网易视频云:HBase – 存储文件HFile结构解析
Hfile文件详解

Table of ContentsHFile存储格式Block块结构HFile存储格式HFile是参照谷歌的SSTable存储格式进行设计的,所有的数据记录都是通过它来完成持久化,其内部主要采用分块的方式进行存储,如图所示:每个HFile内部包含多种不同类型的块结构,这些块结构从逻辑上来讲可归并为两类,分别用于数据存储和数据索引(简称数据块和索引块),其中数据块包括:(1) DATA_BLOCK:存储表格数据(2) BLOOM_CHUNK:存储布隆过滤器的位数组信息(3) META_BLOCK:存储元数据信息(4) FILE_INFO:存储HFile文件信息索引块包括:表格数据索引块(ROOT_INDEX、INTERMEDIATE_INDEX、LEAF_INDEX) 在早期的HFile版本中(version-1),表格数据是采用单层索引结构进行存储的,这样当数据量上升到一定规模时,索引数据便会消耗大量内存,导致的结果是Region加载效率低下(A region is not considered opened until all of its block index data is loaded)。
因此在version-2版本中,索引数据采用多层结构进行存储,加载HFile时只将根索引(ROOT_INDEX)数据载入内存,中间索引(INTERMEDIATE_INDEX)和叶子索引(LEAF_INDEX)在读取数据时按需加载,从而提高了Region的加载效率。
∙元数据索引块(META_INDEX)新版本的元数据索引依然是单层结构,通过它来获取元数据块信息。
∙布隆索引信息块(BLOOM_META)通过索引信息来遍历要检索的数据记录是通过哪一个BLOOM_CHUNK进行映射处理的。
从存储的角度来看,这些数据块会划分到不同的区域进行存储。
1. Trailer区域该区域位于文件的最底部,HFile主要通过它来实现相关数据的定位功能,因此需要最先加载,其数据内容是采用protobuf进行序列化处理的,protocol声明如下:message FileTrailerProto {optional uint64 file_info_offset = 1;optional uint64 load_on_open_data_offset = 2;optional uint64 uncompressed_data_index_size = 3;optional uint64 total_uncompressed_bytes = 4;optional uint32 data_index_count = 5;optional uint32 meta_index_count = 6;optional uint64 entry_count = 7;optional uint32 num_data_index_levels = 8;optional uint64 first_data_block_offset = 9;optional uint64 last_data_block_offset = 10;optional string comparator_class_name = 11;optional uint32 compression_codec = 12;optional bytes encryption_key = 13;}FileInfo数据块在HFile中的偏移量信息;Load-on-open区域在HFile中的偏移量信息;所有表格索引块在压缩前的总大小;所有表格数据块在压缩前的总大小;根索引块中包含的索引实体个数;元数据索引块中包含的索引实体个数;文件所包含的KeyValue总数;表格数据的索引层级数;第一个表格数据块在HFile中的偏移量信息;最后一个表格数据块在HFile中的偏移量信息;在代码层面上Trailer是通过FixedFileTrailer类来封装的,可通过其readFromStream方法用来读取指定HFile的Trailer信息。
hbase hfile的组织结构

hbase hfile的组织结构HBase是一个分布式的、面向列的开源数据库,它构建在Hadoop之上,提供了实时读写访问海量数据的能力。
而HFile则是HBase中存储数据的一种格式,其组织结构非常重要,对于数据的存储和查询都有很大的影响。
本文将详细介绍HBase和HFile的组织结构。
一、HBase1.1 HBase概述HBase是一个基于列族(Column Family)存储模型的分布式数据库,它是Apache Hadoop生态系统中非常重要的一部分。
它采用了Google Bigtable论文中描述的数据模型,并且将其应用到了Apache Hadoop之上。
因此,HBase具有以下特点:(1)可扩展性:可以轻松地添加更多节点来处理更多数据。
(2)高可靠性:可以通过复制来提高数据可靠性。
(3)高性能:支持快速随机读写操作。
(4)灵活性:支持动态添加或删除列族。
1.2 HBase架构HBase架构主要由以下几个部分组成:(1)RegionServer:负责处理客户端请求,并且与HDFS交互来存储和检索数据。
(2)ZooKeeper:用于协调和管理集群状态信息。
(3)Master Server:负责管理RegionServer的分配和负载均衡。
(4)HDFS:用于存储HBase中的数据。
1.3 HBase数据模型HBase的数据模型与传统关系型数据库不同,它采用了基于列族的存储模型。
在HBase中,每个表可以包含多个列族,每个列族可以包含多个列。
对于每行数据,它可以包含所有列族的所有列或者只包含某些列族的某些列。
这种数据存储方式使得HBase非常适合存储海量数据,并且能够支持快速随机读写操作。
二、HFile2.1 HFile概述HFile是HBase中存储数据的一种格式,它是基于块状文件格式(Block-Structured File Format)实现的。
在HBase中,所有数据都被组织成了一个或多个Region。
hbase中数据的存储规格

hbase中数据的存储规格
HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,主要包括HFile和HLog File两种文件类型。
HFile是HBase中KeyValue数据的存储格式,是Hadoop的二进制格式文件。
实际上,StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile。
HFile文件是不定长的,长度固定的只有其中的Trailer和FileInfo两块。
Trailer中有指针指向其他数据块的起始点,而File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN、AVG_VALUE_LEN、LAST_KEY、COMPARATOR、MAX_SEQ_ID_KEY等。
此外,HFile的Data Block和Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,但也需要花费CPU进行压缩和解压缩。
HLog File则是HBase中WAL(Write Ahead Log)的存储格式,物理上是Hadoop的Sequence File。
网易视频云技术分享:HBase BlockCache系列-性能对比测试报告

网易视频云技术分享:HBaseBlockCache系列-性能对比测试报告网易视频云是网易倾力打造的一款基于云计算的分布式多媒体处理集群和专业音视频技术,提供稳定流畅、低时延、高并发的视频直播、录制、存储、转码及点播等音视频的PAAS 服务,在线教育、远程医疗、娱乐秀场、在线金融等各行业及企业用户只需经过简单的开发即可打造在线音视频平台。
HBaseBlockCache系列文章到了终结篇,几个主角的是是非非也该有个了断了,在SlabCache被早早地淘汰之后,站在华山之巅的也就仅剩LRU君(LRUBlockCache)和CBC君(binedBlockCache)。
谁赢谁输,我说了不算,你说了也不算,那就来让数据说话。
这篇文章主要对比LRU君和CBC君(offheap模式)分别在四种场景下几种指标(GC、Throughput、Latency、CPU、IO等)的表现情况。
四种场景分别是缓存全部命中、少大部分缓存命中、少量缓存命中、缓存基本未命中。
需要注意的是,本文的所有数据都来自社区文档,在这里分享也只是给大家一个参考,更加详细的测试数据可以阅读文章《paring BlockCache Deploys》和HBASE-11323附件报告。
说明:本文所有图都以时间为横坐标,纵坐标为对应指标。
每X图都会分别显示LRU 君和CBC君的四种场景数据,总计八种场景,下面数据表示LRU君的四种场景分布在时间段21:36:39~22:36:40,CBC君的四种场景分布在时间段23:02:16~00:02:17,看图的时候需要特别注意。
LRU君:Tue Jul 22 21:36:39 PDT 2014 run size=32, clients=25 ; lrubc time=1200 缓存全部命中Tue Jul 22 21:56:39 PDT 2014 run size=72, clients=25 ; lrubctime=1200 大量缓存命中Tue Jul 22 22:16:40 PDT 2014 run size=144, clients=25 ;lrubc time=1200 少量缓存命中Tue Jul 22 22:36:40 PDT 2014 run size=1000, clients=25 ; lrubc time=1200 缓存基本未命中CBC君:Tue Jul 22 23:02:16 PDT 2014 run size=32, clients=25 ; buckettime=1200 缓存全部命中Tue Jul 22 23:22:16 PDT 2014 run size=72, clients=25 ; bucket time=1200 大量缓存命中Tue Jul 22 23:42:17 PDT 2014 run size=144, clients=25 ; bucket time=1200 少量缓存命中Wed Jul 23 00:02:17 PDT 2014 run size=1000, clients=25 ; bucket time=1200 缓存基本未命中GCGC指标是HBase运维最关心的指标,出现一次长时间的GC就会导致这段时间内业务方的所有读写请求失败,如果业务方没有很好的容错,就会出现丢数据的情况出现。
hfile格式详细介绍

HFile: A Block-Indexed File Formatto Store Sorted Key-Value PairsSep 10, 2009 Schubert Zhang (schubert.zhang@) 1. IntroductionHFile is a mimic of Google’s SSTable. Now, it is available in Hadoop HBase-0.20.0. And the previous releases of HBase temporarily use an alternate file format – MapFile[4], which is a common file format in Hadoop IO package. I think HFile should also become a common file format when it becomes mature, and should be moved into the common IO package of Hadoop in the future.Following words of SSTable are from section 4 of Google’s Bigtable paper.The Google SSTable file format is used internally to store Bigtable data. An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Operations are provided to look up the value associated with a specified key, and to iterate over all key/value pairs in a specified key range. Internally, each SSTable contains a sequence of blocks (typically each block is 64KB in size, but this is configurable). A block index (stored at the end of the SSTable) is used to locate blocks; the index is loaded into memory when the SSTable is opened. A lookup can be performed with a single disk seek: we first find the appropriate block by performing a binary search in the in-memory index, and then reading the appropriate block from disk. Optionally, an SSTable can be completely mapped into memory, which allows us to perform lookups and scans without touching disk.[1]The HFile implements the same features as SSTable, but may provide more or less.2. File FormatData Block SizeWhenever we say Block Size, it means the uncompressed size.The size of each data block is 64KB by default, and is configurable in HFile.Writer. It means the data block will not exceed this size more than one key/value pair. The HFile.Writer starts a new data block to add key/value pairs if the current writing block is equal to or bigger than this size. The 64KB size is same as Google’s [1].To achieve better performance, we should select different block size. If the average key/value size is very short (e.g. 100 bytes), we should select small blocks (e.g. 16KB) to avoid too many key/value pairs in each block, which will increase the latency of in-block seek, because the seeking operation always finds the key from the first key/value pair in sequence within a block.Maximum Key LengthThe key of each key/value pair is currently up to 64KB in size. Usually, 10-100 bytes is a typical size for most of our applications. Even in the data model of HBase, the key (rowkey+column family:qualifier+timestamp) should not be too long.Maximum File SizeThe trailer, file-info and total data block indexes (optionally, may add meta block indexes) will be in memory when writing and reading of an HFile. So, a larger HFile (with more data blocks) requires more memory. For example, a 1GB uncompressed HFile would have about 15600 (1GB/64KB) data blocks, and correspondingly about 15600 indexes. Suppose the average key size is 64 bytes, then we need about 1.2MB RAM (15600X80) to hold these indexes in memory.Compression Algorithm-Compression reduces the number of bytes written to/read from HDFS. -Compression effectively improves the efficiency of network bandwidth and disk space-Compression reduces the size of data needed to be read when issuinga readTo be as low friction as necessary, a real-time compression library is preferred. Currently, HFile supports following three algorithms:(1)NONE (Default, uncompressed, string name=”none”)(2)GZ (Gzip, string name=”gz”)Out of the box, HFile ships with only Gzip compression, which is fairly slow.(3)LZO(Lempel-Ziv-Oberhumer, preferred, string name=”lzo”)To achieve maximal performance and benefit, you must enable LZO, which is a lossless data compression algorithm that is focused on decompression speed.Following figures show the format of an HFile.In above figures, an HFile is separated into multiple segments, from beginning to end, they are:-Data Block segmentTo store key/value pairs, may be compressed.-Meta Block segment (Optional)To store user defined large metadata, may be compressed.-File Info segmentIt is a small metadata of the HFile, without compression. User can add user defined small metadata (name/value) here.-Data Block Index segmentIndexes the data block offset in the HFile. The key of each index is the key of first key/value pair in the block.-Meta Block Index segment (Optional)Indexes the meta block offset in the HFile. The key of each index is the user defined unique name of the meta block.-TrailerThe fix sized metadata. To hold the offset of each segment, etc. To read an HFile, we should always read the Trailer firstly.The current implementation of HFile does not include Bloom Filter, which should be added in the future.The FileInfo is a SortedMap in implementation. So the actual order of thosefields is alphabetically based on the key.3. LZO CompressionLZO is now removed from Hadoop or HBase 0.20+ because of GPL restrictions. To enable it, we should install native library firstly as following.[6][7][8][9](1)Download LZO: /, and build.# ./configure --build=x86_64-redhat-linux-gnu --enable-shared--disable-asm# make# make installThen the libraries have been installed in: /usr/local/lib(2)Download the native connector library/p/hadoop-gpl-compression/, and build.Copy hadoo-0.20.0-core.jar to ./lib.# ant compile-native# ant jar(3)Copy the native library (build/native/Linux-amd64-64) andhadoop-gpl-compression-0.1.0-dev.jar to your application’s libdirectory. If your application is a MapReduce job, copy them to hadoop’s lib directory. Your application should follow the$HADOOP_HOME/bin/hadoop script to ensure that the native hadoop library is on the library path via the system property-Djava.library.path=<path>. [9] For example:Then our application and hadoop/MapReduce can use LZO.4. Performance EvaluationTestbed− 4 slaves + 1 master−Machine: 4 CPU cores (2.0G), 2x500GB 7200RPM SATA disks, 8GB RAM.−Linux: RedHat 5.1 (2.6.18-53.el5), ext3, no RAID, noatime−1Gbps network, all nodes under the same switch.−Hadoop-0.20.0 (1GB heap), lzo-2.0.3Some MapReduce-based benchmarks are designed to evaluate the performance of operations to HFiles, in parallel.−Total key/value entries: 30,000,000.−Key/Value size: 1000 bytes (10 for key, and 990 for value). We have totally 30GB of data.−Sequential key ranges: 60, i.e. each range have 500,000 entries.−Use default block size.−The entry value is a string, each continuous 8 bytes are a filled with a same letter (A~Z). E.g. “BBBBBBBBXXXXXXXXGGGGGGGG……”. We set mapred.tasktracker.map.tasks.maximum=3 to avoid client side bottleneck.(1)WriteEach MapTask for each range of key, which writes a separate HFile with 500,000 key/value entries.(2)Full ScanEach MapTask scans a separate HFile from beginning to end.(3)Random Seek a specified keyEach MapTask opens one separate HFile, and selects a random key within that file to seek it. Each MapTask runs 50,000 (1/10 of the entries) random seeks.(4)Random Short ScanEach MapTask opens one separate HFile, and selects a random key within that file as a beginning to scan 30 entries. Each MapTask runs 50,000 scans, i.e. scans 50,000*30=1,500,000 entries.This table shows the average entries which are written/seek/scanned per second, and per node.In this evaluation case, the compression ratio is about 7:1 for gz(Gzip), and about 4:1 for lzo. Even through the compression ratio is just moderate, the lzo column shows the best performance, especially for writes.The performance of full scan is much better than SequenceFile, so HFile may provide better performance to MapReduce-based analytical applications.The random seek in HFiles is slow, especially in none-compressed HFiles. But the above numbers already show 6X~10X better performance than a disk seek (10ms). Following Ganglia charts show us the overhead of load, CPU, and network. The random short scan makes the similar phenomena.5. Implementation and API5.1 HFile.Writer : How to create and write an HFile(1) ConstructorsThere are 5 constructors. We suggest using following two:public Writer(FileSystem fs, Path path, int blocksize,String compress,final RawComparator<byte []> comparator)public Writer(FileSystem fs, Path path, int blocksize,Compression.Algorithm compress,final RawComparator<byte []> comparator)These two constructors are same. They create file (call fs.create(…)) and get an FSDataOutputStream for writing. Since the FSDataOutputStream iscreated when constructing the HFile.Writer, it will be automatically closed when the HFile.Writer is closed.The other two constructors provide FSDataOutputStream as a parameter. It means the file is created and opened outside of the HFile.Writer, so, when we close the HFile.Writer, the FSDataOutputStream will not be closed. But we do not suggest using these two constructors directly.public Writer(final FSDataOutputStream ostream, final int blocksize, final String compress,final RawComparator<byte []> c)public Writer(final FSDataOutputStream ostream, final int blocksize, final Compression.Algorithm compress,final RawComparator<byte []> c)Another constructor only provides fs and path as parameters, all other attributes are default, i.e. NONE of compression, 64KB of block size, raw ByteArrayComparator, etc.(2) Write Key/Value pairs into HFileBefore key/value pairs are written into an HFile, the application must sort them using the same comparator, i.e. all key/value pairs must be sequentially and increasingly write/append into an HFile. There are following methods to write/append key/value pairs:public void append(final KeyValue kv)public void append(final byte [] key, final byte [] value)public void append(final byte [] key, final int koffset, final int klength, final byte [] value, final int voffset, final int vlength)When adding a key/value pair, they will check the current block size. If the size reach the maximum size of a block, the current block will be compressed and written to the output stream (of the HFile), and then create a new block for writing. The compression is based on each block. For each block, an output stream for compression will be created from beginning of a new block and released when finish.Following chart is the relationship of the output steams OO design:The key/value appending operation is written from the outside (DataOutputStream), and the above OO mechanism will handle the buffer and compression functions and then write to the file in under layer file system.Before a key/value pair is written, following will checked:-The length of Key-The order of Key (must bigger than the last one)(3) Add metadata into HFileWe can add metadata block into an HFile.public void appendMetaBlock(String metaBlockName, byte [] bytes)The application should provide a unique metaBlockName for each metadata block within an HFile.Reminding: If your metadata is large enough (e.g. 32KB uncompressed), you can use this feature to add a separate meta block. It may be compressed in the file.But if your metadata is very small (e.g. less than 1KB), please use following method to append it into file info. File info will not be compressed.public void appendFileInfo(final byte [] k, final byte [] v)(4) CloseBefore the HFile.Writer is closed, the file is not completed written. So, we must call close() to:-finish and flush the last block-write all meta block into file (may be compressed)-generate and write file info metadata-write data block indexes-write meta block indexes-generate and write trailer metadata-close the output-stream.5.2 HFile.Reader: How to read HFileCreate an HFile.Reader to open an HFile, and we can seek, scan and read on it.(1) ConstructorWe suggest using following constructor to create an HFile.Reader.public Reader(FileSystem fs, Path path, BlockCache cache,boolean inMemory)It calls fs.open(…) to open the file, and gets an FSDataInputStream for reading. The input stream will be automatically closed when the HFile.Reader is closed.Another constructor uses InputStream as parameter directly. It means the file is opened outside the HFile.Reader.public Reader(final FSDataInputStream fsdis, final long size,final BlockCache cache, final boolean inMemory)We can use BlockCache to improve the performance of read, and the mechanism of mechanism will be described in other document.(2) Load metadata and block indexes of an HFileThe HFile is not readable before loadFileInfo() is explicitly called . It will read metadata (Trailer, File Info) and Block Indexes (data block and meta block) into memory. And the COMPARATOR instance will reconstruct from file info.BlockIndexThe important method of BlockIndex is:int blockContainingKey(final byte[] key, int offset, int length)It uses binarySearch to check if a key is contained in a block. The return value of binarySearch() is very puzzled:IndexList Before0 1 2 3 4 5 6 …BlockDatabinarySearch() return -1 -2-3-4-5-6-7 -8 …HFileScannerWe must create an HFile.Reader.Scanner to seek, scan, and read on an HFile. HFile.Reader.Scanner is an implementation of HFileScanner interface.To seek and scan in an HFIle, we should do as following:(1)Create a HFile.Reader, and loadFileInfo().(2)In this HFile.Reader, calls getScanner() to obtain an HFileScanner.(3).1 For a scan from the beginning of the HFile, calls seekTo() toseek to the beginning of the first block..2 For a scan from a key, calls seekTo(key) to seek to the position of the key or before the key (if there is not such a key in this HFile)..3 For a scan from before of a key, calls seekBefore(key).(4)Calls next() to iterate over all key/value pairs. The next() willreturn false when it reach the end of the HFile. If an application wants to stop at any condition, it should be implemented by the application itself. (e.g. stop at a special endKey.)(5)If you want lookup a specified key, just call seekTo(key), thereturned value=0 means you found it.(6)After we seekTo(…) or next() to a position of specified key, wecan call following methods to get the current key and value.public KeyValue getKeyValue() // recommendedpublic ByteBuffer getKey()public ByteBuffer getValue()(7)Don’t forget to close the HFile.Reader. But a scanner need not beclosed, since it does not hold any resource.References[1]Google, Bigtable: A Distributed Storage System for Structured Data,/papers/bigtable.html[2]HBase-0.20.0 Documentation,/hbase/docs/r0.20.0/[3]HFile code review and refinement./jira/browse/HBASE-1818[4]MapFile API:/common/docs/current/api/org/apache/hadoop/io/MapFile.html[5]Parallel LZO: Splittable Compression for Hadoop./blog/2009/06/24/parallel-lzo-splittable-compression-for-hadoop//2009/06/parallel-lzo-splittable-on-hadoop-using-cloudera/[6]Using LZO in Hadoop and HBase:/hadoop/UsingLzoCompression[7]LZO: [8]Hadoop LZO native connector library:/p/hadoop-gpl-compression/[9]Hadoop Native Libraries Guide:/common/docs/r0.20.0/native_libraries.html。
hbase catalog 表结构

HBase是一种面向列的分布式数据库,通常用于存储大量结构化数据。
HBase的数据模型是基于表的,而表的结构则是由列族和列修饰符组成的。
1. 列族列族是HBase表的一个重要组成部分。
在HBase中,每一行数据都可以有多个列族。
列族在表创建时就需要定义,并且一旦创建后就无法更改。
列族中的列修饰符可以动态添加和删除。
列族中的列修饰符都具有相同的前缀,并且列族中的列修饰符数量是不限的。
2. 列修饰符列修饰符是表中的一个具体的列。
每一行数据都可以有多个列修饰符。
列修饰符一般包含三个部分:列族前缀、列修饰符标识符、时间戳。
列修饰符的标识符可以使用任意的字符串,但是建议使用有意义的标识符来方便对数据的理解和管理。
3. 表结构HBase的表结构由列族和列修饰符组成。
一张HBase表可以包含多个列族,而每个列族中可以包含多个列修饰符。
表结构的设计需要根据具体的业务需求和数据特点来决定。
通常来说,表的结构设计的好坏直接影响到数据的访问性能和扩展性。
4. 表结构设计原则在进行HBase表结构设计时,需要遵循一些基本原则:- 确定数据访问模式:需要根据业务需求来确定数据的访问模式,从而决定表的结构。
- 合理划分列族:需要根据业务需求和数据特点来合理划分列族,避免不必要的数据冗余和重复。
- 合理设计列修饰符:需要根据业务需求来合理设计列修饰符,使得数据能够被高效地访问和管理。
- 考虑数据增长和扩展性:需要考虑数据的增长和系统的扩展性,设计出能够支持大规模数据存储和访问的表结构。
总结HBase表的结构由列族和列修饰符组成。
在设计表结构时,需要根据业务需求和数据特点来合理划分列族和设计列修饰符,以提高数据的访问性能和管理效率。
需要考虑数据的增长和系统的扩展性,设计出能够支持大规模数据存储和访问的表结构。
为了更好地理解HBase表的结构,我们需要深入探讨列族和列修饰符的设计原则以及相关的最佳实践。
在设计HBase表结构时,列族和列修饰符的合理设计是至关重要的,因为它们直接影响了数据的存储方式、访问性能和系统的扩展性。
网易视频云技术分享:HBase - 建表语句解析

网易视频云技术分享:HBase -建表语句解析网易视频云是网易公司旗下的视频云服务产品,以Paas服务模式,向开发者提供音视频编解码SDK和开放API,助力APP接入音视频功能。
现在,网易视频云的技术专家给大家分享一篇技术性文章:HBase -建表语句解析。
像所有其他数据库一样,HBase也有表的概念,有表的地方就有建表语句,而且建表语句还很大程度上决定了这张表的存储形式、读写性能。
比如我们熟悉的MySQL,建表语句中数据类型决定了数据的存储形式,主键、索引则很大程度上影响着数据的读写性能。
虽然HBase没有主键、索引这些概念,但在HBase的世界里,有些东西和它们一样重要!废话不说,直接奉上一条HBase建表语句,来为各位看官分解剖析:create'NewsClickFeedback',{NAME=>'Toutiao',VERSIONS=>1,BLOCKCACHE=>true,BLOOMFILTER=> 'ROW',COMPRESSION=>'SNAPPY',TTL => ' 259200 '},{SPLITS =>['1','2','3','4','5','6','7','8','9','a','b','c','d','e','f']}上述建表语句表示创建一个表名为“NewsClickFeedback”的表,该表只包含一个列簇“Toutiao”。
接下来重点讲解其他字段的含义以及如何正确设置。
Note:因为篇幅有限本文并不讲解具体的工作原理,后续会有相关专题对其进行分析。
hbase.loadincrementalhfiles 参数-概述说明以及解释

hbase.loadincrementalhfiles 参数-概述说明以及解释1.引言1.1 概述在大数据处理中,HBase作为一种分布式的、面向列的NoSQL数据库,被广泛应用于海量数据存储和实时查询场景。
而hbase.loadincrementalhfiles参数则是HBase中的一个重要参数,用于在数据装载过程中进行性能优化和调整。
该参数主要用于在HBase中,通过将预先生成的HFile文件装载至指定表中来加速数据导入过程。
HFile是一种适用于HBase的数据存储格式,它可以事先进行排序、压缩和索引,并且可以按照特定的分区键进行划分,以提高读写操作的效率。
当需要将大量数据导入HBase表中时,使用hbase.loadincrementalhfiles参数可以避免通过逐条插入数据的方式进行导入,从而大幅提高导入速度。
通过预先生成HFile文件,并使用该参数进行装载,可以实现批量导入操作,减少了网络传输和写入操作的开销,有效降低了导入数据的时间和资源消耗。
然而,虽然hbase.loadincrementalhfiles参数在提高导入速度方面具有显著的优势,但其也存在一定的限制和注意事项。
在使用该参数时,需要注意表的状态、RegionServer的负载以及网络带宽等因素,以避免对HBase集群的性能和稳定性造成不利影响。
本文将对hbase.loadincrementalhfiles参数进行详细介绍和说明其使用方法,通过对该参数的全面认识和合理使用,可以使数据导入过程更加高效、稳定和可靠。
同时,本文还将对该参数进行总结,并给出对其的一些建议,以帮助读者更好地应用和理解hbase.loadincrementalhfiles 参数的作用和价值。
1.2 文章结构本文共分为三个主要部分:引言、正文和结论。
以下是各个部分的详细介绍:1. 引言引言部分主要对本文的主题进行简要介绍,概述文章将要讨论的内容,并强调本文的目的。
网易视频云:HBase – Memstore Flush深度解析

网易视频云:HBase – Memstore Flush深度解析网易视频云技术专家给大家分享一则技术文章:HBase – Memstore Flush深度解析。
Memstore是HBase框架中非常重要的组成部分之一,是HBase能够实现高性能随机读写至关重要的一环。
深入理解Memstore的工作原理、运行机制以及相关配置,对hbase集群管理、性能调优都有着非常重要的帮助。
Memstore 概述HBase中,Region是集群节点上最小的数据服务单元,用户数据表由一个或多个Region组成。
在Region中每个ColumnFamily的数据组成一个Store。
每个Store由一个Memstore和多个HFile组成,如下图所示:之前我们提到,HBase是基于LSM-Tree模型的,所有的数据更新插入操作都首先写入Memstore中(同时会顺序写到日志HLog中),达到指定大小之后再将这些修改操作批量写入磁盘,生成一个新的HFile文件,这种设计可以极大地提升HBase的写入性能;另外,HBase为了方便按照RowKey进行检索,要求HFile中数据都按照RowKey 进行排序,Memstore数据在flush为HFile之前会进行一次排序,将数据有序化;还有,根据局部性原理,新写入的数据会更大概率被读取,因此HBase在读取数据的时候首先检查请求的数据是否在Memstore,写缓存未命中的话再到读缓存中查找,读缓存还未命中才会到HFile文件中查找,最终返回merged的一个结果给用户。
可见,Memstore无论是对HBase的写入性能还是读取性能都至关重要。
其中flush 操作又是Memstore最核心的操作,接下来重点针对Memstore的flush操作进行深入地解析:首先分析HBase在哪些场景下会触发flush,然后结合源代码分析整个flush 的操作流程,最后再重点整理总结和flush相关的配置参数,这些参数对于性能调优、问题定位都非常重要。
网易视频云:HBase – 存储文件HFile结构解析

网易视频云是网易推出的PaaS视频云服务,主要应用于在线教育、直播秀场、远程医疗、企业协作等领域。
今天,网易视频云技术专家与大家分享一下:HBase –存储文件HFile结构解析。
HFile是HBase存储数据的文件组织形式,参考BigTable的SSTable和Hadoop的TFile 实现。
从HBase开始到现在,HFile经历了三个版本,其中V2在0.92引入,V3在0.98引入。
HFileV1版本的在实际使用过程中发现它占用内存多,HFile V2版本针对此进行了优化,HFile V3版本基本和V2版本相同,只是在cell层面添加了Tag数组的支持。
鉴于此,本文主要针对V2版本进行分析,对V1和V3版本感兴趣的同学可以参考其他信息。
HFile逻辑结构HFile V2的逻辑结构如下图所示:文件主要分为四个部分:Scanned block section,Non-scanned block section,Opening-time data section和Trailer。
Scanned block section:顾名思义,表示顺序扫描HFile时所有的数据块将会被读取,包括Leaf Index Block和Bloom Block。
Non-scanned block section:表示在HFile顺序扫描的时候数据不会被读取,主要包括Meta Block和Intermediate Level Data Index Blocks两部分。
Load-on-open-section:这部分数据在HBase的region server启动时,需要加载到内存中。
包括FileInfo、Bloom filter block、data block index和meta block index。
Trailer:这部分主要记录了HFile的基本信息、各个部分的偏移值和寻址信息。
HFile物理结构如上图所示,HFile会被切分为多个大小相等的block块,每个block的大小可以在创建表列簇的时候通过参数blocksize=> ‘65535’进行指定,默认为64k,大号的Block有利于顺序Scan,小号Block利于随机查询,因而需要权衡。
HBase(三)HBase架构与工作原理

HBase(三)HBase架构与⼯作原理⼀、系统架构注意:应该是每⼀个 RegionServer 就只有⼀个 HLog,⽽不是⼀个 Region 有⼀个 HLog。
从HBase的架构图上可以看出,HBase中的组件包括Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等,接下来介绍他们的作⽤。
1、Client1、HBase 有两张特殊表:.META.:记录了⽤户所有表拆分出来的的 Region 映射信息,.META.可以有多个 Regoin-ROOT-:记录了.META.表的 Region 信息,-ROOT-只有⼀个 Region,⽆论如何不会分裂2、Client 访问⽤户数据前需要⾸先访问 ZooKeeper,找到-ROOT-表的 Region 所在的位置,然后访问-ROOT-表,接着访问.META.表,最后才能找到⽤户数据的位置去访问,中间需要多次⽹络操作,不过 client 端会做 cache 缓存。
2、ZooKeeper1、ZooKeeper 为 HBase 提供 Failover 机制,选举 Master,避免单点 Master 单点故障问题2、存储所有 Region 的寻址⼊⼝:-ROOT-表在哪台服务器上。
-ROOT-这张表的位置信息3、实时监控 RegionServer 的状态,将 RegionServer 的上线和下线信息实时通知给 Master4、存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family3、Master1、为 RegionServer 分配 Region2、负责 RegionServer 的负载均衡3、发现失效的 RegionServer 并重新分配其上的 Region4、HDFS 上的垃圾⽂件(HBase)回收5、处理 Schema 更新请求(表的创建,删除,修改,列簇的增加等等)4、RegionServer1、RegionServer 维护 Master 分配给它的 Region,处理对这些 Region 的 IO 请求2、RegionServer 负责 Split 在运⾏过程中变得过⼤的 Region,负责 Compact 操作可以看到,client 访问 HBase 上数据的过程并不需要 master 参与(寻址访问 zookeeper 和 RegioneServer,数据读写访问RegioneServer),Master 仅仅维护者 Table 和 Region 的元数据信息,负载很低。
HBase架构简介

HBase架构简介一、概览图1图1指出了在HBase中其实有两种文件,一种是write-ahead log,而另一种则是真正存储数据的地方。
而这些文件都被HRegionServers来处理。
从图中可以看出,文件最后在HDFS中存在不同的block中。
基本的通信流程是这样的:当一个client需要查询某一特点的row时,它会先连到Zookeeper(事实上是ZK管理的集群),并且从zookeeper获取持有-ROOT-的region的server name,有了这个信息以后,我们就可以去寻找包含刚刚我们查询的row的.META.的region的server name。
这些信息都会被客户端缓存下来。
最后,我们可以通过.META.找到持有我们所查询的rowkey的region。
一旦获取了这个row在哪个region中,这个信息也会被客户端缓存下来,所以下次再访问的时候,就可以直接访问那个region了。
过了一段时间后,客户端就会搜集到相当全面的信息:查询某row时应到哪个region去找,从而不需要去查询.META.了。
当HBase启动时,HMaster负责向各个RS分配region,其中当然也包括了-ROOT-和.META.某RS打开一个Region,这时会创建一个相应的HRegion对象,当HRegion打开时,它会为每一个HColumnFamily创建一个Store,每一个Store 都会有一个或者多个StoreFile的实例,它是对真正的存储文件HFile的轻量级封装。
每一个Store都会有一个MemStore,并且整个RS会共享一个HLog实例。
二、写当一个client向RS发起一个HTable.put(Put)的请求时,第一步先把数据写入write-ahead-log(WAL),被HLog所表示,这个WAL是一个标准的Hadoo SequenceFile,当Server挂掉以后再重启,WAL可以继续将未被持久化的数据持久化。
HBase学习笔记之HFile格式

HBase学习笔记之HFile格式主要看Roger的⽂档,这⾥作为⽂档的补充HFile的格式-HFile的基本结构Trailer通过指针找到Meta index、Data index、File info。
Meta index保存每⼀个元数据在HFile中的位置、⼤⼩、元数据的key值。
Data index保存每⼀个数据块在HFile中的位置、⼤⼩、块第⼀个cell的key值。
File Info保存HFile相关信息。
Meta块保存的是HFile的元数据,⽐如布隆过滤器。
Data块保存的为具体的数据,每个数据块有个Magic头,存储偏移量和⾸Key。
hfile中索引块的⼤⼩默认值是128K,当索引的信息超过128K后,就会新分配⼀个索引块。
hbase对于hfile的访问都是通过索引块来实现的,通过索引来定位所要查的数据到底在哪个数据块⾥⾯。
hfile中的索引块可以分成三中,根索引块,枝索引块,叶索引块。
根索引块是⼀定会有的,但是如果hfile中的数据块⽐较少的话,枝索引块和叶索引块就可能不存在。
当单个的索引块中没有办法存储全部的数据块的信息时,索引块就会分裂,会产⽣叶索引块和根索引块,根索引块是对叶索引块的索引,如果数据块继续增加就会产⽣枝索引块,整个索引结果的层次也会加深。
查看⼀个HFile的内容:hbase org.apache.hadoop.hbase.io.hfile.HFile -f /hbase/v_dm_user_app_d_201406/c64c6f7f7caf7f6d5a3f6bbc209dd2cb/c/0ebf8900a669462c8a9d9d908622928f -v -m -p14/07/10 10:23:33 INFO util.ChecksumType: Checksum can use java.util.zip.CRC32Scanning -> /hbase/v_dm_user_app_d_201406/c64c6f7f7caf7f6d5a3f6bbc209dd2cb/c/0ebf8900a669462c8a9d9d908622928f14/07/10 10:23:33 INFO hfile.CacheConfig: Allocating LruBlockCache with maximum size 246.9m14/07/10 10:23:33 ERROR metrics.SchemaMetrics: Inconsistent configuration. Previous configuration for using table name in metrics: true, new configuration: falseK: 135********|20140608-1/c:Q/1402368323157/Put/vlen=32/ts=0 V: 20140608\x0913519304818\x09\xE5\x85\xB6\xE4\xBB\x96\x090.38K: 135********|20140608-2/c:Q/1402368323157/Put/vlen=37/ts=0 V: 20140608\x0913519304818\x09\xE5\x85\xB6\xE4\xBB\x96-TCP\x0913.87K: 135********|20140608-32/c:Q/1402368323157/Put/vlen=36/ts=0 V: 20140608\x0913519304818\x09vivo\xE5\xAE\x98\xE7\xBD\x91\x0912.0K: 135********|20140608-23/c:Q/1402368323157/Put/vlen=37/ts=0 V: 20140608\x0913519306776\x09HTTP\xE4\xB8\x8A\xE7\xBD\x91\x09205.0K: 135********|20140608-24/c:Q/1402368323157/Put/vlen=36/ts=0 V: 20140608\x0913519306776\x09360\xE7\xBD\x91\xE7\xAB\x99\x09165.0K: 135********|20140608-25/c:Q/1402368323157/Put/vlen=31/ts=0 V: 20140608\x0913519306776\x09\xE6\xB7\x98\xE5\xAE\x9D\x098.0K: 135********|20140608-29/c:Q/1402368323157/Put/vlen=44/ts=0 V: 20140608\x0913519306776\x09\xE5\x8F\x8B\xE7\x9B\x9F\xE6\x9C\x8D\xE5\x8A\xA1\xE5\xB9\xB3\xE5\x8F\xB0\x0915.0K: 135********|20140608-3/c:Q/1402368323157/Put/vlen=33/ts=0 V: 20140608\x0913519306776\x09\xE5\x85\xB6\xE4\xBB\x96\x0925.89K: 135********|20140608-33/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519306776\x09\xE5\xBE\xAE\xE4\xBF\xA1\xE5\xA4\xB4\xE5\x83\x8F\x0963.0K: 135********|20140608-34/c:Q/1402368323157/Put/vlen=35/ts=0 V: 20140608\x0913519306776\x09\xE8\x85\xBE\xE8\xAE\xAF\xE7\xBD\x91\x0990.0K: 135********|20140608-39/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519306776\x09\xE5\xA2\xA8\xE8\xBF\xB9\xE5\xA4\xA9\xE6\xB0\x94\x0911.0K: 135********|20140608-4/c:Q/1402368323157/Put/vlen=39/ts=0 V: 20140608\x0913519306776\x09\xE5\x85\xB6\xE4\xBB\x96-TCP\x091442.83K: 135********|20140608-52/c:Q/1402368323157/Put/vlen=39/ts=0 V: 20140608\x0913519306776\x09\xE5\xBE\xAE\xE4\xBF\xA1\xE5\x9B\xBE\xE7\x89\x87\x09266.0K: 135********|20140608-5/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519609801\x09\xE5\x85\xB6\xE4\xBB\x96-TCP\x09338.97K: 135********|20140608-26/c:Q/1402368323157/Put/vlen=39/ts=0 V: 20140608\x0913519700318\x09\xE5\xBE\xAE\xE4\xBF\xA1\xE5\xA4\xB4\xE5\x83\x8F\x09521.0K: 135********|20140608-31/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519700318\x09\xE8\x85\xBE\xE8\xAE\xAF\xE5\x9B\xBE\xE7\x89\x87\x0931.0K: 135********|20140608-43/c:Q/1402368323157/Put/vlen=37/ts=0 V: 20140608\x0913519700318\x09\xE8\x85\xBE\xE8\xAE\xAF\xE7\xBD\x91\x091391.0K: 135********|20140608-47/c:Q/1402368323157/Put/vlen=32/ts=0 V: 20140608\x0913519700318\x09\xE6\x90\x9C\xE7\x8B\x90\x0976.0K: 135********|20140608-48/c:Q/1402368323157/Put/vlen=47/ts=0 V: 20140608\x0913519700318\x09\xE4\xB8\xAD\xE5\x9B\xBD\xE8\x81\x94\xE9\x80\x9A\xE6\xB2\x83\xE5\x95\x86\xE5\xBA\x97\x0921.0 K: 135********|20140608-57/c:Q/1402368323157/Put/vlen=32/ts=0 V: 20140608\x0913519700318\x09\xE8\xBF\x85\xE9\x9B\xB7\x0965.0K: 135********|20140608-58/c:Q/1402368323157/Put/vlen=37/ts=0 V: 20140608\x0913519700318\x09HTTP\xE4\xB8\x8A\xE7\xBD\x91\x09730.0K: 135********|20140608-59/c:Q/1402368323157/Put/vlen=31/ts=0 V: 20140608\x0913519700318\x09\xE7\x99\xBE\xE5\xBA\xA6\x098.0K: 135********|20140608-6/c:Q/1402368323157/Put/vlen=33/ts=0 V: 20140608\x0913519700318\x09\xE5\x85\xB6\xE4\xBB\x96\x0931.04K: 135********|20140608-62/c:Q/1402368323157/Put/vlen=31/ts=0 V: 20140608\x0913519700318\x0910086\x0925.0K: 135********|20140608-7/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519700318\x09\xE5\x85\xB6\xE4\xBB\x96-TCP\x09685.59K: 135********|20140608-8/c:Q/1402368323157/Put/vlen=33/ts=0 V: 20140608\x0913519700318\x09\xE5\xBD\xA9\xE4\xBF\xA1\x0930.77K: 135********|20140608-10/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519700638\x09\xE5\x85\xB6\xE4\xBB\x96-TCP\x092820.1K: 135********|20140608-11/c:Q/1402368323157/Put/vlen=34/ts=0 V: 20140608\x0913519700638\x09\xE5\xBD\xA9\xE4\xBF\xA1\x09485.94K: 135********|20140608-30/c:Q/1402368323157/Put/vlen=36/ts=0 V: 20140608\x0913519700638\x09\xE8\x85\xBE\xE8\xAE\xAF\xE7\xBD\x91\x09351.0K: 135********|20140608-35/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519700638\x09\xE6\x96\xB0\xE6\xB5\xAA\xE5\xBE\xAE\xE5\x8D\x9A\x0920.0K: 135********|20140608-36/c:Q/1402368323157/Put/vlen=31/ts=0 V: 20140608\x0913519700638\x09\xE6\xB7\x98\xE5\xAE\x9D\x098.0K: 135********|20140608-37/c:Q/1402368323157/Put/vlen=31/ts=0 V: 20140608\x0913519700638\x09\xE7\x82\xB9\xE5\xBF\x83\x093.0K: 135********|20140608-38/c:Q/1402368323157/Put/vlen=35/ts=0 V: 20140608\x0913519700638\x09360\xE7\xBD\x91\xE7\xAB\x99\x0988.0K: 135********|20140608-45/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519700638\x09\xE5\xBE\xAE\xE4\xBF\xA1\xE5\xA4\xB4\xE5\x83\x8F\x0919.0K: 135********|20140608-49/c:Q/1402368323157/Put/vlen=40/ts=0 V: 20140608\x0913519700638\x09\xE5\xBE\xAE\xE4\xBF\xA1\xE5\x9B\xBE\xE7\x89\x87\x091251.0K: 135********|20140608-53/c:Q/1402368323157/Put/vlen=32/ts=0 V: 20140608\x0913519700638\x09\xE6\x96\xB0\xE6\xB5\xAA\x0913.0K: 135********|20140608-54/c:Q/1402368323157/Put/vlen=37/ts=0 V: 20140608\x0913519700638\x09HTTP\xE4\xB8\x8A\xE7\xBD\x91\x09122.0K: 135********|20140608-55/c:Q/1402368323157/Put/vlen=33/ts=0 V: 20140608\x0913519700638\x09\xE7\x99\xBE\xE5\xBA\xA6\x09697.0K: 135********|20140608-56/c:Q/1402368323157/Put/vlen=44/ts=0 V: 20140608\x0913519700638\x09\xE5\xAE\x89\xE6\x99\xBA\xE5\xB8\x82\xE5\x9C\xBA\xE4\xB8\x8B\xE8\xBD\xBD\x0926.0K: 135********|20140608-9/c:Q/1402368323157/Put/vlen=33/ts=0 V: 20140608\x0913519700638\x09\xE5\x85\xB6\xE4\xBB\x96\x0975.75K: 135********|20140608-12/c:Q/1402368323157/Put/vlen=33/ts=0 V: 20140608\x0913519701290\x09\xE5\x85\xB6\xE4\xBB\x96\x0933.79K: 135********|20140608-13/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519701290\x09\xE5\x85\xB6\xE4\xBB\x96-TCP\x09703.16K: 135********|20140608-14/c:Q/1402368323157/Put/vlen=32/ts=0 V: 20140608\x0913519701290\x09\xE5\xBD\xA9\xE4\xBF\xA1\x092.59K: 135********|20140608-18/c:Q/1402368323157/Put/vlen=39/ts=0 V: 20140608\x0913519701290\x09\xE5\xBE\xAE\xE4\xBF\xA1\xE5\x9B\xBE\xE7\x89\x87\x09941.0K: 135********|20140608-19/c:Q/1402368323157/Put/vlen=47/ts=0 V: 20140608\x0913519701290\x09\xE7\x99\xBE\xE5\xBA\xA6\xE5\xBC\x80\xE6\x94\xBE\xE4\xBA\x91\xE5\xB9\xB3\xE5\x8F\xB0\x0929.0 K: 135********|20140608-21/c:Q/1402368323157/Put/vlen=37/ts=0 V: 20140608\x0913519701290\x09\xE9\xAB\x98\xE5\xBE\xB7\xE5\x9C\xB0\xE5\x9B\xBE\x098.0K: 135********|20140608-27/c:Q/1402368323157/Put/vlen=37/ts=0 V: 20140608\x0913519701290\x09\xE5\xBE\xAE\xE4\xBF\xA1\xE5\xA4\xB4\xE5\x83\x8F\x094.0K: 135********|20140608-44/c:Q/1402368323157/Put/vlen=36/ts=0 V: 20140608\x0913519701290\x09\xE8\x85\xBE\xE8\xAE\xAF\xE7\xBD\x91\x09484.0K: 135********|20140608-50/c:Q/1402368323157/Put/vlen=31/ts=0 V: 20140608\x0913519701290\x09\xE6\x90\x9C\xE6\x90\x9C\x092.0K: 135********|20140608-60/c:Q/1402368323157/Put/vlen=36/ts=0 V: 20140608\x0913519701290\x09HTTP\xE4\xB8\x8A\xE7\xBD\x91\x0981.0K: 135********|20140608-61/c:Q/1402368323157/Put/vlen=33/ts=0 V: 20140608\x0913519701290\x09\xE7\x99\xBE\xE5\xBA\xA6\x09255.0K: 135********|20140608-15/c:Q/1402368323157/Put/vlen=33/ts=0 V: 20140608\x0913519702500\x09\xE5\x85\xB6\xE4\xBB\x96\x0917.38K: 135********|20140608-16/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519702500\x09\xE5\x85\xB6\xE4\xBB\x96-TCP\x09174.14K: 135********|20140608-17/c:Q/1402368323157/Put/vlen=34/ts=0 V: 20140608\x0913519702500\x09\xE5\xBD\xA9\xE4\xBF\xA1\x09443.75K: 135********|20140608-20/c:Q/1402368323157/Put/vlen=36/ts=0 V: 20140608\x0913519702500\x09\xE8\x85\xBE\xE8\xAE\xAF\xE7\xBD\x91\x09457.0K: 135********|20140608-22/c:Q/1402368323157/Put/vlen=34/ts=0 V: 20140608\x0913519702500\x09360\xE7\xBD\x91\xE7\xAB\x99\x099.0K: 135********|20140608-28/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519702500\x09\xE8\x85\xBE\xE8\xAE\xAF\xE5\x9B\xBE\xE7\x89\x87\x0951.0K: 135********|20140608-40/c:Q/1402368323157/Put/vlen=38/ts=0 V: 20140608\x0913519702500\x09\xE5\xBE\xAE\xE4\xBF\xA1\xE5\xA4\xB4\xE5\x83\x8F\x0974.0K: 135********|20140608-41/c:Q/1402368323157/Put/vlen=40/ts=0 V: 20140608\x0913519702500\x09\xE5\xBE\xAE\xE4\xBF\xA1\xE5\x9B\xBE\xE7\x89\x87\x091134.0K: 135********|20140608-46/c:Q/1402368323157/Put/vlen=37/ts=0 V: 20140608\x0913519702500\x09HTTP\xE4\xB8\x8A\xE7\xBD\x91\x09407.0K: 135********|20140608-51/c:Q/1402368323157/Put/vlen=31/ts=0 V: 20140608\x0913519702500\x09\xE6\x97\xBA\xE6\x97\xBA\x091.0K: 135********|20140608-42/c:Q/1402368323157/Put/vlen=36/ts=0 V: 20140608\x0913519702564\x09HTTP\xE4\xB8\x8A\xE7\xBD\x91\x0916.0Block index size as per heapsize: 424reader=/hbase/v_dm_user_app_d_201406/c64c6f7f7caf7f6d5a3f6bbc209dd2cb/c/0ebf8900a669462c8a9d9d908622928f,compression=none,cacheConf=CacheConfig:enabled [cacheDataOnRead=true] [cacheDataOnWrite=false] [cacheIndexesOnWrite=false] [cacheBloomsOnWrite=false] [cacheEvictOnClose=false] [cacheCompressed=false],firstKey=135********|20140608-1/c:Q/1402368323157/Put,lastKey=135********|20140608-42/c:Q/1402368323157/Put,avgKeyLen=36,avgValueLen=36,entries=62,length=5841Trailer:fileinfoOffset=5199,loadOnOpenDataOffset=5102,dataIndexCount=1,metaIndexCount=0,totalUncomressedBytes=5768,entryCount=62,compressionCodec=NONE,uncompressedDataIndexSize=49,numDataIndexLevels=1,firstDataBlockOffset=0,lastDataBlockOffset=0,comparatorClassName=org.apache.hadoop.hbase.KeyValue$KeyComparator,majorVersion=2,minorVersion=0Fileinfo:BULKLOAD_SOURCE_TASK = attempt_201406091028_0019_r_000000_0BULKLOAD_TIMESTAMP = \x00\x00\x01F\x83\xAA\xD9EDELETE_FAMILY_COUNT = \x00\x00\x00\x00\x00\x00\x00\x00EARLIEST_PUT_TS = \x00\x00\x01F\x83\xAAnUEXCLUDE_FROM_MINOR_COMPACTION = \x00KEY_VALUE_VERSION = \x00\x00\x00\x01MAJOR_COMPACTION_KEY = \xFFMAX_MEMSTORE_TS_KEY = \x00\x00\x00\x00\x00\x00\x00\x00TIMERANGE = 1402368323157 (1402368323157)hfile.AVG_KEY_LEN = 36hfile.AVG_VALUE_LEN = 36STKEY = \x00\x1713519702564|20140608-42\x01cQ\x00\x00\x01F\x83\xAAnU\x04 Mid-key: \x00\x1613519304818|20140608-1\x01cQ\x00\x00\x01F\x83\xAAnU\x04Bloom filter:Not presentDelete Family Bloom filter:Not presentScanned kv count -> 62。
网易视频云:HBase客户端实践–重试机制

网易视频云:HBase客户端实践–重试机制网易视频云是网易倾力打造的一款基于云计算的分布式多媒体处理集群和专业音视频技术,为客户提供稳定流畅、低时延、高并发的视频直播、录制、存储、转码及点播等音视频的PaaS服务。
在线教育、远程医疗、娱乐秀场、在线金融等各行业及企业用户只需经过简单的开发即可打造在线音视频平台。
现在,网易视频云与大家分享HBase客户端实践–重试机制。
在运维HBase的这段时间里,发现业务用户一方面比较关注HBase本身服务的读写性能:吞吐量以及读写延迟,另一方面也会比较关注HBase客户端使用上的问题,主要集中在两个方面:是否提供了重试机制来保证系统操作的容错性?是否有必要的超时机制保证系统能够fastfail,保证系统的低延迟特性?这个系列我们集中介绍HBase客户端使用上的这两大问题,本文通过分析之前一个真实的案例来介绍HBase客户端提供的重试机制,并通过配置合理的参数使得客户端在保证一定容错性的同时还能够保证系统的低延迟特性。
案发现场最近某业务在使用HBase客户端读取数据时出现了大量线程block的情况,业务方保留了当时的线程堆栈信息,如下图所示:看到这样的问题,首先从日志和监控排查了业务表和region server,确认了在很长时间内确实没有请求进来,除此之外并没有其他有用的信息,同时也没有接到该集群上其他用户的异常反馈,从现象看,这次异常是在特定环境下才会触发的。
案件分析过程1.根据上图图1所示,所有的请求都block在<0x0000000782a936f0>这把全局锁上,这里需要关注两个问题:∙哪个线程持有了这把全局锁<0x0000000782a936f0>?∙这是一把什么样的全局锁(对于问题本身并不重要,有兴趣可以参考步骤3)?2.哪个线程持有了这把锁?2.1 很容易在jstack日志中通过搜索找到全局锁<0x0000000782a936f0>被如下线程持有:定睛一看,该线程持有了这把全局锁,而且处于TIMED_WAITING状态,因此这把锁可能长时间不释放,导致所有需要这把全局锁的线程都阻塞等待。
关于HFile的存储结构梳理以及快速定位rowkey
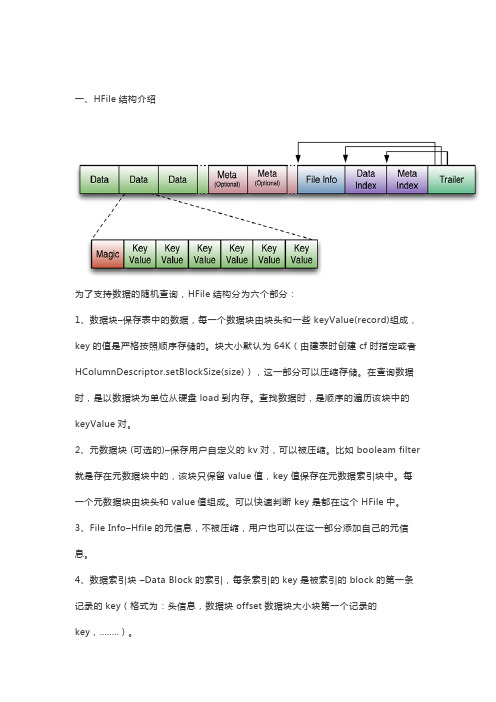
一、HFile结构介绍为了支持数据的随机查询,HFile结构分为六个部分:1、数据块–保存表中的数据,每一个数据块由块头和一些keyValue(record)组成,key的值是严格按照顺序存储的。
块大小默认为64K(由建表时创建cf时指定或者HColumnDescriptor.setBlockSize(size)),这一部分可以压缩存储。
在查询数据时,是以数据块为单位从硬盘load到内存。
查找数据时,是顺序的遍历该块中的keyValue对。
2、元数据块 (可选的)–保存用户自定义的kv对,可以被压缩。
比如booleam filter 就是存在元数据块中的,该块只保留value值,key值保存在元数据索引块中。
每一个元数据块由块头和value值组成。
可以快速判断key是都在这个HFile中。
3、File Info–Hfile的元信息,不被压缩,用户也可以在这一部分添加自己的元信息。
4、数据索引块–Data Block的索引,每条索引的key是被索引的block的第一条记录的key(格式为:头信息,数据块offset数据块大小块第一个记录的key,........)。
这个参数控制hfile中索引块的大小,默认值是128K,也就是说当索引的信息超过128K后,就会新分配一个索引块。
hbase对于hfile的访问都是通过索引块来实现的,通过索引来定位所要查的数据到底在哪个数据块里面。
hfile中的索引块可以分成三中,根索引块,枝索引块,叶索引块。
根索引块是一定会有的,但是如果hfile 中的数据块比较少的话,枝索引块和叶索引块就可能不存在。
当单个的索引块中没有办法存储全部的数据块的信息时,索引块就会分裂,会产生叶索引块和根索引块,根索引块是对叶索引块的索引,如果数据块继续增加就会产生枝索引块,整个索引结果的层次也会加深。
想象一下,如果整个hfile中只有根索引块,那么访问真正的数据的路径是,首先查根索引块定位数据块的位置,然后去查询数据块找到需要的数据。
深入理解HBase的原理及系统架构

深入理解HBase的原理及系统架构HBase的构成物理上来说,HBase是由三种类型的服务器以主从模式构成的。
这三种服务器分别是:Region server,HBase HMaster,ZooKeeper。
其中Region server负责数据的读写服务。
用户通过沟通Region server来实现对数据的访问。
HBase HMaster负责Region的分配及数据库的创建和删除等操作。
ZooKeeper作为HDFS的一部分,负责维护集群的状态(某台服务器是否在线,服务器之间数据的同步操作及master的选举等)。
另外,Hadoop DataNode负责存储所有Region Server所管理的数据。
HBase中的所有数据都是以HDFS文件的形式存储的。
出于使Region server所管理的数据更加本地化的考虑,Region server是根据DataNode分布的。
HBase的数据在写入的时候都存储在本地。
但当某一个region被移除或被重新分配的时候,就可能产生数据不在本地的情况。
这种情况只有在所谓的compaction之后才能解决。
NameNode负责维护构成文件的所有物理数据块的元信息(metadata)。
HBase结构如下图所示:RegionsHBase中的表是根据row key的值水平分割成所谓的region的。
一个region包含表中所有row key位于region的起始键值和结束键值之间的行。
集群中负责管理Region的结点叫做Region server。
Region server负责数据的读写。
每一个Region server大约可以管理1000个region。
Region的结构如下图所示:HBase的HMasterHMaster负责region的分配,数据库的创建和删除操作。
具体来说,HMaster的职责包括:•调控Region server的工作o在集群启动的时候分配region,根据恢复服务或者负载均衡的需要重新分配region。
Hadoop相关知识整理系列之一:HBase基本架构及原理

Hadoop相关知识整理系列之⼀:HBase基本架构及原理1. HBase框架简单介绍HBase是⼀个分布式的、⾯向列的开源数据库,它不同于⼀般的关系数据库,是⼀个适合于⾮结构化数据存储的数据库。
另⼀个不同的是HBase基于列的⽽不是基于⾏的模式。
HBase使⽤和 BigTable⾮常相同的数据模型。
⽤户存储数据⾏在⼀个表⾥。
⼀个数据⾏拥有⼀个可选择的键和任意数量的列,⼀个或多个列组成⼀个ColumnFamily,⼀个Fmaily下的列位于⼀个HFile中,易于缓存数据。
表是疏松的存储的,因此⽤户可以给⾏定义各种不同的列。
在HBase中数据按主键排序,同时表按主键划分为多个Region。
在分布式的⽣产环境中,HBase 需要运⾏在 HDFS 之上,以 HDFS 作为其基础的存储设施。
HBase 上层提供了访问的数据的 Java API 层,供应⽤访问存储在 HBase 的数据。
在 HBase 的集群中主要由 Master 和 Region Server 组成,以及 Zookeeper,具体模块如下图所⽰:简单介绍⼀下 HBase 中相关模块的作⽤:MasterHBase Master⽤于协调多个Region Server,侦测各个RegionServer之间的状态,并平衡RegionServer之间的负载。
HBaseMaster还有⼀个职责就是负责分配Region给RegionServer。
HBase允许多个Master节点共存,但是这需要Zookeeper的帮助。
不过当多个Master节点共存时,只有⼀个Master是提供服务的,其他的Master节点处于待命的状态。
当正在⼯作的Master节点宕机时,其他的Master则会接管HBase的集群。
Region Server对于⼀个RegionServer⽽⾔,其包括了多个Region。
RegionServer的作⽤只是管理表格,以及实现读写操作。
hfile格式详细介绍
HFile: A Block-Indexed File Formatto Store Sorted Key-Value PairsSep 10, 2009 Schubert Zhang (schubert.zhang@) 1. IntroductionHFile is a mimic of Google’s SSTable. Now, it is available in Hadoop HBase-0.20.0. And the previous releases of HBase temporarily use an alternate file format – MapFile[4], which is a common file format in Hadoop IO package. I think HFile should also become a common file format when it becomes mature, and should be moved into the common IO package of Hadoop in the future.Following words of SSTable are from section 4 of Google’s Bigtable paper.The Google SSTable file format is used internally to store Bigtable data. An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Operations are provided to look up the value associated with a specified key, and to iterate over all key/value pairs in a specified key range. Internally, each SSTable contains a sequence of blocks (typically each block is 64KB in size, but this is configurable). A block index (stored at the end of the SSTable) is used to locate blocks; the index is loaded into memory when the SSTable is opened. A lookup can be performed with a single disk seek: we first find the appropriate block by performing a binary search in the in-memory index, and then reading the appropriate block from disk. Optionally, an SSTable can be completely mapped into memory, which allows us to perform lookups and scans without touching disk.[1]The HFile implements the same features as SSTable, but may provide more or less.2. File FormatData Block SizeWhenever we say Block Size, it means the uncompressed size.The size of each data block is 64KB by default, and is configurable in HFile.Writer. It means the data block will not exceed this size more than one key/value pair. The HFile.Writer starts a new data block to add key/value pairs if the current writing block is equal to or bigger than this size. The 64KB size is same as Google’s [1].To achieve better performance, we should select different block size. If the average key/value size is very short (e.g. 100 bytes), we should select small blocks (e.g. 16KB) to avoid too many key/value pairs in each block, which will increase the latency of in-block seek, because the seeking operation always finds the key from the first key/value pair in sequence within a block.Maximum Key LengthThe key of each key/value pair is currently up to 64KB in size. Usually, 10-100 bytes is a typical size for most of our applications. Even in the data model of HBase, the key (rowkey+column family:qualifier+timestamp) should not be too long.Maximum File SizeThe trailer, file-info and total data block indexes (optionally, may add meta block indexes) will be in memory when writing and reading of an HFile. So, a larger HFile (with more data blocks) requires more memory. For example, a 1GB uncompressed HFile would have about 15600 (1GB/64KB) data blocks, and correspondingly about 15600 indexes. Suppose the average key size is 64 bytes, then we need about 1.2MB RAM (15600X80) to hold these indexes in memory.Compression Algorithm-Compression reduces the number of bytes written to/read from HDFS. -Compression effectively improves the efficiency of network bandwidth and disk space-Compression reduces the size of data needed to be read when issuinga readTo be as low friction as necessary, a real-time compression library is preferred. Currently, HFile supports following three algorithms:(1)NONE (Default, uncompressed, string name=”none”)(2)GZ (Gzip, string name=”gz”)Out of the box, HFile ships with only Gzip compression, which is fairly slow.(3)LZO(Lempel-Ziv-Oberhumer, preferred, string name=”lzo”)To achieve maximal performance and benefit, you must enable LZO, which is a lossless data compression algorithm that is focused on decompression speed.Following figures show the format of an HFile.In above figures, an HFile is separated into multiple segments, from beginning to end, they are:-Data Block segmentTo store key/value pairs, may be compressed.-Meta Block segment (Optional)To store user defined large metadata, may be compressed.-File Info segmentIt is a small metadata of the HFile, without compression. User can add user defined small metadata (name/value) here.-Data Block Index segmentIndexes the data block offset in the HFile. The key of each index is the key of first key/value pair in the block.-Meta Block Index segment (Optional)Indexes the meta block offset in the HFile. The key of each index is the user defined unique name of the meta block.-TrailerThe fix sized metadata. To hold the offset of each segment, etc. To read an HFile, we should always read the Trailer firstly.The current implementation of HFile does not include Bloom Filter, which should be added in the future.The FileInfo is a SortedMap in implementation. So the actual order of thosefields is alphabetically based on the key.3. LZO CompressionLZO is now removed from Hadoop or HBase 0.20+ because of GPL restrictions. To enable it, we should install native library firstly as following.[6][7][8][9](1)Download LZO: /, and build.# ./configure --build=x86_64-redhat-linux-gnu --enable-shared--disable-asm# make# make installThen the libraries have been installed in: /usr/local/lib(2)Download the native connector library/p/hadoop-gpl-compression/, and build.Copy hadoo-0.20.0-core.jar to ./lib.# ant compile-native# ant jar(3)Copy the native library (build/native/Linux-amd64-64) andhadoop-gpl-compression-0.1.0-dev.jar to your application’s libdirectory. If your application is a MapReduce job, copy them to hadoop’s lib directory. Your application should follow the$HADOOP_HOME/bin/hadoop script to ensure that the native hadoop library is on the library path via the system property-Djava.library.path=<path>. [9] For example:Then our application and hadoop/MapReduce can use LZO.4. Performance EvaluationTestbed− 4 slaves + 1 master−Machine: 4 CPU cores (2.0G), 2x500GB 7200RPM SATA disks, 8GB RAM.−Linux: RedHat 5.1 (2.6.18-53.el5), ext3, no RAID, noatime−1Gbps network, all nodes under the same switch.−Hadoop-0.20.0 (1GB heap), lzo-2.0.3Some MapReduce-based benchmarks are designed to evaluate the performance of operations to HFiles, in parallel.−Total key/value entries: 30,000,000.−Key/Value size: 1000 bytes (10 for key, and 990 for value). We have totally 30GB of data.−Sequential key ranges: 60, i.e. each range have 500,000 entries.−Use default block size.−The entry value is a string, each continuous 8 bytes are a filled with a same letter (A~Z). E.g. “BBBBBBBBXXXXXXXXGGGGGGGG……”. We set mapred.tasktracker.map.tasks.maximum=3 to avoid client side bottleneck.(1)WriteEach MapTask for each range of key, which writes a separate HFile with 500,000 key/value entries.(2)Full ScanEach MapTask scans a separate HFile from beginning to end.(3)Random Seek a specified keyEach MapTask opens one separate HFile, and selects a random key within that file to seek it. Each MapTask runs 50,000 (1/10 of the entries) random seeks.(4)Random Short ScanEach MapTask opens one separate HFile, and selects a random key within that file as a beginning to scan 30 entries. Each MapTask runs 50,000 scans, i.e. scans 50,000*30=1,500,000 entries.This table shows the average entries which are written/seek/scanned per second, and per node.In this evaluation case, the compression ratio is about 7:1 for gz(Gzip), and about 4:1 for lzo. Even through the compression ratio is just moderate, the lzo column shows the best performance, especially for writes.The performance of full scan is much better than SequenceFile, so HFile may provide better performance to MapReduce-based analytical applications.The random seek in HFiles is slow, especially in none-compressed HFiles. But the above numbers already show 6X~10X better performance than a disk seek (10ms). Following Ganglia charts show us the overhead of load, CPU, and network. The random short scan makes the similar phenomena.5. Implementation and API5.1 HFile.Writer : How to create and write an HFile(1) ConstructorsThere are 5 constructors. We suggest using following two:public Writer(FileSystem fs, Path path, int blocksize,String compress,final RawComparator<byte []> comparator)public Writer(FileSystem fs, Path path, int blocksize,Compression.Algorithm compress,final RawComparator<byte []> comparator)These two constructors are same. They create file (call fs.create(…)) and get an FSDataOutputStream for writing. Since the FSDataOutputStream iscreated when constructing the HFile.Writer, it will be automatically closed when the HFile.Writer is closed.The other two constructors provide FSDataOutputStream as a parameter. It means the file is created and opened outside of the HFile.Writer, so, when we close the HFile.Writer, the FSDataOutputStream will not be closed. But we do not suggest using these two constructors directly.public Writer(final FSDataOutputStream ostream, final int blocksize, final String compress,final RawComparator<byte []> c)public Writer(final FSDataOutputStream ostream, final int blocksize, final Compression.Algorithm compress,final RawComparator<byte []> c)Another constructor only provides fs and path as parameters, all other attributes are default, i.e. NONE of compression, 64KB of block size, raw ByteArrayComparator, etc.(2) Write Key/Value pairs into HFileBefore key/value pairs are written into an HFile, the application must sort them using the same comparator, i.e. all key/value pairs must be sequentially and increasingly write/append into an HFile. There are following methods to write/append key/value pairs:public void append(final KeyValue kv)public void append(final byte [] key, final byte [] value)public void append(final byte [] key, final int koffset, final int klength, final byte [] value, final int voffset, final int vlength)When adding a key/value pair, they will check the current block size. If the size reach the maximum size of a block, the current block will be compressed and written to the output stream (of the HFile), and then create a new block for writing. The compression is based on each block. For each block, an output stream for compression will be created from beginning of a new block and released when finish.Following chart is the relationship of the output steams OO design:The key/value appending operation is written from the outside (DataOutputStream), and the above OO mechanism will handle the buffer and compression functions and then write to the file in under layer file system.Before a key/value pair is written, following will checked:-The length of Key-The order of Key (must bigger than the last one)(3) Add metadata into HFileWe can add metadata block into an HFile.public void appendMetaBlock(String metaBlockName, byte [] bytes)The application should provide a unique metaBlockName for each metadata block within an HFile.Reminding: If your metadata is large enough (e.g. 32KB uncompressed), you can use this feature to add a separate meta block. It may be compressed in the file.But if your metadata is very small (e.g. less than 1KB), please use following method to append it into file info. File info will not be compressed.public void appendFileInfo(final byte [] k, final byte [] v)(4) CloseBefore the HFile.Writer is closed, the file is not completed written. So, we must call close() to:-finish and flush the last block-write all meta block into file (may be compressed)-generate and write file info metadata-write data block indexes-write meta block indexes-generate and write trailer metadata-close the output-stream.5.2 HFile.Reader: How to read HFileCreate an HFile.Reader to open an HFile, and we can seek, scan and read on it.(1) ConstructorWe suggest using following constructor to create an HFile.Reader.public Reader(FileSystem fs, Path path, BlockCache cache,boolean inMemory)It calls fs.open(…) to open the file, and gets an FSDataInputStream for reading. The input stream will be automatically closed when the HFile.Reader is closed.Another constructor uses InputStream as parameter directly. It means the file is opened outside the HFile.Reader.public Reader(final FSDataInputStream fsdis, final long size,final BlockCache cache, final boolean inMemory)We can use BlockCache to improve the performance of read, and the mechanism of mechanism will be described in other document.(2) Load metadata and block indexes of an HFileThe HFile is not readable before loadFileInfo() is explicitly called . It will read metadata (Trailer, File Info) and Block Indexes (data block and meta block) into memory. And the COMPARATOR instance will reconstruct from file info.BlockIndexThe important method of BlockIndex is:int blockContainingKey(final byte[] key, int offset, int length)It uses binarySearch to check if a key is contained in a block. The return value of binarySearch() is very puzzled:IndexList Before0 1 2 3 4 5 6 …BlockDatabinarySearch() return -1 -2-3-4-5-6-7 -8 …HFileScannerWe must create an HFile.Reader.Scanner to seek, scan, and read on an HFile. HFile.Reader.Scanner is an implementation of HFileScanner interface.To seek and scan in an HFIle, we should do as following:(1)Create a HFile.Reader, and loadFileInfo().(2)In this HFile.Reader, calls getScanner() to obtain an HFileScanner.(3).1 For a scan from the beginning of the HFile, calls seekTo() toseek to the beginning of the first block..2 For a scan from a key, calls seekTo(key) to seek to the position of the key or before the key (if there is not such a key in this HFile)..3 For a scan from before of a key, calls seekBefore(key).(4)Calls next() to iterate over all key/value pairs. The next() willreturn false when it reach the end of the HFile. If an application wants to stop at any condition, it should be implemented by the application itself. (e.g. stop at a special endKey.)(5)If you want lookup a specified key, just call seekTo(key), thereturned value=0 means you found it.(6)After we seekTo(…) or next() to a position of specified key, wecan call following methods to get the current key and value.public KeyValue getKeyValue() // recommendedpublic ByteBuffer getKey()public ByteBuffer getValue()(7)Don’t forget to close the HFile.Reader. But a scanner need not beclosed, since it does not hold any resource.References[1]Google, Bigtable: A Distributed Storage System for Structured Data,/papers/bigtable.html[2]HBase-0.20.0 Documentation,/hbase/docs/r0.20.0/[3]HFile code review and refinement./jira/browse/HBASE-1818[4]MapFile API:/common/docs/current/api/org/apache/hadoop/io/MapFile.html[5]Parallel LZO: Splittable Compression for Hadoop./blog/2009/06/24/parallel-lzo-splittable-compression-for-hadoop//2009/06/parallel-lzo-splittable-on-hadoop-using-cloudera/[6]Using LZO in Hadoop and HBase:/hadoop/UsingLzoCompression[7]LZO: [8]Hadoop LZO native connector library:/p/hadoop-gpl-compression/[9]Hadoop Native Libraries Guide:/common/docs/r0.20.0/native_libraries.html。
hbase设计原理

hbase设计原理HBase设计原理是基于Google Bigtable论文的开源分布式数据库。
下面是HBase设计原理的一些关键点:1. 数据模型:HBase使用列族(column families)来组织数据。
列族包含多个列(columns),每个列可以有多个版本(versions)。
数据按照行存储,每一行由行键(row key)唯一标识。
列族可以根据列的相关性来组织,从而提高数据存取的效率。
2. 存储结构:HBase使用HFile作为存储文件格式。
HFile是一种基于B树的索引结构,用于快速查找和访问数据。
HFile将数据分为不同的块,每个块包含多行数据。
HBase将数据以块为单位进行读写,提高了读写性能。
3. 分布式存储:HBase采用分布式存储的方式,数据以Region为单位进行分片和存储。
每个表被划分为多个Region,每个Region存储一部分数据。
每个Region由一个RegionServer负责管理和处理。
RegionServer可以动态地分裂和合并Region,以实现负载均衡和数据分布的优化。
4. 数据一致性:HBase使用ZooKeeper来实现强一致性的读写操作。
ZooKeeper作为分布式协调服务,用于协调不同的RegionServer之间的操作。
通过ZooKeeper,HBase可以保持数据的一致性,避免数据的冲突和竞争。
5. 自动故障恢复:HBase具有自动故障恢复的能力。
当RegionServer发生故障时,HBase会自动将其失效的Region重新分配给其他健康的RegionServer。
这种方式能够在系统发生故障时,保证数据的可用性和一致性。
总的来说,HBase的设计原理是基于分布式存储和协调的理念,通过数据模型和存储结构的设计,实现了高可靠性、高性能和强一致性的分布式数据库。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
网易视频云是网易推出的PaaS视频云服务,主要应用于在线教育、直播秀场、远程医疗、企业协作等领域。
今天,网易视频云技术专家与大家分享一下:HBase –存储文件HFile结构解析。
HFile是HBase存储数据的文件组织形式,参考BigTable的SSTable和Hadoop的TFile 实现。
从HBase开始到现在,HFile经历了三个版本,其中V2在0.92引入,V3在0.98引入。
HFileV1版本的在实际使用过程中发现它占用内存多,HFile V2版本针对此进行了优化,HFile V3版本基本和V2版本相同,只是在cell层面添加了Tag数组的支持。
鉴于此,本文主要针对V2版本进行分析,对V1和V3版本感兴趣的同学可以参考其他信息。
HFile逻辑结构HFile V2的逻辑结构如下图所示:文件主要分为四个部分:Scanned block section,Non-scanned block section,Opening-time data section和Trailer。
Scanned block section:顾名思义,表示顺序扫描HFile时所有的数据块将会被读取,包括Leaf Index Block和Bloom Block。
Non-scanned block section:表示在HFile顺序扫描的时候数据不会被读取,主要包括Meta Block和Intermediate Level Data Index Blocks两部分。
Load-on-open-section:这部分数据在HBase的region server启动时,需要加载到内存中。
包括FileInfo、Bloom filter block、data block index和meta block index。
Trailer:这部分主要记录了HFile的基本信息、各个部分的偏移值和寻址信息。
HFile物理结构如上图所示,HFile会被切分为多个大小相等的block块,每个block的大小可以在创建表列簇的时候通过参数blocksize=> ‘65535’进行指定,默认为64k,大号的Block有利于顺序Scan,小号Block利于随机查询,因而需要权衡。
而且所有block块都拥有相同的数据结构,如图左侧所示,HBase将block块抽象为一个统一的HFileBlock。
HFileBlock支持两种类型,一种类型不支持checksum,一种不支持。
为方便讲解,下图选用不支持checksum的HFileBlock内部结构:上图所示HFileBlock主要包括两部分:BlockHeader和BlockData。
其中BlockHeader 主要存储block元数据,BlockData用来存储具体数据。
block元数据中最核心的字段是BlockType字段,用来标示该block块的类型,HBase中定义了8种BlockType,每种BlockType 对应的block都存储不同的数据内容,有的存储用户数据,有的存储索引数据,有的存储meta元数据。
对于任意一种类型的HFileBlock,都拥有相同结构的BlockHeader,但是BlockData结构却不相同。
下面通过一张表简单罗列最核心的几种BlockType,下文会详细针对每种BlockType进行详细的讲解:HFile中Block块解析上文从HFile的层面将文件切分成了多种类型的block,接下来针对几种重要block进行详细的介绍,因为篇幅的原因,索引相关的block不会在本文进行介绍,接下来会写一篇单独的文章对其进行分析和讲解。
首先会介绍记录HFile基本信息的TrailerBlock,再介绍用户数据的实际存储块DataBlock,最后简单介绍布隆过滤器相关的block。
Trailer Block主要记录了HFile的基本信息、各个部分的偏移值和寻址信息,下图为Trailer内存和磁盘中的数据结构,其中只显示了部分核心字段:HFile在读取的时候首先会解析Trailer Block并加载到内存,然后再进一步加载LoadOnOpen区的数据,具体步骤如下:1. 首先加载version版本信息,HBase中version包含majorVersion和minorVersion两部分,前者决定了HFile的主版本:V1、V2 还是V3;后者在主版本确定的基础上决定是否支持一些微小修正,比如是否支持checksum等。
不同的版本决定了使用不同的Reader对象对HFile进行读取解析2. 根据Version信息获取trailer的长度(不同version的trailer长度不同),再根据trailer 长度加载整个HFileTrailer Block3. 最后加载load-on-open部分到内存中,起始偏移地址是trailer中的LoadOnOpenDataOffset字段,load-on-open部分的结束偏移量为HFile长度减去Trailer长度,load-on-open部分主要包括索引树的根节点以及FileInfo两个重要模块,FileInfo是固定长度的块,它纪录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN,LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等;索引树根节点放到下一篇文章进行介绍。
Data BlockDataBlock是HBase中数据存储的最小单元。
DataBlock中主要存储用户的KeyValue数据(KeyValue后面一般会跟一个timestamp,图中未标出),而KeyValue结构是HBase存储的核心,每个数据都是以KeyValue结构在HBase中进行存储。
KeyValue结构在内存和磁盘中可以表示为:每个KeyValue都由4个部分构成,分别为key length,value length,key和value。
其中key value和value length是两个固定长度的数值,而key是一个复杂的结构,首先是rowkey 的长度,接着是rowkey,然后是ColumnFamily的长度,再是ColumnFamily,最后是时间戳和KeyType(keytype有四种类型,分别是Put、Delete、DeleteColumn和DeleteFamily),value就没有那么复杂,就是一串纯粹的二进制数据。
BloomFilter Meta Block & Bloom BlockBloomFilter对于HBase的随机读性能至关重要,对于get操作以及部分scan操作可以剔除掉不会用到的HFile文件,减少实际IO次数,提高随机读性能。
在此简单地介绍一下Bloom Filter的工作原理,Bloom Filter使用位数组来实现过滤,初始状态下位数组每一位都为0,如下图所示:假如此时有一个集合S = {x1, x2, … xn},Bloom Filter使用k个独立的hash函数,分别将集合中的每一个元素映射到{1,…,m}的范围。
对于任何一个元素,被映射到的数字作为对应的位数组的索引,该位会被置为1。
比如元素x1被hash函数映射到数字8,那么位数组的第8位就会被置为1。
下图中集合S只有两个元素x和y,分别被3个hash函数进行映射,映射到的位置分别为(0,2,6)和(4,7,10),对应的位会被置为1:现在假如要判断另一个元素是否是在此集合中,只需要被这3个hash函数进行映射,查看对应的位置是否有0存在,如果有的话,表示此元素肯定不存在于这个集合,否则有可能存在。
下图所示就表示z肯定不在集合{x,y}中:HBase中每个HFile都有对应的位数组,KeyValue在写入HFile时会先经过几个hash 函数的映射,映射后将对应的数组位改为1,get请求进来之后再进行hash映射,如果在对应数组位上存在0,说明该get请求查询的数据不在该HFile中。
HFile中的位数组就是上述Bloom Block中存储的值,可以想象,一个HFile文件越大,里面存储的KeyValue值越多,位数组就会相应越大。
一旦太大就不适合直接加载到内存了,因此HFile V2在设计上将位数组进行了拆分,拆成了多个独立的位数组(根据Key进行拆分,一部分连续的Key使用一个位数组)。
这样一个HFile中就会包含多个位数组,根据Key进行查询,首先会定位到具体的某个位数组,只需要加载此位数组到内存进行过滤即可,减少了内存开支。
在结构上每个位数组对应HFile中一个Bloom Block,为了方便根据Key定位具体需要加载哪个位数组,HFile V2又设计了对应的索引Bloom Index Block,对应的内存和逻辑结构图如下:Bloom Index Block结构中totalByteSize表示位数组的bit数,numChunks表示Bloom Block的个数,hashCount表示hash函数的个数,hashType表示hash函数的类型,totalKeyCount 表示bloom filter当前已经包含的key的数目,totalMaxKeys表示bloom filter当前最多包含的key的数目, Bloom Index Entry对应每一个bloom filter block的索引条目,作为索引分别指向’scanned block section’部分的Bloom Block,Bloom Block中就存储了对应的位数组。
Bloom Index Entry的结构见上图左边所示,BlockOffset表示对应Bloom Block在HFile 中的偏移量,FirstKey表示对应BloomBlock的第一个Key。
根据上文所说,一次get请求进来,首先会根据key在所有的索引条目中进行二分查找,查找到对应的Bloom Index Entry,就可以定位到该key对应的位数组,加载到内存进行过滤判断。
总结这篇小文首先从宏观的层面对HFile的逻辑结构和物理存储结构进行了讲解,并且将HFile从逻辑上分解为各种类型的Block,再接着从微观的视角分别对Trailer Block、Data Block在结构上进行了解析:通过对trailer block的解析,可以获取hfile的版本以及hfile中其他几个部分的偏移量,在读取的时候可以直接通过偏移量对其进行加载;而对data block 的解析可以知道用户数据在hdfs中是如何实际存储的;最后通过介绍Bloom Filter的工作原理以及相关的Block块了解HFile中Bloom Filter的存储结构。