Process Mapping Traing
如何在计算机视觉技术中处理数据不平衡问题

如何在计算机视觉技术中处理数据不平衡问题在计算机视觉技术中,数据不平衡问题是一个普遍存在的挑战。
数据不平衡指的是在训练数据集中,不同类别的样本数量存在明显的差异。
这种情况下,模型往往会偏向于预测数量较多的类别,而对数量较少的类别性能不佳。
因此,解决数据不平衡问题对于改善计算机视觉任务的性能至关重要。
本文将介绍一些常见的方法来处理数据不平衡问题。
一、数据采样方法1.上采样(Over-sampling)上采样是通过增加少数类别的样本来提高其数量,使得训练数据集中不同类别的样本数量相对均衡。
常见的上采样方法有随机复制、SMOTE(Synthetic Minority Over-sampling Technique)等。
随机复制是指直接将少数类别的样本进行复制,使得其数量与多数类别的样本相当。
这种方法简单直接,但可能会导致训练集中存在大量相似的样本,从而引入模型过拟合的风险。
SMOTE是一种生成合成样本的方法,它通过对少数类别样本之间的插值,生成新的合成样本。
具体而言,SMOTE算法会选取两个近邻样本,利用它们之间的差值加权生成新的合成样本。
这样可以有效增加少数类别样本,并且不会像随机复制一样引入冗余数据。
2.下采样(Under-sampling)下采样是通过减少多数类别的样本来降低其数量,使得训练数据集中不同类别的样本数量相对均衡。
常见的下采样方法有随机删除、近邻规则等。
随机删除是指从多数类别中随机选择一定数量的样本进行删除,使得多数类别的样本数量与少数类别相近。
这种方法简单易行,但可能会导致删除了重要的样本信息,导致模型性能下降。
近邻规则是指通过样本间的距离度量来选择删除的样本。
具体而言,该方法会计算多数类别样本和少数类别样本之间的距离,然后选择最近邻的一部分多数类别样本进行删除。
这样可以减少多数类别样本的数量,并保留了某种程度上的样本差异性。
二、再加权方法再加权方法是通过调整样本权重的方式来平衡训练数据集中不同类别的样本。
queryinst模型算法结构

queryinst模型算法结构1.引言本文将介绍q ue ry in s t模型的算法结构,q ue ry in st是一种用于目标检测的深度学习模型。
首先,我们将介绍q ue ry in st模型的背景和意义。
然后,详细介绍q ue ry in st的算法结构、网络架构和训练过程。
最后,我们将讨论q uer y in st模型的应用领域和未来发展方向。
2.背景和意义目标检测是计算机视觉领域中的重要任务,它可以通过自动识别图像或视频中的目标物体来实现智能分析和决策。
传统的目标检测方法在准确性和效率方面存在一定的限制。
随着深度学习的兴起,基于卷积神经网络的目标检测方法取得了巨大的突破,但仍然存在一些挑战,例如小目标检测和密集目标检测。
q u er yi ns t模型作为一种新的目标检测算法,旨在解决传统方法的限制,并提高目标检测的准确性和效率。
它采用了一种新颖的网络结构和训练方法,可以有效地检测小目标和密集目标。
3.算法结构q u er yi ns t模型主要由以下几个组件组成:3.1主干网络q u er yi ns t模型的主干网络采用了一种深度卷积神经网络,例如R e sN et或E ff ic ien t Ne t。
这个主干网络可以提取图像特征,为后续的目标检测任务提供基础。
3.2Q u e r y B r a n c hq u er yi ns t模型引入了Qu er yB ra nc h来解决小目标检测的问题。
Q u er yB ra nc h负责生成较小的目标框,以便检测小目标。
它包含了一系列不同尺度和长宽比的a nc ho r,并通过对这些a nc ho r进行分类和回归来生成目标框。
3.3I n s t a n c e B r a n c hI n st an ce Br a n ch用于检测密集目标。
它与Q ue ry Br an ch类似,但使用了不同的a nc ho r和目标框生成策略。
工作计划地道英文

IntroductionThis comprehensive work plan outlines a strategic roadmap for enhancing organizational performance through a multifaceted approach that emphasizes quality, efficiency, and continuous improvement. It is designed to provide a clear, actionable framework for achieving our objectives while fostering a culture of excellence and innovation. The plan is structured around five key pillars: (1) Leadership and Culture, (2) Operational Excellence, (3) Talent Management, (4) Customer Centricity, and (5) Technology and Innovation. Each pillar represents a distinct yet interconnected domain that, when synergistically optimized, will propel the organization towards its vision of delivering unparalleled value to stakeholders.I. Leadership and CultureA. Vision and Values Clarification1. Conduct a thorough review and refinement of the organization's vision, mission, and core values to ensure they align with our strategic direction and resonate with all stakeholders.2. Develop a communication strategy to effectively cascade these refreshed guiding principles throughout the organization, utilizing various channels such as town hall meetings, internal newsletters, and leadership workshops.B. Leadership Development1. Implement a leadership development program encompassing coaching, mentoring, and training initiatives to enhance the capabilities of current and future leaders in areas such as strategic thinking, change management, emotional intelligence, and inclusive leadership.2. Establish a robust succession planning process to identify and nurture high-potential talent, ensuring a steady pipeline of capable leaders to drive the organization forward.C. Culture Transformation1. Design and launch a culture transformation initiative focused on embedding a high-performance, customer-centric, and innovative mindset across all levels of the organization. This will involve:- Conducting a cultural audit to assess the current state and identify areas for improvement.- Formulating a culture charter that defines the desired behaviors, norms, and practices.- Implementing targeted interventions, such as workshops, team-building activities, and recognition programs, to foster the desired culture.- Regularly measuring and reporting on cultural progress using relevant metrics and employee feedback mechanisms.II. Operational ExcellenceA. Process Optimization1. Undertake a comprehensive process mapping exercise to identify bottlenecks, inefficiencies, and opportunities for standardization across allcore business processes.2. Implement Lean Six Sigma or similar methodologies to streamline workflows, eliminate waste, and enhance process quality, with a focus on reducing cycle times, minimizing errors, and boosting productivity.B. Performance Metrics and Dashboards1. Develop a robust performance measurement framework that encompasses key performance indicators (KPIs), balanced scorecards, and real-time dashboards to monitor and track progress against strategic objectives at both the organizational and departmental levels.2. Establish regular review meetings (e.g., monthly or quarterly) where senior leadership can analyze performance data, discuss trends, and make data-driven decisions to address issues and capitalize on opportunities.C. Risk Management and Compliance1. Strengthen the organization's risk management framework by conductinga thorough risk assessment, identifying potential threats, and implementing mitigation strategies across all operational domains.2. Ensure strict adherence to regulatory requirements and industry best practices by establishing a robust compliance monitoring system, providing regular training to employees, and conducting periodic audits.III. Talent ManagementA. Talent Acquisition and Retention1. Refine the recruitment strategy to attract top talent by leveraging advanced sourcing techniques, enhancing the employer brand, and streamlining the candidate experience.2. Implement a comprehensive retention strategy encompassing competitive compensation packages, career development opportunities, employee wellness initiatives, and a positive work environment to minimize turnover and maximize employee engagement.B. Learning and Development1. Design and roll out a competency-based learning and development framework that aligns individual skill sets with organizational needs, incorporates both formal training and on-the-job learning, and fosters a culture of continuous learning.2. Invest in digital learning platforms and microlearning modules to facilitate self-paced, personalized learning experiences for employees.C. Performance Management1. Transition to a more agile, continuous performance management approach that emphasizes ongoing feedback, coaching, and goal alignment, replacing traditional annual reviews with regular check-ins and development-focused conversations.2. Introduce a fair and transparent performance evaluation system linked to clearly defined performance standards and development goals, ensuring that rewards and recognition are commensurate with individual contributions and achievements.IV. Customer CentricityA. Customer Experience Strategy1. Develop a customer-centric strategy that encompasses all touchpoints and stages of the customer journey, focusing on understanding customer needs, preferences, and pain points, and designing tailored solutions and experiences to meet them.2. Establish a Voice of the Customer (VoC) program to gather and analyze customer feedback continuously, using insights to drive product/service improvements, process enhancements, and strategic decision-making.B. Customer Relationship Management (CRM)1. Implement a robust CRM system to centralize customer data, facilitate seamless interactions across channels, and enable personalized, data-driven marketing, sales, and service efforts.2. Train employees on effective CRM usage and customer engagement strategies to foster strong, long-lasting customer relationships.C. Customer Service Excellence1. Revamp the customer service function by setting high service standards, providing comprehensive training to frontline staff, and leveraging technology (e.g., chatbots, AI-powered support) to deliver fast, accurate, and empathetic assistance.2. Establish a customer satisfaction measurement system and regularly review metrics to identify areas for improvement and ensure consistent delivery of exceptional service.V. Technology and InnovationA. Digital Transformation1. Develop a digital transformation roadmap that outlines the strategic adoption of emerging technologies (e.g., cloud computing, artificial intelligence, Internet of Things) to enhance operational efficiency, customer experiences, and innovation capabilities.2. Prioritize investments in IT infrastructure upgrades, cybersecurity enhancements, and data analytics tools to create a solid foundation for digital growth.B. Innovation Management1. Establish an innovation management framework that encourages cross-functional collaboration, fosters a culture of experimentation, and supports the development, testing, and scaling of new ideas. This may include setting up innovation labs, organizing hackathons, or implementing an idea management platform.2. Integrate innovation metrics into the performance measurement framework, rewarding teams and individuals who contribute to successful innovation projects and driving accountability for innovation outcomes across the organization.C. Data-Driven Decision Making1. Enhance data literacy across the organization through targeted training programs and the creation of user-friendly dashboards and reports thatdemocratize access to meaningful data insights.2. Embed data-driven decision making into all aspects of the business by establishing a Center of Excellence (CoE) for business intelligence and analytics, providing expert guidance and support to departments in leveraging data to inform strategy and operations.ConclusionThis comprehensive work plan outlines a holistic approach to enhancing organizational performance, addressing critical dimensions such as leadership and culture, operational excellence, talent management, customer centricity, and technology and innovation. By diligently executing this plan, the organization will be well-positioned to achieve its strategic objectives, maintain a competitive edge, and deliver sustained value to all stakeholders. Regular monitoring, review, and adjustment of the plan will be crucial to ensure its continued relevance and effectiveness in a rapidly changing business landscape.。
解决机器学习中的数据不平衡和评估指标问题

解决机器学习中的数据不平衡和评估指标问题在机器学习中,数据不平衡和评估指标问题是常见的挑战。
数据不平衡指的是在训练数据中,不同类别的样本数量差异较大。
评估指标问题则是在不平衡数据集上选择合适的评估指标来衡量模型性能。
为了解决数据不平衡问题,可以采取以下方法:1.重采样技术:通过增加少数类样本或减少多数类样本来平衡数据集。
其中一种常见方法是欠采样,即随机删除多数类样本;另一种方法是过采样,即复制少数类样本或生成新的少数类样本。
但需要注意的是,简单的重采样可能会引入噪声或导致过拟合问题。
2.欺骗型合成数据:通过生成更逼真的少数类样本来平衡数据集。
这可以使用生成对抗网络(GAN)等技术,以便生成与真实样本相似的少数类样本。
这种方法可以有效地增加少数类样本,但需要保证生成的样本与真实样本的分布相匹配,否则可能导致模型泛化能力下降。
3.算法调整:改变模型的训练算法以适应数据不平衡。
例如,在SVM中可以调整类别权重,以使损失函数中的不平衡得到纠正。
在决策树等算法中,可以调整划分阈值或节点分裂规则,以更好地处理不平衡数据。
4.集成方法:通过结合多个模型的预测结果来改善性能。
例如,可以使用Bagging、Boosting或Stacking等集成方法将多个基分类器的预测结果加权平均或组合在一起,从而降低对不平衡数据的敏感性。
对于评估指标问题,传统的评估指标如准确率(Accuracy)在不平衡数据中可能会存在误导性。
例如,在一个99%的多数类和1%的少数类的数据集上,分类器始终将样本预测为多数类,即使准确率也可以达到99%。
为了更全面地评估模型性能,可以使用以下方法:1.灵敏度和特异度:灵敏度(也称为召回率)表示少数类样本中被正确分类的比例,特异度表示多数类样本中被正确分类的比例。
这两个指标可以更全面地衡量模型对不同类别的分类能力。
2.预测精度和查准率:预测精度表示被分类为少数类的样本中正确分类的比例,查准率表示被模型预测为少数类的样本中实际为少数类的比例。
机器学习与人工智能领域中常用的英语词汇

机器学习与人工智能领域中常用的英语词汇1.General Concepts (基础概念)•Artificial Intelligence (AI) - 人工智能1)Artificial Intelligence (AI) - 人工智能2)Machine Learning (ML) - 机器学习3)Deep Learning (DL) - 深度学习4)Neural Network - 神经网络5)Natural Language Processing (NLP) - 自然语言处理6)Computer Vision - 计算机视觉7)Robotics - 机器人技术8)Speech Recognition - 语音识别9)Expert Systems - 专家系统10)Knowledge Representation - 知识表示11)Pattern Recognition - 模式识别12)Cognitive Computing - 认知计算13)Autonomous Systems - 自主系统14)Human-Machine Interaction - 人机交互15)Intelligent Agents - 智能代理16)Machine Translation - 机器翻译17)Swarm Intelligence - 群体智能18)Genetic Algorithms - 遗传算法19)Fuzzy Logic - 模糊逻辑20)Reinforcement Learning - 强化学习•Machine Learning (ML) - 机器学习1)Machine Learning (ML) - 机器学习2)Artificial Neural Network - 人工神经网络3)Deep Learning - 深度学习4)Supervised Learning - 有监督学习5)Unsupervised Learning - 无监督学习6)Reinforcement Learning - 强化学习7)Semi-Supervised Learning - 半监督学习8)Training Data - 训练数据9)Test Data - 测试数据10)Validation Data - 验证数据11)Feature - 特征12)Label - 标签13)Model - 模型14)Algorithm - 算法15)Regression - 回归16)Classification - 分类17)Clustering - 聚类18)Dimensionality Reduction - 降维19)Overfitting - 过拟合20)Underfitting - 欠拟合•Deep Learning (DL) - 深度学习1)Deep Learning - 深度学习2)Neural Network - 神经网络3)Artificial Neural Network (ANN) - 人工神经网络4)Convolutional Neural Network (CNN) - 卷积神经网络5)Recurrent Neural Network (RNN) - 循环神经网络6)Long Short-Term Memory (LSTM) - 长短期记忆网络7)Gated Recurrent Unit (GRU) - 门控循环单元8)Autoencoder - 自编码器9)Generative Adversarial Network (GAN) - 生成对抗网络10)Transfer Learning - 迁移学习11)Pre-trained Model - 预训练模型12)Fine-tuning - 微调13)Feature Extraction - 特征提取14)Activation Function - 激活函数15)Loss Function - 损失函数16)Gradient Descent - 梯度下降17)Backpropagation - 反向传播18)Epoch - 训练周期19)Batch Size - 批量大小20)Dropout - 丢弃法•Neural Network - 神经网络1)Neural Network - 神经网络2)Artificial Neural Network (ANN) - 人工神经网络3)Deep Neural Network (DNN) - 深度神经网络4)Convolutional Neural Network (CNN) - 卷积神经网络5)Recurrent Neural Network (RNN) - 循环神经网络6)Long Short-Term Memory (LSTM) - 长短期记忆网络7)Gated Recurrent Unit (GRU) - 门控循环单元8)Feedforward Neural Network - 前馈神经网络9)Multi-layer Perceptron (MLP) - 多层感知器10)Radial Basis Function Network (RBFN) - 径向基函数网络11)Hopfield Network - 霍普菲尔德网络12)Boltzmann Machine - 玻尔兹曼机13)Autoencoder - 自编码器14)Spiking Neural Network (SNN) - 脉冲神经网络15)Self-organizing Map (SOM) - 自组织映射16)Restricted Boltzmann Machine (RBM) - 受限玻尔兹曼机17)Hebbian Learning - 海比安学习18)Competitive Learning - 竞争学习19)Neuroevolutionary - 神经进化20)Neuron - 神经元•Algorithm - 算法1)Algorithm - 算法2)Supervised Learning Algorithm - 有监督学习算法3)Unsupervised Learning Algorithm - 无监督学习算法4)Reinforcement Learning Algorithm - 强化学习算法5)Classification Algorithm - 分类算法6)Regression Algorithm - 回归算法7)Clustering Algorithm - 聚类算法8)Dimensionality Reduction Algorithm - 降维算法9)Decision Tree Algorithm - 决策树算法10)Random Forest Algorithm - 随机森林算法11)Support Vector Machine (SVM) Algorithm - 支持向量机算法12)K-Nearest Neighbors (KNN) Algorithm - K近邻算法13)Naive Bayes Algorithm - 朴素贝叶斯算法14)Gradient Descent Algorithm - 梯度下降算法15)Genetic Algorithm - 遗传算法16)Neural Network Algorithm - 神经网络算法17)Deep Learning Algorithm - 深度学习算法18)Ensemble Learning Algorithm - 集成学习算法19)Reinforcement Learning Algorithm - 强化学习算法20)Metaheuristic Algorithm - 元启发式算法•Model - 模型1)Model - 模型2)Machine Learning Model - 机器学习模型3)Artificial Intelligence Model - 人工智能模型4)Predictive Model - 预测模型5)Classification Model - 分类模型6)Regression Model - 回归模型7)Generative Model - 生成模型8)Discriminative Model - 判别模型9)Probabilistic Model - 概率模型10)Statistical Model - 统计模型11)Neural Network Model - 神经网络模型12)Deep Learning Model - 深度学习模型13)Ensemble Model - 集成模型14)Reinforcement Learning Model - 强化学习模型15)Support Vector Machine (SVM) Model - 支持向量机模型16)Decision Tree Model - 决策树模型17)Random Forest Model - 随机森林模型18)Naive Bayes Model - 朴素贝叶斯模型19)Autoencoder Model - 自编码器模型20)Convolutional Neural Network (CNN) Model - 卷积神经网络模型•Dataset - 数据集1)Dataset - 数据集2)Training Dataset - 训练数据集3)Test Dataset - 测试数据集4)Validation Dataset - 验证数据集5)Balanced Dataset - 平衡数据集6)Imbalanced Dataset - 不平衡数据集7)Synthetic Dataset - 合成数据集8)Benchmark Dataset - 基准数据集9)Open Dataset - 开放数据集10)Labeled Dataset - 标记数据集11)Unlabeled Dataset - 未标记数据集12)Semi-Supervised Dataset - 半监督数据集13)Multiclass Dataset - 多分类数据集14)Feature Set - 特征集15)Data Augmentation - 数据增强16)Data Preprocessing - 数据预处理17)Missing Data - 缺失数据18)Outlier Detection - 异常值检测19)Data Imputation - 数据插补20)Metadata - 元数据•Training - 训练1)Training - 训练2)Training Data - 训练数据3)Training Phase - 训练阶段4)Training Set - 训练集5)Training Examples - 训练样本6)Training Instance - 训练实例7)Training Algorithm - 训练算法8)Training Model - 训练模型9)Training Process - 训练过程10)Training Loss - 训练损失11)Training Epoch - 训练周期12)Training Batch - 训练批次13)Online Training - 在线训练14)Offline Training - 离线训练15)Continuous Training - 连续训练16)Transfer Learning - 迁移学习17)Fine-Tuning - 微调18)Curriculum Learning - 课程学习19)Self-Supervised Learning - 自监督学习20)Active Learning - 主动学习•Testing - 测试1)Testing - 测试2)Test Data - 测试数据3)Test Set - 测试集4)Test Examples - 测试样本5)Test Instance - 测试实例6)Test Phase - 测试阶段7)Test Accuracy - 测试准确率8)Test Loss - 测试损失9)Test Error - 测试错误10)Test Metrics - 测试指标11)Test Suite - 测试套件12)Test Case - 测试用例13)Test Coverage - 测试覆盖率14)Cross-Validation - 交叉验证15)Holdout Validation - 留出验证16)K-Fold Cross-Validation - K折交叉验证17)Stratified Cross-Validation - 分层交叉验证18)Test Driven Development (TDD) - 测试驱动开发19)A/B Testing - A/B 测试20)Model Evaluation - 模型评估•Validation - 验证1)Validation - 验证2)Validation Data - 验证数据3)Validation Set - 验证集4)Validation Examples - 验证样本5)Validation Instance - 验证实例6)Validation Phase - 验证阶段7)Validation Accuracy - 验证准确率8)Validation Loss - 验证损失9)Validation Error - 验证错误10)Validation Metrics - 验证指标11)Cross-Validation - 交叉验证12)Holdout Validation - 留出验证13)K-Fold Cross-Validation - K折交叉验证14)Stratified Cross-Validation - 分层交叉验证15)Leave-One-Out Cross-Validation - 留一法交叉验证16)Validation Curve - 验证曲线17)Hyperparameter Validation - 超参数验证18)Model Validation - 模型验证19)Early Stopping - 提前停止20)Validation Strategy - 验证策略•Supervised Learning - 有监督学习1)Supervised Learning - 有监督学习2)Label - 标签3)Feature - 特征4)Target - 目标5)Training Labels - 训练标签6)Training Features - 训练特征7)Training Targets - 训练目标8)Training Examples - 训练样本9)Training Instance - 训练实例10)Regression - 回归11)Classification - 分类12)Predictor - 预测器13)Regression Model - 回归模型14)Classifier - 分类器15)Decision Tree - 决策树16)Support Vector Machine (SVM) - 支持向量机17)Neural Network - 神经网络18)Feature Engineering - 特征工程19)Model Evaluation - 模型评估20)Overfitting - 过拟合21)Underfitting - 欠拟合22)Bias-Variance Tradeoff - 偏差-方差权衡•Unsupervised Learning - 无监督学习1)Unsupervised Learning - 无监督学习2)Clustering - 聚类3)Dimensionality Reduction - 降维4)Anomaly Detection - 异常检测5)Association Rule Learning - 关联规则学习6)Feature Extraction - 特征提取7)Feature Selection - 特征选择8)K-Means - K均值9)Hierarchical Clustering - 层次聚类10)Density-Based Clustering - 基于密度的聚类11)Principal Component Analysis (PCA) - 主成分分析12)Independent Component Analysis (ICA) - 独立成分分析13)T-distributed Stochastic Neighbor Embedding (t-SNE) - t分布随机邻居嵌入14)Gaussian Mixture Model (GMM) - 高斯混合模型15)Self-Organizing Maps (SOM) - 自组织映射16)Autoencoder - 自动编码器17)Latent Variable - 潜变量18)Data Preprocessing - 数据预处理19)Outlier Detection - 异常值检测20)Clustering Algorithm - 聚类算法•Reinforcement Learning - 强化学习1)Reinforcement Learning - 强化学习2)Agent - 代理3)Environment - 环境4)State - 状态5)Action - 动作6)Reward - 奖励7)Policy - 策略8)Value Function - 值函数9)Q-Learning - Q学习10)Deep Q-Network (DQN) - 深度Q网络11)Policy Gradient - 策略梯度12)Actor-Critic - 演员-评论家13)Exploration - 探索14)Exploitation - 开发15)Temporal Difference (TD) - 时间差分16)Markov Decision Process (MDP) - 马尔可夫决策过程17)State-Action-Reward-State-Action (SARSA) - 状态-动作-奖励-状态-动作18)Policy Iteration - 策略迭代19)Value Iteration - 值迭代20)Monte Carlo Methods - 蒙特卡洛方法•Semi-Supervised Learning - 半监督学习1)Semi-Supervised Learning - 半监督学习2)Labeled Data - 有标签数据3)Unlabeled Data - 无标签数据4)Label Propagation - 标签传播5)Self-Training - 自训练6)Co-Training - 协同训练7)Transudative Learning - 传导学习8)Inductive Learning - 归纳学习9)Manifold Regularization - 流形正则化10)Graph-based Methods - 基于图的方法11)Cluster Assumption - 聚类假设12)Low-Density Separation - 低密度分离13)Semi-Supervised Support Vector Machines (S3VM) - 半监督支持向量机14)Expectation-Maximization (EM) - 期望最大化15)Co-EM - 协同期望最大化16)Entropy-Regularized EM - 熵正则化EM17)Mean Teacher - 平均教师18)Virtual Adversarial Training - 虚拟对抗训练19)Tri-training - 三重训练20)Mix Match - 混合匹配•Feature - 特征1)Feature - 特征2)Feature Engineering - 特征工程3)Feature Extraction - 特征提取4)Feature Selection - 特征选择5)Input Features - 输入特征6)Output Features - 输出特征7)Feature Vector - 特征向量8)Feature Space - 特征空间9)Feature Representation - 特征表示10)Feature Transformation - 特征转换11)Feature Importance - 特征重要性12)Feature Scaling - 特征缩放13)Feature Normalization - 特征归一化14)Feature Encoding - 特征编码15)Feature Fusion - 特征融合16)Feature Dimensionality Reduction - 特征维度减少17)Continuous Feature - 连续特征18)Categorical Feature - 分类特征19)Nominal Feature - 名义特征20)Ordinal Feature - 有序特征•Label - 标签1)Label - 标签2)Labeling - 标注3)Ground Truth - 地面真值4)Class Label - 类别标签5)Target Variable - 目标变量6)Labeling Scheme - 标注方案7)Multi-class Labeling - 多类别标注8)Binary Labeling - 二分类标注9)Label Noise - 标签噪声10)Labeling Error - 标注错误11)Label Propagation - 标签传播12)Unlabeled Data - 无标签数据13)Labeled Data - 有标签数据14)Semi-supervised Learning - 半监督学习15)Active Learning - 主动学习16)Weakly Supervised Learning - 弱监督学习17)Noisy Label Learning - 噪声标签学习18)Self-training - 自训练19)Crowdsourcing Labeling - 众包标注20)Label Smoothing - 标签平滑化•Prediction - 预测1)Prediction - 预测2)Forecasting - 预测3)Regression - 回归4)Classification - 分类5)Time Series Prediction - 时间序列预测6)Forecast Accuracy - 预测准确性7)Predictive Modeling - 预测建模8)Predictive Analytics - 预测分析9)Forecasting Method - 预测方法10)Predictive Performance - 预测性能11)Predictive Power - 预测能力12)Prediction Error - 预测误差13)Prediction Interval - 预测区间14)Prediction Model - 预测模型15)Predictive Uncertainty - 预测不确定性16)Forecast Horizon - 预测时间跨度17)Predictive Maintenance - 预测性维护18)Predictive Policing - 预测式警务19)Predictive Healthcare - 预测性医疗20)Predictive Maintenance - 预测性维护•Classification - 分类1)Classification - 分类2)Classifier - 分类器3)Class - 类别4)Classify - 对数据进行分类5)Class Label - 类别标签6)Binary Classification - 二元分类7)Multiclass Classification - 多类分类8)Class Probability - 类别概率9)Decision Boundary - 决策边界10)Decision Tree - 决策树11)Support Vector Machine (SVM) - 支持向量机12)K-Nearest Neighbors (KNN) - K最近邻算法13)Naive Bayes - 朴素贝叶斯14)Logistic Regression - 逻辑回归15)Random Forest - 随机森林16)Neural Network - 神经网络17)SoftMax Function - SoftMax函数18)One-vs-All (One-vs-Rest) - 一对多(一对剩余)19)Ensemble Learning - 集成学习20)Confusion Matrix - 混淆矩阵•Regression - 回归1)Regression Analysis - 回归分析2)Linear Regression - 线性回归3)Multiple Regression - 多元回归4)Polynomial Regression - 多项式回归5)Logistic Regression - 逻辑回归6)Ridge Regression - 岭回归7)Lasso Regression - Lasso回归8)Elastic Net Regression - 弹性网络回归9)Regression Coefficients - 回归系数10)Residuals - 残差11)Ordinary Least Squares (OLS) - 普通最小二乘法12)Ridge Regression Coefficient - 岭回归系数13)Lasso Regression Coefficient - Lasso回归系数14)Elastic Net Regression Coefficient - 弹性网络回归系数15)Regression Line - 回归线16)Prediction Error - 预测误差17)Regression Model - 回归模型18)Nonlinear Regression - 非线性回归19)Generalized Linear Models (GLM) - 广义线性模型20)Coefficient of Determination (R-squared) - 决定系数21)F-test - F检验22)Homoscedasticity - 同方差性23)Heteroscedasticity - 异方差性24)Autocorrelation - 自相关25)Multicollinearity - 多重共线性26)Outliers - 异常值27)Cross-validation - 交叉验证28)Feature Selection - 特征选择29)Feature Engineering - 特征工程30)Regularization - 正则化2.Neural Networks and Deep Learning (神经网络与深度学习)•Convolutional Neural Network (CNN) - 卷积神经网络1)Convolutional Neural Network (CNN) - 卷积神经网络2)Convolution Layer - 卷积层3)Feature Map - 特征图4)Convolution Operation - 卷积操作5)Stride - 步幅6)Padding - 填充7)Pooling Layer - 池化层8)Max Pooling - 最大池化9)Average Pooling - 平均池化10)Fully Connected Layer - 全连接层11)Activation Function - 激活函数12)Rectified Linear Unit (ReLU) - 线性修正单元13)Dropout - 随机失活14)Batch Normalization - 批量归一化15)Transfer Learning - 迁移学习16)Fine-Tuning - 微调17)Image Classification - 图像分类18)Object Detection - 物体检测19)Semantic Segmentation - 语义分割20)Instance Segmentation - 实例分割21)Generative Adversarial Network (GAN) - 生成对抗网络22)Image Generation - 图像生成23)Style Transfer - 风格迁移24)Convolutional Autoencoder - 卷积自编码器25)Recurrent Neural Network (RNN) - 循环神经网络•Recurrent Neural Network (RNN) - 循环神经网络1)Recurrent Neural Network (RNN) - 循环神经网络2)Long Short-Term Memory (LSTM) - 长短期记忆网络3)Gated Recurrent Unit (GRU) - 门控循环单元4)Sequence Modeling - 序列建模5)Time Series Prediction - 时间序列预测6)Natural Language Processing (NLP) - 自然语言处理7)Text Generation - 文本生成8)Sentiment Analysis - 情感分析9)Named Entity Recognition (NER) - 命名实体识别10)Part-of-Speech Tagging (POS Tagging) - 词性标注11)Sequence-to-Sequence (Seq2Seq) - 序列到序列12)Attention Mechanism - 注意力机制13)Encoder-Decoder Architecture - 编码器-解码器架构14)Bidirectional RNN - 双向循环神经网络15)Teacher Forcing - 强制教师法16)Backpropagation Through Time (BPTT) - 通过时间的反向传播17)Vanishing Gradient Problem - 梯度消失问题18)Exploding Gradient Problem - 梯度爆炸问题19)Language Modeling - 语言建模20)Speech Recognition - 语音识别•Long Short-Term Memory (LSTM) - 长短期记忆网络1)Long Short-Term Memory (LSTM) - 长短期记忆网络2)Cell State - 细胞状态3)Hidden State - 隐藏状态4)Forget Gate - 遗忘门5)Input Gate - 输入门6)Output Gate - 输出门7)Peephole Connections - 窥视孔连接8)Gated Recurrent Unit (GRU) - 门控循环单元9)Vanishing Gradient Problem - 梯度消失问题10)Exploding Gradient Problem - 梯度爆炸问题11)Sequence Modeling - 序列建模12)Time Series Prediction - 时间序列预测13)Natural Language Processing (NLP) - 自然语言处理14)Text Generation - 文本生成15)Sentiment Analysis - 情感分析16)Named Entity Recognition (NER) - 命名实体识别17)Part-of-Speech Tagging (POS Tagging) - 词性标注18)Attention Mechanism - 注意力机制19)Encoder-Decoder Architecture - 编码器-解码器架构20)Bidirectional LSTM - 双向长短期记忆网络•Attention Mechanism - 注意力机制1)Attention Mechanism - 注意力机制2)Self-Attention - 自注意力3)Multi-Head Attention - 多头注意力4)Transformer - 变换器5)Query - 查询6)Key - 键7)Value - 值8)Query-Value Attention - 查询-值注意力9)Dot-Product Attention - 点积注意力10)Scaled Dot-Product Attention - 缩放点积注意力11)Additive Attention - 加性注意力12)Context Vector - 上下文向量13)Attention Score - 注意力分数14)SoftMax Function - SoftMax函数15)Attention Weight - 注意力权重16)Global Attention - 全局注意力17)Local Attention - 局部注意力18)Positional Encoding - 位置编码19)Encoder-Decoder Attention - 编码器-解码器注意力20)Cross-Modal Attention - 跨模态注意力•Generative Adversarial Network (GAN) - 生成对抗网络1)Generative Adversarial Network (GAN) - 生成对抗网络2)Generator - 生成器3)Discriminator - 判别器4)Adversarial Training - 对抗训练5)Minimax Game - 极小极大博弈6)Nash Equilibrium - 纳什均衡7)Mode Collapse - 模式崩溃8)Training Stability - 训练稳定性9)Loss Function - 损失函数10)Discriminative Loss - 判别损失11)Generative Loss - 生成损失12)Wasserstein GAN (WGAN) - Wasserstein GAN(WGAN)13)Deep Convolutional GAN (DCGAN) - 深度卷积生成对抗网络(DCGAN)14)Conditional GAN (c GAN) - 条件生成对抗网络(c GAN)15)Style GAN - 风格生成对抗网络16)Cycle GAN - 循环生成对抗网络17)Progressive Growing GAN (PGGAN) - 渐进式增长生成对抗网络(PGGAN)18)Self-Attention GAN (SAGAN) - 自注意力生成对抗网络(SAGAN)19)Big GAN - 大规模生成对抗网络20)Adversarial Examples - 对抗样本•Encoder-Decoder - 编码器-解码器1)Encoder-Decoder Architecture - 编码器-解码器架构2)Encoder - 编码器3)Decoder - 解码器4)Sequence-to-Sequence Model (Seq2Seq) - 序列到序列模型5)State Vector - 状态向量6)Context Vector - 上下文向量7)Hidden State - 隐藏状态8)Attention Mechanism - 注意力机制9)Teacher Forcing - 强制教师法10)Beam Search - 束搜索11)Recurrent Neural Network (RNN) - 循环神经网络12)Long Short-Term Memory (LSTM) - 长短期记忆网络13)Gated Recurrent Unit (GRU) - 门控循环单元14)Bidirectional Encoder - 双向编码器15)Greedy Decoding - 贪婪解码16)Masking - 遮盖17)Dropout - 随机失活18)Embedding Layer - 嵌入层19)Cross-Entropy Loss - 交叉熵损失20)Tokenization - 令牌化•Transfer Learning - 迁移学习1)Transfer Learning - 迁移学习2)Source Domain - 源领域3)Target Domain - 目标领域4)Fine-Tuning - 微调5)Domain Adaptation - 领域自适应6)Pre-Trained Model - 预训练模型7)Feature Extraction - 特征提取8)Knowledge Transfer - 知识迁移9)Unsupervised Domain Adaptation - 无监督领域自适应10)Semi-Supervised Domain Adaptation - 半监督领域自适应11)Multi-Task Learning - 多任务学习12)Data Augmentation - 数据增强13)Task Transfer - 任务迁移14)Model Agnostic Meta-Learning (MAML) - 与模型无关的元学习(MAML)15)One-Shot Learning - 单样本学习16)Zero-Shot Learning - 零样本学习17)Few-Shot Learning - 少样本学习18)Knowledge Distillation - 知识蒸馏19)Representation Learning - 表征学习20)Adversarial Transfer Learning - 对抗迁移学习•Pre-trained Models - 预训练模型1)Pre-trained Model - 预训练模型2)Transfer Learning - 迁移学习3)Fine-Tuning - 微调4)Knowledge Transfer - 知识迁移5)Domain Adaptation - 领域自适应6)Feature Extraction - 特征提取7)Representation Learning - 表征学习8)Language Model - 语言模型9)Bidirectional Encoder Representations from Transformers (BERT) - 双向编码器结构转换器10)Generative Pre-trained Transformer (GPT) - 生成式预训练转换器11)Transformer-based Models - 基于转换器的模型12)Masked Language Model (MLM) - 掩蔽语言模型13)Cloze Task - 填空任务14)Tokenization - 令牌化15)Word Embeddings - 词嵌入16)Sentence Embeddings - 句子嵌入17)Contextual Embeddings - 上下文嵌入18)Self-Supervised Learning - 自监督学习19)Large-Scale Pre-trained Models - 大规模预训练模型•Loss Function - 损失函数1)Loss Function - 损失函数2)Mean Squared Error (MSE) - 均方误差3)Mean Absolute Error (MAE) - 平均绝对误差4)Cross-Entropy Loss - 交叉熵损失5)Binary Cross-Entropy Loss - 二元交叉熵损失6)Categorical Cross-Entropy Loss - 分类交叉熵损失7)Hinge Loss - 合页损失8)Huber Loss - Huber损失9)Wasserstein Distance - Wasserstein距离10)Triplet Loss - 三元组损失11)Contrastive Loss - 对比损失12)Dice Loss - Dice损失13)Focal Loss - 焦点损失14)GAN Loss - GAN损失15)Adversarial Loss - 对抗损失16)L1 Loss - L1损失17)L2 Loss - L2损失18)Huber Loss - Huber损失19)Quantile Loss - 分位数损失•Activation Function - 激活函数1)Activation Function - 激活函数2)Sigmoid Function - Sigmoid函数3)Hyperbolic Tangent Function (Tanh) - 双曲正切函数4)Rectified Linear Unit (Re LU) - 矩形线性单元5)Parametric Re LU (P Re LU) - 参数化Re LU6)Exponential Linear Unit (ELU) - 指数线性单元7)Swish Function - Swish函数8)Softplus Function - Soft plus函数9)Softmax Function - SoftMax函数10)Hard Tanh Function - 硬双曲正切函数11)Softsign Function - Softsign函数12)GELU (Gaussian Error Linear Unit) - GELU(高斯误差线性单元)13)Mish Function - Mish函数14)CELU (Continuous Exponential Linear Unit) - CELU(连续指数线性单元)15)Bent Identity Function - 弯曲恒等函数16)Gaussian Error Linear Units (GELUs) - 高斯误差线性单元17)Adaptive Piecewise Linear (APL) - 自适应分段线性函数18)Radial Basis Function (RBF) - 径向基函数•Backpropagation - 反向传播1)Backpropagation - 反向传播2)Gradient Descent - 梯度下降3)Partial Derivative - 偏导数4)Chain Rule - 链式法则5)Forward Pass - 前向传播6)Backward Pass - 反向传播7)Computational Graph - 计算图8)Neural Network - 神经网络9)Loss Function - 损失函数10)Gradient Calculation - 梯度计算11)Weight Update - 权重更新12)Activation Function - 激活函数13)Optimizer - 优化器14)Learning Rate - 学习率15)Mini-Batch Gradient Descent - 小批量梯度下降16)Stochastic Gradient Descent (SGD) - 随机梯度下降17)Batch Gradient Descent - 批量梯度下降18)Momentum - 动量19)Adam Optimizer - Adam优化器20)Learning Rate Decay - 学习率衰减•Gradient Descent - 梯度下降1)Gradient Descent - 梯度下降2)Stochastic Gradient Descent (SGD) - 随机梯度下降3)Mini-Batch Gradient Descent - 小批量梯度下降4)Batch Gradient Descent - 批量梯度下降5)Learning Rate - 学习率6)Momentum - 动量7)Adaptive Moment Estimation (Adam) - 自适应矩估计8)RMSprop - 均方根传播9)Learning Rate Schedule - 学习率调度10)Convergence - 收敛11)Divergence - 发散12)Adagrad - 自适应学习速率方法13)Adadelta - 自适应增量学习率方法14)Adamax - 自适应矩估计的扩展版本15)Nadam - Nesterov Accelerated Adaptive Moment Estimation16)Learning Rate Decay - 学习率衰减17)Step Size - 步长18)Conjugate Gradient Descent - 共轭梯度下降19)Line Search - 线搜索20)Newton's Method - 牛顿法•Learning Rate - 学习率1)Learning Rate - 学习率2)Adaptive Learning Rate - 自适应学习率3)Learning Rate Decay - 学习率衰减4)Initial Learning Rate - 初始学习率5)Step Size - 步长6)Momentum - 动量7)Exponential Decay - 指数衰减8)Annealing - 退火9)Cyclical Learning Rate - 循环学习率10)Learning Rate Schedule - 学习率调度11)Warm-up - 预热12)Learning Rate Policy - 学习率策略13)Learning Rate Annealing - 学习率退火14)Cosine Annealing - 余弦退火15)Gradient Clipping - 梯度裁剪16)Adapting Learning Rate - 适应学习率17)Learning Rate Multiplier - 学习率倍增器18)Learning Rate Reduction - 学习率降低19)Learning Rate Update - 学习率更新20)Scheduled Learning Rate - 定期学习率•Batch Size - 批量大小1)Batch Size - 批量大小2)Mini-Batch - 小批量3)Batch Gradient Descent - 批量梯度下降4)Stochastic Gradient Descent (SGD) - 随机梯度下降5)Mini-Batch Gradient Descent - 小批量梯度下降6)Online Learning - 在线学习7)Full-Batch - 全批量8)Data Batch - 数据批次9)Training Batch - 训练批次10)Batch Normalization - 批量归一化11)Batch-wise Optimization - 批量优化12)Batch Processing - 批量处理13)Batch Sampling - 批量采样14)Adaptive Batch Size - 自适应批量大小15)Batch Splitting - 批量分割16)Dynamic Batch Size - 动态批量大小17)Fixed Batch Size - 固定批量大小18)Batch-wise Inference - 批量推理19)Batch-wise Training - 批量训练20)Batch Shuffling - 批量洗牌•Epoch - 训练周期1)Training Epoch - 训练周期2)Epoch Size - 周期大小3)Early Stopping - 提前停止4)Validation Set - 验证集5)Training Set - 训练集6)Test Set - 测试集7)Overfitting - 过拟合8)Underfitting - 欠拟合9)Model Evaluation - 模型评估10)Model Selection - 模型选择11)Hyperparameter Tuning - 超参数调优12)Cross-Validation - 交叉验证13)K-fold Cross-Validation - K折交叉验证14)Stratified Cross-Validation - 分层交叉验证15)Leave-One-Out Cross-Validation (LOOCV) - 留一法交叉验证16)Grid Search - 网格搜索17)Random Search - 随机搜索18)Model Complexity - 模型复杂度19)Learning Curve - 学习曲线20)Convergence - 收敛3.Machine Learning Techniques and Algorithms (机器学习技术与算法)•Decision Tree - 决策树1)Decision Tree - 决策树2)Node - 节点3)Root Node - 根节点4)Leaf Node - 叶节点5)Internal Node - 内部节点6)Splitting Criterion - 分裂准则7)Gini Impurity - 基尼不纯度8)Entropy - 熵9)Information Gain - 信息增益10)Gain Ratio - 增益率11)Pruning - 剪枝12)Recursive Partitioning - 递归分割13)CART (Classification and Regression Trees) - 分类回归树14)ID3 (Iterative Dichotomiser 3) - 迭代二叉树315)C4.5 (successor of ID3) - C4.5(ID3的后继者)16)C5.0 (successor of C4.5) - C5.0(C4.5的后继者)17)Split Point - 分裂点18)Decision Boundary - 决策边界19)Pruned Tree - 剪枝后的树20)Decision Tree Ensemble - 决策树集成•Random Forest - 随机森林1)Random Forest - 随机森林2)Ensemble Learning - 集成学习3)Bootstrap Sampling - 自助采样4)Bagging (Bootstrap Aggregating) - 装袋法5)Out-of-Bag (OOB) Error - 袋外误差6)Feature Subset - 特征子集7)Decision Tree - 决策树8)Base Estimator - 基础估计器9)Tree Depth - 树深度10)Randomization - 随机化11)Majority Voting - 多数投票12)Feature Importance - 特征重要性13)OOB Score - 袋外得分14)Forest Size - 森林大小15)Max Features - 最大特征数16)Min Samples Split - 最小分裂样本数17)Min Samples Leaf - 最小叶节点样本数18)Gini Impurity - 基尼不纯度19)Entropy - 熵20)Variable Importance - 变量重要性•Support Vector Machine (SVM) - 支持向量机1)Support Vector Machine (SVM) - 支持向量机2)Hyperplane - 超平面3)Kernel Trick - 核技巧4)Kernel Function - 核函数5)Margin - 间隔6)Support Vectors - 支持向量7)Decision Boundary - 决策边界8)Maximum Margin Classifier - 最大间隔分类器9)Soft Margin Classifier - 软间隔分类器10) C Parameter - C参数11)Radial Basis Function (RBF) Kernel - 径向基函数核12)Polynomial Kernel - 多项式核13)Linear Kernel - 线性核14)Quadratic Kernel - 二次核15)Gaussian Kernel - 高斯核16)Regularization - 正则化17)Dual Problem - 对偶问题18)Primal Problem - 原始问题19)Kernelized SVM - 核化支持向量机20)Multiclass SVM - 多类支持向量机•K-Nearest Neighbors (KNN) - K-最近邻1)K-Nearest Neighbors (KNN) - K-最近邻2)Nearest Neighbor - 最近邻3)Distance Metric - 距离度量4)Euclidean Distance - 欧氏距离5)Manhattan Distance - 曼哈顿距离6)Minkowski Distance - 闵可夫斯基距离7)Cosine Similarity - 余弦相似度8)K Value - K值9)Majority Voting - 多数投票10)Weighted KNN - 加权KNN11)Radius Neighbors - 半径邻居12)Ball Tree - 球树13)KD Tree - KD树14)Locality-Sensitive Hashing (LSH) - 局部敏感哈希15)Curse of Dimensionality - 维度灾难16)Class Label - 类标签17)Training Set - 训练集18)Test Set - 测试集19)Validation Set - 验证集20)Cross-Validation - 交叉验证•Naive Bayes - 朴素贝叶斯1)Naive Bayes - 朴素贝叶斯2)Bayes' Theorem - 贝叶斯定理3)Prior Probability - 先验概率4)Posterior Probability - 后验概率5)Likelihood - 似然6)Class Conditional Probability - 类条件概率7)Feature Independence Assumption - 特征独立假设8)Multinomial Naive Bayes - 多项式朴素贝叶斯9)Gaussian Naive Bayes - 高斯朴素贝叶斯10)Bernoulli Naive Bayes - 伯努利朴素贝叶斯11)Laplace Smoothing - 拉普拉斯平滑12)Add-One Smoothing - 加一平滑13)Maximum A Posteriori (MAP) - 最大后验概率14)Maximum Likelihood Estimation (MLE) - 最大似然估计15)Classification - 分类16)Feature Vectors - 特征向量17)Training Set - 训练集18)Test Set - 测试集19)Class Label - 类标签20)Confusion Matrix - 混淆矩阵•Clustering - 聚类1)Clustering - 聚类2)Centroid - 质心3)Cluster Analysis - 聚类分析4)Partitioning Clustering - 划分式聚类5)Hierarchical Clustering - 层次聚类6)Density-Based Clustering - 基于密度的聚类7)K-Means Clustering - K均值聚类8)K-Medoids Clustering - K中心点聚类9)DBSCAN (Density-Based Spatial Clustering of Applications with Noise) - 基于密度的空间聚类算法10)Agglomerative Clustering - 聚合式聚类11)Dendrogram - 系统树图12)Silhouette Score - 轮廓系数13)Elbow Method - 肘部法则14)Clustering Validation - 聚类验证15)Intra-cluster Distance - 类内距离16)Inter-cluster Distance - 类间距离17)Cluster Cohesion - 类内连贯性18)Cluster Separation - 类间分离度19)Cluster Assignment - 聚类分配20)Cluster Label - 聚类标签•K-Means - K-均值1)K-Means - K-均值2)Centroid - 质心3)Cluster - 聚类4)Cluster Center - 聚类中心5)Cluster Assignment - 聚类分配6)Cluster Analysis - 聚类分析7)K Value - K值8)Elbow Method - 肘部法则9)Inertia - 惯性10)Silhouette Score - 轮廓系数11)Convergence - 收敛12)Initialization - 初始化13)Euclidean Distance - 欧氏距离14)Manhattan Distance - 曼哈顿距离15)Distance Metric - 距离度量16)Cluster Radius - 聚类半径17)Within-Cluster Variation - 类内变异18)Cluster Quality - 聚类质量19)Clustering Algorithm - 聚类算法20)Clustering Validation - 聚类验证•Dimensionality Reduction - 降维1)Dimensionality Reduction - 降维2)Feature Extraction - 特征提取3)Feature Selection - 特征选择4)Principal Component Analysis (PCA) - 主成分分析5)Singular Value Decomposition (SVD) - 奇异值分解6)Linear Discriminant Analysis (LDA) - 线性判别分析7)t-Distributed Stochastic Neighbor Embedding (t-SNE) - t-分布随机邻域嵌入8)Autoencoder - 自编码器9)Manifold Learning - 流形学习10)Locally Linear Embedding (LLE) - 局部线性嵌入11)Isomap - 等度量映射12)Uniform Manifold Approximation and Projection (UMAP) - 均匀流形逼近与投影13)Kernel PCA - 核主成分分析14)Non-negative Matrix Factorization (NMF) - 非负矩阵分解15)Independent Component Analysis (ICA) - 独立成分分析16)Variational Autoencoder (VAE) - 变分自编码器17)Sparse Coding - 稀疏编码18)Random Projection - 随机投影19)Neighborhood Preserving Embedding (NPE) - 保持邻域结构的嵌入20)Curvilinear Component Analysis (CCA) - 曲线成分分析•Principal Component Analysis (PCA) - 主成分分析1)Principal Component Analysis (PCA) - 主成分分析2)Eigenvector - 特征向量3)Eigenvalue - 特征值4)Covariance Matrix - 协方差矩阵。
python投影寻踪模糊聚类法

投影寻踪(Projection Pursuit)是一种非线性降维技术,用于寻找高维数据中的低维结构。
在Python中,可以使用scikit-learn库中的PCA(Principal Component Analysis)类来实现投影寻踪。
模糊聚类(Fuzzy Clustering)是一种聚类方法,它允许数据点属于多个聚类。
在Python中,可以使用scikit-learn库中的KMeans类来实现模糊聚类。
下面是一个简单的示例代码,演示如何使用投影寻踪和模糊聚类对高维数据进行处理:
import numpy as np
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
# 生成高维数据
X = np.random.rand(100, 20)
# 使用PCA进行投影寻踪
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 使用KMeans进行模糊聚类
kmeans = KMeans(n_clusters=3, random_state=0).fit(X_pca)
labels = bels_
# 输出聚类结果
print(labels)
在上面的代码中,我们首先生成一个100行20列的高维数据矩阵X。
然后使用PCA将数据降维到2维,得到投影后的数据矩阵X_pca。
接下来,使用KMeans对X_pca进行模糊聚类,得到每个数据点的聚类标签。
最后输出聚类结果。
地图匹配算法的流程和基本原理

地图匹配算法的流程和基本原理英文回答:## Map Matching Algorithm: Workflow and Basic Principles.Workflow:1. GPS Data Preprocessing: Cleaning and filtering raw GPS data to remove noise and outliers.2. Candidate Path Generation: Identifying potential paths the vehicle could have traversed using a road network database.3. Cost Calculation: Assigning weights to different features of the candidate paths (e.g., distance, speed, road type).4. Path Selection: Choosing the most likely path basedon the calculated costs.5. Smoothing: Adjusting the selected path to improveits smoothness and fit with the GPS data.Basic Principles:Dynamic Time Warping: Allowing non-uniform stretching and compression of GPS data points to align them with the road network.Cost Function Optimization: Minimizing a cost function that measures the discrepancy between the GPS data and the matched path.Heuristic Search: Employing techniques such as A or particle filtering to explore the candidate paths efficiently.Probabilistic Modeling: Incorporating probabilistic models to account for uncertainty in GPS data and path selection.Spatial Constraints: Utilizing spatial information (e.g., road segments, intersections) to guide the matching process.## Implementation Considerations.Choice of Cost Function: Different cost functions can be used depending on the application (e.g., distance,travel time, speed consistency).Candidate Path Selection: The size and accuracy of the road network database play a crucial role in generating reliable candidate paths.Smoothing Techniques: Smoothing algorithms (e.g., Kalman filtering, cubic splines) can improve the robustness and accuracy of the matched path.Computational Complexity: Map matching algorithms can be computationally intensive, especially for large datasets.中文回答:## 地图匹配算法,流程和基本原理。
质量风险管理工具介绍

Effect
People Environment Materials
6
ISHIKAWA因果图
The last step consists in thinking about the causes for the problem arising from each one of the main aspects, and drawing them in the diagram. The ultimate cause should be specific, measurable and controllable最后一步包 含思考每一个主要因素的根源,并将其在图中画出。最终的根源应该具 体、可度量和可控制。
Preliminary Hazard Analysis (PHA) 预先危险分析
Probabilistic Risk Analysis (PRA) 概率风险分析
2
Risk Management Tools 风险管理工具
The level of detail and quantification needed helps to determine the tool to use需要的详细程度和定量水平
4
ISHIKAWA因果图
The creation of the diagram starts drawing a horizontal line, at the end of which the problem (effect) is represented. 图 表开始为画一个水平线,水平线的末端为代表的问题( 结果)。 Problem
Failure has never been but it is theoretically possible.失败从来未发生,但是理论上可 能发生。
语义分割的pr曲线

语义分割的pr曲线
语义分割的PR曲线是一种用于评估语义分割模型性能的曲线,由精确率(Precision)和召回率(Recall)两个指标构成。
精确率是指模型预测为正例的样本中,实际为正例的比例;召回率是指所有实际为正例的样本中,模型预测为正例的比例。
PR曲线的绘制过程如下:
1. 对于每个阈值,计算精确率和召回率。
2. 将精确率和召回率绘制在二维空间中,横坐标为召回率,纵坐标为精确率。
3. 绘制PR曲线,连接每个点(召回率,精确率)。
PR曲线的形状反映了模型的性能。
理想情况下,PR曲线应该尽可能接近左上角,即高精确率和高召回率。
此外,PR曲线还可以与ROC曲线进行比较。
ROC曲线是受试者工作特征曲线,由真正率(TPR)和假正率(FPR)构成。
在PR曲线中,曲线和对角线相交的点称为平衡点,平衡点的数值越大,说明分类的效果越好。
投影寻踪和熵权法

投影寻踪和熵权法
投影寻踪(Projection Pursuit)是一种用于高维数据降维和发现数据内在结构的方法。
它的目标是在保持数据关键特征的同时实现降维,帮助揭示数据集的主要结构。
投影寻踪的基本原理是通过对数据进行线性或非线性投影,将数据从高维空间投影到低维空间,并选择最具信息量的投影方向。
最常见的投影方法是优化具有特定目标函数的投影方向,这个目标函数通常与数据内在结构的特征有关。
熵权法(Entropy Weight Method)是一种多指标综合评价方法,常用于多指标决策问题。
它基于信息熵的概念,通过计算各指标的权重,将多个指标的评价结果综合为一个综合指标。
具体而言,熵权法使用信息熵来衡量各指标的不确定性,越大的不确定性对应的指标权重越小。
熵权法的步骤如下:
1.根据具体问题,确定评价指标集合。
2.对每个指标,收集样本数据,计算各指标的数学期望和方
差。
3.计算每个指标的熵值,熵的计算公式为:熵= - Σ (p(i) *
log2(p(i))),其中p(i)表示第i个指标的频率。
4.计算每个指标的权重,权重的计算公式为:权重 = (1-熵) /
Σ (1-熵),确保权重之和为1。
5.进行指标综合评价,根据权重对每个指标的评价结果进行
加权求和,得到综合评价结果。
熵权法在多指标决策、综合评价和排名等领域广泛应用。
它能够从信息熵的角度,系统地考虑各指标的重要性和贡献度,帮助决策者更准确地进行决策和评价。
机器学习中的特征工程详解

机器学习中的特征工程详解机器学习是一门涉及数据分析和模式识别的领域,而特征工程则是机器学习中至关重要的一环。
特征工程可以理解为对原始数据的预处理和转换过程,旨在提取和构造出更有用、更具代表性的特征,以为后续的模型训练和推理提供更好的输入。
本文将详细介绍机器学习中的特征工程,包括特征选择、特征提取和特征转换等方面的内容。
一、特征选择特征选择是指从所有可用特征中选择出最有用和最相关的特征子集,主要有以下几种常见的方法:1. 过滤法:通过统计指标(如相关性、方差等)对特征进行评估和排序,然后选择排名靠前的特征。
这种方法简单、快速,但无法处理特征之间的依赖关系。
2. 包装法:将特征选择问题转化为一个优化问题,在特征子集上训练模型,并通过交叉验证等方法评估模型性能,进而选择最佳特征子集。
3. 嵌入法:在模型训练过程中自动进行特征选择,常见的方法包括L1正则化、决策树等。
二、特征提取特征提取是将原始数据转化为更具代表性和可解释性的特征表示,常见的特征提取方法包括:1. 主成分分析(PCA):通过线性变换将原始特征投影到一个新的特征空间,并保留最具信息量的主成分。
2. 线性判别分析(LDA):通过线性变换将原始特征投影到一个新的特征空间,使得同一类别的样本尽可能接近,不同类别的样本尽可能远离。
3. 非负矩阵分解(NMF):将原始数据分解为非负的部分特征和非负的权重矩阵,能够在一定程度上保留原始数据的结构信息。
三、特征转换特征转换可以理解为对原始特征进行映射和变换,以生成新的特征表示。
常见的特征转换方法包括:1. 多项式特征:通过多项式扩展将原始特征的高次组合作为新的特征,能够增强模型对非线性关系的拟合能力。
2. 字典学习:通过学习一个字典,将原始特征稀疏表示为新的特征,能够捕捉到数据的稀疏性和结构信息。
3. 特征组合:将多个原始特征进行组合和变换,生成新的特征。
常见的方法有特征交叉、特征聚合等。
四、特征工程的重要性特征工程在机器学习中的作用不可忽视。
mmsegmentation训练

mmsegmentation训练
在计算机视觉领域中,图像分割是一个重要的任务,它的目标是将图像分成不同的区域,从而实现对图像的理解和解析。
近年来,深度学习技术的发展极大地推动了图像分割的进步,其中mmsegmentation 是一个基于 PyTorch 的深度学习框架,专门用于图像分割的训练和推理。
在使用 mmsegmentation 进行训练之前,需要准备好训练数据集和相关的配置文件。
可以使用自己的数据集或者公共数据集,例如PASCAL VOC、COCO 等。
配置文件中需要指定模型的参数、数据集的路径、学习率等超参数,以及训练和验证的相关设置。
在训练过程中,可以使用不同的优化器和学习率调度器来优化模型的性能。
mmsegmentation 提供了多种优化器和学习率调度器的选择,例如 SGD、Adam、CosineAnnealingLR 等。
训练过程中可以监测模型的训练损失和验证指标,并根据训练和验证的结果进行模型调整和优化。
在训练结束后,可以使用训练得到的模型进行图像分割的推理。
可以使用单张图像或者整个数据集进行推理,并根据推理结果进行相应的后处理,例如去除细小的分割区域、进行分割结果的可视化等。
总之,mmsegmentation 是一个非常强大的图像分割框架,可以帮助我们更方便地进行图像分割任务的训练和推理。
- 1 -。
神经网络分类器检测异常数据的方法

神经网络分类器检测异常数据的方法神经网络是一种强大的机器学习算法,可以用于分类任务。
然而,在实际应用中,数据集中常常存在异常数据,这些异常数据可能会对分类结果造成严重影响。
因此,检测和处理异常数据是一个重要的任务。
以下是一些常用的方法来检测神经网络分类器中的异常数据。
1.数据探索与可视化分析:在使用神经网络分类器之前,首先对数据进行探索和分析。
通过绘制数据的直方图、散点图、箱线图等,可以发现数据集中是否存在异常值或者异常分布。
这有助于我们了解数据的特征与分布情况,为后续的异常数据检测提供基础。
2.离群点检测:离群点是指与其他数据点明显不同的个别样本。
离群点检测可以通过多种方法来实现,例如基于统计的方法(如均值和标准差方法)、基于距离的方法(如K近邻法和DBSCAN)、基于密度的方法(如LOF和孤立森林)等。
在神经网络分类器中,可以将离群点作为异常数据进行处理。
3.重采样:异常数据通常是在数据集中数量非常少的情况下出现的。
一种简单有效的方法是对数据进行重采样。
通过对异常数据进行复制或者合成新数据,可以增加异常数据的数量,从而提高神经网络分类器对异常数据的识别能力。
4.异常监测模型:异常监测模型是一种专门用于检测和识别异常数据的模型。
这些模型可以根据数据的特征和分布情况,自动学习和发现异常数据。
常见的异常监测模型包括自编码器、深度概率模型和集成模型等。
这些模型可以与神经网络分类器相结合,提高异常数据的识别率。
5.阈值设置:在训练神经网络分类器时,可以设置一个阈值来判断数据是否为异常。
通过调整阈值的大小,可以控制异常数据的识别精度和召回率。
同时,还可以使用交叉验证和网格等方法,选择最优的阈值。
6.特征选择与降维:异常数据通常具有与正常数据不同的特征。
因此,通过特征选择和降维方法,可以去除对异常数据识别无用的特征,从而提高神经网络分类器的性能。
7. 多模型集成:通过集成多个基本分类器的预测结果,可以进一步提高异常数据的检测性能。
数据不平衡处理技术

数据不平衡处理技术数据不平衡是指在一个数据集中,不同类别的样本数量差异较大的情况。
在现实世界中,这种情况经常出现在各种应用中,比如医疗诊断、金融欺诈检测、文本分类等领域。
处理数据不平衡的技术是机器学习和数据挖掘领域中一个重要的问题,因为不平衡的数据会影响模型的性能和准确度。
针对数据不平衡问题,研究者们提出了许多处理技术,以下是一些常见的方法:1. 过采样(Over-sampling),这种方法通过增加少数类样本的数量来平衡数据集。
常见的过采样方法包括随机过采样、SMOTE (Synthetic Minority Over-sampling Technique)等。
2. 欠采样(Under-sampling),这种方法通过减少多数类样本的数量来平衡数据集。
欠采样的方法包括随机欠采样、ClusterCentroids等。
3. 合成抽样(Synthetic Sampling),这种方法通过生成合成的少数类样本来平衡数据集。
除了SMOTE之外,还有一些其他的合成抽样方法,比如ADASYN(Adaptive Synthetic Sampling)等。
4. 集成方法(Ensemble Methods),这种方法通过结合多个分类器的预测结果来改善模型的性能,比如基于Bagging或Boosting的集成方法。
5. 改变评价标准(Changing the Performance Metric),除了调整数据集外,还可以通过改变评价标准来处理数据不平衡问题,比如使用AUC(Area Under Curve)曲线、精确度、召回率等指标来评估模型性能。
以上列举的方法只是处理数据不平衡问题的一部分,实际应用中可能需要根据具体情况选择适合的方法。
处理数据不平衡是一个复杂的问题,需要综合考虑数据特点、应用场景和模型性能等因素,希望未来能够有更多的研究和技术能够解决这一问题,提高机器学习模型的性能和鲁棒性。
使用机器学习算法进行异常检测的步骤和技巧

使用机器学习算法进行异常检测的步骤和技巧异常检测是机器学习领域中的一个重要任务,其目的是识别出与正常行为不符的数据点或模式。
异常检测可以应用于各种领域,例如金融欺诈检测、网络入侵检测和设备故障检测。
在本文中,将介绍使用机器学习算法进行异常检测的一般步骤和一些常用技巧。
步骤一:数据理解和预处理在进行异常检测之前,首先需要对数据进行理解和预处理。
这一步骤包括数据收集、数据探索、数据清洗和特征工程。
数据探索可以帮助我们对数据的分布、相关性和异常值等进行初步分析。
数据清洗可以帮助我们处理缺失值、异常值和重复值等数据质量问题。
特征工程旨在从原始数据中提取有意义的特征,以帮助机器学习算法更好地进行异常检测。
步骤二:选择合适的异常检测算法选择合适的异常检测算法是异常检测的关键步骤。
常见的异常检测算法包括基于统计、基于聚类、基于距离和基于密度的方法。
对于不同的应用场景,选择合适的算法非常重要。
例如,在处理高维数据时,可以考虑使用基于聚类的异常检测算法,如K-means和DBSCAN。
对于时间序列数据,可以使用基于统计的异常检测算法,如均值偏移和孤立森林。
步骤三:训练异常检测模型在选择了合适的异常检测算法之后,需要使用标注的正常数据进行模型训练。
训练过程中,可以利用交叉验证等技术来选择合适的模型超参数。
在训练过程中,需要注意平衡正常数据和异常数据的比例,以避免模型过度拟合或欠拟合。
步骤四:异常检测和评估当训练完成后,可以使用模型来进行异常检测。
将待检测的数据输入训练好的模型中,通过计算异常得分或概率来判断数据是否异常。
通常情况下,得分或概率越高,表示数据越可能是异常。
通过设定适当的阈值,可以将异常数据和正常数据进行分类。
在进行异常检测时,还需关注评估模型的性能。
常用的性能指标包括准确率、召回率、精确率和F1值。
准确率是指预测为异常的样本中实际为异常的比例。
召回率是指实际为异常的样本中被正确预测为异常的比例。
精确率是指预测为异常的样本中实际为异常的比例。
如何处理不平衡数据集的机器学习任务

如何处理不平衡数据集的机器学习任务在机器学习中,不平衡数据集是一种常见的问题,指的是在训练集中不同类别的样本数量不均衡。
这种情况会导致训练得到的模型对于较少样本的类别表现较差,从而影响模型的性能。
因此,处理不平衡数据集是一个关键的任务,下面将介绍几种常见的方法来应对这个问题。
一、重采样技术重采样技术是一种常见的处理不平衡数据集的方法,主要有两种策略:过采样和欠采样。
1.过采样过采样是指增加少数类样本的数量,以使得各类样本的数量比较接近。
常用的过采样方法包括随机过采样、SMOTE(Synthetic Minority Over-sampling Technique)和ADASYN(Adaptive Synthetic Sampling)等。
- 随机过采样是指简单地通过随机复制少数类样本来增加样本数量,但可能导致过拟合问题。
- SMOTE是一种基于样本插值的过采样方法,它通过在少数类样本之间生成一些合成样本来增加样本数量。
- ADASYN是一种自适应的过采样方法,它会根据每个少数类样本周围的密度来决定生成新样本的数量。
2.欠采样欠采样是指减少多数类样本的数量,以使得各类样本的数量比较接近。
常用的欠采样方法包括随机欠采样和NearMiss等。
- 随机欠采样是指随机删除多数类样本来减少样本数量,但可能会导致信息丢失较多的问题。
- NearMiss是一种基于样本选择的欠采样方法,它通过选择离少数类样本最近的多数类样本来减少样本数量。
二、调整模型参数除了重采样技术外,调整模型参数也是处理不平衡数据集的重要方法。
以下是几种常见的调整模型参数的方法:1.修改损失函数在机器学习模型中,损失函数是衡量模型预测结果与真实结果之间差异的指标。
在不平衡数据集中,可以通过修改损失函数来改善模型对于少数类样本的预测性能。
例如,对于逻辑回归模型,可以引入类别权重,使得模型更加关注少数类样本。
2.调整阈值对于二分类模型来说,分类阈值的选择也会影响模型的性能。
利用机器学习技术进行数据分析的步骤详解

利用机器学习技术进行数据分析的步骤详解在进行数据分析时,利用机器学习技术可以帮助我们从海量的数据中提取有用的信息。
机器学习是一种人工智能的分支领域,其目标是通过从过往的经验中学习并自动适应新的数据,从而进行预测和决策。
下面将详细介绍利用机器学习技术进行数据分析的步骤。
第一步是数据收集。
数据是进行机器学习和数据分析的基础,因此收集高质量、全面的数据至关重要。
数据可以来自各种来源,包括数据库、传感器、社交媒体等。
收集到的数据应该包含所需的变量和属性,并确保数据的完整性和准确性。
第二步是数据清洗和预处理。
在进行机器学习之前,需要对数据进行清洗和预处理,以消除噪音、填补缺失值、处理异常数据等。
数据清洗的目的是为了得到干净、可靠的数据集,以提高机器学习模型的准确性和可靠性。
这一步骤通常包括数据去重、数据转换、特征选择等操作。
第三步是特征工程。
特征是指用来描述数据的属性或变量。
在进行机器学习时,选择合适的特征对模型的性能至关重要。
特征工程的目标是从原始数据中提取出有意义的特征,并进行适当的转换和格式化,以便于模型的学习和使用。
常见的特征工程方法包括标准化、归一化、特征构建、特征选择等。
第四步是模型选择与训练。
机器学习的核心是选择合适的模型,并对其进行训练和调优。
选择模型的目标是找到一个可以很好地拟合数据和预测未知样本的模型。
常见的机器学习模型包括线性回归、逻辑回归、决策树、支持向量机、随机森林、神经网络等。
在进行模型训练之前,通常需要将数据集划分为训练集和测试集,以便评估模型的性能。
第五步是模型评估和调优。
在训练完模型后,需要对其进行评估和调优,以确保其在未知数据上的预测能力。
常见的评估指标包括准确率、精确率、召回率、F1分数、AUC等。
如果模型的性能不理想,可以考虑调整模型的参数、添加正则化项、使用交叉验证等方法来提升模型效果。
第六步是模型部署和应用。
当模型训练和调优完成后,可以将其部署到实际应用场景中进行使用。
张伟豪SPSS培训视频8笔记(process插件使用,回归分析)
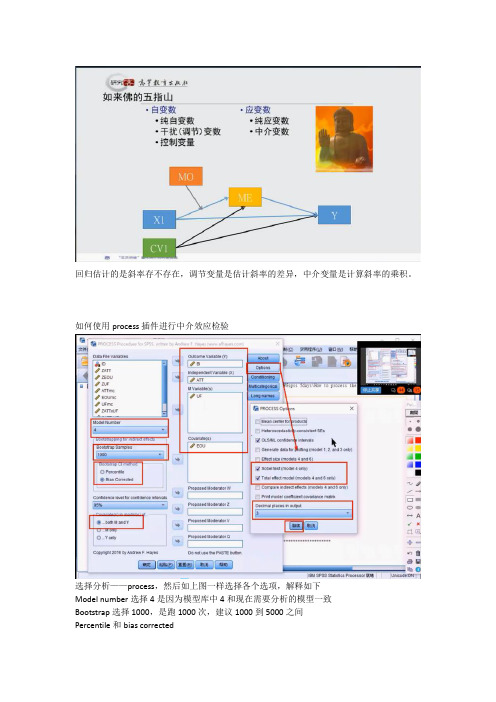
回归估计的是斜率存不存在,调节变量是估计斜率的差异,中介变量是计算斜率的乘积。
如何使用process插件进行中介效应检验选择分析——process,然后如上图一样选择各个选项,解释如下Model number选择4是因为模型库中4和现在需要分析的模型一致Bootstrap选择1000,是跑1000次,建议1000到5000之间Percentile和bias correctedBoth M and Y,是因变量y和中介变量M都要分析变量框中自变量只可以填入一个,如果有两个以上自变量时,把其他自变量填入控制变量covariate框中,因为控制变量也是一种自变量Option选项勾选以上几个选项框,如上图,小数点保留3位小数另外下边这四个选项,表示调节变量放的位置,根据自己设定的模型,对照给出的72个模型,看和那个比较接近,然后把调节变量放到相应的位置上去。
运算后看输出结果上图中eou就解释为控制变量首先看两个因变量的输出,一个是UF,一个是BI。
自变量是ATT和BOU。
也就是说,一会自变量写为BOU,控制变量写为ATT,这两个表也不会改变,因为自变量再怎么改变也都在自变量和控制变量框中。
ATT和BOU对UF这个中介变量的显著性都显著,而且置信区间都不包含0,说明自变量对中介变量的假设成立。
以BI为因变量的输出也一样,两个自变量ATT和EUO对因变量BI一个显著一个不显著,置信区间一个不包含0一个包含0,说明自变量对因变量的假设一个成立一个不成立。
而上边的UF中介变量对自变量BI的影响是显著的。
上图中总效果0.341等于直接效果0.228加上间接效果0.113。
那什么是总效果、直接效果和间接效果呢?看下图XY就是直接效果,a*b就是间接效果,两个相加就是总效果。
上图中间接效果系数是0.113,置信区间不包含0,说明间接效果存在。
而下边的normal theory tests for indirect effect就是sobel检定,p值显著,说明sobel检定也显著。
trainscg函数

trainscg函数Trainscg函数是MATLAB中用于神经网络训练的一种优化算法。
它基于梯度下降法,通过不断更新权重和偏置来最小化神经网络的损失函数,从而提高模型的准确性和泛化能力。
在本文中,我们将深入探讨trainscg函数的原理和应用,以帮助读者更好地理解和运用这一算法。
让我们简要介绍一下神经网络。
神经网络是一种模拟人类大脑神经元之间相互连接的数学模型,用于处理复杂的非线性关系和模式识别问题。
在神经网络中,输入经过一系列的隐藏层神经元的加权和非线性激活函数处理后,最终得到输出结果。
神经网络的训练过程就是通过调整权重和偏置,使得模型的输出尽可能接近真实标签。
trainscg函数的全称是Scaled Conjugate Gradient Backpropagation,它结合了共轭梯度法和梯度下降法的优点,在训练神经网络时表现出色。
与传统的梯度下降法相比,trainscg函数具有更快的收敛速度和更好的泛化能力,能够帮助神经网络更快地学习到数据的特征和规律。
在使用trainscg函数时,我们需要设置一些参数,如最大迭代次数、误差容限、学习率等。
这些参数的选择对神经网络的训练效果至关重要,需要根据具体的数据集和任务来进行调整。
通常情况下,我们可以通过交叉验证等方法来选择最优的参数组合,以获得最佳的训练效果。
除了设置参数外,还需要对数据进行预处理,包括数据归一化、特征工程等步骤,以提高神经网络的训练效率和准确性。
在训练过程中,我们可以通过监控损失函数的变化来评估模型的性能,及时调整参数和优化策略,以达到更好的训练效果。
总的来说,trainscg函数作为一种高效的神经网络训练算法,在实际应用中具有很大的潜力和价值。
通过深入理解其原理和特点,并合理调整参数和数据预处理步骤,我们可以更好地利用trainscg函数来训练神经网络,提高模型的性能和泛化能力,为解决实际问题提供更好的解决方案。
希望本文能够帮助读者更好地理解和运用trainscg函数,进一步推动神经网络在各个领域的发展和应用。
pathseq 参数

pathseq 参数PathSeq参数是一种用于路径分析的工具,它可以帮助研究人员理解和分析复杂的生物学数据。
本文将介绍PathSeq参数的原理、应用以及未来的发展方向。
一、PathSeq参数的原理PathSeq参数基于基因组序列和参考数据库,通过比对和分析DNA或RNA测序数据中的路径信息,来确定样本中存在的微生物种类和数量。
它通过检测样本中的路径特征,如代谢途径、细胞结构和功能等,来推断微生物的存在和功能。
PathSeq参数的原理主要包括以下几个步骤:1. 数据预处理:将原始测序数据进行质量控制、去除低质量序列和人类宿主序列等。
2. 参考数据库构建:选择合适的参考数据库,包括细菌、病毒、真菌等微生物的基因组序列。
3. 比对和分类:将预处理后的测序数据与参考数据库中的序列进行比对,通过比对结果将样本中的序列分类为不同的微生物种类。
4. 路径分析:根据比对结果和参考数据库中的路径信息,推断样本中微生物的代谢途径、细胞结构和功能等信息。
二、PathSeq参数的应用PathSeq参数在微生物组学研究中具有广泛的应用前景,可以用于以下几个方面:1. 疾病诊断:通过分析患者样本中的微生物组成和功能,可以帮助医生对疾病进行诊断和治疗。
例如,通过检测肠道菌群的变化,可以预测肠道疾病的风险。
2. 药物开发:通过分析微生物组成和功能,可以发现新的药物靶点和抗菌药物。
例如,通过分析细菌的代谢途径,可以发现新的抗生素靶点。
3. 环境监测:通过分析环境样本中的微生物组成和功能,可以监测环境污染和生态系统变化。
例如,通过分析土壤样本中的微生物组成,可以评估土壤质量和农业生产力。
4. 食品安全:通过分析食品样本中的微生物组成和功能,可以检测食品中的潜在病原微生物和毒素。
例如,通过分析食品中的细菌菌群,可以评估食品的卫生质量。
三、PathSeq参数的未来发展随着测序技术的不断发展和下一代测序的普及,PathSeq参数在微生物组学研究中的应用将会越来越广泛。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
FMEA Training
6
Building a Process Map
What is a work process?
INPUT
PROCESS
OUTPUT
Transformation (Value-Added) Steps
FMEA Training
7
Building a Process Map
Process Scope
True
FMEA Training
3
Example of a Process Map
Sales
Customer places order
Typical Order Fulfillment Process
Order Entry
Warehousing
Transportation
Is order Yes Send order to
understandings Enables rigorous, thorough examination of the
outputs and inputs
Increases probability of capturing all the y’s and x’s Increases probability of getting to y = f(x). Identification of outputs needing measurement studies
• Identify Major Inputs and Customer Outputs for the Suspect Process
• Identify Possible Connections
FMEA Training
12
Identify Process Steps Within Boundaries
Should be reviewed frequently and updated
y f (x1, x2 ,..., xk )
FMEA Training
5
Benefits of Process Mapping
Reveals “Hidden Factories” Exposes inaccurate assumptions, beliefs, and
• Large, cross-functional processes
that involve many people are called macro processes. Executives tend to view the organization in this manner
• Smaller, local processes are called
6
Paths.
Test
An inspection point creates a pass or fail decision based on objective standards
Inspections may lead to a reversal of
process flow direction, rework loop or a
Select Right Team
Map: Primary Process Alternative Paths Inspection Points
Use Map to Improve Process
• Determine scope of the process as it
relates to the project/product
scrap.
Is the pin seated correctly? Does the O ring function properly?
Specific, objective questions are almost
KPOV KPOV
Y’s CORRECT, IN-SPEC
PROCESS VALUE-ADDED STEPS
KEY PROCESS INPUT VARIABLES
X’s control
KPIV KPIV KPIV
FMEA Training
10
Process Flow Symbols
OPERATION All steps in the process where the object undergoes a change in form or condition.
FMEA Training
13
Map Inspection Points
Signaled by a decision diamond
Decision diamonds must pose a
question -- no exceptions -- remains
consistent with Mapping Alternative
Is a graphical representation of the flow of a process
It contains information that is beneficial to improving the process
It represents the process as it actually exists
Can production Manufacture Product in time For shipping?
No Will customer No Accept back Order?YesFra bibliotekYes
Yes
Yes
Place order on hold Until product available
Expedite manufacturing schedule
Identification of outputs for capability studies
Opportunities for elimination of non-value-added steps or addition of needed steps
Verify which measurement system need confirmation Can provide a snapshot for future comparison
Correct?
Warehouse for picking
Is product Yes Available?
Pick product for order
Does customer haveNo Other shipments?
Ship order
Customer receive order
No
Call customer and Make corrections
1 Paperwork
Dryer Body AsDsreymerbly
2 Label Body
3 Insert Spirol
Pin
4 Assemble
Pistons
5 Assemble
Cover
?
6
7 Store
Test
Why there is one of the steps a diamond?
Dryer Body Assembly
OUTPUTS (Big Y’s)
Part to Print Performance to Spec Visually acceptable Leak free Identified Clean Packaged for use Consistent standard
improvement activities • Complete a Process Mapping Exercise • Learn how to integrate Process Mapping into your
Company SOP
FMEA Training
2
What is a Process Map ?
DELAY All incidences where the object stops or waits on a an operation, transportation, or inspection
INSPECTION All steps in the process where the objects are checked for completeness, quality, outside of the Operation.
DECISION
FMEA Training
11
Develop an Upper Level Process Map
INPUTS
Assembly Labor Procedures Materials Equipment, Fixtures Environment Cleanliness Rework
Process Scope
Select Right Team
Map: Primary Process Alternative Paths Inspection Points
Use Map to Improve Process
DEFECT-FREE CTQ
KEY PROCESS OUTPUT VARIABLES
• Manufacturing Engineers • ME Technicians • Design Engineering • Line Operators • Line Supervisors • Maintenance Technicians
FMEA Training
*
9
Building a Process Map
Yes No
Will customer allow No Consolidated shipments?