C++哈弗曼编码
哈夫曼编码python

哈夫曼编码python一、什么是哈夫曼编码?哈夫曼编码(Huffman Coding)是一种可变长度编码(Variable Length Code),它可以将不同长度的字符编码成等长的二进制串,从而实现数据压缩的目的。
哈夫曼编码是由David A. Huffman在1952年发明的,它是一种贪心算法,可以得到最优解。
二、哈夫曼编码原理1.字符频率统计在进行哈夫曼编码之前,需要先统计每个字符出现的频率。
通常使用一个字典来存储每个字符和其出现的次数。
2.构建哈夫曼树根据字符出现频率构建一个二叉树,其中频率越高的字符离根节点越近。
构建过程中需要用到一个优先队列(Priority Queue),将每个节点按照频率大小加入队列中,并将队列中前两个节点合并为一个新节点,并重新加入队列中。
重复这个过程直到只剩下一个节点,即根节点。
3.生成哈夫曼编码从根节点开始遍历哈夫曼树,在遍历过程中,左子树走0,右子树走1,直到叶子节点。
将路径上经过的0和1分别表示为0和1位二进制数,并把这些二进制数拼接起来,就得到了该字符的哈夫曼编码。
三、哈夫曼编码Python实现下面是一个简单的Python实现:1.字符频率统计```pythonfrom collections import Counterdef get_char_frequency(text):"""统计每个字符出现的频率"""return Counter(text)```2.构建哈夫曼树```pythonimport heapqclass HuffmanNode:def __init__(self, char=None, freq=0, left=None, right=None): self.char = charself.freq = freqself.left = leftself.right = rightdef __lt__(self, other):return self.freq < other.freqdef build_huffman_tree(char_freq):"""根据字符频率构建哈夫曼树"""nodes = [HuffmanNode(char=c, freq=f) for c, f inchar_freq.items()]heapq.heapify(nodes)while len(nodes) > 1:node1 = heapq.heappop(nodes)node2 = heapq.heappop(nodes)new_node = HuffmanNode(freq=node1.freq+node2.freq, left=node1, right=node2)heapq.heappush(nodes, new_node)return nodes[0]```3.生成哈夫曼编码```pythondef generate_huffman_codes(node, code="", codes={}): """生成哈夫曼编码"""if node is None:returnif node.char is not None:codes[node.char] = codegenerate_huffman_codes(node.left, code+"0", codes) generate_huffman_codes(node.right, code+"1", codes)return codes```四、使用哈夫曼编码进行压缩使用哈夫曼编码进行压缩的方法很简单,只需要将原始数据中的每个字符用对应的哈夫曼编码替换即可。
C语言中的数据压缩与解压缩

C语言中的数据压缩与解压缩在计算机科学中,数据压缩是一种常见的技术,用于将大型数据文件或数据流以更小的尺寸存储或传输。
在C语言中,我们可以使用各种算法和技术来实现数据的压缩和解压缩。
本文将详细介绍C语言中常用的数据压缩与解压缩方法。
一、哈夫曼编码1.1 简介哈夫曼编码是一种无损压缩算法,由数学家David A. Huffman于1952年提出。
它根据数据中字符出现的频率来构建一个具有最小编码长度的前缀码。
在C语言中,我们可以使用哈夫曼编码来进行数据的压缩和解压缩。
1.2 压缩过程哈夫曼编码的压缩过程分为以下几个步骤:a) 统计数据中各字符的频率,构建字符频率表。
b) 根据字符频率表构建哈夫曼树。
c) 根据哈夫曼树构建字符编码表。
d) 遍历数据,使用字符编码表将字符转换为对应的编码,并将编码存储。
1.3 解压缩过程哈夫曼编码的解压缩过程分为以下几个步骤:a) 使用压缩时生成的字符编码表,将压缩后的编码转换为对应的字符。
b) 将解压后的字符恢复为原始数据。
二、LZ77压缩算法2.1 简介LZ77是一种常用的数据压缩算法,由Abraham Lempel和Jacob Ziv 于1977年提出。
它利用了数据中的重复出现模式,通过记录重复出现的字符串的位置和长度来实现数据的压缩。
2.2 压缩过程LZ77压缩算法的压缩过程分为以下几个步骤:a) 初始化一个滑动窗口,窗口大小为固定长度。
b) 在滑动窗口内查找与当前字符匹配的最长字符串,并记录字符串的位置和长度。
c) 将匹配的字符串以位置和长度的形式存储,并将窗口向右滑动到匹配字符串的末尾。
d) 重复步骤b和c,直到遍历完所有数据。
2.3 解压缩过程LZ77压缩算法的解压缩过程分为以下几个步骤:a) 根据压缩时存储的位置和长度信息,从滑动窗口中找到对应的字符串。
b) 将找到的字符串输出,并将窗口向右滑动到输出字符串的末尾。
c) 重复步骤a和b,直到解压缩完成。
三、LZ78压缩算法3.1 简介LZ78是一种常用的数据压缩算法,由Abraham Lempel和Jacob Ziv 于1978年提出。
c语言哈夫曼树的构造及编码

c语言哈夫曼树的构造及编码一、哈夫曼树概述哈夫曼树是一种特殊的二叉树,它的构建基于贪心算法。
它的主要应用是在数据压缩和编码中,可以将频率高的字符用较短的编码表示,从而减小数据存储和传输时所需的空间和时间。
二、哈夫曼树的构造1. 哈夫曼树的定义哈夫曼树是一棵带权路径长度最短的二叉树。
带权路径长度是指所有叶子节点到根节点之间路径长度与其权值乘积之和。
2. 构造步骤(1) 将待编码字符按照出现频率从小到大排序。
(2) 取出两个权值最小的节点作为左右子节点,构建一棵新的二叉树。
(3) 将新构建的二叉树加入到原来排序后队列中。
(4) 重复上述步骤,直到队列只剩下一个节点,该节点即为哈夫曼树的根节点。
3. C语言代码实现以下代码实现了一个简单版哈夫曼树构造函数:```ctypedef struct TreeNode {int weight; // 权重值struct TreeNode *leftChild; // 左子节点指针struct TreeNode *rightChild; // 右子节点指针} TreeNode;// 构造哈夫曼树函数TreeNode* createHuffmanTree(int* weights, int n) {// 根据权值数组构建节点队列,每个节点都是一棵单独的二叉树TreeNode** nodes = (TreeNode**)malloc(sizeof(TreeNode*) * n);for (int i = 0; i < n; i++) {nodes[i] = (TreeNode*)malloc(sizeof(TreeNode));nodes[i]->weight = weights[i];nodes[i]->leftChild = NULL;nodes[i]->rightChild = NULL;}// 构建哈夫曼树while (n > 1) {int minIndex1 = -1, minIndex2 = -1;for (int i = 0; i < n; i++) {if (nodes[i] != NULL) {if (minIndex1 == -1 || nodes[i]->weight < nodes[minIndex1]->weight) {minIndex2 = minIndex1;minIndex1 = i;} else if (minIndex2 == -1 || nodes[i]->weight < nodes[minIndex2]->weight) {minIndex2 = i;}}}TreeNode* newNode =(TreeNode*)malloc(sizeof(TreeNode));newNode->weight = nodes[minIndex1]->weight + nodes[minIndex2]->weight;newNode->leftChild = nodes[minIndex1];newNode->rightChild = nodes[minIndex2];// 将新构建的二叉树加入到原来排序后队列中nodes[minIndex1] = newNode;nodes[minIndex2] = NULL;n--;}return nodes[minIndex1];}```三、哈夫曼编码1. 哈夫曼编码的定义哈夫曼编码是一种前缀编码方式,它将每个字符的编码表示为二进制串。
哈夫曼编码集和定长编码集构成的二叉树

哈夫曼编码集和定长编码集构成的二叉树在信息论和计算机科学中,哈夫曼编码集和定长编码集构成的二叉树是一个非常重要的概念。
它们是用来表示和压缩数据的有效方法,也被广泛应用在数据传输和存储中。
理解这个概念对于深入研究数据处理和编码技术至关重要。
在本文中,我将对哈夫曼编码集和定长编码集构成的二叉树进行深度和广度的探讨,以便读者能更全面地理解这一概念。
1. 哈夫曼编码集和定长编码集的概念解释哈夫曼编码集和定长编码集是两种不同的编码方法,用于将数据进行压缩或表示。
定长编码集是一种固定长度的编码方式,例如每个字符都用8位二进制数表示。
而哈夫曼编码集是一种根据数据的出现频率来动态分配编码长度的方法,出现频率高的字符使用较短的编码,出现频率低的字符使用较长的编码。
哈夫曼编码集通常能够更有效地压缩数据,因为它充分利用了数据的统计特性。
2. 哈夫曼编码集和定长编码集构成的二叉树哈夫曼编码集和定长编码集构成的二叉树是通过将编码集中的每个字符构建成一个叶节点,然后根据编码长度和频率构建一棵二叉树。
在这棵二叉树中,出现频率高的字符对应的叶节点距离根节点较近,而出现频率低的字符对应的叶节点距离根节点较远。
这样就能够根据字符的编码快速地找到对应的二进制表示,从而实现高效的数据压缩和传输。
3. 深入探讨哈夫曼编码集和定长编码集构成的二叉树哈夫曼编码集和定长编码集构成的二叉树在数据压缩和编码领域有着广泛的应用。
它不仅能够有效地压缩数据,还能够提高数据传输和存储的效率。
通过深入研究这一概念,我们能够更全面地了解数据压缩的原理和方法,从而更好地应用于实际场景中。
4. 个人观点和理解对于哈夫曼编码集和定长编码集构成的二叉树,我认为它是一种非常高效且优雅的数据表示和压缩方法。
它通过合理地利用数据的统计特性,能够在不损失数据准确性的前提下大大减小数据的存储和传输开销。
在实际应用中,我们可以根据数据的特点选择合适的编码方式,以达到最佳的压缩效果。
哈夫曼编码证明
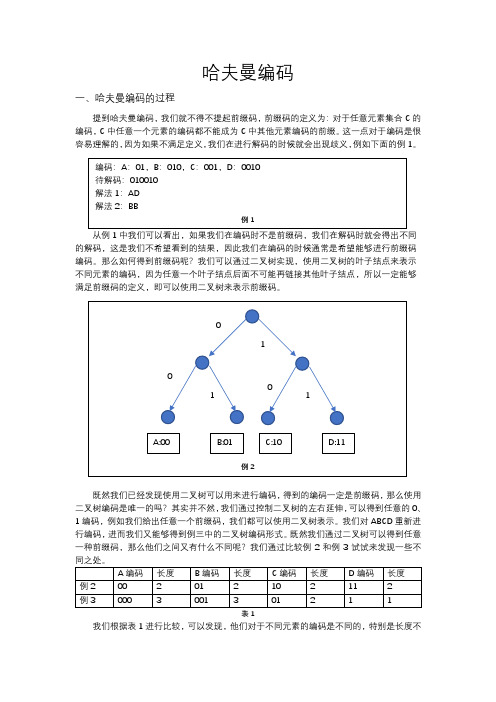
哈夫曼编码一、哈夫曼编码的过程提到哈夫曼编码,我们就不得不提起前缀码,前缀码的定义为:对于任意元素集合C的编码,C中任意一个元素的编码都不能成为C中其他元素编码的前缀。
这一点对于编码是很容易理解的,因为如果不满足定义,我们在进行解码的时候就会出现歧义,例如下面的例1。
从例1中我们可以看出,如果我们在编码时不是前缀码,我们在解码时就会得出不同的解码,这是我们不希望看到的结果,因此我们在编码的时候通常是希望能够进行前缀码编码。
那么如何得到前缀码呢?我们可以通过二叉树实现,使用二叉树的叶子结点来表示不同元素的编码,因为任意一个叶子结点后面不可能再链接其他叶子结点,所以一定能够满足前缀码的定义,即可以使用二叉树来表示前缀码。
既然我们已经发现使用二叉树可以用来进行编码,得到的编码一定是前缀码,那么使用二叉树编码是唯一的吗?其实并不然,我们通过控制二叉树的左右延伸,可以得到任意的0、1编码,例如我们给出任意一个前缀码,我们都可以使用二叉树表示。
我们对ABCD重新进行编码,进而我们又能够得到例三中的二叉树编码形式。
既然我们通过二叉树可以得到任意一种前缀码,那么他们之间又有什么不同呢?我们通过比较例2和例3试试来发现一些不表1我们根据表1进行比较,可以发现,他们对于不同元素的编码是不同的,特别是长度不同。
如果我们从存储角度来看,我们当然希望相同的A BCDA…元素集合尽量短,这样可以节省空间,这是与不同的编码方式有着很大的关系的,如果我们给出一个字符串:ABCD ,然后使用例2和例3中两种编码方式,这会发现例1:00011011(共占8位),例2:000001011(共占9位),那么就是例1更占有优势,但是我们也一定发现了,这里ABCD 都是仅仅出现了一次,所以这是不是也和出现频率有关呢?我们再给出一个字符串:ABCDDD ,然后使用例2和例3中两种编码方式,这会发现例1:000110111111(共占12位),例2:00000101111(共占11位),这时换成例2的编码方式更占有优势了。
《信息论与编码》第5章哈夫曼编码

什么是哈夫曼编码方法
1952年由美国计算机科学家戴维· 哈夫曼先生提出 是一种数据压缩技术 该方法依据字符出现的概率进行编码 ,其基本思想为: 出现概率高的字符使用较短的编码 出现概率低的则使用较长的编码 使编码之后的码字的平均长度最短
哈夫曼编码方法
哈夫曼编码方法包含两个过程
哈夫曼编码方法包含两个过程
编码过程和译码过程
编码过程 译码过程
构建哈夫曼树 CreatHT(W,&HT)
输入是字符频度表W
表中记录的是原码报文中出现的不同符号个数和频率
输出是哈夫曼树HT
进行哈夫曼译码 HuffmanDecod(HT,CC,W,&OC)
输入的是哈夫曼树HT、代码报文CC和字符频度表W 输出的是原码报文OC
OC
输出OC 到哈夫曼译码系统之外 返回开头
字母a的编码为110 字母n的编码为111
1
4 n
因此,在电文中出现频率 高的字母的编码相对短, 而出现频率低的字母的编 码相对长
111 字符编码表HC=((d,0),(i,10),(a,110),(n,111))
哈夫曼编码过程演示
编码 A1 A2 A3 0.23 0.21 0.18
1
0 1 0 1 0.10 0
编码过程和译码过程
编码过程
构建哈夫曼树 CreatHT(W,&HT)
输入是字符频度表W
表中记录的是原码报文中出现的不同符号个数和频率
输出是哈夫曼树HT
进行哈夫曼编码 HuffmanCoding(HT,&HC)
输入是哈夫曼树HT 输出是字符编码表HC
哈夫曼编码算法与分析

算法与分析1.哈夫曼编码是广泛地用于数据文件压缩的十分有效的编码方法。
给出文件中各个字符出现的频率,求各个字符的哈夫曼编码方案。
2.给定带权有向图G =(V,E),其中每条边的权是非负实数。
另外,还给定V中的一个顶点,称为源。
现在要计算从源到所有其他各顶点的最短路长度。
这里路的长度是指路上各边权之和。
3.设G =(V,E)是无向连通带权图,即一个网络。
E中每条边(v,w)的权为c[v][w]。
如果G的子图G’是一棵包含G的所有顶点的树,则称G’为G的生成树。
生成树上各边权的总和称为该生成树的耗费。
在G的所有生成树中,耗费最小的生成树称为G的最小生成树。
求G的最小生成树。
求解问题的算法原理:1.最优装载哈夫曼编码1.1前缀码对每一个字符规定一个0,1串作为其代码,并要求任一字符的代码都不是其它字符代码的前缀,这种编码称为前缀码。
编码的前缀性质可以使译码方法非常简单。
表示最优前缀码的二叉树总是一棵完全二叉树,即树中任一结点都有2个儿子结点。
平均码长定义为:B(T)=∑∈CcTcdcf)()(f(c):c的码长,dt(c):c的深度使平均码长达到最小的前缀码编码方案称为给定编码字符集C的最优前缀码。
1.2构造哈夫曼编码哈夫曼提出构造最优前缀码的贪心算法,由此产生的编码方案称为哈夫曼编码。
哈夫曼算法以自底向上的方式构造表示最优前缀码的二叉树T。
算法以|C|个叶结点开始,执行|C|-1次的“合并”运算后产生最终所要求的树T。
编码字符集中每一字符c的频率是f(c)。
以f为键值的优先队列Q用在贪心选择时有效地确定算法当前要合并的2棵具有最小频率的树。
一旦2棵具有最小频率的树合并后,产生一棵新的树,其频率为合并的2棵树的频率之和,并将新树插入优先队列Q。
经过n-1次的合并后,优先队列中只剩下一棵树,即所要求的树T。
可用最小堆实现优先队列Q。
2.单源最短路径Dijkstra算法是解单源最短路径问题的贪心算法。
其基本思想是,设置顶点集合S并不断地作贪心选择来扩充这个集合。
c++哈夫曼编码的实现

c++哈夫曼编码的实现=================哈夫曼编码是一种非常有效的数据压缩算法,它的主要思想是通过统计数据中各种符号的频率来构建一棵哈夫曼树,从而实现对原始数据的编码。
在C语言中,我们可以使用动态规划来实现哈夫曼编码。
一、哈夫曼编码的基本原理--------------哈夫曼编码是一种可变长度编码,其编码长度取决于原始数据中各个符号的频率。
频率越高的符号,其编码长度越短。
通过统计数据中各个符号的出现频率,我们可以构建出一棵哈夫曼树,这棵树中的每个节点都代表一个符号,节点的权值就是该符号的频率。
通过遍历哈夫曼树,我们可以得到每个符号的编码,从而实现数据的压缩。
二、C语言实现哈夫曼编码------------下面是一个简单的C语言程序,实现了哈夫曼编码的功能:```c#include <stdio.h>#include <stdlib.h>#include <stdbool.h>#define MAX_SYMBOL_COUNT 100 // 最大符号数量#define HUF_TREE_DEPTH 3 // 哈夫曼树深度为3typedef struct Node {char symbol; // 符号struct Node* left; // 左子节点struct Node* right; // 右子节点double frequency; // 频率} Node;// 创建新节点Node* createNode(char symbol, double frequency) {Node* node = (Node*)malloc(sizeof(Node));node->symbol = symbol;node->frequency = frequency;node->left = NULL;node->right = NULL;return node;}// 构建哈夫曼树Node* buildHuffmanTree(char* symbols, int symbolCount) { // 根据频率进行排序,从小到大排列double frequencies[MAX_SYMBOL_COUNT];for (int i = 0; i < symbolCount; i++) {frequencies[i] = symbols[i] == ' ' ? 0.0 : symbols[i] ? symbols[i] : -1; // 检查字符是否存在}qsort(frequencies, symbolCount, sizeof(double), compare); // 使用qsort进行排序Node* root = NULL; // 根节点为空,需要手动构建哈夫曼树int index = 0; // 下一个需要创建节点的索引(0到symbolCount-1之间)double currentFrequency = frequencies[index]; // 当前节点频率(如果不为空)while (index < symbolCount){ // 遍历所有符号和频率,直到遍历完为止if (root == NULL){ // 如果根节点为空,创建根节点并指向当前节点root = createNode(NULL, currentFrequency);} else{ // 如果根节点不为空,查找下一个需要创建节点的索引和当前节点频率是否小于当前节点频率的倒数index++; // 下一个需要创建节点的索引增加一个位置(包括当前节点)if (frequencies[index] / currentFrequency <1.0 / HUF_TREE_DEPTH) { // 如果满足条件,创建新的子节点并递归构建哈夫曼树(当前节点)Node* child = createNode(symbols[index], frequencies[index]); // 创建子节点并保存符号和频率信息if (root->left == NULL){ // 如果当前节点的左子节点为空,将当前节点设置为左子节点并递归构建哈夫曼树(左子树)root->left = child;} else{ // 如果当前节点的右子节点为空,将当前节点设置为右子节点并递归构建哈夫曼树(右子树)root->right = child;} // 更新根节点的左右子节点信息并递归构建哈夫曼树(父节点)} else{ // 如果当前节点不足以生成新的子节点(由于被优先排序)继续处理下一个节点 currentFrequency = frequencies[index]; // 将当前节点的频率设置为下一个需要创建节点的频率(避免重复处理同一个符号)} // 更新索引和当前频率信息(继续处理下一个符号)} // 结束while循环(处理完所有符号和频率)}。
哈夫曼编码-数据结构-C++程序

数据结构课程设计一、目的《数据结构》是一门实践性较强的软件基础课程,为了学好这门课程,必须在掌握理论知识的同时,加强上机实践。
本课程设计的目的就是要达到理论与实际应用相结合,使同学们能够根据数据对象的特性,学会数据组织的方法,能把现实世界中的实际问题在计算机内部表示出来,并培养基本的、良好的程序设计技能。
二、要求通过这次设计,要求在数据结构析逻辑特性和物理表示,数据结构的选择的应用、算法的设计及其实现等方面中深对课程基本内容的理解。
同时,在程序设计方法以及上机操作等基本技能和科学作风方面受到比较系统和严格的训练。
三、内容2.哈夫曼编码/译码器【问题描述】设计一个利用哈夫曼算法的编码和译码系统,重复地显示并处理以下项目,直到选择退出为止。
【基本要求】(1)初始化:键盘输入字符集大小n、n个字符和n个权值,建立哈夫曼树;(2)编码:利用建好的哈夫曼树生成哈夫曼编码;(3)输出编码;(4)设字符集及频度如下表:字符空格A B C D E F G H I J K L M频度186 64 13 22 32 103 21 15 47 57 1 5 32 20字符N O P Q R S T U V W X Y Z频度57 63 15 1 48 51 80 23 8 18 1 16 1【选做内容】(1)译码功能;(2)显示哈夫曼树;(3)界面设计的优化。
哈夫曼编写编译码一、问题描述利用哈夫曼编码进行通信可以大大提高信道利用率,这要求在发送端通过一个编码系统对待传输预先编码,在接收端将传来的数据进行译码。
对于双工通道,每端都需要一个完整的编/译码系统。
试为这样的信息收发站写一个哈夫曼码的编/译码系统。
二、概要设计1.哈夫曼树的定义:在一棵二叉树中,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树。
2.哈夫曼树的构造:假设有N个权值,则构造出的哈夫曼树有N个叶子结点。
N个权值分别设为W1,W2,……….Wn,则哈夫曼树的构造规则为:(1)将W1,W2,……….Wn看成有N棵树的森林;(2)在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左,右子树,且新树的根结点为其左,右子树结点权值之和;(3)从森林中删除选取取的两面三刀棵树,并将新树加入森林;(4)重复(2)(3)步,直到森林中只剩一棵树为止,该树即为我们所求得的哈夫曼树。
哈夫曼编码与解码C语言知识讲解

哈夫曼编码与解码C语言#include "stdio.h" /*I/O函数*/#include"stdlib.h" /*其他库函数声明*/int num;/*记录结点数*/int codenum=0;/*已经获得的编码个数*/char filename[20]=""; /*存储文件名*/typedef struct /*哈夫曼结点存储结构*/{char ch; /*结点字符*/int w; /*结点权值*/int lchild,rchild; /*左右孩子的数组下标*/}HafuNode,*HafuTree;HafuTree ht;/*声明一个指向树结点到指针*/typedef struct{char ch; /*叶子结点字符*/char codestr[20]; /*字符编码*/}HafuCode;HafuCode code[27];/*用于存放对应字符到哈夫曼编码*/void InitHafuArry(){ /*导入文件计算权值,生成只含有叶子结点的HafuNode数组*/int j,i,k;HafuNode tmpht;FILE *fp; /*定义一指向打开文件的指针*/char ch;/*用于存储一个字母*/char location[30]="D:\\";ht=(HafuTree)malloc(53*sizeof(HafuNode)); /*为哈夫曼数分配内存空间*/ if(ht==NULL) return ;for(i=0;i<53;i++) /*初始化所以的数据单元,每个单元自成一棵树*/ {ht[i].w=0; /*权值初始化为0*/ht[i].lchild=ht[i].rchild=-1; /*左右子为空*/}num=0;printf("File name:");scanf("%s",filename);strcat(location,filename);fp=fopen(location,"r");if(!fp) /*返回1时即存在文件*/{printf("Open Error");return;}while(!feof(fp))/*没到结尾时返回0*/{ch=fgetc(fp);if(ch==' '||ch<='z'&&ch>='a'||ch<='Z'&&ch>='A'){printf("%c",ch);if(ch==' ') ch='#';for(j=0;j<num;j++){if(ht[j].ch==ch){break;}}if(j==num) /*找到新字符*/{ht[num].ch=ch; /*将新字符存入并将权值加1*/ht[num].w++;num++;}else{ht[j].w++; /*将已有字符权值加1*/}}}fclose(fp);printf("\n");for(i=0;i<num;i++) /*对叶子结点按权值进行升序排序*/{k=i;for(j=i+1;j<num;j++){if(ht[j].w<ht[k].w)/*如果后面发现权值比i小的则将其下标记录下来,循环完之后找到最小的*/k=j;}if(k!=i) /*如果权值最小的不是第i个元素则交换位置,将小的放到前面*/ {tmpht=ht[i];ht[i]=ht[k];ht[k]=tmpht;}}}int CreateHafuman(HafuTree ht){ /*在数组ht中生成哈夫曼数,返回根节点下标*/int i,k,j,root;HafuNode hfnode;codenum=0;for(i=0;i<num-1;i++){ /*需生成num-1个结点*/k=2*i+1; /*每次取最前面两个结点,其权值必定最小*/hfnode.w=ht[k].w+ht[k-1].w;hfnode.lchild=k-1;hfnode.rchild=k;for(j=num+i;j>k;j--) /*将新结点插入有序数组中*/{if(ht[j].w>hfnode.w){ht[j+1]=ht[j];}else break;}ht[j]=hfnode;root=j;/*一直跟随新生成的结点,最后新生成的结点为根结点*/}return root;}void GetHafuCode(HafuTree ht,int root,char *codestr){ /*ht是哈夫曼树,root是根结点下标,codestr是来暂时存放叶子结点编码的,一开始为空*/FILE *out;int len,i;FILE *fp; /*定义一指向打开文件的指针*/char ch;/*用于存储一个字母*/char location[30]="D:\\";if(ht[root].lchild==-1){/*遇到递归终点是叶子结点记录叶子结点的哈夫曼编码*/code[codenum].ch=ht[root].ch;strcpy(code[codenum].codestr,codestr);codenum++;}else /*不是终点则继续递归*/{len=strlen(codestr);codestr[len]='0'; /*左分支编码是0*/codestr[len+1]=0; /*向左孩子递归之前调整编码序列末尾加0,相当于加了个‘\0’(null)其十进制值是0,以便下次循环时添加字符,否则会被覆盖掉*/GetHafuCode(ht,ht[root].lchild,codestr); /*向左递归*/len=strlen(codestr);codestr[len-1]='1';/*右分支编码为1,想右递归之前末尾编码0改为1*/ GetHafuCode(ht,ht[root].rchild,codestr); /*向右递归*/len=strlen(codestr);codestr[len-1]=0; /*左右孩子递归返回后,删除编码标记末尾*/}strcat(location,filename);fp=fopen(location,"r");if(!fp) /*返回1时即存在文件*/{printf("Open Error");return;}out=fopen("D:\\code.txt","w+") ;if(!out){/*printf("Write Error"); */return;}while(!feof(fp))/*没到结尾时返回0*/{ch=fgetc(fp); /*再打开源文件,对照哈夫曼编码译成编码*/if(ch==' '||ch<='z'&&ch>='a'||ch<='Z'&&ch>='A'){ if(ch==' ') ch='#'; /*如果是空格就用#号代替*/for(i=0;i<codenum;i++){ /*找到字符所对应到哈夫曼编码*/if(ch==code[i].ch){ /*将所得哈夫曼编码输出到文件中*/fputs(code[i].codestr,out);}}}}fclose(fp); /*关闭打开到两个文件*/fclose(out);}void decodeHafuCode(HafuTree ht,int root) /*将哈夫曼编码翻译为明文*/ {FILE *fp2; /*定义一指向打开文件的指针*/char ch;/*用于存储一个字母*/int curr=root;/*当前结点到下标*/char filename2[20]="";/*获得文件名*/char location[30]="D:\\";printf("File name:");scanf("%s",filename);strcat(location,filename);fp2=fopen(location,"r");if(!fp2) /*返回1时即存在文件*/{printf("Open Error2");return;}printf("Code:");while(!feof(fp2))/*没到结尾时返回0*/{ch=fgetc(fp2);if(ch>='0'&&ch<='1')/*将编码过滤出来*/{printf("%c",ch); /*将密文输出显示*/}}printf("\n");rewind(fp2); /*将文件指针位置定位在开头*/while(!feof(fp2))/*没到结尾时返回0*/{ch=fgetc(fp2);if(ch>='0'&&ch<='1')/*将编码过滤出来*/{if(ch=='0') /*如果为0则当前结点向左走*/{if(ht[curr].lchild!=-1){curr=ht[curr].lchild;/*若有左子则去左子*/}else{curr=root; /*没有则返回根结点*/}}if(ch=='1') /*如果为1则当前结点向右走*/{if(ht[curr].rchild!=-1){curr=ht[curr].rchild;/*若有右子则去右子*/}else{curr=root; /*没有则返回根结点*/}}if(ht[curr].lchild==-1&&ht[curr].rchild==-1)/*若为叶子结点则打印输出*/ {printf("%c",ht[curr].ch=='#'?' ':ht[curr].ch);curr=root; /*回到根结点继续索引*/}}}fclose(fp2);}void main(){ int root;int i;char codestr[20]="";int control;/*显示菜单可选择编码、译码还是退出*/printf("================Menu==============\n");printf("chose 1:encode\n");printf("chose 2:decode\n");printf("chose 3:exit\n");scanf("%d",&control);while(control!=3) /*只有没有选择退出就一直循环*/{if(control==1) /*选择编码选项*/{FILE *output;char ch;InitHafuArry(); /*初始化结点*/root=CreateHafuman(ht); /*造一棵哈夫曼树*/GetHafuCode(ht,root,codestr);/*根据哈夫曼树将明文译成密码*/ printf("Code:");output=fopen("D:\\CODE.TXT","r");if(!output) /*返回1时即存在文件*/{printf("Open Error3");continue;}while(!feof(output))/*没到结尾时返回0*/{ch=fgetc(output);if(ch>='0'&&ch<='1')/*将编码过滤出来*/{printf("%c",ch); /*将密文输出显示*/}}fclose(output);/*将打开文件关闭*/}if(control==2) /*如果选择译码,则调用译码函数*/{decodeHafuCode(ht,root);}if(control==3) /*如果选择3则退出程序*/{exit(0);}/*若没有退出则继续打印菜单提示供选择*/printf("\n\n================Menu==============\n"); printf("chose 1:encode\n");printf("chose 2:decode\n");printf("chose 3:exit\n");getch();scanf("%d",&control);}}。
哈夫曼编码及其解码全过程

哈夫曼编码及其解码全过程1.引言1.1 概述在这篇长文中,我们将介绍哈夫曼编码及其解码的全过程。
哈夫曼编码是一种可变字长编码技术,它通过统计字符出现频率来构建编码表,使得出现频率高的字符使用较短的编码,出现频率低的字符使用较长的编码,从而实现高效的数据压缩。
在本文中,我们将详细探讨哈夫曼编码的过程,包括哈夫曼树的构建和编码表的生成。
此外,我们还将介绍哈夫曼解码的过程,包括解码表的生成和解码过程。
最后,我们将总结哈夫曼编码及其解码,并展望其在实际应用中的前景。
通过阅读本文,读者将全面了解哈夫曼编码及其解码的原理和实现方法。
【1.2 文章结构】本文共分为三个部分,分别是引言、正文和结论。
下面将对每个部分进行详细的说明。
(1) 引言部分包括三小节。
首先是概述,将简要介绍哈夫曼编码及其解码的基本概念和作用。
其次是文章结构,将列出本文的整体结构以及各个部分的内容。
最后是目的,阐述撰写这篇长文的目标和意义。
(2) 正文部分是本文的核心部分,分为两个小节。
第一个小节是哈夫曼编码过程,将详细介绍哈夫曼树的构建和编码表的生成过程。
具体而言,将介绍如何根据字符的出现频率构建哈夫曼树,并通过遍历哈夫曼树生成对应的编码表。
第二个小节是哈夫曼解码过程,将详细介绍解码表的生成和解码的具体步骤。
具体而言,将介绍如何根据编码表构建解码表,并通过解码表将编码还原成原始字符。
(3) 结论部分也包括两个小节。
首先是总结,将对整篇文章的内容进行简要回顾,并总结哈夫曼编码及其解码的关键步骤和特点。
其次是应用前景,将探讨哈夫曼编码在实际应用中的潜在价值和发展前景,展示其在数据压缩和信息传输等领域的重要性。
通过对文章结构的明确描述,读者可以清晰地了解到本文的整体内容安排,从而更好地理解和阅读本文的各个部分。
1.3 目的本文的目的是介绍哈夫曼编码及其解码的全过程。
通过详细阐述哈夫曼编码的构建和解码过程,使读者能够深入理解哈夫曼编码的原理和应用。
使用哈夫曼编码方法,求出编码和平均码长c语言方式

哈夫曼编码是一种常用的无损数据压缩算法,通过利用字符出现的频率来构建可变长度的编码表,以实现高效的数据压缩。
本文将以C语言为例,介绍如何使用哈夫曼编码方法求出编码和平均码长。
1. 哈夫曼编码原理哈夫曼编码是一种前缀编码(Prefix Codes),即任何字符的编码都不是其他字符编码的前缀。
这种编码方式可以保证编码的唯一性,不会出现歧义。
哈夫曼编码的原理是通过构建哈夫曼树来实现对字符的编码,具体步骤如下:1)统计字符出现的频率,并根据频率构建最小堆或优先队列。
2)从频率最低的两个字符中选择一个根节点,频率之和作为其父节点的频率,将父节点重新插入到最小堆或优先队列中。
3)重复以上步骤,直到最小堆或优先队列中只剩下一个节点,即哈夫曼树的根节点。
4)根据哈夫曼树,得到字符的编码。
从根节点开始,左子树标记为0,右子树标记为1,沿途记录路径上的编码即可。
2. C语言实现哈夫曼编码以下是使用C语言实现哈夫曼编码的伪代码:```c#include <stdio.h>#include <stdlib.h>#include <string.h>// 定义哈夫曼树节点typedef struct Node {char data; // 字符数据int freq; // 字符频率struct Node* left;struct Node* right;} Node;// 创建哈夫曼树节点Node* createNode(char data, int freq) {Node* node = (Node*)malloc(sizeof(Node)); node->data = data;node->freq = freq;node->left = NULL;node->right = NULL;return node;}// 构建哈夫曼树Node* buildHuffmanTree(char* data, int* freq, int size) {// 构建最小堆或优先队列// 构建哈夫曼树}// 生成字符编码void generateHuffmanCode(Node* root, char* code, int depth) { // 生成编码}// 输出字符编码void printHuffmanCode(Node* root) {// 输出编码}// 计算平均码长double calculateAvgCodeLength(Node* root, int depth) {// 计算平均码长}int main() {char data[] = {'a', 'b', 'c', 'd', 'e', 'f'};int freq[] = {5, 9, 12, 13, 16, 45};int size = sizeof(data) / sizeof(data[0]);Node* root = buildHuffmanTree(data, freq, size);char code[100];generateHuffmanCode(root, code, 0);printHuffmanCode(root);double avgCodeLength = calculateAvgCodeLength(root, 0);return 0;}```以上伪代码实现了使用C语言构建哈夫曼树、生成字符编码和计算平均码长的过程。
哈夫曼编码详解(C语言实现)

哈夫曼编码详解(C语言实现)哈夫曼编码是一种常见的前缀编码方式,被广泛应用于数据压缩和传输中。
它是由大卫·哈夫曼(David A. Huffman)于1952年提出的,用于通过将不同的字符映射到不同长度的二进制码来实现数据的高效编码和解码。
1.统计字符频率:遍历待编码的文本,记录每个字符出现的频率。
2.构建哈夫曼树:根据字符频率构建哈夫曼树,其中出现频率越高的字符位于树的较低层,频率越低的字符位于树的较高层。
3.生成编码表:从哈夫曼树的根节点开始,遍历哈夫曼树的每个节点,为每个字符生成对应的编码。
在遍历过程中,从根节点到叶子节点的路径上的“0”表示向左,路径上的“1”表示向右。
4.进行编码:根据生成的编码表,将待编码的文本中的每个字符替换为对应的编码。
5.进行解码:根据生成的编码表和编码结果,将编码替换为原始字符。
下面是一个用C语言实现的简单哈夫曼编码示例:```c#include <stdio.h>#include <stdlib.h>#include <string.h>//定义哈夫曼树的节点结构体typedef struct HuffmanNodechar data; // 字符数据int freq; // 字符出现的频率struct HuffmanNode *left; // 左子节点struct HuffmanNode *right; // 右子节点} HuffmanNode;//定义编码表typedef structchar data; // 字符数据char *code; // 字符对应的编码} HuffmanCode;//统计字符频率int *countFrequency(char *text)int *frequency = (int *)calloc(256, sizeof(int)); int len = strlen(text);for (int i = 0; i < len; i++)frequency[(int)text[i]]++;}return frequency;//创建哈夫曼树HuffmanNode *createHuffmanTree(int *frequency)//初始化叶子节点HuffmanNode **leaves = (HuffmanNode **)malloc(256 * sizeof(HuffmanNode *));for (int i = 0; i < 256; i++)if (frequency[i] > 0)HuffmanNode *leaf = (HuffmanNode*)malloc(sizeof(HuffmanNode));leaf->data = (char)i;leaf->freq = frequency[i];leaf->left = NULL;leaf->right = NULL;leaves[i] = leaf;} elseleaves[i] = NULL;}}//构建哈夫曼树while (1)int min1 = -1, min2 = -1;for (int i = 0; i < 256; i++)if (leaves[i] != NULL)if (min1 == -1 , leaves[i]->freq < leaves[min1]->freq) min2 = min1;min1 = i;} else if (min2 == -1 , leaves[i]->freq < leaves[min2]->freq)min2 = i;}}}if (min2 == -1)break;}HuffmanNode *parent = (HuffmanNode*)malloc(sizeof(HuffmanNode));parent->data = 0;parent->freq = leaves[min1]->freq + leaves[min2]->freq;parent->left = leaves[min1];parent->right = leaves[min2];leaves[min1] = parent;leaves[min2] = NULL;}HuffmanNode *root = leaves[min1];free(leaves);return root;//生成编码表void generateHuffmanCode(HuffmanNode *root, HuffmanCode *huffmanCode, char *code, int depth)if (root->left == NULL && root->right == NULL)code[depth] = '\0';huffmanCode[root->data].data = root->data;huffmanCode[root->data].code = strdup(code);return;}if (root->left != NULL)code[depth] = '0';generateHuffmanCode(root->left, huffmanCode, code, depth + 1);}if (root->right != NULL)code[depth] = '1';generateHuffmanCode(root->right, huffmanCode, code, depth + 1);}//进行编码char *encodeText(char *text, HuffmanCode *huffmanCode)int len = strlen(text);int codeLen = 0;char *code = (char *)malloc(len * 8 * sizeof(char));for (int i = 0; i < len; i++)strcat(code + codeLen, huffmanCode[(int)text[i]].code);codeLen += strlen(huffmanCode[(int)text[i]].code);}return code;//进行解码char* decodeText(char* code, HuffmanNode* root) int len = strlen(code);char* text = (char*)malloc(len * sizeof(char)); int textLen = 0;HuffmanNode* node = root;for (int i = 0; i < len; i++)if (code[i] == '0')node = node->left;} elsenode = node->right;}if (node->left == NULL && node->right == NULL) text[textLen] = node->data;textLen++;node = root;}}text[textLen] = '\0';return text;int maichar *text = "Hello, World!";int *frequency = countFrequency(text);HuffmanNode *root = createHuffmanTree(frequency);HuffmanCode *huffmanCode = (HuffmanCode *)malloc(256 * sizeof(HuffmanCode));char code[256];generateHuffmanCode(root, huffmanCode, code, 0);char *encodedText = encodeText(text, huffmanCode);char *decodedText = decodeText(encodedText, root);printf("Original Text: %s\n", text);printf("Encoded Text: %s\n", encodedText);printf("Decoded Text: %s\n", decodedText);//释放内存free(frequency);free(root);for (int i = 0; i < 256; i++)if (huffmanCode[i].code != NULL)free(huffmanCode[i].code);}}free(huffmanCode);free(encodedText);free(decodedText);return 0;```上述的示例代码实现了一个简单的哈夫曼编码和解码过程。
2021年艺术设计模拟试卷与答案解析27

2021年艺术设计模拟试卷与答案解析27一、单选题(共30题)1.下列压缩编码方法()不属于统计编码。
A:差分脉冲编码调制B:行程编码C:哈夫曼编码D:算术编码【答案】:A【解析】:2.选集的使用有除()外有3种基本方式。
A:选定工作区域的范围B:限制工作区域的范围C:保护区域(或蒙住该区域)D:选择对象(或对象组)【答案】:A【解析】:3.“有病治病,无病防身”这种说法违反了功能的()原则。
A:安全感B:适用性C:简洁性D:合理性【答案】:B【解析】:4.组合字体效益性的描述不正确的是()。
A:艺术表现与客观实际高度统一B:具有很强的实用性C:百事可乐、三星、丰田、索尼都是成功的代表D:用艺术表现方法和技巧的高低判断是否优秀()【答案】:A【解析】:5.数字化视频光盘即DVD是用激光读取的。
然而,DVD有两侧而不是一侧,并且每一侧可以有两层。
()A:两层数据轨迹都是从内部螺旋向外发散B:两层数据轨迹都是从外部开始螺旋向内C:第一层数据轨迹从内部螺旋向外发散,第二层从外部开始螺旋向内D:第一层数据轨迹从外部开始螺旋向内,第二层从内部螺旋向外发散【答案】:C【解析】:6.不支持即点即播,也不支持交互控制的点播方式是()。
A:NVODB:TVODC:无正确答案D:IVOD【答案】:A【解析】:7.Photoshop中,橡皮擦工具的作用是()。
A:用来擦除不同图像区域的颜色B:填充颜色C:用背景色擦除选区中的颜色D:用前景色擦除选区中的颜色【答案】:A【解析】:8.在多媒体会议系统中,对于信道描述正确的是()。
A:上行信道数据量小于下行信道B:上行信道数据量等于下行信道C:上行信道数据量大于下行信道D:无正确答案【答案】:B【解析】:9.艺术创作过程的最后一个阶段是()。
A:艺术传达活动B:艺术构思活动C:艺术创作活动D:艺术体验活动【答案】:A【解析】:艺术传达活动作为创作过程的最后一个阶段,它是指艺术家借助一定的物质材料和艺术媒介,运用艺术技巧和艺术手法,将自己在艺术构思活动中形成的审美意象物态化,成为可供其他人欣赏的艺术作品和艺术形象。
哈夫曼编码原理

哈夫曼编码原理
哈夫曼编码是一种可变长度编码,它利用出现频率较高的字符用较短的编码,而用较长的编码表示出现频率较低的字符,从而达到压缩数据的目的。
哈夫曼编码的原理是:首先统计每个字符在文本中出现的频率,然后将每个字符看作一个叶子节点,构建一棵哈夫曼树。
在哈夫曼树中,每个叶子节点表示一个字符,每个非叶子节点表示一个字符集合,其权值为其子节点权值之和。
从根节点到每个叶子节点的路径上的编码就是该字符的哈夫曼编码,其中左子树路径上添加0,右子树路径上添加1。
在编码过程中,将文本中的每个字符替换为其对应的哈夫曼编码,这样可以将文本压缩为较短的二进制串。
在解码过程中,根据哈夫曼树的结构,将二进制串从根节点开始逐位遍历,遇到0就向左子树走,遇到1就向右子树走,直到遍历到叶子节点,即可得到原始字符。
哈夫曼编码的优点是可以根据文本中字符的出现频率来构建编码表,从而达到更好的压缩效果。
哈夫曼编码译码器数据结构C语言

一、需求分析目前,进行快速远距离通信的主要手段是电报,即将需传送的文字转化成由二级制的字符组成的字符串.例如,假设需传送的电文为“ABACCDA",它只有4种字符,只需两个字符的串,便可以分辨。
假设A 、B 、C 、D 、的编码分别为00,01,10和11,则上述7个字符的电文便为“00010010101100”,总长14位,对方接受时,可按二位一分进行译码。
当然,在传送电文时,希望总长尽可能地短.如果对每个字符设计长度不等的编码,且让电文中出现次数较多的字符采用尽可能短的编码,则传送电文的总长便可减少。
如果设计A 、B 、C 、D 的编码分别为0,00,1,01,则上述7个字符的电文可转换成总长为9的字符串“000011010"。
但是,这样的电文无法翻译,例如传送过去的字符串中前4个字符的字串“0000”就可以有很多种译法,或是“AAAA ”或者“BB ”,或者“ABA ”等.因此,若要设计长短不等的编码,则必须是任一字符的编码都不是另一个字符的编码的前缀,这种编码称作前缀编码。
然而,如何进行前缀编码就是利用哈夫曼树来做,也就有了现在的哈夫曼编码和译码.二、概要设计利用哈夫曼树编/译码 (一)、建立哈夫曼树 (二)、对哈夫曼树进行编码 (三)、输出对应字符的编码 (四)、译码过程主要代码实现: struct code //结构体的定义 { char a ; int w ; int parent; int lchild; int rchild; };void creation(code *p,int n ,int m ); //建立哈夫曼树 void coding (code *p,int n ); //编码 void display (code *p ,int n ,int m); //输出函数 void translate (char **hc,code *p,int n); //译码三、 详细设计(一)、建立哈夫曼树2 3 4 5 * * * 6 7序号:权值: 1 2 3 4 3 6 10 6 图3-1 图(二)、对哈夫曼树进行编码 主要代码实现: for(c=i,f=p [i ].parent;f!=0;c=f ,f=p [f ]。
哈夫曼编码c语言代码

哈夫曼编码c语言代码1.统计数据中每个字符出现的次数。
2.根据每个字符出现的次数建立哈夫曼树。
3.根据哈夫曼树构建每个字符的编码,相同的字符具有不同的编码。
4.用编码替换原数据中的字符。
根据上述步骤,我们可以得到以下的C语言实现。
C语言实现哈夫曼编码在C语言中,我们可以使用结构体来表示哈夫曼树节点及其信息:```ctypedef struct node 。
char content;int freq;struct node某 left;struct node某 right;} node;```其中content表示节点所代表的字符,freq表示该字符在数据中出现的次数,left和right分别指向节点的左右子节点。
我们可以使用一个链表来存储所有的字符及其出现的次数:```ctypedef struct listNode 。
node某 n;struct listNode某 ne某t;} listNode;```这个链表可以通过遍历数据,统计每个字符出现的次数来构建。
我们可以使用一个堆来存储所有的树节点,每次从堆中取出频率最小的两个节点,构建一个新的节点,然后将这个新节点插入堆中。
重复这个过程直到堆中只剩下一个根节点,这个节点就是哈夫曼树的根节点。
```ctypedef struct heap 。
int size;node某某 nodes;} heap;```定义堆的时候,size表示堆中节点的数量,nodes是一个数组,存储所有的节点。
我们可以使用一棵二叉堆来实现堆的操作,即将频率最小的节点放在堆的顶部。
构建好哈夫曼树后,我们可以通过遍历树来给每个字符一个独一无二的编码。
编码的时候,我们可以使用一个栈来存储每个节点的信息,然后倒序输出栈中的内容来得到编码。
最后,我们可以使用编码替换原数据中的字符。
在解码的时候,我们只需要将编码反向遍历树即可还原原始数据。
总结。
哈夫曼编码的原理及C++实现

哈夫曼编码的原理及C++实现哈夫曼编码(Huffman Coding)是一种非常经典的编码方式,实现起来也很简单,在实际的笔试面试过程中有可能会遇到,这里介绍一下它的原理和一个使用优先队列的实现版本。
一编码原理哈夫曼编码是一种可变长的编码,它依据字符出现的概率来决定字符编码的长度,使得出现概率大的字符编码长度短,出现概率小的字符的编码长度长,于是可以减少整体的编码的长度。
哈弗曼编码时首先根据待编码的文本统计出每个字符出现的概率,组成初始的节点。
然后每次取出概率最小的两个节点,新建一个节点,使得新建节点的左右儿子为选取的两个节点,并且其概率是两个节点概率之和,把新建的节点再放进所有节点中重新选择最小的两个节点。
重复此过程直到只剩一个节点,这个就是哈夫曼树的根节点。
以下以字符串"aaaaaabbbbccddd"为例进行说明,为了方便,以字符出现的频数来代替频率(实际中通常使用的是频率,二者效果上是一样的),经过统计,可以知道每个字符出现的频数为a b c d6 4 2 3具体建树过程如下:(1)首先节点权值为6、4、2、3,选择最小的2和3,组成一个根节点为5的组合节点。
(2)当前节点权值为6、4、5,选择最小的4和5,组成一个根节点为9的组合节点。
(3)当前节点权值为6、9,选择最小的6和9,组成一个根节点为15的组合节点。
(4)当前节点权值为15,只有一个节点,哈夫曼树建立完成。
图示如下:要从哈夫曼树得到每个字符的编码,只要在哈夫曼树中从根节点遍历到该字符节点,每次向左走时加一个0,向右走时加一个1,最终得到的字符串即为该字符的编码字符串。
如从上图可以看到,a的编码为0,b的编码为10,c的编码为110,d的编码为111。
当遇到一个新的字符串时,比如说"abcd",要对其编码,只需要把其中的每个字符相应地替换成其编码字符串即可。
当已知一个编码后的字符串,比如说"010110111",要对其解码时,只需从左到右依次扫描该编码串,当读到的串在哈弗曼编码表里有对应的字符时即解码为该字符,然后继续扫描。
最优前缀码(哈夫曼编码)

最优前缀码(哈夫曼编码)1、问题给定字符集C={x1,x2,…,xn}和每个字符的频率f(xi),求关于C的⼀个最优前缀码,即总码长度最短且没有⼆义性。
2、解析哈夫曼编码的基本思想是以字符的使⽤频率作为权构建⼀棵哈夫曼树,然后利⽤哈夫曼树对字符进⾏编码。
构造⼀棵哈夫曼树,是将所要编码的字符作为叶⼦结点,该字符在⽂件中的使⽤频率作为叶⼦结点的权值,以⾃底向上的⽅式,通过 n−1 次的“合并”运算后构造出的⼀棵树,核⼼思想是权值越⼤的叶⼦离根越近。
哈夫曼算法采取的贪⼼策略是每次从树的集合中取出没有双亲且权值最⼩的两棵树作为左右⼦树3、设计1 #include<cstdio>2 #include<cstdlib>3 #include<cstring>4 #include<algorithm>5using namespace std;67#define n 6 //叶⼦数⽬8#define m 2*n-1 //树中结点总数9 typedef struct{ //结点类型10double weight; //结点的权值11int parent,lchild,rchild;//双亲指针及左右孩⼦12}HTNode;13 typedef HTNode HuffmanTree[m];//HuffmanTree是向量类型1415 typedef struct{ //⽤于SelectMin函数中排序的结点类型16int id; //保存根结点在向量中的序号17double weight; //保存根结点的权值18}temp;1920 typedef struct{ //编码结点21char ch; //存储字符22char bits[n+1]; //存放编码位串23}CodeNode;24typedef CodeNode HuffmanCode[n];2526void InitHuffmanTree(HuffmanTree T){27//初始化哈夫曼树28//将2n-1个结点⾥的三个指针均置为空(即置为-1),权值置为029for(int i=0;i<m;i++){30 T[i].lchild=-1;31 T[i].rchild=-1;32 T[i].parent=-1;33 T[i].weight=0;34 }35}3637void InputWeight(HuffmanTree T){38//输⼊叶⼦权值39//读⼈n个叶⼦的权值存于向量的前n个分量中40for(int i=0;i<n;i++){41double x;42 scanf("%lf",&x);43 T[i].weight=x;44 }45}4647bool cmp(temp a,temp b){48//⽤于排序的⽐较函数49return a.weight<b.weight;50}5152void SelectMin(HuffmanTree T,int k,int *p1,int *p2){53//在前k个结点中选择权值最⼩和次⼩的根结点,其序号分别为p1和p254 temp x[m]; //x向量为temp类型的向量55int i,j;56for(i=0,j=0;i<=k;i++){ //寻找最⼩和次⼩根节点的过程57if(T[i].parent==-1){//如果是根节点,则进⾏如下操作58 x[j].id=i; //将该根节点的序号赋值给x59 x[j].weight=T[i].weight;//将该根节点的权值赋值给x60 j++; //x向量的指针后移⼀位61 }62 }63 sort(x,x+j,cmp); //对x按照权值从⼩到⼤排序64//排序后的x向量的第⼀和第⼆个位置中存储的id是所找的根节点的序号值65 *p1=x[0].id;66 *p2=x[1].id;67}6869void CreateHuffmanTree(HuffmanTree T){70//构造哈夫曼树,T[m-1]为其根结点71int i,p1,p2;72 InitHuffmanTree(T); //将T初始化73 InputWeight(T); //输⼊叶⼦权值74for(i=n;i<m;i++){75//在当前森林T[0..i-1]的所有结点中,选取权最⼩和次⼩的76//两个根结点T[p1]和T[p2]作为合并对象77//共进⾏n-1次合并,新结点依次存于T[i]中7879 SelectMin(T,i-1,&p1,&p2);//选择权值最⼩和次⼩的根结点,其序号分别为p1和p2 8081//将根为T[p1]和T[p2]的两棵树作为左右⼦树合并为⼀棵新的树82//新树的根是新结点T[i]83 T[p1].parent=T[p2].parent=i;//T[p1]和T[p2]的两棵树的根结点指向i84 T[i].lchild=p1; //最⼩权的根结点是新结点的左孩⼦85 T[i].rchild=p2; //次⼩权的根结点是新结点的右孩⼦86 T[i].weight=T[p1].weight+T[p2].weight;//新结点的权值是左右⼦树的权值之和87 }88}8990void CharSetHuffmanEncoding(HuffmanTree T,HuffmanCode H){91//根据哈夫曼树T求哈夫曼编码表H92int c,p;//c和p分别指⽰T中孩⼦和双亲的位置93char cd[n+1];//临时存放编码94int start;//指⽰编码在cd中的起始位置95 cd[n]='\0';//编码结束符96 getchar();97for(int i=0;i<n;i++){//依次求叶⼦T[i]的编码98 H[i].ch=getchar();//读⼊叶⼦T[i]对应的字符99 start=n;//编码起始位置的初值100 c=i;//从叶⼦T[i]开始上溯101while((p=T[c].parent)>=0){//直⾄上溯到T[c]是树根为⽌102//若T[c]是T[p]的左孩⼦,则⽣成代码0;否则⽣成代码1103if(T[p].lchild==c)104 cd[--start]='0';105else106 cd[--start]='1';107 c=p;//继续上溯108 }109 strcpy(H[i].bits,&cd[start]);//复制编码位串110 }111}112113int main(){114 HuffmanTree T;115 HuffmanCode H;116 printf("请输⼊%d个叶⼦结点的权值来建⽴哈夫曼树:\n",n);117 CreateHuffmanTree(T);118 printf("请输⼊%d个叶⼦结点所代表的字符:\n",n);119 CharSetHuffmanEncoding(T,H);120 printf("哈夫曼树已经建好,哈夫曼编码已经完成,输出如下:\n");121 printf("哈夫曼树:\n");122for(int i=0;i<m;i++){123 printf("id:%d weight:%.1lf parent:%d",i,T[i].weight,T[i].parent);124 printf(" lchild:%d rchild:%d\n",T[i].lchild,T[i].rchild);125 }126 printf("哈夫曼编码:\n");127double wpl=0.0;128for(int i=0;i<n;i++){129 printf("id:%d ch:%c code:%s\n",i,H[i].ch,H[i].bits);130 wpl+=strlen(H[i].bits)*T[i].weight;131 }132 printf("平均码长为:%.2lf\n",wpl);133return0;134 }4、分析0(nlogn)频率排序;for循环0(n),插⼊操作0(logn),算法时间复杂度是0(nlogn) 5、源码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一.实验目的
问题描述:
设计一个利用哈夫曼算法的编码和译码系统,重复地显示并处理以下项目,直到选择退出为止。
基本要求:
(1)初始化:键盘输入字符集大小n、n个字符和n个权值,建立哈夫曼树;
(2)编码:利用建好的哈夫曼树生成哈夫曼编码;
(3)输出编码;
二.问题分析
假设有N个权值,则构造出的哈夫曼树有N个叶子结点。
N个权值分别设为
W1,W2,……….Wn,则哈夫曼树的构造规则为:
(1)将W1,W2,……….Wn看成有N棵树的森林;
(2)在森林中选出两个根结点的权值最小的树合并,作为一棵新树的
左,右子树,且新树的根结点为其左,右子树结点权值之和;
(3)从森林中删除选取取的两面三刀棵树,并将新树加入森林;
(4)重复(2)(3)步,直到森林中只剩一棵树为止,该树即为我们所求得的哈夫曼树。
3具体代码
#include<iostream.h>
#include<stdio.h>
#include<malloc.h>
#define MAX 25
typedef struct
{
char data;
int weight;
int parent;
int lchild;
int rchild;
} HTNode;
typedef struct
{
char cd[MAX];
int start;
} HuffmanCode;
int main()
{
HTNode ht[2*MAX]; HuffmanCode hcd[MAX], d;
int i, k, f, l, r, n, c, s1, s2;
cout<<"* * * * * * * * * * * * * * * * * * * * * \n" <<"\t哈夫曼编码与译码系统\n"<<"* * * * * * * * * * * * * * * * * * * * * \n";
cout<<"\n请输入哈夫曼码元素个数:";
cin>>n;
cout<<"请输入各个元素的结点值与权值:\n";
for(i=1;i<=n;i++)
{
cout<<" 第"<<i<<"个元素-->\n\t结点值:";
cin>>&ht[i].data;
cout<<"\t权值:";
cin>>ht[i].weight;
}
for(i=1;i<=2*n-1;i++)
ht[i].parent=ht[i].lchild=ht[i].rchild=0;
for(i=n+1;i<=2*n-1;i++)
{
s1=s2=32767;
l=r=0;
for(k=1;k<=i-1;k++)
if(ht[k].parent==0)
if(ht[k].weight<s1)
{
s2=s1;
r=l;
s1=ht[k].weight;
l=k;
}
else if(ht[k].weight<s2)
{
s2=ht[k].weight;
r=k;
}
ht[l].parent=i;
ht[r].parent=i;
ht[i].weight=ht[l].weight+ht[r].weight;
ht[i].lchild=l;
ht[i].rchild=r;
}
for(i=1;i<=n;i++)
{
d.start=n+1;
c=i;
f=ht[i].parent;
while(f!=0)
{
if(ht[f].lchild==c)
d.cd[--d.start]='0';
else
d.cd[--d.start]='1';
c=f;
f=ht[f].parent;
}
hcd[i]=d;
}
cout<<"输出哈夫曼编码:\n";
for(i=1;i<=n;i++)
{
cout<<ht[i].data<<": ";
for(k=hcd[i].start;k<=n;k++)
cout<<hcd[i].cd[k];
cout<<"\n";
}
l: cout<<"\n请选择编码/译码/退出系统: (B/Y/E): "; char hfm;
cin>>hfm;
if(hfm=='e')
return 0;
else
{
switch(hfm)
{
case'b':
{
int q ;
char bs;
cout<<"\n* * * 哈夫曼编码* * *\n";
cout<<"请输入字符代码"<<endl;
for(q=0;bs!=10;q++)
{
bs=getchar();
for(i=1;i<=n;i++)
{
if (bs==ht[i].data)
for(k=hcd[i].start;k<=n;k++)
cout<<hcd[i].cd[k];
}
}
cout<<endl;
}
break;
case'y':
{
char e;
int t,u;
t=2*n-1;
cout<<"\n* * * 哈夫曼译码* * *\n";
cout<<"\n请输入哈夫曼码: "<<endl;
for(u=0;e!=10;u++)
{
if(ht[t].lchild!=0)
{
e=getchar();
if(e=='0')
t=ht[t].lchild;
else
t=ht[t].rchild;
}
else
{
cout<<ht[t].data;
t=2*n-1;
}
}
cout<<endl;
} break;
}
goto l;
}
return 0;
}
4实验截图
5实验总结
哈弗曼二叉树是基于贪心性质和最优子结构性质的一个问题,在编写过程中,我对二叉树有了更加深入的认识,但和上一个背包问题一样,感觉自己编程能力不强,有些东西自己知道运行过程但是却无法把它用C++的形势描述出来。
这项能力还需要锻炼
最后说句题外话:感觉对这份报告不是很满意,和背包问题一样:问题分析中只有中文没有相应的代码注释,但是在问题分析下面就是具体代码,如果写了感觉功能有点重叠。
所以就没写。