VC-mfc中使用反射内存卡
VC++学习:分析MFC中的映射

VC++学习:分析MFC中的映射作者:jiangsheng/CSDN条件查找映射MFC中大量使用了BEGIN_XXX_MAP这样的宏,以及映射进行查找优化,例如消息映射,OLE命令映射,以及接口等等。
每个映射包含一个指向基类的映射的指针。
这样,当一个类需要根据一定的条件查找一个对象时,它会查找本类对象,如果没有找到,那么会查找基类,直到根基类。
这类查找包含Windows 消息,命令,事件和OLE命令的分发,和对象实现的接口的查询等等。
下面是函数BOOL CWnd::OnWndMsg(UINT message, WPARAM wParam, LPARAM lParam, LRESUL T* pResult)的部分代码,演示了如何根据消息的ID查找处理函数。
const AFX_MSGMAP* pMessageMap; pMessageMap = GetMessageMap();UINT iHash; iHash = (LOWORD((DWORD_PTR)pMessageMap) ^ message) & (iHashMax-1); AfxLockGlobals(CRIT_WINMSGCACHE);AFX_MSG_CACHE* pMsgCache; pMsgCache = &_afxMsgCache[iHash];const AFX_MSGMAP_ENTRY* lpEntry;if (message == pMsgCache->nMsg && pMessageMap == pMsgCache->pMessageMap){// cache hitlpEntry = pMsgCache->lpEntry;AfxUnlockGlobals(CRIT_WINMSGCACHE);if (lpEntry == NULL)return FALSE;// cache hit, and it needs to be handledif (message < 0xC000)goto LDispatch;elsegoto LDispatchRegistered;}else{// not in cache, look for itpMsgCache->nMsg = message;pMsgCache->pMessageMap = pMessageMap;#ifdef _AFXDLLfor (/* pMessageMap already init'ed */; pMessageMap->pfnGetBaseMap != NULL;pMessageMap = (*pMessageMap->pfnGetBaseMap)())#elsefor (/* pMessageMap already init'ed */; pMessageMap != NULL;pMessageMap = pMessageMap->pBaseMap)#endif{// Note: catch not so common but fatal mistake!!// BEGIN_MESSAGE_MAP(CMyWnd, CMyWnd)#ifdef _AFXDLLASSERT(pMessageMap != (*pMessageMap->pfnGetBaseMap)());#elseASSERT(pMessageMap != pMessageMap->pBaseMap);#endifif (message < 0xC000){// constant window messageif ((lpEntry = AfxFindMessageEntry(pMessageMap->lpEntries,message, 0, 0)) != NULL){pMsgCache->lpEntry = lpEntry;AfxUnlockGlobals(CRIT_WINMSGCACHE);goto LDispatch;}}else{// registered windows messagelpEntry = pMessageMap->lpEntries;while ((lpEntry = AfxFindMessageEntry(lpEntry, 0xC000, 0, 0)) != NULL) {UINT* pnID = (UINT*)(lpEntry->nSig);ASSERT(*pnID >= 0xC000 || *pnID == 0);// must be successfully registeredif (*pnID == message){pMsgCache->lpEntry = lpEntry;AfxUnlockGlobals(CRIT_WINMSGCACHE);goto LDispatchRegistered;}lpEntry++; // keep looking past this one}}}pMsgCache->lpEntry = NULL;AfxUnlockGlobals(CRIT_WINMSGCACHE);return FALSE;}LDispatch:注意对查找结果的缓存可以提高查找的效率。
反射内存简介

反射内存简介内部编号:(YUUT-TBBY-MMUT-URRUY-UOOY-DBUYI-0128)反射内存网络(RFM网络)是基于环状/星状、高速复制的共享内存网络。
它支持不同总线结构的多计算机系统,并且可以使用不同的操作系统来共享高速的,稳定速率的实时数据。
反射内存可广泛用于各种领域,例如实时的飞行仿真器、核电站仿真器、电讯、高速过程控制(轧钢厂和制铝厂)、高速测试和测量以及军事系统。
与那些需要为附加的软件开发时间,测试,维护,文档,以及额外的CPU要求提供开销的传统的连接方法相比,RFM产品的网络提供了性价比极为优越的高性能的选择。
反射内存的优点:■ 高速的、基于2.12G波特率的网络,最大传输速率可达174Mbyte/s;■ 简单易用;■ 与操作系统和处理器无关;■ 彻底省去软件开发开销和周期;■ 可以实现实时连接的稳定的数据传输;■ 可以与通用的计算机和总线连接;■ 比标准通信和技术更为优越;■ 极短的数据传输延迟;■ 简单的软件,较低的管理费用和较高的抗干扰能力;■ 节点间距离可达10公里(单模)/300米(多模)。
反射内存实时网的特点VMIC反射内存是一种通过局域网在互连的计算机间提供高效的数据传输的技术,强实时网络设计人员已经越来越多地采用这种技术。
VMIC反射内存实时局域网的概念十分简单,就是设计一种网络内存板,在分布系统中实现内存至内存的通信,并且没有软件开销。
每台结点机上插一块反射内存卡,卡上带有双口内存,各层软件既可以读也可以写这些内存,当数据被写入一台机器的反射内存卡的内存中后,反射内存卡自动地通过光纤传输到其他连在网络上的反射内存卡的内存里,通常,只需几百纳秒的时间延迟,所有的反射内存卡上的内存将写入同样的内容。
而各成员在访问数据时,只要访问本地的反射内存卡中的内存即可。
VMIC反射内存具有以下主要特点:(1)高速度和高性能VMIC5565系列,传输速度达到174M字节/秒。
反射内存卡系统结构与使用

反射内存卡系统结构与使用反射内存卡基于PCI 接口,是反射内存实时光纤网络产品系列中的一个。
两个以上的反射内存卡,或反射内存卡系列中的它板卡可以用标准光纤线连接组成反射内存网,反射内存网络中的每个板卡被称做一个“节点”。
反射内存卡可以在使用在不同的体系结构和不同的操作系统的计算机,工作站,PLC 和其它嵌入式控制器中进行实时共享数据。
5565系统反射内存卡快速、灵活并且容易操作。
一个数据写到内存(SDRAM)后该数据被传输到所有的网络上板卡的内存中。
板载的电路自动进行数据传输,所有其它节点的数据更新都不需要CPU 的参与。
经典的VMIPCI-5565 反射内存卡包括一组在PLX 芯片内的控制寄存器和一组FPGA 内的RFM 控制寄存器。
因为这两组寄存器从物理上分布在两个独立的器件上,通过两个不同的内存区域访问。
相反,反射内存卡的两组寄存器在同一个FPGA 内。
两组寄存器可以被组合。
但是为了保证软件连续性和向后兼容,两组寄存器继续像VMIPCI-5565 中一样保持分离。
此外,个别内部寄存器的位功能,在适用的情况下,仍然是兼容的。
反射内存卡反射内存只包括一个DMA 通道。
射内存网中的每个反射内存节点(任何5565 反射内存卡)以菊花链的形式用光纤线跳线互联。
第一块卡的发送必须连接到第二块卡的接收端,第二块卡的发送端连接到第三块卡的接收端,以此类推,直到再连接到第一块卡的接收端完成一个完整的环形连接。
也可以将所有节点连接到一个或多个ACC-5595 反射内存HUB,每个节接收和发送都必须连接,如果没有检测到光信号或失去同步反射内存卡RFM-5565 将不会发送数据包(例如光纤线已损坏)。
反射内存网中每个节点的节点号必须为一,节点号通过板上的拨码开关S2 进行设置,任何两个节点不能有设置成同一个节点号,每个板卡的节点号可以在通过NODEID 进行读取显示,节点号的顺序并不重要。
主系统对反射内存卡的板载SDRAM 的写操作后,反射内内卡的硬件检测电路将自动发起一个整个反射内存网的数据传输动作。
反射内存卡原理

反射内存卡原理
反射内存卡是一种使用反射原理来传输数据的存储设备。
它采用光纤
技术,利用光的反射来传输数据,类似于激光光盘的读写原理。
反射内存卡由一个光学读写头和一个多点触摸屏组成。
当用户需要存
储数据时,将数据输入反射内存卡中,它会被转化成由光学读写头发出的
激光光束。
光束会在反射内存卡上反弹,并在光学读写头上形成一个图案。
这个图案代表着存储的数据,然后被感应到并且被电子系统保存起来。
当需要读取数据时,反射内存卡会通过触摸屏显示数据,并且将读取
光束的光反射回光学读写头。
然后,读写头会将反射回来的光束转化为数据,并将其通过电子系统保存或者传输。
这种原理的优势是光线反射的速度非常快,而且反射内存卡能够储存
远大于普通存储媒介的数据,同时还能够更快地读取和写入数据。
但反射
内存卡的制造成本较高,因此在市场上并不常见。
MFC问题分析及解决方法

【文件名称】MFC分析及解决方法【项目代号】经验总结【拟制】康宗学【时间】2011-04-02【评审】【时间】目录1. Visual C++/MFC 简介 (3)2.CDC双缓冲方法浅析 (4)3.各类型变量之间的转换 (7)4.VS2005之后的C++中char 转wchar_t 及wchar_t转char的方法 (9)1. Visual C++/MFC 简介学习MFC,首先要对Windows API有一定的了解,否则无法深入学习MFC。
至少要知道Windows对程序员来说意味着什么,它能完成什么工作,它的一些常用数据结构等。
另一点是不要过分依赖于Wizards。
Wizards能做许多工作,但同时掩饰了太多的细节。
应当看看AppWizard和ClassWizard为你所做的工作。
在mainfrm.cpp 中运行调试器来观察一下MFC运行的流程。
除非你理解了生成的代码的含义,否则无法了解程序是如何运行。
还有很重要的一点就是要学会抽象的把握问题,不求甚解。
许多人一开始学习Visual C++就试图了解整个MFC类库,实际上那几乎是不可能的。
一般的学习方法是,先大体上对MFC有个了解,知道它的概念、组成、基本约定等。
从最简单的类入手,由浅入深,循序渐进、日积月累的学习。
一开始使用MFC提供的类时,只需要知道它的一些常用的方法、外部接口,不必要去了解它的细节和内部实现,把它当做一个模块或者说黑盒子来用,这就是一种抽象的学习方法。
在学到一定程度时,再可以深入研究,采用继承的方法对原有的类的行为进行修改和扩充,派生出自己所需的类。
学习MFC,最重要的一点是理解和使用MFC类库,而不是记忆。
下面简单介绍一下MFC的主要构成。
总的来说,MFC可分为两个主要部分:(1)基础类(2)宏和全程函数。
MFC基础类MFC中的类按功能来分可划分为以下几类:基类;应用程序框架类 *应用程序类 *命令相关类文档/视类 *线程类可视对象类窗口类视类对话框类 *属性表控制类菜单类 *设备描述表绘画对象类通用类文件诊断异常收集模板收集其他支持类OLE2类OLE基类OLE可视编辑包装程序类OLE 可视编辑服务器程序类OLE数据传输类OLE对话框类其他OLE类数据库类有* 的为一开始在项目工作区的class中能够就看得见的宏和全局函数若某个函数或变量不是某个类的一个成员,那么它是一个全程函数或变量。
MFC控件使用方法

MFC控件使用方法VC2012下MFC程序各控件的常用方法分类:vc控件2013-02-16 16:32 94人阅读评论(0) 收藏举报一下控件的用法全部在VC2012下调试通过,特发文收藏(部分内容来自或参考自网络):Static Text:将ID号改成唯一的一个,如:IDC_XX,然后进一次类向导点确定产生这个ID,之后更改Caption属性:GetDlgItem(IDC_XX)->SetWindowText(L"dsgdhfgdffd");设置字体:CFont *pFont= new CFont;pFont->CreatePointFont(120,_T("华文行楷"));GetDlgItem(IDC_XX)->SetFont(pFont);Edit Control:设置文本:SetDlgItemT ext(IDC_XX,L"iuewurebfdjf");获取所有输入:建立类向导创建一个成员变量(假设是shuru1,shuru2……)类型选value,变量类型任选。
UpdateData(true);GetDlgItem(IDC_XX)->SetWindowText(shuru1);第一句更新所有建立了变量的对话框组件,获取输入的值。
第二句将前面的IDC_XX的静态文本内容改为shuru1输入的内容。
若类型选用control:1.设置只读属性:shuru1.SetReadOnly(true);2.判断edit中光标状态并得到选中内容(richedit同样适用)int nStart,nEnd;CString strTemp;shuru1.GetSel(nStart,nEnd);if(nStart== nEnd){strTemp.Format(_T("光标在%d" ),nStart);AfxMessageBox(strTemp);}else{//得到edit选中的内容shuru1.GetWindowText(strTemp);strTemp= strTemp.Mid(nStart,nEnd-nStart);AfxMessageBox(strTemp);}其中nStart和nEnd分别表示光标的起始和终止位置,从0开始。
GE反射内存卡基本资料

连接方式
工作环境
电源:+3.3VDC,最大1.5A。 工作温度:0到65摄氏度,存储温度:-40到 85摄氏度 相对湿度:20%到80%
特性 板载128Mbyte内存 网络传输高速,实时,确定 高速光纤网络波特率可达2.125G 低延迟率:节点间百纳秒级延迟 数据可以在256个独立系统(节点)间共享 与操作系统,处理器和总线方式无关 传输距离:多模最高300米,单模可达10公里 网络中断能力–点到点或广播中断 在PCI, PMC, CPCI及VME平台间数据可自由进行交换 支持PCI64位66M传输,支持3.3或5V总线电平。 错误检测功能 冗余传输模式 数据包长度为4到64BYTES 两个独立的DMA通道 支持DMA和PIO模式传输 节点间数据传输过程无需CPU参与,易于使用 支持WindowsNT,Windows 2000,VxWorks和Linux等OS PCI总线兼容 PCI-5565
GE系类---PCI5565反射内存卡 基本资料整理
Hale Waihona Puke 2014.8.20工作原理
特性
连接方式
工作环境
工作原理 反射内存网主要是由反射内存卡通过光纤连接而成的,网络上 的每台计算机插入一块。反射内存卡形成各个节点,而每个节 点的网络内存卡上的存储器中都有网络内存网上其它节点的共 享数据拷贝。反射内存卡可以插在多种总线的主板上,如VME、 PCI、CompactPCI、PMC接口等。每个反射内存卡都占有一 段内存地址,网上任何计算机向本地反射内存卡写数据时,该 数据和相应内存地址被广播到网上所有其他反射内存卡并存储 在相同的位置。 所以计算机将数据写入其本地反射内存卡后的,极短时间内, 网上所有计算机都可以访问这个新数据。反射内存卡使用简单 的读写方式,反射内存网上的数据传输是纯硬件操作,不需要 考虑网络的通信协议,软件上只需要几行代码就可完成对网络 内存卡的读、写操作,因此它与以太网等其他传统网络相比具 有更低的数据传输延迟、更快的传输速度,更简单灵活的使用 操作,可以满足实时系统快速反应周期的要求,而采用其他网 络就很难满足这种要求。
MFC的消息反射机制

MFC的消息反射机制1、消息反射解释: ⽗窗⼝将⼦窗⼝发给它的通知消息,⾸先反射回⼦窗⼝进⾏处理(即给⼦窗⼝⼀个机会,让⼦窗⼝处理此消息),这样通知消息就有机会能被⼦窗⼝⾃⾝进⾏处理。
2、MFC中引⼊消息反射的原因: 在Windows的消息处理中,⼦窗⼝的发给其⽗窗⼝的通知消息只能由其⽗窗⼝进⾏处理,这使得⼦窗⼝的⾃⾝能动性⼤⼤降低(你想,它连改变⾃⼰的背景⾊,处理⼀个⾃⾝滚动问题都要其⽗窗⼝来完成),为了解决这个问题,在MFC中引⼊了反射消息 “Reflect Message”的概念,进⾏消息反射,可以使得控制⼦窗⼝能够⾃⾏处理与⾃⾝相关的⼀些消息,增强了封装性,从⽽提⾼了控制⼦窗⼝的可重⽤性。
消息反射的处理流程(不考虑OLE控制)⼀、消息反射处理流程图: 1、⽗窗⼝收到控制⼦窗⼝发来的通知消息后,调⽤它的虚函数CWnd::OnNotify.CWnd::OnNotify()主体部分:{//此时,hWndCtrl,为发送窗⼝,即⼦窗⼝的窗⼝句柄if (ReflectLastMsg(hWndCtrl, pResult))return TRUE; // ⼦窗⼝已处理了此消息AFX_NOTIFY notify;notify.pResult = pResult;notify.pNMHDR = pNMHDR;return OnCmdMsg(nID, MAKELONG(nCode, WM_NOTIFY), ¬ify, NULL);} 分析:⾸先,调⽤ReflectLastMsg(hCtrlChildWnd,...)给⼦窗⼝⼀个⾃⾝处理的机会,将消息反射给⼦窗⼝处理,函数返回 TRUE,表明⼦窗⼝处理了此消息。
反之,表⽰⼦窗⼝未处理此消息,此时,调⽤OnCmdMsg(...)由⽗窗⼝进⾏通常的处理。
2、ReflectLastMsg中: 主要是调⽤发送窗⼝的SendChildNotifyLastMsg(...)。
=024=反射内存的相关安装和测试

文档编号:HL2M -2010-024HL2M 控制系统项目(二十四)反射内存的相关安装和测试核工业西南物理研究院106室控制系统研发课题组总页数9 撰稿 夏 凡 赵 丽 版次 1.0 工作起止日期 2010-1-20至2010-1-28S W IP2010年HL2M控制系统项目目录一、硬件安装与连接 (1)二、Windows下的测试 (1)1、驱动安装与连接测试 (1)2、单台PC读写测试 (2)3、点对点读写测试 (2)二、Linux下的编译和测试 (3)1、下载linux驱动程序包 (3)2、安装正确的linux内核版本 (3)3、修改build指向的目录 (4)4、修改两个文件 (5)5、编译 (5)6、安装驱动程序 (5)7、运行诊断程序 (6)一、硬件安装与连接硬件包括两张VMICI5565卡,Hub5595一台。
尾纤两根。
厂家设定的板卡NodeID都为0X00,改变5565板上跳线的位置,使卡的NodeID不重复。
网路连接如下图所示。
二、Windows下的测试1、驱动安装与连接测试在两台Windows操作系统计算机上正确安装VMIC5565卡,连接好光纤;重新启动操作系统,操作系统发现新硬件;将文件夹162-000447-940中PMC5565.sys驱动文件添加给新发现的硬件,完成驱动安装。
板卡和Hub连接和工作时,Status,SIG.DET,OWN.Data状态灯显示正常。
运行文件夹中提供的Setup.exe程序,安装RFM2g Util程序,在两台PC 机的控制台模式下,运行RFM2g Util程序,键入“1”,打开VMIC5565卡。
获取板级ID和节点ID,通过checkring, 来检查两张板卡间的通讯是否正常。
2、单台PC读写测试通过运行performance命令,测试本地读写得到的带宽和每秒读写次数,这个指标与计算机平台的配置和性能有关系。
其中一台测试结果如下所示, 其中,IOps表示每秒读写次数,MBps为带宽。
(整理)反射内存卡资料整理.

result = RFM2gRead( Handle, OFFSET_2, (void *)inbuffer, BUFFER_SIZE*4);
//关闭设备
RFM2gClose( &Handle );
//通用错误处理
if( result != RFM2G_SUCCESS )
#define OFFSET_1 0x1000//写数据起始位置4k
#define OFFSET_2 0x2000//读数据起始位置8k
#define TIMEOUT 60000//超时时间60s
#define DEVICE_PREFIX "\\\\.\\rfm2g"//win系统的PCI设备名前缀
printf ("0x00000000\n");
break;
case 0x00010000:
printf ("0x04000000\n");
break;
case 0x00020000:
printf ("0x08000000\n");
break;
case 0x00030000:
printf ("0x0c000000\n");
printf (" devfn 0x%08x\n", Config.PciConfig.devfn);
printf (" revision 0x%02x\n", Config.PciConfig.revision);
printf (" rfm2gOrBase 0x%08x\n", Config.PciConfig.rfm2gOrBase);
使用MFC读取大文件

// 将文件数据映射到进程的地址空间
PBYTE pbFile = (PBYTE)MapViewOfFile(hFileMapping,
FILE_MAP_ALL_ACCESS,
(DWORD)(qwFileOffset>>32), (DWORD)(qwFileOffset&0xFFFFFFFF), dwBytesInBlock);
DWORD dwCreationDisposition,
DWORD dwFlagsAndAttributes,
HANDLE hTemplateFile);
函数CreateFile()即使是在普通的文件操作时也经常用来创建、打开文件,在处理内存映射文件时,该函数来创建/打开一个文件内核对象,并将其句柄返回,在调用该函数时需要根据是否需要数据读写和文件的共享方式来设置参数dwDesiredAccess和dwShareMode,错误的参数设置将会导致相应操作时的失败。
VC读取大文件
VC++中使用内存映射文件处理大文件
摘要: 本文给出了一种方便实用的解决大文件的读取、存储等处理的方法,并结合相关程序代码对具体的实现过程进行了介绍。
引言
文件操作是应用程序最为基本的功能之一,Win32 API和MFC均提供有支持文件处理的函数和类,常用的有Win32 API的CreateFile()、WriteFile()、ReadFile()和MFC提供的CFile类等。一般来说,以上这些函数可以满足大多数场合的要求,但是对于某些特殊应用领域所需要的动辄几十GB、几百GB、乃至几TB的海量存储,再以通常的文件处理方法进行处理显然是行不通的。目前,对于上述这种大文件的操作一般是以内存映射文件的方式来加以处理的,本文下面将针对这种Windows核心编程技术展开讨论。
反射内存卡性能表安全操作及保养规程

反射内存卡性能表安全操作及保养规程反射内存卡是一种基于全闪存技术的存储设备,具有速度快、可靠性高、体积小、重量轻等优点,在各类便携式电子设备中得到了广泛应用。
为了保证反射内存卡的安全使用,本文将介绍反射内存卡的性能表、安全操作规程和保养规程。
反射内存卡性能表反射内存卡性能表是描述反射内存卡主要性能参数的表格,通常包括以下内容:1. 容量容量是反射内存卡最基本的参数,表示反射内存卡可以存储的数据大小。
反射内存卡的容量通常以GB或TB为单位。
2. 读取速度读取速度是反射内存卡的一个关键性能指标,表示反射内存卡读取数据的速度。
反射内存卡的读取速度通常以MB/s为单位。
3. 写入速度写入速度是反射内存卡的另一个关键性能指标,表示反射内存卡写入数据的速度。
反射内存卡的写入速度通常以MB/s为单位。
4. 工作温度范围反射内存卡的工作温度范围表示反射内存卡可以正常工作的温度范围。
一般来说,反射内存卡的工作温度范围是 -25℃到85℃。
5. 电压电压是反射内存卡的另一个基本参数,表示反射内存卡需要的电压。
反射内存卡通常需要3.3V或5V的电压。
6. 接口类型反射内存卡的接口类型表示反射内存卡和主机之间的接口类型。
反射内存卡的接口类型通常有SD、microSD、CF,以及USB等。
反射内存卡安全操作规程为了保证反射内存卡的安全使用,以下是反射内存卡的安全操作规程:1. 避免使用设计容量以下的反射内存卡反射内存卡存储数据时需要使用闪存芯片,如果容量不足会给芯片带来过大压力,导致芯片寿命缩短。
2. 避免频繁读写操作虽然反射内存卡读写速度比传统存储设备快,但频繁读写操作对芯片寿命会造成很大影响,因此需要尽量避免频繁读写操作。
3. 避免反复插拔反复插拔反射内存卡不仅会损伤内部插座,还容易引起芯片松动而无法正确读取,因此在使用过程中要避免反复插拔。
4. 避免操作环境过热或过寒在过热或过寒的环境下使用反射内存卡,可能会导致芯片受损,因此需要避免在极端温度下使用反射内存卡。
机器视觉之VC MFC 进程间通信方法总结

VC/MFC 进程间通信方法总结摘要随着人们对应用程序的要求越来越高,单进程应用在许多场合已不能满足人们的要求。
编写多进程/多线程程序成为现代程序设计的一个重要特点,在多进程程序设计中,进程间的通信是不可避免的。
Microsoft Win32 API提供了多种进程间通信的方法,全面地阐述了这些方法的特点,并加以比较和分析,希望能给读者选择通信方法提供参考。
1 进程与进程通信进程是装入内存并准备执行的程序,每个进程都有私有的虚拟地址空间,由代码、数据以及它可利用的系统资源(如文件、管道等)组成。
多进程/多线程是Windows操作系统的一个基本特征。
Microsoft W in32应用编程接口(Application Programming Interface, API)提供了大量支持应用程序间数据共享和交换的机制,这些机制行使的活动称为进程间通信(InterProcess Communication, IPC),进程通信就是指不同进程间进行数据共享和数据交换。
正因为使用Win32 API进行进程通信方式有多种,如何选择恰当的通信方式就成为应用开发中的一个重要问题,下面本文将对Win32中进程通信的几种方法加以分析和比较。
2 进程通信方法2.1 文件映射文件映射(Memory-Mapped Files)能使进程把文件内容当作进程地址区间一块内存那样来对待。
因此,进程不必使用文件I/O操作,只需简单的指针操作就可读取和修改文件的内容。
Win32 API允许多个进程访问同一文件映射对象,各个进程在它自己的地址空间里接收内存的指针。
通过使用这些指针,不同进程就可以读或修改文件的内容,实现了对文件中数据的共享。
应用程序有三种方法来使多个进程共享一个文件映射对象。
(1)继承:第一个进程建立文件映射对象,它的子进程继承该对象的句柄。
(2)命名文件映射:第一个进程在建立文件映射对象时可以给该对象指定一个名字(可与文件名不同)。
反射内存卡资料整理
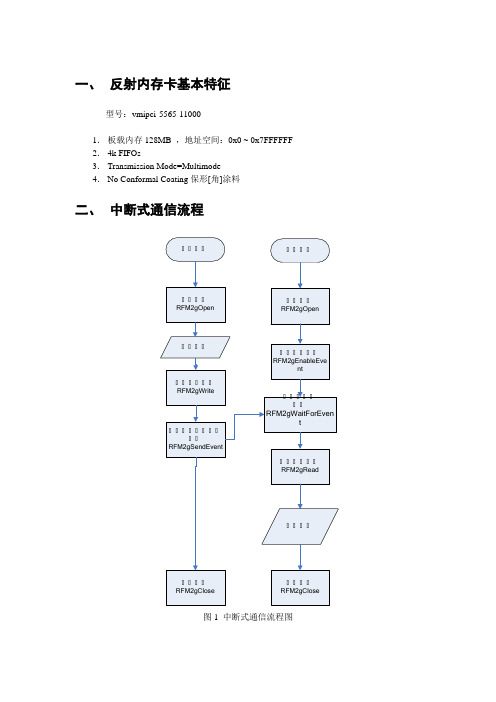
一、反射内存卡基本特征型号:vmipci-5565-110001.板载内存128MB ,地址空间:0x0 ~ 0x7FFFFFF 2.4k FIFOs3.Transmission Mode=Multimode4.No Conformal Coating保形[角]涂料二、中断式通信流程图1 中断式通信流程图2.1 特点:一、发送方和接收方通过事件进行同步,CPU占用少;二、发送方可以向多个指定的接收方发送数据,即1对多方式;也可以实现广播方式。
2.2 注意事项:1.当接收方调用RFM2gWaitForEvent函数后,将挂起当前线程。
直到有事件发生或等待超时才能恢复,因此接收部分的代码应采用多线程编程;2.RFM2gSendEvent需要指定接收设备的NodeID,该参数由板卡上的跳线决定(EachRFM2g device on an RFM2g network is uniquely identified by its node ID, which ismanually set by jumpers on the device when the RFM2g network is installed. The driverdetermines the node ID when the device is initialized)。
本机的NodeID可以通过APIRFM2gNodeID获取;如果采取广播方式,则参数NodeID应指定为宏定义RFM2G_NODE_ALL;3.数据读写有两种方式:直接读写和内存映射。
直接读写的相关函数有:RFM2gRead和RFM2gWrite。
内存映射的相关函数有:RFMUserMemory和RFMUnMapUserMemory。
后者将板载内存按页(page)映射到程序的内存空间,对映射内存的操作将直接反应到板载内存上。
按照手册的解释:使用内存映射后,数据的传输将使用PIO方式,不使用DMA方式。
VCMFC 内存泄漏查找方法

VC/MFC 内存泄漏的个人总结分类:内存2008-04-15 17:101548人阅读评论(2)收藏举报首先先看看下面的内容吧!我就是认真阅读了它,并结合自己所学的东西,解决了一个超难得问题(自己觉得!嘿嘿)关于MF C下检查和消除内存泄露的技巧摘要本文分析了Windows环境使用MFC调试内存泄露的技术,介绍了在Windows环境下用VC++查找,定位和消除内存泄露的方法技巧。
关键词:VC++;CRT 调试堆函数;试探法。
编译环境VC++6.0技术原理检测内存泄漏的主要工具是调试器和CRT 调试堆函数。
若要启用调试堆函数,请在程序中包括以下语句:#define CRTDBG_MAP_ALLOC #include <stdlib.h> #include <crtdbg.h>注意#include 语句必须采用上文所示顺序。
如果更改了顺序,所使用的函数可能无法正确工作。
通过包括 crtdbg.h,将malloc 和free 函数映射到其“Debug”版本_malloc_dbg 和_free_dbg,这些函数将跟踪内存分配和释放。
此映射只在调试版本(在其中定义了_DE BUG)中发生。
发布版本使用普通的malloc 和free 函数。
#define 语句将CRT 堆函数的基版本映射到对应的“Debug”版本。
并非绝对需要该语句,但如果没有该语句,内存泄漏转储包含的有用信息将较少。
在添加了上面所示语句之后,可以通过在程序中包括以下语句来转储内存泄漏信息:_CrtDumpMemoryLeaks();当在调试器下运行程序时,_CrtDumpMemoryLeaks 将在“输出”窗口中显示内存泄漏信息。
内存泄漏信息如下所示:Detected memory leaks! Dumping objects -> C:PROGRAM FILESVISUALSTUDIOMy P rojectsleaktestleaktest.cpp(20) : {18} normal block at 0x00780E80, 64 bytes long. Data:<> CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD Object dump complete.如果不使用#define _CRTDBG_MA P_ALLOC 语句,内存泄漏转储如下所示:Detected memory leaks! Dumping objects -> {18} normal block at 0x00780E80, 64 bytes long. Data: < > CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD Object dump complete.未定义_CRTDBG_MAP_ALLOC 时,所显示的会是:内存分配编号(在大括号内)。
Windows下PCI-5565反射内存网程序设计

RFM2G_UINT32 Length );
功能:直接读取反射内存卡板载内存中的数据
参数:rh
RFM2g 设备句柄
Offset
指定要读取的板载内存起始地址
64MB 卡的有效值范围为(0x0,0x3FFFFFF)
128MB 卡的有效值范围为(0x0,0x7FFFFFF)
256MB 卡的有效值范围为(0x0,0xFFFFFFF)
功能:清除网络中断
参数:rh
RFM2g 设备句柄
EventType 指定要清除哪个网络中断
(8) RFM2gGetEventCount()
语法:STDRFM2GCALL RFM2gGetEventCount(RFM2GHANDLE rh, RFM2GEVENTTYPE EventType),
RFM2G_UINT32 *Count);
反射内存网主要是由反射内存卡通过光纤等传输介质连接而成。反射内存网上的每台计 算机插入一个反射内存卡形成各个节点,每个节点的反射内存卡上的存储器中都有反射内存 网上其它节点的共享数据拷贝。每个反射内存卡都占有一段内存地址,反射内存网上的任何 计算机向本地反射内存卡写数据时,该数据被传播到网上所有其它反射内存卡并存储在相同 的位置。因此在计算机将数据写入本地反射内存卡后的极短时间内,反射内存网上的所有计 算机都可以访问这个新数据。反射内存卡使用简单的读写方式,软件上只需要几行代码就可 以完成对反射内存卡的读写操作,反射内存网上的数据传输是纯硬件操作,不需要考虑网络 的通信协议。因此它与以太网等其它传统网络相比具有更低的数据传输延迟、更快的数据传 输速率、更简单灵活的操作使用,可以满足实时系统快速反应周期的要求。
图 1 环型拓扑结构的反射内存网 星型结构是由一个光纤 Hub 和若干反射内存卡组成。安装了反射内存卡的计算机通过光 纤连接到 Hub 上,仍以三个节点为例说明其组网方法,如图 2 所示。Hub 提供了一个共享内 存空间,每个节点在本地反射内存卡上都有一个该共享内存空间的映射。当任意一个节点在 本地反射内存卡的内存空间中操作时,Hub 上的共享内存空间的数据就会被更新,同时其它 节点上的共享内存映射空间的对应数据也会被立即更新。