Hadoop集群测试报告
hadoop实验报告

hadoop实验报告
Hadoop是一个开源的分布式存储和分析框架,是用Java语言开发的,它提供了一种
松散耦合的并行处理模型,使得在硬件节点之间进行大数据分布式处理变得容易和可扩展。
从原理上讲,它把大量的计算任务分成若干小任务,然后把这些子任务分发给有大量可用
计算节点的集群。
它使用了MapReduce编程模型,可以有效地处理海量数据。
Hadoop主要由HDFS(Hadoop分布式文件系统)和YARN(Yet Another Resource Negotiator)2个子系统组成。
HDFS定位是分布式文件系统,它提供了一种可扩展的、高
性能和可靠的数据访问机制。
而MapReduce是Hadoop旗下主打的分布式数据处理框架,YARN是负责资源调度和管理的核心模块,它基于提交的任务的数量,量化资源的分配。
最近,在学校的课程中,我学习如何在Hadoop上安装和实现一些简单的任务。
利用Hadoop实验,我建立了一个模拟的三节点的Hadoop集群,其中包括一个namenode和两
个datanode。
通过搭建Hadoop环境,并运行一些MapReduce程序,加深了对Hadoop分布式数据存储、计算和管理系统架构和工作原理的理解。
这次实验,也为进一步开展更多实践性的Hadoop应用奠定了基础,以上只是一个简
单认识,采用实践的方式,才是对Hadoop的最好的学习方式。
实际上,才能对Hadoop
的功能有一个更加深入的理解,才能真正发挥好这个强大的分布式存储和计算系统,给用
户带来更好的体验。
Hadoop大数据平台-测试报告及成功案例

select fmc.client_no, acct.base_acct_no, trans.tran_amt, trans.tran_date, acct.internal_key
Hive表数据导出
测试步骤:
1.Hive创建一张与待导出表完全相同的数据表export,并设置对应的数据格式(例如使用‘|’作为分隔符)
2.HiveETL将数据导入到export表中
3.使用“hdfs dfs -get”从HDFS中导出数据
Snappy+Parquet
=> txt
导出txt
到本地磁盘
导出数据
行数
导出数据
文件大小
“Groupby” SQL
13.31s
11s
18336384
837MB
“Join” SQL
38.38s
25s
57152010
3.3GB
HBase表数据导出
测试步骤:
1.Hive中创建一张数据表,映射到HBase
2.Hive中创建一张与HBase映射表完全一致的数据表export,并设置对应的数据格式(例如使用‘|’作为分隔符)
select his.tran_date, his.branch, his.tran_type, sum(his.tran_amt), count(*), count(distinct his.base_acct_no), his.cr_dr_maint_ind, y
from
sym_rb_tran_hist his
hadoop集群搭建实训报告

实训项目名称:搭建Hadoop集群项目目标:通过实际操作,学生将能够搭建一个基本的Hadoop集群,理解分布式计算的概念和Hadoop生态系统的基本组件。
项目步骤:1. 准备工作介绍Hadoop和分布式计算的基本概念。
确保学生已经安装了虚拟机或者物理机器,并了解基本的Linux命令。
下载Hadoop二进制文件和相关依赖。
2. 单节点Hadoop安装在一台机器上安装Hadoop,并配置单节点伪分布式模式。
创建Hadoop用户,设置环境变量,编辑Hadoop配置文件。
启动Hadoop服务,检查运行状态。
3. Hadoop集群搭建选择另外两台或更多机器作为集群节点,确保网络互通。
在每个节点上安装Hadoop,并配置集群节点。
编辑Hadoop配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml等。
配置SSH无密码登录,以便节点之间能够相互通信。
4. Hadoop集群启动启动Hadoop集群的各个组件,包括NameNode、DataNode、ResourceManager、NodeManager 等。
检查集群状态,确保所有节点都正常运行。
5. Hadoop分布式文件系统(HDFS)操作使用Hadoop命令行工具上传、下载、删除文件。
查看HDFS文件系统状态和报告。
理解HDFS的数据分布和容错机制。
6. Hadoop MapReduce任务运行编写一个简单的MapReduce程序,用于分析示例数据集。
提交MapReduce作业,观察作业的执行过程和结果。
了解MapReduce的工作原理和任务分配。
7. 数据备份和故障恢复模拟某一节点的故障,观察Hadoop集群如何自动进行数据备份和故障恢复。
8. 性能调优(可选)介绍Hadoop性能调优的基本概念,如调整副本数、调整块大小等。
尝试调整一些性能参数,观察性能改善情况。
9. 报告撰写撰写实训报告,包括项目的目标、步骤、问题解决方法、实验结果和总结。
Hoop集群测试报告

H o o p集群测试报告 Prepared on 24 November 2020测试报告一、集群设置1.服务器配置磁盘44T磁盘吞吐预计100M/s2.Had oop服务部署HADOOP-12-151 NameNode、Balancer、Hive Gateway、Spark Gateway、ResourceManager、Zk ServerHADOOP-12-152 DataNode、SNN、HFS、Hive Gateway、WebHCat、Hue、Impala Deamon、CMServer Monitor、CM Activity Monitor、CM Host Monitor、CM Event Server、CMAl ert Publisher、Oozie Server、Spark History Server、Spark Gateway、NodeManager、JobHistory Server、Zk ServerHADOOP-12-153 DataNode、Hive Gateway、HiveMetastore、HiveServer2、Impala Catal og、Impala StateStore、Impala Deamon、Spark Gateway、NodeManager、Zk Server HADOOP-12-154 DataNode、Hive Gateway、Impala Deamon、Spark Gateway、NodeManager、Sqoop2HADOOP-12-155 DataNode、Hive Gateway、Impala Deamon、Spark Gateway、NodeManager、Zk ServerHADOOP-12-156 DataNode、Hive Gateway、Impala Deamon、Spark Gateway、NodeManager、Zk Server3.had oop参数设置yarn-allocation-mb 32768-allocation-mb 4096-vcores 24-pmem-ratiomapreduce40968192307261441536100151555dfs3二、基准测试1.HDFS读写的吞吐性能连续10次执行如下写操作,其性能见图示:cd /opt/clouderahdfsadmin hadoopTestDFSIO -write -nrFiles 10 -fileSize 1000 -resFile /tmp/其具体数据见表格:HDFS写文件吞吐均值:/S平均执行时间:占用带宽:/S结论:HDFS写,其磁盘吞吐基本上处于理想状态,且在此吞吐水平上其网络带宽占用较少,没有造成明显的带宽负载。
hadoop实验报告

hadoop实验报告为了更好地理解和应用大数据处理技术,我们在实验室完成了一次Hadoop实验。
本文将介绍我们的实验内容、使用的方法、数据分析结果及经验分享。
1.实验内容本次实验以获取HTTP请求日志为主要数据源,通过Hadoop 技术对这些数据进行统计和分析,得出有意义的结论。
我们的目标是:- 把这些日志数据解析成可读、可处理的格式;- 通过MapReduce框架,统计HTTP请求中不同字段的访问情况,分析访问量、热点内容等;- 通过Hive和Pig工具,进一步深入数据,进行数据挖掘和预测分析。
2.方法为了使实验过程更高效,我们采用了虚拟机技术,并在其中搭建好了Hadoop集群环境。
具体操作步骤如下:- 在虚拟机中安装Ubuntu操作系统;- 安装Java、Hadoop;- 将HTTP请求日志导入Hadoop分布式文件系统(HDFS)中;- 利用Hadoop的MapReduce框架处理数据,将结果保存到HDFS;- 通过Hive和Pig分别进行数据查询和分析。
3.数据分析结果在实验中,我们使用了相应的程序和工具,最终得出了以下数据分析结果:- 不同的HTTP请求方法中,最高访问量的为GET请求,占总访问量的80%以上;- 在所有请求中,占比最高的页面为“/”,占总访问量的60%左右;- 分析出前十个访问量最多的网页,可以进一步了解用户访问兴趣和热点内容。
同时,我们也利用Hive和Pig工具进行了数据挖掘和预测分析。
在Hive中,通过对HTTP请求的数据进行透视,可以发现一个趋势:随着时间的推移,对不同请求方式的访问比例出现了较大变化;在Pig中,我们则进行了关联查询,得出了各个网页之间的关系和可能的用户行为。
4.经验分享在本次实验中,我们深入了解了Hadoop技术和大数据处理的方法,也得到了一些有益的经验和建议:- 在配置Hadoop集群时,需注意不同组件的版本和兼容性;- 在编写MapReduce程序时,应根据实际需要和数据特点,合理设计算法和逻辑;- 在使用Hive和Pig工具时,应熟悉数据的类型和查询语言,避免出现语法错误和数据倾斜。
hadoop分布式ha集群建构本科实验报告

hadoop分布式ha集群建构本科实验报告一、引言Hadoop是一个开源的分布式计算平台,具有良好的扩展性和容错性。
为了提高Hadoop集群的可用性,可以使用HA(高可用)机制。
本实验通过搭建Hadoop分布式HA集群,探索了其基本原理和操作流程,并对其性能进行了评估。
二、实验目的1. 理解Hadoop分布式HA集群的原理;2. 掌握搭建Hadoop HA集群的操作流程;3. 通过性能评估比较单节点和HA集群的性能差异。
三、实验环境1. 操作系统:Ubuntu 18.04;2. Hadoop版本:3.3.1;3. 虚拟机工具:VMware Workstation 16 Pro。
四、实验步骤1. 在VMware中安装两台虚拟机(节点1和节点2),分别配置静态IP地址;2. 在两台节点上安装Java和SSH,并配置免密码登录;3. 下载Hadoop压缩包并解压,在节点1上配置HDFS、YARN和Secondary NameNode;4. 在节点2上配置HDFS和YARN,配置作为NameNode的节点互信;5. 修改HDFS和YARN的配置文件,设置HA集群相关参数;6. 启动HA集群,并验证配置是否成功。
五、实验结果1. HA集群的配置成功,并且节点1作为Active NameNode,节点2作为Standby NameNode;2. 当节点1故障时,节点2会自动切换为Active NameNode,保证集群的高可用性;3. HA集群具有较好的扩展性和容错性,能够处理大规模数据的并行计算任务。
六、实验结论通过本实验,我们成功搭建了Hadoop分布式HA集群,并验证了其高可用性。
HA 集群能够保证在出现故障时自动切换,并提供了良好的扩展性和容错性。
实验结果表明,HA集群在处理大规模数据的并行计算任务时具有良好的性能。
七、实验感想通过本次实验,我深入了解了Hadoop分布式HA集群的原理和操作流程。
在实践中,遇到了一些问题,例如配置文件的修改和调试等,在与同学们的讨论和助教的帮助下,最终成功完成了实验。
Hadoop云计算平台实验报告

数据校验技术提高了数据的高可靠性。NameNode 执行文件系统的名字空间操作, 比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体 DataNode 节 点的映射。 DataNode 负责存放数据块和处理文件系统客户端的读写请求。在 NameNode 的统一调度下进行数据块的创建、删除和复制。
责任务执行。用户提交基于 MapReduce 变成规范的作业之后,JobTracker 根据作 业的输入数据的分布情况(在 HDFS 之中) ,将 Map 任务指派到存储这些数据块 的 DataNode 上执行(DataNode 也充当了 TaskTracker) ,Map 完成之后会根据用 户提交的 Reduce 任务数对中间结果进行分区存储在 Map 任务节点本地的磁盘, 执行 Reduce 任务的节点(由 JobTracker 指派)通过轮询的方式从各 Map 节点拉 取 Reduce 的输入数据,并在 Reduce 任务节点的内存进行排序后进行合并作为 reduce 函数的输入,输出结果又输出到 HDFS 中进行存储。
Hadoop 云计算平台实验报告
金松昌 11069010 唐明圣 11069033 尹洪 11069069
实验目标
1. 掌握 Hadoop 安装过程 2. 理解 Hadoop 工作原理 3. 测试 Hadoop 系统的可扩展性 4. 测试 Hadoop 系统的稳定性 5. 测试 Hadoop 系统的可靠性
排序
分片 0
Map
复制 合并
reduce
分区 0
HDFS 副本
分片 1
Map HDFS 副本
reduce Map
分区 1
分片 2
图 2 MapReduce 数据处理流程示意图
组建hadoop集群实验报告

组建hadoop集群实验报告一、实验目的本次实验的目的是通过组建Hadoop 集群,熟悉和掌握Hadoop 的部署过程和相关技术,加深对分布式计算的理解并掌握其应用。
二、实验环境- 操作系统:Ubuntu 20.04- Hadoop 版本:3.3.0- Java 版本:OpenJDK 11.0.11三、实验步骤1. 下载和安装Hadoop在官方网站下载Hadoop 的二进制文件,并解压到本地的文件夹中。
然后进行一些配置,如设置环境变量等,以确保Hadoop 可以正常运行。
2. 配置Hadoop 集群a) 修改核心配置文件在Hadoop 的配置目录中找到`core-site.xml` 文件,在其中添加以下配置:xml<configuration><property><name>fs.defaultFS</name><value>hdfs:localhost:9000</value></property></configuration>b) 修改HDFS 配置文件在配置目录中找到`hdfs-site.xml` 文件,在其中添加以下配置:xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>c) 修改YARN 配置文件在配置目录中找到`yarn-site.xml` 文件,在其中添加以下配置:xml<configuration><property><name>yarn.resourcemanager.hostname</name><value>localhost</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</nam e><value>org.apache.hadoop.mapred.ShuffleHandler</value></property></configuration>3. 启动Hadoop 集群在终端中执行以下命令来启动Hadoop 集群:bashstart-all.sh这将启动Hadoop 中的所有守护进程,包括NameNode、DataNode、ResourceManager 和NodeManager。
Hadoop企业级大数据平台-测试报告

Hadoop企业级大数据平台
测试报告
目录
1.测试目的 (3)
2.测试环境 (3)
2.1.硬件环境 (3)
2.2.软件环境 (4)
3.测试内容 (4)
3.1.基本功能 (4)
3.1.1.HDFS功能验证 (4)
3.1.2.YARN功能验证 (6)
3.1.3.扩容测试 (8)
3.2.性能 (9)
3.2.1.HDFS性能测试 (9)
3.2.2.YARN性能测试 (12)
3.3.高可用 (16)
3.3.1.HDFS高可用测试 (16)
3.3.2.YARN高可用测试 (18)
3.3.3.Kerberos高可用测试 (21)
1.测试目的
通过功能、性能、高可用测试,验证Hadoop是否满足在大数据基础架构平台对精细化营销和客流分析应用的需求。
2.测试环境
2.1.硬件环境
硬件位置信息:
硬件配置清单:
硬件配置表:
2.2.软件环境
3.测试内容
3.1.基本功能
3.1.1.H DFS功能验证
测试截图:
3.1.2.Y ARN功能验证
测试截图:
3.1.3.扩容测试
3.2.性能
3.2.1.H DFS性能测试
读测试截图:
写测试截图:
3.2.2.Y ARN性能测试
测试截图:
3.3.高可用
3.3.1.H DFS高可用测试
测试截图:
3.3.2.Y ARN高可用测试
测试截图:
3.3.3.K erberos高可用测试
第21页。
云计算Hadoop运行环境的配置实验报告

以上操作的目的,是确保每台机器除了都能够使用ip地址访问到对方外,还可以通过主
注意:另外2台也要运行此命令。
)查看证书
hadooptest身份,进入hadooptest家目录的 .ssh文件夹。
(3)新建“认证文件”,在3台机器中运行如下命令,给每台机器新建“认证文件”注意:另外2台也要运行此命令。
其次,虚拟机之间交换证书,有三种拷贝并设置证书方法:
hadoops1机器里的authorized_keys也有三份证书,内容如下:hadoops2机器里的authorized_keys也有三份证书,内容如下:
) Java环境变量配置
继续以root操作,命令行中执行命令”vi m /etc/profile”,在最下面加入以下内容,
.实验体会
通过这次的实验熟悉并了Hadoop运行环境,并学会了如何使用它。
这次实验成功完成了Hadoop 集群,3个节点之间相互ping通,并可以免密码相互登陆,完成了运行环境java安装和配置。
hadoop实验报告总结

hadoop实验报告总结Hadoop是一个大数据处理框架,它可以处理 petabyte 级别的数据存储和处理。
在大数据时代,Hadoop 的使用越来越普及,因此学习和掌握 Hadoop 成为了当今大数据从业人员的必修课。
本实验报告旨在介绍 Hadoop 的使用,以及在使用过程中所遇到的问题和解决方法。
我们需要了解 Hadoop 的基本架构。
Hadoop 的基本组成部分包括 HDFS(Hadoop Distributed File System),MapReduce,YARN(Yet Another Resource Negotiator)等。
HDFS 是一个用于存储和管理大数据的分布式文件系统,MapReduce 是一种用于分布式数据处理的编程模型,YARN 则是一个资源管理系统。
这三个组成部分相互配合,使得Hadoop 可以完成大数据存储和处理的任务。
在本次实验中,我们主要使用 HDFS 和 MapReduce 进行操作。
在使用 HDFS 进行操作之前,我们需要了解 HDFS 的基本概念和几个关键点。
HDFS 的文件以块的形式存储在不同的数据节点中,每个块的大小默认为 128MB。
每个文件至少会存储在三个数据节点中,以确保数据的容错性和高可用性。
HDFS 还具有很好的扩展性,可以根据需要增加更多的数据节点。
在使用 HDFS 进行操作时,我们可以使用 Hadoop 自带的命令行界面或者使用 GUI工具,如 Apache Ambari。
在本次实验中,我们使用了 Hadoop 自带的命令行界面进行操作。
在操作中,我们通过以下几个步骤实现了文件的上传、下载和删除操作:1. 使用命令 `hdfs dfs -put` 上传文件到 HDFS 上。
2. 使用命令 `hdfs dfs -get` 从 HDFS 上下载文件到本地。
3. 使用命令 `hdfs dfs -rm` 删除 HDFS 上的文件。
在使用 HDFS 时还需要注意以下几个关键点:1. 在上传文件时需要指定文件的大小和副本数,默认情况下副本数为 3。
hadoop 实验报告

hadoop 实验报告Hadoop 实验报告引言Hadoop是一个开源的分布式存储和计算框架,被广泛应用于大数据处理和分析领域。
本实验旨在通过搭建Hadoop集群,进行数据处理和分析,以验证Hadoop在大数据环境下的性能和可靠性。
实验环境本次实验使用了3台虚拟机,每台虚拟机配置了4核CPU和8GB内存。
其中一台作为NameNode和ResourceManager,其余两台作为DataNode和NodeManager。
所有虚拟机运行的操作系统为CentOS 7.0。
实验步骤1. 安装Hadoop首先在每台虚拟机上安装Hadoop,并配置好环境变量和相关参数。
然后在NameNode上配置HDFS和YARN,并在DataNode上配置HDFS和NodeManager。
2. 启动集群依次启动NameNode、DataNode和ResourceManager、NodeManager,确保集群正常运行。
3. 数据处理将一份大数据文件上传至HDFS,并通过MapReduce程序对数据进行处理和分析,例如统计单词频率或计算数据的平均值等。
4. 性能测试通过在集群上运行不同规模的数据处理任务,记录下任务的运行时间和资源利用率,评估Hadoop的性能和扩展性。
实验结果经过实验,我们得出了以下结论:1. Hadoop集群的搭建和配置相对复杂,需要对Hadoop的各个组件有深入的了解和掌握。
2. Hadoop集群在处理大规模数据时表现出了良好的性能和扩展性,能够有效地利用集群资源进行并行计算。
3. Hadoop的容错机制能够保证集群在节点故障时的稳定运行,数据的可靠性得到了保障。
结论通过本次实验,我们深入了解了Hadoop的工作原理和性能特点,验证了Hadoop在大数据环境下的可靠性和高效性。
同时也发现了Hadoop在搭建和配置上的一些难点和挑战,这需要我们在实际应用中不断摸索和实践。
相信随着大数据技术的不断发展,Hadoop将会在各个领域发挥越来越重要的作用。
Hadoop环境配置与实验报告
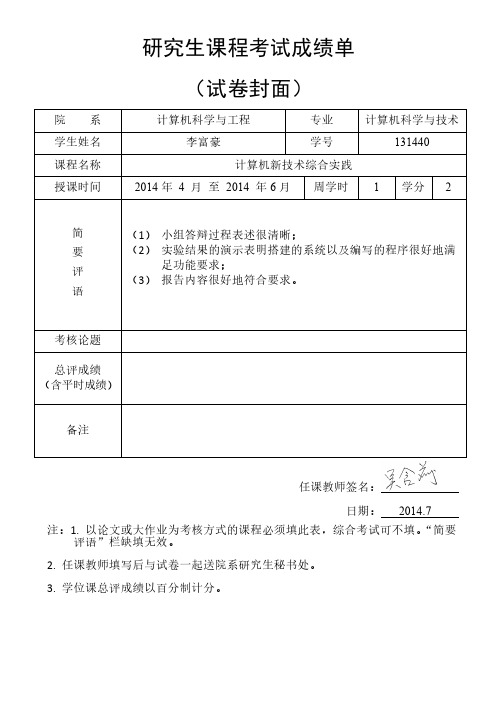
研究生课程考试成绩单
(试卷封面)
计算机科学与工程
专业
计算机科学与技术
李富豪
学号
131440
计算机新技术综合实践
2014 年 4 月 至 2014 年 6 月 周学时 1 学分 2
简
(1) 小组答辩过程表述很清晰;
要
(2) 实验结果的演示表明搭建的系统以及编写的程序很好地满
2
目录
1 集群部署介绍 ...................................................................................................................... 3 1.1 Hadoop 简介 ................................................................................................................. 3 1.2 环境说明 ....................................................................................................................... 3 1.3 网络配置 ....................................................................................................................... 3 1.3.1 编辑当前机器名称 ................................................................................................ 3 1.3.2 修改当前机器 IP.................................................................................................... 4 1.3.3 配置 hosts 文件 ..................................................................................................... 4 1.4 所需软件 ....................................................................................................................... 6 1.4.1 JDK 软件................................................................................................................. 6 1.4.2 Hadoop 软件 .......................................................................................................... 6
hadoop实训报告文字

Hadoop实训报告引言Hadoop是一个开源的分布式计算平台,用于处理大规模数据集的存储和分析。
在本次实训中,我们学习了Hadoop的基本概念和使用方法,并通过实践掌握了Hadoop的各种组件及其功能。
实训内容1. Hadoop概述首先,我们学习了Hadoop的基本概念和架构。
Hadoop由HDFS(Hadoop分布式文件系统)和MapReduce两个核心组件组成。
HDFS用于存储大规模数据集,并提供高可靠性和容错性。
MapReduce是一种分布式计算模型,用于将数据分成多个小块,在集群中并行处理。
2. Hadoop安装与配置接下来,我们进行了Hadoop的安装与配置。
首先,我们下载了Hadoop的安装包,并解压到本地目录。
然后,我们配置了Hadoop的环境变量,使其能够在命令行中被识别。
3. Hadoop集群搭建为了更好地理解Hadoop的分布式特性,我们搭建了一个Hadoop集群。
我们使用了三台虚拟机,分别作为一个主节点和两个从节点。
在主节点上配置了HDFS和MapReduce的相关文件,并在从节点上配置了对应的通信信息。
4. Hadoop基本操作在学习了Hadoop的基本概念和架构后,我们开始进行一些基本的Hadoop操作。
首先,我们学习了Hadoop的文件操作命令,如上传、下载、删除等。
然后,我们学习了Hadoop的作业操作命令,如提交作业、查看作业状态等。
5. Hadoop应用开发在掌握了Hadoop的基本操作后,我们开始进行Hadoop应用的开发。
我们使用Java语言编写了一个简单的MapReduce程序,用于统计一个文本文件中的单词出现次数。
通过编写这个程序,我们更深入地理解了MapReduce的工作原理和应用。
6. Hadoop性能优化最后,我们学习了Hadoop的性能优化方法。
我们通过调整各种参数和配置文件,来提高Hadoop的运行效率和并行性能。
我们还学习了如何监控Hadoop集群的运行状态,并根据监控结果进行调整和优化。
hadoop实验报告

基于hadoop的大规模文本处理技术实验专业班级:软件1102学生姓名:张国宇学号:Setup Hadoop on Ubuntu 11.04 64-bit提示:前面的putty软件安装省略;直接进入JDK的安装。
1. Install Sun JDK<安装JDK>由于Sun JDK在ubuntu的软件中心中无法找到,我们必须使用外部的PPA。
打开终端并且运行以下命令:sudo add-apt-repository ppa:ferramroberto/javasudo apt-get updatesudo apt-get install sun-java6-binsudo apt-get install sun-java6-jdkAdd JAVA_HOME variable<配置环境变量>:先输入粘贴下面文字:sudo vi /etc/environment再将下面的文字输入进去:按i键添加,esc键退出,X保存退出;如下图:export JAVA_HOME="/usr/lib/jvm/java-6-sun-1.6.0.26"Test the success of installation in Terminal<在终端测试安装是否成功>:sudo . /etc/environmentjava –version2. Check SSH Setting<检查ssh的设置>ssh localhost如果出现“connection refused”,你最好重新安装 ssh(如下命令可以安装):sudo apt-get install openssh-server openssh-client如果你没有通行证ssh到主机,执行下面的命令:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsacat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys3. Setup Hadoop<安装hadoop>安装 apache2sudo apt-get install apache2下载hadoop:1.0.4解压hadoop所下载的文件包:tar xvfz hadoop-1.0.4.tar.gz下载最近的一个稳定版本,解压。
hadoop实验报告

hadoop实验报告1. 引言随着互联网的快速发展和大数据时代的到来,传统的数据处理方法已经无法满足海量数据的处理需求。
在这个背景下,分布式存储和计算框架Hadoop应运而生。
本篇文章将从搭建集群环境、数据导入、任务执行和性能评估等方面进行Hadoop实验的报告。
2. 搭建集群环境在实验开始之前,我们需要搭建一个Hadoop集群环境。
首先,我们需要准备一台主节点和若干台从节点。
主节点将负责整个集群的协调工作,从节点将执行具体的任务。
通过配置和启动Hadoop的各个组件,我们可以实现数据的并行计算和故障容错。
为了确保集群的高可用性和性能,我们还可以使用Hadoop的分布式文件系统HDFS来存储数据。
3. 数据导入数据的导入是Hadoop实验的第一步。
在本次实验中,我们选择了一份包含大量文本数据的文件作为输入。
通过Hadoop提供的命令行工具,我们可以将数据导入到HDFS中进行后续的处理。
不同的数据导入方式可以根据实际需求选择,一般包括本地文件上传、网络数据传输等。
4. 任务执行在集群环境搭建完成并将数据导入到HDFS之后,我们可以开始执行具体的计算任务。
Hadoop支持两种模型:MapReduce和Spark。
MapReduce是Hadoop最早的计算模型,其核心思想是将大规模的数据集划分成许多小的数据块,由多个Mapper和Reducer并行地执行计算任务。
而Spark则是一种更加灵活和高效的计算模型,它将数据集以弹性分布式数据集(RDD)的形式存储在内存中,通过多次迭代快速进行计算。
5. 性能评估对于一个分布式计算框架来说,性能评估是非常重要的。
通过对Hadoop实验中的任务执行时间、计算效率和数据处理能力等指标的测量,我们可以评估集群的性能瓶颈并寻找优化的方法。
常见的性能评估指标包括吞吐量、数据处理速度和并发处理能力等。
6. 结果与讨论在本次实验中,我们成功搭建了一个Hadoop集群环境,并将大量的文本数据导入到HDFS中。
Hadoop大数据性能测试总结报告

Hadoop大数据性能测试总结报告版本信息1. 概述 (3)1.1性能测试背景 (3)1.2性能测试目标 (3)1.3性能测试范围 (3)1.4硬件配置 (3)2. 性能测试结果 (4)2.1.单交易基准测试 (4)2.2峰值测试结果 (7)2.3测试结果 (10)1.概述1.1性能测试背景1.2性能测试目标验证hadoop和本地数据的列表的读取速度和文件下载速递的优劣性1.3性能测试范围本次性能测试需要获得的性能指标如下所列:1.列表的读取速度2. 打开图片(文件的下载速递)1.4硬件配置硬件配置:XEON8核1.87G 8G内存550G硬盘2•性能测试结果2.1.单交易基准测试场景名称业务运行时间Thi nkTime平均响应时间(S)用户数目的基准测试打开列表20 min30.006100验证单一交易的性能,作为其它测试类别结果的参考打开图片20 min30.057100如上图:每秒增加个用户,持续加到,以个用户开始运行,持续分钟每秒点击数:▼ iGr^pfiMinrnum |Giaph iGrohM^wnum 菁Graph Medan ▼ [GiapbiSW Deviser ■]o 4Q510062 [ 12,67用户运行动态:Le genl 4 X Run34}223« 36秒。
带宽使用情况:ThroughputDOM 01.DO 0Z0003…00 04. DO QS.OD Dft.DO 07.00 D8J0 OSiMl 10.00 1tD0 12_Cffl 13.00 M.00 1S.M 1S.00 117:00 1S.OO 1^00 20:00Elapsed scenarco lime mm.ssM.000,000 4S.QOO.DOO - 46.000.000-44.000.000 ; 4^000,000 \ «.000,000 I 3S-Q00.D00 ] 36.000.003^ 9OOG.OOO \S_000,000 ] ^,000.000 \^000.000^盘000,000 1 ^LOOQ,OOO^ 20.000.000^18.mQO0^ 馆』go込14.000.000^12.000,000」 10.000.000 n 8-000.000 JLegend良旳日用 * | Gaph Mawwm 审|曲妙辰左"[▼ |G 咱phMd. DeMi3od ・|| 如上图:随着时间的增加,每秒点击数在不断变化,但趋于平稳,平均约为 47次每秒,最高可达 49.5次每47 41148 563▼ Heaguffefnent审」由咄|窗别仙"SiaMitry R*>wt HfliMiing ¥m«rt Ki ts p«r See^ad Trfen&telivh盘¥■!■■(;・ Trunsn^^Tiie®00.00 Dl:00 02:00 03:W 04:00 053 06.OD 07:M M.Q0 09.W 10:00 11J0 12M 13:00 14.00 I5.G0 W.0Q 17JD lfi.04 19.00 20JDEldred scenana lime mmrssHits per Second| Hits p-sr Second. Tbrira^aipixl| Tr«ns«ctii^n S^rnnftryTr ^DX -SL "'" Rtt 百FOIVX ® Tim« |呂unmKTF RvpoT t | Runnin.(: Vusrirt~7T —F//jr—*—- _ • - _ -■—「* ■ ■ »-■—*—■•— ■.——"■一 A-•— ■—A —. i rI.!1fILt^indl| Me-asuremenf 〒旧曲制hnimunn ▼[舀vgrapgGraph Mamvum〒 GF^g-hMecianT] Graph $ld Deviatipr ▼ | 「Thiowi 力put &474935 75 35559965 7474931E322 3BJZ3S95 625「531591R^1B"rF 玉叫**埜1苜%"[亀rs如上图,最高带宽峰值是 50000000B ,远小于100M/S 的局域网传输速率上线,所以不存在带宽瓶颈。
hadoop实验报告

hadoop实验报告一、引言Hadoop是一个开源的分布式系统框架,用于存储和处理大规模数据集。
本实验旨在通过使用Hadoop框架,实践分布式存储和处理数据的能力,并深入了解HDFS和MapReduce的工作原理。
本报告将详细描述实验的步骤、结果和分析,以及洞察到的有关Hadoop的相关知识。
二、实验环境在本次实验中,我们使用以下环境:- 操作系统:Ubuntu 18.04- Hadoop版本:2.7.3- Java版本:1.8.0_181三、实验步骤1. 安装和配置Hadoop首先,需要下载合适版本的Hadoop并进行安装。
在安装完成后,需要进行相关的配置。
通过编辑hadoop-env.sh和core-site.xml文件,设置Java路径和Hadoop的基本配置。
接着,配置hdfs-site.xml文件以指定Hadoop分布式文件系统(HDFS)的副本数量。
最后,修改mapred-site.xml文件以设定MapReduce的配置。
2. 启动Hadoop集群在完成Hadoop的安装和配置后,需要启动Hadoop集群。
运行start-all.sh脚本,该脚本将启动Hadoop的各个组件,包括NameNode、SecondaryNameNode、DataNode和ResourceManager。
通过运行JPS命令,可以检查各个组件是否成功启动。
3. 创建HDFS文件夹并上传数据使用Hadoop的命令行工具,例如Hadoop fs命令,可以在HDFS上创建文件夹和上传数据。
首先,创建一个文件夹用于存储实验数据。
然后,使用put命令将本地文件上传到HDFS上的指定位置。
4. 编写MapReduce程序为了进行数据处理,需要编写一个MapReduce程序。
MapReduce是Hadoop的核心组件,用于高效地处理大规模数据。
编写MapReduce程序需要实现Mapper和Reducer类,并根据需求定义map()和reduce()方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
测试报告
一、集群设置
1.服务器配置
CPU 24
带宽1024M
磁盘44T
磁盘吞吐预计100M/s
2.Hadoop服务部署
HADOOP-12-151 NameNode、Balancer、Hive Gateway、Spark Gateway、ResourceManager、Zk Server HADOOP-12-152 DataNode、SNN、HFS、Hive Gateway、WebHCat、Hue、Impala Deamon、CM Server Monitor、CM Activity Monitor、CM Host Monitor、CM Event Server、CM Alert
Publisher、Oozie Server、Spark History Server、Spark Gateway、NodeManager、
JobHistory Server、Zk Server
HADOOP-12-153 DataNode、Hive Gateway、HiveMetastore、HiveServer2、Impala Catalog、Impala StateStore、Impala Deamon、Spark Gateway、NodeManager、Zk Server HADOOP-12-154 DataNode、Hive Gateway、Impala Deamon、Spark Gateway、NodeManager、Sqoop2 HADOOP-12-155 DataNode、Hive Gateway、Impala Deamon、Spark Gateway、NodeManager、Zk Server
3.hadoop参数设置
yarn
-allocation-mb 4096
-allocation-mb 32768
-allocation-mb 4096
-vcores 24
-pmem-ratio 3.1
mapreduce
4096
8192
6144
1536
100
15
0.08
0.9
15
5
5
dfs
35
3
二、基准测试
1.HDFS读写的吞吐性能
1.1 连续10次执行如下写操作,其性能见图示:
cd /opt/cloudera
hdfsadmin hadoopTestDFSIO -write -nrFiles 10 -fileSize 1000 -resFile
/tmp/TestDFSIO_results.log
其具体数据见表格:
HDFS写文件吞吐均值:26.76M/S
平均执行时间:61.54S
占用带宽:53.52M/S
结论:HDFS写,其磁盘吞吐基本上处于理想状态,且在此吞吐水平上其网络带宽占用较少,没有造成明显的带宽负载。
1.2连续10次执行如下读操作,其性能见图示:
hdfsadmin hadoopTestDFSIO -read -nrFiles 10 -fileSize 1000 -resFile /tmp/TestDFSIO_results.log Map Task平均吞吐:67.5M/S 。
文件的平均IO速度:288.5M/S,基本符合理想状态。
附:I. 带宽计算过程:
10000/61.54/26.76=6,10个文件则10个进程并发,复本数为2,则有1份网络传输,10个进程并发在5台机器上,基本上每台机器有2个写进程,则网络流量大约为:26.76M/S*1*2=53.52M,远远低于千兆网络的带宽。
II. 清除测试数据:
dfsadmin hadoopTestDFSIO –clean
20
写性能:
基本上与之前相当。
读性能:
Map Task平均吞吐:65.1M/S 。
文件的平均IO速度:198.5M/S。
2.mrbench基准测试
重复执行小作业50次,检查平均执行时间
hdfsadmin hadoopmrbench -numRuns 50
基本情况,上述操作完全来自默认值:
inputlines:1
mapper:2
reducer:1
完成时间:17986ms,即17秒。
修改上述各参数的设置,inputlines:100000
mapper:1000
reducer:200
hdfsadmin hadoopmrbench -numRuns 10 -inputLines 100000 -maps 1000 -reduces 200
完成时间:190131ms,即190秒。
在此参数设置下,集群负载很重,mapper&reducer总数明显超过了集群一般可以承受的水平。
继续调整参数设置,inputlines:100000
mapper:100
reducer:5
hdfsadmin hadoopmrbench -numRuns 10 -inputLines 100000 -maps 100 -reduces 5
完成时间:28682ms,即28秒。
在此参数设置下,基本上符合集群负载的一般水平,mapper&reducer数设置较为合理,完成时间比较理想,即数据量越大,Hadoop越能够体现其优势。
20
hdfsadmin hadoopmrbench -numRuns 50
15996ms,16s
hdfsadmin hadoopmrbench -numRuns 10 -inputLines 100000 -maps 100 -reduces 5
28975ms,29s
3.利用全局排序Terasort测试MapReduce执行性能
cd /opt/cloudera
生成10G数据:
hdfsadmin hadoop jar hadoop-examples.jar teragen -=100 /home/songuanglei/gen10G
排序:
hdfsadmin hadoop jar hadoop-examples.jar terasort -=[100/60/10/5] /home/songuanglei/gen10G /home/songuanglei/output10G
map数目为2,不断调整reducer数目为100、60、10、5,其执行时间趋势如下图:
结论:reducer数越接近集群节点数目,其执行速度越快。
生成100G数据:
hdfsadmin hadoop jar hadoop-examples.jar teragen -=100 /home/songuanglei/gen100G
排序:
hdfsadmin hadoop jar hadoop-examples.jar terasort -=[100/6010/5] /home/songuanglei/gen100G /home/songuanglei/output100G
map数目为800,不断调整reducer数目为100、60、10、5,其执行时间趋势如下图:
结论:随着处理数据的增大,map阶段耗时显着增加,成为整个Job执行的重点,reducer数越接近集群节点数目,其执行速度越快。
附:I. 验证是否有序
hdfsadmin hadoop jar hadoop-examples.jar teravalidate /home/songuanglei/output100G
/home/songuanglei/validate100G
4.利用wordcount测试MR执行性能
wordcount是CPU资源消耗型的
操作如下:
hdfsadmin hadoop jar hadoop-examples.jar wordcount -=10
/user/songguanglei/201408_status_data.csv /user/songguanglei/output
基本情况:
输入文件:622MB
默认mapper数:5
分别设置reducer数据为60、10、5,分别得出CPU time spent (ms)值:218340、130900、124540
结论:设置适当的情况下,2分钟可以完成600MB文件的单词统计。
20
基本情况:
输入文件:622MB
默认mapper数:5
分别设置reducer数据为60、10、5,分别得出CPU time spent (ms)值:189050、105950、99390
结论:修改这两个参数后,性能有所提升。