redo丢失与恢复1
ORACLE数据库基础知识总结

ORACLE数据库基础知识总结1、RMAN全备备份⽂件的顺序备份归档⽇志、所有的数据⽂件、控制⽂件、spfile、再次备份归档⽇志2、redo⽇志丢失恢复redo⽇志的三种状态是current、active、inactiveinactive,可以重建 clear logactive、current不能变成inactive,只能通过不完全恢复进⾏恢复,然后重建⽇志⽂件3、⼝令⽂件丢失恢复丢失可重建 orapwd file= password= enfries=重建完成之后ORACLE正常使⽤4、控制⽂件丢失恢复a> rman 可以备份控制⽂件b> 控制⽂件可以cp⼀份备⽤c> 控制⽂件可以重建⼿写5、体系结构物理:ORACLE数据库包括instance、database两部分。
instance包括SGA(系统全局区)跟⼀些后台进程组成的。
SGA包括:share pool、db buffer cache、redo log buffer、流池、⼤型池、JAVA POOL、share pool(共享池) :库缓存:缓存最近执⾏的代码,同样的sql多次执⾏不需要频繁读取数据字典中得数据数据字典缓存:存储oracle中得对象定义PL/SQL区:缓存存储过程、函数触发器等数据库对象。
db buffer cache(数据库缓存区)redo log buffercache(⽇志缓存区)常见的后台进程:DBWn:⽤于数据库缓存写⼊磁盘LGWn:⽤于log⽇志写⼊磁盘CKPT:检查点进程SMON:实例维护进程,系统监视器MMON:AWR主要进程PMON:维护⽤户进程,进程监视器ARCN:归档进程database包括数据⽂件、控制⽂件、⽇志⽂件等。
逻辑:oracle数据块-区-段-表空间-数据库-⽅案多个oracle数据块组成⼀个区,多个区组成⼀个段,多个段组成⼀个表空间,多个表空间组成⼀个数据库表空间和数据⽂件的关系:表空间是由⼀个或多个数据⽂件组成的,⼀个数据⽂件只属于⼀个表空间,表空间的⼤⼩是所有数据⽂件⼤⼩的总和。
oracle19c redolog 切换机制

oracle19c redolog 切换机制标题:Oracle 19c Redo日志切换机制:解析与实施步骤引言Redo日志是Oracle数据库系统中非常重要的组成部分,它记录了对数据库进行的重要操作,以便在发生故障时进行恢复。
在Oracle 19c版本中,改进了Redo 日志的性能和稳定性,并提供了一种新的Redo日志切换机制。
本文将逐步探讨Oracle 19c Redo日志切换机制的实施步骤,帮助读者更好地理解和使用这一功能。
1. Redo日志简介Redo日志是Oracle数据库的重要组成部分,它记录了数据库的变更操作,以便在发生故障时进行恢复。
Redo日志包含了数据库中发生的所有变更操作,例如插入、更新和删除操作,以及对索引和表空间的结构修改等。
通过不断地刷新Redo日志,Oracle数据库确保了数据的持久性和一致性。
2. Oracle 19c Redo日志切换机制的意义在之前的Oracle版本中,Redo日志切换是依靠日志组中的日志序列号的连续递增来实现的。
当当前日志组快要用完时,Oracle会自动切换到下一个可用的日志组并递增日志序列号。
然而,在高负载的数据库环境中,频繁的Redo日志切换可能导致性能下降,因为切换操作会引起额外的IO开销。
为了解决这个问题,Oracle 19c引入了新的Redo日志切换机制,该机制可以根据数据库的负载情况来进行切换,以最小化额外的IO开销。
这个新机制将在下面的步骤中详细解释。
3. 步骤一:启用自动切换在Oracle 19c中,需要先启用自动切换功能才能使用新的Redo日志切换机制。
可以通过以下命令启用自动切换:ALTER DATABASE ENABLE THREAD SPIN这个命令会开启一个线程监控数据库的负载情况,并在必要时触发Redo日志的切换。
4. 步骤二:配置自动切换的阈值在默认情况下,Oracle 19c使用了一组预定义的阈值来监控数据库的负载情况,然后触发Redo日志的切换。
ORACLE控制文件-redolog和数据文件的总结

控制文件:解决版本问题命令,用高版本覆盖低版本ORA-00214: control file '/u01/oracle/oradata/orcl/control01.ctl' version 781 inconsistent with file '/u01/oracle/oradata/orcl/control02.ctl' version 779SQL> ho cp /u01/oracle/oradata/orcl/control01.ctl /u01/oracle/oradata/orcl/control02.ctlSQL> ho cp /u01/oracle/oradata/orcl/control01.ctl /u01/oracle/oradata/orcl/control03.ctl;SQL> alter database mount;控制文件应控制在100M之内,如果超过100M一般通过重建来减少。
控制文件备份:归档模式:SQL> alter database backup controlfile to '/u01/oracle/control2012.bak';任意模式下:SQL> alter database backup controlfile to trace as '/u01/oracle/backctl.txt';rman备份:SQL> ho rman target /RMAN> backup current controlfile或者这样:RMAN> backup database include current controlfile;或者把rman自动备份控制文件打开RMAN> CONFIGURE CONTROLFILE AUTOBACKUP On控制文件的恢复:控制文件应有多份,放在不同的硬盘上版本不一致问题:1.拷贝版本高的来覆盖版本低的ORA-00214: control file '/u01/oracle/oradata/orcl/control01.ctl' version 781 inconsistent with file '/u01/oracle/oradata/orcl/control02.ctl' version 779SQL> ho cp /u01/oracle/oradata/orcl/control01.ctl /u01/oracle/oradata/orcl/control02.ctlSQL> ho cp /u01/oracle/oradata/orcl/control01.ctl /u01/oracle/oradata/orcl/control03.ctl;SQL> alter database mount;2.或者修改初始参数中的参数文件个数(不推荐使用)控制文件丢失:修改隐藏参数,不验证一致性alter system set "_allow_resetlogs_corruption"=true scope=spfile重做日志管理:1.组成员要分散,磁盘IO要快2.日志文件大小分配要合理保证每个组的切换时间应该不小于20分钟左右切换日志:Alter system switch logfile;添加日志组:alter database add logfile group 4 '/u01/oracle/oradata/orcl/redo04.log' size 50m; 下次切换日志会优先使用此文件其中group 4 可以省略不写,系统会自动分配添加有多个成员的组:alter database add logfile ('/u01/oracle/oradata/orcl/redo06.log','/u01/oracle/oradata/orcl/redo6.log') size 50m;往已经有的组里添加成员:alter database add logfile member '/u01/oracle/oradata/orcl/redo4.log' to group 4; 大小默认是组内已有成员的大小。
损坏数据文件的恢复方法

损坏数据文件的恢复方法一:非归档模式下丢失或者损坏数据文件A:OS备份恢复方案在非归档模式下损坏或者丢失数据文件,如果有相应的备份,在一定程度上是可以恢复的,但是如果oracle过多的读写操作记录信息而导致redo重写的时候,恢复就会停滞,非归档下系统能自动恢复的仅仅限于redo中存在的记录。
可以成功恢复案例:SQL> startupORACLE instance started.Total System Global Area 235999352 bytesFixed Size 450680 bytesVariable Size 201326592 bytesDatabase Buffers 33554432 bytesRedo Buffers 667648 bytesDatabase mounted.Database openedSQL> create table test(a int);Table created.SQL> insert into test values(1);1 row created.SQL> /1 row created.SQL> /1 row created.SQL> /1 row created.SQL> commit;Commit complete.SQL> exit;[oracle@www oradata]$ cd cicro/[oracle@www cicro]$ lscontrol01.ctl cwmlite01.dbf indx01.dbf redo02.log temp01.dbfusers01.dbf control02.ctl drsys01.dbf odm01.dbf redo03.logtools01.dbf xdb01.dbf control03.ctl example01.dbf redo01.log system01.dbf undotbs01.dbf[oracle@www cicro]$ pwd/opt/oracle/oradata/cicro[oracle@www cicro]$ sqlplus "/as sysdba"SQL> shutdown immediateDatabase closed.Database dismounted.ORACLE instance shut down.SQL>exit;[oracle@www cicro]$ cp ./*.dbf ../[oracle@www cicro]$ sqlplus "/as sysdba"SQL*Plus: Release 9.2.0.1.0 - Production on Tue Jul 25 19:44:31 2006 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to:Oracle9i Release 9.2.0.1.0 - ProductionJServer Release 9.2.0.1.0 – ProductionConnected to an idle instance.SQL> startupORACLE instance started.Total System Global Area 235999352 bytesFixed Size 450680 bytesVariable Size 201326592 bytesDatabase Buffers 33554432 bytesRedo Buffers 667648 bytesDatabase mounted.Database opened.SQL> insert into test values(3333);1 row created.SQL> /1 row created.SQL> /1 row created.SQL> /1 row created.SQL> commit;Commit complete.SQL> select * from test;A----------1113333333333338 rows selected.SQL> shutdown immediateDatabase closed.Database dismounted.ORACLE instance shut down.SQL>exit;[oracle@www cicro]$ rm –rf ./*.dbf[oracle@www cicro]$ sqlplus "/as sysdba"Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.Connected to an idle instance.SQL> startupORACLE instance started.Total System Global Area 235999352 bytesFixed Size 450680 bytes技术社区Variable Size 201326592 bytesDatabase Buffers 33554432 bytesRedo Buffers 667648 bytesDatabase mounted.ORA-01157: cannot identify/lock data file 1 - see DBWR trace fileORA-01110: data file 1: '/opt/oracle/oradata/cicro/system01.dbf'SQL> quit[oracle@www cicro]$ mv ../*.dbf .[oracle@www cicro]$ lscontrol01.ctl cwmlite01.dbf indx01.dbf redo02.log temp01.dbf users01.dbf control02.ctl drsys01.dbf odm01.dbf redo03.log tools01.dbf xdb01.dbf control03.ctl example01.dbf redo01.log system01.dbf undotbs01.dbf[oracle@www cicro]$ sqlplus "/as sysdba"SQL*Plus: Release 9.2.0.1.0 - Production on Tue Jul 25 17:56:06 2006Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.Connected to:Oracle9i Release 9.2.0.1.0 - ProductionJServer Release 9.2.0.1.0 - ProductionSQL> recover database;Media recovery complete.SQL> alter database open;Database altered.SQL> select * from test;A----------111333333333333333333338 rows selected.至此,恢复成功!不完全恢复的案例基本操作与上面相同,还是首先建立一张表,然后插入数据:1:建表,写入数据,然后关闭数据库SQL> create table gaojf1 as select * from all_objects;T able created.SQL> insert into gaojf1 select * from gaojf1;29614 rows created.SQL> /59228 rows created. (即为现在此表数据有118456列)SQL>commit;SQL>shutdown immediate2:备份所有的数据文件3:启动数据库继续插入数据[oracle@www cicro]$ sqlplus "/as sysdba"SQL*Plus: Release 9.2.0.1.0 - Production on Tue Jul 25 18:07:19 2006 Copyright (c) 1982, 2002, Oracle Corporation.Connected to:Oracle9i Release 9.2.0.1.0 - ProductionJServer Release 9.2.0.1.0 - ProductionSQL> insert into gaojf1 select * from gaojf1;118456 rows created.SQL> /236912 rows created.SQL> /473824 rows created.SQL> /947648 rows created.SQL> commit;Commit complete.SQL> select count(*) from gaojf1;COUNT(*)----------1895296SQL> /1895296 rows created.SQL> /技术社区3790592 rows created.(如果能够完全恢复,此表应该有3790592*2列)SQL> commit;Commit complete.期间,查看日志信息如下:Wed Jul 26 13:02:54 2006Thread 1 opened at log sequence 1Current log# 3 seq# 1 mem# 0: /opt/oracle/oradata/cicro/redo03.log Successful open of redo thread 1.Wed Jul 26 13:03:56 2006Thread 1 advanced to log sequence 2Current log# 1 seq# 2 mem# 0: /opt/oracle/oradata/cicro/redo01.logWed Jul 26 13:05:41 2006Thread 1 advanced to log sequence 3Current log# 2 seq# 3 mem# 0: /opt/oracle/oradata/cicro/redo02.logWed Jul 26 13:09:04 2006Thread 1 advanced to log sequence 4Current log# 3 seq# 4 mem# 0: /opt/oracle/oradata/cicro/redo03.logWed Jul 26 13:09:29 2006Thread 1 advanced to log sequence 5Current log# 1 seq# 5 mem# 0: /opt/oracle/oradata/cicro/redo01.log 可以看到,redo文件在不断的循环重写,当一个redo写完后继续写第二个redo,然后是第三个,当第三个写完后继续回来重写第一个,依此类推。
redo和undo的实例操作

redo和undo的实例操作【Redo和Undo的实例操作】引言:在日常生活和工作中,我们经常需要进行各种操作,无论是写文章、编辑照片还是编写代码,都可能需要修改、撤销和重做一些操作。
为了提高效率和减少错误,许多应用程序和工具都提供了redo和undo功能。
本文将以中括号为主题,通过一系列实例操作来详细介绍redo和undo的使用方法和场景。
一、什么是redo和undo功能在许多软件和工具中,redo和undo是常见的操作功能。
它们分别代表重新执行和撤销上一步操作。
redo功能用于重新执行刚刚撤销的操作,而undo功能则用于撤销刚刚进行的操作。
这两个功能被广泛用于文本编辑、图像处理、编程开发等领域。
二、文本编辑中的redo和undo操作1. 打开一个文本编辑器,并输入一段文字。
2. 选中其中的一个词组,并点击编辑菜单中的"复制"操作。
3. 将光标移动到其他位置,并点击编辑菜单中的"粘贴"操作。
此时,复制的词组将会出现在新的位置。
4. 点击编辑菜单中的"undo"按钮,可以撤销刚才的粘贴操作。
词组将会返回到原来的位置。
5. 点击编辑菜单中的"redo"按钮,可以重新执行刚才的粘贴操作。
词组会再次出现在新的位置。
三、图像处理中的redo和undo操作1. 打开一张图片,并选择图像编辑工具。
2. 在图片上使用画笔工具画一个中括号"["。
3. 点击编辑菜单中的"undo"按钮,可以撤销刚才的绘制操作。
图片上的中括号会消失。
4. 点击编辑菜单中的"redo"按钮,可以重新执行刚才的绘制操作。
中括号会再次出现在图片上。
四、编程开发中的redo和undo操作1. 打开一个代码编辑器,并编写一个简单的函数。
2. 完成函数编写后,点击编辑菜单中的"undo"按钮,可以撤销刚才的编辑操作。
redo 和 undo 通俗理解

redo 和 undo 通俗理解redo和undo是两个常见的操作功能,用于在计算机程序和软件中进行撤销和重做操作。
它们在各种应用程序和操作系统中都有广泛的应用,为用户提供了更方便、更高效的操作体验。
我们先来理解一下redo的概念。
redo,即重做操作,是指对之前撤销的操作进行再次执行。
当用户进行了一系列操作后,如果想要回到之前的某个状态,可以使用undo撤销操作。
而当用户在撤销之后,又想回到之前的状态,可以使用redo重做操作。
redo操作的实现方式通常是将之前执行过的操作记录下来,当用户需要重做时,系统会按照记录的顺序重新执行这些操作,从而恢复到之前的状态。
那么,什么时候需要使用redo操作呢?一种常见的情况是在编辑文档的过程中。
假设我们在一个文本编辑器中对文本进行了一系列的修改,包括增加、删除、修改等操作。
如果我们在某个时间点上想要回到之前的某个状态,可以使用undo操作进行撤销。
但是,如果撤销过头了,又想回到之前的状态,这时就可以使用redo操作进行重做。
redo操作可以帮助用户在编辑文档时更加灵活地进行操作,提高了效率和用户体验。
接下来,我们来看一下undo的概念。
undo,即撤销操作,是指将之前的操作还原到之前的状态。
当用户在进行一系列操作后,如果发现之前的某个操作有误或不符合需求,可以使用undo操作将之前的操作一一撤销,恢复到之前的状态。
undo操作的实现方式通常是将每个操作的前一个状态保存下来,当用户需要撤销时,系统会将当前状态还原到之前的状态,从而实现撤销操作。
那么,什么时候需要使用undo操作呢?一种常见的情况是在编辑文档的过程中。
假设我们在一个文本编辑器中对文本进行了一系列的修改,包括增加、删除、修改等操作。
如果我们发现之前的某个操作有误,可以使用undo操作将其撤销,恢复到之前的状态。
undo操作可以帮助用户在编辑文档时更加轻松地进行操作,避免了错误的发生,提高了工作效率。
日志文件全部丢失的处理方法
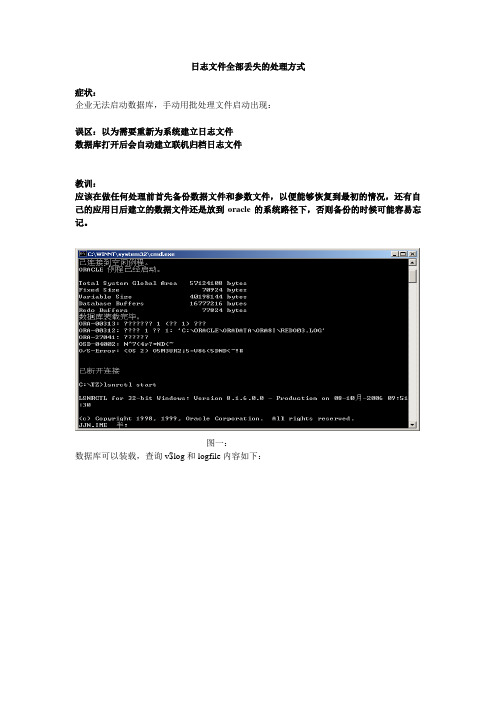
日志文件全部丢失的处理方式症状:企业无法启动数据库,手动用批处理文件启动出现:误区:以为需要重新为系统建立日志文件数据库打开后会自动建立联机归档日志文件教训:应该在做任何处理前首先备份数据文件和参数文件,以便能够恢复到最初的情况,还有自己的应用日后建立的数据文件还是放到oracle的系统路径下,否则备份的时候可能容易忘记。
图一:数据库可以装载,查询v$log和logfile内容如下:察看数据文件的目录发现所有联机日志文件丢失经查询group 1对应文件为redo03.log是当前的日志文件现场处理方式:一、启动oracle到mount状态sqlplus /nologstartup mount二、清除日志alter database clear unarchived logfile group 2;数据库已更改alter database clear unarchived logfile group 3;数据库已更改alter database clear unarchived logfile group 1;出错,当前日志不允许清除三、想重新建立联机日志文件未成结果显示出错ora-01184,系统中已经存在要增加的日志文件alter database add logfile group 2 ('c:\oracle\oradata\ora8i\redo02.log') size 1m reuse;alter database add logfile member 'c:\oracle\oradata\ora8i\redo022.log' size 1m reuse to group 2;四、在本地测试完毕后,决定使用隐含参数进行处理:(中间有用户按此过程操作的,在之前备份了一下数据文件和参数文件的目录,但是由于出错,远程又无法看到,所以在下午让其将备份的文件拷回来,我来重新进行操作。
自考数据库系统原理(第6章)(代码:4735)练习题6

练习题66.1 名词解释1)事务:事务是构成单一逻辑工作单元的操作集合。
要么完整地执行,要么完全不执行。
2)数据库的一致性:一个事务独立执行的结果,应保持数据库的一致性,即数据不会因事务的执行而遭受破坏。
3)数据库的可恢复性:系统能把数据库从被破坏、不确定的状态,恢复到最近一个正确的状态,DBMS的这种能力称为数据库的可恢复性(Recovery)4)并发操作:在多用户共享系统中,许多事务可能同时对同一数据进行操作,这种操作称为并发操作。
5)封锁:封锁是系统保证对数据项的访问以互斥方式进行的一种手段。
6)X锁:事务T对某数据加了X锁后,其他事务要等T解除X锁后,才能对这个数据进行封锁。
7)S锁:事务T对某数据加了S锁后,仍允许其他事务再对该数据加S锁,但在对该数据的所有S锁都解除之前决不允许任何事务对该数据加X锁。
8)调度:事务的执行次序称为“调度”。
9)串行调度:多个事务依次执行,称为事务的串行调度。
10)并发调度:利用分时的方法,同时处理多个事务,则称为事务的并发调度。
11)可串行化调度:如果一个并发调度的执行结果与某一串行调度的执行结果等价,那么这个并发调度称为“可串行化的调度”。
12)不可串行化调度:如果一个并发调度的执行结果不与某一串行调度的执行结果等价,那么这个并发调度称为“不可串行化调度”。
6.2事务的COMMIT语句和ROLLBACK语句各做什么事情?答:COMMIT(提交):语句表示事务执行成功地结束,此时告诉系统,DB要进入一个新的正确状态,该事务对DB的所有更新都已交付实施(写入磁盘)。
ROLLBACK(“回退”或“回滚”):语句表示事务执行不成功地结束,此时告诉系统,已发生错误,DB可能处在不正确的状态,该事务对DB的所有更新必须被撤消,DB应恢复该事务到初始状态。
6.3试叙述事务的四个性质,并解释每一个性质由DBMS的哪个子系统实现?每一个性质对DBS有什么益处?答:①事务的原子性:是指一个事务对DB的所有操作,是一个不可分割的工作单元。
redo介绍及具体使用

--REDO LOG的作用1、记录ORACLE数据库的变化2、可以避免数据提交后直接写入数据文件【安全+性能】3、实例恢复和介质恢复都需要redooracle世界,有3种数据:undo、redo和data。
而redo 应"提交事务不丢失"而生的一种机制,服务于两类场景:一是实例恢复、一是介质恢复实例恢复:当数据库发生故障时,确保缓存中的数据不会丢失,保证数据库的一致性介质恢复:当数据文件发生故障时,能够恢复数据Redo: 记录了数据库的所有历史变更,它包含数据文件的所有变更,但不包含参数文件和控制文件【因为数据库启动时先启动参数文件与控制文件之后才到redo的】数据库异常关机(比如突然断电,shutdown abort:它会立即关闭数据库,等同于断电)之后,这时已经commit的事务已经记录到online redo log中,下次启动数据库时,oracle进行恢复操作,将online redo log中的事务操作调入内存中,进行相应操作后将redo数据记入到数据文件中,数据操作完成。
对于没有commit而已经写入数据文件或回退段的数据,也要进行回滚操作,将数据恢复到rollback的状态,使数据文件和控制文件恢复到崩溃前的一致性状态。
总之,数据库下次打开时会占用比正常关闭更长的时间。
注意:并不是所有异常关机后,下次启动时都可以恢复到正常状态,异常关机容易导致坏块的产生,这种情况下数据库是不能正常启动的,如果处理不当,将会导致大量数据的丢失联机重做日志组:由一个或多个相同的日志文件组成一个联机重做日志组至少两个日志组,每组一个成员(建议每组两个成员,分散放开到不同的磁盘) 由LGWR后台进程同时将日志内容写入到一个组的所有成员联机重做日志:记录了数据的所有变化(DML,DDL或管理员对数据所作的结构性更改等)提供恢复机制(对于意外删除或宕机利用日志文件实现数据恢复) 可以被分组管理重做日志组内的每一个联机日志文件称为一个成员一个组内的每一个成员具有相同的日志序列号(log sequence number),且成员的大小相同每次日志切换时,Oracle服务器分配一个新的LSN号给即将写入日志的日志文件组,就是v$log中的sequence#, LSN号依次递增,当日志文件切换时,都会切换到当前最小的LSN号的日志文件组。
Chapter 8_ Disaster Recovery

数据备份
– 仅备份database,不包括log – Need RESTORE SYSTEM utility to recover the system to an arbitrary PIT
DB2 9 and z/OS 1.8 enhancement. Initial copy copies every track. Subsequent copies only copy changed tracks. Creates a persistent relationship. Only one persistent relationship per source volume.
最小化损失
◦ DB2中UR(Unit of Recovery)为单位的log记录了每个 update的细节 ◦ 可用于恢复每个交易数据 ◦ 以checkpoint的形式汇总系统统计信息 ◦ 通过缩短扫描的log记录长度来加速恢复过程
最小化开销
其他系统信息
◦ Dataset 状态信息 (打开, 关闭, etc)
Min Wang Tongji University mailto: min.wang@
What happens in case of corruption 备份, 恢复和重启策略
◦ Recovery Logs的单位 ◦ DB2的Checkpoints ◦ Utilities和工具
电力故障、软件缺陷都可能导致系统故障
系统故障会导致不稳定存储设备中的数据丢失
◦ 包括那些仍在buffers里还没来得及写出去的、虽然是已提交的交 易
解决方案
◦ 已提交但是还没有写入磁盘的数据
redo和undo日志

redo和undo⽇志在数据库系统中,既有存放数据的⽂件,也有存放⽇志的⽂件。
⽇志在内存中也是有缓存Log buffer,也有磁盘⽂件log file,本⽂主要描述存放⽇志的⽂件。
MySQL中的⽇志⽂件,有这么两类常常讨论到:undo⽇志与redo⽇志。
1 undo1.1 undo是啥undo⽇志⽤于存放数据修改被修改前的值,假设修改 tba 表中 id=2的⾏数据,把Name=’B’ 修改为Name = ‘B2’ ,那么undo⽇志就会⽤来存放Name=’B’的记录,如果这个修改出现异常,可以使⽤undo⽇志来实现回滚操作,保证事务的⼀致性。
对数据的变更操作,主要来⾃ INSERT UPDATE DELETE,⽽UNDO LOG中分为两种类型,⼀种是 INSERT_UNDO(INSERT操作),记录插⼊的唯⼀键值;⼀种是 UPDATE_UNDO(包含UPDATE及DELETE操作),记录修改的唯⼀键值以及old column记录。
Id Name1A2B3C4D1.2 undo参数MySQL跟undo有关的参数设置有这些:1 mysql> show global variables like '%undo%';2 +--------------------------+------------+3 | Variable_name | Value |4 +--------------------------+------------+5| innodb_max_undo_log_size |1073741824 |6| innodb_undo_directory | ./ |7| innodb_undo_log_truncate |OFF |8| innodb_undo_logs |128 |9| innodb_undo_tablespaces |3 |10 +--------------------------+------------+1112 mysql> show global variables like '%truncate%';13 +--------------------------------------+-------+14 | Variable_name | Value |15 +--------------------------------------+-------+16| innodb_purge_rseg_truncate_frequency |128 |17| innodb_undo_log_truncate |OFF |18 +--------------------------------------+-------+innodb_max_undo_log_size控制最⼤undo tablespace⽂件的⼤⼩,当启动了innodb_undo_log_truncate 时,undo tablespace 超过innodb_max_undo_log_size 阀值时才会去尝试truncate。
数据库redo undo题目

数据库redo undo题目数据库中的redo和undo是指数据库事务处理中的两个重要概念。
redo是一种用于恢复数据库到崩溃前状态的技术,而undo则是用于回滚事务或者撤销对数据库的修改操作。
下面我将从多个角度来解释这两个概念。
首先,redo是一种用于恢复数据库中已提交事务所做的修改的技术。
在数据库中,当一个事务提交后,其所做的修改会被写入到事务日志中,这个过程称为redo。
这样,即使数据库发生了崩溃,系统可以通过重放事务日志中的redo信息来恢复数据库到崩溃前的状态,确保数据的一致性和持久性。
另一方面,undo是用于回滚事务或者撤销对数据库的修改操作的技术。
当一个事务需要回滚时,系统会通过事务日志中的undo信息来撤销该事务所做的修改,将数据库恢复到事务开始之前的状态。
这样可以确保数据库的完整性和一致性。
从实现角度来看,redo和undo通常是通过事务日志来实现的。
事务日志记录了事务的开始、提交、以及所做的修改操作,包括redo和undo信息。
数据库系统会定期将事务日志持久化到磁盘上,以确保即使数据库发生崩溃,系统也能够通过重放事务日志来恢复数据库。
此外,redo和undo还与数据库的恢复和并发控制有关。
在数据库的并发控制中,redo和undo信息可以用于实现事务的隔离和并发执行。
而在数据库的恢复机制中,redo和undo信息则可以确保数据库的一致性和持久性。
总之,redo和undo是数据库事务处理中非常重要的概念,它们通过记录和重放事务日志中的redo和undo信息,确保了数据库的完整性、一致性和持久性,同时也为数据库的并发控制和恢复提供了重要的支持。
这些技术的应用使得数据库系统能够更好地处理事务,并保证数据的安全性和可靠性。
oracle学习之redo

oracle学习之redoOracle的重做⽇志基本概念及原理重做⽇志⽂件 redo log file 通常也称为⽇志⽂件,它是保证数据库安全和数据库备份与恢复的⽂件,是数据库安全和恢复的最基本的保障。
管理员可以根据⽇志⽂集和数据库备份⽂件,将崩溃的数据库恢复到最近⼀次记录⽇志时的状态。
所以在⽇常⼯作当中,管理员维护重做⽇志⽂件也是⼗分必要的。
1、概述重做⽇志⽂件⽤于记录事务操作所引起的数据的变化,包括回滚段事务表、回滚块、数据块上的事务槽、数据⾏的变化等,当执⾏DDL、DML操作时,有LGWR进程将⽇志缓冲区中与事务相关的重做记录写⼊到重做⽇志⽂件中。
当丢失或损坏数据库中的数据时,Oracle会根据redo⽂件中的记录恢复丢失的数据。
1.1史记讲解法来理解⽇志记录的原理buffercache⾥⾯有⼀堆的buffer,假设在buffercache上站着⼀个⼈,它能够看到buffercache⾥⾯所有的buffer,⽽且这个⼈眼睛特别快,对buffercache来讲⼤量的sql语句执⾏,在⼀个时间其中的某个buffercache中的块被改了,下⼀个时间另外⼀个buffercache中的块被改了,时间差了⼏毫秒,就是说在短时间内,⼤量的buffer被修改了,然后这个⼈就拿着⼀个本在记录,严格按照时间来记录buffer的⼀个改变过程,机上在这个时间点哪个buffer发⽣什么样的改变。
也就是说这个⼈,以极快的速度严格的按照时间顺序来记录buffer的⼀个改变过程,这些⽇志会记录到logbuffer⾥⾯去,最后logbuffer会通过LGWR这个进程写到磁盘上的redolog⾥⾯去。
也就是说,我们的⽇志记录的是BUFFER的改变,并且按照时间顺序记录的,所以说⽇志⾥⾯记录的就是buffer⾥严格的按照时间顺序记录的buffer的整个改变过程。
⽇志记录的是buffer的改变,⽇志是以buffer为单位来记录的,⼀个块的改变⾄少记录⼀条⽇志,安装改变的时间顺序来记录的。
oracle redolog解析

标题:Oracle Redo Log解析一、概述在Oracle数据库中,Redo Log是一个关键的概念,它记录了数据库中发生的所有变更操作,包括插入、更新、删除等操作,它是数据库恢复和数据持久性的重要保障。
本文将对Oracle Redo Log进行详细解析,包括其概念、结构、作用以及相关操作。
二、Redo Log的概念Redo Log是Oracle数据库中的一组文件,用来记录数据库中的所有更改操作,称为Redo记录。
Redo Log记录了数据库中的数据修改操作的详细信息,包括修改的对象、修改的语句以及修改的时间等。
Redo Log的作用在于保证数据库的恢复性和持久性,同时也是实现Oracle数据库的高可用性的重要手段。
三、Redo Log的结构Redo Log是由多个组成的,每个组成中有多个成员。
每个成员中记录了一段时间内数据库的更改操作,当一个成员记录满后,系统将在下一个成员中继续记录。
Redo Log的结构包括了多个组成以及每个组成中的成员,这种结构保证了Redo Log能够持续记录数据库的更改操作,并且保证了数据的一致性和恢复性。
四、Redo Log的作用Redo Log的主要作用在于保证数据库的恢复性和持久性。
当数据库发生意外故障或者因为其他原因造成数据丢失时,Redo Log能够帮助数据库进行恢复,保证数据的完整性和一致性。
Redo Log也是Oracle数据库实现高可用性的重要手段,它可以帮助数据库实现在线备份、热备份和数据保护等功能。
五、Redo Log的相关操作在Oracle数据库中,Redo Log是一个重要的组成部分,它需要进行一系列的管理和维护操作。
包括Redo Log文件的创建、删除、切换、清理等操作,同时还需要进行Redo Log的监控和性能调优等工作。
在实际的数据库管理工作中,对Redo Log的合理管理和操作是非常重要的,它直接影响着数据库的性能和稳定性。
结论通过对Oracle Redo Log的详细解析,我们可以了解到Redo Log作为Oracle数据库中重要的组成部分,对数据库的恢复性和持久性起着至关重要的作用。
oracle数据丢失恢复数据方法

oracle数据丢失恢复数据方法在使用Oracle数据库过程中,数据丢失是一种常见的问题。
当数据库中的数据丢失时,我们需要及时采取措施来进行数据恢复,以避免数据的长期丢失。
本文将介绍一些常用的Oracle数据丢失恢复方法,帮助我们有效地处理这个问题。
1. 数据库备份与恢复数据库备份是一种常见的防范措施,它可以帮助我们在数据丢失后快速恢复数据库。
在Oracle中,我们可以使用RMAN(Recovery Manager)工具来实现数据库备份和恢复。
RMAN可以备份整个数据库或者特定的表空间、数据文件等,同时也支持增量备份,大大减少了备份所需的时间和空间。
当数据库发生数据丢失时,我们可以使用RMAN来恢复备份的数据库文件,确保数据的完整性。
2. 闪回技术Oracle提供了闪回技术,可以帮助我们恢复数据库到某个历史时间点的状态。
通过闪回技术,我们可以将数据库中的数据、表结构等回滚到特定的时间点,从而实现数据的恢复。
闪回技术相比于传统的数据恢复方法,具有更高的效率和更少的风险。
我们可以使用闪回查询(FLASHBACK QUERY)来查看历史数据,使用闪回表(FLASHBACK TABLE)来恢复特定表的状态,使用闪回数据库(FLASHBACK DATABASE)来恢复整个数据库。
3. 日志文件恢复Oracle数据库在运行过程中会生成大量的日志文件,这些日志文件记录了数据库的操作、变更等信息。
当数据库发生数据丢失时,我们可以通过日志文件的恢复来还原数据。
在Oracle数据库中,我们可以使用归档日志文件(Archive Log)或在线重做日志文件(Online Redo Log)来进行数据恢复。
归档日志文件可以将数据库中的所有变更操作记录下来,当数据丢失时,我们可以将归档日志文件应用到数据库中,恢复数据的完整性。
同时,我们也可以使用在线重做日志文件来进行数据恢复,将重做日志文件中的操作应用到数据库中。
4. 数据库导入导出数据库导入导出是一种常见的数据恢复方法。
redo和undo区别讨论

redo和undo区别讨论英⽂解释:名词:两种流程,redo重做流程,undo撤销还原流程;或则是redo⽇志与undo段的简称动词:redo即重做,undo即撤销还原。
翻译有时候为了简单,常把动词和名称混⽤。
不同场景不同的使⽤。
1.redo记录了什么:redo即redo⽇志,记录数据库变化的⽇志(区别我们常见的简单的⽂本⽇志,redo⽇志⾥⾯记录的都是数据啊,表数据啊等等压缩处理,但也很⼤)。
只要你修改了数据块那么就会记录redo信息,当然nologging除外了。
修改的数据块包括:表所在数据块(表数据块),索引所在数据块(索引数据块),以及undo段所在数据块(undo数据块)!!2.undo记录了什么:undo即undo段,是指数据库为了保持读⼀致性,存储历史数据在⼀个位置。
为什么要保持读⼀致性?⽐如有两个⽤户访问数据库,当然并发罗。
A是更改,B是查询。
--A更改还没有提交,B查询的话,数据肯定为历史数据,这个历史数据就是来源于UNDO段,--A更改未提交,需要回滚rollback,回滚rollback的数据也来⾄于UNDO段。
结论:为了并发时读⼀致性成功,那么DML操作,肯定先写UNDO段。
3.前滚与回滚:--⽅向相对性:前滚,是指从“以前正常点”往前,⼀直到崩溃点回滚,是指从“崩溃点”往后,⼀直到数据⼀致性(因为前滚操作后,由于事务未提交的数据也写⼊了“表数据块”,所以要⽤Undo数据块进⾏覆盖--详细解释:前滚:当实例崩溃时,可以使⽤redo从以前正常的点前滚到崩溃点。
(前滚从⼀致性检查点,“即当时检查过所有的SCN是全部⼀致的时间点”,⼀直往前滚到崩溃的时间点)。
当数据库回到⼀致性检查点时,相当于之后什么都没有发⽣过,数据全被清空了。
(穿越了!O(∩_∩)O~)数据库只好根据redo模拟⼈的操作,使⽤redo⾥的信息重做(use redo log to redo),构造undo块,表块,索引块等。
redo log数据恢复原理

redo log数据恢复原理
Redo Log的恢复原理主要基于事务的原子性和持久性。
当数据库系统(例如MySQL)执行增删改操作时,会记录这些操作的redo log日志。
如果在数据库系统运行过程中出现宕机或者断电等故障,有些缓存页的数据可能还没有来得及写入磁盘。
在数据库系统重启时,系统会根据redo log日志进行数据重做,将数据恢复到宕机或者断电前的状态,从而保证了更新的数据不会丢失。
这个过程就是通过redo log进行数据恢复的过程。
以上内容仅供参考,建议查阅数据库相关书籍或咨询专业人士获取更多专业解答。
重建redo的方法

重建redo的方法
在数据库管理系统中,redo日志是一种重要的机制,用于确保数据的持久
性和一致性。
当发生故障或崩溃时,可以通过重放redo日志来恢复数据库到最近一次提交的状态。
然而,有时候可能需要重建redo日志,例如在数据库迁移、复制或升级过程中。
下面是一些重建redo日志的方法:
1. 通过备份恢复:如果在数据库备份过程中,保存了完整的备份文件并且备份文件是可靠的,那么可以使用备份文件来重建redo日志。
将备份文件还原到一个临时数据库中,并启动数据库以生成新的redo日志。
2. 使用逻辑日志导入:如果无法使用完整的备份文件,但有逻辑备份文件(如SQL脚本或逻辑备份工具生成的文件),可以使用逻辑日志导入来重建redo日志。
逻辑日志导入工具会解析逻辑备份文件,并将其中的操作转换为对数据库的修改,并生成相应的redo日志。
3. 通过事务日志导入:如果有事务日志文件(如二进制日志文件),可以使用事务日志导入工具来重建redo日志。
事务日志导入工具会解析事务日志文件,并将其中的操作转换为对数据库的修改,并生成相应的redo日志。
4. 使用数据库恢复工具:某些数据库管理系统提供了专门的工具来重建redo
日志。
这些工具可以检查数据库的物理结构,通过分析数据文件中的数据页来重建redo日志。
使用这些工具可以快速而准确地重建redo日志。
无论使用哪种方法,重建redo日志都是一个复杂的过程,需要谨慎操作。
在进行重建操作之前,应该备份好数据库和相关的日志文件,以防止数据丢失。
另外,需要确保重建后的redo日志与原始日志的顺序和内容一致,以确保数据库的一致性和完整性。
recover与resetlog

有关SCN 和RESETLOG的一些资料简单说两句:要理解recover database using backup controlfile,先理解recover database也就是说,不加using backup controlfile的情况。
在普通的recover database 或者recover tablespace, recover datafile时,Oracle会以当前controlfile所纪录的SCN为准,利用archive log和redo log的redo entry, 把相关的datafile 的block恢复到“当前controlfile所纪录的SCN”而某些情况下,Oracle需要把数据恢复到比当前controlfile所纪录的SCN还要靠后的位置(比如说,control file是backup controlfile , 或者controlfile是根据trace create的。
),这时候,就需要用using backup controlfile. 恢复就不会受“当前controlfile所纪录的SCN”的限制。
这时候的限制就来自于你的语句(until time , until scn),或者可用的archive log(until cancel) ...-------------------------------------------首先这里我们先介绍四个SCN概念。
1、系统检查点scn当一个检查点动作完成后,Oracle就把系统检查点的SCN存储到控制文件中。
select checkpoint_change# from v$database;2,数据文件检查点scn当一个检查点动作完成后,Oracle就把每个数据文件的scn单独存放在控制文件中。
select name,checkpoint_change# from v$datafile;3,启动scnOracle把这个检查点的scn存储在每个数据文件的文件头中,这个值称为启动scn,因为它用于在数据库实例启动时,检查是否需要执行数据库恢复。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
oracle备份测试1、关闭数据库;2、手动删除所有redo文件;3、启动数据库;SQL> startupORACLE例程已经启动。
Total System Global Area 612368384 bytesFixed Size 1250428 bytes Variable Size 255855492 bytes Database Buffers 348127232 bytesRedo Buffers 7135232 bytes 数据库装载完毕。
ORA-00313: 无法打开日志组 1 (用于线程 1) 的成员ORA-00312: 联机日志 1 线程 1:'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\REDO01.LOG'ORA-00312: 联机日志 1 线程 1: 'F:\REDO\REDO01_B.LOG'SQL>4、查看当前日志状态;SQL> select group#,members,archived,status from v$log;GROUP# MEMBERS ARC STATUS---------- ---------- --- ----------------1 2 YES INACTIVE2 2 NO CURRENT3 2 YES INACTIVESQL>5、clear生成非当前的日志;SQL>alter database clear logfile group1;数据库已更改。
SQL>6、继续打开数据库;SQL> alter database open;alter database open*第 1 行出现错误:ORA-00313: 无法打开日志组 2 (用于线程 1) 的成员ORA-00312: 联机日志 2线程 1:'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\REDO02.LOG'ORA-00312: 联机日志 3 线程 1: 'F:\REDO\REDO02_B.LOG'SQL>SQL> alter database clear logfile group 2;alter database clear logfile group 2*第 1 行出现错误:ORA-00350: 日志 2(实例 orcl 的日志, 线程 1) 需要归档ORA-00312: 联机日志 2 线程 1:'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\REDO02.LOG'ORA-00312: 联机日志 2 线程 1: 'F:\REDO\REDO02_B.LOG'报错;因为group2是当前状态;此时只能从其它目录copy有效备份。
然后在alter database;SQL>alter database clear unarchived logfile group2;数据库已更改。
然后再重建Group 3,方法同重建 Group 1;SQL> alter database clear logfile group 3;数据库已更改。
SQL> alter database open;数据库已更改。
注意:倘若没有物理有效备份文件,数据库则将无法打开;用clear logifle 这种方法,对于处于CURRENT状态的Redo,只能通过COPY有效的物理备份去打开数据库,否则无法打开;B、Resetlogs打开恢复方法1、关闭数据库;2、手动删除所有redo文件;3、启动数据库;SQL> startupORACLE 例程已经启动。
Total System Global Area 612368384 bytesFixed Size 1250428 bytesVariable Size 276827012 bytesDatabase Buffers 327155712 bytesRedo Buffers 7135232 bytes数据库装载完毕。
ORA-00313: 无法打开日志组 1 (用于线程 1) 的成员ORA-00312: 联机日志 1 线程 1:'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\REDO01.LOG'ORA-00312: 联机日志 1 线程 1: 'F:\REDO\REDO01_B.LOG'4、使用Recover database until cancel;SQL> recover database until cancel;完成介质恢复。
此时还是无法打开数据库;SQL> alter database open;alter database open*第 1 行出现错误:ORA-01589: 要打开数据库则必须使用 RESETLOGS 或 NORESETLOGS 选项5、通过RESETLOGS打开数据库:SQL>alter database open resetlogs;数据库已更改。
此种方法应该可以说超越clear logfile了,在没有数据库冷备份数据文件的前提下,可以考虑此种方法。
但是要注意的是:通过NORESETLOGS选项是无法正常打开数据库的。
通过此种方法恢复数据库建议恢复之后必须立即做个全备份。
因为resetlogs已经清除了所有的日志序列。
C、通过重建控制文件恢复redo1、关闭数据库;2、手动删除所有redo文件;3、启动数据库;SQL> startupORACLE 例程已经启动。
Total System Global Area 612368384 bytesFixed Size 1250428 bytesVariable Size 276827012 bytesDatabase Buffers 327155712 bytesRedo Buffers 7135232 bytes数据库装载完毕。
ORA-00313: 无法打开日志组 1 (用于线程 1) 的成员ORA-00312: 联机日志 1 线程 1:'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\REDO01.LOG'ORA-00312: 联机日志 1 线程 1: 'F:\REDO\REDO01_B.LOG'、4、获得重建控制文件脚本:SQL>alter database backup controlfile to trace;数据库已更改。
SQL>@?/rdbms/admin/gettrcname.sql;TRACE_FILE_NAME--------------------------------------------------------------------------------E:\ORACLE\PRODUCT\10.2.0\ADMIN\ORCL\UDUMP/orcl_ora_1136.trc编辑以上文件就可以获得重建控制文件的脚本了。
5、运行生成的生成控制文件的脚本:SQL> STARTUP NOMOUNTORACLE 例程已经启动。
Total System Global Area 612368384 bytesFixed Size 1250428 bytesVariable Size 281021316 bytesDatabase Buffers 322961408 bytesRedo Buffers 7135232 bytesSQL> CREATE CONTROLFILE REUSE DATABASE "ORCL" RESETLOGS ARCHIVELOG2 MAXLOGFILES 163 MAXLOGMEMBERS 34 MAXDATAFILES 1005 MAXINSTANCES 86 MAXLOGHISTORY 2927 LOGFILE8 GROUP 1 (9 'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\REDO01.LOG',10 'F:\REDO\REDO01_B.LOG'11 ) SIZE 50M,12 GROUP 2 (13 'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\REDO02.LOG',14 'F:\REDO\REDO02_B.LOG'15 ) SIZE 50M,16 GROUP 3 (17 'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\REDO03.LOG',18 'F:\REDO\REDO03_B.LOG'19 ) SIZE 50M20 -- STANDBY LOGFILE21 DATAFILE22 'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\SYSTEM01.DBF',23 'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\UNDOTBS01.DBF',24 'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\SYSAUX01.DBF',25 'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\USERS01.DBF',26 'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\EXAMPLE01.DBF',27 'E:\ORACLE\PRODUCT\10.2.0\ORADATA\ORCL\TEST.DBF'28 CHARACTER SET ZHS16GBK29 /控制文件已创建。
6、以resetlogs方式打开数据库:SQL>alter database open resetlogs;数据库已更改。
SQL>7、全备数据库;此种方法稍微繁琐了点。
但是稳妥。
综上三种方法都是在正常关闭数据库的情况下丢失redo文件的恢复方法。
这三种方法中的每种恢复过来之后,数据都不会丢失,因为数据库正常关闭,不会有数据存于redo中。
一定要注意的是凡是通过“alter database open resetlogs”方式打开数据库的,必须对数据库进行全备!附:gettrcname.sql脚本SELECT d.VALUE|| '/'|| LOWER (RTRIM (i.INSTANCE, CHR (0)))|| '_ora_'|| p.spid|| '.trc' trace_file_nameFROM (SELECT p.spidFROM v$mystat m, v$session s, v$process pWHERE m.statistic# = 1 AND s.SID = m.SID AND p.addr = s.paddr) p,(SELECT t.INSTANCEFROM v$thread t, v$parameter vWHERE = 'thread'AND (v.VALUE = 0 OR t.thread# = TO_NUMBER (v.VALUE))) i,(SELECT VALUEFROM v$parameterWHERE NAME = 'user_dump_dest') d/此脚本转自eygle的相关资料。