Lucene漫谈
lucene 基本概念

lucene 基本概念Lucene 基本概念Lucene 是一个开源的全文搜索引擎库,被广泛地应用于高性能搜索和索引任务中。
它是 Apache 软件基金会的一个开源项目,并且被许多知名的商业产品使用。
本文将通过一步一步的方式,来介绍 Lucene 的基本概念和其原理。
一、Lucene 是什么?Lucene 是一个基于 Java 的全文搜索引擎库。
它提供了一系列的 API 和工具,用于创建、维护和搜索大规模文本数据集。
通过将文本数据索引到 Lucene 的索引库中,我们可以快速地进行全文搜索、排序和过滤等操作。
二、Lucene 的基本原理1. 倒排索引倒排索引是 Lucene 的核心概念之一。
它是一种数据结构,用于从词项到文档的映射。
通常,我们将文本数据分割成单词,然后对每个词项构建一个索引条目,该条目指向包含该词项的文档。
例如,假设我们有三个文档:文档1 包含 "Lucene 是一个搜索引擎库",文档2 包含 "Apache Lucene 是一个全文搜索库",文档3 包含 "Lucene 是基于 Java 的"。
在倒排索引中,我们将按照词项构建索引,如下所示:词项文档Lucene 1, 2, 3是 1, 2, 3一个 1, 2, 3搜索引擎库 1全文搜索库 2基于 3Java 3倒排索引的优势在于它能够快速地确定包含特定词项的文档,并且支持更复杂的查询表达式。
2. 分词器分词器是将原始文本分割成词项的模块。
Lucene 提供了多种分词器,如标准分词器、简单分词器等。
分词器还可以根据具体的需求进行定制。
分词器在构建索引和搜索时起到关键作用,它们确保在索引和搜索阶段都使用相同的分词规则。
3. 文档和字段在 Lucene 中,文档是一个最小的索引单位。
它由多个字段组成,每个字段包含一个词项或多个词项。
字段可以是文本、数值或日期等不同类型。
Lucene 中的文档和字段的设计灵活,可以根据实际需求进行定义和修改。
lucene原理

lucene原理Lucene是Apache软件基金会下的一个开放源代码的全文信息检索的开发工具包,它实现了完整的文档搜索引擎。
它提供两种索引类型:结构化索引和文档索引,两种索引类型都有它们各自的优势和缺点,取决于实际需要。
Lucene提供了一个组件化的架构,它利用一个高效的索引系统来实现搜索。
此外,Lucene还提供了许多的文本处理功能,如词法分析,摘要,跟踪搜索日志,等等。
而且,Lucene和其他全文搜索系统不同,它允许用户定制自己的索引和结构,从而满足特定的搜索需求。
Lucene的核心是索引机制,它可以对一系列文档进行检索、搜索、高级搜索。
它利用微机二进制索引结构可以快速访问准确的结果,还可以在全文检索时进行模糊处理,识别文档中的同义词等。
Lucene还跟踪文档更新,可以检测何时需要重组全文索引,从而实现快速响应搜索需要。
除此之外,Lucene还可以搜索特定的文档,文本,页面,网页或者指定的网站。
Lucene的设计出发点是提供全文搜索的性能,而不仅仅是提供精确的搜索词语。
这意味着Lucene可以提供精确的搜索,使用的是数据结构和算法来实现搜索,搜索的结果可以按照权重排序,并且可以对搜索结果进行筛选,从而更好地满足搜索用户的需求。
Lucene通过提供文档过滤器和搜索过滤器,可以用来限定搜索结果的范围。
此外,Lucene 还提供了一系列的分析器,来处理原始的文档,包括不同类型的文件,如Word文档,PDF文档,HTML文档等等。
基于Lucene的搜索服务可以满足各种不同的搜索需求。
用户可以根据自己的关键字设置搜索条件,也可以应用不同类型的条件,如限制搜索结果的数量,搜索结果的排序等。
Lucene利用高效的计算方法和索引技术,能够提供快速准确的搜索结果,并对不同类型的数据进行处理,进一步提高搜索效率。
lucene面试题

lucene面试题一、Lucene简介Lucene是一个开源的全文检索引擎工具包,可以轻松地将其集成到应用程序中,以方便地实现全文检索功能。
它提供了强大且灵活的API接口,使用户可以对文档中的内容进行快速、高效的搜索和索引。
Lucene的核心是基于倒排索引原理,通过将文档中的单词映射到文档的地址来进行搜索,从而提高了搜索的速度和效率。
二、Lucene的特点和优势1. 高性能:Lucene使用高效的倒排索引和缓存机制,能够快速处理大量数据和复杂查询。
2. 可扩展性:Lucene提供了灵活的架构和API接口,可以根据需求进行扩展和定制。
3. 多语言支持:Lucene支持多种语言的分词器,可以处理各种类型的文档。
4. 高度可配置:Lucene的配置项丰富,可以根据需要进行灵活的配置和调优。
5. 支持多种数据格式:Lucene能够处理各种格式的数据,包括文本文件、HTML、XML、Word文档等。
三、Lucene的应用场景1. 搜索引擎:Lucene可以用于构建搜索引擎,实现快速、准确的搜索和检索功能。
2. 文本分析:Lucene提供了丰富的文本处理和分析功能,可以对文档进行分词、词性标注、去重等操作。
3. 数据挖掘:Lucene可以对大量数据进行索引和搜索,用于数据挖掘和信息提取。
4. 商业应用:Lucene可以用于构建企业内部搜索、电子文档管理系统、知识库等应用。
四、Lucene面试常见问题1. 什么是Lucene的倒排索引原理?2. 如何创建一个基本的Lucene索引?3. Lucene中的Query和Filter有什么区别?如何使用它们?4. 什么是Analyzer?有哪些常见的分词器?5. Lucene的排序原理是什么?如何进行排序?6. Lucene如何处理关键词的模糊匹配?7. Lucene的搜索结果评分算法是怎样的?8. 如何在Lucene中实现多字段的搜索?9. 如何优化Lucene的性能?10. Lucene与Elasticsearch有何区别?五、结语通过对Lucene的介绍和常见面试问题的概述,希望能够对读者了解Lucene的基本概念和使用方法有所帮助。
Lucene入门+实现

Lucene⼊门+实现Lucene简介详情见:()lucene实现原理其实⽹上很多资料表明了,lucene底层实现原理就是倒排索引(invertedindex)。
那么究竟什么是倒排索引呢?经过Lucene分词之后,它会维护⼀个类似于“词条--⽂档ID”的对应关系,当我们进⾏搜索某个词条的时候,就会得到相应的⽂档ID。
不同于传统的顺排索引根据⼀个词,知道有哪⼏篇⽂章有这个词。
图解:Lucene在搜索前⾃⾏⽣成倒排索引,相⽐数据库中like的模糊搜索效率更⾼!Lucene 核⼼API索引过程中的核⼼类1. Document⽂档:他是承载数据的实体(他可以集合信息域Field),是⼀个抽象的概念,⼀条记录经过索引之后,就是以⼀个Document的形式存储在索引⽂件中的。
2. Field:Field 索引中的每⼀个Document对象都包含⼀个或者多个不同的域(Field),域是由域名(name)和域值(value)对组成,每⼀个域都包含⼀段相应的数据信息。
3. IndexWriter:索引过程的核⼼组件。
这个类⽤于创建⼀个新的索引并且把⽂档加到已有的索引中去,也就是写⼊操作。
4. Directroy:是索引的存放位置,是个抽象类。
具体的⼦类提供特定的存储索引的地址。
(FSDirectory 将索引存放在指定的磁盘中,RAMDirectory ·将索引存放在内存中。
)5. Analyzer:分词器,在⽂本被索引之前,需要经过分词器处理,他负责从将被索引的⽂档中提取词汇单元,并剔除剩下的⽆⽤信息(停⽌词汇),分词器⼗分关键,因为不同的分词器,解析相同的⽂档结果会有很⼤的不同。
Analyzer是⼀个抽象类,是所有分词器的基类。
搜索过程中的核⼼类1. IndexSearcher :IndexSearcher 调⽤它的search⽅法,⽤于搜索IndexWriter 所创建的索引。
2. Term :Term 使⽤于搜索的⼀个基本单元。
lucense详解

另外,如果是在选择全文引擎,现在也许是试试Sphinx的时候了:相比Lucene速度更快,有中文分词的支持,而且内置了对简单的分布式检索的支持;基于Java的全文索引/检索引擎——LuceneLucene不是一个完整的全文索引应用,而是是一个用Java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能。
Lucene的作者:Lucene的贡献者Doug Cutting是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎(Apple的Copland操作系统的成就之一)的主要开发者,后在Excite担任高级系统架构设计师,目前从事于一些INTERNET底层架构的研究。
他贡献出的Lucene的目标是为各种中小型应用程序加入全文检索功能。
Lucene的发展历程:早先发布在作者自己的,后来发布在SourceForge,2001年年底成为APACHE基金会jakarta的一个子项目:/lucene/已经有很多Java项目都使用了Lucene作为其后台的全文索引引擎,比较著名的有:对于中文用户来说,最关心的问题是其是否支持中文的全文检索。
但通过后面对于Lucene 的结构的介绍,你会了解到由于Lucene良好架构设计,对中文的支持只需对其语言词法分析接口进行扩展就能实现对中文检索的支持。
全文检索≠ like "%keyword%"通常比较厚的书籍后面常常附关键词索引表(比如:北京:12, 34页,上海:3,77页……),它能够帮助读者比较快地找到相关内容的页码。
而数据库索引能够大大提高查询的速度原理也是一样,想像一下通过书后面的索引查找的速度要比一页一页地翻内容高多少倍……而索引之所以效率高,另外一个原因是它是排好序的。
对于检索系统来说核心是一个排序问题。
由于数据库索引不是为全文索引设计的,因此,使用like "%keyword%"时,数据库索引是不起作用的,在使用like查询时,搜索过程又变成类似于一页页翻书的遍历过程了,所以对于含有模糊查询的数据库服务来说,LIKE对性能的危害是极大的。
lucene简介原理及实践(共48张)

Analyzer
在一个文档被索引之前,首先需要对文档内容进行分词处理, 并且而剔除一些冗余的词句(例如:a,the,they等),这部分工作
就是由 Analyzer 来做的。
Analyzer 类是一个抽象类,它有多个实现。
BrazilianAnalyzer, ChineseAnalyzer, CJKAnalyzer, CzechAnalyzer, DutchAnalyzer, FrenchAnalyzer, GermanAnalyzer, GreekAnalyzer, KeywordAnalyzer, PatternAnalyzer, PerFieldAnalyzerWrapper, RussianAnalyzer, SimpleAnalyzer, SnowballAnalyzer, StandardAnalyzer, StopAnalyzer, ThaiAnalyzer, WhitespaceAnalyzer
通过实现特定API,完成文档建立索引的工 作
第7页,共48页。
Lucene搜索机制-B 基于(jīyú)索引搜索
Lucene通过特定的类,可以对索引进行操 作
通过特定的类,封装搜索结果,供应用程 序处理
第8页,共48页。
Lucene系统结构
第9页,共48页。
Lucene包结构(jiégòu)功能表
第19页,共48页。
Field
Field 对象(duìxiàng)是用来描述一个文档的某个属性的,比如一封电子邮件的标 题和内容可以用两个 Field 对象分别描述。
Field(String name, byte[] value, Field.Store store) Create a stored field with binary value.
es的lucene作用

es的lucene作用Es的Lucene作用Lucene是一个开源的全文搜索引擎库,被广泛应用于各种编程语言和领域,其中包括Elasticsearch(简称Es),是一个基于Lucene 构建的分布式搜索与分析引擎。
本文将重点介绍Es的Lucene作用,并探讨其在搜索引擎领域中的重要性。
一、Lucene的基本概念和原理Lucene是一个高效、可扩展的全文搜索引擎库,它提供了一套简单而强大的API,可以用于创建索引、搜索和生成文本摘要。
其核心原理是将文本数据分析、索引和搜索的过程进行分离,以实现高效的全文搜索。
1. 数据分析(Analysis):Lucene提供了一系列的文本分析器(Analyzer),用于将输入的文本进行分词、词干提取、大小写转换等处理。
分析器的作用是将原始文本转化为一组有意义的词条(Term),以便于后续的索引和搜索操作。
2. 索引(Indexing):Lucene使用倒排索引(Inverted Index)的方式来存储和管理文本数据。
倒排索引是一种将词条映射到文档的数据结构,它可以快速地根据词条进行搜索,并找到包含该词条的文档。
3. 搜索(Searching):Lucene提供了丰富的搜索API,可以根据关键词、短语、通配符等进行检索,并按照相关度对搜索结果进行排序。
搜索过程利用倒排索引来定位匹配的文档,并根据各种算法计算文档与查询的相关度。
二、Es中的Lucene应用Es是一个基于Lucene的分布式搜索与分析引擎,它在Lucene的基础上进行了功能扩展和性能优化,提供了更强大的分布式搜索和数据分析能力。
1. 分布式搜索:Es将数据分片存储在多个节点上,并使用分布式索引的方式来实现高性能的搜索。
当用户发起搜索请求时,Es会将查询分发到各个节点,并将结果进行合并和排序,最后返回给用户。
2. 数据分析与聚合:Es提供了丰富的数据聚合功能,可以对文档进行分组、统计、排序等操作。
用户可以通过聚合操作获取关于数据的各种统计信息,如平均值、最大值、最小值等,以及根据条件进行数据筛选和分析。
lucene对比中文近义词用法

标题:探讨Lucene对比中文近义词用法1. 简介为了更好地理解Lucene对比中文近义词用法,我们首先需要了解Lucene的基本概念和中文近义词的特点。
Lucene是一个全文检索引擎库,它提供了丰富的API,可以用于构建强大的全文搜索功能。
而中文近义词则是指在中文语境中,表达相似意义的词语,这些词语在不同的语境中可能会有微小的差别,但整体的意思是相通的。
2. Lucene的基本原理和功能Lucene通过倒排索引的方式来快速定位文档中的关键词,从而实现全文搜索的功能。
它采用了分词器来处理文本,将文本分割成若干个独立的单词,并将这些单词进行索引。
在搜索时,用户输入的查询语句也经过相同的分词处理,再与索引进行匹配,最终返回相关的文档。
3. 中文近义词的特点在中文语境中,由于词语的复杂性和多义性,往往会存在大量的近义词。
这些近义词可能在不同的场景中有不同的使用方式,但它们的基本意思是一致的。
“喜欢”和“爱好”就是一对中文近义词,它们都表示喜爱或偏好的意思,只是在语感上有细微的区别。
4. Lucene对比中文近义词用法在使用Lucene进行搜索时,对于中文近义词的处理往往是一个挑战。
由于中文的特殊性,同一个词可能存在多种不同的表达方式,而传统的搜索引擎很难将它们准确地匹配在一起。
针对这一问题,Lucene提供了同义词扩展的功能,可以将一些近义词视作同一个词来处理。
这样一来,用户在搜索时无需考虑到所有的近义词,只需要输入其中一个,就能够搜索到相关的文档。
5. 个人观点和总结通过对Lucene对比中文近义词用法的探讨,我们可以发现,Lucene在处理中文近义词时的确存在一些挑战,但它也提供了相应的解决方案。
在实际应用中,我们可以根据具体的需求,合理地进行同义词扩展,以提升搜索结果的准确性和覆盖范围。
对于中文近义词的掌握也需要结合具体的语境和语气来理解,不能简单地进行机械替换。
Lucene对比中文近义词用法的探讨,有助于我们更好地理解和应用这一强大的全文搜索引擎库。
lucene 原理

lucene 原理Lucene是一种开源的信息检索(IR)库,它提供了高效、可扩展的全文检索和索引功能。
下面是Lucene的一些详细原理解释:1. 倒排索引(Inverted Index):Lucene使用倒排索引的数据结构来实现全文检索。
传统的索引是从文档到词语的映射,而倒排索引则是从词语到文档的映射。
每个词语都对应一个或多个包含该词语的文档列表,方便快速地找到包含特定词语的文档。
2. 分词(Tokenization):在索引之前,Lucene会将文本分为一系列的词语或术语,这个过程称为分词。
分词的目的是将长文本拆分为可以被索引和搜索的离散单元。
Lucene提供多种分词器,以适应不同语言和需求。
3. 索引结构:Lucene使用多级索引结构以提高检索效率。
索引被划分为多个段(segments),每个段包含一个或多个文档。
每个段内部使用B树(B-tree)或前缀树(Trie)等数据结构来组织词项(term)和文档的映射关系。
4. 倒排列表(Inverted List):倒排列表是倒排索引的核心数据结构,用于存储每个词语在哪些文档中出现。
每个词语对应一个倒排列表,包含了所有出现该词语的文档ID及其相关的词频、位置和其他统计信息。
5. 相关性评分(Relevance Scoring):在执行搜索时,Lucene使用相关性评分算法来确定文档与查询的匹配程度。
默认的相关性评分算法是基于向量空间模型的TF-IDF(Term Frequency-Inverse Document Frequency),它考虑了词项在文档中出现的频率和在整个语料库中的重要性。
6. 查询解析和执行:Lucene使用查询解析器将用户的查询语句解析为内部查询对象。
查询对象由不同的查询类型(如词项查询、范围查询、布尔查询等)组成,并通过布尔运算来组合和匹配文档。
Lucene通过遍历倒排索引和倒排列表来执行查询,并根据相关性评分对文档进行排序。
lucene 底层原理

Lucene的底层原理主要包括索引原理和搜索原理。
首先,Lucene的索引原理是建立在对文本内容进行深入理解的基础上的。
它将文本内容进行分词处理,形成一个个独立的词语或短语,然后对这些词语或短语进行索引。
这个过程主要涉及到两个步骤:一是对文本内容的分词处理,即将文本分成一个个有意义的词语或短语;二是对这些词语或短语进行索引,即建立它们与对应文本的映射关系。
这种映射关系可以通过一种称为“倒排索引”的技术来实现,它通过将文本中的词语映射到包含该词语的文档,从而实现快速检索。
其次,Lucene的搜索原理是基于其索引原理的。
当用户进行搜索时,Lucene会根据用户输入的关键词,在倒排索引中找到对应的文档。
这个过程涉及到对关键词的分析和处理,以及根据一定的算法对搜索结果进行排序。
排序的依据可以根据需要进行设置,比如相关性、时间、重要程度等。
此外,Lucene还提供了丰富的功能和接口,方便用户进行自定义配置和扩展。
比如,用户可以根据需要对索引的建立方式、分词算法、排序规则等进行调整,以达到更好的搜索效果。
同时,Lucene
还支持多语言、多平台的应用,可以广泛应用于各种场景中。
总之,Lucene的底层原理主要包括索引原理和搜索原理,通过深入理解文本内容,建立倒排索引,实现对文本的高效检索。
同时,Lucene还提供了丰富的功能和接口,方便用户进行自定义配置和扩展。
Lucene学习总结之四:Lucene索引过程分析(1)

对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后的文章中进行分析。
Lucene的索引过程,很多的博客,文章都有介绍,推荐大家上网搜一篇文章:《Annotated Lucene》,好像中文名称叫《Lucene源码剖析》是很不错的。
想要真正了解Lucene索引文件过程,最好的办法是跟进代码调试,对着文章看代码,这样不但能够最详细准确的掌握索引过程(描述都是有偏差的,而代码是不会骗你的),而且还能够学习Lucene的一些优秀的实现,能够在以后的工作中为我所用,毕竟Lucene是比较优秀的开源项目之一。
由于Lucene已经升级到3.0.0了,本索引过程为Lucene 3.0.0的索引过程。
一、索引过程体系结构Lucene 3.0的搜索要经历一个十分复杂的过程,各种信息分散在不同的对象中分析,处理,写入,为了支持多线程,每个线程都创建了一系列类似结构的对象集,为了提高效率,要复用一些对象集,这使得索引过程更加复杂。
其实索引过程,就是经历下图中所示的索引链的过程,索引链中的每个节点,负责索引文档的不同部分的信息,当经历完所有的索引链的时候,文档就处理完毕了。
最初的索引链,我们称之基本索引链。
为了支持多线程,使得多个线程能够并发处理文档,因而每个线程都要建立自己的索引链体系,使得每个线程能够独立工作,在基本索引链基础上建立起来的每个线程独立的索引链体系,我们称之线程索引链。
线程索引链的每个节点是由基本索引链中的相应的节点调用函数addThreads创建的。
为了提高效率,考虑到对相同域的处理有相似的过程,应用的缓存也大致相当,因而不必每个线程在处理每一篇文档的时候都重新创建一系列对象,而是复用这些对象。
所以对每个域也建立了自己的索引链体系,我们称之域索引链。
域索引链的每个节点是由线程索引链中的相应的节点调用addFields 创建的。
Lucene 概念介绍

Lucene介绍概念介绍Lucene 是一个基于 Java 的全文检索工具包,你可以利用它来为你的应用程序加入索引和检索功能。
Lucene 不是一个完整的应用程序,而是一个信息检索包,它方便你为你的应用程序添加索引和搜索功能。
Lucene的优点(1)索引文件格式独立于应用平台。
Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。
然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search[11])、分组查询等等。
架构概览Lucene 使用各种解析器对各种不同类型的文档进行解析。
比如对于 HTML 文档,HTML 解析器会做一些预处理的工作,比如过滤文档中的 HTML 标签等等。
HTML 解析器的输出的是文本内容,接着 Lucene 的分词器(Analyzer)从文本内容中提取出索引项以及相关信息,比如索引项的出现频率。
接着 Lucene 的分词器把这些信息写到索引文件中。
用Lucene索引文档只要你能将要索引的文件转化成文本格式,Lucene 就能为你的文档建立索引。
比如,如果你想为 HTML 文档或者 PDF 文档建立索引,那么首先你就需要从这些文档中提取出文本信息,然后把文本信息交给 Lucene 建立索引。
参考代码介绍:Analyzer luceneAnalyzer = new StandardAnalyzer();这条语句创建了类 StandardAnalyzer 的一个实例,这个类是用来从文本中提取出索引项的。
lucene原理

lucene原理
Lucene是一种开源的搜索库,主要用于实现全文搜索功能。
它采用了倒排索引的数据结构,能够高效地检索文本内容。
倒排索引是Lucene的核心概念之一。
它通过将每个文档中的
单词与该文档的标识进行关联,建立一个映射表。
这样,当用户想要搜索某个单词时,Lucene只需在倒排索引中查找包含
该单词的文档标识,而不需要逐个扫描每个文档。
这种索引方式能够大大提高搜索的效率。
除了倒排索引外,Lucene还采用了一系列的优化技术来提高
搜索的性能。
其中之一是布尔过滤器,它可以根据条件筛选出满足特定条件的文档。
另外,Lucene还支持模糊搜索和通配
符搜索等高级搜索功能,可以更准确地匹配用户的查询。
在使用Lucene进行搜索时,用户首先需要创建一个索引,并
对待搜索的文本进行分词处理。
Lucene提供了一些内置的分
词器,也支持用户自定义分词器。
然后,用户可以使用查询解析器来解析查询语句,并将其转换为查询对象。
最后,用户可以通过查询对象执行搜索操作,获取符合条件的文档列表。
总的来说,Lucene是一个功能强大且高效的搜索引擎库,可
以应用于各种领域的信息检索任务。
它的核心原理是倒排索引,通过优化技术和高级搜索功能,能够快速准确地为用户提供搜索结果。
lucene面试题

lucene面试题Lucene是一个开源的全文搜索引擎库,被广泛应用于各个领域。
在Lucene的使用和应用过程中,可能会遇到一些面试题,下面将介绍一些常见的Lucene面试题及其解答。
1. 请简要介绍一下Lucene的特点和优势。
Lucene是一个基于Java的全文搜索引擎库,具有以下特点和优势:- 高性能:Lucene使用倒排索引结构来提高搜索效率,能快速索引和检索大量的文本数据。
- 可扩展性:Lucene提供了灵活的API和丰富的插件机制,可以方便地进行功能扩展和定制化开发。
- 多语言支持:Lucene支持多种语言的分词器,可以适应不同语种的文本搜索需求。
- 分布式搜索:Lucene可以通过与Apache Solr或Elasticsearch等搜索服务器配合使用,实现分布式的高性能搜索。
- 易于使用:Lucene提供了简单易用的API和文档,使得开发人员可以快速上手使用和集成。
2. 什么是倒排索引?请简要说明其原理和优势。
倒排索引是一种常见的用于实现全文搜索的索引结构,其原理是通过将词汇表中的每个词都映射到包含该词的文档列表,从而实现根据关键词进行文档检索。
倒排索引的优势包括:- 提高搜索效率:倒排索引结构可以快速定位到包含关键词的文档,减少搜索范围,提高搜索效率。
- 减少存储空间:倒排索引使用了词汇表和文档列表的结构,可以有效地压缩和存储文本数据。
- 支持复杂的搜索操作:倒排索引支持布尔查询、短语查询、通配符查询等复杂的搜索操作,提供了灵活的搜索功能。
3. 请说明Lucene索引的创建和更新过程。
Lucene索引的创建和更新过程主要包括以下几个步骤:1)创建IndexWriter:通过创建IndexWriter对象来打开索引目录,并进行索引的写入操作。
2)创建Document:将待索引的文档内容转换为Lucene的Document对象,其中可以添加不同字段的内容。
3)将Document添加到索引中:通过调用IndexWriter的addDocument方法将Document对象添加到索引中。
一步一步跟我学习lucene(14)---lucene搜索之facet查询原理和facet查询实例
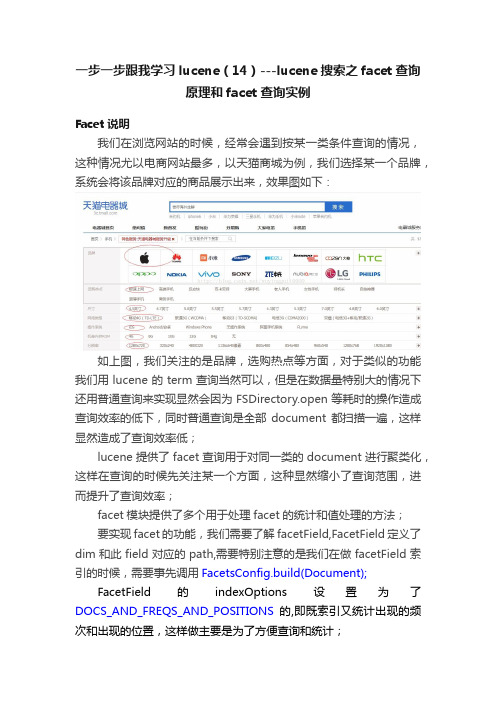
一步一步跟我学习lucene(14)---lucene搜索之facet查询原理和facet查询实例Facet说明我们在浏览网站的时候,经常会遇到按某一类条件查询的情况,这种情况尤以电商网站最多,以天猫商城为例,我们选择某一个品牌,系统会将该品牌对应的商品展示出来,效果图如下:如上图,我们关注的是品牌,选购热点等方面,对于类似的功能我们用lucene的term查询当然可以,但是在数据量特别大的情况下还用普通查询来实现显然会因为FSDirectory.open等耗时的操作造成查询效率的低下,同时普通查询是全部document都扫描一遍,这样显然造成了查询效率低;lucene提供了facet查询用于对同一类的document进行聚类化,这样在查询的时候先关注某一个方面,这种显然缩小了查询范围,进而提升了查询效率;facet模块提供了多个用于处理facet的统计和值处理的方法;要实现facet的功能,我们需要了解facetField,FacetField定义了dim和此field对应的path,需要特别注意的是我们在做facetField索引的时候,需要事先调用FacetsConfig.build(Document);FacetField的indexOptions设置为了DOCS_AND_FREQS_AND_POSITIONS的,即既索引又统计出现的频次和出现的位置,这样做主要是为了方便查询和统计;相应的在存储的时候我们需要利用FacetsConfig和DirectoryTaxonomyWriter;DirectoryTaxonomyWriter用来利用Directory来存储T axono 信息到硬盘;DirectoryTaxonomyWriter的构造器如下:[java] view plain copy1.public DirectoryTaxonomyWriter(Directory directory, Ope nMode openMode,2.TaxonomyWriterCache cache) throws IOException {3.4.dir = directory;5.IndexWriterConfig config = createIndexWriterConfig(ope nMode);6.indexWriter = openIndexWriter(dir, config);7.8.// verify (to some extent) that merge policy in effect would preserve category docids9.assert !(indexWriter.getConfig().getMergePolicy() instanc eof TieredMergePolicy) :10."for preserving category docids, merging none-adjacent segments is not allowed";11.12.// after we opened the writer, and the index is locked, it's safe to check13.// the commit data and read the index epoch14.openMode = config.getOpenMode();15.if (!DirectoryReader.indexExists(directory)) {16.indexEpoch = 1;17.} else {18.String epochStr = null;19.Map<String, String> commitData = readCommitData( directory);20.if (commitData != null) {21.epochStr = commitData.get(INDEX_EPOCH);22.}23.// no commit data, or no epoch in it means an old tax onomy, so set its epoch to 1, for lack24.// of a better value.25.indexEpoch = epochStr == null ? 1 : Long.parseLong( epochStr, 16);26.}27.28.if (openMode == OpenMode.CREATE) {29.++indexEpoch;30.}31.32.FieldType ft = new FieldType(TextField.TYPE_NOT_STO RED);33.ft.setOmitNorms(true);34.parentStreamField = new Field(Consts.FIELD_PAYLOAD S, parentStream, ft);35.fullPathField = new StringField(Consts.FULL, "", Field.S tore.YES);36.37.nextID = indexWriter.maxDoc();38.39.if (cache == null) {40.cache = defaultTaxonomyWriterCache();41.}42.this.cache = cache;43.44.if (nextID == 0) {45.cacheIsComplete = true;46.// Make sure that the taxonomy always contain the ro ot category47.// with category id 0.48.addCategory(new FacetLabel());49.} else {50.// There are some categories on the disk, which we ha ve not yet51.// read into the cache, and therefore the cache is inco mplete.52.// We choose not to read all the categories into the ca che now,53.// to avoid terrible performance when a taxonomy ind ex is opened54.// to add just a single category. We will do it later, afte r we55.// notice a few cache misses.56.cacheIsComplete = false;57.}58.}由上述代码可知,DirectoryTaxonomyWriter先打开一个IndexWriter,在确保indexWriter打开和locked的前提下,读取directory对应的segments中需要提交的内容,如果读取到的内容为空,说明是上次的内容,设置indexEpoch为1,接着对cache进行设置;判断directory中是否还包含有document,如果有设置cacheIsComplete为false,反之为true;时候不早了,今天先写到这里,明天会在此基础上补充,大家见谅编程实践我对之前的读取文件夹内容的做了个facet索引的例子对BaseIndex修改了facet的设置,相关代码如下[java] view plain copy1.package com.lucene.index;2.3.4.5.import java.io.File;6.import java.io.IOException;7.import java.nio.file.Paths;8.import java.text.ParseException;9.import java.util.List;10.import java.util.concurrent.CountDownLatch;11.12.import org.apache.lucene.document.Document;13.import org.apache.lucene.document.Field;14.import org.apache.lucene.facet.FacetResult;15.import org.apache.lucene.facet.Facets;16.import org.apache.lucene.facet.FacetsCollector;17.import org.apache.lucene.facet.FacetsConfig;18.import org.apache.lucene.facet.taxonomy.FastTaxono myFacetCounts;19.import org.apache.lucene.facet.taxonomy.directory.Dir ectoryTaxonomyReader;20.import org.apache.lucene.facet.taxonomy.directory.Dir ectoryTaxonomyWriter;21.import org.apache.lucene.index.IndexOptions;22.import org.apache.lucene.index.IndexWriter;23.import org.apache.lucene.index.Term;24.import org.apache.lucene.search.IndexSearcher;25.import org.apache.lucene.search.MatchAllDocsQuery;26.import org.apache.lucene.search.Query;27.import org.apache.lucene.store.Directory;28.import org.apache.lucene.store.FSDirectory;29.import org.apache.lucene.store.RAMDirectory;30.31.import com.lucene.search.SearchUtil;32.33.34.public abstract class BaseIndex<T> implements Run nable{35./**36.* 父级索引路径37.*/38.private String parentIndexPath;39./**40.* 索引编写器41.*/42.private IndexWriter writer;43.private int subIndex;44./**45.* 主线程46.*/47.private final CountDownLatch countDownLatch1;48./**49.*工作线程50.*/51.private final CountDownLatch countDownLatch2;52./**53.* 对象列表54.*/55.private List<T> list;56./**57.* facet查询58.*/59.private String facet;60.protected final FacetsConfig config = new FacetsConf ig();61.protected final static String indexPath = "index1";62.protected final static DirectoryTaxonomyWriter taxo Writer;63.static{64.try {65.Directory directory = FSDirectory.open(Paths.get(inde xPath, new String[0]));66.taxoWriter = new DirectoryTaxonomyWriter(directory) ;67.} catch (IOException e) {68.throw new ExceptionInInitializerError("BaseIndex initi alizing error");69.}70.}71.public BaseIndex(IndexWriter writer,CountDownLatch countDownLatch1, CountDownLatch countDownLatch2,72.List<T> list, String facet){73.super();74.this.writer = writer;75.this.countDownLatch1 = countDownLatch1;76.this.countDownLatch2 = countDownLatch2;77.this.list = list;78.this.facet = facet;79.}80.public BaseIndex(String parentIndexPath, int subIndex ,81.CountDownLatch countDownLatch1, CountDownLatch countDownLatch2,82.List<T> list) {83.super();84.this.parentIndexPath = parentIndexPath;85.this.subIndex = subIndex;86.try {87.//多目录索引创建88.File file = new File(parentIndexPath+"/index"+subInd ex);89.if(!file.exists()){90.file.mkdir();91.}92.this.writer = IndexUtil.getIndexWriter(parentIndexPath +"/index"+subIndex, true);93.} catch (IOException e) {94.// TODO Auto-generated catch block95. e.printStackTrace();96.};97.this.subIndex = subIndex;98.this.countDownLatch1 = countDownLatch1;99.this.countDownLatch2 = countDownLatch2;100.this.list = list;101.}102.public BaseIndex(String path,CountDownLatch count DownLatch1, CountDownLatch countDownLatch2,103.List<T> list) {104.super();105.try {106.//单目录索引创建107.File file = new File(path);108.if(!file.exists()){109.file.mkdir();110.}111.this.writer = IndexUtil.getIndexWriter(path,true);112.} catch (IOException e) {113.// TODO Auto-generated catch block114. e.printStackTrace();115.};116.this.countDownLatch1 = countDownLatch1;117.this.countDownLatch2 = countDownLatch2;118.this.list = list;119.}120.121./**创建索引122.* @param writer123.* @param carSource124.* @param create125.* @throws IOException126.* @throws ParseException127.*/128.public abstract void indexDoc(IndexWriter writer,T t) throws Exception;129./**批量索引创建130.* @param writer131.* @param t132.* @throws Exception133.*/134.public void indexDocs(IndexWriter writer,List<T> t) th rows Exception{135.for (T t2 : t) {136.indexDoc(writer,t2);137.}138.}139./**带group的索引创建140.* @param writer141.* @param docs142.* @throws IOException143.*/144.public void indexDocsWithGroup(IndexWriter writer,S tring groupFieldName,String groupFieldValue,List<Document> docs) throws IOException{145.Field groupEndField = new Field(groupFieldName, gro upFieldValue, Field.Store.NO, Field.Index.NOT_ANALYZED);146.docs.get(docs.size()-1).add(groupEndField);147.//148.writer.updateDocuments(new Term(groupFieldName, groupFieldValue),docs);mit();150.writer.close();151.}152.@Override153.public void run() {154.try {155.countDownLatch1.await();156.System.out.println(writer);157.indexDocs(writer,list);158.} catch (InterruptedException e) {159.// TODO Auto-generated catch block160. e.printStackTrace();161.} catch (Exception e) {162.// TODO Auto-generated catch block163. e.printStackTrace();164.}finally{165.countDownLatch2.countDown();166.try {mit();168.writer.close();169.} catch (IOException e) {170.// TODO Auto-generated catch block171. e.printStackTrace();172.}173.}174.}175.}相应得,document的索引需要利用DirectoryTaxonomyWriter 来进行原有document的处理[java] view plain copy1.package com.lucene.index;2.3.import java.util.List;4.import java.util.concurrent.CountDownLatch;5.6.import org.apache.lucene.document.Document;7.import org.apache.lucene.document.Field;8.import org.apache.lucene.document.LongField;9.import org.apache.lucene.document.StringField;10.import org.apache.lucene.document.TextField;11.import org.apache.lucene.facet.FacetField;12.import org.apache.lucene.index.IndexWriter;13.import org.apache.lucene.index.IndexWriterConfig;14.import org.apache.lucene.index.Term;15.16.import com.lucene.bean.FileBean;17.18.public class FileBeanIndex extends BaseIndex<FileBe an>{19.private static String facet;20.21.public FileBeanIndex(IndexWriter writer, CountDownL atch countDownLatch12, CountDownLatch countDownLatch1,22.List<FileBean> fileBeans, String facet1) {23.super(writer, countDownLatch12, countDownLatch1, fi leBeans, facet);24.facet = facet1;25.}26.@Override27.public void indexDoc(IndexWriter writer, FileBean t) t hrows Exception {28.Document doc = new Document();29.String path = t.getPath();30.System.out.println(t.getPath());31.doc.add(new StringField("path", path, Field.Store.YES)) ;32.doc.add(new LongField("modified", t.getModified(), Fi eld.Store.YES));33.doc.add(new TextField("content", t.getContent(), Field. Store.YES));34.doc.add(new FacetField("filePath", new String[]{facet}) );35.//doc = config.build(taxoWriter,doc);36.if (writer.getConfig().getOpenMode() == IndexWriterC onfig.OpenMode.CREATE){37.//writer.addDocument(doc);38.writer.addDocument(this.config.build(taxoWriter, doc) );39.}else{40.writer.updateDocument(new Term("path", t.getPath()), this.config.build(taxoWriter, doc));41.}mit();43.}44.45.46.}测试facet功能的测试类:[java] view plain copy1.package com.lucene.search;2.3.import java.io.IOException;4.import java.nio.file.Paths;5.import java.util.ArrayList;6.import java.util.List;7.8.import org.apache.lucene.facet.FacetResult;9.import org.apache.lucene.facet.Facets;10.import org.apache.lucene.facet.FacetsCollector;11.import org.apache.lucene.facet.FacetsConfig;12.import belAndValue;13.import org.apache.lucene.facet.taxonomy.FastTaxono myFacetCounts;14.import org.apache.lucene.facet.taxonomy.TaxonomyR eader;15.import org.apache.lucene.facet.taxonomy.directory.Dir ectoryTaxonomyReader;16.import org.apache.lucene.index.DirectoryReader;17.import org.apache.lucene.search.IndexSearcher;18.import org.apache.lucene.search.MatchAllDocsQuery;19.import org.apache.lucene.search.Query;20.import org.apache.lucene.store.Directory;21.import org.apache.lucene.store.FSDirectory;22.import org.junit.Test;23.24.public class TestSearchFacet {25.public static Directory directory;26.public static Directory taxoDirectory;27.public static TaxonomyReader taxoReader;28.protected final static FacetsConfig config = new Face tsConfig();29.static {30.try {31.directory = FSDirectory.open(Paths.get("index", new S tring[0]));32.taxoDirectory = FSDirectory.open(Paths.get("index1", new String[0]));33.taxoReader = new DirectoryTaxonomyReader(taxoDire ctory);34.} catch (IOException e) {35.// TODO Auto-generated catch block36. e.printStackTrace();37.}38.}39.40.public static void testSearchFacet() {41.try {42.DirectoryReader indexReader = DirectoryReader.open( directory);43.IndexSearcher searcher = new IndexSearcher(indexRe ader);44.FacetsCollector fc = new FacetsCollector();45.FacetsCollector.search(searcher, new MatchAllDocsQu ery(), indexReader.maxDoc(), fc);46.Facets facets = new FastTaxonomyFacetCounts(taxoRe ader, config, fc);47.List<FacetResult> results =facets.getAllDims(100);48.for (FacetResult facetResult : results) {49.System.out.println(facetResult.dim);belAndValue[] values = belValues;51.for (LabelAndValue labelAndValue : values) {52.System.out.println("\t"+bel +" "+l abelAndValue.value);53.}54.55.}56.57.indexReader.close();58.taxoReader.close();59.} catch (IOException e) {60.// TODO Auto-generated catch block61. e.printStackTrace();62.}63.}64.65.public static void main(String[] args) {66.testSearchFacet();67.}68.69.}。
lucence 字典表数据结构

lucence 字典表数据结构探究一、介绍Lucene是一个全文检索引擎API,它提供了一个非常丰富的查询语言,并且非常快速和可扩展。
在Lucene中,字典表数据结构是其中一个非常关键且重要的组成部分。
本文将重点探讨和分析Lucene中的字典表数据结构,从深度和广度两个方面进行全面评估,并据此撰写一篇有价值的文章。
二、常见数据结构概述在Lucene中,字典表是一种用于存储词汇的数据结构。
它使用有序数组或有序链表存储,每个词和它的编号一一对应。
字典表的主要作用是将词汇映射为编号,方便后续的索引和检索。
常见的字典表数据结构包括有序数组、有序链表和trie树等。
1. 有序数组有序数组是一种非常简单且直观的字典表数据结构。
它将词汇按照字典顺序存储在数组中,并且可以通过二分查找等方法快速定位特定的词汇。
有序数组的优点是查询速度快,但插入和删除操作的效率较低。
2. 有序链表与有序数组相比,有序链表在插入和删除操作时具有更好的灵活性。
它可以通过链表节点的指针来维护词汇的顺序,并且在插入和删除时不需要进行整体的移动。
但是在查询过程中,由于需要顺序扫描链表,因此查询效率相对较低。
3. trie树trie树是一种特殊的字典表数据结构,它采用了前缀树的思想。
trie树可以非常高效地支持词汇的前缀匹配,因此在自动补全、拼写检查等场景中非常实用。
然而,trie树在空间利用上存在一定的浪费,且插入和删除操作的效率相对较低。
三、深度和广度的探讨从深度和广度的角度来探讨Lucene中的字典表数据结构,可以从以下几个方面展开讨论。
1. 深度在深度上,我们可以对每种数据结构的实现原理、查找算法、空间复杂度和时间复杂度等进行详细分析。
有序数组是如何通过二分查找来实现快速查找的;有序链表是如何通过指针来进行插入和删除操作的;trie树是如何通过前缀匹配来快速定位词汇的。
通过深度的探讨,可以让我们更加深入地理解每种数据结构的优缺点和适用场景。
Lucene简介(一)

Lucene简介(一)Lucene 是一个基于Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。
Lucene 目前是 Apache Jakarta 家族中的一个开源项目。
也是目前最为流行的基于 Java 开源全文检索工具包。
建立索引为了对文档进行索引,Lucene 提供了五个基础的类,他们分别是Document, Field, IndexWriter, Analyzer, Directory。
下面我们分别介绍一下这五个类的用途:(1)DocumentDocument 是用来描述文档的,这里的文档可以指一个 HTML 页面,一封电子邮件,或者是一个文本文件。
一个 Document 对象由多个 Field 对象组成的。
可以把一个 Document 对象想象成数据库中的一个记录,而每个 Field 对象就是记录的一个字段。
(2)FieldField 对象是用来描述一个文档的某个属性的,比如一封电子邮件的标题和内容可以用两个 Field 对象分别描述。
Field.Store.YES:存储字段值(未分词前的字段值)Field.Store.NO:不存储,存储与索引没有关系PRESS:压缩存储,用于长文本或二进制,但性能受损Field.Index.ANALYZED:分词建索引Field.Index.ANALYZED_NO_NORMS:分词建索引,但是Field的值不像通常那样被保存,而是只取一个byte,这样节约存储空间Field.Index.NOT_ANALYZED:不分词且索引Field.Index.NOT_ANALYZED_NO_NORMS:不分词建索引,Field的值去一个byte保存TermVector表示文档的条目(由一个Document和Field定位)和它们在当前文档中所出现的次数Field.TermVector.YES:为每个文档(Document)存储该字段的TermVectorField.TermVector.NO:不存储TermVectorField.TermVector.WITH_POSITIONS:存储位置Field.TermVector.WITH_OFFSETS:存储偏移量Field.TermVector.WITH_POSITIONS_OFFSETS:存储位置和偏移量(3)Analyzer在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由Analyzer 来做的。
一步一步跟我学习lucene(8)---lucene搜索之索引的查询原理和查询工具类

一步一步跟我学习lucene(8)---lucene搜索之索引的查询原理和查询工具类昨天我们了解了lucene搜索之IndexSearcher构建过程(/wuyinggui10000/article/details/4569866 7),对lucene的IndexSearcher有一个大体的了解,知道了怎么创建IndexSearcher,就要开始学会使用IndexSearcher进行索引的搜索,本节我们学习索引的查询原理和根据其相关原理写索引查询的工具类的编写;IndexSearcher常用方法IndexSearcher提供了几个常用的方法:•IndexSearcher.doc(int docID) 获取索引文件中的第n个索引存储的相关字段,返回为Document类型,可以据此读取document 中的Field.STORE.YES的字段;•IndexSearcher.doc(int docID, StoredFieldVisitor fieldVisitor) 获取StoredFieldVisitor指定的字段的document,StoredFieldVisitor定义如下[java] view plain copy1.StoredFieldVisitor visitor = new DocumentStoredFieldVisi tor(String... fields);•IndexSearcher.doc(int docID, Set<String> fieldsToLoad) 此方法同上边的IndexSearcher.doc(int docID, StoredFieldVisitor fieldVisitor) ,其实现如下图•IndexSearcher.count(Query query) 统计符合query条件的document个数•IndexSearcher.searchAfter(final ScoreDoc after, Queryquery, int numHits) 此方法会返回符合query查询条件的且在after 之后的numHits条记录;其实现原理为:先读取当前索引文件的最大数据条数limit,然后判断after是否为空和after对应的document的下标是否超出limit的限制,如果超出的话抛出非法的参数异常;设置读取的条数为numHits和limit中最小的(因为有超出最大条数的可能,避免超出限制而造成的异常)接下来创建一个CollectorManager类型的对象,该对象定义了要返回的T opDocs的个数,上一页的document的结尾(after),并且对查询结果进行分析合并最后调用search(query,manager)来查询结果•IndexSearcher.search(Query query, int n) 查询符合query条件的前n个记录•IndexSearcher.search(Query query, Collector results) 查询符合collector的记录,collector定义了分页等信息•IndexSearcher.search(Query query, int n,Sort sort, boolean doDocScores, boolean doMaxScore) 实现任意排序的查询,同时控制是否计算hit score和max score是否被计算在内,查询前n条符合query条件的document;•IndexSearcher.search(Query query, CollectorManager<C, T>collectorManager) 利用给定的collectorManager获取符合query 条件的结果,其执行流程如下:先判断是否有ExecutorService执行查询的任务,如果没有executor,IndexSearcher会在单个任务下进行查询操作;如果IndexSearcher有executor,则会由每个线程控制一部分索引的读取,而且查询的过程中采用的是future机制,此种方式是边读边往结果集里边追加数据,这种异步的处理机制也提升了效率,其执行过程如下:编码实践我中午的时候写了一个SearchUtil的工具类,里边添加了多目录查询和分页查询的功能,经测试可用,工具类和测试的代码如下:[java] view plain copy1.package com.lucene.search.util;2.3.import java.io.File;4.import java.io.IOException;5.import java.nio.file.Paths;6.import java.util.Set;7.import java.util.concurrent.ExecutorService;8.9.import org.apache.lucene.document.Document;10.import org.apache.lucene.index.DirectoryReader;11.import org.apache.lucene.index.IndexReader;12.import org.apache.lucene.index.MultiReader;13.import org.apache.lucene.search.BooleanQuery;14.import org.apache.lucene.search.IndexSearcher;15.import org.apache.lucene.search.Query;16.import org.apache.lucene.search.ScoreDoc;17.import org.apache.lucene.search.TopDocs;18.import org.apache.lucene.search.BooleanClause.Occur ;19.import org.apache.lucene.store.FSDirectory;20.21./**lucene索引查询工具类22.* @author lenovo23.*24.*/25.public class SearchUtil {26./**获取IndexSearcher对象27.* @param indexPath28.* @param service29.* @return30.* @throws IOException31.*/32.public static IndexSearcher getIndexSearcherByParent Path(String parentPath,ExecutorService service) throws IOExcep tion{33.MultiReader reader = null;34.//设置35.try {36.File[] files = new File(parentPath).listFiles();37.IndexReader[] readers = new IndexReader[files.length] ;38.for (int i = 0 ; i < files.length ; i ++) {39.readers[i] = DirectoryReader.open(FSDirectory.open(P aths.get(files[i].getPath(), new String[0])));40.}41.reader = new MultiReader(readers);42.} catch (IOException e) {43.// TODO Auto-generated catch block44. e.printStackTrace();45.}46.return new IndexSearcher(reader,service);47.}48./**根据索引路径获取IndexReader49.* @param indexPath50.* @return51.* @throws IOException52.*/53.public static DirectoryReader getIndexReader(String i ndexPath) throws IOException{54.return DirectoryReader.open(FSDirectory.open(Paths.g et(indexPath, new String[0])));55.}56./**根据索引路径获取IndexSearcher57.* @param indexPath58.* @param service59.* @return60.* @throws IOException61.*/62.public static IndexSearcher getIndexSearcherByIndex Path(String indexPath,ExecutorService service) throws IOExcepti on{63.IndexReader reader = getIndexReader(indexPath);64.return new IndexSearcher(reader,service);65.}66.67./**如果索引目录会有变更用此方法获取新的IndexSearcher这种方式会占用较少的资源68.* @param oldSearcher69.* @param service70.* @return71.* @throws IOException72.*/73.public static IndexSearcher getIndexSearcherOpenIfC hanged(IndexSearcher oldSearcher,ExecutorService service) thr ows IOException{74.DirectoryReader reader = (DirectoryReader) oldSearch er.getIndexReader();75.DirectoryReader newReader = DirectoryReader.openIf Changed(reader);76.return new IndexSearcher(newReader, service);77.}78.79./**多条件查询类似于sql in80.* @param querys81.* @return82.*/83.public static Query getMultiQueryLikeSqlIn(Query ...querys){84.BooleanQuery query = new BooleanQuery();85.for (Query subQuery : querys) {86.query.add(subQuery,Occur.SHOULD);87.}88.return query;89.}90.91./**多条件查询类似于sql and92.* @param querys93.* @return94.*/95.public static Query getMultiQueryLikeSqlAnd(Query .. . querys){96.BooleanQuery query = new BooleanQuery();97.for (Query subQuery : querys) {98.query.add(subQuery,Occur.MUST);99.}100.return query;101.}102./**根据IndexSearcher和docID获取默认的document 103.* @param searcher104.* @param docID105.* @return106.* @throws IOException107.*/108.public static Document getDefaultFullDocument(Inde xSearcher searcher,int docID) throws IOException{109.return searcher.doc(docID);110.}111./**根据IndexSearcher和docID112.* @param searcher113.* @param docID114.* @param listField115.* @return116.* @throws IOException117.*/118.public static Document getDocumentByListField(Inde xSearcher searcher,int docID,Set<String> listField) throws IOExc eption{119.return searcher.doc(docID, listField);120.}121.122./**分页查询123.* @param page 当前页数124.* @param perPage 每页显示条数125.* @param searcher searcher查询器126.* @param query 查询条件127.* @return128.* @throws IOException129.*/130.public static TopDocs getScoreDocsByPerPage(int pa ge,int perPage,IndexSearcher searcher,Query query) throws IOE xception{131.TopDocs result = null;132.if(query == null){133.System.out.println(" Query is null return null ");134.return null;135.}136.ScoreDoc before = null;137.if(page != 1){138.TopDocs docsBefore = searcher.search(query, (page-1)*perPage);139.ScoreDoc[] scoreDocs = docsBefore.scoreDocs;140.if(scoreDocs.length > 0){141.before = scoreDocs[scoreDocs.length - 1];142.}143.}144.result = searcher.searchAfter(before, query, perPage);145.return result;146.}147.public static TopDocs getScoreDocs(IndexSearcher se archer,Query query) throws IOException{148.TopDocs docs = searcher.search(query, getMaxDocId(s earcher));149.return docs;150.}151./**统计document的数量,此方法等同于matchAllDocsQuery查询152.* @param searcher153.* @return154.*/155.public static int getMaxDocId(IndexSearcher searcher ){156.return searcher.getIndexReader().maxDoc();157.}158.159.}相关测试代码如下:[java] view plain copy1.package com.lucene.index.test;2.3.import java.io.IOException;4.import java.util.HashSet;5.import java.util.Set;6.import java.util.concurrent.ExecutorService;7.import java.util.concurrent.Executors;8.9.import org.apache.lucene.document.Document;10.import org.apache.lucene.index.Term;11.import org.apache.lucene.search.IndexSearcher;12.import org.apache.lucene.search.Query;13.import org.apache.lucene.search.ScoreDoc;14.import org.apache.lucene.search.TermQuery;15.import org.apache.lucene.search.TopDocs;16.17.import com.lucene.search.util.SearchUtil;18.19.public class TestSearch {20.public static void main(String[] args) {21.ExecutorService service = Executors.newCachedThrea dPool();22.try {23.24.IndexSearcher searcher = SearchUtil.getIndexSearcher ByParentPath("index",service);25.System.out.println(SearchUtil.getMaxDocId(searcher));26.Term term = new Term("content", "lucene");27.Query query = new TermQuery(term);28.TopDocs docs = SearchUtil.getScoreDocsByPerPage(2, 20, searcher, query);29.ScoreDoc[] scoreDocs = docs.scoreDocs;30.System.out.println("所有的数据总数为:"+docs.totalHits);31.System.out.println("本页查询到的总数为:"+scoreDocs.length);32.for (ScoreDoc scoreDoc : scoreDocs) {33.Document doc = SearchUtil.getDefaultFullDocument(s earcher, scoreDoc.doc);34.//System.out.println(doc);35.}36.System.out.println("\n\n");37.TopDocs docsAll = SearchUtil.getScoreDocs(searcher, query);38.Set<String> fieldSet = new HashSet<String>();39.fieldSet.add("path");40.fieldSet.add("modified");41.for (int i = 0 ; i < 20 ; i ++) {42.Document doc = SearchUtil.getDocumentByListField(s earcher, docsAll.scoreDocs[i].doc,fieldSet);43.System.out.println(doc);44.}45.46.} catch (IOException e) {47.// TODO Auto-generated catch block48. e.printStackTrace();49.}finally{50.service.shutdownNow();51.}52.}53.54.}。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Powered By Lucene
/jakarta-lucene/PoweredBy
Part Three:Lucene In Action! Three: Action!
几个重要概念
analyzer Analyzer是分析器,它的作用是把一个字符串按某种规则划 分成一个个词语,并去除其中的无效词语。 document 用户提供的源是一条条记录,它们可以是文本文件、字符串 或者数据库表的一条记录等等。一条记录经过索引之后,就是以一个 Document的形式存储在索引文件中的。用户进行搜索,也是以 Document列表的形式返回。 field 一个Document可以包含多个信息域,例如一篇文章可以包含 “标题”、“正文” 等信息域,这些信息域就是通过Field在 Document中存储的。 Field有两个属性可选:存储和索引。通过存储属性你可以 控制是否对这个Field进行存储;通过索引属性你可以控制是否对该 Field进行索引。
并发访问
本质
输入:若干 字符串
提供:全文 搜索服务
输出:搜索 的关键词在 哪
来一点想象:
站内新闻索引,建立资料库 高效的对一个数据库进行全文检索 利用其扩展接口,做自己的搜索引擎 ……
Performance
250万记录,300M左右文本,生成索引380M左 右,800线程下平均处理时间300ms。 37000记录,索引数据库中的两个varchar字段, 索引文件2.6M,800线程下平均处理时间1.5ms。
Core的组成 Core的组成
search Search包含了从索引中搜索结果的各种类,例如刚才说的各 种Query类,包括TermQuery、BooleanQuery等就在这个包里。 store Store包含了索引的存储类,例如Directory定义了索引文件 的存储结构,FSDirectory为存储在文件中的索引,RAMDirectory为 存储在内存中的索引,MmapDirectory为使用内存映射的索引。 util Util包含一些公共工具类,例如时间和字符串之间的转换工 具。
SandBox中提供的Analyzer
◦ ChineseAnalyzer ◦ CJKAnalyzer
/java/2_3_2/lucene-sandbox/index.html
中科院ICTCLAS
◦
imdict-chinese-analyzer是 imdict智能词典的智能中文分词模 块,作者高小平,算法基于隐马尔科夫模型(Hidden Markov Model, HMM),是中国科学院计算技术研究所的ictclas中文分词程序的重 新实现(基于Java),可以直接为lucene搜索引擎提供中文分词支 持。
Core的组成 Core的组成
对于外部应用来说, 索引模块(index)、检索 模块(search)是主要的 外部应用入口
Core的组成 Core的组成
analysis Analysis包含一些内建的分析器,例如按空白字符分词的 WhitespaceAnalyzer,添加了stopwrod过滤的StopAnalyzer,最常用 的是StandardAnalyzer。 document Document包含文档的数据结构,例如Document类定义了存储 文档的数据结构,Field类定义了Document的一个域。 index Index包含了索引的读写类,例如对索引文件的segment进行 写、合并、优化的IndexWriter类和对索引进行读取和删除操作的 IndexReader类。 queryParser QueryParser包含了解析查询语句的类。Lucene有很多种 Query类,它们都继承自Query,执行各种特殊的查询,QueryParser 的作用就是解析查询语句,按顺序调用各种 Query类查找出结果。
Lucene
Nutch
网络爬虫 和Web相 关的一些
Part Two:Lucene能做什么 Two:Lucene能做什么
Lucene的创新 Lucene的创新
Lucene 其他开源全文检索系统 可以进行增量的索引(Append),可以 很多系统只支持批量的索引, 增量索引和批 对于大量数据进行批量索引,并且接 有时数据源有一点增加也需要 口设计用于优化批量索引和小批量的 量索引 重建索引。 增量索引。 Lucene没有定义具体的数据源,而是 一个文档的结构,因此可以非常灵活 很多系统只针对网页,缺乏其 数据源 的适应各种应用(只要前端有合适的 他格式文档的灵活性。 转换器把数据源转换成相应结构), Lucene的文档是由多个字段组成的, 甚至可以控制那些字段需要进行索引, 那些字段不需要索引,近一步索引的 字段也分为需要分词和不需要分词的 缺乏通用性,往往将文档整个 索引内容抓取 类型: 索引了 需要进行分词的索引,比如:标题, 文章内容字段 不需要进行分词的索引,比如:作 者/日期字段
演示
More…
定制优化自己的Analyzer 处理多种文档格式(PDF、doc、html etc.) Lucene Port:Perl,Python,C++,.Net…etc. SandBox ……
Thank you!
Q&A
Reference
[1]征服Ajax+Lucene构建搜索引擎 作者: 李刚 出版社: 人民邮电出 版社 [2]Lucene漫谈—入门与介绍 /blog/186861 [3] Lucene:基于Java的全文检索引擎简介 作者:车东 /tech/lucene.html [4]Lucene in action 作者: Otis Gospodnetic,Erik Hatcher
简单实践1--建立索引 简单实践1--建立索引
建立索引的最简单的代码
简单实践2--尝试搜索 简单实践2--尝试搜索
尝试搜索的最简单的代码
简单实践3--Hack 简单实践3--Hack The Analyzer
内置的StandardAnalyzer对于中英文字符流的实际处理测试
简单实践4--中文分词改进 简单实践4--中文分词改进
◦ /
Part Four:一个简单的搜索引擎 Four:一个简单的搜索引擎
Really Simple
三个文件:
◦ Constants.java—用静态变量来存放路径 ◦ LuceneIndex.java—用来建立索引 ◦ LuceneSearch.java—用来进行搜索
工作方式
源字符串 经过analyzer处 理 将信息写入 Document的各 Field
经过analyzer处 理
提供搜索关键 词
建立索引并存 储
搜索索引找出 Document
从Document提 取所需Field
Lucene的结构 Lucene的结构
Lucene:
Core--core是lucene稳定的核心部分 Sandbox--sandbox包含了一些附加功能,例 如各种分析器。
History
贡献者:
Doug Cutting是一位资深全文索引/检索专家,曾经是V-Twin搜 索引擎(Apple的Copland操作系统的成就之一)的主要开发者。作为 Lucene和Nutch两大Apach Open Source Project的始创人(其实还有 Lucy, Lucene4C 和Hadoop等相关子项目),Doug Cutting 一直为搜 索引擎的开发人员所关注。他终于在为Yahoo以Contractor的身份工 作4年后,于06年正式以Employee的身份加入Yahoo。他贡献出的 Lucene的目标是为各种中小型应用程序加入全文检索功能。
几个重要概念
term term是搜索的最小单位,它表示文档的一个词语,term由两 部分组成:它表示的词语和这个词语所出现的field。 tocken tocken是term的一次出现,它包含trem文本和相应的起止偏 移,以及一个类型字符串。一句话中可以出现多次相同的词语,它们 都用同一个term表示,但是用不同的tocken,每个tocken标记该词语 出现的地方。 segment 添加索引时并不是每个document都马上添加到同一个索引文 件,它们首先被写入到不同的小文件,然后再合并成一个大索引文件, 这里每个小文件都是一个segment。
Keywords
Lucene: 1、搜索引擎 2、全文信息检索 3、非完整应用 4、工具包 5、基于Java 6、开源项目
Summary
Apache Lucene是一个基于Java全文搜索引擎, 利用它可以轻易地为Java软件加入全文搜寻功能。 Lucene不是一个完整的搜索应用程序,而是一个 基于 Java 的全文信息检索工具包,为你的应用程 序提供索引和搜索功能,可以方便的嵌入到各种应 用中实现针对应用的全文索引/检索功能。 Lucene 目前是 Apache Jakarta 家族中的一个 开源项目。也是目前最为流行的基于 Java 开源全 文检索工具包。
发展历程:
最先发布在作者自己的,后来发布在Source Forge,2001年年底成为APACHE基金会jakarta的一个子项目: /lucene/
Tip:
Lucene VS Nutch
Lucene是一个提供全文文本搜索的函数库,它不是一个应用软件。 它提供很多API函数让你可以运用到各种实际应用程序中。 Nutch是一个建立在Lucene核心之上的Web搜索的实现,它是一个真正 的应用程序。
Lucene漫谈 Lucene漫谈
--入门及介绍
ZekChang Twitter:@ZekChang Twitter:@ZekChang Mail:zekchang@
Outline
Lucene是什么? Lucene能做什么? Lucene怎样做到这些? 一个非常简单的搜索引擎
Part One:什么是Lucene One:什么是L的创新