中文分词技术研究
汉语分词技术研究现状与应用展望

续的字符串( , C )输 出是汉语的词 串( . CC C… ,
2 1 通用 词表和 切分 规范 .
… ) 这里 , 可 以是单字词也可 以是多字 ,
词. 那么 , 在这个过程中, 我们所要解决 的关键问题是什么 , 我们又有什么样 的解决方案呢? 至今为止 , 分词系统仍然没有一个统一的具有权威性的分词词表作为分词依据. 这不能不说是分词系
要 解决 的重要 问题 ,
除了同音词的自动辨识 , 汉语的多音字 自动辨识仍然需要分词 的帮助. 例如 : 校 、 、 、 、 等都 “ 行 重 乐 率” 是多音字. 无论是拼音 自动标注还是语音合成都需要识别出正确的拼音. 而多音字的辨识可以利用词以及
句子中前后词语境 , 即上下文来实现. 如下面几个多音字都可以通过所在的几组词得 以定音 : ) 、 z n ) 重(hn ) 快乐(e/ jo 对 行( ag 列/ x g 进 重(h g 量/ cog 新、 i n o 1)音乐 (u ) 率 (h a) 效 ye 、 sui领/
率( ) 1. v
2 汉语分词所面临 的关键 问题
汉语分词是由计算机 自动识别文本中的词边界的过程. 从计算机处理过程上看 , 分词系统的输入是连
定义两个字的互信息计算两个汉字结合程互信息体现了汉字之间结合关系的紧密程度需要大量的训练文本用以建立模型的参数到底哪种分词算法的准确度更高目前尚无定论对于任何一个成熟的分单独依靠某一种算法来实现都需要综合不同的算法汉语分词技术的应用国内自80年代初就在中文信息处理领域提出了自动分词从而产生了一些实用京航空航天大学计算机系1983年设计实现的cdws分词系统是我国第一个实用的自度约为625开发者自己测试结果下同早期分词系统机系研制的abws自动分词系统和北京师范大学现代教育研究所研制的书面汉语这些都是将新方法运用于分词系统的成功尝试具有很大的理论意义随后比较有代表性的有清华大学seg和segtag分词系统复旦分词系统州大学改进的mm分词系统北大计算语言所分词系统分词和词类标注相结合在自然语言处理技术中中文处理技术比西文处理技术要落后很大一段距离文不能直接采用就是因为中文必需有分词这道工序汉语分词是其他中文信息处理是汉语分词的一个应用语音合成自动分类自动摘要要用到分词因为中文需要分词可能会影响一些研究但同时也为一些企业带来机会参考文献汉语信息处理词汇01部分朱德熙
中文分词技术的研究

一
至关重 要 的因素 。 所周 知 , 众 中文 文本与英 文文本 的表 示 方法 有 所不 同 , 英文 文本 中词 与词 中间都 由空 格或
标 点符 号隔开 , 因而 词与词 之间 的界限很 明显 , 以很 可 容 易地 获 取关键 词 , 中文 文 本 中词 与词则 元 明显 的 而
第2卷 3
第 3 期
电 脑 开 发 与 应 用
文章 编 号 :0 35 5 ( 0 0 0 -0 10 1 0—8 0 2 1 )30 0 — 3
中文 分 词技 术 的研 究
Re e r h o i s o d S g e a i n Te hn q e s a c n Ch ne e W r e m nt to c i u s
依 赖 于 分词 词典 的好 坏 , 于无 词典 的分 词算 法 不需 基 要利 用词 典 信息 , 通过 对 大规 模 的生语 料库 进 行 统 它 计分析 , 自动 地 发现 和学 习词汇 , 分词精 度 来 看 , 从 基
于词典 的分 词算法 要大 大优于无 词典 的分词算 法 。
3 1 基 于足 够 的词 来供 分 析程 序处 理 , 计
算 机如何 完成这 一过 程 ? 其处 理过程 就称为分 词算 法 。
现 有的分 词 算法 按 照 是否 使用 分词 词典 来 分 , 可 分 为基 于 词 典 的 分 词 算 法 和 基 于 无 词 典 的 分 词 算
定 的工 具从 大规 模 的动 态信 息流 中 自动筛 选 出满足
用户 需求 的信 息 , 同时 屏蔽 掉无 用信 息 的过程 。 目前很
面向专利文献的中文分词技术的研究

面 向专 利 文 献 的 中 文 分 词 技 术 的 研 究
张桂 平 , 东 生 , 刘 尹宝 生 , 徐立 军 , 雪 雷 苗
( 阳 航 空工 业 学 院 知识Байду номын сангаас二 程 中心 ,辽 宁 沈 阳 1 0 3 ) 沈 r 1 0 4
摘
要 : 对 专利 文 献 的 特 点 , 文提 出 了一 种 基 于 统计 和 规 则相 结合 的 多 策略 分 词 方 法 。该 方 法 利 用 文 献 中潜 针 该
c e e od r s t n t e co e a d o nng ts ,w ih i pr ve n u hiv sgo e uls i h ls n pe i e t t m o s o nkn w n w o d e o nii s w e1 o r s r c g ton a l. Ke r s:c y wo d omput ra e ppl a i i ton; Chie e i o ma i o e sn c n s nf r ton pr c s i g; Chi s wo d s gm e t ton; pa e t o um e ; ne e r e nai t n d c nt c nt x n or a in o e ti f m to
Re e r h o i e e W o d S g e a i n f r Pa e tDo u e t s a c n Ch n s r e m nt to o t n c m n s Z HANG Gupn ,L U o g h n YI B o h n ,XU i n lig I D n s e g, N a s e g Lj ,M I ee u AO Xu li
lr e s a ec r u n h p cfcc n e ti f r t n h sme h d e fc i ey s l e h r b e o h u — fv — a g c l o p s a d t e s e i o tx n o ma i ,t i i o t o fe tv l o v s t e p o l m ft eO t - o o
中文分词技术的研究及在Nutch中的实现

O 引 言
I Anlzr中 文 分 词 器 采 用 字 典 分 词 法 并 结 合 正 反 向 全 切 分 以 K aye
擎排序算法都是保 密的, 我们无法知道搜索出来的排序结果是如何算 P o ig a zr分 词 器 , 然 后 是 MMa a zr分 词 器 ,最 慢 的 是 adnAnl e y nl e y 出来 的不 同 , 任何人都 可以查看 N t ue h的排序算 法 , 而且一 些搜索 引 I A aye 分 词器 k n lz r 擎的排名还有很多商业 因素 , 比如 百 度 的 排 名 就 和竞 价 有 关 . 样 的 这
An lz r lzr aye ̄ y e; ma
11 测 试 文 本 的 选 择 .
对 准确 度 进 行 测 试 用 句 为 : “ 北 科 技 大 学 坐 落 在 太 行 山 东 麓 的河 北 省 省 会 石 家庄 市 .9 6 河 1 9 年 由河 北 轻 化 工 学 院 、 北 机 电 学 院 和 河北 省 纺织 职 工 大 学 合 并 组 建 河
CJ KAn lzr I C nl e 、 ay e 、K a a zr y MMAnlzr E 、adnAnlzr。 a e( )P o ig ayey y J
_
中 文分 析 部 分 ( 询 和 索 引 )将 下载 的 中 文 分 词 包 放 到 11 查 : . 目录 } 下, 打开 N t D e m nA aye.v , uc ou e tn l raa 修改 tkn t a 方 法 如 下 h z j o eSr m e p biTk n t a tk nt a Sr gilN me R a e ed r u l o eSr m oe Sr m(tnf d a , edr ae) c e e i e r {
中文分词与词性标注技术研究与应用

中文分词与词性标注技术研究与应用中文分词和词性标注是自然语言处理中常用的技术方法,它们对于理解和处理中文文本具有重要的作用。
本文将对中文分词和词性标注的技术原理、研究进展以及在实际应用中的应用场景进行综述。
一、中文分词技术研究与应用中文分词是将连续的中文文本切割成具有一定语义的词语序列的过程。
中文具有词汇没有明确的边界,因此分词是中文自然语言处理的基础工作。
中文分词技术主要有基于规则的方法、基于词典的方法和基于机器学习的方法。
1.基于规则的方法基于规则的中文分词方法是根据语法规则和语言学知识设计规则,进行分词操作。
例如,按照《现代汉语词典》等标准词典进行分词,但这种方法无法处理新词、歧义和未登录词的问题,因此应用受到一定的限制。
2.基于词典的方法基于词典的中文分词方法是利用已有的大规模词典进行切分,通过查找词典中的词语来确定分词的边界。
这种方法可以处理新词的问题,但对未登录词的处理能力有所限制。
3.基于机器学习的方法基于机器学习的中文分词方法是利用机器学习算法来自动学习分词模型,将分词任务转化为一个分类问题。
常用的机器学习算法有最大熵模型、条件随机场和神经网络等。
这种方法具有较好的泛化能力,能够处理未登录词和歧义问题。
中文分词技术在很多自然语言处理任务中都起到了重要的作用。
例如,在机器翻译中,分词可以提高对齐和翻译的质量;在文本挖掘中,分词可以提取关键词和构建文本特征;在信息检索中,分词可以改善检索效果。
二、词性标注技术研究与应用词性标注是给分好词的文本中的每个词语确定一个词性的过程。
中文的词性标注涉及到名词、动词、形容词、副词等多个词性类别。
词性标注的目标是为后续的自然语言处理任务提供更精确的上下文信息。
1.基于规则的方法基于规则的词性标注方法是根据语法规则和语境信息,确定每个词语的词性。
例如,根据词语周围的上下文信息和词语的词义来判断词性。
这种方法需要大量的人工制定规则,并且对于新词的处理能力较差。
中文分词技术的研究现状与困难

四、解决方案
为了克服中文分词技术的研究困难,以下一些解决方案值得:
1、优化分词算法:针对分词算法的复杂性问题,可以尝试优化算法的设计和 实现,提高其效率和准确性。例如,可以通过引入上下文信息、利用语言学知 识等方式来改进算法。
2、改进信息检索技术:在信息检索领域,可以尝试将先进的排序算法、推荐 系统等技术引入到检索过程中,以提高检索效果。此外,还可以研究如何基于 用户行为和反馈来优化检索结果。
3、缺乏统一的评价标准:中文分词技术的评价标准尚未统一,这使得不同研 究之间的比较和评估变得困难。建立通用的中文分词技术评价标准对于推动相 关研究的发展至关重要。
4、特定领域的应用场景:中文分词技术在不同领域的应用场景中面临着不同 的挑战。例如,在金融领域中,需要分词技术对专业术语进行精确识别;在医 疗领域中,需要处理大量未登录词和生僻字。如何针对特定领域的应用场景进 行优化,是中文分词技术的重要研究方向。
3、建立大型标注语料库:通过建立大型标注语料库,可以为分词算法提供充 足的训练数据,提高其准确性和自适应性。此外,标注语料库也可以用于开发 基于规则的分词方法和测试集的构建。
4、研究跨领域的应用场景:针对不同领域的应用场景,可以研究如何将中文 分词技术进行迁移和适配。例如,可以通过知识图谱等技术将不同领域的知识 引入到分词过程中,以提高分词效果。
然而,各种分词方法也存在一定的局限性和不足。例如,基于规则的分词方法 需要人工编写规则和词典,难以维护和更新;基于统计的分词方法需要大量标 注语料库,而且训练模型的时间和计算成本较高;基于深度学习的分词方法虽 然取得了较好的效果,但也需要耗费大量的时间和计算资源进行训练。
三、研究困难
中文分词技术的研究面临着诸多困难和挑战,以下是一些主要词方法:该方法主要依靠人工编写的分词规则来进行分词。 代表性的工作包括台湾大学开发的中文分词系统“THULAC”和北京大学开发 的“PKU中文分词系统”。这些系统均基于词典和规则,具有较高的准确率和 召回率。
基于深度学习方法的中文分词和词性标注研究

基于深度学习方法的中文分词和词性标注研究中文分词和词性标注是自然语言处理中的重要任务,其目的是将输入的连续文字序列切分成若干个有意义的词语,并为每个词语赋予其对应的语法属性。
本文将基于深度学习方法对中文分词和词性标注进行研究。
一、深度学习方法介绍深度学习是一种基于神经网络的机器学习方法,在自然语言处理领域中应用广泛。
经典的深度学习模型包括卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)、长短时记忆网络(LongShort-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU)等。
在对中文分词和词性标注任务的研究中,CNN、RNN以及LSTM均被采用。
CNN主要用于序列标注任务中的特征提取,RNN及LSTM则用于序列建模任务中。
GRU是LSTM的一种简化版本,在应对大规模文本序列的过程中更为高效。
二、中文分词中文分词是将一段连续的汉字序列切分成有意义的词语。
传统的中文分词方法主要包括基于词典匹配的分词和基于统计模型的分词。
基于词典匹配的分词方法基于预先构建的词典,将待切分文本与词典进行匹配。
该方法精度较高,但需要较为完整的词典。
基于统计模型的分词方法则通过学习汉字之间的概率关系来进行分词。
该方法不依赖于完整的词典,但存在歧义问题。
深度学习方法在中文分词任务中也有较好的表现,通常采用基于序列标注的方法。
具体步骤如下:1. 以汉字为单位对输入文本进行编码;2. 使用深度学习模型进行序列标注,即对每个汉字进行标注,标记为B(词的开头)、M(词的中间)或E(词的结尾),以及S(单字成词);3. 将标注后的序列按照词语切分。
其中,深度学习模型可以采用CNN、RNN、LSTM或GRU等模型。
三、中文词性标注中文词性标注是为每个词语赋予其对应的语法属性,通常使用含有标注数据的语料库进行训练。
中文分词相关技术简介

中文分词相关技术简介目前对汉语分词方法的研究主要有三个方面:基于规则的分词方法、基于统计的分词方法和基于理解的分词方法。
基于规则的分词方法基于规则的分词方法,这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个"充分大的"机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。
常用的方法:最小匹配算法(Minimum Matching),正向(逆向)最大匹配法(Maximum Matching),逐字匹配算法,神经网络法、联想一回溯法,基于N-最短路径分词算法,以及可以相互组合,例如,可以将正向最大匹配方法和逆向最大匹配方法结合起来构成双向匹配法等。
目前机械式分词占主流地位的是正向最大匹配法和逆向最大匹配法。
◆最小匹配算法在所有的分词算法中,最早研究的是最小匹配算法(Minimum Matching),该算法从待比较字符串左边开始比较,先取前两个字符组成的字段与词典中的词进行比较,如果词典中有该词,则分出此词,继续从第三个字符开始取两个字符组成的字段进行比较,如果没有匹配到,则取前3个字符串组成的字段进行比较,依次类推,直到取的字符串的长度等于预先设定的阈值,如果还没有匹配成功,则从待处理字串的第二个字符开始比较,如此循环。
例如,"如果还没有匹配成功",取出左边两个字组成的字段与词典进行比较,分出"如果";再从"还"开始,取"还没",字典中没有此词,继续取"还没有",依次取到字段"还没有匹配"(假设阈值为5),然后从"没"开始,取"没有",如此循环直到字符串末尾为止。
这种方法的优点是速度快,但是准确率却不是很高,比如待处理字符串为"中华人民共和国",此匹配算法分出的结果为:中华、人民、共和国,因此该方法基本上已经不被采用。
中文分词技术研究

分词算法一般有三类:基于字符串匹配、基于语义分析、基于统计。
复杂的分词程序会将各种算法结合起来以便提高准确率。
Lucene被很多公司用来提供站内搜索,但是Lucene本身并没有支持中文分词的组件,只是在Sandbox里面有两个组件支持中文分词:ChineseAnalyzer和CJKAnalyzer。
ChineseAnalyzer 采取一个字符一个字符切分的方法,例如"我想去北京天安门广场"用ChineseAnalyzer分词后结果为:我#想#去#北#京#天#安#门#广#场。
CJKAnalyzer 则是二元分词法,即将相邻的两个字当成一个词,同样前面那句用CJKAnalyzer 分词之后结果为:我想#想去#去北#北京#京天#天安#安门#门广#广场。
这两种分词方法都不支持中文和英文及数字混合的文本分词,例如:IBM T60HKU现在只要11000元就可以买到。
用上述两种分词方法建立索引,不管是搜索IBM还是11000都是没办法搜索到的。
另外,假如我们使用"服务器"作为关键字进行搜索时,只要文档包含"服务"和"器"就会出现在搜索结果中,但这显然是错误的。
因此,ChineseAnalyzer和CJKAnalyzer虽然能够简单实现中文的分词,但是在应用中仍然会感觉到诸多不便。
基于字符串匹配的分词算法用得很多的是正向最大匹配和逆向最大匹配。
其实这两种算法是大同小异的,只不过扫描的方向不同而已,但是逆向匹配的准确率会稍微高一些。
"我想去北京天安门广场"这句使用最大正向分词匹配分词结果:我#想去#北京#天安门广场。
这样分显然比ChineseAnalyzer和CJKAnalyzer来得准确,但是正向最大匹配是基于词典的,因此不同的词典对分词结果影响很大,比如有的词典里面会认为"北京天安门"是一个词,那么上面那句的分词结果则是:我#想去#北京天安门#广场。
中文分词技术在交通管理系统中的应用研究
SlC & E NL0 CNE T0 OOY E H
匝圆
中文分 词技 术 在 交 通 管 理 系 统 中的 应 用研 究
李 娜 ( 国人 民解放 军后勤 工程学 院 重 庆 4 1 1 ) 中 0 1 3
摘 要: 如何 建立适 于交通管理 系统下 信息检索 子 系统 中的分词模块 是提 高检 索性 能的关键所 在。 本文 在分析 交通 管理领域特 点的基础 上, 出了 提 适合 交通 管理领域 的分词 方法 , 实现 了适 用于该领域 内的分 词 系统 。 实验结 果表 明, 系统 测试的准确率 和 召回率分别 ̄ 1 9 . _ ,5 J
9 和9 1 % 5. %。
关键词 : 中文分词 歧 义切分 N最优路 径 人 名识 别 地名识 别 中图分 类 号 : P T 2 文 献标 识 码 : A 文 章编 号 : 6 2 3 9 ( o O 0 () 2 3 2 1 7 - 7 1 2 1 ) 3a一0 5 —0
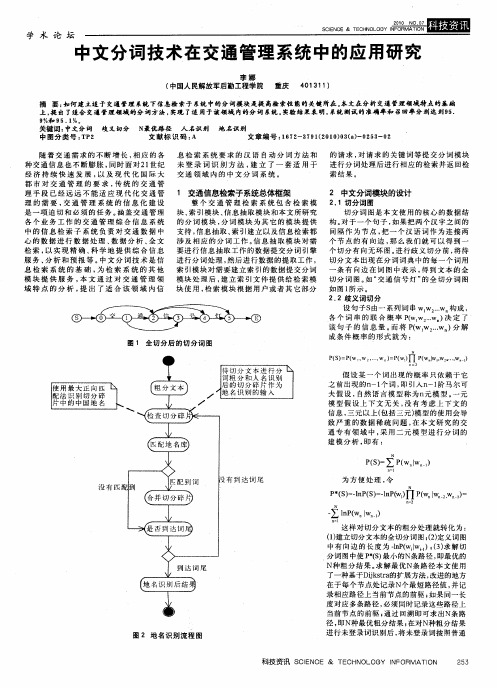
2 中文分词模块 的设计
2. 1切分 词 图 切 分 词 图是 本 文 使 用 的核 心 的数 据 结 构。 于一个句子 , 对 如果 把 两 个 汉 字之 间的 间 隔 作 为 节 点 , 一 个 汉 语 词 作 为 连 接 两 把
个 节 点 的 有 向 边 , 么 我 们 就 可 以 得 到 一 那 个切 分 有 向无 环 图 。 行 歧 义 切 分 前 , 待 进 将 切分 文 本 出现 在 分 词 词 典 中 的每 一 个 词 用 条 有 向边 在 词 图 中 表 示 , 到文 本 的 全 得 切 分 词 图 。 “ 通 信 号 灯 ” 全 切 分 词 图 如 交 的 如 图l 示 。 所 2 2歧义 词切 分 . 设 句子 s 由一 系列 词 串 w w W 构 成 , . 各 个 词 串 的 联 合 概 率 Pw, . 决 定 了 ( w W ) 该 句 子 的 信 息 量 。 将 Pw W . ) 解 而 ( w 分 成条件概率的形式就 为 :
中文分词技术在智能评分系统中的应用研究

中图分类号 :T P 3 9 1
文献标识码 : A
文章编号 :1 6 7 4 - 7 7 1 2( 2 0 1 4 ) 0 2 息技术 的普 及和发展,计算机智 能阅卷 已经得到 多 ,就越有可 能构成一个词 。从统计 学上讲就是求概 率的 问 了广 泛的应用 ,如 :大 学英语等级考试 、计算机 等级考试等 题 ,可 以通过对 训练 文本 中相邻 出现 的各个字 的组合 的频率 国家 级考 试 中的客观题 都参用 了计算机智 能阅卷 。同时一些 进行统计学 习,计算它们 的互现信 息得 出规律 。在 中文处理 远程考试 系统在主观题 智能评分方面也取得 了许 多成果 ,中 时 ,如果文本 串中的字与字互现信 息大于某个值 时,就可 以 文分 词是 自然语言处理 系统中的重要步骤 ,而主观题 智能评 判断此字组可 能构成 了一个词 。该 方法又称为无字 典分词 。 分首 要解 决的 问题就是 中文分词,本文试从现有 的中文分词 互现 信 息 的计 算 ,设有 词 A和 B ,A B之 间 的互现 信 息 为: 技术进行 了探讨 ,并就智能评分系统 中的应用做出研 究分析。 M ( A , B ) = 供中P( A , B ) 为A 、 B 相邻出 现的频率, 中文分词技术概述 P( A )为 A出现 的频率 ,P( B ) 为 B出现 的频率 。 中文分词是指按照 一定的算法 ,将一个 中文序 列切分成 ( 三 )依据 理解 的分词算法 。该方 法又称依据人 工智能 个 一个 单独 的词 。分词就 是计 算机 自动识别文 中词的边界 的分词方法 ,这种方 法模拟 了人对句 子的理解过程 ,其 基本 的过程 。我们知道 ,在英文 中,单词之间是 以空格 作为 自然 思想就是对文本 串进 行句法 、语义 理解 ,并利用句法信 息和 分界 符的,而 中文只是字 、句和 段能通过 明显 的分 界符来简 语义信 息来进行分词 并处理歧 义现象 。此算法一般包括三个 单划 界,唯独词没有一个 形式上的分界符 ,人工 在阅读时 , 部分 :分词子系统、句法语义子系统和总控部分。分词子系统 都需要通 过对句子分词才 能正确理解意思 ,可见 中文 分词技 是在 总控部分的协调下,来得到有关 的词、句子等的句法 ,通 术对主观题智能评分有着重要的意义 。 过语义信息对分词中的歧义进行判 断的。此分词方法通常使用 二、现有的中文分词技术 较大量的语言知识及信息。 由于汉语 中语言知识较为笼统、 复杂, 在近 3 0年 的研 究 中,各 位开发 人员研 究 了中文分 词技 很难将各种语 言信息完全组织成机器可直接读取 的形式,因此 术在 词典和概率方面统 计的一些算法 。 目前 中文 分词主要算 目前依据理解的分词系统还不成熟。 法有 三大类 :依据词典 的分词方法 ,依据统计 的分词方法 , 三 、中文分词算法在智能评 分系统 中的应用 依据理解 的分词方法 。 就 以往客观 题人工阅卷过程来 看,教师通常首先 查看正 下面 简要介绍一下这些算法 。 确答案 中的关键 点,然后再与学生答案 对 比,通过学 生答 对 ( 一 )依据 字典 的分词算法。又名机械分词 算法,此方 关键点所 占的比重来 确定学生得分情况 。基 于这样 的阅卷 过 法是根据 词库确立词典 ,然 后以一定策略将准备分 析的中文 程,尝试通过 中文分词模拟人工 阅卷过程 。 字符 串和这个词典 中的各词进行 比对 ,如果在词典中能找到, 首先 ,题库 中试题 要配有相应 的答 案及 关键 点,记 为一 则 比对 成功,那么就需要 一个相当大容量 的中文 词典,词典 个集合 ,如:关键字 = { K 1 ,K 2 ,K 3 …. K n ) 。在对学生 的答 案 的词语越 广泛 ,分词的越准 确。依据 比对方 向的不一 样可分 使用 中文 分词技术 中 删 法和 R M M法结合 ,得出学生答案中所 为正 向比对和逆 向比如 ;依据 长度 比对 的情况 ,分 为最大 比 占关键词 的比例 ,给相应的得分 。 对和最 小 比对;其 中最常用 的方 法是正 向最大 比对法 和逆 向 四、结束语 最大 比对法 。正向最大比对法 ( M a x i m u m at M c h i n g M e t h o d ), 本文就现有 的中文分词技术做 出了分析,系统地 阐述 了 其主要思想为:从待匹配的文本 串最左端开始,依次取出 i , 三种算法,他们都有各 自的优缺点 :首先依 据词典 的分词 算 2 ,3 ,…n 个字符来与 已有的词典 比较,看看在词典 中是否有 法简单 , 易于实现, 不足在于比对速度慢, 歧义 问题较难解决 这个词,若有,则匹配成功,将它放入词队列或数组中暂存, 依据 统计的分词算法 可以发现所有 的歧 义切分,但统计语 言 接着对 中文语句 /字 串中剩余的部分进匹配,直到全部分词完 的精 度和决策算法又在很 大程度上决定 了解 决歧义 的方法 , 毕。正向最大匹配算法按照从左到右 的顺序进行匹配,在分词 并且速度较慢 。后面又分析 了中文分词算法在 智能评分系 统 要遵循所谓的最大化原则,即确保 已扫描出的词不是某个 已存 中的应用,具体采用 了依 据词典 的分词 算法。 由于 中文 的复 在词 的前 缀。逆 向最 大 比对 法 ( R e v e r s e M a x i m u m M a t c h i n g 杂性 , 决定 了中文分词技术还不够成熟, 很多技术还在探索 中。 M e t h o d )。R M M法的主要 原理 与 删 法相 同,区别在于 分词的 参考文献: 扫描方 向。 如A 代表词典 , M A X 表示 A中的最长文本 串长度 , Ⅲ 1袁春凤 . 主观题 的计算机 自动批发技 术研 究 盯 ] . 计算 s t r i n g为准备切分 开的字符 串。删 法 是从 s t r i n g中取 出长 机 应 用研 究 , 2 0 0 4 ( 0 2 ) : 1 8 1 — 1 8 5 . 度为M A X的子 串 ( 即最长 文本 串)和 A中的词条进 行 比对 。 『 2 ] 高斯 丹 . 基 于 自然语 言理解的主观试题 自动批 发技 术 如 果成功 ,那么该 子串为词,然后指针 向后移 M AX 个 汉字后 的 研 究 与 初 步 实现 [ D1 . 继 续 比对 ,否则该子 串每次减少一个进行 比对。 由于汉语 多 『 3 1 谭 冬晨 . 主观题 评 分 算 法模 型研 究 f 【 ) ] . 电子 科技 大 数情 况下 中心词位 置相对靠后 ,所 以逆 向最 大匹配法 的精度 学 , 2 0 1 1 . 『 4 ] 贾电如 . 基 于 自然语语 句结构及语 义相似 度计算主观 要高于正 向最 大匹配法,在实际应用 中通 常将 正 向最大匹配 2 0 0 9 ( 0 5 ) : 5 — 7 . 算法 与逆 向最 大匹配算法两者结合起来 使用,这样可提高分 题评分算法的研究 卟 信 息化 纵横 , 词结果的正确率 。 [ 作者简介 ]张微微 ( 1 9 8 2 . 0 4 一 ),女 ,黑龙江讷河人 , ( 二 )依据 统计的分词算法 。该方 法的主要 思想 :词 是 稳定 的组合 ,因此 在上下文 中,相邻 的字同时 出现 的次数 越 教师 ,讲师 ,理学学士,研究方 向:计算机软件应 用。
深入了解中文的语言分析技术研究

深入了解中文的语言分析技术研究一、简介中文作为世界上最古老的语言之一,是全球使用人数最多的语言之一。
近年来,中文的语言分析技术得到了越来越多的关注。
本文旨在深入了解中文的语言分析技术研究。
二、中文分词技术在中文语言分析技术中,分词是一项基础性的技术,它将一条连续的汉字序列划分成一个个有意义的词,是中文语言处理的第一步。
由于中文语言没有明显的单词形式,所以分词技术在中文语言处理中的作用尤为重要。
中文分词技术中,最经典的方法是基于“规则+字典”的方法。
简单地说,就是将大量的中文词语进行归纳整理,形成中文词典,然后根据一定的规则,将句子中的汉字序列进行匹配,得到分词结果。
这种方法的优点是可控性好,缺点是需要手工编写规则和词典,对大规模语料的处理效率较低。
而随着机器学习算法的发展,现在又出现了基于统计学的方法,如隐马尔可夫模型、条件随机场等,这些方法可以利用大量的语料进行自动学习,减轻了手工编写的工作量,同时也提高了分词的精度和效率。
三、中文句法分析技术中文句法分析指的是对中文语句结构进行分析和描述,并将其转化为计算机可处理的形式。
这项技术在中文自然语言处理中起着重要作用。
由于中文句法结构的复杂性,中文句法分析技术一度是自然语言处理研究中最棘手的问题之一。
中文句法分析技术分为基于规则的方法和基于统计学的方法。
基于规则的方法需要手工编写规则,对句子结构有一定的先验知识,所以对于一些特定领域的应用效果较好;而基于统计学的方法则更加注重大规模语料的自动学习,对于一些复杂结构的句子处理效果较好。
四、中文情感分析技术中文情感分析技术指的是对中文文本中所包含的情感进行分析和评价。
伴随着社交媒体的兴起,越来越多的人将自己的情感、心情以及观点表达在社交媒体上,因此对中文情感分析技术的需求也越来越大。
中文情感分析技术主要分为两种方法:基于规则和基于机器学习。
基于规则的方法依靠人工编写的词典和规则进行情感判断,相对简单,但存在有效性低的问题;而基于机器学习的方法则依靠大量的语料进行学习,获得更好的情感分析效果。
基于Lucene的中文分词技术研究

向或逆 向最大匹配 的方法来分 词。例如 ,假设词 典包括 如下
的 词语 :
今天 / 很好” 。
天
天气
很
好
很好
输入 “ 今天天气很好 ” ,最后 的分词结 果为 “ 今天 , 天气
正 向最大匹配 和逆向最大 匹配 的实 现大 同小 异 ,最 大的 区别 就是正 向最 大匹配是 正向扫描字符 串 ,逆 向最大 匹配是
除 了这 两种 ,另外 一种最 少切分 的方法是使 每一句 中切 出的词数最小 。 22 基于统计 的分词方法 .
所周 知 ,英 语等西方 语言是使 用空格 和标 点来分 隔单词 。但 是在 汉语等 亚洲语种 中 ,一 般使用 表意文 字 ,而 不是使 用 由
字母 组成 的单词 。所 以相对 于西方语 言 ,L c n 中文 分词 ue e对
a c a y c ur c ・
Ke r s h n s e me t t n; u e e; xma t h n ma i m rb b l y y wo d :C i e e s g n ai o L c n ma i lma c i g; x mu p a i t o i
1 引 言
的效果并不是很好 。L cn 处理 中文分词常用方法有 3种 : ue e ()单字方式 : 【 【 【 【 [ 【 。 1 咬】 死】 猎】 人】 的】 狗]
() 二元覆 盖方式 : 【 2 咬死】 [ 死猎】 [ 人1 【 的1 猎 人 【 的狗】 。
w r e e t t n meh d a d ma i m r b b l y p rii l t o i h i t ov h r b e o n e u t o o d s g n a i t o n x mu p o a i t a t p e me d wh c s o s le t e p o l m f ma y r s l f m o i c h s
基于Hash结构词典的逆向回溯中文分词技术研究

中图法分类 号: P 9 T 31
文献标 识码 : A
文章编号 :0 072 2 L) 355 —4 10 .04(O O 2 —180
Re e s c ta kngr s ac fCh n s e m e tto v reba k r c i e e r h o i e es g n ai n ba e n d cinay o s tu t r s d o ito r fHa h sr cu e
55 2 1, 2) 18 00 1(3 3
计算 机 工 程 与设 计 C m u r ni e n d e g o pt E g er g n D s n e n i a i
・开 发 与应 用 ・
基于 H s 结构词典的逆向回溯中文分词技术研究 ah
梁 桢 , 李 禹生
( 汉 工业 学院 计 算机 与信 息工程 系,湖北 武 汉 4 0 2 ) 武 3 0 3
b s d o it n r t s t c u e i p e e t d F rt , f r h s f ce c ff s r i t n r t a h s u t e a ls a e n d ci a y wi Ha h S r t r r s n e . i l o h u s sy o ei u t n i in y o r t i wo d d ci ay wi h s t c u , t o h r r a
LI AN G e , LI u s e g Zh n —h n Y
( p r n f mp tr n fr t nE gn eig Wu a oye h i Unv ri , Wu a 3 0 3 De at t me o Co ue dI o mai n ie r , a n o n h nP ltc nc iest y h n4 0 2 ,Chn ) ia
基于神经网络的中文分词技术研究

基于神经网络的中文分词技术研究
中文分词是将连续的汉字序列切分为有意义的词语的过程。
传统的中文分词方法主要基于词典、规则和统计等方法,但这些方法在处理复杂的语言现象时存在一定的局限性。
近年来,基于神经网络的中文分词技术逐渐受到广泛关注。
这些技术通过神经网络模型学习中文分词任务的特征和规律,具有更好的泛化能力和鲁棒性。
以下是一些常见的基于神经网络的中文分词技术:
1.基于循环神经网络(RNN)的中文分词:RNN是一种递归神经网络结构,能够处理序列数据。
通过将汉字序列作为输入,RNN可以对每个汉字的边界进行预测,从而实现中文分词。
2.基于长短期记忆网络(LSTM)的中文分词:LSTM是一种特殊的RNN 结构,能够捕捉长期依赖关系。
通过LSTM网络,可以更好地处理一词多义、歧义和复合词等语言现象,提高中文分词的准确性。
3.基于注意力机制的中文分词:注意力机制是一种能够学习输入序列不同位置重要性的技术。
通过引入注意力机制,可以使神经网络更加关注汉字序列中与分词有关的信息,提高中文分词的效果。
4. 基于Transformer模型的中文分词:Transformer是一种基于自注意力机制的神经网络模型,具有较强的并行计算能力。
通过使用Transformer模型,可以有效地处理中文分词任务,并且在大规模语料库上获得较好的性能。
基于神经网络的中文分词技术在不同的任务和数据集上取得了较好的效果。
然而,由于中文分词任务的复杂性和语言差异,仍然存在一些困难
和挑战。
未来的研究可以进一步探索如何融合多种神经网络技术、优化网络结构和改进训练算法,以提高中文分词的性能和效果。
中文分词技术

一、为什么要进行中文分词?词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。
Lucene中对中文的处理是基于自动切分的单字切分,或者二元切分。
除此之外,还有最大切分(包括向前、向后、以及前后相结合)、最少切分、全切分等等。
二、中文分词技术的分类我们讨论的分词算法可分为三大类:基于字典、词库匹配的分词方法;基于词频度统计的分词方法和基于知识理解的分词方法。
第一类方法应用词典匹配、汉语词法或其它汉语语言知识进行分词,如:最大匹配法、最小分词方法等。
这类方法简单、分词效率较高,但汉语语言现象复杂丰富,词典的完备性、规则的一致性等问题使其难以适应开放的大规模文本的分词处理。
第二类基于统计的分词方法则基于字和词的统计信息,如把相邻字间的信息、词频及相应的共现信息等应用于分词,由于这些信息是通过调查真实语料而取得的,因而基于统计的分词方法具有较好的实用性。
下面简要介绍几种常用方法:1).逐词遍历法。
逐词遍历法将词典中的所有词按由长到短的顺序在文章中逐字搜索,直至文章结束。
也就是说,不管文章有多短,词典有多大,都要将词典遍历一遍。
这种方法效率比较低,大一点的系统一般都不使用。
2).基于字典、词库匹配的分词方法(机械分词法)这种方法按照一定策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。
识别出一个词,根据扫描方向的不同分为正向匹配和逆向匹配。
根据不同长度优先匹配的情况,分为最大(最长)匹配和最小(最短)匹配。
根据与词性标注过程是否相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
常用的方法如下:(一)最大正向匹配法 (MaximumMatchingMethod)通常简称为MM法。
其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。
中文分词技术研究

基 于 字符 串 配 的分 词 方 法 也 称 为 机 械 切分 方 法 。它 是 基 于 规 则 的切 分 方 法 ,按 照 一 定 的策 略 将 待分 析 的字 符 串与 充 分 大 的机 器 词 典 中 的词 条 进 行 匹 配 ,若 在 词 典 中找 到某 个 字 符 串 ,则 配 成
中 图 分 类 号 :T 3 11 P9. 文 献 标 识 码 :A 文 章 编 号 : 10 ~0 1 ( 0 0 0 —0 4 -0 09 3 2 2 l) 5 0 0 5
随 着科 学技 术 的飞速 发 展 ,我 们 已经进 入 了数 字 信息 化 时代 。Itre 作 为 当今 世 界上 最 大 的信 nen t
第5 期
于 洪 波 :巾 文分 词技 术研 究
41
2 中 文分 词 的 几 种 算 法
近几 年来 ,人们 对 中文 分词 技 术 有 了 一定 的研 究 ,先 后 提 m 了多 种有 效 的分 词算 法 。这 些算 法 主
要 分 为 _大 类 :基于 字符 串匹 配 的分 词 方法 、基 于统 计 的分词 方法 和 基于 知识 理 解 的分词 方法 二 。
因此 ,进行 中文信息过滤 ,首先就要对 文本预处理 ,进行 中文分词 ,将其表示成可计算和推理 的模型。中文 自动分词是对 中文文本进行 自动分类 的第一步 ,也是中文文本处理 的重要环节。中文
分词就是将连续 的字序列按照一定的规范重新组合成词序列的过程。其主要任务就是通过计算机 自 动 完成 对 中文句 子 的切分 ,识 别 独 立 的词 ,并在 词 与词 之 间用 空 格 分 割 开 。
文 和英 文 在语 法 规 则 、词 的结 构 上都 不 一 样 ,因此 针 对 中文 分词 的算 法 就 不 能 简 单 地 套 用英 文 的 分
基于三元统计模型的汉语分词及标注一体化研究

基于三元统计模型的汉语分词及标注一体化研究一、概述在当今信息爆炸的时代,人们在互联网上获取信息的渠道日益丰富,而语言是信息传递的重要方式。
而要实现语言信息的自动化处理,首先需要解决的就是语言的分词和标注问题。
汉语作为一种表意丰富、语法灵活的语言,其分词和标注任务考验着自然语言处理技术的智慧和实力。
二、基于三元统计模型的汉语分词研究1. 传统分词方法传统的汉语分词方法主要是基于词典的最大匹配和最短路径算法,通过查找词典和规则对文本进行切分。
然而这种方法难以处理歧义和新词问题,从而推动了基于统计模型的汉语分词研究。
2. 三元统计模型三元统计模型是一种基于马尔科夫假设的模型,通过对语料进行统计分析,得到词语之间的概率关系,从而实现对文本的自动分词。
该模型综合考虑了词语的左邻词、右邻词和当前词之间的关系,能够有效地解决歧义和新词问题,提高了分词的准确性和鲁棒性。
3. 分词效果评估基于三元统计模型的汉语分词研究取得了显著的成果,广泛应用于自然语言处理系统中。
通过对分词效果的评估,可以发现该模型在处理复杂句子和生僻词时表现出了较高的准确性和稳定性,为汉语信息处理提供了有力支持。
三、基于三元统计模型的汉语标注一体化研究1. 传统标注方法传统的汉语标注方法主要是基于规则和词典的人工标注,难以适应语言的多变性和复杂性。
而基于统计模型的汉语标注一体化研究成为了研究的热点。
2. 标注一体化模型基于三元统计模型的汉语标注一体化研究将分词和词性标注合并为一个统一的模型,通过对语料进行联合统计,得到词语和词性之间的联合概率关系,从而提高了标注的一致性和稳定性。
3. 标注一体化效果评估基于三元统计模型的汉语标注一体化研究为形成了较为完善的标注体系,在分词和词性标注的一致性和准确性上取得了显著的进展。
该模型在处理长句和多义词时表现出了较高的鲁棒性和可靠性,为汉语信息处理的全面性提供了技术支持。
四、个人观点与总结基于三元统计模型的汉语分词及标注一体化研究,是自然语言处理领域的重要突破之一。
中文分词技术的研究现状与困难

中图分类号:TP391.1 文献标识码:A 文章编号:1009-2552(2009)07-0187-03中文分词技术的研究现状与困难孙铁利,刘延吉(东北师范大学计算机学院,长春130117)摘 要:中文分词技术是中文信息处理领域的基础研究课题。
而分词对于中文信息处理的诸多领域都是一个非常重要的基本组成部分。
首先对中文分词的基本概念与应用,以及中文分词的基本方法进行了概述。
然后分析了分词中存在的两个最大困难。
最后指出了中文分词未来的研究方向。
关键词:中文分词;分词算法;歧义;未登录词State of the art and difficulties in Chinesew ord segmentation technologyS UN T ie2li,LI U Y an2ji(School of Computer,N ortheast N orm al U niversity,Ch angchun130117,China) Abstract:Chinese w ord segmentation is a basic research issue on Chinese in formation processing tasks.And Chinese w ord segmentation is a very im portant com ponent in many field of Chinese information process.The paper proposes an unsupervised training method for acquiring probability m odels that accurately segment Chinese character sequences into w ords.Then it presents a detailed analysis of the tw o great dificulties in w ord segmentation.And finally,it points out the research problems to be res olved on Chinese w ord segmentation.K ey w ords:Chinese w ord segmentation;segmentation alg orithm;ambiguity;unlisted w ords0 引言随着计算机网络的飞速普及,人们已经进入了信息时代。
词频统计中文分词技术的研究

词频统计 中文分词技术的研 究
朱 小 娟 , 陈特 放
( 中南 大学 信息科 学 与工程学院 ,长沙 4 0 7 ) 10 5
摘要:本文详细介绍了一个基于词频统计的中文分词 系统的设 计和实现 。系 统选用了三种统计原理分别进行统计:互信息 . N元统计模型和 t 测试。论 一 文 还 对这 三 种 原 理 的处 理 结 果 进 行 比 较 分析 各 种统 计 原 理 的统 计 特 点 、 以 及各自所适合应用的地方。
参 考 文献
【J周 明辉 . 1 面向对象的容错中间件的研究 与实现: 【 博士学位论文 】 .
长沙 :国防科学技术大学 , 2 0 . 02
【JGe re 2 o g Co o r ,J a Dol r,Tm Kid eg Ditiue ulu i e n s li e i mo n b r srb td S se :Co c p sa d DeinF ut dt n[ ]北 京 :机 械 出 y tms n e t n sg 、o rh e io M . i
维普资讯
经Hale Waihona Puke 证性能或行 为的属性。对 』功能性属性的修改 只需修 改改动基层 对涉及 能或行 为属 的修 改.则仅修改 层。 反射也提高了可重
,
仪器仪表用广
使容错中间件具有对应用 环境 的 自 应能力。 适
刚性, 层对象既 町以独立使 叮以和九层对象结合使用具备某 些额外属性 ,且吲样的厄层对缘 .可被重用米为不 同的基层对象附 加 同样的性能或行为属一:
一
32 基 于 反射 的 容错 中 间件 .
基 于 反射 的 容错 L 问件 是在 原 有 的容 错 中间 件 的 基础 上 。增 加 } J 反射机制,为 错应 用提取通用 的容错 属性,利用反射 的可 见性, 使得这些容错应H 的容错属性能够动态的配置管理 = I 目前。在 COR BA 容错 系统实现 中 ,没 有运 用反射 时,采 用 开发特殊的 O B来处理组通信 和容错 策略 ,即将 容错功能集成到 R ORB中 以满足特 定应用 的要求 ,或通 过将消息转 发给一个组通信 系统和其它负责处理复制的组件米实现容错。运用 反射方法的,如 F I NDS系统,它使刚开放 C+ RE +编译器来拦截对象的交互动作并 访问皋层对象 的属 性以实现 容 错 : 还有 d n miTAO, ya c 通过在 TAO 的基础 l实现运行期反射 来达剑容钳 的 目的。 基J ‘ 反射的容锚 中间件采J 发布 /订阅模型 ,为各分 布式对 象 = f j 提供容铝支持。接结构 为在 水的奔错中r 司件结构中增加容错属性 的收集 和评估模块和 错反射模块。容错 属性收集 主要收集动态配 置用的关键容错属性 .同叫根据模块 内设置 的属性 的有 效性等属 性.提供评f +机制.即匹配收集的属悱和 有效的属性 .向容错反射 模块提供相应的评估结粜信 息。反射模块根据评估信息 ,重配置容 错属性,使应_ 环境达到史佳的容错忡能 。在 系统运 行的过程 中, L } j 容错中『件通过 卜 方 ,1断的 实脱对 容车 『 I J 述 持属性对动态重配 置,
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
中文分词技术研究
摘要:分词技术做为WEB文本摘要的一个重要的技术环节,在WEB文本摘要技术中占有很重要的地位,本文从分词方法及分词算法两个角度对中文分词技术进行研究与分析。
关键词:中文分词未登录词特征词
词是最小的能够独立活动的有意义的语言成分,是计算机处理信息的基本单位。
词界(Word Houndury)是词语之间的间隔,词界之间的标志是两个词间的分隔符。
汉语分词的过程也就是找出词界的过程。
1.分词方法
1.1基于词典的分词方法
M最大,最小匹配标志,1为最大匹配,-1为最小匹配
分词的过程,即可以表示为在DAG中,从P0到Pn+1的路径中利用评价函数选取最佳路径的过程。
1.2基于统计的分词方法
1.2.1统计分词模型
N元语言模型。
1.2.2 N元模型
N元语言模型是一种常用的统计语言模型,利用其展开P(W)为:
2.未登录词及分词算法
2.1未登录词问题
未登录词问题源于分词中词典的大小,词典中容量有限。
则必定存在词典中没有出现的词,你为未登录词,未登录词,包括词典中未登录的人名、地名、机构名、新词语等。
在实际的书面文本中,特别是在新闻类文本中,大量包含人名、地名、机构名等,未登录词的处理成为文本自动切分的一个十分突出的问题。
2.2中文自动分词的基本算法
2.2.1正向最大匹配法(MM,Maximum Match Method)
该方法的基本思想是,从待切分语句中,沿正向(从左到右的阅读方向)截取一定长
度(称为最大词长)的字符串。
然后将这个字符串与词典中的词进行匹配,若匹配成功,则确定这个字符串为一个词。
然后,将指向被匹配语句的指针正向移动该字符串长的距离,继续进行下一次匹配。
若匹配不成功,则将字符串长度逐次减一,再进行匹配,直到成功为止。
这种方法的优点是时间复杂度低、易于实现。
2.2.2特征词库法
特征词库法实际上是一种“分而治之”的分词方法,其基本思想是:
事先建立一个特征词库,其中包含各种具有切分特征的词;
对给定的待分词的汉字串S,首先根据特征词库将S分割成苦干个较短的子串;
然后对每个子串分别采用机械匹配法进行切分。
特征词库法的理论依据是汉语中存在一些开态标志。
比如,各种词缀(包括前缀和后缀)、虚词和重叠词,这些形态标志可为汉语的切分提供重要依据,在自动切分时应尽可能加以利用。
一般在分词的预处理阶段应考虑这种方法的应用。
2.2.3约束矩阵法
引入约束矩阵算法之前,先解释一下什么叫歧义切分,所谓歧义切分是指相同的汉字串被切分成不同的词的序列。
如汉字串“计算机房”既可切成“计算机/房”也可被切成“计算/机房”。
歧义切可分为交集型歧义切分和组合型歧义切分。
交集型歧义切分是指形为ABC的汉字串既可切分成AB/C又可切分成A/BC。
所谓组合型歧义切分是指AB汉字串既可切成AB又可切成A/B,当某个汉字串具有歧义切分时,如何在不同的切分中先一个正确的结果?约束矩阵法是为解决这个问题而提出来。