source_compute, teardown=True)network_info = work_api.get_instance_nw_info(context,instance)# TODO(mriedem): Get BDMs here and pass them to the driver.# 删除虚拟机self.driver.confirm_migration(context, migration, instance,network_info)# 更新迁移状态migration.status = 'confirmed'with migration.obj_as_admin():migration.save()# 更新资源rt = self._get_resource_tracker()rt.drop_move_claim(context, instance, migration.source_node,old_instance_type, prefix='old_')instance.drop_migration_context()冷迁移过程总结:(1)nova-api收到冷迁移请求,验证权限、配额等并获取虚拟机信息,通过消息队列向nova-conductor发起冷迁移请求(2)nova-conductor通过消息队列请求nova-scheduler选择可迁移⽬的宿主机(3)获取到⽬的宿主机后,nova-conductor通过消息队列请求⽬的宿主机的nova-compute服务做资源准备⼯作(4)⽬的宿主机进⾏资源准备⼯作,⽐如执⾏claim机制检测和预分配资源,完成后通过消息队列请求源宿主机进⾏虚拟机迁移准备⼯作(5)源宿主机进⾏关机、卸载⽹络设备、磁盘等资源,完成后通过消息队列请求⽬的宿主机让它初始化好虚拟机所需的资源,⽐如⽹络虚拟设备的创建和磁盘挂载等并更新虚拟机状态为等待被确认。
云计算下的虚拟机迁移技术综述分析

云计算下的虚拟机迁移技术综述分析随着云计算的发展,虚拟化技术逐渐成为企业级应用领域中不可或缺的一环。
虚拟机(Virtual Machine,VM)作为虚拟化技术的核心,其灵活性和高效性得到了广泛认可和应用。
然而,在实际应用过程中,虚拟机的迁移技术成为了一个备受关注的话题。
虚拟机的迁移指的是将虚拟机从一台物理机器迁移到另一台物理机器的过程。
虚拟机迁移技术的目标是实现对虚拟机的无感知迁移,同时保证迁移过程中数据的一致性和服务的可用性。
虚拟机迁移技术可以实现动态的负载均衡、资源利用率最大化、容错和维护等多种需求。
虚拟机迁移技术是一项复杂的技术,在云计算环境中,由于数据中心规模的增大和各种平台和协议的多样化,虚拟机迁移技术也面临着诸多挑战。
下面我们将综述当前云计算下主流的虚拟机迁移技术,以及它们的优缺点和适用场景。
1. 基于存储快照的迁移技术存储快照技术指的是将存储系统中的数据快照保存下来,再复制到新的存储设备,从而达到快速迁移数据的目的。
基于存储快照技术实现虚拟机迁移,一般的步骤如下:(1)将虚拟机的磁盘文件通过存储快照方式复制到目标物理机。
(2)将虚拟机的内存状态通过网络传输到目标物理机。
(3)在目标物理机上根据接收到的内存状态,恢复虚拟机的运行。
优点:(1)迁移速度快:由于存储快照技术可实现高速复制文件,因此能够快速完成虚拟机的迁移过程。
(2)迁移过程中对服务的干扰较小:在迁移过程中,业务的数据和应用状态均不会受到干扰,从而保证了服务的可用性和一致性。
缺点:(1)虚拟机的存储设备必须支持存储快照技术。
(2)需要占用较大存储空间:由于需要进行存储快照,因此需要占用较大的存储空间,同时也需要考虑存储带宽和I/O性能的问题。
适用场景:对于I/O密集型的应用和大型企业应用,存储快照技术具有较高的灵活性和可用性,可以实现较快的迁移速度,因此更适合在这类场景下使用。
2. 基于迁移协议的迁移技术迁移协议技术指的是根据一定的网络协议,通过将虚拟机的内存状态迁移至目标物理机,从而实现虚拟机的迁移。
迁移学习10大经典算法

迁移学习10大经典算法在机器研究领域中,迁移研究是一种利用已学到的知识来解决新问题的方法。
迁移研究算法可以帮助我们将一个或多个已经训练好的模型的知识迁移到新的任务上,从而加快研究过程并提高性能。
以下是迁移研究领域中的10大经典算法:1. 预训练模型方法(Pre-trained models):通过在大规模数据集上进行预训练,然后将模型迁移到新任务上进行微调。
2. 领域自适应方法(Domain adaptation):通过将源领域的知识应用到目标领域上,解决领域差异导致的问题。
3. 迁移特征选择方法(Transfer feature selection):选择和目标任务相关的有效特征,减少特征维度,提高模型性能。
4. 迁移度量研究方法(Transfer metric learning):通过研究一个度量空间,使得源领域和目标领域之间的距离保持一致,从而实现知识迁移。
5. 多任务研究方法(Multi-task learning):通过同时研究多个相关任务的知识,提高模型的泛化能力。
6. 迁移深度卷积神经网络方法(Transfer deep convolutional neural networks):使用深度卷积神经网络进行特征提取,并迁移到新任务上进行训练。
7. 迁移增强研究方法(Transfer reinforcement learning):将已有的增强研究知识应用到新任务上,优化智能体的决策策略。
8. 迁移聚类方法(Transfer clustering):通过将已有的聚类信息应用到新数据上,实现对未标记数据的聚类。
9. 迁移样本选择方法(Transfer sample selection):通过选择源领域样本和目标领域样本的子集,减少迁移研究中的负迁移影响。
10. 迁移异构研究方法(Transfer heterogeneous learning):处理源领域和目标领域数据类型不一致的问题,例如将文本数据和图像数据进行迁移研究。
虚拟化迁移技术架构

虚拟化迁移技术架构虚拟化迁移技术架构是一种将虚拟机从一个物理主机迁移到另一个物理主机的技术。
这种技术可以帮助企业在不影响业务的情况下,实现服务器的升级、维护和故障恢复等操作。
本文将介绍虚拟化迁移技术架构的基本原理和实现方法。
虚拟化迁移技术架构的基本原理是将虚拟机的状态从源主机传输到目标主机。
这个过程需要保证虚拟机的状态在传输过程中不会丢失,同时还需要保证虚拟机在目标主机上能够正常运行。
为了实现这个目标,虚拟化迁移技术架构通常包括以下几个组件:1. 虚拟机监控器(VMM):VMM是虚拟化技术的核心组件,它负责管理虚拟机的创建、启动、停止和删除等操作。
在虚拟化迁移过程中,VMM需要将虚拟机的状态保存到磁盘上,并在目标主机上重新创建虚拟机。
2. 虚拟机文件系统(VMFS):VMFS是一种专门为虚拟机设计的文件系统,它可以将虚拟机的磁盘映像文件保存在共享存储设备上。
在虚拟化迁移过程中,VMFS可以帮助将虚拟机的磁盘映像文件从源主机传输到目标主机。
3. 虚拟机网络(VMnet):VMnet是一种虚拟化网络,它可以将虚拟机连接到物理网络上。
在虚拟化迁移过程中,VMnet可以帮助将虚拟机的网络配置信息从源主机传输到目标主机。
4. 虚拟机迁移控制器(VMotion Controller):VMotion Controller 是一个独立的组件,它负责协调虚拟机的迁移过程。
在虚拟化迁移过程中,VMotion Controller可以帮助将虚拟机的状态从源主机传输到目标主机,并在传输过程中保证虚拟机的连续性和一致性。
虚拟化迁移技术架构的实现方法有很多种,其中最常用的方法是基于VMware vSphere的VMotion技术。
VMotion技术可以在不停机的情况下将虚拟机从一个物理主机迁移到另一个物理主机。
在VMotion技术中,虚拟机的状态会被保存到共享存储设备上,并在目标主机上重新创建虚拟机。
在整个迁移过程中,虚拟机的网络连接和存储连接都不会中断,用户可以在不知情的情况下继续使用虚拟机。
云计算中基于多目标优化的虚拟机整合算法

云计算中基于多目标优化的虚拟机整合算法云计算是一种基于互联网的计算模式,通过将计算资源进行集中、共享和管理,提供按需使用的计算服务。
虚拟机整合是云计算中的一项重要任务,其目的是将虚拟机合理地分配到物理机上,以达到资源利用的最优化。
在云计算环境中,虚拟机是云服务提供商为用户提供的计算资源,其能够独立运行在物理机上,具有独立的硬件资源和操作系统。
虚拟机整合算法的设计需要考虑多个目标,如资源利用率、性能和能耗等。
多目标优化是一种同时考虑多个目标的优化方法。
在虚拟机整合算法中,多目标优化算法能够通过考虑多个指标,找到一组解集合,使得各指标之间相互平衡,达到整体性能的最优化。
虚拟机整合算法的一个基本思路是将虚拟机和物理机的匹配过程看作一个多目标优化问题,通过合适的优化算法来求解最优解。
具体来说,虚拟机整合算法通常分为以下几个步骤:1. 虚拟机和物理机的分类:需要将虚拟机和物理机进行分类,将具有相似需求和性能的虚拟机分配到相应的物理机上。
这样可以减少不同类型虚拟机之间的干扰,提高整合算法的效果。
2. 虚拟机和物理机的匹配:在分类之后,需要将虚拟机和物理机进行匹配,找到最优的分配方案。
这个过程通常通过遗传算法、蚁群算法等多目标优化算法来实现。
这些算法会考虑多个指标,如资源利用率、网络延迟、负载均衡等,以找到最优的分配方案。
3. 虚拟机的迁移:在虚拟机整合过程中,由于资源的动态变化或用户需求的变化,可能需要对已经分配的虚拟机进行迁移。
迁移算法通常会考虑当前系统的状态、虚拟机间的干扰、迁移的时间成本等因素,以找到最优的迁移方案。
4. 虚拟机整合的动态调整:虚拟机整合算法通常需要进行动态调整,以适应不断变化的系统需求和资源状况。
动态调整算法通常会定期监测系统的状态,并基于已有的虚拟机整合方案进行优化调整,以提高整体性能。
在实际的云计算环境中,虚拟机整合算法的效果受多个因素的影响,如虚拟机的类型、数量、用户需求的变化等。
基于CloudStack和OpenStack的KVM虚拟机跨平台迁移方法

成将磁盘镜像文件迁移到目的宿主物理主机中,然
后再将虚拟机内存执行状态迁移到宿主物理主机
中即可完成迁移。 以上迁移方法虽然都可以完成 KVM 虚拟机的
迁移任务,但是在 OpenStack 和 CloudStack 环境中, 简单使用传统的虚拟机迁移方法无法使云计算平
置自动生成一个配置文件,配置文件中的 SourceFile 项指明了保存用户对虚拟机操作的磁盘 镜像文件的路径,打开 SourceFile 文件,其中的 BackingFile 项指明了用户选择的操作系统磁盘镜
第 Z1 期
郑楠等:基于 CloudStack 和 OpenStack 的 KVM 虚拟机跨平台迁移方法
·73·
的方法正在被同时使用以上 2 种 IaaS 云计算平台 技 术 的 实 现 方 法 所 取 代 。 在 OpenStack 和 CloudStack 2 种 IaaS 云计算平台共存的环境中,一 个重要的问题就是怎样在 2 个平台间稳定地实现虚
第 35 卷第 Z1 期 2014 年 10 月
doi:10.3969/j.issn.1000-436x.2014.z1.014
通信学报
Journal on Communications
Vol.35 No. Z1 October 2014
基于 CloudStack 和 OpenStack 的 KVM 虚拟机跨平台迁移方法
ZHENG Nan1, CHEN Li-nan1,2, ZHENG Li-xiong3, MA Yan1,4
(1. Network Information Center, Institute of Network Technology, Beijing University of Posts and Communications, Beijing 100876, China; 2. School of Information Management, Beijing Information Science & Technology University, Beijing 100192, China;
云计算平台中的虚拟机迁移技术使用指南

云计算平台中的虚拟机迁移技术使用指南随着云计算技术的快速发展,虚拟化技术成为了企业部署和管理IT基础设施的重要手段之一。
其中,虚拟机迁移技术成为了云计算平台中的关键功能之一,它可以帮助用户提高系统可靠性、灵活性和效率。
本文将介绍虚拟机迁移技术的基本概念、工作原理以及使用指南。
一、虚拟机迁移技术的基本概念虚拟机迁移是指将运行在一台物理主机上的虚拟机实例迁移到另一台物理主机上的过程。
该技术通过将虚拟机的内存、存储和网络状态完整地在不同主机之间复制和传输,实现实时、无缝的迁移。
虚拟机迁移技术既能提供容错能力,避免服务器故障导致的业务中断,也能实现资源动态调整,提高整体系统的利用率。
二、虚拟机迁移技术的工作原理虚拟机迁移技术的实现需要满足几个关键条件:源主机和目标主机之间的物理网络连通、共享存储空间、与迁移相关的系统状态追踪以及可实现内存共享和同步的虚拟化技术。
具体而言,虚拟机迁移技术包括以下几个主要步骤:1. 迁移准备:确定源主机和目标主机之间的网络连接是否通畅,并验证双方是否满足迁移的条件。
2. 迁移前的状态追踪:在虚拟机迁移过程中,需要追踪运行在源主机上的虚拟机的内存、CPU、网络状态等信息。
3. 迁移过程:将虚拟机的内存、CPU、磁盘和网络状态等实时迁移到目标主机上。
这可以通过在源主机上暂停虚拟机,将内存和磁盘状态复制到目标主机上,然后让目标主机接管虚拟机从而完成迁移。
4. 迁移后的状态同步:在虚拟机迁移完成后,需要同步源主机和目标主机的状态信息,并进行必要的校验,确保迁移的完整性和正确性。
三、虚拟机迁移技术的使用指南虚拟机迁移技术的有效使用可以提高系统的可靠性和性能,使得企业可以更好地应对许多常见的运维和业务挑战。
以下是一些使用虚拟机迁移技术的指南:1. 提高系统的可用性:通过在物理主机故障时自动迁移虚拟机,实现业务的高可用性。
在选择虚拟化平台时,要确保其支持自动虚拟机迁移功能,并根据实际需求进行配置。
vmware虚拟机故障迁移原理

vmware虚拟机故障迁移原理虚拟机故障迁移是指在虚拟化环境中,当一个虚拟机出现故障时,系统可以将其迁移到另一台正常运行的物理主机上,以保证虚拟机的高可用性和可靠性。
vmware在虚拟机故障迁移方面提供了多种实现方式,包括vMotion、Storage vMotion和Fault Tolerance 等技术。
我们来介绍vMotion技术。
vMotion是vmware虚拟化平台中一种实时迁移虚拟机的技术,它允许在不中断虚拟机运行的情况下将其从一个物理主机迁移到另一个物理主机上。
vMotion技术的实现原理是将虚拟机的内存、CPU和设备状态通过高速网络传输到目标主机上,并在目标主机上恢复虚拟机的运行状态。
这个过程是无感知的,对虚拟机和用户来说是透明的。
vMotion技术的实现需要满足一定的条件。
首先,源主机和目标主机之间需要有足够的网络带宽来支持虚拟机的内存和设备状态的传输。
其次,源主机和目标主机需要使用共享存储,以便虚拟机的磁盘数据可以在迁移过程中保持一致。
最后,源主机和目标主机需要使用相同版本的vmware虚拟化软件,以保证虚拟机的硬件和软件环境一致。
除了vMotion技术,vmware还提供了Storage vMotion技术。
Storage vMotion是一种将虚拟机的磁盘数据从一个存储设备迁移到另一个存储设备的技术。
与vMotion技术不同的是,Storage vMotion只迁移虚拟机的磁盘数据,而不涉及虚拟机的内存和设备状态。
这使得Storage vMotion可以在更广泛的条件下实现虚拟机的故障迁移。
实现Storage vMotion技术需要满足一定的条件。
首先,源存储设备和目标存储设备之间需要有足够的带宽来支持虚拟机磁盘数据的传输。
其次,源存储设备和目标存储设备需要使用相同的存储协议,以保证数据能够正常传输。
最后,源存储设备和目标存储设备需要支持虚拟机磁盘的在线迁移。
除了vMotion和Storage vMotion技术,vmware还提供了Fault Tolerance技术。
虚拟机动态迁移的原理与应用(二)

虚拟机动态迁移的原理与应用虚拟化技术的快速发展,使得云计算成为当今信息技术领域的热门话题。
虚拟机作为云计算的基础,其可实现动态迁移的技术成为了研究的热点。
本文将介绍虚拟机动态迁移的原理与应用,以及它对现代信息技术的影响。
一、虚拟机动态迁移的原理虚拟机动态迁移是指将正在运行的虚拟机从一个物理主机迁移到另一个物理主机的过程。
其原理主要包括两个方面:迁移过程和状态迁移。
首先,迁移过程包括预复制和转发两个阶段。
预复制阶段,虚拟机的内存和CPU状态被复制到目标主机上,同时源主机继续运行,记录发生在源主机上的内存写操作。
转发阶段,源主机上发生的内存写操作被转发到目标主机,使得两个主机内存保持一致。
预复制和转发可以通过网络实现,从而实现虚拟机的无缝迁移。
其次,状态迁移是指将虚拟机的状态由源主机迁移到目标主机。
虚拟机的状态包括内存、硬盘、网络等资源的状态。
在预复制和转发的过程中,虚拟机的状态已经被复制到目标主机上,因此在状态迁移阶段,只需将源主机上的虚拟机状态切换到目标主机即可完成迁移过程。
二、虚拟机动态迁移的应用虚拟机动态迁移技术在现代信息技术中有着广泛的应用。
以下将从数据中心管理、资源利用率和系统可靠性三个方面介绍其应用。
首先,在数据中心管理方面,虚拟机动态迁移技术可以实现对虚拟机的灵活管理。
通过动态迁移,可以对表现出性能瓶颈的虚拟机进行负载均衡,提高整体的性能。
同时,当某一物理主机需要进行维护或升级时,可以将其上运行的虚拟机迁移到其他主机上,从而保证服务的连续性。
其次,在资源利用率方面,虚拟机动态迁移技术可以帮助提高资源利用率。
通过对虚拟机的动态迁移,可以根据负载情况将虚拟机从繁忙的主机迁移到空闲的主机上,实现资源的高效利用。
此外,虚拟机动态迁移还可以根据用户需求进行资源调度,提高资源利用率。
最后,在系统可靠性方面,虚拟机动态迁移技术可以提高系统的可用性和容错性。
当一台物理主机发生故障时,通过将其上运行的虚拟机迁移到其他主机上,可以避免服务中断,提高系统的容错能力。
FusionSphere虚拟化套件技术白皮书

华为FusionSphere 6.5.0 虚拟化套件技术白皮书pg. i1 摘要云计算并不是一种新的技术,而是在一个新理念的驱动下产生的技术组合。
这个理念就是—敏捷IT。
在云计算之前,企业部署一套服务,需要经历组网规划,容量规划,设备选型,下单,付款,发货,运输,安装,部署,调试的整个完整过程。
这个周期在大型项目中需要以周甚至月来计算。
在引入云计算后,这整个周期缩短到以分钟来计算。
IT业有一条摩尔定律,芯片速度容量每18个月提升一倍。
同时,IT行业还有一条反摩尔定律,所有无法追随摩尔定律的厂家将被淘汰。
IT行业是快鱼吃慢鱼的行业,使用云计算可以提升IT设施供给效率,不使用则会拖慢产品或服务的扩张脚步,一步慢步步慢。
云计算当然还会带来别的好处,比如提升复用率缩减成本,降低能源消耗,缩减维护人力成本等方面的优势,但在反摩尔定律面前,已经显得不是那么重要。
业界关于云计算技术的定义,是通过虚拟化技术,将不同的基础设施标准化为相同的业务部件,然后利用这些业务部件,依据用户需求自动化组合来满足各种个性化的诉求。
云着重于虚拟化,标准化,和自动化。
FusionSphere是一款成熟的Iaas层的云计算解决方案,除满足上面所述的虚拟化,标准化和自动化诉求外,秉承华为公司二十几年电信化产品的优秀基因,向您提供开放,安全可靠的产品。
本文档向您讲述华为FusionSphere解决方案中所用到的相关技术,通过阅读本文档,您能够了解到:⚫云的虚拟化,标准化,自动化这些关键衡量标准是如何在FusionSphere解决方案中体现的;⚫FusionSphere解决方案是如何做到开放,安全可靠的;⚫FusionSphere解决方案所包含的部件,所涉及的主要技术领域,使用的主要单点技术;⚫针对FusionSphere提供的各种技术选择,您怎样使用它们来满足您的业务诉求;本书分为如下章节:第一章,就是本章,给您对云计算,云平台有一个概括性的认识,并对本文档的阅读给出指导。
网络虚拟化:可感知虚拟机的网络

他们 会 收 到 一 个 端 口被 禁 用 的 警 告 。 而对 于 vwt , S ih c
因为 他 们 只 能 控 制 这个 宿 主 的 物 理 N C的 上行 链 路端 I
的虚拟机和基础设施的其他部分提供连接 实现这一
功 能 的 方 法 是 将 一 种 新 型 转 发 模 式 融 人 物 理 交 换 机 中 . 流 量 能 够 从 来 时 的 端 口“ 路 返 回” 从 而 简 化 同 使 原 .
一
口 . 不 能 控 制 一 个 vwt 而 S ih上许 多 虚 拟 机 端 口 . 以 c 所 他 们 就 失 去 了 对端 口的控 制
另 外 .虚 拟 交 换 机 一 般 都 是 由服 务 器 管 理 员 来 配
服 务器 上 虚拟 机 之 间 的通 信 “ 路 返 回” 式 ( 称 原 模 或
流量 . 也无法整合 vwt S ih和物理 交换机 。 c
虚 拟 交 换 机 还 有 的 一 个 问 题 是 关 于 添 加 网 络 设
备 大 多数 网 络 管 理 员喜 欢 控 制 连 接 到 他 们 网 络 的设 备 他 们 一般 会 禁 用 那 些 没 有 使用 的端 口。 在 所 有 端 并
能 . 需 通 过 服 务 器 外 部 的 物理 交 换 机 。 无
进行 虚拟化 的技术 .其 目的是在 网络 虚拟化中实现更
好 的可 管 理 性 、 略 实施 、 策 安全 性 和 可 扩 展 性 。 支持 虚 拟 化功 能 的 物 理 交换 机需 要 实 现 的 功 能 主
要有 :
情 况 是 V 连 接 到 相 同 的 v wth和该 v w th上 的相 M Si c Si c
( ) 明确识 别 虚拟 化 服 务 器 中的 每 一 拟化服务器解决方案 , 例如
机器学习技术中的迁移学习算法

机器学习技术中的迁移学习算法迁移学习算法是机器学习领域中的重要技术之一。
它旨在通过将一个任务中学习到的知识应用到另一个相关任务上,来提高模型的性能和泛化能力。
在实际应用中,迁移学习算法可以帮助解决数据不足、领域差异大和时间成本高等问题,同时还能加速模型的训练和优化过程。
本文将详细介绍几种常见的迁移学习算法。
一、领域自适应(Domain Adaptation)领域自适应是迁移学习中常用的算法之一,其目的是将源领域的知识迁移到目标领域上。
在领域自适应中,我们假设源领域和目标领域具有一定的关联性,但存在一定的差异。
该算法通过对源领域数据进行特征选择、特征映射或数据重标定等方式,使得源领域的知识在目标领域中仍然有效。
领域自适应算法可以通过最大化源领域和目标领域之间的相似性,进一步优化模型的泛化能力。
二、迁移聚类(Transfer Clustering)迁移聚类是迁移学习中的一个重要分支领域,其目的是通过迁移学习算法将源领域中学习到的聚类信息应用到目标领域中。
在迁移聚类中,我们利用源领域数据的聚类结果来辅助目标领域的聚类任务,并通过相似性匹配来找到对应的类别。
迁移聚类算法可以有效地减少目标领域样本的标注成本,提高聚类效果和效率。
三、迁移深度学习(Transfer Learning with Deep Learning)迁移深度学习是近年来兴起的一种迁移学习算法,其基于深度学习网络模型,并结合领域自适应和迁移学习的思想,进一步提高模型的性能。
迁移深度学习算法主要利用预训练的深度神经网络模型,在源领域上进行训练,然后将该模型应用到目标领域上重新调优和微调。
通过这种方式,可以利用源领域的大规模标注数据来提取通用的特征表示,从而加速目标领域模型的训练和迭代过程。
四、迁移度量学习(Transfer Metric Learning)迁移度量学习是一种通过建立距离度量或相似度度量来实现迁移学习的算法。
在迁移度量学习中,我们迁移源领域的度量矩阵到目标领域,从而通过学习目标领域的度量矩阵,来优化模型的分类效果。
虚拟化技术的实现方法与架构设计分析

虚拟化技术的实现方法与架构设计分析虚拟化技术是一种在计算机领域中应用广泛的技术,它通过逻辑上的隔离和资源的抽象,使得一个物理计算机可以同时运行多个虚拟的计算环境,或者是将一个计算环境分割成多个逻辑上独立的部分。
虚拟化技术不仅提高了计算资源的利用率,还简化了系统的管理和维护工作。
本文将介绍虚拟化技术的实现方法和架构设计,并分析其优势和适用场景。
一、虚拟化技术的实现方法1. 操作系统层虚拟化操作系统层虚拟化是一种基于宿主操作系统的虚拟化方法,通过在宿主操作系统上运行多个虚拟机实例来实现虚拟化。
常见的操作系统层虚拟化技术包括Docker和LXC(Linux Container)。
这种方法的优势在于高效和轻量级,可以将资源的管理和分配交给宿主操作系统来完成,减少了虚拟化软件的开销。
操作系统层虚拟化适用于需要高密度部署和快速启动的场景,如云计算和容器化应用。
2. 硬件层虚拟化硬件层虚拟化是一种在硬件层面上实现的虚拟化方法,通过在物理服务器上运行虚拟机监控器(VMM)来实现虚拟化。
常见的硬件层虚拟化技术包括VMware和Xen。
这种方法的优势在于可以直接访问底层硬件资源,提供了更高的隔离性和安全性。
硬件层虚拟化适用于需要完全隔离和较高性能的场景,如企业数据中心和虚拟桌面基础设施。
3. 网络虚拟化网络虚拟化是一种将网络资源进行虚拟化的技术,通过将物理网络划分为多个逻辑网络来实现虚拟化。
常见的网络虚拟化技术包括VLAN(Virtual LAN)和VXLAN(Virtual Extensible LAN)。
这种方法的优势在于提高了网络资源的利用率和灵活性,可以根据需求动态地创建和管理逻辑网络。
网络虚拟化适用于需要隔离和灵活配置网络环境的场景,如多租户云环境和虚拟专用网络。
二、虚拟化技术的架构设计1. 单一服务器架构在单一服务器架构中,虚拟机监控器(VMM)作为一个软件层运行在物理服务器上,负责管理和分配物理资源给虚拟机实例。
FusionCompute架构原理介绍

将vCPU调度到其它Node运行
适用场景
• 针对大规格、高性能虚拟机场景,适用Oracle、 SQL Server等关键应用
• 能感知NUMA架构的其它应用的性能提升
特性价值
• 针对Oracle等关键应用,可使应用性能提升 20%!
虚拟化前 虚拟化后 60% 10% 10% 60%
Server1 Server2 Server1 Server2
白天
晚上
60%
10%
70%
70%
VM 1
10%
VM 1 60%
Server VM 2 Server VM 2
白天
晚上
代码编译 OA办公
峰值时间 谷底时间
24时 8时
8时 24时
第4页
价值2:虚拟化技术提高可用性
第10页
主要功能特性
第11页
兼容行业特殊操作系统
FusionCo
mpute 控制域
客户VM
客户VM
客户VM
客户VM
PV后端 驱动
PV 前端驱动
PV 前端驱动
PV 前端驱动
PV 前端驱动
FusionCompute
客户VM
客户VM
定制化…
PV 前端驱动
PV 前端驱动
• 兼容一个新的操作系统,需要厂商提供配套的PV驱动程序,华为具备PV驱动开发能力 • 兼容主流的Windows、Linux操作系统
第14页
虚拟机热迁移技术(VM Motion)
App
App
FusionCompute
云计算中的虚拟机迁移与负载均衡

云计算中的虚拟机迁移与负载均衡随着云计算技术的快速发展,虚拟机迁移和负载均衡成为保障云计算系统高效运行的重要手段。
在本文中,将探讨云计算中虚拟机迁移与负载均衡的原理、优势以及应用。
一、虚拟机迁移虚拟机迁移(Virtual Machine Migration)是指将一个正在运行的虚拟机从一台物理服务器迁移到另一台物理服务器的过程。
虚拟机迁移可以在不影响用户服务的情况下实现对虚拟机的动态迁移和管理。
虚拟机迁移的原理如下:1. 冷迁移:将虚拟机关闭,将其存储状态迁移到目标服务器,然后在目标服务器上启动虚拟机。
2. 温迁移:将虚拟机暂停,将其存储状态迁移到目标服务器,然后在目标服务器上恢复虚拟机的运行。
3. 热迁移:将虚拟机的计算和存储状态实时同步到目标服务器,然后切换虚拟机的运行环境到目标服务器。
虚拟机迁移的优势:1. 资源优化:通过动态迁移虚拟机,可以根据实时负载情况合理分配物理服务器资源,提高资源利用率。
2. 故障恢复:当一台物理服务器出现故障时,可以迅速将其上的虚拟机迁移到其他正常工作的服务器上,实现故障恢复。
3. 节能降耗:通过合理运用虚拟机迁移技术,可以降低云计算系统的能耗,减少功耗成本。
4. 提高可用性:虚拟机迁移可以实现对虚拟机的动态管理,提高系统的可用性和灵活性。
二、负载均衡负载均衡(Load Balancing)是一种将网络请求分发到多个服务器上的技术,以实现资源的均衡分配,提高服务的性能和可靠性。
在云计算环境中,虚拟机负载均衡是保障云计算系统平稳运行的关键。
虚拟机负载均衡的原理如下:1. 负载检测:通过监控虚拟机的性能指标(如CPU利用率、内存利用率、网络流量等),实时感知虚拟机的负载情况。
2. 负载分配:当检测到某台虚拟机负载过高时,负载均衡器将请求动态分发到其他负载较低的虚拟机上,以实现资源的均衡分配。
3. 负载转发:负载均衡器作为请求的入口,根据一定的负载均衡策略(如轮询、最小连接数等),将请求转发到合适的虚拟机上。
超融合迁移方案

超融合迁移方案简介超融合(Hyperconvergence,简称HCI)是一种将计算、存储和网络功能集成到一个硬件平台上的解决方案。
相比传统的分布式架构,超融合具有易于管理、高度可扩展和灵活的特点,因此在许多企业中得到了广泛应用。
但是,在将应用程序迁移到超融合环境时,需要谨慎考虑迁移方案,以确保顺利完成迁移并最大化利用超融合的优势。
本文将介绍一种超融合迁移方案,该方案包括准备阶段、迁移阶段和测试阶段,以及相关的注意事项和最佳实践。
准备阶段在开始迁移之前,需要进行一些准备工作。
以下是准备阶段的步骤:1. 评估现有环境首先,评估当前的环境和应用程序需求。
了解当前的硬件和软件配置、性能需求以及数据的容量和增长趋势。
这将帮助确定超融合平台的规模和配置。
2. 选择超融合平台根据评估结果选择适合的超融合平台。
考虑平台的性能、可扩展性、可靠性和管理功能等因素,并选择符合需求的超融合平台。
3. 规划网络架构超融合平台的网络架构至关重要。
根据应用程序需求和超融合平台的特点,规划网络架构,确保网络连接的可靠性和性能。
4. 迁移计划制定迁移计划,明确迁移的时程和步骤。
考虑低峰期进行迁移,以减少对业务的影响。
确保迁移计划和步骤得到相关部门和人员的理解和支持。
迁移阶段一旦准备阶段完成,就可以开始迁移阶段。
以下是迁移阶段的步骤:1. 数据迁移迁移数据是迁移阶段的首要任务。
根据数据量的大小和网络带宽的限制,选择适当的数据传输方法。
可以选择直接连接或使用网络传输工具进行迁移。
2. 应用程序迁移完成数据迁移后,开始应用程序的迁移。
根据应用程序的类型和复杂程度,选择适合的迁移方法。
这可能包括重新配置服务器、导出/导入数据、复制和同步数据库等操作。
3. 配置和测试完成应用程序迁移后,对超融合平台进行配置和测试。
确保硬件和软件的配置符合预期,并进行性能和稳定性测试。
如果有必要,对配置进行调整,以优化性能和可靠性。
测试阶段在迁移完成后,进行测试阶段是必不可少的。
迁移模型法的计算

迁移模型法的计算
摘要:
一、迁移模型法的概述
二、迁移模型法的计算方法
三、迁移模型法的应用实例
四、迁移模型法的优缺点分析
正文:
一、迁移模型法的概述
迁移模型法,是一种在数据处理中应用广泛的方法,主要通过将一个模型在训练集上的表现,迁移到新的数据集上,以达到对新数据进行预测或分类的目的。
这种模型法的主要优点是能够节省大量的训练时间和数据,提高模型的泛化能力。
二、迁移模型法的计算方法
迁移模型法的计算方法主要包括以下几个步骤:
1.训练模型:首先,使用训练集对模型进行训练,得到一个初始模型。
2.计算迁移矩阵:根据训练集上的模型表现,计算出迁移矩阵。
迁移矩阵是一个描述模型在不同任务上的表现差异的矩阵,可以帮助我们了解模型在不同任务上的泛化能力。
3.迁移学习:根据迁移矩阵,对新任务的数据进行处理,使得模型在新任务上的表现能够得到提高。
三、迁移模型法的应用实例
迁移模型法在许多领域都有广泛的应用,例如在自然语言处理中,可以使
用预训练的词向量模型,通过迁移模型法,快速地训练出针对特定任务的模型。
在计算机视觉中,也可以使用预训练的图像分类模型,通过迁移模型法,对新的图像数据进行分类。
四、迁移模型法的优缺点分析
迁移模型法的主要优点是能够节省大量的训练时间和数据,提高模型的泛化能力。
同时,迁移模型法也能够提高模型在新任务上的表现。
然而,迁移模型法也存在一些缺点,例如迁移矩阵的计算可能会受到训练集和测试集的数据分布差异的影响,导致模型在新任务上的表现不佳。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第12卷第14期2017年7月中国科技论文CHINA SCIENCEPAPERVol.12No.14Jul. 2017一种迁移成本可感知的虚拟机整合算法窦晖,齐勇(西安交通大学电子与信息工程学院,西安710049)摘要:针对当前8a+数据中心硬件资源利用率比较低的问题,提出了 1种迁移成本可感知的虚拟机整合算法,可以在给定的 迁移成本约束条件下完成多维资源虚拟机实例的整合。
该算法基于模拟退火算法的思想,通过逐次增加虚拟机的迁移次数迭 代产生新的虚拟机整合策略,能够准确地计算出虚拟机整合过程所造成的迁移成本;通过为新的虚拟机整合策略设置接受概 率,保证虚拟机整合过程实现开机数减少,资源利用率提高的优化目标。
模拟实验的结果表明,所提出的多维资源虚拟机整合 算法可以在给定的迁移成本约束条件下将服务器的开机数平均减少4.71%,有效提高IaaS数据中心的硬件资源利用率。
该算 法对不同的虚拟机资源需求类型同样有效,利用该虚拟机整合算法,有助于降低IaaS服务提供商的基础设施成本和电力成本。
关键词:云计算;基础设施即服务;虚拟机整合;虚拟机迁移;模拟退火中图分类号:TP311 文献标志码:A文章编号=2095 - 2783(2017)14- 1640 - 06N ovel m ig ra tio n cost-aw are a lg o rith m fo r V M c o n s o lid a tio n in IaaSDOU Hui,QI Yong{School o f Electronics and Inform ation Engineering #9/an Jiaotong University ,9/an710049, China) Abstract:A novel migration c ost-aware algorithm for VM consolidation is proposed in this paper to improve the utilization of hardware resource in I aaS, which is capable to consolidate the multi-resource VM instances under a given migration cost constraint.According to the Simulated Annealing theory,in order to accurately calculate the migration cost during the whole consolt-dation, this algorithm iteratively generates new policies of VM consolidation by introducing time.In order to make the VM consolidation proceed towards the target of reducing the active server number as well a s to improve the resource utilization, this algorithm also develops the acceptance rules for the new consolidation policies.The results of simulated experiments show t hat the algorithm for multi-resource VM consolidation proposed in this paper is able to reduce the active server number by4.71% i n average within the given migration cost constraint.In addition,this algorithm also works well under different types of VM resource demands.In conclusion,both the initial infrastructure cost and the operating electricity cost of IaaS service providers can be reduced with the help of this VM consolidation algorithm.Keywords:cloud computing;IaaS;VM consolidation;VM migration;Simulated Annealing基础设施即服务如今已经成为最为主流的云计 算服务模式之一。
IaaS服务提供商将计算基础设施 通过互联网以虚拟机实例的形式出租给用户,用户 可以根据其实际需求动态地增加或者减少租用的计 算资源,从而节约初始投入成本和运营成本。
然而,目前IaaS数据中心的硬件资源利用率并不理想。
例 如,Amazon EC2数据中心服务器的C P U利用率仅 在3%$17%之间(1)。
低资源利用率会给IaaS服务 提供商带来额外的基础设施成本和电力成本开销[23]。
因此,如何通过虚拟机实例地合理部署,以减少IaaS数据中心的服务器开机数,提高硬件资源 利用率,成为Ia a S服务提供商面临的1个关键问题。
IaaS数据中心向用户提供的虚拟机实例包括C P U、内存、存储等多维硬件资源。
多维资源虚拟机 的部署问题通常可以被形式化为一个多维向量装箱 问题。
由于基于降序首次适应算法(FFD)的启发式部署策略(]可能会极大地偏离最优解,D otProduct 算法(7]最近被提出,并应用于求解多维资源虚拟机 部署问题。
D otP roduct算法的核心思想在于尽可能 为每台开启的服务器选择与其剩余硬件资源能够互 补的虚拟机实例进行部署,从而达到减少服务器总 开机数,提高硬件资源利用率的目的。
然而,D otP roduct算法依然不能直接应用于Ia a S数据中 心,原因在于,用户虚拟机实例的动态创建和撤销只 关注新创建的虚拟机实例如何部署会不可避免地产 生资源碎片,从而降低IaaS数据中心的硬件资源利 用率。
为此,近年来,基于虚拟机迁移技术的虚拟机 整合算法(11]被用于动态调优IaaS数据中心用户虚 拟机实例的部署。
由于虚拟机迁移会造成明显的性 能和能耗开销(2],在实际应用中必须考虑虚拟机整 合算法所产生的迁移成本。
本文主要关注如何在给 定的虚拟机迁移成本约束条件下进行多维资源虚拟 机的整合,以减少IaaS数据中心的服务器开机数,提收稿日期=2017-04-17基金项目=国家自然科学基金资助项目(61272460)高等学校博士学科点专项科研基金资助项目(20120201110010)第一作者=窦晖1989 — "男,博士研究生,主要研究方向为云计算、数据中心负载调度与电费管理通信作者:齐勇,教授,主要研究方向为数据中心与云计算、分布式系统、大数据系统、软件系统安全等,qiy@m all.xtu. edu cn第14期窦晖,等:一种迁移成本可感知的虚拟机整合算法1641高硬件资源利用率。
由于整合前、后2种虚拟机的部署状态之间可 能存在指数数量级的虚拟机迁移顺序,已有的研究 工作[1314]只能够尽量减少在虚拟机整合过程中所产 生的迁移成本。
然而,为了满足虚拟机迁移成本约 束,虚拟机整合算法必须能够准确地获得其造成的 迁移成本。
因此,如何准确计算虚拟机迁移成本是 解决带有迁移成本约束的多维资源虚拟机整合问题 的关键和挑战。
针对上述问题和挑战,本文对IaaS数据中心的 服务场景进行建模,将带有迁移成本约束的多维资 源虚拟机整合问题形式化为1个受约束的组合优化 问题;利用模拟退火算法[15]可行解随机移动和迭代 改进的特点,设计并实现了 1种迁移成本可感知的虚 拟机整合算法SAVM C,可以在满足迁移成本约束的 前提下完成多维资源虚拟机实例的整合,从而减少 IaaS数据中心的服务器开机数,提高硬件资源利用率。
模拟实验的结果表明了本文提出的算法的有效性。
1多维资源虚拟机整合1.1 IaaR数据中心服务场景建模假设IaaS数据中心拥有W台同构的服务器,服 务器* , 1iV]的硬件资源维数为D,包括C P U、内存、存储、网络带宽等,并且将第, [1,D])种硬 件资源的容量记为。
为了模拟IaaS数据中心用 户虚拟机实例的动态创建和撤销,假设在每个时间 槽^开始时,新申请创建的用户虚拟机实例总数为 V⑴。
虚拟机实例需求的资源维数同样为D,并且 虚拟机实例7 , (,V!)]对服务器第^种硬件资源 的需求量为^ ;同时,假设虚拟机实例j的运行寿命 为&个时间槽,之后就会被撤销,其占用的服务器硬 件资源得到释放。
值得注意的是,在IaaS数据中心,新申请创建的 用户虚拟机实例个数V G)、每个虚拟机实例的资源 需求&和运行寿命&均完全由动态变化的用户请求决定。
由于IaaS数据中心用户虚拟机实例在动态 地创建和撤销,只关注新创建的虚拟机实例如何部 署会不可避免地降低硬件资源利用率。
因此需要进 行虚拟机整合以减少IaaS数据中心服务器的开机 数,提高硬件资源利用率。
1.2多维资源虚拟机整合问题形式化假设在每个时间槽开始时,IaaS数据中心使用 D otP roduct算法进行新创建用户虚拟机实例的部署。
由于只关注新创建的虚拟机实例如何部署,在 时间槽t的部署结束后,数据中心的服务器开机数可 能会达到特定的阈值,需要对数据中心剩余的用户 拟机 合。
假设在时间槽t的部署结束后,数据中心剩余的 用户虚拟机实例总数为M⑴,并用actvm⑴表示这些虚拟机实例的集合。
虚拟机实例与服务器之间的 放置关系用二进制变量;j t)表亦,巧t) = 1表亦 虚拟机实例j被部署在服务器*上。
当虚拟机整合 完成后,所有的用户虚拟机实例必须被部署到某一 台服务器上,表示为V"X y!) = 1,6 j ,a c tv m t)。
(1)同时,=所有用户虚拟机实例的硬件资源需求都 应该得到满足,也就是说部署到同一台服务器上的拟机 硬 资 的 求 和 过务器上 应的资 容 ,$"x t](t) *r@ /C@6k, [1,D], 6,, [1,N] j,a c t v m(t)!)此外,由于虚拟机迁移会造成性能和能耗开销,1个可行的虚拟机整合算法必须要考虑整合过程带 来的虚拟机迁移成本。