好用的PDF文字识别软件推荐
翻译pdf的软件

翻译pdf的软件翻译PDF的软件PDF是一种广泛使用的电子文档格式,可以在不同的平台上进行查看和共享。
对于需要处理不同语言的人来说,翻译PDF文件可能是一个具有挑战性的任务。
幸运的是,有许多专门用于翻译PDF文件的软件可供使用。
下面我们将介绍几个流行的翻译PDF的软件。
1. Adobe Acrobat Pro:Adobe Acrobat Pro是一款功能强大的PDF编辑和处理软件,它还提供了翻译PDF文件的功能。
它内置了OCR(光学字符识别)技术,可以将PDF文件中的文本转换为可编辑的格式,并支持多种语言的翻译。
2. Google翻译:作为最常用的在线翻译工具之一,Google翻译也可以用于翻译PDF文件。
用户只需将PDF文件上传到Google翻译网页或使用Google翻译手机应用程序,选择源语言和目标语言,即可获得翻译结果。
然而,Google翻译对于包含复杂格式和布局的PDF文件可能不是最佳选择。
3. ABBYY FineReader:ABBYY FineReader是一款专业的OCR软件,可用于识别和翻译PDF文件中的文本。
它支持多种语言,并具有准确的OCR识别功能,可以处理各种类型的PDF文件。
用户只需将PDF文件导入到软件中,选择所需的语言,即可生成可编辑的文本和翻译结果。
4. TranslatePDF:TranslatePDF是一个专门用于翻译PDF文件的在线工具。
用户只需将PDF文件上传到网站,选择源语言和目标语言,然后点击翻译按钮,即可获得翻译后的PDF文件。
该工具支持多种常见语言,但可能对于复杂的排版和布局不够准确。
5. SDL Trados Studio:SDL Trados Studio是一款专业的翻译工具,可以用于翻译各种文件格式,包括PDF文件。
它支持多语言翻译和术语管理,并提供了先进的记忆功能,可以加快翻译速度并提高一致性。
然而,SDL Trados Studio可能对于不熟悉翻译工具的用户来说学习曲线较高。
最新版迅捷OCR文字识别软件的使用方法

最新版迅捷OCR文字识别软件的使用方法随着现在人工智能化的不断发展,工作中很多的问题都可以通过使用一些办公软件进行解决,就像图片文字识别的问题,就可以通过借助迅捷OCR文字识别软件轻松实现这个问题。
而今天小编要来为大家分享的便是最新版的迅捷OCR文字识别软件的使用方法。
下面我们就一起来看一下吧。
使用工具:迅捷OCR文字识别软件
软件介绍:该软件是一款智能化的OCR图片文字识别软件。
支持PDF 识别、扫描件识别、图片文字识别、caj文件识别等功能,所以在办公中遇到上面所说到的问题迅捷OCR文字识别软件https:///ocr是不错的选择。
操作步骤:
步骤一:准备好一张图片,然后再打开电脑上的图片文字识别工具,如果电脑上没有安装的,可以直接电脑百度搜索迅捷办公,进入其官网,将最新版迅捷OCR文字识别软件安装到电脑上。
步骤二:软件安装好后,打开该软件时会出现一个添加文件的选项,点击退出按钮,退出这个选项。
步骤三:上面的选项退出后,在页面的上方,选择图片局部识别功能,进入图片局部识别页面后,点击页面左上角的添加文件按钮,将0需要识别的图片添加进来。
步骤四:图片添加进来后,可以在页面的左下角修改识别后的文件的输出目录,以防识别后找不到识别后的文件。
步骤五:这时就可以拖动鼠标,将需要识别的文字用文本框框选出来了,文字框选出来后,软件就会自动对框选出来的文字进行自动识别转换。
步骤六:等待文字识别转换结束后,就可以,点击保存为TXT的按钮,对识别转换后的文字进行修改编辑了。
最新版的迅捷OCR文字识别软件介绍及它的使用方法上面已经为大家做过简单的介绍了,该软件可以轻松实现PDF、caj等文件的识别转换,可谓是办公中不可或缺的好帮手啊。
常用9款OCR软件介绍

常用9款OCR软件介绍展开全文1、ABBYY***ABBYY FineReader简介:驰名品牌,全球都在用,国外4大OCR公司之一,众多打印机、扫描仪都自带它为ocr软件。
安装程序约300MB,选择词库安装后约500MB。
评价:功能齐全,众多软件中应该是第一。
缺点:占cpu/内存大。
有时会识别出一些不存在的字(和正确的字很相像,但不存在。
造字?)友情提醒:Win有Corporate 和Professional (企业和专业)版,也有苹果Mac版,大家选自己要的。
***ABBYY Screenshot Reader简介: 功能类似汉王屏幕摘抄、Mini Ocr是专门OCR识别屏幕截图用的。
2、I.R.I.S. Readiris简介:驰名品牌,全球都在用,国外4大OCR公司之一,众多印机、扫描仪都自带它为ocr软件。
安装程序约200MB,选择词库安装后约100MB。
评价:功能可以,对表格的识别率ms比ABBYY FineReader高。
没遇到FineReader的造字问题。
缺点:没自带校对功能。
友情提醒:一定用Asian版,没写Asian的不支持中文!导入图片时勾上“使用300dpi分辨率” 不然若图片不达标会弹出提示叫你从扫。
(废话,我要是有好的干嘛不用,设计师nc)Win有Corporate 和Professional (企业和专业)版,也有苹果Mac版,大家选自己要的。
3、汉王简介:国产企业,值得支持缺点:不支持多页单TIF文档***汉王文本王文豪7600评价:功能满全的,自带的几个小工具不错(汉王拼图精灵、汉王屏幕摘抄、汉王照片摘抄)友情提醒:1.貌似该公司目前开发重点是硬件,2007后出了文本王文豪7600就没更新了。
2.网上一个366MB的是完整CD ,包括了Hwdochasp 和hwdocsafe 这两个文件夹,大家装hwdocsafe 文件夹里的。
另166MB的是光光hwdocsafe 这个文件夹。
WPSOffice如何进行PDF文档文本识别和提取

WPSOffice如何进行PDF文档文本识别和提取PDF是一种非常流行的电子文档格式,但是由于其文本不可编辑和选择性复制的限制,给一些编辑和处理带来很大的不便,而WPSOffice则提供了一种方便快捷的解决方案:文本识别和提取。
本文将详细介绍WPSOffice如何进行PDF文档文本识别和提取。
一、WPSOffice是什么?WPSOffice是由中国金山公司开发的办公软件,在全球范围内有着非常广泛的用户群体。
其主要包括文字处理、表格处理和演示文稿三大功能模块,支持多种常见的文件格式。
二、WPSOffice PDF文本识别简介WPSOffice的PDF文本识别功能可以帮助用户将PDF文档中的图片和文字提取出来,变成可编辑和可选择的文本内容。
相比于手动输入或者复制粘贴,这种方式更加高效和准确。
同时,WPSOffice还支持将提取后的文本内容直接保存为Word或者其他格式,方便后续编辑和处理。
三、WPSOffice PDF文本识别操作步骤1. 打开WPSOffice软件,在主界面中找到“PDF转换”选项卡,点击“PDF转Word”或者“PDF转TXT”按钮(取决于你想将PDF文档转换为Word格式或者纯文本格式)。
2. 点击“添加文件”按钮,并选择需要转换的PDF文档。
3. 在“输出设置”中选择需要的转换格式和保存路径。
4. 点击“立即转换”按钮,等待转换过程完成。
5. 转换完成后,你就可以在指定的保存路径下找到转换后的文件,再进行后续的编辑和处理。
四、WPSOffice PDF文本识别优点1. 高效准确:WPSOffice的PDF文本识别可以将PDF中的文字和图片迅速提取出来,提高了处理效率,同时识别准确率也较高。
2. 方便后续处理:提取出来的文字和图片可以方便地进行后续的编辑和处理,避免了手动输入或者复制粘贴带来的繁琐和错误。
3. 支持多种文本格式:WPSOffice不仅支持将PDF转换为Word格式,还支持将其转换为纯文本格式,可以满足不同用户的不同需求。
文字识别软件哪个识别率高
文字识别软件哪个识别率高
随着现在科技的发展,我们可以将图片转换为文字格式,然后保存为Word,那么到底文字识别软件那个识别率高一点呢?小编就用亲身经历和你们推荐一款软件:捷速OCR文字识别软件。
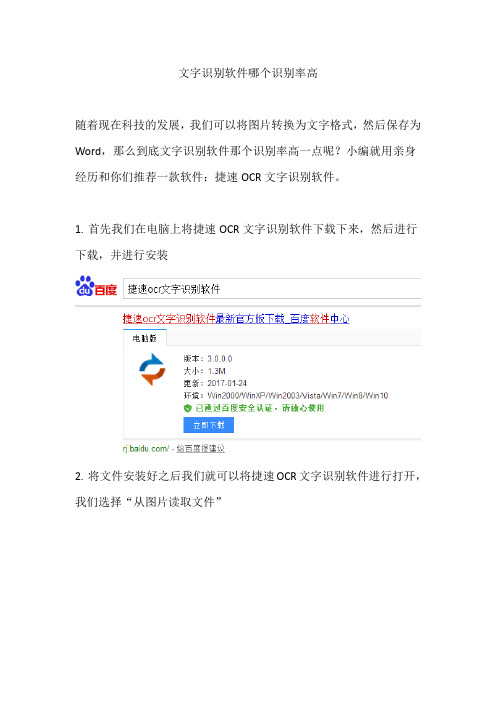
1.首先我们在电脑上将捷速OCR文字识别软件下载下来,然后进行下载,并进行安装
2.将文件安装好之后我们就可以将捷速OCR文字识别软件进行打开,我们选择“从图片读取文件”
3.然后我们将文件进行选择,然后将图片文件导入到软件中
4.将文件导入之后我们点击菜单栏中的“识别”,既可看到右侧有已经转换好的文件了
5.将文件转换好之后我们就可以将一些瑕疵进行修改,然后保存为Word格式就可以了!打开文件后我们会发现这款文字识别软件的识别率还是很高的。
以上就是小编的一些个人见解和看法,希望对你们有所帮助,无论是
方法还是操作都很简单,小伙伴们看完之后记得保存,相信这款软件对你肯定会有帮助的如果小伙伴们还对PDF扫描图片文件转换成Word的方法/1620.html感兴趣的话可以去看一看哦,相信肯定会对你有所帮助的!。
如何识别PDF中的文字

我们在进行PDF文件编辑时,如果你的PDF文件内容是以图片的形式保存的,那么很难编辑复制,这时候就需要借助PDF文件识别软件的帮忙了。
那么PDF文件识别软件哪个好呢?如果你不知道,不妨看看小编的想法吧。
方法一:软件识别软件名称:迅捷OCR文字识别软件软件优点:迅捷OCR文字识别软件是一款好用的电脑OCR文字识别软件,支持图片批量识别、图片局部识别、PDF文档识别等多种功能。
操作简单,识别结果精准。
操作步骤:1:打开软件在电脑中安装好迅捷OCR文件识别软件,打开软件后,在“OCR文字识别”页面中,我们可以找到“PDF文档识别”选项,点击进入PDF文字识别页面。
2:添加文件点击添加文件,在迅捷OCR文字识别软件中支持批量添加与批量识别,完成添加后,进入识别页面。
3:PDF文件识别PDF文件识别页面,识别结果是以文件的形式保存的,所以我们可以在页面最下方设置文件保存格式,比如DOC、DOCX等,还可以设置文件保存位置。
完成设置后,点击开始识别。
4:识别结果PDF文字识别完成后,点击操作可以预览文件识别结果,而识别结果也会自动以文件的形式保存在电脑中。
方法二:在线网站识别在线网站:迅捷PDF转换器网站优势:迅捷PDF转换器在线网站支持文档处理、文档转换、图片文字识别等多种功能,其中图片文字识别功能包括图片局部识别、扫描PDF识别、扫描票证识别等多种功能。
操作步骤:1:打开网站在电脑浏览器中搜索迅捷PDF转换器在线网站,打开网站后,我们在“图片文字识别”功能中找到“扫描PDF识别”选项,开始准备进行PDF文件识别。
2:自定义设置在页面下方的自定义设置功能中,我们可以进行页码选择、转换结果保存格式选择以及识别效果选择,完成设置后,开始添加文件。
3:添加PDF文件在线网站支持批量添加与批量识别PDF文件,点击“选择文件”便可完成PDF 文件的添加,添加完成后自动开始识别。
4:识别结果识别结束后,如果你想将结果保存在电脑中,点击“立即下载”即可。
用迅捷OCR文字识别软件进行PDF文字识别的方法

用迅捷OCR文字识别软件进行PDF文字识别的方法
PDF文字识别应该怎样进行实现呢?工作中PDF文字识别的问题总是会时常出现,那么遇到这个问题我们应该怎样进行解决呢?今天小编就通过借助迅捷OCR文字识别软件来为大家分享一个进行PDF文字识别的方法,来帮助大家解决工作中所遇到的PDF文字识别的问题吧。
使用工具:迅捷OCR文字识别软件
软件介绍:该软件是一款智能化的OCR图片文字识别软件。
支持PDF 识别、扫描件识别、图片文字识别、caj文件识别等功能,所以在办公中遇到上面所说到的问题迅捷OCR文字识别软件https:///ocr是不错的选择。
操作步骤:
步骤一:先准备好一份PDF文件,然后在电脑上安装一款图片文字识别软件,可以电脑百度搜索迅捷办公,进入其官网将迅捷OCR文字识别软件下载到电脑上。
步骤二:打开该软件时,会弹出一个添加文件的选项,通过该选项,将准备好的PDF文件添加进来。
步骤三:文件添加进来后,可以在软件的左下角,将识别后的文件的输出目录进行修改。
步骤四:修改好后,在等待识别的文件上方,可以将文件的识别格式,和识别效果进行修改。
步骤五:上面的选项修改好后,就可以点击页面左下角的一键识别按钮,软件就会自动对PDF文件进行识别了。
步骤六:等待软件识别结束后,就可以点击打开文件按钮,对识别后的文字进行查看和编辑了。
用迅捷OCR文字识别软件进行PDF文字识别的方法已经分享结束了,大家可以看到操作起来还是很简单的,而且迅捷OCR文字识别软件,还支持图片文字识别转换,caj文件识别转换,功能多多,大家可以使用看看哦。
WPSOffice中如何进行PDF文件文字识别和翻译

WPSOffice中如何进行PDF文件文字识别和翻译随着信息时代的到来,电子文档的使用越来越广泛。
而PDF文件作为一种常见的电子文档格式,在各个领域中被广泛应用。
然而,有时候我们在处理PDF文件时,可能需要对其中的文字进行识别和翻译,以便更好地进行文档阅读和理解。
在WPSOffice中,我们可以方便地进行PDF文件文字识别和翻译,本文将介绍具体操作方法。
首先,我们需要确保已经打开了WPSOffice软件,并且正常地加载了PDF文件。
接下来,我们可以按照以下步骤进行文字识别和翻译操作。
第一步,文字识别:WPSOffice中提供了强大的文字识别功能,可以帮助我们快速将PDF文件中的文字提取出来。
具体操作如下:1. 在PDF文件打开后的界面上方菜单栏中,点击“工具”选项卡。
2. 在下拉菜单中选择“OCR识别”选项,进入文字识别功能界面。
3. 点击“选择区域”按钮,用鼠标在PDF文件中选择需要识别的文本区域。
可以选择整页或者部分文本区域。
4. 在选择文本区域后,点击“开始识别”按钮,WPSOffice将自动进行文字识别并将结果显示在界面右侧的文本框中。
第二步,文字翻译:在完成文字识别后,我们可以利用WPSOffice的翻译功能对提取出的文字进行翻译。
具体操作如下:1. 在文字识别结果的文本框中,选中需要翻译的文字。
2. 在右侧的“翻译”文本框中,WPSOffice会自动给出翻译结果。
如果需要更多的翻译选项,可以点击“更多选项”按钮,选择其他翻译服务提供商进行参考。
3. 点击“确定”按钮,翻译结果将显示在界面的下方。
通过以上步骤,我们可以轻松地进行PDF文件文字识别和翻译。
除此之外,WPSOffice还提供了其他实用的功能,如PDF文件的合并、拆分、加密等,可以根据个人需求进行操作。
同时,WPSOffice的界面简洁美观,操作简单易懂,为用户提供了良好的使用体验。
综上所述,WPSOffice软件中的文字识别和翻译功能能够帮助我们高效地处理PDF文件,提取出文本并进行翻译,轻松实现内容的阅读和理解。
WPSOffice如何进行PDF文档像识别和文字识别

WPSOffice如何进行PDF文档像识别和文字识别PDF文档是一种常用的电子文档格式,但由于其一般为图片或扫描件的形式,无法直接编辑和复制其中的文字内容,给我们的工作和学习带来了不便。
然而,WPSOffice提供了便捷的PDF文档像识别和文字识别功能,使我们能够轻松提取和编辑PDF文档中的文字信息。
本文将介绍WPSOffice如何进行PDF文档像识别和文字识别的操作步骤。
1. 打开WPSOffice软件首先,在电脑上打开WPSOffice软件。
如果你还没有安装WPSOffice,请先下载安装最新版的WPSOffice软件。
2. 导入PDF文档在WPSOffice软件中,点击“文件”菜单,然后选择“打开”选项。
在弹出的对话框中,找到你需要进行像识别和文字识别的PDF文档,双击打开该文档。
3. 进行PDF文档像识别WPSOffice提供了强大的PDF文档像识别功能,可以将PDF文档中的图片转换为可编辑和复制的文字。
在打开的PDF文档中,点击右上角工具栏中的“识别”按钮。
软件将自动进行像识别的处理,并在转换完成后显示识别的结果。
4. 进行文字识别除了像识别,WPSOffice还支持文字识别的功能,可以将图片中的文字提取出来。
在打开的PDF文档中,选中你需要进行文字识别的部分,然后右键点击,选择“文字识别”选项。
软件将自动进行文字识别的处理,并将提取的文字显示在页面上。
5. 编辑和复制文字内容一旦完成了PDF文档的像识别和文字识别,你就可以方便地编辑和复制其中的文字内容了。
选中需要编辑的文字,直接进行修改即可。
要复制文字内容,只需选中文字,然后使用快捷键Ctrl+C进行复制,即可在其他文档或编辑器中进行粘贴操作。
通过上述的操作步骤,我们可以轻松地利用WPSOffice进行PDF文档像识别和文字识别,提取和编辑PDF文档中的文字内容,极大地方便了我们的工作和学习。
无论是工作中需要编辑和整理的合同文件,还是学习中需要提取和引用的研究文献,WPSOffice都能够帮助我们处理各种类型的PDF文档,提高工作和学习的效率。
PDF等文档中文字和CAD图形的识别提取

PDF等文档中文字和CAD图形的识别提取陆仁钉适用于:PDF、CAJ和图像转电子版文档;PDF中CAD图形提取;(一)文本识别PDF的文字提取和编辑需要用到Adobe的专业软件Acrobat,该软件可完成PDF的所有操作。
如果不安装Acrobat,或是需要识别其他类似扫描件的文字对象,可使用其他OCR软件。
OCR,全称Optical Character Recognition,即光学字符识别技术。
常用的OCR软件有:一、CAJ Viewer6.0:国产CAJ格式的阅读器,可识别包括PDF在内的多种文件格式(见下图),准确率良好。
菜单栏-工具-文字识别(点击下拉箭头全部展开才能看见),识别后可选择复制到剪贴板或发送到WPS/WORD。
CAJ Viewer支持的格式:二、Microsoft Office Document Imaging微软官方的Office组件,office2003默认安装,2007版本需要在安装选项中手动选中;已安装的office2007可在控制面板的程序卸载页选择,进行更改,展开office工具选项后在Microsoft Office Document Imaging上点击选“安装全部程序”;Microsoft Office Document Imaging安装完成即可在office工具下找到并打开,如下图;支持的格式:mdi和tiff或tif,但mdi不能直接打开,双击打开时会提示不是有效的win32应用程序。
mdi不能直接双击打开报错:Microsoft Office Document Imaging安装后同时也作为虚拟打印机(image writer)使用,在识别图像或文档格式前,需将其打印为mdi或tiff;若要在发送到Word的所选内容中包括图片,请选中“在输出时保持图片版式不变”复选框,但效果一般不好,需要图片时可框选后右键“复制图像”。
常见问题:开始OCR识别时“Microsoft Office Document Imaging已停止。
readiris pdf 22使用手册

Readiris PDF 22是一款强大的光学识别OCR软件,具有以下特点:
1. 支持多达128种文字语言的识别,几乎覆盖全世界所有语言。
2. 识别准确度高,识别率可达到98%以上。
3. 支持将纸张、PDF文件、图片文件的文字元素扫描成文字。
4. 具有多稿处理功能,可以将多篇文件扫描后一并识别,存储为Word文档格式,并保留原稿版面,方便二次处理。
5. 具有自动分析、自动识别功能,操作简单快捷。
6. 内建的过滤系统可以将文稿上的文字、图片、表格自动分类识别。
7. 支持简体中文、繁体中文、日文、韩文等亚洲语言。
在使用Readiris PDF 22时,需要注意以下几点:
1. 在进行文字扫描和识别时,要保证扫描的文字清晰、无模糊,以免影响识别的准确度。
2. 在使用多稿处理功能时,要保证每篇文稿的格式和排版一致,以便正确识别和存储。
3. 在使用自动分析、自动识别功能时,要保证文稿的整洁和清晰,避免出现乱码或错误识别的情况。
4. 在使用内建的过滤系统时,可以根据需要自行设置过滤规则,以便更好地分类识别文稿上的元素。
5. 在使用亚洲语言时,要保证输入的语言编码和字体正确,以免出现乱码或无法正确显示的情况。
总之,Readiris PDF 22是一款功能强大、操作简单的OCR软件,可以帮助用户快速将纸张、PDF文件、图片文件的文字元素扫描成文字,并进行多语言识别和处理。
WPSOffice附加功能PDF转换OCR识别等实用工具

WPSOffice附加功能PDF转换OCR识别等实用工具WPSOffice是一款功能强大的办公软件套件,其中的附加功能提供了许多实用工具,例如PDF转换和OCR识别。
这些功能可以帮助用户更高效地进行办公和处理文件。
本文将介绍WPSOffice附加功能中的PDF转换和OCR识别工具,并说明它们的优势和用途。
一、PDF转换工具PDF(Portable Document Format)是一种常用的文档格式,具有跨平台、保持格式不变等优势。
然而,有时我们需要将PDF文件转换为其他格式,以便更方便地编辑和使用。
WPSOffice提供了一套便捷的PDF转换工具,可以将PDF文件转换为Word、Excel、PowerPoint等常见的办公文档格式。
1. PDF转Word将PDF转换为Word格式可以方便地进行编辑、修改和重新格式化。
WPSOffice的PDF转Word工具具有高质量的转换效果,可以保留原始文档的布局、图片、表格等元素,确保转换后的Word文档与原始PDF 文件完全一致。
用户只需几个简单的步骤,即可将PDF转换为可编辑的Word文档,提高工作效率。
2. PDF转Excel有时候,我们需要对PDF中的数据进行处理和分析,而PDF并不方便进行编辑和计算。
WPSOffice的PDF转Excel工具可以将PDF中的表格数据完整地转换为Excel格式,保留原有的列、行、公式等信息。
这使得用户可以轻松地对数据进行编辑、排序、筛选和计算,提供了更大的灵活性和便利性。
3. PDF转PowerPoint在演示和分享文件时,常常需要将PDF转换为PowerPoint格式。
WPSOffice的PDF转PowerPoint工具可以将PDF中的页面内容转换为演示文稿,用户可以对转换后的PowerPoint文件进行编辑、添加动画和效果,制作出精美的演示文稿。
这为用户展示和分享文件提供了更多的选择和可能性。
二、OCR识别工具OCR(Optical Character Recognition)即光学字符识别,是一项能够将图片或扫描件中的文字内容转换为可编辑文档的技术。
汉王PDFOCR使用说明及使用诀窍

去,以提高识别准确率。点击 r”使用鼠标将光 标箭头移动到当前图像边框处,此时箭头变为卡 住图像边框的上下双箭头。按下鼠标左键,将该 位置的图像边框向内移动,将多余的版面噪音框 掉,有效图像为当前图像框范围内的图像。
剪切噪音点击工具栏中的哪按钮,按住鼠标 左键,拖动鼠标选中图像中的噪音(黑点或黑 框),放开鼠标左键,就可以将噪音清除。
如果选中’‘输出到外部编辑器“,则系统 在保存文件的同时调入相应的文字处理程序。比 如选择输出日丁 ML 格式,系统马上进入 IE 浏览 器。TXT 格式只保存文字、表格部分,不保存 RTF 格式可以用 WORD,WPS 等文字处理软件编辑日丁 ML 格式可以输出到 IE 等网络浏览器 XLS 格式可 以用 Excel 等软件编辑。
影响处理效果。
自己的随笔中。木子是怕别人发现的。毕竟初高中总是认为谈恋爱那就是不正经
扫描亮度亮度选择是否恰当直接关系到图 像的清晰度,而图像的清晰度又直接影响后续的 识别质量,因此必须根据稿件的实际质量来选择 亮度。所要达到的扫描质量为保证每个扫描汉字 的图像清晰,不能出现过浓或过淡。
扫描精度对于其它类型的扫描仪可参照相 应的使用手册进行选择。对于本系统而言扫描精 度控制在 300dpi 为好,这样既可保证良好的识 别效果,又能减少扫描操作所需时间。扫描之后 的图像直接传送回本系统的图像处理界面。图像 文件自动存储到系统默认路径下的默认文件名, 文件名和识别参数显示在管理条窗口内。(扫描 的具体操作请参考扫描仪使用手册)。
扫描文稿时,先准备好扫描仪点击工具栏上 的 0 进入扫描程序,1 短要扫描的稿件放置在扫 描仪的适当位置上,屏幕上显示扫描仪配置窗口 (这里以扫描仪 AV620C 为例)。在扫描之前,可 以通过扫描窗口选择扫描精度、扫描方式和纸张 大小。本系统支持黑白二值模式、灰度模式以及 彩色模式,即选择黑白扫描方式、灰度扫描方式 和彩色扫描方式。建议不要大量采用灰度、彩色 扫描模式扫描文件因为彩色图像文件占用大量 的内存和 CPU,操作速度会很慢;而且背景图案会
OCR文字识别软件哪个好用?分享提取纯图片PDF文件中文字的方法
OCR文字识别是什么?OCR文字识别就是对图片上的文字内容进行识别,然后输出可以编辑的文本。
当我们的文件都是图片格式且需要提取图片中文字内容,尤其是在需要处理纯图片格式的PDF文件时,就需要使用到OCR文字识别功能。
那么有什么软件具备OCR文字识别功能?该怎样操作才能完整提取出纯图片格式的PDF文件中的文字内容?我给大家分享两个方法。
第一个方法是使用PDF转换器。
嗨格式PDF转换器中就有OCR文字识别功能。
打开嗨格式PDF转换器后,我们点击“PDF转文件”。
然后可以选择“PDF转Word”或者“PDF转TXT”。
分别点击这两个转换功能,都可以看到它们的界面上的“OCR 文字识别”。
我以“PDF转Word为例”,给大家讲一下下面的操作。
进入PDF转Word界面后,我们就需要先将纯图片格式的PDF文件添加进界面的转换区域,点击一下中间会直接出现一个打开文件的对话框。
纯图片格式的PDF文件较多的话,在添加文件时全选进行高效的批量转换即可。
文件添加后,启用“OCR文字识别功能”。
转化模式也可以选择一下。
最后我们就只需要点击“开始转换”就好了。
PDF文件稍后会转换成Word 文档,纯图片格式PDF文件中的文字内容就这样简单的提取出来了。
想要提取纯图片格式PDF文件中的文字内容还有一个方法,我们可以使用图像文字识别工具。
首先需要打开PDF文件,然后找到电脑中的截图工具对PDF文件中的文字部分进行截图。
保存一下截好的图片,接着我们打开图像文字识别工具。
将图片上传到识别工具中,工具会自动识别图片中的文字。
识别出的文字会出现在下方的方框中,我们点击一下方框下的“复制内容”。
最后将文字内容粘贴到指定位置即可。
这个方法也可以实现纯图片格式PDF文件的文字提取,不过相对来说操作较为繁琐,多个PDF文件处理起来效率会很低。
提取出纯图片格式PDF文件中文字内容的方法就分享到这里了。
大家现在应该都了解OCR文字识别功能了吧,有兴趣的小伙伴可以动手操作一下哦~。
提取图片中或扫描版PDF的文字

提取图片中(或扫描版PDF)的文字如果在书上看到一篇好文章用相机拍下来,或是纸质文章需要输入到电脑时,如果数量比较大,手动输入会很慢,下面介绍几中方法将图片中的文字转化为文本,同样适用于影印版PDF。
1 ABBYY FineReader 11软件泰比(ABBYY)FineReader提供直观的文件扫描与转换成可编辑、可搜索的电子格式工具。
泰比(ABBYY)FineReader可以识别与转换几乎所有打印的文档类型,包括书籍、志上的文章与复杂的布局、表格与电子表格、图片,甚至以准确的精度发。
下载地址:网上随便一搜就很多例如:破解补丁:#破解方法:将下载的文件替换安装文件即可。
2 Office2003 自带组件Microsoft Office Document Imaging如果Office装的是精简版,那么在就没装这个组件,可以自己装一下或是下载完整版。
装完后如下图。
第一步:转换文件格式。
用ACDSee打开你的.jpg文件,单击界面上的“浏览器”按钮(或者双击当前图片都可以进入到浏览器界面),在打开的浏览器中,右键这个文件,在右键菜单中选择“工具/转换文件格式”;在转换文件格式对话框中,选择TIFF格式,两次下一步后,就开始转换,结果是将你当前的.jpg文件转换成了.tif 文件。
第二步:将图片转换为文字。
选择:开始/所有程序/Microsoft Office/Microsoft Office工具/Microsoft Office Document Imaging,打开这个工具后,菜单:文件/打开,找到你保存的那个.tif 文件,打开它。
然后选择菜单:工具/使用OCR识别文本;梢等一会儿,继续菜单:工具/将文本发送到Word。
这样,这幅图片就到了Word中成了可以编辑的文字内容了。
因为OCR识别并非百分之百成功,所以有些位置可能需要你进行手动修改。
界面如下:3 通过PDF->文字也就是先将图片转化为PDF,然后再提取。
pdf文件提取文字方法

pdf文件提取文字方法作为文字提取专家,我经常需要从各种格式的文件中提取文字,其中PDF 文件是最常见的一种。
下面,我将详细介绍如何从PDF文件中提取文字,包括所需工具、操作步骤以及注意事项。
一、所需工具从PDF文件中提取文字,需要使用到PDF阅读器和OCR(Optical Character Recognition,光学字符识别)软件。
常见的PDF阅读器有Adobe Reader、Foxit Reader等,而OCR软件则有ABBYY FineReader、Adobe Acrobat等。
其中,Adobe Acrobat既可以作为PDF阅读器,也可以作为OCR软件使用。
二、操作步骤打开PDF文件首先,需要使用PDF阅读器打开需要提取文字的PDF文件。
在打开文件之前,确保已经安装了PDF阅读器和OCR软件,并且这些软件能够正常运行。
选择OCR软件如果PDF文件中的文字无法直接复制,那么需要使用OCR软件进行文字识别。
在选择OCR软件时,可以根据自己的需求和预算进行选择。
一般来说,商业OCR软件的识别率更高,但价格也更贵。
而免费OCR软件虽然识别率稍低,但对于一些简单的文字提取任务已经足够了。
进行OCR识别在选择好OCR软件后,需要将其打开,并将需要识别的PDF文件导入到OCR 软件中。
然后,根据软件的提示,进行OCR识别。
在识别过程中,可以根据需要设置识别语言、识别精度等参数。
导出识别结果OCR识别完成后,软件会将识别结果以文本格式输出。
此时,可以将识别结果复制到剪贴板中,或者将其保存为TXT、DOC等格式的文本文件。
三、注意事项确保PDF文件质量PDF文件的质量会直接影响OCR识别的准确率。
如果PDF文件存在模糊、扭曲、背景干扰等问题,那么OCR识别的准确率会大大降低。
因此,在进行OCR 识别之前,需要尽可能保证PDF文件的质量。
选择合适的OCR软件不同的OCR软件在识别率、识别速度、支持的语言等方面存在差异。
CAJViewer软件进行pdf文字识别以及公式截取的使用说明
CAJViewer软件进行pdf文字识别以及公式截取的使用说明
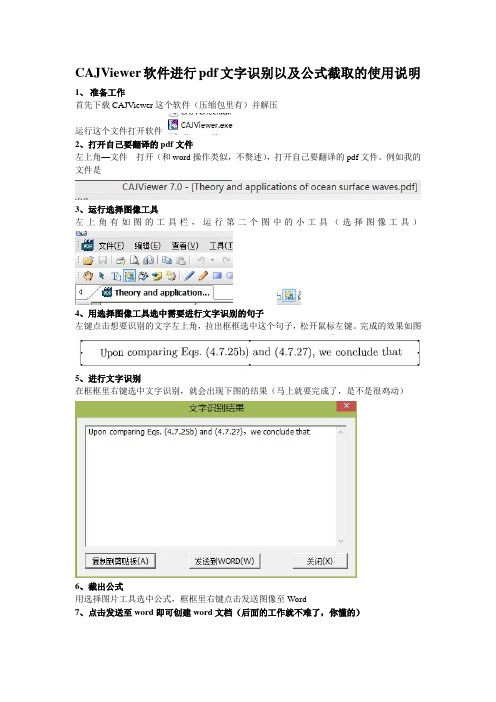
1、准备工作
首先下载CAJViewer这个软件(压缩包里有)并解压
运行这个文件打开软件
2、打开自己要翻译的pdf文件
左上角—文件---打开(和word操作类似,不赘述),打开自己要翻译的pdf文件。
例如我的文件是
3、运行选择图像工具
左上角有如图的工具栏,运行第二个图中的小工具(选择图像工具)
4、用选择图像工具选中需要进行文字识别的句子
左键点击想要识别的文字左上角,拉出框框选中这个句子,松开鼠标左键。
完成的效果如图
5、进行文字识别
在框框里右键选中文字识别,就会出现下图的结果(马上就要完成了,是不是很鸡动)
6、截出公式
用选择图片工具选中公式,框框里右键点击发送图像至Word
7、点击发送至word即可创建word文档(后面的工作就不难了,你懂的)。
最好用的PDF转WORD软件ABBYY 12安装教程及使用方法
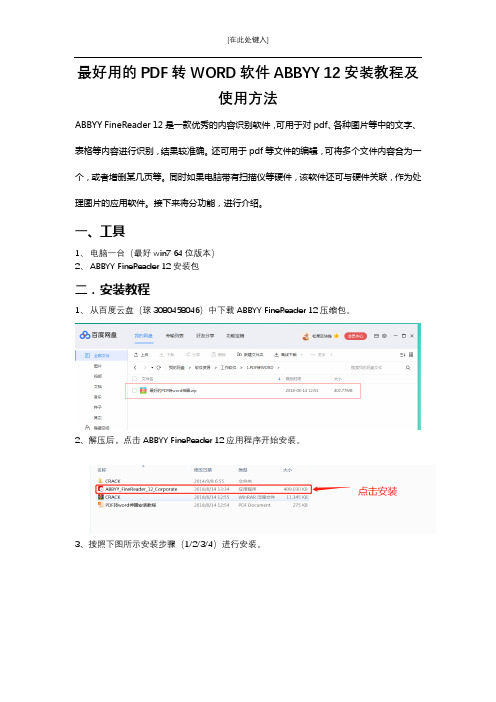
最好用的PDF转WORD软件ABBYY 12安装教程及使用方法ABBYY FineReader 12是一款优秀的内容识别软件,可用于对pdf、各种图片等中的文字、表格等内容进行识别,结果较准确。
还可用于pdf等文件的编辑,可将多个文件内容合为一个,或者增删某几页等。
同时如果电脑带有扫描仪等硬件,该软件还可与硬件关联,作为处理图片的应用软件。
接下来将分功能,进行介绍。
一、工具1、电脑一台(最好win7 64位版本)2、ABBYY FineReader 12安装包二.安装教程1、从百度云盘(球3080458046)中下载ABBYY FineReader 12压缩包。
2、解压后,点击ABBYY FineReader 12应用程序开始安装。
3、按照下图所示安装步骤(1/2/3/4)进行安装。
4、安装目录可以按照默认C盘目录进行安装。
如果为了电脑流程性,也可以安装到其他盘。
5、安装图例完成安装。
6、运行Del_Lic_Serv。
显示成功即可。
7、点击文件夹CRACK,将FixFiles中所有文件复制黏贴到软件安装目录下,C:\Program Files (x86)\ABBYY\FineReader 12 。
全部替换。
8、运行程序即可使用。
二、使用方法1、打开软件。
这个为默认快捷窗口,如果想方便快速创建任务,可以在右下角关闭,希望下次不显示此提示,可取消勾选启动显示后,点关闭。
2、识别pdf文件图片等内容。
点击文件—打开PDF文件或图像/或者直接选择“打开”,选择需要转换的PDF文件或者图像——确定。
即可完成对PDF文本的转换。
点击保存,可以到处WORD格式,或者其他需要格式。
(识别PDF文档)(识别图片)3、对识别的图像等结果进行手动编辑。
如歪斜矫正、对比度调节等,使结果效果更好。
选中某一页后,上方点击编辑图像,即可进入编辑页面,对具体内容进行调整。
4、ABBYY FineReader 12可以作为硬件的应用软件使用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
好用的PDF文字识别软件推荐
文案工作者,在工作中要处理各种文字资料,那么就会经常遇到将PDF中的文字进行整理编辑的事情了,这时我们便需要用到文字识别软件了,可是有什么好用的PDF文字识别软件呢?那么小编就为大家推荐一款吧。
需要的工具:捷速OCR文字识别软件
软件介绍:该软件具备改进图片处理算法:软件进一步改进图像处理算法,提高扫描文档显示质量,更好地识别拍摄文本。
所以想要实现图片转word文字,捷速OCR文字识别/是不错的选择。
操作步骤:
1.打开电脑浏览器,下载并运行捷速OCR文字识别软件。
2.打开捷速0CR文字识别软件,点击退出按钮,退出该选项。
3.点击软件正上方“高级识别”按钮。
4.随后点击软件左上方“添加”按钮,以选择自己需要转换的PDF图
片。
5.打开PDF图片后点击软件上方的“内容解析”按钮,就会出现一些
图片识别框和文字识别框,这些识别框是可以根据自己的需要进行删减的。
6.点击软件上方的“识别”按钮,软件就会自动识别图片中的文字内容,
软件所识别的文字是可以修改的,我们可以选中需要修改的文字部分进行修改。
7.点击软件上方的“保存为Word”按钮,软件就可以成功的将PDF图
片转换成Word文字的形式,这时就可对文字进行编辑了。
通过上面的分析大家可以看到这款文字识别软件,还是比较好用的,如果你还不知道哪个文字识别软件好用的话,不妨试试这个。