B45-4.5.2.Thum-2指令集详解
亿丰电子伺服手册

2.1 系统组成与接线 ................................................................................................ - 8 -
第 3 章 显示与操作 ........................................................................................- 25 -
3.1 面板组成.......................................................................................................... - 25 -
!!
产品到达后,进行确认、安装、配线、运行维护、检查时,以下是必须遵守的重要事项: ●安装时注意事项:
!警告
严禁安装在潮湿及会发生腐蚀的环境、有易燃性气体的环境下、可燃物的附近及灰尘、金属粉 末较多的环境,否则有可能会发生触电和火灾。
●配线时的注意事项:
!警告
◢ 伺服驱动器的接地端子必须接地,否则,可能会发生触电和火灾。 ◢ 严禁把伺服驱动器的输出端子 U, V, W ,连接至三相电源,否则,可能受伤和引发火灾。 ◢ 严禁把220V驱动器连接至380V电源,否则可以触电和引发火灾。 ◢ 务必将电源端子、电机输出端子拧紧,否则有可能会引发火灾。
2.3.3 速度/转矩控制接线图(标准版).......................................................................................- 23 2.3.4 速度/转矩控制接线图(进阶版).......................................................................................- 24 -
B45-4.2.ARM-Thumb-Thumb2指令指令基础(2019)

LDR R2,[R3,#0x0C]
• 6) 多寄存器寻址
多寄存器寻址一次可传送几个寄存器值,允许一条指令
传送16个寄存器的任何子集或所有寄存器。多寄存器寻址
指令举R6例0如x下?04?:
0x04 0x4000000C
LDMIRA4R10!x,?0{3?R2-R7,R12} 0;;x将R02R3~1指R7向0、的xR41单02元中0中0(R0的10自数0动据8 加读1出)到 STMIRA3R00!x,?0{2?R2-R7,R12} 0;x将0寄2 存器0Rx24~0R070、0R0102的4 值保
• 9) 相对寻址
相对寻址是基址寻址的一种变通。由程序计数器
PC提供基准地址,指令中的地址码字段作为偏移量,
两者相加后得到的地址即为操作数的有效地址。相
对寻址指令举例如下:
BL SUBR1
;调用到SUBR1子程序
BEQ LOOP
;条件跳转到LOOP标号处
...
LOOP MOV R6,#1
...
SUBR1...
R2 0x?01? R1 0x40000000
0;;x存(0R1到0自R0存动指0储加x向器14的)0存00储0;00单0元中
LDMIA R1!,{R2-R4,R6}
• 7 )堆栈寻址
堆栈是一个按特定顺序进行存取的存储区,操作 顺序为“后进先出” 。堆栈寻址是隐含的,它使用 一个专门的寄存器(堆栈指针)指向一块存储区域(堆 栈),指针所指向的存储单元即是堆栈的栈顶。存储 器堆栈可分为两种:
地址的存储单元中,即寄存器为操作数的地址指针。 寄存器间接寻0址x4指00令00举00例00如x下AA:
LDR R1,[R2]
第3章Thumb-2指令系统4H解析

3.1 Thumb-2指令集简介
Cortex-M3处理器使用的是Thumb-2指令集的子集,它的指 令工作状态只有Thumb-2状态。 Thumb-2继承了传统的Thumb指令集和ARM指令集的各自优 点,并不是Thumb的升级,包含16-bit指令集和32-bit指 令集两种长度的指令子集。 Thumb-2指令集体系架构,无需处理器进行工作状态的显 示切换,就可运行16位与32位混合代码,并由同一汇编器 对其进行汇编。
ASR算术右移(Arithmetic Shift Right):移位过程中保 持符号位不变,即若源操作数为正数,则数据位的高端空 出的位补0,否则补1;
可采用的移位操作
ROR循环右移(Rtate Right):由数据位的低端移出的位填 入数据位的高端空出的位;
RRX带扩展的循环右移(Rotate Right eXtended by 1 place):操作数右移一位,高端空出的位用原C标志值填 充。
R2 R1
0xAA 0xAA 0x55
MOV R1,R2
SUB
R0,R1,R2
;将R1的值减去R2的值,结果存R0
2、立即寻址
• 地址码字段(第一或第二操作数)直接给出是一整数 (称立即数),例: SUBS R0,R0,#1 ;R0减1结果放入R0,影响标志位
MOV R0,#0xFF000 ;将立即数0xFF000装入R0 程序存储 MOV R0,#0xFF00
条件码 EQ NE CS/HS CC/LO MI PL VS VC HI LS GE LT GT LE AL
指令执行条件码
在 Cortex-M3中,只有分支转移指令(B指令)才可以随 意使用条件码。例: BEQ label ;当 Z = = 1 时,程序转移到label 对于其它指令,只有在IF-THEN(IT)指令块中(最多4条) 才能加条件码,且必须加条件码。 IT已经带了一个T,最多再带3个T或E(与T相反的条件),T 、E排列无顺序。例: … CMP R0, R1 ; 比较R0和R1的值,影响标志位 ITTEE GT ; 下带4条指令,如R0>R1既GT成立,否则LE成立 MOVGT R2, R0 ; GT成立,则 R2 = R0 MOVGT R3, R1 ; GT成立,则 R3 = R1 MOVLE R2, R1 ; LE成立,则 R2 = R1 MOVLE R3, R0 ; LE成立,则 R3 = R0 …
GEN2指令集
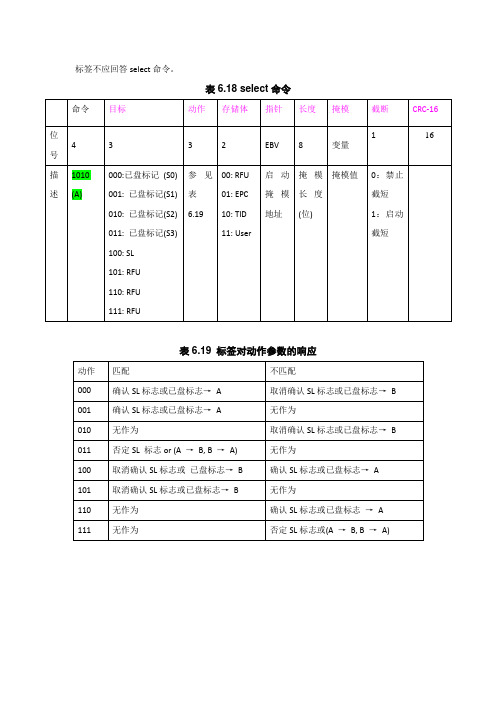
标签不应回答select命令。
表6.18 select命令表6.19 标签对动作参数的响应表6.20 Query命令表6.21 标签应答Query命令前同步码应先于Query 命令,并表明盘存周期开始。
其它发信则以帧同步开始。
CRC-5从第一个操作码位计算到最后的Q位。
若标签收到的Query命令有一个CRC-5错误,则应忽略该命令。
收到Query命令后,Sel和目标匹配的标签在(0,2Q-1)的范围内挑选一个随机数,将该数值载入其槽计数器。
如果响应该Query命令的标签以零载入其槽计数器,则该标签对Query命令的应答应按表6.21所示,否则该标签应保持沉默。
如果处于确认状态、开放状态或保护状态的标签收到的Query命令的通话参数与前通话匹配,则应为该通话倒转其已盘标记(即A→B或B→A)。
如果处于确认状态、开放状态或保护状态的标签收到的Query命令的通话参数与前通话不匹配,则应在开始新的盘存周期时保持前通话的已盘标记不变。
表6.23 标签应答QueryAdjust命令QueryAdjust命令调整Q,其它盘存周期参数不变。
如果标签收到的QueryAdjust命令的通话数与启动该盘存周期的Query命令中的通话数不同,则应忽略该命令。
若标签收到的QueryAdjust命令的UpDn值与上述规定值不同,则应忽略该命令。
标签应保持当前Q值的计数。
启动该盘存周期的Query命令规定初始Q值。
一个或一个以上的后续QueryAdjust命令可以修改Q值。
收到QueryAdjust命令后,标签应首先更新Q值,然后在(0,2Q-1)范围内挑选一个随机值,将该值载入其槽计数器内。
处于确认状态、开放状态或保护状态下的标签收到QueryAdjust命令后应为当前通话倒转其已盘标记(即A→B或B→A),并转换成就绪状态。
表6.25 标签应答QueryRep命令QueryRep命令指示标签使其槽计数器减值。
若槽计数器在减值后槽=0,则应向询问机反向散射一个RN16。
笔记本cpu详解

笔记本CPU型号大全前言对于笔记本处理器市场来说,半年的时间可以有很多事情发生。
而作为移动处理器市场的执牛耳者,英特尔笔记本处理器的进化速度也有有目共睹,其中不乏新技术的出现,当然也有厂商的营销策略在里面。
而在过去的半年中,笔记本处理器市场也发生了根本性的变化。
相比半年前,最大的一点就是45nm笔记本处理器的出现,更小的发热量,更强的性能,让英特尔在笔记本处理器领域如日中天;而另外一点就是移动版赛扬双核处理器的出现让更多的消费者以更低的价格就能享受到双核带来的乐趣,相比英特尔的强势,AMD在移动处理器方面的动作就比较少了,前段时间可以说是没什么大的动作,不过其最新的PUMA处理器已经发布,期待AMD在笔记本处理器领域能有更大的进步。
可以说电脑已经成为人们生活中不可缺少的一部分,而随着时代的进步,笔记本电脑和台式机之间的性能上的差距是越来越小,价格上也是逐步降低。
越来越多的人开始将眼光转移到笔记本身上,可以说,这是一个时代进步的标志。
笔记本的轻便易于携带、对电源的依赖性低,这些优点成为人们买电脑的首选。
可以说人们购买笔记本问的第一句话就是采用的什么处理器,由此可见处理器在笔记本中所占的分量。
而笔记本处理器也从当初的80386SL发展到如今的酷睿2双核,甚至出现了酷睿2至尊版处理器,笔记本处理器的发展可以说是日新月异,造成了笔记本市场上各种各样的CPU同时出现,好多消费者感觉都是无所适从,不知道该买哪一种。
确实这种情况的出现有一定的市场原因,毕竟处理器生产商为了满足各种层次的消费者,对应也生产出了各种类型的处理器,但这些却给消费者带来了困惑。
而作为IT媒体,我们有责任、有义务让消费者了解其中的规律,这样在以后购买笔记本的时候就能有所参考,不再被市场上种类繁多的处理器型号所迷惑,在选购笔记本时真正做到有所取舍!处理器术语简介主频:CPU的主频,即CPU内核工作的时钟频率(CPU Clock Speed)。
45纳米

突进中的困惑
45纳米我们天天说45nm制程,但真正明白其含义的朋友恐怕并不多,这里我们首先来明确下这个概念。 45nm(1μm=1000nm,1nm为10亿分之一米)不是指的芯片上每个晶体管的大小,也不是指用于蚀刻芯片形成电路 时采用的激光光源的波长,而是指芯片上晶体管的栅极宽度,衡量半导体制程的参数很多,比如芯片上晶体管和 晶体管之间导线连线的宽度,简称线宽。(此处应为连线的高度,线宽在一个技术时代里(比如45nm工艺)是可 以不断缩小的,而线的高度是不变的)。半导体业界也经常用线宽这个工艺尺寸来代表硅芯片生产工艺的水平。早 期的连线采用铝,后来很多国外的大公司采用铜导线了。
我们知道,一般的晶体管可分为低电阻层、多晶硅栅极和二氧化硅电介层。其中,二氧化硅电介层在65纳米 时代已降低至相当于五层原子的厚度,再进一步缩小则会遭遇电介层的漏电而达到极限。
但是,对业界影响深远的摩尔定律并没有因此而失去效力。经历千万次的试验,英特尔将一种熔沸点和强度 都极高且抗腐蚀性的新型金属铪(Hf)运用到芯片处理技术当中,创造出英特尔45纳米高K金属栅极硅制程技术层, 替换二氧化硅电介层。
英特尔®多路(Wide)动态执行,每时钟周期可传递更多的指令,从而节省执行时间并提高电源使用效率。
英特尔®智能功效管理,旨在为笔记本电脑提供更高的节能效果及更卓越的电池使用效率。
ARM Cortex各系列处理器分类比较之欧阳引擎创编

Cortex-M系列欧阳引擎(2021.01.01)M0:Cortex-M0是目前最小的ARM处理器,该处理器的芯片面积非常小,能耗极低,且编程所需的代码占用量很少,这就使得开发人员可以直接跳过16位系统,以接近8 位系统的成本开销获取32 位系统的性能。
Cortex-M0 处理器超低的门数开销,使得它可以用在仿真和数模混合设备中。
M0+:以Cortex-M0 处理器为基础,保留了全部指令集和数据兼容性,同时进一步降低了能耗,提高了性能。
2级流水线,性能效率可达1.08 DMIPS/MHz。
M1:第一个专为 FPGA 中的实现设计的 ARM 处理器。
Cortex-M1 处理器面向所有主要FPGA 设备并包括对领先的FPGA 综合工具的支持,允许设计者为每个项目选择最佳实现。
M3:适用于具有较高确定性的实时应用,它经过专门开发,可使合作伙伴针对广泛的设备(包括微控制器、汽车车身系统、工业控制系统以及无线网络和传感器)开发高性能低成本平台。
此处理器具有出色的计算性能以及对事件的优异系统响应能力,同时可应实际中对低动态和静态功率需求的挑战。
M4:由 ARM 专门开发的最新嵌入式处理器,用以满足需要有效且易于使用的控制和信号处理功能混合的数字信号控制市场。
M7:在 ARM Cortex-M 处理器系列中,Cortex-M7 的性能最为出色。
它拥有六级超标量流水线、灵活的系统和内存接口(包括AXI 和AHB)、缓存(Cache)以及高度耦合内存(TCM),为MCU 提供出色的整数、浮点和 DSP 性能。
互联:64位 AMBA4 AXI, AHB外设端口 (64MB 到 512MB)指令缓存:0 到 64kB,双路组相联,带有可选 ECC数据缓存:0 到 64kB,四路组相联,带有可选 ECC指令TCM:0 到 16MB,带有可选 ECC数据TCM:0 到 16MB,带有可选 ECCCortex-M系列规格对比Cortex-A系列:ARM Cortex-A 系列是一系列用于复杂操作系统和用户应用程序的应用程序处理器。
Thumb2指令表(中文)

Rd := SAT(Rm + SAT(Rn * 2))
Q
SUB{S} Rd, Rn, <Operand2>
N Z C V Rd := Rn – Operand2
N
SBC{S} Rd, Rn, <Operand2>
N Z C V Rd := Rn + Operand2 - C的非
N
T2 SUB Rd, Rn, #<imm12>
T
6 <prefix>ADD16 Rd, Rn, Rm
Rd[31:16] := Rn[31:16] + Rm[31:16], Rd[15:0] := Rn[15:0] + Rm[15:0]
G
6 <prefix>SUB16 Rd, Rn, Rm
Rd[31:16] := Rn[31:16] – Rm[31:16], Rd[15:0] := Rn[15:0] – Rm[15:0]
一个由大括号括起来的,用逗号隔开的寄存器列表。如:{ and }。 加载或存储的寄存器列表,不能包含程序计数器PC。 列表须有程序计数器。将SPSR拷贝到CPSR中,用于从异常处理返回。 正或负号。(+号有可能被忽略.) 见表: ARM结构版本 中断标志。一个或多个a,i,f(异常、中断、快速中断). 见表: 处理器模式 由<p_mode>所指定处理器模式的堆栈指针SP 位域的最低有效位 位域的宽度。<width> + <lsb> 必须≤32 如果x置位,RsX为Rs循环移动16位的结果。否则RsX为Rs。 若 ! 存在 (预先定义),则数据传送后更新基址寄存器(Rn)。 若S存在,则更新标志位 若T存在,进用户特权模式 若R存在,则恢复最近的结果,否则丢弃结果。
Thumb-2指令系统

⑥ Thumb代码和标准ARM代码不能混杂使用,必须 显式地在两种工作状态间进行切换,这迫使程序员必 须将所有的16位代码与32位代码分开并隔离到独立的 模块中。
1. 概述(续)
对于ARM体系架构的来说(续):
⑦ 其次,两种工作状态之间来回切换需要消耗时间, 导致代码运行速度降低大约15%,不仅要增加代码, 而且还需要几十个前导(preamble)以及后同步指令 (postamble)来组织指针并清空CPU的流水线。
1. 概述(续)
对于ARM体系架构的来说(续):
⑤ 但是,有限的Thumb指令仅对基本的算术和逻辑 操作有用:
➢ Thumb状态下,处理器将仅可使用有限数量的寄存器, R8-R12的使用受到限制,
➢ 无法完成诸如处理中断、长跳转、原子存储器(atomic memory)操作,或协处理器操作等等复杂任务,
Thumb-2指令系统 (Thumb-2指令体系架构)
主要内容
1. 概述 2. Thumb-2指令集分类 3. 统一的汇编语言 4. Cortex-M3常用的Thumb-2指令
集 5. 小结
1. 概述
• 对于确定的微处理器而言,编写紧凑的代 码以降低消耗显得至关重要。
• 通常,存储器的大小是固定的,而产品的 功能特性却各异,选择恰当的处理器并精 心调整代码是明智的。
1. 概述(续)
• Cortex-M3处理器使用的指令集是Thumb-2 指令集的子集,它的(指令)工作状态只 有一个,那就是Thumb-2状态。
• Cortex-M3处理器的两种工作状态:
① Thumb-2状态 ② 调试状态
2. Thumb-2指令集分类
双串口单片机(51单片机)

W77E58 规格书
..........................................................................................................................3 2. 特性.....................................................................................................................................3 3. 管脚配置..............................................................................................................................4 4. 管脚描述..............................................................................................................................5 5. 方块图 .................................................................................................................................7 6. 功能描述..............................................................................................................................8 7. 存储器组织 ..........................................................................................................................9
cortex-a7 thumb2指令

Cortex-A7 Thumb-2指令是ARM架构中一个非常重要的部分,它对于提高处理器的性能和效率起着至关重要的作用。
在本篇文章中,我将会从浅入深地探讨cortex-a7 thumb2指令的相关知识,并共享我个人对这一主题的理解和观点。
1. Cortex-A7 Thumb-2指令简介让我们对Cortex-A7 Thumb-2指令进行一个简要的介绍。
Thumb-2指令集是ARM架构中的一种指令集,它被设计用来取代之前的Thumb指令集,并且在处理器的性能和代码密度方面有着显著的优势。
作为Cortex-A7处理器的一部分,Thumb-2指令集在执行速度和功耗方面都有着非常出色的表现。
2. Cortex-A7 Thumb-2指令的特性接下来,让我们来详细了解一下Cortex-A7 Thumb-2指令的特性。
Thumb-2指令集采用了16位和32位指令的混合编码方式,这样既能够保持较高的代码密度,又能够提高指令的执行效率。
Thumb-2指令集还引入了一些新的指令,使得处理器能够更加高效地执行各种复杂的操作。
3. Cortex-A7 Thumb-2指令的应用Cortex-A7 Thumb-2指令在各种应用中都有着广泛的应用。
无论是在移动设备、嵌入式系统还是物联网设备中,Cortex-A7处理器都能够通过Thumb-2指令集提供出色的性能和效率。
而且,在一些对功耗和性能有着严格要求的场合,Cortex-A7 Thumb-2指令更是表现出了独特的优势。
4. 个人观点和总结就我个人来说,我认为Cortex-A7 Thumb-2指令集的出现和应用对于ARM架构的发展起到了至关重要的作用。
它不仅使得处理器的性能得到了大幅提升,还使得处理器在功耗和代码密度方面能够有着更好的表现。
Cortex-A7 Thumb-2指令集无疑是ARM架构中的一大利器,它将继续在各个领域发挥着重要作用。
Cortex-A7 Thumb-2指令集作为ARM架构中的重要组成部分,它的出现和应用对于提高处理器的性能和效率有着非常重要的意义。
迅驰2平台英特尔移动处理器参数表

Centrino 2三个组件包括PM/GM45芯片组、45nm酷睿2双/四核处理器、Intel WiFi Link 5000系列无线网卡。
QX: Quad-Core Extreme SegmentX: Extreme SegmentT: Mobile Highly Performance SegmentP: Power Optimized Energy Efficient higher Performance Segment迅驰2平台已知的移动处理器参数见下表:型号主频L2FSB制程TDP核心双核Montevina平台(迅驰2平台:搭配GM45、GM47、PM45芯片组)英特尔酷睿2至尊移动处理器:Core 2 Extreme QX9300 2.53 GHz12M1066MHz45nm45W Penryn四核Core 2 Extreme X9100 3.06 GHz6M1066MHz45nm44W Penryn√英特尔酷睿4双核移动处理器Core 2 Extreme Q9100 2.26 GHz12M1066MHz45nm45W Penryn四核Core 2 Extreme Q9000 2.00 GHz6M1066MHz45nm45W Penryn四核英特尔酷睿2双核移动处理器:Core 2 Duo T9800293 GHz6M1066MHz45nm35W Penryn√Core 2 Duo T9600 2.80 GHz6M1066MHz45nm35W Penryn√Core 2 Duo T9550 2.66 GHz6M1066MHz45nm35W Penryn√Core 2 Duo T9400 2.53 GHz6M1066MHz45nm35W Penryn√Core 2 Duo P9500 2.53 GHz6M1066MHz45nm25W Penryn√Core 2 Duo P8700 2.53 GHz3M1066MHz45nm25W Penryn√Core 2 Duo P8600 2.40 GHz3M1066MHz45nm25W Penryn√Core 2 Duo P8400 2.26 GHz3M1066MHz45nm25W Penryn√Core 2 Duo P7450 2.13 GHz3M1066MHz45nm25W Penryn√Core 2 Duo P7350 2.00 GHz3M1066MHz45nm25W Penryn√Montevina平台(迅驰2 SFF平台:搭配GS45芯片组)英特尔酷睿2双核移动处理器:Core 2 Duo SP9400 2.40 GHz6M1066MHz45nm25W Penryn√Core 2 Duo SP9300 2.26 GHz6M1066MHz45nm25W Penryn√英特尔酷睿2双核低电压、超低电压移动处理器Core 2 Duo SL9400 1.86 GHz6M1066MHz45nm17W Penryn√Core 2 Duo SL9300 1.60 GHz6M1066MHz45nm17W Penryn√Core 2 Duo SU9400 1.40 GHz3M800MHz45nm10W Penryn√Core 2 Duo SU9300 1.20 GHz3M800MHz45nm10W Penryn√Core 2 Duo SU3300 1.20 GHz3M800MHz45nm5W Penryn√英特尔酷睿2双核移动处理器(搭配GM45、GM47、PM45芯片组)Core 2 Duo T6600 2.20 GHz2M800MHz45nm35W Penryn√Core 2 Duo T6400 2.00 GHz2M800MHz45nm35W Penryn√Core 2 Duo T5900 2.20 GHz2M800MHz65nm35W Merom√Core 2 Duo T5800* 2.00 GHz2M800MHz65nm35W Merom√英特尔奔腾双核移动处理器(搭配GM47、GM45、GL40芯片组)Pentium Dual Core T4200 2.00 GHz1M800MHz45nm25W Penryn√Pentium Dual Core T3400 2.16 GHz1M667MHz65nm35W Merom√Pentium Dual Core T3200* 2.00 GHz1M667MHz65nm35W Merom√英特尔赛扬双核移动处理器(搭配GM47、GM45、GL40芯片组): Celeron Dual Core T1800 2.00 GHz1M667MHz65nm35W Merom√Celeron Dual Core T1700 1.83 GHz1M667MHz65nm35W Merom√Celeron Dual Core T1600 1.66 GHz1M667MHz65nm35W Merom√英特尔赛扬移动处理器:Celeron M 585 2.16 GHz1M667MHz65nm25W Merom Celeron M 575 2.00 GHz1M667MHz65nm25W Merom英特尔赛扬超低电压版移动处理器:Celeron M 723 1.20 GHz1M800MHz65nm10W Meromk 5000系列无线网卡。
PWM技术揭秘

PWM技術揭秘V4 動力引擎(4 階段PWM)何謂PWM (脈衝寬度調節,Pulse Width Modulation)?穩定及充足的電源支援對電腦系統而言是必要的。
然而,電腦系統電源傳輸的最大問題在於輸出階段產生的電源流失及熱度消耗。
傳統的線性輸出階段提供電腦系統連續的電壓;然而,此方法將會浪費大量的電力。
脈衝寬度調節(PWM) 是一種使用數位輸出來傳輸類比電路,用以最大化能量傳輸及電池壽命的先進技術。
4 階段PWM 的優點AOpen 主機板是專為效能及穩定而製作。
當市面上充斥著由不肖製造廠商在主機板上使用低品質及成本的材料,進而影響您系統的穩定、不明的系統當機,以及主機板過熱的情況,AOpen 已經決定在我們的產品中採用堅固的材料來維持我們優良製造廠商的長久聲譽。
正如V6 引擎給予您的車子在道路上行駛時更多的馬力,主機板同樣需要更強大且更具爆發力的電源以保護您的系統。
因為在 4 階段格式中採用 4 個平行PWM 控制器通道,此主機板提供能夠搭配符合與日漸增之CPU 溫度的最適電源密度、瞬間電流回應及熱度效能。
同時,有一點可以確定的是,4 階段PWM 控制器絕對優於 3 階段或 2 階段PWM 控制器,如同3000c.c 的車子當然優於2000c.c 的車子的原理。
因此,具備強大且更穩定的電源是目前主機板所必須要有的條件。
對於正在期待800 MHz 外頻CPU 的使用者而言,4 階段電源將是必要的。
AOpen 主機板擁有獨特的4 階段電源解決方案,將可提供CPU 充足的電源。
下列兩圖顯示 4 階段及 3 階段PWM 之間的外觀差異。
4 階段PWM 包含四個輸出件且每個輸出件提供一個獨立的脈衝寬度調節訊號。
一般而言,這些輸出件大都靠近CPU 插槽。
使用者在購買前可以計算一下此數目。
如果我們以60W 的電源消耗讓3 階段PWM 控制器分擔作說明,測試顯示它會帶給週邊元件較高的溫度,進而增加主機板的溫度,如此將影響CPU 超頻或高負荷時的系統穩定性。
如何使用Thumb2改善代码性能和密度

基址加载到寄存器中,这时就会需要把 32-b i t常数加载到寄存器中。在之前的 架构中需要通过literal pools(嵌在指令 流中的32位常数)来完成这样的操作, 对32位常量的访问一般通过P C相对寻 址来实现。 L i t e r a l p o o l s可以保存常量并简
化访问这些常量的代码,但是,在 H a r v a r d架构的处理器中会引起额外的 并且,在T h u m b-2技术下也不再像以 往那样需要在A R M/T h u m b两套指令之 间切换。 对于之前在A R M处理器上已经有 上面的表格为该指令的一个简单应 开销。这些开销来自于需要额外的时钟 周期来使数据端口能够对指令流进行访 问;这种访问可能是需要把指令流加载 的数据缓存中,或者从数据端口直接访 问指令存储器。 将32位常量分成16比特的两个部 用例子。如果被操作的比特位的范围在 A R M指令可支持的范围内,共需要三 条A R M指令;如果被操作的比特位的 范围超出了A R M指令可支持的范围, 会需要更多的指令才能完成特定的功 能。T h u m b-2指令集很好的解决了这 个问题。值得注意的是,A R M指令序 列还需要使用一个额外的寄存器来保存 中间变量。 1 比特反转指令 Thumb-2技术使得开发者可以更快 的完成产品最优化设计。 在性能和代码大小之间取得平衡 通过分析ARM/Thumb编译器产生的 该指令可以把源寄存器的bit [n] 赋 值到目标寄存器的b i t [31-n]。如果不 使用该指令实现同样的功能会需要很多 条指令才能完成,例如有可能需要连续 的15条指令才能完成所有比特的反转交 换;同时还需要一个保存中间变量的寄 存器。而使用比特反转指令可以明显降 低需要的指令的数目。比特反转指令在 一些D S P算法(例如F F T中)中会经常 用到。 1 16-bit 常数 新指令对性能和代码密度的改进 1 位操作指令 为了提高处理压缩数据结构的效 率,新的ARM架构为Thumb-2指令集和 ARM指令集增加了一些新的指令来实现 比特位的插入和抽取。这样,开发者进 行比特位的插入和抽取所需的指令数目 就可以明显减少,使用压缩的数据结构 为了增加处理常数的灵活性,新架 T h u m b-2指令集引入了一条跳转 构中为T h u m b-2指令集和A R M指令集 增加了两条新的指令。MOVW可以把一 个16-b i t 常数加载到寄存器中,并用 0填充高比特位;另一条指令M O V T可 以把一个16-b i t 常数加载到寄存器高 16比特中。这两条指令组合使用就可 以把一个32-b i t常数加载到寄存器中。 通常在访问外设寄存器之前会把外设的 1 IT - if then 大多数ARM指令都支持条件执行功 能。这个特性在编译短的条件执行代码 表指令。它综合了A R M/T h u m b的优 点,在压缩的数据表上可以使用最少的 指令来实现跳转表功能,最终可以以最 小的代码和数据实现最优的性能。 1 跳转表指令 使用跳转表来控制程序的执行方向 是高级语言的一个常见特性,使用ARM 和Thumb指令集都可以很好的实现这个 功能。使用ARM指令集一般是为了生成 高性能的代码,编译器会以代码密度为 代价对性能进行优化。而Thumb编译器 则会使用压缩的数据表来尽可能的降低 代码大小。 分保存在两条指令中,意味着数据直接 在指令流中,不再需要通过数据端口来 访问了。相对于literal pool方式,这种 解决办法可以消除通过数据端口访问指 令流的额外开销,进而提高性能,降低 功耗。 长时间开发经验的开发者来说,使用 Thumb-2技术是非常简单的。开发者只 需要关注对整体性能影响最大的那部分 代码,其他的部分可以使用缺省的编译 配置就可以了。这样在享有高性能、高 代码密度的优势的时候,可以很快的更 新设计并迅速将产品推向市场。
4指令集和时钟分析

❖ 本STM32开发平台使用8MHz外部时钟,经PLL倍频(9倍) 后系统时钟SysCLK=72MHz,FCLK=HCLK=72MHz, PCLK1=36MHz, PCLK2=72MHz。
RCC->APB1RSTR = 0x00000000;//复位结束 RCC->APB2RSTR = 0x00000000; RCC->AHBENR = 0x00000014; //睡眠模式闪存和SRAM时钟使能.其他关闭. RCC->APB2ENR = 0x00000000; //外设时钟关闭. RCC->APB1ENR = 0x00000000; RCC->CR |= 0x00000001; //使能内部高速时钟HSION RCC->CFGR &= 0xF8FF0000; //复位SW[1:0],HPRE[3:0],PPRE1[2:0],PPRE2[2:0],ADCPRE[1:0],MCO[2:0] RCC->CR &= 0xFEF6FFFF; //复位HSEON,CSSON,PLLON RCC->CR &= 0xFFFBFFFF; //复位HSEBYP RCC->CFGR &= 0xFF80FFFF; //复位PLLSRC, PLLXTPRE, PLLMUL[3:0] and USBPRE RCC->CIR = 0x00000000; //关闭所有中断 //以上代码确保RCC复位,可省略
❖ Cortex-M3处理器支持的Thumb-2指令集基于精简指令集计 算机(RISC)原理设计,是16位Thumb指令集的一个超集, 同时支持16位和32位指令,指令集和相关译码机制较为简单, 在一定程度上降低了软件开发难度。
ARM指令集 (32位)
第3章 Thumb-2指令系统

功能描述
将8位立即数传到目标寄存器 将寄存器值传给低目标寄存器 寄存器值取反后传给目标寄存器
将12位立即数传送到寄存器中
将移位后的寄存器值传到寄存器 将16位立即数传送到寄存器的高 半字[31:16] 16位立即数传到寄存器的低半字 [15:0],将高半字[31:16]清零 读特殊功能寄存器SReg 写特殊功能寄存器SReg
LDR R2,[R3,#0x0C]
6、多寄存器寻址
多寄存器寻址一次可传送几个寄存器值,允许一条指令 传送16个寄存器的任何子集或所有寄存器。例:
LDMIA R1!,{R2-R4,R6} ;将R1指向单元中的数据存到 ;R2~R4、R6中(R1自动加4)
R6 0x0??4 R4 0x0??3 R3 0x0??2 R2 0x0??1 R1 0x400000010
存储器访问指令
LDR LDRH LDRB LDRSH LDRSB LDRD LDM<IA/FD
/DB/EA> STR STRH STRB STRD STM<IA/EA
1、数据传送指令
指令
MOV <Rd>, #<immed_8> MOV <Rd>, <Rn> MVN <Rd>, <Rm>
MOV{S}.W <Rd>, #<immed_12> MOV{S}.W <Rd>, <Rm>{,<shift>}
MOVT.W <Rd>, #<immed_16>
MOVW.W <Rd>, #<immed_16>
计算机组成原理第二版课后习题答案之欧阳史创编

第1章计算机系统概论1. 什么是计算机系统、计算机硬件和计算机软件?硬件和软件哪个更重要?解:计算机系统:由计算机硬件系统和软件系统组成的综合体。
计算机硬件:指计算机中的电子线路和物理装置。
计算机软件:计算机运行所需的法度及相关资料。
硬件和软件在计算机系统中相互依存,缺一不成,因此同样重要。
2. 如何理解计算机的条理结构?答:计算机硬件、系统软件和应用软件构成了计算机系统的三个条理结构。
(1)硬件系统是最内层的,它是整个计算机系统的基础和核心。
(2)系统软件在硬件之外,为用户提供一个基本操纵界面。
(3)应用软件在最外层,为用户提供解决具体问题的应用系统界面。
通常将硬件系统之外的其余层称为虚拟机。
各条理之间关系密切,上层是下层的扩展,下层是上层的基础,各条理的划分不是绝对的。
3. 说明高级语言、汇编语言和机器语言的不同及其联系。
答:机器语言是计算机硬件能够直接识另外语言,汇编语言是机器语言的符号暗示,高级语言是面向算法的语言。
高级语言编写的法度(源法度)处于最高层,必须翻译成汇编语言,再由汇编法度汇编成机器语言(目标法度)之后才干被执行。
4. 如何理解计算机组成和计算机体系结构?答:计算机体系结构是指那些能够被法度员所见到的计算机系统的属性,如指令系统、数据类型、寻址技术组成及I/O 机理等。
计算机组成是指如何实现计算机体系结构所体现的属性,包含对法度员透明的硬件细节,如组成计算机系统的各个功能部件的结构和功能,及相互连接办法等。
5. 冯•诺依曼计算机的特点是什么?解:冯•诺依曼计算机的特点是:P8●计算机由运算器、控制器、存储器、输入设备、输出设备五年夜部件组成;●指令和数据以同同等位置寄存于存储器内,并可以按地址拜访;●指令和数据均用二进制暗示;●指令由操纵码、地址码两年夜部分组成,操纵码用来暗示操纵的性质,地址码用来暗示操纵数在存储器中的位置;●指令在存储器中顺序寄存,通常自动顺序取出执行;●机器以运算器为中心(原始冯•诺依曼机)。
Get清风ARM指令集指南

ARM-指令集指南ARM 指令集指南.txt人永远不知道谁哪次不经意的跟你说了再见之后就真的再也不见了。
一分钟有多长?这要看你是蹲在厕所里面,还是等在厕所外面……ARM指令集2021-03-12 15:27跳转指令跳转指令用于实现程序流程的跳转,在ARM 程序中有如下两种方法可以实现程序流程的跳转:l 使用专门的跳转指令。
l 直接向程序计数器PC 写入跳转地址值。
通过向程序计数器PC写入跳转地址值,可以实现在4GB的地址空间中的任意跳转,在跳转之前结合使用“MOV LR, PC〞等类似指令,可以保存将来的返回地址值,从而实现在4GB连续的线性地址空间的子程序调用。
ARM指令集中的跳转指令可以完成从当前指令向前或向后的32MB的地址空间的跳转,包括以下4条指令:l B 跳转指令。
l BL 带返回的跳转指令。
l BLX 带返回和状态切换的跳转指令。
l BX 带状态切换的跳转指令。
(1) B指令B指令的格式为:B 目标地址B指令是最简单的跳转指令。
一旦遇到一个B指令, ARM处理器将立即跳转到给定的目标地址,从那里继续执行。
注意存储在跳转指令中的实际值是相对当前PC值的一个偏移量,而不是一个绝对地址,它的值由汇编器来计算(参考寻址方式中的相对寻址)。
它是24位有符号数,左移两位后有符号扩展为32位,表示的有效偏移为26位(前后32MB的地址空间)。
如下所示:B Label; 程序无条件跳转到标号Label 处执行CMP R1, #0; 当CPSR 存放器中的Z 条件码置位时, 程序跳转到标号Label 处执行BEQ Label(2) BL指令BL指令的格式为:BL 目标地址BL是另一个跳转指令,但跳转之前,会在存放器R14中保存PC的当前内容,因此,可以通过将R14的内容重新加载到PC中,来返回到跳转指令之后的那个指令处执行。
该指令是实现子程序调用的一个根本但常用的手段,如下所示:BL Label; 当程序无条件跳转到标号Label 处执行时, 同时将当前的PC 值保存到R14 中(3) BLX指令BLX指令的格式为:BLX 目标地址BLX指令从ARM指令集跳转到指令中所指定的目标地址,并将处理器的工作状态有ARM状态切换到Thumb状态,该指令同时将PC的当前内容保存到存放器R14中。
B45M E45说明书

B45M E45说明书处理器• 支持Socket 1150 架构的4th Generation Intel® Core™ i7 / Core™ i5 / Core™ i3 / Pentium® / Celeron® 处理器CPU 支持情况请查询 CPU 支持状态表,上述规格仅供参考。
芯片组• Intel® B5 芯片组内存• 支持4条DDR3 DIMM 1066/1333/1600 内存, 最高可支持达32GB 内存容量• 支持双通道模块• 支持non-ECC, un-buffered 内存• 支持 Intel® Extreme Memory Profile (XMP)插槽• 1 个PCIe 3.0 x16 插槽• 2 个PCIe 2.0 x1 插槽• 1 个PCI 插槽内建SATA• SATA III 控制器整合内建于 Intel® B5 芯片- 可达 6Gb/sec 传输速率- B5 芯片可链接 4 个 SATA III 装置(SATA1~4)• SATA II 控制器整合内建于 Intel®B5 芯片- 可达 3Gb/s传输速率- B5 芯片可链接 2 个 SATA II 装置 (SATA5~6)支持 Intel® 快速启动技术 (Intel® Rapid Start Technology)、Intel®智能联机技术 (Intel® Smart Connect Technology)** 系统需求为 Windows 7 或 Windows 操作系统以及 Intel Core 系列处理器USB• 4 个 USB 3.0 端口(2 个位于背板,2 个为内建)• 个 USB 2.0 端口(4 个位于背板,4 个为内建)内建音效• Chipset integrated by Realtek® ALC7- 7.1-声道高音质音效内建网络• 1 个 PCI Express 网络端口支持 10/100/1000 快速以太网络由 Realtek® 111G 提供内置输出/输入接口- 1 x ATX 24-Pin 电源接口- 1 x 4-pin ATX 12V 电源接口- 1 x 4-pin CPU 风扇接口- 1 x 4-pin 系统风扇电源接口- 1 x 3-pin 系统风扇电源接口- 4 x SATA 6Gb/s接口- 2 x SATA 3Gb/s 接口- 1 x 清除 CMOS 跳线- 2 x USB 2.0 接口- 1 x USB 3.0 接口- 1 x 串行端口接口- 1 x 并行端口接口- 1 x TPM 模块接口- 1 x 前置音效接口- 1 x 机壳开启警示切换接口背板后置输出/输入接口- 1 x PS/2 键盘接口- 1 x PS/2 鼠标接口- 4 x USB 2.0 接口- 2 x USB 3.0 接口- 1 x RJ45 网络接口- 1 x 3 合1 音效输出/输入接口- 1 x VGA 接口,最高分辨率达 1920x1200 @60Hz, 24bpp- 1 x DVI-D 接口,最高分辨率达 1920x1200 @60Hz, 24bpp- 1 x HDMI 接口,最高分辨率达 4096x2160 @24Hz, 24bpp/ 2560x1600 @60Hz, 24bpp/ 1920x100 @60Hz, 36bpp本支持双屏幕显示和三屏幕显示功能HDMI+VGA VGA+DVI-D DVI-D+HDMIHDMI+VGA+DVI-D 延伸模式(延展桌面至第二与第三屏幕) ◯◯◯◯共享模式(所有屏幕显示相同桌面) ◯◯◯◯BIOS• 此主板的 BIOS 提供即插即用功能, 能自动侦测板子上的外围设备和扩充卡• 此主板提供桌面管理接口(DMI)功能, 能记录你主板的规格。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
.W后缀指定32 位指令,使用“.N”指定16位指令。
如果没有给出后缀,汇编器会先试着用16 位指令以缩小代码体积,如果不 行再使用32 位指令。因此,使用“.N”其实是多此一举,不过汇编器可能仍然 允许这样的语法。
对于艺高胆大的玩家来说,使用以PC 为目的寄存器 的MOV 和LDR 指令也可以实现转移,并且往往能借此实 现很多常人想不到的绝活,常见形式有:
MOV PC, R0 ;转移地址由R0 给出 LDR PC, [R0] ;转移地址存储在R0 所指向的存储器中 POP {…,PC} ;把返回地址以弹出堆栈的风格送给PC,
BEQ.W label
这些条件组合还可以用在If‐Then 语句块中,比如:
CMP R0, R1
;比较R0,R1
ITTET GT
;If R0>R1 Then(T代表Then,E代表Else)
MOVGT R2, R0
MOVGT R3, R1
MOVLE R2, R0
MOVGT R3, R1
在CM3 中,下列指令可以更新PSR 中的标志: •������ 16 位算术逻辑指令 •������ 32 位带S 后缀的算术逻辑指令 •������ 比较指令(如,CMP/CMN)和测试指令(如TST/TEQ) •������ 直接写 PSR/APSR (MSR 指令)
LDR R0, =address1 ; R0= 0x4000
…
address1
0x4000: DCD 0x0
;0x4000 处记录的是一个数据
(2) ADR 指令则是“厚道人”,它决不会修改LSB。
例如: ADR r0, address1 ;R0=0x4000,没有“=”号
… address1 0x4000: MOV R0, R1
4)统一的汇编语言
为了最有力地支持Thumb-2,引了一个
“统一汇编语言(UAL)”语法机制
对于16 位指令和32 位指令均能实现的一些操作(常见于数据处理操作),有时虽然指令 的实际操作数不同,或者对立即数的长度有不同的限制,但是汇编器允许开发者以相同的语法 格式书写,并且由汇编器来决定是使用16 位指令,还是使用32 位指令。Thumb 的语法和 ARM的语法虽不同,但在有了UAL 之后,两者的书写格式就统一了。
当使用16 位加法时,会自动更新APSR 中的标志位。然而,在使用 了“.W”显式指定了32 位指令后,就可以通过“S”后缀手工控制对APSR 的更新,如:
ADD.W R0, R1, R2 ; 不更新标志位 ADDS.W R0, R1, R2 ; 更新标志位
3) 子程呼叫与无条件转移指令
最基本的无条件转移指令有两条:
ADR 将如实地加载0x4000。注意,语法略有不同,没有“=”号。
2) 数据处理指令
数据处理乃是处理器的看家本领,CM3 当然要出类拔萃,它提供了丰 富多彩的相关指令,每种指令的用法也是花样百出。限于篇幅,这里只列出 最常用的使用方式。就以加法为例,常见的有:
ADD R0, R1 ; R0 += R1 ADD R0, #0x12 ; R0 += 12 ADD.W R0, R1, R2 ; R0 = R1+R2 虽然助记符都是ADD,但是二进制机器码是不同的。
大多数16 位算术逻辑指令不由分说就会更新标志位 (不是所有,例如ADD.N Rd, Rn, Rm 是16 位指令,但不更新标志位——译 注),32 位的都可以让你使用S 后缀来控制。例如:
ADDS.W R0, R1, R2 ;使用32 位Thumb-2 指令,并更新标志 ADD.W R0, R1, R2 ;使用32 位Thumb-2 指令,但不更新标志位 ADD R0, R1 ;使用16 位Thumb 指令,无条件更新标志位 ADDS R0, #0xcd ;使用16 位Thumb 指令,无条件更新标志位
(APSR ) C
Thumb-2 寄存器集
R0 R1 R2 R3 R4 R5 R6 R7 R8 R9 R10 R11 R12 堆栈指针(R13) 连接寄存器(R14) 程序计数器(R15)
当前程序状态寄存器
(APSR )
C
3) 后缀的使用
在 ARM 处理器Thumb2 指令,可以带有后缀。
在 Cortex-M3 中,对条件后缀的使用有限制: 只有B转移指令和IF-THEN 指令块才可以使用条件码后缀。 S后缀可以和条件后缀一起使用。
LDMIA SP!, {R0-R3, PC} ;等效于 PUSH {R0-R3, PC}
; R8 值变为0x8010,每存一次曾一次,先存储后自增
STMIA.W R8!, {r0-R3}
; R8 值的“一个内部复本”先自减后存储,但是R8 的值不变
STMDB.W R8, {R0-R3}
LDR.W R0, [R1, #20]! ;预索引
STR.W R0, [R1], #-12 ;后索引
PUSH/POP 作为堆栈专用操作,也属于数据传送指令类。 通常PUSH/POP 对子的寄存器列表是一致的, 但是PC 与LR 的使用方式有所通融,如:
PUSH {R0-R3, LR} ;子程序入口
…
POP {R0-R3, PC} ;子程序出口
在这个例子中,旁路了LR,直截了当地返回。
(1)对于LDR,如果汇编器发现要产生立即数是一个程序地址,它会自动 地把LSB 置位,例如:
LDR r0, =address1 ; R0= 0x4000 | 1 … address1 0x4000: MOV R0, R1
在这个例子中,汇编器会·认出address1 是一个程序地址,所以自动置位 LSB。另一方面,如果汇编器发现要加载的是数据地址,则不会自作聪明,多机 灵啊!看:
16位指令MOV 支持8 位立即数加载,如:
MOV R0, #0x12
32位指令 MOVW 和 MOVT 可以支持16位立即数加载:
MOVW R0,#0xff00
32位立数加载
LDR R0,=0x88009000 ;等价于LDR R0,[PC,#lab]
LDR, r0, =0x12345678
LDR 和ADR 都有能力产生地址,但是语法和行为不同。
4.5.1 Thumb-2指令集使用“要点”
注:本节描述是ARM公司汇编器的语法,其它汇编器的可 能略有区别。
1)CM3 编程模型
2).Thumb寄存器与Thumb-2寄存器器集映射关系
Thumb 寄存器集
R0 R1 R2 R3 R4 R5 R6 R7
堆栈指针(SP) 连接寄存器(LR) 程序计数器(PC) 当前程序状态寄存器
通常,只有系统软件(如OS)才会操作这类寄存器,应 用程序,尤其是用C 编写的应用程序,是从来不关心这些 的。
立即数加载
程序写多了你就会感觉到,程序中会经常使用立即数。最典型的就是:当你要 访问某个地址时,你必须先把该地址加载到一个寄存器中,这就包含了一个32 位立 即数加载操作。
M3 中的MOV/MVN 指令族负责加载立即数,各个成员支持的立即数位数不同。
用于在寄存器间传送数据的指令是MOV。比如,如果 要把R3 的数据传送给R8,则写作:
MOV R8, R3 MOV 的一个衍生物是MVN,它把寄存器的内容取反后 再传送。
LDM/STM 如果Rd 是R13(即SP),则与POP/PUSH 指令等效。
STMDB SP!, {R0-R3, LR} ;等效于 PUSH {R0-R3, LR}
5) Thumb-2指令清单 见教材4.5节
4.6 Thumb2指令特色指令介绍
1)数据传送指令
处理器的基本功能之一就是数据传送。CM3 中的数据传送类 型包括 •������ 两个寄存器间传送数据 •������ 寄存器与存储器间传送数据 •������ 寄存器与特殊功能寄存器间传送数据 •������ 把一个立即数加载到寄存器
ADD R0, R1
; 使用传统的Thumb 语法, -> XPSR _ _ _ _
ADD R0, R0, R1 ; UAL 语法允许的等价写法(R0=R0+R1), .
;但翻译成32位宽指令不影响xPSR
.
ANDS R0, R0, R1 ;完全等价的UAL 语法(必须有S 后缀)
在Thumb-2 指令集中,有些操作既可以由16 位指令完成,也可以由32 位指 令完成。
B Label
;转移到Label 处对应的地址
BX reg ;转移到由寄存器reg 给出的地址
在BX 中,reg 的最低位指示出在转移后,将进入的 状态是ARM(LSB=0)还是Thumb(LSB=1)。既然CM3 只在 Thumb 中运行,就必须保证reg 的LSB=1,否则fault 伺 候。
呼叫子程序时,需要保存返回地址,正点的指令是:
BL Label ;转移到Label 处对应的地址,并且把转移前的下
条指令地址保存到LR
BLX reg ;转移到由寄存器reg 给出的地址,根据REG 的
LSB 切换处理器状态,
;并且把转移前的下条指令地址保存到LR
执行这些指令后,就把返回地址存储到LR(R14)中了,从而才能使 用”BX LR”等形式返回。使用BLX 要小心,因为它还带有改变状态的功能。因 此reg 的LSB 必须是1,以确保不会试图进入ARM 状态。如果忘记置位LSB,则 fault 伺候。
(1) 绝大多数情况下,程序是用C 写的,C 编译器也会尽
可能地使用短指令。
(2) 当立即数超出一定范围时,或者32 位指令能更好地适