并行计算实验报告一
并行计算的实验
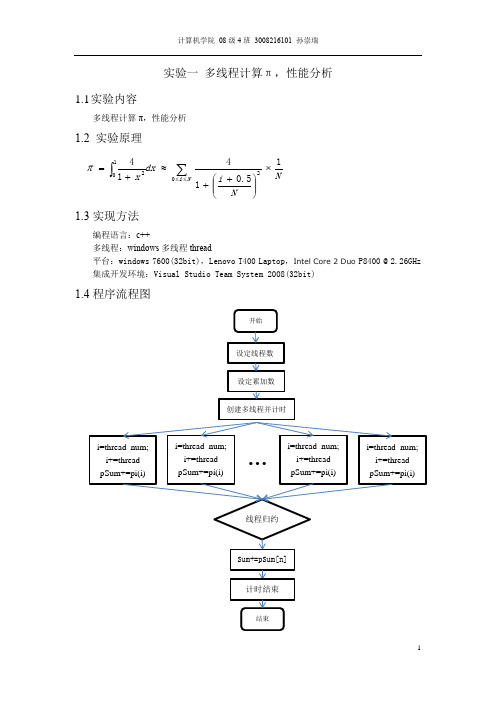
实验一多线程计算π,性能分析1.1 实验内容多线程计算π,性能分析1.2 实验原理1.3实现方法编程语言:c++多线程:windows 多线程thread平台:windows 7600(32bit),Lenovo T400 Laptop ,IntelCore 2 Duo P8400 @ 2.26GHz集成开发环境:Visual Studio Team System 2008(32bit)1.4程序流程图NN i dx x Ni 15.0141402102⨯⎪⎪⎭⎫⎝⎛++≈+=∑⎰≤≤π1.5实验结果线程数NUM_THREAD=4N π Time-cost100 3.14160098692312 3ms1000 3.14159273692313 4ms10000 3.14159265442313 5ms100000 3.14159265359813 25ms1000000 3.14159265358990 82ms1.6性能分析精度随叠加次数N的增大而趋近于π的真实值,计算时间也随之增高;相同的叠加次数下,因为是双核处理器,线程数为2时计算性能最高。
理论性能提升有极限值,所以不会因为线程的增多而性能无限增强。
当线程数很大时,计算时间增加很快。
1.7总结展望第一次编写并行化的程序,对多线程编程有了初步的认识。
由于是在Visual Studio平台下编程,很多知识是从Lunix平台移植过来的,虽然表现形式有少许差别,但核心思想一致。
通过学习,对windows多线程编程有了一定的掌握。
实验二3PCF计算多线程实现2.1实验内容▪定义:–点集D、R。
–定义D中的点为a i∈D,R中的点为b i∈R。
–距离:r1、r2、r3、err▪求:–满足以下条件的三元组(空间中三角形)的数目•<a i, b m, b n>,|a i-b m|=r1±err且|a i-b n|=r2±err且|b m-b n|=r3±err2.2实验原理对于D中每一点a i,在R中找到与之距离为r1的点集R’,找到与之距离为r2的点集R’’。
多核编程与并行计算实验报告 (1)

多核编程与并行计算实验报告姓名:日期:2014年 4月20日实验一// exa1.cpp : Defines the entry point for the console application.//#include"stdafx.h"#include<windows.h>#include<process.h>#include<iostream>#include<fstream>using namespace std;void ThreadFunc1(PVOID param){while(1){Sleep(1000);cout<<"This is ThreadFunc1"<<endl;}}void ThreadFunc2(PVOID param){while(1){Sleep(1000);cout<<"This is ThreadFunc2"<<endl;}}int main(){int i=0;_beginthread(ThreadFunc1,0,NULL);_beginthread(ThreadFunc2,0,NULL);Sleep(3000);cout<<"end"<<endl;return 0;}实验二// exa2.cpp : Defines the entry point for the console application. //#include"stdafx.h"#include<windows.h>#include<iostream>using namespace std;DWORD WINAPI FunOne(LPVOID param){while(true){Sleep(1000);cout<<"hello! ";}return 0;}DWORD WINAPI FunTwo(LPVOID param){while(true){Sleep(1000);cout<<"world! ";}return 0;}int main(int argc, char* argv[]){int input=0;HANDLE hand1=CreateThread (NULL, 0, FunOne, (void*)&input, CREATE_SUSPENDED, NULL); HANDLE hand2=CreateThread (NULL, 0, FunTwo, (void*)&input, CREATE_SUSPENDED, NULL);while(true){cin>>input;if(input==1){ResumeThread(hand1);ResumeThread(hand2);}else{SuspendThread(hand1);SuspendThread(hand2);}};TerminateThread(hand1,1);TerminateThread(hand2,1);return 0;}实验三// exa3.cpp : Defines the entry point for the console application.//#include"stdafx.h"#include<windows.h>#include<iostream>using namespace std;int globalvar = false;DWORD WINAPI ThreadFunc(LPVOID pParam){cout<<"ThreadFunc"<<endl;Sleep(200);globalvar = true;return 0;}int main(){HANDLE hthread = CreateThread(NULL, 0, ThreadFunc, NULL, 0, NULL);if (!hthread){cout<<"Thread Create Error ! "<<endl;CloseHandle(hthread);}while (!globalvar)cout<<"Thread while"<<endl;cout<<"Thread exit"<<endl;return 0;}实验四:// exa4.cpp : Defines the entry point for the console application. //#include"stdafx.h"#include<windows.h>#include<process.h>#include<iostream>#include<fstream>using namespace std;HANDLE evRead, evFinish;void ReadThread(LPVOID param){WaitForSingleObject (evRead ,INFINITE);cout<<"Reading"<<endl;SetEvent (evFinish);}void WriteThread(LPVOID param){cout<<"Writing"<<endl;SetEvent (evRead);}int main(int argc , char * argv[]){evRead = CreateEvent (NULL ,FALSE ,FALSE ,NULL) ;evFinish = CreateEvent (NULL ,FALSE ,FALSE ,NULL) ;_beginthread(ReadThread , 0 , NULL) ;_beginthread(WriteThread , 0 , NULL) ;WaitForSingleObject (evFinish,INFINITE) ;cout<<"The Program is End"<<endl;return 0 ;}实验五// exa5.cpp : Defines the entry point for the console application. //#include"stdafx.h"#include<windows.h>#include<process.h>#include<iostream>#include<fstream>using namespace std;int total = 100 ;HANDLE evFin[2] ;CRITICAL_SECTION cs ;void WithdrawThread1(LPVOID param){EnterCriticalSection(&cs) ;if ( total-90 >= 0){total -= 90 ;cout<<"You withdraw 90"<<endl;}elsecout<<"You do not have that much money"<<endl;LeaveCriticalSection(&cs) ;SetEvent (evFin[0]) ;}void WithdrawThread2(LPVOID param){EnterCriticalSection(&cs) ;if ( total-20 >= 0){total -= 20 ;cout<<"You withdraw 20"<<endl;}elsecout<<"You do not have that much money"<<endl;LeaveCriticalSection(&cs) ;LeaveCriticalSection(&cs) ;SetEvent (evFin[1]) ;}int main(int argc , char * argv[]){evFin[0] = CreateEvent (NULL,FALSE,FALSE,NULL) ;evFin[1] = CreateEvent (NULL,FALSE,FALSE,NULL) ;InitializeCriticalSection(&cs) ;_beginthread(WithdrawThread1 , 0 , NULL) ;_beginthread(WithdrawThread2 , 0 , NULL) ;WaitForMultipleObjects(2 ,evFin ,TRUE ,INFINITE) ;DeleteCriticalSection(&cs) ;cout<<total<<endl;return 0 ;}实验六:// exa6.cpp : Defines the entry point for the console application.//#include"stdafx.h"#include<windows.h>#include<iostream.h>#define THREAD_INSTANCE_NUMBER 3LONG g_fResourceInUse = FALSE;LONG g_lCounter = 0;DWORD ThreadProc(void * pData) {int ThreadNumberTemp = (*(int*) pData);HANDLE hMutex;cout << "ThreadProc: " << ThreadNumberTemp << " is running!" << endl;if ((hMutex = OpenMutex(MUTEX_ALL_ACCESS, FALSE, "Mutex.Test")) == NULL) { cout << "Open Mutex error!" << endl;}cout << "ThreadProc " << ThreadNumberTemp << " gets the mutex"<< endl;ReleaseMutex(hMutex);CloseHandle(hMutex);return 0;}int main(int argc, char* argv[]){int i;DWORD ID[THREAD_INSTANCE_NUMBER];HANDLE h[THREAD_INSTANCE_NUMBER];HANDLE hMutex;if ( (hMutex = OpenMutex(MUTEX_ALL_ACCESS, FALSE, "Mutex.Test")) == NULL) { if ((hMutex = CreateMutex(NULL, FALSE, "Mutex.Test")) == NULL ) { cout << "Create Mutex error!" << endl;return 0;}}for (i=0;i<THREAD_INSTANCE_NUMBER;i++){h[i] = CreateThread(NULL,0,(LPTHREAD_START_ROUTINE) ThreadProc,(void *)&ID[i],0,&(ID[i]));if (h[i] == NULL)cout << "CreateThread error" << ID[i] << endl;elsecout << "CreateThread: " << ID[i] << endl;}WaitForMultipleObjects(THREAD_INSTANCE_NUMBER,h,TRUE,INFINITE);cout << "Close the Mutex Handle! " << endl;CloseHandle(hMutex);return 0;}实验七// exa7.cpp : Defines the entry point for the console application.//#include"stdafx.h"#include<windows.h>#include<iostream.h>#define THREAD_INSTANCE_NUMBER 3DWORD foo(void * pData) {int ThreadNumberTemp = (*(int*) pData);HANDLE hSemaphore;cout << "foo: " << ThreadNumberTemp << " is running!" << endl;if ((hSemaphore = OpenSemaphore(SEMAPHORE_ALL_ACCESS, FALSE, "Semaphore.Test")) == NULL) {cout << "Open Semaphore error!" << endl;}cout << "foo " << ThreadNumberTemp << " gets the semaphore"<< endl;ReleaseSemaphore(hSemaphore, 1, NULL);CloseHandle(hSemaphore);return 0;}int main(int argc, char* argv[]){int i;DWORD ThreadID[THREAD_INSTANCE_NUMBER];HANDLE hThread[THREAD_INSTANCE_NUMBER];HANDLE hSemaphore;if ((hSemaphore = CreateSemaphore(NULL,0,1, "Semaphore.Test")) == NULL ) { cout << "Create Semaphore error!" << endl;return 0;}for (i=0;i<THREAD_INSTANCE_NUMBER;i++){hThread[i] = CreateThread(NULL,0,(LPTHREAD_START_ROUTINE) foo,(void *)&ThreadID[i],0,&(ThreadID[i]));if (hThread[i] == NULL)cout << "CreateThread error" << ThreadID[i] << endl;elsecout << "CreateThread: " << ThreadID[i] << endl;}WaitForMultipleObjects(THREAD_INSTANCE_NUMBER,hThread,TRUE,INFINITE);cout << "Close the Semaphore Handle! " << endl;CloseHandle(hSemaphore);return 0;}实验八:// exa8.cpp : Defines the class behaviors for the application.//#include"stdafx.h"#include"exa8.h"#include"MainFrm.h"#include"exa8Doc.h"#include"exa8View.h"#ifdef _DEBUG#define new DEBUG_NEW#undef THIS_FILEstatic char THIS_FILE[] = __FILE__;#endif///////////////////////////////////////////////////////////////////////////// // CExa8AppBEGIN_MESSAGE_MAP(CExa8App, CWinApp)//{{AFX_MSG_MAP(CExa8App)ON_COMMAND(ID_APP_ABOUT, OnAppAbout)// NOTE - the ClassWizard will add and remove mapping macros here.// DO NOT EDIT what you see in these blocks of generated code!//}}AFX_MSG_MAP// Standard file based document commandsON_COMMAND(ID_FILE_NEW, CWinApp::OnFileNew)ON_COMMAND(ID_FILE_OPEN, CWinApp::OnFileOpen)END_MESSAGE_MAP()/////////////////////////////////////////////////////////////////////////////// CExa8App constructionCExa8App::CExa8App(){// TODO: add construction code here,// Place all significant initialization in InitInstance}/////////////////////////////////////////////////////////////////////////////// The one and only CExa8App objectCExa8App theApp;/////////////////////////////////////////////////////////////////////////////// CExa8App initializationBOOL CExa8App::InitInstance(){AfxEnableControlContainer();// Standard initialization// If you are not using these features and wish to reduce the size// of your final executable, you should remove from the following// the specific initialization routines you do not need.#ifdef _AFXDLLEnable3dControls(); // Call this when using MFC in a shared DLL #elseEnable3dControlsStatic(); // Call this when linking to MFC statically#endif// Change the registry key under which our settings are stored.// TODO: You should modify this string to be something appropriate// such as the name of your company or organization.SetRegistryKey(_T("Local AppWizard-Generated Applications"));LoadStdProfileSettings(); // Load standard INI file options (including MRU) // Register the application's document templates. Document templates// serve as the connection between documents, frame windows and views.CSingleDocTemplate* pDocTemplate;pDocTemplate = new CSingleDocTemplate(IDR_MAINFRAME,RUNTIME_CLASS(CExa8Doc),RUNTIME_CLASS(CMainFrame), // main SDI frame windowRUNTIME_CLASS(CExa8View));AddDocTemplate(pDocTemplate);// Parse command line for standard shell commands, DDE, file openCCommandLineInfo cmdInfo;ParseCommandLine(cmdInfo);// Dispatch commands specified on the command lineif (!ProcessShellCommand(cmdInfo))return FALSE;// The one and only window has been initialized, so show and update it.m_pMainWnd->ShowWindow(SW_SHOW);m_pMainWnd->UpdateWindow();return TRUE;}///////////////////////////////////////////////////////////////////////////// // CAboutDlg dialog used for App Aboutclass CAboutDlg : public CDialog{public:CAboutDlg();// Dialog Data//{{AFX_DATA(CAboutDlg)enum { IDD = IDD_ABOUTBOX };//}}AFX_DATA// ClassWizard generated virtual function overrides//{{AFX_VIRTUAL(CAboutDlg)protected:virtual void DoDataExchange(CDataExchange* pDX); // DDX/DDV support //}}AFX_VIRTUAL// Implementationprotected://{{AFX_MSG(CAboutDlg)// No message handlers//}}AFX_MSGDECLARE_MESSAGE_MAP()};CAboutDlg::CAboutDlg() : CDialog(CAboutDlg::IDD){//{{AFX_DATA_INIT(CAboutDlg)//}}AFX_DATA_INIT}void CAboutDlg::DoDataExchange(CDataExchange* pDX){CDialog::DoDataExchange(pDX);//{{AFX_DATA_MAP(CAboutDlg)//}}AFX_DATA_MAP}BEGIN_MESSAGE_MAP(CAboutDlg, CDialog)//{{AFX_MSG_MAP(CAboutDlg)// No message handlers//}}AFX_MSG_MAPEND_MESSAGE_MAP()// App command to run the dialogvoid CExa8App::OnAppAbout(){CAboutDlg aboutDlg;aboutDlg.DoModal();}///////////////////////////////////////////////////////////////////////////// // CExa8App message handlers、实验九:using System;using System.Threading;class Test{static void Main(){ThreadStart threadDelegate = new ThreadStart(Work.DoWork);Thread newThread = new Thread(threadDelegate);newThread.Start();Work w = new Work();w.Data = 42;threadDelegate = new ThreadStart(w.DoMoreWork);newThread = new Thread(threadDelegate);newThread.Start();}}class Work{public static void DoWork(){Console.WriteLine("Static thread procedure.");}public int Data;public void DoMoreWork(){Console.WriteLine("Instance thread procedure. Data={0}", Data);}实验十:using System;using System.Threading;class Test{static int total = 100;public static void WithDraw1(){int n=90;if (n <= total){total -= n;Console.WriteLine("You have withdrawn. n={0}", n);Console.WriteLine("total={0}", total);}else{Console.WriteLine("You do not enough money. n={0}", n);Console.WriteLine("total={0}", total);}}public static void WithDraw2()int n = 20;if (n <= total){total -= n;Console.WriteLine("You have withdrawn. n={0}", n);Console.WriteLine("total={0}", total);}else{Console.WriteLine("You do not enough money. n={0}", n);Console.WriteLine("total={0}", total);}}public static void Main(){ThreadStart thread1 = new ThreadStart(WithDraw1);Thread newThread1 = new Thread(thread1);ThreadStart thread2 = new ThreadStart(WithDraw2);Thread newThread2 = new Thread(thread2);newThread1.Start();newThread2.Start();}}实验十一:// exa11.cpp : Defines the entry point for the console application.//#include"stdafx.h"#include<windows.h>#include<conio.h>#include<stdio.h>#define THREAD_INSTANCE_NUMBER 3LONG g_fResourceInUse = FALSE;LONG g_lCounter = 0;CRITICAL_SECTION cs;DWORD ThreadProc1(void * pData) {int ThreadNumberTemp = (*(int*) pData);printf("ThreadProc1: %d is running!\n",ThreadNumberTemp );EnterCriticalSection(&cs);printf("ThreadProc1 %d enters into critical section\n",ThreadNumberTemp);Sleep(1000);LeaveCriticalSection(&cs);return 0;}DWORD ThreadProc2(void * pData) {int ThreadNumberTemp = (*(int*) pData);printf("ThreadProc2: %d is running!\n",ThreadNumberTemp );EnterCriticalSection(&cs);printf("ThreadProc2 %d enters into critical section\n",ThreadNumberTemp);Sleep(1000);LeaveCriticalSection(&cs);return 0;}int main(int argc, char* argv[]){int i;DWORD ID1,ID2;HANDLE h1,h2;InitializeCriticalSection(&cs);printf("Create the critical section \n");h1 = CreateThread(NULL,0,(LPTHREAD_START_ROUTINE) ThreadProc1,(void *)&ID1,0,&(ID1));if (h1 == NULL)printf("CreateThread error %d \n",ID1);elseprintf("CreateThread %d \n",ID1);h2= CreateThread(NULL,0,(LPTHREAD_START_ROUTINE) ThreadProc2,(void *)&ID2,0,&(ID2));if (h2== NULL)printf("CreateThread error %d \n",ID2);elseprintf("CreateThread %d \n",ID2);WaitForSingleObject (h1,INFINITE);WaitForSingleObject (h2,INFINITE);printf("Delete the critical section \n");DeleteCriticalSection(&cs);getch();return 0;}。
华科并行实验报告

一、实验模块计算机科学与技术二、实验标题并行计算实验三、实验目的1. 了解并行计算的基本概念和原理;2. 掌握并行编程的基本方法;3. 通过实验加深对并行计算的理解。
四、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 并行计算平台:OpenMP五、实验步骤1. 准备实验环境首先,在计算机上安装OpenMP库,并配置环境变量。
2. 编写并行计算程序编写一个简单的并行计算程序,实现以下功能:(1)计算斐波那契数列的第n项;(2)计算素数的个数;(3)计算矩阵乘法。
以下为斐波那契数列的并行计算程序示例:```cpp#include <omp.h>#include <iostream>using namespace std;int main() {int n = 30;int fib[31] = {0};fib[0] = 0;fib[1] = 1;#pragma omp parallel forfor (int i = 2; i <= n; i++) {fib[i] = fib[i - 1] + fib[i - 2];}cout << "斐波那契数列的第" << n << "项为:" << fib[n] << endl; return 0;}```3. 编译程序使用g++编译器编译程序,并添加OpenMP库支持。
```bashg++ -fopenmp -o fib fib.cpp```4. 运行程序在命令行中运行编译后的程序,观察结果。
5. 分析结果通过对比串行计算和并行计算的结果,分析并行计算的优势。
六、实验过程1. 准备实验环境,安装OpenMP库并配置环境变量;2. 编写并行计算程序,实现斐波那契数列的并行计算;3. 编译程序,并添加OpenMP库支持;4. 运行程序,观察结果;5. 分析结果,对比串行计算和并行计算的性能。
并行实验快速排序实验报告完整版

华南师范大学实验报告学生姓名学 号专 业计算机科学与技术年级、班级课程名称并行计算实验项目快速排序的并行算法实验时间 2011 年 6 月 10 日实验类型实验指导老师实验评分3.1实验目的与要求1.熟悉快速排序的串行算法2.熟悉快速排序的并行算法3.实现快速排序的并行算法3.2 实验环境及软件单台或联网的多台PC机, Linux操作系统, MPI系统。
3.3实验内容1.快速排序的基本思想2.单处理机上快速排序算法3.快速排序算法的性能4.快速排序算法并行化5.描述了使用2m个处理器完成对n个输入数据排序的并行算法。
6.在最优的情况下并行算法形成一个高度为logn的排序树7、完成快速排序的并行实现的流程图8、完成快速排序的并行算法的实现3.4实验步骤3.4.1.快速排序(Quick Sort)是一种最基本的排序算法, 它的基本思想是: 在当前无序区R[1, n]中取一个记录作为比较的“基准”(一般取第一个、最后一个或中间位置的元素), 用此基准将当前的无序区R[1, n]划分成左右两个无序的子区R[1, i-1]和R[i, n](1≤i≤n), 且左边的无序子区中记录的所有关键字均小于等于基准的关键字, 右边的无序子区中记录的所有关键字均大于等于基准的关键字;当R[1, i-1]和R[i, n]非空时, 分别对它们重复上述的划分过程, 直到所有的无序子区中的记录均排好序为止。
3.4.2.单处理机上快速排序算法输入: 无序数组data[1,n]输出: 有序数组data[1,n]Begincall procedure quicksort(data,1,n)Endprocedure quicksort(data,i,j)Begin(1) if (i<j) then(1.1)r = partition(data,i,j)(1.2)quicksort(data,i,r-1);(1.3)quicksort(data,r+1,j);end ifEndprocedure partition(data,k,l)Begin(1) pivo=data[l](2) i=k-1(3) for j=k to l-1 doif data[j]≤pivo theni=i+1exchange data[i] and data[j]end ifend for(4) exchange data[i+1] and data[l](5) return i+1End3.4.3.快速排序算法的性能主要决定于输入数组的划分是否均衡, 而这与基准元素的选择密切相关。
华科计算机并行实验报告

课程设计报告题目:并行实验报告课程名称:并行编程原理与实践专业班级:学号:姓名:指导教师:报告日期:计算机科学与技术学院目录1,实验一 (1)1 实验目的与要求 (1)1.1实验目的 (1)1.2实验要求 (1)2 实验内容 (1)2.1.1熟悉pthread编程 (1)2.1.2简单的thread编程 (2)2.2.1熟悉openMP编程 (3)2.3.1熟悉MPI编程 (4)2,实验2~5 (7)1 实验目的与要求 (7)2 算法描述 (7)3.实验方案 (8)4实验结果与分析 (8)3 心得体会 (10)附录: (10)3 蒙特.卡罗算法求π的并行优化 (19)1.蒙特.卡罗算法基本思想 (19)2.工作过程 (20)3.算法描述 (20)4 设计与实现 (21)5 结果比较与分析 (23)6 思考与总结 (24)1,实验一1 实验目的与要求1.1实验目的1)熟悉并行开发环境,能进行简单程序的并行开发,在Linux下熟练操作。
2)熟悉一些并行工具,如pthread,OpenMP,MPI等进行并行编程3)培养并行编程的意识1.2实验要求1)利用pthread、OpenMP、MPI等工具,在Linux下进行简单的并行编程,并且掌握其编译、运行的方法。
2)理解并行计算的基础,理解pthread、OpenMP、MPI等并行方法。
2 实验内容2.1.1熟悉pthread编程Linux系统下的多线程遵循POSIX线程接口,称为 pthread。
编写Linux下的多线程程序,需要使用头文件pthread.h,连接时需要使用库libpthread.a。
下面是pthread编程的几个常用函数:1,int pthread_create(pthread_t *restrict tidp,const pthread_attr_t *restrict attr, void *(*start_rtn)(void),void *restrict arg);返回值:若是成功建立线程返回0,否则返回错误的编号形式参数:pthread_t *restrict tidp 要创建的线程的线程id指针const pthread_attr_t *restrict attr 创建线程时的线程属性void* (start_rtn)(void) 返回值是void类型的指针函数void *restrict arg start_rtn的行参2 , int pthread_join( pthread_t thread, void **retval );thread表示线程ID,与线程中的pid概念类似;retval用于存储等待线程的返回值连接函数pthread_join()是一种在线程间完成同步的方法。
并行计算实验报告一

并行计算实验报告一江苏科技大学计算机科学与工程学院实验报告评定成绩指导教师实验课程:并行计算宋英磊实验名称:Java多线程编程学号: 姓名: 班级: 完成日期:2014年04月22日1.1 实验目的(1) 掌握多线程编程的特点;(2) 了解线程的调度和执行过程;(3) 掌握资源共享访问的实现方法。
1.2 知识要点1.2.1线程的概念(1) 线程是程序中的一个执行流,多线程则指多个执行流;(2) 线程是比进程更小的执行单位,一个进程包括多个线程;(3) Java语言中线程包括3部分:虚拟CPU、该CPU执行的代码及代码所操作的数据。
(4) Java代码可以为不同线程共享,数据也可以为不同线程共享; 1.2.2 线程的创建(1) 方式1:实现Runnable接口Thread类使用一个实现Runnable接口的实例对象作为其构造方法的参数,该对象提供了run方法,启动Thread将执行该run方法;(2) 方式2:继承Thread类重写Thread类的run方法;1.2.3 线程的调度(1) 线程的优先级, 取值范围1,10,在Thread类提供了3个常量,MIN_PRIORITY=1、MAX_ PRIORITY=10、NORM_PRIORITY=5;, 用setPriority()设置线程优先级,用getPriority()获取线程优先级; , 子线程继承父线程的优先级,主线程具有正常优先级。
(2) 线程的调度:采用抢占式调度策略,高优先级的线程优先执行,在Java 中,系统按照优先级的级别设置不同的等待队列。
1.2.4 线程的状态与生命周期说明:新创建的线程处于“新建状态”,必须通过执行start()方法,让其进入到“就绪状态”,处于就绪状态的线程才有机会得到调度执行。
线程在运行时也可能因资源等待或主动睡眠而放弃运行,进入“阻塞状态”,线程执行完毕,或主动执行stop方法将进入“终止状态”。
1.2.5 线程的同步--解决资源访问冲突问题(1) 对象的加锁所有被共享访问的数据及访问代码必须作为临界区,用synchronized加锁。
并行计算与分布式系统实验报告

并行计算与分布式系统实验报告1. 引言“彼岸花,开过就只剩残香。
”这是一句来自中国古代文学名篇《红楼梦》的名言。
它告诉我们,珍贵的事物往往难以长久保持,只有通过合理的分工与协作,才能实现最大的效益。
在计算机科学领域,这句话同样适用。
并行计算和分布式系统正是通过有效地利用计算资源,实现高效的数据处理与任务分工,从而提高计算效率和系统性能。
2. 并行计算介绍并行计算是一种利用多个处理器或计算节点同时执行计算任务的方法。
它通过将大型计算问题划分为多个小的子问题,并同时解决这些子问题,大幅提高计算速度。
并行计算有两种主要的形式:数据并行和任务并行。
数据并行将大型数据集分割成多个小块,分别交给不同的处理器进行处理;任务并行将不同的任务分配到不同的处理器上同时执行。
3. 分布式系统介绍分布式系统是一组互连的计算机节点,通过网络相互协作以实现共同的目标。
分布式系统可以分布在不同地理位置的计算机上,通过消息传递和远程过程调用等通信机制实现节点间的协作。
分布式系统具有高可靠性、可扩展性和容错性的特点,并广泛应用于云计算、大数据处理和分布式存储等领域。
4. 并行计算和分布式系统的关系并行计算和分布式系统之间存在密切的关系。
分布式系统提供了并行计算所需的底层基础设施和通信机制,而并行计算则借助分布式系统的支持,实现任务的并行处理和数据的高效交换。
通过充分利用分布式系统中的计算资源,可以实现更高效的并行计算,并加速大规模数据处理和科学计算。
5. 并行计算与分布式系统实验在完成本次实验中,我们使用了一台集群式分布式系统,包括8台计算节点和1台主控节点。
我们利用MPI(Message Passing Interface)实现了一个并行计算的案例,该案例通过并行处理大规模图像数据,实现图像的快速处理和分析。
实验中,我们首先将图像数据划分成多个小块,并分发给不同的计算节点进行处理。
每个计算节点利用并行算法对图像进行滤波和边缘检测,然后将处理结果返回给主控节点。
并行计算实验一报告

并行计算实验一报告广东技术师范学院实验报告计算机科学与学院: 计算机科学学院专业: 班级: 成绩: 技术姓名: 学号: 组别: 组员: 实验地点: 工业中心203 实验日期: 指导教师签名: 预习情况操作情况考勤情况数据处理情况实验 (一) 项目名称: 建立并行计算平台一、实验目的在一个局域网中建立能够互相通信的两台计算机,为以后实验建立一个实验平台。
二、实验内容:1.1 系统要求安装MPICH for Microsoft Windows 对系统有如下要求:Windows NT4/2000/XP 的Professional 或Server 版(不支持Windows 95/98) 所有主机必须能够建立TCP/IP 连接MPICH 支持的编译器有:MS VC++ 6.x,MS VC++.NET,Compaq Visual Fortran 6.x,Intel Fortran,gcc ,以及g77 。
安装MPICH ,必须以管理员的身份登录。
1.2 安装以管理员的身份登录每台主机,在所有主机上建立一个同样的账户(当然也可以每个机器使用不同的用户名和账户,然后建立一个配置文件,使用命令行的方式运行程序),然后,运行下载的安装文件,将MPICH 安装到每台主机上。
打开“任务管理器”中的“进程”选项卡,查看是否有一个mpd.exe 的进程。
如果有的话说明安装成功。
以后每次启动系统,该进程将自动运行。
打开任务管理器如下:1.3 注册与配置安装好MPICH 之后还必须对每台计算机进行注册和配置才能使用。
其中注册必须每台计算机都要进行,配置只要在主控的计算机执行就行了。
注册的目的是,将先前在每台计算机上申请的账号与密码注册到MPICH 中去,这样MPICH 才能在网络环境中访问每台主机。
配置方法:运行“mpich\mpd\bin\MPIRegister.exe”首先会提示输入用户账号,然后会提示输入两边密码,之后会问你是否保持上面的设定。
并行计算实验报告(高性能计算与网格技术)

并行计算实验报告(高性能计算与网格技术)高性能计算和网格技术实验报告实验题目OpenMP和MPI编程姓名学号专业计算机系统结构指导教师助教所在学院计算机科学与工程学院论文提交日期一、实验目的本实验的目的是通过练习掌握OpenMP 和MPI 并行编程的知识和技巧。
1、熟悉OpenMP 和MPI 编程环境和工具的使用;2、掌握并行程序编写的基本步骤;3、了解并行程序调试和调优的技巧。
二、实验要求1、独立完成实验内容;2、了解并行算法的设计基础;3、熟悉OpenMP和MPI的编程环境以及运行环境;4、理解不同线程数,进程数对于加速比的影响。
三、实验内容3.1、矩阵LU分解算法的设计:参考文档sy6.doc所使用的并行算法:在LU分解的过程中,主要的计算是利用主行i对其余各行j,(j>i)作初等行变换,各行计算之间没有数据相关关系,因此可以对矩阵A 按行划分来实现并行计算。
考虑到在计算过程中处理器之间的负载均衡,对A采用行交叉划分:设处理器个数为p,矩阵A的阶数为n,??p=,对矩阵A行交叉划分后,编号为i(i=0,1,…,p-1)的处理器存有m/nA的第i, i+p,…, i+(m-1)p行。
然后依次以第0,1,…,n-1行作为主行,将其广播给所有处理器,各处理器利用主行对其部分行向量做行变换,这实际上是各处理器轮流选出主行并广播。
若以编号为my_rank 的处理器的第i行元素作为主行,并将它广播给所有处理器,则编号大于等于my_rank的处理器利用主行元素对其第i+1,…,m-1行数据做行变换,其它处理器利用主行元素对其第i,…,m-1行数据做行变换。
根据上述算法原理用代码表示如下(关键代码):for(k = 0;k<n;k++)< p="">{for (i = 0; i < THREADS_NUM; i++) {thread_data_arrray[i].thread_id = i;thread_data_arrray[i].K_number = k;thread_data_arrray[i].chushu = a[k][k];//创建线程rc = pthread_create(&pid[i], NULL, work,(void*)&thread_data_arrray[i]);…}for (i = 0; i < THREADS_NUM; i++){//等待线程同步rc = pthread_join(pid[i], &ret); …}}void *work(void *arg){struct thread_data *my_data;my_data = (struct thread_data*)arg;int myid = my_data->thread_id; //线程IDint myk = my_data->K_number; //外层循环计数Kfloat mychushu = my_data->chushu; //对角线的值int s, e;int i, j;s = (N-myk-1) * myid / THREADS_NUM; //确定起始循环的行数的相对位置e = (N-myk-1) * (myid + 1) / THREADS_NUM;//确定终止循环的行数的相对位置for (i = s+myk+1; i < e+myk+1; i++) //由于矩阵规模在缩小,找到偏移位置 { a[i][myk]=a[i][myk]/mychushu; for (j = myk+1; j < N; j++) a[i][j]=a[i][j]-a[i][myk]*a[myk][j]; }//printMatrix(a); return NULL;}第一部分为入口函数,其创建指定的线程数,并根据不同的线程id 按行划分矩阵,将矩阵的不同部分作为参数传递给线程,在多处理器电脑上,不同的线程并行执行,实现并行计算LU 分解。
并行计算实验报告

分析 :这样的加速比 , 是符合预测 , 很好的 . 附 :(实验 源码 ) 1 pi.cpp #include <cstdio> #include <cstdlib> #include <cstring> #include <cctype> #include <cmath> #include <ctime> #include <cassert>
#include <climits> #include <iostream> #include <iomanip> #include <string> #include <vector> #include <set> #include <map> #include <queue> #include <deque> #include <bitset> #include <algorithm> #include <omp.h> #define MST(a, b) memset(a, b, sizeof(a)) #define REP(i, a) for (int i = 0; i < int(a); i++) #define REPP(i, a, b) for (int i = int(a); i <= int(b); i++) #define NUM_THREADS 4 using namespace std; const int N = 1e6; double sum[N]; int main() { ios :: sync_with_stdio(0); clock_t st, ed; double pi = 0, x; //串行 st = clock(); double step = 1.0 / N; REP(i, N) { x = (i + 0.5) * step; pi += 4.0 / (1.0 + x * x); } pi /= N; ed = clock(); cout << fixed << setprecision(10) << "Pi: " << pi << endl; cout << fixed << setprecision(10) << "串行用时: " << 1.0 * (ed - st) / CLOCKS_PER_SEC << endl; //并行域并行化 pi = 0; omp_set_num_threads(NUM_THREADS); st = clock(); int i; #pragma omp parallel private(i) { double x; int id; id = omp_get_thread_num();
并行实验报告

实验名称:并行处理技术在图像识别中的应用实验目的:1. 了解并行处理技术的基本原理和应用场景。
2. 掌握并行计算环境搭建和编程技巧。
3. 分析并行处理技术在图像识别任务中的性能提升。
实验时间:2023年10月15日-2023年10月25日实验设备:1. 主机:****************************,16GB RAM2. 显卡:NVIDIA GeForce RTX 2080 Ti3. 操作系统:Windows 10 Professional4. 并行计算软件:OpenMP,MPI实验内容:本实验主要分为三个部分:1. 并行计算环境搭建2. 图像识别任务并行化3. 性能分析和比较一、并行计算环境搭建1. 安装OpenMP和MPI库:首先在主机上安装OpenMP和MPI库,以便在编程过程中调用并行计算功能。
2. 编写并行程序框架:使用C++编写一个并行程序框架,包括并行计算函数和主函数。
3. 编译程序:使用g++编译器编译程序,并添加OpenMP和MPI库的相关编译选项。
二、图像识别任务并行化1. 数据预处理:将原始图像数据转换为适合并行处理的格式,例如将图像分割成多个子图像。
2. 图像识别算法:选择一个图像识别算法,如SVM(支持向量机)或CNN(卷积神经网络),并将其并行化。
3. 并行计算实现:使用OpenMP或MPI库将图像识别算法的各个步骤并行化,例如将图像分割、特征提取、分类等步骤分配给不同的线程或进程。
三、性能分析和比较1. 实验数据:使用一组标准图像数据集进行实验,例如MNIST手写数字识别数据集。
2. 性能指标:比较串行和并行处理在图像识别任务中的运行时间、准确率等性能指标。
3. 结果分析:分析并行处理在图像识别任务中的性能提升,并探讨影响性能的因素。
实验结果:1. 并行处理在图像识别任务中显著提升了运行时间,尤其是在大规模数据集上。
2. 并行处理对准确率的影响较小,甚至略有提升。
并行计算实验报告

实验报告课程名称并行计算机体系结构实验名称并行计算机体系结构实验指导教师纪秋实验日期 _ 2011.4 ______学院计算机学院专业计算机科学与技术学生姓名 _______查隆冬_______ 班级/学号计科0804 /2008011183 成绩 ________ _________并行计算机体系结构实验报告⒈安装Mpich、配置文件、小组互相ping通网络的过程和指令(一)安装Mpich(1)本机插入MPICH光盘,双击桌面的计算机图标->CD-RW/DVD-ROM Drive图标;系统自动挂载cdrom到/media下。
(桌面出现新光盘图标XCAT-MPICH2.即挂载成功)(2)Cp /media/cdrecorder/mpich2-1.0.6.tar.gz /usr;本机拷贝mpich2-1.0.6.tar.gz到/usr目录下(3)Cd /usr ;进入usr目录下(4)Tar zxvf mpich2-1.0.6.tar.gz ;解压mpich2-1.0.6.tar.gz到当前目录(5)cd mpich2-1.0.6 ;进入mpich2-1.0.6目录(6)./configure –enable–f90 –prefix=/opt/mpich ;生成mpi的makefile 和设置mpich路径启用f90编译器(7)make ; 编译(8)make install ;将编译好的文件安装,安装结束后在/opt下生成mpich文件夹(9) which mpdboot ; 查找文件(二)配置环境变量(1)打开终端,输入 vi/etc/bashrc(2)在最后一行与倒数第2行之间输入(用insert键输入)export PATH=/opt/mpich/bin:$PATHexport PATH=/opt/intel/cc/10.0.026/bin:$PATHexport PATH=/opt/intel/fc/10.0.026/bin:$PATHexport LD_LIBRARY_PATH=/opt/intel/cc/10.0.026/lib:$LD_LIBRARY_PATH LD_LIBRARY_PATH=/opt/intel/fc/10.0.026/lib:$LD_LIBRARY_PATH按esc键退出;输入:wq (保存退出文件)cat /etc/bashrc ;查看文件(三)小组互相ping通网络的过程和指令(1)设置一个MPD节点配置文件在/root下新建 mpd.hosts文件,打开终端输入:cd /rootvim mpd.hosts ;使用vim文本编辑器(按insert键插入)s06 ;本机的主机号s02s12s17s18按esc键退出;按shift键和输入:wq (保存退出文件)cat /root/mpd.hosts ;查看文件(2)将主机名与相应的IP地址绑定打开终端输入:vi /etc/hosts (输入与保存退出步骤同上) 10.10.10.106 s0610.10.10.102 s0210.10.10.112 s1210.10.10.117 s1710.10.10.118 s18(3)设置两个MPD密码配置文件打开终端输入:(输入与保存退出步骤同上) cd /rootvi mpd.confMPD_SECRETWORD=123456cd /etcvi mpd.confMPD_SECRETWORD=123456(4)用绝对模式修改以下3个文件的权限打开终端输入:cd /etcls –l mpd.confchmod 600 mpd.conf ;修改该文件权限为本机可读、可写,同组和其他人没有任何权限cd /rootls –l mpd.confchmod 600 mpd.conf ;修改该文件权限为本机可读、可写,同组和其他人没有任何权限ls –l mpd.hostschmod 600 mpd.hosts ;修改该文件权限为本机可读、可写,同组和其他人没有任何权限(5)检查本组IP是否已互相连通打开终端输入:ping s02 ;s12、 s17 、s18 同上如连通,则输入ctrl+c 退出(6)启动参与与运算的节点1)首先启动本机mpdboot –n 1 –f mpd.hosts ;1为本机2)查看本机是否已启动s06 10.10.10.106若以启动则退出,输入:mpdallexit⒉编译pi.c小组并行计算π值。
MPI并行设计程序实验报告一:MPI简介对MPI的定义是多种多样的,但

MPI 并行设计程序实验报告:MPI 简介对MPI 的定义是多种多样的,但不外乎下面四个方面,它们限定了MPI 的内涵和外延:1、MPI是一个库,而不是一门语言。
许多人认为,MPI就是一种并行语言,这是不准确的。
但是,按照并行语言的分类,可以把FORTRAN+M或C+M P看作是一种在原来串行语言基础之上扩展后得到的,并行语言MPI库可以被FORTRAN77/C/Fortran90/C++调用,从语法上说,它遵守所有对库函数/过程的调用规则,和一般的函数/过程没有什么区别;2、MPI 是一种标准或规范的代表,而不特指某一个对它的具体实现,迄今为止,所有的并行计算机制造商都提供对MPI的支持,可以在网上免费得到MPI 在不同并行计算机上的实现,一个正确的MPI程序可以不加修改地在所有的并行机上运行;3、MPI 是一种消息传递编程模型,并成为这种编程模型的代表。
事实上,标准MPI虽然很庞大,但是它的最终目的是服务于进程间通信这一目标的;4、MPI是多点接口(Multi Poi nt In terface)的简称,是西门子公司开发的用于PLC之间通讯的保密的协议。
MPI通讯是当通信速率要求不高、通信数据量不大时,可以采用的一种简单经济的通讯方式。
MPI 通信可使用PLC S7-200/300/400 、操作面板TP/OP 及上位机MP l/PROFIBUS通信卡,女口CP 5512/C P5611/C P5613等进行数据交换。
MPI网络的通信速率为19.2Kbps~12Mbps最多可以连接32个节点,最大通讯距离为50m但是可能通过中断器来扩展长度。
:实验目的通过把几台电脑并行联立起来,共同去运行一个并行程序。
三:实验过程(1)虚拟机安装,可以选择VMware和VirtualPC,从网上可以下载(2) 基于虚拟机,配置多机网络环境(3) 安装MPICH从CBL网站下载,(4) 在虚拟上安装VC6.0(5) 并行程序设计(6) 编写实验报告实验步骤:1. 在每台电脑中创建一个用户iSii :虞来»锻闰计》机« 口甸哪円 起悔酣*協助的離戶K 名功阿InttrMi 槍Jiffi 警的 ffl 于启动逬轻仲J®用起厚的讣jSsOLOibumc SQLDtb^c^r ^SUF?DE1_J Cjt^Htustvfl Corpoif«2. 设置一个共享文件]二[新建丈件夹3. 在VC 中运行程序Xes»□碰)ff 勃匸二I~1'.11 WI IIUJIIB^h I MFiCHi[十J TDD0;lOAD[_「J share5ftfAdairtiiT ■^h41.pJbit I.^TUSajQMIOTl ^TTJdl_pXZDOIInt4TT*t 来3M 户 B 动rn ig4t 殊户Ihit vin aeeowi ii iL»d "b, 谨* -亍裤Ira 支勇的!I 廣.■晤H *. I .注■■严« ・P. IIMFHFH't»W4fW. <wbi wbi. |1. ■ e,ii・甲砂・■ bw..If, .“■4・ViH R IwLri r »h ■ ■■I耳1PH |・—H ■阳■■袖■ WU* W外■刪"I**.-1 t iM«d ■ i乂EfH**4.运行程序放入share中5.关闭防火墙翎能撥--------- !糜用!厂JJ 'm?™T Farr.ilT, . j6.然后映射网络驱动器,将两台pc机联机H F M r K 匡^IPt ;S ■二庄'■< 鼻.|I■^■■K* *^E=ijd=Kt□逅QJ I 耳成]| [ 取消I7.在程序中打开mpich的工具Ji WFICH”角Jumpih&t ►■1』Mil rb a管理工具►雇iBpdVser gui deMPICH Confi duration, toolWriCH Job m uiag;erMPICH Update toolMriHunriLteriLet Esjlarer□u.tl&«k Exp rsEiMindEE Media Flajner 8.工具配置■FICB ConfitraraticmH "厂 n ■ J:.i I 「\ ; . ! ;「r irJjc bftiftd eflaredoutput 卜二 ; Io 若口a i^la J ■口-Ltg I wi Ascl^i. s-LLopt IoiiimL c. Lc 匚■!nttwofk driv* n 丸pp 」坞 ot 『?_th* miTrfiTi 十 nircmb 由r 苧四:实验总结趣,在以后的学习中,我会更加努力的学习关于计算机的知识。
并行计算实验报告

学生实验报告书实验课程名称开课学院指导教师姓名学生姓名学生专业班级并行计算理学院余新华罗云信计1202班2014 2015学年第2 学期2、开机瞬间按F2,设定BIOS 从CD-ROM 启动系统。
保存设置后重启,则开机自动加载镜像。
班级 信计1202日期 2014.06.09 成绩评定姓名 rm —"罗云 实验室 数学207 老师签名学号 0121214410203实验 名称 所用软件 Linux 的安装与使用入门VMware workstati on实 验 目 的 及 内 容1、在虚拟机上实践Linux 系统的安装2、掌握linux 命令的使用入门linux 系统的安装1、 首先,下载一份CentOS 6.5的系统镜像文件,装进虚拟机的虚拟光驱。
赃■轴2 GB4 a 话疙汨 ZD GftCEm/DvD l :E£j正在便闺交件D :!3S^£^料由宮…T=^iM!E雅B 卡w±存阳旬盹蟲SIP :3、进入CentOS系统引导设置界面,语言、时区、网卡等使用默认选项。
调整分区时为linux系统分配/boot、/root、/home 禾口swap块,/boot 为弓I导区分配200MB左右即可,其他区块大小应根据需要事先规划好,如果分配的不合理也可以进入系统后使用fdisk命令进行调整。
Please Select A Qevlce11«K t^toLTC POiKi 1WEWkinwFflfTTHlIv 诃OKWp 旳 Et«wnIvnnC 139% 1mcE4 z■¥_WMP -Miap虬JKTfl 电Jwn»✓* Hurd Olvea*d«x w jbvazM97» v^stejcrptiy^ [屈 .Jrt*/R<5tf串kb系统安装形式选择Basic Serve ,以服务器的形式安 装即可。
并行计算实验报告

并行计算实验报告并行计算实验报告引言:并行计算是一种有效提高计算机性能的技术,它通过同时执行多个计算任务来加速计算过程。
在本次实验中,我们将探索并行计算的原理和应用,并通过实验验证其效果。
一、并行计算的原理并行计算是指将一个计算任务分成多个子任务,并通过多个处理器同时执行这些子任务,以提高计算速度。
其原理基于两个关键概念:任务划分和任务调度。
1. 任务划分任务划分是将一个大的计算任务划分成多个小的子任务的过程。
划分的目标是使得每个子任务的计算量尽可能均衡,并且可以并行执行。
常见的任务划分方法有数据划分和功能划分两种。
- 数据划分:将数据分成多个部分,每个处理器负责处理其中一部分数据。
这种划分适用于数据密集型的计算任务,如图像处理和大规模数据分析。
- 功能划分:将计算任务按照功能划分成多个子任务,每个处理器负责执行其中一个子任务。
这种划分适用于计算密集型的任务,如矩阵运算和模拟仿真。
2. 任务调度任务调度是将划分后的子任务分配给不同的处理器,并协调它们的执行顺序和通信。
任务调度的目标是最大程度地减少处理器之间的等待时间和通信开销,以提高整体计算效率。
二、并行计算的应用并行计算广泛应用于科学计算、大数据处理、人工智能等领域。
它可以加速计算过程,提高计算机系统的性能,并解决一些传统计算方法难以处理的问题。
1. 科学计算并行计算在科学计算中起到至关重要的作用。
例如,在天气预报模型中,通过将地球划分成多个网格,每个处理器负责计算其中一个网格的气象数据,可以加快模型的计算速度,提高预报准确性。
2. 大数据处理随着大数据时代的到来,传统的串行计算方法已经无法满足大规模数据的处理需求。
并行计算可以将大数据分成多个部分,通过多个处理器同时处理,提高数据的处理速度。
例如,谷歌的分布式文件系统和MapReduce框架就是基于并行计算的思想。
3. 人工智能人工智能算法通常需要大量的计算资源来进行模型训练和推理。
并行计算可以在多个处理器上同时执行算法的计算任务,加快模型的训练和推理速度。
并行计算实验报告

并行计算实验报告《并行计算实验报告》摘要:本实验报告旨在介绍并行计算的基本概念和原理,并通过实验结果展示并行计算在提高计算效率和性能方面的优势。
实验采用了不同的并行计算技术和工具,并对比了串行计算和并行计算的性能表现,以验证并行计算在处理大规模数据和复杂计算任务时的优越性。
1. 引言并行计算是一种利用多个处理器或计算节点同时进行计算任务的技术。
它可以显著提高计算效率和性能,特别是在处理大规模数据和复杂计算任务时。
本实验报告将通过一系列实验来展示并行计算的优势和应用场景。
2. 实验设计本次实验采用了多种并行计算技术和工具,包括MPI(Message Passing Interface)、OpenMP和CUDA。
实验分为两个部分:第一部分是对比串行计算和并行计算的性能表现,第二部分是针对特定应用场景的并行计算实验。
3. 实验结果在第一部分实验中,我们对比了串行计算和MPI并行计算的性能表现。
实验结果显示,随着计算规模的增加,MPI并行计算的性能优势逐渐显现,尤其在处理大规模数据时表现更为明显。
而在第二部分实验中,我们针对图像处理任务使用了OpenMP和CUDA进行并行计算,实验结果显示,这两种并行计算技术都能够显著提高图像处理的速度和效率。
4. 结论通过实验结果的对比和分析,我们可以得出结论:并行计算在处理大规模数据和复杂计算任务时具有明显的优势,能够显著提高计算效率和性能。
不同的并行计算技术和工具适用于不同的应用场景,选择合适的并行计算方案可以最大程度地发挥计算资源的潜力。
5. 展望未来,随着计算资源的不断增加和并行计算技术的不断发展,我们相信并行计算将在更多领域得到应用,为我们解决更多复杂的计算问题提供强大的支持和帮助。
综上所述,本实验报告通过实验结果展示了并行计算在提高计算效率和性能方面的优势,为并行计算技术的应用和发展提供了有力的支持和验证。
并行计算实验

并行计算实验报告学院软件学院年级2008级班级一班学号3007218144姓名赵立夫2010 年 3 月31 日实验一 多线程计算π及性能分析作者:赵立夫完成时间:3月31日一、 实验内容1. 掌握Thread 类用法2. 掌握java 多线程同步方法3. 使用多线程计算π;4. 对结果进行性能评价。
二、 实验原理使用积分方法,即计算π值,并使用java 多线程进行多线程操作。
三、 程序流程图N N i dx x N i 15.0141402102⨯⎪⎭⎫ ⎝⎛++≈+=∑⎰≤≤π图1-1 主线程流程图四、实现方法1.方法简述:本程序使用java多线程方法:首先启动主进程,输入基数N和线程数threadNum;第二步,通过主进程创建子进程并为每个子进程分配计算任务;第三步,子进程执行计算认为并将结果返回到数组sums[]中;最后,主进程将sums[]元素进行累加得到最终结果并输出。
2.程序的主要方法PaiThread类,实现计算指定区间内的累加和threadHandle.start()启动子线程,子线程将自动执run()方法threadHandle.join()确保主进程在所有子进程计算完毕后执行后续任务。
五、实验结果1.实验结果数据表编号计算基数子线程数计算结果使用时间1 1000000 0 3.1415946535889754 36ms2 1000000 2 3.1415946535889017 26ms3 1000000 3 3.141594653588898 22ms4 1000000 4 3.141594653588918 25ms5 1000000 5 3.141594653588914 26ms6 100000 3 3.141612653498134 14ms7 10000000 3 3.141592853589695 80ms2.部分结果截图图1-2 单线程pai计算结果图图1-3多线程pai计算结果图3.理论性能及实际结果分析编号子线程数(不包括主线程)计算结果使用时间加速比1 0 3.1415946535889754 36ms 1.02 2 3.1415946535889017 26ms 1.383 3 3.141594653588898 22ms 1.644 4 3.141594653588918 25ms 1.445 5 3.141594653588914 26ms 1.38本程序使用多线程方法来提升程序的执行速度,所以当线程数不断增多时,程序运行时间应逐渐减少;再考虑到创建进程和信息传递的开销,当线程数大于计算机的内核数量时,程序运行时间应该随着线程数目的增加而增加。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
江苏科技大学计算机科学与工程学院实验报告实验名称:Java多线程编程学号:姓名:班级:完成日期:2014年04月22日1.1 实验目的(1) 掌握多线程编程的特点;(2) 了解线程的调度和执行过程;(3)掌握资源共享访问的实现方法。
1.2 知识要点1.2.1线程的概念(1)线程是程序中的一个执行流,多线程则指多个执行流;(2)线程是比进程更小的执行单位,一个进程包括多个线程;(3)Java语言中线程包括3部分:虚拟CPU、该CPU执行的代码及代码所操作的数据。
(4)Java代码可以为不同线程共享,数据也可以为不同线程共享;1.2.2 线程的创建(1) 方式1:实现Runnable接口Thread类使用一个实现Runnable接口的实例对象作为其构造方法的参数,该对象提供了run方法,启动Thread将执行该run方法;(2)方式2:继承Thread类重写Thread类的run方法;1.2.3 线程的调度(1) 线程的优先级●取值范围1~10,在Thread类提供了3个常量,MIN_PRIORITY=1、MAX_PRIORITY=10、NORM_PRIORITY=5;●用setPriority()设置线程优先级,用getPriority()获取线程优先级;●子线程继承父线程的优先级,主线程具有正常优先级。
(2) 线程的调度:采用抢占式调度策略,高优先级的线程优先执行,在Java中,系统按照优先级的级别设置不同的等待队列。
1.2.4 线程的状态与生命周期说明:新创建的线程处于“新建状态”,必须通过执行start()方法,让其进入到“就绪状态”,处于就绪状态的线程才有机会得到调度执行。
线程在运行时也可能因资源等待或主动睡眠而放弃运行,进入“阻塞状态”,线程执行完毕,或主动执行stop方法将进入“终止状态”。
1.2.5 线程的同步--解决资源访问冲突问题(1) 对象的加锁所有被共享访问的数据及访问代码必须作为临界区,用synchronized加锁。
对象的同步代码的执行过程如图14-2所示。
synchronized关键字的使用方法有两种:●用在对象前面限制一段代码的执行,表示执行该段代码必须取得对象锁。
●在方法前面,表示该方法为同步方法,执行该方法必须取得对象锁。
(2) wait()和notify()方法用于解决多线程中对资源的访问控制问题。
●wait()方法:释放对象锁,将线程进入等待唤醒队列;●notify()方法:唤醒等待资源锁的线程,让其进入对象锁的获取等待队列。
(3)避免死锁指多个线程相互等待对方释放持有的锁,并且在得到对方锁之前不会释放自己的锁。
1.3 上机测试下列程序样例1:利用多线程编程编写一个龟兔赛跑程序。
乌龟:速度慢,休息时间短;兔子:速度快,休息时间长;【参考程序1】字符方式下实现方案class Animal extends Thread {int speed; //速度public Animal( String str,int speed) {super(str); //线程名用动物名代表this.speed=speed;}public void run() {int distance=0;int sleepTime;while (distance<=1000) {System.out.println(getName()+"is at"+distance);try {distance+=speed; //每次跑的距离简单用速度计算sleepTime=(int)( speed+Math.random()*speed); //速度快休息时间要长sleep(sleepTime);} catch (InterruptedException e) {}}}}public class Race {public static void main(String arg[]) {Animal a1, a2;a1=new Animal("rabit",100);a2=new Animal("turtle",20);a2.setPriority(Thread.MAX_PRIORITY); //让乌龟的运行优先级更高a1.start();a2.start();}}【编程技巧】(1)速度快,跑的距离增加也快,这里简单地将速度加到距离上,未考虑跑的时间;(2)为了让乌龟得到更多的运行机会,采取两项措施,一让线程的睡眠时间与速度成正比,二是让乌龟得到更高的优先级。
【参考程序2】—图形方式下,图14-3为程序的运行演示。
public class runner extends Applet implements Runnable {int BeginX=10,EndX=200; //起点和终点的x坐标int RabbitX = BeginX,RabbitY=100; //兔子的起点int TortoiseX=BeginX, TortoiseY=200; //乌龟的起点int RabbitRestTime=800,TortoiseRestTime=50; //各自休息时间int RabbitSpeed=15,TortoiseSpeed=1; //各自速度int state=0; //比赛状态, 0代表比赛进行中,1代表兔子赢,2代表乌龟赢Thread rabbit;Thread tortoise;public void init() {rabbit = new Thread(this,"rabbit"); //创建名为rabit的线程tortoise = new Thread(this,"tortoise"); //创建名为tortoise的线程}public void paint(Graphics g) {g.drawString("龟",TortoiseX,TortoiseY);g.drawString("兔",RabbitX,RabbitY);g.setColor(Color.red);for(int j=70;j<=230;j+=10) g.drawString("|",EndX+8,j); //绘制终点线g.setColor(Color.black);if(state==1) g.drawString("兔子赢了!!",250,300);else if(state==2) g.drawString("乌龟赢了!!",250,300);}public void start() {rabbit.start();tortoise.start();}public void run() {String currentRunning;while (state==0) {currentRunning=Thread.currentThread().getName();//得到当前线程的名程if(currentRunning.equals("rabbit")) { //是兔子try{Thread.sleep((int)(Math.random()*RabbitRestTime));}catch(InterruptedException e){ }RabbitX+=RabbitSpeed;if(RabbitX>EndX) RabbitX=EndX;}else if(currentRunning.equals("tortoise")) { //是乌龟try{Thread.sleep((int)(Math.random()*TortoiseRestTime));}catch(InterruptedException e){ }TortoiseX+=TortoiseSpeed;if(TortoiseX > EndX) TortoiseX=EndX;}if (RabbitX == EndX) state=1;else if ( TortoiseX == EndX) state=2;repaint();}}}【编程技巧】(1)创建两个代表兔子和乌龟的线程,根据线程名决定各自的速度和休息时间。
(2)根据是否到达终点决定state值的变化;(3)线程的run方法内的循环条件是state值为0。
样例2:编写选号程序,在窗体中安排6个标签,每个标签上显示0~9之间的一位数字,每位数字用一个线程控制其变化,点击“停止”按钮则所有标签数字停止变化。
【参考程序】import java.awt.*;import java.awt.event.*;public class MyFrame extends Frame{MyLabel x[]=new MyLabel[6]; //安排6个标签,每个标签显示1个数字Button control;public MyFrame(String title) {super(title);Panel disp=new Panel();disp.setLayout(new FlowLayout());for (int i=0;i<6;i++ ) {x[i]=new MyLabel();disp.add(x[i]);new Thread(x[i]).start();}add("Center",disp);control=new Button("停止");add("North",control);pack();setVisible(true);control.addActionListener(new ActionListener(){public void actionPerformed(ActionEvent e) {for(int i=0;i<6;i++)x[i].stop=true;}});}public static void main(String args[]) {new MyFrame("Test");}class MyLabel extends Label implements Runnable{int value;boolean stop=false;public MyLabel(){super("number");value=0;}public void run() {for (; ; ) {value=(int)(Math.random()*10); //产生一个0到9的数字setText(Integer.toString(value));try {Thread.sleep(500);}catch (InterruptedException e) { }if (stop) //停止标记为true,退出循环,结束运行break;}}}}【编程技巧】(1) 将每个标签定义为线程方式运行,在运行中利用随机数产生数字显示。