多元统计分析重点.doc
多元统计分析 (2)

多元统计分析简介多元统计分析是指对多个变量进行统计分析,旨在揭示变量之间的关联性以及它们对整体数据的贡献。
它是一种在现代数据科学和数据分析中常用的方法,可以为人们提供深入了解数据的结构和特征的洞察力。
在本文档中,我们将介绍多元统计分析的基本概念,包括主成分分析、聚类分析和因子分析等。
主成分分析主成分分析(Principal Component Analysis,简称PCA)是一种常用的多元统计分析方法,它通过线性变换将原始的高维数据转换为低维的主成分,从而减少数据的维度,并保留原始数据的大部分信息。
主成分分析的核心思想是寻找能够描述原始数据方差最大的轴,这些轴称为主成分。
主成分分析可以帮助我们发现变量之间的相关性,并找到数据中的模式或规律。
主成分分析的使用步骤通常包括以下几个步骤:1.数据标准化:对原始数据进行标准化处理,使得数据满足均值为0、方差为1的标准正态分布。
2.计算协方差矩阵:计算标准化后的数据的协方差矩阵。
3.计算特征值和特征向量:通过对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。
4.选择主成分:根据特征值的大小,选择解释方差最大的前几个特征向量作为主成分。
5.数据投影:将原始数据投影到选择的主成分上,得到降维后的数据。
主成分分析在实际应用中具有广泛的应用场景,例如在数据可视化、数据降维、特征提取等领域。
聚类分析聚类分析是一种将数据根据其相似性分为不同组别的方法。
它是通过计算样本之间的距离或相似性,将样本划分为具有相似特征的组别。
聚类分析的目标是使得组内的差异最小化,而组间的差异最大化,从而实现样本间的聚类。
聚类分析的常见方法包括层次聚类和K均值聚类。
层次聚类是一种基于距离或相似性矩阵的聚类方法,它通过不断合并最相似的样本或组别,形成聚类树状结构。
K均值聚类是一种基于距离度量的迭代聚类算法,它通过不断更新样本的聚类中心,将样本划分为K个不相交的簇。
聚类分析在数据挖掘、模式识别、市场分析等领域中被广泛应用。
利用spss对某个班成绩的多元统计分析.doc

对一所重点学校某个班成绩的综合分析摘要随着社会竞争的越来越激烈,家长和老师对于学生成绩的态度愈加重视,对于学生将来的发展与前途也同样感到一丝忧虑,因此及时公布学生的学习成绩并且能够增其长补其短对于学生将会有很大的帮助。
本文利用某所重点学校某个班的成绩单来分析这个班学生成绩的优劣,以达到取长补短的目的,主要应用了SPSS软件对成绩进行了综合性的分析。
关键词:综合分析;SPSS软件;成绩目录1.对应分析的概述 (1)2.聚类分析的概述 (3)2.1聚类分析的定义 (3)2.2聚类的方法分类 (3)2.3系统聚类法的基本步骤 (3)3.判别分析的概述 (4)3.1判别分析的基本思想 (4)3.2判别分析与聚类分析的关系 (4)4.在SPSS软件上的操作步骤 (5)4.1对应分析的操作步骤 (5)4.2聚类分析与判别分析的操作步骤 (6)5.结果分析 (7)5.1对应表 (7)5.2汇总 (7)5.3概述行点和概述列点 (8)5.6 特征值 (11)5.7 显著性检验 (11)5.8 标准化典型判别式函数系数 (11)5.9 结构矩阵 (12)5.10 群组重心的函数 (12)5.11 分类函数系数 (13)6.结论 (14)7.对创新的认识 (15)参考文献 (16)附录 (17)1.对应分析的概述对应分析(correspondence analysis )又称为相应分析,是一种目的在于揭示变量和样品之间或者定性变量资料中变量与其类别之间的相互关系的多元统计分析方法。
根据分析资料的类型不同,对应分析分为定性资料(分类资料)的对应分析和连续性资料的对应分析(基于均数的对应分析)。
其中,根据分析变量个数的多少,定性资料的对应分析又分为简单对应分析和多重对应分析。
对两个分类变量进行的对应分析称为简单对应分析,对两个以上的分类变量进行的对应分析称为多重对应分析。
对应分析实际是在R 型因子分析和Q 型因子分析的基础上发展起来的一种方法。
多元统计分析整理版.doc

1、主成分分析的目的是什么?主成分分析是考虑各指标间的相互关系,利用降维的思想把多个指标转换成较少的几个相互独立的、能够解释原始变量绝大部分信息的综合指标,从而使进一步研究变得简单的一种统计方法。
它的目的是希望用较少的变量去解释原始资料的大部分变异,即数据压缩,数据的解释。
常被用来寻找判断事物或现象的综合指标,并对综合指标所包含的信息进行适当的解释。
2、主成分分析基本思想?主成分分析就是设法将原来指标重新组合成一组新的互相无关的几个综合指标来代替原来指标。
同时根据实际需要从中选取几个较少的综合指标尽可能多地反映原来的指标的信息。
● 设p 个原始变量为 ,新的变量(即主成分)为 ,主成分和原始变量之间的关系表示为?3、在进行主成分分析时是否要对原来的p 个指标进行标准化?SPSS 软件是否能对数据自动进行标准化?标准化的目的是什么?需要进行标准化,因为因素之间的数值或者数量级存在较大差距,导致较小的数被淹没,导致主成分偏差较大,所以要进行数据标准化; 进行主成分分析时SPSS 可以自动进行标准化;标准化的目的是消除变量在水平和量纲上的差异造成的影响。
求解步骤⏹ 对原来的p 个指标进行标准化,以消除变量在水平和量纲上的影响 ⏹ 根据标准化后的数据矩阵求出相关系数矩阵 ⏹ 求出协方差矩阵的特征根和特征向量⏹ 确定主成分,并对各主成分所包含的信息给予适当的解释版本二:根据我国31个省市自治区2006年的6项主要经济指标数据,表二至表五,是SPSS 的输出表,试解释从每张表可以得出哪些结论,进行主成分分析,找出主成分并进行适当的解释:(下面是SPSS 的输出结果,请根据结果写出结论) 表一:数据输入界面p 21p x x x ,,, 21p ,21p y y y ,,, 21表二:数据输出界面a)此表为相关系数矩阵,表示的是各个变量之间的相关关系,说明变量之间存在较强的相关系数,适合做主成分分析。
观察各相关系数,若相关矩阵中的大部分相关系数小于0.3,则不适合作因子分析。
多元统计分析多元统计分析1

多元统计分析是一门具有很强应用性的课程;它在自然科学 和社会科学等各个领域中得到广泛的应用;它包括了很多非常有 用的数据处理方法.
3.变量间的相互联系
(1) 相互依赖关系:分析一个或几个变量的变化是否依赖于另一些变 量的变化?如果是,建立变量间的定量关系式,并用于预测或控制---回 归分析.
(2) 变量间的相互关系: 分析两组变量间的相互关系---典型相关分 析等.
(3)两组变量间的相互依赖关系---偏最小二乘回归分析.
4.多元数据的统计推断 参数估计和假设检验问题.特别是多元正态分布的均值向量和协 方差阵的估计和假设检验等问题。
在实际问题中,很多随机现象涉及到的变量不只一个,而经常是 多个变量,而且这些变量间又存在一定的联系。
一、多元统计分析研究的对象和内容
我们先看一个例子,考察学生的学习情况时,就需了解学生在几 个主要科目的考试成绩。下表给出从中学某年级随机抽取的12名学生 中5门主要课程期末考试成绩。
序号 1 2 3 4 5 6 7 8 9 10 11 12
之后R.A.Fisher、H.Hotelling、S.N.Roy、许宝騄等人作了一系列 奠基的工作,使多元统计分析在理论上得到迅速的发展,在许多领域中 也有了实际应用.二十世纪50年代中期,随着电子计算机的出现和发展, 使得多元统计分析在地质、气象、医学、社会学等方面得到广泛的应 用.60年代通过应用和实践又完善和发展了理论,由于新理论、新方法的 不断出现又促使它的应用范围更加扩大.
多元统计分析大纲

多元统计分析大纲多元统计分析是指将多个自变量同时考虑进入统计模型中,以分析它们对因变量的联合影响。
多元统计分析旨在寻找多个自变量与因变量之间的关联关系,并通过建立合适的模型来解释这种关系。
在多元统计分析中,常用的方法包括多元方差分析、多元回归分析和主成分分析等。
一、多元方差分析多元方差分析是对多个自变量对因变量的影响进行分析的一种统计方法。
它可以同时考虑多个自变量之间的交互作用,并通过分析方差的差异来验证因变量的差异是否是由于自变量的不同水平而引起的。
在进行多元方差分析时,需要注意选择适当的方差分析模型、检验假设并进行方差分析表的解读。
二、多元回归分析多元回归分析是用于分析多个自变量对因变量的影响程度的一种统计方法。
它可以通过建立线性回归方程来描述自变量与因变量之间的关系,并通过回归系数的显著性检验来判断自变量对因变量的影响是否显著。
在进行多元回归分析时,需要注意自变量间的相关性、模型的拟合度以及假设的验证等问题。
三、主成分分析主成分分析是一种用于降维和提取主要信息的多元分析方法。
它通过线性变换将多个相关的自变量转化为少数几个无关的主成分,并根据主成分的方差大小来解释原始数据的方差贡献。
主成分分析可以帮助研究者分析多个自变量之间的关系、减少冗余信息和简化模型等方面。
在进行主成分分析时,需要注意选择适当的主成分数量、解读主成分的含义和解释数据的方差贡献等问题。
四、多元判别分析多元判别分析是一种用于分类和判别的多元分析方法。
它通过建立判别函数来将多个自变量分为不同的类别,并根据自变量的线性组合确定每个类别的特征。
多元判别分析可以帮助研究者预测新观测值的类别、区分不同群体之间的差异和评估判别函数的准确性等。
在进行多元判别分析时,需要注意选择适当的判别函数、评估模型的准确性和解读变量的判别效果等问题。
总结:多元统计分析是研究多个自变量对因变量关系的重要方法。
在进行多元统计分析时,需要注意选择适当的统计方法、控制变量的选择和方差分析的假设检验等问题。
多元统计分析的基础知识

多元统计分析的基础知识多元统计分析是统计学中的一个重要分支,它主要研究多个变量之间的关系和规律。
在实际应用中,多元统计分析被广泛运用于市场调研、医学研究、社会科学等领域。
本文将介绍多元统计分析的基础知识,包括多元回归分析、主成分分析和聚类分析等内容。
一、多元回归分析多元回归分析是一种用于研究多个自变量与一个因变量之间关系的统计方法。
在多元回归分析中,我们可以通过建立数学模型来预测或解释因变量的变化。
多元回归分析的基本模型可以表示为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y表示因变量,X1、X2、...、Xn表示自变量,β0、β1、β2、...、βn表示回归系数,ε表示误差。
在进行多元回归分析时,我们需要关注各个自变量对因变量的影响程度,以及它们之间的相互关系。
通过多元回归分析,我们可以得出各个自变量对因变量的贡献度,从而更好地理解变量之间的关系。
二、主成分分析主成分分析是一种降维技术,它可以将多个相关变量转换为少数几个无关变量,这些无关变量被称为主成分。
主成分分析的主要目的是降低数据的维度,同时保留尽可能多的信息。
在主成分分析中,我们首先计算原始变量之间的协方差矩阵,然后通过特征值分解得到特征向量,进而得到主成分。
主成分通常按照特征值的大小排列,前几个主成分包含了大部分数据的信息。
通过主成分分析,我们可以发现数据中的模式和结构,从而更好地理解数据的特点和规律。
主成分分析在数据降维、变量筛选和数据可视化等方面有着广泛的应用。
三、聚类分析聚类分析是一种将数据集中的个体或对象划分为若干个类别的方法,使得同一类别内的个体之间相似度较高,不同类别之间相似度较低。
聚类分析的主要目的是发现数据中的内在结构和模式。
在聚类分析中,我们可以选择不同的距离度量和聚类算法来进行分析。
常用的聚类算法包括K均值聚类、层次聚类和密度聚类等。
通过聚类分析,我们可以将数据集中的个体进行分类,从而更好地理解数据的组成和特点。
多元统计分析研究的重点和内容和方法

一、什么是多元统计分析多元统计分析是运用数理统计地方法来研究多变量(多指标)问题地理论和方法,是一元统计学地推广.多元统计分析是研究多个随机变量之间相互依赖关系以及内在统计规律地一门统计学科.二、多元统计分析地内容和方法1、简化数据结构(降维问题)将具有错综复杂关系地多个变量综合成数量较少且互不相关地变量,使研究问题得到简化但损失地信息又不太多.(1)主成分分析(2)因子分析(3)对应分析等2、分类与判别(归类问题)对所考察地变量按相似程度进行分类.(1)聚类分析:根据分析样本地各研究变量,将性质相似地样本归为一类地方法.(2)判别分析:判别样本应属何种类型地统计方法.例5:根据信息基础设施地发展状况,对世界20个国家和地区进行分类.考察指标有6个:1、X1:每千居民拥有固定电话数目2、X2:每千人拥有移动电话数目3、X3:高峰时期每三分钟国际电话地成本4、X4:每千人拥有电脑地数目5、X5:每千人中电脑使用率6、X6:每千人中开通互联网地人数3、变量间地相互联系一是:分析一个或几个变量地变化是否依赖另一些变量地变化.(回归分析)二是:两组变量间地相互关系(典型相关分析)4、多元数据地统计推断点估计参数估计区间估计统u检验计参数t检验推F检验断假设相关与回归检验卡方检验非参秩和检验秩相关检验1、假设检验地基本原理小概率事件原理小概率思想是指小概率事件(P<0.01或P<0.05等)在一次试验中基本上不会发生.反证法思想是先提出假设(检验假设H0),再用适当地统计方法确定假设成立地可能性大小,如可能性小,则认为假设不成立;反之,则认为假设成立. 2、假设检验地步骤 (1)提出一个原假设和备择假设例如:要对妇女地平均身高进行检验,可以先假设妇女身高地均值等于 160 cm (u=160cm ).这种原假设也称为零假设( null hypothesis ),记为 H 0 . 2.1 均值向量地检验1、正态总体均值检验地类型根据样本对其总体均值大小进行检验( One-Sample T Test ) 如妇女身高地检验.根据来自两个总体地独立样本对其总体均值地检验( Indepent Two-Sample T Test ) 如两个班平均成绩地检验.配对样本地检验( Pair-Sample T Test ) 如减肥效果地检验.多个总体均值地检验 A 、总体方差已知 用u 检验,检验地拒绝域为即 B 、总体方差未知用样本方差 代替总体方差 ,这种检验叫t 检验.(2)根据来自两个总体地独立样本对其总体均值地检验 目地是推断两个样本分别代表地总体均数是否相等.其检验过程与上述两种t 检验也没有大地差别,只是假设地表达和t 值地计算公式不同. 两样本均数比较地t 检验,其假设一般为:12{}W z u α-=>1122{}W z uzuαα--=<->或2s2σⅢ 0μμ= 0μμ< α--<1u z )1(1--<-n t t αH0:µ1=µ2,即两样本来自地总体均数相等.H1:µ1>µ2或µ1<µ2,即两样本来自地总体均数不相等,检验水准为0.05.计算t统计量时是用两样本均数差值地绝对值除以两样本均数差值地标准误.相应地假设检验问题为:H0:μ1=μ2H1: μ1大于μ2μ1 为第一组地总体均值,而μ2 为第二组地总体均值.用SPSS 处理数据:Spss 选项:Analyze—Compare Means —Independent-Samples T Test3、配对样本地检验(paired samples )(针对同样地样本)考察实验前后样本均值有无差异.能够很好地控制非实验因素对结果地影响注意:实验前后两个样本两个样本并不独立注意:同一样本实验前后并不独立,但不同样本之间却相互独立.配对样本地检验实际上是用配对差值与总体均数“0”进行比较,即推断差数地总体均数是否为“0”.故其检验过程与依据样本均数推断总体均数大小地t检验类似,即:A、建立假设H0:µd=0,即差值地总体均数为“0”,H1:µd>0或µd<0,即差值地总体均数不为“0”,检验水平为α.B. 计算统计量进行配对设计t检验时t值为差值均数与0之差地绝对值除以差值标准误地商,其中差值标准误为差值标准差除以样本含量算术平方根地商.C. 确定概率,作出判断以自由度v(对子数减1)查t界值表,若P<α,则拒绝H0,接受H1,若P>=α,则还不能拒绝H0.例4:要比较50个人在减肥前和减肥后地重量.这样就有了两个样本,每个都有50个数目.这里不能用前面地独立样本均值差地检验;这是因为两个样本并不独立.每一个人减肥后地重量都和自己减肥前地重量有关.但不同人之间却是独立地.令减肥前地重量均值为μ1 ,而减肥后地均值为μ2 ;这样所要进行地检验为:H0:μ1=μ2H1:μ1大于μ2一、方差分析地基本思想 1、定义方差分析又称变异数分析或F 检验,其目地是推断两组或多组资料地总体均数是否相同,检验两个或多个样本均数地差异是否有统计学意义. 2、了解方差分析中几个重要概念: (1)观测因素或称为观测变量如:考察农作物产量地影响因素.农作物产量就是观测变量.(2)控制因素或称控制变量进行试验(实验)时,我们称可控制地试验条件为因素(Factor),因素变化地各个等级为水平(Level). 影响农作物产量地因素,如品种、施肥量、土壤等.如果在试验中只有一个因素在变化,其他可控制地条件不变,称它为单因素试验; 若试验中变化地因素有两个或两个以上,则称为双因素或多因素试验 .方差分析就是从观测变量地方差入手,研究诸多控制变量(因素)中哪些变量是对观测变量有显著影响地变量3、方差分析地基本原理设有r 个总体,各总体分别服从 …… ,假定各总体方差相等.现从各总体随机抽取样本.透过各总体地样本数据推断r 个总体地均值是否相等?:至少有一组数据地平均值与其它组地平均值有显著性差异. 分析地思路:用离差平方和(SS )描述所有样本总地变异情况,将总变异分为两个来源:(1)组内变动(within groups ),代表本组内各样本与该组平均值地离散程度,即水平内部(组内)方差 (2)组间变动(between groups ),代表各组平均值关于总平均值地离散程度.即水平之间(组间)方差即:SS 总=SS 组间+SS 组内消除各组样本数不同地影响--离差平方和除以自由度(即均方差).从而构造统计量:方差分析地基本思想就是通过组内方差与组间方差地比值构造地F 统计量,将其与给定显著性水平、自由度下地F 值相对比,判定各组均数间地差异有无统计学意义. 零假设否定域:例2 SIM 手机高、中、低三种收入水平被调查者地用户满意度是否有显著性差异 即:研究被调查者地收入水平是否会影响其对SIM 手机地满意程度.SPSS 处理:Analyze — Compare Mean — One-Way ANOV A 多元方差分析(操作参见书例2.1,第36页): SPSS 选项: Analyze — General Linear Model — Multivariate 可用男、女生地身高、体重、胸围组成地样本均数向量推论该年级男、女生身体发育指标地总体均数向量μ1和μ2相等与否, 得到: F=8.8622,P=0.0008.拒绝该年级男女生身体发育指标地总体均数向量相等地假设,从而可认为该校男女生身体发育状况不同. 4、方差分析地应用条件(1)可比性,若资料中各组均数本身不具可比性则不适用方差分析.21(,)N μσ22(,)N μσ2(,)rN μσ012:rH μμμ==1H (1)SS r F SS -=组间组内(n-r)1,()r n r FF α--(2)正态性,各组地观察数据,是从服从正态分布地总体中随机抽取地样本.即偏态分布资料不适用方差分析.对偏态分布地资料应考虑用对数变换、平方根变换、倒数变换、平方根反正弦变换等变量变换方法变为正态或接近正态后再进行方差分析.(3)方差齐性,各组地观察数据,是从具有相同方差地相互独立地总体中抽取得到地.即若组间方差不齐则不适用方差分析.依据涉及地分析变量多少分为:一元方差分析、多元方差分析依据对分析变量地影响因素地数量分为:单因素方差分析、多因素方差分析一、什么是聚类分析? 聚类分析(P54)是根据“物以类聚”地道理,对样品或指标进行分类地一种多元统计分析方法.将个体或对象分类,使得同一类中地对象之间地相似性比与其他类地对象地相似性更强.聚类分析地目地(P54)使类内对象地同质性最大化和类间对象地异质性最大化.二、聚类分析地基本思想:是根据一批样品地多个观测指标,具体地找出一些能够度量样品或指标之间相似程度地统计量,然后利用统计量将样品或指标进行归类.把相似地样品或指标归为一类,把不相似地归为其他类.直到把所有地样品(或指标)聚合完毕. 相似样本或指标地集合称为类. 1、聚类分析地类型有:对样本分类,称为Q 型聚类分析 对变量分类,称为R 型聚类分析Q 型聚类是对样本进行聚类,它使具有相似性特征地样本聚集在一起,使差异性大地样本分离开来. R 型聚类是对变量进行聚类,它使具有相似性地变量聚集在一起,差异性大地变量分离开来,可在相似变量中选择少数具有代表性地变量参与其他分析,实现减少变量个数,达到变量降维地目地. 2、聚类分析地方法: 系统聚类(层次聚类) 非系统聚类(非层次聚类)系统聚类法包括:凝聚方式聚类、分解方式聚类非系统聚类法包括:模糊聚类法、K -均值法(快速聚类法)等等 常用距离:(1)、明考夫斯基距离(Minkowski distance)明氏距离有三种特殊形式:(1a )、绝对距离(Block 距离):当q=1时 (1b)欧氏距离(Euclidean distance):当q=2时(1c)切比雪夫距离:当 时gpk gjk ik ij x x d 11)||(∑=-=()∑=-=pk jkik ij x x d 11()2112)(2⎥⎦⎤⎢⎣⎡-=∑=pk jk ik ij x x d q =∞jkik pk ij x x d -=∞≤≤1max )(当各变量地单位不同或测量值范围相差很大时,不应直接采用明氏距离,而应先对各变量地数据作标准化处理,然后用标准化后地数据计算距离.常用地标准化处理:其中 为第j 个变量地样本均值;为第j 个变量地样本方差.(4)马氏距离*1,2,,1,2,,ij x x x i n j p--===11njij i x x n -==∑211()1n jjij ji s x x n -==--∑)()(2j i 1j i x x x x -∑'-=-ij d 1/2[()()]ij d -'=-∑-1i j i j x x x x马氏距离与上述各种距离地主要不同就是马氏距离考虑了观测变量之间地相关性.如果假定各变量之间相互独立,即观测变量地协方差矩阵是对角矩阵,则马氏距离就退化为用各个观测指标地标准差地倒数作为权数进行加权地欧氏距离.因此,马氏距离不仅考虑了观测变量之间地相关性,而且也考虑到了各个观测指标取值地差异程度,为了对马氏距离和欧氏距离进行一下比较,以便更清楚地看清二者地区别和联系,现考虑一个例子.1、类地定义相似样本或指标地集合称为类. (数学表达见63-64页定义3.1-3.4)2、类地特征描述: 设类G 这一集合有xx x m......,21m 为G 内地样本数.其特征:(1)均值(或称为重心)(2)协方差矩阵(3) G 地直径d 12=[(7.9-7.68)2+(39.77-50.37)2+(8.49-11.35)2+(12.94-13.3)2+(19.27-19.25)2+(11.05-14.59)2+(2.04-2.75)2+(13.29-14.87)2]0.5=11.67d 13=13.80 d 14=13.12 d 15=12.80 d 23=24.63 d 24=24.06 d 25=23.54 d 34=2.2 d 35=3.51 d 45=2.21 1 2 3 4 5 D1= 1 0河南与甘肃地距离最近,2 11.67 0先将二者(3和4)合为3 13.80 24.63 0 一类 G6={G2,G4}4 13.12 24.06 2.20 05 12.80 23.54 3.51 2.21 011mGii x xm-==∑'1()()mG iG i G i s xx x x --==--∑11G Gs n ∑=-,max G iji j GD d ∈=判别分析根据已知对象地某些观测指标和所属类别来判断未知对象所属类别地一种统计学方法.如何判断(判断依据)? 利用已知类别地样本信息求判别函数,根据判别函数对未知样本所属类别进行判别 判别分析地特点(基本思想)1、是根据已掌握地、历史上若干样本地p 个指标数据及所属类别地信息,总结出该事物分类地规律性,建立判别公式和判别准则. 2、根据总结出来地判别公式和判别准则,判别未知类别地样本点所属地类别.判别分析地目地:识别一个个体所属类别3、判别分析和聚类分析往往联合使用.当总体分类不清楚时,先用聚类分析对一批样本进行分类,再用判别分析构建判别式对新样本进行判别.此外判别分析变量情况: 被解释变量为属性变量; 解释变量是定量变量. 判别分析类型及方法(1)按判别地组数来分,有两组判别分析和多组判别分析(2)按区分不同总体所用地数学模型来分,有线性判别和非线性判别 (3)按判别对所处理地变量方法不同有逐步判别、序贯判别. (4)按判别准则来分,有费歇尔判别准则、贝叶斯判别准则距离判别基本思想即:首先根据已知分类地数据,分别计算各类地重心即各组(类)地均值,判别地准则是对任给样品,计算它到各类平均数地距离,哪个距离最小就将它判归哪个类.(一)两个总体地距离判别法 1、方差相等先考虑两个总体地情况,设有两个协差阵∑相同地p 维正态总体,对给定地样本Y ,判别一个样本Y 到底是来自哪一个总体,一个最直观地想法是计算Y 到两个总体地距离.故我们用马氏距离来给定判别规则,有:2、当总体地协方差已知,且不相等贝叶斯(Bayes)判别 ---------(考计算题) ()()()()⎪⎩⎪⎨⎧=<∈<∈),(),(22121222222121G y d G y d G d G d G G d G d G 如待判,,,如,,,,如,y y y y y y ()()()()⎪⎩⎪⎨⎧=<∈<∈),(),(22121222222121G y d G y d G d G d G G d G d G 如待判,,,如,,,,如,yy y y y y )()()()(),(),(111121221222μμμμ-∑'---∑'-=---y y y y y y G d G d )()()()(),(),(1112121222μμμμ-'---'-=---y y y y y y ∑∑G d G d 22211y y y μμμ12---'+'-'=∑∑∑)2(1111μμμ---∑'+∑'-∑'-11y y y )(]2)([221121y μμμμ-∑'+-=-221μμμ+=令),,,()(21'=-∑=-p a a a 211μμα贝叶斯判别法是通过计算被判样本x 属于k 个总体地条件概率P (n/x),n=1,2…..k. 比较k 个概率地大小,将样本判归为来自出现概率最大地总体(或归属于错判概率最小地总体)地判别方法.☐ 一、最大后验概率准则☐ 例7:设有G 1,G2和G3三个类,欲判别某样本x 0属于哪一类.已知现利用后验概率准则计算 x0 属于各组地后验概率:贝叶斯公式:所谓Fisher 判别法,就是用投影地方法将k 个不同总体在p 维空间上地点尽可能分散,同一总体内地各样本点尽可能地集中.用方差分析地思想则可构建一个较好区分各个总体地线性判别法 -------- (只作了解)例:设先验概率、误判损失及概率密度如下:,30.0,65.0,05.0321===q q q 10.0)(01=x f 63.0)(02=x f 4.2)(03=x f 004.01345.1005.04.230.063.065.010.005.010.005.0)()()(3101101==⨯+⨯+⨯⨯==∑=i ii x f q x f q x G P 361.01345.14095.04.230.063.065.010.005.063.065.0)()()(3102202==⨯+⨯+⨯⨯==∑=i ii x f q x f q x G P 635.01345.172.04.230.063.065.010.005.04.230.0)()()(3103303==⨯+⨯+⨯⨯==∑=i ii x f q x f q x G P )()|()()|()|(i i i i i B P B A P B P B A P A B P ∑=判别为G1G2G3G1 C(1/1)=0C(2/1)=20C(3/1)=80 G2 C(1/2)=400 C(2/2)= 0C(3/2)=200真 实 组G3C(1/3)=100 C(2/3)=500 C(3/3)=0先验概率 P1=0.55 P2=0.15 P3=0.30 概率密度f1=0.46f2=1.5F3=0.70试用贝叶斯判别法将样本x0判到G1、G2、G3中地一个.考虑与不考虑误判损失地结果如何?1、考虑误判损失:误判到G1地平均损失为ECM1=0.55*0.46*0+0.15*1.5*400+0.30*0.70*100=误判到G2地平均损失为ECM2=0.55*0.46*20+0.15*1.5*0+0.30*0.70*50=误判到G3地平均损失为ECM3=0.55*0.46*80+0.15*1.5*200+0.30*0.70*0=其中ECM2最小,故将x0判别到G2.2、不考虑误判损失:将x0判别到G1地条件概率为:P(G1/x0) =(0.55*0.46)/(0.55*0.46+0.15*1.5+0.30*0.70)=将x0判别到G2地条件概率为:P(G2/x0) =(0.15*1.5)/(0.55*0.46+0.15*1.5+0.30*0.70)=将x0判别到G3地条件概率为:P(G3/x0) =(0.30*0.70)/(0.55*0.46+0.15*1.5+0.30*0.70)=其中P(G1/x0) 取值最大,故将x0判别到G1.主成分分析地重点1、掌握什么是主成分分析?2、理解主成分分析地基本思想和几何意义?3、理解主成分求解方法:协方差矩阵与相关系数矩阵地差异?4、掌握运用SPSS或SAS软件求解主成分5、对软件输出结果进行正确分析主成分分析:将原来较多地指标简化为少数几个新地综合指标地多元统计方法.主成分:由原始指标综合形成地几个新指标.依据主成分所含信息量地大小成为第一主成分,第二主成分等等.主成分分析得到地主成分与原始变量之间地关系:1、主成分保留了原始变量绝大多数信息.2、主成分地个数大大少于原始变量地数目.3、各个主成分之间互不相关.4、每个主成分都是原始变量地线性组合.满足如下地条件:1、每个主成分地系数平方和为1.即2、主成分之间相互独立,即无重叠地信息.即122221=+++piiiuuupjijiFFCovji,,,,,,),(210=≠=3、主成分地方差依次递减,重要性依次递减,即F1、F2….Fp 分别称为原变量地第一、第二….第p 个主成分.根据旋转变换地公式: IU U U U ='='-,1旋转变换地目地:为了使得n 个样品点在Fl 轴方向上地离散程度最大,即Fl 地方差最大.总体主成分地求解及其性质矩阵知识回顾: (1)特征根与特征向量A 、若对任意地k 阶方阵C ,有数字 与向量 满足: ,则称 为C 地特征根, 为C 地相应于 地特征向量.B 、同时,方阵C 地特征根 是k 阶方程 地根. (2)任一k 阶方阵C 地特征根 地性质:(3)任一k 阶地实对称矩阵C 地性质: A 、实对称矩阵C 地非零特征根地数目=C 地秩 B 、k 阶地实对称矩阵存在k 个实特征根C 、实对称矩阵地不同特征根地特征向量是正交地D 、若 是实对称矩阵C 地单位特征向量,则若矩阵 ,是由特征向量 所构成地,则有:因子分析地重点1、什么是因子分析?2、理解因子分析地基本思想3、因子分析地数学模型以及模型中公共因子、因子载荷变量共同度地统计意义4、因子旋转地意义5、结合SPSS 软件进行案例分析 1、什么是因子分析?因子分析是主成分分析地推广,也是利用降维地思想,由研究原始变量相关矩阵或协方差矩阵地内部依赖关系出发,把一些具有错综复杂关系地多个变量归结为少数几个综合因子地一种多元统计分析方法.2、因子分析地基本思想:把每个研究变量分解为几个影响因素变量,将每个原始变量分解成两部分因素,一部分是由所有变量共)()(21p F Var F Var F Var ≥≥≥ )(⎩⎨⎧+-=+=θθθθcos sin sin cos 212211x x y x x y x U '=⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫ ⎝⎛-=⎪⎪⎭⎫ ⎝⎛2121cos sin sin cos x x y y θθθθ正交矩阵,即有为旋转变换矩阵,它是U 'λξξλξC =λλλ0=-I C λj λ对角线上的元素之和矩阵C C tr kj j==∑=)(1λj ξjj j C λξξ='ξj ξ⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=k j j C λλξξ01'同具有地少数几个公共因子组成地,另一部分是每个变量独自具有地因素,即特殊因子.4、主成分分析分析与因子分析地联系和差异:因子分析是主成分分析地推广,是主成分分析地逆问题.主成分分析是将原始变量加以综合、归纳;因子分析是将原始变量加以分解、演绎. (1)主成分分析仅仅是变量变换,而因子分析需要构造因子模型.(2)主成分分析:原始变量地线性组合表示新地综合变量,即主成分; 因子分析:用潜在地假想变量(公共因子)和随机影响变量(特殊因子)地线性组合表示原始变量.用假设地公因子来“解释”相关矩阵内部地依赖关系. (3)主成分分析中主成分个数和变量个数相同,它是将一组具有相关关系地变量变换为一组互不相关地变量,在解决实际问题时,一般取前m 个主成分; 因子分析地目地是用尽可能少地公因子,以便构造一个结构简单地因子模型.共同度----又称共性方差或公因子方差(community 或common variance )就是变量与每个公共因子之负荷量地平方总和(一行中所有因素负荷量地平方和).变量 地共同度是因子载荷矩阵地第i 行地元素地平方和.记为从共同性地大小可以判断这个原始实测变量与公共因子间之关系程度.如因子分析案例中 共同度h12=(0.896)平方+(0.341)平方=0.919 因子负荷量(或称因子载荷)----是指因子结构中原始变量与因子分析时抽取出地公共因子地相关程度.版权申明本文部分内容,包括文字、图片、以及设计等在网上搜集整理.版权为个人所有This article includes some parts, including text, pictures, and design. Copyright is personal ownership.h8c52。
多元统计分析考试重点

@什么是多元统计分析多元统计分析是运用数理统计的方法来研究多变量(多指标)问题的理论和方法,是一元统计学的推广@多元统计分析的内容和方法1、简化数据结构,将具有错综复杂关系的多个变量综合成数量较少且互不相关的变量,使研究问题得到简化但损失的信息又不太多。
(1)主成分分析(2)因子分析(3)对应分析等2、分类与判别,对所考察的变量按相似程度进行分类。
(1)聚类分析:根据分析样本的各研究变量,将性质相似的样本归为一类的方法。
(2)判别分析:判别样本应属何种类型的统计方法。
@方差分析的基本思想:方差分析又称变异数分析或F检验,其目的是推断两组或多组资料的总体均数是否相同,检验两个或多个样本均数的差异是否有统计学意义。
应用条件: (1)可比性,若资料中各组均数本身不具可比性则不适用方差分析。
(2)正态性,各组的观察数据,是从服从正态分布的总体中随机抽取的样本。
(3)方差齐性,各组的观察数据,是从具有相同方差的相互独立的总体中抽取得到的。
@聚类分析:是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。
将个体或对象分类,使得同一类中的对象之间的相似性比与其他类的对象的相似性更强。
使类内对象的同质性最大化和类间对象的异质性最大化@聚类分析的基本思想:是根据一批样品的多个观测指标,具体地找出一些能够度量样品或指标之间相似程度的统计量,然后利用统计量将样品或指标进行归类。
把相似的样品或指标归为一类,把不相似的归为其他类。
直到把所有的样品(或指标)聚合完毕. @判别分析的特点(基本思想)1、是根据已掌握的、历史上若干样本的p个指标数据及所属类别的信息,总结出该事物分类的规律性,建立判别公式和判别准则。
2、根据总结出来的判别公式和判别准则,判别未知类别的样本点所属的类别。
@聚类分析的类型有:(1)对样本分类,称为Q型聚类分析(2)对变量分类,称为R型聚类分析 # Q型聚类是对样本进行聚类,它使具有相似性特征的样本聚集在一起,使差异性大的样本分离开来。
多元统计分析的重点和内容和方法

多元统计分析的重点和内容和方法多元统计分析的重点和内容及方法多元统计分析(Multivariate Statistical Analysis)是统计学中一种重要的分析方法,该方法可以同时考虑多个变量之间的关系,揭示数据中隐藏的模式和结构,帮助研究者更全面地理解数据。
本文将重点介绍多元统计分析的内容、方法和一些常用的技术工具。
一、多元统计分析的重点和内容多元统计分析的重点在于研究多个变量之间的关系,以及这些变量对于总体的贡献程度。
在多元统计分析中,通常需要考虑以下几个内容:1. 变量之间的关系分析:多元统计分析可以帮助研究者揭示多个变量之间的关联关系。
通过计算变量之间的相关系数、协方差矩阵等参数,可以判断变量之间是否存在线性关系、正相关还是负相关。
同时,多元统计分析还能够通过降维技术,如主成分分析和因子分析,将多个相关的变量汇总为少数几个主成分或因子,便于进一步分析。
2. 总体的组成和结构:多元统计分析可以揭示总体的组成和结构。
通过聚类分析,可以将样本划分为不同的分类,从而了解总体的内在结构。
聚类分析通常采用欧氏距离或相关系数作为度量指标,采用不同的聚类算法(如层次聚类、K均值聚类等)可以得到不同的聚类结果。
3. 变量对总体的贡献程度:多元统计分析还可以通过方差分析、回归分析等方法,定量地分析每个变量对总体的贡献程度。
方差分析(ANOVA)可以帮助研究者确定变量之间的差异是否具有统计学意义,进而判断它们对总体的贡献程度。
回归分析可以通过拟合回归方程来预测和解释因变量的变化程度,进而评估解释变量对总体的贡献程度。
二、多元统计分析的方法在进行多元统计分析时,可以根据不同的数据类型和问题选择适合的方法。
以下是常用的几种多元统计分析方法:1. 相关分析:相关分析用于度量不同变量之间的线性相关程度。
可以通过计算变量之间的相关系数(如皮尔逊相关系数)来描述变量之间的关系。
相关系数的取值范围为-1到1,接近1表示正相关,接近-1表示负相关,接近0表示无相关。
多元统计分析重点.doc

多元统计分析重点宿舍版第一讲:多元统计方法及应用;多元统计方法分类(按变量、模型、因变量等) 多元统计分析应用选择题:①数据或结构性简化运用的方法有:多元回归分析,聚类分析,主成分分析,因子分析 ②分类和组合运用的方法有:判别分析,聚类分析,主成分分析 ③变量之间的相关关系运用的方法有:多元回归,主成分分析,因子分析, ④预测与决策运用的方法有:多元回归,判别分析,聚类分析 ⑤横贯数据:{因果模型(因变量数):多元回归,判别分析相依模型(变量测度):因子分析,聚类分析多元统计分析方法选择题:①多元统计方法的分类:1)按测量数据的来源分为:横贯数据(同一时间不同案例的观测数据),纵观数据(同样案例在不同时间的多次观测数据) 2)按变量的测度等级(数据类型)分为:类别(非测量型)变量,数值型(测量型)变量3)按分析模型的属性分为:因果模型,相依模型 4)按模型中因变量的数量分为:单因变量模型,多因变量模型,多层因果模型第二讲:计算均值、协差阵、相关阵;相互独立性第三讲:主成分定义、应用及基本思想,主成分性质,主成分分析步骤主成分定义:何谓主成分分析 就是将原来的多个指标(变量)线性组合成几个新的相互无关的综合指标(主成分),并使新的综合指标尽可能多地反映原来的指标信息。
主成分分析的应用 :(1)数据的压缩、结构的简化;(2)样品的综合评价,排序主成分分析概述——思想:①(1)把给定的一组变量X1,X2,…XP ,通过线性变换,转换为一组不相关的变量Y1,Y2,…YP 。
(2)在这种变换中,保持变量的总方差(X1,X2,…Xp 的方差之和)不变,同时,使Y1具有最大方差,称为第一主成分;Y2具有次大方差,称为第二主成分。
依次类推,原来有P 个变量,就可以转换出P 个主成分(3)在实际应用中,为了简化问题,通常找能够反映原来P 个变量的绝大部分方差的q (q<p )个主成分。
主成分性质:1)性质1:主成分的协方差矩阵是对角阵:(2)性质2:主成分的总方差等于原始变量的总方差(3)性质3:主成分Yk 与原始变量Xi 的相关系数为:ρ(YK,Xi )=√λ√σiitki,并称之为因子负荷量(或因子载荷量)。
多元统计分析知识点多元统计分析课件精品

多元统计分析知识点多元统计分析课件精品多元统计分析(1)题目:多元统计分析知识点目录第一章绪论 (1)§1.1什么是多元统计分析 ............................ 1 §1.2多元统计分析能解决哪些实际问题 .... 2 §1.3主要内容安排 ........................................ 2 第二章多元正态分布 .. (2)§2.1基本概念 ................................................ 2 §2.2多元正态分布的定义及基本性质 .. (8)1.(多元正态分布)定义 ..................... 92.多元正态变量的基本性质 ............... 10 §2.3多元正态分布的参数估计12(,,,)p X X X X '= (11)1.多元样本的概念及表示法 ............... 122. 多元样本的数值特征 ..................... 123.μ和 ∑的最大似然估计及基本性质.............................................................. 15 4.Wishart 分布 (17)第五章 聚类分析 (18)§5.1什么是聚类分析 .................................. 18 §5.2距离和相似系数 . (19)1.Q —型聚类分析常用的距离和相似系数 (20)2.R型聚类分析常用的距离和相似系数 (25)§5.3八种系统聚类方法 (26)1.最短距离法 (27)2.最长距离法 (30)3.中间距离法 (32)4.重心法 (35)5.类平均法 (37)6.可变类平均法 (38)7.可变法 (38)8.离差平方和法(Word方法) (38)第六章判别分析 (39)§6.1什么是判别分析 (39)§6.2距离判别法 (40)1、两个总体的距离判别法 (40)2.多总体的距离判别法 (45)§6.3费歇(Fisher)判别法 (46)1.不等协方差矩阵两总体Fisher判别法 (46)2.多总体费歇(Fisher)判别法 (51)§6.4贝叶斯(Bayes)判别法 (58)1.基本思想 (58)2.多元正态总体的Bayes判别法 (59)§6.5逐步判别法 (61)1.基本思想 (61)2.引入和剔除变量所用的检验统计量 (62)3.Bartlett近似公式 (63)第一章绪论§1.1什么是多元统计分析在自然科学、社会科学以及经济领域中,常常需要同时观察多个指标。
多元统计分析讲义

多元统计分析讲义(第四章)(总16页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--《多元统计分析》Multivariate Statistical Analysis主讲:统计学院许启发()统计学院应用统计学教研室School of Statistics2004年9月第三章主成分分析【教学目的】1.让学生了解主成分分析的背景、基本思想;2.掌握主成分分析的基本原理与方法;3.掌握主成分分析的操作步骤和基本过程;4.学会应用主成分分析解决实际问题。
【教学重点】1.主成分分析的几何意义;2.主成分分析的基本原理。
§1 概述一、什么是主成分分析1.研究背景在实际问题的研究中,为了全面分析问题,往往涉及众多有关的变量。
但是,变量太多不但会增加计算的复杂性,而且也给合理地分析问题和解释问题带来困难。
一般说来,虽然每个变量都提供了一定的信息,但其重要性有所不同。
实际上,在很多情况下,众多变量间有一定的相关关系,人们希望利用这种相关性对这些变量加以“改造”,用为数较少的新变量来反映原变量所提供的大部分信息,通过对新变量的分析达到解决问题的目的。
主成分分析及典型相关分析便是在这种降维的思维下产生的处理高维数据的统计方法。
本章主要介绍主成分分析。
主成分分析的基本方法是通过构造原变量的适当的线性组合,以产生一系列互不相关的新变量,从中选出少数几个新变量并使它们含有尽可能多的原变量带有的信息,从而使得用这几个新变量代替原变量分析问题和解决问题成为可能。
当研究的问题确定之后,变量中所含“信息”的大小通常用该变量的方差或样本方差来度量。
概括地说,主成分分析(principal component analysis)就是一种通过降维技术把多个指标约化为少数几个综合指标的综合统计分析方法,而这些综合指标能够反映原始指标的绝大部分信息,它们通常表现为原始几个指标的线性组合。
多元统计分析(最终版)
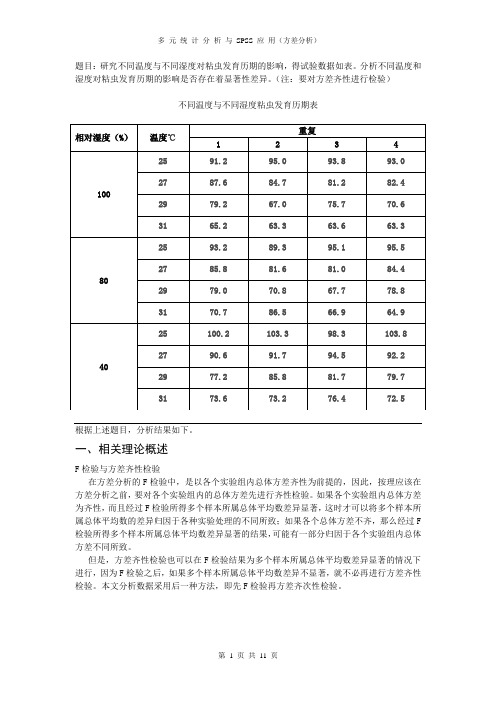
题目:研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表。
分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异。
(注:要对方差齐性进行检验)不同温度与不同湿度粘虫发育历期表根据上述题目,分析结果如下。
一、相关理论概述F 检验与方差齐性检验在方差分析的F 检验中,是以各个实验组内总体方差齐性为前提的,因此,按理应该在方差分析之前,要对各个实验组内的总体方差先进行齐性检验。
如果各个实验组内总体方差为齐性,而且经过F 检验所得多个样本所属总体平均数差异显著,这时才可以将多个样本所属总体平均数的差异归因于各种实验处理的不同所致;如果各个总体方差不齐,那么经过F 检验所得多个样本所属总体平均数差异显著的结果,可能有一部分归因于各个实验组内总体方差不同所致。
但是,方差齐性检验也可以在F 检验结果为多个样本所属总体平均数差异显著的情况下进行,因为F 检验之后,如果多个样本所属总体平均数差异不显著,就不必再进行方差齐性检验。
本文分析数据采用后一种方法,即先F 检验再方差齐次性检验。
相对湿度(%) 温度℃ 重复1 2 3 4 10025 91.2 95.0 93.8 93.0 2787.6 84.7 81.2 82.4 29 79.2 67.0 75.7 70.6 31 65.2 63.3 63.6 63.3 8025 93.2 89.3 95.1 95.5 2785.8 81.6 81.0 84.4 29 79.0 70.8 67.7 78.8 31 70.7 86.5 66.9 64.9 4025 100.2 103.3 98.3 103.8 2790.6 91.7 94.5 92.2 29 77.2 85.8 81.7 79.7 3173.673.276.472.5二、从单因子方差角度分析(一)在假定相对湿度不变的情况下分析1、假定相对湿度恒为40%,分析不同温度对粘虫发育历期的影响。
如下表: 温度℃重复252729311100.2 90.6 77.2 73.6 2 103.3 91.7 85.8 73.2 3 98.3 94.5 81.7 76.4 4 103.8 92.2 79.7 72.5 Ti 405.6 369324.4295.7T 2i164511.36136161105235.36 87438.49在本例中,r=4,m=4, n=16 ,=1394.7,= 123413.4696T 2/n=(1394.7)2/16=121574.2556 (式1)( 式2)(式3)S E =S T -S A =1839.214-1762.297=76.917 (式4)数据的方差分析表见表1.表1 粘虫发育历期方差分析表粘虫发育历期 (相对湿度40%)来源平方和 df 均方 F 显著性 组间 1762.297 3 587.432 91.646.000组内 76.917 12 6.410总数1839.21415分析表1可知,F 0.05(3,12)=3.49,F 值=,91.646,F>F 0.05,P=0.000<0.05,说明在相对湿度为40%时,不同温度对粘虫发育历期有显著影响。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多元统计分析重点宿舍版第一讲:多元统计方法及应用;多元统计方法分类(按变量、模型、因变量等) 多元统计分析应用选择题:①数据或结构性简化运用的方法有:多元回归分析,聚类分析,主成分分析,因子分析 ②分类和组合运用的方法有:判别分析,聚类分析,主成分分析 ③变量之间的相关关系运用的方法有:多元回归,主成分分析,因子分析, ④预测与决策运用的方法有:多元回归,判别分析,聚类分析 ⑤横贯数据:{因果模型(因变量数):多元回归,判别分析相依模型(变量测度):因子分析,聚类分析多元统计分析方法选择题:①多元统计方法的分类:1)按测量数据的来源分为:横贯数据(同一时间不同案例的观测数据),纵观数据(同样案例在不同时间的多次观测数据) 2)按变量的测度等级(数据类型)分为:类别(非测量型)变量,数值型(测量型)变量3)按分析模型的属性分为:因果模型,相依模型 4)按模型中因变量的数量分为:单因变量模型,多因变量模型,多层因果模型第二讲:计算均值、协差阵、相关阵;相互独立性第三讲:主成分定义、应用及基本思想,主成分性质,主成分分析步骤主成分定义:何谓主成分分析 就是将原来的多个指标(变量)线性组合成几个新的相互无关的综合指标(主成分),并使新的综合指标尽可能多地反映原来的指标信息。
主成分分析的应用 :(1)数据的压缩、结构的简化;(2)样品的综合评价,排序主成分分析概述——思想:①(1)把给定的一组变量X1,X2,…XP ,通过线性变换,转换为一组不相关的变量Y1,Y2,…YP 。
(2)在这种变换中,保持变量的总方差(X1,X2,…Xp 的方差之和)不变,同时,使Y1具有最大方差,称为第一主成分;Y2具有次大方差,称为第二主成分。
依次类推,原来有P 个变量,就可以转换出P 个主成分(3)在实际应用中,为了简化问题,通常找能够反映原来P 个变量的绝大部分方差的q (q<p )个主成分。
主成分性质:1)性质1:主成分的协方差矩阵是对角阵:(2)性质2:主成分的总方差等于原始变量的总方差(3)性质3:主成分Yk 与原始变量Xi 的相关系数为:ρ(YK,Xi )=√λ√σiitki,并称之为因子负荷量(或因子载荷量)。
主成分分析的具体步骤:①将原始数据标准化;②建立变量的相关系数阵;③求的特征根为**10p λλ≥≥≥L ,相应的特征向量为***12,,,p T T T L ;④由累积方差贡献率确定主成分的个数(m ),并写出主成分为**()i i Y T '=X ,1,2,,i m =L第四讲:因子分析定义,因子载荷统计意义,因子分析模型及假设,因子旋转因子分析定义:因子分析就是通过对多个变量的相关系数矩阵的研究,找出同时影响或支配所有变量的共性因子的多元统计方法。
因子载荷统计意义: 1.因子载荷ija 的统计意义对于因子模型1122i i i ij j im m iX a F a F a F a F ε=++++++L L 1,2,,i p =L我们可以得到,iX 与jF 的协方差为:1Cov(,)Cov(,)mi j ik k i j k X F a F F ε==+∑=1Cov(,)Cov(,)mik k j i j k a F F F ε=+∑=ija如果对iX 作了标准化处理,iX 的标准差为1,且jF 的标准差为1,因此,Cov(,)Cov(,)i j X F i j ijX F r X F a === (7.6)那么,从上面的分析,我们知道对于标准化后的iX ,ija 是iX 与jF 的相关系数,它一方面表示iX 对jF 的依赖程度,绝对值越大,密切程度越高;另一方面也反映了变量iX 对公共因子jF 的相对重要性。
了解这一点对我们理解抽象的因子含义有非常重要的作用。
2.变量共同度2i h 的统计意义设因子载荷矩阵为A ,称第i 行元素的平方和,即2211,2,,miij j h a i p===∑L (7.7)为变量iX 的共同度。
由因子模型,知2221122()()()()()i i i im m i D X a D F a D F a D F D ε=++++L22212()i i im i a a a D ε=++++L22i i h σ=+ (7.8)这里应该注意,(7.8)式说明变量iX 的方差由两部分组成:第一部分为共同度2i h ,它描述了全部公共因子对变量iX 的总方差所作的贡献,反映了公共因子对变量iX 的影响程度。
第二部分为特殊因子i ε对变量i X 的方差的贡献,通常称为个性方差。
如果对iX 作了标准化处理,有221i i h σ=+ (7.9) 3、公因子jF 的方差贡献2jg 的统计意义设因子载荷矩阵为A ,称第j 列元素的平方和,即2211,2,,pjij i g a j m===∑L为公共因子jF 对X 的贡献,即2jg 表示同一公共因子jF 对各变量所提供的方差贡献之总和,它是衡量每一个公共因子相对重要性的一个尺度。
因子分析模型及假设数学模型:每一个变量都可以表示成公共因子的线性函数与特殊因子之和,即:Xi=ai1*F1+a12*F2+…+aim*Fm+εi (i=1,2,…,p)式中的F1,F2,…Fm 称为公共因子,εi 称为Xi 的特殊因子。
该模型可用矩阵表示为:X=AF+ε,且满足:(1)m ≤p(2)Cov(F,ε)=0,即公共因子与特殊因子是不相关的;(3)DF=D(F)=⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡1...0,0,0....0...0,1,00...0,0,1=Im,即各个公共因子不相关且方差为1;(4)D ε=D(ε)=⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡σσσ22221...0,0,0....0...0,,00...0,0,p ,即各个特殊因子不相关,方差不要求相等。
因子旋转因子旋转的目的:初始因子的综合性太强,难以找出因子的实际意义,因此需要通过坐标旋转,使因子负荷两极分化, 要么接近于0,要么接近于∓1,从而降低因子的综合性,使其实际意义凸现出来,以便于解释因子。
因子旋转的基本方法:一类是正交旋转(保持因子间的正交性,3种,常用最大方差旋转),一类是斜交旋转(因子间不一定正交)公共因子提取个数:(1)选特征值大于等于1的因子(主成分)作为初始因子,通过求响应的标准化正交特征向量来计算因子载荷(2)碎石图:删去特征值变平缓的那些因子(3)累计方差贡献率大于85%第五讲:聚类类型,系统聚类、K-均值聚类思想及步骤,系统聚类方法,相似性测度方法聚类类型:根据分类的对象可将聚类分析分为:系统Q 型与R 型(即样品聚类与变量聚类)系统聚类、K-均值聚类思想及步骤:①系统聚类的基本思想:距离相近的样本(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。
②聚类过程及步骤:假设总共有n个样品(或变量),第一步将每个样品(或变量)独自聚成一类,共有n类;第二步根据所确定的样品(或变量)“距离”公式,把距离较近的两个样品(或变量)聚合为一类,其它的样品(或变量)仍各自聚为一类,共聚成n-1类;第三步将“距离”最近的两个类进一步聚成一类,共聚成n-2类;…,以上步骤一直进行下去,最后将所有的样品(或变量)全聚成一类。
最后可以画谱系图分析。
③快速聚类的基本思想,步骤:(也称为K-均值法,逐步聚类,迭代聚类),基本思想是将每一个样品分配给最近中心(均值)的类中,具体的算法步骤如下:(1)将所有的样品分成K个初始类;(2)通过欧氏距离将某个样品划入离中心最近的类中,并对获得样品与失去样品的类,重新计算重心坐标。
(3)重复步骤2,直到所有的样品都不能再分配时为止。
系统聚类方法:最短距离法(单连接),最长距离法(完全连接),中间距离法,类平均法(组间平均连接法),可变类平均法,重心法,可变法,离差平方和法相似性测度方法:不同样本相似性度量:距离测度里包括:明氏,马氏,和兰式不同变量相似度的度量:包括:夹角余弦,相关系数。
第六讲:判别分析及各判别方法思想,判别分析假设条件,距离判别与贝叶斯判别关系判别分析定义:一种进行统计判别和分组的技术手段。
它可以就一定数量案例的一个分组变量和相应的其他多元变量的已知信息,确定分组与其他多元变量之间的数量关系,建立判别函数(discriminant Function )。
然后便可以利用这一数量关系对其他已知多元变量信息、但未知分组类型所属的案例进行判别分组。
各判别方法思想:①距离判别:求新样品X 到G 1的距离与到G 2的距离之差,如果其值为正,X 属于G 2;否则X 属于G 1 ②Bayes 判别:由于k 个总体出现的先验概率分别为kq q q ,,,21Λ,则用规则R 来进行判别所造成的总平均损失为∑==ki i R i r q R g 1),()(∑∑===k i kj i R i j P i j C q 11),|()|( (4.12)所谓Bayes 判别法则,就是要选择,使得(4.12)式表示的总平均损失)(R g 达到极小。
③Fisher 判别的基本思想和步骤:从K 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数:U(X)=X pXp X X '...2211μμμμ=+++,其中系数μ=(μ1,μ2,…,μp )’确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。
有了线性判别函数后,对于一个新的样品,将它的p 个指标值代入线性判别函数式中求出U(X)值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。
判别分析假设条件:判别分析的假设之一,是每一个判别变量(解释变量)不能是其他判别变量的线性组合。
即不存在多重共线性问题。
判别分析的假设之二,是各组变量的协方差矩阵相等。
判别分析最简单和最常用的形式是采用线性判别函数,它们是判别变量的简单线性组合。
在各组协方差矩阵相等的假设条件下,可以使用很简单的公式来计算判别函数和进行显著性检验。
判别分析的假设之三,是各判别变量之间具有多元正态分布,即每个变量对于所有其他变量的固定值有正态分布。
在这种条件下可以精确计算显著性检验值和分组归属的概率。
当违背该假设时,计算的概率将非常不准确。
距离判别与贝叶斯判别关系:距离判别中两个总体的距离判别规则为:12,()0,()0G W G W ∈≥⎧⎨∈<⎩X X X X 如果如果,而贝kG G G ,,,21ΛkR R R ,,,21Λ叶斯判别规则为:⎩⎨⎧<∈≥∈dV G d V G )(,)(,21x x x x 当当,二者唯一差别仅在于阀值点,从某种意义上讲,距离判别是贝叶斯判别的特殊情形。