多元统计spss课程考题
多元统计上机练习及答案(附数据)

均值协方差估计1.通过SPSS将产业数据命名:V1:第一产业;V2:第二产业;V3:第三产业。
2. 求X=(V1,V2,V3)’的均值向量估计(给出SPSS的相关输出表格及结果)。
通过SPSS从表1中得知所求向量的样本均值为(554.0797, 2142.4481, 1675.703)‘。
3. 求D(X)的估计量(给出SPSS的相关输出表格及结果)。
通过SPSS的相关中的双变量模块,得到如下输出表格。
通过表2得知随机向量的样本协差阵为:4.根据Pearson相关系数,试判断三个产业中,哪两个产业的相关性最高?通过表2得知,V2与V3的Pearson相关系数为0.968,即第二产业与第三产业相关程度最高。
均值向量比较及方差分析数据描述:数据中给出了不同民族(1,2,3)、城乡(1,2)居民的收入及文化程度信息,试根据数据回答以下问题。
1.就城乡居民来讲,收入及文化收入服从二元正态分布吗(为什么,请列明理由)?服从二维正态分布。
2.城乡的居民收入及文化程度存在着差异吗?(请通过均值向量检验作出回答,要求写明假设检验,检验统计的选择及依据,检验结果及依据。
)表2:Box's 共變異數矩陣等式檢定aBox's M 共變異等式檢定.112F .034df1 3df2 87120.000顯著性.992檢定因變數的觀察到的共變異數矩陣在群組內相等的空假設。
a. 設計:截距 + 城乡城乡的居民收入及文化程度不存在着差异。
3. 该数据适合通过方差分析来比较不同民族的收入及文化程度差异吗(请列明理由及依据【正态性及方差齐性检验】)。
表5:Box's 共變異數矩陣等式檢定aBox's M 共變異等式檢定2.354F .338df1 6df2 10991.077顯著性.917檢定因變數的觀察到的共變異數矩陣在群組內相等的空假設。
a. 設計:截距 + 民族数据通过了正态性及方差齐性检验,所以该数据适合通过方差分析来比较不同民族的收入及文化程度差异.4. 如果该数据适合做方差分析,初步的检验结果是什么?需要进一步做两两比较吗?表6:多變數檢定a效果數值 F 假設 df 錯誤 df 顯著性截距Pillai's 追蹤.995 2046.322b 2.000 20.000 .000Wilks' Lambda.005 2046.322b 2.000 20.000 .000 (λ)Hotelling's 追蹤 204.632 2046.322b 2.000 20.000 .000Roy's 最大根204.632 2046.322b 2.000 20.000 .000 民族Pillai's 追蹤.898 8.561 4.000 42.000 .000Wilks' Lambda.103 21.166b 4.000 40.000 .000 (λ)Hotelling's 追蹤 8.702 41.332 4.000 38.000 .000Roy's 最大根8.700 91.352c 2.000 21.000 .000a. 設計:截距 + 民族b. 確切的統計資料c. 統計資料是 F 的上限,其會產生顯著層次上的下限。
spss统计分析期末考试题及答案

spss统计分析期末考试题及答案一、选择题(每题2分,共20分)1. 在SPSS中,数据视图和变量视图分别对应于:A. 变量列表和数据表B. 数据表和变量列表C. 数据集和变量集D. 变量集和数据集答案:B2. SPSS中用于描述数据分布特征的统计量不包括:A. 平均值B. 中位数C. 众数D. 方差答案:D3. 在SPSS中进行独立样本T检验时,需要满足的假设条件不包括:A. 独立性B. 正态性C. 方差齐性D. 线性答案:D4. 下列哪个选项不是SPSS中的数据类型?A. 数值型B. 字符串型C. 日期型D. 图片型答案:D5. 在SPSS中,进行相关分析时,通常使用的统计方法是:A. 回归分析B. 方差分析C. 卡方检验D. 皮尔逊相关系数答案:D6. SPSS中,用于创建新变量的命令是:A. COMPUTEB. DESCRIPTIVESC. T-TESTD. FREQUENCIES答案:A7. 在SPSS中,执行因子分析时,通常使用的方法是:A. 主成分分析B. 聚类分析C. 回归分析D. 判别分析答案:A8. SPSS中,用于检验两个分类变量之间关系的统计方法是:A. 相关分析B. 回归分析C. 卡方检验D. 方差分析答案:C9. 在SPSS中,进行多变量回归分析时,需要满足的假设条件不包括:A. 线性关系B. 误差项独立C. 误差项同方差性D. 变量之间独立答案:D10. SPSS中,用于创建数据集的命令是:A. GET FILEB. SAVEC. OPEN DATAD. NEW答案:D二、简答题(每题10分,共40分)1. 简述SPSS中数据清洗的常用步骤。
答案:数据清洗的常用步骤包括:数据导入、数据预览、缺失值处理、异常值检测、数据转换和数据编码。
2. 解释SPSS中因子分析的目的和基本步骤。
答案:因子分析的目的是将多个变量简化为几个不相关的因子,以揭示变量之间的内在关系。
基本步骤包括:确定因子数量、提取因子、旋转因子和因子得分计算。
多元统计学多元统计分析试题(A卷)(答案)

《多元统计分析》试卷1、若),2,1(),,(~)(n N X p =∑αμα 且相互独立,则样本均值向量X 服从的分布为2、变量的类型按尺度划分有_间隔尺度_、_有序尺度_、名义尺度_。
3、判别分析是判别样品 所属类型 的一种统计方法,常用的判别方法有__距离判别法_、Fisher 判别法、Bayes 判别法、逐步判别法。
4、Q 型聚类是指对_样品_进行聚类,R 型聚类是指对_指标(变量)_进行聚类。
5、设样品),2,1(,),,('21n i X X X X ip i i i ==,总体),(~∑μp N X ,对样品进行分类常用的距离有:明氏距离,马氏距离2()ijd M =)()(1j i j i x x x x -∑'--,兰氏距离()ij d L =6、因子分析中因子载荷系数ij a 的统计意义是_第i 个变量与第j 个公因子的相关系数。
7、一元回归的数学模型是:εββ++=x y 10,多元回归的数学模型是:εββββ++++=p p x x x y 22110。
8、对应分析是将 R 型因子分析和Q 型因子分析结合起来进行的统计分析方法。
9、典型相关分析是研究两组变量之间相关关系的一种多元统计方法。
一、填空题(每空2分,共40分)1、设三维随机向量),(~3∑μN X ,其中⎪⎪⎪⎭⎫ ⎝⎛=∑200031014,问1X 与2X 是否独立?),(21'X X 和3X 是否独立?为什么?解: 因为1),cov(21=X X ,所以1X 与2X 不独立。
把协差矩阵写成分块矩阵⎪⎪⎭⎫⎝⎛∑∑∑∑=∑22211211,),(21'X X 的协差矩阵为11∑因为12321),),cov((∑='X X X ,而012=∑,所以),(21'X X 和3X 是不相关的,而正态分布不相关与相互独立是等价的,所以),(21'X X 和3X 是独立的。
多元统计分析上机习题

1. 下面的表,分别为某企业1991年~1995年5年中各季度计划完成和实际完成的产量(单位:万吨)数据资料,试建立一个SPSS数据文件保存这两个表中的数据。
年份一季度二季度三季度四季度计划数实际数计划数实际数计划数实际数计划数实际数19911412.51821.41818.52020.4 19921717.21819.81719.22022.5 19931616.52016.81817.72119.6 19941818.42019.22020.52220.8 19952020.52125.82522.52524.5 19911412.51821.41818.52020.4然后对建立的数据文件分别按季度、年汇总各季度和各年度的计划产量和实际完成的产量、平均产量。
2. 用四种不同的饲料喂养大白鼠,每组4只,然后测其肝重占体重的比值(肝/体重比值,%),数据如下。
试比较四组均数间有无差异?表14 四组资料的肝重占体重比值(%)的测定结果A饲料B饲料C饲料D饲料2.62 2.82 2.913.922.23 2.763.02 3.002.36 2.433.28 3.322.40 2.733.18 3.043. 对12份血清分别用原方法(检测时间20分钟)和新方法(检测时间10分钟)测谷-丙转氨酶,结果见表。
问两法所得结果有无差别?表18 12份血清用原法和新法测血清谷-丙转氨酶(nmol·S-1/L)结果的比较编号原法新法1 60 802 142 1523 195 2434 80 825 242 2406 220 2207 190 2058 25 38 9 212 243 10 38 44 11 236 200 12951005. 让10个失眠患者分别服用甲乙两种安眠药,观察延长睡眠时间的情况,得到如下配对数据:甲药延时量 1.90 0.80 1.10 0.10 -0.10 4.40 5.50 1.60 4.60 3.40乙药延时量 0.70 -1.60 -0.20 -1.2 -0.10 3.40 3.70 0.80 0.00 2.20在显著检验性水平α= 0.05下,试用配对样本的T 检验过程,检验两种药物的疗效有无显著差异?6. 一工厂的两个化验员每天同时从工厂的冷却水中取样,测量一次水中的含氯量(ppm ),下面列出10天的记录:化验员A : 1.15 1.86 0.75 1.82 1.14 1.65 1.90 0.89 1.12 1.09 化验员B : 1.00 1.90 0.90 1.80 1.20 1.70 1.95 1.87 1.69 1.92设各化验员的化验结果服从正态分布,试选用适当的检验过程,检验两个化验员测量 的结果之间是否有显著差异? (α= 0.05、0.01)4. 将手术要求基本相同的15名患者随机分3组,在手术过程中分别采用A ,B ,C 三种麻醉诱导方法,在T 0(诱导前)、T 1、T 2、T 3,T 4 五个时相测量患者的收缩压,数据记录见表。
多元统计分析试题(A卷)(答案)

多元统计分析试题(A卷)(答案)《多元统计分析》试卷一、填空题(每空2分,共40分)1、若且相互独立,则样本均值向量X服从的分布为2、变量的类型按尺度划分有_间隔尺度_、_有序尺度_、名义尺度_。
3、判别分析是判别样品的一种统计方法,常用的判别方法有___、、、。
4、Q型聚类是指对_进行聚类,R型聚类是指对进行聚类。
'5、设样品,总体X~Np(,对样品进行分类常用的距离有:明氏距离,马氏距离,兰氏距离6、因子分析中因子载荷系数aij的统计意义是_第i个变量与第j个公因子的相关系数。
7、一元回归的数学模型是:,多元回归的数学模型是:。
8、对应分析是将和结合起来进行的统计分析方法。
9、典型相关分析是研究两组变量之间相关关系的一种多元统计方法。
二、计算题(每小题10分,共40分)1、设三维随机向量,其中130,问X1与X2是否独立?和X3是否独立?为什么?解:因为,所以X1与X2不独立。
把协差矩阵写成分块矩阵,的协差矩阵为因为,而,所以和X3是不相关的,而正态分布不相关与相互独立是等价的,所以和X3是独立的。
2、设抽了五个样品,每个样品只测了一个指标,它们分别是1 ,2 ,4.5 ,6 ,8。
若样本间采用明氏距离,试用最长距离法对其进行分类,要求给出聚类图。
x1013.55702.54601.53.502x2x3解:样品与样品之间的明氏距离为:D(0)样品最短距离是1,故把X1与X2合并为一类,计算类与类之间距离(最长距离法){x1,x2}03.55701.53.502x3x4得距离阵 D(1)类与类的最短距离是1.5,故把X3与X4合并为一类,计算类与类之间距离(最长距离法)得距离阵D(2){x1,x2}057{x3,x4}x5类与类的最短距离是3.5,故把{X3,X4}与X5合并为一类,计算类与类之间距离(最{x1,x2}07长距离法)得距离阵D(3)分类与聚类图(略)(请你们自己做)3、设变量X1,X2,X3的相关阵为0.631.000.350.35,R的特征值和单位化特征向量分别为TTT(1)取公共因子个数为2,求因子载荷阵A。
多元统计分析SPSS实验练习(2016)
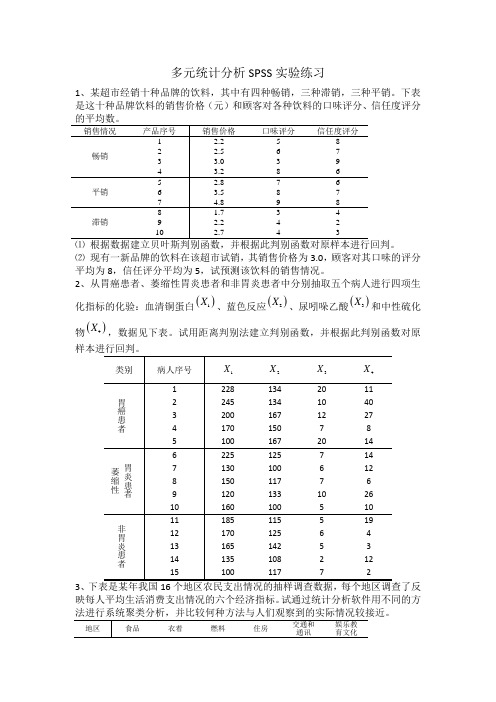
多元统计分析SPSS 实验练习1、某超市经销十种品牌的饮料,其中有四种畅销,三种滞销,三种平销。
下表是这十种品牌饮料的销售价格(元)和顾客对各种饮料的口味评分、信任度评分⑵ 现有一新品牌的饮料在该超市试销,其销售价格为3.0,顾客对其口味的评分平均为8,信任评分平均为5,试预测该饮料的销售情况。
2、从胃癌患者、萎缩性胃炎患者和非胃炎患者中分别抽取五个病人进行四项生化指标的化验:血清铜蛋白()1X 、蓝色反应()2X 、尿吲哚乙酸()3X 和中性硫化物()4X ,数据见下表。
试用距离判别法建立判别函数,并根据此判别函数对原3、映每人平均生活消费支出情况的六个经济指标。
试通过统计分析软件用不同的方4、下表是2003年我国省会城市和计划单列市的主要经济指标:人均GDP 1x (元)、人均工业产值2x (元)、客运总量3x (万人)、货运总量4x (万吨)、地方财政预算内收入5x (亿元)、固定资产投资总额6x (亿元)、在岗职工占总人口的比例7x (%)、在岗职工人均工资额8x (元)、城乡居民年底储蓄余额9x (亿元)。
试通过统计分析软件进行系统聚类分析,并比较何种方法与人们观察到的实际情况较资料来源:《中国统计年鉴2004》5、下表是我国1991-2003年的固定资产投资价格指数,试对这段时期进行分段,试用主成10、 某年级学生的期末考试中,有的课程闭卷考试,有的课程开卷考试。
44名试对闭卷(1X ,2X )和开卷(3X ,4X ,5X )两组变量进行典型相关分析。
多元统计期末考试试题

多元统计期末考试试题一、选择题(每题2分,共20分)1. 以下哪项不是多元统计分析中常用的数据预处理方法?- A. 标准化- B. 归一化- C. 特征选择- D. 数据清洗2. 多元回归分析中,当自变量之间存在高度相关性时,我们通常称之为:- A. 多重共线性- B. 正态性- C. 同方差性- D. 独立性3. 以下哪项不是主成分分析(PCA)的目的?- A. 降维- B. 特征选择- C. 变量解释- D. 增加数据的维度4. 聚类分析中,若要衡量聚类效果,常用的指标不包括:- A. 轮廓系数- B. 熵- C. 戴维斯-库尔丁指数- D. 距离方差5. 因子分析中,因子载荷矩阵的元素表示:- A. 观测变量的均值- B. 因子的方差- C. 观测变量与因子之间的关系- D. 因子之间的相关性二、简答题(每题10分,共30分)1. 请简述多元线性回归分析的基本假设,并说明违反这些假设可能带来的问题。
2. 描述主成分分析(PCA)的基本步骤,并说明其在数据降维中的应用。
3. 聚类分析与分类分析有何不同?请举例说明。
三、计算题(每题25分,共50分)1. 假设有一组数据,包含三个变量X1、X2和Y,数据如下:| X1 | X2 | Y ||-|-|-|| 1 | 2 | 3 || 2 | 4 | 6 || 3 | 6 | 9 || 4 | 8 | 12 |请计算多元线性回归模型的参数,并检验模型的显著性。
2. 给定以下数据集,进行K-means聚类分析,选择K=3,并计算聚类中心。
| 变量1 | 变量2 | 变量3 ||--|-|-|| 1.2 | 2.3 | 3.4 || 1.5 | 2.5 | 3.6 || 4.1 | 5.2 | 6.3 || 4.4 | 5.6 | 6.8 || 7.1 | 8.2 | 9.3 || 7.4 | 8.6 | 9.9 |四、论述题(每题30分,共30分)1. 论述因子分析与主成分分析的异同,并讨论它们在实际应用中可能遇到的问题及解决方案。
spss统计练习题及答案

SPSS统计练习题及答案一、选择题(选择类)(A)1、在数据中插入变量的操作要用到的菜单是:A Insert Variable;B Insert Case;C Go to Case;D Weight Cases(C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是:A Sort Cases;B Select Cases;C Compute;D Categorize Variables(C)3、Transpose菜单的功能是:A 对数据进行分类汇总;B 对数据进行加权处理;C 对数据进行行列转置;D 按某变量分割数据(A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明:A. 按照0.05显著性水平,拒绝H0,说明三种城市的平均身高有差别;B. 三种城市身高没有差别的可能性是0.043;C. 三种城市身高有差别的可能性是0.043;D. 说明城市不是身高的一个影响因素(B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A 家庭主妇和女大学生对同种商品喜好的差异;B 服用某种药物前后病情的改变情况;C 服用药物和没有服用药物的病人身体状况的差异;D性别和年龄对雇员薪水的影响二、填空题(填空类)6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。
7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。
8、One-Samples T Test过程用于进行样本所在总体均数___与__已知总体均数_的比较。
三、名词解释(问答类)9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。
多元统计期末考试题及答案

多元统计期末考试题及答案一、选择题(每题2分,共20分)1. 在多元线性回归中,如果一个变量的系数为0,这意味着什么?A. 该变量对因变量没有影响B. 该变量与因变量完全相关C. 该变量与因变量无关D. 该变量是多余的2. 主成分分析(PCA)的主要目的是什么?A. 减少数据的维度B. 增加数据的维度C. 找到数据的均值D. 找到数据的中位数3. 以下哪个不是聚类分析的优点?A. 可以揭示数据的内在结构B. 可以用于分类C. 可以减少数据的维度D. 可以找到数据的异常值4. 在因子分析中,如果一个因子的方差贡献率很低,这通常意味着什么?A. 该因子对数据的解释能力很强B. 该因子对数据的解释能力很弱C. 该因子是多余的D. 该因子是重要的5. 以下哪个是多元统计分析中常用的距离度量?A. 欧氏距离B. 曼哈顿距离C. 切比雪夫距离D. 所有以上选项二、简答题(每题10分,共30分)6. 解释什么是多元线性回归,并简述其在实际问题中的应用。
7. 描述主成分分析(PCA)的基本原理,并举例说明其在数据分析中的作用。
8. 简述聚类分析的过程,并讨论其在商业数据分析中的应用。
三、计算题(每题25分,共50分)9. 假设有以下数据集,包含两个变量X和Y,以及它们的观测值:| 观测 | X | Y |||||| 1 | 2 | 3 || 2 | 3 | 4 || 3 | 4 | 5 || 4 | 5 | 6 |请计算X和Y的协方差,并解释其意义。
10. 给定以下数据集,进行聚类分析,并解释聚类结果:| 观测 | 变量1 | 变量2 |||-|-|| 1 | 1.5 | 2.5 || 2 | 2.0 | 3.0 || 3 | 3.5 | 4.5 || 4 | 4.0 | 5.0 |多元统计期末考试题答案一、选择题1. A2. A3. C4. B5. D二、简答题6. 多元线性回归是一种统计方法,用于分析两个或两个以上的自变量(解释变量)与一个因变量之间的关系。
《统计软件SPSS》考查试题库

1.请使用SPSS计算21名从事某作业工人的血红蛋白量(g%)的均数、标准差、标准误、最大值、最小值、全距、几何均数。
数据如下:14.8 15.4 13.7 14.1 14.4 15.3 14.2 14.8 14.9 12.8 15.6 15.9 14.7 14.4 13.7 15.4 16.4 12.5 17.0 14.4 14.42.试用SPSS对下述数据进行正态性检验。
50例链球菌咽峡炎患者的潜伏期频数分布表潜伏期(小时)12~24~36~48~60~72~84~96~108~120病例数 1 7 11 11 7 5 4 2 2⑴把上述数据库文件转换成SPSS的数据文件;⑵生成两个新变量:理论课成绩:其值为主观和客观考试成绩之和,格式为整数;总评成绩:其值为理论成绩70%+实验课成绩30%,格式为小数点后保留一位;4.将钩端螺旋体病人的血清分别用标准株和水生株作凝溶试验,测得稀释倍数如下,问两组的平均效价有无差别?标准株(11人):100 200 400 400 400 400 800 1600 1600 1600 3200水生株( 9人):100 100 100 200 200 200 200 400 4005.52例麻疹患者恢复期血清麻疹病毒特异性1gG荧光抗体滴度的频数分布如下,求平均抗体滴度。
抗体滴度1:40 1:80 1:160 1:320 1:640 1:1280例数 3 2 17 19 0 16.A、B两因素伴随3H-TdR掺入对K562细胞抑制情况的试验结果如下表,相对抑制值越大,表明抑制能力越强。
试进行分析。
A:氧浓度重复试验编号B(药物)B1 B2 B3 B4A1(含氧3%) 1 0.31 0.46 0.29 0.492 0.18 0.39 0.18 0.513 0.12 0.40 0.12 0.624 0.13 0.34 0.13 0.53A2(含氧20%) 1 0.29 0.65 0.87 0.742 0.27 0.84 0.39 0.783 0.29 0.45 0.57 1.454 0.28 0.63 0.64 1.417.某医师研究A、B和C三种药物治疗肝炎的效果,将32只大白鼠感染肝炎后,按性别相同、体重接近的条件配成8个配伍组,然后将各配伍组中4只大白鼠随机分配到各组:对照组不给药物,其余三组分别给予A、B和C药物治疗。
多元统计复习题答案

多元统计复习题答案一、单项选择题1. 多元统计分析中,用于描述多个变量之间关系的统计方法是()。
A. 相关分析B. 聚类分析C. 因子分析D. 主成分分析答案:C2. 以下哪个不是多元统计分析中常用的降维方法?()A. 主成分分析B. 因子分析C. 聚类分析D. 典型相关分析答案:C3. 在多元统计分析中,用于识别数据集中的异常值或离群点的统计方法是()。
A. 马氏距离B. 箱线图C. 相关系数D. 卡方检验答案:B二、多项选择题1. 多元统计分析中,以下哪些方法可以用来进行变量选择?()A. 逐步回归B. 岭回归C. 偏最小二乘回归D. 主成分分析答案:A|B|C2. 多元统计分析中,以下哪些方法可以用来进行数据的分类?()A. 判别分析B. 聚类分析C. 因子分析D. 典型相关分析答案:A|B三、判断题1. 多元统计分析中的因子分析可以用于变量的降维。
(对)2. 多元统计分析中的主成分分析和因子分析是完全相同的方法。
(错)3. 多元统计分析中的聚类分析可以用于识别数据集中的异常值。
(错)四、简答题1. 简述多元统计分析中主成分分析(PCA)的主要步骤。
答:主成分分析的主要步骤包括:数据标准化、计算协方差矩阵、求解特征值和特征向量、选择主成分、构造主成分得分。
2. 描述多元统计分析中判别分析的应用场景。
答:判别分析在多元统计分析中主要应用于根据已有的分类变量来预测新样本的分类,例如在医学诊断、市场细分、信用评分等领域。
五、计算题1. 给定一组数据,计算其主成分得分。
答:首先需要对数据进行标准化处理,然后计算协方差矩阵,接着求解特征值和特征向量,最后根据特征值的大小选择前几个主成分,并计算对应的得分。
2. 利用判别分析对一组数据进行分类,并给出分类结果。
答:首先需要确定分类的依据,然后计算各类别的判别函数,接着对新样本进行判别分析,最后根据判别得分将样本分类到相应的类别中。
(完整版)多元统计分析试题及答案

(完整版)多元统计分析试题及答案试题:1. 试解释多元统计分析的含义及其与单变量和双变量统计分析的区别。
2. 简述卡方检验方法及适用场景。
3. 请解释回归分析中的回归系数及其p值的含义及作用,简单说明如何进行回归模型的选择和评估。
4. 试解释主成分分析的原理及目的,如何进行主成分分析及如何解释因子载荷矩阵。
5. 请列举和简要解释聚类分析和判别分析的适用场景,并说明两种方法的区别。
答案:1. 多元统计分析是一种将多个变量进行综合分析的方法。
与单变量和双变量统计分析不同的是,多元统计分析可以处理多个自变量和因变量的组合关系,从而探究它们之间的综合关系。
该方法通常适用于探究多种变量在某个问题中的关系、探究影响某一结果变量的因素、探究各个变量相互作用的影响等。
2. 卡方检验是根据样本数据与期望值的差异来判断观察值与理论预期是否相符,以此来验证假设是否成立的方法。
它通常用于对某个现象进行分类的相关度检验。
适用场景包括:样本的数量大于等于40,且至少有一个期望值小于5;变量为分类变量,且分类类别数不超过10个。
卡方检验的原理是将观察值和期望值进行比较,并计算卡方值,然后根据卡方值与自由度的乘积查找p值,从而得出结论。
3. 回归系数是回归方程中自变量与因变量之间的关系,在线性回归中,回归系数表示每一个自变量单位变化与因变量单位变化的关系。
p值是评估回归系数是否具有显著性的指标。
回归模型的选择有两种方法:一种是逐步回归分析,根据不同的准则进行多个回归模型的比较,选择最优的模型;另一种是正则化回归,通过加入惩罚项来保证回归模型具有良好的泛化性能。
回归模型的评估有多种方法,包括:残差分析、R方值、方差齐性检验、变量的共线性检验等。
4. 主成分分析是一种将多维数据降维处理的方法,它的目的是通过数据的变换,将多个变量转化为一些综合指标,这些指标是原始变量的线性组合。
主成分分析的步骤包括:数据标准化、计算协方差矩阵或相关系数矩阵、计算特征值和特征向量、选取主成分。
spss统计试题及答案

spss统计试题及答案SPSS统计试题及答案1. 单项选择题- 1.1 SPSS中,用于进行数据描述性分析的命令是()。
- A. DESCRIPTIVES- B. FREQUENCIES- C. MEANS- D. T-TEST- 答案:A- 1.2 在SPSS中,要进行方差分析,应该使用以下哪个命令?() - A. DESCRIPTIVES- B. ANOVA- C. REGRESSION- D. CROSSTABS- 答案:B2. 多项选择题- 2.1 下列哪些选项是SPSS中的数据类型?()- A. Numeric- B. String- C. Date- D. Time- 答案:A、B、C、D- 2.2 在SPSS中,进行相关性分析可以使用以下哪些命令?()- A. CORRELATIONS- B. REGRESSION- C. CROSSTABS- D. MEANS- 答案:A、B3. 简答题- 3.1 简述SPSS中如何进行数据的导入和导出。
- 答案:在SPSS中,数据的导入可以通过“文件”菜单下的“打开”选项,选择“数据”并导入不同格式的数据文件。
数据的导出则可以通过“文件”菜单下的“另存为”选项,选择导出为SPSS、Excel、CSV等格式。
- 3.2 解释在SPSS中进行回归分析的步骤。
- 答案:在SPSS中进行回归分析的步骤包括:打开数据文件,选择“分析”菜单下的“回归”选项,选择“线性”或“逻辑”回归,指定因变量和自变量,点击“确定”进行分析。
4. 计算题- 4.1 假设有一组数据:10, 15, 20, 25, 30。
计算这组数据的平均值和标准差。
- 答案:平均值 = (10+15+20+25+30)/5 = 20;标准差 =√[(10-20)²+(15-20)²+(20-20)²+(25-20)²+(30-20)²]/5 =7.071。
spss考试题及答案

spss考试题及答案1. 单选题:在SPSS中,以下哪个选项不是数据清洗的步骤?A. 缺失值处理B. 异常值检测C. 数据转换D. 数据备份答案:D2. 多选题:在SPSS中进行描述性统计分析时,可以输出哪些统计量?A. 均值B. 中位数C. 众数D. 标准差E. 方差答案:A, B, C, D, E3. 判断题:在SPSS中,使用“描述统计”功能可以计算出数据的峰度。
对错答案:错4. 填空题:在SPSS中,进行相关性分析时,可以使用_________菜单下的“相关性”选项。
答案:分析5. 简答题:请简述SPSS中因子分析的步骤。
答案:因子分析的步骤包括:a. 确定分析变量b. 进行KMO和Bartlett的球形度检验c. 选择提取方法(如主成分分析或因子分析)d. 确定因子数量e. 进行因子旋转(如需要)f. 解释因子6. 案例分析题:某研究者收集了一组数据,想要使用SPSS进行方差分析。
请描述方差分析的一般步骤。
答案:方差分析的一般步骤如下:a. 确定研究假设b. 选择合适的方差分析类型(如单因素方差分析或多因素方差分析)c. 输入数据并设置因子和因变量d. 进行方差分析e. 检查方差齐性f. 进行后续多重比较(如果需要)g. 解释结果7. 操作题:使用SPSS进行回归分析,并解释回归系数的意义。
答案:进行回归分析的步骤包括:a. 选择分析菜单下的回归选项b. 选择线性回归c. 设置因变量和自变量d. 运行回归分析e. 查看输出结果f. 解释回归系数,即自变量每变化一个单位,因变量预期的变化量以上即为SPSS考试题及答案的排版及格式。
多元统计分析简答题

1、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设H0和H1; 第二,给出检验的统计量及其服从的分布;第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。
协差阵的检验检验0=ΣΣ0p H =ΣI : /2/21exp 2np n e tr n λ⎧⎫⎛⎫=-⎨⎬ ⎪⎩⎭⎝⎭S S00p H =≠ΣΣI : /2/2**1exp 2np n e tr n λ⎧⎫⎛⎫=-⎨⎬ ⎪⎩⎭⎝⎭S S检验12k ===ΣΣΣ012k H ===ΣΣΣ:统计量/2/2/2/211i i kkn n pn np k iii i nnλ===∏∏SS2. 针对一个总体均值向量的检验而言,在协差阵已知和未知的两种情形下,如何分别构造的统计量?3. 作多元线性回归分析时,自变量与因变量之间的影响关系一定是线性形式的吗?多元线性回归分析中的线性关系是指什么变量之间存在线性关系? 答:作多元线性回归分析时,自变量与因变量之间的影响关系不一定是线性形式。
当自变量与因变量是非线性关系时可以通过某种变量代换,将其变为线性关系,然后再做回归分析。
多元线性回归分析的线性关系指的是随机变量间的关系,因变量y 与回归系数βi 间存在线性关系。
多元线性回归的条件是:(1)各自变量间不存在多重共线性; (2)各自变量与残差独立;(3)各残差间相互独立并服从正态分布; (4)Y 与每一自变量X 有线性关系。
4.回归分析的基本思想与步骤 基本思想:所谓回归分析,是在掌握大量观察数据的基础上,利用数理统计方法建立因变量与自变量之间的回归关系函数表达式(称回归方程式)。
回归分析中,当研究的因果关系只涉及因变量和一个自变量时,叫做一元回归分析;当研究的因果关系涉及因变量和两个或两个以上自变量时,叫做多元回归分析。
此外,回归分析中,又依据描述自变量与因变量之间因果关系的函数表达式是线性的还是非线性的,分为线性回归分析和非线性回归分析。
应用多元统计分析试题及答案

一、填空题:1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法.2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著.3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。
通常聚类分析分为 Q型聚类和 R型聚类。
4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。
5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。
6、若()(,), Px N αμα∑=1,2,3….n且相互独立,则样本均值向量x服从的分布为_x~N(μ,Σ/n)_。
二、简答1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。
在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。
选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。
被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。
2、简述相应分析的基本思想。
相应分析,是指对两个定性变量的多种水平进行分析。
设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。
对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。
要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。
相应分析即是通过列联表的转换,使得因素 A 和因素B具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。
把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A、B的联系。
3、简述费希尔判别法的基本思想。
从k个总体中抽取具有p个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数系数:确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。
将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。
多元统计分析模拟试题

多元统计分析模拟试题(两套:每套含填空、判断各二十道)A卷1)判别分析常用的判别方法有距离判别法、贝叶斯判别法、费歇判别法、逐步判别法。
2)Q型聚类分析是对样品的分类,R型聚类分析是对变量_的分类。
3)主成分分析中可以利用协方差矩阵和相关矩阵求解主成分。
4)因子分析中对于因子载荷的求解最常用的方法是主成分法、主轴因子法、极大似然法5)聚类分析包括系统聚类法、模糊聚类分析、K-均值聚类分析6)分组数据的Logistic回归存在异方差性,需要采用加权最小二乘估计7)误差项的路径系数可由多元回归的决定系数算出,他们之间的关系为=8)最短距离法适用于条形的类,最长距离法适用于椭圆形的类。
9)主成分分析是利用降维的思想,在损失很少的信息前提下,把多个指标转化为几个综合指标的多元统计方法。
10)在进行主成分分析时,我们认为所取的m(m<p,p为所有的主成分)个主成分的累积贡献率达到85%以上比较合适。
11)聚类分析的目的在于使类内对象的同质性最大化和类间对象的异质性最大化12)是随机变量,并且有,那么服从(卡方)分布。
13)在对数线性模型中,要先将概率取对数,再分解处理,公式:14)将每个原始变量分解为两部分因素,一部分是由所有变量共同具有的少数几个公共因子组成的,另一部分是每个变量独自具有的因素,即特殊因子15)判别分析的最基本要求是分组类型在两组之上,每组案例的规模必须至少一个以上,解释变量必须是可测量的16)当被解释变量是属性变量而解释变量是度量变量时判别分析是合适的统计分析方法17)多元正态分布是一元正态分布的推广18)多元分析的主要理论都是建立在多元正态总体基础上的,多元正态分布是多元分析的基础19)因子分析中,把变量表示成各因子的线性组合,而主成分分析中,把主成分表示成各变量的线性组合。
20)统计距离包括欧氏距离和马氏距离两类1)因子负荷量是指因子结构中原始变量与因子分析时抽取出的公共因子的相关程度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多元统计考题
1.一个城市居民家庭收入(x1)和庭院面积(x2)如数据集1(data1),请用变量x1和x2对数据集1进行系统聚类和k-均值聚类,要求将数据分为两类。
填写系统聚类、Ward法分
2.一个城市居民家庭,按其有无割草机分为俩组,有割草机记为1,无割草机记为0。
运用判别分析对数据集1(data1)中1,2,13,和14号样本进行判别,并写出典型判别函数。
3.测量20名学生的生理指标和运动指标共计6个变量(data2),试对这六个成分分析。
(1)当贡献率超过85%时应该选取几个主成分,
(2)写出第一个主成分,(此处写非标准化的) 必须选得分中的—显示因子得分系数矩阵,看成分得分系数矩阵还要乘上根号它的方差
(3)第一个主成分的方差。
看成分矩阵竖列
4.测量20名学生的生理指标和运动指标共计6个变量(data2),试对这六个变量进行因子分析。
(1)运用主成分法、最大方差法进行旋转,进行因子分析,表达因子模型
(2)解释前两个公共因子含义,看旋转成份矩阵,f与x的关系系数大小,即表示f在xi上的载荷较大在了解x的含义
(3)因子得分表达式,成分得分系数矩阵,写时是否需要标准化。
(4)计算变量腰围的共同度,并表达第一公因子方差贡献。
看成分矩阵,∑横2=共同度竖∑2=某因子方差
5.观察仰卧起坐(因变量),体重和腰围(自变量)之间的关系,建立回归模型
(1)写出模型的表达式
(2)模型的决定系数(R2)和模型检验的结果。
6。