LL1语法分析器_B12040921
LL1语法分析器_B12040921

for subExpression in expression: subExpression = (subExpression) for char in subExpression[:-1]: if char in Vn: index = (char)+1 string = subExpression[index:] followLink[char].append(''.join(string))
FirstDict[nChar] = []
lock = 1
while First and lock<100:
for nChar in Vn: if (nChar): #如果 nChar 的 First 还没求完毕
first = First[nChar]
LL1语法分析范文

LL1语法分析范文LL(1)语法分析是一种基于预测分析表的语法分析方法,它通过预测下一个输入符号,从而选择相应的产生式来推导语法树。
在LL(1)语法分析中,L表示从左到右扫描输入,L表示最左推导,1表示每个输入符号有唯一的产生式。
LL(1)语法分析具有简单、高效和容易实现的特点,适用于上下文无关文法(CFG)的语法分析。
LL(1)语法分析器可以通过构建预测分析表来实现,其中行代表文法符号,列表示下一个输入符号,表格的每个条目表示选择的产生式。
由于LL(1)语法分析器使用的是确定性选择,它们可以在一次扫描中完成语法分析。
1.构建预测分析表。
2.初始化输入符号栈和语法树栈,将文法的起始符号设为输入符号栈的栈顶。
3.从输入中读取下一个符号a。
4.如果输入符号栈的栈顶是终结符号,则进行匹配。
如果与a相等,则将栈顶和输入符号栈中的元素均弹出;如果不相等,则报错。
5.如果输入符号栈的栈顶是非终结符号,则在预测分析表中查找(栈顶,a)对应的产生式,将其逆序压入语法树栈,并将其右侧的非终结符号逆序压入输入符号栈。
6.重复步骤3-5,直到输入符号栈为空或者出错。
1. 对于每个产生式A -> α,计算First(α),将其加入预测分析表中。
2. 如果First(α)中包含ε,则将Follow(A)的元素加入预测分析表中。
LL(1)语法分析器的优点是简单、高效,且容易实现。
它可以在一次扫描中完成语法分析,并可以通过构建预测分析表进行可预测的语法分析。
因此,它是一种常用的语法分析方法,特别适用于上下文无关文法(CFG)。
然而,LL(1)语法分析器也有一些局限性。
由于LL(1)语法分析器使用的是确定性选择,它无法处理左递归文法,并且对于一些左因子冲突的文法也无法正常工作。
此外,由于LL(1)语法分析器使用的是自顶向下的分析方法,它对左递归的处理相对困难,容易导致无限递归。
因此,对于一些复杂的文法,LL(1)语法分析器可能不合适,需要使用其他更强大的语法分析方法。
LL1语法分析

北华航天工业学院《编译原理》课程实验报告课程实验题目:LL(1)语法分析实验作者所在系部:计算机科学与工程系作者所在专业:计算机科学与技术作者所在班级:xxx作者学号:xxxxx _ 作者姓名:xxxx指导教师姓名:xxxx完成时间:2011年4月28日一、实验目的理解预测分析表方法的实现原理。
二、实验内容及要求编写一通用的预测法分析程序,要求有一定的错误处理能力,出错后能够使程序继续运行下去,直到分析过程结束。
可通过不同的文法(通过数据表现)进行测试。
给定算术表达式文法,编写程序。
测试数据:1.算术表达式文法E→TE’E’→ +TE’|- TE’|εT→FT’T’→*FT’ |/ FT’ |%FT’|εF→(E) |id|num2.作业3.10 文法三、实验程序设计说明1.实验方案设计主要函数之间的调用关系如下图所示:2.程序源代码源代码如下:#include <iostream>#include <cstdio>#include <stack>using namespace std;struct Node1{ char vn;char vt;char s[10];}MAP[20];//存储分析预测表每个位置对应的终结符,非终结符,产生式int k;//用R代表E',W代表T',e代表空char start='E';int len=8;charG[10][10]={"E->TR","R->+TR","R->e","T->FW","W->*FW","W->e","F->(E)","F->i "};//存储文法中的产生式char VN[6]={'E','R','T','W','F'};//存储非终结符char VT[6]={'i','+','*','(',')','#'};//存储终结符char SELECT[10][10]={"(,i","+","),#","(,i","*","+,),#","(","i"};//存储文法中每个产生式对应的SELECT集char Right[10][8]={"->TR","->+TR","->e","->FW","->*FW","->e","->(E)","->i"}; //用R代表A',W代表B',e代表空/*char start='A';int len=6;char G[10][10]={"A->aR","R->ABl","R->e","B->dW","W->bW","W->e"};char VN[6]={'A','R','B','W'};char VT[6]={'a','d','b','#','l'};char SELECT[10][10]={"a","a","d,#","d","b","l"};char Right[10][6]={"->aR","->ABl","->e","->dW","->bW","->e"};*/stack <char> stak;bool compare(char *a,char *b){ int i,la=strlen(a),j,lb=strlen(b);for(i=0;i<la;i++)for(j=0;j<lb;j++){ if(a[i]==b[j])return 1; }return 0;}char *Find(char vn,char vt){ int i;for(i=0;i<k;i++){ if(MAP[i].vn==vn && MAP[i].vt==vt)return MAP[i].s;}return "error";}char * Analyse(char * word){ char p,action[10],output[10];int i=1,j,l=strlen(word),k=0,l_act,m;while(!stak.empty())stak.pop();stak.push('#');stak.push(start);printf("___________________________________________________________\n");printf("\n 对符号串%s的分析过程\n",word);printf(" -----------------------------------------------------------------------\n");printf("\n");printf(" 步骤栈顶元素剩余输入串动作\n");printf(" -----------------------------------------------------------------------\n");p=stak.top();while(p!='#'){ printf("%7d ",i++);p=stak.top();stak.pop();printf("%6c ",p);for(j=k,m=0;j<l;j++)output[m++]=word[j];output[m]='\0';printf("%10s",output);if(p==word[k]){ if(p=='#'){ printf(" 分析成功\n");return "SUCCESS";}printf(" 匹配终结符“%c”\n",p);k++;}else{ strcpy(action,Find(p,word[k]));if(strcmp(action,"error")==0){ printf(" 没有可用的产生式\n");return "ERROR"; }printf(" 展开非终结符%c%s\n",p,action);int l_act=strlen(action);if(action[l_act-1]=='e')continue;for(j=l_act-1;j>1;j--)stak.push(action[j]);}} if(strcmp(output,"#")!=0)return "ERROR";}int main (){ freopen("in1.txt","r",stdin);//freopen("in2.txt","r",stdin);char source[100];int i,j,flag,l,m;//printf("\n***为了方便编写程序,用R代表E',W代表T',e代表空*****\n\n");printf("\n****为了方便编写程序,用R代表A',W代表B',e代表空*****\n\n");printf("该文法的产生式如下:\n");for(i=0;i<len;i++)printf(" %s\n",G[i]);printf("___________________________________________________________\n");printf("\n该文法的SELECT集如下:\n");for(i=0;i<len;i++){ printf(" SELECT(%s) = { %s }\n",G[i],SELECT[i]); }printf("___________________________________________________________\n");//判断是否是LL(1)文法flag=1;for(i=0;i<8;i++){ for(j=i+1;j<8;j++){if(G[i][0]==G[j][0]){ if(compare(SELECT[i],SELECT[j])){flag=0;break;}}} if(j!=8)break; }if(flag)printf("\n有相同左部产生式的SELECT集合的交集为空,所以文法是LL(1)文法。
LL(1)语法分析器 代码 java 编译原理,带注释,可运行

public class Accept {public static StringBuffer stack=new StringBuffer("#E");public static StringBuffer stack2=new StringBuffer("i*i+i#");public static String a;public static void main(String arts[]){//stack2.deleteCharAt(0);System.out.print(accept(stack,stack2));}public static boolean accept(StringBuffer stack,StringBuffer stack2){//判断识别与否boolean result=true;outer:while (true) {System.out.format("%-9s",stack+"");System.out.format("%9s",stack2+"");System.out.format("%15s",a+"\n");char c1 = stack.charAt(stack.length() - 1);char c2 = stack2.charAt(0);if(c1=='#'&&c2=='#')return true;switch (c1) {case'E':if(!E(c2)) {result=false;break outer;}break;case'P': //P代表E’if(!P(c2)) {result=false;break outer;}break;case'T':if(!T(c2)) {result=false;break outer;}break;case'Q': //Q代表T’if(!Q(c2)) {result=false;break outer;}break;case'F':if(!F(c2)) {result=false;break outer;}break;default: {//终结符的时候if(c2==c1){stack.deleteCharAt(stack.length()-1);stack2.deleteCharAt(0);//System.out.println();}else{return false;}}}if(result=false)break outer;}return result;}public static boolean E(char c) {//语法分析子程序 Eboolean result=true;if(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("PT");a="E->TP";}else if(c=='('){stack.deleteCharAt(stack.length()-1);stack.append("PT");a="E->TP";}else{System.err.println("E 推导时错误!不能匹配!");result=false;}return result;}public static boolean P(char c){//语法分析子程序 Pboolean result=true;if(c=='+') {stack.deleteCharAt(stack.length()-1);stack.append("PT+");a="P->+TP";}else if(c==')') {stack.deleteCharAt(stack.length()-1);//stack.append("");a="P->0";}else if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");a="P->0";}else{System.err.println("P 推导时错误!不能匹配!");result=false;}return result;}public static boolean T(char c) {//语法分析子程序 Tboolean result=true;if(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("QF");a="T->FQ";}else if(c=='(') {stack.deleteCharAt(stack.length()-1);stack.append("QF");a="T->FQ";}else{result=false;System.err.println("T 推导时错误!不能匹配!");}return result;}public static boolean Q(char c){//语法分析子程序 Qboolean result=true;if(c=='+') {stack.deleteCharAt(stack.length()-1);//stack.append("");a="Q->0";}else if(c=='*') {stack.deleteCharAt(stack.length()-1);stack.append("QF*");a="Q->*FQ";}else if(c==')') {stack.deleteCharAt(stack.length()-1);//stack.append("");a="Q->0";}else if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");a="Q->0";}else{result=false;System.err.println("Q 推导时错误!不能匹配!");}return result;}public static boolean F(char c) {//语法分析子程序 Fboolean result=true;if(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("i");a="F->i";}else if(c=='(') {stack.deleteCharAt(stack.length()-1);stack.append(")E(");a="F->(E)";}else{result=false;System.err.println("F 推导时错误!不能匹配!");}return result;}/* public static StringBuffer changeOrder(String s){//左右交换顺序StringBuffer sb=new StringBuffer();for(int i=0;i<s.length();i++){sb.append(s.charAt(s.length()-1-i));}return sb;}*/}#E i*i+i# null#PT i*i+i# E->TP#PQF i*i+i# T->FQ#PQi i*i+i# F->i#PQ *i+i# F->i #PQF* *i+i# Q->*FQ #PQF i+i# Q->*FQ #PQi i+i# F->i #PQ +i# F->i #P +i# Q->0 #PT+ +i# P->+TP #PT i# P->+TP #PQF i# T->FQ #PQi i# F->i #PQ # F->i #P # Q->0 # # P->0 true。
编译原理实验报告《LL(1)语法分析器构造》(推荐文档)

《LL(1)分析器的构造》实验报告一、实验名称LL(1)分析器的构造二、实验目的设计、编制、调试一个LL(1)语法分析器,利用语法分析器对符号串的识别,加深对语法分析原理的理解。
三、实验内容和要求设计并实现一个LL(1)语法分析器,实现对算术文法:G[E]:E->E+T|TT->T*F|FF->(E)|i所定义的符号串进行识别,例如符号串i+i*i为文法所定义的句子,符号串ii+++*i+不是文法所定义的句子。
实验要求:1、检测左递归,如果有则进行消除;2、求解FIRST集和FOLLOW集;3、构建LL(1)分析表;4、构建LL分析程序,对于用户输入的句子,能够利用所构造的分析程序进行分析,并显示出分析过程。
四、主要仪器设备硬件:微型计算机。
软件: Code blocks(也可以是其它集成开发环境)。
五、实验过程描述1、程序主要框架程序中编写了以下函数,各个函数实现的作用如下:void input_grammer(string *G);//输入文法Gvoid preprocess(string *G,string *P,string &U,string &u,int &n,int &t,int &k);//将文法G预处理得到产生式集合P,非终结符、终结符集合U、u,int eliminate_1(string *G,string *P,string U,string *GG);//消除文法G中所有直接左递归得到文法GGint* ifempty(string* P,string U,int k,int n);//判断各非终结符是否能推导为空string* FIRST_X(string* P,string U,string u,int* empty,int k,int n);求所有非终结符的FIRST集string FIRST(string U,string u,string* first,string s);//求符号串s=X1X2...Xn的FIRST集string** create_table(string *P,string U,string u,int n,int t,int k,string* first);//构造分析表void analyse(string **table,string U,string u,int t,string s);//分析符号串s2、编写的源程序#include<cstdio>#include<cstring>#include<iostream>using namespace std;void input_grammer(string *G)//输入文法G,n个非终结符{int i=0;//计数char ch='y';while(ch=='y'){cin>>G[i++];cout<<"继续输入?(y/n)\n";cin>>ch;}}void preprocess(string *G,string *P,string &U,string &u,int &n,int &t,int &k)//将文法G预处理产生式集合P,非终结符、终结符集合U、u,{int i,j,r,temp;//计数char C;//记录规则中()后的符号int flag;//检测到()n=t=k=0;for( i=0;i<50;i++) P[i]=" ";//字符串如果不初始化,在使用P[i][j]=a时将不能改变,可以用P[i].append(1,a)U=u=" ";//字符串如果不初始化,无法使用U[i]=a赋值,可以用U.append(1,a) for(n=0;!G[n].empty();n++){ U[n]=G[n][0];}//非终结符集合,n为非终结符个数for(i=0;i<n;i++){for(j=4;j<G[i].length();j++){if(U.find(G[i][j])==string::npos&&u.find(G[i][j])==string::npos)if(G[i][j]!='|'&&G[i][j]!='^')//if(G[i][j]!='('&&G[i][j]!=')'&&G[i][j]!='|'&&G[i][j]!='^')u[t++]=G[i][j];}}//终结符集合,t为终结符个数for(i=0;i<n;i++){flag=0;r=4;for(j=4;j<G[i].length();j++){P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';/* if(G[i][j]=='('){ j++;flag=1;for(temp=j;G[i][temp]!=')';temp++);C=G[i][temp+1];//C记录()后跟的字符,将C添加到()中所有字符串后面}if(G[i][j]==')') {j++;flag=0;}*/if(G[i][j]=='|'){//if(flag==1) P[k][r++]=C;k++;j++;P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';r=4;P[k][r++]=G[i][j];}else{P[k][r++]=G[i][j];}}k++;}//获得产生式集合P,k为产生式个数}int eliminate_1(string *G,string *P,string U,string *GG)//消除文法G1中所有直接左递归得到文法G2,要能够消除含有多个左递归的情况){string arfa,beta;//所有形如A::=Aα|β中的α、β连接起来形成的字符串arfa、betaint i,j,temp,m=0;//计数int flag=0;//flag=1表示文法有左递归int flagg=0;//flagg=1表示某条规则有左递归char C='A';//由于消除左递归新增的非终结符,从A开始增加,只要不在原来问法的非终结符中即可加入for(i=0;i<20&&U[i]!=' ';i++){ flagg=0;arfa=beta="";for(j=0;j<100&&P[j][0]!=' ';j++){if(P[j][0]==U[i]){if(P[j][4]==U[i])//产生式j有左递归{flagg=1;for(temp=5;P[j][temp]!=' ';temp++) arfa.append(1,P[j][temp]);if(P[j+1][4]==U[i]) arfa.append("|");//不止一个产生式含有左递归}else{for(temp=4;P[j][temp]!=' ';temp++) beta.append(1,P[j][temp]);if(P[j+1][0]==U[i]&&P[j+1][4]!=U[i]) beta.append("|");}}}if(flagg==0)//对于不含左递归的文法规则不重写{GG[m]=G[i]; m++;}else{flag=1;//文法存在左递归GG[m].append(1,U[i]);GG[m].append("::=");if(beta.find('|')!=string::npos) GG[m].append("("+beta+")");else GG[m].append(beta);while(U.find(C)!=string::npos){C++;}GG[m].append(1,C);m++;GG[m].append(1,C);GG[m].append("::=");if(arfa.find('|')!=string::npos) GG[m].append("("+arfa+")");else GG[m].append(arfa);GG[m].append(1,C);GG[m].append("|^");m++;C++;}//A::=Aα|β改写成A::=βA‘,A’=αA'|β,}return flag;}int* ifempty(string* P,string U,int k,int n){int* empty=new int [n];//指示非终结符能否推导到空串int i,j,r;for(r=0;r<n;r++) empty[r]=0;//默认所有非终结符都不能推导到空int flag=1;//1表示empty数组有修改int step=100;//假设一条规则最大推导步数为100步while(step--){for(i=0;i<k;i++){r=U.find(P[i][0]);if(P[i][4]=='^') empty[r]=1;//直接推导到空else{for(j=4;P[i][j]!=' ';j++){if(U.find(P[i][j])!=string::npos){if(empty[U.find(P[i][j])]==0) break;}else break;}if(P[i][j]==' ') empty[r]=1;//多步推导到空else flag=0;}}}return empty;}string* FIRST_X(string* P,string U,string u,int* empty,int k,int n){int i,j,r,s,tmp;string* first=new string[n];char a;int step=100;//最大推导步数while(step--){// cout<<"step"<<100-step<<endl;for(i=0;i<k;i++){//cout<<P[i]<<endl;r=U.find(P[i][0]);if(P[i][4]=='^'&&first[r].find('^')==string::npos) first[r].append(1,'^');//规则右部首符号为空else{for(j=4;P[i][j]!=' ';j++){a=P[i][j];if(u.find(a)!=string::npos&&first[r].find(a)==string::npos)//规则右部首符号是终结符{first[r].append(1,a);break;//添加并结束}if(U.find(P[i][j])!=string::npos)//规则右部首符号是非终结符,形如X::=Y1Y2...Yk{s=U.find(P[i][j]);//cout<<P[i][j]<<":\n";for(tmp=0;first[s][tmp]!='\0';tmp++){a=first[s][tmp];if(a!='^'&&first[r].find(a)==string::npos)//将FIRST[Y1]中的非空符加入first[r].append(1,a);}}if(!empty[s]) break;//若Y1不能推导到空,结束}if(P[i][j]==' ')if(first[r].find('^')==string::npos)first[r].append(1,'^');//若Y1、Y2...Yk都能推导到空,则加入空符号}}}return first;}string FIRST(string U,string u,string* first,string s)//求符号串s=X1X2...Xn的FIRST集{int i,j,r;char a;string fir;for(i=0;i<s.length();i++){if(s[i]=='^') fir.append(1,'^');if(u.find(s[i])!=string::npos&&fir.find(s[i])==string::npos){ fir.append(1,s[i]);break;}//X1是终结符,添加并结束循环if(U.find(s[i])!=string::npos)//X1是非终结符{r=U.find(s[i]);for(j=0;first[r][j]!='\0';j++){a=first[r][j];if(a!='^'&&fir.find(a)==string::npos)//将FIRST(X1)中的非空符号加入fir.append(1,a);}if(first[r].find('^')==string::npos) break;//若X1不可推导到空,循环停止}if(i==s.length())//若X1-Xk都可推导到空if(fir.find(s[i])==string::npos) //fir中还未加入空符号fir.append(1,'^');}return fir;}string** create_table(string *P,string U,string u,int n,int t,int k,string* first)//构造分析表,P为文法G的产生式构成的集合{int i,j,p,q;string arfa;//记录规则右部string fir,follow;string FOLLOW[5]={")#",")#","+)#","+)#","+*)#"};string **table=new string*[n];for(i=0;i<n;i++) table[i]=new string[t+1];for(i=0;i<n;i++)for(j=0;j<t+1;j++)table[i][j]=" ";//table存储分析表的元素,“ ”表示error for(i=0;i<k;i++){arfa=P[i];arfa.erase(0,4);//删除前4个字符,如:E::=E+T,则arfa="E+T"fir=FIRST(U,u,first,arfa);for(j=0;j<t;j++){p=U.find(P[i][0]);if(fir.find(u[j])!=string::npos){q=j;table[p][q]=P[i];}//对first()中的每一终结符置相应的规则}if(fir.find('^')!=string::npos){follow=FOLLOW[p];//对规则左部求follow()for(j=0;j<t;j++){if((q=follow.find(u[j]))!=string::npos){q=j;table[p][q]=P[i];}//对follow()中的每一终结符置相应的规则}table[p][t]=P[i];//对#所在元素置相应规则}}return table;}void analyse(string **table,string U,string u,int t,string s)//分析符号串s{string stack;//分析栈string ss=s;//记录原符号串char x;//栈顶符号char a;//下一个要输入的字符int flag=0;//匹配成功标志int i=0,j=0,step=1;//符号栈计数、输入串计数、步骤数int p,q,r;string temp;for(i=0;!s[i];i++){if(u.find(s[i])==string::npos)//出现非法的符号cout<<s<<"不是该文法的句子\n";return;}s.append(1,'#');stack.append(1,'#');//’#’进入分析栈stack.append(1,U[0]);i++;//文法开始符进入分析栈a=s[0];//cout<<stack<<endl;cout<<"步骤分析栈余留输入串所用产生式\n";while(!flag){// cout<<"步骤分析栈余留输入串所用产生式\n"cout<<step<<" "<<stack<<" "<<s<<" ";x=stack[i];stack.erase(i,1);i--;//取栈顶符号x,并从栈顶退出//cout<<x<<endl;if(u.find(x)!=string::npos)//x是终结符的情况{if(x==a){s.erase(0,1);a=s[0];//栈顶符号与当前输入符号匹配,则输入下一个符号cout<<" \n";//未使用产生式,输出空}else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}if(x=='#'){if(a=='#') {flag=1;cout<<"成功\n";}//栈顶和余留输入串都为#,匹配成功else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}if(U.find(x)!=string::npos)//x是非终结符的情况{p=U.find(x);q=u.find(a);if(a=='#') q=t;temp=table[p][q];cout<<temp<<endl;//输出使用的产生式if(temp[0]!=' ')//分析表中对应项不为error{r=9;while(temp[r]==' ') r--;while(r>3){if(temp[r]!='^'){stack.append(1,temp[r]);//将X::=x1x2...的规则右部各符号压栈i++;}r--;}}else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}step++;}if(flag) cout<<endl<<ss<<"是该文法的句子\n";}int main(){int i,j;string *G=new string[50];//文法Gstring *P=new string[50];//产生式集合Pstring U,u;//文法G非终结符集合U,终结符集合uint n,t,k;//非终结符、终结符个数,产生式数string *GG=new string[50];//消除左递归后的文法GGstring *PP=new string[50];//文法GG的产生式集合PPstring UU,uu;//文法GG非终结符集合U,终结符集合uint nn,tt,kk;//消除左递归后的非终结符、终结符个数,产生式数string** table;//分析表cout<<" 欢迎使用LL(1)语法分析器!\n\n\n";cout<<"请输入文法(同一左部的规则在同一行输入,例如:E::=E+T|T;用^表示空串)\n";input_grammer(G);preprocess(G,P,U,u,n,t,k);cout<<"\n该文法有"<<n<<"个非终结符:\n";for(i=0;i<n;i++) cout<<U[i];cout<<endl;cout<<"该文法有"<<t<<"个终结符:\n";for(i=0;i<t;i++) cout<<u[i];cout<<"\n\n 左递归检测与消除\n\n";if(eliminate_1(G,P,U,GG)){preprocess(GG,PP,UU,uu,nn,tt,kk);cout<<"该文法存在左递归!\n\n消除左递归后的文法:\n\n"; for(i=0;i<nn;i++) cout<<GG[i]<<endl;cout<<endl;cout<<"新文法有"<<nn<<"个非终结符:\n";for(i=0;i<nn;i++) cout<<UU[i];cout<<endl;cout<<"新文法有"<<tt<<"个终结符:\n";for(i=0;i<tt;i++) cout<<uu[i];cout<<endl;//cout<<"新文法有"<<kk<<"个产生式:\n";//for(i=0;i<kk;i++) cout<<PP[i]<<endl;}else{cout<<"该文法不存在左递归\n";GG=G;PP=P;UU=U;uu=u;nn=n;tt=t;kk=k;}cout<<" 求解FIRST集\n\n";int *empty=ifempty(PP,UU,kk,nn);string* first=FIRST_X(PP,UU,uu,empty,kk,nn);for(i=0;i<nn;i++)cout<<"FIRST("<<UU[i]<<"): "<<first[i]<<endl;cout<<" 求解FOLLOW集\n\n";for(i=0;i<nn;i++)cout<<"FOLLOW("<<UU[i]<<"): "<<FOLLOW[i]<<endl; cout<<"\n\n 构造文法分析表\n\n"; table=create_table(PP,UU,uu,nn,tt,kk,first);cout<<" ";for(i=0;i<tt;i++) cout<<" "<<uu[i]<<" ";cout<<"# "<<endl;for( i=0;i<nn;i++){cout<<UU[i]<<" ";for(j=0;j<t+1;j++)cout<<table[i][j];cout<<endl;}cout<<"\n\n 分析符号串\n\n";cout<<"请输入要分析的符号串\n";cin>>s;analyse(table,UU,uu,tt,s);return 0;}3、程序演示结果(1)输入文法(2)消除左递归(3)求解FIRST和FOLLOW集(4)构造分析表(5)分析符号串匹配成功的情况:匹配失败的情况五、思考和体会1、编写的LL(1)语法分析器应该具有智能性,可以由用户输入任意文法,不需要指定终结符个数和非终结符个数。
LL1语法分析器_B12040921

实验报告
(2014/2015 学年第二学期)
课程名称 实验名称 实验时间 指导单位 指导教师
编译原理
语法分析器的构造
2015
年 5 月 29 日
计算机学院软件工程系
蒋凌云
学生姓名 学院(系)
Cjj
班级学号
计算机学院 专业
B--------NIIT
成绩
批阅人
日期
.
.
实验报告
实验名称
语法分析器的构造
self.firstSet,
def Judge(self, string): """判断字符串是否为当前文法的句子 """ isMatch = False
1
.
analyseStack = ["#", self.start] StringStack = list(string) + ["#"] print u"="*25,u"判断字符串=%s"%string,u"="*25 print "%-30s%-12s%s"%(u"分析栈",u"余留输入串",u"所用生成式") try:
classAnalyseMachine(object):
def __init__(self): pass
def load(self, Grammers): """载入文法规则 参数 Grammers: 文法的规则列表 """
self.Grammers = Grammers self.noLeftRecursionGrammers = self.__NoLeftRecursion(self.Grammers) self.start = self.Grammers[0][0] self.nChars = self.__GetVn(self.noLeftRecursionGrammers) self.tChars = self.__GetVt(self.noLeftRecursionGrammers) self.firstSet = self.FirstSet(self.noLeftRecursionGrammers) self.followSet = self.FollowSet(self.noLeftRecursionGrammers) self.analyseTable = self.AnalyseTable(self.noLeftRecursionGrammers, self.followSet)
LL1语法分析程序实验报告

LL1语法分析程序实验报告实验目的:通过编写LL(1)语法分析程序,加深对语法分析原理的理解,掌握语法分析方法的实现过程,并验证所编写的程序的正确性。
实验准备:1.了解LL(1)语法分析的原理和步骤;2.根据语法规则,构建一个简单的文法;3.准备一组测试用例,包括符合语法规则的输入和不符合语法规则的输入。
实验步骤:1.根据文法规则,构建预测分析表;2.实现LL(1)语法分析程序;3.编写测试用例进行测试;4.分析测试结果。
实验结果:我根据上述步骤,编写了一个LL(1)语法分析程序,并进行了测试。
以下是我的测试结果:测试用例1:输入:9+7*(8-5)分析结果:成功测试用例2:输入:3+*5分析结果:失败测试用例3:输入:(3+5)*分析结果:失败测试用例4:输入:(3+5)*2+4分析结果:成功分析结果符合预期,说明我编写的LL(1)语法分析程序是正确的。
在测试用例1和测试用例4中,分析结果是成功的,而在测试用例2和测试用例3中,分析结果是失败的,这是因为输入不符合文法规则。
实验总结:通过本次实验,我进一步理解了LL(1)语法分析的原理和步骤。
编写LL(1)语法分析程序不仅要根据文法规则构建预测分析表,还要将预测分析表与输入串进行比对,根据匹配规则进行预测分析,最终得到分析结果。
在实验过程中,我发现在构建预测分析表和编写LL(1)语法分析程序时需要仔细思考和调试才能保证正确性。
通过本次实验,我对语法分析方法的实现过程有了更深入的认识,对于将来在编译原理方面的学习和工作有了更好的准备。
编译原理语法分析器

编译原理语法分析器编译原理语法分析器是编译器中的重要组成部分,它负责将源代码解析成抽象语法树,为后续的语义分析和代码生成做准备。
本文将介绍语法分析器的原理、分类和常用算法。
一、语法分析器的原理语法分析器的主要任务是根据给定的文法定义,将源代码解析成一个个语法单元,并构建出一棵抽象语法树。
它通过递归下降、预测分析和LR分析等算法来实现。
1. 递归下降法递归下降法是一种基于产生式的自顶向下分析方法。
它从文法的开始符号出发,通过不断地推导和回溯,逐步地构建抽象语法树。
递归下降法易于理解和实现,但对左递归和回溯有一定的局限性。
2. 预测分析法预测分析法也是自顶向下的分析方法,它通过预测下一个输入符号来选择适当的产生式进行推导。
为了提高效率,预测分析法使用预测分析表来存储各个非终结符和终结符的关系。
3. LR分析法LR分析法是一种自底向上的分析方法,它使用LR自动机和LR分析表来进行分析。
LR自动机是一个有限状态控制器,通过状态转移和规约动作来解析源代码。
LR分析表存储了状态转移和规约的规则。
二、语法分析器的分类根据语法分析器的特性和实现方式,可以将其分为LL分析器和LR 分析器。
1. LL分析器LL分析器是基于递归下降法和预测分析法的一类分析器。
它从左到右、从左到右地扫描源代码,并根据预测分析表进行推导。
常见的LL分析器有LL(1)分析器和LL(k)分析器。
2. LR分析器LR分析器是基于LR分析法的一类分析器。
它先通过移进-归约的方式建立一棵语法树,然后再进行规约操作。
LR分析器具有强大的语法处理能力,常见的LR分析器有LR(0)、SLR(1)、LR(1)和LALR(1)分析器。
三、常用的语法分析算法除了递归下降法、预测分析法和LR分析法,还有一些其他的语法分析算法。
1. LL算法LL算法是一种递归下降法的改进算法,它通过构造LL表和预测分析表实现分析过程。
LL算法具有很好的可读性和易于理解的特点。
2. LR算法LR算法是一种自底向上的分析方法,它通过建立LR自动机和构造LR分析表来进行分析。
编译原理实验二:LL(1)语法分析器

编译原理实验⼆:LL(1)语法分析器⼀、实验要求 1. 提取左公因⼦或消除左递归(实现了消除左递归) 2. 递归求First集和Follow集 其它的只要按照课本上的步骤顺序写下来就好(但是代码量超多...),下⾯我贴出实验的⼀些关键代码和算法思想。
⼆、基于预测分析表法的语法分析 2.1 代码结构 2.1.1 Grammar类 功能:主要⽤来处理输⼊的⽂法,包括将⽂法中的终结符和⾮终结符分别存储,检测直接左递归和左公因⼦,消除直接左递归,获得所有⾮终结符的First集,Follow集以及产⽣式的Select集。
#ifndef GRAMMAR_H#define GRAMMAR_H#include <string>#include <cstring>#include <iostream>#include <vector>#include <set>#include <iomanip>#include <algorithm>using namespace std;const int maxn = 110;//产⽣式结构体struct EXP{char left; //左部string right; //右部};class Grammar{public:Grammar(); //构造函数bool isNotTer(char x); //判断是否是终结符int getTer(char x); //获取终结符下标int getNonTer(char x); //获取⾮终结符下标void getFirst(char x); //获取某个⾮终结符的First集void getFollow(char x); //获取某个⾮终结符的Follow集void getSelect(char x); //获取产⽣式的Select集void input(); //输⼊⽂法void scanExp(); //扫描输⼊的产⽣式,检测是否有左递归和左公因⼦void remove(); //消除左递归void solve(); //处理⽂法,获得所有First集,Follow集以及Select集void display(); //打印First集,Follow集,Select集void debug(); //⽤于debug的函数~Grammar(); //析构函数protected:int cnt; //产⽣式数⽬EXP exp[maxn]; //产⽣式集合set<char> First[maxn]; //First集set<char> Follow[maxn]; //Follow集set<char> Select[maxn]; //select集vector<char> ter_copy; //去掉$的终结符vector<char> ter; //终结符vector<char> not_ter; //⾮终结符};#endif 2.1.2 AnalyzTable类 功能:得到预测分析表,判断输⼊的⽂法是否是LL(1)⽂法,⽤预测分析表法判断输⼊的符号串是否符合刚才输⼊的⽂法,并打印出分析过程。
实行二LL1语法分析器

曲阜师范大学实验报告No. 2010416573 计算机系2010年级网络工程二班组日期2012-10-9姓名王琳课程编译原理成绩教师签章陈矗实验名称: LL(1)语法分析器实验报告【实验目的】1. 了解LL(1)语法分析是如何根据语法规则逐一分析词法分析所得到的单词,检查语法错误,即掌握语法分析过程。
2. 掌握LL(1)语法分析器的设计与调试。
【实验内容】文法:E ->TE’ ,E’-> +TE‘ | ,T-> FT’ ,T’->* FT’ | ,F-> (E ) |i针对上述文法,编写一个LL(1)语法分析程序:1. 输入:诸如i i *i 的字符串,以#结束。
2. 处理:基于分析表进行LL(1)语法分析,判断其是否符合文法。
3. 输出:串是否合法。
【实验要求】1. 在编程前,根据上述文法建立对应的、正确的预测分析表。
2. 设计恰当的数据结构存储预测分析表。
3. 在C、C++、Java 中选择一种擅长的编程语言编写程序,要求所编写的程序结构清晰、正确。
【实验环境】1.此算法是一个java 程序,要求在eclipse软件中运行2.硬件windows 系统环境中【实验分析】读入文法,判断正误,如无误,判断是否是LL(1)文法,若是构造分析表【实验程序】package llyufa;public class Accept2 {public static StringBuffer stack=new StringBuffer("#E");public static StringBuffer stack2=new StringBuffer("i+i*i+i#");public static void main(String arts[]){//stack2.deleteCharAt(0);System.out.print(accept(stack,stack2));}public static boolean accept(StringBuffer stack,StringBuffer stack2){//判断识别与否boolean result=true;o uter:while (true) {System.out.format("%-9s",stack+"");System.out.format("%9s",stack2+"\n");char c1 = stack.charAt(stack.length() - 1);char c2 = stack2.charAt(0);if(c1=='#'&&c2=='#')return true;switch (c1) {case'E':if(!E(c2)) {result=false;break outer;}break;case'P': //P代表E’if(!P(c2)) {result=false;break outer;}break;case'T':if(!T(c2)) {result=false;break outer;}break;case'Q': //Q代表T’if(!Q(c2)) {result=false;break outer;}break;case'F':if(!F(c2)) {result=false;break outer;}break;default: {//终结符的时候if(c2==c1){stack.deleteCharAt(stack.length()-1);stack2.deleteCharAt(0);//System.out.println();}else{return false;}}}if(result=false)break outer;}r eturn result;}public static boolean E(char c) {//语法分析子程序 Eb oolean result=true;i f(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("PT");}e lse if(c=='('){stack.deleteCharAt(stack.length()-1);stack.append("PT");}e lse{System.err.println("E 推导时错误!不能匹配!");result=false;}r eturn result;}public static boolean P(char c){//语法分析子程序 Pb oolean result=true;i f(c=='+') {stack.deleteCharAt(stack.length()-1);stack.append("PT+");}e lse if(c==')') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse{System.err.println("P 推导时错误!不能匹配!");result=false;}r eturn result;}public static boolean T(char c) {//语法分析子程序 Tb oolean result=true;i f(c=='i') {stack.deleteCharAt(stack.length()-1);}e lse if(c=='(') {stack.deleteCharAt(stack.length()-1);stack.append("QF");}e lse{result=false;System.err.println("T 推导时错误!不能匹配!");}r eturn result;}public static boolean Q(char c){//语法分析子程序 Qb oolean result=true;i f(c=='+') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse if(c=='*') {stack.deleteCharAt(stack.length()-1);stack.append("QF*");}e lse if(c==')') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse{result=false;System.err.println("Q 推导时错误!不能匹配!");}r eturn result;}public static boolean F(char c) {//语法分析子程序 Fb oolean result=true;i f(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("i");}e lse if(c=='(') {stack.deleteCharAt(stack.length()-1);}e lse{result=false;System.err.println("F 推导时错误!不能匹配!");}r eturn result;}/* public static StringBuffer changeOrder(String s){//左右交换顺序S tringBuffer sb=new StringBuffer();f or(int i=0;i<s.length();i++){sb.append(s.charAt(s.length()-1-i));}r eturn sb;}*/}【执行结果】【小结】通过这次的实验,更深入的了解了编译原理,熟悉了语法分析器的制作和使用,了解了更多关于语言的知识,极大地提高了动手能力。
编译原理课程设计-LL(1)语法分析器的构造

LL(1)语法分析器的构造摘要语法分析的主要任务是接收词法分析程序识别出来的单词符由某种号串,判断它们是否语言的文法产生,即判断被识别的符号串是否为某语法部分。
一般语法分析常用自顶向下方法中的LL分析法,采用种方法时,语法分程序将按自左向右的顺序扫描输入的的符号串,并在此过程中产生一个句子的最左推导,即LL是指自左向右扫描,自左向右分析和匹配输入串。
经过分析,我们使用VC++作为前端开发工具,在分析语法成分时比较方便直观,更便于操作。
运行程序的同时不断修正改进程序,直至的到最优源程序。
关键字语法分析文法自顶向下分析 LL(1)分析最左推导AbstractGrammatical analysis of the main tasks was to receive lexical analysis procedure to identify the words from a website, string, and judge whether they have a grammar of the language, that is, judging by the series of symbols to identify whether a grammar part. General syntax analysis commonly used top-down methods of LL analysis, using methods, Grammar hours will be from the procedures of the order left-to-right scanning input string of symbols, and in the process produced one of the most left the sentence is derived, LL is scanned from left to right, From left to right analysis and matching input strings. After analysis, we use VC + + as a front-end development tool for the analysis of syntax ingredients more convenient visual, more easy to operate. Operational procedures at the same time constantly improving procedures, until the source of optimal .Key WordsGrammatical analysis grammar Top-down analysis LL (1) AnalysisMost left Derivation目录摘要 (1)引言 (3)第一章设计目的 (4)第二章设计的内容和要求 (5)2.1 设计内容 (5)2.2 设计要求 (5)2.3 设计实现的功能 (5)第三章设计任务的组织和分工 (6)3.1 小组的任务分工 (6)3.2 本人主要工作 (6)第四章系统设计 (9)4.1 总体设计 (9)4.2 详细设计 (9)第五章运行与测试结果 (22)5.1 一组测试数据 (22)5.2 界面实现情况 (23)第六章结论 (27)课程设计心得 (28)参考文献 (29)致谢 (30)附录(核心代码清单) (31)引言编译器的构造工具是根据用户输入的语言的文法,编译器的构造工具可以生成程序来处理以用户输入的文法书写的文本。
LL(1) 语法分析实验 (4学时)——学实验报告

大学实验报告
No. 2
课程编译原理成绩教师签章
实验名称:LL(1) 语法分析实验(4学时)
一、实验目的:
1. 了解LL(1)语法分析是如何根据语法规则逐一分析词法分析所得到的单词,检查语法错误,即掌握语法分析过程。
2. 掌握LL(1)语法分析器的设计与调试
二、实验内容:
文法:E→TE’,E’→+TE’|ε,T→FT’,T’→*FT’|ε,F→(E) | i
针对上述文法,编写一个LL(1)语法分析程序:
1. 输入:诸如i+i*i 的字符串,以#结束。
2. 处理:基于分析表进行LL(1)语法分析,判断其是否符合文法。
3. 输出:串是否合法。
三、实验要求:
1. 在编程前,根据上述文法建立对应的、正确的预测分析表。
2. 设计恰当的数据结构存储预测分析表。
3. 任选C/C++/Java中的一种作为编程语言,要求所编程序结构清晰。
四、实验环境:
系统要求:WindowsXP系统
内存:256M以上
软件支持:Microsoft Visual C++6.0
开发语言:C++
五、实验分析:
1.通过文法:E→TE’,E’→+TE’|ε,T→FT’,T’→*FT’|ε,F→(E) | i 产生
六、实验过程:
七、实验结论:。
算术表达式的LL(1)语法分析器

算术表达式的 LL(1)语法分析器摘要:语法分析是编译程序的核心部分,对其进行研究有着重要意义。
本文介绍了编译过程语法分析阶段使用的LL(1)预测分析法的相关概念,并以算术表达式为例,对LL(1)语法分析器的构成及具体实现进行了详细的阐述。
关键词:语法分析;算术表达式;LL(1)文法;LL(1)语法分析器;Arithmetic Expressions of LL(1) ParserZhang Huixia(College of Computer and Information Technology, Liaoning Normal University, Dalian Liaoning 116000, China)Abstract:Syntax analysis is the core part of compiler.It is ofgreat significance to study it .This paper introduces the relevant concepts of LL(1) predictive analysis method used in the parsing stage of compilation process,and takes arithmetic expressions for example to elaborate the structure and concrete implementation of LL(1) parser.Key words:syntax analysis; arithmetic expressions; LL(1) grammar; LL(1) parser前言编译程序极大地推动了计算机的发展,现已成为计算机系统的重要组成部分。
语法分析(Syntax Analysis)是编译程序的第二阶段,也是核心功能之一,其主要任务是根据语法规则检查词法分析器输出的单词序列是否是该语言文法的正确句子[1]。
LL(1)语法分析

LL(1)语法分析程序一、程序功能说明本程序通过从键盘读入输入字符串,分析是否是符合文法的语言。
每次通过取字符串中未分析的第一个字符,与分析栈中栈顶元素共同来查表,得要相应的产生式放入反序栈内。
如果是字符串中的字符与栈顶元素相同则该字符分析完毕,同时进行出栈与读入字符串下一字符操作。
如果栈顶符号与字符串结尾符相匹配,则分析栈被拆空,输入字符串完全得到了匹配,分析成功。
二、数据结构描述1、SqStack分析栈:typedefstruct{char stack[100];int top;}SqStack;通过Push()与Pop()操作对栈进行操作,将某一元素进栈或者使其出栈。
2、用三维数组来存放LL(1)分析表char table[7][8][3]={{{'T','X'},{},{},{},{},{'T','X'},{},{}},{{},{'A','T','X'},{'A','T','X'},{},{},{},{'$'},{'$'}},{{'F','Y'},{},{},{},{},{'F','Y'},{},{}},{{},{'$'},{'$'},{'M','F','Y'},{'M','F','Y'},{},{'$'},{'$'}},{{'i'},{},{},{},{},{'(','E',')'},{},{}},{{},{'+'},{'-'},{},{},{},{},{}},{{},{},{},{'*'},{'/'},{},{},{}},};并且为了设计方便,将原文法中的E`与T`改写为X与Y,将空字符串ε改写为$。
LL(1)法分析器

LL(1)语法分析器实验报告书目录第一章概述 (3)1.1 开发平台 (3)1.2 实验目的 (3)1.3 实验要求 (3)第二章语法分析器的实现 (3)2.1 LL(1)语法分析器原理 (3)2.2 求出能推出空的终结符 (4)2.3 FIRST集的确定 (4)2.4 FOLLOW集的确定 (4)2.5 SELECT集的确定 (4)2.6 LL(1)文法的判别 (4)2.7 逻辑结构 (4)2.8 预测分析表的生成 (5)2.9 句子的判定 (5)2.10 其他说明 (5)第三章系统运行与测试 (6)3.1 程序运行环境 (6)3.2 运行界面 (6)3.3 系统测试 (8)第四章总述 (11)4.1 程序综述 (11)4.2小组工作总结 (11)第一章概述1.1 开发平台本程序基于Microsoft Visual Studio 2008开发,使用C#语言。
1.2 实验目的掌握LL(1)分析法的基本原理,掌握LL(1)分析表的构造方法,掌握LL(1)驱动程序的构造方法。
1.3 实验要求编写一个语法分析器,不限语言,方法。
第二章语法分析器的实现2.1 LL(1)语法分析器原理语法分析是编译过程的核心部分,它的主要任务是按照程序的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行词法检查,为语义分析和代码生成作准备。
这里采用自顶向下的LL(1)分析方法。
语法分析程序的流程图如图5-4所示。
语法分析程序流程图2.2 求出能推出空的终结符见许英俊报告2.3 FIRST集的确定见邹杰光报告2.4 FOLLOW集的确定见张志峰报告2.5 SELECT集的确定见叶凯翔报告2.6 LL(1)文法的判别见叶凯翔报告2.7 逻辑结构一个LL(1)分析器由一张分析表、一个分析栈和一个总控程序组成。
其逻辑结构如图2-1所式。
2.8 预测分析表的生成见许英俊报告2.9 句子的判定当一个文法确定是LL(1)文法时就可以对输入的语句进行判定了。
基于VC++的LL(1)语法分析器设计与实现.doc

基于VC++的LL (1)语法分析器设计与实现作者姓名:晏丽智 指导老师:王一宾摘要:语法分析是编译过程的核心部分,可以粗略的分为自上而下分析法和自下而上分析法。
LL (1)文法是一类可以进行确定的自上而下语法分析的文法。
本文首先阐述了LL (1)文法的基本理论,然后着重讨论了LL (1)语法分析器的设计,最后用VC++实现了LL (1)语法分析器。
关键词:LL (1)文法,FIRST 集,FOLLOW 集,预测分析表0引言语法分析是编译过程的核心部分,它的任务是在词法分析识别出单词符号串的基础上,分析并判定程序的语法结构是否符合语法规则。
LL (1)文法是一类可以进行确定的自上而下语法分析的文法。
本文讨论了LL (1)语法分析器的工作原理和过程,重点说明了FIRST 集、FOLLOW 集以及预测分析表的构造。
1 LL (1)语法分析器的基本理论1.1 理论基础语法分析是编译过程的核心部分,它的任务是在词法分析识别出单词符号串的基础上,分析并判定程序的语法结构是否符合语法规则。
语法分析器工作本质:按文法的产生式,识别输入符号串是否为一个句子,判断是否能从文法的开始符号出发推导出这个输入串。
LL (1)文法是一类可以进行确定的自上而下语法分析的文法。
自上而下分析方法的基本思想是从文法的开始符号出发,向下推导,推出句子;即对任何输入串,试图用一切可能的办法,从文法开始符号出发,自上而下地为输入串建立一棵语法树[1]。
实现这种自上而下分析法存在许多困难,首先是递归问题,一个文法是含有左递归的,如果存在非终结符P ,有P Pa,则含有左递归的文法将使上述的自上而下的分析过程陷入无限循环。
因此,使用自上而下分析法必须消除文法的左递归。
其次是回溯问题。
由于回溯造成的匹配虚假现象,把已经做的一大堆语义工作推倒重来。
这些事情既麻烦又费时间,所以,最好应设法消除回溯。
1.2 左递归的消除直接消除见诸于产生式中的左递归是比较容易的。
LL(1)语法分析 任意输入一个文法符号串,并判断它是否为文法的一个句子
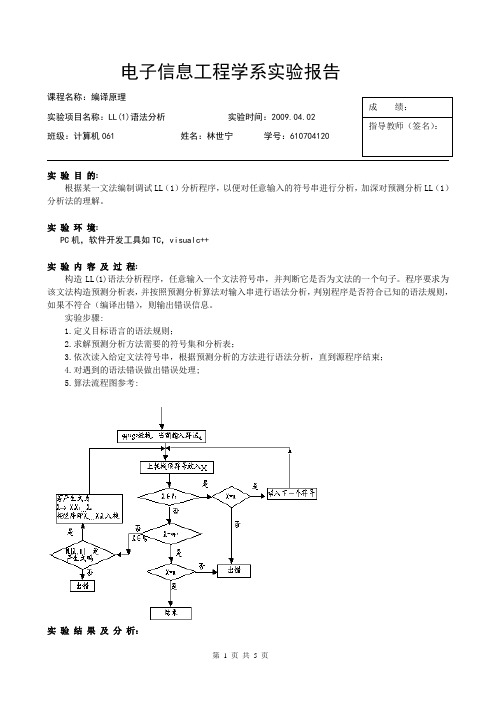
电子信息工程学系实验报告课程名称:编译原理成绩:实验项目名称:LL(1)语法分析实验时间:2009.04.02指导教师(签名):班级:计算机061 姓名:林世宁学号:610704120实验目的:根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析,加深对预测分析LL(1)分析法的理解。
实验环境:PC机,软件开发工具如TC,visualc++实验内容及过程:构造LL(1)语法分析程序,任意输入一个文法符号串,并判断它是否为文法的一个句子。
程序要求为该文法构造预测分析表,并按照预测分析算法对输入串进行语法分析,判别程序是否符合已知的语法规则,如果不符合(编译出错),则输出错误信息。
实验步骤:1.定义目标语言的语法规则;2.求解预测分析方法需要的符号集和分析表;3.依次读入给定文法符号串,根据预测分析的方法进行语法分析,直到源程序结束;4.对遇到的语法错误做出错误处理;5.算法流程图参考:实验结果及分析:该LL(1)语法分析程序,能对输入的文法符号串,进行分析并判断它是否为文法的一个句子。
实验心得:通过本次实验加深对预测分析LL(1)分析法的理解,能撑握编写LL(1)分析程序对任意输入的符号串进行分析。
附录:#include<stdio.h>#include<stdlib.h>#include<string.h>#include<dos.h>char A[20];char B[20];char v1[20]={'i','+','*','(',')','#'};char v2[20]={'E','G','T','S','F'};int j=0,b=0,top=0,l;typedef struct type{char origin;char array[5];int length;}type;type e,t,g,g1,s,s1,f,f1;type C[10][10];void print(){ int a;for(a=0;a<=top+1;a++)printf("%c",A[a]);printf("\t\t");}void print1(){ int j;for(j=0;j<b;j++)printf(" ");for(j=b;j<=l;j++)printf("%c",B[j]);printf("\t\t\t");}void main(){ int m,n,k=0,flag=0,finish=0;char ch,x;type cha;e.origin='E';strcpy(e.array,"TG");e.length=2;t.origin='T';strcpy(t.array,"FS");t.length=2;g.origin='G';strcpy(g.array,"+TG");g.length=3;g1.origin='G';g1.array[0]='^';g1.length=1;s.origin='S';strcpy(s.array,"*FS");s.length=3;s1.origin='S';s1.array[0]='^';s1.length=1;f.origin='F';strcpy(f.array,"(E)");f.length=3;f1.origin='F';f1.array[0]='i';f1.length=1;for(m=0;m<=4;m++)for(n=0;n<=5;n++)C[m][n].origin='N'; C[0][0]=e;C[0][3]=e;C[1][1]=g;C[1][4]=g1;C[1][5]=g1;C[2][0]=t;C[2][3]=t;C[3][1]=s1;C[3][2]=s;C[3][4]=C[3][5]=s1;C[4][0]=f1;C[4][3]=f;printf("提示:本程序只能对由'i','+','*','(',')'构成的以'#'结束的字符串进行分析,\n"); printf("请输入要分析的字符串:");do{scanf("%c",&ch);if ((ch!='i') &&(ch!='+') &&(ch!='*')&&(ch!='(')&&(ch!=')')&&(ch!='#')){printf("输入串中有非法字符\n");exit(1);}B[j]=ch;j++;}while(ch!='#');l=j;ch=B[0];A[top]='#'; A[++top]='E';printf("步骤\t\t分析栈 \t\t剩余字符 \t\t所用产生式 \n");do{x=A[top--];printf("%d",k++);printf("\t\t");for(j=0;j<=5;j++)if(x==v1[j]){flag=1;break;}if(flag==1){if(x=='#'){finish=1;printf("acc!\n");getchar();getchar();exit(1);}if(x==ch){print();print1();printf("%c匹配\n",ch);ch=B[++b];flag=0;}else{print();print1();printf("%c出错\n",ch);exit(1);}}else{for(j=0;j<=4;j++)if(x==v2[j]){ m=j;break;}for(j=0;j<=5;j++)if(ch==v1[j]){ n=j;break;}cha=C[m][n];if(cha.origin!='N'){print();print1();printf("%c->",cha.origin);for(j=0;j<cha.length;j++)printf("%c",cha.array[j]);printf("\n");for(j=(cha.length-1);j>=0;j--) A[++top]=cha.array[j]; if(A[top]=='^')top--;}else{ print();print1();printf("%c出错\n",x);exit(1);}}}while(finish==0);}备注:以上各项空白处若填写不够,可自行扩展。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二、 实验环境(实验设备)
Mac OS X + Python
1
-------------------------------------------------------------------------------
三、 实验原理及内容
AnalyseMachine:
Load( )方法 载入文法规则,自动求出 First 集,Follow 集,分析表
while analyseStack: xm = analyseStack[-1] ai = StringStack[0] print "%-20s%20s%10s"%("".join(analyseStack),"".join(StringStack), ""), if xm in self.nChars: analyseStack.pop() expression = self.analyseTable[xm][ai] if expression == "ERROR": print raise ValueError print expression, index = expression.find("::=") + 3 if self.__Split(expression[index:])[::-1] != ["~"]: analyseStack += self.__Split(expression[index:])[::-1] #逆序加入 elif xm == ai and xm != "#": analyseStack.pop() StringStack.pop(0) elif xm == ai and xm == "#": analyseStack.pop() isMatch = True print
self.firstSet,
def Judge(self, string): """判断字符串是否为当前文法的句子 """ isMatch = False
1
-------------------------------------------------------------------------------
Judge( )方法 判断某一字符串是否为当前文法的句子
程序代码
#coding:utf-8 #LL(1)分析法 #By:Importcjj #由于仓促,代码有很多地方不是科学,但是基本功能已经实现 #2015-6-15
class AnalyseMachine(object):
def __init__(self): pass
def load(self, Grammers): """载入文法规则 参数 Grammers: 文法的规则列表 """
self.Grammers = Grammers self.noLeftRecursionGrammers = self.__NoLeftRecursion(self.Grammers) self.start = self.Grammers[0][0] self.nChars = self.__GetVn(self.noLeftRecursionGrammers) self.tChars = self.__GetVt(self.noLeftRecursionGrammers) self.firstSet = self.FirstSet(self.noLeftRecursionGrammers) self.followSet = self.FollowSet(self.noLeftRecursionGrammers) self.analyseTable = self.AnalyseTable(self.noLeftRecursionGrammers, self.followSet)
计算机学院软件工程系
蒋凌云
学生姓名 学院(系)
Cjj
班级学号
计算机学院 专 业
B--------NIIT
成绩
批阅人
日期
-------------------------------------------------------------------------------
-------------------------------------------------------------------------------
analyseStack = ["#", self.start] StringStack = list(string) + ["#"] print u"="*25,u"判断字符串=%s"%string,u"="*25 print "%-30s%-12s%s"%(u"分析栈",u"余留输入串",u"所用生成式") try:
-------------------------------------------------------------------------------
实验报告
(2014/2015 学年 第二学期)
课程名称 实验名称 实验时间 指导单位 指导教师
编பைடு நூலகம்原理
语法分析器的构造
2015
年 5 月 29 日
实验报告
实验名称
语法分析器的构造
指导教师 蒋凌云
实验类型
上机
实验学时
4
实验时间 2015-5-14
一、 实验目的和要求
设计、编制、调试一个 LL(1)语法分析程序,利用语法分析器
对符号串进行识别,加深对语法分析原理的理解。
要 求设计 并实现一 个 LL(1) 语法分析 器,实 现对算数 文法
E->E+T|T T->T*F|F F->(E)|i 所定义的符号串进行识别。
def FirstSet(self, Grammers): """构造文法的 First 集 """ speSymbol = "::=" Vn = self.nChars Vt = self.tChars
except Exception as e: pass
result = u"%s 为文法定义的句子" if isMatch else u"%s 不是文法定义的句子" print result%string print u"="*25,u"判断字符串=%s"%string,"="*25 return isMatch