a gaussian process guide particle filter for tracking 3D human pose in video
非线性贝叶斯滤波算法综述_曲从善

得了很多有价值的研究成果。本文从递归贝叶斯估 计的框架出发, 给出非线性滤波的统一描述, 并分门 别类地对各种非线性滤波的原理、 方法及特点做出 分析和评述, 最后介绍了非线性滤波研究的新动态 , 并对其发展作了简单展望。
由上面的计算过程可以看出, 递归贝叶斯估计 有两个步骤, 即式 ( 6) ( Chapman- Kolmogoro equation, CK 方程) 所示的贝叶斯预测 步骤 ( 时间更新 ) 和式 ( 8) 所示的修正步骤 ( 量测更新 ) , 其 过程如图 1 所 [ 17] 示 。
| xk ) p ( x k | Yk- 1 ) d xk ( 7)
滤波和 Markov Chain Monte
等非线性滤波技术的研究 , 并取
3) 在 k 时刻 , 已经获得新的量测数据 y k , 可利 用贝叶斯公式计算得到后验概率密度函数 p ( xk | Yk ) = p ( y k | xk ) p ( x k | Yk - 1 ) p ( y k | Yk - 1 ) ( 8)
x p( x Q
k ^ T
k
| Yk ) d xk
( 3)
Q
( x k - xk ) ( xk - x k ) p ( x k | Yk ) d xk ( 4)
^
式( 3) 可以推广到状态函数的估计而不是状态本身 的估计 , 因此, 后验概率密度函数 p ( xk | Yk ) 在滤波 理论中起着非常重要的作用。 p ( xk | Yk ) 封 装了状 态向量 x k 的所有信息 , 因为它同时蕴含了量测 Yk 和先验分布 x k - 1 的信息。在给定先验密度 p ( x k - 1 | Yk - 1 ) 以及最近的观测 y k 时 , 通过式 ( 5) 所示的贝叶 斯定理来计算后验概率密度
函数功能解释(英文版)
tifs2seq
Create a MATLAB sequence from a multi-frame TIFF file.
Geometric Transformations
imtransf orm2
2-D image transformation with fixed output location.
Computes and displays the error between two matrices. Decodes a TIFS2CV compressed image sequence. Decodes a Huffman encoded matrix. Builds a variable-length Huffman code for a symbol source. Compresses an image using a JPEG approximation. Compresses an image using a JPEG 2000 approximation. Computes the ratio of the bytes in two images/variables. Decodes an IM2JPEG compressed image. Decodes an IM2JPEG2K compressed image. Decompresses a 1-D lossless predictive encoded matrix. Huffman encodes a matrix. Compresses a matrix using 1-D lossles predictive coding. Computes a first-order estimate of the entropy of a matrix. Quantizes the elements of a UINT8 matrix. Displays the motion vectors of a compressed image sequence. Compresses a multi-frame TIFF image sequence. Decodes a variable-length bit stream.
高斯辅助粒子算法

高斯辅助粒子算法高斯辅助粒子算法(Gaussian Process Particle Filter,GPPF)是一种基于高斯过程的粒子滤波算法,其主要应用在非线性系统的状态估计和滤波问题中。
该算法融合了高斯过程的非参数建模和粒子滤波的优点,能够提高滤波的准确性和鲁棒性。
本文将对GPPF 算法的原理、优势以及应用进行详细介绍与分析。
一、GPPF算法的原理1.1 高斯过程高斯过程是一种用来描述随机函数的工具,其能够通过有限数据对一个未知函数进行建模和预测。
在GPPF算法中,高斯过程被用来对系统的状态进行建模,将状态空间映射到一个高维的特征空间中。
高斯过程的非参数性质使得其能够灵活地适应复杂的系统动态,并且能够提供对未知函数的不确定性估计。
1.2 粒子滤波粒子滤波是一种适用于非线性、非高斯系统的状态估计方法,其基本思想是通过一组随机样本(粒子)来近似表示系统的后验概率分布。
通过对粒子的重采样和更新,可以逐步优化对系统状态的估计。
普通的粒子滤波在处理高维状态空间和复杂系统动态时面临着计算复杂度和采样效率的挑战。
1.3 GPPF算法GPPF算法将高斯过程和粒子滤波相结合,通过将高斯过程的非参数建模引入到粒子滤波的采样和更新过程中,能够有效地提高滤波算法的准确性和鲁棒性。
具体来说,GPPF算法首先使用高斯过程对系统状态进行建模,并从该模型中生成粒子的初始化状态。
然后,在每次更新过程中,通过高斯过程的模型进行状态更新和观测值的更新,并对粒子进行重采样,从而逐步优化对系统状态的估计。
2.3 对系统动态的适应性由于高斯过程能够灵活地适应复杂的系统动态和非线性关系,GPPF算法能够在处理各种不确定性和复杂背景下,依然能够提供可靠的状态估计和滤波结果。
这使得GPPF算法在实际应用中更加具有优势。
3.1 无人车辆定位与导航在无人车辆的定位与导航中,由于环境的复杂性和传感器数据的不确定性,传统的滤波算法往往难以满足实际需求。
2019转载 粒子滤波 PF Particle Filte.doc

转载粒子滤波PF Particle Filte原文地址:粒子滤波(PF:Particle Filter)作者:Geoinformatics粒子滤波(PF:Particle Filter)的思想基于蒙特卡洛方法(Monte Carlo methods),它是利用粒子集来表示概率,可以用在任何形式的状态空间模型上。
其核心思想是通过从后验概率中抽取的随机状态粒子来表达其分布,是一种顺序重要性采样法(Sequential Importance Sampling)。
简单来说,粒子滤波法是指通过寻找一组在状态空间传播的随机样本对概率密度函数进行近似,以样本均值代替积分运算,从而获得状态最小方差分布的过程。
这里的样本即指粒子,当样本数量N→∝时可以逼近任何形式的概率密度分布。
尽管算法中的概率分布只是真实分布的一种近似,但由于非参数化的特点,它摆脱了解决非线性滤波问题时随机量必须满足高斯分布的制约,能表达比高斯模型更广泛的分布,也对变量参数的非线性特性有更强的建模能力。
因此,粒子滤波能够比较精确地表达基于观测量和控制量的后验概率分布,可以用于解决SLAM问题。
粒子滤波的应用粒子滤波技术在非线性、非高斯系统表现出来的优越性,决定了它的应用范围非常广泛。
另外,粒子滤波器的多模态处理能力,也是它应用广泛有原因之一。
国际上,粒子滤波已被应用于各个领域。
在经济学领域,它被应用在经济数据预测;在军事领域已经被应用于雷达跟踪空中飞行物,空对空、空对地的被动式跟踪;在交通管制领域它被应用在对车或人视频监控;它还用于机器人的全局定位。
粒子滤波的缺点虽然粒子滤波算法可以作为解决SLAM问题的有效手段,但是该算法仍然存在着一些问题。
其中最主要的问题是需要用大量的样本数量才能很好地近似系统的后验概率密度。
机器人面临的环境越复杂,描述后验概率分布所需要的样本数量就越多,算法的复杂度就越高。
因此,能够有效地减少样本数量的自适应采样策略是该算法的重点。
基于改进卡尔曼滤波和粒子滤波算法的遮挡情况下快速视觉目标跟踪(IJIGSP-V6-N10-6)

Published Online September 2014 in MECS (/) DOI: 10.5815/ijigsp.2014.10.06
Fast Visual Object Tracking Using Modified kalman and Particle Filtering Algorithms in the Presence of Occlusions
G.Mallikarjuna Rao
Scientist ‗E‗, DRDO (RCI), Hyderabad, Andhra Pradesh, India Email:mallikarjun.guttikonda@gபைடு நூலகம்
Copyright © 2014 MECS
I.J. Image, Graphics and Signal Processing, 2014, 10, 43-54
44
Fast Visual Object Tracking Using Modified kalman and Particle Filtering Algorithms in the Presence of Occlusions
II. KALMAN FILTER The Kalman filter could be an algorithmic answer to the discrete-data linear filtering problem. There has been a lot of analysis has been done on this specific filter and it has been used extensively within the field of visual object tracking. As from the literature, the Kalman filter is one in every of the foremost widespread technique that's used for visual object tracking [5], [6]. A. The basic idea The Kalman filter offers an estimate of the state of a dynamic system from noisy measurements. It offers a recursive minimum variance estimate of the state of the system. To be ready to apply the Kalman filter to present estimate of the position in setting, a discrete-time state space model is required. This consists of a state equation and a measuring equation. The state equation is given by:
Ornstein–Uhlenbeck process - Wikipedia, the f

Ornstein–Uhlenbeck process - Wikipedia,the f...Ornstein–Uhlenbeck process undefinedundefinedFrom Wikipedia, the free encyclopediaJump to: navigation, searchNot to be confused with Ornstein–Uhlenbeck operator.In mathematics, the Ornstein–Uhlenbeck process (named after LeonardOrnstein and George Eugene Uhlenbeck), is a stochastic process that, roughly speaking, describes the velocity of a massive Brownian particle under the influence of friction. The process is stationary, Gaussian, and Markov, and is the only nontrivial process that satisfies these three conditions, up to allowing linear transformations of the space and time variables.[1] Over time, the process tends to drift towards its long-term mean: such a process is called mean-reverting.The process x t satisfies the following stochastic differential equation:where θ> 0, μ and σ> 0 are parameters and W t denotes the Wiener process. Contents[hide]1 Application in physical sciences2 Application in financialmathematics3 Mathematical properties4 Solution5 Alternative representation6 Scaling limit interpretation7 Fokker–Planck equationrepresentation8 Generalizations9 See also10 References11 External links[edit] Application in physical sciencesThe Ornstein–Uhlenbeck process is a prototype of a noisy relaxation process. Consider for example a Hookean spring with spring constant k whose dynamics is highly overdamped with friction coefficient γ. In the presence of thermal fluctuations with temperature T, the length x(t) of the spring will fluctuate stochastically around the spring rest length x0; its stochastic dynamic is described by an Ornstein–Uhlenbeck process with:where σ is derived from the Stokes-Einstein equation D = σ2 / 2 = k B T / γ for theeffective diffusion constant.In physical sciences, the stochastic differential equation of an Ornstein–Uhlenbeck process is rewritten as a Langevin equationwhere ξ(t) is white Gaussian noise with .At equilibrium, the spring stores an averageenergy in accordance with the equipartition theorem.[edit] Application in financial mathematicsThe Ornstein–Uhlenbeck process is one of several approaches used to model (with modifications) interest rates, currency exchange rates, and commodity prices stochastically. The parameter μ represents the equilibrium or mean value supported by fundamentals; σ the degree of volatility around it caused by shocks, and θ the rate by which these shocks dissipate and the variable reverts towards the mean. One application of the process is a trading strategy pairs trade.[2][3][edit] Mathematical propertiesThe Ornstein–Uhlenbeck process is an example of a Gaussian process that has a bounded variance and admits a stationary probability distribution, in contrast tothe Wiener process; the difference between the two is in their "drift" term. For the Wiener process the drift term is constant, whereas for the Ornstein–Uhlenbeck process it is dependent on the current value of the process: if the current value of the process is less than the (long-term) mean, the drift will be positive; if the current valueof the process is greater than the (long-term) mean, the drift will be negative. In other words, the mean acts as an equilibrium level for the process. This gives the process its informative name, "mean-reverting." The stationary (long-term) variance is given byThe Ornstein–Uhlenbeck process is the continuous-time analogue ofthe discrete-time AR(1) process.three sample paths of different OU-processes with θ = 1, μ = 1.2, σ = 0.3:blue: initial value a = 0 (a.s.)green: initial value a = 2 (a.s.)red: initial value normally distributed so that the process has invariant measure [edit] SolutionThis equation is solved by variation of parameters. Apply Itō–Doeblin's formula to thefunctionto getIntegrating from 0 to t we getwhereupon we seeThus, the first moment is given by (assuming that x0 is a constant)We can use the Itōisometry to calculate the covariance function byThus if s < t (so that min(s, t) = s), then we have[edit] Alternative representationIt is also possible (and often convenient) to represent x t (unconditionally, i.e.as ) as a scaled time-transformed Wiener process:or conditionally (given x0) asThe time integral of this process can be used to generate noise with a 1/ƒpower spectrum.[edit] Scaling limit interpretationThe Ornstein–Uhlenbeck process can be interpreted as a scaling limit of a discrete process, in the same way that Brownian motion is a scaling limit of random walks. Consider an urn containing n blue and yellow balls. At each step a ball is chosen at random and replaced by a ball of the opposite colour. Let X n be the number of blueballs in the urn after n steps. Then converges to a Ornstein–Uhlenbeck process as n tends to infinity.[edit] Fokker–Planck equation representationThe probability density function ƒ(x, t) of the Ornstein–Uhlenbeck process satisfies the Fokker–Planck equationThe stationary solution of this equation is a Gaussian distribution with mean μ and variance σ2 / (2θ)[edit ] GeneralizationsIt is possible to extend the OU processes to processes where the background driving process is a L évy process . These processes are widely studied by OleBarndorff-Nielsen and Neil Shephard and others.In addition, processes are used in finance where the volatility increases for larger values of X . In particular, the CKLS (Chan-Karolyi-Longstaff-Sanders) process [4] with the volatility term replaced by can be solved in closed form for γ = 1 / 2 or 1, as well as for γ = 0, which corresponds to the conventional OU process.[edit ] See alsoThe Vasicek model of interest rates is an example of an Ornstein –Uhlenbeck process.Short rate model – contains more examples.This article includes a list of references , but its sources remain unclear because it has insufficient inline citations .Please help to improve this article by introducing more precise citations where appropriate . (January 2011)[edit ] References^ Doob 1942^ Advantages of Pair Trading: Market Neutrality^ An Ornstein-Uhlenbeck Framework for Pairs Trading ^ Chan et al. (1992)G.E.Uhlenbeck and L.S.Ornstein: "On the theory of Brownian Motion", Phys.Rev.36:823–41, 1930. doi:10.1103/PhysRev.36.823D.T.Gillespie: "Exact numerical simulation of the Ornstein–Uhlenbeck process and its integral", Phys.Rev.E 54:2084–91, 1996. PMID9965289doi:10.1103/PhysRevE.54.2084H. Risken: "The Fokker–Planck Equation: Method of Solution and Applications", Springer-Verlag, New York, 1989E. Bibbona, G. Panfilo and P. Tavella: "The Ornstein-Uhlenbeck process as a model of a low pass filtered white noise", Metrologia 45:S117-S126,2008 doi:10.1088/0026-1394/45/6/S17Chan. K. C., Karolyi, G. A., Longstaff, F. A. & Sanders, A. B.: "An empirical comparison of alternative models of the short-term interest rate", Journal of Finance 52:1209–27, 1992.Doob, J.L. (1942), "The Brownian movement and stochastic equations", Ann. of Math.43: 351–369.[edit] External linksA Stochastic Processes Toolkit for Risk Management, Damiano Brigo, Antonio Dalessandro, Matthias Neugebauer and Fares TrikiSimulating and Calibrating the Ornstein–Uhlenbeck process, M.A. van den Berg Calibrating the Ornstein-Uhlenbeck model, M.A. van den BergMaximum likelihood estimation of mean reverting processes, Jose Carlos Garcia FrancoRetrieved from ""。
ps中文英文对照

ps中英对照模式Muliply , 正片叠底Scree n,滤色Overlay ,叠加Soft Light, 柔光Hard Light, 强光Color Dodge, 颜色减淡Color,颜色加深Burn Darken , 变暗Lighten, 变亮Difference, 差值Exclusion, 排除Hue,色相Saturation, 饱和度Color, 混合Luminosity 亮度**********************Accented Edges|| 强化的边缘Actual Pixels|| 实际象素Add Layer Clipping Path|| 添加图层剪切路径Add Layer Mask||添加图层蒙板Add Noise||加入杂色Add To Workflow||添加到工作流程Add Vector Mask||添加矢量遮罩Adjustments^ 调整Adjust|| 调整Adobe Online||Adobe 在线Again|| 再次All Layers|| 所有图层All||全选Angled Stroke|| 成角的线条Annotations|| 注释Anti-Alias Crisp|| 消除锯齿明晰Anti-Alias None|| 消除锯齿无Anti-Alias Smooth|| 消除锯齿平滑Anti-Alias Strong|| 消除锯齿强Apply lmage||应用图像Arbitrary|| 任意角度Arrange Icons|| 排列图标Arrange Linked|| 对齐链接图层Arrange|| 排列Artistic|| 艺术效果Assign Profile|| 制定配置文件Assing Profile|| 制定配置文件Auto Color|| 自动色彩Auto Contrast|| 自动对比度Auto Laves|| 自动色阶Automate^ 自动**********************Background From Layer|| 背景图层Bas Relief|| 基底凸现Batch||批处理Bevel and Emboss|| 斜面和浮雕Bitmap|| 位图Bits/Channel|| 位通道Blending Options|| 混合选项Blur More|| 进一步模糊Blu r||模糊Border|| 扩边Bottom Edges|| 底边Brightness/Contrast|| 亮度/对比度Bring Forward|| 前移一层Bring to Front|| 置为顶层Browse|| 浏览Brush Strokes|| 画笔描边**********************CCW||逆时针度CMYK Colo川CMYK 颜色CW||顺时针度Calculations^ 计算Calculations^ 运算Cancel Check Out|| 取消登出Canvas Size|| 画布大小Cascade|| 层叠Chalk / Charcoal|| 粉笔和炭笔Change Layer Content|| 更改图层内容Channel Mixer|| 通道混合器Charcoal|| 炭笔Check In|| 登记Check Out|| 登出Check Spelling|| 检查拼写Chrome|| 铬黄Clear Guides|| 清除参考线Clear Layer Effects|| 清除图层样式Clear Slices|| 清除切片Clea川清除Clipboard|| 剪贴板Close All|| 关闭全部Close|| 关闭Clouds|| 云彩Color Balance|| 色彩平衡Color Halftone|| 彩色半调Color Overlay|| 颜色叠加Color Range||色彩范围Color Settings|| 颜色设置Color Table|| 颜色表Colored Pencil|| 彩色铅笔Conditional Mode Change|| 条件模式更改Contact Sheet II|| 联系表IIContact Sheet|| 联系表Conte Crayon||Conte 蜡笔Conte Crayon|| 彩色粉笔Contract|| 收缩Convert to Profile|| 转换为配置文件Convert to Shape|| 转变为形状Copy Layer Effects|| 拷贝图层样式Copy Merged||合并拷贝Copy||拷贝Covert To Paragraph Text||转换为段落文字Craquelure|| 龟裂缝Create Droplet|| 创建快捷批处理Create Laye川创建图层Create Work Path|| 创建工作路径Crop||裁切Crosshatch|| 阴影线Crystallize|| 晶格化Current Path|| 当前路径Curves|| 曲线Custom|| 自定Custom||自定义Cutout||剪贴画Cutout|| 木刻Cut||剪切**********************D Transform||D 变换Dark Strokes|| 深色线条De-Interlace|| 隔行Define Brush|| 定义画笔Define Custom Shape|| 定义自定形状Define Pattern|| 设置图案Define|| 去边Delete Laye川删除图层Delete Workspace^ 删除工作空间Delete|| 删除Desaturate|| 去色Deselect^ 取消选择Despeckle|| 去斑Difference Clouds|| 分层云彩Diffuse Glow|| 扩散亮光Diffuse"扩散Digimarc|| 数字标识Displace^ 置换Display / Cursors|| 显示与光标Distort|| 扭曲Distribute Linked|| 分布链接的document Bounds|| 文档边界documents|| 文档Drop Shadow|| 投影Dry Brush|| 干笔画Dry Brush|| 干画笔Duotone||双色调Duplicate Laye川复制图层Duplicate^ 复制Dust / Scratches|| 蒙尘与划Free Transform^ 自由变换Indexed Color|| 索引色流程痕Free Transform^ 自由变形Indexed Color|| 索引颜色Matting|| 修边**********************Fresco|| 壁画Ink Outlines|| 油墨概况Maximum||最大值Edit||编辑**********************Inner Glow|| 内发光Median||中间值Embed Watermark|| 嵌入水印Gamut Wiring|| 色域警告Inner Shadow|| 内阴影Memory / Image Cache|| 内存Emboss|| 浮雕Gaussian Blu川高斯模糊Inverse|| 反选和图像高速缓存Enable Layer Clipping General|| 常规Invert|| 反相Memory / Image Cache|| 内存Path||启用图层剪切路径Glass|| 玻璃**********************与图像高速缓存Enable Layer Mask|| 启用图层Global Light|| 全局光Jump to||跳转到Merge Linked||合并链接图层蒙板Glowing Edges|| 照亮边缘**********************Merge Visible|| 合并可见图Enable Vector Mask|| 启用矢Gradient Map|| 渐变映射Lab Color||Lab 颜色层量遮罩Gradient Overlay|| 渐变叠加Last Filte川上次滤镜操作Mezzotint|| 铜版雕刻Equalize^ 色彩均化Gradient|| 渐变Layer Clipping Path|| 图层剪Minimum||最小值Equalize^ 色调均化Grain|| 颗粒贴路径Mode||模式Exit||退出Graphic Pen|| 绘图笔Layer Content Options|| 图层Modify|| 修改Expand|| 扩展Grayscale|| 灰度内容选项Monitor RGB|| 显示器RGB Export|| 输出Grid||网格Layer From Background^ 背景Mosaic||马赛克Extracts 抽出Group Linked|| 于前一图层编图层Mosained Tiles|| 马赛克拼贴Extras||显示额外的组Layer Properties|| 图层属性Motion Blur|| 动感模糊Extrude|| 突出Group with Previous|| 和前一Layer Set From Linked|| 来自Motion Blur|| 动态模糊**********************图层编组链接的图层组Multi-Page PDF to PSD|| 多页Facet||彩块化Grow||扩大选区Layer Set From Linked|| 图层PDF至U PSDFade||消退Guides / Grid||参考线与网格组来自链接的Multichannel|| 多通道Feathe川羽化Guides, Grid / Slices|| 参考Layer Set|| 图层组**********************NTSCFile Handling^ 文件处理线,网格与切片Layer Style|| 图层样式Colors||NTSC 色彩File lnfo|| 文件简介Guides||参考线Layer via Copy|| 通过拷贝的Neon Glow||霓虹灯光File||文件**********************图层New Adjustment Layer|| 新调Fill Content|| 填充内容Halftone Pattern|| 半色调图Layer via Cut||通过剪切的图整图层Fill|| 填充案层New Fill Laye川新填充图层Film Grain|| 胶片颗粒Hidden Layers|| 隐藏的图层Laye川图层New Guides||新参考线Filte川滤镜Hide All Effects|| 显示/ 隐藏Left Edges|| 左边New Guide||新参考线Find Edges|| 查找边缘全部效果Lens Flare|| 镜头光晕New Layer Based Slice|| 基于Find and Replace Text|| 寻找Hide All|| 隐藏全部Levels|| 色阶图层的切片并替换文字Hide Selection|| 隐藏选区Lighting Effects|| 光照效果New View||新视图Fit on Screen|| 满画布显示High Pass||高反差保留Linked Layers|| 链接的图层New Window|| 新窗口Fix Image|| 限制图像Histogram|| 直方图Linked Layers|| 链接图层New||新建Flatten Image|| 合并图层Histories|| 历史纪录Liquify|| 液化Noise|| 杂色Flatten Image|| 平整图像Horizontal Cente 川水平居Load Selection|| 载入选区None|| 无Flip Canvas Horizontal|| 画中Lock All Linked Layers|| 锁Note Pape川便条纸布水平翻转Horizontal|| 水平定所有链接图层Notes|| 注释Flip Canvas Vertical^ 画布Hue/Saturation|| 色相/ 饱和Lock Guides|| 锁定参考线**********************垂直翻转度Lock Slices|| 锁定切片Ocean Ripple|| 海洋波纹Flip Horizontal|| 水平翻转**********************Logoff All Servers|| 注销所Offset|| 位移Flip Hpeizontal|| 水平翻转Image Size|| 图像大小有服务器Open As||打开为Flip Vertical|| 垂直翻转lmage|| 图像**********************Open From Workflow|| 从工作Fragment^ 碎片Import|| 输入Manage Workflow|| 管理工作流程打开Open Recent||最近打开文件Print Size|| 打印尺寸Save Workspace^保存工作空路径Open||打开Print With Preview|| 预览并间Show/Hide Status Bar|| 显示/ Options|| 选项打印Save as||保存为隐藏状态栏Other|| 其它Print|| 打印Save for Web|| 存储为Web所Show/Hide Styles|| 显示/ 隐Outer Glow|| 外发光Proof Color|| 校样颜色用格式藏样式**********************Proof Setup|| 校样设置Save||保存Show/Hide Swatches|| 显示/PDF lmage||PDF 图像Purge||清除内存数据Save||存储隐藏色板Page Setup||页面设置**********************Saving Files|| 存储文件Show/Hide Tools|| 显示/ 隐藏Paint Daubs|| 涂抹棒RGB Color||RGB 颜色Scale Effects|| 缩放效果工具Palette Knife|| 调色刀Radial Blur|| 径向模糊Scale|| 缩放Show||显示Paste Into|| 粘贴入Rasterize|| 栅格化Selection Edges|| 选区边缘Similar|| 选区相似Paste Layer Effects To Read Watermark|| 读取水印Selection|| 选择Simulate Ink Black|| 模拟墨Linked||将图层样式粘贴的链Remove Black Matte|| 移除黑Selective Color|| 可选颜色黑八、、接的色杂边Send Backward|| 后移一层Simulate Paper White|| 模拟Paste Layer Effects To Remove Black Matte|| 移去黑Send to Back|| 置为底层纸白Linked||粘贴图层样式到链接色杂边Shape|| 形状Sketch|| 素描层Remove White Matte|| 移除白Sharpen Edges|| 锐化边缘Skew||斜切Paste Layer Effects|| 粘贴图色杂边Sharpen More|| 进一步锐化Slices|| 切片层样式Remove White Matte|| 移去白Sharpen|| 锐化Smart Blur|| 特殊模糊Paste|| 粘贴色杂边Shear|| 切变Smooth|| 平滑Patchwork|| 拼缀图Rende川渲染Show Extras Options|| 显示额Smudge Stick|| 绘画涂抹Path to lllustrator|| 路径到Replace All Missing Fonts|| 外选项Snap To||对齐到Illustrator 替换所以缺欠文字Show Extras|| 显示额外的Snap||对齐Pattern Make川制作图案Replace Colo川替换颜色Show Guides||锁定参考线Solarize|| 曝光过度Pattern Overlay|| 图案叠加Reselect|| 重新选择Show Rulers||显示标尺Solid Colo川纯色Pattern|| 图案Reset Palette Locations|| Show/Hide Actions|| 显示/ 隐Spatter|| 喷笔Perspective^ 透视复位调板位置藏动作Spatter|| 喷溅Photocopy|| 副本Reticulation|| 网状Show/Hide Channels|| 显示/ Spherize|| 球面化Picture package|| 图片包Reveal All|| 显示全部隐藏通道Sponge|| 海绵Pinch|| 挤压Reveal Selection|| 显示选区Show/Hide Character|| 显示/ Sprayed Strokes|| 喷色描边Pixelate|| 像素化Reverl All|| 显示全部隐藏字符Sprayed Strokes|| 喷色线条Place|| 置入Revert|| 恢复Show/Hide Color|| 显示/ 隐藏Stained Glass|| 染色玻璃Plaster|| 塑料效果Right Edges|| 右边颜色Stamp|| 图章Plastic Wrap|| 塑料包装Ripple|| 波纹Show/Hide History|| 显示/ 隐Step Backward|| 返回Plug-Ins / Scratch Disks|| Rotate Canvas|| 旋转画布藏历史记录Step Forward|| 向前增效工具与暂存盘Rotate ° CCW|逆时针旋转度Show/Hide Info|| 显示/ 隐藏Stroke|| 描边Pointillize|| 点状化Rotate ° CW||顺时针旋转度信息Stylize|| 风格化Polar Coordinates|| 极坐标Rotate ° ||旋转度Show/Hide Layers|| 显示/ 隐Sumi-e||烟灰墨Poster Edges|| 海报边缘Rotate|| 旋转藏图层**********************Posterize|| 色调分离Rough Pastels|| 粗糙彩笔Show/Hide Navigator|| 显示/ Target Path|| 目标路径Preferences|| 预设Rulers||显示标尺隐藏导航Texture Fill|| 纹理填充Preset Manager|| 预置管理器**********************Show/Hide Options|| 显示/ 隐Texture|| 纹理Prespective|| 透视Sacle|| 缩放藏选项Texturixe川纹理化Print One Copy|| 打印一份拷Satin|| 光泽Show/Hide Paragraph|| 显示/ Threshold|| 阈值贝Save As||存储为隐藏段落Tiles|| 拼贴Print Options|| 打印选项Save Selection|| 存储选区Show/Hide Paths|| 显示/ 隐藏Tile||拼贴Tools|| 工具Top Edges|| 顶边Torn Edges|| 撕边Trace Contou川等高线Transform Selection^ 变换选区Transform^ 变换Transparency / Gamut|| 透明区域与色域Trap||陷印Trim||修整Twirl|| 旋转扭曲Type||文字**********************UnGroup||取消编组Underpainting||底纹效果Undo Check Out|| 还原注销Undo||还原Ungroup||取消编组Units / Rulers|| 单位与标尺Unsharp Mask||USM 锐化Update All Text Layers|| 更新所有文本图层Update|| 更新Upload To Server|| 上载到服务器**********************Variations|| 变化Vector Mask|| 矢量遮罩Verify State|| 校验状态Vertical Cente川垂直居中Vertical|| 垂直Video|| 视频View||视图**********************WIA Support||WIA 支持Warp Text||文字变形Water Pape川水彩纸Watercolor|| 水彩Wave||波浪WebPhoto Gallery|| 网上图片库Windows|| 窗口Wind|| 风Workflows Options|| 工作流程选项Workgroup Servers|| 工作组服务器Workgroup^ 工作组Working Black Plate|| 处理黑版Working CMY Plate|| 处理CMY 版Working CMYK|| 处理CMYK Working Cyan Plate|| 处理青版Working Magenta Plate|| 处理洋红版Working Yellow Plate|| 处理黄版Workspace||工作空间**********************Zigzag|| 水波Zoom In|| 放大Zoom Out|| 缩小**********************° CCW|逆时针度° CW|顺时针度。
基于容积卡尔曼滤波的高斯粒子滤波算法

基于容积卡尔曼滤波的高斯粒子滤波算法作者:赵丹丹刘静娜贺康建来源:《计算技术与自动化》2017年第01期摘要:高斯粒子滤波是一种免重采样的粒子滤波,不会出现粒子退化,但其重要性密度函数由于没有考虑到最新量测信息,使得滤波性能明显下降,且该算法没有较高的实时性。
针对这个问题提出一种基于CKF的高斯粒子滤波算法—CKGPF算法。
该算法利用CKF算法构造高斯粒子滤波的重要性密度函数,且在时间更新阶段借助CKF算法来完成只对高斯分布参数的更新。
仿真结果表明,CKGPF算法相比于标准GPF算法不仅提高了滤波精度,而且还具有较好的实时性。
关键词:高斯粒子滤波;重要性密度函数;实时性;容积卡尔曼滤波中图分类号:TP391 文献标识码:ADOI:10.3969/j.issn.10036199.2017.01.017粒子滤波[1]是一种基于蒙特卡洛思想的非线性、非高斯系统的滤波方法,已在定位、目标跟踪、无线通信、目标识别等领域得到了深入研究[2-4]和广泛应用。
但在标准的粒子滤波算法中,一般把先验概率密度函数作为重要性密度函数,这种方法没有把最新的量测值考虑进去,因而使得从重要性概率密度函数采样得到的样本与从真实后验概率密度函数采样得到的样本之间存在很大的偏差,特别是当似然分布比较陡峭或是似然函数位于状态转移概率密度的尾部时,出现的偏差就更为显著。
因此,为了在算法中将最新的量测信息考虑进去,通常是将不同卡尔曼滤波和粒子滤波结合来构造重要性密度函数[5-7],但文献[8]已给出证明盲目将两种算法结合来构造新的重要性密度函数并不一定能获得较好的滤波精度,且会增加计算复杂度,降低算法的实时性,而且粒子滤波本身就存在实时性较差的问题。
随着有限集多目标跟踪的出现,粒子滤波也进入了随机集粒子滤波[9]新的发展阶段。
文献[10]更是实现了随机集粒子滤波对多目标跟踪的应用。
高斯粒子滤波[11]是针对解决粒子滤波重采样中样本枯竭问题的一种改进的粒子滤波,具有更高的滤波精度。
英文原文--An Improved Particle Swarm Optimization Algorithm

An Improved Particle Swarm Optimization AlgorithmLin Lu, Qi Luo, Jun-yong Liu, Chuan LongSchool of Electrical Information, Sichuan University, Chengdu, Sichuan, China, 610065lvlin@AbstractA hierarchical structure poly-particle swarm optimization (HSPPSO) approach using the hierarchical structure concept of control theory is presented. In the bottom layer, parallel optimization calculation is performed on poly-particle swarms, which enlarges the particle searching domain. In the top layer, each particle swam in the bottom layer is treated as a particle of single particle swarm. The best position found by each particle swarm in the bottom layer is regard as the best position of single particle of the top layer particle swarm. The result of optimization on the top layer particle swarm is fed back to the bottom layer. If some particles trend to local extremumin particle swarm optimization (PSO) algorithm implementation, the particle velocity is updated and re-initialized. The test of proposed method on four typical functions shows that HSPPSO performance is better than PSO both on convergence rate and accuracy.1. IntroductionParticle swarm optimization algorithm first proposed by Dr. Kennedy and Dr. Eberhart in 1995 is a new intelligent optimization algorithm developed in recent years, which simulates the migration and aggregation of bird flock when they seek for food[1]. Similar to evolution algorithm, PSO algorithm adopts a strategy based on particle swarm and parallel global random search. PSO algorithm determines search path according to the velocity and current position of particle without more complicated evolution operation. PSO algorithm has better performance than early intelligent algorithms on calculation speed and memory occupation, and has less parameters and is easier to realize.At present, PSO algorithm is attracting more and more attention of researchers, and has been widely used in fields like function optimization, combination optimization, neural network training, robot path programming, pattern recognition, fuzzy system control and so on[2]. In addition, The study of PSO algorithm also has infiltrated into electricity, communications, and economic fields. Like other random search algorithms, there is also certain degree of premature phenomenon in PSO algorithm. So in order to improve the optimization efficiency, many scholars did improvement researches on basic PSO algorithm, such as modifying PSO algorithm with inertia weight[3], modifying PSO algorithm with contraction factor[4], and combined algorithm with other intelligent algorithm[5]. These modified algorithms have further improvement in aspects like calculation efficiency, convergence rate and so on.Proper coordination between global search and local search is critical for algorithm finally converging to global optimal solution. Basic PSO algorithm has simple concept and is easy to control parameters, but it takes the entire optimization as a whole without detailed division, and it searches on the same intensity all along that to a certain extent leads to premature convergence. A hierarchical structure poly-particle swarm optimization approach utilizing hierarchy concept of control theory is presented, in which the parallel optimization calculation employs poly-particle swarm in the bottom layer, which is equivalent to increase particle number and enlarges the particle searching domain. To avoid algorithm getting in local optimum and turning into premature, disturbance strategy is introduced, in which the particle velocity is updated and re-initialized when the flying velocity is smaller than the minimum restrictions in the process of iteration. The best position found by each poly-particle swarm in the bottom layer is regard as best position of single particle in the top layer. The top layer performs PSO optimization and feeds the global optimal solution back to the bottom layer. Independent search of the poly-particle swarm on bottom layer can be used to ensure that the optimization to carry out in a wider area. And in top layer, particle swarm’s tracking of current global optimal solution can be used to ensure theconvergence of the algorithm. Several benchmark functions have been used to test the algorithm in this paper, and the results show that the new algorithm performance well in optimization result and convergence characteristic, and can avoid premature phenomenon effectively.2. Basic PSO algorithmPSO algorithm is swarm intelligence based evolutionary computation technique. The individual in swarm is a volume-less particle in multidimensional search space. The position in search space represents potential solution of optimization problem, and the flying velocity determines the direction and step of search. The particle flies in search space at definite velocity which is dynamically adjusted according to its own flying experience and its companions’ flying experience, i.e., constantly adjusting its approach direction and velocity by tracing the best position found so far by particles themselves and that of the whole swarm, which forms positive feedback of swarm optimization. Particle swarm tracks the two best current positions, moves to better region gradually, and finally arrives to the best position of the whole search space.Supposing in a D dimension objective search space, PSO algorithm randomly initializes a swarm formed by m particles, then the position X i (potential solution of optimization problem)of ith particle can be presented as {x i 1 , x i 2 ,… , x iD }, substitute them into the object function and adaptive value will be come out, which can be used to evaluate the solution. Accordingly, flying velocity can be represented as {v i 1, v i 2,…, v iD }. Individual extremum P i {p i 1 , p i 2 ,… , p iD } represents the best previous position of the ith particle, and global extremum P g {p g 1 , p g 2 ,… , p gD } represents the best previous position of the swarm. Velocity and position are updated each time according to the formulas below.1112211max max 11min min 11()()if ,;if ,;k k k k k k id id id id gd id k k id id k k id id k k k id id idv wv c r p x c r p x v v v v v v v v x x v +++++++⎧=+−+−⎪>=⎪⎨<=⎪⎪=+⎩ (1) In the formula, k represents iteration number; w is inertia weight; c 1, c 2 is learning factor; r 1, r 2 is two random numbers in the range [0,1].The end condition of iteration is that the greatest iteration number appears or the best previous position fits for the minimum adaptive value.The first part of formula (1) is previous velocity of particle, reflecting the memory of particle. The second part is cognitive action of particle, reflecting particle’sthinking. The third part is social action of particle, reflecting information sharing and mutual cooperation between particles.3. Hierarchical structure poly-particle swarm optimizationDuring the search of PSO algorithm, particles always track the current global optimum or their own optimum, which is easy to get in local minimum [6]. Aiming at this problem in traditional PSO, this paper proposes a hierarchical structure poly-particle swarm optimization approach as the following.(1) Based on hierarchical control concept of control theory, two-layer ploy-particle swarm optimization is introduced. There are L swarms on bottom layer and p ig represents global optimum of ith swarm. There is a swarm on top layer and p g represents global optimum of top layer. Figure 1 represents scheme of HSPPSO.Figure 1Supposing there are L swarms in bottom layer, m particles in each swarm, then parallel computation of L swarms is equivalent to increasing the number of particle to L*m, which expands search space. The parallel computation time of ploy-particle swarms doesn’t increase with the number of particle. Besides individual and global extremum of the particle swarm, poly-particle swarm global extremum is also considered to adjust the velocity and position ofparticles in L swarms. Correction 33()k kg ij c r p x −isadded to the algorithm, and the iteration formulas are as the following. 111223311max max 11min min 11()()()if ,;if ,;k k k k k k k k ij ij ij ij ig ij g ij k k ij ij k k ij ij k k k ij ij ijv wv c r p x c r p x c r p x v v v v v v v v x x v +++++++⎧=+−+−+−⎪>=⎪⎪⎨<=⎪⎪=+⎪⎩ (2)In the formula, c 3 is learning factor; r 3 is random numbers in the range [0,1]. i represents swarm and i=1,…, L ,j represents particle and j=1,…, m ,x ijBottom layerlrepresents the position variable of jth particle in ith swarm; p ij represents individual extremum of jth particle in ith swarm.The fourth part of the formula (2) represents the influence of global experience to particle, reflecting information sharing and mutual cooperation between particles and global extremum.The top layer will commence secondary optimization after ploy-particle swarm optimization on bottom layer, which takes each swarm in L swarms for a particle and swarm optimum p ig for individual optimum of current particle. The iteration formulas of particle velocity update are as the following.1112211max max 11min min 11()()if ,;if ,;k k k k kk i i ig i g i k k i i k k i i k k k i i iv wv c r p x c r p x v v v v v v v v x x v +++++++⎧=+−+−⎪>=⎪⎨<=⎪⎪=+⎩ (3) The top layer PSO algorithm adjusts particle velocity according to the global optimum of each swarm on bottom layer. Independent search of the L poly-particle swarm on the bottom layer can be used to ensure the optimization to be carried out in a wider area. On top layer, particle swarm’s tracking of current global optimal solution can be used to ensure the convergence of the algorithm, in which both attentions are paid to the precision and efficiency of the optimization process.(2) Introduce disturbance strategy. Optimization is guided by the cooperation and competition between particles in PSO algorithm. Once a particle finds a position which is currently optimum, other particles will quickly move to the spot, and gather around the point. Then the swarm will lose variety and there will be no commutative effect and influence between particles. If particles have no variability, the whole swarm will stagnate at the point. If the point is local optimum, particle swarm won’t be able to search the other areas and will get in local optimum which is so-called premature phenomenon. To avoid premature, the particle velocity need to be updated and re-initialized without considering the former strategy when the velocity of particles on the bottom layer is less than boundary value and the position of particle can’t be updated with velocity.4. Algorithm flow(1) Initialization. Set swarm number L, particleswarm scales m and algorithm parameters: inertia weight, learning factor, velocity boundary value, and the largest iterative number.(2) Each swarm on bottom layer randomly generates m original solutions, which are regarded as currentoptimum solution p ij of particles meanwhile. Adaptive value of all particles is computed. The optimum adaptive value of all particles is regarded as current optimum solution p ig of swarm, which is transferred to top layer.(3) Top layer accepts L p ig from bottom layer as original value of particles, which are regarded as their own current optimum solution p ig of particles meanwhile. The optimum adaptive value of all particles is regarded as current optimum solution p g of swarm, which is transferred to bottom layer.(4) Bottom layer accepts p g form top layer, updates velocity and position of particle according to formula (2), if velocity is less than the boundary value, the particle velocity is updated and re-initialized.(5) Bottom layer computes adaptive value of particles, and compares with current individual extremum. The optimum value is regarded as current optimum solution p ij of particles. The minimum value of p ij is compared with global extremum. The optimum value is regarded as current global extremum p ig of swarm, which is transferred to top layer.(6) Top layer accepts p ig from bottom layer. The optimum adaptive value of p ig is compared with current global extremum p g . The optimum adaptive value is regarded as current global extremum p g . Velocity and position of each particle are updated according to formula (3).(7) Top layer computes adaptive value of particles, and compares with current individual extremum. The optimum value is regarded as current optimum solution p ig of particles. The minimum value of p ig is compared with global extremum p g . The optimum value is regarded as current global extremum p g of swarm, which is transferred to bottom layer.(8) Evaluate end condition of iteration, if sustainable then output the result p g , if unsustainable then turn to (4).5. ExampleIn order to study algorithm performance, tests are done on four common benchmark functions: Spherical, Rosenbrock, Griewank and Rastrigin. The adaptive value of the four functions is zero. Spherical and Rosenbrock are unimodal function, while Griewank and Rastrigin are multimodal function which has a great of local minimum.f 1:Sphericalfunction 211(),100100ni i i f x x x ==−≤≤∑f 2:Rosenbrock function222211()[100()(1)], 100100ni i i i i f x x x x x +==×−+−−≤≤∑f 3:Griewank function23111()(100)1,4000nn i i i f x x ===−−+∑∏100100i x −≤≤ f 4:Rastrigin function241()(10cos(2)10), 100100nii i i f x x x x π==−+−≤≤∑Set the dimension of four benchmark function to 10, the corresponding maximum iteration number to 500, swarm scale m to 40, number of swarm to 5, inertia weight to 0.7298, c1, c2 and c3 to 1.4962. Each test is operated 10 times randomly.Table 1 presents the results of four benchmark test function with PSO and HSPPSO.Table1.Compare of simulation resultsfunction algorithm minimummaximum averagef1PSO HSPPSO 3.0083e-93.5860e-12 8.9688e-5 1.9550e-7 3.5601e-84.2709e-11 f2PSO HSPPSO 5.74414.2580 8.8759 7.8538 7.659975.5342 f3PSO HSPPSO 00 24.9412 2.3861 7.36575 0.23861 f4PSO HSPPSO 4.97500.995013.9392 7.9597 10.15267 4.4806Table 1 shows that HSPPSO performance is better than PSO in searching solution, and gets better results than PSO both in test for local searching and global searching. Though the difference of HSPPSO between PSO in searching solution of unimodal function is not obvious, HSPPSO performance is better than PSO for multimodal function, which indicates that HSPPSO has better application foreground in avoiding premature convergence and searching global optimum.Figure 2 to 9 are adaptive value evolution curve after 10 times random iteration for four benchmark functions with HSPPSO and PSO, which indicates that HSPPSO performance is better than PSO both in initial convergence velocity and iteration time. PSO even cannot find optimum value in some tests.Figure 2.HSPPSO test function f1Figure 3.PSO test function f1Figure 4.HSPPSO test function f2Figure 5.PSO test function f2Figure 6.HSPPSO test function f3Adaptive valueIteration numberIteration numberAdaptive valueIteration numberAdaptive valueAdaptive valueIteration number Adaptive valueIteration numberFigure 7.PSO test function f3Figure 8.HSPPSO test function f4 Figure 9.PSO test function f4 6. ConclusionComparing with basic PSO, HSPPSO proposed in this paper can get better adaptive value and have faster convergence rate on condition of the same iteration step. HSPPSO provides a new idea for large scale system optimization problem.References[1] J Kennedy, R Eberhart. Particle Swarm Optimization[C].In:Proceedings of IEEE International Conference on Neural Networks, 1995, V ol 4, 1942-1948. [2] Vanden Bergh F, Engelbrecht A P. Training Product Unit Networks Using Cooperative Particle Swarm Optimization [C]. IEEE International Joint Conference on Neural Networks, Washington DC, USA.2001,126-131.[3] Shi Y, Eberhart R C. A modified particle swarm optimizer[C] IEEE World Congress on Computational Intelligence, 1998: 69- 73[4] Eberhart R C, Shi paring inertia weights and constriction factors in particle swarm optimization[C] Proceedings of the IEEE Conference on Evolutionary Computation, ICEC, 2001: 84- 88[5] Lφvbjerg M, Rasmussen T K, Krink T.Hybrid particle swarm optimizer with breeding and subpopulations[C] Third Genetic and Evolutionary Computation Conference. Piscataway, NJ: IEEE Press, 2001[6] WANG Ling. Intelligent Optimization Algorithms with Applications. Beijing: Tsinghua University Press, 2001.Iteration number Adaptive valueIteration number Adaptive value Adaptive valueIteration number。
S t e r e o M a t c h i n g 文 献 笔 记

立体匹配综述阅读心得之Classification and evaluation of cost aggregation methods for stereo correspondence学习笔记之基于代价聚合算法的分类,主要针对cost aggregration 分类,20081.?Introduction经典的全局算法有:本文主要内容有:从精度的角度对比各个算法,主要基于文献【23】给出的评估方法,同时也在计算复杂度上进行了比较,最后综合这两方面提出一个trade-off的比较。
2?Classification?of?cost?aggregation?strategies?主要分为两种:1)The?former?generalizes?the?concept?of?variable?support?by? allowing?the?support?to?have?any?shape?instead?of?being?built?u pon?rectangular?windows?only.2)The?latter?assigns?adaptive?-?rather?than?fixed?-?weights?to?th e?points?belonging?to?the?support.大部分的代价聚合都是采用symmetric方案,也就是综合两幅图的信息。
(实际上在后面的博客中也可以发现,不一定要采用symmetric的形式,而可以采用asymmetric+TAC的形式,效果反而更好)。
采用的匹配函数为(matching?(or?error)?function?):Lp distance between two vectors包括SAD、Truncated SAD [30,25]、SSD、M-estimator [12]、similarity?function?based?on?point?distinctiveness[32] 最后要指出的是,本文基于平行平面(fronto-parallel)support。
Process for producing a particle filter
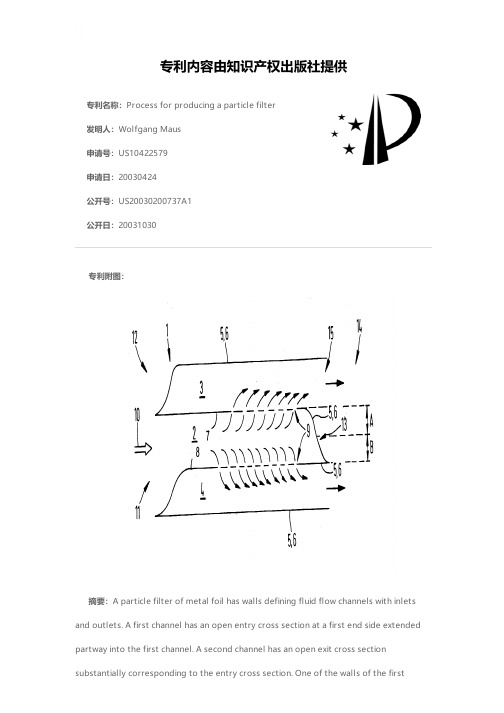
专利名称:Process for producing a particle filter发明人:Wolfgang Maus申请号:US10422579申请日:20030424公开号:US20030200737A1公开日:20031030专利内容由知识产权出版社提供专利附图:摘要:A particle filter of metal foil has walls defining fluid flow channels with inlets and outlets. A first channel has an open entry cross section at a first end side extended partway into the first channel. A second channel has an open exit cross sectionsubstantially corresponding to the entry cross section. One of the walls of the firstchannel has filter passage perforations leading to the second channel. A closure in the first channel, opposite the entry cross section, toward a second end side, closes off the first channel to the fluid. A process for producing a particle filter from metal foil includes pulling the metal foil from an endless storage device. A joining element or strip is applied to the metal foil. The metal foil is shaped into subsequent channels. The metal foil is wound or stacked to form first and second channels in opposite directions. The first channel has an open entry cross section at the first end side extending partway into the first channel. The first channel has a closure opposite the entry cross section toward the second end side. Mutually bearing contact surfaces of the channels are joined, creating a wholly metal foil particle filter.申请人:EMITEC GESELLSCHAFT FUR EMISSIONSTECHNOLOGIE MBH更多信息请下载全文后查看。
matlab 高斯滤波函数应用

MATLAB高斯滤波函数的实际应用情况1. 应用背景图像处理是计算机视觉领域的重要研究方向,而图像滤波是图像处理中的基础操作之一。
高斯滤波是一种常见且广泛应用的线性平滑滤波方法,通过对图像进行高斯模糊处理,可以去除噪声、平滑图像、减少细节等,从而提升后续图像处理算法的性能。
MATLAB作为一种强大的数值计算和数据可视化工具,在图像处理方面提供了丰富的函数库和工具箱。
其中,高斯滤波函数(imgaussfilt)是MATLAB中常用的图像平滑方法之一,它能够实现对图像进行高斯模糊处理。
2. 应用过程2.1 函数介绍MATLAB中的imgaussfilt函数可以对输入图像进行高斯模糊处理。
该函数基于高斯核(Gaussian kernel)对输入图像进行卷积操作,从而实现平滑效果。
B = imgaussfilt(A, sigma)其中,A为输入图像矩阵,sigma为高斯核标准差。
输出结果矩阵B与输入图像矩阵A具有相同的尺寸。
2.2 应用步骤使用MATLAB的高斯滤波函数进行图像处理的一般步骤如下:1.读取原始图像:使用imread函数读取待处理的原始图像,得到一个图像矩阵。
2.图像预处理(可选):根据具体应用场景,对原始图像进行预处理操作,例如灰度化、裁剪等。
3.高斯滤波处理:调用imgaussfilt函数对预处理后的图像进行高斯模糊处理,得到平滑后的图像矩阵。
4.结果显示或保存:使用imshow函数将平滑后的图像显示在屏幕上,或使用imwrite函数保存为文件。
3. 应用效果高斯滤波在实际应用中具有广泛的应用场景和良好的效果。
以下是几个典型应用情况。
3.1 噪声去除在数字摄影、医学影像等领域中,由于成像设备或传感器本身存在噪声,导致最终获取的图像存在不可忽视的噪声。
通过对这些噪声进行高斯模糊处理,可以有效降低噪声的影响,提升图像质量。
例如,在医学影像中,高斯滤波可以有效去除X射线图像中的背景噪声,提取出更清晰的关键结构。
ZEISS Mineralogic矿产高级图像处理和图像分析技术说明书

ZEISS Mineralogic MiningAdvanced Image Processing and Image AnalysisZEISS Mineralogic MiningAdvanced Image Processing and Image AnalysisAuthors: S. Graham Carl Zeiss Microscopy Ltd, UK Igor Željko Tonžetić P rincipal Consulting Mineralogist,Indigo Research Laboratories Date:June 2016IntroductionAutomated Mineralogy (AM) solutions such as Mineralogic Mining are built on a Scanning Electron Microscope (SEM) platform with Energy Dispersive Spectrometers (EDS) top rovide chemical analysis of the minerals in the sample.M ineralogic, unlike other AM techniques, also incorporates an advanced image processing and image analysis capability which utilize the high resolution images generated by the SEM from the Back Scattered Electron Detector (BSD), the Secondary Electron (SE) detector and the Cathodolumi-nescence (CL) detector.The advanced image processing has numerous benefits such as offering image processing on any input image (BSE, SE, CL etc.), improved speed of analysis through advanced seg-mentation of the input signal, flexibility in recipe creation, improved particle delineation features and an invert function that allows recognition of coal mounted in resin. These im-provements are combined with an image analysis capability that uses the high resolution input image to measure the particles. The measurements selected can have minimum and maximum acceptance criteria for analysis and also be change and processed post analysis.Utilization of BSE, SE and CL Input SignalsMineralogic Mining has the ability to use any input image that can be generated by the detectors on the SEM. Any of these signals can be utilized as the input image for the image processing and image analysis recipes. Due to thisd evelopment and the ability to utilize the variety of input images, this opens up AM to a variety of new and exciting applications. The application outlined in Figure 1 is using the CL detector and the phase searching image processingf unctionality to search for zircons in a thin section. Each analysis will have two distinctive layers; the classified false coloured mineral maps and the high resolution input image (BSE, SE, CL). These images are stored to provide as econd data layer to provide information from the analysis. In addition, because these images are stored, changes to the image analysis recipe can be applied to the analysis by repro-cessing the data using the Retrospective Analysis functionality.Advanced Image Processing – Speed and Data O ptim ization A simple way to speed up an analysis on particulate samples is to use a spot centroid analysis method whereby a single EDS analysis is taken from the centre of each particle. The particles are identified by applying a single threshold to seg-ment the image and removing the resin / background from the a nalysis. This single analysis point is used to classify thate ntire particle. However, this analysis mode is based on the assumption that the particle is fully liberated and accurately represented by this single analysis point. This assumption is seldom the truth and can produce misleading data on the samples characteristics.Figure 1 Zoned Zircons that have been identified and segmented using theCL detector in ZEISS Mineralogic Mining.The advanced image processing in Mineralogic Mining can circumvent this issue by using multiple thresholds where discrete BSE values can be grouped for a spot centroida nalysis. If we take the following example, of a particle con-taining a precious metal grain, a sulphide grain and a silicate grain; the advanced image processing recipe can be created with 3 thresholds to segment the one particle based on the 3 distinctive groups of BSE values. These grains will then have a spot centroid analysis taken from the centre and that composition will be given to the segmented grain.Advanced Image Analysis – Improved Particle D elineationWhile Mineralogic Mining has built in the advanced image processing capability, the images generated on Mineralogic have image quality and data acquisition optimization at the core of the analysis. Because of this, the optimal EDS working distance in SIGMA 300, is a mere 8.5 mm from the polep iece to the sample surface. This is a result of the optimized chamber for improved solid angle geometry of the EDS. The closer working distance provides multiple benefits to help delineate particle boundaries and further help separatet ouching particles. This works in conjunction with thea dvanced image processing library for superior particles eparation and delineation.Figure 2 Coal macerals are shown in white as the BSE threshold has beeninverted to differentiate the macerals from the resin without over stretching the BSE contrast.To further help the high resolution imaging in Mineralogics olution to delineate particles, the advanced imagep rocessing has multiple functions that can be applied.N umerous examples exist, such as delineate, erode, dilate, sharpen, smoothing and watershed that can be applied and customised in image processing recipes. Each advanced image processing function can be used to provide subtle but effective changes to improve the high resolution image for automated analysis.In addition, any remaining particles can be separated offlineafter the analysis has finished. This particle separator func-tionality is two-fold and contains; a) an automatic particle separation algorithm and b) a manual particle separation function that can be used, utilizing the high resolution input image to separate any particles the automatic algorithm fails to split.Advanced Image Analysis – Avoiding Extreme C ontrast SettingsTraditionally, any AM analysis of coal is problematic based on the insufficient difference to differentiate the coal from the dark resin background. Therefore, carnauba wax was often used to mount the coal which had a subtle difference and could be differentiated providing the contrast was stretched. Stretching the contrast setting comes with its own inherent problems associated with increased noise on the BSE image. A identified solution would be to invert the SEM signals which was never possible with AM systems. These simple problems thus outline the difficulty in using AM to successful characterise coal macerals.The advanced image processing options in Mineralogic allow the input signal (BSE) to be inverted thus (Figure 2.) allowing improved differentiation of low atomic number substances without encountering issues from having the increase the contrast levels to differentiate the coal from the resin.Advanced Image Analysis – Recipe Customizability The Image Analysis recipes can be fully customized andc reated to provide specific data required for each sample. Each recipe will contain only the selected measurements thatare required for that specific sample. The Image Analysis measurements can also be used to help select particles youwish to analyse. For example, if you only want to analyse particles that have an area greater than 100 µm2 you simply enter this into the minimum Area criteria.As the Mineralogic system stores the high resolution input images (BSE, SE, CL etc.) the Image Analysis recipe can be edited and reprocessed offline if specific measurements were missed or later deemed to be required.Advanced Image Analysis –Ball Mill vs. Stirred Mill ComparisonMineralogic Mining and its advanced image analysis measure-ments on the high resolution input images were used in a comparative study with historical AM solutions to try toa ssess the difference in particle shape and size. Mineralogic was successful in measuring the hypothesised difference in particle shape. Figure 3 summarizes the findings by showing the clear difference in bronzite, anorthite and picotite roundness from the processing within the Stirred Mill and the Ball Mill measured by Mineralogic Mining. This analysis of the particles by Mineralogic Mining is attributed to the measurements being carried out on the high resolu t ion input image.ConclusionMineralogic Mining has an advanced image processing and image analysis capability that is built into the core of the AM solution. These capabilities have the ease of use, flexibility and application suitability to be used and to solve an array of problems across the fields of geology, mineralogy, metallurgy and material science.Figure 3 Shape factor comparisons between the Ball Mill and the Stirred Mill as measured by ZEISS Mineralogic Mining. Here the data is suggesting that the Ball Mill is contributing to more rounded particles.Carl Zeiss Microscopy GmbH Notfortherapeutic,treatmentormedicaldiagnosticevidence.Notallproductsareavailableineverycountry.ContactyourlocalZEISSrepresentativeformoreinformation.EN_42_13_199|CZ1-218|Design,scopeofdeliveryandtechnicalprogresssubjecttochangewithoutnotice.|©CarlZeissMicroscopyGmbH。
高斯模糊算法

How to program a Gaussian Blur without using 3rd party librariesWhat is a Gaussian Blur?Something I found fairly difficult to find online was a simple explanation on how to implement my own Gaussian Blur function. This article will explain how to implement one.The basic idea behind a Gaussian Blur is that each pixel becomes the average of the pixels around it, sort of. Instead of simply taking the average of all the pixels around it, you take a weighted average. The weighting of each pixel is greater if it is closer to the pixel you are currently blurring. The Gaussian Blur technique simply describes how to weigh each neighboring pixel. Imagine the pixel you are currently blurring is located at the peak of the hump in the image below and the pixels around it are receiving less weight as they get farther away. You can consider the image below to be considering up to 5 pixels away, this means the Gaussian blur has a ‘window’ of size 10, also known as a kernel size.This is where the Gaussian equation comes in, using it we can find out how much weight we want each pixel to receive and pixels receive less weight depending on its distance to the center pixel.Let’s explain what everything in this equation means:σ(lowercase sigma) – This is the blurring factor, the larger this number is, the smoother/blurrier the image becomes.e - This is simply euler’s number, a co nstant, 2.71828182846x – This is the distance from the origin — The horizontal distance to the center pixel.y –This is the distance from the origin —The vertical distance to the center pixel.This means that x and y in this equation will be zero for the center pixel (the current pixel we want to blur), and x^2 + y^2 increases as we get farther away from the center, causing lower weights for pixels farther away.Calculating a Gaussian Matrix, also known as a KernelLet’s say we wanted to find out how we would weigh neighboring pixels if we wanted a ‘window’ or ‘kernel size’ of 3 for our Gaussian blur. Of course the center pixel (the pixel we are actually blurring) will receive the most weight. Lets choose a σof 1.5 for how blurry we want our image.Here’s what our weight window would look like:With each weighting evaluated it looks like this: (Notice that the weighting for the center pixel is greatest)If you’re pretty observant you’ll notice that this matrix doesn’t add up 1. For this to represent a weights, all the weights when summed together will have to add up to 1. We can multiply each number by 1/sum to ensure this is true. The sum of this matrix is 0.4787147. This means we need to multiply the matrix by 1/0.4787147 so that all elements end up adding up to 1. We finally get the following matrix which represents how we will weight each pixel during a blur.Applying this Gaussian Kernel Matrix to an image.Lets say this is our image: (Each number can represent a pixel color from 0-255)To blur this image we need to ‘apply’ our kernel matrix to each pixel, i.e. we need to blur each pixel.Let’s say we want to blur pixel #25 (the p ixel whose color is 25 in our image matrix). This means we get pixel 25 and replace 25 with the average of its neighbors. We weigh each of the neighbors (and 25 itself) with the kernel matrix we created earlier. So it would go as follows:Now that we have weighed each neighbor appropriately, we need to add up all the values we have and replace 25 with this new value!Loop this process with every single pixel and you will have a blurred image.CaveatsCorner PixelsWhen you need to apply this kernel matrix to a pixel in a corner, where you don’t have enough room to apply the matrix, a neat trick is to either ‘wrap around’ the image and use the pixels on the opposite side. This tends to work well if the image is intended to be tiled (typically not though) If you look at the image of the fish at the top of this article, you can tell that wrapping was used for the top row of the image since it is so dark. Another very simple solution is to just copy one of the nearest pixels into spots which are missing pixels so you can complete the process. The end result is definitely acceptable.Time ComplexityIt turns out that the simple procedure described above can be improved greatly. The time complexity of the above algorithm isO(rows*cols*kernelwidth*kernelheight). Gaussian blur has a special property called separability, the blur can be applied to each kernel row first in 1 pass, then each kernel column in another and you can achieve the same result. This means that you do not need to traverse the entire kernel matrix for each pixel. This lowers the time complexity toO(rows*cols*kernelheight + rows*cols*kernelwidth).You can read more on the Separability property on the Gaussian Blur wikipedia page.。
高斯滤波器在子弹三维图像特征提取中的应用

高斯滤波器在子弹三维图像特征提取中的应用乔培玉;何昕;魏仲慧;王方雨;林为才【期刊名称】《液晶与显示》【年(卷),期】2012(27)5【摘要】In order to compare the bullet automatically, the 3D texture information acquisition system of the bullet based on the structure light is established. Because the central axis and acquisition system axis 31 is difficult to completely overlap when we acquired three-dimensional information of bullets, so the corresponding coordinate rotation is need, especially when the bullet was deformed, it is unable to utilize the information that the bullet is approximate a cylindrical, this is very difficult for bullet extraction. Therefore this paper used the Gaussian approximation filter to get the mean line determined by Gauss filter, and then 3-D bullet information subtracts from mean line determined by Gauss filter, the bullet texture was extracted. 'Twelve order IIR digitai Gauss filter is designed using the impulse response method, its amplitude transmission characteristic deviation is less than 1.38% , significantly better than the ISO11562 specified 2. 5%. This method makes the bullet extraction process more simply, and the extraction result is more accurately, improving the accuracy of bullet comparison obviously.%为了弹痕的自动比对,建立了基于结构光的子弹三维纹理信息获取系统.由于在采集三维信息时子弹的中轴线与采集系统的y坐标轴很难做到完全重合,这需要进行相应的坐标旋转,尤其是在子弹变形时,无法利用子弹近似圆柱提取这一信息,这都给弹痕提取带来了很大的困难.本系统采用高斯逼近滤波器的方法获取高斯滤波中线,然后将三维弹痕信息与高斯滤波中线相减,进而提取出子弹的弹痕信息.利用冲激响应不变法设计了十二级的ⅡR型数字高斯滤波器,所设计的高斯逼近滤波器最大幅度偏差只有1.38%,大大优于ISO11562规定的2.5%的最大幅度偏差.此方法使得弹痕提取过程更简单,提取结果更精确,对后续弹痕比对的准确率有明显的提升.【总页数】5页(P708-712)【作者】乔培玉;何昕;魏仲慧;王方雨;林为才【作者单位】中国科学院长春光学精密机械与物理研究所,吉林长春 130033;中国科学院研究生院,北京 100049;中国科学院长春光学精密机械与物理研究所,吉林长春 130033;中国科学院长春光学精密机械与物理研究所,吉林长春 130033;中国科学院长春光学精密机械与物理研究所,吉林长春 130033;中国科学院长春光学精密机械与物理研究所,吉林长春 130033【正文语种】中文【中图分类】TN911.73【相关文献】1.多个空间高斯源信号情况下成组三维图像特征提取方法 [J], 武兴杰;曾令李;李明;沈辉;王晓红;胡德文2.基于高斯滤波器及费合尔准则的特征提取方法 [J], 李晋徽;杨俊安;项要杰3.基于非高斯二维Gabor滤波器的生物特征提取算法 [J], 陈熙;张戈4.基于高斯和近似的扩展切片高斯混合滤波器及其在多径估计中的应用 [J], 陈杰;程兰;甘明刚5.基于高斯小波滤波器的语音识别特征提取方法 [J], 孙颖;张雪英因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
A Gaussian Process Guided Particle Filter forTracking3D Human Pose in Video Suman Sedai,Mohammed Bennamoun,Member,IEEE,and Du Q.Huynh,Member,IEEEAbstract—In this paper,we propose a hybrid method that com-bines Gaussian process learning,a particlefilter,and annealing to track the3D pose of a human subject in video sequences. Our approach,which we refer to as annealed Gaussian process guided particlefilter,comprises two steps.In the training step, we use a supervised learning method to train a Gaussian process regressor that takes the silhouette descriptor as an input and produces multiple output poses modeled by a mixture of Gaussian distributions.In the tracking step,the output pose distributions from the Gaussian process regression are combined with the annealed particlefilter to track the3D pose in each frame of the video sequence.Our experiments show that the proposed method does not require initialization and does not lose tracking of the pose.We compare our approach with a standard annealed particlefilter using the HumanEva-I dataset and with other state of the art approaches using the HumanEva-II dataset. The evaluation results show that our approach can successfully track the3D human pose over long video sequences and give more accurate pose tracking results than the annealed particle filter.Index Terms—3D human pose tracking,Gaussian process regression,particlefilter,hybrid method.I.I NTRODUCTION AND M OTIVATIONI MAGE and video-based human pose estimation and track-ing is a popular research area due to its large number of applications including surveillance,security and human computer interaction.For example,in video-based smart sur-veillance systems,3D poses can be used to infer the action of a subject in a scene and detect abnormal behaviors.It can provide an advanced human computer interface for gaming and virtual reality applications.Also,3D poses of a person computed over a number of video frames can be useful for biometric applications to recognize a person.These applica-tions require simple video cameras or still images as input and,as a result,provide a low cost solution in contrast to marker-based systems.Manuscript received January5,2012;revised September15,2012and March13,2013;accepted June12,2013.Date of publication July4,2013; date of current version September12,2013.This work was supported in part by the ARC Discovery Project under Grant DP0771294.The associate editor coordinating the review of this manuscript and approving it for publication was Prof.Nikolaos V.Boulgouris.S.Sedai was with the University of Western Australia,Crawley,WA6009, Australia.He is now with IBM Research Australia,Melbourne3000,Australia (e-mail:ssedai@).M.Bennamoun and D.Q.Huynh are with the University of Western Australia,Crawley,WA6009,Australia(e-mail:mohammed.bennamoun@ .au;du.huynh@.au).Color versions of one or more of thefigures in this paper are available online at .Digital Object Identifier10.1109/TIP.2013.2271850Human pose estimation and tracking systems can be broadly classified into three different approaches:discriminative, generative and hybrid methods.In generative methods,the output pose is estimated by searching the solution space for a pose that best explains the observed image features[1],[2].In this approach,a generative model is constructed which measures how close the hypothesized pose is to the observed image features.A hypothesized pose that is most consistent with the observed image features is chosen as the output pose.Particlefilter[2], [3]is a generative tracking method to estimate the pose in each frame using an estimate of the previous frame and the motion information.Given an image of a human subject,there are multiple3D human poses associated with the image.Such pose ambiguities can be resolved using images from multiple camera views[4].In discriminative methods,a regression function that maps image features to the pose parameters is obtained using supervised learning[5],[6].Although discriminative methods can quickly estimate the3D pose,they can produce incorrect predictions for new inputs if the system is trained using small datasets.Moreover,the relationship between image features and the human pose is often multimodal.For example,when the human silhouette is used as an image feature,one sil-houette can be associated with more than one pose,resulting in ambiguities.In such cases,multiple discriminative models are needed to build one-to-many relationships between image features and poses[5],[7].Discriminative methods are powerful for specific tasks such as human pose estimation as they are only based on the mapping from the input to the desired output.The generative methods,on the other hand,areflexible because they provide room for using partial knowledge of the solution space and exploit the human body model to explore the solution space. Due to their different ways of predicting thefinal output,the two methods are considered to complement each other.Thus hybrid generative and discriminative methods have shown to have the potential to improve pose estimation performance.As a result,they have gained more attention recently.In hybrid methods,such as the ones presented in Refs.[8], [9],a discriminative mapping function is used to generate a pose hypothesis space.The pose is then estimated by searching the hypothesis space using a generative method.The method of Ref.[8]is only based on pose estimation from a single image and is therefore unable to track the pose from a video sequence.Moreover,these methods assume that the pose hypothesis space generated from the discriminative model is1057-7149©2013IEEEalways correct and hence fail to handle the case when the discriminative model predicts incorrect poses.In this paper,we propose a hybrid discriminative and generative method to track the3D human pose from both single and multiple cameras.For the discriminative model,we use a mixture of Gaussian Process(GP)regression models, which are obtained by training GP models in different regions of the pose space.The GP regression has the advantage of being able to give a probabilistic estimate of the3D human pose.It provides an effective way of incorporating more confident discriminative predictions into the tracking process while discarding the uncertain ones.To the best of our knowledge,this is thefirst hybrid method that takes into account the predictive uncertainty of the discriminative model and combines it with a generative model to improve pose estimation.We treat the probabilistic output from the GP regression as one component of the hypothesis space.In the tracking step,we combine this hypothesis space with the hypothesis space obtained from the motion model and the search for the optimal pose is performed using an annealed particlefilter.A major contribution of this paper is the introduction of a novel method to combine Gaussian Process regression and annealed particlefilter for3D human pose tracking. Our method can probabilistically discard uncertain predictions from the regression model and hence only use predictions that are likely to be correct to track the3D pose.Moreover,our method can resolve ambiguities when motion information is used along with the image cues from multiple views during pose tracking.The organization of the paper is as follows.Section II presents the related work.Section III presents the details of the training of the discriminative model.Section IV presents the proposed AGP-PF method for3D human pose tracking. Section V provides the experimental results and Section VI concludes the paper.II.B ACKGROUND AND R ELATED W ORKIn discriminative estimation,a direct mapping between image features and the pose parameters is learned using a training dataset.Examples of discriminative learning includes nearest neighbor based(example based)regression[6]and sparse regression[10],[11].Often the relationship between the image features and the pose space is multimodal.The multimodal relationship is established by learning the one-to-many mapping functions that are defined in terms of a mixture of sparse regressors[5],[7]or Gaussian Process regression[12],[13].This setting produces a multiplicity of the pose solutions that can either be ranked using a gating function[14]or be verified using an observation likelihood [8]or be disambiguated using temporal constancy[11].For effective pose estimation using a discriminative approach,it is important that image features are compact and distinctive. Approaches such as[15],[16]use a metric learning method to suppress the feature components that are irrelevant to pose estimation.Recent research shows that feature selection and pose estimation can be carried out using regression trees[17]and random forest[18].Other methods such as[19],[20] use dimensionality reduction to make the feature vector more distinctive for pose estimation.The fusion of multiple image cues based on regression has also been used to improve the pose estimation performance[21],[22].In another approach [23],2D trajectories of the human limbs in a video are used as features and the mapping between the trajectory features and the3D poses is modelled using Gaussian Process regression. It has also been shown that pose estimation performance can be improved by taking into account the dependencies between the output dimensions,e.g.,using structural SVM[24]and Gaussian Process regression[25].Dimensionality reduction can also be used to address the correlation between output dimensions,e.g.,the training of mapping function is performed in a lower dimensional subspace of features and pose so as to make use of unlabelled data[26].In generative inference,the pose that best explains the observed image features is determined from a population of hypothesized poses.A search algorithm is used to search the prior pose space for the pose that exhibits the maximum likelihood value for the observed image feature[1],[27]. Generative methods thus consist of three basic components:a state prior(pose hypotheses),an observation likelihood model (matching function),and a search algorithm.The search algorithm can be local or global in nature.Most of the local search algorithms employ Newton’s optimization method[4],[28].Global search methods are based on stochas-tic sampling techniques where the solution space is represented by a set of points sampled according to some hypotheses. Successful global search algorithms include annealing[27], Markov Chain Monte-Carlo[29],covariance scaled sampling [1],and Dynamic Programming[30].In order to refine the pose tracking,the sampling based global search techniques have been combined with some local search techniques[31], [32].In order to reduce the search space,the pose prior space based on a predefined set of activities,such as walking and jogging,has been used[33].Pose priors based on models that constrain the human body pose to physically plausible config-urations have also been used to reduce the search space[34]. In order to compute the likelihood of a pose hypothesis, image features,such as silhouettes,edges[1],[27],color [29],[30]and learned features[35],have been used.First, the human body model corresponding to the hypothesized pose is projected onto the image feature space to obtain a model feature(a.k.a template feature).The likelihood value is computed as a similarity measure between the observed image feature and the template feature.For3D pose esti-mation,human body models based on cylinders[33],[36], superquadrics[37]and3D surfaces[4],[9]are commonly used.For2D pose estimation,a simple rectangular cardboard model has been used[38],[39].To reduce the complexity of tracking in higher dimensions, prior models based on a lower-dimensional representation of the pose have been used.The commonly used models include linear models such as the Principal Component Analysis [33]and non-linear approximation such as the Mixture of Factor Analysers[40].In another approach[41],the Restricted Boltzmann Machine is used to model human motion in adiscrete latent space.A more commonly used non-linear dimensionality reduction technique for pose tracking is the Gaussian Process Latent Variable Model(GPLVM)[42],[43], which does not always provide a smooth latent space as required for tracking.To overcome this problem,a Gaussian Process Dynamical Model(GPDM)[44]which uses non-linear regression to model the motion dynamics in a latent space in a GPLVM framework can be employed.Tracking in the latent space often has a lower computational complexity;however, it has also been argued that models based on dimensionality reduction have limited capacity[45].In the hybrid methods,discriminative and generative approaches are combined together to exploit their complemen-tary power to predict the pose more accurately.To combine these two methods,the observation likelihood obtained from a generative model is used to verify the pose hypotheses obtained from the discriminative mapping functions for pose estimation[8],[9].In other work,e.g.,[45],generative and discriminative models are iteratively trained using Expectation Maximization(EM).In each step of the EM,the predictions made by one model are used to train the other model. Recently,the work of Ref.[46]combines the discriminative and generative models by applying distance constraints to the predictions made by the discriminative model and verifying them using image likelihoods.None of these approaches utilizes the prediction uncertainty of the discriminative model to track the3D human pose.In this paper,we propose a hybrid method that takes into account the prediction uncertainty of the discriminative model and effectively combines it with the generative model.We use Gaussian Process regression as the discriminative model.The probabilistic output poses from the discriminative model are integrated with a particlefilter and a subsequent annealing step for3D human pose tracking.Consequently,the pose tracking performance is improved,since the search space is reduced to only include the correct hypotheses generated from the discriminative model combined with the hypotheses of the motion model.This is an extension of our previous work[47],where we used a Relevance Vector Machine as a discriminative model combined with a particlefilter for 2D pose tracking.GP regression has been used in Ref.[48] to learn the dynamical model and the observation likelihood model for object tracking.However,their method does not involve a mapping from the feature space to the output space. Our method,on the other hand,uses GP regression to learn a discriminative model which gives a conditional distribution of the3D human pose.In this paper,we use a generic form of the motion model and observation likelihood model for tracking.In another purely discriminativefiltering-based approach[49],the unreliability of the observation is modelled using a probabilistic classifier to regulate the predictions from multiple regressors.Our method,on the other hand,models the prediction uncertainty by the variance of the prediction from the Gaussian Process regressor and hence does not require a separate classifier to model the unreliability.Furthermore, unlike[49],our method incorporates the image likelihoods obtained from the generative model to verify the pose hypothe-ses and to estimate the target statedistribution.Fig.1.A block diagram showing the training of the mixture of Gaussian Process regression models.III.T RAINING S TEPIn the training step,we use supervised learning to construct a multimodal mapping between the shape descriptor space and the3D pose space.Once the mapping model is trained, the multimodal3D poses can be estimated using the trained model.A block diagram showing the training of our mixture of Gaussian Process regressors is shown in Fig.1.Given the training images,wefirst extract the silhouette images using background subtraction[50].Then,we extract the silhouette descriptors using Discrete Cosine Transform(DCT).We divide the3D pose space into K clusters and we train the mapping from the silhouette descriptor space to the3D pose space of each cluster.Thefinal output of the training stage is a mixture of Gaussian Process regression models.A.Feature and Pose RepresentationA review of many shape and appearance descriptors that are applicable to discriminative pose estimation is available in Ref.[51].In this paper,we use the silhouette as an image feature and the Discrete Cosine Transform(DCT)of the silhouette as the shape descriptor.We use the DCT because it is simple to compute and yet more discriminative than other shape descriptors[51],[52].It is shown in Ref.[52]that the DCT descriptor outperforms other shape descriptors such as Histogram of Shape Contexts and Lipschitz embeddings for human pose estimation.The DCT descriptor,which belongs to the family of orthog-onal moments,represents the silhouette image by the sum of two dimensional cosine functions of different frequencies characterized by the various coefficients.The DCT has been popularly used for image compression.First a silhouette window is cropped from the foreground image obtained from background subtraction.As shown in Fig.2,the cropped imageputation of the DCT descriptor from a silhouette image.is scaled to the size of H ×W and the DCT descriptor for the image window is computed asM p ,q =W −1 x =0H −1 y =0f p (x )g q (y )I (x ,y ),(1)for p =0,...,W −1;q =0,...,H −1,where f p (x )=αp cos {p π(x +0.5)/W };g q (y )=αq cos {q π(y +0.5)/H };and αp =√(1+min (p ,1))/W and αq =√(1+min (q ,1))/H .We take W =64and H =128pixels.This window size is the most commonly used size for human subjects that are in an upright pose.The DCT descriptor has a nice property that most of the rich information about the silhouette is encoded in just a few of its coefficients.We empirically found that setting the descriptor to a 64dimen-sional vector (corresponding to 8rows and 8columns of the DCT matrix M )is sufficient to represent each silhouette.In this paper,we assume that the subject is upright in the image.Although the DCT descriptor is not rotation invariant,it does not affect the pose estimation so long as the human subject is in an upright pose in the image.It is possible to handle athletic motions such as handstands and cartwheels by training a separate discriminative model for such activities and using a classifier to select the most appropriate model for an input feature.Since the silhouette is centered and re-scaled to the standard size,the descriptor is invariant to translation and scale.We represent each 3D pose as the relative orientations of the body parts in terms of Euler angles.We take the torso as the root segment and the orientation of the torso segment is measured with respect to a global coordinate system.The orientations of the upper arms are measured relative to the orientations of the torso.The orientations of the lower arms are measured relative to the upper arms.Relative orientations between the upper legs and the torso and between the lower and upper legs are defined in a similar manner.B.Mixture of Gaussian Process (MGP)RegressorsWe use a supervised learning technique to estimate the 3D pose directly from the silhouette descriptor.We learn the piecewise mapping of Gaussian Process (GP)regressor [53]from the shape descriptor space x ∈R m to the 3D pose space y ∈R d using the training data samples T = x (i ),y (i ) ,for i =1,...,N ,where N is the number of training samples.With such a mixture of Gaussian Process (MGP)regressionmodel [54],the GP regressors are trained for each region ofthe data space and a separate classifier is used to select the GP model that is appropriate for an input feature.First,the 3D pose space is partitioned into K clusters using the hierarchical k-means algorithm.The training set is then divided into K subsets,T 1,...,T K ,such that x (i ),y (i ) ∈T k if y (i )belongs to the k th cluster.We assume that the components of the output vector y are independent of each other so we train the separate GP regression model for each output component of y =[y 1,...,y d ]T .Without loss of generality,we drop the subscript q in y q (which represents the q th component of y )and present only a one-dimensional Gaussian Process regression.In each cluster,the relationship between x (i )and each component y (i )of the training pose instance y (i )(the superscript (i )represents the i th training instance)is modeled byy (i )=f k (x (i ))+ (i )k ,(2)where (i )k ∼N (0,β−1k )and the βk is the hyper-parameter representing the precision of the noise.From the definition of a Gaussian Process [53],the joint distribution of the output variables is given by a Gaussian:p (y k |X k )=N (0,C k ),(3)where y k = y (i ),...,y (N k ) T ,X k =x (1),...,x (N k ) T for all y (i )∈k th cluster,and C k is a covariance matrix whose entries are given by C k (i ,j )=κ(x (i ),x (j ))+β−1δij .The covariance function κ(x (i ),x (j ))can be expressed asκ(x (i ),x (j ))=θk ,1exp −θk ,22 x (i )−x (j ) 2 +θk ,3,(4)where the parameters k = θk ,1,θk ,2,θk ,3,βkare referred to as the hyper-parameters of the GP and δij is the Kronecker’s delta function.This covariance function combines the Radial Basis Function (RBF)and a bias term.The learning of the hyper-parameters is based on the evaluation of the likelihood function p (y k | k )and the maximization of the log likelihood using a gradient based optimization technique such as con-jugate gradient.The log likelihood function for a Gaussian process can be evaluated asln p (y k | k )=−12ln |C k |−12y T kC −1k y k −N k2ln (2π).(5)Once the hyper-parameters are trained,the next step isto predict the output pose component y k ∗for the unseen test feature vector x ∗.This requires the evaluation of the predictive distribution p (y k ∗|y k ,X k ).Let us define y k ∗=y (1),...,y (N K ),y k ∗ T ,whose joint distribution is given byp (y k ∗)=N (0,C k ∗),(6)where C k ∗∈R (N k +1)×(N k +1)is a covariance matrix.That is,C k ∗= C k c k ∗c T k ∗c k ,(7)where the vector c k ∗has elements c k ∗(i )=κ(x (i ),x ∗),fori =1,...,N k ,and the scalar c k =κ(x ∗,x ∗)+β−1k=θk ,1+θk ,3+β−1k from Eq.(4).The conditional distribu-tion p (y k ∗|y k ,X k )is a Gaussian distribution with mean and variance given byy k ∗=c T k ∗C −1k y k(8)σ2k (x ∗)=c k −(c k ∗)T C −1k c k ∗.(9)In this manner,we obtain the prediction for each componentof the pose vector.Let y q ,k ∗be the prediction for the q th com-ponent of the pose vector and σ2q ,k (x ∗)be the corresponding variance.The full pose vector is y k ∗=y 1,k ∗,...,y d ,k ∗ T and the corresponding covariance matrix becomes k (x ∗)=diag (σ21,k ∗,...,σ2d ,k ∗).The multimodal relationship between the silhouette descriptor x and the 3D pose vector y is thus represented by a mixture of K regressors:p (y |x ∗)=K k =1g k (x ∗)N (y k ∗, k (x ∗)),(10)where g k (x )is a K -class classifier which gives the probabilitythat the k th GP regressor is selected to predict the given feature instance x ∗.We model the multi-class classifier g k (x )as a multinomial logistic regressor (i.e.,the softmax function):g k (x )=exp (−v T k x ) Kj =1exp −(v Tj x ),(11)where v k is an m -dimensional parameter vector.The parame-ter vectors v 1,...,v K are estimated from the training data x (i ),l (i ) N i =1,where l (i )= l (i )1,...,l (i )K and l (i )kdenotes the probability that feature vector x (i )belongs to the k th cluster.We set l (i )k=1if y (i )belongs to the k th cluster,otherwise we set it to 0.The maximum likelihood estimation of the parame-ter vectors is then performed using the iteratively reweighted least squares method.We use a fast method based on bound optimization described in [55]to train these parameter vectors.Instead of the multinomial logistic regressor,an alternative is to model the multi-class classifier g k (x )as a function of the variance of the k th GP mode,i.e.,by setting g k (x )∝1/trace ( k (x )).As the average variance of the prediction is lower when the test feature is closer to the training samples,a higher weight is given to the cluster which is closer to the test feature vector.In our empirical evaluation shown in Table III,we found that the pose estimation performance of the MGP regressor is improved when the multinomial logistic regressor is used in comparison to the case when the function of the variance is used.1)Pose Space Clustering:The motivation behind clustering the pose space and learning discriminative model in each cluster is to model the depth ambiguities introduced by the silhouettes.For that purpose,we cluster the pose space into six partitions using hierarchical k-means.At the first level,the pose space is partitioned into four clusters representing poses which face forward,backward,left and right with respect to the camera by a careful initialization.At the second level,each cluster that represents the lateral pose (left or right)is further partitioned into two clusters.Figure 3shows the representative poses in each cluster alongwithpose spaceC1C2C3C4C5C6Fig.3.Representative pose in each cluster obtained using hierarchical k-means.Each pose is rendered as a 3D cylindrical model with red denoting left limbs and blue denoting right limbs.Silhouettes that give rise to ambigu-ous poses are also shown (Figure best viewed in color).the silhouettes that give rise to ambiguous poses.Clusters C1and C2model the forward-backward ambiguity as the silhouette S1could be generated from the poses that are both in C1and C2.Similarly,clusters C3and C4model the ambiguity associated with the silhouette S2;clusters C5and C6model the ambiguity associated with the silhouette S3.Other approaches address the ambiguities by sampling from the multimodal posterior obtained from a mixture of regressors models [5],[7].In another interesting approach [56],it is shown that the ambiguous poses can be distinguished by sampling from the posterior in a latent space that is shared by both the observation and the pose spaces.In their approach,the posterior in the latent space is obtained using the GPLVM model.This approach of hard clustering could result in a poor prediction performance at the boundary of the clusters.How-ever,since we used the Gaussian Process regression as the discriminative model,such poor predictions could often be detected as they tend to produce larger prediction variances.In Section IV-C,we discuss the adoption of a probabilistic method to discard poor predictions made by the MGP regres-sion model during the tracking of the 3D pose.The method of Ref.[12]provides an interesting solution to the boundary problem in that a MGP regressor is trained on the subset of the data that is closest to the test feature.However,their method requires computing the GP hyper-parameters for each test image.Fig.4.A block diagram showing the testing of our proposed3D poseTracking System.The3D human pose for each video frame is predicted fromthe mixture of GP regressions;The tracking incorporates the predicted pose,prediction uncertainty,edges and silhouette observations using the AGP-PFmethod.IV.P OSE T RACKINGIn the tracking step,our goal is to determine the3Dpose of a person in the video frames.The block diagram ofour proposed tracking method is shown in Fig.4.For eachimage frame in a video,the human pose is predicted using aMixture of Gaussian Process(MGP)regressors(Section III).The output of the MGP regressors is a mixture of Gaussiandistributions.The output distribution is taken as one com-ponent of the hypothesis space.The other component beingthe output pose distribution of the previous frame.Theoutput pose is then computed by searching the combinedpose hypothesis space using our proposed AGP-PF trackingmethod.Our method needs a human body model to compute thelikelihood of each pose hypothesis.In this paper,we use a3D cylindrical model of the human body.Each body part isrepresented by a tapered cylinder as shown in Fig.5.Thelength of the body parts and the diameters of the cylinders areassumed to befixed for a given person and is initialized at thebeginning of the tracking.We use human kinematic constraints to determine thedegrees of freedom(DOF)of the pose.The torso has sixdegrees of freedom after incorporating the global translationand rotation.The head,upper arms and upper legs have threedegrees of freedom each.The forearms have one degree offreedom each(they are only allowed to rotate about theirY axis)and the lower legs have two degrees of freedom(they are allowed to rotate about their X and Y axes).Hencethe human body model shown in Fig.5has27degrees offreedom.We enforce the joint angle limit by restricting thevariation of the angles to a kinematically possible range.Thekinematically possible angles are computed from the trainingdata.In this paper,we use our proposed Gaussian Process guidedparticlefilter for pose tracking.Below,we willfirst givea review of a standard particlefilter(for completeness)inSection IV-B followed by our proposed Gaussian Processguided particlefilter for pose tracking in SectionIV-C.Fig.5.A3D human body model in a neutral pose.Each body part of themodel is approximated by a tapered cylinder.The X-axis is denoted by alarge circled dot and is perpendicular to both the Y-and Z-axes.A.Likelihood distributionGiven an image observation denoted by r t at time t,thelikelihood density p(r t|y t)measures how well a hypothesizedpose vector y t explains the image observation r t.In ourmethod,the likelihood value is computed by matching the3Dhuman body model corresponding to the hypothesized posewith the observed image features.We use the silhouette andedge features of the image to compute the likelihood of eachpose state vector.Wefirst project the3D cylindrical modelcorresponding to the hypothesized pose onto the image planeusing the camera calibration matrix to obtain the hypothesizededge features and the hypothesized region features.The likeli-hood value is computed by matching the hypothesized featureswith the observed image features.We use the silhouette andedge features of the observed image to compute the likelihoodbased on two cost measures:silhouette cost and edge cost,asdetailed below.1)Silhouette Cost:The silhouette cost measures how wellthe region projected by the hypothesized modelfits into theobserved silhouette.Given a3D pose hypothesis,wefirstgenerate a binary image H of the corresponding3D humanbody model such that H(x,y)=1if the pixel corresponds tothe hypothesized foreground and H(x,y)=0otherwise.Anexample of a hypothesized foreground is shown in Fig.6(d).Let Z be the observed silhouette image as shown in Fig.6(b).The part of the silhouette Z that is not explained by the modelregion H is given by R1=Z∩¯H,where∩denotes the pixel-wise“and”operator and¯H denotes the inverted image of H.Similarly,the part of the model region that is not explained bythe silhouette is given by R2=H∩¯Z.Since our objective isto minimize these unexplained silhouette and model regions,the cost can be expressed asC sil=0.5Area(R1)Area(Z)+Area(R2)Area(H),(12)。