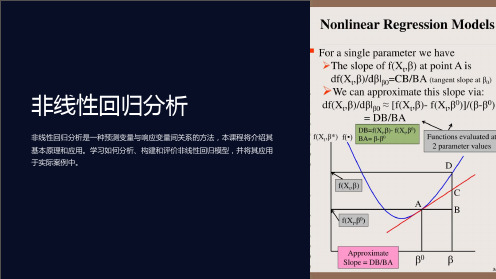
第九章 非线性回归与极大似然估计ppt课件
《非线性回归分析》课件
封装式
• 基于模型的错误率和复 杂性进行特征选择。
• 常用的封装方法包括递 归特征消除法和遗传算 法等。
嵌入式
• 特征选择和模型训练同 时进行。
• 与算法结合在一起的特 征选择方法,例如正则 化(Lasso、Ridge)。
数据处理方法:缺失值填充、异常值 处理等
1
网格搜索
通过预定义的参数空间中的方格进行搜
随机搜索
2
索。
在预定义的参数空间中进行随机搜索。
3
贝叶斯调参
使用贝叶斯优化方法对超参数进行优化。
集成学习在非线性回归中的应用
集成学习是一种将若干个基学习器集成在一起以获得更好分类效果的方法,也可以用于非线性回归建模中。
1 堆叠
使用多层模型来组成一个 超级学习器,每个模型继 承前一模型的输出做为自 己的输入。
不可避免地存在数据缺失、异常值等问题,需要使用相应的方法对其进行处理。这是非线性回归 分析中至关重要的一环。
1 缺失值填充
常见的方法包括插值法、代入法和主成分分析等。
2 异常值处理
常见的方法包括删除、截尾、平滑等。
3 特征缩放和标准化
为了提高模型的计算速度和准确性,需要对特征进行缩放和标准化。
偏差-方差平衡与模型复杂度
一种广泛用于图像识别和计算机 视觉领域的神经网络。
循环神经网络
一种用于处理序列数据的神经网 络,如自然语言处理。
sklearn库在非线性回归中的应用
scikit-learn是Python中最受欢迎的机器学习库之一,可以用于非线性回归的建模、评估和调参。
1 模型建立
scikit-learn提供各种非线 性回归算法的实现,如 KNN回归、决策树回归和 支持向量机回归等。
极大似然估计

6
第1章 极大似然估计
1.2.4
方差矩阵的估计方法
( = ∂ 2 LnL −E ′ ∂θ0 ∂θ0 [ [ ])−1
由渐进公式 [I (θ0 )]
−1
ˆ带入上式作为θ ˆ的方差估计量,即信息矩阵的逆, 可以将θ ( ˆ) = Var(θ 在线性回归模型中, [I (θ0 )]−1 = [ ∂ 2 LnL −E ∂θ∂θ′ ( −E ] = [ ])−1
n n i=1 i=1
梯度向量也称为得分向量(score vector) 。梯度向量g 为k × 1向量。将所有观测值对 应的gi 构成的矩阵G = [g1 , g2 , . . . , gN ]′ (N × k )称为梯度向量的贡献矩阵。梯度向量g 的每 个元素为矩阵G的各列的和。 似然函数的二阶导数称为海赛矩阵(Hessian Matrix) : ∂ 2 ln f (y |θ) ∑ ∂ 2 ln f (yi |θ) ∑ H= = = Hi ∂θ∂θ′ ∂θ∂θ′
i=1 i=1
(1.2)
λxi e−λ xi !
第2节
1.2.1 极大似然估计的原理
极大似然估计
极 大 似 然 估 计 是 指 使 得 似 然 函 数 极 大 化 的 参 数 估 计 方 法,即 估 计 那 些 使 得 样 本(x1 , x2 , . . . , xN )出现的概率最大的参数。 例1.3. 正态分布的ML估计 对于n个相互独立的随机变量x = (x1 , x2 , . . . , xn ), xi ∼ N (µ, σ 2 )(i = 1, 2, . . . , n)。 根 据前面推导的(x1 , x2 , . . . , xn )的联合似然函数: ∑n (xi − µ)2 n n LnL(µ, σ |x) = − ln(σ 2 ) − ln(2π ) − i=1 2 2 2σ 2
极大似然估计

第1章 极大似然估计极大似然估计是非线性模型中非常重要的一种估计方法。
最小二乘法是极大似然估计在线性模型中的特例。
1.1 似然函数假设随机变量x t 的概率密度函数为 f (x t ),其参数用θ= (θ1, θ2, …, θk )表示,则对于一组固定的参数 θ来说,x t 的每一个值都与一定的概率相联系。
即给定参数θ,随机变量x t 的概率密度函数为f (x t )。
相反若参数 θ未知,当得到观测值x t 后,把概率密度函数看作给定x t 的参数 θ的函数,这即是似然函数。
L (θ| x t ) = f (x t | θ)似然函数L (θ| x t ) 与概率密度函数f (x t | θ) 的表达形式相同。
所不同的是在f (x t | θ) 中参数 θ是已知的,x t 是未知的;而在L (θ| x t ) 中x t 是已知的观测值,参数 θ是未知的。
对于n 个独立的观测值x =(x 1, x 2, …, x n ),其联合概率密度函数为1(|)(|)ni i f f x ==∏x θθ其对应的似然函数为:11(|)(|)(|)nn i i i i LnL LnL x f x ====∑∏θx θθ经常使用的是对数似然函数,即对L (θ| x t )取自然对数:LnL (θ| x t ) =log[f (x t | θ)]例 1.1正态分布随机变量的似然函数设一组随机变量x i ,(i = 1, 2, …, n )是相互独立的,且服从正态分布N (μ,σ2)。
存在N 个独立的观测值x =(x 1, x 2, …, x n )。
x i 的似然函数为221/22()1(,|)(|,)exp (2)2i i i i x L x f x μμσμσπσσ⎛⎫-==-⎪⎝⎭=1i x μφσσ-⎛⎫- ⎪⎝⎭其中,φ表示标准正态分布的概率密度函数,2()2x x φ⎛⎫=- ⎪⎝⎭x i 的对数似然函数为:21(,|)ln()ln ()2i i i x LnL x μμσσφσ-⎛⎫=-+ ⎪⎝⎭其中,21ln ()ln(2)22x x φπ=--(x 1, x 2, …, x n )的联合似然函数为21(,|)ln()ln ()2n i i x n LnL μμσσφσ=-⎛⎫=-+ ⎪⎝⎭∑x=2221()ln()ln(2)222n i i x n n μσπσ=----∑ 例 1.2 泊松分布的对数似然函数假设每5分钟到达商店的顾客的数目服从Poisson 分布,有N 个样本观测值(x 1, x 2, …, x N )。
非线性回归课件

§8.1 可化为线性回归的曲线回归
C o effi ci en ts
St andardi zed
U ns tandardize Cdoef f icie C oef f icients nts
Model
B Std. ErrorBeta
t
1
(C ons t8a.n1t9) 0 .043
190. 106
《非线性回归》PPT课件
§8.2 多项式回归
称回归模型
yi=β0+β1xi1+β2xi2+β11
x
2 i1
+β22
x
2 i2
+β12xi1xi2+εi
为二元二阶多项式回归模型。
它的回归系数中分别含有两个自变量的线性项系数β1 和β2, 二次项系数β11 和β22,并含有交叉乘积项系数β12。 交叉乘积项表示 x1与 x2的交互作用。
线性回归 y=b0+b1t
Regression Residuals
Analysis of Variance:
DF Sum of Squares
1
9454779005.1
16
1588574273.6
Mean Square 9454779005.1
99285892.1
F
Signif F
95.22782 .0000
Adjus t ed Rof t he
Model R R SquareSquareEs t imD atuerbin-W at s on
1
. 996a . 992
.89.971601E-02
. 616
a.Predic t ors : (C onst ant ), T
应用回归分析.ppt

统计依赖关系
正相关 线性相关 不相关 相关系数:
负相关 1 XY 1
正相关 非线性相关 不相关
负相关
2019年8月28
感谢你的观看
有因果关系 回归分析 无因果关系 相关分析
9
1 .1 变量间的统计关系
• 注意 (1)不线性相关并不意味着不相关。 (2)有相关关系并不意味着一定有因果关系。 (3)相关分析对称地对待任何(两个)变量,
2019年8月28
感谢你的观看
18
1 .4 建立实际问题回归模型的过程
五.模型的检验与修改
检验: 1. 回归方程
2. 回归系数
3. 拟合优度
4. 随机误差项序列的相关性 异方差
修改:从设置变量是否合理开始—是否遗漏变量,变量间的依 赖性是否强,样本容量是否少,理论模型是否合适等等.
六. 回归模型的应用
函数关系
商品的销售额与销售量之间的关系 y = px 圆的面积与半径之间的关系
S=R2
、原原材材料料消价耗格额(x与3)之产间量的(x关1) 系、单位产量消耗(x2) y = x1 x2 x3
2019年8月28
感谢你的观看
5
1 .1 变量间的统计关系
y(万元)
6000 5000 4000 3000 2000 1000
0 0
y = 1000x
123456 x(万辆)
图1.1 函数关系图
2019年8月28
感谢你的观看
6
1 .1 变量间的统计关系
相关关系的例子
子女身高 (y)与父亲身高(x)之间的关系 收入水平(y)与受教育程度(x)之间的关系 粮食亩产量(y)与施肥量(x1) 、降雨量(x2) 、温度(x3)之 间的关系 商品的消费量(y)与居民收入(x)之间的关系 商品销售额(y)与广告费支出(x)之间的关系
《回归分析 》课件

通过t检验或z检验等方法,检验模型中各个参数的显著性,以确定 哪些参数对模型有显著影响。
拟合优度检验
通过残差分析、R方值等方法,检验模型的拟合优度,以评估模型是 否能够很好地描述数据。
非线性回归模型的预测
预测的重要性
非线性回归模型的预测可以帮助我们了解未来趋势和进行 决策。
预测的步骤
线性回归模型是一种预测模型,用于描述因变 量和自变量之间的线性关系。
线性回归模型的公式
Y = β0 + β1X1 + β2X2 + ... + βpXp + ε
线性回归模型的适用范围
适用于因变量和自变量之间存在线性关系的情况。
线性回归模型的参数估计
最小二乘法
最小二乘法是一种常用的参数估计方法,通过最小化预测值与实 际值之间的平方误差来估计参数。
最大似然估计法
最大似然估计法是一种基于概率的参数估计方法,通过最大化似 然函数来估计参数。
梯度下降法
梯度下降法是一种迭代优化算法,通过不断迭代更新参数来最小 化损失函数。
线性回归模型的假设检验
线性假设检验
检验自变量与因变量之间是否存在线性关系 。
参数显著性检验
检验模型中的每个参数是否显著不为零。
残差分析
岭回归和套索回归
使用岭回归和套索回归等方法来处理多重共线性问题。
THANKS
感谢观看
04
回归分析的应用场景
经济学
研究经济指标之间的关系,如GDP与消费、 投资之间的关系。
市场营销
预测产品销量、客户行为等,帮助制定营销 策略。
生物统计学
研究生物学特征与疾病、健康状况之间的关 系。
回归分析法PPT课件

线性回归模型的参数估计
最小二乘法
通过最小化误差平方和的方法来估计 模型参数。
最大似然估计
通过最大化似然函数的方法来估计模 型参数。
参数估计的步骤
包括数据收集、模型设定、参数初值、 迭代计算等步骤。
参数估计的注意事项
包括异常值处理、多重共线性、自变 量间的交互作用等。
线性回归模型的假设检验
假设检验的基本原理
回归分析法的历史与发展
总结词
回归分析法自19世纪末诞生以来,经历 了多个发展阶段,不断完善和改进。
VS
详细描述
19世纪末,英国统计学家Francis Galton 在研究遗传学时提出了回归分析法的概念 。后来,统计学家R.A. Fisher对其进行了 改进和发展,提出了线性回归分析和方差 分析的方法。随着计算机技术的发展,回 归分析法的应用越来越广泛,并出现了多 种新的回归模型和技术,如多元回归、岭 回归、套索回归等。
回归分析法的应用场景
总结词
回归分析法广泛应用于各个领域,如经济学、金融学、生物学、医学等。
详细描述
在经济学中,回归分析法用于研究影响经济发展的各种因素,如GDP、消费、投资等;在金融学中,回归分析法 用于股票价格、收益率等金融变量的预测;在生物学和医学中,回归分析法用于研究疾病发生、药物疗效等因素 与结果之间的关系。
梯度下降法
基于目标函数对参数的偏导数, 通过不断更新参数值来最小化目 标函数,实现参数的迭代优化。
非线性回归模型的假设检验
1 2
模型检验
对非线性回归模型的适用性和有效性进行检验, 包括残差分析、正态性检验、异方差性检验等。
参数检验
通过t检验、z检验等方法对非线性回归模型的参 数进行假设检验,以验证参数的显著性和可信度。
精品课程医学统计学教学课件-logistic回归分析

详细描述
队列研究在医学中常用于评估危险因素对疾病发生和发展的影响,以及评估预防 措施的效果。通过长期追踪和研究对象的定期随访,收集各组人群的结局数据, 分析暴露因素与结局之间的关联。
随机对照试验
随着大数据和人工智能技术的不断发 展,Logistic回归分析在医学领域的 应用越来越广泛。未来的研究将更加 注重Logistic回归分析与其他先进技 术的结合,如深度学习、机器学习等 ,以提高模型的预测精度和稳定性。
未来的研究将更加关注Logistic回归 分析在临床实践中的应用,如疾病预 测、诊断和治疗方案的制定等。同时 ,如何将Logistic回归分析与其他统 计方法结合,以更好地解决医学实际 问题,也是值得探讨的方向。
课件采用了多种教学方法,如理论讲解、案例分析、软件操作等,使学生能够全面了解和 掌握Logistic回归分析的技能。
教学效果
通过本课件的学习,学生能够熟练掌握Logistic回归分析的基本原理和应用,提高解决实 际问题的能力,为后续的医学研究和临床实践打下坚实的基础。
研究展望
研究前沿
研究方向
教学改进
03
Logistic回归分析在医学 中的应用
病例对照研究
总结词
病例对照研究是一种回顾性研究方法,通过比较病例组和对 照组的暴露情况,探讨疾病与暴露因素之间的关联。
详细描述
在医学领域,病例对照研究常用于探讨病因、预测风险和评 估干预措施的效果。通过收集病例组和对照组的相关信息, 分析暴露因素与疾病发生之间的关系,为病因推断提供依据 。
利用样本数据,建立Logistic回归模 型,描述自变量与因变量之间的关系。
非线性回归分析PPT课件
10
第10页/共30页
(2)剩余标准差s:类似于一元线性回归中标准差的估
计公式,此剩余标准差可用残差平方和来获得,即
s
( yi yi )2
n2
s为诸观测点yi与由曲线给出的拟合值yˆi 间的平均偏离 程度的度量,s越小,方程越好。
11
第11页/共30页
在观测数据给定后,不同的曲线选择不会影响
6
对上述非线性函数,参数估计最常用的方 法是“线性化”方法。
以1/y=a+b/x为例,为了能采用一元线性
回归分析方法,我们作如下变换
u=1/x,v=1/y 则曲线函数就化为如下的直线v=bu
这是理论回归函数。对数据而言,回归方程 为
vi=a+ bui + i 于是可用一元线性回归的方法估计出a,b。
5
第5页/共30页
本例中,散点图呈现呈现一个明显的向上且
上凸的趋势,可能选择的函数关系有很多,比 如,我们可以给出如下四个曲线函数:
1) 1/y=a+b/x
2)
y
y
y10a=0ab+a bexlnx/bx(b
0)
3)
4)
在初步选出可能的函数关系(即方程)后,我
们必须解决两个问题第6页:/共如30页何估计所选方程中的
➢ 回归分析和相关分析目的不同
在回归分析中,寻找的是变量之间的关系,代表这种关系的方程可能就是所期望 的结果,也可能是所期望预测的均值。
21
第21页/共30页
虚拟变量回归预测
22
第22页/共30页
虚拟变量回归预测
1.虚拟变量 品质变量不像数量变量那样表现为具体的数值。
它只能以品质、属性、种类等形式来表现。要在回 归模型中引入此类品质变量,必须首先将具有属性 性质的品质变量数量化。通常的做法是令某种属性 出现对应于1,不出现对应于0。这种以出现为1, 未出现为0形式表现的品质变量,就称为虚拟变量。 2.带虚拟变量的回归模型
极大似然估计.ppt

d
2、用上述求导方法求参数的MLE有时行不通,这时 要用极大似然估计原理来求 .
例1 设ξ1,ξ2,…, ξn是取自母体 ξ~b(1, p) 的一个子样,
求参数p的极大似然估计.
0 1分布
解:的概率函数为: P( x) px (1 p)1x ( x 0,1)
n
(1)似然函数 : L( p; x1,, xn ) pxi (1 p)1xi
§6.2 极大似然估计
(maximum likelihood estimate 简记为MLE或ML估计)
极大似然估计是在母体类型已知条件下使用的一 种参数估计方法 .
它首先是由德国数学家高斯在1821年提出的 , 费歇在1922年重新发现了这一方法,并首先研究了 这种方法的一些性质 .
极大似然原理:
i 1
n
n
xi
n xi
pi1 (1 p) i1
( xi 0,1)
n
n
(2)ln L ( xi )ln p (n xi )ln(1 p)
i 1
i 1
令
d
ln L dp
n
(
i 1
xi
)
1 p
(n
n
i 1
xi
)
1
1
p
0
(3) pˆ L
1 n
n i 1
xi
x
pˆ L
pˆ L是p的一致无偏估计量
解:该母体ξ服从两点分布:
ξ0 1 P 1-p p 因此,出现此子样的可能性的大小,是概率
P(1 1,2 1,3 0,4 1,5 1) 子样的联合分布列 P(1 1)P(2 1)P(3 0)P(4 1)P(5 1) p p (1 p) p p p4(1 p)记为 L( p)
非线性回归

非线性回归一、介绍线性回归是一种基本的统计方法,在许多领域中都有广泛的应用。
然而,在现实世界中,很多问题并不满足线性关系。
这时,非线性回归就成为了一种更加适用的方法。
二、非线性回归模型非线性回归模型是通过拟合非线性函数来描述自变量和因变量之间的关系。
一般来说,非线性回归模型可以分为参数模型和非参数模型。
1. 参数模型参数模型是指非线性函数中包含一些参数,通过最小化残差的平方和来估计这些参数的值。
常见的参数模型包括指数模型、幂函数模型、对数模型等。
2. 非参数模型非参数模型是指非线性函数中没有参数,通过直接拟合数据来建立模型。
常见的非参数模型包括样条函数模型、神经网络模型等。
三、非线性回归的应用非线性回归在许多领域中都有广泛的应用,特别是在生物学、经济学、工程学等领域中。
下面介绍几个非线性回归的应用实例:1. 生物学研究非线性回归在生物学研究中有很多应用,其中一个典型的例子是用来描述酶动力学的反应速率方程。
酶动力学研究中,根据酶底物浓度和反应速率的关系来建立非线性回归模型,从而研究酶的活性和底物浓度之间的关系。
2. 经济学分析非线性回归在经济学中也有许多应用,其中一个典型的例子是用来描述经济增长模型。
经济增长模型中,根据投资、人口增长率等因素来建立非线性回归模型,从而预测国家的经济增长趋势。
3. 工程学设计非线性回归在工程学设计中有很多应用,其中一个典型的例子是用来描述材料的应力-应变关系。
材料的应力-应变关系通常是非线性的,通过非线性回归模型可以更准确地描述材料的力学性能。
四、非线性回归的优缺点非线性回归相对于线性回归具有一些优点和缺点。
下面分别介绍:1. 优点非线性回归可以更准确地描述自变量和因变量之间的关系,适用于不满足线性关系的问题。
非线性回归的模型形式更灵活,可以通过选择适当的函数形式来更好地拟合数据。
2. 缺点非线性回归相比线性回归更复杂,需要更多的计算资源和时间。
非线性回归的参数估计也更加困难,需要依赖一些优化算法来找到最优解。
非线性回归分析江南大学张荷观.pptx

记 (1, 2 ,, p ) , 高斯–牛顿法的具体方法如下。
第9页/共47页
(1)
先取参数的一组初值 B0 (b10 , b20 ,, bp0 ) , 根据泰勒级数并 只取线性项, 得
y f (x1, x2 ,, xk ;b10 , b20 ,, bp0 )
p i 1
f
i
b B0 i0
p f
i1 i
B0 i '
第10页/共47页
(3-6)
最小二乘估计
令
MLeabharlann yf(x1 , x2 ,, xk ;b10 , b20 ,, bp0 )
p i 1
f
i
b B0 i0
Zi
f
i
B0 , i 1,2,, p
对给定的初始值 B0 , M 和 Zi 都是确定的。则得线性回归模型
停止迭代。 在实际工作中这几个标准可替换, 但无明显优劣, 一般可同时
使用。
第23页/共47页
第三节 非线性回归评价和假设捡验 与线性回归分析一样,非线性回归分析在建立回归方程后进行评 价和捡验。主要有回归方程拟合度的评价,以及回归方程和回归系数 的显著性捡验等。非线性回归的最小二乘估计不是BLUE, 但一般条 件下是一致估计。
直到满足要求, 即得参数的最小二乘估计。
直接搜索法和格点搜索法都是低效的, 在实际工作中很少采用。
第8页/共47页
三、高斯–牛顿(Gauss - Newton)法 高斯–牛顿法是一种常用的迭代法。 非线性回归模型不能通过变换转化为线性回归模型, 但可以利 用泰勒展开式转化为线性回归模型。设非线性回归模型
第九章 非线性回归与极大似然估计

1、似然比检验(LR)
如果我们希望检验一些 0的原假设,
设LnL(UR )代表没有限制条件时对数似然函数 的极大值, LnL(R )代表有限制条件时对数似然函数
的极大值,则似然比定义为 LnL(R ) . LnL(UR )
LnL越大表明对数据的拟合程度越好,分母 来自无条件模型,变量个数越多,拟合越好,因此分 子小于分母,似然比在0到1间。分子是在原假设成立 下参数的极大似然函数值,是零假设的最佳表示。而 分母则表示在在任意情况下参数的极大似然函数值。 比值的最大极限值为1,其值靠近1,说明局部的最大 和全局最大近似,零假设成立可能性就越大。
p(Yi )
ห้องสมุดไป่ตู้
1
2
2
exp[
1
2
2
(Yi
X i)2 ]
则似然函数是密度函数在所有N个观测处取值
的连乘积:
L(Y1,Y2 , YN , , , ) P(Y1)P(Y2 ) P(YN )
1
(2 2 )N 2
exp[
1
2
2
(Yi
X
i)2
]
极大似然估计的目标是寻找最可能生成样本观测值
关紧要”的,系数显著为零,R2非常小,则当我们从 有约束的模型变动到无约束的模型时,加进来的k-q个
变量的系数应该为零,原假设成立。
反之,辅助回归式的拟合优度十分好,R2非常大,
则从有约束的模型变动到无约束的模型时,加进来的kq个变量的系数至少有一个显著不为零,则接受备择假
设。
最后,用辅助回归式得到的R2计算 LM统计量的值 LM=NR2,LM服从m个自由度的 2(m) 分布,其中m表示约束条件个数。
矩估计和极大似然估计PPT课件

已知常数, 参数θ 看成自变量, 得到似然 函数 L(θ );
(3). 求似然函数 L(θ) 的最大值点 (常常转化 为求ln L(θ)的最大值点) ,即θ的MLE;
(4). 在最大值点的表达式中,代入样本值, 就得参数 θ 的极大似然估计。
第30页/共45页
i1
i
X )2
即
n 1S2. n
第13页/共45页
如:正态总体N(, 2) 中和2的矩估计为
ˆ X ,
ˆ 2
1 n
n
(X i
i 1
X )2.
第14页/共45页
设总体 X 的分布函数中含 k 个未知参数
1,2 ,k .
步骤一:记总体X的m阶原点矩 E(Xm)为am ,
m =1,2,…,k. 一般地, am (m=1, 2,…, K) 是总体分布
Xn,要去估计未知参数θ 。
一种直观的想法是:哪个参数(多个参数 时是哪组参数) 使得现在的出现的可能性 (概 率) 最大,哪个参数(或哪组参数)就作为参数 的估计。这就是 极大似然估计原理。 如果
L(ˆ) max L( ).
θ 可能变化空间,
称为参数空间。
称 ˆ为θ 的极大似然估计 (MLE)。
若θ 是向量,上述似然方程需用似然方程组
代替 。
ln ln
L(1,2
1 L(1,2
,,k ,,k
) )
0, 0,
2
ln
L(1,2
,,k
)
0
k
● 用上述方法求参数的极大似然估计有时行不
通,这时要用极大似然原理来求 。
第32页/共45页
例2:某机器生产的金属杆用于汽车刹车系统,
人教A版高中数学选修233.非线性回归分析教学PPT课件

身高
180 175 170 165 160 155 150
32 34 36 38 40 42
选变量
画散点图
选模型
估计参数
一元线性模型建立过程
解:选取脚码为解释变量x,身高为预报变量y
180 175 170 165 160 155 150
30
身高
身高 线性 (身高)
35
40
45
假设线性回归方程为 :ŷ=bx+a
合作探究——能力提升
通过适当变换,将下列函数转化成线性型函数
⑴ 幂函数曲线 y=axb
合作探究——能力提升
⑴ 幂函数曲线 y=axb 处理方法:两边取自然对数得:lny=lna+blnx; 再令 u=_______,
v=________, c=________. 得到线性函数u=bv+c 。
合作探究——能力提升
分析和预测
最小二乘法
提出问题
一只红铃虫的产卵数y与温度x 有关,现收集了7组观测数据如下:
温度x 21 23 25 27 29 32 35 产卵数y 7 11 21 24 66 115 325
试建立y与x之间的回归方程; 预测温度为28℃时红铃虫的产卵数目。
问题解决
建立什么样的函数模型?
人教A版高中数学选修233.非线性回归 分析教 学PPT 课件
通过适当变换,将下列函数转化成线性型函数
(2)指数曲线 y=aebx
b
(3)倒指数函数 y ae x
(4) 对数曲线 y=a+blnx
课堂小结
1 怎样建立回归模型? 2 化未知为已知的数学思想
课外阅读
1、华尔街根据民众情绪抛售股票; 2、对冲基金依据购物网站的顾客评论,分析企业产 品销售状况; 3、银行根据求职网站的岗位数量,推断就业率; 4、投资机构搜集并分析上市企业声明,从中寻找破 产的蛛丝马迹; 5、美国疾病控制和预防中心依据网民搜索,分析全 球范围内流感等病疫的传播状况;
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二、极大似然估计法 1、极大似然估计的思想
设总体分布的密度函数 为p( X ; ),为未知参数 . 相互独立的随机样本 X 1 , X n取自总体, 因此随机样本的联合密 度函数为: L( X ; ) p( X ; ),
i 1 n
反映X 1 , X n被抽取的概率 , 称L( X ; )为似然函数. ˆ越接近真实值,L ( X ; ˆ)越接近X , X 的估计值
Y , Y 的参数 , 和 的值 ,即求使对数似然 1 N 达到大的 , 和 值 。
对数似然函数
极大似然估计的目标是 寻找最可能生成样本 测值
2 2 2 LnL ( N / 2 ) ln( 2 ) ( N / 2 ) ln( ) ( / 2 ) ( Y X ) i i
2、标准线性模型的极大似然估计
标准线性模型 Y X u ,每一个 Y , i i i i服从正态 1 2 p ( Y ) exp[ ( Y X ) ] i i i 2 2 2 2 1
2 即 Y ~ N ( X , ), 其概率密度函数可表 为 i i
则似然函数是密度函数在所有N个观测处取值 的连乘积:
L ( Y , Y , Y , , , ) P ( Y ) P ( Y ) P ( Y ) 1 2 N 1 2 N 1 1 2 exp[ ( Y X ) i ] N 2 i 2 2 2 ( 2 )
1 2 exp[ 2( Y f ( X , X , X , , , )) ] i 1 i 2 i ki 1 2 p 2 2 2
则 N 个观测值的对数似然函 数为 ( /2 ) ( Y f( X X , , , )) i 1 i,X 2 i, ki 1 2 p
p p
f ( ) | 0 令左边为一个新的因变量,右边 i
并把它们作为新的初始 值 ,得到新的线性回
f ) | u i( 1 i 1 i 对这个方程运用普通最小二乘法,得到一组新估计 , , ) 。不断重复这个重新线性化的过程直 值( 12 22 p 2 到估计的参数收敛。
令对数似然函数对 , ,求偏导并令它们等于零 得 极大似然估计量 : ˆ
ML
2 ˆML
(X X)( Y Y ) ˆ ; (X X) ˆX ) ˆ (Y
i i 2 i 2 i i
ˆX Y ML
N
显然 , , 的极大似然估计量与 OLS 估计量完全相 , ˆ 是最优线性无偏估计量 ˆ 和 因此 ,
p
为一组新的自变量, ( , , ) 为未知参 1 2 p 数,则原模型转化成线性模型,可以用普通最小 二乘法来估计这些参数。 将 ( , p) 的第一次估计值记为 ( , , p1), 1 2, 11 21
f Y f( X ,X , X , ) ( ) | 1 2 k 1, 1 2, 1 p 1 i 1 1 i 1 i
第九章 非线性 回归与极大似然 估计
非线性回归模型:
Y f ( X , X , X , ,2 , ) u 1 2 k 1 p
其中f是k个自变量和p个回归系数的非线性函数。
用来决定系数估计值的标准与线性回归的 标准一样,即误差平方和最小化,称为非线性 最小二乘估计。 在线性回归情况下,求最小乘估计在计算 上很简单。对于非性方程,有若干不同的寻找 使误差平方和达到最小的系数估计方法。
ML ML 2 2 ˆML 仍是 的渐近有效估计量 。
2 2 ˆML 但 ( 虽然是一致的 ) 却是 的有偏估计量 ,性函数 Y f (X ,X X , p)u , 1 2, k, 1 2, 假设 u 服从均值为 0 的正态分布 , 那么给定 X 和 ,Y 的密度函数可写成 p ( Y ) i, X i, 1
对非线性函数 Y f ( X , X , X , , , ) u 1 2 k 1 2 p
泰勒级数展开法(循环线性法):
对给定的初始值 , , p0, 10 20 在该处附近将 f展开为泰勒级数 ,
并略去所有二次项和以 后的所有高次项 :
f Y f ( X , X , X , , , ) () | ( ) u 1 2 k 10 20 p 0 i i 0 0
p i 1 i
p
f Y f( X ,X , X , ) ( ) | 1 2 k 1, 0 2, 0 p 0 i 0 0 i 1 i f ) | u i( 0 i 1 i
1
n
ˆ)值越大。 被抽取的真实概率 ,因此L( X ; ˆ) max L( X ; )的 ˆ作为的 所以, 用满足L( X ;
ˆ . 极大似然估计值 , 记为 ML
因为 L (X;)与 lnL (X;)有相同的极值点 , 所以一般通过将 lnL (X;)对 求导并使之等于 0 来得到参数的极大似然 估计值 . lnL (X;)称为对数似然函数 .
2 2
LnL p ( Y ) ( N /2 ) ln( 2 ) ( N /2 ) ln( ) i,X i
2
令对数似然函数对每一 个 和 求偏导并令它们等于零 , 可得到关于 p1 未知数 p1 个非线性方程组 , 求解过程较复杂 。 但最终的极大似然估计 量都是一致的和 渐近有效的 。