XP下 vs2008 +cuda4.0配置
VS2008,DDK,XP和DDKWizard搭建驱动开发环境

但2kddk写出来的东西,xp和2k都能用
4. 想写个兼容性比较好的驱动,应该用什么版本的 DDK 呢?
兼容性最好应该是用xpddk编译出来的驱动在xp上用,2kddk编译出来的在2k上用。
代码也许是一样的,但最好到各自的平台上编译一下。
我怎么很好用啊:eek:
--------------------------------------------------------------------------------
pfzhao2008-07-30, 15:27
DDKBUILD集成环境,可用在任何VS,所以VS6一样可以。
下面简要介绍一下配合DDKWizard对WindowsXP下驱动程序的开发环境进行配置:
1. 安装VisualStudio 2008。既然是开发Windows下的驱动程序,MS的开发工具是一定的了,出了VS2008,当然使用。
okbaby2008-08-06, 12:23
...
很好啊,我最近刚更新到VS2008,很爽啊
--------------------------------------------------------------------------------
snowbirdcn2008-08-06, 14:28
zhuwg2008-07-28, 08:14
- -
vs2008 解决方案

vs2008 解决方案
《VS2008 解决方案:提高编程效率的利器》
Visual Studio 2008 (以下简称VS2008)是微软推出的一款集成
开发环境,为开发人员提供了丰富的工具和功能,以便于更高效地进行软件开发。
然而,有时候在使用VS2008的过程中可
能会遇到一些问题,这就需要寻找相应的解决方案来解决这些问题。
首先,当我们遇到VS2008出现异常或者运行缓慢的情况时,
可以尝试进行一些基本的操作。
比如,可以清理解决方案并重新生成项目,有时候这能够解决一些由于缓存等原因导致的问题。
另外,也可以尝试升级VS2008到较新的版本,以获得更
好的性能和稳定性。
其次,对于一些特定的错误或者bug,我们也可以通过查找相
关的解决方案来解决。
这通常可以通过查阅官方文档、搜索网络论坛或者咨询其他开发者来获得帮助。
有时候,甚至可以通过修改一些设置或者添加一些插件来解决一些问题。
此外,还可以考虑使用一些第三方工具或者插件来增强
VS2008的功能。
比如,可以使用一些代码优化工具来提高编
程效率,或者使用一些调试工具来解决一些难以调试的问题。
这些工具和插件通常能够为我们提供更好的开发体验。
总的来说,VS2008是一个非常强大的开发工具,但是在使用
过程中也可能会遇到一些问题。
我们可以通过一些基本的操作、
查找相关的解决方案、使用第三方工具等方式来解决这些问题,从而提高我们的编程效率。
希望以上提到的方法能够帮助大家更好地使用VS2008,获得更好的开发体验。
vs2008的系统要求

Visual Studio 2008 安装要求目录∙ 1. 系统要求∙ 1.1. 支持的体系结构∙ 1.2. 支持的操作系统∙ 1.3. 硬件要求∙ 2. 已知问题∙ 2.1. 安装∙ 2.2. 卸载∙ 2.2.1. 在安装有Visual Studio 早期版本的计算机上∙ 2.2.2. 在未安装Visual Studio 早期版本的计算机上∙1. 系统要求1.1. 支持的体系结构∙x86∙x64 (WOW)1.2. 支持的操作系统∙Microsoft Windows X P∙Microsoft Windows Server 2003∙Windows Vista1.3. 硬件要求∙最低要求:1.6 GHz CPU、384 MB RAM、1024x768 显示器、5400 RPM 硬盘∙建议配置:2.2 GHz 或速度更快的CPU、1024 MB 或更大容量的RAM、1280x1024 显示器、7200 RPM 或更高转速的硬盘∙在Windows Vista 上:2.4 GHz CPU、768 MB RAM2. 已知问题2.1. 安装2.1.1. Visual Studio SharePoint 工作流功能具有特定的安装要求。
若要使用Visual Studio Tools for Office 中的SharePoint 工作流开发工具,请按照指定的顺序完成下列安装步骤。
1. 安装Windows Server 2003。
2. 安装Internet 信息服务(IIS)。
在“控制面板”中依次选择“添加/删除Windows 组件”、“应用程序服务器”、“详细信息”和“Internet 信息服务(IIS)”。
3. 安装 .NET Framework 2.0 和 .NET Framework 3.0。
4. 在IIS 管理器中启用 2.0.5727。
5. 安装Microsoft Office SharePoint Server 2007。
CUDA4.0 X32 + Windows7 32bit + Visual Studio2008+ Visual Assist安装指南

CUDA4.0 X32 + Windows7 32bit + Visual Studio2008+ Visual Assist安装指南1,需要安装的软件:CUDA Toolkit4.0 + GPUComputing SDK + CUDA Wizard + +对应的显卡驱动+ Visual Assist破解版+ VS2008下载地址:/cuda-toolkit-402,先安装显卡,得确保显卡支持CUDA加速。
查询是否支持可看此网站:/cuda-gpus3,再安装Toolkit4.0和SDK,最好选择默认。
在Win7环境下,Toolkit4.0安装后文件路径为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v3.2SDK默认安装文件路径为:C:\ProgramData\NVIDIA Corporation\NVIDIA GPU Computing SDK 4.0,注意:ProgramData Win7为隐藏文件,XP系统下默认安装路径为C:\Documents and Settings\All Users\ApplicationData\NVIDIACorporation\NVIDIA GPU Computing SDK 4.04,C:\ProgramData\NVIDIACorporation\NVIDIA GPU Computing SDK 4.0\C\src该目录下,为SDK所带的demo程序,有VS2005、VS2008和VS2010三个版本。
5,安装CUDAWizard,下载地址:/projects/cudavswizard/安装后,重新打开VS2008,此时【新建项目类型】多了【CUDA】一项,此时可以新建CUDA C程序了。
但此时肯定编译通不过,缺少必要的环境变量设置。
6,Ctrl+R,输入cmd,进入命令提示窗口输入setcuda,看是否出现以CUDA开头的环境变量,如果没有,说明SDK安装不正确,重新安装之后,在环境变量中设置【用户变量】中的【path】,添加上C:\ProgramData\NVIDIACorporation\NVIDIA GPU Computing SDK 4.0\C\bin\win32\Debug和C:\ProgramData\NVIDIACorporation\NVIDIA GPU Computing SDK 4.0\C\bin\win32\Release7,打开VS2008,【工具】-【选项】-【项目和解决方案】-【VC++目录】-【包含文件】添加上C:\ProgramFiles\NVIDIA GPU Computing Toolkit\CUDA\v4.0\include、和C:\ProgramData\NVIDIACorporation\NVIDIA GPU Computing SDK 4.0\C\common\inc【库文件】添加上C:\ProgramFiles\NVIDIA GPU Computing Toolkit\CUDA\v4.0\lib和C:\ProgramData\NVIDIACorporation\NVIDIA GPU Computing SDK 4.0\C\common\lib【源文件】添加上C:\ProgramData\NVIDIACorporation\NVIDIA GPU Computing SDK 4.0\C\common\src8,【工具】-【选项】-【项目和解决方案】-【VC++项目设置】-【C/C++文件扩展名】添加上*.cu【包括的扩展名】添加上.cuh【规则文件搜索路径】C:\ProgramData\NVIDIACorporation\NVIDIA GPU Computing SDK 4.0\C\common9,产生一些必须的库文件打开文件夹C:\ProgramData\NVIDIACorporation\NVIDIA GPU Computing SDK 4.0\C\common用VS打开Release_vs2008.sln(包含有cutil_vs2008和rendercheckgl_vs2008项目),选择【生成】-【批生成】,选择【Debug|Win32】和【Release|Win32】,点击【生成】,即可生成一些必须的库文件。
如何在XP安装Microsoft Visual Studio 2008

如何在XP安装Microsoft Visual Studio 2008安装准备:(1)从官方网站下载Microsoft Visual Studio 2008 简体中文专业版。
(2)下载最新版的Windowsinstaller,安装.net framework3.5必须。
(3)下载.net framework3.5安装包3、安装步骤(1)安装Windowsinstaller最新版。
(2)安装.net framework3.5。
[注:如果不在这里安装,在安装VS2008时也会安装,但那时要保证网络畅通,因为VS2008安装.net framework3.5是边下载边安装的,一旦网络不稳定就会报错。
](3)安装VS2008。
(4)将试用版改为正式版。
安装完成后,在“控制面板”中启动“添加删除程序”,选中Vs2008,点击“更改/删除”,点击“下一步”,找到“升级到Miscrosoft Visual Studio 2008”输入框,输入序列号:PYHYP-WXB3B-B2CCM-V9DX9-VDY8T,点击“升级”,弹出提示后点击“完成”即可。
4、常见问题(1)Visual Studio Web 创作组件(Visual Studio Authoring Component)安装失败,出现错误界面之后,setup.exe随即停止工作。
这个问题与已安装的Office软件有关,最好此时先删除Office软件,等VS2008安装完成后再重新安装最好。
(2)安装失败时重新安装注意事项。
要确定是用管理员账号登录的系统,安装失败后清除所有临时文件并重新启动计算机,如果安装中途出错则需要清理注册表,否则易出现“找不到一个或多个组件,请重新安装程序”错误。
使用regedit32.exe打开系统注册表,查找项目:HKEY_CLASSES_ROOT/Installer/Products一项一项的选中其下的所有子项目,查看右边的“Product Name”,找到Product Name“Visual Studio .NET XXXXXXX ”的项目。
CUDA + Qt + VS2008 编程环境的配置

实际上,CUDA应用于Qt,相当于在已有的project中添加所谓的CUDA build customizations
在NVIDIA CUDA GETTING STARTED GUIDE FOR MICROSOFT WINDOWS文档中(对应的文件名可能是 CUDA_Getting_Started_Windows.pdf)提到:
NVSDKCOMPUTE_ROOT - E:\ProgramData\NVIDIA Corporation\NVIDIA GPU Computing SDK 4.2
$(NVSDKCOMPUTE_ROOT)\C\common\lib - E:\ProgramData\NVIDIA Corporation\NVIDIA GPU Computing SDK 4.2\C\common\lib,相比之下似乎应该再多一级\Win32
cutil32.dll and cutil32D.dll (or cutil64.dll and cutil64D.dll) are the release and debug dynamic-link libraries, which also are copied to NVIDIA GPU
1. Open the Visual Studio 2010 project, right click on the project name, and select “Build Customizations...”, then select the CUDA Toolkit version you would like to 32 release and/or debug configurations of the cutil library, use the solution files located in NVIDIA GPU Computing SDK\C\common. The output
CUDA 4.0 + Visual Studio 开发环境搭建

CUDA 4.0 + Visual Studio 开发环境搭建基于GPU加速的并行计算, 已经成为通用计算领域的一种趋势了, 通过你的显卡可以很轻松的让你的PC得到媲美超级计算机的计算能力.下面以CUDA 4.0和vs2008为例, 介绍一下基于CUDA的开发环境的搭建. 假设你已经安装了vs2008或者其他IDE.1. 去Nvidia官网下载下面三个软件包, 要对应你自己的操作系统(32位或64位), 另外各自的版本号也需要对应(1) 开发驱动(devdriver)(2)工具包(cudatoolkit)(3)SDK样例代码(gpucomputingsdk)安装过程一路next就可以了2. 安装完这些软件后,我们可以开始创建一个CUDA的程序了。
网上有很多手动配置工程的方法,非常繁琐。
我们可以选择使用赵开勇博士发布的自动化工具:CUDA VS Wizard,这个安装后会在VS中显示CUDA的项目模板。
免去了繁琐的手工配置。
这个工具的项目主页是:/projects/cudavswizard/下载的时候一定要根据自己系统的版本来选择32位还是64位的版本。
如果操作系统是32位的,却安装了64位版本的Wizard,在vs中创建cuda project时就会出错。
sourceforge上默认提供的就是64位的版本。
3. 安装好Wizard,剩下的工作就比较简单了。
在VS中建立一个CUDA工程,先不要选择EmptyProject,建好后直接编译。
顺利的话应该可以编译通过。
如果编译不成功,提示找不到cutil32D.lib的话, 那需要去SDK下面的C\common目录编译一下cutil_vs2008这个工程, 默认路径是C:\Documents and Settings\All Users\Application Data\NVIDIA Corporation\NVIDIA GPU Computing SDK 4.0\C\common 然后编译出的cutil32D.lib复制到你的工程目录或者是cuda的lib路径下就可以了如果运行时会提示找不到cutil32D.dll。
vs2008常用配置

vs2008常用配置1. 怎样调整代码排版的格式?选择:编辑—>高级—>设置文档的格式或编辑—>高级—>设置选中代码的格式。
格式化cs代码:Ctrl+k+f格式化aspx代码:Ctrl+k+d2. 怎样跳转到指定的某一行?两种方法:Ⅰ. Ctrl+GⅡ. 单击状态栏中的行号3. 怎样创建矩形选区?两种方法:Ⅰ. 摁住alt键,然后拖动鼠标即可。
Ⅱ. 按住Shift+Alt点击矩形的左上和右下位置即可。
4. 怎样快速隐藏或显示当前代码段?Ctrl+M,M5. 怎样快速切换不同的窗口?Ctrl+Tab6. 怎样生成解决方案?Ctrl+Shift+B7. 怎样快速添加代码段?输入prop然后按两次tab即可插入自动属性public int MyProperty { get; set; },(输入try,class,foreach等等,按两次tab也有类似效果。
)8. 怎样调用智能提示?两种方法:Ⅰ. Ctrl+JⅡ. Alt+→9. 怎样调用参数信息提示?光标放到参数名上面,然后输入Ctrl+Shif+空格。
10. 怎样查看代码的详细定义?打开:视图—>代码定义窗口然后你再在页面中把鼠标点到某个方法上。
11. 怎样创建区域以方便代码的阅读?#region代码区域#endregion12. 怎样同时修改多个控件的属性?选中多个控件,然后右键属性,这个时候这些控件共有的属性就会出现,修改之后所有的控件都会变化。
13. 怎样快速添加命名空间?对于引用了dll,但代码中没有引用其命名空间的类,输入类名后在类名上按Ctrl+.即可自动添加该类的引用命名空间语句。
14. 怎样实现快速拷贝或剪切一行?光标只要在某行上,不用选中该行,直接按Ctrl+c 或Ctrl+x 就可以拷贝或剪切该行。
15. 怎样使用任务管理器?假如我们开发的项目很大,在项目中有些代码没有完成,我们可以做一下标记,便于将来查找。
cuda编程环境搭建_CUDA4.0+VS2010+Win7(32)_winXP(32)补充

环境搭建:CUDA4.0+VS2010+Win7_32/WinXP(对前人文档做了一点点修改)系统环境:Win7 32旗舰(对于winXP来说,Parallel Nsight安装不成功)如何查看系统是多少位:运行+cmd+sysinfo 说明是32位的,也可以通过“我的电脑+右键属性”如果windowXP没有写”_64”则说明是32位的。
要安装的是:CUDA 4.0 + VS2010基本安装:1.VS2010, VS2010sp1 慢慢装吧,耐心等待。
2.VassistX 这个可以以后装也行(可选)。
3.安装显卡驱动。
4.cuda tool kit 4.0和cuda tools 4.0依次安装,比较快。
(这里我还安装了Parallel NSight2.0只有vista以上的系统才可以装上,不支持XP)5.cuda sdk 4.0这个安装要说明一下,建议不要按缺省路径安装,否则文件不好查找。
如指定到如下格式路径:D:\Program Files\NVIDIA Corporation\NVIDIA GPU Computing SDK 4.0。
下面把文字里这个路径用字符串“SDK_PA TH”表示。
6.工具库生成:7.现在VS可以打开Cuda SDK的例子试试了,不过在这之前有两个工具库最好先生成一下。
1.使用VS2010打开SDK_PA TH \ c\common\cutil vs2010.slnVS2010 选“生成->批生成”,全选,生成所有配置需要的lib.目的:生成各配置需要的cutilxx[D].lib XX:32 [D]debug模式lib存放的位置:SDK_PATH \ c\common\lib\(win32)2.同上方法,打开SDK_PATH\share\ shrUtils_vs2010.sln 选“批生成”目的:生成各配置需要的shrUtilxx.lib XX:32 [D]debug模式lib存放的位置:SDK_PA TH\share\lib\(Win32)注:这个项目编译时会提示有两个.cpp找不到,直接把他们从项目里移去即可。
CUDA4.1 VS2008 配置

CUDA4.1 VS2008 配置今天总算把cuda的环境搭建好了。
在此记录一下平台搭建的过程。
首先需要安装VS 2008。
然后从英伟达官网上下载开发包、驱动和工具包。
保证驱动和开发包、工具包均为同一版本。
我下载的是4.1的最新版本。
即cudatoolkit_4.1.28_win_32.msi 、devdriver_4.1_winxp_32_286.19_general.exe 、gpucomputingsdk_4.1.28_win_32.exe 。
然后开始安装,首先装好对应的驱动,其次装工具包,最后装开发包。
工具包的路径是默认的,即C:\Program Files\NVIDIA GPU ComputingToolkit\CUDA\v4.1\,而开发包可以更改路径,我选择的路径是D:\NVIDIA Corporation\NVIDIA GPU Computing SDK 4.1\。
装好之后,需要配置VS 2008。
首先需要将C:\Program Files\NVIDIA GPU ComputingToolkit\CUDA\v4.1\extras\visual_studio_integration\rules路径下面的4个rules文件拷贝到VS安装路径下面的VC\VCProjectDefaults 中,这样就可以在VS 2008中打开位于D: \ProgramData \NVIDIA Corporation\NVIDIA GPU Computing SDK 4.1\C\src 的工程样例了。
为了显示关键字高亮,需要将D:\ C:\ProgramData\NVIDIA Corporation\NVIDIA GPU Computing SDK 4.1\C\doc\syntax_highlighting\visual_studio_8下面的usertype.dat拷贝到VS安装路径下面的Common7\IDE目录中。
CUDA环境配置总结

CUDA环境配置总结一、操作系统:(1)windows操作系统:1.windows xp:(1)win32_xp_ CUDA3.0_VS2010_配置指南-DOC(2)xp下vs2008 +cuda4.0配置(3)win32_xp_ CUDA3.0_VS2008_开发环境配置(4)xp_vs2008_MFC环境中CUDA2.3程序的配置与调试-PDF(5)win32_XP_CUDA_ vs2005_SDK&ToolKit2.3配置说明(6)VS2008+CUDA3.2在台式WINXP下的安装超详细步骤2.win7(1)Win7_x64_VS2010下配置CUDA 4.0(2)Win7_Visual Studio2010配置CUDA 4.0(3)Win7(x32)下配置CUDA3.2+VS2010(4)Win7_VS2008配置CUDA3.2手册-DOC(5)Win7_CUDA3.2_on_VS2008(6)Win7_x64_vs2008 _cuda2.3配置指南-DOC(7)Win7_32_基于Visual_Studio 2005_的CUDA3.2开发平台搭建-pdf(8)CUDA4.0 X32 + Windows7 32bit + Visual Studio2008+ Visual Assist安装指南(9)Win7_64_+Visual_Studio 2010_CUDA4.0+V AssistX 安装经验(10)win7_32_基于Visual Studio 2010 的CUDA4.0 环境配置(11)环境搭建:CUDA4.0+VS2010+Win7_32(2)linux操作系统:(1)CUDA 在linux系统上安装指南-PDF(2)CUDA_C_Getting_Started_Linux-pdf(3)linux集群安装与并行计算-pdf(4)Linux操作系统关于集群的安装与并行计算-txt(5)Linux_并行计算环境使用-pdf(6)Linux环境CUDA4.0入门:安装前的准备二、Cuda版本:Cuda4.0:(1)xp下vs2008 +cuda4.0配置(2)Win7_x64_VS2010下配置CUDA 4.0(3)Win7_Visual Studio2010配置CUDA 4.0(4)Win7_64_+Visual_Studio 2010_CUDA4.0+V AssistX 安装经验Cuda3.2:(1)Win7(x32)下配置CUDA3.2+VS2010(2)Win7_VS2008配置CUDA3.2手册-DOC(3)Win7_CUDA3.2_on_VS2008(4)Win7_32_基于Visual_Studio 2005_的CUDA3.2开发平台搭建-pdf(5)VS2008+CUDA3.2在台式WINXP下的安装超详细步骤Cuda3.0:(1)Win32_xp_ CUDA3.0_VS2010_配置指南-DOC(2)win32_xp_ CUDA3.0_VS2008_开发环境配置Cuda2.3:(1)xp_vs2008_MFC环境中CUDA2.3程序的配置与调试-PDF(2)win32_XP_CUDA_ vs2005_SDK&ToolKit2.3配置说明(3)Win7_x64_vs2008 _cuda2.3配置指南-DOC三、开发平台:Vs2010:(1)VS2010下配置CUDA 4.0(win7 x64)(2)Visual Studio2010配置CUDA 4.0(3)window7(x32)下配置CUDA3.2+VS2010(4)VS2010_CUDA3.0_xp x32配置指南-DOC(5)Win7_64_+Visual_Studio 2010_CUDA4.0+V AssistX 安装经验Vs2008:(1)VS2008配置CUDA3.2手册-DOC(2)XP下vs2008 +cuda4.0配置(3)CUDA3.2_on_VS2008(4)CUDA_VS2008_开发环境配置(5)vs2008_x64_cuda配置指南-DOC(6)xp_vs2008_MFC环境中CUDA程序的配置与调试-PDF(7)VS2008+CUDA3.2在台式WINXP下的安装超详细步骤Vs2005:(1)vs2005 cuda环境配置(2)基于Visual_Studio 2005_的CUDA3.2开发平台搭建-pdf(win7 x32)(3)CUDA_win32_XP_vs2005_SDK&ToolKit2.3配置说明(4)CUDA+VS2005环境配置及编译(5)CUDA3.1 X32 + Windows 7 32bit + Visual Studio 2005 + Visual assist安装指南CUDA软硬件环境简介-PDFCUDA开发环境配置。
vs2008入门教程

Visual Studio 2008 入门教程目录Visual Studio 2008 入门教程 (1)2、选择矩形区域(框式) (5)3、分割窗口和创新建窗口 (5)4、全屏模式 Shift + Alt + Enter (6)5、利用查找组合框查找当前文档 (6)6、文档自动换行 (6)7、创建和修改VS的快捷键 (6)8、使用快捷键来注释和取消注释 (7)9、格式化文档、选中文本或当前行 (7)10、转换代码中的空格和Tab字符 (7)11、在当前行的上面和下面插入一行 (7)12、调整字符、词或行的顺序 (7)13、删除一行开头的水平空白字符 (8)14、如何跟踪编辑后的修改(修订) (8)15、使用快捷键进行字符大小写转换 (8)16、改变书签的颜色 (8)17、用Ctrl +W选中当前单词 (8)18、剪切和粘贴折叠代码 (8)19、折叠和展开代码 (9)20、隐藏大纲标记,但仍可以大纲显示 (9)21、隐藏水平或垂直滚动条 (9)22、不用跳转行的对话框来实现转到某行 (9)23、通过返回标记,在编辑器向前或向后定位代码 (9)24、退回上一步的代码“Ctrl+=” (9)25、将光标移到文档当前视图的顶部或底部(无需滚动) (10)26、快捷方式剪切和删除当前行 (10)27、在选中代码段交换光标的位置 (10)28、在标准工具栏上使用撤销 (10)29、避免意外复制空行 (10)31、启动URL定位 (10)32、设置键盘映射方位为:Emacs 和Brief (11)33、设置书签并在书签之间跳转 (11)34、在书签窗口中,定位书签 (11)36、用Ctrl+J语句完成(强迫智能感知) (12)37、增大语句完成提示信息字体 (12)38、在语句完成窗口用键盘切换“通用”和“所有”标签页 (12)39、显示函数的参数 (12)40、复制粘贴函数的参数 (13)41、显示函数的快速信息 (13)42、利用智能感知完成单词 (13)43、使用Ctrl+F在当前文档快速查找 (14)44、在编辑器查找隐藏文本 (14)45、在项目和解决方案里查找 (14)46、使用F3查找下一个匹配结果 (14)47、不打开查找窗口,使用快捷键查找选中的文本 (15)48、给所有快速查询的结果标记上书签 (15)在“快速查找”窗口单击“全部创建标签”按钮,就是在所有匹配的文本所在行,标记上书签。
Windows 7 64bit +VS2008+ CUDA 4.0安装配置完全过程
Windows 7 64bit +VS2008+ CUDA 4.0安装配置完全过程安装CUDA4.0时,碰到了很多意外,花费了较多时间,最终取得了成功,现对期间的经验教训总结如下,供大家分享,期待提高大家的工作质量和效率。
一 安装环境Windows 7 64bit 家庭版,VS2008(安装了X64编译器),CUDA 4.0 64bit版本;二 安装软件Windows 7 64bit 家庭版是购买笔记本时自带的系统,不再详说。
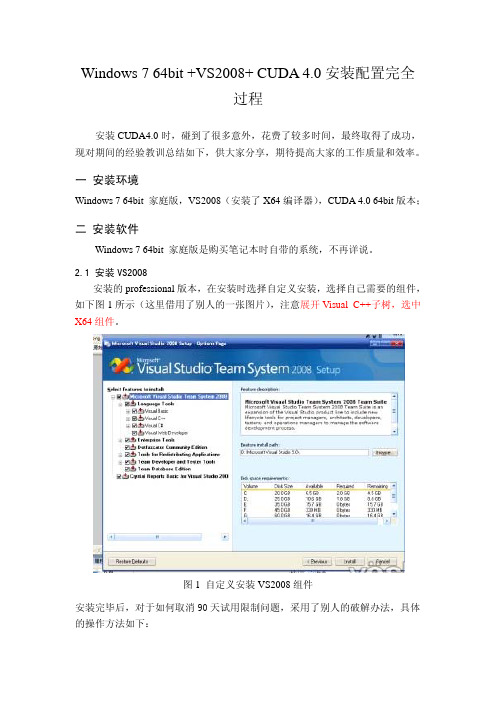
2.1 安装VS2008安装的professional版本,在安装时选择自定义安装,选择自己需要的组件,如下图1所示(这里借用了别人的一张图片),注意展开Visual C++子树,选中X64组件。
图1 自定义安装VS2008组件安装完毕后,对于如何取消90天试用限制问题,采用了别人的破解办法,具体的操作方法如下:打开 控制面板 Î 添加删除程序, 找到VS2008的安装项,运行VS2008的安装卸载程序,出现如下图2所示界面:图2 VS2008的安装卸载界面下载 破解程序CrackVS2008ForWindows7.zip,然后右键点击该破解程序,选择以管理员身份运行,出现如下的图3所示界面:图3 破解程序界面点击图3右上角 按钮“Bug 微软”,则久违的图4界面出现了:图4 破解后的界面输入相应的序列号,就可以了,以下是收集的序列号:1.Visual Studio 2008 Professional Edition:XMQ2Y-4T3V6-XJ48Y-D3K2V-6C4WT2.Visual Studio 2008 Team Test Load Agent:WPX3J-BXC3W-BPYWP-PJ8CM-F7M8T3.Visual Studio 2008 Team System:PYHYP-WXB3B-B2CCM-V9DX9-VDY8T4.Visual Studio 2008 Team Foundation Server:WPDW8-M962C-VJX9M-HQB4Q-JVTDM2.2 安装CUDA4.0在nvidia的下载网页上,下载了64bit的开发组件,包括driver、tookit、sdk 等主要组件,具体如下:devdriver_4.0_winvista-win7_64_275.33_notebook.execudatoolkit_4.0.17_win_64.msigpucomputingsdk_4.0.19_win_64.execudatools_4.0.17_win_64.msiCUDA4_0BuildCustomizationFix.zip注意驱动选择台式机或者笔记本版本。
VS2008应用环境的调试、配置和测试解析

在“工具”-“选项”-“项目和解决方案” -“VC++目录”-“库文件”中,添加:
F:\Program Files\DXSDK\Lib F:\Program Files\DXSDK\Samples\C++\DirectShow\BaseClasses\Debug F:\Program Files\DXSDK\Samples\C++\DirectShow\BaseClasses\Release
在“工具”-“选项”-“项目和解决方案” -“VC++目录”-“包含文件”中,添加:
F:\Program Files\DXSDK\Include F:\Program Files\DXSDK\Samples\C++\Common\include F:\Program Files\DXSDK\Samples\C++\DirectShow\BaseClasses
开发环境的配置
OpenCV在VS2008中的配置
在“工具”-“选项”-“项目和解决方案”- “VC++目录”-“包含文件”中,添加:
F:\Program Files\OpenCV\cv\include F:\Program Files\OpenCV\cxcore\include F:\Program Files\OpenCV\otherlibs\highgui F:\Program Files\OpenCV\cvaux\include F:\Program Files\OpenCV\otherlibs\cvcam\include F:\Program Files\OpenCV\filters\ProxyTrans
2 Visual Stdio 2008简介
CUDA+VS2008+环境配置

若正常会有类似信息
Running on......
device 0:Quadro FX 580
Range Mode
Host to Device Bandwidth for Pinned memory
Transfer Size (Bytes) Bandwidth(MB/s)
Number of multiprocessors: 4
Number of cores: 32
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 16384 bytes
Press ENTER to exit...
2.3 执行deviceQuery.exe查看显卡具体型号
.\ deviceQuery.exe
若正常会有类似信息
CUDA Device Query (Runtime API) version (CUDART static linking)
CUDA Capability Major revision number: 1
CUDA Capability Minor revision number: 1
Total amount of global memory: 536870912 bytes
10240000 5101.1
Range Mode
Device to Host Bandwidth for Pinned memory
Transfer Size (Bytes) Bandwidth(MB/s)
10240000 4650.8
CUDA 4.0 用户手册说明书

CUDA 4.0The ‘Super’ Computing Company From Super Phones to Super ComputersCUDA 4.0 for Broader Developer AdoptionCUDA 4.0Application Porting Made SimplerRapid Application PortingUnified Virtual Addressing Faster Multi-GPU ProgrammingNVIDIA GPUDirect™ 2.0 Easier Parallel Programming in C++ThrustCUDA 4.0: Highlights•Share GPUs across multiple threads •Single thread access to all GPUs •No-copy pinning of system memory •New CUDA C/C++ features•Thrust templated primitives library •NPP image/video processing library •Layered TexturesEasier Parallel Application Porting•Auto Performance Analysis •C++ Debugging•GPU Binary Disassembler•cuda-gdb for MacOSNew & ImprovedDeveloper Tools•NVIDIA GPUDirect™ v2.0•Peer-to-Peer Access •Peer-to-Peer Transfers•Unified Virtual AddressingFasterMulti-GPU ProgrammingEasier Porting of Existing ApplicationsShare GPUs across multiple threadsEasier porting of multi-threaded appspthreads / OpenMP threads share a GPULaunch concurrent kernels fromdifferent host threadsEliminates context switching overheadNew, simple context management APIsOld context migration APIs still supported Single thread access to all GPUs Each host thread can now access allGPUs in the systemOne thread per GPU limitation removedEasier than ever for applications totake advantage of multi-GPUSingle-threaded applications can nowbenefit from multiple GPUsEasily coordinate work across multipleGPUs (e.g. halo exchange)No-copy Pinning of System MemoryReduce system memory usage and CPU memcpy() overheadEasier to add CUDA acceleration to existing applications Just register malloc’d system memory for async operations and then call cudaMemcpy() as usualAll CUDA-capable GPUs on Linux or WindowsRequires Linux kernel 2.6.15+ (RHEL 5)Before No-copy Pinning With No-copy Pinning Extra allocation and extra copy requiredJust register and go!cudaMallocHost(b) memcpy(b, a) memcpy(a, b) cudaFreeHost(b)cudaHostRegister(a)cudaHostUnregister(a)cudaMemcpy() to GPU, launch kernels, cudaMemcpy() from GPU malloc(a)New CUDA C/C++ Language FeaturesC++ new/deleteDynamic memory managementC++ virtual functionsEasier porting of existing applicationsInline PTXEnables assembly-level optimizationC++ Templatized Algorithms & Data Structures (Thrust) Powerful open source C++ parallel algorithms & data structures Similar to C++ Standard Template Library (STL)Automatically chooses the fastest code path at compile time Divides work between GPUs and multi-core CPUsParallel sorting @ 5x to 100x fasterData Structures •thrust::device_vector •thrust::host_vector •thrust::device_ptr •Etc.Algorithms •thrust::sort •thrust::reduce •thrust::exclusive_scan •Etc.NVIDIA Performance Primitives (NPP) library10x to 36x faster image processingInitial focus on imaging and video related primitivesGPU-Accelerated Image ProcessingData exchange & initialization Set, Convert, CopyConstBorder, Copy, Transpose, SwapChannelsColor ConversionRGB To YCbCr (& vice versa),ColorTwist, LUT_LinearThreshold & Compare OpsThreshold, CompareStatisticsMean, StdDev, NormDiff, MinMax,Histogram,SqrIntegral, RectStdDev Filter FunctionsFilterBox, Row, Column, Max, Min, Median, Dilate, Erode, SumWindowColumn/RowGeometry TransformsMirror, WarpAffine / Back/ Quad,WarpPerspective / Back / Quad, ResizeArithmetic & Logical OpsAdd, Sub, Mul, Div, AbsDiffJPEGDCTQuantInv/Fwd, QuantizationTableLayered Textures – Faster Image ProcessingIdeal for processing multiple textures with same size/format Large sizes supported on Tesla T20 (Fermi) GPUs (up to 16k x 16k x 2k)e.g. Medical Imaging, Terrain Rendering (flight simulators), etc.Faster PerformanceReduced CPU overhead: single binding for entire texture arrayFaster than 3D Textures: more efficient filter cachingFast interop with OpenGL / Direct3D for each layerNo need to create/manage a texture atlasNo sampling artifactsLinear/Bilinear filtering applied only within a layerCUDA 4.0: Highlights•Auto Performance Analysis •C++ Debugging•GPU Binary Disassembler•cuda-gdb for MacOSNew & ImprovedDeveloper Tools•Share GPUs across multiple threads •Single thread access to all GPUs •No-copy pinning of system memory •New CUDA C/C++ features•Thrust templated primitives library •NPP image/video processing library •Layered TexturesEasier Parallel Application Porting•NVIDIA GPUDirect™ v2.0•Peer-to-Peer Access •Peer-to-Peer Transfers•Unified Virtual AddressingFasterMulti-GPU ProgrammingNVIDIA GPUDirect™:Towards Eliminating the CPU Bottleneck•Direct access to GPU memory for 3rd party devices•Eliminates unnecessary sys mem copies & CPU overhead•Supported by Mellanox and Qlogic •Up to 30% improvement in communication performanceVersion 1.0for applications that communicateover a network•Peer-to-Peer memory access, transfers & synchronization•Less code, higher programmer productivityVersion 2.0for applications that communicatewithin a nodeBefore NVIDIA GPUDirect™ v2.0Required Copy into Main MemoryGPU 1GPU 1 MemoryGPU 2GPU 2 MemoryPCI-eCPUChip System MemoryTwo copies required:1. cudaMemcpy(GPU2, sysmem)2. cudaMemcpy(sysmem, GPU1)NVIDIA GPUDirect™ v2.0:Peer-to-Peer CommunicationDirect Transfers between GPUsGPU 1GPU 1 MemoryGPU 2GPU 2 MemoryPCI-eCPUChip System MemoryOnly one copy required:1. cudaMemcpy(GPU2, GPU1)GPUDirect v2.0: Peer-to-Peer CommunicationDirect communication between GPUsFaster - no system memory copy overheadMore convenient multi-GPU programmingDirect TransfersCopy from GPU0 memory to GPU1 memoryWorks transparently with UVADirect AccessGPU0 reads or writes GPU1 memory (load/store)Supported on Tesla 20-series and other Fermi GPUs 64-bit applications on Linux and Windows TCCUnified Virtual AddressingEasier to Program with Single Address SpaceNo UVA: Multiple Memory SpacesUVA : Single Address SpaceSystem MemoryCPU GPU 0 GPU 0 MemoryGPU 1 GPU 1 MemorySystem MemoryCPU GPU 0 GPU 0 Memory GPU 1GPU 1 MemoryPCI-ePCI-e0x0000 0xFFFF0x0000 0xFFFF0x0000 0xFFFF0x00000xFFFFUnified Virtual AddressingOne address space for all CPU and GPU memoryDetermine physical memory location from pointer valueEnables libraries to simplify their interfaces (e.g. cudaMemcpy)Supported on Tesla 20-series and other Fermi GPUs64-bit applications on Linux and Windows TCCBefore UVA With UVASeparate options for each permutation One function handles all cases cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevicecudaMemcpyDefault(data location becomes an implementation detail)CUDA 4.0: Highlights•NVIDIA GPUDirect™ v2.0•Peer-to-Peer Access •Peer-to-Peer Transfers•Unified Virtual AddressingFasterMulti-GPU Programming•Share GPUs across multiple threads •Single thread access to all GPUs •No-copy pinning of system memory •New CUDA C/C++ features•Thrust templated primitives library •NPP image/video processing library •Layered TexturesEasier Parallel Application Porting•Auto Performance Analysis •C++ Debugging•GPU Binary Disassembler•cuda-gdb for MacOSNew & ImprovedDeveloper ToolsAutomated Performance Analysis in Visual ProfilerSummary analysis & hintsSessionDeviceContextKernelNew UI for kernel analysisIdentify limiting factorAnalyze instruction throughputAnalyze memory throughputAnalyze kernel occupancyNew Features in cuda-gdbFermidisassemblyBreakpoints on all instances of templated functionsC++ symbols shown in stack trace viewNow available for both Linux and MacOSinfo cuda threadsautomatically updated in DDD(cuobjdump)cuda-gdb Now Available for MacOSDetails @ /object/cuda-gdb.htmlNVIDIA Parallel Nsight™ Pro 1.5ProfessionalCUDA Debugging ✓Compute Analyzer ✓CUDA / OpenCL Profiling ✓Tesla Compute Cluster (TCC) Debugging ✓Tesla Support: C1050/S1070 or higher ✓Quadro Support: G9x or higher ✓Windows 7, Vista and HPC Server 2008 ✓Visual Studio 2008 SP1 and Visual Studio 2010 ✓OpenGL and OpenCL Analyzer ✓DirectX 10 & 11 Analyzer, Debugger & Graphics✓inspectorGeForce Support: 9 series or higher ✓CUDA Registered Developer ProgramAll GPGPU developers should become NVIDIA Registered Developers Benefits include:Early Access to Pre-Release SoftwareBeta software and librariesCUDA 4.0 Release Candidate available nowSubmit & Track Issues and BugsInteract directly with NVIDIA QA engineersNew benefits in 2011Exclusive Q&A Webinars with NVIDIA EngineeringExclusive deep dive CUDA training webinarsIn-depth engineering presentations on pre-release softwareAdditional Information…CUDA Features OverviewCUDA Developer Resources from NVIDIACUDA 3rd Party EcosystemPGI CUDA x86GPU Computing Research & EducationNVIDIA Parallel Developer ProgramGPU Technology Conference 2011CUDA Features OverviewNew in CUDA 4.0Hardware Features ECC Memory Double PrecisionNative 64-bit Architecture Concurrent Kernel Execution Dual Copy Engines6GB per GPU supportedOperating System Support MS Windows 32/64 Linux 32/64 Mac OS X 32/64Designed for HPC Cluster Management GPUDirectT esla Compute Cluster (TCC) Multi-GPU supportGPUDirect tm (v 2.0)Peer-Peer CommunicationPlatformC supportNVIDIA C CompilerCUDA C Parallel Extensions Function Pointers Recursion Atomics malloc/freeC++ supportClasses/Objects Class Inheritance PolymorphismOperator Overloading Class Templates Function Templates Virtual Base Classes NamespacesFortran supportCUDA Fortran (PGI)Unified Virtual Addressing C++ new/deleteC++ Virtual FunctionsProgramming ModelNVIDIA Library SupportComplete math.h Complete BLAS Library (1, 2 and 3)Sparse Matrix Math LibraryRNG LibraryFFT Library (1D, 2D and 3D)Video Decoding Library (NVCUVID)Video Encoding Library (NVCUVENC)Image Processing Library (NPP)Video Processing Library (NPP) 3rd Party Math Libraries CULA T ools (EM Photonics) MAGMA Heterogeneous LAPACK IMSL (Rogue Wave) VSIPL (GPU VSIPL) Thrust C++ LibraryTemplated Performance Primitives LibraryParallel LibrariesNVIDIA Developer T oolsParallel Nsightfor MS Visual Studio cuda-gdb Debugger with multi-GPU support CUDA/OpenCL Visual Profiler CUDA Memory Checker CUDA DisassemblerGPU Computing SDKNVMLCUPTI 3rd Party Developer T ools Allinea DDT RogueWave /T otalview Vampir T auCAPS HMPPParallel Nsight Pro 1.5Development T oolsCUDA Developer Resources from NVIDIALibraries and EnginesMath LibrariesCUFFT, CUBLAS, CUSPARSE, CURAND, math.h 3rd Party LibrariesCULA LAPACK, VSIPL NPP Image LibrariesPerformance primitives for imagingApp Acceleration Engines Ray Tracing: Optix, iRayVideo Encoding / DecodingNVCUVENC / VCUVIDDevelopmentT oolsCUDA T oolkit Complete GPU computing development kit cuda-gdbGPU hardware debuggingcuda-memcheck Identifies memory errors cuobjdumpCUDA binary disassembler Visual ProfilerGPU hardware profiler for CUDA C and OpenCLParallel Nsight ProIntegrated developmentenvironment for Visual StudioSDKs and Code SamplesGPU Computing SDKCUDA C/C++, DirectCompute, OpenCL code samples and documentationBooksCUDA by Example GPU Computing Gems Programming Massively Parallel Processors Many more…Optimization GuidesBest Practices for GPU computing and graphics developmentCUDA 3rd Party EcosystemParallel DebuggersMS Visual Studio withParallel Nsight ProAllinea DDT DebuggerT otalView Debugger Parallel Performance T ools ParaT ools VampirTrace TauCUDA Performance T ools PAPIHPC T oolkit Cloud Providers Amazon EC2Peer 1OEM’sDellHPIBMInfiniband Providers MellanoxQLogicCluster Management Platform HPCPlatform Symphony Bright Cluster manager Ganglia Monitoring System Moab Cluster SuiteAltair PBS ProJob SchedulingAltair PBSproTORQUEPlatform LSFMPI LibrariesComing soon…PGI CUDA FortranPGI Accelerator (C/Fortran) PGI CUDA x86CAPS HMPPpyCUDA (Python) Tidepowerd (C#) JCuda (Java)Khronos OpenCLMicrosoft DirectCompute3rd Party Math Libraries CULA T ools (EM Photonics) MAGMA Heterogeneous LAPACK IMSL (Rogue Wave)VSIPL (GPU VSIPL)NAGCluster T ools Parallel LanguageSolutions & APIs Parallel T ools Compute Platform ProvidersPGI CUDA x86 Compiler BenefitsDeploy CUDA apps onlegacy systems without GPUsLess code maintenancefor developersTimelineApril/May 1.0 initial releaseDevelop, debug, test functionalityAug 1.1 performance releaseMulticore, SSE/AVX supportProven Research Vision John Hopkins University Nanyan University Technical University-Czech CSIRO SINTEF HP Labs ICHECBarcelona SuperComputer Center Clemson University Fraunhofer SCAIKarlsruhe Institute Of TechnologyWorld Class Research Leadership and Teaching University of Cambridge Harvard University University of Utah University of Tennessee University of MarylandUniversity of Illinois at Urbana-Champaign Tsinghua UniversityTokyo Institute of Technology Chinese Academy of Sciences National Taiwan University Georgia Institute of TechnologyGPGPU Education 350+ UniversitiesAcademic Partnerships / FellowshipsGPU Computing Research & EducationMass. Gen. Hospital/NE Univ North Carolina State University Swinburne University of Tech. Techische Univ. Munich UCLAUniversity of New Mexico University Of Warsaw-ICMVSB-Tech University of Ostrava And more coming shortly.“Don’t kid yourself. GPUs are a game-changer.” said Frank Chambers, a GTC conference attendee shopping for GPUs for his finite element analysis work. “What we are seeing here is like going from propellers to jet engines. That made transcontinental flights routine. Wide access to this kind of computing power is making things like artificial retinas possible, and that wasn’t predicted to happen until 2060.”- Inside HPC (Sept 22, 2010)GPU Technology Conference 2011October 11-14 | San Jose, CAThe one event you can’t afford to miss▪Learn about leading-edge advances in GPU computing▪Explore the research as well as the commercial applications▪Discover advances in computational visualization▪T ake a deep dive into parallel programmingWays to participate▪Speak – share your work and gain exposure as a thought leader▪Register – learn from the experts and network with your peers▪Exhibit/Sponsor – promote your company as a key player in the GPU ecosystem。
CUDA环境搭建,当前未连接到NVIDIA_GPU的解决办法

CUDA环境搭建我的硬体配置:lenovo V460的笔记本(显卡是Geforce 310M)需要用到的软件:我用的所有软件版本都是配合cuda4.0的cudatoolkit cudaSDK Nsight VS2008一.软件下载在官网上分别下载以上软件:以下列出了下载后的名称,提供参考以防下载错了:1.显卡驱动:联想官网的不是最新的需要在NV官网上下载最新的(我觉得最好去NV首页下载,找到适合自己机型的显卡驱动,而不是在cuda develop上面下):275.33-notebook-win7-winvista-32bit-international-whql.exe2.cudatoolkit :去NV cuda开发者官网下载,下载后的名称:cudatoolkit_4.0.17_win_32.msi3.cudaSDK:去NV cuda开发者官网下载,下载后的名称:gpucomputingsdk_4.0.17_win_32.exe4.Nshght:这款也是NV官网上免费下载的,下载后的名称:Parallel_Nsight_Win32_2.0.11166.msi二.软件安装1.安装VS2008,2.依次安装显卡驱动——cudaToolkit——cudaSDK——Nsight三以上都完成了之后,在VS里面就生成了一个NVIDIA选项,你可以直接建立cuda项目了四:.cuda准备工作完成,你可以编写cuda代码了五:我所遇到的问题:1.NV显卡驱动怎么也装不成功,或者安装成功了,但是用不了,提示:您当前未连接到NVIDIA GPU的显示器?由于我的是联想双显卡切换的机器,这是导致这个问题的主要原因:下面给出了解决办法:开机进入bios 把Graphics相关的一个选项的值“switchable”改为另外一个,不用你自己填写,可以选择,只要你选就行了.2.安装Nsight就不要安装开勇老师的那个软件了,我之前用那个总是提示我,无法找到“cutil32D.lib”等各种lib,Nsight,就没问题,不过如果你之前安装了开勇的,那么可能安装Nsight也要出问题,慎重!目录内容提要写作提纲正文一、资产减值准备的理论概述 (4)(一)固定资产减值准备的概念 (4)(二)固定资产减值准备的方法 (5)(三)计提资产减值准备的意义 (5)二、固定资产减值准备应用中存在的问题分析 (5)(一)固定资产减值准备的计提模式不固定 (5)(二)公允价值的获取 (6)(三)固定资产未来现金流量现值的计量 (7)(四)利用固定资产减值准备进行利润操纵 (8)三、解决固定资产减值准备应用中存在的问题的对策 (10)(一)确定积累时间统一计提模式 (10)(二)统一的度量标准 (11)(三)提高固定资产可收回金额确定方式的操作性 (11)(四)加强对固定资产减值准备计提的认识 (12)(五)完善会计监督体系 (12)参考文献 (15)内容提要在六大会计要素中,资产是最重要的会计要素之一,与资产相关的会计信息是财务报表使用者关注的重要信息。
vs2008工程配置参数

也许你已经习惯了VS默认的工程文件保存路径,但有些人希望工程的源文件和生成文件能按照自己的安排对号入座,方便管理。
例如希望把所有的*.h文件放入include文件夹,.cpp文件放入source文件夹,.lib文件放入lib文件夹,把大量的中间文件丢进TEMP等等。
下面是一个动态链接库的配置:VS2008+SP1首先解决方案配置设置4个(当然这个根据你自己需求,如果库没有用到TCHAR之类的宏,那么一般定义Debug和Release就OK拉。
)DebugReleaseUnicode_DebugUnicode_Release四个配置的公共设置是配置属性->常规->输出目录:$(SolutionDir)Temp\Link\$(ProjectName)\$(ConfigurationName)\配置属性->常规->中间目录:$(SolutionDir)Temp\Compile\$(ProjectName)\$(ConfigurationName)\当编译时候以上文件目录会自动生成。
配置属性->常规->配置类型:这个当然都必须选择一样的啦,这里的示例为动态链接库(.dll)配置属性->连接器->高级->导入库:$(TargetDir)$(TargetName).lib配置属性->生成事件->生成后事件->命令行:copy $(TargetPath) $(ProjectDir)Bin\;copy $(TargetDir)$(TargetName).lib $(ProjectDir)Bin\;copy $(ProjectDir)include\I$(ProjectName).h $(ProjectDir)Bin\;Bin文件夹得自己生成哦。
I$(ProjectName).h这个是接口的头文件了,方便C++调用哈。
如果有def文件,配置属性->连接器->输入->模块定义文件:source/mc_log.def注意def文件中千万别定义LIBRARY,否则所有的lib文件都将导入该定义名的dll文件,会出现几个媳妇抢老公的场面。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
XP下 vs2008 +cuda4.0配置
zhongliangv
2011-8-12
在前人的基础上,我今天安装了cuda4.0,总结一下自己的经验。
首先下载三个软件:
devdriver_4.0_winxp_32_270.81_general.exe,cudatoolkit_4.0.17_win_32.msi,gpucomputingsdk_4.0.19_win_32.exe
再下载 VAssistX破解版(正式版非免费)
1.顺序安装driver,toolkit和sdk,我采用的都不是默认路径,方便以后查阅,sdk安装目录为E:\Program Files\NVIDIA GPU Computing SDK 4.0。
Toolkit 本来想安装在E盘DEE ,结果发现只能安装在C盘C:\Program Files\NVIDIA GPU Computing Toolkit,因为没有选择路径这一项。
2.编译sdk中的例子,验证cuda是否能正常使用,注意cuda工程中有*.sln文件(支持2005,2008,2010的都有),打开看看,发现其实和makefile的效果一致的,而且其格式和XML的格式有点相似,都是采用节的格式,其中包含了路径设置,sln中的路径设置都是相对路径而非绝对路径。
sln目的是执行工程相关的编译命令(有两种方式release和debug),方便。
还有,每个工程中有自己的sln文件,同时在src目录下还有所有例子的sln,这样可以一次都编译所有的例子。
对了,注意的是,后面在运行cuda程序的时候有可能出现找不到库的情况,那是因为你没有对相应的源码进行编译,所以也可以有针对性的分别编译。
必须编译的有:C\common中的src,这个是用来产生cutil的相关库的:cutil32.lib,cutil32.dll,cutil32D.dll,cutil32D.lib(D就是用debug编译的)。
Shared中的src也要编译,这个是用来生成shrUtils32.lib的。
3.Parallel Nsight是仅支持win7和vista的,不支持XP的,我的是XP,暂时不用了,过段时间重装系统再装吧。
4.有三种方法创建cuda工程。
接下来就是创建cuda工程了,最简单的办法是使用C\src中提供的模板,很方便的。
1.首先将原有文件名替换为自己想要的工程名字,其次,sln中的工程名也要替换,最后属性设置中Linker->general右边的outfile路径中的可执行程序名字当然也要改成自己的工程名字了。
注意的是使用模板必须在C\src中编译(上面说过了,sln中的路径是相对路径),这样只要移除源文件,再add自己的源文件就可以了,方便,建议使用这一种。
2.可以放在任何路径下,在1中的基础上,首先修改sln中的路径可以使用新的相对路径最好是改成绝对路径;其次,将属性中涉及到相对路径的设置要改成新的相对路径或绝对路径。
3.自己创建cuda工程,创建一个console的空工程,右击工程名,选择custom Build Rules…,选择CUDA Runtime API Build Rule。
在Tools->Options->Projects and Solutions->VC++ Directories 在Show
directories for 中选择Include files 增添include文件:sdk中common/inc 和share/inc; toolkit中cuda/include三个头文件;选择Libraries files 添加库文件:sdk中的common\lib\Win32和share/lib/wen32;toolkit中的cuda/lib。
然后以后就可以只在新建的工程属性中设置一个:Linker->Input->Additional Dependencies中增添cudart.lib cutil32.lib即可。
(以后用到其它的库也得加进去)(后面才发现其实这些配置完全可以参考src中的例子的设置即可,只要将例子中的相对路径的设置改成绝对路径就可以了。
还有啊,在tools中的设置是对所有工程有效的,也可以单独对某个工程的属性设置)
5.安装VAssistX,由于是破解版的,下载了三个版本的最终才装上了,更奇怪的是我花了一下午的时间找方法设置,重启vs很多次就是不生效,吃晚饭回来,结果生效了,真是奇怪了。
配置过程如下:首先关闭VS2008,使用regedit打开注册表,找到如下位置:
HKEY_CURRENT_USER\Software\Whole Tomato\Visual Assist X\VANet9。
在右边找到ExtSource项目,鼠标右键选修改,添加:.cu;.cuh;关闭注册表。
打开VS,点击VAssistX->Visual Assist X Options ……,然后就是
Projects->C/C++ Directories,左边Platform中选Custom,右边“show Directories for”中选:“Other include files”,然后开始依次添加头文件路径:Sdk中的\c\common\inc;sdk中的\shared\inc;Toolkit中的
CUDA\v4.0\include。
其实这三个文件夹里面全是头文件,包含着函数的定义,之所以在VAssistX里加载这些目录,是为了让VAssistX识别此目录下的所有头文件内所包含的函数,(注意:如果是自己头文件的函数想让VAssistX识别,也可以采用如此的方式),这样,这些文件中的函数就可以高亮显示了,还可以方便找到函数的定义,还能智能提示,方便多了;如果不生效的话就在
Tools->Options->Projects and Solutions->VC++ Directories中加入头文件;还不行的话就在 view->other windows->propety manager对话框中点击工程,下拉列表中有Debug|win32 Release|win32 ,选中其中任何一个点击弹出属性对话框,点击工程名字,下拉列表中有“microsoft er" ,双击弹出“microsoft er”对话框,找到VC++目录选项,在右边的“包含目录”选项里,单击鼠标,选编辑,加入所需要的头文件就可以了。