MRB Nov(2014.10.21-2014.11.20)
项目进度表_Project_Schedule
3 1 2
2014.11.18 2014.11.19 2014.11.21 2014.11.21
2014.11.18 2014.11.20 2014.11.23 2014.11.27
2014.11.25 2014.11.26 2014.11.26 2014.12.06
7
2014.11.21
2014.11.27
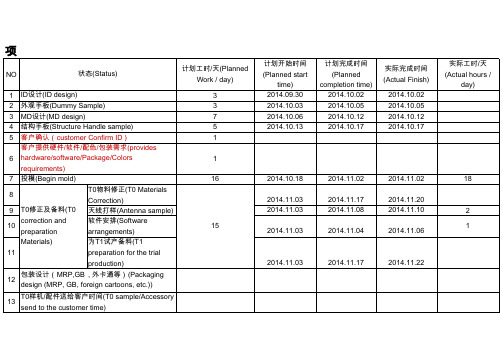
BIS/SAR/ROHS样 BIS 机/配件送检时间 14 SAR (BIS/SAR/ROHS ROHS sample / 15 客户确认(customerConfirm ) 16 T1试产(T1 trial production) T1检讨及出修正资料(T1 review and the 17 correction data) 天线性能验证(Antenna 18 Performance Verification) 19 软件测试(Software test) 电子原器件性能测试 20 (Performance testing of 品质可靠性测试 electronic components) (Reliability testing) 结构原器件性能测试 (Structure of the 21 Components performance test) 整机可靠性能测试(Mobile 22 reliability test) T1物料修正(T1 Materials 23 Correction) 天线调整样(Antenna 24 T1修正及备料(T1 adjustment) correction and preparation)
15 2014.11.28 2014.11.29 2014.11.29
2014.11.28
2014.12.12
2014.12.09
Scheduling flow shops using differential evolution algorithm

Discrete OptimizationScheduling flow shops using differential evolution algorithmGodfrey Onwubolu *,Donald DavendraDepartment of Engineering,The University of the South Pacific,P.O.Box 1168,Suva,FijiReceived 17January 2002;accepted 5August 2004Available online 21November 2004AbstractThis paper describes a novel optimization method based on a differential evolution (exploration)algorithm and its applications to solving non-linear programming problems containing integer and discrete variables.The techniques for handling discrete variables are described as well as the techniques needed to handle boundary constraints.In particular,the application of differential evolution algorithm to minimization of makespan ,flowtime and tardiness in a flow shop manufacturing system is given in order to illustrate the capabilities and the practical use of the method.Experiments were carried out to compare results from the differential evolution algorithm and the genetic algorithm,which has a reputation for being very powerful.The results obtained have proven satisfactory in solution quality when compared with genetic algorithm.The novel method requires few control variables,is relatively easy to implement and use,effec-tive,and efficient,which makes it an attractive and widely applicable approach for solving practical engineering prob-lems.Future directions in terms of research and applications are given.Ó2004Elsevier B.V.All rights reserved.Keywords:Scheduling;Flow shops;Differential evolution algorithm;Optimization1.IntroductionIn general,when discussing non-linear programming,the variables of the object function are usually as-sumed to be continuous.However,in practical real-life engineering applications it is common to have the problem variables under consideration being discrete or integer values.Real-life,practical engineering opti-mization problems are commonly integer or discrete because the available values are limited to a set of commercially available standard sizes.For example,the number of automated guided vehicles,the number of unit loads,the number of storage units in a warehouse operation are integer variables,while the size of a pallet,the size of billet for machining operation,etc.,are often limited to a set of commercially available 0377-2217/$-see front matter Ó2004Elsevier B.V.All rights reserved.doi:10.1016/j.ejor.2004.08.043*Corresponding author.Tel.:+679212034;fax:+679302567.E-mail address:onwubolu_g@usp.ac.fj (G.Onwubolu).European Journal of Operational Research 171(2006)674–692/locate/ejorG.Onwubolu,D.Davendra/European Journal of Operational Research171(2006)674–692675 standard sizes.Another class of interesting optimization problem isfinding the best order or sequence in which jobs have to be machined.None of these engineering problems has a continuous objective function; rather each of these engineering problems has either an integer objective function or discrete objective func-tion.In this paper we deal with the scheduling of jobs in aflow shop manufacturing system.Theflow shop scheduling-problem is a production planning-problem in which n jobs have to be pro-cessed in the same sequence on m machines.The assumptions are that there are no machine breakdowns and that all jobs are pre-emptive.This is commonly the case in many manufacturing systems where jobs are transferred from machine to machine by some kind of automated material handling systems.For large problem instances,typical of practical manufacturing settings,most researchers have focused on developing heuristic procedures that yield near optimal-solutions within a reasonable computation time. Most of these heuristic procedures focus on the development of permutation schedules and use makespan as a performance measure.Some of the well-known scheduling heuristics,which have been reported in the literature,include Palmer(1965),Campbell et al.(1970),Gupta(1971),Dannenbring(1977),Hundal and Rajagopal(1988)and Ho and Chang(1991).Cheng and Gupta(1989)and Baker and Scudder(1990)pre-sented a comprehensive survey of research work done inflow shop scheduling.In recent years,a growing body of literature suggests the use of heuristic search procedures for combi-natorial optimization problems.Several search procedures that have been identified as having great poten-tial to address practical optimization problems include simulated annealing(Kirkpatrick et al.,1983), genetic algorithms(Goldberg,1989),tabu search(Glover,1989,1990),and ant colony optimization(Dor-igo,1992).Consequently,over the past few years,several researchers have demonstrated the applicability of these methods,to combinatorial optimization problems such as theflow shop scheduling(see for example, Widmer and Hertz,1989;Ogbu and Smith,1990;Taillard,1990;Chen et al.,1995;Onwubolu,2000).More recently,a novel optimization method based on differential evolution(exploration)algorithm(Storn and Price,1995)has been developed,which originally focused on solving non-linear programming problems containing continuous variables.Since Storn and Price(1995)invented the differential evolution(explora-tion)algorithm,the challenge has been to employ the algorithm to different areas of problems other than those areas that the inventors originally focussed on.Although application of DE to combinatorial optimi-zation problems encountered in engineering is scarce,researchers have used DE to design complex digital filters(Storn,1999),and to design mechanical elements such as gear train,pressure vessels and springs (Lampinen and Zelinka,1999).This paper presents a new approach based on differential evolution algorithm for solving the problem of scheduling n jobs on m machines when all jobs are available for processing and the objective is to minimize the makespan.Other objective functions considered in the present work include meanflowtime and total tardiness.2.Problem formulationAflow shop scheduling is one in which all jobs must visit machines or work centers in the same sequence. Processing of a job must be completed on current machine before processing of the job is started on suc-ceeding machine.This means that initially all jobs are available and that each machine is restricted to pro-cessing only one job at any particular time.Since thefirst machine in the facility arrangement is thefirst to be visited by each job,the other machines are idle and other jobs are queued.Although queuing of jobs is prohibited in just-in-time(JIT)manufacturing environments,flow shop manufacturing continues tofind applications in electronics manufacturing,and space shuttle processing,and has attracted much research work(Onwubolu,2002).Theflow shop can be formatted generally by the sequencing of n jobs on m ma-chines under the precedence condition,with typical objective functions being the minimizing of average flowtime,minimizing the time required to complete all jobs or makespan,minimizing maximum tardiness,and minimizing the number of tardy jobs.If the number of jobs is relatively small,then the problem can be solved without using any generic optimizing algorithm.Every possibility can be checked to obtain results and then sequentially compared to capture the optimum value.But,more often,the number of jobs to be processed is large,which leads to big-O order of n !Consequently,some kind of algorithm is essential in this type of problem to avoid combinatorial explosion.The standard three-field notation (Lawler et al.,1995)used is that for representing a scheduling problem as a j b j F (C ),where a describes the machine environment,b describes the deviations from standard sched-uling assumptions,and F (C )describes the objective C being optimized.In the work reported in this paper,we are solving the n /m /F k F (C max )problem.Other problems solved include F ðC Þ¼F ðP C i Þand F ðC Þ¼F ðP T j Þ.Here a =n /m /F describes the multiple-machines flow shop problem,b =null,and F ðC Þ¼F ðC max ;P C i ;and P T j Þfor makespan,mean flowtime,and total tardiness,respectively.Stating these problem descriptions more elaborately,the minimization of completion time (makespan)for a flow shop schedule is equivalent to minimizing the objective function I :I ¼X n j ¼1C m ;j ;ð1Þs :t :C i ;j ¼max C i À1;j ;C i ;j À1ÀÁþP i ;j ;ð2Þwhere C m ,j =the completion time of job j ,C 1,1=k (any given value),C i ;j ¼P j k ¼1C 1;k ;C j ;i ¼P i k ¼1C k ;1,i )machine number,j )job in sequence,P i ,j )processing time of job j on machine i .For a given sequence,the mean flowtime,MFT =1P m i ¼1P n j ¼1c ij ,while the condition for tardiness is c m ,j >d j .The constraint of Eq.(2)applies to these two problem descriptions.3.Differential evolutionThe differential evolution (exploration)[DE]algorithm introduced by Storn and Price (1995)is a novel parallel direct search method,which utilizes NP parameter vectors as a population for each generation G .DE can be categorized into a class of floating-point encoded,evolutionary optimization algorithms .Currently,there are several variants of DE.The particular variant used throughout this investigation is the DE/rand/1/bin scheme.This scheme will be discussed here and more detailed descriptions are provided (Storn and Price,1995).Since the DE algorithm was originally designed to work with continuous variables,the opti-mization of continuous problems is discussed first.Handling discrete variables is explained later.Generally,the function to be optimized,I ,is of the form I ðX Þ:R D !R .The optimization target is to minimize the value of this objective function I ðX Þ,min ðI ðX ÞÞ;ð3Þby optimizing the values of its parameters X ={x 1,x 2,...,x D },X 2R D ,where X denotes a vector composed of D objective function ually,the parameters of the objective function are also subject to lower and upper boundary constraints,x (L )and x (U ),respectively,x ðL Þj P x j P x ðU Þj8j 2½1;D :ð4Þ3.1.InitializationAs with all evolutionary optimization algorithms,DE works with a population of solutions,not with a sin-gle solution for the optimization problem.Population P of generation G contains NP solution vectors called individuals of the population and each vector represents potential solution for the optimization problem 676G.Onwubolu,D.Davendra /European Journal of Operational Research 171(2006)674–692P ðG Þ¼X ðG Þi ¼x ðG Þj ;i ;i ¼1;...;NP ;j ¼1;...;D ;G ¼1;...;G max :ð5ÞIn order to establish a starting point for optimum seeking,the population must be initialized.Often there is no more knowledge available about the location of a global optimum than the boundaries of the problem variables.In this case,a natural way to initialize the population P (0)(initial population)is to seed it with random values within the given boundary constraints:P ð0Þ¼x ð0Þj ;i ¼x ðL Þj þrand j ½0;1 Âx ðU Þj Àx ðL Þj 8i 2½1;NP ;8j 2½1;D ;ð6Þwhere rand j [0,1]represents a uniformly distributed random value that ranges from zero to one.3.2.MutationThe self-referential population recombination scheme of DE is different from the other evolutionary algorithms.From the first generation onward,the population of the subsequent generation P (G +1)is obtained on the basis of the current population P (G ).First a temporary or trial population of candidate vectors for the subsequent generation,P 0ðG þ1Þ¼V ðG þ1Þ¼v ðG þ1Þj ;i ,is generated as follows:v ðG þ1Þj ;i ¼x ðG Þj ;r 3þF Âx ðG Þj ;r 1Àx ðG Þj ;r 2 ;if rand j ½0;1 <CR _j ¼k ;x ðG Þi ;j ;otherwise ;8<:ð7Þwhere i 2[1,NP];j 2[1,D ],r 1,r 2,r 32[1,NP],randomly selected,except:r 15r 25r 35i ,k =(int(rand i [0,1]·D )+1),and CR 2[0,1],F 2(0,1].Three randomly chosen indexes,r 1,r 2,and r 3refer to three randomly chosen vectors of population.They are mutually different from each other and also different from the running index i .New random values for r 1,r 2,and r 3are assigned for each value of index i (for each vector).A new value for the random num-ber rand[0,1]is assigned for each value of index j (for each vector parameter).3.3.CrossoverThe index k refers to a randomly chosen vector parameter and it is used to ensure that at least one vector parameter of each individual trial vector V (G +1)differs from its counterpart in the previous generation X (G ).A new random integer value is assigned to k for each value of the index i (prior to construction of each trial vector).F and CR are DE control parameters.Both values remain constant during the search process.Both values as well as the third control parameter,NP (population size),remain constant during the search pro-cess.F is a real-valued factor in range [0.0,1.0]that controls the amplification of differential variations.CR is a real-valued crossover factor in the range [0.0,1.0]that controls the probability that a trial vector will be selected form the randomly chosen,mutated vector,V ðG þ1Þj ;i instead of from the current vector,x ðG Þj ;i .Gener-ally,both F and CR affect the convergence rate and robustness of the search process.Their optimal values are dependent both on objective function characteristics and on the population size,ually,suitable values for F ,CR and NP can be found by experimentation after a few tests using different values.Practical advice on how to select control parameters NP,F and CR can be found in Storn and Price (1995,1997).3.4.SelectionThe selection scheme of DE also differs from the other evolutionary algorithms.On the basis of the cur-rent population P (G )and the temporary population P 0(G +1),the population of the next generation P (G +1)is created as follows:G.Onwubolu,D.Davendra /European Journal of Operational Research 171(2006)674–692677XðGþ1Þi ¼VðGþ1Þi;if I VðGþ1Þi6IðXðGÞiÞ;XðGÞi;otherwise:8<:ð8ÞThus,each individual of the temporary or trial population is compared with its counterpart in the current population.The one with the lower value of cost-function IðXÞto be minimized will propagate the pop-ulation of the next generation.As a result,all the individuals of the next generation are as good or better than their counterparts in the current generation.The interesting point concerning the DE selection scheme is that a trial vector is only compared to one individual vector,not to all the individual vectors in the cur-rent population.3.5.Boundary constraintsIt is important to notice that the recombination operation of DE is able to extend the search outside of the initialized range of the search space(Eqs.(6)and(7)).It is also worthwhile to notice that sometimes this is a beneficial property in problems with no boundary constraints because it is possible tofind the optimum that is located outside of the initialized range.However,in boundary-constrained problems,it is essential to ensure that parameter values lie inside their allowed ranges after recombination.A simple way to guarantee this is to replace parameter values that violate boundary constraints with random values generated within the feasible range:uðGþ1Þj;i ¼xðLÞjþrand j½0;1 ÂðxðUÞjÀxðLÞjÞ;if uðGþ1Þj;i<xðLÞj_uðGþ1Þj;i>xðUÞj;uðGþ1Þi;j;otherwise;(ð9Þwhere i2[1,NP];j2[1,D].This is the method that was used for this work.Another simple but less efficient method is to reproduce the boundary constraint violating values according to Eq.(7)as many times as is necessary to satisfy the boundary constraints.Yet another simple method that allows bounds to be approached asymptotically while minimizing the amount of disruption that results from resetting out of bound values(Price,1999) isuðGþ1Þj;i ¼ðxðGÞj;iþxðLÞjÞ=2;if uðGþ1Þj;i<xðLÞj;ðxðGÞj;iþxðUÞjÞ=2;if uðGþ1Þj;i>xðUÞj;uðGþ1Þj;i;otherwise:8>><>>:ð10Þ3.6.Conventional technique for integer and discrete optimization by DESeveral approaches have been used to deal with discrete variable optimization.Most of them round offthe variable to the nearest available value before evaluating each trial vector.To keep the population robust,successful trial vectors must enter the population with all of the precision with which they were generated(Storn and Price,1997).In its canonical form,the differential evolution algorithm is only capable of handling continuous vari-ables.Extending it for optimization of integer variables,however,is rather mpinen and Zelinka (1999)discuss how to modify DE for mixed variable optimization.They suggest that only a couple of sim-ple modifications are required.First,integer values should be used to evaluate the objective function,even though DE itself may still works internally with continuousfloating-point values.Thus, Iðy iÞ;i2½1;D ;ð11Þ678G.Onwubolu,D.Davendra/European Journal of Operational Research171(2006)674–692wherey i ¼x i for continuous variables;INTðx iÞfor integer variables;&wherey i ¼x i;INTðx iÞ: &x i2X:INT()is a function for converting a real-value to an integer value by truncation.Truncation is performed here only for purposes of cost-function value evaluation.Truncated values are not elsewhere assigned. Thus,DE works with a population of continuous variables regardless of the corresponding object variable type.This is essential for maintaining the diversity of the population and the robustness of the algorithm. Second,in case of integer variable,instead of Eq.(6),the population should be initialized as follows: Pð0Þ¼xð0Þj;i¼xðLÞjþrand j½0;1 ÂðxðUÞjÀxðLÞjþ1Þ8i2½1;NP ;8j2½1;D :ð12ÞAdditionally,instead of Eq.(9),the boundary constraint handling integer variables should be performed as follows:uðGþ1Þj;i ¼xðLÞjþrand j½0;1 ÂðxðUÞjÀxðLÞjþ1Þ;if INTðuðGþ1Þj;iÞ<xðLÞj_INTðuðGþ1Þj;iÞ>xðUÞj;uðGþ1Þi;ji;otherwise;(ð13Þwhere i2[1,NP];j2[1,D].They also discuss how discrete values can also be handled in a straightforward manner.Suppose that the subset of discrete variables,X(d),contains l elements that can be assigned to var-iable x:XðdÞ¼xðdÞi;i2½1;l ;ð14Þwhere xðdÞi<xðdÞiþ1.Instead of the discrete value x i itself,we may assign its index,i,to x.Now the discrete variable can be handled as an integer variable that is boundary constrained to range1,...,l.To evaluate the objective func-tion,the discrete value,x i,is used instead of its index i.In other words,instead of optimizing the value of the discrete variable directly,we optimize the value of its index i.Only during evaluation is the indicated discrete value used.Once the discrete problem has been converted into an integer one,the previously de-scribed methods for handling integer variables can be applied(Eqs.(11)–(13)).3.7.Forward transformation and backward transformation techniqueThe problem formulation is already discussed in Section2.Solving theflow shop-scheduling problem and indeed most combinatorial optimization problems requires discrete variables and ordered sequence, rather than relative position indexing.To achieve this,we developed two strategies known as forward and backward transformation techniques respectively.In this paper,we present a forward transformation method for transforming integer variables into continuous variables for the internal representation of vec-tor values since in its canonical form,the DE algorithm is only capable of handling continuous variables.G.Onwubolu,D.Davendra/European Journal of Operational Research171(2006)674–692679We also present a backward transformation method for transforming a population of continuous variablesobtained after mutation back into integer variables for evaluating the objective function(Onwubolu,2001). Both forward and backward transformations are utilized in implementing the DE algorithm used in the present study for theflow shop-scheduling problem.Fig.1shows how to deal with this inherent represen-tational problem in DE.Level0deals with integer numbers(which are used in discrete problems).At this level,initialization andfinal solutions are catered for.In the problem domain areas of scheduling,TSP,etc., we are not only interested in computing the objective function cost,we are also interested in the proper order of jobs or cities respectively.Level1of Fig.1deals withfloating point numbers,which are suited for DE.At this level,the DE operators(mutation,crossover,and selection)take place.To transform the integer at level0intofloating point numbers at level1for DEÕs operators,requires some specific kind of coding.This type of coding is highly used in mathematics and computing science.For the basics of trans-forming an integer number into its real number equivalence,interested readers may refer to Michalewicz (1994),and Onwubolu and Kumalo(2001)for its application to optimizing machining operations using genetic algorithms.3.7.1.Forward transformation(from integer to real number)In integer variable optimization a set of integer number is normally generated randomly as an initial solution.Let this set of integer number be represented asz0i2z0:ð15ÞLet the real number(floating point)equivalence of this integer number be z i.The length of the real number depends on the required precision,which in our case,we have chosen two places after the decimal point. The domain of the variable z i has length equal to5;the precision requirement implies that the range be [0...4].Although0is considered since it is not a feasible solution,the range[0.1,1,2,3,4]is chosen,which gives a range of5.We assign each feasible solution two decimal places and this gives us5·100=500.Accordingly,the equivalent continuous variable for z0iis given as100¼102<5Â1026103¼1000:ð16ÞThe mapping from an integer number to a real number z i for the given range is now straightforward,given asz i¼À1þz0iÂ510À1:ð17Þ680G.Onwubolu,D.Davendra/European Journal of Operational Research171(2006)674–692Eq.(17)results in most conversion values being negative;this does not create any accuracy problem any way.After some studies by Onwubolu(2001),the scaling factor f=100was found to be adequate for con-verting virtually all integer numbers into their equivalent positive real numbers.Applying this scaling factor of f=100givesz i¼À1þz0iÂfÂ510À1¼À1þz0iÂ50010À1:ð18ÞEq.(18)is used to transform any integer variable into an equivalent continuous variable,which is then used for the DE internal representation of the population of vectors.Without this transformation,it is not pos-sible to make useful moves towards the global optimum in the solution space using the mutation mecha-nism of DE,which works better on continuous variables.For example in afive-job scheduling problem, suppose the sequence is given as{2,4,3,1,5}.This sequence is not directly used in DE internal representa-tion.Rather,applying Eq.(18),the sequence is transformed into a continuous form.Thefloating-pointequivalence of thefirst entry of the given sequence,z0i ¼2,is z i¼À1þ2Â500103À1¼0:001001.Other valuesare similarly obtained and the sequence is therefore represented internally in the DE scheme as {0.001001,1.002,0.501502,À0.499499,and1.5025}.3.7.2.Backward transformation(from real number to integer)Integer variables are used to evaluate the objective function.The DE self-referential population muta-tion scheme is quite unique.After the mutation of each vector,the trial vector is evaluated for its objective function in order to decide whether or not to retain it.This means that the objective function values of the current vectors in the population need to be also evaluated.These vector variables are continuous(from the forward transformation scheme)and have to be transformed into their integer number equivalence. The backward transformation technique is used for convertingfloating point numbers to their integer num-ber equivalence.The scheme is given as follows:z0 i ¼ð1þz iÞÂð103À1Þ500:ð19ÞIn this present form the backward transformation function is not able to properly discriminate between variables.To ensure that each number is discrete and unique,some modifications are required as follows: a¼intðz0iþ0:5Þ;ð20Þb¼aÀz0i;ð21ÞzÃi ¼ðaÀ1Þ;if b>0:5;a;if b<0:5:&ð22ÞEq.(22)gives zÃi ,which is the transformed value used for computing the objective function.It should bementioned that the conversion scheme of Eq.(19),which transforms real numbers after DE operations into integer numbers is not sufficient to avoid duplication;hence,the steps highlighted in Eqs.(20)–(22)are important.In our studies,these modifications ensure that after mutation,crossover and selection opera-tions,the convertedfloating numbers into their integer equivalence in the set of jobs for a new scheduling solution,or set of cities for a new TSP solution,etc.,are not duplicated.As an example,we consider a set of trial vector,z i={À0.33,0.67,À0.17,1.5,0.84}obtained after mutation.The integer values corresponding to the trial vector values are obtained using Eq.(22)as follows:G.Onwubolu,D.Davendra/European Journal of Operational Research171(2006)674–692681z0 1¼ð1À0:33ÞÂð103À1Þ=500¼1:33866;z02¼ð1þ0:67ÞÂð103À1Þ=500¼3:3367;z0 3¼ð1À0:17ÞÂð103À1Þ=500¼1:65834;z04¼ð1þ1:50ÞÂð103À1Þ=500¼4:9950;z05¼ð1þ0:84ÞÂð103À1Þ=500¼3:6763;a1¼intð1:333866þ0:5Þ¼2;b1¼2À1:33866¼0:66134>0:5;zÃ1¼2À1¼1;a2¼intð3:3367þ0:5Þ¼4;b2¼4À3:3367¼0:6633>0:5;zÃ2¼4À1¼3;a3¼intð1:65834þ0:5Þ¼2;b3¼2À1:65834¼0:34166<0:5;zÃ3¼2;a4¼intð4:995þ0:5Þ¼5;b4¼5À4:995¼0:005<0:5;zÃ4¼5;a5¼intð3:673þ0:5Þ¼4;b5¼4À3:673¼0:3237<0:5;zÃ5¼4:This can be represented schematically as shown in Fig.2.The set of integer values is given aszÃi ¼f1;3;2;5;4g.This set is used to obtain the objective function values.Like in GA,after mutation,crossover,and boundary checking operations,the trial vector obtained fromthe backward transformation is continuously checked until feasible solution is found.Hence,it is not nec-essary to bother about the ordered sequence,which is crucially important in the type of combinatorial opti-mization problems we are concerned with.Feasible solutions constitute about10–15%of the total trial vectors.3.8.DE strategiesPrice and Storn(2001)have suggested ten different working strategies of DE and some guidelines in applying these strategies for any given problem.Different strategies can be adopted in the DE algorithm depending upon the type of problem for which it is applied.Table1shows the ten different working strat-egies proposed by Price and Storn(2001).The general convention used in Table1is as follows:DE/x/y/z.DE stands for differential evolution algorithm,x represents a string denoting the vector to be perturbed,y is the number of difference vectors considered for perturbation of x,and z is the type of crossover being used(exp:exponential;bin:binomial). Thus,the working algorithm outline by Storn and Price(1997)is the seventh strategy of DE,that is,DE/ rand/1/bin.Hence the perturbation can be either in the best vector of the previous generation or in any ran-domly chosen vector.Similarly for perturbation,either single or two vector differences can be used.For perturbation with a single vector difference,out of the three distinct randomly chosen vectors,the weighted vector differential of any two vectors is added to the third one.Similarly for perturbation with two vector682G.Onwubolu,D.Davendra/European Journal of Operational Research171(2006)674–692。
Understanding individual human mobility patterns

a r X i v :0806.1256v 1 [p h y s i c s .s o c -p h ] 7 J u n 2008Understanding individual human mobility patternsMarta C.Gonz´a lez,1,2C´e sar A.Hidalgo,1and Albert-L´a szl´o Barab´a si 1,2,31Center for Complex Network Research and Department of Physics and Computer Science,University of Notre Dame,Notre Dame IN 46556.2Center for Complex Network Research and Department of Physics,Biology and Computer Science,Northeastern University,Boston MA 02115.3Center for Cancer Systems Biology,Dana Farber Cancer Institute,Boston,MA 02115.(Dated:June 7,2008)Despite their importance for urban planning [1],traffic forecasting [2],and the spread of biological [3,4,5]and mobile viruses [6],our understanding of the basic laws govern-ing human motion remains limited thanks to the lack of tools to monitor the time resolved location of individuals.Here we study the trajectory of 100,000anonymized mobile phone users whose position is tracked for a six month period.We find that in contrast with the random trajectories predicted by the prevailing L´e vy flight and random walk models [7],human trajectories show a high degree of temporal and spatial regularity,each individual being characterized by a time independent characteristic length scale and a significant prob-ability to return to a few highly frequented locations.After correcting for differences in travel distances and the inherent anisotropy of each trajectory,the individual travel patterns collapse into a single spatial probability distribution,indicating that despite the diversity of their travel history,humans follow simple reproducible patterns.This inherent similarity in travel patterns could impact all phenomena driven by human mobility,from epidemic prevention to emergency response,urban planning and agent based modeling.Given the many unknown factors that influence a population’s mobility patterns,ranging from means of transportation to job and family imposed restrictions and priorities,human trajectories are often approximated with various random walk or diffusion models [7,8].Indeed,early mea-surements on albatrosses,bumblebees,deer and monkeys [9,10]and more recent ones on marine predators [11]suggested that animal trajectory is approximated by a L´e vy flight [12,13],a random walk whose step size ∆r follows a power-law distribution P (∆r )∼∆r −(1+β)with β<2.While the L´e vy statistics for some animals require further study [14],Brockmann et al.[7]generalized this finding to humans,documenting that the distribution of distances between consecutive sight-ings of nearly half-million bank notes is fat tailed.Given that money is carried by individuals, bank note dispersal is a proxy for human movement,suggesting that human trajectories are best modeled as a continuous time random walk with fat tailed displacements and waiting time dis-tributions[7].A particle following a L´e vyflight has a significant probability to travel very long distances in a single step[12,13],which appears to be consistent with human travel patterns:most of the time we travel only over short distances,between home and work,while occasionally we take longer trips.Each consecutive sightings of a bank note reflects the composite motion of two or more indi-viduals,who owned the bill between two reported sightings.Thus it is not clear if the observed distribution reflects the motion of individual users,or some hitero unknown convolution between population based heterogeneities and individual human trajectories.Contrary to bank notes,mo-bile phones are carried by the same individual during his/her daily routine,offering the best proxy to capture individual human trajectories[15,16,17,18,19].We used two data sets to explore the mobility pattern of individuals.Thefirst(D1)consists of the mobility patterns recorded over a six month period for100,000individuals selected randomly from a sample of over6million anonymized mobile phone users.Each time a user initiates or receives a call or SMS,the location of the tower routing the communication is recorded,allowing us to reconstruct the user’s time resolved trajectory(Figs.1a and b).The time between consecutive calls follows a bursty pattern[20](see Fig.S1in the SM),indicating that while most consecutive calls are placed soon after a previous call,occasionally there are long periods without any call activity.To make sure that the obtained results are not affected by the irregular call pattern,we also study a data set(D2)that captures the location of206mobile phone users,recorded every two hours for an entire week.In both datasets the spatial resolution is determined by the local density of the more than104mobile towers,registering movement only when the user moves between areas serviced by different towers.The average service area of each tower is approximately3km2 and over30%of the towers cover an area of1km2or less.To explore the statistical properties of the population’s mobility patterns we measured the dis-tance between user’s positions at consecutive calls,capturing16,264,308displacements for the D1and10,407displacements for the D2datasets.Wefind that the distribution of displacements over all users is well approximated by a truncated power-lawP(∆r)=(∆r+∆r0)−βexp(−∆r/κ),(1)withβ=1.75±0.15,∆r0=1.5km and cutoff valuesκ|D1=400km,andκ|D2=80km(Fig.1c,see the SM for statistical validation).Note that the observed scaling exponent is not far fromβB=1.59observed in Ref.[7]for bank note dispersal,suggesting that the two distributions may capture the same fundamental mechanism driving human mobility patterns.Equation(1)suggests that human motion follows a truncated L´e vyflight[7].Yet,the observed shape of P(∆r)could be explained by three distinct hypotheses:A.Each individual follows a L´e vy trajectory with jump size distribution given by(1).B.The observed distribution captures a population based heterogeneity,corresponding to the inherent differences between individuals.C.A population based heterogeneity coexists with individual L´e vy trajectories,hence(1)represents a convolution of hypothesis A and B.To distinguish between hypotheses A,B and C we calculated the radius of gyration for each user(see Methods),interpreted as the typical distance traveled by user a when observed up to time t(Fig.1b).Next,we determined the radius of gyration distribution P(r g)by calculating r g for all users in samples D1and D2,finding that they also can be approximated with a truncated power-lawP(r g)=(r g+r0g)−βr exp(−r g/κ),(2) with r0g=5.8km,βr=1.65±0.15andκ=350km(Fig.1d,see SM for statistical validation). L´e vyflights are characterized by a high degree of intrinsic heterogeneity,raising the possibility that(2)could emerge from an ensemble of identical agents,each following a L´e vy trajectory. Therefore,we determined P(r g)for an ensemble of agents following a Random Walk(RW), L´e vy-Flight(LF)or Truncated L´e vy-Flight(T LF)(Figure1d)[8,12,13].Wefind that an en-semble of L´e vy agents display a significant degree of heterogeneity in r g,yet is not sufficient to explain the truncated power law distribution P(r g)exhibited by the mobile phone users.Taken together,Figs.1c and d suggest that the difference in the range of typical mobility patterns of indi-viduals(r g)has a strong impact on the truncated L´e vy behavior seen in(1),ruling out hypothesis A.If individual trajectories are described by a LF or T LF,then the radius of gyration should increase in time as r g(t)∼t3/(2+β)[21,22]while for a RW r g(t)∼t1/2.That is,the longer we observe a user,the higher the chances that she/he will travel to areas not visited before.To check the validity of these predictions we measured the time dependence of the radius of gyration for users whose gyration radius would be considered small(r g(T)≤3km),medium(20<r g(T)≤30km)or large(r g(T)>100km)at the end of our observation period(T=6months).Theresults indicate that the time dependence of the average radius of gyration of mobile phone users is better approximated by a logarithmic increase,not only a manifestly slower dependence than the one predicted by a power law,but one that may appear similar to a saturation process(Fig.2a and Fig.S4).In Fig.2b,we have chosen users with similar asymptotic r g(T)after T=6months,and measured the jump size distribution P(∆r|r g)for each group.As the inset of Fig.2b shows,users with small r g travel mostly over small distances,whereas those with large r g tend to display a combination of many small and a few larger jump sizes.Once we rescale the distributions with r g(Fig.2b),wefind that the data collapses into a single curve,suggesting that a single jump size distribution characterizes all users,independent of their r g.This indicates that P(∆r|r g)∼r−αg F(∆r/r g),whereα≈1.2±0.1and F(x)is an r g independent function with asymptotic behavior F(x<1)∼x−αand rapidly decreasing for x≫1.Therefore the travel patterns of individual users may be approximated by a L´e vyflight up to a distance characterized by r g. Most important,however,is the fact that the individual trajectories are bounded beyond r g,thus large displacements which are the source of the distinct and anomalous nature of L´e vyflights, are statistically absent.To understand the relationship between the different exponents,we note that the measured probability distributions are related by P(∆r)= ∞0P(∆r|r g)P(r g)dr g,whichsuggests(see SM)that up to the leading order we haveβ=βr+α−1,consistent,within error bars, with the measured exponents.This indicates that the observed jump size distribution P(∆r)is in fact the convolution between the statistics of individual trajectories P(∆r g|r g)and the population heterogeneity P(r g),consistent with hypothesis C.To uncover the mechanism stabilizing r g we measured the return probability for each indi-vidual F pt(t)[22],defined as the probability that a user returns to the position where it was first observed after t hours(Fig.2c).For a two dimensional random walk F pt(t)should follow ∼1/(t ln(t)2)[22].In contrast,wefind that the return probability is characterized by several peaks at24h,48h,and72h,capturing a strong tendency of humans to return to locations they visited before,describing the recurrence and temporal periodicity inherent to human mobility[23,24].To explore if individuals return to the same location over and over,we ranked each location based on the number of times an individual was recorded in its vicinity,such that a location with L=3represents the third most visited location for the selected individual.Wefind that the probability offinding a user at a location with a given rank L is well approximated by P(L)∼1/L, independent of the number of locations visited by the user(Fig.2d).Therefore people devote mostof their time to a few locations,while spending their remaining time in5to50places,visited with diminished regularity.Therefore,the observed logarithmic saturation of r g(t)is rooted in the high degree of regularity in their daily travel patterns,captured by the high return probabilities(Fig.2b) to a few highly frequented locations(Fig.2d).An important quantity for modeling human mobility patterns is the probabilityΦa(x,y)tofind an individual a in a given position(x,y).As it is evident from Fig.1b,individuals live and travel in different regions,yet each user can be assigned to a well defined area,defined by home and workplace,where she or he can be found most of the time.We can compare the trajectories of different users by diagonalizing each trajectory’s inertia tensor,providing the probability offinding a user in a given position(see Fig.3a)in the user’s intrinsic reference frame(see SM for the details).A striking feature ofΦ(x,y)is its prominent spatial anisotropy in this intrinsic reference frame(note the different scales in Fig3a),and wefind that the larger an individual’s r g the more pronounced is this anisotropy.To quantify this effect we defined the anisotropy ratio S≡σy/σx, whereσx andσy represent the standard deviation of the trajectory measured in the user’s intrinsic reference frame(see SM).Wefind that S decreases monotonically with r g(Fig.3c),being well approximated with S∼r−ηg,forη≈0.12.Given the small value of the scaling exponent,other functional forms may offer an equally goodfit,thus mechanistic models are required to identify if this represents a true scaling law,or only a reasonable approximation to the data.To compare the trajectories of different users we remove the individual anisotropies,rescal-ing each user trajectory with its respectiveσx andσy.The rescaled˜Φ(x/σx,y/σy)distribution (Fig.3b)is similar for groups of users with considerably different r g,i.e.,after the anisotropy and the r g dependence is removed all individuals appear to follow the same universal˜Φ(˜x,˜y)prob-ability distribution.This is particularly evident in Fig.3d,where we show the cross section of ˜Φ(x/σ,0)for the three groups of users,finding that apart from the noise in the data the curves xare indistinguishable.Taken together,our results suggest that the L´e vy statistics observed in bank note measurements capture a convolution of the population heterogeneity(2)and the motion of individual users.Indi-viduals display significant regularity,as they return to a few highly frequented locations,like home or work.This regularity does not apply to the bank notes:a bill always follows the trajectory of its current owner,i.e.dollar bills diffuse,but humans do not.The fact that individual trajectories are characterized by the same r g-independent two dimen-sional probability distribution˜Φ(x/σx,y/σy)suggests that key statistical characteristics of indi-vidual trajectories are largely indistinguishable after rescaling.Therefore,our results establish the basic ingredients of realistic agent based models,requiring us to place users in number propor-tional with the population density of a given region and assign each user an r g taken from the observed P(r g)ing the predicted anisotropic rescaling,combined with the density function˜Φ(x,y),whose shape is provided as Table1in the SM,we can obtain the likelihood offinding a user in any location.Given the known correlations between spatial proximity and social links,our results could help quantify the role of space in network development and evolu-tion[25,26,27,28,29]and improve our understanding of diffusion processes[8,30].We thank D.Brockmann,T.Geisel,J.Park,S.Redner,Z.Toroczkai and P.Wang for discus-sions and comments on the manuscript.This work was supported by the James S.McDonnell Foundation21st Century Initiative in Studying Complex Systems,the National Science Founda-tion within the DDDAS(CNS-0540348),ITR(DMR-0426737)and IIS-0513650programs,and the U.S.Office of Naval Research Award N00014-07-C.Data analysis was performed on the Notre Dame Biocomplexity Cluster supported in part by NSF MRI Grant No.DBI-0420980.C.A.Hi-dalgo acknowledges support from the Kellogg Institute at Notre Dame.Supplementary Information is linked to the online version of the paper at /nature.Author Information Correspondence and requests for materials should be addressed to A.-L.B.(e-mail:alb@)[1]Horner,M.W.&O’Kelly,M.E.S Embedding economies of scale concepts for hub networks design.Journal of Transportation Geography9,255-265(2001).[2]Kitamura,R.,Chen,C.,Pendyala,R.M.&Narayaran,R.Micro-simulation of daily activity-travelpatterns for travel demand forecasting.Transportation27,25-51(2000).[3]Colizza,V.,Barrat,A.,Barth´e l´e my,M.,Valleron,A.-J.&Vespignani,A.Modeling the WorldwideSpread of Pandemic Influenza:Baseline Case and Containment Interventions.PLoS Medicine4,095-0110(2007).[4]Eubank,S.,Guclu,H.,Kumar,V.S.A.,Marathe,M.V.,Srinivasan,A.,Toroczkai,Z.&Wang,N.Controlling Epidemics in Realistic Urban Social Networks.Nature429,180(2004).[5]Hufnagel,L.,Brockmann,D.&Geisel,T.Forecast and control of epidemics in a globalized world.Proceedings of the National Academy of Sciences of the United States of America101,15124-15129 (2004).[6]Kleinberg,J.The wireless epidemic.Nature449,287-288(2007).[7] D.Brockmann,D.,Hufnagel,L.&Geisel,T.The scaling laws of human travel.Nature439,462-465(2006).[8]Havlin,S.&ben-Avraham,D.Diffusion in Disordered Media.Advances in Physics51,187-292(2002).[9]Viswanathan,G.M.,Afanasyev,V.,Buldyrev,S.V.,Murphy,E.J.,Prince,P.A.&Stanley,H.E.L´e vyFlight Search Patterns of Wandering Albatrosses.Nature381,413-415(1996).[10]Ramos-Fernandez,G.,Mateos,J.L.,Miramontes,O.,Cocho,G.,Larralde,H.&Ayala-Orozco,B.,L´e vy walk patterns in the foraging movements of spider monkeys(Ateles geoffroyi).Behavioral ecol-ogy and Sociobiology55,223-230(2004).[11]Sims D.W.et al.Scaling laws of marine predator search behaviour.Nature451,1098-1102(2008).[12]Klafter,J.,Shlesinger,M.F.&Zumofen,G.Beyond Brownian Motion.Physics Today49,33-39(1996).[13]Mantegna,R.N.&Stanley,H.E.Stochastic Process with Ultraslow Convergence to a Gaussian:TheTruncated L´e vy Flight.Physical Review Letters73,2946-2949(1994).[14]Edwards,A.M.,Phillips,R.A.,Watkins,N.W.,Freeman,M.P.,Murphy,E.J.,Afanasyev,V.,Buldyrev,S.V.,da Luz,M.G.E.,Raposo,E.P.,Stanley,H.E.&Viswanathan,G.M.Revisiting L´e vyflightsearch patterns of wandering albatrosses,bumblebees and deer.Nature449,1044-1049(2007). [15]Sohn,T.,Varshavsky,A.,LaMarca,A.,Chen,M.Y.,Choudhury,T.,Smith,I.,Consolvo,S.,High-tower,J.,Griswold,W.G.&de Lara,E.Lecture Notes in Computer Sciences:Proc.8th International Conference UbiComp2006.(Springer,Berlin,2006).[16]Onnela,J.-P.,Saram¨a ki,J.,Hyv¨o nen,J.,Szab´o,G.,Lazer,D.,Kaski,K.,Kert´e sz,K.&Barab´a si A.L.Structure and tie strengths in mobile communication networks.Proceedings of the National Academy of Sciences of the United States of America104,7332-7336(2007).[17]Gonz´a lez,M.C.&Barab´a si,plex networks:From data to models.Nature Physics3,224-225(2007).[18]Palla,G.,Barab´a si,A.-L.&Vicsek,T.Quantifying social group evolution.Nature446,664-667(2007).[19]Hidalgo C.A.&Rodriguez-Sickert C.The dynamics of a mobile phone network.Physica A387,3017-30224.[20]Barab´a si,A.-L.The origin of bursts and heavy tails in human dynamics.Nature435,207-211(2005).[21]Hughes,B.D.Random Walks and Random Environments.(Oxford University Press,USA,1995).[22]Redner,S.A Guide to First-Passage Processes.(Cambridge University Press,UK,2001).[23]Schlich,R.&Axhausen,K.W.Habitual travel behaviour:Evidence from a six-week travel diary.Transportation30,13-36(2003).[24]Eagle,N.&Pentland,A.Eigenbehaviours:Identifying Structure in Routine.submitted to BehavioralEcology and Sociobiology(2007).[25]Yook,S.-H.,Jeong,H.&Barab´a si A.L.Modeling the Internet’s large-scale topology.Proceedings ofthe Nat’l Academy of Sciences99,13382-13386(2002).[26]Caldarelli,G.Scale-Free Networks:Complex Webs in Nature and Technology.(Oxford UniversityPress,USA,2007).[27]Dorogovtsev,S.N.&Mendes,J.F.F.Evolution of Networks:From Biological Nets to the Internet andWWW.(Oxford University Press,USA,2003).[28]Song C.M.,Havlin S.&Makse H.A.Self-similarity of complex networks.Nature433,392-395(2005).[29]Gonz´a lez,M.C.,Lind,P.G.&Herrmann,H.J.A system of mobile agents to model social networks.Physical Review Letters96,088702(2006).[30]Cecconi,F.,Marsili,M.,Banavar,J.R.&Maritan,A.Diffusion,peer pressure,and tailed distributions.Physical Review Letters89,088102(2002).FIG.1:Basic human mobility patterns.a,Week-long trajectory of40mobile phone users indicate that most individuals travel only over short distances,but a few regularly move over hundreds of kilometers. Panel b,displays the detailed trajectory of a single user.The different phone towers are shown as green dots,and the V oronoi lattice in grey marks the approximate reception area of each tower.The dataset studied by us records only the identity of the closest tower to a mobile user,thus we can not identify the position of a user within a V oronoi cell.The trajectory of the user shown in b is constructed from186 two hourly reports,during which the user visited a total of12different locations(tower vicinities).Among these,the user is found96and67occasions in the two most preferred locations,the frequency of visits for each location being shown as a vertical bar.The circle represents the radius of gyration centered in the trajectory’s center of mass.c,Probability density function P(∆r)of travel distances obtained for the two studied datasets D1and D2.The solid line indicates a truncated power law whose parameters are provided in the text(see Eq.1).d,The distribution P(r g)of the radius of gyration measured for the users, where r g(T)was measured after T=6months of observation.The solid line represent a similar truncated power lawfit(see Eq.2).The dotted,dashed and dot-dashed curves show P(r g)obtained from the standard null models(RW,LF and T LF),where for the T LF we used the same step size distribution as the onemeasured for the mobile phone users.FIG.2:The bounded nature of human trajectories.a,Radius of gyration, r g(t) vs time for mobile phone users separated in three groups according to theirfinal r g(T),where T=6months.The black curves correspond to the analytical predictions for the random walk models,increasing in time as r g(t) |LF,T LF∼t3/2+β(solid),and r g(t) |RW∼t0.5(dotted).The dashed curves corresponding to a logarithmicfit of the form A+B ln(t),where A and B depend on r g.b,Probability density function of individual travel distances P(∆r|r g)for users with r g=4,10,40,100and200km.As the inset shows,each group displays a quite different P(∆r|r g)distribution.After rescaling the distance and the distribution with r g(main panel),the different curves collapse.The solid line(power law)is shown as a guide to the eye.c,Return probability distribution,F pt(t).The prominent peaks capture the tendency of humans to regularly return to the locations they visited before,in contrast with the smooth asymptotic behavior∼1/(t ln(t)2)(solid line)predicted for random walks.d,A Zipf plot showing the frequency of visiting different locations.The symbols correspond to users that have been observed to visit n L=5,10,30,and50different locations.Denoting with(L)the rank of the location listed in the order of the visit frequency,the data is well approximated by R(L)∼L−1. The inset is the same plot in linear scale,illustrating that40%of the time individuals are found at theirfirsttwo preferred locations.FIG.3:The shape of human trajectories.a,The probability density functionΦ(x,y)offinding a mobile phone user in a location(x,y)in the user’s intrinsic reference frame(see SM for details).The three plots, from left to right,were generated for10,000users with:r g≤3,20<r g≤30and r g>100km.The trajectories become more anisotropic as r g increases.b,After scaling each position withσx andσy theresulting˜Φ(x/σx,y/σy)has approximately the same shape for each group.c,The change in the shape of Φ(x,y)can be quantified calculating the isotropy ratio S≡σy/σx as a function of r g,which decreases as S∼r−0.12(solid line).Error bars represent the standard error.d,˜Φ(x/σx,0)representing the x-axis cross gsection of the rescaled distribution˜Φ(x/σx,y/σy)shown in b.。
2014 MCM Problems翻译

问题A:除非超车否则靠右行驶的交通规则在一些汽车靠右行驶的国家(比如美国,中国等等),多车道的高速公路常常遵循以下原则:司机必须在最右侧驾驶,除非他们正在超车,超车时必须先移到左侧车道在超车后再返回。
建立数学模型来分析这条规则在低负荷和高负荷状态下的交通路况的表现。
你不妨考察一下流量和安全的权衡问题,车速过高过低的限制,或者这个问题陈述中可能出现的其他因素。
这条规则在提升车流量的方面是否有效?如果不是,提出能够提升车流量、安全系数或其他因素的替代品(包括完全没有这种规律)并加以分析。
在一些国家,汽车靠左形式是常态,探讨你的解决方案是否稍作修改即可适用,或者需要一些额外的需要。
最后,以上规则依赖于人的判断,如果相同规则的交通运输完全在智能系统的控制下,无论是部分网络还是嵌入使用的车辆的设计,在何种程度上会修改你前面的结果?问题B:大学传奇教练体育画报是一个为运动爱好者服务的杂志,正在寻找在整个上个世纪的“史上最好的大学教练”。
建立数学模型选择大学中在一下体育项目中最好的教练:曲棍球或场地曲棍球,足球,棒球或垒球,篮球,足球。
时间轴在你的分析中是否会有影响?比如1913年的教练和2013年的教练是否会有所不同?清晰的对你的指标进行评估,讨论一下你的模型应用在跨越性别和所有可能对的体育项目中的效果。
展示你的模型中的在三种不同体育项目中的前五名教练。
除了传统的MCM格式,准备一个1到2页的文章给体育画报,解释你的结果和包括一个体育迷都明白的数学模型的非技术性解释。
ICM使用网络模型去测量影响力一种测量学术研究影响力的技术是建立和测量“引用”和相关作者的网络。
共同创作一个手稿通常意味着在研究者间存在很强的相关联系。
20世纪最著名的学术相关作者之一就是数学家Paul Erdös,他有超过500个相关作者,发表过1400篇论文。
这也许非常讽刺,Paul Erdös同样是跨学科科学网络研究的创始人之一,尤其通过他和Alfred Renyi的1959年《在随机图》这篇论文,Erdös作为一个合作者的角色在数学领域是至关重要的,数学家们经常会通过分析Erdös的令人惊奇的广大的相关作者网络测量他们和Erdös的亲密程度(closeness)(看这个网站see the website /enp/)。
stochastic calculus for fractional brownian motion and related processes附录

kH (t, u)dWu = CH Γ (1 + α)
(2)
R
α (I− 1(0,t) )(x)dWx
(see Lemma 1.1.3). Therefore, the first equality is evident, since
0 R t
(kH (t, u))2 x)α )2 dx +
k n
2H
2
.
C . n2
(B.0.12)
References
[AOPU00] Aase, K., Øksendal, B., Privault, N., Ubøe, J.: White noise generalization of the Clark-Haussmann-Ocone theorem with applications to mathematical finance. Finance Stoch., 4, 465–496 (2000) [AS96] Abry, P., Sellan, F.: The wavelet-based synthesis for fractional Brownian motion proposed by F. Sellan and Y. Meyer: Remarks and fast implementation. Appl. Comp. Harmon. Analysis, 3, 377–383 (1996) [AS95] Adler, R.J.; Samorodnitsky, G.: Super fractional Brownian motion, fractional super Brownian motion and related self-similar (super) processes. Ann. Prob., 23, 743–766 (1995) [ALN01] Al` os, E., Le´ on, I.A., Nualart, D.: Stratonovich stochastic calculus with respect to fractional Brownian motion with Hurst parameter less than 1/2. Taiwanesse J. Math., 5, 609–632 (2001) [AMN00] Al` os, E., Mazet, O., Nualart, D.: Stochastic calculus with respect to fractional Brownian motion with Hurst parameter less than 1/2. Stoch. Proc. Appl., 86, 121–139 (2000) [AMN01] Al` os, E., Mazet, O., Nualart, D.: Stochastic calculus with respect to Gaussian processes. Ann. Prob., 29, 766–801 (2001) [AN02] Al` os, E., Nualart, D.: Stochastic integration with respect to the fractional Brownian motion. Stoch. Stoch. Rep., 75, 129–152 (2002) [And05] Androshchuk, T.: The approximation of stochastic integral w.r.t. fBm by the integrals w.r.t. absolutely continuous processes. Prob. Theory Math. Stat., 73, 11–20 (2005) [AM06] Androshchuk, T., Mishura Y.: Mixed Brownian–fractional Brownian model: absence of arbitrage and related topics. Stochastics: Intern. J. Prob. Stoch. Proc., 78, 281–300 (2006) [AG03] Anh, V., Grecksch, W.: A fractional stochastic evolution equation driven by fractional Brownian motion. Monte Carlo Methods Appl. 9, 189–199 (2003)
BinomialLinkFunctions:二项链接功能

following table:
Example (continued)
> beetle<-read.table("BeetleData.txt",header=TRUE)
> head(beetle)
Dose Num.Beetles Num.Killed
(Intercept) -34.935
2.648 -13.19 <2e-16 ***
Dose
19.728
1.487 13.27 <2e-16 ***
--Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
yi
i 1
n
e
xi T ˆ
• Logit:
pˆ i
• Probit:
pˆ i ( xiT ˆ )
• C Log Log:
pˆ i 1 exp{ exp[ xiT ˆ ]}
1 e
xi T ˆ
Differences in Link Functions
probLowerlogit <- vector(length=1000)
family = binomial) > summary(logitmodel)
> probitmodel<-glm(cbind(Num.Killed,Num.Beetles-Num.Killed) ~ Dose, data = beetle,
Finding community structure in networks using the eigenvectors of matrices

M. E. J. Newman
Department of Physics and Center for the Study of Complex Systems, University of Michigan, Ann Arbor, MI 48109–1040
We consider the problem of detecting communities or modules in networks, groups of vertices with a higher-than-average density of edges connecting them. Previous work indicates that a robust approach to this problem is the maximization of the benefit function known as “modularity” over possible divisions of a network. Here we show that this maximization process can be written in terms of the eigenspectrum of a matrix we call the modularity matrix, which plays a role in community detection similar to that played by the graph Laplacian in graph partitioning calculations. This result leads us to a number of possible algorithms for detecting community structure, as well as several other results, including a spectral measure of bipartite structure in neteasure that identifies those vertices that occupy central positions within the communities to which they belong. The algorithms and measures proposed are illustrated with applications to a variety of real-world complex networks.
From Data Mining to Knowledge Discovery in Databases

s Data mining and knowledge discovery in databases have been attracting a significant amount of research, industry, and media atten-tion of late. What is all the excitement about?This article provides an overview of this emerging field, clarifying how data mining and knowledge discovery in databases are related both to each other and to related fields, such as machine learning, statistics, and databases. The article mentions particular real-world applications, specific data-mining techniques, challenges in-volved in real-world applications of knowledge discovery, and current and future research direc-tions in the field.A cross a wide variety of fields, data arebeing collected and accumulated at adramatic pace. There is an urgent need for a new generation of computational theo-ries and tools to assist humans in extracting useful information (knowledge) from the rapidly growing volumes of digital data. These theories and tools are the subject of the emerging field of knowledge discovery in databases (KDD).At an abstract level, the KDD field is con-cerned with the development of methods and techniques for making sense of data. The basic problem addressed by the KDD process is one of mapping low-level data (which are typically too voluminous to understand and digest easi-ly) into other forms that might be more com-pact (for example, a short report), more ab-stract (for example, a descriptive approximation or model of the process that generated the data), or more useful (for exam-ple, a predictive model for estimating the val-ue of future cases). At the core of the process is the application of specific data-mining meth-ods for pattern discovery and extraction.1This article begins by discussing the histori-cal context of KDD and data mining and theirintersection with other related fields. A briefsummary of recent KDD real-world applica-tions is provided. Definitions of KDD and da-ta mining are provided, and the general mul-tistep KDD process is outlined. This multistepprocess has the application of data-mining al-gorithms as one particular step in the process.The data-mining step is discussed in more de-tail in the context of specific data-mining al-gorithms and their application. Real-worldpractical application issues are also outlined.Finally, the article enumerates challenges forfuture research and development and in par-ticular discusses potential opportunities for AItechnology in KDD systems.Why Do We Need KDD?The traditional method of turning data intoknowledge relies on manual analysis and in-terpretation. For example, in the health-careindustry, it is common for specialists to peri-odically analyze current trends and changesin health-care data, say, on a quarterly basis.The specialists then provide a report detailingthe analysis to the sponsoring health-care or-ganization; this report becomes the basis forfuture decision making and planning forhealth-care management. In a totally differ-ent type of application, planetary geologistssift through remotely sensed images of plan-ets and asteroids, carefully locating and cata-loging such geologic objects of interest as im-pact craters. Be it science, marketing, finance,health care, retail, or any other field, the clas-sical approach to data analysis relies funda-mentally on one or more analysts becomingArticlesFALL 1996 37From Data Mining to Knowledge Discovery inDatabasesUsama Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth Copyright © 1996, American Association for Artificial Intelligence. All rights reserved. 0738-4602-1996 / $2.00areas is astronomy. Here, a notable success was achieved by SKICAT ,a system used by as-tronomers to perform image analysis,classification, and cataloging of sky objects from sky-survey images (Fayyad, Djorgovski,and Weir 1996). In its first application, the system was used to process the 3 terabytes (1012bytes) of image data resulting from the Second Palomar Observatory Sky Survey,where it is estimated that on the order of 109sky objects are detectable. SKICAT can outper-form humans and traditional computational techniques in classifying faint sky objects. See Fayyad, Haussler, and Stolorz (1996) for a sur-vey of scientific applications.In business, main KDD application areas includes marketing, finance (especially in-vestment), fraud detection, manufacturing,telecommunications, and Internet agents.Marketing:In marketing, the primary ap-plication is database marketing systems,which analyze customer databases to identify different customer groups and forecast their behavior. Business Week (Berry 1994) estimat-ed that over half of all retailers are using or planning to use database marketing, and those who do use it have good results; for ex-ample, American Express reports a 10- to 15-percent increase in credit-card use. Another notable marketing application is market-bas-ket analysis (Agrawal et al. 1996) systems,which find patterns such as, “If customer bought X, he/she is also likely to buy Y and Z.” Such patterns are valuable to retailers.Investment: Numerous companies use da-ta mining for investment, but most do not describe their systems. One exception is LBS Capital Management. Its system uses expert systems, neural nets, and genetic algorithms to manage portfolios totaling $600 million;since its start in 1993, the system has outper-formed the broad stock market (Hall, Mani,and Barr 1996).Fraud detection: HNC Falcon and Nestor PRISM systems are used for monitoring credit-card fraud, watching over millions of ac-counts. The FAIS system (Senator et al. 1995),from the U.S. Treasury Financial Crimes En-forcement Network, is used to identify finan-cial transactions that might indicate money-laundering activity.Manufacturing: The CASSIOPEE trou-bleshooting system, developed as part of a joint venture between General Electric and SNECMA, was applied by three major Euro-pean airlines to diagnose and predict prob-lems for the Boeing 737. To derive families of faults, clustering methods are used. CASSIOPEE received the European first prize for innova-intimately familiar with the data and serving as an interface between the data and the users and products.For these (and many other) applications,this form of manual probing of a data set is slow, expensive, and highly subjective. In fact, as data volumes grow dramatically, this type of manual data analysis is becoming completely impractical in many domains.Databases are increasing in size in two ways:(1) the number N of records or objects in the database and (2) the number d of fields or at-tributes to an object. Databases containing on the order of N = 109objects are becoming in-creasingly common, for example, in the as-tronomical sciences. Similarly, the number of fields d can easily be on the order of 102or even 103, for example, in medical diagnostic applications. Who could be expected to di-gest millions of records, each having tens or hundreds of fields? We believe that this job is certainly not one for humans; hence, analysis work needs to be automated, at least partially.The need to scale up human analysis capa-bilities to handling the large number of bytes that we can collect is both economic and sci-entific. Businesses use data to gain competi-tive advantage, increase efficiency, and pro-vide more valuable services to customers.Data we capture about our environment are the basic evidence we use to build theories and models of the universe we live in. Be-cause computers have enabled humans to gather more data than we can digest, it is on-ly natural to turn to computational tech-niques to help us unearth meaningful pat-terns and structures from the massive volumes of data. Hence, KDD is an attempt to address a problem that the digital informa-tion era made a fact of life for all of us: data overload.Data Mining and Knowledge Discovery in the Real WorldA large degree of the current interest in KDD is the result of the media interest surrounding successful KDD applications, for example, the focus articles within the last two years in Business Week , Newsweek , Byte , PC Week , and other large-circulation periodicals. Unfortu-nately, it is not always easy to separate fact from media hype. Nonetheless, several well-documented examples of successful systems can rightly be referred to as KDD applications and have been deployed in operational use on large-scale real-world problems in science and in business.In science, one of the primary applicationThere is an urgent need for a new generation of computation-al theories and tools toassist humans in extractinguseful information (knowledge)from the rapidly growing volumes ofdigital data.Articles38AI MAGAZINEtive applications (Manago and Auriol 1996).Telecommunications: The telecommuni-cations alarm-sequence analyzer (TASA) wasbuilt in cooperation with a manufacturer oftelecommunications equipment and threetelephone networks (Mannila, Toivonen, andVerkamo 1995). The system uses a novelframework for locating frequently occurringalarm episodes from the alarm stream andpresenting them as rules. Large sets of discov-ered rules can be explored with flexible infor-mation-retrieval tools supporting interactivityand iteration. In this way, TASA offers pruning,grouping, and ordering tools to refine the re-sults of a basic brute-force search for rules.Data cleaning: The MERGE-PURGE systemwas applied to the identification of duplicatewelfare claims (Hernandez and Stolfo 1995).It was used successfully on data from the Wel-fare Department of the State of Washington.In other areas, a well-publicized system isIBM’s ADVANCED SCOUT,a specialized data-min-ing system that helps National Basketball As-sociation (NBA) coaches organize and inter-pret data from NBA games (U.S. News 1995). ADVANCED SCOUT was used by several of the NBA teams in 1996, including the Seattle Su-personics, which reached the NBA finals.Finally, a novel and increasingly importanttype of discovery is one based on the use of in-telligent agents to navigate through an infor-mation-rich environment. Although the ideaof active triggers has long been analyzed in thedatabase field, really successful applications ofthis idea appeared only with the advent of theInternet. These systems ask the user to specifya profile of interest and search for related in-formation among a wide variety of public-do-main and proprietary sources. For example, FIREFLY is a personal music-recommendation agent: It asks a user his/her opinion of several music pieces and then suggests other music that the user might like (<http:// www.ffl/>). CRAYON(/>) allows users to create their own free newspaper (supported by ads); NEWSHOUND(<http://www. /hound/>) from the San Jose Mercury News and FARCAST(</> automatically search information from a wide variety of sources, including newspapers and wire services, and e-mail rele-vant documents directly to the user.These are just a few of the numerous suchsystems that use KDD techniques to automat-ically produce useful information from largemasses of raw data. See Piatetsky-Shapiro etal. (1996) for an overview of issues in devel-oping industrial KDD applications.Data Mining and KDDHistorically, the notion of finding useful pat-terns in data has been given a variety ofnames, including data mining, knowledge ex-traction, information discovery, informationharvesting, data archaeology, and data patternprocessing. The term data mining has mostlybeen used by statisticians, data analysts, andthe management information systems (MIS)communities. It has also gained popularity inthe database field. The phrase knowledge dis-covery in databases was coined at the first KDDworkshop in 1989 (Piatetsky-Shapiro 1991) toemphasize that knowledge is the end productof a data-driven discovery. It has been popular-ized in the AI and machine-learning fields.In our view, KDD refers to the overall pro-cess of discovering useful knowledge from da-ta, and data mining refers to a particular stepin this process. Data mining is the applicationof specific algorithms for extracting patternsfrom data. The distinction between the KDDprocess and the data-mining step (within theprocess) is a central point of this article. Theadditional steps in the KDD process, such asdata preparation, data selection, data cleaning,incorporation of appropriate prior knowledge,and proper interpretation of the results ofmining, are essential to ensure that usefulknowledge is derived from the data. Blind ap-plication of data-mining methods (rightly crit-icized as data dredging in the statistical litera-ture) can be a dangerous activity, easilyleading to the discovery of meaningless andinvalid patterns.The Interdisciplinary Nature of KDDKDD has evolved, and continues to evolve,from the intersection of research fields such asmachine learning, pattern recognition,databases, statistics, AI, knowledge acquisitionfor expert systems, data visualization, andhigh-performance computing. The unifyinggoal is extracting high-level knowledge fromlow-level data in the context of large data sets.The data-mining component of KDD cur-rently relies heavily on known techniquesfrom machine learning, pattern recognition,and statistics to find patterns from data in thedata-mining step of the KDD process. A natu-ral question is, How is KDD different from pat-tern recognition or machine learning (and re-lated fields)? The answer is that these fieldsprovide some of the data-mining methodsthat are used in the data-mining step of theKDD process. KDD focuses on the overall pro-cess of knowledge discovery from data, includ-ing how the data are stored and accessed, howalgorithms can be scaled to massive data setsThe basicproblemaddressed bythe KDDprocess isone ofmappinglow-leveldata intoother formsthat might bemorecompact,moreabstract,or moreuseful.ArticlesFALL 1996 39A driving force behind KDD is the database field (the second D in KDD). Indeed, the problem of effective data manipulation when data cannot fit in the main memory is of fun-damental importance to KDD. Database tech-niques for gaining efficient data access,grouping and ordering operations when ac-cessing data, and optimizing queries consti-tute the basics for scaling algorithms to larger data sets. Most data-mining algorithms from statistics, pattern recognition, and machine learning assume data are in the main memo-ry and pay no attention to how the algorithm breaks down if only limited views of the data are possible.A related field evolving from databases is data warehousing,which refers to the popular business trend of collecting and cleaning transactional data to make them available for online analysis and decision support. Data warehousing helps set the stage for KDD in two important ways: (1) data cleaning and (2)data access.Data cleaning: As organizations are forced to think about a unified logical view of the wide variety of data and databases they pos-sess, they have to address the issues of map-ping data to a single naming convention,uniformly representing and handling missing data, and handling noise and errors when possible.Data access: Uniform and well-defined methods must be created for accessing the da-ta and providing access paths to data that were historically difficult to get to (for exam-ple, stored offline).Once organizations and individuals have solved the problem of how to store and ac-cess their data, the natural next step is the question, What else do we do with all the da-ta? This is where opportunities for KDD natu-rally arise.A popular approach for analysis of data warehouses is called online analytical processing (OLAP), named for a set of principles pro-posed by Codd (1993). OLAP tools focus on providing multidimensional data analysis,which is superior to SQL in computing sum-maries and breakdowns along many dimen-sions. OLAP tools are targeted toward simpli-fying and supporting interactive data analysis,but the goal of KDD tools is to automate as much of the process as possible. Thus, KDD is a step beyond what is currently supported by most standard database systems.Basic DefinitionsKDD is the nontrivial process of identifying valid, novel, potentially useful, and ultimate-and still run efficiently, how results can be in-terpreted and visualized, and how the overall man-machine interaction can usefully be modeled and supported. The KDD process can be viewed as a multidisciplinary activity that encompasses techniques beyond the scope of any one particular discipline such as machine learning. In this context, there are clear opportunities for other fields of AI (be-sides machine learning) to contribute to KDD. KDD places a special emphasis on find-ing understandable patterns that can be inter-preted as useful or interesting knowledge.Thus, for example, neural networks, although a powerful modeling tool, are relatively difficult to understand compared to decision trees. KDD also emphasizes scaling and ro-bustness properties of modeling algorithms for large noisy data sets.Related AI research fields include machine discovery, which targets the discovery of em-pirical laws from observation and experimen-tation (Shrager and Langley 1990) (see Kloes-gen and Zytkow [1996] for a glossary of terms common to KDD and machine discovery),and causal modeling for the inference of causal models from data (Spirtes, Glymour,and Scheines 1993). Statistics in particular has much in common with KDD (see Elder and Pregibon [1996] and Glymour et al.[1996] for a more detailed discussion of this synergy). Knowledge discovery from data is fundamentally a statistical endeavor. Statistics provides a language and framework for quan-tifying the uncertainty that results when one tries to infer general patterns from a particu-lar sample of an overall population. As men-tioned earlier, the term data mining has had negative connotations in statistics since the 1960s when computer-based data analysis techniques were first introduced. The concern arose because if one searches long enough in any data set (even randomly generated data),one can find patterns that appear to be statis-tically significant but, in fact, are not. Clearly,this issue is of fundamental importance to KDD. Substantial progress has been made in recent years in understanding such issues in statistics. Much of this work is of direct rele-vance to KDD. Thus, data mining is a legiti-mate activity as long as one understands how to do it correctly; data mining carried out poorly (without regard to the statistical as-pects of the problem) is to be avoided. KDD can also be viewed as encompassing a broader view of modeling than statistics. KDD aims to provide tools to automate (to the degree pos-sible) the entire process of data analysis and the statistician’s “art” of hypothesis selection.Data mining is a step in the KDD process that consists of ap-plying data analysis and discovery al-gorithms that produce a par-ticular enu-meration ofpatterns (or models)over the data.Articles40AI MAGAZINEly understandable patterns in data (Fayyad, Piatetsky-Shapiro, and Smyth 1996).Here, data are a set of facts (for example, cases in a database), and pattern is an expres-sion in some language describing a subset of the data or a model applicable to the subset. Hence, in our usage here, extracting a pattern also designates fitting a model to data; find-ing structure from data; or, in general, mak-ing any high-level description of a set of data. The term process implies that KDD comprises many steps, which involve data preparation, search for patterns, knowledge evaluation, and refinement, all repeated in multiple itera-tions. By nontrivial, we mean that some search or inference is involved; that is, it is not a straightforward computation of predefined quantities like computing the av-erage value of a set of numbers.The discovered patterns should be valid on new data with some degree of certainty. We also want patterns to be novel (at least to the system and preferably to the user) and poten-tially useful, that is, lead to some benefit to the user or task. Finally, the patterns should be understandable, if not immediately then after some postprocessing.The previous discussion implies that we can define quantitative measures for evaluating extracted patterns. In many cases, it is possi-ble to define measures of certainty (for exam-ple, estimated prediction accuracy on new data) or utility (for example, gain, perhaps indollars saved because of better predictions orspeedup in response time of a system). No-tions such as novelty and understandabilityare much more subjective. In certain contexts,understandability can be estimated by sim-plicity (for example, the number of bits to de-scribe a pattern). An important notion, calledinterestingness(for example, see Silberschatzand Tuzhilin [1995] and Piatetsky-Shapiro andMatheus [1994]), is usually taken as an overallmeasure of pattern value, combining validity,novelty, usefulness, and simplicity. Interest-ingness functions can be defined explicitly orcan be manifested implicitly through an or-dering placed by the KDD system on the dis-covered patterns or models.Given these notions, we can consider apattern to be knowledge if it exceeds some in-terestingness threshold, which is by nomeans an attempt to define knowledge in thephilosophical or even the popular view. As amatter of fact, knowledge in this definition ispurely user oriented and domain specific andis determined by whatever functions andthresholds the user chooses.Data mining is a step in the KDD processthat consists of applying data analysis anddiscovery algorithms that, under acceptablecomputational efficiency limitations, pro-duce a particular enumeration of patterns (ormodels) over the data. Note that the space ofArticlesFALL 1996 41Figure 1. An Overview of the Steps That Compose the KDD Process.methods, the effective number of variables under consideration can be reduced, or in-variant representations for the data can be found.Fifth is matching the goals of the KDD pro-cess (step 1) to a particular data-mining method. For example, summarization, clas-sification, regression, clustering, and so on,are described later as well as in Fayyad, Piatet-sky-Shapiro, and Smyth (1996).Sixth is exploratory analysis and model and hypothesis selection: choosing the data-mining algorithm(s) and selecting method(s)to be used for searching for data patterns.This process includes deciding which models and parameters might be appropriate (for ex-ample, models of categorical data are differ-ent than models of vectors over the reals) and matching a particular data-mining method with the overall criteria of the KDD process (for example, the end user might be more in-terested in understanding the model than its predictive capabilities).Seventh is data mining: searching for pat-terns of interest in a particular representa-tional form or a set of such representations,including classification rules or trees, regres-sion, and clustering. The user can significant-ly aid the data-mining method by correctly performing the preceding steps.Eighth is interpreting mined patterns, pos-sibly returning to any of steps 1 through 7 for further iteration. This step can also involve visualization of the extracted patterns and models or visualization of the data given the extracted models.Ninth is acting on the discovered knowl-edge: using the knowledge directly, incorpo-rating the knowledge into another system for further action, or simply documenting it and reporting it to interested parties. This process also includes checking for and resolving po-tential conflicts with previously believed (or extracted) knowledge.The KDD process can involve significant iteration and can contain loops between any two steps. The basic flow of steps (al-though not the potential multitude of itera-tions and loops) is illustrated in figure 1.Most previous work on KDD has focused on step 7, the data mining. However, the other steps are as important (and probably more so) for the successful application of KDD in practice. Having defined the basic notions and introduced the KDD process, we now focus on the data-mining component,which has, by far, received the most atten-tion in the literature.patterns is often infinite, and the enumera-tion of patterns involves some form of search in this space. Practical computational constraints place severe limits on the sub-space that can be explored by a data-mining algorithm.The KDD process involves using the database along with any required selection,preprocessing, subsampling, and transforma-tions of it; applying data-mining methods (algorithms) to enumerate patterns from it;and evaluating the products of data mining to identify the subset of the enumerated pat-terns deemed knowledge. The data-mining component of the KDD process is concerned with the algorithmic means by which pat-terns are extracted and enumerated from da-ta. The overall KDD process (figure 1) in-cludes the evaluation and possible interpretation of the mined patterns to de-termine which patterns can be considered new knowledge. The KDD process also in-cludes all the additional steps described in the next section.The notion of an overall user-driven pro-cess is not unique to KDD: analogous propos-als have been put forward both in statistics (Hand 1994) and in machine learning (Brod-ley and Smyth 1996).The KDD ProcessThe KDD process is interactive and iterative,involving numerous steps with many deci-sions made by the user. Brachman and Anand (1996) give a practical view of the KDD pro-cess, emphasizing the interactive nature of the process. Here, we broadly outline some of its basic steps:First is developing an understanding of the application domain and the relevant prior knowledge and identifying the goal of the KDD process from the customer’s viewpoint.Second is creating a target data set: select-ing a data set, or focusing on a subset of vari-ables or data samples, on which discovery is to be performed.Third is data cleaning and preprocessing.Basic operations include removing noise if appropriate, collecting the necessary informa-tion to model or account for noise, deciding on strategies for handling missing data fields,and accounting for time-sequence informa-tion and known changes.Fourth is data reduction and projection:finding useful features to represent the data depending on the goal of the task. With di-mensionality reduction or transformationArticles42AI MAGAZINEThe Data-Mining Stepof the KDD ProcessThe data-mining component of the KDD pro-cess often involves repeated iterative applica-tion of particular data-mining methods. This section presents an overview of the primary goals of data mining, a description of the methods used to address these goals, and a brief description of the data-mining algo-rithms that incorporate these methods.The knowledge discovery goals are defined by the intended use of the system. We can distinguish two types of goals: (1) verification and (2) discovery. With verification,the sys-tem is limited to verifying the user’s hypothe-sis. With discovery,the system autonomously finds new patterns. We further subdivide the discovery goal into prediction,where the sys-tem finds patterns for predicting the future behavior of some entities, and description, where the system finds patterns for presenta-tion to a user in a human-understandableform. In this article, we are primarily con-cerned with discovery-oriented data mining.Data mining involves fitting models to, or determining patterns from, observed data. The fitted models play the role of inferred knowledge: Whether the models reflect useful or interesting knowledge is part of the over-all, interactive KDD process where subjective human judgment is typically required. Two primary mathematical formalisms are used in model fitting: (1) statistical and (2) logical. The statistical approach allows for nondeter-ministic effects in the model, whereas a logi-cal model is purely deterministic. We focus primarily on the statistical approach to data mining, which tends to be the most widely used basis for practical data-mining applica-tions given the typical presence of uncertain-ty in real-world data-generating processes.Most data-mining methods are based on tried and tested techniques from machine learning, pattern recognition, and statistics: classification, clustering, regression, and so on. The array of different algorithms under each of these headings can often be bewilder-ing to both the novice and the experienced data analyst. It should be emphasized that of the many data-mining methods advertised in the literature, there are really only a few fun-damental techniques. The actual underlying model representation being used by a particu-lar method typically comes from a composi-tion of a small number of well-known op-tions: polynomials, splines, kernel and basis functions, threshold-Boolean functions, and so on. Thus, algorithms tend to differ primar-ily in the goodness-of-fit criterion used toevaluate model fit or in the search methodused to find a good fit.In our brief overview of data-mining meth-ods, we try in particular to convey the notionthat most (if not all) methods can be viewedas extensions or hybrids of a few basic tech-niques and principles. We first discuss the pri-mary methods of data mining and then showthat the data- mining methods can be viewedas consisting of three primary algorithmiccomponents: (1) model representation, (2)model evaluation, and (3) search. In the dis-cussion of KDD and data-mining methods,we use a simple example to make some of thenotions more concrete. Figure 2 shows a sim-ple two-dimensional artificial data set consist-ing of 23 cases. Each point on the graph rep-resents a person who has been given a loanby a particular bank at some time in the past.The horizontal axis represents the income ofthe person; the vertical axis represents the to-tal personal debt of the person (mortgage, carpayments, and so on). The data have beenclassified into two classes: (1) the x’s repre-sent persons who have defaulted on theirloans and (2) the o’s represent persons whoseloans are in good status with the bank. Thus,this simple artificial data set could represent ahistorical data set that can contain usefulknowledge from the point of view of thebank making the loans. Note that in actualKDD applications, there are typically manymore dimensions (as many as several hun-dreds) and many more data points (manythousands or even millions).ArticlesFALL 1996 43Figure 2. A Simple Data Set with Two Classes Used for Illustrative Purposes.。
Effect of alloying elements on the microstructure and mechanical properties of nanostructured

LetterEffect of alloying elements on the microstructure and mechanical properties of nanostructured ferritic steels produced by spark plasmasinteringSomayeh Pasebani,Indrajit Charit ⇑Department of Chemical and Materials Engineering,University of Idaho,Moscow,ID 83844,USAa r t i c l e i n f o Article history:Received 23November 2013Received in revised form 23January 2014Accepted 29January 2014Available online 15February 2014Keywords:NanostructuresMechanical alloying Powder metallurgyTransmission electron microscopy High temperature alloya b s t r a c tSeveral Fe–14Cr based alloys with varying compositions were processed using a combined route of mechanical alloying and spark plasma sintering.Microstructural characteristics of the consolidated alloys were examined via transmission electron microscopy and atom probe tomography,and mechanical prop-erties evaluated using microhardness nthanum oxide (0.5wt.%)was added to Fe–14Cr leading to improvement in microstructural stability and mechanical properties mainly due to a high number den-sity of La–Cr–O-enriched nanoclusters.The combined addition of La,Ti (1wt.%)and Mo (0.3wt.%)to the Fe–14Cr base composition further enhanced the microstructural stability and mechanical properties.Nanoclusters enriched in Cr–Ti–La–O with a number density of 1.4Â1024m À3were found in this alloy with a bimodal grain size distribution.After adding Y 2O 3(0.3wt.%)along with Ti and Mo to the Fe–14Cr matrix,a high number density (1.5Â1024m À3)of Cr–Ti–Y–O-enriched NCs was also detected.For-mation mechanism of these nanoclusters can be explained through the concentrations and diffusion rates of the initial oxide species formed during the milling process and initial stages of sintering as well as the thermodynamic nucleation barrier and their enthalpy of formation.Ó2014Elsevier B.V.All rights reserved.1.IntroductionNanostructured ferritic steels (NFSs),a subcategory of oxide dis-persion strengthened (ODS)steels,have outstanding high temper-ature strength,creep strength [1,2]and excellent radiation damage resistance [3].These enhanced properties of NFSs have been attrib-uted to the high number density of Y–Ti–O-enriched nanoclusters (NCs)with diameter of 1–2nm [4].The Y–Ti–O-enriched NCs have been found to be stable under irradiation and effective in trapping helium [5].These NCs are formed due to the mechanical alloying (MA)of Fe–Cr–Ti powder with Y 2O 3during high energy ball milling followed by hot consolidation route such as hot isostatic pressing (HIP)or hot extrusion [6–8].Alinger et al.[4]have investigated the effect of alloying elements on the formation mechanism of NCs in NFSs processed by hot isostatic pressing (HIP)and reported both Ti and high milling energy were necessary for the formation of ler and Parish [9]suggested that the excellent creep properties in yttria-bearing NFSs result from the pinning of thegrain boundaries by a combined effect of solute segregation and precipitation.Although HIP and hot extrusion are commonly used to consoli-date the NFSs,anisotropic properties and processing costs are con-sidered challenging issues.Recently,spark plasma sintering (SPS)has been utilized to sinter the powder at a higher heating rate,low-er temperature and shorter dwell time.This can be done by apply-ing a uniaxial pressure and direct current pulses simultaneously to a powder sample contained in a graphite die [10].Except for a few studies on consolidation of simple systems such as Fe–9Cr–0.3/0.6Y 2O 3[11]and Fe–14Cr–0.3Y 2O 3[10],the SPS process has not been extensively utilized to consolidate the NFSs with complex compositions.Recently,the role of Ti and Y 2O 3in processing of Fe–16Cr–3Al–1Ti–0.5Y 2O 3(wt.%)via MA and SPS was investigated by Allahar et al.[12].A bimodal grain size distribution in conjunc-tion with Y–Ti–O-enriched NCs were obtained [12,13].In this study,Fe–14Cr (wt.%)was designed as the base or matrix alloy,and then Ti,La 2O 3and Mo were sequentially added to the ferritic matrix and ball milled.This approach allowed us to study the effect of individual and combined addition of solutes on the formation of NCs along with other microstructural evolutions.Furthermore,SPS instead of other traditional consolidation methods was used to consolidate the NFS powder.The mixture/10.1016/j.jallcom.2014.01.2430925-8388/Ó2014Elsevier B.V.All rights reserved.⇑Corresponding author.Tel.:+12088855964;fax:+12088857462.E-mail address:icharit@ (I.Charit).of Fe–Cr–Ti–Mo powder with Y2O3was also processed and characterized in a similar manner for comparison with the rest of the developed alloys.2.ExperimentalThe chemical compositions of all the developed alloys along with their identi-fying names in this study are given in Table1.High energy ball milling was per-formed in a SPEX8000M shaker mill for10h using Ar atmosphere with the milling media as steel balls of8mm in diameter and a ball to powder ratio(BPR) of10:1.A Dr.Sinter Lab SPS-515S was used to consolidate the as-milled powder at different temperatures(850,950and1050°C)for7min using the pulse pattern 12–2ms,a heating rate of100°C/min and a pressure of80MPa.The SPSed samples were in the form of disks with8mm in height and12mm in diameter.The density of the sintered specimens was measured by Archimedes’method. Vickers microhardness tests were performed using a Leco LM100microhardness tester operated at a load of1000g–f(9.8N).A Fischione Model110Twin-Jet Elec-tropolisher containing a mixture of CH3OH–HNO3(80:20by vol.%)as the electrolyte and operated at aboutÀ40°C was used to prepare specimens for transmission elec-tron microscopy(TEM).A FEI Tecnai TF30–FEG STEM operating at300kV was used. The energy dispersive spectroscopy(EDS)attached with the STEM was used to roughly examine the chemical composition of the particles.A Quanta3D FEG instrument with a Ga-ion source focused ion beam(FIB)was used to prepare spec-imens for atom probe tomography(APT)studies on14L,14LMT and14YMT sam-ples.The APT analysis was carried out using a CAMECA LEAP4000X HR instrument operating in the voltage mode at50–60K and20%of the standing volt-age pulse fraction.The atom maps were reconstructed using CAMECA IVAS3.6soft-ware and the maximum separation algorithm to estimate the size and chemical composition of NCs.This was applied to APT datasets each containing20–30million ions for each specimen.Lower evaporationfield of the nanoparticles and trajectory aberrations caused estimation of higher Fe atoms in the nanoclusters.Although the contribution of Fe atoms from the matrix was examined here,the matrix-correction was not addressed in this study.3.Results and discussionThe TEM brightfield micrographs for the various alloys SPSed at 950°C for7min are illustrated in Fig.1a–d.The microstructure of 14Cr alloy shown in Fig.1a revealed a complex microstructure with submicron subgrain-like structures,relatively high density of dislocations and low number density of oxide nanoparticles. The nanoparticles were larger(25–65nm)than the other SPSed al-loys and found to have chemical compositions close to Cr2O3and FeCr2O4as analyzed by energy dispersive spectroscopy.The microstructure of the consolidated14L alloy is shown in Fig.1b.The microstructure consisted of more ultrafine grains (<1l m but>100nm),a few nanograins with sharp boundaries and a higher number of nanoparticles mainly in the grain interiors. The number density of nanoparticles was higher than that of14Cr alloy shown in Fig.1a but lower than14LMT(Fig.1c)and14YMT (Fig.1d).In14L alloy,the nanoparticles with2–11nm in diameter were found inside the grains(hard to be observed at magnification given in Fig.1b and micrographs taken at higher magnifications was used for this purpose)whereas the nanoparticles with 50–80nm in diameter were located at the grain boundary regions. The particles on the boundaries are likely to be mainly Cr2O3and LaCrO3,but the chemical analysis of those smallest particles could not be done precisely due to the significant influence of the ferritic matrix.Fig.1c shows the microstructure of the SPSed14LMT alloy, consisting of both ultrafine grains(as defined previously)and nanograins(6100nm).The nanoparticles present in the micro-structure were complex oxides of Fe,Cr and Ti.The nanoparticles with faceted morphology and smaller than10nm in diameter were enriched in La and Ti.No evidence of stoichiometric La2TiO5or La2Ti2O7particles was observed based on the EDS and diffraction data.A similar type of microstructure was revealed in the SPSed 14YMT alloy as shown in Fig.1d.The particle size distribution histograms of the14Cr,14L, 14LMT and14YMT alloys are plotted in Fig.2a–d,respectively. Approximately1000particles were sampled from each alloy to de-velop the histograms.The average particle size decreased in order of14Cr,14L,14LMT and14YMT.The highest fraction of the particle size as shown in the histograms of14Cr,14L,14LMT and14YMT was found to be associated with25±5nm(18±2.5%),10±5nm (28±3%),5±1nm(40±6%)and5±1nm(46±5%)in diameter, respectively.The number density of nanoparticles smaller than 5±1nm was higher in14YMT than14LMT alloy.The3-D APT maps for14L alloy revealed a number density (%3Â1022mÀ3)of CrO–La–O-enriched NCs.The average Guinier radius of these NCs was1.9±0.6nm.The average composition of the NCs in14L was estimated by using the maximum separation algorithm to be Fe–17.87±3.4Cr–32.61±3.2O–8.21±1.1La(at.%).A higher number density(%1.4Â1024mÀ3)and smaller NCs with average Guinier radius of 1.43±0.20nm were observed in the APT maps for14LMT alloy as shown in Fig.3a.The NCs were Cr–Ti–La–O-enriched with the average composition of Fe–10.9±2.8Cr–30.9±3.1O–17.3±2.5Ti–8.2±2.2La(at.%).According to the LEAP measurements,the chemical composition of NCs dif-fered considerably from stoichiometric oxides.A large amount of Fe and Cr was detected inside the NCs,and La/Ti and La/O ratios were not consistent with La2TiO5or La2Ti2O7as expected based on thermodynamic calculations,rather the ratios were sub-stoichi-ometric.The3-D APT maps for14YMT alloy were similar to14YMT alloy as shown in Fig.3b.The NCs with an average radius of 1.24±0.2nm and a number density of1.5Â1024mÀ3were Cr–Ti–Y–O-enriched.The chemical composition of NCs was estimated close to Fe–8.52±3.1Cr–37.39±4.5O–24.52±3.1Ti–10.95±3.1Y (at.%).The matrix-corrected compositions are currently being ana-lyzed and will be reported in a full-length publication in near future.The relative density of various alloys sintered at850–1050°C is shown in Fig.4a.Generally,a higher density was obtained in the specimens sintered at higher temperatures.At850and950°C, the density of unmilled14Cr specimen(97.2%and97.5%)was higher than the milled/SPSed14Cr(92.8%and95.5%)because the unmilled powder particles were less hard(due to absence of strain hardening)and plastically deformed to a higher degree than the milled powder leading to a higher density.Adding0.5and 0.7wt.%of La2O3and0.3wt.%Y2O3to the14Cr matrix significantly decreased the density of the specimen,especially at850and 950°C;however,adding Ti to14L and14Y improved the density to some extent.The microhardness data of various alloys processed at different temperatures are shown in Fig.4b.In general,microhardness in-creased with increasing SPS temperatures up to950°C and then decreased.Both Y and La increased the hardness due to the disper-sion hardening effect.The hardness increased at the higher content of La due to the greater effect of dispersion hardening.Adding Ti separately to the14Cr matrix improved the hardness due to theTable1The alloy compositions and processing conditions(milled for10h and SPSed at850-1050°C for7min).Alloy ID Elements(wt.%)Cr Ti La2O3Y2O3Mo Fe14Cr-unmilled140000Bal.14Cr140000Bal.14T141000Bal.14L1400.500Bal.14Y14000.30Bal.14LM1400.500.3Bal.14LT1410.500Bal.14LMT(0.3)1410.300.3Bal.14LMT1410.500.3Bal.14LMT(0.7)1410.700.3Bal.14YMT14100.30.3Bal.S.Pasebani,I.Charit/Journal of Alloys and Compounds599(2014)206–211207dispersion hardening but only at lower temperature(850°C).The coarsening of Ti-enriched particles at above850°C plausibly decreased the hardness.However,at950°C,higher hardness (457HV)was achieved by a combined addition of La and Ti toFig.2.Particle size frequency histogram for(a)14Cr,(b)14L,(c)14LMT and(d)14YMT alloys. Fig.1.TEM brightfield micrographs for various alloys(a)14Cr,(b)14L,(c)14LMT and(d)14YMT.the14Cr matrix to produce14LT.Further addition of Mo to14LT improved the hardness through solid solution strengthening in 14LMT(495HV).High dislocation density and no well-defined grain boundaries were characteristics of14Cr alloy as shown in Fig.1a.The presence of a low number density and larger oxide particles(FeCr2O4and Cr2O3)at the boundaries could not create an effective pinning effect during sintering.As a result,some of these particles became confined within the grain interiors.The coarse grains had the capacity to produce and store high density of dislocations that subsequently resulted in the strain hardening effect.The hardening mechanism in14Cr alloy can thus be attributed to greater disloca-tion activities and resulting strain hardening effect.The grain boundary or precipitation hardening cannot be the dominant mechanism because of larger particles,greater inter-particle spac-ing and weakened Zener drag effect at the temperature of sinter-ing.Such strain hardening capability in nanocrystalline Fe consolidated via SPS was reported by other researchers,too [14,15].Interestingly,the high hardness in Fe–14Cr alloy consoli-dated via SPS at1100°C for4min by Auger et al.[10]wasFig.3.Three-dimensional atom maps showing NCs for(a)14LMT–91Â34Â30nm3and(b)14YMT–93Â30Â30nm3.Fig.4.(a)The relative density and(b)microhardness values for different SPSed alloys processed at different SPS temperatures for a dwell time of7min.attributed to the formation of martensitic laths caused by higher carbon content diffusing from the die,possible Cr segregation and rapid cooling during SPS.It is noteworthy to mention that no martensite lath was observed in the consolidated14Cr alloy in the present study.The level of solutes in the bcc matrix could be much greater than the equilibrium level,associated with a large number of vacancies created during milling.Our recent study[16]has shown that high energy ball milling has a complex role in initiating nucle-ation of La–Ti–O-enriched NCs in14LMT alloy powder,with a mean radius of%1nm,a number density of3.7Â10À24mÀ3and a composition of Fe–12.11Cr–9.07Ti–4.05La(at.%).The initiation of NCs during ball milling of NFSs has also been investigated by other researchers[8,17,18].According to Williams et al.[8],due to a low equilibrium solubility of O in the matrix,the precipitation of nanoparticles is driven by an oxidation reaction,subsequently resulting in reduction of the free energy.As the SPS proceeds,the number density of NCs would decrease and larger grain boundary oxides would form with the grain structure developing simulta-neously during the sintering process[8].Formation of larger grain boundary oxides as shown in Fig.1a could have been preceded by segregation of O and Cr to grain boundaries leading to a decrease in the level of the solutes in the ferritic matrix.The initial oxides forming in a chromium-rich matrix can be Cr2O3as suggested by Williams et al.[8].However,formation of LaCrO3in14L alloy (shown in Fig.1b)was associated with a higher reduction in the free energy according to the enthalpy of formation of various oxi-des given in Table2.The presence of nanoparticles caused grain boundary pinning and subsequently stabilized the nanocrystalline grains.The high density of defects(dislocations and vacancies)in a supersaturated solid solution,such as14LMT and14YMT alloys, could dramatically increase the driving force for accelerated sub-grain formation during the initial stage of sintering.At the initial stage,the vacancies created during the milling are annihilated [8,17].Meanwhile,the temperature is not high enough to produce a significant number of thermal vacancies;subsequently,any nucleation of new NCs will be prevented.As the SPS proceeds with no nucleation of new NCs,the high concentrations of extra solutes in the matrix are thermodynamically and kinetically required to precipitate out to form larger oxide particles.The larger solute-enriched oxide particles can be formed more favorably on the grain boundaries due to the higher boundary diffusivity.On the other hand,it should be considered that there is a dynamic plastic deformation occurring within the powder particles during SPS. The interaction of larger particles and dislocations introduced by dynamic hot deformation can explain the coarsening in some grains;because larger particles could not effectively pin the dislo-cations and the grain boundary migration could be facilitated fol-lowing the orientation with lower efficiency of Zener drag mechanism[19].Once the extra solutes present in the matrix pre-cipitated out,the microstructure will remain very stable because of the grain boundary pinning by triple-junctions of the grain bound-aries themselves[20],along with the high density of NCs and other ultrafine oxide particles[8].Further coarsening of the grains will be prevented even for longer dwell times at950°C.Therefore,a bi-modal grain size distribution emerged.The hardening of14LMT and14YMT alloys were attributed to a combined effect of solid solution strengthening,Hall-Petch strengthening and precipitation hardening.Based on the APT studies of the as-milled powder[16]and for-mation mechanism of the oxide particles suggested by Williams et al.[8]it could be speculated that in14LMT and14YMT alloys, Cr–O species formfirst and then absorb Ti and La/Y.This is associ-ated with a change in the interfacial energy of Cr–O species even though it is not thermodynamically the most favorable oxide.It has been established that the driving force for the oxide precipi-tates to form is the low solubility limit of oxygen in the ferritic ma-trix.The change in free energy due to oxidation reaction and nucleation of oxide nanoparticles is the leading mechanism[8].The majority of the oxygen required to generate the oxide nano-particles may be provided from the surface oxide during milling process.Furthermore,higher concentrations of Cr led to greater nucleation of Cr–O by influencing the kinetics of oxide formation. Concentrations and diffusivities of the oxide species along with the energy barrier for nucleation will control the nucleation of oxide nanoparticles.After the Cr–O formed during sintering,the Ti–O and Y/La-enriched clusters could form.The sub-stoichiome-tric NCs in14LMT and14YMT alloys were not due to insufficient level of O in the matrix[8].Formation of stoichiometric Y2Ti2O7 and Y2TiO5requires very high temperatures[8],which were outside the scope of this study.4.ConclusionThe SPSed Fe–14Cr alloy was found to have a higher hardness at room temperature due to the strain hardening effect.The stability of its microstructure at high temperatures was improved by addi-tion of La forming the Cr–La–O-enriched NCs.Adding La and Ti to Fe–14Cr matrix significantly improved the mechanical behavior and microstructural stability further due to the high number density of Cr–Ti–La–O-enriched NCs in14LMT alloy.It is demon-strated that the potential capability of La in developing new NFSs is promising but further investigations on their thermal and irradiation stability will still be required.AcknowledgementThis work was supported partly by the Laboratory Directed Research and Development Program of Idaho National Laboratory (INL),and by the Advanced Test Reactor National Scientific User Facility(ATR NSUF),Contract DE-AC07-05ID14517.The authors gratefully acknowledge the assistance of the staff members at the Microscopy and Characterization Suite(MaCS)facility at the Center for Advanced Energy Studies(CAES).References[1]M.J.Alinger,G.R.Odette,G.E.Lucas,J.Nucl.Mater.307–311(2002)484.[2]R.L.Klueh,J.P.Shingledecker,R.W.Swindeman,D.T.Hoelzer,J.Nucl.Mater.341(2005)103.[3]M.J.Alinger,G.R.Odette,D.T.Hoelzer,J.Nucl.Mater.329–333(2004)382.[4]M.J.Alinger,G.R.Odette,D.T.Hoelzer,Acta Mater.57(2009)392.Table2The standard enthalpies of formation of various oxide compounds at25°C[8,21,22].Element CompositionÀD H f(kJ molÀ1(oxide))Cr Cr2O31131CrO2583Fe Fe3O41118Fe2O3822Ti TiO543TiO2944Ti2O31522Ti3O52475Y Y2O31907YCrO31493Y2Ti2O73874La La2O31794La2Ti2O73855LaCrO31536210S.Pasebani,I.Charit/Journal of Alloys and Compounds599(2014)206–211[5]G.R.Odette,M.L.Alinger,B.D.Wirth,Annu.Rev.Mater.Res.38(2008)471.[6]ai,T.Okuda,M.Fujiwara,T.Kobayashi,S.Mizuta,H.Nakashima,J.Nucl.Sci.Technol.39(2002)872.[7]ai,M.Fujiwara,J.Nucl.Mater.307–311(2002)749.[8]C.A.Williams,P.Unifantowicz,N.Baluc,G.D.Smith,E.A.Marquis,Acta Mater.61(2013)2219.[9]ler,C.M.Parish,Mater.Sci.Technol.27(2011)729.[10]M.A.Auger,V.De Castro,T.Leguey,A.Muñoz,Pareja,R,J.Nucl.Mater.436(2013)68.[11]C.Heintze,M.Hernández-Mayoral, A.Ulbricht, F.Bergner, A.Shariq,T.Weissgärber,H.Frielinghaus,J.Nucl.Mater.428(2012)139.[12]K.N.Allahar,J.Burns,B.Jaques,Y.Q.Wu,I.Charit,J.I.Cole,D.P.Butt,J.Nucl.Mater.443(2013)256.[13]Y.Q.Wu,K.N.Allahar,J.Burns,B.Jaques,I.Charit,D.P.Butt,J.I.Cole,Cryst.Res.Technol.(2013)1,/10.1002/crat.201300173.[14]K.Oh-Ishi,H.W.Zhang Hw,T.Ohkubo,K.Hono,Mater.Sci.Eng.A456(2007)20.[15]B.Srinivasarao,K.Ohishi,T.Ohkubo,K.Hono,Acta Mater.57(2009)3277.[16]S.Pasebani,I.Charit,Y.Q.Wu, D.P.Butt,J.I.Cole,Acta Mater.61(2013)5605.[17]M.L.Brocq,F.Legendre,M.H.Mathon,A.Mascaro,S.Poissonnet,B.Radiguet,P.Pareige,M.Loyer,O.Leseigneur,Acta Mater.60(2012)7150.[18]M.Brocq,B.Radiguet,S.Poissonnet,F.Cuvilly,P.Pareige,F.Legendre,J.Nucl.Mater.409(2011)80.[19]H.K.D.H.Bhadeshia,Mater.Sci.Eng.A223(1997)64.[20]H.K.D.H.Bhadeshia,Mater.Sci.Technol.16(2000)1404.[21]W.Gale,T.Totemeier,Smithells Metals Reference Book,Amsterdam,Holland,2004.[22]T.J.Kallarackel,S.Gupta,P.Singh,J.Am.Ceram.Soc.(2013)1,http:///10.1111/jace.12435.S.Pasebani,I.Charit/Journal of Alloys and Compounds599(2014)206–211211。
组织结构变革中的路径依赖与路径创造机制研究——以联想集团为例

组织结构变革中的路径依赖与路径创造机制研究——以联想集团为例李海东;林志扬【摘要】Due to the strong tendency of historical determinism, the classical path dependence theory can not explain the significant technical and institutional change and the generation of a new path. These issues promote the researchers to switch the research perspective and pay more attention to the path creation and path breaking. Strategic action has a attribute of path dependence, and according to the contention that strategy determines structure and structure follows strategy, the article illustrates that path dependence is embedded in organizational structure system. From the perspective of the organizational structure model evolution! the mechanism of path dependence formation and path creation is discussed. At the same time, the dual impact of path dependence and path creation in organizational structure change on organizational operation is also discussed. Finally, the article takes Lenovo Group of China modern IT industry as an example to illustrates path dependence and path creation in the evolution process of Lenovo Group's organizational structure model.%经典的路径依赖理论因具有较强的历史决定论倾向,因而无法解释重大的技术和制度变革以及新路径的产生,这些问题推动着研究者将研究视角转向了路径创造和路径突破.战略行为具有路径依赖的特征,根据“战略决定结构、结构跟随战略”的思想,组织结构系统内生地蕴含着路径依赖特性.从组织结构模式演进的角度对组织中的路径依赖形成机制和路径创造机制进行研究,并讨论了组织结构变革中的路径依赖和路径创造对组织运行的双重影响.以联想集团为例,探讨了联想集团组织结构模式选择演化历程中的路径依赖和路径创造.【期刊名称】《管理学报》【年(卷),期】2012(009)008【总页数】12页(P1135-1146)【关键词】路径依赖;组织结构变革;路径创造;自我增强机制;联想集团【作者】李海东;林志扬【作者单位】景德镇陶瓷学院工商管理学院;厦门大学管理学院【正文语种】中文【中图分类】C93组织作为一个开放性系统,不断地与外部环境进行物质、能量和信息的交换。
Unit-2-Principles-ofCorrespondence

4 the unusually high capacity of specialists ( doctors, theologians, philosophers, scientists ,etc)
In such a translation one is concerned with the dynamic relationship, that the relationship between receptor and message should be substantially the same as that which existed between the original receptors and the message.
The nature of the message
Messages differ primarily in the degree to which content or form is the dominant consideration.Of course, the content of a message can never be completely abstracted from the form, and form is nothing apart from content; but in some messages the content is of primary consideration, and in others the form must be given a higher priority.
Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease trans

Reproduction numbers and sub-threshold endemicequilibria for compartmental models of disease transmissionP.van den Driesschea,1,James Watmough b,*,2aDepartment of Mathematics and Statistics,University of Victoria,Victoria,BC,Canada V8W 3P4b Department of Mathematics and Statistics,University of New Brunswick,Fredericton,NB,Canada E3B 5A3Received 26April 2001;received in revised form 27June 2001;accepted 27June 2001Dedicated to the memory of John JacquezAbstractA precise definition of the basic reproduction number,R 0,is presented for a general compartmental disease transmission model based on a system of ordinary differential equations.It is shown that,if R 0<1,then the disease free equilibrium is locally asymptotically stable;whereas if R 0>1,then it is unstable.Thus,R 0is a threshold parameter for the model.An analysis of the local centre manifold yields a simple criterion for the existence and stability of super-and sub-threshold endemic equilibria for R 0near one.This criterion,together with the definition of R 0,is illustrated by treatment,multigroup,staged progression,multistrain and vector–host models and can be applied to more complex models.The results are significant for disease control.Ó2002Elsevier Science Inc.All rights reserved.Keywords:Basic reproduction number;Sub-threshold equilibrium;Disease transmission model;Disease control1.IntroductionOne of the most important concerns about any infectious disease is its ability to invade a population.Many epidemiological models have a disease free equilibrium (DFE)at whichtheMathematical Biosciences 180(2002)29–48/locate/mbs*Corresponding author.Tel.:+1-5064587323;fax:+1-5064534705.E-mail addresses:pvdd@math.uvic.ca (P.van den Driessche),watmough@unb.ca (J.Watmough).URL:http://www.math.unb.ca/$watmough.1Research supported in part by an NSERC Research Grant,the University of Victoria Committee on faculty research and travel and MITACS.2Research supported by an NSERC Postdoctoral Fellowship tenured at the University of Victoria.0025-5564/02/$-see front matter Ó2002Elsevier Science Inc.All rights reserved.PII:S0025-5564(02)00108-630P.van den Driessche,J.Watmough/Mathematical Biosciences180(2002)29–48population remains in the absence of disease.These models usually have a threshold parameter, known as the basic reproduction number,R0,such that if R0<1,then the DFE is locally as-ymptotically stable,and the disease cannot invade the population,but if R0>1,then the DFE is unstable and invasion is always possible(see the survey paper by Hethcote[1]).Diekmann et al.[2]define R0as the spectral radius of the next generation matrix.We write down in detail a general compartmental disease transmission model suited to heterogeneous populations that can be modelled by a system of ordinary differential equations.We derive an expression for the next generation matrix for this model and examine the threshold R0¼1in detail.The model is suited to a heterogeneous population in which the vital and epidemiological parameters for an individual may depend on such factors as the stage of the disease,spatial position,age or behaviour.However,we assume that the population can be broken into homo-geneous subpopulations,or compartments,such that individuals in a given compartment are indistinguishable from one another.That is,the parameters may vary from compartment to compartment,but are identical for all individuals within a given compartment.We also assume that the parameters do not depend on the length of time an individual has spent in a compart-ment.The model is based on a system of ordinary equations describing the evolution of the number of individuals in each compartment.In addition to showing that R0is a threshold parameter for the local stability of the DFE, we apply centre manifold theory to determine the existence and stability of endemic equilib-ria near the threshold.We show that some models may have unstable endemic equilibria near the DFE for R0<1.This suggests that even though the DFE is locally stable,the disease may persist.The model is developed in Section2.The basic reproduction number is defined and shown to bea threshold parameter in Section3,and the definition is illustrated by several examples in Section4.The analysis of the centre manifold is presented in Section5.The epidemiological ramifications of the results are presented in Section6.2.A general compartmental epidemic model for a heterogeneous populationConsider a heterogeneous population whose individuals are distinguishable by age,behaviour, spatial position and/or stage of disease,but can be grouped into n homogeneous compartments.A general epidemic model for such a population is developed in this section.Let x¼ðx1;...;x nÞt, with each x i P0,be the number of individuals in each compartment.For clarity we sort the compartments so that thefirst m compartments correspond to infected individuals.The distinc-tion between infected and uninfected compartments must be determined from the epidemiological interpretation of the model and cannot be deduced from the structure of the equations alone,as we shall discuss below.It is plausible that more than one interpretation is possible for some models.A simple epidemic model illustrating this is given in Section4.1.The basic reproduction number can not be determined from the structure of the mathematical model alone,but depends on the definition of infected and uninfected compartments.We define X s to be the set of all disease free states.That isX s¼f x P0j x i¼0;i¼1;...;m g:In order to compute R0,it is important to distinguish new infections from all other changes inpopulation.Let F iðxÞbe the rate of appearance of new infections in compartment i,Vþi ðxÞbe therate of transfer of individuals into compartment i by all other means,and VÀi ðxÞbe the rate oftransfer of individuals out of compartment i.It is assumed that each function is continuously differentiable at least twice in each variable.The disease transmission model consists of non-negative initial conditions together with the following system of equations:_x i¼f iðxÞ¼F iðxÞÀV iðxÞ;i¼1;...;n;ð1Þwhere V i¼VÀi ÀVþiand the functions satisfy assumptions(A1)–(A5)described below.Sinceeach function represents a directed transfer of individuals,they are all non-negative.Thus,(A1)if x P0,then F i;Vþi ;VÀiP0for i¼1;...;n.If a compartment is empty,then there can be no transfer of individuals out of the compartment by death,infection,nor any other means.Thus,(A2)if x i¼0then VÀi ¼0.In particular,if x2X s then VÀi¼0for i¼1;...;m.Consider the disease transmission model given by(1)with f iðxÞ,i¼1;...;n,satisfying con-ditions(A1)and(A2).If x i¼0,then f iðxÞP0and hence,the non-negative cone(x i P0, i¼1;...;n)is forward invariant.By Theorems1.1.8and1.1.9of Wiggins[3,p.37]for each non-negative initial condition there is a unique,non-negative solution.The next condition arises from the simple fact that the incidence of infection for uninfected compartments is zero.(A3)F i¼0if i>m.To ensure that the disease free subspace is invariant,we assume that if the population is free of disease then the population will remain free of disease.That is,there is no(density independent) immigration of infectives.This condition is stated as follows:(A4)if x2X s then F iðxÞ¼0and VþiðxÞ¼0for i¼1;...;m.The remaining condition is based on the derivatives of f near a DFE.For our purposes,we define a DFE of(1)to be a(locally asymptotically)stable equilibrium solution of the disease free model,i.e.,(1)restricted to X s.Note that we need not assume that the model has a unique DFE. Consider a population near the DFE x0.If the population remains near the DFE(i.e.,if the introduction of a few infective individuals does not result in an epidemic)then the population will return to the DFE according to the linearized system_x¼Dfðx0ÞðxÀx0Þ;ð2Þwhere Dfðx0Þis the derivative½o f i=o x j evaluated at the DFE,x0(i.e.,the Jacobian matrix).Here, and in what follows,some derivatives are one sided,since x0is on the domain boundary.We restrict our attention to systems in which the DFE is stable in the absence of new infection.That is, (A5)If FðxÞis set to zero,then all eigenvalues of Dfðx0Þhave negative real parts.P.van den Driessche,J.Watmough/Mathematical Biosciences180(2002)29–4831The conditions listed above allow us to partition the matrix Df ðx 0Þas shown by the following lemma.Lemma 1.If x 0is a DFE of (1)and f i ðx Þsatisfies (A1)–(A5),then the derivatives D F ðx 0Þand D V ðx 0Þare partitioned asD F ðx 0Þ¼F 000 ;D V ðx 0Þ¼V 0J 3J 4;where F and V are the m Âm matrices defined byF ¼o F i o x j ðx 0Þ !and V ¼o V i o x jðx 0Þ !with 16i ;j 6m :Further ,F is non-negative ,V is a non-singular M-matrix and all eigenvalues of J 4have positive real part .Proof.Let x 02X s be a DFE.By (A3)and (A4),ðo F i =o x j Þðx 0Þ¼0if either i >m or j >m .Similarly,by (A2)and (A4),if x 2X s then V i ðx Þ¼0for i 6m .Hence,ðo V i =o x j Þðx 0Þ¼0for i 6m and j >m .This shows the stated partition and zero blocks.The non-negativity of F follows from (A1)and (A4).Let f e j g be the Euclidean basis vectors.That is,e j is the j th column of the n Ân identity matrix.Then,for j ¼1;...;m ,o V i o x jðx 0Þ¼lim h !0þV i ðx 0þhe j ÞÀV i ðx 0Þh :To show that V is a non-singular M-matrix,note that if x 0is a DFE,then by (A2)and (A4),V i ðx 0Þ¼0for i ¼1;...;m ,and if i ¼j ,then the i th component of x 0þhe j ¼0and V i ðx 0þhe j Þ60,by (A1)and (A2).Hence,o V i =o x j 0for i m and j ¼i and V has the Z sign pattern (see Appendix A).Additionally,by (A5),all eigenvalues of V have positive real parts.These two conditions imply that V is a non-singular M-matrix [4,p.135(G 20)].Condition (A5)also implies that the eigenvalues of J 4have positive real part.Ã3.The basic reproduction numberThe basic reproduction number,denoted R 0,is ‘the expected number of secondary cases produced,in a completely susceptible population,by a typical infective individual’[2];see also [5,p.17].If R 0<1,then on average an infected individual produces less than one new infected individual over the course of its infectious period,and the infection cannot grow.Conversely,if R 0>1,then each infected individual produces,on average,more than one new infection,and the disease can invade the population.For the case of a single infected compartment,R 0is simply the product of the infection rate and the mean duration of the infection.However,for more complicated models with several infected compartments this simple heuristic definition of R 0is32P.van den Driessche,J.Watmough /Mathematical Biosciences 180(2002)29–48insufficient.A more general basic reproduction number can be defined as the number of new infections produced by a typical infective individual in a population at a DFE.To determine the fate of a‘typical’infective individual introduced into the population,we consider the dynamics of the linearized system(2)with reinfection turned off.That is,the system _x¼ÀD Vðx0ÞðxÀx0Þ:ð3ÞBy(A5),the DFE is locally asymptotically stable in this system.Thus,(3)can be used to de-termine the fate of a small number of infected individuals introduced to a disease free population.Let wi ð0Þbe the number of infected individuals initially in compartment i and letwðtÞ¼w1ðtÞ;...;w mðtÞðÞt be the number of these initially infected individuals remaining in the infected compartments after t time units.That is the vector w is thefirst m components of x.The partitioning of D Vðx0Þimplies that wðtÞsatisfies w0ðtÞ¼ÀV wðtÞ,which has the unique solution wðtÞ¼eÀVt wð0Þ.By Lemma1,V is a non-singular M-matrix and is,therefore,invertible and all of its eigenvalues have positive real parts.Thus,integrating F wðtÞfrom zero to infinity gives the expected number of new infections produced by the initially infected individuals as the vector FVÀ1wð0Þ.Since F is non-negative and V is a non-singular M-matrix,VÀ1is non-negative[4,p.137 (N38)],as is FVÀ1.To interpret the entries of FVÀ1and develop a meaningful definition of R0,consider the fate of an infected individual introduced into compartment k of a disease free population.The(j;k)entry of VÀ1is the average length of time this individual spends in compartment j during its lifetime, assuming that the population remains near the DFE and barring reinfection.The(i;j)entry of F is the rate at which infected individuals in compartment j produce new infections in compartment i. Hence,the(i;k)entry of the product FVÀ1is the expected number of new infections in com-partment i produced by the infected individual originally introduced into compartment k.Fol-lowing Diekmann et al.[2],we call FVÀ1the next generation matrix for the model and set R0¼qðFVÀ1Þ;ð4Þwhere qðAÞdenotes the spectral radius of a matrix A.The DFE,x0,is locally asymptotically stable if all the eigenvalues of the matrix Dfðx0Þhave negative real parts and unstable if any eigenvalue of Dfðx0Þhas a positive real part.By Lemma1, the eigenvalues of Dfðx0Þcan be partitioned into two sets corresponding to the infected and uninfected compartments.These two sets are the eigenvalues of FÀV and those ofÀJ4.Again by Lemma1,the eigenvalues ofÀJ4all have negative real part,thus the stability of the DFE is determined by the eigenvalues of FÀV.The following theorem states that R0is a threshold parameter for the stability of the DFE.Theorem2.Consider the disease transmission model given by(1)with fðxÞsatisfying conditions (A1)–(A5).If x0is a DFE of the model,then x0is locally asymptotically stable if R0<1,but un-stable if R0>1,where R0is defined by(4).Proof.Let J1¼FÀV.Since V is a non-singular M-matrix and F is non-negative,ÀJ1¼VÀF has the Z sign pattern(see Appendix A).Thus,sðJ1Þ<0()ÀJ1is a non-singular M-matrix;P.van den Driessche,J.Watmough/Mathematical Biosciences180(2002)29–483334P.van den Driessche,J.Watmough/Mathematical Biosciences180(2002)29–48where sðJ1Þdenotes the maximum real part of all the eigenvalues of the matrix J1(the spectral abscissa of J1).Since FVÀ1is non-negative,ÀJ1VÀ1¼IÀFVÀ1also has the Z sign pattern.Ap-plying Lemma5of Appendix A,with H¼V and B¼ÀJ1¼VÀF,we have ÀJ1is a non-singular M-matrix()IÀFVÀ1is a non-singular M-matrix:Finally,since FVÀ1is non-negative,all eigenvalues of FVÀ1have magnitude less than or equal to qðFVÀ1Þ.Thus,IÀFVÀ1is a non-singular M-matrix;()qðFVÀ1Þ<1:Hence,sðJ1Þ<0if and only if R0<1.Similarly,it follows thatsðJ1Þ¼0()ÀJ1is a singular M-matrix;()IÀFVÀ1is a singular M-matrix;()qðFVÀ1Þ¼1:The second equivalence follows from Lemma6of Appendix A,with H¼V and K¼F.The remainder of the equivalences follow as with the non-singular case.Hence,sðJ1Þ¼0if and only if R0¼1.It follows that sðJ1Þ>0if and only if R0>1.ÃA similar result can be found in the recent book by Diekmann and Heesterbeek[6,Theorem6.13].This result is known for the special case in which J1is irreducible and V is a positive di-agonal matrix[7–10].The special case in which V has positive diagonal and negative subdiagonal elements is proven in Hyman et al.[11,Appendix B];however,our approach is much simpler(see Section4.3).4.Examples4.1.Treatment modelThe decomposition of fðxÞinto the components F and V is illustrated using a simple treat-ment model.The model is based on the tuberculosis model of Castillo-Chavez and Feng[12,Eq.(1.1)],but also includes treatment failure used in their more elaborate two-strain model[12,Eq.(2.1)].A similar tuberculosis model with two treated compartments is proposed by Blower et al.[13].The population is divided into four compartments,namely,individuals susceptible to tu-berculosis(S),exposed individuals(E),infectious individuals(I)and treated individuals(T).The dynamics are illustrated in Fig.1.Susceptible and treated individuals enter the exposed com-partment at rates b1I=N and b2I=N,respectively,where N¼EþIþSþT.Exposed individuals progress to the infectious compartment at the rate m.All newborns are susceptible,and all indi-viduals die at the rate d>0.Thus,the core of the model is an SEI model using standard inci-dence.The treatment rates are r1for exposed individuals and r2for infectious individuals. However,only a fraction q of the treatments of infectious individuals are successful.Unsuc-cessfully treated infectious individuals re-enter the exposed compartment(p¼1Àq).The diseasetransmission model consists of the following differential equations together with non-negative initial conditions:_E¼b1SI=Nþb2TI=NÀðdþmþr1ÞEþpr2I;ð5aÞ_I¼m EÀðdþr2ÞI;ð5bÞ_S¼bðNÞÀdSÀb1SI=N;ð5cÞ_T¼ÀdTþr1Eþqr2IÀb2TI=N:ð5dÞProgression from E to I and failure of treatment are not considered to be new infections,but rather the progression of an infected individual through the various compartments.Hence,F¼b1SI=Nþb2TI=NB B@1C CA and V¼ðdþmþr1ÞEÀpr2IÀm Eþðdþr2ÞIÀbðNÞþdSþb1SI=NdTÀr1EÀqr2Iþb2TI=NB B@1C CA:ð6ÞThe infected compartments are E and I,giving m¼2.An equilibrium solution with E¼I¼0has the form x0¼ð0;0;S0;0Þt,where S0is any positive solution of bðS0Þ¼dS0.This will be a DFE if and only if b0ðS0Þ<d.Without loss of generality,assume S0¼1is a DFE.Then,F¼0b100;V¼dþmþr1Àpr2Àm dþr2;givingVÀ1¼1ðdþmþr1Þðdþr2ÞÀm pr2dþr2pr2m dþmþr1and R0¼b1m=ððdþmþr1Þðdþr2ÞÀm pr2Þ.A heuristic derivation of the(2;1)entry of VÀ1and R0are as follows:a fraction h1¼m=ðdþmþr1Þof exposed individuals progress to compartment I,a fraction h2¼pr2=ðdþr2Þof infectious individuals re-enter compartment E.Hence,a fractionh1of exposed individuals pass through compartment I at least once,a fraction h21h2passthroughat least twice,and a fraction h k 1h k À12pass through at least k times,spending an average of s ¼1=ðd þr 2Þtime units in compartment I on each pass.Thus,an individual introduced into com-partment E spends,on average,s ðh 1þh 21h 2þÁÁÁÞ¼s h 1=ð1Àh 1h 2Þ¼m =ððd þm þr 1Þðd þr 2ÞÀm pr 2Þtime units in compartment I over its expected lifetime.Multiplying this by b 1gives R 0.The model without treatment (r 1¼r 2¼0)is an SEI model with R 0¼b 1m =ðd ðd þm ÞÞ.The interpretation of R 0for this case is simpler.Only a fraction m =ðd þm Þof exposed individuals progress from compartment E to compartment I ,and individuals entering compartment I spend,on average,1=d time units there.Although conditions (A1)–(A5)do not restrict the decomposition of f i ðx Þto a single choice for F i ,only one such choice is epidemiologically correct.Different choices for the function F lead to different values for the spectral radius of FV À1,as shown in Table 1.In column (a),treatment failure is considered to be a new infection and in column (b),both treatment failure and pro-gression to infectiousness are considered new infections.In each case the condition q ðFV À1Þ<1yields the same portion of parameter space.Thus,q ðFV À1Þis a threshold parameter in both cases.The difference between the numbers lies in the epidemiological interpretation rather than the mathematical analysis.For example,in column (a),the infection rate is b 1þpr 2and an exposed individual is expected to spend m =ððd þm þr 1Þðd þr 2ÞÞtime units in compartment I .However,this reasoning is biologically flawed since treatment failure does not give rise to a newly infected individual.Table 1Decomposition of f leading to alternative thresholds(a)(b)Fb 1SI =N þb 2TI =N þpr 2I 0000B B @1C C A b 1SI =N þb 2TI =N þpr 2I m E 000B B @1C C A Vðd þm þr 1ÞE Àm E þðd þr 2ÞI Àb ðN ÞþdS þb 1SI =N dT Àr 1E Àqr 2I þb 2TI =N 0B B @1C C A ðd þm þr 1ÞE ðd þr 2ÞI Àb ðN ÞþdS þb 1SI =N dT Àr 1E Àqr 2I þb 2TI =N 0B B @1C C A F0b 1þpr 200 0b 1þpr 2m 0 V d þm þr 10Àm d þr 2d þm þr 100d þr 2 q (FV À1)b 1m þpr 2mðd þm þr 1Þðd þr 2Þffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffib 1m þpr 2mðd þm þr 1Þðd þr 2Þs 36P.van den Driessche,J.Watmough /Mathematical Biosciences 180(2002)29–484.2.Multigroup modelIn the epidemiological literature,the term‘multigroup’usually refers to the division of a het-erogeneous population into several homogeneous groups based on individual behaviour(e.g., [14]).Each group is then subdivided into epidemiological compartments.The majority of mul-tigroup models in the literature are used for sexually transmitted diseases,such as HIV/AIDS or gonorrhea,where behaviour is an important factor in the probability of contracting the disease [7,8,14,15].As an example,we use an m-group SIRS-vaccination model of Hethcote[7,14]with a generalized incidence term.The sample model includes several SI multigroup models of HIV/ AIDS as special cases[8,15].The model equations are as follows:_I i ¼X mj¼1b ijðxÞS i I jÀðd iþc iþ iÞI i;ð7aÞ_S i ¼ð1Àp iÞb iÀðd iþh iÞS iþr i R iÀX mj¼1b ijðxÞS i I j;ð7bÞ_Ri¼p i b iþc i I iþh i S iÀðd iþr iÞR i;ð7cÞfor i¼1;...;m,where x¼ðI1;...;I m;S1;...;S m;R1;...;R mÞt.Susceptible and removed individu-als die at the rate d i>0,whereas infected individuals die at the faster rate d iþ i.Infected in-dividuals recover with temporary immunity from re-infection at the rate c i,and immunity lasts an expected1=r i time units.All newborns are susceptible,and a constant fraction b i are born into each group.A fraction p i of newborns are vaccinated at birth.Thereafter,susceptible individuals are vaccinated at the rate h i.The incidence,b ijðxÞdepends on individual behaviour,which determines the amount of mixing between the different groups(see,e.g.,Jacquez et al.[16]). The DFE for this model isx0¼ð0;...;0;S01;...;S0m;R01;...;R0mÞt;whereS0 i ¼b i d ið1Àp iÞþr iðÞd iðd iþh iþr iÞ;R0 i ¼b iðh iþd i p iÞd iðd iþh iþr iÞ:Linearizing(7a)about x¼x0givesF¼S0i b ijðx0ÞÂÃandV¼½ðd iþc iþ iÞd ij ;where d ij is one if i¼j,but zero otherwise.Thus,FVÀ1¼S0i b ijðx0Þ=ðd iÂþc iþ iÞÃ:P.van den Driessche,J.Watmough/Mathematical Biosciences180(2002)29–4837For the special case with b ij separable,that is,b ijðxÞ¼a iðxÞk jðxÞ,F has rank one,and the basic reproduction number isR0¼X mi¼1S0ia iðx0Þk iðx0Þd iþc iþ i:ð8ÞThat is,the basic reproduction number of the disease is the sum of the‘reproduction numbers’for each group.4.3.Staged progression modelThe staged progression model[11,Section3and Appendix B]has a single uninfected com-partment,and infected individuals progress through several stages of the disease with changing infectivity.The model is applicable to many diseases,particularly HIV/AIDS,where transmission probabilities vary as the viral load in an infected individual changes.The model equations are as follows(see Fig.2):_I 1¼X mÀ1k¼1b k SI k=NÀðm1þd1ÞI1;ð9aÞ_Ii¼m iÀ1I iÀ1Àðm iþd iÞI i;i¼2;...;mÀ1;ð9bÞ_Im¼m mÀ1I mÀ1Àd m I m;ð9cÞ_S¼bÀbSÀX mÀ1k¼1b k SI k=N:ð9dÞThe model assumes standard incidence,death rates d i>0in each infectious stage,and thefinal stage has a zero infectivity due to morbidity.Infected individuals spend,on average,1=m i time units in stage i.The unique DFE has I i¼0,i¼1;...;m and S¼1.For simplicity,define m m¼0. Then F¼½F ij and V¼½V ij ,whereF ij¼b j i¼1;j6mÀ1;0otherwise;&ð10ÞV ij¼m iþd i j¼i;Àm j i¼1þj;0otherwise:8<:ð11ÞLet a ij be the(i;j)entry of VÀ1.Thena ij¼0i<j;1=ðm iþd iÞi¼j;Q iÀ1k¼jm kQ ik¼jðm kþd kÞj<i:8>>><>>>:ð12ÞThus,R0¼b1m1þd1þb2m1ðm1þd1Þðm2þd2Þþb3m1m2ðm1þd1Þðm2þd2Þðm3þd3ÞþÁÁÁþb mÀ1m1...m mÀ2ðm1þd1Þ...ðm mÀ1þd mÀ1Þ:ð13ÞThe i th term in R0represents the number of new infections produced by a typical individual during the time it spends in the i th infectious stage.More specifically,m iÀ1=ðm iÀ1þd iÀ1Þis the fraction of individuals reaching stage iÀ1that progress to stage i,and1=ðm iþd iÞis the average time an individual entering stage i spends in stage i.Hence,the i th term in R0is the product of the infectivity of individuals in stage i,the fraction of initially infected individuals surviving at least to stage i,and the average infectious period of an individual in stage i.4.4.Multistrain modelThe recent emergence of resistant viral and bacterial strains,and the effect of treatment on their proliferation is becoming increasingly important[12,13].One framework for studying such sys-tems is the multistrain model shown in Fig.3,which is a caricature of the more detailed treatment model of Castillo-Chavez and Feng[12,Section2]for tuberculosis and the coupled two-strain vector–host model of Feng and Velasco-Hern a ndez[17]for Dengue fever.The model has only a single susceptible compartment,but has two infectious compartments corresponding to the two infectious agents.Each strain is modelled as a simple SIS system.However,strain one may ‘super-infect’an individual infected with strain two,giving rise to a new infection incompartment。
Single defect centres in diamond-A review

phys. stat. sol. (a) 203, No. 13, 3207–3225 (2006) / DOI 10.1002/pssa.200671403© 2006 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim Review ArticleSingle defect centres in diamond: A reviewF. Jelezko and J. Wrachtrup *3. Physikalisches Institut, Universität Stuttgart, 70550 Stuttgart, GermanyReceived 9 February 2006, revised 28 July 2006, accepted 9 August 2006Published online 11 October 2006PACS 03.67.Pp, 71.55.–r, 76.30.Mi, 76.70.–rThe nitrogen vacancy and some nickel related defects in diamond can be observed as single quantum sys-tems in diamond by their fluorescence. The fabrication of single colour centres occurs via generation of vacancies or via controlled nitrogen implantation in the case of the nitrogen vacancy (NV) centre. The NV centre shows an electron paramagnetic ground and optically excited state. As a result electron and nuclear magnetic resonance can be carried out on single defects. Due to the localized nature of the electron spin wavefunction hyperfine coupling to nuclei more than one lattice constant away from the defect as domi-nated by dipolar interaction. As a consequence the coupling to close nuclei leads to a splitting in the spec-trum which allows for optically detected electron nuclear double resonance. The contribution discusses the physics of the NV and other defect centre from the perspective of single defect centre spectroscopy.© 2006 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim1 IntroductionThe ever increasing demand in computational power and data transmission rates has inspired researchers to investigate fundamentally new ways to process and communicate information.Among others, physicists explored the usefulness of “non-classical”, i.e. quantum mechanical systems in the world of information processing. Spectacular achievements like Shors discovery of the quantum factoring algorithm [1] or the development of quantum secure data communication gave birth to the field of quantum information processing (QIP) [2]. After an initial period where the physical nature of infor-mation was explored [3] and how information processing can be carried out by unitary transformation in quantum mechanics, researchers looked out for systems which might be of use as hardware in QIP. From the very beginning it became clear that the restrictions on the hardware of choice are severe, in particular for solid state systems. Hence in the recent past scientists working in the development of nanostructured materials and quantum physics have cooperated on different solid-state systems to define quantum me-chanical two-level system, make them robust against decoherence and addressable as individual units. While the feasibility of QIP remains to be shown, this endeavour will deepen our understanding of quan-tum mechanics and also marks a new area in material science which now also has reached diamonds as a potential host material. The usefulness of diamond is based on two properties. First defects in diamond are often characterized by low electron phonon coupling, mostly due to the low density of phonon states i.e. high Debye temperature of the material [4]. Secondly, colour centres in diamond are usually found to be very stable, even under ambient conditions. This makes them unique among all optically active solid-state systems.* Corresponding author: e-mail: wrachtrup@physik.uni-stuttgart.de3208 F. Jelezko and J. Wrachtrup: Single defect centres in diamond: A review© 2006 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim The main goal of QIP is the flexible generation of quantum states from individual two-level systems (qubits). The state of the individual qubits should be changed coherently and the interaction strength among them should be controllable. At the same time, those systems which are discussed for data com-munication must be optically active which means, that they should show a high oscillator strength for an electric dipole transition between their ground and some optically excited state. Individual ions or ion strings have been applied with great success. Here, currently up to eight ions in a string have been cooled to their ground state, addressed and manipulated individually [5]. Owing to careful construction of the ion trap, decoherence is reduced to a minimum [6]. Landmark experiments, like teleportation of quantum states among ions [7, 8] and first quantum algorithms have been shown in these systems [9, 10].In solid state physics different types of hardware are discussed for QIP. Because dephasing is fast in most situations in solids only specific systems allow for controlled generation of a quantum state with preservation of phase coherence for a sufficient time. Currently three systems are under discussion. Su-perconducting systems are either realized as flux or charge quantized individual units [11]. Their strength lies in the long coherence times and meanwhile well established control of quantum states. Main pro-gresses have been achieved with quantum dots as individual quantum systems. Initially the electronic ground as well as excited states (exciton ground state) have been used as definition of qubits [12]. Mean-while the spin of individual electrons either in a single quantum dot or coupled GaAs quantum dots has been subject to control experiments [13–15]. Because of the presence of paramagnetic nuclear spins, the electron spin is subject to decoherence or a static inhomogeneous frequency distribution. Hence, a further direction of research are Si or SiGe quantum dots where practically no paramagnetic nuclear spins play a significant role. The third system under investigation are phosphorus impurities in silicon [16]. Phospho-rus implanted in Si is an electron paramagnetic impurity with a nuclear spin I = 1/2. The coherence times are known to be long at low temperature. The electron or nuclear spins form a well controllable two-level system. Addressing of individual spins is planned via magnetic field gradients. Major obstacles with respect to nanostructuring of the system have been overcome, while the readout of single spins based on spin-to-charge conversion with consecutive detection of charge state has not been successful yet. 2 Colour centres in diamondThere are more then 100 luminescent defects in diamond. A significant fraction has been analysed in detail such that their charge and spin state is known under equilibrium conditions [17]. For this review nitrogen related defects are of particular importance. They are most abundant in diamond since nitrogen is a prominent impurity in the material. Nitrogen is a defect which either exists as a single substitutional impurity or in aggregated form. The single substitutional nitrogen has an infrared local mode of vibration Fig. 1 (online colour at: ) Schematic represen-tation of the nitrogen vacancy (NV) centre structure.phys. stat. sol. (a) 203, No. 13 (2006) 3209 © 2006 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim65070075080050010001500T =300KT =1.8K F l u o r e s c e n c e I n t e n s i t y ,C t s Wavelength,nm ZPL 637.2nmat 1344 cm –1. The centre is at a C 3v symmetry site. It is a deep electron donor, probably 1.7 eV below the conduction band edge. There is an EPR signal associated with this defect, called P1, which identifies it to be an electron paramagnetic system with S = 1/2 ground state [17]. Nitrogen aggregates are, most com-monly, pairs of neighbouring substitutional atoms, the A aggregates, and groups of four around a va-cancy, the B aggregate. All three forms of nitrogen impurities have distinct infrared spectra.Another defect often found in nitrogen rich type Ib diamond samples after irradiation damage is the nitrogen vacancy defect centre, see Fig. 1. This defect gives rise to a strong absorption at 1.945 eV (637 nm) [18]. At low temperature the absorption is marked by a narrow optical resonance line (zero phonon line) followed by prominent vibronic side bands, see Fig. 2. Electron spin resonance measure-ment have indicated that the defect has an electron paramagnetic ground state with electron spin angular momentum S = 1 [19]. The zero field splitting parameters were found to be D = 2.88 GHz and E = 0 indicating a C 3v symmetry of the electron spin wavefunction. From measurements of the hyperfine cou-pling constant to the nitrogen nuclear spin and carbon spins in the first coordination shell it was con-cluded that roughly 70% of the unpaired electron spin density is found at the three nearest neighbour carbon atoms, whereas the spin density at the nitrogen is only 2%. Obviously the electrons spend most of their time at the three carbons next to the vacancy. To explain the triplet ground state mostly a six elec-tron model is invoked which requires the defect to be negatively charged i.e. to be NV – [20]. Hole burn-ing experiments and the high radiative recombination rate (lifetime roughly 11 ns [21], quantum yield 0.7) indicate that the optically excited state is also a spin triplet. The width of the spectral holes burned into the inhomogeneous absorption profile were found to be on the order of 50 MHz [22, 23]. Detailed investigation of the excited state dephasing and hole burning have caused speculations to as whether the excited state is subject to a J an–Teller splitting [24, 25]. From group theoretical arguments it is con-cluded that the ground state is 3A and the excited state is of 3E symmetry. In the C 3v group this state thus comprises two degenerate substrates 3E x,y with an orthogonal polarization of the optical transition. Photon echo experiments have been interpreted in terms of a Jan Teller splitting of 40 cm –1 among these two states with fast relaxation among them [24]. However, no further experimental evidence is found to sup-port this conclusion. Hole burning experiments showed two mechanisms for spectral hole burning: a permanent one and a transient mechanism with a time scale on the order of ms [23]. This is either inter-preted as a spin relaxation mechanism in the ground state or a metastable state in the optical excitation-emission cycle. Indeed it proved difficult to find evidence for this metastable state and also number and energetic position relative to the triplet ground and excited state are still subject of debate. Meanwhile it seems to be clear that at least one singlet state is placed between the two triplet states. As a working hypothesis it should be assumed throughout this article that the optical excitation emission cycle is de-scribed by three electronic levels.Fig. 2 Fluorescence emission spectra of single NVcentres at room temperature and LHe temperatures.Excitation wavelength was 514 nm.3210 F. Jelezko and J. Wrachtrup: Single defect centres in diamond: A review© 2006 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim 3 Optical excitation and spin polarizationGiven the fact that the NV centre has an electron spin triplet ground state with an optically allowed tran-sition to a 3E spin triplet state one might wonder about the influence of optical excitation on the electron spin properties of the defect. Indeed in initial experiments no electron spin resonance (EPR) signal of the defect was detected except when subject to irradiation in a wavelength range between 450 and 637 nm[19]. Later on it became clear that in fact there is an EPR signal even in the absence of light, yet the signal strength is considerably enhanced upon illumination [26]. EPR lines showed either absorptive or emissive line shapes depending on the spectral position. This indicates that only specific spin sub-levels are affected by optical excitation [27]. In general a S = 1 electron spin system is described by a spin Hamiltonian of the following form: e ˆˆˆH g S SDS β=+B . Here g e is the electronic g -factor (g = 2.0028 ± 0.0003); B 0 is the external magnetic field and D is the zero field splitting tensor. This ten-sor comprises the anisotropic dipolar interaction of the two electron spins forming the triplet state aver-aged over their wave function. The tensor is traceless and thus characterized by two parameters, D and E as already mentioned above. The zero field splitting causes a lifting of the degeneracy of the spin sub-levels m s = ±1,0 even in the absence of an external magnetic field. Those zero field spin wave functions T x,y,z do not diagonalize the full high-field Hamiltonian H but are related to these functions by121212=x T T T ββαα-+-=-〉〉,121211y T T T ββαα-++=+〉〉,12120|.z T T αββα+=〉〉 The expectation value of S z for all three wave functions ,,,,||x y z z x y z T S T 〈〉 is zero. Hence there is no magnetization in zero external field. There are different ways to account for the spin polarization process in an excitation scheme involving spin triplets. To first order optical excitation is a spin state conserving process. However spin–orbit (LS) coupling might allow for a spin state change in the course of optical excitation. Cross relaxation processes on the other hand might cause a strong spin polarization as it is observed in the optical excitation of various systems, like e.g. GaAs. However, optical spectroscopy and in particular hole burning data gave little evidence for non spin conserving excitation processes in the NV centre. In two laser hole burning experiments data have been interpreted by assuming different zero field splitting parameters in ground and excited state exc exc (2GHz,0,8GHz)D E ªª by an otherwise spin state preserving optical excitation process [28]. Indeed this is confirmed by later attempts to gener-ate ground state spin coherence via Raman process [29], which only proves to be possible when ground state spin sublevels are brought close to anticrossing by an external magnetic field. Another spin polaris-ing mechanism involves a further electronic state in the optical excitation and emission cycle [30, 31]. Though being weak, LS coupling might be strong enough to induce intersystem crossing to states with different spin symmetry, e.g. a singlet state. Indeed the relative position of the 1A singlet state with re-spect to the two triplet states has been subject of intense debate. Intersystem crossing is driven by LS induced mixing of singlet character into triplet states. Due to the lack of any emission from the 1A state or noticeable absorption to other states, no direct evidence for this state is at hand up to now. However, the kinetics of photo emission from single NV centres strongly suggests the presence of a metastable state in the excitation emission cycle of the state. As described below the intersystem crossing rates from the ex-cited triplet state to the singlet state are found to be drastically different, whereas the relaxation to the 3A state might not depend on the spin substate. This provides the required optical excitation dependent relaxa-tion mechanism. Bulk as well as single centre experiments show that predominantly the m s = 0 (T z ) sublevel in the spin ground state is populated. The polarization in this state is on the order of 80% or higher [27].phys. stat. sol. (a) 203, No. 13 (2006) 3211 © 2006 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim4 Spin properties of the NV centreBecause of its paramagnetic spin ground and excited state the NV centre has been the target of numerous investigations regarding its magnetooptical properties. Pioneering work has been carried out in the groups of Manson [32–36], Glasbeek [37–39] and Rand [26, 40, 41].The hyperfine and fine structure splitting of the NV ground state has been used to measure the Aut-ler–Townes splitting induced by a strong pump field in a three level system. Level anticrossing among the m s = 0 and m s = –1 allows for an accurate measurement of the hyperfine coupling constant for the nitrogen nucleus, yielding an axially symmetric hyperfine coupling tensor with A || = 2.3 MHz and A ^ = 2.1 MHz [42, 43]. The quadrupole coupling constant P = 5.04 MHz. Because of its convenient access to various transitions in the optical, microwave and radiofrequency domain the NV centre has been used as a model system to study the interaction between matter and radiation in the linear and non-linear regime. An interesting set of experiments concerns electromagnetically induced transparency in a Λ-type level scheme. The action of a strong pump pulse on one transition in this energy level scheme renders the system transparent for radiation resonant with another transitions. Experiments have been carried out in the microwave frequency domain [44] as well as for optical transitions among the 3A ground state and the 3E excited state [29]. Here two electron spin sublevels are brought into near level anticrossing such that an effective three level system is generated with one excited state spin sublevel and two allowed optical transitions. A 17% increase in transmission is detected for a suitably tuned probe beam.While relatively much work has been done on vacancy and nitrogen related impurities comparatively little is known about defects comprising heavy elements. For many years it was difficult to incorporate heavy elements as impurities into the diamond lattice. Only six elements have been identified as bonding to the diamond lattice, namely nitrogen, boron, nickel, silicon, hydrogen and cobalt. Attempts to use ion implantation techniques for incorporation of transition metal ions were unsuccessful. This might be due to the large size of the ions and the small lattice parameters of diamond together with the metastability of the diamond lattice at ambient pressure. Recent developments in crystal growth and thin film technology have made it possible to incorporate various dopants into the diamond lattice during growth. This has enabled studies of nickel defects [45, 46]. Depending on the annealing conditions Ni can form clusters with various vacancies and nitrogen atoms in nearest neighbour sites. Different Ni related centres are listed with NE as a prefix and numbers to identify individual entities. The structure and chemical compo-k 23k 12k 31k 213A 3E 1AOptical excitation 3A 3E 1A z x,yz´x´y´k 23k 31a bFig. 3 a) Three level scheme describing the optical excitation and emission cycle of single NV centres. 3A and 3E are the triplet ground and excited state. 1A is a metastable singlet state. No information is at hand presently about the number and relative position of singlet levels. The arrows and k ij denote the rates of transition among the various states. b) More detailed energy level scheme differentiating between trip-let sublevels in the 3A and 3E state.3212 F. Jelezko and J. Wrachtrup: Single defect centres in diamond: A review© 2006 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim sition of defects have mostly been identified by EPR on the basis of the hyperfine coupling to nitrogen nuclei [46]. A particularly rich hyperfine structure has been identified for the NE8 centre.Analysis of the angular dependence of the EPR spectrum for the NE8 centre showed that this centre has electronic spin S = 1/2 and a g -value typical of a d -ion with more than half filled d -shell. The NE8 centre has been found not only in HPHT synthetic diamonds but also in natural diamonds which contain the nickel-nitrogen centres NE1 to NE3 [46]. The structure of the centre is shown in Fig. 4. It comprises 4 substitutional nitrogen atoms and an interstitial Ni impurity. The EPR signature of the system has been correlated to an optical zero phonon transition at around 794 nm. The relative integral intensity of the zero phonon line and the vibronic side band at room temperature is 0.7 (Debey–Waller factor) [47]. The fluorescence emission statistics of single NE8 emitters shows a decay to a yet unidentified metastable state with a rate of 6 MHz.5 Single defect centre experimentsExperiments on single quantum systems in solids have brought about a considerable improvement in the understanding of the dynamics and energetic structure of the respective materials. In addition a number of quantum optical phenomena, especially when light–matter coupling is concerned, have been investi-gated. As opposed to atomic systems on which first experiments on single quantum systems are well established, similar experiments with impurity atoms in solids remain challenging. Single quantum sys-tems in solids usually strongly interact with their environment. This has technical as well as physical consequences. First of all single solid state quantum systems are embedded in an environment which, for example, scatters excitation light. Given a diffraction limited focal volume usually the number of matrix atoms exceed those of the quantum systems by 106–108. This puts an upper limit on the impurity content of the matrix or on the efficiency of inelastic scattering processes like e.g. Raman scattering from the matrix. Various systems like single hydrocarbon molecules, proteins, quantum dots and defect centres have been analysed [48]. Except for some experiments on surface enhanced Raman scattering the tech-nique usually relies on fluorescence emission. In this technique an excitation laser in resonance with a strongly allowed optical transition of the system is used to populate the optically excited state (e.g. the 3E state for the NV centre), see Fig. 3a. Depending on the fluorescence emission quantum yield the system either decays via fluorescence emission or non-radiatively, e.g. via inter-system-crossing to a metastable Fig. 4 (online colour at: ) Structure of the NE8 cen-tre.phys. stat. sol. (a) 203, No. 13 (2006) 3213© 2006 WILEY-VCH Verlag GmbH & Co. KGaA, WeinheimF l u o r .I n t e n s i t y ,k C t s /s Excitation power,mW.state (1A in the case of the NV). The maximum numbers of photons emitted are given when the optical transition is saturated. In this case the maximum fluorescence intensity is given as312123F max 3123()=.2k k k I k k Φ++ Here k 31 is the relaxation rate from the metastable to the ground state and k 21 is the decay rate of the opti-cally excited state, k 23 is the decay rate to the metastable state and φF marks the fluorescence quantum yield. For the NV centre I max is about 107 photon/s. I max critically depends on a number of parameters. First of all the fluorescence quantum yield limits the maximum emission. A good example to illustrate this is the GR1 centre, the neutral vacancy defect in diamond. The overall lifetime of the excited state for this defect is 1 ns at room temperature. However, the radiative lifetime is on the order of 100 ns. Hence φF is on the order of 0.01. Given the usual values for k 21 and k 31 this yields an I max which is too low to allow for detecting single GR1 centres with current technology. Figure 5 shows the saturation curve of a single NV defect. Indeed the maximum observable emission rate from the NV centre is around 105 pho-tons/s which corresponds well to the value estimated above, if we assume a detection efficiency of 0.01. Single NV centres can be observed by standard confocal fluorescence microscopy in type Ib diamond. In confocal microscopy a laser beam is focussed onto a diffraction limited spot in the diamond sample and the fluorescence is collected from that spot. Hence the focal probe volume is diffraction limited with a volume of roughly 1 µm 3. In order to be able to detect single centres it is thus important to control the density of defects. For the NV centre this is done by varying the number of vacancies created in the sam-ple by e.g. choosing an appropriate dose of electron irradiation. Hence the number of NV centres de-pends on the number of vacancies created and the number of nitrogen atoms in the sample. Figure 7 shows an image of a diamond sample where the number of defects in the sample is low enough to detect the fluorescence from single colour centres [49]. As expected the image shows diffraction limited spots. From the image alone it cannot be concluded whether the fluorescence stems from a single quantum system or from aggregates of defects. To determine the number of independent emitters in the focal vol-ume the emission statistics of the NV centre fluorescence can be used [50–52]. The fluorescence photon number statistics of a single quantum mechanical two-level system deviates from a classical Poissoniandistribution. If one records the fluorescence intensity autocorrelation function 2()()=()t I t g t ΙττΙ+2〈()〉〈〉 for short time τ one finds g 2(0) = 0 if the emission stems from a single defect centre (see Fig. 6). This is due to the fact that the defect has to be excited first before it can emit a single photon. Hence a single defect never emits two fluorescence photons simultaneously, in contrast to the case when a number of independent emitters are excited at random. If one adopts the three level scheme from Fig. 3a, rate equa-tions for temporal changes of populations in the three levels can be set up. The equations are solved by 12(2)()=1(1)e e ,k k g K K τττ-++Fig. 5 Saturation curve of the fluorescence inten-sity of a single NV centre at T = 300 K. Excitationwavelength is 514 nm. The power is measured atthe objective entrance.3214F. Jelezko and J. Wrachtrup: Single defect centres in diamond: A review © 2006 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheimg (2)(τ)τ,nswith rates 1,2=k -P = k 21 + k 12 + k 23 + k 31 and Q = k 31(k 21 + k 12) + k 23(k 31 + k 12) with23231123112= .k k k k k K k k+-- This function reproduces the dip in the correlation function g 2(τ) for τ → 0 shown in Fig. 6, which indicates that the light detected originates from a single NV. The slope of the curve around 0τ= is de-terminded by the pumping power of the laser k 12 and the decay rate k 21. For larger times τ a decay of the correlation function becomes visible. This decay marks the ISC process from the excited triplet 3E to the metastable singlet state 1A. Besides the spin quantum jumps detected at low temperature the photon sta-tistics measurements are the best indication for detection of single centres. It should be noted that the radiative decay time depends on the refractive index of the surrounding medium as 1/n medium . Because n medium of diamond is 2.4 the decay time should increase significantly if the refractive index of the sur-rounding is reduced. This is indeed observed for NV centres in diamond nanocrystals [51]. It should beFig. 7 (onl ine col our at: ) Confocal fl uorescence image of various diamond sampl es with different electron irradiation dosages.Fig. 6 Fluorescence intensity autocorrelation function of a single NV defect at room temperature.phys. stat. sol. (a) 203, No. 13 (2006) 3215 © 2006 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheimnoted, that owing to their stability single defect centres in diamond are prime candidates for single pho-ton sources under ambient conditions. Such sources are important for linear optics quantum computing and quantum cryptography. Indeed quantum key distribution has been successful with fluorescence emis-sion from single defect centres [53].A major figure of merit for single photon sources is the signal to background ratio, given (e.g.) by the amplitude of the correlation function at 0τ=. This ratio should be as high as possible to ensure that a single bit of information is encoded in a single photon only. The NV centre has a broad emission range which does not allow efficient filtering of background signals. This is in sharp contrast to the NE8 defect which shows a very narrow, only 1.2 nm wide spectrum. As a consequence the NE8 emission can be filtered out efficiently [47]. The correlation function resembles the one from the NV centre. Indeed the photophysical parameters of the NV and NE8 are similar, yet under comparable experimental conditions the NE8 shows an order of magnitude improvement in signal-to-background ratio because of the nar-rower emission range.Besides application in single photon generation, photon statistical measurements also allow to derive conclusions on photoionization and photochromism of single defects. Most notably the NV centre is speculated to exist in two charge forms, the negatively charged NV with zero phonon absorption at 637 nm and the neutral from NV 0 with absorption around 575 nm [20, 54]. Although evidence existed that both absorption lines stem from the same defect no direct charge interconversion has been shown in bulk experiments. The best example for a spectroscopically resolved charge transfer in diamond is the vacancy, which exists in two stable charge states. In order to observe the charge transfer from NV to NV 0 photon statistical measurements similar to the ones described have been carried out, except for a splitting of photons depending on the emission wavelength [55]. This two channel set up allows to detect the emission of NV 0 in one and NV in another detector arm. Figure 8 shows the experimental result. For delay time 20,()g ττ= shows a dip, indicating the sub-Poissonian statistics of the light emitted. It should -300-200-10001002000,00,40,8g (2)(τ)τ,nsPhotonsDichroicBSStartNV 0Stop NV - Fig. 8 (online colour at: ) Fluorescence cross correlation function between the NV 0 and NV emission of a single defect.。
Deformable Medical Image Registration

Deformable Medical Image Registration:A Survey Aristeidis Sotiras*,Member,IEEE,Christos Davatzikos,Senior Member,IEEE,and Nikos Paragios,Fellow,IEEE(Invited Paper)Abstract—Deformable image registration is a fundamental task in medical image processing.Among its most important applica-tions,one may cite:1)multi-modality fusion,where information acquired by different imaging devices or protocols is fused to fa-cilitate diagnosis and treatment planning;2)longitudinal studies, where temporal structural or anatomical changes are investigated; and3)population modeling and statistical atlases used to study normal anatomical variability.In this paper,we attempt to give an overview of deformable registration methods,putting emphasis on the most recent advances in the domain.Additional emphasis has been given to techniques applied to medical images.In order to study image registration methods in depth,their main compo-nents are identified and studied independently.The most recent techniques are presented in a systematic fashion.The contribution of this paper is to provide an extensive account of registration tech-niques in a systematic manner.Index Terms—Bibliographical review,deformable registration, medical image analysis.I.I NTRODUCTIOND EFORMABLE registration[1]–[10]has been,alongwith organ segmentation,one of the main challenges in modern medical image analysis.The process consists of establishing spatial correspondences between different image acquisitions.The term deformable(as opposed to linear or global)is used to denote the fact that the observed signals are associated through a nonlinear dense transformation,or a spatially varying deformation model.In general,registration can be performed on two or more im-ages.In this paper,we focus on registration methods that involve two images.One is usually referred to as the source or moving image,while the other is referred to as the target orfixed image. In this paper,the source image is denoted by,while the targetManuscript received March02,2013;revised May17,2013;accepted May 21,2013.Date of publication May31,2013;date of current version June26, 2013.Asterisk indicates corresponding author.*A.Sotiras is with the Section of Biomedical Image Analysis,Center for Biomedical Image Computing and Analytics,Department of Radi-ology,University of Pennsylvania,Philadelphia,PA19104USA(e-mail: aristieidis.sotiras@).C.Davatzikos is with the Section of Biomedical Image Analysis,Center for Biomedical Image Computing and Analytics,Department of Radi-ology,University of Pennsylvania,Philadelphia,PA19104USA(e-mail: christos.davatzikos@).N.Paragios is with the Center for Visual Computing,Department of Applied Mathematics,Ecole Centrale de Paris,92295Chatenay-Malabry,France,and with the Equipe Galen,INRIA Saclay-Ile-de-France,91893Orsay,France,and also with the Universite Paris-Est,LIGM(UMR CNRS),Center for Visual Com-puting,Ecole des Ponts ParisTech,77455Champs-sur-Marne,France. Digital Object Identifier10.1109/TMI.2013.2265603image is denoted by.The two images are defined in the image domain and are related by a transformation.The goal of registration is to estimate the optimal transforma-tion that optimizes an energy of the form(1) The previous objective function(1)comprises two terms.The first term,,quantifies the level of alignment between a target image and a source image.Throughout this paper,we in-terchangeably refer to this term as matching criterion,(dis)sim-ilarity criterion or distance measure.The optimization problem consists of either maximizing or minimizing the objective func-tion depending on how the matching term is chosen.The images get aligned under the influence of transformation .The transformation is a mapping function of the domain to itself,that maps point locations to other locations.In gen-eral,the transformation is assumed to map homologous loca-tions from the target physiology to the source physiology.The transformation at every position is given as the addition of an identity transformation with the displacementfield,or.The second term,,regularizes the trans-formation aiming to favor any specific properties in the solution that the user requires,and seeks to tackle the difficulty associ-ated with the ill-posedness of the problem.Regularization and deformation models are closely related. Two main aspects of this relation may be distinguished.First, in the case that the transformation is parametrized by a small number of variables and is inherently smooth,regularization may serve to introduce prior knowledge regarding the solution that we seek by imposing task-specific constraints on the trans-formation.Second,in the case that we seek the displacement of every image element(i.e.,nonparametric deformation model), regularization dictates the nature of the transformation. Thus,an image registration algorithm involves three main components:1)a deformation model,2)an objective function, and3)an optimization method.The result of the registration algorithm naturally depends on the deformation model and the objective function.The dependency of the registration result on the optimization strategy follows from the fact that image regis-tration is inherently ill-posed.Devising each component so that the requirements of the registration algorithm are met is a de-manding process.Depending on the deformation model and the input data,the problem may be ill-posed according to Hadamard’s definition of well-posed problems[11].In probably all realistic scenarios, registration is ill-posed.To further elaborate,let us consider some specific cases.In a deformable registration scenario,one0278-0062/$31.00©2013IEEEseeks to estimate a vector for every position given,in general, scalar information conveyed by image intensity.In this case,the number of unknowns is greater than the number of constraints. In a rigid setting,let us consider a consider a scenario where two images of a disk(white background,gray foreground)are registered.Despite the fact that the number of parameters is only 6,the problem is ill-posed.The problem has no unique solution since a translation that aligns the centers of the disks followed by any rotation results in a meaningful solution.Given nonlinear and nonconvex objective functions,in gen-eral,no closed-form solutions exist to estimate the registration parameters.In this setting,the search methods reach only a local minimum in the parameter space.Moreover,the problem itself has an enormous number of different facets.The approach that one should take depends on the anatomical properties of the organ(for example,the heart and liver do not adhere to the same degree of deformation),the nature of observations to be regis-tered(same modality versus multi-modal fusion),the clinical setting in which registration is to be used(e.g.,offline interpre-tation versus computer assisted surgery).An enormous amount of research has been dedicated to de-formable registration towards tackling these challenges due to its potential clinical impact.During the past few decades,many innovative ideas regarding the three main algorithmic registra-tion aspects have been proposed.General reviews of thefield may be found in[1]–[7],[9].However due to the rapid progress of thefield such reviews are to a certain extent outdated.The aim of this paper is to provide a thorough overview of the advances of the past decade in deformable registration.Never-theless,some classic papers that have greatly advanced the ideas in thefield are mentioned.Even though our primary interest is deformable registration,for the completeness of the presenta-tion,references to linear methods are included as many prob-lems have been treated in this low-degree-of-freedom setting before being extended to the deformable case.The main scope of this paper is focused on applications that seek to establish spatial correspondences between medical im-ages.Nonetheless,we have extended the scope to cover appli-cations where the interest is to recover the apparent motion of objects between sequences of successive images(opticalflow estimation)[12],[13].Deformable registration and opticalflow estimation are closely related problems.Both problems aim to establish correspondences between images.In the deformable registration case,spatial correspondences are sought,while in the opticalflow case,spatial correspondences,that are associ-ated with different time points,are looked for.Given data with a good temporal resolution,one may assume that the magnitude of the motion is limited and that image intensity is preserved in time,opticalflow estimation can be regarded as a small defor-mation mono-modal deformable registration problem.The remainder of the paper is organized by loosely following the structural separation of registration algorithms to three com-ponents:1)deformation model,2)matching criteria,and3)op-timization method.In Section II,different approaches regarding the deformation model are presented.Moreover,we also chose to cover in this section the second term of the objective function, the regularization term.This choice was motivated by the close relation between the two parts.In Section III,thefirst term of the objective function,the matching term,is discussed.The opti-mization methods are presented in Section IV.In every section, particular emphasis was put on further deepening the taxonomy of registration method by grouping the presented methods in a systematic manner.Section V concludes the paper.II.D EFORMATION M ODELSThe choice of deformation model is of great importance for the registration process as it entails an important compromise between computational efficiency and richness of description. It also reflects the class of transformations that are desirable or acceptable,and therefore limits the solution to a large ex-tent.The parameters that registration estimates through the op-timization strategy correspond to the degrees of freedom of the deformation model1.Their number varies greatly,from six in the case of global rigid transformations,to millions when non-parametric dense transformations are considered.Increasing the dimensionality of the state space results in enriching the de-scriptive power of the model.This model enrichment may be accompanied by an increase in the model’s complexity which, in turns,results in a more challenging and computationally de-manding inference.Furthermore,the choice of the deformation model implies an assumption regarding the nature of the defor-mation to be recovered.Before continuing,let us clarify an important,from imple-mentation point of view,aspect related to the transformation mapping and the deformation of the source image.In the in-troduction,we stated that the transformation is assumed to map homologous locations from the target physiology to the source physiology(backward mapping).While from a theoretical point of view,the mapping from the source physiology to the target physiology is possible(forward mapping),from an implemen-tation point of view,this mapping is less advantageous.In order to better understand the previous statement,let us consider how the direction of the mapping influences the esti-mation of the deformed image.In both cases,the source image is warped to the target domain through interpolation resulting to a deformed image.When the forward mapping is estimated, every voxel of the source image is pushed forward to its esti-mated position in the deformed image.On the other hand,when the backward mapping is estimated,the pixel value of a voxel in the deformed image is pulled from the source image.The difference between the two schemes is in the difficulty of the interpolation problem that has to be solved.In thefirst case,a scattered data interpolation problem needs to be solved because the voxel locations of the source image are usually mapped to nonvoxel locations,and the intensity values of the voxels of the deformed image have to be calculated.In the second case,when voxel locations of the deformed image are mapped to nonvoxel locations in the source image,their intensities can be easily cal-culated by interpolating the intensity values of the neighboring voxels.The rest of the section is organized by following coarsely and extending the classification of deformation models given 1Variational approaches in general attempt to determine a function,not just a set of parameters.SOTIRAS et al.:DEFORMABLE MEDICAL IMAGE REGISTRATION:A SURVEY1155Fig.1.Classi fication of deformation models.Models that satisfy task-speci fic constraints are not shown as a branch of the tree because they are,in general,used in conjunction with physics-based and interpolation-based models.by Holden [14].More emphasis is put on aspects that were not covered by that review.Geometric transformations can be classi fied into three main categories (see Fig.1):1)those that are inspired by physical models,2)those inspired by interpolation and ap-proximation theory,3)knowledge-based deformation models that opt to introduce speci fic prior information regarding the sought deformation,and 4)models that satisfy a task-speci fic constraint.Of great importance for biomedical applications are the con-straints that may be applied to the transformation such that it exhibits special properties.Such properties include,but are not limited to,inverse consistency,symmetry,topology preserva-tion,diffeomorphism.The value of these properties was made apparent to the research community and were gradually intro-duced as extra constraints.Despite common intuition,the majority of the existing regis-tration algorithms are asymmetric.As a consequence,when in-terchanging the order of input images,the registration algorithm does not estimate the inverse transformation.As a consequence,the statistical analysis that follows registration is biased on the choice of the target domain.Inverse Consistency:Inverse consistent methods aim to tackle this shortcoming by simultaneously estimating both the forward and the backward transformation.The data matching term quanti fies how well the images are aligned when one image is deformed by the forward transformation,and the other image by the backward transformation.Additionally,inverse consistent algorithms constrain the forward and backward transformations to be inverse mappings of one another.This is achieved by introducing terms that penalize the difference between the forward and backward transformations from the respective inverse mappings.Inverse consistent methods can preserve topology but are only asymptotically symmetric.Inverse-consistency can be violated if another term of the objective function is weighted more importantly.Symmetry:Symmetric algorithms also aim to cope with asymmetry.These methods do not explicitly penalize asym-metry,but instead employ one of the following two strategies.In the first case,they employ objective functions that are by construction symmetric to estimate the transformation from one image to another.In the second case,two transformation functions are estimated by optimizing a standard objective function.Each transformation function map an image to a common domain.The final mapping from one image to another is calculated by inverting one transformation function and composing it with the other.Topology Preservation:The transformation that is estimated by registration algorithms is not always one-to-one and cross-ings may appear in the deformation field.Topology preserving/homeomorphic algorithms produce a mapping that is contin-uous,onto,and locally one-to-one and has a continuous inverse.The Jacobian determinant contains information regarding the injectivity of the mapping and is greater than zero for topology preserving mappings.The differentiability of the transformation needs to be ensured in order to calculate the Jacobian determi-nant.Let us note that Jacobian determinant and Jacobian are in-terchangeably used in this paper and should not be confounded with the Jacobian matrix.Diffeomorphism:Diffeomoprhic transformations also pre-serve topology.A transformation function is a diffeomorphism,if it is invertible and both the function and its inverse are differ-entiable.A diffeomorphism maps a differentiable manifold to another.1156IEEE TRANSACTIONS ON MEDICAL IMAGING,VOL.32,NO.7,JULY2013In the following four subsections,the most important methods of the four classes are presented with emphasis on the approaches that endow the model under consideration with the above desirable properties.A.Geometric Transformations Derived From Physical Models Following[5],currently employed physical models can be further separated infive categories(see Fig.1):1)elastic body models,2)viscousfluidflow models,3)diffusion models,4) curvature registration,and5)flows of diffeomorphisms.1)Elastic Body Models:a)Linear Models:In this case,the image under deforma-tion is modeled as an elastic body.The Navier-Cauchy Partial Differential Equation(PDE)describes the deformation,or(2) where is the forcefield that drives the registration based on an image matching criterion,refers to the rigidity that quanti-fies the stiffness of the material and is Lamésfirst coefficient. Broit[15]first proposed to model an image grid as an elastic membrane that is deformed under the influence of two forces that compete until equilibrium is reached.An external force tries to deform the image such that matching is achieved while an internal one enforces the elastic properties of the material. Bajcsy and Kovacic[16]extended this approach in a hierar-chical fashion where the solution of the coarsest scale is up-sam-pled and used to initialize thefiner one.Linear registration was used at the lowest resolution.Gee and Bajscy[17]formulated the elastostatic problem in a variational setting.The problem was solved under the Bayesian paradigm allowing for the computation of the uncertainty of the solution as well as for confidence intervals.Thefinite element method(FEM)was used to infer the displacements for the ele-ment nodes,while an interpolation strategy was employed to es-timate displacements elsewhere.The order of the interpolating or shape functions,determines the smoothness of the obtained result.Linear elastic models have also been used when registering brain images based on sparse correspondences.Davatzikos[18]first used geometric characteristics to establish a mapping be-tween the cortical surfaces.Then,a global transformation was estimated by modeling the images as inhomogeneous elastic ob-jects.Spatially-varying elasticity parameters were used to com-pensate for the fact that certain structures tend to deform more than others.In addition,a nonzero initial strain was considered so that some structures expand or contract naturally.In general,an important drawback of registration is that when source and target volumes are interchanged,the obtained trans-formation is not the inverse of the previous solution.In order to tackle this shortcoming,Christensen and Johnson[19]pro-posed to simultaneously estimate both forward and backward transformations,while penalizing inconsistent transformations by adding a constraint to the objective function.Linear elasticity was used as regularization constraint and Fourier series were used to parametrize the transformation.Leow et al.[20]took a different approach to tackle the incon-sistency problem.Instead of adding a constraint that penalizes the inconsistency error,they proposed a unidirectional approach that couples the forward and backward transformation and pro-vides inverse consistent transformations by construction.The coupling was performed by modeling the backward transforma-tion as the inverse of the forward.This fact was also exploited during the optimization of the symmetric energy by only fol-lowing the gradient direction of the forward mapping.He and Christensen[21]proposed to tackle large deforma-tions in an inverse consistent framework by considering a se-quence of small deformation transformations,each modeled by a linear elastic model.The problem was symmetrized by consid-ering a periodic sequence of images where thefirst(or last)and middle image are the source and target respectively.The sym-metric objective function thus comprised terms that quantify the difference between any two successive pairs of images.The in-ferred incremental transformation maps were concatenated to map one input image to another.b)Nonlinear Models:An important limitation of linear elastic models lies in their inability to cope with large defor-mations.In order to account for large deformations,nonlinear elastic models have been proposed.These models also guar-antee the preservation of topology.Rabbitt et al.[22]modeled the deformable image based on hyperelastic material properties.The solution of the nonlinear equations was achieved by local linearization and the use of the Finite Element method.Pennec et al.[23]dropped the linearity assumption by mod-eling the deformation process through the St Venant-Kirchoff elasticity energy that extends the linear elastic model to the non-linear regime.Moreover,the use of log-Euclidean metrics in-stead of Euclidean ones resulted in a Riemannian elasticity en-ergy which is inverse consistent.Yanovsky et al.[24]proposed a symmetric registration framework based on the St Venant-Kir-choff elasticity.An auxiliary variable was added to decouple the regularization and the matching term.Symmetry was im-posed by assuming that the Jacobian determinants of the defor-mation follow a zero mean,after log-transformation,log-normal distribution[25].Droske and Rumpf[26]used an hyperelastic,polyconvex regularization term that takes into account the length,area and volume deformations.Le Guyader and Vese[27]presented an approach that combines segmentation and registration that is based on nonlinear elasticity.The authors used a polyconvex regularization energy based on the modeling of the images under deformation as Ciarlet-Geymonat materials[28].Burger et al.[29]also used a polyconvex regularization term.The au-thors focused on the numerical implementation of the registra-tion framework.They employed a discretize-then-optimize ap-proach[9]that involved the partitioning voxels to24tetrahedra.2)Viscous Fluid Flow Models:In this case,the image under deformation is modeled as a viscousfluid.The transformation is governed by the Navier-Stokes equation that is simplified by assuming a very low Reynold’s numberflow(3) These models do not assume small deformations,and thus are able to recover large deformations[30].Thefirst term of theSOTIRAS et al.:DEFORMABLE MEDICAL IMAGE REGISTRATION:A SURVEY1157Navier-Stokes equation(3),constrains neighboring points to de-form similarly by spatially smoothing the velocityfield.The velocityfield is related to the displacementfield as.The velocityfield is integrated in order to estimate the displacementfield.The second term al-lows structures to change in mass while and are the vis-cosity coefficients.Christensen et al.[30]modeled the image under deformation as a viscousfluid allowing for large magnitude nonlinear defor-mations.The PDE was solved for small time intervals and the complete solution was given by an integration over time.For each time interval a successive over-relaxation(SOR)scheme was used.To guarantee the preservation of topology,the Jaco-bian was monitored and each time its value fell under0.5,the deformed image was regridded and a new one was generated to estimate a transformation.Thefinal solution was the con-catenation of all successive transformations occurring for each regridding step.In a subsequent work,Christensen et al.[31] presented a hierarchical way to recover the transformations for brain anatomy.Initially,global affine transformation was per-formed followed by a landmark transformation model.The re-sult was refined byfluid transformation preceded by an elastic registration step.An important drawback of the earliest implementations of the viscousfluid models,that employed SOR to solve the equa-tions,was computational inefficiency.To circumvent this short-coming,Christensen et al.employed a massive parallel com-puter implementation in[30].Bro-Nielsen and Gramkow[32] proposed a technique based on a convolutionfilter in scale-space.Thefilter was designed as the impulse response of the linear operator defined in its eigen-function basis.Crun et al.[33]proposed a multi-grid approach towards handling anisotropic data along with a multi-resolution scheme opting forfirst recovering coarse velocity es-timations and refining them in a subsequent step.Cahill et al.[34]showed how to use Fourier methods to efficiently solve the linear PDE system that arises from(3)for any boundary condi-tion.Furthermore,Cahill et al.extended their analysis to show how these methods can be applied in the case of other regu-larizers(diffusion,curvature and elastic)under Dirichlet,Neu-mann,or periodic boundary conditions.Wang and Staib[35]usedfluid deformation models in an atlas-enhanced registration setting while D’Agostino et al. tackled multi-modal registration with the use of such models in[36].More recently,Chiang et al.[37]proposed an inverse consistent variant offluid registration to register Diffusion Tensor images.Symmetrized Kullback-Leibler(KL)diver-gence was used as the matching criterion.Inverse consistency was achieved by evaluating the matching and regularization criteria towards both directions.3)Diffusion Models:In this case,the deformation is mod-eled by the diffusion equation(4) Let us note that most of the algorithms,based on this transforma-tion model and described in this section,do not explicitly state the(4)in their objective function.Nonetheless,they exploit the fact that the Gaussian kernel is the Green’s function of the diffu-sion equation(4)(under appropriate initial and boundary condi-tions)to provide an efficient regularization step.Regularization is efficiently performed through convolutions with a Gaussian kernel.Thirion,inspired by Maxwell’s Demons,proposed to perform image matching as a diffusion process[38].The proposed algo-rithm iterated between two steps:1)estimation of the demon forces for every demon(more precisely,the result of the appli-cation of a force during one iteration step,that is a displace-ment),and2)update of the transformation based on the cal-culated forces.Depending on the way the demon positions are selected,the way the space of deformations is defined,the in-terpolation method that is used,and the way the demon forces are calculated,different variants can be obtained.The most suit-able version for medical image analysis involved1)selecting all image elements as demons,2)calculating demon forces by considering the opticalflow constraint,3)assuming a nonpara-metric deformation model that was regularized by applying a Gaussianfilter after each iteration,and4)a trilinear interpo-lation scheme.The Gaussianfilter can be applied either to the displacementfield estimated at an iteration or the updated total displacementfield.The bijectivity of the transformation was en-sured by calculating for every point the difference between its initial position and the one that is reached after composing the forward with the backward deformationfield,and redistributing the difference to eachfield.The bijectivity of the transformation can also be enforced by limiting the maximum length of the up-date displacement to half the voxel size and using composition to update the transformation.Variants for the contour-based reg-istration and the registration between segmented images were also described in[38].Most of the algorithms described in this section were inspired by the work of Thirion[38]and thus could alternatively be clas-sified as“Demons approaches.”These methods share the iter-ative approach that was presented in[38]that is,iterating be-tween estimating the displacements and regularizing to obtain the transformation.This iterative approach results in increased computational efficiency.As it will be discussed later in this section,this feature led researchers to explore such strategies for different PDEs.The use of Demons,as initially introduced,was an efficient algorithm able to provide dense correspondences but lacked a sound theoretical justification.Due to the success of the algo-rithm,a number of papers tried to give theoretical insight into its workings.Fischer and Modersitzki[39]provided a fast algo-rithm for image registration.The result was given as the solution of linear system that results from the linearization of the diffu-sion PDE.An efficient scheme for its solution was proposed while a connection to the Thirion’s Demons algorithm[38]was drawn.Pennec et al.[40]studied image registration as an energy minimization problem and drew the connection of the Demons algorithm with gradient descent schemes.Thirion’s image force based on opticalflow was shown to be equivalent with a second order gradient descent on the Sum of Square Differences(SSD) matching criterion.As for the regularization,it was shown that the convolution of the global transformation with a Gaussian。
纳瓦霍密码——精选推荐

------精品WORD文档推荐:阅读、浏览、收藏、下载更加方便------------以下是正文------纳瓦霍密码(Navajo code):美国军队在第二次世界大战太平洋战场使用的一种密码,因该密码系统基于纳瓦霍族语言,故名。
军事当局决定选取纳瓦霍语作为代码的原因主要是因为该语言的语法和音质对于非纳瓦霍人而言几乎是无法学习的,而且该语言是没有书面形式的。
纳瓦霍族密码,区别于普通的密码系统,号称日军永远无法破解的密码。
当时美军招聘了29名印第安纳瓦霍族人被征召入伍,因为他们的语言外族人无法听懂,所以美军将他们训练成了专门的译电员,人称“风语者”。
1历史溯源纳瓦霍密码20世纪第二次世界大战,美军遭遇珍珠港袭击后,被迫对日宣战。
但交战初期,美军的密码屡被日军破译,致使其在战场上吃尽了苦头。
就在美军高层为此焦急万分的时候,1942年初的一天,位于洛杉矶的美国海军办公室来了一位自称菲利浦·约翰斯顿的美国白人。
他提出了一个十分大胆的建议———征召美国最大的印第安部落纳瓦霍人入伍,使用纳瓦霍人的语言编制更加安全可靠的密码。
这种被称为“鸟语”的纳瓦霍语是一种没有文字而又极为复杂的语言,依靠其族人世世代代的口耳相传而得以延续。
纳瓦霍语的语法和发音都极为怪异,听起来有点像野兽的怪叫。
它以语调的强弱不同来表达语言内涵,同一个音用四种不同的声调说出来就表达四种不同的意思。
一个会讲纳瓦霍语的人曾说,纳瓦霍语的词汇十分生动、形象,“一个词就可以让你的脑海中浮现出整幅画面。
”约翰斯顿之所以能够提出这个构想,是因为他从小就跟随父亲———一位长期在印第安人保护地传教的牧师,在纳瓦霍人聚居区生活,所以对纳瓦霍人和他们的语言非常熟悉。
而在当时,纳瓦霍语对部落外的人来说,无异于“鸟语”。
因为这种语言口口相传,没有文字,其语法、声调、音节都非常复杂,没有经过专门的长期训练,根本不可能弄懂它的意思。
根据当时的资料记载,通晓这一语言的非纳瓦霍族人全球不过30人,而其中没有一个是日本人。
无监督的磁共振图像重建方法研究进展

MR 图像重建。 具体来说,基于 K 空间域的方法主
要通过对不完全采样的 K 空间域数据进行二次处
理来构造成对的训练数据,从而学习 K 空间域的隐
式先验信息,但其对包括欠采样方式在内的成像条
件有较高的要求。 基于图像域的方法主要利用生成
模型对图 像 域 数 据 的 先 验 分 布 进 行 建 模, 以 约 束
的子集,其中一个子集作为神经网络的输入以生成
习方法就不再适用,而通过无监督的深度学习技术,
重建结果,另一个子集被用作计算损失函数,通过这
实现在缺少配对训练数据场景下的高质量 MR 图像
重建成为了研究者们关注的重点。
无监督的 MR 图像重建是指在没有配对的训练
数据的情况下,从有限的数据中学习先验信息,并利
and promote clinical applications of MR imaging.
【 Keywords】 accelerated magnetic resonance imaging; image reconstruction; deep learning; unsupervised
效利用 [8] 。 尽管这种多次划分的处理提高了算法
高的要求,且其构造训练数据的方式依然是对不完
全采样的 K 空间数据进行二次欠采样,这会减少提
供给网络的信息,使其在高倍采样率条件下的重建
性能受到限制。
此外,利用 K 空间域冗余信息进行互相补充以
获取近似的全采样数据,是另外一种构造成对训练
数据的方式。 受 Noise2Noise 模型 [9] 的启发,对同一
作者单位:1 复旦大学大数据学院( 上海 200433)
2 复旦大学人类表型组研究院( 上海 201203)
Production of reactive oxygen species by plant NADPH oxidases

Update on Production of Reactive Oxygen Species by Rboh Production of Reactive Oxygen Species by Plant NADPH Oxidases1Moshe Sagi and Robert Fluhr*Albert Katz Department of Dryland Technologies,Jacob Blaustein Institute for Desert Research, Ben-Gurion University,Beer Sheva84105,Israel(M.S.);and Department of Plant Sciences, Weizmann Institute of Science,Rehovot76100,Israel(R.F.)NADPH oxidases(NOX)catalyze the production of superoxides,a type of reactive oxygen species(ROS). The dramatic induction of ROS production by human NOX2in activated blood phagocytic cells and its role in promoting pathogen killing has long motivated research in this area(Babior et al.,2002).In plants,the NOX homologs have been named respiratory burst oxidase homologs(Rboh)and they are also involved in ROS production in response to pathogens(Sagi and Fluhr,2001;Torres et al.,2002).However,the discovery of new types of animal NOX genes and new functions for plant Rboh genes underlines diverse roles for NOX-generated ROS in eukaryotic cell biology,in-cluding animal and plant defense,development,hor-mone biosynthesis,and cellular signal transduction (Foreman et al.,2003;Kwak et al.,2003;Lambeth,2004; Sagi et al.,2004;Torres et al.,2005).This Update will focus on recent advances in our understanding of intrinsic molecular properties of Rboh as they are related to their function in plants.STRUCTURAL SIMILARITIES INNOX-LIKE ENZYMESNOX homologs in the plant and animal kingdoms contain cytosolic FAD-and NADPH-binding domains and six conserved transmembrane helices.The third andfifth bind two heme groups through four critical His residues.The heme groups are required for trans-fer of electrons across the membrane to oxygen,the extracellular(EC)acceptor,to generate the superoxide radical(Torres et al.,1998;Lambeth,2004).Their pres-ence in animals,plants,andfilamentous fungi indi-cates a common ancient unicellular origin,although they are conspicuously absent in Saccharomyces and Candida(Lara-Ortiz et al.,2003).All seven human NOX members contain the core transmembrane part,and some include additional N-terminal diversification of calcium-binding elonga-tion factor(EF)hands and EF hands together with a peroxidase-like subdomain.The latter type,called DUOX, is unique in producing both superoxide and hydrogen peroxide(H2O2)products(Ameziane-El-Hassani et al., 2005).In contrast,the Arabidopsis(Arabidopsis thaliana) genome contains10members of basically similar struc-tures,with EF hands at the N terminus.Closely related, but still different from the animal NOX,are the Arabi-dopsis ferric-chelate reductases(Fig.1A;AtFRO)and their yeast(Saccharomyces cerevisiae)counterparts,FRE1 and FRP1,which belong to a superfamily offlavocyto-chromes that transport electrons across membranes (Robinson et al.,1999;Staiger,2002).AtFRO are found in roots and participate in the release of insoluble iron from Fe III oxide hydrates by their reduction to the soluble transport-ready Fe21form.DIVISION OF LABOR IN THE MULTIGENERboh FAMILYRboh enzymatic function is to supply ROS for phys-iological and developmental purposes and,in animals,a diversification in function is becoming evident.The inspection of digital northern activities in Arabidopsis gathered from recent Affymetrix microarray slides re-flects analogous gene specialization(Table I).The tissue-specific division of transcript distribution falls into three basic classes;expression throughout the plant(AtrbohD and F),in the roots(Atrboh A–G,I),and in a pollen-specific manner(Atrboh H and J).The tissue-specific expression is reflected in the phylogenetic distribution shown in Figure1A in which H and J form a small subclade.In the main clade,gene members are differ-entiated by their expression sensitivity to environmental inputs.The most common abiotic inducers of Atrboh transcript accumulation include conditions of anoxia/ hypoxia(Branco-Price et al.,2005)and nitrogen stress, where AtrbohC to F are also induced by a variety of biotic stresses.Analysis of mutants has specifically identified AtrbohC in root hair development(Foreman et al.,2003),AtrbohD as the major constitutively active form,and AtrbohF as a biotic stress-inducible form (Torres et al.,2002).The diverse transcription patterns suggest Rboh will function in broad aspects of growth1This work was supported in part by the Israel Science Founda-tion(grant no.417/03),the Minerva Foundation,Germany,and the Weizmann-Argentina Fundacion Antorchas.*Corresponding author;e-mail robert.fluhr@weizmann.ac.il;fax 972–8–9344181.The author responsible for distribution of materials integral to the findings presented in this article in accordance with the policy described in the Instructions for Authors()is: Robert Fluhr(robert.fluhr@weizmann.ac.il)./cgi/doi/10.1104/pp.106.078089.and physiological response.To what degree the detection of these transcripts reflects actual activity remains to be examined.MEMBRANE LOCALIZATION OF RbohAND COMPARTMENTALIZATION OF SUPEROXIDE PRODUCTIONCellular fractionation of plant tissue indicates that Rboh proteins are localized into the plasmalemma membrane(Sagi and Fluhr,2001;Simon-Plas et al., 2002).Interestingly,NtrbohD was found to be enriched in tobacco(Nicotiana tabacum)Bright-Yellow2cells on chemically distinct membrane microdomains,called lipid rafts,that may indicate a requirement for cou-pling to other membrane components(Mongrand et al.,2004).The precise submembrane distribution of Rboh is likely critical for its function,as noted in the asymmetric distribution of Rboh activity in AtrbohC-dependent ROS signaling in root hair growth(Foreman et al.,2003;Carol et al.,2005)and in Rboh involvement in xylem differentiation(Barcelo,2005).Additionally, intracellular locations have been reported for human NOX2and DUOX(Lambeth,2004;Ameziane-El-Hassani et al.,2005;Murillo and Henderson,2005),but are yet to be noted in plant Rboh biology.ROS can function as cellular second messengers that are likely to modulate many different proteins,leading to a variety of responses(Mori and Schroeder,2004). However,an enzymatic dismutation step mustfirst take place to produce from the superoxide(O22)the more stable H2O2derivative that is required for a viable long-range cell-to-cell signal or for passing membranes(Allan and Fluhr,1997).Thus,the impli-cations for vectorial transfer of charge and EC super-oxide accumulation are important to understand the complexity of Rboh biology(Fig.1B).How is the superoxide product dismutated to give rise to the H2O2 intercellular signal?In humans,an EC-superoxide dismutase(SOD)is thought to play an important role in maintenance of EC matrix biology(Petersen et al.,2004),but in plants only a paucity of evidence supports EC-SOD activity.Although secretory motifs are absent for known plant SODs,a high pI-SOD iso-form(hipI-SOD)showed an EC developmental buildup in the secondary cell wall of Zinnia elegans and Pinus sylvestris(Karpinska et al.,2001;Karlsson et al.,2005). Similarly,the nectar of the tobaccoflower contains large amounts of H2O2supplied in part by tandem action of Rboh and an EC germin-like SOD proteincalled Nectarin I(Carter and Thornburg,2004).Whether other germin-like genes function in the capacity of EC-SOD is unknown.The superoxide product is membrane impermeable in animals due to its negative charge in ambient conditions of pH(pKa of superoxide is4.8;e.g.blood pH is7.4).However,under conditions of exceptionally low pH,the superoxide can be protonated and,as such,has been shown to functionally cross yeast membrane compartments(Wallace et al.,2004).In plants,the physiological range of EC pH is5,in which 16%of the superoxide would be in the membrane-permeable hydroperoxyl(HO2Á)form.Thus,the external pH status could moderate the compartmentalization of superoxides produced by Rboh outside the mem-brane and perhaps enable the participation of cyto-plasmic SOD in the catalysis of H2O2formation. Figure1.Structure of Rboh and their phylogenetic distribution.A, Phylogenetic tree comparing Arabidopsis Atrboh with AtFRO and mammalian HsNOX2and HsNOX5proteins.Atrboh members are listed in Table parisons included HsNOX2(P04839),HsNOX5 (AF317889),AtFRO1(At1g01590),and AtFRO2(At1g01580).Only the carboxy terminus with homology to gp91phox/NOX2(excluding the EF hands)was used in the alignment.The phylogenetic analyses were made by neighbor-joining tree with ClustalX.The length of the horizontal lines connecting the sequences is proportional to the estimated amino acid substitutions/site between these sequences.Bootstrap values from1,000 iterations are shown.B,Schematic diagram of Rboh structure as predicted to be located in the membrane,showing the irreversible transfer of charge from cellular NADPH to EC oxygen.Shown are the N-terminal region EF hands juxtaposed to the C-terminal end to indicate an interaction by which calcium-dependent activity is regulated.Respiratory Burst Oxidase Homolog Mode of ActionDIRECT CONTROL OF Rboh ACTIVITY BY CALCIUMNOX2requires cytosolic proteinare essential for itsactivation (Lambeth,2004).In contrast,plant Rboh is stimulated directly by Ca 21,likely mediated by the N-terminal extension contain-ing EF-hand calcium-binding motifs (Sagi and Fluhr,2001).The mammalian NOX5containing N-terminal EF-hand motifs is expressed in lymphoid organs and testis and generates superoxide in response to phys-iological intracellular Ca 21bursts (Banfiet al.,2004).Indeed,Ca 21binding induced conformational change of NOX5,leading to enzyme activation through N-and C-terminal intramolecular interaction.Inter-estingly,although NOX2is not stimulated directly by Ca 21,it can be stimulated by the EF-hands-containing myeloid-related proteins MRP8and MRP14in a cyto-solic effector-independent manner (Berthier et al.,2003).Moreover,in human monocytes,the assembly and activation of NOX2in the NOX enzyme complex is regulated by calcium and protein kinase C-dependent phosphorylation (Cathcart,2004).Taken together,stim-ulation by calcium is emerging as an inherently con-served trait of NOX and Rboh enzymes.ROS In planta,cytosolic Ca 21spiking can be seen to precede NOX activation as part of elicitor-induced defense responses (Nurnberger and Scheel,2001;Zhao et al.,2005).For example,in tobacco cells,elicitors induce dynamic cytosolic Ca 21spiking from a resting level of 50to 100n M to 1to 5m M in 2to 5min (Lecourieux et al.,2002).Thus,it is possible that calcium directly initiates Rboh activation.However,ROS production from the initial Ca 21-dependent acti-vation of a NOX subsequently triggers a larger Ca 21influx (Pugin et al.,1997;Pei et al.,2000;Kadota et al.,2004).In this scenario,ROS functions as a cellular second messenger activating Ca 21-permeable chan-nels in a redox-controlled manner (Mori and Schroeder,2004).AtrbohC was implicated in ROS-dependent activation of Ca 21channels during root hair growth (Foreman et al.,2003)and AtrbohD and AtrbohF in abscisic acid (ABA)-induced activation of Ca 21chan-nels in guard cells (Kwak et al.,2003),suggesting the existence of a reiterated ROS to a calcium signal transduction module.If Ca 21is involved in Rboh activation as well as serving as a target for the Rboh product,a potential self-amplifying loop will be formed.Similar,but longer,timescale activation loops were suggested in a mitogen-activated protein kinase cascade and H 2O 2-dependent increase of Rboh mRNA levels in Nicotiana benthamiana (Yoshioka et al.,2003).Presumably,runaway activation of Rboh can be tem-pered by cellular mechanisms for rapid calcium re-moval,substrate (NADPH)depletion (Hunt et al.,2004),or depletion of the superoxide product by interaction of superoxide with nitric oxide and other scavenging systems (Delledonne et al.,2001).The interplay of ROS and calcium offers a nexus for the fascinating and daunting prospect of signaling cross-talk (Bowler and Fluhr,2000).OTHER REGULATORY MECHANISMS:ALKALINIZATION AND SMALL GTPasesMedium (or apoplast)alkalinization can precede NOX activation.It is thought to result from elicitor-induced depolarization of the plasma membrane and subsequent K 1/H 1exchange followed by Ca 21influx/Cl 2efflux (Simon-Plas et al.,1997;Nurnberger and Scheel,2001;Zhao et al.,2005).Inactivation of the NtrbohD-dependent ROS accumulation does not affectTable I.Rboh tissue-specific and environmental response activitiesRbohProtein CodeTissue Specificity aInduction/Repression bA At5g07390Root,elongation zone Induction:hypoxia/salt stress,genotoxic,nitrogen starvation.B At1g09090Root,elongation zone Induction:anoxia,hypoxia,methyl jasmonate,UVB,elevated in rbohC mutant.Repressed:ABA,cold,zeatin cycloheximide.C At5g51060Root,elongation zone Induction:Botrytis cinerea ,Pseudomonas syringae ,Agrobacterium,ozone.Repression:cycloheximide,H 2O 2,6-benzyl adenine.DAt5g47910All plant partsInduction:cycloheximide,anoxia,H 2O 2,chitin,ozone,AgNO 3,methyl jasmonate,Frankliniella occidentalis ,Phytophthora infestans ,P.syringae.Repression:ABA,high CO 2.E At1g19230Cell suspension,root,and seeds Induction:Agrobacterium,nitrogen starvation,genotoxic.Repression:senescence.F At1g64060All plant partsInduction:Agrobacterium,brassinolide.Repression:isoxaben.G At4g25090Root,elongation zone Induction:low nitrogen,salicylic acid,Glc,Suc.H At5g60010Stamens,pollen–I At4g11230Root,elongation zone Induction:anoxia,cycloheximide,norflurazone.JAt3g45810Stamens,pollen–aBased on data from the 2,180-microarray database compiled in GENEVESTIGATOR.Tissue signals that are significantly higher than background(P #0.06)are indicated.Experiments are summarized in https://www.genevestigator.ethz.ch (Zimmermann et al.,2004).bInduction of more than 2-fold or,where indicated,repression by 0.5-fold and above 200in the relative signal value are indicated.Sagi and Fluhrthe EC pH change(Simon-Plas et al.,2002),which is attributed mainly to the activity of a plasmalemma H1-ATPase(Simon-Plas et al.,1997).Whereas Rboh activation appears to be preceded by alkalinization,a special case of concomitant EC acidification is associ-ated with AtFRO activity.In that case,acidification of the root rhizosphere carried out by a proton-pumping system enhances local solubility of Fe III ions before reduction of the Fe III-chelate complex(Staiger,2002). Whether pH changes preceding protein enzyme acti-vation are common for all Rboh members is unknown. In mammalian phagocytes,the small GTPase Rac is among the cytosolic accessory factors that activate ROS production by NOX2(Lambeth,2004).Despite the apparent lack of similar accessory homologs in plants,plant Rac homologs(called ROP for Rho-like proteins)appear to regulate ROS defense production most likely via NOX(Kawasaki et al.,1999;Baxter-Burrell et al.,2002;Moeder et al.,2005).Interestingly,in ozone-stimulated cell death,the concomitant activa-tion of membrane-bound NOX is mediated through the G a-subunit of the heterotrimeric G protein(Joo et al.,2005).The role of ROP GTPases appears to be more than simple activation of Rboh,but is involved in accurate spatial emulation of ROS.A RhoGDI(SCN1/ AtRhoGDI)likely controls the activity of a ROP GTPase,resulting in root hair tip-focused activation of AtrbohC(Carol et al.,2005).Without SCN1/AtRhoGDI, the Rboh activity as detected by nitroblue terazolium is spatially deregulated and spread throughout the hair cell.Asymmetric bursts of NOX activity in Z. elegans are important to pinpoint the supply of H2O2 for peroxidase-based polymerization of lignin.In this case,Rac-like GTPase protein is detected on the plasma membrane juxtaposed to the site facing devel-oping tracheary elements(Nakanomyo et al.,2002). How GTPases and other upstream modulators of Rboh activity operate mechanistically remains to be elucidated,although their juxtaposition with Rboh on lipid rafts may facilitate their direct or indirect inter-action(Mongrand et al.,2004).THE LANGUAGE OF Rboh ROSROS produced by NOX have EC and intracellular ramifications.EC-ROS products are associated with direct oxidative cross-linking of cell wall components during defense(Apel and Hirt,2004),differentiation of plant vascular tissue(Nakanomyo et al.,2002),and suberization in wounded potato(Solanum tuberosum) tubers(Razem and Bernards,2003).Opposing depo-lymerization properties of ROS are likely employed in NADPH-dependent cell loosening that takes place as a prelude to cell wall expansion(Rodriguez et al.,2002). In these cases,the Rboh is meant to deliver a spatially localized product because of the rapid EC dissipation of H2O2(Allan and Fluhr,1997).Plant Rboh also functions as intercellular signal transponders to create local ROS transients that send a message.In addition to ABA-induced guard cell closure and root hair growth,H2O2acts as a second messenger for the induction of defense genes in re-sponse to systemin and jasmonate during wound responses(Orozco-Cardenas et al.,2001).Repressing Rboh activity altered redox-related metabolism and induced multiple pleiotropic developmental effects in addition to hindering systemic wound responses(Sagi et al.,2004).These results suggest that ROS generated by Rboh act in several hormone-signaling pathways. How will this message be interpreted specifically to modulate cell death,wound response,reaction to hypoxia,stimulation of growth,etc.?How will the cellular ROS scavenging system modify this response (Davletova et al.,2005)?In the simplest case,a differ-entiated cell will interpret the message from the mod-ule in a manner specific to each cell type,such as stomatal closure in guard cells or elongation in root hairs.When choices are to be made between multiple possible cellular responses,the strength,pulse length, and spatial context,as well as the interaction of ROS with other signals,are likely to play a role.Sequence data from this article can be found in the GenBank/EMBL data libraries under accession numbers P04839(HsNOX2),AAG33638(HsNOX5), NP_196356(AtrbohA),NP_973799(AtrbohB),AAS15724(AtrbohC),NP_199602 (AtrbohD),NP_173357(AtrbohE),NP_564821(AtrbohF),NP_194239(AtrbohG), NP_200809(AtrbohH),NP_192862(AtrbohI),NP_190167(AtrbohJ),NP_171665 (AtFRO1),and NP_171664(AtFRO2).Received January29,2006;revised March5,2006;accepted March5,2006; published June12,2006.LITERATURE CITEDAllan AC,Fluhr R(1997)Two distinct sources of elicited reactive oxygen species in tobacco epidermal cells.Plant Cell9:1559–1572Ameziane-El-Hassani R,Morand S,Boucher JL,Frapart YM,Apostolou D,Agnandji D,Gnidehou S,Ohayon R,Noel-Hudson MS,Francon J, et al(2005)Dual oxidase-2has an intrinsic Ca21-dependent H2O2-generating activity.J Biol Chem280:30046–30054Apel K,Hirt H(2004)Reactive oxygen species:metabolism,oxidative stress,and signal transduction.Annu Rev Plant Biol55:373–399 Babior BM,Lambeth JD,Nauseef W(2002)The neutrophil NADPH oxidase.Arch Biochem Biophys397:342–344BanfiB,Tirone F,Durussel I,Knisz J,Moskwa P,Molnar GZ,Krause KH, Cox JA(2004)Mechanism of Ca21activation of the NADPH oxidase5 (NOX5).J Biol Chem279:18583–18591Barcelo AR(2005)Xylem parenchyma cells deliver the H2O2necessary for lignification in differentiating xylem vessels.Planta220:747–756 Baxter-Burrell A,Yang ZB,Springer PS,Bailey-Serres J(2002)RopGAP4-dependent Rop GTPase rheostat control of Arabidopsis oxygen depri-vation tolerance.Science296:2026–2028Berthier S,Paclet MH,Lerouge S,Roux F,Vergnaud S,Coleman AW, Morel F(2003)Changing the conformation state of cytochrome b(558) initiates NADPH oxidase activation—MRP8/MRP14regulation.J Biol Chem278:25499–25508Bowler C,Fluhr R(2000)The role of calcium and activated oxygens as signals for controlling cross-tolerance.Trends Plant Sci5:241–246 Branco-Price C,Kawaguchi R,Ferreira RB,Bailey-Serres J(2005) Genome-wide analysis of transcript abundance and translation in Arabidopsis seedlings subjected to oxygen deprivation.Ann Bot(Lond)96: 647–660Carol RJ,Takeda S,Linstead P,Durrant MC,Kakesova H,Derbyshire P, Drea S,Zarsky V,Dolan L(2005)A RhoGDP dissociation inhibitor spatially regulates growth in root hair cells.Nature438:1013–1016 Respiratory Burst Oxidase Homolog Mode of ActionCarter C,Thornburg RW(2004)Is the nectar redox cycle afloral defense against microbial attack?Trends Plant Sci9:320–324Cathcart MK(2004)Regulation of superoxide anion production by NADPH oxidase in monocytes/macrophages—contributions to athero-sclerosis.Arterioscler Thromb Vasc Biol24:23–28Davletova S,Rizhsky L,Liang H,Shengqiang Z,Oliver DJ,Coutu J, Shulaev V,Schlauch K,Mittler R(2005)Cytosolic ascorbate peroxidase 1is a central component of the reactive oxygen gene network of Arabidopsis.Plant Cell17:268–281Delledonne M,Zeier J,Marocco A,Lamb C(2001)Signal interactions between nitric oxide and reactive oxygen intermediates in the plant hypersensitive disease resistance response.Proc Natl Acad Sci USA98: 13454–13459Foreman J,Demidchik V,Bothwell JHF,Mylona P,Miedema H,Torres MA,Linstead P,Costa S,Brownlee C,Jones JDG,et al(2003)Reactive oxygen species produced by NADPH oxidase regulate plant cell growth.Nature422:442–446Hunt L,Lerner F,Ziegler M(2004)NAD—new roles in signalling and gene regulation in plants.New Phytol163:31–44Joo JH,Wang SY,Chen JG,Jones AM,Fedoroff NV(2005)Different signaling and cell death roles of heterotrimeric G protein a-and b-subunits in the Arabidopsis oxidative stress response to ozone.Plant Cell17:957–970Kadota Y,Goh T,Tomatsu H,Tamauchi R,Higashi K,Muto S,Kuchitsu K (2004)Cryptogein-induced initial events in tobacco BY-2cells:pharma-cological characterization of molecular relationship among cytosolic Ca21transients,anion efflux and production of reactive oxygen species.Plant Cell Physiol45:160–170Karlsson M,Melzer M,Prokhorenko I,Johansson T,Wingsle G(2005) Hydrogen peroxide and expression of hipI-superoxide dismutase are associated with the development of secondary cell walls in Zinnia elegans.J Exp Bot56:2085–2093Karpinska B,Karlsson M,Schinkel H,Streller S,Suss KH,Melzer M, Wingsle G(2001)A novel superoxide dismutase with a high isoelectric point in higher plants:expression,regulation,and protein localization.Plant Physiol126:1668–1677Kawasaki T,Henmi K,Ono E,Hatakeyama S,Iwano M,Satoh H, Shimamoto K(1999)The small GTP-binding protein Rac is a regulator of cell death in plants.Proc Natl Acad Sci USA96:10922–10926Kwak JM,Mori IC,Pei ZM,Leonhardt N,Torres MA,Dangl JL,Bloom RE,Bodde S,Jones JDG,Schroeder JI(2003)NADPH oxidase AtrbohD and AtrbohF genes function in ROS-dependent ABA signaling in Arabidopsis.EMBO J22:2623–2633Lambeth JD(2004)Nox enzymes and the biology of reactive oxygen.Nature Rev Immunol4:181–189Lara-Ortiz T,Riveros-Rosas H,Aguirre J(2003)Reactive oxygen species generated by microbial NADPH oxidase NoxA regulate sexual devel-opment in Aspergillus nidulans.Mol Microbiol50:1241–1255 Lecourieux D,Mazars C,Pauly N,Ranjeva R,Pugin A(2002)Analysis and effects of cytosolic free calcium increases in response to elicitors in Nicotiana plumbaginifolia cells.Plant Cell14:2627–2641Moeder W,Yoshioka K,Klessig DF(2005)Involvement of the small GTPase Rac in the defense responses of tobacco to pathogens.Mol Plant-Microbe Interact18:116–124Mongrand S,Morel J,Laroche J,Claverol S,Carde JP,Hartmann MA, Bonneu M,Simon-Plas F,Lessire R,Bessoule JJ(2004)Lipid rafts in higher plant cells—purification and characterization of triton X-100-insoluble microdomains from tobacco plasma membrane.J Biol Chem 279:36277–36286Mori IC,Schroeder JI(2004)Reactive oxygen species activation of plant Ca21channels:a signaling mechanism in polar growth,hormone trans-duction,stress signaling,and hypothetical mechanotransduction.Plant Physiol135:702–708Murillo I,Henderson LM(2005)Expression of gp91(phox)/Nox2in COS-7 cells:cellular localization of the protein and the detection of outward proton currents.Biochem J385:649–657Nakanomyo I,Kost B,Chua NH,Fukuda H(2002)Preferential and asymmetrical accumulation of a Rac small GTPase mRNA in differen-tiating xylem cells of Zinnia elegans.Plant Cell Physiol43:1484–1492 Nurnberger T,Scheel D(2001)Signal transmission in the plant immune response.Trends Plant Sci6:372–379Orozco-Cardenas ML,Narvaez-Vasquez J,Ryan CA(2001)Hydrogen peroxide acts as a second messenger for the induction of defense genes in tomato plants in response to wounding,systemin,and methyl jasmonate.Plant Cell13:179–191Pei ZM,Murata Y,Benning G,Thomine S,Klusener B,Allen GJ,Grill E, Schroeder JI(2000)Calcium channels activated by hydrogen peroxide mediate abscisic acid signalling in guard cells.Nature406:731–734 Petersen SV,Oury TD,Ostergaard L,Valnickova Z,Wegrzyn J,Thogersen IB,Jacobsen C,Bowler RP,Fattman CL,Crapo JD,et al(2004)Extra-cellular superoxide dismutase(EC-SOD)binds to type I collagen and protects against oxidative fragmentation.J Biol Chem279:13705–13710 Pugin A,Frachisse JM,Tavernier E,Bligny R,Gout E,Douce R,Guern J (1997)Early events induced by the elicitor cryptogein in tobacco cells: involvement of a plasma membrane NADPH oxidase and activation of glycolysis and the pentose phosphate pathway.Plant Cell9:2077–2091 Razem FA,Bernards MA(2003)Reactive oxygen species production in association with suberization:evidence for an NADPH-dependent oxidase.J Exp Bot54:935–941Robinson NJ,Procter CM,Connolly EL,Guerinot ML(1999)A ferric-chelate reductase for iron uptake from soils.Nature397:694–697 Rodriguez AA,Grunberg KA,Taleisnik EL(2002)Reactive oxygen species in the elongation zone of maize leaves are necessary for leaf extension.Plant Physiol129:1627–1632Sagi M,Davydov O,Orazova S,Yesbergenova Z,Ophir R,Stratmann JW, Fluhr R(2004)Plant respiratory burst oxidase homologs impinge on wound responsiveness and development in Lycopersicon esculentum.Plant Cell16:616–628Sagi M,Fluhr R(2001)Superoxide production by plant homologues of the gp91(phox)NADPH oxidase:modulation of activity by calcium and by tobacco mosaic virus infection.Plant Physiol126:1281–1290Simon-Plas F,Elmayan T,Blein JP(2002)The plasma membrane oxidase NtrbohD is responsible for AOS production in elicited tobacco cells.Plant J31:137–147Simon-Plas F,Rusterucci C,Milat ML,Humbert C,Montillet JL,Blein JP (1997)Active oxygen species production in tobacco cells elicited by cryptogein.Plant Cell Environ20:1573–1579Staiger D(2002)Chemical strategies for iron acquisition in plants.Angew Chem Int Ed Engl41:2259–2264Torres MA,Dangl JL,Jones JDG(2002)Arabidopsis gp91(phox)homo-logues AtrbohD and AtrbohF are required for accumulation of reactive oxygen intermediates in the plant defense response.Proc Natl Acad Sci USA99:517–522Torres MA,Jones JDG,Dangl JL(2005)Pathogen-induced,NADPH oxidase-derived reactive oxygen intermediates suppress spread of cell death in Arabidopsis thaliana.Nat Genet37:1130–1134Torres MA,Onouchi H,Hamada S,Machida C,Hammond-Kosack KE, Jones JDG(1998)Six Arabidopsis thaliana homologues of the human respiratory burst oxidase(gp91(phox)).Plant J14:365–370Wallace MA,Liou LL,Martins J,Clement MHS,Bailey S,Longo VD, Valentine JS,Gralla EB(2004)Superoxide inhibits4Fe-4S cluster enzymes involved in amino acid biosynthesis—cross-compartment pro-tection by CuZn-superoxide dismutase.J Biol Chem279:32055–32062 Yoshioka H,Numata N,Nakajima K,Katou S,Kawakita K,Rowland O, Jones JDG,Doke N(2003)Nicotiana benthamiana gp91(phox)homologs NbrbohA and NbrbohB participate in H2O2accumulation and resistance to Phytophthora infestans.Plant Cell15:706–718Zhao J,Davis LC,Verpoorte R(2005)Elicitor signal transduction leading to production of plant secondary metabolites.Biotechnol Adv23:283–333 Zimmermann P,Hirsch-Hoffmann M,Hennig L,Gruissem W(2004) GENEVESTIGATOR:Arabidopsis microarray database and analysis toolbox.Plant Physiol136:2621–2632Sagi and Fluhr。
bogdanov分类 -回复

bogdanov分类-回复什么是Bogdanov分类?Bogdanov分类是一种用于对文本进行主题分类的方法,它基于Bogdanov变换(Bogdanov Transformation)和聚类算法。
这种分类方法最早由俄罗斯数学家Bogdanov于20世纪初提出,一直被广泛应用于自然语言处理、文本挖掘和信息检索等领域。
本文将详细介绍Bogdanov分类的原理和具体步骤,并使用一个案例来演示它的应用过程。
首先,我们需要了解Bogdanov变换的概念和原理。
Bogdanov变换是一种将文本转化为向量表示的方法,它通过计算每个单词在文档中的频率和重要性来构建向量空间模型。
在Bogdanov变换中,每个单词都被赋予一个权重值,该权重值由该单词在文档中的频率和在整个语料库中的出现次数共同决定。
这样,文本就可以被表示为多个维度的向量,每个维度对应一个单词。
通过计算向量之间的相似度,我们可以判断文本之间的相关性和相似性。
接下来,我们来讲解Bogdanov分类的具体步骤。
首先,我们需要准备一个已标注好的文本集合作为训练数据。
训练数据中的每个文本都被赋予一个或多个标签,用来表示其所属的主题或类别。
然后,我们将训练数据进行Bogdanov变换,得到每个文本对应的向量表示。
接着,我们使用聚类算法对这些向量进行聚类分析,将相似的文本分为同一类。
最后,我们将测试数据进行Bogdanov变换,并使用之前得到的聚类模型对其进行分类。
在实际应用中,我们可以选择不同的聚类算法来执行第三步的聚类分析。
常见的聚类算法包括K均值聚类、层次聚类和密度聚类等。
选择合适的聚类算法可以提高分类的准确性和效果。
下面,我们通过一个案例来演示Bogdanov分类的应用过程。
假设我们有一篇新闻报道的文本集合,其中包含了多个不同的主题,如政治、经济、体育等。
我们首先将这些文本进行Bogdanov变换,得到每个文本的向量表示。
然后,我们使用K均值聚类算法对这些向量进行聚类分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
备注
PPAP 已提交 DV不算 报告已经提供
DefectResults
SQE
未处理 未处理 换货 未处理 换货 换货 扣款
月报状态 N N N N Y Y 下月 N N Y Y 下月 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y 下月 下月 Y
Lucy Lucy Lucy Lucy Lucy Lucy Lucy
SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG
PCB来料尺寸不符 造成无法分板 料号:11018901 批 原因不明 次:1437 厂商:苏杭 PCB来料MARK外圈氧化,NXT无法识别,无法正常生 不确定是供应商原因,不算 产。 PCB来料氧化 料号:81026901 批次 1437 厂商:苏杭 拒焊不算 PCB来料板面有绿油漆 氧化 PCB来料涂层不全 PCB来料板面有异物7PCS 漏洞:1PCS 料号: 原因不明 81043901 批次:1443 厂商:苏杭 PCB来料焊盘偏移 料号:812124901 批次:1443 厂 商:苏杭 PCB来料涂层不全 1PCS 板面漏铜1PCS 异物:1PCS 料号:95207901 批次:1437 厂商:苏杭 PCB板子上贴有不良标示20% pcb来料涂层不全 料号:81018901 批次:1435 厂 商:苏杭 pcb来料板面漏铜 料号:812124901 批次:1443 厂 商:苏杭 PCB来料涂层不全 料号:61106901 批次:1423 厂 商:苏杭 PCB来料板面涂层不全2pcs,板面漏铜1pcs,料号: 83713901 批次:1433 厂商:苏杭 PCB来料板面漏铜 料号 81117901 厂商:苏杭 批次: 1443 PCB来料板面漏铜 料号:83713901 批次:1433 厂 商:苏杭 PCB来料板面漏铜 1PCS 涂层不全 料号:812673901 批次:1439 厂商:苏杭 pcb来料板面漏铜 pcb来料定位孔小 料号:61106901 批次:1421 厂商:苏杭 pcb来料板面漏铜 料号:812673901 批次:1435 厂 商:苏杭 pcb来料涂层不全 料号:81025901 批次:1437 厂 商:苏杭 PCB来料板面漏洞 2PCS 料号:15248901 批次:1443 厂商:苏杭 pcb来料板面漏铜 料号:81025901 批次:1437 厂 商:苏杭 PCBA面板来料漏铜 PCB来料涂层不全 料号:1PCS 氧化:1PCS 料号: 81025901 批次:1431 厂商:苏杭 PCB来料美不美漏铜 1PCS 涂层不全 1PCS 批次: 1443 供应商:苏杭 PCB来料涂层不良 PCB来料涂层不良 PCB来料板面漏铜 料号 11014901 批次:1431 厂商: 苏杭 PCB来料涂层不全 料号81005901 批次:1431 厂 商:苏杭 PCB来料板面漏铜1PCS 涂层不全1PCS 料号: 812673901 批次:1443 厂商:苏杭 PCB来料漏洞 料号:812124901 批次:1443 厂商:苏 杭 PCB来料喷锡不良
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
DefectDetails1 1.来料版本升C0,区分库存。2.来料报告上弯曲线宽 0.06+/-0.002inch未管控。 首次来料无PPAP. PCB印刷锡膏后整体偏移。 来料无报告,无FA. PCB来料板边漏铜 PCB板漏洞 内部问题
RejectQuant ity 6032 480 344 336 320 176 72 32 16 1 1 8 7 5
64235 qc5 64075 QC5 64138 QC5 63552 QC5 64565 ipqc 64578 QC6 63810 ipqc 64370 IPQC 64616 ipqc 64530 IPQC 64497 IPQC 64499 IPQC 64390 ipqc 63623 ipqc
64278 qc6 64493 ipqc 64492 ipqc 64556 ipqc 64101 IPQC 64353 ipqc 64352 ipqc 63562 ipqc 63672 ipqc 63673 ipqc 64521 ipqc 64526 IPQC 64006 IPQC 64173 ipqc 64264 ipqc 64266 ipqc 64265 ipqc 64311 IPQC 63731 ipqc 63592 IPQC 64614 ipqc 64615 ipqc 64527 IPQC
Partnumber 81023901B 81124901 812804901 912148901 81025902 81025902B ST11018911 81005901 81026911b 61106901 81043901 81043911 ST612109911 ST95207911
Manufacturer SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG
SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG SUHANG
Lucy Lucy Lucy Lucy
扣款
Lucy
未处理
Lucy
未处理 换货
Lucy Lucy
PCB来料PAD点漏铜 1PCS PAD点漏铜 料号: 81025901 批次:1437 厂商:苏杭 pcb来料板面漏铜 料号:81026902 批次:1439 厂 商:苏杭 PCB来料板面漏铜 料号812673901 批次:1435 厂商: 苏杭 PCB来料板面漏铜 料号:15287901 批次:1437 厂 商:苏杭 PCB来料涂层不全,料号:11029901,批次1439,厂商 苏杭 pcb来料板面漏铜 料号:81043901 批次:1437 厂 商:苏杭 pcb 来料涂层不全 料号:812673901 批次:1437 厂 商:苏杭 pcb来料板面异物 料号:15248901 批次:1439 厂 商:苏杭 pcb来料板面氧化 料号:81026902 批次:1435 厂 商:苏杭 PCB来料定位孔堵孔 料号:81119901 批次:1443 厂 商:苏杭 PCB来料板面异物 PCB来料板面异物 料号:812673901 批次:1443 厂 商:苏杭 pcb来料板面漏洞288pcs涂层不全1PCS 料号: 81025902 批次:1443 厂商:苏杭 pcb来料板面漏洞 料号:81009901 批次:1437 厂 商:苏杭 pcb来料涂层不全 料号:84110901 批次:1443 厂 商:苏杭 pcb来料板面漏铜 料号:15287901 批次:1441 厂 商:苏杭 pcb来料板面异物 料号:812673901 批次:1437 厂 商:苏杭 pcb来料板面漏铜 料号:11037901 批次:1439 厂 商:苏杭 PCB来料帮忙氧化 料号:83713902 批次:1433 厂 商:苏杭 PCB来料漏铜,料号91012901,批号2014.11.5 PCB来料板面异物料号812124901批号1443供应商苏杭 PCB来料涂层不良,料号:812673901批号:1441供应 商:苏杭 PCB来料板面异物 料号:812673901 批次:1443 厂 商:苏杭 PCB来料帮忙异物 料号:95216901 批次:1445 厂 商:苏杭 PCB来料涂层不全 料号:81005901 批次:1441 厂 商:苏杭 PCB来料帮忙漏铜 料号:81025901 批次:1445 厂 商:苏杭 PCB来料板面漏铜 料号:812674501 批次:1351 厂 商:苏杭 PCB来料绿油漆 料号:812673901 批次:1439 厂 商:苏杭 pcb来料板面漏铜 料号:812124901 批次:1443 厂 商:苏杭
2014-11-10 8:37 2014-11-16 19:14 2014-11-16 19:12 2014-11-18 19:18 2014-11-5 7:02 2014-11-12 7:28 2014-11-12 7:24 2014-10-21 19:17 2014-10-27 7:19 2014-10-27 7:22 2014-11-17 19:14 2014-11-18 4:17 2014-11-3 7:06 2014-11-6 19:14 2014-11-10 7:12 2014-11-10 7:15 2014-11-10 7:13 2014-11-11 7:07 2014-10-28 7:56 2014-10-22 18:10 2014-11-20 6:56 2014-11-20 7:00 2014-11-18理 换货 换货 未处理
Lucy Lucy Lucy Lucy
扣款
Lucy
扣款
换货 扣款
Lucy Lucy Lucy
扣款
Lucy
扣款
Lucy
扣款
Lucy
扣款
Lucy
扣款
Lucy
扣款
Lucy
扣款
Lucy
扣款
Lucy
扣款
Lucy
扣款
Lucy
扣款 扣款 扣款
Lucy Lucy Lucy