websphere性能调优
WebSphere7部署、调试和调优

WebSphere 7.0 使用作者:李琳目录1 部署应用 (2)1.1 数据源配置 (2)1.1.1 配置JDBC提供程序 (2)1.1.2 配置JNDI数据源 (2)1.1.3 安全配置 (3)1.2 部署应用程序 (3)1.3 配置热部署(动态加载) (4)1.3.1 更新程序的动态加载 (4)1.3.2 服务器加载策略 (4)1.3.3 JSP加载策略 (4)2 在WebSphere7上调试应用程序 (5)2.1 设置Websphere为调试状态 (5)2.2 部署应用程序 (5)2.3 MyEclipse/Eclipse配置 (5)2.3.1 配置远程跟踪 (5)2.3.2 配置部署目录 (6)2.3.3 调试 (7)3 性能监视 (8)3.1 PMI设置 (8)3.2 TPV监控 (8)4 JVM的参数调节和监控 (9)4.1 JVM的参数调节 (9)4.2 JVM的运行监控 (10)5 线程池 (10)5.1 IBM HTTP Server (10)5.2 Web容器线程池 (11)5.2.1 Web容器线程池参数 (11)5.2.2 Web容器线程池监控 (11)5.3 数据库连接池的参数调节和监控 (11)5.3.1 数据库连接池的参数调节 (11)5.3.2 数据库连接池的运行监控 (12)6 设置Servlet高速缓存 (12)7 Web响应监控 (13)1部署应用1.1数据源配置数据源配置分为三步:1)配置JDBC提供程序2)配置JNDI数据源3)安全配置1.1.1配置JDBC提供程序配置JDBC提供程序,需要相应的JDBC驱动软件包。
如Oracle是ojdbc6.jar。
1)进入资源/JDBC/JDBC提供程序。
2)选择作用域3)选择新建一个提供程序。
4)选择正确的数据库类型Oracle。
5)选择提供程序类型为Oracle JDBC Driver。
6)选择实现类型为连接池数据源。
WebSphere配置文档(性能参数调优)
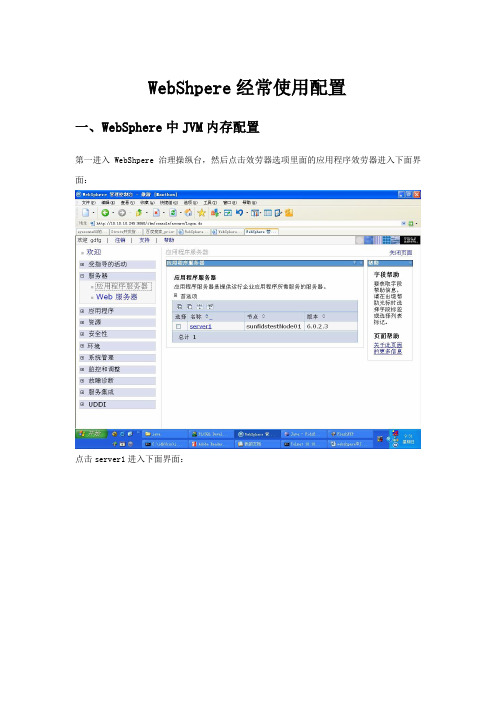
WebShpere经常使用配置一、W ebSphere中JVM内存配置第一进入WebShpere治理操纵台,然后点击效劳器选项里面的应用程序效劳器进入下面界面:点击server1进入下面界面:点击Java和进程治理里面的进程概念进入下面界面:点击Java虚拟机进入下面界面:在那个页面的下方有初始堆大小和最大堆大小两个参数是设置JVM内存大小,必然要把两个参数设置的一样大。
如图:二、W ebSphere中JVM内存监控利用说明进入WebSphere操纵台,点击监控和调整中性能查看器中的当前活动,如以下图所示:点击server1进入以下图界面:点击性能模块,选择里面的JVM运行中,会谈出询问你是不是安装SVG查看器,点击确信。
如以下图:确信后会显现以下图:用下拉条拖动到以下图所示的地址点击win98-XP下载文件,下载完毕后安装,然后点击查看模块按钮,就会显现以下图:如此就能够够监控内存的转变了。
三、关于WebContainer线程池大小进行调整为了知足多个客户端造成的大的客户端并发数量,关于WebContainer的线程池大小进行调整。
此线程池大小代表了WebSphere所能够保护的最大及最小同时响应并发客户端请求的线程数。
建议将WebContainer最大和最小大小都设为120。
不要选择具体调整方式为: > > > WebContainer 界面中调整。
(1)(2)(3)(4)四、W ebSphere的数据源配置第一进入WebShpere操纵台,点击环境选项下的WebShpere变量,如下图:在本页下方有个参数,如下图:点击进入后在值这一项中输入ORACLE_ JDBC驱动的途径, 如下图:点击确信按钮并保留配置。
然后成立连接池,点击左面导航栏里面的资源中的JDBC提供程序,如下图:在图的下方,点击新建按钮,进入添加页面,如下图:按实际情形进行选择,如下图:选择好后点击下一步,如下图:在本页下方有一个类途径,按真实情形填写,如下图:点击确信按钮并保留配置,就添加成功了,如下图:点击Oracle JDBC Driver后进入修改界面,如下图::在页面的右边,有个数据源选项,如下图::点击进入,如下图::点击新建按钮后,进入新建页面,如下图::然后把JNDI名称改成和应用的数据源的名称一样,把“将此数据源用于容器治理的持久化性(CMP)”那个选项去除掉,如下图::在那个页面的下方有一个Oracle数据源属性,把里面的URL依如实际情形配置一下,如下图:然后点击确认并保留配置,就添加成功了,如下图::然后点击Oracle JDBC Driver DataSource,进入修改界面,如下图::在页面的右面的相关项里面有个,点击进入,如下图:点击新建按钮,进入新建页面,如下图:依如实际情形填写,如下图:点击确信并保留,就添加成功了,如下图:然后退到Oracle JDBC Driver DataSource页面,如下图:在图的下方有个组件治理的认证别名,把你适才添加的认证选择上,如下图:然后点击确信并保留,如此就配置数据连接池就配置好了,能够点击页面上面的测试连接进行测试。
WebSphere参数调优

(1)选定应用程序服务器的 JVM 堆是否与同一机器上的其它应用程序服务器 JVM 堆共享物理内存。例如,您是以本地方式还是以远程方式运行监视器?
(2)指定 JVM 堆驻留在物理内存中并防止交换到磁盘。
(3)将起始 JVM 堆大小设置为最大 JVM 堆大小的 1/4。
(4)如果机器上只有一个应用程序服务器,则将最大 JVM 堆大小设置为以下值:
5、应用程序服务器 > server1 >进程定义 >Java 虚拟机->初始堆大小
Java 虚拟机(JVM)堆大小设置将影响 Java 对象的无用数据收集。堆设置过大,会占用过多的内存,使内存资源耗尽,从而会频繁的进行I/O操作来使用虚拟内存。堆设置过小,会使得对象可分配空间变小,从而会频繁的使用垃圾收集机制来释放内存空间,而每次垃圾收集,都会耗ueueConnectionFactory.createQueueConnection() 方法将等待“in use”连接变为可用。对于这种情况,该方法等待连接的最大等待时间是由连接池的连接超时属性指定的
9、资源 -> WebSphere JMS 提供程序->WebSphere 队列连接工厂->点击所创建的工厂->配置->会话池
二、具体参数设置
省略!
4、应用程序服务器 > server1 >Web 容器->定制属性
MaxKeepAliveConnections:表示系统同时保存的最大连接个数,超过这一个数时最近最少被使用的连接将被关闭, 整型,缺省值是:300;
MaxKeepAliveRequests:客户端请求被保持到一个请求队列,此属性用于决定请求队列可保持的最大客户端请求数,整型,缺省值是:100;
WebsphereJVM堆分析与优化

Websphere性能分析与优化——从Heapdump浅谈JVM堆设置不同版本的JDK可以设置的JVM堆大小是不一样的,而JVM堆的大小直接制约系统的性能,合理设置每个应用服务器中的JVM堆,在系统性能优化中是十分关键的一步。
一般来说,JVM堆可设置的大小受其版本限制,可分为以下两大类:1、32位的JDK,JVM堆最大可设置到1.5G左右2、64位的JDK,JVM堆大小暂无限制那我们该如何调整JVM的堆大小呢?在Was上如何去设定一个合理的值且多大的值才算是合理的呢?首先我们来了解下JVM堆大小对系统有哪些主要的影响,在JVM堆不足的情况下将会导致系统:1、频繁的垃圾回收(引发系统资源紧张情况,集群环境下CPU资源消耗就更严重)2、OOM,内存溢出(out of memory)系统繁忙时,一般都是在处理大量的客户端请求,或是在进行多个复杂的计算,它们都需要向JVM堆申请空间进行对象的创建。
在堆空间不足的情况下,应用系统会出现以下一些情况,从而大大降低客户的感知度:1、请求操作响应时间长2、请求操作失败,资源等待操作,内存溢出为了保证系统的性能,提高系统稳定性,我们就需要对JVM堆的详细使用情况刨根问底,以此估出一个合理的值来设置JVM堆大小。
有专家给出建议,Was每个Server的线程池不宜配置过大,一般建议值在50-120之间,而JVM堆则设置在2G内。
这个建议针对大部分系统都是适用的,如果在这个配置上系统运行还出现性能问题,可先从应用程序角度着手优化。
因为无论线程池的线程大小是多少,每个线程给系统带来的主要压力就是JVM堆资源的占用。
在32位的Java虚拟机上,JVM堆最大可设置到1.5G左右。
假设请求从客户端来到Was,Was从线程池中分配一个线程处理这个请求,同时从JVM堆空间申请相应的资源进行操作。
假设这是一个上传5MB的Excel的线程,那么在上传与处理这个Excel过程中,线程占用的JVM堆的资源会越来越多,甚至有可能需要向JVM堆申请超过30MB的空间(当然30MB的堆空间不是绝对,这与代码设计密切相关,如果到Excel上传过程中,还要进行分析,封装,持久化等操作)。
WebSphere的性能优化

五、隔离CMS系统,服务器优化从前面的介绍,大家应该记得,我们开始是固定CMS,分离其它应用,但遭遇失败。
现在是反过来,干脆把CMS系统赶出WAS平台。
说实话,项目经理做这个决定,我认为已经是鼓出很大勇气了。
当时我们想在一个备用AIX机上安装CMS产品测试,但最后还是没有做成:CMS这类文章发布系统很难安装,也不好测试,又没有liscence,而且还有一堆准备工作。
绝对没有著名的openCMS安装那么简单,当然功能远远比它复杂。
而且,我们当时也低估了后来的工作,总觉得问题好解决。
在很遥远的06年中期,CMS厂商在客户那边一台AIX的Tomcat上部署了一套CMS产品。
但当时客户执意要求将其跑在WAS上,也就是现在的情况。
最开始,客户还要求我们必须用WAS的集群(我们买的就是WAS 的ND版),无奈该CMS不支持。
要是集群,又是死伤一遍。
其实,现在想想,我们当时太被动,CMS这种东西,就供公司的几十个编辑用,一个普通Tomcat就完全够用。
而且,把它和面向公网的Internet应用混在一起,完全没有必要。
也许,被动是因为我的实力造成的。
我们决定背水一战时,已经做过周密的计划:某年某月某日晚上8:00......CMS产品负责人现场切换xx(我)负责WAS相关参数调整yy负责AIX参数。
zz负责应用的测试…..总之,该行动涉及到客户方、产品提供商、公司高层、项目组。
每个人都密切关注,不下20人。
每个人都守在电脑前,随时听候调遣,当天晚上,我们都没有准备回家睡觉,大家齐心协力。
真没想到,整个式切换工作,一个小时就顺利完成!第二天,客户编辑打开浏览器,她们一定想不到昨晚大家准备经历一场厮杀….系统持续平稳地运行了一周,然后是漫长的五一,我回湖北黄冈老家休息了八天。
回来时,一切依旧。
当天晚上,我们这边主要做了两项工作:1、JVM的Heap参数,共五个。
2、AIX的IO、Paging Space等共六个。
当然还有其他人的工作,譬如测试、监控。
websphere性能设置和日常维护

websphere性能设置和日常维护一、确认磁盘空间是否满足要求1、 WebSphere 应用服务器自身代码的占用空间。
这个空间一般在1G左右,在不同的系统平台上略有差异。
2、概要文件所占的空间。
WebSphere应用服务器V6.1创建的概要文件基本类型有3种,每个概要文件所占用的空间如下:应用程序服务器(Application Server):在WebSphere应用服务器安装没有选择安装样本程序时,这一概要文件所占磁盘空间约为200M;Deployment Manager:30M;定制概要文件(Custom,即node agent):10M。
3、如果要安装WEB服务器,则在WEB服务器所在服务器上要预留WEB服务器所占的磁盘空间。
IBM HTTP服务器一般占用110M左右的空间。
4、如果安装WEB服务器,则在WEB服务器所在机器上通常也要安装Web Server Plug-in组件,该组件所占磁盘空间约为200M。
5、 WebSphere 应用服务器系统日志的占用空间。
日志空间的估算要结合系统对日志的配置情况。
WebSphere应用服务器的主要日志有SystemOut.log,SystemErr.log。
我们可设置日志文件的大小和保存的历史日志文件数量,从而可以估算出其需要的空间。
6、如果有WEB服务器,需考虑WEB服务器的日志空间。
如果客户开启了WEB服务器的访问日志access.log(默认开启),此日志增长的速度极快,要预留足够的空间。
7、备份文件需要的空间。
WebSphere应用服务器提供了一个备份命令(backupConfig.bat/sh),用来备份应用服务器的配置及其上应用。
我们建议在系统稳定之后及时备份。
对于一个典型生产系统,WebSphere应用服务器这个配置文件经常超过100M。
可在发出backupConfig命令时,使用-logfile参数指定该备份文件的存放位置。
8、系统出错时日志,例如,JVM在发生OutOfMemory时,在大多数平台上WebSphere 应用服务器会默认写javacore文件和heapdump文件,记录错误出现时的JVM Heap、线程情况,以备错误诊断使用。
was8.5性能优化

WebSphere(was8.5)性能优化2018年8月10日整理目录1.WAS中的基本调优步骤 (3)2.WAS 性能差的几种表现及解决方法 (4)3.案例说明 (4)4.WAS配置优化概要 (5)4.1 服务线程池 (5)4.2 数据源连接池 (7)4.3 数据源语句高速缓存大小 (9)4.4 JVW堆参数设置 (11)4.5 设置会话管理 (13)4.6 WEB容器高速缓存开启 (14)4.6 调整JVW日志 (16)5.TPV 监控列表 (17)1.WAS中的基本调优步骤部署在WAS上的J2EE应用程序,其性能是由多个因素决定的。
例如网络、数据库、内存分配、WAS服务器的配置以及应用程序的设计。
对于一个标准的J2EE应用,一个请求到来时,往往需要经过多次转发:网络 > Web服务器Web容器 > EJB容器 > 数据库。
而每一次转发,都可能造成请求处理的瓶颈,使得应用程序整体性能下降。
如果我们把每一次转发的待处理资源都看成一个队列,如图3:待处理资源队列对于WAS调优,要记住的一个基本原则就是,使得在队列中等待的请求的数量最小化。
在实践中我们发现,为了达到这个目的,最有效的配置方式就是使得队列成为一个“漏斗”。
也就是说,越靠近客户端的队列,其容量越大,而后面的队列,其容量要略小于或等于前面的队列。
按照这个原则,调优的基本步骤如下:1.设置的是Web Server的最大并发用户:这个设置是在conf/httpd.conf这个文件里面配置的。
在Unix系统中,对应的属性是MaxClient;在Windows系统中,对应的属性是ThreadsPerChild。
2.设置Web Container的最大、最小并发用户:在管理控制台中点击应用程序服务器 > server1 > 线程池 >WebContainer,根据观察的性能情况和应用情况输入合适的最小、最大进程数。
利用负载均衡技术对WEBSPhere应用做优化

对于内部征管系统设计的解决方案应该提供无限的可扩展性和投资保护,对于用户而言可以灵活的扩大服务器群和服务器的数量,确保当前系统网络方案的所有投资都可以在未来得到最大限度的利用。
对于WebSphere系统平台的各个处理架构中,不可能只采用一台服务器解决所 有用户的访问请求。现在较为流行的网络结构配置为多台Web服务器通过可做应用负载均衡的负载均衡设备平均分配用户请求,以对最终用户提供服务。
2、WebSphere系统平台的可靠性提高:
随着电信的网路建设的不断扩容,系统用户的不断激增,如果只有单台的web服务器出现宕机或web服务停止等故障,容易造成服务器节点的单点故障。通过具有负载均衡能力的设备的使用,通过web服务器组的方式,能够保证和实现系统的冗余,同时通过两台负载均衡设备的使用,能够保证当一台服务器负载均衡设备出现问题,后台的web服务仍然能够通过另一台负载均衡设备正常工作,当正常情况时两台负载均衡设备同时工作,最大程度的保证了链路的畅通和用户投资,实现了365X24的不间断服务保障。
4、WebSphere系统平台的管理性提高:
对于Web应用来说,对服务器的维护经常需要对服务或者服务器进行重启工作,所以经常涉及到服务器的下线和上线的问题。系统应当有良好的机制保证服务器的维护工作不会对用户产生影响。这点通常是通过负载均衡设备来实现。
当服务器要重新投入到工作中时,或有新的服务器加入时,在负载均衡产品对该服务器设置为Warmup状态,负载均衡产品会在一定时间内从较少用户请求Session到最大用户请求分发给该服务器,保障系统的安全稳定运行。
利用负载均衡技术对WEBSPhere应用做优化
Websphere性能优化

Websphere性能优化Websphere性能优化页面静态方案通过IBM Http Server(下文称为IHS)静态页面分离技术与利用WebSpere Application Server(下文称为WAS)的动态高速缓存(Dynamic Cache)技术优化访问页面性能。
客户端访问静态页面无须与后端数据交互,减少了容器与数据源的压力,从而达到优化系统的性能。
IBM Http Server不但可以作为 WAS 的前一级 Http 请求队列的缓冲,减轻WAS的压力,还可以利用其静态页面分离方案减轻部分压力。
在系统的部署或者构建的时候,我们可以把一些非重要的静态页面放在IHS 中,当客户端发送请求访问该页面资源时,由IHS直接响应请求并将静态页面资源返回客户端,无须再经过WAS,从而达到减轻达到WAS 负担的目的。
除了IHS静态页面分离方案,另外还可以利用WAS的动态高速缓存技术,将J2EE应用中静态的(Html、Flash、Css、Js、Jpg、Gif图片等文件)和动态的(需要与数据库、Web Service等服务交互才能得到的数据)内容缓存到应用服务器的JVM中(如:Jsp、Servlet、*.do等请求)。
在访问相关被缓存的资源时,所有的相关输出都可以直接从JVM的内容中获得,而无须再与数据库、Web Service、静态文件等交互,从而有效地提高系统的性能。
IHS分离静态内容方案整个操作过程主要分3步完成n 关闭Was的File Serving Servlet服务n 重新生成插件(Plugin-cfg.xml)n 修改IHS配置文件并拷贝静态文件到指定的目录关闭Was的File Serving Servlet服务1) 在Was中部署的Web应用中分别找到2个在/WEB-INF/ 目录下面的 ibm-web-ext.xmi 文件。
参考路径:ØIBM/WebSphere/AppServer/profiles/节点/conf/cell/applications/应用包名/ deployments/应用包名/应用包名/WEB-INF/目录下ØIBM/WebSphere/AppServer/profiles/节点/应用安装部署目录/应用包名/应用包名/WEB-INF/目录下2) 打开 ibm-web-ext.xmi 文件,找到 fileServingEnabled 属性项,把它设为flase, 默认是ture。
WebSphere性能调优

WebSphere性能调优对于大多数开发者来讲,WebSphere并不陌生,但遇到性能瓶颈问题,往往束手无策。
根据本人多个项目的性能调优经验,现简要给出WebSphere性能调优的参考文档。
一、JVM的调整用IE打开websphere管理界面(http://server:9060/ibm/console),在管理界面上进入“服务器-》应用程序服务器-》server1-》Java 和进程管理-》进程定义-》Java虚拟机”下进行JVM的设置。
一般原则:最小堆和最大堆不要设置成一样的。
服务器为websphere专享的话,其最大堆应为物理内存的1/2以上,最小堆应为物理内存的1/4。
堆设置不应太大,否则会加长GC 时间,不利于系统回收内存。
如果系统出现“Out of memory”这样的错误,请选中“详细垃圾回收”选项,以便进行内存分析。
产生的Heap Dump文件一般在IBM/WebSphere/AppServer/profiles/下。
二、TCP传输通道调整根据websphere原理,TCP通道决定客户端连接服务器的数目。
在管理界面上进入“服务器-》应用程序服务器-》server1-》Web 容器设置-》Web 容器传输链-》WCInboundAdmin-》TCP传输通道”,可根据需要进行设置。
三、线程池调整线程池大小决定了有多少http请求被websphere响应。
在管理界面上进入“服务器-》应用程序服务器-》server1-》其他属性-》线程池-》WebContainer”下进行设置。
一般原则:线程池数可与并发用户数一致,同时要考虑CPU的承载能力。
一般情况下,每个CPU承载的线程池数不应超过50个,CPU利用率不超过80%。
当空线程数较少、CPU 利用率低时,可适当增加线程数。
四、连接池调整连接池的大小决定应用程序向后台数据库请求连接的大小。
选择“资源》JDBC》数据源”,确认作用域,然后选择某个数据源(本例采用Default Datasource),点击进入:点击“数据池属性”,进入如下图:参数调整原则:最大连接池数应小于线程池的最大值。
(2024年)WebSphere入门

利用WebSphere开发工具提高效率
01 02
使用WebSphere Studio
WebSphere Studio是IBM提供的一个集成开发环境( IDE),支持WebSphere应用的开发、调试和部署。开发 者可以利用其提供的可视化工具和向导,快速创建和配置 WebSphere应用。
集成其他开发工具
WebSphere Application Server 是一种功 能完善、开放的Web应用程序服务器,是 IBM电子商务应用框架的基石。
WebSphere Portal
WebSphere Portal提供了创建、部署和管 理企业级门户网站的完整解决方案。
WebSphere MQ
WebSphere Commerce
2024/3/26
启用GC日志分析
通过配置WebSphere的JVM参数,启用GC日志记录,并使用专业工具进行分析,以优化Java堆内存的 使用。
20
常见性能问题定位方法分享
分析线程堆栈
当系统出现性能问题时,可 以通过获取线程堆栈信息, 分析线程的状态和调用栈,
定位到具体的性能瓶颈。
监控数据库连接池
9字
确保系统满足WebSphere 的最低硬件要求,包括足够 的内存、磁盘空间和处理器 速度。
9字
确保已安装Java Development Kit(JDK) 的适当版本,并设置 JAVA_HOME环境变量。
2024/3/26
9字
检查操作系统版本是否与 WebSphere兼容,并安装 所需的补丁和更新。
数据库连接池的性能问题往 往会导致整个应用性能下降 ,因此需要监控连接池的使 用情况,包括连接数、等待
时间等。
WebSphere优化

WebSphere优化优化WebSphereWebSphere⾥的profile刚配完,⼀般默认的heapsize即Xms与Xmx值只有256mb,⽽IBM WAS是⼏个J2EE服务器中最吃内存的机器,在布署⼀些EAR应⽤时,如果你的EAR中使⽤的lib即jar files较多,加载时往往会超出256mb的限制,如果你的WAS在安装完后不进⾏适当的优化就⽤来布署应⽤,很快就会成死机状,然后在相应的profile的⽬录中会留下⼀堆的heapdump即内存out of memory并造成了was档机后留下的dump⽂件。
因此在装完WAS配完profile后,请先进⾏适当的优化。
修改系统打开⽂件数(windows系统忽略)如果你的机器为Linux/Unix,请:调整Linux/Unix系统允许打开的最⼤⽂件数,系统默认⼀般为1024。
我们可以执⾏ulimit -n可查看这个数值。
通过vi /etc/security/limits.conf加⼊以下两⾏:* soft nofile 300000* hard nofile 300000重新系统后通过ulimit -a可以查看结果优化数据库连接池更改Web容器线程池⼤⼩该参数在管理控制台⾥的“服务器→应⽤程序服务器→server1→线程池”的“WebContainer”中进⾏设置,将“最⼤⼤⼩”的默认值50改成40,“最⼩⼤⼩”的默认值10改成40。
逐⼀对每个成员做相应的修改。
不要勾选“允许线程分配超过最⼤线程⼤⼩”。
更改会话超时和启⽤servlet⾼速缓存该参数在管理控制台⾥的“服务器→应⽤程序服务器→server1→会话管理”的“会话超时”中进⾏设置,将默认的30改成15;在“服务器→应⽤程序服务器→server1→Web容器设置→Web容器”。
逐⼀对每个成员做相应的修改。
记得Web容器⾥勾选“启⽤servlet⾼速缓存”。
更改JVM参数即修改相应的heap size与添加⼀些JVM调优参数该参数在管理控制台⾥的“服务器→应⽤程序服务器→server1→进程定义→Java虚拟机”⾥定义注意:这边的通⽤JVM参数就是IBM的jvm优化参数了,因为这个是IBM JDK,和ORACLE-SUN的JDK不⼀样的。
WebSphere性能优化_线程池的设置

WebSphere性能优化:线程池的设置作者:hashei前言What is the Cause of the Performance Problem? 或者是How to Improve the Performance?这是我们在系统开发、部署过程中都会面对的问题,但是却很难回答。
从下面的这幅图就可以看到,一个系统的性能瓶颈(bottleneck),可能在网络、防火墙,也能在Http Server,Application Server,或者是数据库;系统中一个或者多个“短板”的存在,就能让系统无法达到设计时的目标,无法满足已经签在合同里的SLA……虽然性能问题牵涉到方方面面,但是本系列关注点在于中间件这一层。
希望能用合理的配置避免诸如OutOfMemory(某些情况下)、数据库连接不够的发生,同时能应用一些参数使系统在不优化代码的情况下有5%到100%的提升。
Websphere开发与应用社区()是面向中间件开发应用和系统架构设计人员的技术交流社区,主要服务对象以websphere家族产品的用言归正传池(Pool)是WebSphere中最常涉及的概念之一。
从网络、Web 服务器、Web 容器、EJB 容器,一直到数据源,每一个环节都线程池、连接池的影子。
要想恰当配置这些池的大小,首先要了解漏斗模型。
Websphere开发与应用社区()是面向中间件开发应用和系统架构设计人员的技术交流社区,主要服务对象以websphere家族产品的用通常,WebSphere应用中的一个请求到达服务器,到真正开始处理,要经过一系列的连接池。
广域网上可能有大量的并发用户同时访问Web服务器,Web服务器上同时活动(Active)的连接可能高达10000个。
但Web服务器到应用服务器(Web容器)的连接池大小可能只有200。
Web容器到EJB容器的连接池更小,可能是80。
然后,经过数据源(Data source)到数据库的连接最大可能只有25个。
WebSphere应用程序服务器集群部署和调优论文

浅析WebSphere应用程序服务器集群的部署和调优【摘要】本文通过对websphere集群实施过程的描述以及部分参数的调整,阐释了websphere应用程序服务器的系统架构,及其参数调整。
文中所部署的系统,上线后至本文完成,保持了7*24小时无故障运行,根据实际测试及用户反馈系统性能有了成倍的提高,充分显示了集群的高可用和扩展性。
【关键词】中间件;websphere集群;优化随着java技术的广泛应用,中间件平台逐渐成为应用系统的重要组成部分,进而对中间件系统的高可用和整体性能提出了很高的要求。
本文主要讨论新疆电信xx平台部署使用websphere应用程序服务器集群及其调优的经验。
一、业务挑战xx平台,应用程序a、b、c部署在单机环境,操作系统为 linux,中间件为websphere 6.1 应用程序服务器,随着业务开展,用户数不断增加,逐渐出现了页面打开缓慢,中间件频繁挂起的问题,影响用户使用业务,有必要进行软硬件升级并保证系统至少能达到99%的可用性。
二、系统部署方案的选择方案一是主机数量为3台,分别部署应用程序a、b、c到三台主机上,每台主机承载一个应用程序,一台主机发生故障不影响其他业务,但发生故障主机所承载业务失效。
不产生冗余,服务器mtbf60000小时无故障。
方案二是主机数量为4台,应用程序a、b、c部署到三台主机组成的websphere集群,一台主机发生故障不影响任何业务,出现故障后脱离集群,恢复后重新加入集群即可,另增加一台服务器作为部署管理器和http服务器。
有冗余产生,服务器mtbf180000小时无故障。
对比以上方案,方案2采用集群环境后,系统的高可用性有明显提高,且部署使用了独立的http服务器,隐蔽了系统的逻辑架构,相比websphere自带的http服务,ihs服务器更加健壮、安全。
三、规划系统架构主机iisp.dm 安装部署管理器(概要文件类型为deployment manager)、ihs(ibm http server);主机iisp.cust、iisp.rpt、iisp.ap分别安装应用程序服务器(概要文件类型为应用程序服务器)。
websphere性能优化的几个方法

websphere性能优化的几个方法1,更改http server的配置文件参数KeepAlive。
原因:这个值说明是否保持客户与HTTP SERVER的连接,如果设置为ON,则请求数到达MaxKeepAliveRequests设定值时请求将排队,导致响应变慢。
方法:打开ibm http server安装目录,打开文件夹conf,打开文件httpd.conf,查找KeepAlive值,改ON为OFF,其默认为ON2,更改http server的配置文件参数ThreadsPerChild值到更大数目,默认为50原因:服务器响应线程的数量方法:打开ibm http server安装目录,打开文件夹conf,打开文件httpd.conf,查找ThreadsPerChild值,默认为50,改到更大数目,视用户数多少而定,一般改到客户机数量的1.1倍,如200台,则设为2203,关闭http server日志纪录原因:http server的日志IO影响性能方法:打开ibm http server安装目录,打开文件夹conf,打开文件httpd.conf,查找CustomLog值,找到没有注释的那行(行的开头没有符号"#"),将那行用符号"#"注释掉,以关闭日志纪录,提高处理性能。
4,更改Websphere的服务器处理线程数原因:线程的数量影响同时并发的请求数量方法:打开管理控制台,依次打开目录树,服务器->server1->web容器->线程池,修改"最大大小"的值,默认是50,改到更大数目,具体视总用户数量和机器的配置而定,一般设置其等于或小于http server设置的MaxKeepAliveRequests的值。
在Windows和UNIX上配置和优化WebSphereMQ性能

在Windows和UNIX上配置和优化WebSphereMQ性能在Windows 和UNIX 上配置和优化WebSphere MQ 性能WebSphere MQ 队列管理器的缺省配置可很好地处理平均处理负载,但并没有针对性能进行优化。
本文将说明如何为在Windows、UNIX 或Linux 上运行的WebSphere MQ 队列管理器优化消息处理性能。
引言使用缺省属性创建的IBM? WebSphere? MQ 队列管理器配置为使用适当的内存和磁盘空间来提供全功能队列管理器。
不过,其中并没有针对性能进行优化,您可以进行一系列配置更改,以提高WebSphere MQ 的消息处理性能。
本文将说明如何对Windows?、UNIX? 或Linux? 上运行的WebSphere MQ 队列管理器进行这些优化工作。
优化选项包括:队列管理器日志队列管理器通道队列管理器侦听器队列缓冲区大小下表显示了哪个优化区域适用于哪种消息类型:应用于非持久消息应用于持久消息队列管理器日志N Y队列管理器通道Y Y队列管理器侦听器Y Y队列缓冲区大小Y Y队列管理器的一些优化更改必须在定义队列管理器之前实现,因此请在进行任何设置工作之前通读本文,否则可能就需要进行一些重复工作了。
此类更改在相关部分中标识。
建议:将优化应用到所连接的所有队列管理器,因为使用多个队列管理器的消息传递性能将依赖于所有这些队列管理器的性能。
您应该有一定Windows 和UNIX 上的WebSphere MQ 配置经验。
本文中,参数及其值的描述基于WebSphere MQ V6,使用了名为MyQueueManager的队列管理器。
请在注册表项名称和目录名称中使用您的队列管理器进行相应的替换。
在UNIX 和Linux 上配置WebSphere MQ 时,要使用相同的设置qm.ini 配置文件的方法。
UNIX 上所有对配置参数的引用也适用于Linux,不过本文将仅仅讨论在UNIX 上的情况。
WebSphere Enterprise Service Bus 中的大型对象最佳实践和调优

WebSphere Enterprise Service Bus 中的大型对象最佳实践和调优设计模式和调优Martin Ross, 性能分析师, IBM简介:确保在大型对象系统处理方面获得最优性能是中间件软件用户面临的一个常见问题。
通常,大于或等于1M 的对象被认为是“大型对象”,需要特别注意。
本文旨在提供在64 位生产环境中利用WebSphere Enterprise Service Bus (ESB) V7 产品高效处理大型对象的一些必要信息和建议。
标记本文!发布日期: 2011 年12 月01 日级别:中级原创语言:英文简介确保在大型对象系统处理方面获得最优性能是中间件软件用户面临的一个常见问题。
通常,大于或等于1M 的对象被认为是“大型对象”,需要特别注意。
本文旨在提供在64 位生产环境中利用WebSphere Enterprise Service Bus (ESB) V7 产品高效处理大型对象的一些必要信息和建议。
回页首注意事项和影响因素本节提供关于处理大型对象时的主要注意事项和影响因素的信息。
JVM 限制64 位架构的主要优势在于内存管理和可访问性。
增加的数据总线带宽实现了对32 位架构上通常可用的4GB 以上可寻址内存空间的支持。
尽管Java 堆的大小限制取决于操作系统,但32 位JVM 拥有1.4GB 左右的限制并不少见。
64 位架构提供的增加的内存支持减轻了对Java 堆大小的约束,在大型对象上执行操作时,这种约束可能成为32 位系统上的一个限制因素。
一般来说,应该总是使用64 位JVM 来服务大型对象。
内存中BO 的大小应该注意,内存中业务对象(BO) 的大小可能比线路上可用的表示要大得多。
可能的原因有几个,最主要的有特征编码差别、消息流通过系统时所做的修改、事务处理过程中用于支持错误处理和回滚的BO 副本。
并发对象的数量可实现的响应时间通常与正在处理的并发对象的数量成反比,尽管现代SMP 硬件正在一定程度上帮助缓解这些限制。
IBM WebSphere Application Server for z OS 线程调优考虑因素

WebSphere Application Server for z/OS Understanding WAS z/OS Thread TuningConsiderationsVersion Date: May 30, 2013See "Document Change History" on page 10 for a descriptionof the changes in this version of the documentIBM Advanced Technical SkillsGaithersburg, MDTD106098 at/support/techdocs© IBM Corporation 2013Table of Contents Overview (4)WAS z/OS Thread Tuning Considerations (5)1 Controller Region (5)2 z/OS WLM Work Queue (5)3 Dispatch Threads in the Servant Region (5)4 Number of Processors (6)5 Nature of the Application (6)6 Maximum Open Connections (7)7 Multiple Servants (7)8 Front-end HTTP Handling (7)Overall Conclusion (9)Document Change History (10)OverviewWe often are asked about the relationship between HTTP clients and thread tuning on WAS z/OS.This question usually comes up in the context of trying to address a performance issue. And the question is often phrased in the form of "How do I add more threads to a WAS z/OS server?"The short answer is "Adding more threads may not be the answer. The thread model for WAS z/OS is different than on WAS for the distributed platforms."The reason it is different is because WAS z/OS has a "multi-JVM" model1 (separate control region and servant region) with z/OS WLM between the Controller and the Servant. This makes the receipt of inbound HTTP asynchronous from the dispatch to the execution threads.This short document will provide a technical overview of the WAS z/OS thread environment and how to approach tuning with respect to threads.The following picture is used as a guide to the discussion that follows:1For more detail on the "multi-JVM" model, see WP101740 at /support/techdocsWAS z/OS Thread Tuning Considerations1 Controller RegionThis hosts the HTTP listener ports. The Controller Region (CR) has a thread pool related toinitial handling of the inbound request, but it unrelated to the dispatch threads.When a request is received the CR dispatches the request to a thread in the CR and it veryquickly handles the request and places it on the z/OS WLM queue. The CR thread is then free to handle the next request.Note:The CR uses the authorized ASYNC I/O interface to z/OS TCPIP. This allows the CR threads to handle I/O requests very efficiently for HTTP and IIOP requests. This is what allows us to have arelatively small number of threads handle a large number of requests and a large number ofconnections.We have seen WebSphere control regions with over 40,000 long lived (many hours long) SSLconnections. One benchmark test validated the ability to have 125,000 concurrent socketsconnected to one CR.Work placed on the z/OS WLM work queue will get dispatched to a thread in the SR (see notes2 and 3). If no thread is available the work remains queued in WLM.The threads in the CR are unrelated to the dispatch threads in the Servant Region because of the z/OS WLM work queue. That makes request handling in the CR asynchronous from request handling in the SR.Key Point:Do not confuse CR threads with SR dispatch threads because they are not the same thing.We have very rarely seen cases where the CR thread pool needed increasing. The defaultvalue of 25 threads in the CR has proved more than enough in nearly every case we've seen.2 z/OS WLM Work QueueThis provides the decoupling of the request received in the CR from the dispatch to the ORBthread in the servant region. This is what makes the received request asynchronous fromdispatch to worker thread.This is exclusive to WAS z/OS. This is what makes managing thread pools different than ondistributed WAS. Requests that can not be immediately handled by a thread in the application JVM are "parked" here until a dispatch thread opens up to take the work. The depth of theWLM work queues dynamically expand and contract to handle temporary work spikes.More than one WLM work queue exists between the CR and the SR, but that level of detail isoutside the scope of this discussion. If you wish to know more, see WP101740 at/support/techdocs.3 Dispatch Threads in the Servant RegionThese are the threads on which the request is dispatched and the work is processed.The number of dispatch threads a Servant Region has a function of what's defined for the "z/OS Workload Profile," which is found under the server's "ORB service" and then "z/OS additionalsettings".Four pre-defined profiles are provided, and starting with V7 a profile of "Custom" that allows you to specify the number of threads.•ISOLATE = 1 thread for the servant region•IOBOUND = 3 times the number of processors22There's a bit more math involved. Three times the number of processors is a good rule of thumb. In reality it is "3X CPU" or "5", whichever is the bigger number; and if that number is larger than 30, then 30 is the operative number of threads.•CPUBOUND = the number of processors3•LONGWAIT = 40 threads•CUSTOM = based on the value provided for the "servant_region_custom_thread_count"environment variable4Key Point:More threads is not necessarily better. It depends on the number of processors (note 4 ) and the nature of the application (note 5 )4 Number of ProcessorsThe maximum number of threads that can be dispatched to CPU at the same time is equal tothe number of processors.For example, that's why the "CPUBOUND" profile limited threads to the number of processors.If the nature of the application called for intensive CPU-bound processing, then having morethreads does no good -- if all the processors are occupied with CPU-bound work, additionalthreads will simply wait.Key Point:With distributed WAS additional threads are used to "park" excess work, but on WAS z/OS that is not needed. WAS z/OS has the WLM work queues which is where excess work is"parked." When a thread opens in the servant region, WLM dispatches the work from thequeue to the thread.The "IOBOUND" profile was intended for applications that make calls elsewhere (to CICS, DB2, or a call to another JVM). Once the call is made the thread is freed from the CPU. But the work unit is not yet done, so the thread is still occupied. It's just not using the CPU. Therefore, more threads are needed than processors.Is 3X the appropriate number? It depends on the nature of the application and how long theapplication on average spends waiting for the I/O to complete. The 3X number was determined to be a good number on average for the fixed profile "IOBOUND."If the applications have longer wait times then the "LONGWAIT" profile may be moreappropriate. That provides a fixed value of 40 threads.Finally, the "CUSTOM" value allows you to set up to 500 threads5 if running in 64-bit mode.Key Points:•More is not necessarily better. It is a relationship between the number of processorsand the proportion of time the request spends on the CPU vs. waiting for an I/O call tocomplete.•Requests that arrive in excess of what the servant region can handle are queued inWLM. They are only dispatched to the servant when a thread in the servant frees totake work.5 Nature of the ApplicationIt is very important to understand what the application is doing, and in particular what portion of the time on the servant thread is spent on the CPU vs. waiting for some a request to somebackend process to complete.This understanding can be arrived at by understanding the application design, or by taking Java Core dumps at periodic intervals and using available tools to evaluate the state of the threads across the intervals.Applications that spend the majority of their time in CPU without doing any other calls suggest more of a CPU-bound model. There is no good reason to have more threads than processors because when all processors are occupied the other threads will do unproductive waiting forCPU.3In reality it is "Number of CPUs minus 1" or "3", whichever is the bigger number.4The default is 40 threads; the maximum you may specify is 100 if the server is in 31-bit mode, 500 if in 64-bit mode.5 A very large number we do not expect many -- if any -- to actually use or need.Applications that spend a minority of time in CPU relative to time waiting on a response to some I/O call suggest more of a IOBOUND or LONGWAIT model. Here is makes some sense to have more threads than processors because it allows more concurrent requests to begin the request processing and then wait for the I/O response to come back.But configuring more threads does not necessarily mean more work accomplished -- depending on the overall architecture design is is very possible to have too many requests to backend systems going at once. If the backend data system is overwhelmed, then more waiting threads in the WAS servant region does nothing to improve throughput. The answer in that case is better tuning of the backend systems that are overwhelmed.Key Point:Over-configuring dispatch threads in the WAS servant when the inhibitor is really the backend I/O systems may lead to dispatch or transaction timeouts caused by threadswaiting too long for the response.Timeouts that occur after dispatch to the servant threads incurs more overhead thantimeouts that occur closer to the client.It is far better to reject clients from entering an overloaded system than to accept them andtime them out when dispatched and in the middle of executing the request transaction.6 Maximum Open ConnectionsThis is merely the number of open TCP connections permitted on this TCP channel for this server.It is not directly related to the number of dispatch threads in the servant.How many is needed is a function of the number of clients facing the server and the nature of average connection. It is also influenced by the nature of any front-end devices (note 8 ) the clients pass through.Clients that make very short-lived connections intermittently may not require any change to the default value of 20,000.Clients that make a connection and hold onto it for a long time may require a change to this.If client TCP connections are terminated at some front-end device, and a fewer number of long-lived connections are created from front-end device to WAS z/OS server, then the defaultnumber if likely sufficient.7 Multiple ServantsIt is possible to configure WAS z/OS to host multiple servant regions behind the controllerregion.Going from one servant to two servants doubles the configured dispatch threads available. But it does not double the number of processors on the LPAR, nor does it double the capacity of any backend systems the application will call. So increasing the number of servants does not necessarily increase the throughput. It can increase the throughput based on the capacity of other components of the system, but it does not by itself increase throughput.Multiple servant regions provides two key advantages1.Higher availability ... separate JVMs in separate address spaces with automatic WLMrestart of failed regions2.Increased total heap as each servant has its own configured JVM heap to hold objectscreated by the application.Key Point:Increasing the number of servant regions will not necessarily increase throughput. It is better to have a good understanding of why you wish to increase servant regions before youdo so. Make sure you have the system capacity to support the additional memoryrequirements, and make sure the backend systems being called are capable of handling theadditional work that results.8 Front-end HTTP HandlingThe existence of front-end HTTP handling functions (such as HTTP Servers running the WAS Plugin, or the Proxy Server, or DataPower devices, or other solutions) can have a bearing on some of these tuning properties:•If they are used to spray requests across a WAS z/OS cluster then the total clients end up being split across cluster members. The number of clients presenting themselves toany given cluster member is a fraction of of the total.•They can be used to terminate the TCP (and possibly even the SSL) connection from the client and present fewer and more long-lived connections back to the WAS z/OSserver•They can be used to serve content from the edge, thus removing work from the WAS z/OS server that might otherwise occupy threads to serve up static content •They can be used to pre-process security function or pre-process XML validation, thus removing some portion of error handling work from the WAS z/OS servers But it's important to keep in mind that the rules we spelled out before still apply for that work which is presented to the CR from the front-end device. Or said another way, if the request flows from the front-end device and is received by the CR, then everything we've said to this point still applies.Overall ConclusionHere we offer a bullet summary of the points made earlier in the document:•The threads in the CR are not related to the dispatch threads in the servant region.•The CR very quickly handles requests and queues to the WLM work queue. The CR threads pool is almost never the bottleneck.•The WLM work queue is what provides the asynchronous de-coupling between receipt of request by CR and the dispatch of work to the worker thread in the servant region.•Work in the WLM work queue is never dispatched to a servant until a thread in the servant is free to take it. WAS z/OS works on a "pull" model rather than a "push."•Temporary periods where requests exceed ability to process results in an expansion of the WLM work queue.•As servant region(s) are able to pull the work and process the WLM work queue depth decreases.•The WLM work queue is what provides a place to "park" work that has no place to be executed. configuring extra threads to "park" excess work is not needed with WAS z/OS.•There is a balance to be achieved between the number of dispatch threads in the servant, the number of CPUs in the LPAR and the nature of the application. More threads is notnecessarily better.•There is a balance to be achieved between the number of requests handled by WAS servant threads and the ability of backend systems to handle the calls from those threads.Adding more threads to the WAS z/OS applications making calls to an overloaded DB2 orCICS environment does not increase throughput.•If client requests exceed the ability of the overall system to handle the work, then it is better to reject the client request as close to the client as possible. Configuring more threads inWAS has the potential of (a) creating more overhead handling the request further into thearchitecture, and (b) incurring more overhead handling the errors that result from requestand transaction timeouts that may occur if a request is started but can not be completed.Document Change HistoryCheck the date in the footer of the document for the version of the document.April 18, 2013Original documentApril 24, 2013Updated threads possible with CUSTOM workload profile. Original document indicated 100, but the actual value when in 64-bit mode is 500.May 30, 2013Added a footnote to the IOBOUND and CPUBOUND workload profile descriptions.The number of threads for each described in this document is a bit of anoversimplification. A bit more insight into the actual math used was provided.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.设置Web Container的最大、最小并发用户
在管理控制台中点击应用程序服务器> server1 > 线程池>WebContainer,根据观察的性能情况和应用情况输入合适的最小、最大进程数。
如将最大进程数改为:400,如下图:
2.对象请求代理(ORB)的线程池大小:
在管理控制台中点击应用程序服务器> server1 > ORB 服务> 线程池,根据观察的性能情况和应用情况输入合适的最小、最大进程数。
如将最大进程数改为:100,如下图所示
3.JVM 堆参数设置的性能调优
应用程序服务器 > server1 > 进程定义 > Java 虚拟机,根据硬件物理内存和应用情况输入合适的初始堆大小、最大堆大小。
如将初始堆大小改为768、最大堆大小改为2048。
2048为最大值,如下图所示:
4.设置数据库的连接池属性:
JDBC 提供者 >数据库JDBC 驱动名称 > 数据源 > 数据源名称> 连接池,根据观察的性能情况和应用情况输入合适的最小、最大连接数。
分别更改uissdbpool 、uissdbpoolgw 连接池的属性,如下图所示:
5.ORB 参数调用方式的性能调优:
应用程序服务器 > server1 > ORB 服务>选中按引用传递。
如下图所示;。