xml学习笔记
学习笔记

Android开发流程:应用规划:※确定功能。
※必须的界面及界面跳转的流程。
※需要的数据及数据的来源及格式。
※是否需要服务端支持。
※是否需要本地数据库支持。
※是否需要特殊权限。
※是否需要后台服务。
二架构设计:※分层。
※网络连接。
※数据处理-xml、domain。
※封装Activity。
三界面设计:※主界面确定。
※模块界面、列表、查看、编辑界面。
※菜单、按钮、对话框、提示信息。
※界面总体颜色。
四数据操作和存储:※数据来源。
※数据类型。
※存储方式。
五业务实现:※客户端业务解析。
六页面跳转:※每个页面间的跳转。
※菜单、按钮、事件等。
贪心算法当然也有正确的时候。
求最小生成树的Prim算法和Kruskal算法都是漂亮的贪心算法。
贪心法的应用算法有Dijkstra的单源最短路径和Chvatal的贪心集合覆盖启发式所以需要说明的是,贪心算法可以与随机化算法一起使用,具体的例子就不再多举了。
其实很多的智能算法(也叫启发式算法),本质上就是贪心算法和随机化算法结合——这样的算法结果虽然也是局部最优解,但是比单纯的贪心算法更靠近了最优解。
例如遗传算法,模拟退火算法。
MATLAB中四个取整函数具体使用方法如下:Matlab取整函数有: fix, floor, ceil, round.fix朝零方向取整,如fix(-1.3)=-1; fix(1.3)=1;floor朝负无穷方向取整,如floor(-1.3)=-2; floor(1.3)=1;ceil朝正无穷方向取整,如ceil(-1.3)=-1; ceil(1.3)=2;round四舍五入到最近的整数,如round(-1.3)=-1;round(-1.52)=-2;round(1.3)=1;round(1.52)=2。
Matlab中的用法:intersect:取交集,/intersect.htmlunique:取各自独立的部分,/unique.htmlunion:取并集(当然,去了冗余),/union.html拟合以及插值还有逼近是数值分析的三大基础工具,通俗意义上它们的区别在于:拟合是已知点列,从整体上靠近它们,插值是已知点列并且完全经过点列;逼近是已知曲线,或者点列,通过逼近使得构造的函数无限靠近它们。
XML 元素介绍

XML 元素介绍元素标识命名的信息节,并使用标记构建标识元素的名称、开始和结束。
元素还可以包含属性名称和值,用于提供有关内容的其他信息,并指出了这些信息的逻辑结构。
1、定义元素元素是以树形分层结构排列的,它可以嵌套在其他元素中。
在XML 文档中,元素也分为非空元素和空元素两种类型。
一个XML 非空元素是由开始标记、结束标记以及标记之间的数据构成的。
开始标记和结束标记用来描述标记之间的数据。
就是一个非空元素,如果把非空元素的文本内容转换为空元素的属性,那么转换后的空元素可以写为<hello content="下午好"></hello>。
2、XML 元素特性元素是对XML 文档数据内容的容器,它代表的是一些离散的对象,因此,对元素特性的了解有助于对XML 文档语法的理解。
本部分内容将通过以下两个特性来系统地掌握XML 元素。
(1)XML 元素的可扩展性XML 文档可以被扩展携带更多的信息。
这些信息可以由用户自定义元素来表对于非空元素,开始标记和结束标记必须成对出现,且大小写一致。
无论用户编写什么内容的XML文件,只要编写的XML文件遵守XML文档的语法格式,那么应用程序就能够正确解读XML文件中所包含的信息。
(2)XML元素的关联性XML元素是相互关联的,除根元素外,其他元素之间都是父元素与子元素的关系。
这种关联性使相关信息构成层次结构,具体实例如下所示:上述代码保存为school.xml文件中。
该文件描述了一个学校情况。
根元素为sc hool,schoole元素的子元素为若干个grade元素;而grade元素的子元素为若干个c lass元素;而class元素的子元素是若干个teachers和students元素;通过元素之间关联关系来描述显示世界中的关系。
2、XML元素命名规则XML元素命名规则与Java、C等命名规则类似,它也是一种对大小写敏感的语言。
XML学习资料

XML什么是XML可扩展标记语言(extensible markup language,XML)·标记语言:用某种“记号”来表示某种特殊信息的语言,它是一套标记符号和相关语法的集合·两类标记语言:①专用标记语言:基于特殊用途的需要,被某一种或者几种应用软件所支持来表示某种特殊信息;HTML:应用在WWW上面的网页,其重点在于信息的显示②通用标记语言:不针对某一特殊应用,只是用来描述数据的内容和结构,即(元标记语言),为不同应用提供数据交流的平台。
SGML:标准通用标记语言,由于其复杂,很难编写解释器,在其规范上,出于易用性考虑,发展了XMLXML( eXtensible Markup Language,可扩展标记语言)可以定义自己的一组标签使人们或程序能够理解这些标签XML、SGML、HTML的关系XML与SGML、HTML的关系:⑴SGML是所有标记语言的母语言,HTML和XML都派生自SGML;⑵XML从根本上讲就是SGML的一个子集,而HTML是SGML定义的一种应用;⑶HTML只是一个有限标记集合,不能自定义扩展,仅作为一种数据表示技术,不能揭示数据的含义;XML的特性XML的核心是数据:在XML中数据与样式分离,提高XML文档的利用率以及数据容量与质量XML数据自我描述性用户可以自己定义标记的名称XML支持Unicode字符集它允许使用双字节的字符来定义标记和编写程序,可以很方便使用中文来命名XML文档中的元素和属性,具有可读性。
XML不仅仅作一个记录数据的数据格式,常与以下技术结合使用。
①DTD(文档类型定义):为XML文档提供元素、属性、顺序等规则,根据DTD来验证文档是否合法;②DOM(文档对象模型):为应用程序提供相应处理文档的接口③CSS(层叠样式表):为元素指定显示格式④XSL(可扩展样式语言)元素和标记XML文档由元素构成,每个元素由开始标记和结束标记组成,或者表示为空元素标记。
XML从入门到深入(超详细)

XML从⼊门到深⼊(超详细)⼀:什么是XML XML (eXtensible Markup Language)指可扩展标记语⾔,标准通⽤标记语⾔的⼦集,简称XML。
是⼀种⽤于标记电⼦⽂件使其具有结构性的标记语⾔。
XML可以标记数据、定义数据类型,可以允许⽤户对⾃⼰标记语⾔进⾏⾃定义,是对⼈和机器都⽐较友好的数据承载⽅式;XML其前⾝是SGML(标准通⽤标记语⾔)。
传统的系统已经远远不⾜以来表达复杂的信息,简单的语⾔根本⽆法表达出⼀些细微的差别,需要更完整的语⾔来表达⽹络世界⾥⽇益丰富复杂的信息内涵 XML - 可扩展标记语⾔便由此诞⽣,它不像HTML追求美观的效果,⽽不重视实际交流应⽤现象,所以XML语⾔的出现核⼼是⽤来展⽰及数据的交互,它的出现把⽹络表达的语⾔集合推进了⼀⼤步,XML传递信息,具有跨平台的特性(如:WebService)它作为数据交互和⽹络计算基础,尤其是在电⼦商务应⽤上的出⾊表现,现在已经没⼈怀疑它给信息社会带来的⾰命性影响(随着2021的到来JSON也是⼀个不错的选择)<?xml version="1.0" encoding="UTF-8" standalone="yes" ?><Students><Student><name>蚂蚁⼩哥</name><address>安徽六安</address></Student><Student><name>欧阳康康</name><address>安徽六安</address></Student></Students>1:编写XML注意事项①:XML 中的每个元素都是成对出现的,有开始和结束,⾃闭和标签除外,但是都得有 '/'结束标志如:<student>xxxxx</student> ⾃闭和:<student name='xxx' />②:每个XML⽂档都有且只有⼀个根元素(Root Element)③:XML标签对⼤⼩写敏感④:XML必须正确嵌套⑤:同级标签以所缩进对齐⑥:元素名称可以包含字母,数字,但不能以数字开头⑦:元素名称中不能含有空格或者 ' : '号⑧:如出现特殊字符需要转义如:<,>,",',&....2:使⽤XML的优缺点优点:①:XML是使⽤信息⾃描述的新语⾔(没有约束的情况下)②:信息共享(⾃定义数据格式,⽽且很容易使⽤⼯具读写)③:数据传递(⽀持各种通道传递数据,如WebService就使⽤XML传输数据)④:数据重⽤、分离数据和显⽰、⽂档包含语义、⽅便阅读有⾯向对象的树形结构缺点:①:数据量⼤是传输效果不好,因为XML定义了和数据⽆关的标签3:XML基本语法第⼀⾏必须是XML的声明<?xml ?>version:xml的版本,必须设定,当前只有'1.0'版本encoding:当前xml⾥⾯的数据格式,默认UTF-8standalone:标记是否是⼀个独⽴的xml,默认yes如果设置 no 表⽰这个XML不是独⽴的⽽是依赖于外部的DTD约束⽂件(后⾯说)<?xml version="1.0" encoding="UTF-8" standalone="yes" ?><Students><Student><name>蚂蚁⼩哥</name><address>安徽六安</address></Student></Students>⼆:XML专⽤标记 XML其实是有专⽤的标记,也可以理解是XML的基本语法,但是这些语法你在看HTML语法时也看到过,因它们都属于⼀个⼤家族,只是应⽤的⽅向不⼀样⽽导致的差异有部分不⼀样1:XML注释 语法:<!-- 这是⼀个注释 --><?xml version="1.0" encoding="UTF-8" standalone="yes" ?><School><!--定义学⽣对象这是⼀个注释--><Student id="st01" name="张三" age="23"/></School>①:注释⾥的内容不要出现 --②:不要把注释写在元素中间如<Student <!--这⾥注释报错--> ></Student>③:注释不可嵌套2:XML处理PI指令 其实XML⾥的PI指令⼤家可以理解为XML设置样式的,但是考虑到XML是⽤于存储数据的载体,所以这个指令⽤的也不多 语法:<?⽬标指令?> 如引⼊CSS样式:<?xml-stylesheet type='css类型' href='引⼊css样式地址'> CSS类型可以设置 type='text/css' type='text/xsl'<?xml version="1.0" encoding="UTF-8" standalone="yes" ?><!--引⼊PI指令注意只能放在头部并引⼊style.css样式--><?xml-stylesheet type='text/css' href='./style.css' ?><School><!--定义学⽣对象这是⼀个注释--><Student><name>蚂蚁⼩哥</name></Student></School><!--CSS样式-->name {font: normal 500 22px "微软雅⿊";color:#f69;}3:XML之CDATA节 ⽤于把整段⽂本解析为纯字符串数据⽽不是标记的情况,其实包含在CDATA节中的特殊字符<、>、&都会当作字符展⽰<?xml version="1.0" encoding="UTF-8" standalone="yes" ?><School><!--定义学⽣对象这是⼀个注释--><Student><!--使⽤<![CDATA[xxx]]>可以把特殊字符当作⽂本--><name><![CDATA[我是⼀个"⽂本":想不到把]]></name></Student></School> 那么问题来的,如果我不使⽤CDATA节包裹的话在⽂本区域输⼊<,>等就会和关键字符冲突,我们需要使⽤转义<?xml version="1.0" encoding="UTF-8" standalone="yes" ?><School><!--定义学⽣对象这是⼀个注释--><Student><!--这⾥的蚂蚁⼩< > 哥报错 <>⼲扰,我们要使⽤转义--><!--<name>蚂蚁⼩<>哥</name>--><name>蚂蚁⼩<>哥</name></Student></School><!--常⽤⽹页转义字符 xml也可以使⽤--><!--显⽰结果描述实体名称实体编号空格  < ⼩于号 < <> ⼤于号 > >& 和号 & &" 引号 " "' 撇号 '(IE不⽀持) '¢分 ¢ ¢£ 镑 £ £¥ ⽇圆 ¥ ¥§ 节 § §© 版权 © ©® 注册商标 ® ®× 乘号 × ×÷ 除号 ÷ ÷-->XML中转义字符的使⽤三:核⼼DTD语法约束1:什么是DTD,为什么使⽤DTD DTD是⽂档类型定义(Document Type Definiyion),它是⽤来描述XML⽂档结构,⼀个DTD⽂档会包含如下内容:元素(ELEMENT):的定义规则,描述元素之间的关系规则属性(ATTLIST):的定义规则,可以定义具体的标签内部属性为什么使⽤DTD:①:DTD⽂档与XML⽂档实例关系如类与对象关系②:有了DTD,每个XML⽂件可以携带⼀个⾃⾝格式描述③:有了DTD,不同组织的⼈可以使⽤⼀个通⽤DTD来交换数据④:应⽤程序可以使⽤⼀个标准的DTD校验从外部世界接受来的XML是否是⼀个有效标准XML⑤:可以使⽤DTD校验⾃⼰的XML数据2:DTD定义⽂档规则(DOCTYPE)DTD⽂档的声明及引⽤有三种:内部DTD⽂档:<!DOCTYPE 根元素[定义元素属性等等内容]>外部DTD⽂档:<!DOCTYPE 根元素 SYSTEM 'DTD⽂件路径'>内外部DTD⽂档结合:<!DOCTYPE 根元素 SYSTEM 'DTD⽂件路径'[定义元素属性等等内容]><?xml version="1.0" encoding="UTF-8" standalone="yes" ?><!--注:此时我这⾥⾯的 ELEMENT 定义元素的我后⾯介绍--><!DOCTYPE Student[<!ELEMENT Student (name)><!ELEMENT name (#PCDATA)>]><Student><name>蚂蚁⼩哥</name></Student>内部定义DTD⽂档<?xml version="1.0" encoding="UTF-8" standalone="yes" ?><!DOCTYPE Student SYSTEM './st.dtd'><Student><name>蚂蚁⼩哥</name></Student><!--下⾯是⽂件 st.dtd--><!DOCTYPE Student[<!ELEMENT Student (name)><!ELEMENT name (#PCDATA)>]>外部定义DTD⽂档<?xml version="1.0" encoding="UTF-8" standalone="yes" ?><!DOCTYPE Student SYSTEM './st.dtd'[<!ELEMENT Student (name,age,sex)><!ELEMENT sex (#PCDATA)>]><Student><name>蚂蚁⼩哥</name><age>23</age><sex>男</sex></Student><!--外部引⽤的st.dtd⽂件--><?xml version="1.0" encoding="UTF-8" ?><!--这⾥不能写DOCTYPE,因为这个可以当作元素引⽤,具体规则在上⾯定义--><!ELEMENT name (#PCDATA)><!ELEMENT age (#PCDATA)>内外部定义DTD⽂档3:DTD元素的定义(ELEMENT)语法:<!ELEMENT 元素名称(NAME) 元素类型(COUTENT)>注:ELEMENT关键字元素名称:就是⾃定义的⼦标签名称元素类型:EMPTY:该元素不能包含⼦元素和⽂本,但是可以有属性,这类元素称为⾃闭和标签ANY:该元素可以包含任意在DTD中定义的元素内容#PCDATA:可以包含任何字符数据,设置这个就不能包含⼦元素了,⼀般设置具体value混合元素类型:只包含⼦元素,并且这些⼦元素没有⽂本混合类型:包含⼦元素和⽂本数据混合体<!-- 定义空元素EMPTY --><?xml version="1.0" encoding="UTF-8" standalone="yes" ?><!DOCTYPE Student[<!ELEMENT Student EMPTY>]><!--约束为空元素所以写成⾃闭和标签,--><Student/><!-- 定义组合元素(student,teacher)并为每个元素设置类型(#PCDATA) --><?xml version="1.0" encoding="UTF-8" standalone="yes" ?><!DOCTYPE School[<!ELEMENT School (student,teacher)><!ELEMENT student (#PCDATA)><!ELEMENT teacher (#PCDATA)>]><School><student>我是学⽣</student><teacher>我是⽼师</teacher></School><!-- 设置任意元素ANY 虽然student元素内部没有再设置元素⽽设置ANY,那我就可以在编写任意⼦元素,前提在⾥⾯有定义 --><?xml version="1.0" encoding="UTF-8" standalone="yes" ?><!DOCTYPE School[<!ELEMENT School (student)><!ELEMENT student ANY><!ELEMENT name (#PCDATA)><!ELEMENT address (#PCDATA)>]><School><student><name>蚂蚁⼩哥</name><address>安徽六安</address></student></School><!-- 元素组合及混合,可以使⽤通配符 --><?xml version="1.0" encoding="UTF-8" standalone="yes" ?><!DOCTYPE School[<!ELEMENT School (student*,teacher?)><!ELEMENT student (#PCDATA)><!ELEMENT teacher (#PCDATA)>]><School><student>我是学⽣A</student><student>我是学⽣B</student></School>DTD元素定义具体代码通配符:() ⽤来元素分组如:(a|b|c),(d,e),f 分三组| 在列表中选⼀个如(a|b)只能选⼀个表⽰a|b必须出现并⼆选⼀+ 该对象⾄少出现⼀次或多次如(a+) 该元素可以出现多次* 该对象允许出现0次到多次如(a*) 该元素可以不出现或出现多次表⽰可出现⼀次或者不出现(a?) a可以出现,或者不出现, 常⽤按照顺序出现(a,b,c) 表⽰依次a,b,c4:DTD属性的定义(ATTLIST)语法:<!ATTLIST 元素名称属性名称类型属性特点>元素名称:我们⾃定义的元素名称属性类型:我们为元素上添加⾃定义属性类型:CDATA:任意字符(理解为任意字符的字符串)ID:以字母开头唯⼀值字符串,IDREF/IDREFS:可以指向⽂档中其它地⽅声明的ID类型值(设置此值是可以在⽂档上存在的)使⽤IDREFS时可以使⽤空格隔开NMTOKEN/NMTOKENS:NMTOKEN是CDATA的⼀个⼦集,设置该属性时只能写英⽂字母、数字、句号、破折号下划线、冒号,但是属性值⾥⾯不能有空格 NMTOKENS:它是复数,如果设置多个值由空格隔开 Enumerated: 事先定义好⼀些值,属性的值必须在所列出的值范围内属性特点:#REQUIRED表⽰必须设置此属性#IMPLIED表⽰此属性可写可不写#FIXED value表⽰元素实例中该属性的值必须是指定的固定值#Default value为属性提供⼀个默认值<!-- 第⼀种写法 --><?xml version="1.0" encoding="UTF-8" standalone="yes" ?><!DOCTYPE School[<!ELEMENT School (student*)><!ELEMENT student EMPTY><!--定义了⼀个id属性类型为ID 必须值--><!ATTLIST student id ID #REQUIRED><!--设置了name属性为任意字符的字符串必须值--><!ATTLIST student name CDATA #REQUIRED ><!--设置address 类型为多个常规字符串且不需要⼀定存在此属性--><!ATTLIST student address NMTOKENS #IMPLIED><!--设置srcID 该属性的值只能从id上⾯上取--><!ATTLIST student srcID IDREFS #IMPLIED>]><School><student id="st001" name="蚂蚁⼩哥"/><student id="st002" name="欧阳;*)*^%$:⼩⼩" address="安徽_六安安徽_合肥"/><student id="st003" name="许龄⽉" srcID="st001 st002"/></School><!-- 第⼆种写法 --><?xml version="1.0" encoding="UTF-8" standalone="yes" ?><!DOCTYPE School[<!ELEMENT School (student*)><!ELEMENT student EMPTY><!--简便写法,全部放在⼀起写--><!--设置了name属性为任意字符的字符串不⼀定要设置此属性,但是设置必须按照指定的值--> <!ATTLIST studentid ID #REQUIREDname CDATA #FIXED '我们名字都⼀样'address CDATA '默认都是安徽'sex (男|⼥) #REQUIRED>]><School><student id="st001" sex="男" name="我们名字都⼀样"/><student id="st002" sex="⼥"/><student id="st003" sex="男" name="我们名字都⼀样"/></School>DTD的属性定义具体代码5:DTD实体定义(ENTITY)实体分类:普通内部实体,普通外部实体,内部参数实体,外部参数实体语法:普通内部实体定义:<!ENTITY 实体名 "实体值">普通外部实体引⼊:<!ENTITY 实体名 SYSTEM "URI/URL">内部参数实体定义:<!ENTITY % 实体名 "实体值">外部参数实体引⼊:<!ENTITY % 实体名 SYSTEM "URI/URL">⽰例定义:<!ENTITY name "蚂蚁⼩哥"><!ENTITY address "安徽六安">⽰例XML⾥使⽤:<name>&name;</name>使⽤范围:定义实体分为内部实体(定义在当前xml⽂件)和外部实体(定义在外部dtd⽂件⾥)<!-- 内部普通实体 --><?xml version="1.0" encoding="UTF-8" standalone="yes" ?><!DOCTYPE Student[<!ELEMENT Student (name,address)><!ELEMENT name (#PCDATA)><!ELEMENT address (#PCDATA)><!ENTITY name "蚂蚁⼩哥"><!ENTITY address "安徽六安">]><Student><name>&name;</name><address>&address;</address></Student>DTD实体定义代码6:使⽤命名空间(Namespace) 避免元素名冲突,使⽤URL作为XML的Namespaces(这样也有约束和提⽰好处) 语法:xmlns:[prefix]="URL" 元素和属性都可以应⽤命名空间 XML的元素名是不固定的,当两个不同类型的⽂档使⽤同样的名称描述两个不同类型的元素的时候就会出现命名冲突<?xml version="1.0" encoding="UTF-8" standalone="yes" ?><h:table xmlns:h="/1999/xhtml"><h:tr><h:td>名称A</h:td><h:td>名称B</h:td></h:tr></h:table>四:核⼼Schema语法约束1:什么是XML Schema XML Schema描述了XML⽂档的结构。
fastxml简单常用注解学习笔记

fastxml简单常⽤注解学习笔记fastxml 简单常⽤注解学习笔记@JsonNaming@JsonIgnoreProperties@JsonIgnore@JsonFormat@JsonDeserialize@JsonSerialize@JsonProperty如下User类package oft;import com.fasterxml.jackson.annotation.JsonFormat;import com.fasterxml.jackson.annotation.JsonIgnore;import com.fasterxml.jackson.annotation.JsonIgnoreProperties;import com.fasterxml.jackson.annotation.JsonProperty;import com.fasterxml.jackson.databind.PropertyNamingStrategy;import com.fasterxml.jackson.databind.annotation.JsonDeserialize;import com.fasterxml.jackson.databind.annotation.JsonNaming;import com.fasterxml.jackson.databind.annotation.JsonSerialize;import java.math.BigDecimal;import java.util.Date;/*** Created by xinxingegeya on 2015/3/7.*/@JsonNaming(PropertyNamingStrategy.LowerCaseWithUnderscoresStrategy.class)@JsonIgnoreProperties(value = {"enabled", "age", "bigDecimal"}, ignoreUnknown = true)public class User {private String username;@JsonIgnoreprivate String passwd;@JsonFormat(pattern = "yyyy-MM-dd")@JsonDeserialize(using = CustomDateDeserialize.class)private Date createDate;private boolean enabled;private int age;private BigDecimal bigDecimal;@JsonSerialize(using = CustomDoubleSerialize.class)private double helloDouble;// 该属性没有setter和getter⽅法,如果想要序列化必须标注该注解@JsonProperty(value = "belong_to_role")private boolean belongToRole = false;public double getHelloDouble() {return helloDouble;}public void setHelloDouble(double helloDouble) {this.helloDouble = helloDouble;}public String getUsername() {return username;}public void setUsername(String username) {ername = username;}public String getPasswd() {return passwd;}public void setPasswd(String passwd) {this.passwd = passwd;}public Date getCreateDate() {return createDate;}public void setCreateDate(Date createDate) {this.createDate = createDate;}public boolean isEnabled() {return enabled;}public void setEnabled(boolean enabled) {this.enabled = enabled;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public BigDecimal getBigDecimal() {return bigDecimal;}public void setBigDecimal(BigDecimal bigDecimal) {this.bigDecimal = bigDecimal;}}相关的类package oft;import com.fasterxml.jackson.core.JsonParser;import com.fasterxml.jackson.databind.DeserializationContext;import com.fasterxml.jackson.databind.JsonDeserializer;import java.io.IOException;import java.text.ParseException;import java.text.SimpleDateFormat;import java.util.Date;public class CustomDateDeserialize extends JsonDeserializer<Date> {private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");@Overridepublic Date deserialize(JsonParser jp, DeserializationContext ctxt) throws IOException { Date date = null;try {date = sdf.parse(jp.getText());} catch (ParseException e) {e.printStackTrace();}return date;}}package oft;import com.fasterxml.jackson.core.JsonGenerator;import com.fasterxml.jackson.databind.JsonSerializer;import com.fasterxml.jackson.databind.SerializerProvider;import java.io.IOException;import java.text.DecimalFormat;public class CustomDoubleSerialize extends JsonSerializer<Double> {private DecimalFormat df = new DecimalFormat("##.00");@Overridepublic void serialize(Double value, JsonGenerator jgen,SerializerProvider provider) throws IOException {jgen.writeString(df.format(value));}}测试类,package oft;import org.junit.Test;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.math.BigDecimal;import java.util.Date;/*** Created by xinxingegeya on 2015/3/7.*/public class TestJson {private static final JsonMapper mapper = new JsonMapper();private static Logger logger = LoggerFactory.getLogger(TestJson.class);/*** fastxml序列化json*/@Testpublic void test76() {User user = new User();user.setAge(19);user.setBigDecimal(new BigDecimal(12));user.setCreateDate(new Date());user.setEnabled(true);user.setPasswd("122");user.setUsername("admin");user.setHelloDouble(3.1);String json = mapper.toJson(user);(json);}@Testpublic void testu68() {String helloJson = "{\"username\":\"admin\",\"passwd\":\"122\",\"createDate\":\"2015-03-07 13:25:47\",\"birthday\":\"2015-03-07 13:25:47\"}"; User user = mapper.fromJson(helloJson, User.class);(user.toString());(user.getCreateDate().toString());}}最后附上⼀个Json序列化的⼯具类,该⼯具类是从springside项⽬中拿来的。
XML文件基本操作

XML:Extensible Markup Language(可扩展标记语言)的缩写,是用来定义其它语言的一种元语言,其前身是SGML(Standard GeneralizedMarkup Language,标准通用标记语言)。
它没有标签集(tag set),也没有语法规则(grammatical rule),但是它有句法规则(syntax rule)。
任何XML文档对任何类型的应用以及正确的解析都必须是良构的(well-formed),即每一个打开的标签都必须有匹配的结束标签,不得含有次序颠倒的标签,并且在语句构成上应符合技术规范的要求。
XML文档可以是有效的(valid),但并非一定要求有效。
所谓有效文档是指其符合其文档类型定义(DTD)的文档。
如果一个文档符合一个模式(schema)的规定,那么这个文档是"模式有效的(schema valid)"。
XML文件在存储、交换和传输数据信息上有着很方便处理,那么今天这篇文章主要讲一下用C#如何实现对XML文件的基本操作,如:创建xml文件,增、删、改、查xml的节点信息。
所使用的方法很基础,方便易懂(用于自己的学习和记忆只需,同时也希望能够给你带来一些帮助,如有不合适的地方欢迎大家批评指正)。
本文的主要模块为:①:生成xml文件②:遍历xml文件的节点信息③:修改xml文件的节点信息④:向xml文件添加节点信息⑤:删除指定xml文件的节点信息假设我们需要设计出这样的一个xml文件来存储相应的信息,如下所示:<Computers><Computer ID="11111111" Description="Made in China"><name>Lenovo</name><price>5000</price></Computer><Computer ID="2222222" Description="Made in USA"><name>IBM</name><price>10000</price></Computer></Computers>那么如何生成这个xml文件?又怎么读取这个xml文件的节点信息,以及如何对这个xml文件的节点信息作相应的操作?请看如下代码示例:【注:因为我们要使用xml相关的语法和方法,所以一定要引入命名空间System.Xml】1using System;2 using System.Collections.Generic;3 using System.Linq;4 using System.Text;5 using System.Xml;67 namespace OperateXML8{9class Program10 {11staticvoid Main(string[] args)12 {13try14 {15//xml文件存储路径16string myXMLFilePath ="E:\\MyComputers.xml";17//生成xml文件18 GenerateXMLFile(myXMLFilePath);19//遍历xml文件的信息20 GetXMLInformation(myXMLFilePath);21//修改xml文件的信息22 ModifyXmlInformation(myXMLFilePath);23//向xml文件添加节点信息24 AddXmlInformation(myXMLFilePath);25//删除指定节点信息26 DeleteXmlInformation(myXMLFilePath);27 }28catch (Exception ex)29 {30 Console.WriteLine(ex.ToString());31 }32 }3334priva test aticvoid GenerateXMLFile(string xmlFilePath)35 {36try37 {38//初始化一个xml实例39 XmlDocumentmyXmlDoc =new XmlDocument();40//创建xml的根节点41 XmlElementrootElement = myXmlDoc.CreateElement("Computers");42//将根节点加入到xml文件中(AppendChild)43 myXmlDoc.AppendChild(rootElement);4445//初始化第一层的第一个子节点46 XmlElement firstLevelElement1 = myXmlDoc.CreateElement("Computer"); 47//填充第一层的第一个子节点的属性值(SetAttribute)48 firstLevelElement1.SetAttribute("ID", "11111111");49 firstLevelElement1.SetAttribute("Description", "Made in China");50//将第一层的第一个子节点加入到根节点下51 rootElement.AppendChild(firstLevelElement1);52//初始化第二层的第一个子节点53 XmlElement secondLevelElement11 = myXmlDoc.CreateElement("name"); 54//填充第二层的第一个子节点的值(InnerText)55 secondLevelElement11.InnerText ="Lenovo";56 firstLevelElement1.AppendChild(secondLevelElement11);57 XmlElement secondLevelElement12 = myXmlDoc.CreateElement("price");58 secondLevelElement12.InnerText ="5000";59 firstLevelElement1.AppendChild(secondLevelElement12);606162 XmlElement firstLevelElement2 = myXmlDoc.CreateElement("Computer");63 firstLevelElement2.SetAttribute("ID", "2222222");64 firstLevelElement2.SetAttribute("Description", "Made in USA");65 rootElement.AppendChild(firstLevelElement2);66 XmlElement secondLevelElement21 = myXmlDoc.CreateElement("name");67 secondLevelElement21.InnerText ="IBM";68 firstLevelElement2.AppendChild(secondLevelElement21);69 XmlElement secondLevelElement22 = myXmlDoc.CreateElement("price");70 secondLevelElement22.InnerText ="10000";71 firstLevelElement2.AppendChild(secondLevelElement22);7273//将xml文件保存到指定的路径下74 myXmlDoc.Save(xmlFilePath);75 }76catch (Exception ex)77 {78 Console.WriteLine(ex.ToString());79 }80 }8182privatestaticvoid GetXMLInformation(string xmlFilePath)83 {84try85 {86//初始化一个xml实例87 XmlDocumentmyXmlDoc =new XmlDocument();88//加载xml文件(参数为xml文件的路径)89 myXmlDoc.Load(xmlFilePath);90//获得第一个姓名匹配的节点(SelectSingleNode):此xml文件的根节点91 XmlNoderootNode = myXmlDoc.SelectSingleNode("Computers");92//分别获得该节点的InnerXml和OuterXml信息93string innerXmlInfo = rootNode.InnerXml.ToString();94string outerXmlInfo = rootNode.OuterXml.ToString();95//获得该节点的子节点(即:该节点的第一层子节点)96 XmlNodeListfirstLevelNodeList = rootNode.ChildNodes;97foreach (XmlNode node in firstLevelNodeList)98 {99//获得该节点的属性集合100 XmlAttributeCollectionattributeCol = node.Attributes; 101foreach (XmlAttributeattri in attributeCol)102 {103//获取属性名称与属性值104string name = ;105string value = attri.Value;106 Console.WriteLine("{0} = {1}", name, value);107 }108109//判断此节点是否还有子节点110if (node.HasChildNodes)111 {112//获取该节点的第一个子节点113 XmlNode secondLevelNode1 = node.FirstChild;114//获取该节点的名字115string name = ;116//获取该节点的值(即:InnerText)117string innerText = secondLevelNode1.InnerText;118 Console.WriteLine("{0} = {1}", name, innerText);119120//获取该节点的第二个子节点(用数组下标获取)121 XmlNode secondLevelNode2 = node.ChildNodes[1];122 name = ;123 innerText = secondLevelNode2.InnerText;124 Console.WriteLine("{0} = {1}", name, innerText);125 }126 }127 }128catch (Exception ex)129 {130 Console.WriteLine(ex.ToString());131 }132 }133134privatestaticvoid ModifyXmlInformation(string xmlFilePath) 135 {136try137 {138 XmlDocumentmyXmlDoc =new XmlDocument();139 myXmlDoc.Load(xmlFilePath);140 XmlNoderootNode = myXmlDoc.FirstChild;141 XmlNodeListfirstLevelNodeList = rootNode.ChildNodes;142foreach (XmlNode node in firstLevelNodeList)143 {144//修改此节点的属性值145if (node.Attributes["Description"].Value.Equals("Made in USA")) 146 {147 node.Attributes["Description"].Value ="Made in HongKong";148 }149 }150//要想使对xml文件所做的修改生效,必须执行以下Save方法151 myXmlDoc.Save(xmlFilePath);152 }153catch (Exception ex)154 {155 Console.WriteLine(ex.ToString());156 }157158 }159160privatestaticvoid AddXmlInformation(string xmlFilePath)161 {162try163 {164 XmlDocumentmyXmlDoc =new XmlDocument();165 myXmlDoc.Load(xmlFilePath);166//添加一个带有属性的节点信息167foreach (XmlNode node in myXmlDoc.FirstChild.ChildNodes)168 {169 XmlElementnewElement = myXmlDoc.CreateElement("color"); 170 newElement.InnerText ="black";171 newElement.SetAttribute("IsMixed", "Yes");172 node.AppendChild(newElement);173 }174//保存更改175 myXmlDoc.Save(xmlFilePath);176 }177catch (Exception ex)178 {179 Console.WriteLine(ex.ToString());180 }181 }182183privatestaticvoid DeleteXmlInformation(string xmlFilePath)184 {185try186 {187 XmlDocumentmyXmlDoc =new XmlDocument();188 myXmlDoc.Load(xmlFilePath);189foreach (XmlNode node in myXmlDoc.FirstChild.ChildNodes)190 {191//记录该节点下的最后一个子节点(简称:最后子节点)192 XmlNodelastNode = stChild;193//删除最后子节点下的左右子节点194 lastNode.RemoveAll();195//删除最后子节点196 node.RemoveChild(lastNode);197 }198//保存对xml文件所做的修改199 myXmlDoc.Save(xmlFilePath);200 }201catch (Exception ex)202 {203 Console.WriteLine(ex.ToString());204 }205 }206 }207}208上面的这个例子,首先是通过GenerateXMLFile方法在E盘创建出了我们预想的xml文件;然后通过GetXMLInformation方法对刚刚生成的xml文件进行了信息的读取;之后通过ModifyXmlInformation方法对xml文件信息作出相应的修改(<Computer ID="2222222" Description="Made in USA">修改成为<Computer ID="2222222" Description="Made in HongKong">);再之后通过AddXmlInformation方法向xml文件中添加了一个带有属性值的color节点;最后通过DeleteXmlInformation方法将刚刚添加上的color节点删除掉。
XML入门基础:XML的语法规则

XML入门基础:XML的语法规则想索取更多相关资料请加qq:649085085或登录PS;本文档由北大青鸟广安门收集自互联网,仅作分享之用。
提纲:一.XML语法规则二.元素的语法三.注释的语法四.CDATA的语法五.Namespaces的语法六.entity的语法七.DTD的语法一.XML语法规则XML的文档和HTML的原代码类似,也是用标识来标识内容。
创建XML 文档必须遵守下列重要规则:规则1:必须有XML声明语句这一点我们在上一章学习时已经提到过。
声明是XML文档的第一句,其格式如下:<?xml version="1.0" standalone="yes/no" encoding="UTF-8"?>声明的作用是告诉浏览器或者其它处理程序:这个文档是XML文档。
声明语句中的version表示文档遵守的XML规范的版本;standalone表示文档是否附带DTD 文件,如果有,参数为no;encoding表示文档所用的语言编码,默认是UTF-8。
规则2:是否有DTD文件如果文档是一个"有效的XML文档"(见上一章),那么文档一定要有相应DTD文件,并且严格遵守DTD文件制定的规范。
DTD文件的声明语句紧跟在XML 声明语句后面,格式如下:<!DOCTYPE type-of-doc SYSTEM/PUBLIC "dtd-name">其中:"!DOCTYPE"是指你要定义一个DOCTYPE;"type-of-doc"是文档类型的名称,由你自己定义,通常于DTD文件名相同;"SYSTEM/PUBLIC"这两个参数只用其一。
SYSTEM是指文档使用的私有DTD文件的网址,而PUBLIC则指文档调用一个公用的DTD文件的网址。
delphi操作xml学习笔记之二简单读写

delphi操作xml学习笔记之二简单读写作者: cactus123456标题: delphi操作xml学习笔记之二简单读写关键字: xml 简单读写 dom分类: 个人专区密级: 公开XML的二十个热点问题翻译:Chen Zhihong这些日子,几乎每个人都在谈论XML (Extensible Markup Language),但是很少有人真正理解其含义。
XML的推崇者认为它能够解决所有HTML不能解决的问题,让数据在不同的操作系统或应用之间进行灵活交换。
确实,所有的观察家们都同意XML将引发一场内容发布和知识交换的革命。
谁先进入这个领域,谁就能够大获其利。
这里的20个有关XML的热门问题能够让你成为一XML“专家”,或至少让你能够在今后看准XML的发展方向。
1 什么是XML? 11 OSD和CDF与XML 的关系如何?2 XML何以重要? 12 电子商务(e-commerce)和XML?3 SGML、HTML和XML有什么联系? 13 XML中的层叠样式?4 如何实现XML? 14 XML如何改进超链接?5 什么是文件类型定义(DTD)? 15 服务器上支持XML吗?6 什么是格式完整和有效的文件? 16 谁应该学习XML?7 如何在浏览器中阅读XML? 17 有哪些编写XML的工具可供我使用?8 RDF和XML有何联系? 18 XML的国际化?9 Netscape浏览器中如何实现XML? 19 XML的未来在哪里?10 Microsoft浏览器中如何实现XML? 20 哪里能学到更多的XML知识?1.什么是XML?XML代表扩展标识语言(Extensible Markup Language). 由万维网联盟(W3C)带头, XML在1998年2月10日成为正式的规范.XML开发者会告诉你XML不是一种语言,而是一个定义其他语言的系统. 你可能已经听说过, 或使用过这些语言中的一种,--如Microsoft 支持"推技术"的 Channel Definition format(CDF).正从事于XML相关建议工作的W3C, 称XML为"表达数据中结构的共同语法". 结构化的数据指的是其内容,意义或应用被标记的数据. 例如, HTML中<H1>标记指定文本为某一字体和大小, XML的标记将明确确定信息的种类: <BYLINE>标记可以识别文档的作者, <PRICE>标记可以在一个存货清单中包含某一项目的成本 .通过将结构,内容和表现分离, 同一个XML源文档只写一次, 可以用不同的方法表现出来: 在计算机屏幕上, 在手提电话显示屏上, 在为盲人服务的设备上翻译成语音, 等等. 它可以在可能开发的任何通讯产品上工作. 一个XML文档因此可以比其书写时的作者和显示技术生存得更久.所以, XML将不仅限于Internet, 例如, 可以服务于整个出版业, 特别是对于想制作可出现在多种媒体上的文档的人. 一些使用Standard Generalized Markup Language (SGML)多年的大型文档出版商将转向XML. 还有, 独立于平台的XML是为Web开发的, 这是它将最具影响的地方.XML在Web的真正实力在于它是如何与文档对象模型(Document Object Model,DOM)交互的. DOM定义了访问XML文档数据的接口.程序员利用DOM可以用标准的方法编写动态的内容. 换句话说, 他们可以使用它来使浏览器文档树中的一部分特定内容按照一定的方式表现, 例如, 当用户将鼠标移至文字上时, 这些文字变成蓝色. Netscape Navigator 和 Microsoft Internet Explorer浏览器都有各自的DOM, 但是他们都称将在其下一版本的浏览器中支持W3C 的标准DOM.2.XML何以重要?Web领袖之间的说法是内容至上.可是不幸地是:内容经常和其表现紧密结合.请问你多少次在网页中遇到一个小小的提示:"最好在800x600像素的分辨率上显示"?XML将帮助解决以上问题, 因为网站建设者不用再指明在哪里显示什么, 而是指明文档的结构. 例如, 你可以说明文档的标题, 作者, 关联文档的清单, 等等. 然后, 任何一个有XML浏览器的设备都可以给出最适合它的文档版本, 这样的设备可以是一个掌上型计算机, 置顶盒, 或高速的工作站.但是, 也许XML的最佳特性是其内在的可扩展性. 公司和组织能够扩展XML来满足新的挑战和应用. 一个基于XML的语言已经在使用--微软的Channel Definition format (CDF)-- 还有更多将出现, 包括Resource Definition format (RDF) 和 Open Software Description (OSD).XML 也允诺成为交换数据和文档的标准机制. 例如, XML可能成为不同厂商的数据库在Internet上交换信息的一种方法.现在准确地决定XML的方向还有一些早. 但是, 其各种可能性是令人敬畏的,这就是为什么围绕着XML有如此多的激动的一个重要原因.3.SGML、HTML和XML有什么联系?SGML是在文字处理应用中表达数据的一个方法. 它已经出现十多年了, XML和HTML都是从SGML 发展而来的文档形式. 因此, 它们都有一些共同点, 如相似的语法和标记的使用.但是HTML是SGML的一个应用, 而XML是SGML的一个子集. 区别是重要的. 基本上HTML不能用来定义新的应用, 而XML可以. 例如,RDF和CDF都是使用XML 定义的应用. XML和HTML更象表兄弟, 而不是亲兄弟. 事实上, XML 和SGML是兼容的-- XML文档可以通过任何SGML制作或浏览工具阅读. 但是, XML没有SGML那么复杂, 它是设计用于有限带宽的网络的, 如Internet. XML规范的合作者Tim Bray说, XML的设计出发点是取SGML的优点, 去除复杂的部分, 使其保持轻巧, 可以在Web上工作.HTML,SGML和XML将继续用于其合适的地方, 它们中的任何一个不会使其他一个废弃. HTML仍是在Web上快速出版数据的最简单的方法, 大部分短期的数据, 如会议议程或广告宣传册. 如果数据会长期使用, 并且需要更多的一些结构, Web建造者将愿意使用XML. 不同于HTML和XML, SGML可能永远不会在Internet上被广泛接受, 因为它从来没有为某个网络协议的需求而设计或优化过. 对于高端的, 复杂结构的出版应用, SGML将继续适用.4.如何实现XML?XML将以几个不同的方式应用. 一个是在人机之间交换数据, 如从Web服务器至用户的浏览器. 另外一个是在不同的应用之间交换数据, 或者是机器之间交换数据.在这些情况下, 你都可能需要三层架构: 后端数据库, 针对数据的处理逻辑的中间层服务器, 以及数据进一步显示和处理的客户端. 数据库可以从多个数据来源接收信息, 可能已经是XML格式的数据. 中间层然后收集数据并在最终的表现层上输出和表现..现在, 网页有时候以这种方法传送 --CNET的从一个数据库中发表数据.但是要获得一页的新的视图,如的新的“打印机友好”选项, 服务器必须产生一个新的页面. 一份适当格式化的XML文档将允许客户端的应用为不同的媒体修改文档的表现形式, 比如为打印机.5.什么是DTD?文档类型定义(DTD)是一套关于标记符的语法规则.它告诉你可以在文档中使用哪些标记符,它们应该按什么次序出现,哪些标记符可以出现于其它标记符中,哪些标记符有属性,等等.DTD原来是为使用SGML 开发的, 它可以是XML文档的一部分, 但是它通常是一份单独的文档或者一系列文档因为XML本身不是一种语言,而是定义语言的一个系统,它没有象HTML一样拥有一个通用的DTD.相反, 想使用XML进行数据交换的工业或组织可以定义它们自己的DTD. 如果一个组织想用XML 来标识仅在内部使用的文档, 它可以创造自己私有的DTD. 比如华尔街杂志交互版本拥有一个DTD 来详细说明每一版, 其中有关于页, 文章, 概要, 标题下署名等等的信息.刊物目前使用SGML DTD,但是它也正在开发一个XML版本. 关于DTD并不是没有争议的. 一些人感到它给商业业务增加了实实在在的价值, 而一些人感觉它限制了创造性. 还有一些人认为DTD有用, 但是还做得不够. 微软正尝试用它的XML数据提议来解决上一个抱怨, 但是批评者说这些改进应该在DTD规范本身进行.一些供应商, 包括微软, 已经提议了替代DTD的一个方法, 称为schema. 他们已经将其以XML数据提交给了W3C. 就象DTD, Schema 提供了文档的规则, 并指出用什么标记符, 标记符的属性, 之间的联系, 等等.但是,不同于DTD, schema可以定义数据类型. 例如, DTD可能有一个标记符<PRICE>, 而标记符之间的内容可以是数字或字符串. Schema 可以规定只输入数字.这个方法显然有其优点, 特别是用于应用,对象,或数据库之间的数据传输. 唯一的问题是它将成为DTD规范, 还是XML的一个扩展.6.什么是结构良好和有效的文件?基本上有两类相关的XML文档: 结构良好的和有效的. 结构良好的XML文档遵守XML语法的一般规则, 这些规则比HTML和SGML的更为严格. XML的字符数据决不会吊在那里, 没有某种结束标识符, 或者是象<MYTAG></MYTAG> 成对出现的结束标识符, 或者是一个特别的在右尖括弧前带有一个斜杠的空元素标记, 比如 <MYTAG/>; XML 标识总是以左尖括弧或& 开始; 元素类型和属性名称是大小写区分的; 属性需要引号; 等等.有效的 XML 文档遵守某个特定的DTD.确认XML文档正确性的工作主要由制作出版工具承担, 而XML浏览器为读取XML文档, 只需要检查其构造的良好性. 这样, 制作工具中的解析器得要检查构造良好性和有效性, 而浏览器仅要考虑寻找已经构造良好的XML.7 如何在浏览器中阅读XML?阅读XML文档的工具一般称为XML解析器, 虽然其更正式的名称是XML处理器. XML处理器将数据传送到应用软件, 以做制作, 出版, 查询, 或显示. XML不给应用软件提供应用程序接口 (API), 它只是把数据传给应用软件. XML处理器不解析非结构良好的数据. Netscape 和Microsoft 都已经将XML解析器包含在其浏览器中, 或正计划将其包含到浏览器中.XML开发者团体提供免费的XML阅读器和解析器, 来应用到应用软件或XML制作软件:Textuality的 Lark, 来自XML标准的作者之一.Microstar的 AElfred, 一个基于Java的解析器.DataChannel的DXP, 前身为著名的NXP, 或已经增加了API的Norbert的 (Mikula) XML 解析器.8 RDF和XML有何联系?如果XML提供了表达语言的能力,那么XML应用则是特定的语言.资源描述框架(Resource Description Framework,RDF) 是这样的一个应用软件:使用XML的语法进行数据建模.RDF是一种描述和访问数据方法. 这意味着RDF是关于数据的数据, 或者说元数据. 在Web中, 这些元数据将被用于建立标准的站点地图, 更精确的搜索结果, 和分层次的主题索引. RDF也允许智能书签, 当被索引的网页变化时, 书签随之发生变化. 如果你跟踪内容定期更新的站点, 比如CNET的 , 将很有用.对于网站建设者,建立可被搜索引擎引用的其网站内容的元数据并不困难. 我们很快就会有商业化的软件, 来自动产生给定站点的RDF文件.XML元数据也将活跃数据描述和评估的市场. 有许多评级机构在网上出现, 他们评估一切数据, 从保护孩子安全的站点到最佳电影或葡萄酒站点. RDF可以使用的等级的语法来描述评级机构.人们将选择有他们感觉最合适的词汇表的评级机构,词汇表指的是评级机构给不同类型内容评级使用的特别的一套术语 -- 从性和暴力到葡萄酒酸度.9 Netscape浏览器中如何实现XML?Netscape将在Communicator/Navigator 5.0中以一个代号为Aurora的交付部件来支持XML元数据. Aurora利用RDF来获得Netscape所称的"桌面信息全面集成."Aurora在网络、桌面和数据库之间查找和管理信息.它将在桌面上以"窗口"菜单的界面出现,会聚指向当前项目, 研究主题或日常活动等资源的指针.RDF使Aurora的导航条指向不同数据类型(文字处理文档、表格数据、电子邮件消息、数据库内容)的本地文件, 也指向Internet 或Intranet 服务器上的资源(搜索和查询的结果、书签链接等).Netscape 5.0 版浏览器中提供了一个读取RDF的XML解析器,在产品最终交付前会以beta版出现.除了该RDF的实现, Netscape正计划将一个通用的XML解析器包含在浏览器中, 而其浏览器可以和其他的XML应用软件一起工作, 比如化学标记语言(CML)和数学标记语言(MathML)."我们要使Navigator成为一个XML平台,"Netscape原理工程师R.V. Guha这样说.Guha 原来开发过MCF (Meta Content format), MCF 后来加入了RDF规范.10 Microsoft浏览器中如何实现XML?微软的Internet Explorer 4.0 是第一个实现XML的网络浏览器. 微软提供了一对XML处理器:浏览器所携带的用C++写的解析器, 和一个Web建造者可以从中下载和加入他们自己的应用程序的Java解析器的源代码. Java解析器是一个有效的解析器, 就是说它根据一个DTD 或Schema来进行检查.为了提高性能,浏览器所带的C++版的解析器是一个非有效的解析器.据微软的产品经理Steve Sklepowich称, 这两个解析器都是"通用的", 因为它们不依靠特定的XML应用, 如CDF.由于XML数据和其表现分离, 在一个浏览器本身实际显示XML的能力需要样式表,例如XSL.同时, 微软使用了它所称的XML数据源对象(XML Data Source Object,XML DSO).它应用了动态HTML的数据捆绑能力, 将一端的XML数据和另一端的HTML数据相链接.IE 4.0访问XML文档,从中查询数据, 然后作为HTML显示出来.微软也使用了XML对象模型来让开发者与浏览器中的XML数据进行交互. 它的实现是通过将HTML作为基于文档对象模型(DOM)的对象显现, 尽管HTML 和 DOM 并非直接兼容. DOM 让脚本和程序访问结构化的XML数据.Sklepowich说, 虽然目前在微软, XML的重心在浏览器, XML将最终出现在"任何HTML已经出现了的地方".Bill Gates 已经公开宣布微软Office 未来的版本将支持XML, 而且公司也计划支持电子邮件包和制作XML工具的标准.11 OSD和CDF与XML的关系如何?CDF和OSD是微软支持的两个XML应用.通过其XML解析器,微软的 Internet Explorer 4.0读CDF文件来驱动和控制推频道所带来的页.根据RDF所做的工作, CDF提议又递交给W3C,以利用RDF的能力来显示不同数据元素之间的联系.Open Software Description 是用于描述软件部件的词汇表, 带有语法如从属, 版本和平台. OSD 描述如何表现一个部件的特性, 以及如何将该部件安装到计算机上. 它可以用于下载一个完整的软件包, 但是它主要设计用于不断增加的更新. OSD 单独工作或和CDF一起工作, 来定义应用频道. OSD建议由微软和Marimba领导的一组销售商于1997年8月提供给W3C.12 电子商务(e-commerce)和XML?CommerceNet是著名的非赢利性网上商务协会,它拥有500多个成员.数年来CommerceNet努力帮助e-commerce 产品和系统一起工作. 其概念是允许信息在不同目录之间, 从目录到付款系统, 在付款系统之间交换. 已经发现XML可以在两个重要方面帮助实现以上概念: 内容定义和信息交换.内容定义:CommerceNet 正在定义通用于多种商业事务的数据元素. 这个称作商务核心(Commerce Core)的东西将定义如何给诸如公司名称、地址、价格、条款和数量等事物作标识.信息交换:开放,基于文本的XML用于服务器之间交换事务信息很理想.CommerceNet 提议用基于XML的通用商务语言(Common Business Language,CBL)来描述产品和服务目录软件, 关于商业规则和系统的元数据, 以及表格和消息的软件. 许多CBL 取自已经存在的Electronic Data Interchange (EDI) 辞典, EDI辞典识别公认的术语, 如发票和采购订单. 但是CBL超越EDI的商业-到-商业的重点, 包含了零售事务和横向的供应链 -- 从供应商到批发商到零售商.这样的一个CBL应用是为使目录互用的产品信息互换( Product Information Exchange,PIX)规范. CommerceNet设计PIX, 以帮助供应商和他们的分销商更容易地交换产品数据. 长远的目标是工业组织--而非 CommerceNet--来将CBL作为特定的DTD的一个共同基础使用. 一些着重于工业的初步尝试已经宣布了:Internt开放支付(OBI): 一个在Internet上进行国际性的商业间购物的标准.OBI基于目前的Internet标准, 如SSL(安全性)、SET(信用卡交易)和X.509(数字认证). OBI的支持者有Commerce One、Connect、Intelisys、InterWorld、Microsoft、Netscape、Open Market、和Oracle.开放贸易协议(OTP): 一个在Web上向消费者售物的一致的, 可共同操作的环境. 规则将包括从如何降价促销, 付款选择, 到产品运输, 接收和问题解决. OTP由MasterCard International, DigiCash, CyberCash, Hewlett-Packard, IBM, AT&T Universal Card, Netscape, Royal Bank of Canada, 和一些其他金融机构和技术公司支持.Internet内容交换标准(ICE): Vignette, Firefly Network, 和一些其他公司--包括微软--正在开发一个叫作ICE的规范, 使能够在站点之间交换在线资产, 无论那是内容, 应用程序, 或是元数据. ICE将利用现有的标准, 包括 OPS/P3P (使个人数据可靠交换), CDF,OSD和RDF.13 XML中的层叠样式?因为XML将内容和表现分离, Web建造者需要新的方法来控制设计, 显示和输出. style sheet 是问题的答案. 目前, 有三种可用于XML的样式表:Cascading style Sheets (CSS)Extensible style Language (XSL)Document style Semantics and Specification Language (DSSSL).如果5.0版的浏览器支持XML, XML对现有的CSS标准的支持将会处理大部分基本的风格和页面问题. 但是CSS对于专业出版商可能不够强大. 所以, 另一端存在着DSSSL, 一个在使用SGML的高端出版商中流行的ISO (国际标准组织)标准. 然而, DSSSL是复杂的, 它处理的打印文档管理在Web上很少有用.现在剩下了XSL,特别为XML而写的样式表.XSL目前上交给了W3C作为一个建议标准,其中的XSL转换部分(XSLT)已经于1999年11月成为正式的规范. 它给了Web开发者和用户较HTML更多的表现灵活性. 例如, HTML的<H2>标识符在所有浏览器上的表现是基本一样的, 但是XSL让开发者指定他们的页面元素如何表现(尽管用户可以在个人设置中重载它).XSL较CSS更强大, 因为它使Web建造者创建可以动态改变其表现的文档. 例如, 你可以包含这样的程序语句, "如果一个XML元素的属性为数值10, 显示为绿色, 否则为黑色." 或者你可以将"仅供内部使用"作为属性给一个段落标上, 这样它在某些情况下不会出现. XSL被设计用于脚本语言如javascript.14 XML如何改进超链接?XML超链接比基本的HTML风格的超链接多了一些新的特性, 包括无需手写许多javascript代码就能创建"聪明的"链接. 而且在XML, 链接本身成为了对象, 可以象其他对象一样被管理.原来的链接规范--XLL, 或XML链接语言--正被分为两个不同的规范: XPointer 和 XLink.XPointer: 在HTML, 要链接到一个页面的中间, 页面作者必须在那儿加上定位标识符. 使用XPointer, 你可以"取址到" (不是"连接到")其他人的文本的任何部分. 显而易见, 这样将有助于工作于法律文件, 科学和学术论文, 甚至W3C规范!XLink: 当用户点击一个HTML超链接时, 当前的网页被连接到的文件替代. XLink令Web建立者给链接增加行为. 例如, 现在, 你必须用一些javascript, 使在链接处弹出一个独立的窗口, 但是XLink让Web 建立者对链接进行编码来执行一系列动作, 包括弹出一个链接选择的菜单.另一个应用可以是弹出一个对话框, 可能是一个提醒用户它们正要更新数据库的警告. 链接弹出菜单可能需要用户点击一个框来表示在进一步处理前他们接受义务. 现在, 实现这样的功能要写许多的脚本代码.XML也让Web建立者创建类似Web环工作的Extended Link, Web环是通过"下一个/前一个"行进来导航的自己选择出来的关于相同主题的网站组. 对于弹出菜单太长的相关链接站点表, Web建立者可以创建一个链接表, 这个表在不同的站点, 页面时会有变化. 用户可以点击一个图标来自动转移到环中的下一个成员. 现在这样的功能需要CGI scripts, 而Extended Links 提供了一个标准的, 非私有的建立资源间联系的方法.仍然有更多的问题需要解决, 特别是在行为政策方面. 必须由一种方法来协调以下三方面的关系: 文档作者对链接所建议的行为, 用户所喜好的显示链接信息的方式, 以及是否和何时忽视用户的意愿的政策.15 服务器上支持XML吗?XML被设计成供长久使用的, 高价值的文档的储存格式. XML不是只让你定义标识符, 它也允许你定义文档的储存结构. 一篇HTML文档仅存在于一个文件中, 而一个XML文档可以由存放在不同地点的多个文件(称为实体)组成. 这提出了作为文档存储库的XML服务器的概念.服务器软件供应商已正在支持XML:Enigma, Insight 4.0这是一个提供给出版商处理大型文档的专业电子出版软件解决方案. 目前和Insight捆绑在一起的Enigma SGML/XML style Sheet Editor, 也可以作为一个独立产品提供.Hynet Technologies, Digital Library SystemDigital Library System (DLS) 将文档和文档部件作为标准软件对象进行管理, 允许引入在Adobe FrameMaker和Microsoft Word中创建的文档, 或者SGML/XML文件.Inso, DynaText Professional Publishing System这是一个进行索引, 搜索和制作脚本的软件, 它可以工作于运行在Windows NT 3.51 或 4.0, 或 Sun Solaris 2.5上的Microsoft的 IIS 和 Netscape的 Enterprise and FastTrack servers.Open Market, FolioOpen Market的 Folio 4 信息管理和发送产品将XML文档引入带索引的数据库, 以在IP网络上传递内容, 或将内容送至CD-ROM. 在一月份, Open Market宣布增强对XML的支持, 允许文档以它们的本身格式进行索引和保证安全. 同时, Folio产品也将可以和其它基于标准的制作, 解析和生成XML文档的解决方案相互操作. 它的产品包括Folio siteDirector (分发信息), Folio SecurePublish (事务管理软件), 和Folio Publisher (电子出版).WebMethods, Web Automation ServerWeb Automation Server 帮助公司将基于浏览器的应用软件和其它应用软件的数据相结合. 它是基于XML的服务器, 使用WebMethods自己的在机器间进行Web数据交换的WIDL (Web Interface Definition Language). (该公司已经将WIDL作为标准提议上交给 World Wide Web Consortium.)16 谁应该学习XML?所有的Web建立者需要足够了解XML,以决定是否使用它.E-commerce站点和管理数据库中大量文档的站点是显然的首选对象.经理可能不需要学习XML语法或如何建立DTD,他们仍要理解XML的潜力并加以利用.如果最终的目的只是让人来读信息, HTML能足够满足标识信息的要求. 但是如果你想要为自动处理数据作准备, 你必须考虑将XML纳入你的出版系统. 并非每一个工作在Web站点的HTML制作者必须成为XML制作者, 但是某些员工应该精通于XML--特别当站点的工作对象是值得为将来使用而管理的数据和文档时.当然,XML的功能也意味着复杂性--一些Web建立者已经发现他们可以在几天内掌握HTML的基础, 而他们可能需要花几个星期来适应XML.只有你自己才能决定是否值得花这些时间.17 有哪些编写XML的工具可供我使用?幸运的是, Web建立者不用完全靠他们自己从头开始创建XML了. 市场上已经有了创建, 管理和发送XML的工具, 并且一些公司也在进行开发.Adobe: 在1998年中期, Adobe将介绍可以输出到XML的FrameMaker 和 FrameMaker+SGML 的过渡版本. 这些产品的完整版本将能够输入XML. Adobe有一名代表在W3C的XML工作组, Adobe也参与了XLink, Cascading style Sheets和 RDF的工作, 所以我们可以期待这些技术将在Adobe未来的产品中出现.Allaire: HomeSite 4.0 和 Cold Fusion 4.0 都预计在今年夏天出品, 它们将支持XML, 包括style sheets. HomeSite 3.0中已经提供了一个CDF附加软件.ArborText: 在SGML领域内长期工作的ArborText, 于一月份发布了XML styler, 一个免费的基于Java的XSL编辑器. 它的图形用户界面可以让我们勿需知道XML语法就能进行编辑. 将来, ArborText 会把XML styler集成到Adept中, Adept是公司给打印出版提供的XML制作工具.DataChannel: 一个免费的, 基于Java的有效的解析器, 称为 DXP (DataChannel XML Parser; 基于 Norbert Mikula 著名的NXP). 可以从该公司的Web站点获得. 它新发布的是免费的XML工具包, XML 开发环境, 它包括了一套部件, 帮助人们开始学习和应用XML.Inso: 该公司提供它称为的"首个集成的, 端对端的, 创建, 转换, 存储, 管理, 索引, 查询XML内容, 将其发布到Web, CD-ROM和打印机上的出版解决方案." 其产品包括DynaTag 4.0, DynaBase 3.0, DynaText 3.1, 和所附的工具 DynaWeb.IntraNet Solutions: Intra.doc Management System的下一版本, IntraNet Solution的基于Web的文档管理系统, 将会管理XML部件和文档之间的关系, 提供和第三方XML制作工具的集成链接管理, 完善在浏览器中XML对象的使用, 并在Intra.doc存储库和XML编辑器之间提供一个交互的元数据模型.Microsoft: 微软希望在年底交付Office 9.0, 据报道, 它将有对XML的支持.Microstar: ActiveSG/XML 是一套在Internet上设计和配置基于事务的XML/SGML系统的工具和技术. Microstar也提供了免费的Ælfred XML 解析器.SoftQuad: HTML 编辑器 HotMetal Pro 将很快提供 Live Data Base Pages, 一个让开发者将HTML数据拉入数据库并以XML来返回的附加软件.Vignette: StoryServer 3.2 在Web上交付能使用XML的应用和内容. 它结合了关系型数据库, 多媒体和XML内容创建的工具. StoryServer 是一个Web内容应用平台, 供建立, 管理, 和交付基于服。
android学习笔记
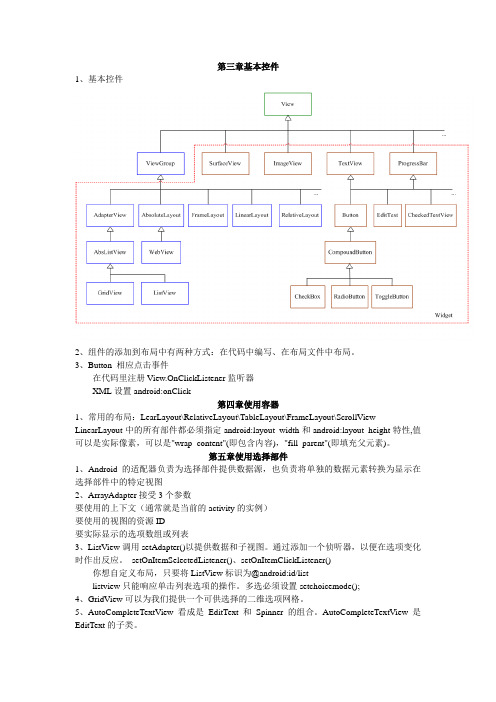
第三章基本控件1、基本控件2、组件的添加到布局中有两种方式:在代码中编写、在布局文件中布局。
3、Button 相应点击事件在代码里注册View.OnClickListener监听器XML设置android:onClick第四章使用容器1、常用的布局:LearLayout\RelativeLayout\TableLayout\FrameLayout\ScrollView LinearLayout中的所有部件都必须指定android:layout_width和android:layout_height特性,值可以是实际像素,可以是"wrap_content"(即包含内容),"fill_parent"(即填充父元素)。
第五章使用选择部件1、Android 的适配器负责为选择部件提供数据源,也负责将单独的数据元素转换为显示在选择部件中的特定视图2、ArrayAdapter接受3个参数要使用的上下文(通常就是当前的activity的实例)要使用的视图的资源ID要实际显示的选项数组或列表3、ListView调用setAdapter()以提供数据和子视图。
通过添加一个侦听器,以便在选项变化时作出反应。
setOnItemSelectedListener()、setOnItemClickListener()你想自定义布局,只要将ListView标识为@android:id/listlistview只能响应单击列表选项的操作。
多选必须设置setchoicemode();4、GridView可以为我们提供一个可供选择的二维选项网格。
5、AutoCompleteTextView看成是EditText和Spinner的组合。
AutoCompleteTextView是EditText的子类。
Android:completeThreshold:表示在触发列表筛选功能之前,用户必须输入的最少字符数目AutoCompleteTextView不支持选择侦听器,我们可以注册一个TextWatcher,从而在文本变化时,也可以收到通知。
python的xml.dom学习笔记==

print node.prefix
print node.nodeType,node.nodeValue,node.nodeName
print node.localName
print node.childNodes
print node.firstChild,stChild
通过另外一种方式获得link标签
text/css stylesheet :///css/common.css
text/css stylesheet :///Skins/kubrick/style.css
text/css stylesheet :///css/common2.css
application/rsd+xml EditURI :///rollenholt/rsd.xml
application/wlwmanifest+xml wlwmanifest :///rollenholt/wlwmanifest.xml
['ATTRIBUTE_NODE', 'CDATA_SECTION_NODE', 'COMMENT_NODE', 'DOCUMENT_FRAGMENT_NODE', 'DOCUMENT_NODE', 'DOCUMENT_TYPE_NODE', 'ELEMENT_NODE', 'ENTITY_NODE', 'ENTITY_REFERENCE_NODE', 'NOTATION_NODE', 'PROCESSING_INSTRUCTION_NODE', 'TEXT_NODE', '__doc__', '__init__', '__module__', '__nonzero__', '__repr__', '_attrs', '_attrsNS', '_call_user_data_handler', '_child_node_types', '_get_attributes', '_get_childNodes', '_get_firstChild', '_get_lastChild', '_get_localName', '_get_tagName', '_magic_id_nodes', 'appendChild', 'attributes', 'childNodes', 'cloneNode', 'firstChild', 'getAttribute', 'getAttributeNS', 'getAttributeNode', 'getAttributeNodeNS', 'getElementsByTagName', 'getElementsByTagNameNS', 'getInterface', 'getUserData', 'hasAttribute', 'hasAttributeNS', 'hasAttributes', 'hasChildNodes', 'insertBefore', 'isSameNode', 'isSupported', 'lastChild', 'localName', 'namespaceURI', 'nextSibling', 'nodeName', 'nodeType', 'nodeValue', 'normalize', 'ownerDocument', 'parentNode', 'prefix', 'previousSibling', 'removeAttribute', 'removeAttributeNS', 'removeAttributeNode', 'removeAttributeNodeNS', 'removeChild', 'replaceChild', 'schemaType', 'setAttribute', 'setAttributeNS', 'setAttributeNode', 'setAttributeNodeNS', 'setIdAttribute', 'setIdAttributeNS', 'setIdAttributeNode', 'setUserData', 'tagName', 'toprettyxml', 'toxml', 'unlink', 'writexml']
OpenXmlSDK学习笔记(1):Word的基本结构

OpenXmlSDK学习笔记(1):Word的基本结构能写多少篇我就不确定了,可能就这⼀篇就太监了,也有可能会写不少。
OpenXml SDK 相信很多⼈都不陌⽣,这个就是管Office⼀家的⽂档格式,Word, Excel, PowerPoint等都⽤到这个。
并且,这个格式主要是给Word 2007以上使⽤的。
如果是⽤到其中Excel部分,那建议直接使⽤NPOI这样的成品类库就⾏。
⼀、WordprocessingML的理解在看⽂档和使⽤的时候,就可以发现这样的⼀个命名空间:Wordprocessing。
也可以看到这样的名词WordprocessingML。
什么意思呢,Office家的这个产品叫Word,其作⽤是处理⽂字。
所以,Wordprocessing翻译成⽂字处理就⾏了。
对于OpenXml结构的docx⽂件那就是⼀个压缩包。
你把后缀名从docx改成zip就可以⽤解压软件打开了。
在其中,可以看到这样的结构:这个结构⾥,第⼀个⽂件夹word就是我们要关注的内容,这个⽂件夹⾥是这样的:有图⽚的话会更复杂⼀点,再多⼀个media⽂件夹,⾥⾯存着图⽚。
不过这个⽆关紧要,本次我的需求只是简单的输出⼀个纯⽂档的证明⽂件。
所以,不要管图⽚了。
在这⾥,重点需要注意注意的xml有两个,document.xml和styles.xml。
他们分别对应着docx⽂件的样式部分和正⽂部分,⼤致就是这样的:也就是说,如果我们需要通过代码编辑⼀个纯⽂本的Word,那就是修改这两个xml就可以了。
甚⾄于,如果不需要搞样式的话,只要改docment.xml就⾏了。
这两个Xml适⽤的标准就是 ISO/IEC 29500,并且这种Xml就称为:WordprocessingML。
但是,⼿写xml可太刑了。
把整个 ISO/IEC 29500:2016 读完怕不是半条命就要去掉了。
再等你把代码写完,恐怕你的⼯作就已经凉凉了。
所以呢,微软⾃⼰出了个 OpenXml SDK 帮助开发者编辑这种Xml⽂件。
XML基础知识课件

PPT学习交流
7
XML与HTML的比较
• HTML将数据和其显示效果混在一起,它是一种表现技术 ; XML 文档只是存储了数据和描述了数据之间的关系,没有规定该如何 显示数据。
• HTML的格式要求比较松散 ;而XML是非常严格的标记语言。
• HTML的标记集合是固定的;而XML只是提供了一个标准,人们 可以按照这个标准来定义自己专用的标记。
PPT学习交流
13
元素的标记名称建议
• 不要使用“.”,因为在很多程序语言中,“.”用于引用对象的属性。 • 最好不要用减号(-),而以下划线(_)代替,以避免与表达式中的
减号(-)运算符发生冲突。 • 名称尽量简短,以减少XML文档的大小。 • 名称的大小写尽量采用同一标准,要么全部大写,要么全部小写。 • 名称可以使用非英文字符,例如中文,但是有些软件可能不支持非英
11
元素定义
• 一个XML元素由一个标记来定义,包括开始和结束标记以及其中 的内容,例如:
<书名>Java就业培训教程</书名>
• 一个元素中可以嵌套若干子元素。
• 格式良好的XML文档必须有且仅有一个根元素,其它元素都是这 个根元素的子孙元素。
• 空元素可以不使用结束标记,但必须在起始标记的结束定界符 (>)前面增加一个正斜杠(/)字符,例如:
PPT学习交流
4
XML的起源与作用
• 在线电子商务活动交换的电子文档必须采用某种标准格式,统一电 子文档的标准规范是电子商务的基础。
• HTML不适合作为电子商务的文档标准。 • SGML(Standard Generalized Markup Language)过于复杂,无法
xhtml学习笔记(精髓)

Basic Tables Module (基础表格模块) 定义基本的表格元素 (table)。
5、XHTML DTD
XHTML 定义了三种文件类型声明。使用最普遍的是 XHTML Transitional。
<!DOCTYPE> 是强制使用的。一个 XHTML 文档有三个主要的部分:DOCTYPE 、Head 、Body (在 XHTML 文档中,文档类型声明总是位于首行。)
a、3种文档类型声明
!DOCTYPE html PUBLIC
"-//W3C//DTD XHTML 1.0 Transitional//EN"
"/TR/xhtml1/DTD/xhtml1-transitional.dtd"
c、框架 DTD 包含过渡 DTD 中的一切,外加框架。
DTD 规定了使用通用标记语言(SGML)的网页的语法。
诸如 HTML 这样的通用标记语言应该使用 DTD 来规定应用于某种特定文档中的标签的标记语言(SGML)的文档类型声明或 DTD 中,XHTML 被详细地进行了描述。
XHTML DTD 使用精确的可被计算机读取的语言来描述合法的 XHTML 标记的语法和句法。
今天的市场中存在着不同的浏览器技术,某些浏览器运行在计算机中,某些浏览器则运行在移动电话和手持设备上。而后者没有能力和手段来解释糟糕的标记语言。
因此,通过把 HTML 和 XML 各自的长处加以结合,我们得到了在现在和未来都能派上用场的标记语言 - XHTML。
XHTML 可以被所有的支持 XML 的设备读取,同时在其余的浏览器升级至支持 XML 之前,XHTML 使我们有能力编写出拥有良好结构的文档,这些文档可以很好地工作于所有的浏览器,并且可以向后兼容。
XML实用教程PPT课件

2024/2/24
7
表7.1 支持DSO的HTML元素 HTML元素
a applet button div frame iframe img
input type="button"
7 XML数据源对象
理解数据岛和数据源对象的概念 掌握数据绑定的方法 熟悉HTML文档中嵌入XML数据的方法 了解支持DSO的HTML元素 掌握HTML与XML结合的方法 学会综合运用DSO。
2024/2/24
1
7.1 数据岛、XML数据源对象与数据绑定
7.1.1 数据岛和XML数据源对象
11
7.4.2 HTML中的XML数据岛记录集页面管理
采用内嵌XML文档或“SRC”属性导入XML文件
XML标记的处理还可以用<OBJECT>标记建立 DSO对象
<OBJECT ID=”xmlDSO” CLASSID=”CLSID:550dda30-054111d2-9ca90060b0ec3d39”></OBJECT>
2024/2/24
12
可以使用脚本语言加载DSO数据源(XML文件),如:
<script language="JavaScript"> var xmldoc = xmlDSO.XMLDocument; xmlDSO.async=false; xmldoc.load("code7_6.xml"); </script>
Object、Data Consumers、Binding Agent和 Table Repetition Agent。 用于绑定的XML文档可以是嵌入到HTML文件内部的,也 可以从外部载入。
第一行代码学习笔记

2015/11/131、当Intent在组件间传递时,组件如果想告知Android系统自己能够响应和处理哪些Intent,那么就需要用到IntentFilter对象。
除了用于过滤广播的IntentFilter可以在代码中创建外,其他的IntentFilter必须在AndroidManifest.xml文件中进行声明。
2、静态注册实现开机启动3、不要在onReceive()方法中添加过多的逻辑或者进行任何的耗时操作,因为在广播接收器中是不允许开启线程的,当onReceive()方法运行了较长时间而没有结束时,程序就会报错。
4、发送有序广播5、MODE_PRIVA TE 仍然是默认的操作模式,和直接传入0 效果是相同的,表示只有当前的应用程序才可以对这个SharedPreferences文件进行读写6、android:layout_span控件跨越的列数7、要调用setCancelable()方法将对话框设为不可取消2015/11/161、Log for Java创建对话框两种方式activity、fragment设计模式蓝牙低功耗模式通信1、静态注册实现开机启动:程序在未启动的情况下就能接收到广播。
2、在广播接收器中是不允许开启线程的3、发送标准广播在发送广播之前,我们还是需要先定义一个广播接收器来准备接收此广播才行,不然发出去也是白发。
4、发送有序广播: sendOrderedBroadcast()方法接收两个参数,第一个参数仍然是Intent,第二个参数是一个与权限相关的字符串,这里传入null就行了。
5、设定广播接收器的先后顺序: android:priority 属性给广播接收器设置了优先级,优先级比较高的广播接收器就可以先收到广播。
6、中断广播: 在onReceive()方法中调用了abortBroadcast()方法,就表示将这条广播截断,后面的广播接收器将无法再接收到这条广播。
5.4 使用本地广播1、系统全局广播:即发出的广播可以被其他任何的任何应用程序接收到,并且我们也可以接收来自于其他任何应用程序的广播。
XML 入门

XML 语法
<?xml version="1.0" encoding="ISO-8859-1"?> encoding="ISO-8859<note> <to>Lin</to> <from>Ordm</from> <heading>Reminder</heading> <body>Don't forget me this weekend!</body> </not 文档必须有一个根元素 所有的
XML文档中的第一个元素就是根元素
XML中的注释 中的注释
<!-- 这是一个注释 -->
XML 语法(续)
XML元素可以拥有属性。 元素可以拥有属性。 元素可以拥有属性
属性值必须使用引号,单引号、双引号都可以 使用数据既可以存储在子元素中也可以存储在属性中
XML解析器
有不同的方法来划分解析器种类:
验证或非验证解析器
验证解析器(Validating parser)在解析 XML 文档同时进行验证 非验证解析器(Non-validating parser) 忽略所有的验证错误
支持 Document Object Model (DOM) 的解析器 支持 Simple API for XML (SAX) 的解析器
Android学习笔记之AndroidManifest.xml文件解析(详解)

Android学习笔记之AndroidManifest.xml⽂件解析(详解)⼀、关于AndroidManifest.xmlAndroidManifest.xml 是每个android程序中必须的⽂件。
它位于整个项⽬的根⽬录,描述了package中暴露的组件(activities, services, 等等),他们各⾃的实现类,各种能被处理的数据和启动位置。
除了能声明程序中的Activities, ContentProviders, Services, 和Intent Receivers,还能指定permissions和instrumentation(安全控制和测试)⼆、AndroidManifest.xml结构<?xmlversion="1.0"encoding="utf-8"?><manifest><application><activity><intent-filter><action/><category/></intent-filter></activity><activity-alias><intent-filter></intent-filter><meta-data/></activity-alias><service><intent-filter></intent-filter><meta-data/></service><receiver><intent-filter></intent-filter><meta-data/></receiver><provider><grant-uri-permission/><meta-data/></provider><uses-library/></application><uses-permission/><permission/><permission-tree/><permission-group/><instrumentation/><uses-sdk/><uses-configuration/><uses-feature/><supports-screens/></manifest>三、各个节点的详细介绍上⾯就是整个am(androidManifest).xml的结构,下⾯以外向内开始阐述~~1、第⼀层(<Manifest>):(属性)A、xmlns:androidB、package指定本应⽤内java主程序包的包名,它也是⼀个应⽤进程的默认名称C、sharedUserIdD、sharedUserLabel⼀个共享的⽤户名,它只有在设置了sharedUserId属性的前提下才会有意义E、versionCode是给设备程序识别版本(升级)⽤的必须是⼀个interger值代表app更新过多少次,⽐如第⼀版⼀般为1,之后若要更新版本就设置为2,3等等。
Java相关课程系列笔记之五XML学习笔记(建议用WPS打开)

>XML学习笔记Java相关课程系列笔记之五笔记内容说明XML(范传奇老师主讲,占笔记内容100%);目录一、 XML基本语法 0XML介绍 0XML元素 0XML属性 0实体引用 0CDATA段 (1)DTD声明元素 (1)DTD声明元素:声明空元素 (2)DTD声明元素:含有PCDATA (2)DTD声明元素:带有子元素(子元素列表)的元素 (2)DTD声明元素:声明只出现一次的元素 (3)DTD声明元素:声明可多次出现的元素 (3)DTD声明元素:子元素只能是其中之一的情况 (3)DTD声明元素:子元素可以是元素也可以是文本 (3)DTD声明元素:总结 (4)DTD中声明元素的属性 (4)属性类型 (4)属性值的约束 (4)DTD命名空间介绍 (4)二、 Schema简介 (5)Schema的作用 (5)Schema文件的扩展名xsd (5)三、 Java解析XML (6)Java与XML共同点 (6)Java解析XML有两种方式 (6)JDOM/DOM4J (6)DOM解析 (6)SAX解析 (6)案例:使用DOM4J包的核心API解析xml文件 (6)案例:使用DOM4J包的核心API写入xml文件 (6)四、 XPath语言 (8)XPath基本介绍 (8)使用XPath的好处 (8)XPath基本语法 (8)DOM4J对XPath的支持 (8)五、附文件 (9)一、XML基本语法XML介绍1)XML是可扩展标记语言(EXtensible Markup Language)。
2)XML是独立于软件和硬件的信息传输工具。
3)XML是以文本的形式存在于一个文本文件中的,一般该文件的后缀名就是“.xml”,例如:。
4)XML的设计宗旨是传输信息(尤其是结构比较复杂的数据),而不是显示数据。
5)XML可以描绘树状结构的数据。
因为这个特点,除了传输数据外,更多时候我们使用XML作为配置文件。
XML学习总结(二)——XML入门

XML学习总结(⼆)——XML⼊门⼀、XML语法学习 学习XML语法的⽬的就是编写XML ⼀个XML⽂件分为如下⼏部分内容:⽂档声明元素属性注释CDATA区、特殊字符处理指令(processing instruction)1.1、xml语法——⽂档声明 在编写XML⽂档时,需要先使⽤⽂档声明,声明XML⽂档的类型。
最简单的声明语法:<?xml version="1.0" ?> 例如:1<?xml version="1.0"?>2<softCompany>3<company>MicroSoft</company>4<company>google</company>5<company>Apple</company>6</softCompany> 浏览器解析结果如下: ⽤encoding属性说明⽂档的字符编码:<?xml version="1.0" encoding="GB2312" ?> 当XML⽂件中有中⽂时,必须使⽤encoding属性指明⽂档的字符编码,例如:encoding="GB2312"或者encoding="utf-8",并且在保存⽂件时,也要以相应的⽂件编码来保存,否则在使⽤浏览器解析XML⽂件时,就会出现解析错误的情况。
例如:1<?xml version="1.0"?>2<softCompany>3<company>MicroSoft</company>4<company>google</company>5<company>Apple</company>6<company>百度</company>7</softCompany> 这个XML⽂件中没有使⽤encoding属性来指明⽂档的字符编码,但⽂档⾥⾯有“百度”这样的中⽂字符,在使⽤IE浏览器解析该XML⽂件时,IE就不知道该使⽤什么编码去解析该⽂件,就⽆法解析了,出现的错误如下图(图-1)所⽰: 图-1 要想正确解析该XML⽂档,就可以使⽤encoding属性指明该⽂档的字符编码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
XML学习笔记
1.eXtensible Markup Language(可扩展标记语言)。
2.为什么要学习XML:
数据交换的需要,电子商务的基础,可扩展的开放的标记语言。
配置文件等...
3.XML核心技术:
文档描述、验证、约束技术、DTD/Schema
文档转换技术XSL
数据查询技术XPath
链接技术XLink/XPointer
编程接口DOM/SAX
4.Document Type Definition(DTD,文档类型定义)
5.XML的优越性:
(1)XML是使信息自描述的新语言
(2)自定义数据格式,而且很容易使用工具读写
(3)支持各种通道的数据传输
(4)数据重用
(5)分离数据和显示
(6)可扩展
(7)文档包含语意
(8)容易阅读/工具/树形结构面向对象编程
6.实体:
作用:避免重复输入(宏,变量)
XML中预定义实体:实体--符号
<--< >--> &--&
"--" '--'
自定义实体语法:
<!DOCTYPE 根元素[
<!ENTITY 实体名"实体内容">
]>
引用已定义的实体:
&实体名;
7.格式正规的XML文档:
(1)必须有XML声明语句
<?xml version="1.0" encoding="utf-8"?>
(2)必须有且仅有一个根元素
(3)标记大小写敏感
(4)属性值用引号
(5)标记成对
(6)空标记关闭
(7)元素正确嵌套
8.格式正规(well formed)的XML文档。
符合XML语法要求的XML文档就是格
式正规的XML文档。
9.有效的(valid)XML文档。
首先XML文档是个格式正规的文档,然后
又需要满足DTD的要求,这样的XML文档成为有效的XML文档。
10.什么是DTD、为什么要用DTD
DTD用来描述XML文档的结构,一个DTD文档包含:
元素(ELEMENT)的定义规则,元素之间的关系规则,属性(ATTLIST)的定义规则,可使用的实体(ENTITY)或符号(NOTATION)规则
11.DTD文档与XML文档实例的关系,类似类与对象的关系,数据库表结构与数据记录的关系。
有了DTD,每个XML文件可以携带一个自身格式的描述。
有了DTD,不同组织的人可以使用一个通用DTD用来交换数据。
应用程序可以使用一个标准DTD校验从外部世界接受来的XML数据是否有效。
可以使用DTD校验自己的XML数据
12.DTD文档的声明及引用:
内部DTD文档 <!DOCTYPE 根元素[定义内容]>
外部DTD文档 <!DOCTYPE 根元素 SYSTEM "DTD文件路径"
内外部DTD文档结合 <!DOCTYPE 根元素 SYSTEM "DTD文件路径"[定义内容]> 13.修饰符号:
()用来给元素分组
| 在列出的对象中选择一个
+ 该对象最少出现一次(1或多次)
* 该对象允许出现任意多次(0到多次)
?该对象可以出现,当只能出现一次(0到1次)
,对象必须按指定的顺序出现
14.属性:
语法:<!ATTLIST 元素名称
属性名称类型属性特点
......
>
15.属性类型:CDATA
属性值可以是任何字符(包括数字和中文)
<!ATTLIST 木偶
姓名 CDATA #REQUIRED
>
16.属性类型-IDREF/IDREFS
IDREF属性的值指向文档中其它地方声明的ID类型的值。
IDREFS同IDREF,但是可以具有由空格分开的多个引用。
17.属性的特点
#REQUIRED(必须有),#IMPLIED(可以忽略),#FIXED(指定的固定值)
#DEFAULT (提供的默认值)
18.关于普通实体与参数实体
(1)普通实体是在dtd中定义,xml中使用,使用的格式为:%address; (2)参数实体是在dtd中定义,dtd中使用,定义的时候使用%,使用的时候也需要使用%,%address;
19.为何要Schema
DTD的局限性:
(1)DTD不遵守XML语法(写XML文档实例时候用一种语法,写DTD的时候用另外一种语法)
(2)DTD数据类型有限(与数据库数据类型不一致)
(3)DTD不可扩展
(4)DTD不支持命名空间(命名冲突)
Schema的新特性
(1)Schema基于XML语法
(2)Schema可以用能处理XML文档的工具处理
(3)Schema大大扩充了数据类型,可以自定义数据类型
(4)Schema支持元素的继承-Object-Oriented
(5)Schema支持属性组
20.所有的Schema文档,其根元素必须为Schema
21.SimpleType与ComplexType的区别:
(1)SimpleType类型的元素没有子元素,也没有属性。
(2)当需要定义的元素包含了子元素或者属性时,必须要使用ComplexType (3)SimpleContent,用于ComplexType元素上,用于限定该ComplexType的内容类型,表示该ComplexType没有子元素,同时该ComplexType需要有属性,否则它就成为SimpleType了。
22.简单工厂模式:
简单工厂模式是类的创建模式,又叫做静态工厂方法(Static Factory Method)模式。
简单工厂模式是由一个工厂对象决定创建出那一种产品类的实例。
通常它根据自变量的不同返回不同的类的实例。
23.通过DOCTYPE可以明确指定文档的根元素,Schema不能。
24.DOM:Document Object Model(文档对象模型)
对于XML应用开发来说,DOM就是一个对象化的XML数据接口,一个与语言无关、与平台无关的标准接口规范
25.要严格区分XML文档树中根结点与根元素结点:
根结点(Document)代表的是XML文档本身,是我们解析XML文档的入口,而根元素结点则表示XML文档的根元素,它对应于XML文档的Root
26.simpleType元素:定义一个简单类型
三种方式:
Restrict限定一个范围
List从列表中选择
Union包含一个值的结合
27.DOM的基本对象:
一切都是节点(对象)
Node对象:DOM结构中最为基本的对象
Document对象:代表整个XML的文档
NodeList对象:包含一个或者多个Node的列表
Element对象:代表XML文档中的标签元素
28.JAXP(Java API for XML Parsing):用于XML解析的JAVA API
29.SAX(Simple APIs for XML),面向XML的简单APIs
30.使用DOM解析XML时,首先将XML文档加载到内存当中,然后可以通过随机的访问方式访问内存中的DOM树;SAX是基于事件而且是顺序执行的,一旦经过了某个元素,我们就没有办法再去访问它了,SAX不必事先将整个XML文档加载到内存当中,因此它占据内存要比DOM小,对于大型的XML文档来说,通常会使用SAX而不是DOM进行解析。
31.简单类型值的约束:
Enumeration,fractionDigits,length,maxExclusive,maxInclusive,maxLength ,minExclusive,minInclusive,minLength,patter,totalDigits,whiteSpace 32.XML Schema中,有3类共7种指示器
All,sequence,choice,minOccurs,maxOccurs,Group,attributeGroup,
Any,anyAttribute
33.方法链编程风格(method chain style)
34.对于JDOM的Format类的getRawFormat方法通常用于XML数据的网络传输,因为这种格式会去掉所有不必要的空白,因此能够减少网络传输的数据量。