第4章 pandas统计分析基础(1)
如何使用Pandas进行数据清洗和分析

如何使用Pandas进行数据清洗和分析第一章:介绍Pandas库Pandas是一个强大的数据处理和分析工具,它提供了大量的函数和方法,能够帮助我们进行数据清洗和分析。
Pandas库基于Numpy库,可以处理大小可变的数据集,并且具有灵活的操作方式。
在开始使用Pandas进行数据清洗和分析之前,我们首先需要了解Pandas库的基本知识。
第二章:数据清洗数据清洗是数据分析的第一步,它的目的是处理数据集中的缺失值、异常值和重复值,以确保分析结果的准确性和可信度。
Pandas库提供了一系列的函数和方法,可以方便地进行数据清洗。
2.1 缺失值处理缺失值是指数据集中的空值或者未定义的值。
在进行数据分析之前,我们通常需要处理缺失值。
Pandas库中的dropna()方法可以用来删除包含缺失值的行或列,而fillna()方法可以用来填充缺失值。
2.2 异常值处理异常值是指数据集中的极端值,它们可能对分析结果产生不良影响。
Pandas库提供了一些函数和方法,可以帮助我们检测和处理异常值。
例如,通过使用describe()方法可以查看数据集的统计摘要信息,通过使用drop()方法可以删除包含异常值的行或列。
2.3 重复值处理重复值是指数据集中的重复观测。
在进行数据分析之前,我们通常需要处理重复值。
Pandas库中的duplicated()方法可以用来检测重复值,而drop_duplicates()方法可以用来删除重复值。
第三章:数据分析数据分析是对数据集进行统计、计算和推断的过程,它的目的是发现数据的规律和趋势,并从中得到有关数据的有用信息。
Pandas库提供了丰富的函数和方法,可以方便地进行数据分析。
3.1 数据统计数据统计是数据分析的基础工作,它可以帮助我们了解数据集的基本特征。
Pandas库提供了一系列的统计函数,如mean()、median()、mode()和std()等,可以用来计算数据集的均值、中位数、众数和标准差等统计指标。
使用Pandas进行数据处理和分析的教程

使用Pandas进行数据处理和分析的教程Pandas是一个强大的Python库,用于数据处理和分析。
它提供了高性能的数据结构和数据分析工具,可以帮助我们轻松地处理和分析大规模数据。
本文将详细介绍如何使用Pandas进行数据处理和分析。
以下是具体步骤:1. 安装Pandas首先,我们需要在Python环境中安装Pandas库。
可以通过在命令行中运行`pip install pandas`来安装Pandas。
2. 导入Pandas在开始使用Pandas之前,需要先导入Pandas库。
可以使用以下语句导入Pandas:```import pandas as pd```3. 加载数据在使用Pandas进行数据处理和分析之前,我们需要将数据加载到Pandas的数据结构中。
Pandas提供了几种常用的数据结构,例如Series和DataFrame。
其中,DataFrame是最常用的数据结构,类似于Excel表格。
可以使用以下方法从不同的数据源加载数据:- 从CSV文件加载数据:`df = pd.read_csv('data.csv')`- 从Excel文件加载数据:`df = pd.read_excel('data.xlsx')`- 从数据库加载数据:`df = pd.read_sql('SELECT * FROM data', con)`4. 数据预览加载数据之后,可以使用一些方法来预览数据。
例如,可以使用`head()`方法查看前几行的数据,默认为前5行。
可以使用`tail()`方法查看后几行的数据。
5. 数据清洗在进行数据分析之前,通常需要对数据进行清洗。
这包括处理缺失值、重复值、异常值等。
Pandas提供了一些方法来进行数据清洗,例如:- 处理缺失值:可以使用`dropna()`方法删除包含缺失值的行或列;可以使用`fillna(value)`方法用指定的值填充缺失值。
数据分析库-Pandas数值计算和统计基础

常用数学、统计方法In [1]:import numpy as np import pandas as pd # 导入numpy、pandas模块key1 key2 key3a 4.0 1.0 1b 5.0 2.0 2c 3.0 NaN 3d NaN 4.0 je 2.0 5.0 kfloat64 float64 object-----key1 3.5key2 3.0dtype: float64 <class 'pandas.core.series.Series'>单独统计一列: 3.0-----a 2.5b 3.5c 3.0d 4.0e 3.5dtype: float64-----key1 NaNkey2 NaNdtype: float64-----# 基本参数:axis 、skipnaimport numpy as np import pandas as pddf = pd.DataFrame({'key1':[4,5,3,np.nan,2],'key2':[1,2,np.nan,4,5],'key3':[1,2,3,'j','k']},index = ['a','b','c','d','e'])print (df)print (df['key1'].dtype,df['key2'].dtype,df['key3'].dtype)print ('-----')m1 = df.mean()print (m1,type (m1))print ('单独统计一列:',df['key2'].mean())print ('-----')# np.nan :空值# .mean()计算均值# 只统计数字列# 可以通过索引单独统计一列m2 = df.mean(axis =1)print (m2)print ('-----')# axis 参数:默认为0,以列来计算,axis=1,以行来计算,这里就按照行来汇总了m3 = df.mean(skipna =False )print (m3)print ('-----')# skipna 参数:是否忽略NaN ,默认True ,如False ,有NaN 的列统计结果仍未NaN# 主要数学计算方法,可用于Series和DataFrame(1)df = pd.DataFrame({'key1':np.arange(10),'key2':np.random.rand(10)*10})print(df)print('-----')print(df.count(),'→ count统计非Na值的数量\n')print(df.min(),'→ min统计最小值\n',df['key2'].max(),'→ max统计最大值\n') print(df.quantile(q=0.75),'→ quantile统计分位数,参数q确定位置\n')print(df.sum(),'→ sum求和\n')print(df.mean(),'→ mean求平均值\n')print(df.median(),'→ median求算数中位数,50%分位数\n')print(df.std(),'\n',df.var(),'→ std,var分别求标准差,方差\n')print(df.skew(),'→ skew样本的偏度\n')print(df.kurt(),'→ kurt样本的峰度\n')key1 key20 0 6.7926381 1 1.0490232 2 5.4412243 3 4.6676314 4 2.0536925 5 9.8130066 6 5.0748847 7 1.5266518 8 8.5192159 9 3.543486-----key1 10key2 10dtype: int64 → count统计非Na值的数量key1 0.000000key2 1.049023dtype: float64 → min统计最小值9.81300585173231 → max统计最大值key1 6.750000key2 6.454785Name: 0.75, dtype: float64 → quantile统计分位数,参数q确定位置key1 45.00000key2 48.48145dtype: float64 → sum求和key1 4.500000key2 4.848145dtype: float64 → mean求平均值key1 4.500000key2 4.871257dtype: float64 → median求算数中位数,50%分位数key1 3.027650key2 2.931062dtype: float64key1 9.166667key2 8.591127dtype: float64 → std,var分别求标准差,方差 key1 0.000000key2 0.352466dtype: float64 → skew样本的偏度key1 -1.20000key2 -0.79798dtype: float64 → kurt样本的峰度In [4]:# 主要数学计算方法,可用于Series和DataFrame(2)df['key1_s'] = df['key1'].cumsum()df['key2_s'] = df['key2'].cumsum()print(df,'→ cumsum样本的累计和\n')df['key1_p'] = df['key1'].cumprod()df['key2_p'] = df['key2'].cumprod()print(df,'→ cumprod样本的累计积\n')print(df.cummax(),'\n',df.cummin(),'→ cummax,cummin分别求累计最大值,累计最小值\n') # 会填充key1,和key2的值key1 key2 key1_s key2_s0 0 6.792638 0 6.7926381 1 1.049023 1 7.8416612 2 5.4412243 13.2828853 3 4.667631 6 17.9505154 4 2.053692 10 20.0042085 5 9.813006 15 29.8172136 6 5.074884 21 34.8920977 7 1.526651 28 36.4187498 8 8.519215 36 44.9379639 9 3.543486 45 48.481450 → cumsum样本的累计和key1 key2 key1_s key2_s key1_p key2_p0 0 6.792638 0 6.792638 0 6.7926381 1 1.049023 1 7.841661 0 7.1256332 2 5.4412243 13.282885 0 38.7721603 3 4.667631 6 17.950515 0 180.9741314 4 2.053692 10 20.004208 0 371.6651515 5 9.813006 15 29.817213 0 3647.1523016 6 5.074884 21 34.892097 0 18508.8747437 7 1.526651 28 36.418749 0 28256.5951968 8 8.519215 36 44.937963 0 240724.0060559 9 3.543486 45 48.481450 0 853002.188425 → cumprod样本的累计积 key1 key2 key1_s key2_s key1_p key2_p0 0.0 6.792638 0.0 6.792638 0.0 6.7926381 1.0 6.792638 1.0 7.841661 0.0 7.1256332 2.0 6.792638 3.0 13.282885 0.0 38.7721603 3.0 6.792638 6.0 17.950515 0.0 180.9741314 4.0 6.792638 10.0 20.004208 0.0 371.6651515 5.0 9.813006 15.0 29.817213 0.0 3647.1523016 6.0 9.813006 21.0 34.892097 0.0 18508.8747437 7.0 9.813006 28.0 36.418749 0.0 28256.5951968 8.0 9.813006 36.0 44.937963 0.0 240724.0060559 9.0 9.813006 45.0 48.481450 0.0 853002.188425key1 key2 key1_s key2_s key1_p key2_p0 0.0 6.792638 0.0 6.792638 0.0 6.7926381 0.0 1.049023 0.0 6.792638 0.0 6.7926382 0.0 1.049023 0.0 6.792638 0.0 6.7926383 0.0 1.049023 0.0 6.792638 0.0 6.7926384 0.0 1.049023 0.0 6.792638 0.0 6.7926385 0.0 1.049023 0.0 6.792638 0.0 6.7926386 0.0 1.049023 0.0 6.792638 0.0 6.7926387 0.0 1.049023 0.0 6.792638 0.0 6.7926388 0.0 1.049023 0.0 6.792638 0.0 6.7926389 0.0 1.049023 0.0 6.792638 0.0 6.792638 → cummax,cummin分别求累计最大In [5]:In [6]:值,累计最小值0 a1 s2 d3 v4 a5 s6 d7 c8 f9 g10 gdtype: object['a' 's' 'd' 'v' 'c' 'f' 'g'] <class 'numpy.ndarray'>0 a1 s2 d3 v4 c5 f6 gdtype: object['a' 'c' 'd' 'f' 'g' 's' 'v']d 2a 2s 2c 1f 1g 2v 1dtype: int64# 唯一值:.unique()s = pd.Series(list ('asdvasdcfgg'))sq = s.unique()print (s)print (sq,type (sq))print (pd.Series(sq))# 得到一个唯一值数组# 通过pd.Series 重新变成新的Seriessq.sort()print (sq)# 重新排序# 值计数:.value_counts()sc = s.value_counts(sort = False ) # 也可以这样写:pd.value_counts(sc, sort = False)print (sc)# 得到一个新的Series ,计算出不同值出现的频率# sort 参数:排序,默认为TrueIn [7]:######## 课后小练习,请查看 “pandas 课程作业.docx” ########作业1:如图创建一个Dataframe (5*2,值为0-100的随机值),并分别计算key1和key2的均值、中位数、累积和作业2:写出一个输入元素直接生成数组的代码块,然后创建一个函数,该函数功能用于判断一个Series 是否是唯一值数组,返回“是”和“不是”0 101 112 123 134 14dtype: int32key1 key20 a 41 s 52 d 63 c 74 b 85 v 96 a 107 s 118 d 12-----0 False1 False2 False3 False4 Truedtype: boolkey1 key20 True False1 False False2 False False3 False False4 False True5 False False6 True False7 False False8 False False# 成员资格:.isin()s = pd.Series(np.arange(10,15))df = pd.DataFrame({'key1':list ('asdcbvasd'),'key2':np.arange(4,13)})print (s)print (df)print ('-----')print (s.isin([5,14]))print (df.isin(['a','bc','10',8]))# 用[]表示# 得到一个布尔值的Series 或者Dataframe。
《Python数据分析与机器学习》课程教学大纲

附录A 教学大纲课程名称:Python数据分析与机器学习适用专业:计算机科学与技术、智能科学与技术相关专业先修课程:高等数学、线性代数、概率论与数理统计、Python程序设计语言总学时:66学时授课学时:34学时实验(上机)学时:32学时一、课程简介本课程可作为计算机科学与技术、智能科学与技术相关专业的必修课,也可作为其它本科专业的选修课,或者其它专业低年级研究生的选修课。
数据分析与机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、算法复杂度理论等多门学科,研究如何从数据中获得信息,通过学习人类识别事物的基本规律,让“机器”能够自动进行模式识别的原理和方法。
本书包括两部分内容,第一部分重点介绍了与Python语言相关的数据分析内容,包括Numpy、Pandas、Matplotlib、Scipy、Seaborn和Sklearn等。
第二部分与Python语言相关的机器学习内容,包括数据预处理、特征工程、指标评价、K近邻算法、决策树、线性模型、朴素贝叶斯、支持向量机、Kmeans算法和文本分析示例。
二、课程内容及要求第1章 Python与数据分析(2学时)主要内容:1. python特点2. 数据分析流程3. 数据分析库4. Python编辑器基本要求:了解数据分析的基本概念;了解数据分析流程、数据分析库、python编辑器的安装和使用。
重点:数据分析流程、数据分析库、掌握Anaconda的安装、配置方法。
难点:数据分析流程、数据分析库、python编辑器。
第2章Numpy-数据分析基础工具(4学时)主要内容:1.ndarray对象2.创建ndarray对象3.数组变换4.索引和切片5.线性代数基本要求:掌握Numpy数值计算方法,主要包括数组和矩阵运算。
重点:掌握ndarray对象、创建数组变换、索引和切片、线性代数难点:掌握ndarray对象、创建数组变换、索引和切片、线性代数第3章Matplotlib-数据可视化工具(4学时)主要内容:1.绘图步骤2. 子图基本操作3.各类图4. 概率分布基本要求:掌握Matplotlib数据可视化绘图基础,参数设置及常用绘图。
Python 数据分析与应用 第4章 pandas统计分析基础(1)图文

查看DataFrame的常用属性
基础属性
函数 values index columns dtypes
size ndim shape
返回值 元素 索引 列名 类型 元素个数 维度数 数据形状(行列数目)
查改增删DataFrame数据
1.查看访问DataFrame中的数据——数据基本查看方式
➢ 对单列数据的访问:DataFrame的单列数据为一个Series。根据DataFrame的定 义可以知晓DataFrame是一个带有标签的二维数组,每个标签相当每一列的列名。 有以下两种方式来实现对单列数据的访问。 • 以字典访问某一个key的值的方式使用对应的列名,实现单列数据的访问。 • 以属性的方式访问,实现单列数据的访问。(不建议使用,易引起混淆)
coerce_float
接收boolean。将数据库中的decimal类型的数据转换为 pandas中的float64类型的数据。默认为True。
columns
接收list。表示读取数据的列名。默认为None。
读写数据库数据
2.数据库数据存储
数据库数据读取有三个函数,但数据存储则只有一个to_sql方法。
读写文本文件
1.文本文件读取
➢ 文本文件是一种由若干行字符构成的计算机文件,它是一种典型的顺序文件。 ➢ csv是一种逗号分隔的文件格式,因为其分隔符不一定是逗号,又被称为字符分隔
文件,文件以纯文本形式存储表格数据(数字和文本)。
读写文本文件
1.文本文件读取
➢ 使用read_table来读取文本文件。
pandas.read_table(filepath_or_buffer, sep=’\t’, header=’infer’, names=None, index_col=None, dtype=None, engine=None, nrows=None)
《Python数据分析与应用》实验二 pandas统计分析基础
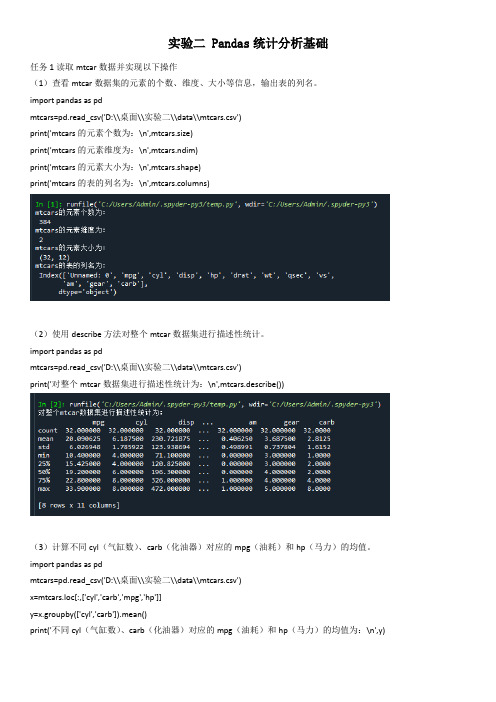
实验二 Pandas统计分析基础任务1读取mtcar数据并实现以下操作(1)查看mtcar数据集的元素的个数、维度、大小等信息,输出表的列名。
import pandas as pdmtcars=pd.read_csv('D:\\桌面\\实验二\\data\\mtcars.csv')print('mtcars的元素个数为:\n',mtcars.size)print('mtcars的元素维度为:\n',mtcars.ndim)print('mtcars的元素大小为:\n',mtcars.shape)print('mtcars的表的列名为:\n',mtcars.columns)(2)使用describe方法对整个mtcar数据集进行描述性统计。
import pandas as pdmtcars=pd.read_csv('D:\\桌面\\实验二\\data\\mtcars.csv')print('对整个mtcar数据集进行描述性统计为:\n',mtcars.describe())(3)计算不同cyl(气缸数)、carb(化油器)对应的mpg(油耗)和hp(马力)的均值。
import pandas as pdmtcars=pd.read_csv('D:\\桌面\\实验二\\data\\mtcars.csv')x=mtcars.loc[:,['cyl','carb','mpg','hp']]y=x.groupby(['cyl','carb']).mean()print('不同cyl(气缸数)、carb(化油器)对应的mpg(油耗)和hp(马力)的均值为:\n',y)(4)输出mpg和hp前5个元素。
Python技术学习报告

《Python技术》课程学习报告本学期的《Python技术》课程已经结束,我将从《Python技术》课程归纳总结和本课程的学习体会两部分展示我在本门课程的收获与体会。
一、《Python技术》课程归纳(基于课本概述)第一章---Python数据分析概述本章根据目前的数据分析发展状况,将数据分析具象化,首先介绍了数据分析的概念、流程、目的以及应用场景,阐述了使用Python进行数据分析的优势,列举说明了Python数据分析重要类库的功能,比如NumPy库、Pandas库、Matplotlib库、scikit-learn等。
紧接着阐述了Anaconda的特点,如何安装Anaconda 数据分析环境。
最后学习了Python数据分析工具Jupyter Notebook的使用方法。
第二章---Numpy数值分析基础本章重点介绍了NumPy重要的基础内容,比如NumPy的部分常用属性和方法,包括NumPy的“心脏”ndarray及其索引,生成随机数,创建矩阵,使用通用函数计算,以及进行统计分析的常用函数,为后面真正进入数据分析课程内容的学习和学习其他数据分析库(如pandas)打下了坚实的基础。
第三章---Matplotlib数据可视化基础本章介绍了pyplot绘图的基本语法、常用参数。
以2000~2017年各季度国民生产总值数据为例,介绍了分析特征间相关关系的散点图、分析特征间趋势关系的折线图、分析特征内部数据分布的直方图和饼图,以及分析特征内部数据分散情况的箱线图,为我们后续深入学习Matplotlib数据可视化打下了深厚的基础。
第四章---pandas统计分析基础本章以餐饮数据为例,介绍了数据库数据、CSV数据和Excel数据3种常用的数据读取与写入方式。
阐述了DataFrame的常用属性、方法与描述性统计相关内容。
介绍了时间数据的转换、信息提取与算术运算。
同时还剖析了分组聚合方法groupby的原理、用法和3种聚合方法。
第4章 Pandas

4.1.2 Series索引
• Series的索引方法有以下三种。 • 第一种,与list和numpy中的一维数组的方法
不相同,形式相同。但需要注意的是此时的值 不是numpy中对应概念的下标,而是pandas中 的索引值,所以不能出现负数。 • 第二种方法,与list和numpy中的一维数组的 方法不相同,形式也不同,要使用.loc,同样 也不能出现负数。 • 第三种方法,与list和numpy中的一维数组的 方法相同,形式不同,要使用.iloc,可以出 现负数。
• 分组的最主要的作用就是对各个组别进行 分组描述。这里返回的是对各个组别的统 计的结果。
4.1.9 其他
• series还包含了其他一些方法。比如查看 部分数据的head和tail,取样方法sample, 条件筛选where和mask,以及判断是否在另 一个序列中的isin方法。
4.2 DataFrame
• Pangdas中的数据框对象DataFrame可以看 作是Series对象的集合,他们共用同一个 索引。所以DataFrame具有Series的相应方 法,这里不再赘述,可参考4.1小节的内容。 本小节主要根据具体的操作对DataFrame对 象进行讲解。
4.1.4 二元运算
• series的二元运算和numpy中一元数组的运 算相似。
4.1.5 统计方法
• series中提供了常用的统计方法。除了 Numpy中已有的方法外,还增加了一些比较 边界的方法,比如describe方法可以一次 性返回多个统计值。
4.1.6 缺失值处理
第 4 章 pandas统计分析基础《Python数据分析与可视化》教学课件

5000}
obj1 = pd.Series(sdata)
states = ['California', 'Ohio', 'Oregon', 'Texas']
obj2 = pd.Series(sdata, index = states)
print(obj1+obj2)
Out[7]:
California
《Python数据分析与可视化》
✩精品课件合集
Python数据分析与可视化
第 4 章 Pandas统计分析基础
第 4 章 Pandas统计分析基础
❖ Pandas(Python Data Analysis Library)是基于NumPy的数 据分析模块,它提供了大量标准数据模型和高效操作大型数据集所 需的工具,可以说Pandas是使得Python能够成为高效且强大的数 据分析环境的重要因素之一。
Python数据分析与可视化
21
2023年5月25日星期四
4.1 Pandas中的数据结构
❖4.1.3 索引对象
每个索引都有一些方法和属性,它们可用于设置逻辑并回答有关该索
引所包含的数据的常见问题。Index的常用方法和属性见表4-1。
方法 append diff intersection union isin delete drop insert is_monotonic is.unique unique
print(obj)
Out[1]: 0 1
1 -2
23
3 -4Байду номын сангаас
dtype: int64
Python数据分析与可视化
6
机器学习--pandas统计分析

描述性统计
计算DataFrame的描述性统计信息和其他相关操作。 其中大多数是sum(),mean()等聚合函数,重要函数如下:
描述性统计
描述性统计
describe()函数应用
内容纲要
全面推动学习者能力提升
升级实践教学 激发技术创新 助力产业变革
机器学习
—— pandas统计分析
算术运算
算术运算
算术运算有加减乘除,DataFrame中的算术运算是df中 对应位置的元素的算术运算,如果没有共同的元素,则 用NaN代替。
算术运算
算术运算之加法案例
内容纲要
全面推动学习者能力提升
升级实践教学 激发技术创新 助力产业变革
机器学习 —— pandas统计分析
时间序列处理
时间序列处理
在 Pandas 中关于时间序列的常见对象有 6 种,分别为: Timestamp(时间戳)、DatetimeIndex(时间戳索引)、 Period(时间段)、PeriodIndex(时间段索引)、以时间 为元素的 Series 和以及以时间索引的 DataFrame。
升级实践教学 激发技术创新 助力产业变革
机器学习
—— pandas统计分析
增删改查
增删改查
1、准备数据
增删改查
2、增加数据 方法1:添加一个新表
增删改查
2、增加数据 方法2:直接添加数据
增删改查
2、增加数据 方法3:通过insert方法添加数据
增删改查
3、删除数据 使用DataFrame.drop()函数来删除数据
时间序列处理
4、时间索引对象处理之重采样
时间序列处理
常用时间系列频率参数
内容纲要
Python数据分析从入门到精通

读书笔记
细看了一下pandas,粗读了一下numpy。
目录分析
第1章 了解数 析环境
1.1 什么是数据分析 1.2 数据分析的重要性 1.3 数据分析的基本流程 1.4 数据分析常用工具 1.5 小结
2.1 Python概述 2.2 搭建Python开发环境 2.3 集成开发环境PyCharm 2.4 数据分析标准环境Anaconda 2.5 Jupyter Notebook开发工具 2.6 Spyder开发工具 2.7 开发工具比较与代码共用 2.8 小结
Python数据分析从入门到精通
读书笔记模板
01 思维导图
03 读书笔记 05 作者介绍
目录
02 内容摘要 04 目录分析 06 精彩摘录
思维导图
本书关键字分析思维导图
预测
概述
数据分析
数据
综合
分析
统计
数据
数据
统计 第章
应用
分析
小结
过程
项目
实现
图表
数据分析
内容摘要
《Python数据分析从入门到精通》全面介绍了使用Python进行数据分析所必需的各项知识。全书共分为14章, 包括了解数据分析、搭建Python数据分析环境、Pandas统计分析、Matplotlib可视化数据分析图表、Seaborn可 视化数据分析图表、第三方可视化数据分析图表Pyecharts、图解数组计算模块NumPy、数据统计分析案例、机器 学习库Scikit-Learn、注册用户分析(MySQL版)、电商销售数据分析与预测、二手房房价分析与预测,以及客 户价值分析。
谢谢观看
6.1 Seaborn图表概述 6.2 Seaborn图表之初体验 6.3 Seaborn图表的基本设置 6.4 常用图表的绘制 6.5 综合应用 6.6 小结
学习使用数据科学工具Pandas

学习使用数据科学工具Pandas 第一章:Pandas的介绍Pandas是一个开源的、高性能的数据分析工具,它提供了灵活且易于使用的数据结构,使用户能够高效地进行数据操作和分析。
Pandas是Python中最常用的数据分析库之一,它的名字来自于“Panel data”,表示多维数据的面板。
Pandas具有强大的数据处理和清洗能力,可以处理来自不同数据源的数据,包括CSV文件、MySQL数据库以及Web API等。
第二章:Pandas的数据结构Pandas的数据结构主要包括Series和DataFrame。
Series是一维数组,类似于列的数据集合。
它由索引和值组成,可以进行快速的标签访问和处理。
DataFrame是二维表格,类似于一张数据库中的表,由多个Series组成。
DataFrame具有行和列的索引,可以方便地进行数据筛选、统计和分析。
第三章:数据处理与清洗Pandas提供了丰富的数据处理和清洗函数,使得数据的清洗变得更加简洁高效。
例如,可以使用dropna()函数删除含有缺失值的行或列;使用fillna()函数填充缺失值;使用apply()函数对数据进行自定义处理;使用concat()函数合并数据等。
Pandas还支持处理重复值、重命名列名、数据类型转换等操作,使得数据处理变得更加灵活方便。
第四章:数据统计与分析在数据统计和分析方面,Pandas提供了丰富的函数和方法,可以方便地进行数据的统计和分析。
例如,可以使用describe()函数生成数据的统计摘要;使用groupby()函数对数据进行分类汇总;使用sort_values()函数对数据进行排序;使用plot()函数进行数据可视化等。
Pandas还支持进行数学运算、逻辑运算、统计运算等,可以满足用户对数据的各种需求。
第五章:数据的导入与导出Pandas支持多种数据格式的导入和导出,可以方便地与其他数据分析工具进行数据交互。
例如,可以使用read_csv()函数导入CSV文件;使用read_excel()函数导入Excel文件;使用to_csv()函数导出为CSV文件;使用to_excel()函数导出为Excel文件等。
pandas常用统计函数

pandas常用统计函数Pandas是Python中最常用的数据分析工具之一。
它提供了各种功能强大的统计函数,可以帮助我们对数据进行探索和分析。
本文将重点介绍Pandas中常用的统计函数,并一步一步地回答与这些函数相关的问题。
为了更好地理解Pandas的统计函数,我们首先需要了解一些基本概念。
在数据分析中,我们通常会使用一些描述性统计方法,如计算均值、中位数、标准差等。
这些统计指标可以帮助我们了解数据的分布情况和趋势。
问题1:如何计算数据的均值和中位数?Pandas提供了mean()和median()函数来计算数据的均值和中位数。
mean()函数可以计算数据的算术平均值,而median()函数可以计算数据的中位数。
例如,我们有一个包含一组数值的数据集,可以使用这两个函数来获取相应的统计指标。
问题2:如何计算数据的标准差和方差?Pandas提供了std()和var()函数来计算数据的标准差和方差。
std()函数可以计算数据的标准差,而var()函数可以计算数据的方差。
标准差是衡量数据离散程度的一种指标,方差则是标准差的平方。
这两个函数在数据分析中非常有用,可以帮助我们了解数据的分布情况。
问题3:如何计算数据的最大值和最小值?Pandas提供了max()和min()函数来计算数据的最大值和最小值。
max()函数返回给定数据集的最大值,min()函数返回给定数据集的最小值。
通过这两个函数,我们可以得到数据集的范围,进一步了解数据的特征。
问题4:如何计算数据的百分位数?Pandas提供了quantile()函数来计算数据的百分位数。
百分位数是指在一组有序数据中某个特定百分比的数据的值。
例如,我们可以使用quantile()函数获取数据集的中位数,即50的百分位数。
通过计算不同百分位数的值,我们可以更全面地了解数据的分布情况。
除了上述常用的统计函数外,Pandas还提供了一些其他有用的函数,如sum()、count()和describe()等。
Pandas统计分析基础

Pandas统计分析基础Pandas 统计分析基础import numpy as npimport matplotlib.pyplot as pltimport pandas as pd⽂本⽂件读取读取⽂本⽂件。
pd.read_table(['filepath_or_buffer', "sep='\\t'", 'delimiter=None', "header='infer'", 'names=None', 'index_col=None', 'usecols=None', 'squeeze=False', 'prefix=None', 'man gle_dupe_cols=True', 'dtype=None', 'engine=None', 'converters=None', 'true_values=None', 'false_values=None', 'skipinitialspace=False', 'skiprows=None', 'nrows=None', 'na_values=None', 'keep_default_na=True', 'na_filter=True', 'verbose=False', 'skip_blank_lines=True', 'parse_dates=False', 'infer_datetime _format=False', 'keep_date_col=False', 'date_parser=None', 'dayfirst=False', 'iterator=False', 'chunksize=None', "compression='infer'", 'thousands=None', " decimal=b'.'", 'lineterminator=None', 'quotechar=\'"\'', 'quoting=0', 'escapechar=None', 'comment=None', 'encoding=None', 'dialect=None', 'tupleize_cols=No ne', 'error_bad_lines=True', 'warn_bad_lines=True', 'skipfooter=0', 'doublequote=True', 'delim_whitespace=False', 'low_memory=True', 'memory_map=Fal se', 'float_precision=None'],)读取 CSV ⽂件。
学习使用Pandas处理和分析数据的基本方法

学习使用Pandas处理和分析数据的基本方法第一章:Pandas简介与安装Pandas是一个强大的数据分析库,提供了大量的数据处理和分析工具。
首先,我们需要安装Pandas库。
在命令行中输入pip install pandas即可完成安装。
第二章:数据结构Pandas提供了两种主要的数据结构:Series和DataFrame。
Series是一维数组,可以类比为带有索引的列表。
它可以存储不同类型的数据,并且提供了许多便捷的方法来处理数据。
第三章:读取和写入数据Pandas支持从多种文件格式中读取数据,包括CSV、Excel、SQL和HTML等。
在读取数据时,可以指定数据的分隔符、编码和列的类型等信息。
读取的数据将被存储为DataFrame对象。
第四章:数据清洗在数据分析过程中,数据清洗是一个重要的步骤。
Pandas提供了丰富的函数和方法来处理缺失值、重复值和异常值。
可以使用dropna()函数删除包含缺失值的行或列,使用fillna()函数填充缺失值,使用drop_duplicates()函数删除重复值。
第五章:数据选择与操作Pandas提供了灵活的数据选择与操作功能。
可以使用方括号或loc、iloc等函数来选择指定的行、列或单个元素。
可以使用布尔索引、逻辑运算符和isin()函数等来过滤数据。
可以使用apply()函数和匿名函数来对数据进行逐行或逐列的操作。
第六章:统计分析Pandas提供了丰富的统计分析方法,可以计算数据的均值、中位数、标准差等基本统计量。
可以通过describe()函数获得数据的描述性统计信息。
还可以使用groupby()函数进行分组和聚合操作,通过pivot_table()函数进行数据透视表的生成。
第七章:数据可视化数据可视化是数据分析的重要环节之一。
Pandas可以与Matplotlib等库结合使用,实现数据的可视化展示。
可以使用plot()函数绘制折线图、柱状图、散点图等常见图表。
Python数据分析库Pandas入门

Python数据分析库Pandas入门Python是一种广泛使用的编程语言,它具有简单易学、功能强大的特点,被广泛应用于数据分析领域。
在Python中,有许多数据分析库可供使用,而Pandas就是其中最受欢迎和常用的库之一。
本文将介绍Pandas库的基本用法和功能,以帮助读者快速入门。
一、安装Pandas库要使用Pandas库,首先需要将其安装到您的系统中。
您可以使用以下命令通过Python包管理工具pip来安装Pandas库:```pip install pandas```安装完成后,您可以在Python脚本中导入Pandas库并开始使用它。
二、Pandas的数据结构Pandas库提供了两种主要的数据结构:Series和DataFrame。
1. SeriesSeries是一种类似于一维数组的数据结构,它由一组数据和与之相关的索引组成。
可以使用以下方式创建一个Series对象:```pythonimport pandas as pddata = [10, 20, 30, 40, 50]s = pd.Series(data)```通过上述代码,我们创建了一个包含5个元素的Series对象,其中的数据为[10, 20, 30, 40, 50]。
Series对象还会自动生成默认的索引。
2. DataFrameDataFrame是一种二维的数据结构,类似于数据库表格或Excel电子表格。
它由行和列组成,并且可以包含不同类型的数据。
可以使用以下方式创建一个DataFrame对象:```pythondata = {'name': ['Alice', 'Bob', 'Charlie'],'age': [25, 30, 35],'city': ['New York', 'London', 'Tokyo']}df = pd.DataFrame(data)```通过上述代码,我们创建了一个包含3行3列的DataFrame对象,其中的数据包括姓名、年龄和城市信息。
pandas数据处理基本功能

pandas数据处理基本功能Pandas是一个强大的数据处理库,它提供了许多基本功能,方便我们对数据进行操作和分析。
本文将介绍Pandas的基本功能,以帮助读者更好地理解和使用该库。
Pandas可以读取各种类型的数据文件,如CSV、Excel、SQL数据库等。
读取数据非常简单,只需一行代码即可完成。
例如,我们可以使用`read_csv`函数读取CSV文件,使用`read_excel`函数读取Excel 文件。
在数据读取完成后,我们可以使用Pandas提供的函数来查看数据的基本信息。
例如,使用`head`函数可以查看数据的前几行,使用`shape`属性可以查看数据的维度,使用`info`函数可以查看数据的详细信息。
接下来,我们可以对数据进行筛选和过滤。
Pandas提供了强大的索引和切片功能,可以根据条件筛选出符合要求的数据。
例如,我们可以使用`loc`函数根据行标签进行筛选,使用`iloc`函数根据行号进行筛选。
除了筛选和过滤,Pandas还提供了丰富的数据处理和转换功能。
我们可以使用`fillna`函数填充缺失值,使用`drop_duplicates`函数去除重复值,使用`replace`函数替换特定值等等。
这些功能可以帮助我们清洗和处理数据,使其更加规范和准确。
Pandas还支持数据的聚合和统计分析。
我们可以使用`groupby`函数对数据进行分组,然后使用聚合函数(如`sum`、`mean`、`count`等)对每个组进行统计。
这样可以帮助我们更好地理解数据的特征和趋势。
Pandas还可以帮助我们将数据可视化。
它集成了Matplotlib库,可以直接使用Pandas提供的函数进行绘图。
例如,我们可以使用`plot`函数绘制折线图、柱状图、散点图等。
这样可以更直观地展示数据的分布和变化。
Pandas是一个功能强大的数据处理库,它提供了丰富的功能和方法,方便我们对数据进行操作和分析。
通过学习和掌握Pandas的基本功能,我们可以更好地处理和理解数据,为后续的数据分析和建模工作打下坚实的基础。
pandas知识点汇总

Pandas知识点汇总Pandas是一个基于Python的数据分析工具,提供了丰富的数据结构和数据分析函数,使得数据处理变得更加高效和便捷。
本文将介绍一些常用的Pandas知识点,帮助读者更好地理解和使用该工具。
1. 导入Pandas库要使用Pandas,首先需要导入相关的库。
通常使用以下方式导入Pandas:import pandas as pd这样,我们就可以使用pd作为Pandas库的别名,方便后续的代码编写。
2. 创建Pandas数据结构Pandas提供了两种主要的数据结构:Series和DataFrame。
2.1 SeriesSeries是一种一维的数据结构,类似于一维数组或列表。
可以通过以下方式创建一个Series:s = pd.Series([1, 3, 5, np.nan, 6, 8])上述代码将创建一个包含整数和NaN值的Series。
2.2 DataFrameDataFrame是一种二维的数据结构,类似于表格或Excel中的数据。
可以通过以下方式创建一个DataFrame:data = {'name': ['Alice', 'Bob', 'Charlie', 'David'],'age': [25, 30, 35, 40],'country': ['USA', 'Canada', 'UK', 'Australia']}df = pd.DataFrame(data)上述代码将创建一个包含姓名、年龄和国家的DataFrame。
3. 数据选择和过滤Pandas提供了多种方法用于选择和过滤数据。
3.1 选择列要选择DataFrame中的特定列,可以使用以下方式:df['name'] # 选择'name'列3.2 选择行要选择DataFrame中的特定行,可以使用以下方式:df.iloc[0] # 选择第一行3.3 条件过滤要根据条件过滤DataFrame中的数据,可以使用以下方式:df[df['age'] >30] # 过滤出年龄大于30的行4. 数据清洗在实际的数据分析过程中,经常需要进行数据清洗,以确保数据的质量和一致性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
大数据挖掘专家
9
读写文本文件
1.文本文件读取
read_table和read_csv函数中的sep参数是指定文本的分隔符的,如果分隔符指定错误,在读取数据的时 候,每一行数据将连成一片。
header参数是用来指定列名的,如果是None则会添加一个默认的列名。 encoding代表文件的编码格式,常用的编码有utf-8、utf-16、gbk、gb2312、gb18030等。如果编码
大数据挖掘专家
15
查改增删DataFrame数据
1.查看访问DataFrame中的数据——数据基本查看方式
对单列数据的访问:DataFrame的单列数据为一个Series。根据DataFrame的定义可以知晓DataFrame 是一个带有标签的二维数组,每个标签相当每一列的列名。有以下两种方式来实现对单列数据的访问。 • 以字典访问某一个key的值的方式使用对应的列名,实现单列数据的访问。 • 以属性的方式访问,实现单列数据的访问。(不建议使用,易引起混淆)
pandas.read_table(filepath_or_buffer, sep=’\t’, header=’infer’, names=None, index_col=None, dtype=None, engine=None, nrows=None)
使用read_csv函数来读取csv文件。
大数据挖掘专家
13
目录
1
读写不同数据源的数据
2
掌握DataFrame的常用操作
3
转换与处理时间序列数据
大数据挖掘专家
14
查看DataFrame的常用属性
基础属性
函数 values index columns dtypes
size ndim shape
返回值 元素 索引 列名 类型 元素个数 维度数 数据形状(行列数目)
index_col 接收int、sequence或者False。表示索引列的位置,取值为sequence则代表多重索引。默认为None。
dtype
接收dict。代表写入的数据类型(列名为key,数据格式为values)。默认为None。
大数据挖掘专家
12
读写Excel文件
2.Excel文件储存
将文件存储为Excel文件,可以使用to_excel方法。其语法格式如下。
指定错误数据将无法读取,IPyth文件
2.文本文件储存
文本文件的存储和读取类似,结构化数据可以通过pandas中的to_csv函数实现以csv文件格式存储文件。
DataFrame.to_csv(path_or_buf=None, sep=’,’, na_rep=”, columns=None, header=True,
pandas.read_csv(filepath_or_buffer, sep=’\t’, header=’infer’, names=None, index_col=None, dtype=None, engine=None, nrows=None)
大数据挖掘专家
8
读写文本文件
1.文本文件读取
read_table和read_csv常用参数及其说明。
参数名称 filepath
sep header names
index_col
dtype engine nrows
说明 接收string。代表文件路径。无默认。 接收string。代表分隔符。read_csv默认为“,”,read_table默认为制表符“[Tab]”。 接收int或sequence。表示将某行数据作为列名。默认为infer,表示自动识别。 接收array。表示列名。默认为None。 接收int、sequence或False。表示索引列的位置,取值为sequence则代表多重索引。默认为 None。 接收dict。代表写入的数据类型(列名为key,数据格式为values)。默认为None。 接收c或者python。代表数据解析引擎。默认为c。 接收int。表示读取前n行。默认为None。
DataFrame.to_excel(excel_writer=None, sheetname=None’, na_rep=”, header=True, index=True, index_label=None, mode=’w’, encoding=None)
to_csv方法的常用参数基本一致,区别之处在于指定存储文件的文件路径参数名称为excel_writer,并且 没有sep参数,增加了一个sheetnames参数用来指定存储的Excel sheet的名称,默认为sheet1。
大数据挖掘专家
11
读写Excel文件
1.Excel文件读取
pandas提供了read_excel函数来读取“xls”“xlsx”两种Excel文件。
pandas.read_excel(io, sheetname=0, header=0, index_col=None, names=None, dtype=None)
大数据挖掘专家
18
查改增删DataFrame数据
1.查看访问DataFrame中的数据——loc,iloc访问方式
loc方法是针对DataFrame索引名称的切片方法,如果传入的不是索引名称,那么切片操作将无法执行。 利用loc方法,能够实现所有单层索引切片操作。loc方法使用方法如下。
对多列数据访问:访问DataFrame多列数据可以将多个列索引名称视为一个列表,同时访问DataFrame 多列数据中的多行数据和访问单列数据的多行数据方法基本相同。
大数据挖掘专家
17
查改增删DataFrame数据
1.查看访问DataFrame中的数据——数据基本查看方式
对某几行访问: • 如果只是需要访问DataFrame某几行数据的实现方式则和上述的访问多列多行相似,选择所有列,使 用“:”代替即可。 • head和tail也可以得到多行数据,但是用这两种方法得到的数据都是从开始或者末尾获取的连续数据 。默认参数为访问5行,只要在方法后方的“()”中填入访问行数即可实现目标行数的查看。
大数据挖掘专家
4
读写数据库数据
1.数据库数据读取
pandas三个数据库数据读取函数的参数几乎完全一致,唯一的区别在于传入的是语句还是表名。
参数名称 sql or
table_name con
index_col
说明
接收string。表示读取的数据的表名或者sql语句。无默认。
接收数据库连接。表示数据库连接信息。无默认 接收int,sequence或者False。表示设定的列作为行名, 如果是一个数列则是多重索引。默认为None。
大数据挖掘专家
16
查改增删DataFrame数据
1.查看访问DataFrame中的数据——数据基本查看方式
对某一列的某几行访问:访问DataFrame中某一列的某几行时,单独一列的DataFrame可以视为一个 Series(另一种pandas提供的类,可以看作是只有一列的DataFrame),而访问一个Series基本和访问 一个一维的ndarray相同。
参数名称
说明
io
接收string。表示文件路径。无默认。
sheetname 接收string、int。代表excel表内数据的分表位置。默认为0。
header 接收int或sequence。表示将某行数据作为列名。默认为infer,表示自动识别。
names
接收int、sequence或者False。表示索引列的位置,取值为sequence则代表多重索引。默认为None。
大数据挖掘专家
6
读写文本文件
1.文本文件读取
文本文件是一种由若干行字符构成的计算机文件,它是一种典型的顺序文件。 csv是一种逗号分隔的文件格式,因为其分隔符不一定是逗号,又被称为字符分隔文件,文件以纯文本形
式存储表格数据(数字和文本)。
大数据挖掘专家
7
读写文本文件
1.文本文件读取
使用read_table来读取文本文件。
大数据,成就未来
pandas统计分析基础
2019/5/26
目录
1
读写不同数据源的数据
2
掌握DataFrame的常用操作
3
转换与处理时间序列数据
大数据挖掘专家
2
读写数据库数据
1.数据库数据读取
pandas提供了读取与存储关系型数据库数据的函数与方法。除了pandas库外,还需要使用SQLAlchemy库建立对 应的数据库连接。SQLAlchemy配合相应数据库的Python连接工具(例如MySQL数据库需要安装mysqlclient或者 pymysql库),使用create_engine函数,建立一个数据库连接。
read_sql_query则只能实现查询操作,不能直接读取数据库中的某个表。
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True)
read_sql是两者的综合,既能够读取数据库中的某一个表,也能够实现查询操作。
pandas.read_sql(sql, con, index_col=None, coerce_float=True, columns=None)
coerce_float
接收boolean。将数据库中的decimal类型的数据转换为 pandas中的float64类型的数据。默认为True。
columns 接收list。表示读取数据的列名。默认为None。
大数据挖掘专家
5
读写数据库数据
2.数据库数据存储
数据库数据读取有三个函数,但数据存储则只有一个to_sql方法。