正则表达式1
01到20的正则表达式

01到20的正则表达式
摘要:
1.正则表达式的概念
2.01 到20 的正则表达式的规则
3.01 到20 的正则表达式的应用
正文:
正则表达式是一种用于匹配字符串模式的字符集,通常用于文本搜索和数据提取工具中。
在计算机科学中,正则表达式通常被用来检查一个字符串是否符合某种模式。
01 到20 的正则表达式,是指匹配0 到20 之间的任意数字的正则表达式。
01 到20 的正则表达式的规则,通常可以写作d{1,20},其中d表示匹配任意一个数字,{1,20}表示匹配的字符数量在1 到20 之间。
这个正则表达式可以匹配0 到20 之间的任意数字,无论是一位数、两位数还是三位数。
01 到20 的正则表达式的应用非常广泛,例如在文本搜索中,可以用来查找文本中出现的0 到20 之间的数字。
在数据提取中,可以用来提取数据中的0 到20 之间的数字。
在编程中,可以用来检查用户输入的数字是否在0 到20 之间。
语料库检索之正则表达式

语料库检索之正则表达式 之一
时态语态 一般现在时 be动词的一般现在时 \w{1,}_VB(M|Z|R) \w{1,}_[^V][^VD][^NG] 上面这个搜出的例子少。 下面这个搜出的例子多。实际应用时,尽量使用下面这个表达式。 \w{1,}_VB(M|Z|R) \w{1,}_[^V]* 实义动词的一般现在时 \w{1,}_VV(Z|I|0) 这两个正则表达式尽可能别采用并列的方式合并,那样检索出的结果没有分别采用这两个不同的表达式检索出来的结果多。 合并之后的表达式 \w{1,}_VV(Z|I|0) |\w{1,}_VB(M|Z|R) \w{1,}_[^V]* \w{1,}_VV[ZI0] |\w{1,}_VB[MZR] \w{1,}_[^V]* \w{1,}_VV[ZI0] |\w{1,}_VB[MZR] \w{1,}_[^V]\w+ 上面三个表达式效果类似。
ห้องสมุดไป่ตู้
整数或小数正则表达式

整数或小数正则表达式
在编程中,经常需要使用正则表达式来匹配数字,尤其是整数和小数。
以下是一些常用的正则表达式:
1. 匹配整数:
^[1-9]d*$
解析:^ 表示开头,[1-9] 表示第一个数字不能为0,d* 表示0个或多个数字,$ 表示结尾。
例如,123、456、789 这些都是符合要求的整数。
2. 匹配负整数:
^-[1-9]d*$
解析:与匹配整数相同,只是在开头加了一个负号。
例如,-123、-456、-789 这些都是符合要求的负整数。
3. 匹配小数:
^[1-9]d*.d+|0.d*[1-9]d*$
解析:^ 表示开头,[1-9]d* 表示整数部分为1-9开头的数字,.d+ 表示小数点后面至少有一位数字,| 表示或者,0.d*[1-9]d* 表示小数点前面为0,小数点后面至少有一位数字,$ 表示结尾。
例如,3.14、0.5、123.456 这些都是符合要求的小数。
4. 匹配负小数:
^-([1-9]d*.d+|0.d*[1-9]d*)$
解析:与匹配小数相同,只是在整个正则表达式开头和结尾加了一个负号,表示匹配负数。
例如,-3.14、-0.5、-123.456 这些都是符合要求的负小数。
以上是一些常用的正则表达式,可以方便地匹配整数和小数。
在实际编程中,可以根据需要进行调整和扩展。
php正则表达式1

ห้องสมุดไป่ตู้ \W : 表示任意一个非字, 除了a-zA-Z0-9_以外的任意一个字符 [^a-zA-Z0-9_]
4. 自己定义一个原子表[], 可以匹配方括号中的任何一个原子
[a-z5-8]
}else{
echo "<font color='red'>正则表达式{$pattern} 和字符串 {$string} 匹配失败</font>";
}
除了字母、数字和正斜线\ 以外的任何字符都可以为定界符号
| |
/ /
{ }
! !
没有特殊需要,我们都使用正斜线作为正则表达式的定界符号
2. 原子 img \s .
注意:原子是正则表达式的最基本组成单位,而且必须至少要包含一个原子
POSIX 扩展正则表达式函数(ereg_)
Perl 兼容正则表达式函数(preg_)
这个函数功能一样, 找一个处理字符串效率高的
注意:推荐使用Perl 兼容正则表达式函数库(只学这一种)
学习正则表达式时,有两方面需要学习:
一、正则表达式的模式如何编写
语法:
1. 定界符号 //
"/\<img\s*src=\".*?\"\/\>/"
一、正则表达式也是一个字符串
二、由具有特殊意义的字符组成的字符串
三、具有一点编写规则,也是一种模式
四、看作是一种编程语言(是用一些特殊字符,按规则编写出一个字符串,形成一种模式---正则表达式)
[^a-z] 表示取反, 就是除了原子表中的原子,都可以表示(^必须在[]内的第一个字符处出现)
01到20的正则表达式

01到20的正则表达式摘要:1.正则表达式的概念2.01到20的正则表达式介绍3.正则表达式的应用场景4.正则表达式编写规则5.总结正文:正则表达式(Regular Expression),又称规则表达式、常规表达式,是一种用于匹配字符串模式的文本字符串。
在计算机科学中,正则表达式通常用于文本搜索和数据提取工具中,可以快速找到符合特定规则的文本。
在本文中,我们将重点介绍如何用正则表达式表示01到20的数字。
首先,我们需要了解正则表达式的基本语法和规则。
正则表达式由一系列字符和元字符组成,用于描述字符串的模式。
常见的元字符有:.(匹配任意字符)、*(匹配前面的字符0次或多次)、+(匹配前面的字符1次或多次)、?(匹配前面的字符0次或1次)、{n}(匹配前面的字符n次)、{n,}(匹配前面的字符n 次或多次)、{n,m}(匹配前面的字符n到m次)。
对于表示01到20的数字,我们可以使用以下正则表达式:```^(0[1-9]|1[0-9]|20)$```解释如下:- `^` 表示字符串的开始- `(0[1-9]|1[0-9]|20)` 表示匹配01到20的数字,其中:- `0[1-9]` 匹配以0开头的1到9的数字- `1[0-9]` 匹配以1开头的10到19的数字- `20` 匹配数字20- `$` 表示字符串的结束正则表达式在许多编程语言和工具中都有广泛应用,例如Python、Java、JavaScript等。
除了本文提到的表示01到20的数字,正则表达式还可以用于匹配电子邮件地址、电话号码、日期等多种场景。
熟练掌握正则表达式对于编程和文本处理工作非常有帮助。
总之,正则表达式是一种强大的文本处理工具,通过灵活组合字符和元字符,可以快速找到符合特定规则的字符串。
java 1到10的正则表达式

java 1到10的正则表达式正则表达式(Regular Expression)是描述一组字符串结构的规则,它可以用来匹配、搜索、替换字符串。
在编程中,正则表达式是一种强大的工具,可以帮助我们快速有效地处理字符串。
本文将以“java 1到10的正则表达式”为主题,一步一步回答,并讨论如何利用正则表达式在Java中匹配1到10的数字。
首先,让我们深入了解正则表达式的基本概念。
正则表达式是由普通字符(例如字母、数字)和特殊字符(例如字符类、量词)组成的模式。
它可以用来定义我们要匹配的字符串规则。
在Java中,我们使用java.util.regex包提供的正则表达式类来处理正则表达式。
主要的类包括Pattern和Matcher。
Pattern类用于定义正则表达式,而Matcher类则用于在给定输入中进行匹配操作。
我们想要匹配1到10的数字,首先需要了解数字的特点。
数字是0到9之间的字符,我们可以使用字符类来表示这个范围。
在正则表达式中,字符类使用方括号[ ]来定义,将要匹配的字符放在方括号内。
因此,我们可以使用字符类[1-9]来表示从1到9的数字。
那么如何匹配数字10呢?由于数字10由两个字符组成,我们可以使用量词来表示多个字符的匹配。
在正则表达式中,量词用于指定前面字符/字符类的匹配次数。
常见的量词包括*(匹配0次或多次)、+(匹配1次或多次)和?(匹配0次或1次)。
在本例中,我们可以使用量词{1}来表示数字1的匹配次数,然后再跟上数字0。
因此,我们可以将[1-9]{1}0表示为数字10的匹配。
然而,以上的正则表达式仍然无法匹配数字0。
为了完整地表示1到10的数字,我们可以使用管道符号来将两个正则表达式组合在一起。
在正则表达式中,管道符号用于分隔多个可选模式,只要其中之一匹配成功即可。
因此,我们将[1-9]{1}0和0组合起来,得到完整的正则表达式:[1-9]{1}0 0。
接下来,让我们在Java中使用这个正则表达式来匹配字符串。
正则表达式(一)基本表达式
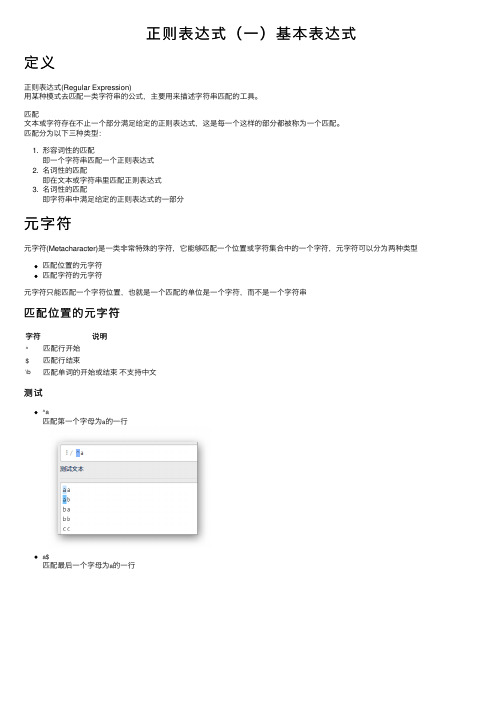
正则表达式(⼀)基本表达式定义正则表达式(Regular Expression)⽤某种模式去匹配⼀类字符串的公式,主要⽤来描述字符串匹配的⼯具。
匹配⽂本或字符存在不⽌⼀个部分满⾜给定的正则表达式,这是每⼀个这样的部分都被称为⼀个匹配。
匹配分为以下三种类型:1. 形容词性的匹配即⼀个字符串匹配⼀个正则表达式2. 名词性的匹配即在⽂本或字符串⾥匹配正则表达式3. 名词性的匹配即字符串中满⾜给定的正则表达式的⼀部分元字符元字符(Metacharacter)是⼀类⾮常特殊的字符,它能够匹配⼀个位置或字符集合中的⼀个字符,元字符可以分为两种类型匹配位置的元字符匹配字符的元字符元字符只能匹配⼀个字符位置,也就是⼀个匹配的单位是⼀个字符,⽽不是⼀个字符串匹配位置的元字符字符说明^匹配⾏开始$匹配⾏结束\b匹配单词的开始或结束不⽀持中⽂测试^a匹配第⼀个字母为a的⼀⾏a$匹配最后⼀个字母为a的⼀⾏^a$匹配只有⼀个字母a的⼀⾏\bStr匹配以Str为开头的单词ing\b匹配以ing为结尾的单词\bString\b仅匹配String这个单词\b字符如何识别哪个是单词呢?以标点符号或空格分隔的字符串将被识别为单词,⽽且\b只能⽤于英⽂,不能⽤于中⽂匹配字符的元字符元字符都是按照单个字符进⾏匹配字符说明. (点号)匹配除换⾏符之外的任意字符\w匹配任意单词字符(字母,数字,下划线)\W匹配任意⾮单词字符\s匹配任意空⽩字符(空格,制表符,换⾏符,中⽂全⾓空格)\S匹配任意⾮空⽩字符\d匹配任意数字 0~9的任意⼀个数字\D匹配任意⾮数字测试.全部字符匹配\w匹配了全部的单词字符,除了下划线之外的标点符号和汉字都被排除在外\W匹配结果和\w刚好相反,注意那个下划线是属于单词字符的\s有2个空格被匹配,注意!这⾥总共有6个符号被匹配了,除了两个空格还有1~4⾏末的换⾏符\S除了2个空格和4个换⾏符,其余字符全部匹配\d匹配所有的数字\D匹配所有数字之外的字符元字符组合仅仅是元字符就可以⾃由组合来实现不同的匹配效果\w\w匹配连续的两个单词字符\w\s注意第三⾏最后匹配的m是和⾏末的换⾏符⼀起匹配成功的⽂字匹配字符类字符类是⼀个字符集合,如果该字符集合中的任何⼀个字符被匹配,则它会找到该匹配项。
js0到1的正则表达式

您可以使用以下正则表达式来匹配字符串中的"0"到"1"之间的任意数字:
```regex
[0-1]
```
这个正则表达式表示匹配单个字符,该字符在"0"和"1"之间。
如果您想匹配一个或多个连续的数字,可以使用以下正则表达式:
```regex
[0-1]+
```
这个正则表达式表示匹配一个或多个连续的字符,每个字符都在"0"和"1"之间。
请注意,这些正则表达式仅适用于匹配单个字符或一系列连续字符。
如果您需要匹配更复杂的模式或字符串,请提供更多详细信息,以便我可以提供更准确的帮助。
最全的常用正则表达式大全

最全的常⽤正则表达式⼤全⼀、校验数字的表达式1 数字:^[0-9]*$2 n位的数字:^\d{n}$3 ⾄少n位的数字:^\d{n,}$4 m-n位的数字:^\d{m,n}$5 零和⾮零开头的数字:^(0|[1-9][0-9]*)$6 ⾮零开头的最多带两位⼩数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$7 带1-2位⼩数的正数或负数:^(\-)?\d+(\.\d{1,2})?$8 正数、负数、和⼩数:^(\-|\+)?\d+(\.\d+)?$9 有两位⼩数的正实数:^[0-9]+(.[0-9]{2})?$10 有1~3位⼩数的正实数:^[0-9]+(.[0-9]{1,3})?$11 ⾮零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$12 ⾮零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$13 ⾮负整数:^\d+$ 或 ^[1-9]\d*|0$14 ⾮正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$15 ⾮负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$16 ⾮正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$17 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$18 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$19 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$⼆、校验字符的表达式1 汉字:^[\u4e00-\u9fa5]{0,}$2 英⽂和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$3 长度为3-20的所有字符:^.{3,20}$4 由26个英⽂字母组成的字符串:^[A-Za-z]+$5 由26个⼤写英⽂字母组成的字符串:^[A-Z]+$6 由26个⼩写英⽂字母组成的字符串:^[a-z]+$7 由数字和26个英⽂字母组成的字符串:^[A-Za-z0-9]+$8 由数字、26个英⽂字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$9 中⽂、英⽂、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$10 中⽂、英⽂、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$11 可以输⼊含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+12 禁⽌输⼊含有~的字符:[^~\x22]+三、特殊需求表达式1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?3 InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$4 ⼿机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$6 国内电话号码(0511-*******、021-********):\d{3}-\d{8}|\d{4}-\d{7}7 ⾝份证号(15位、18位数字):^\d{15}|\d{18}$8 短⾝份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$9 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$10 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$11 强密码(必须包含⼤⼩写字母和数字的组合,不能使⽤特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$12 ⽇期格式:^\d{4}-\d{1,2}-\d{1,2}13 ⼀年的12个⽉(01~09和1~12):^(0?[1-9]|1[0-2])$14 ⼀个⽉的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$15 钱的输⼊格式:16 1.有四种钱的表⽰形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$17 2.这表⽰任意⼀个不以0开头的数字,但是,这也意味着⼀个字符"0"不通过,所以我们采⽤下⾯的形式:^(0|[1-9][0-9]*)$18 3.⼀个0或者⼀个不以0开头的数字.我们还可以允许开头有⼀个负号:^(0|-?[1-9][0-9]*)$19 4.这表⽰⼀个0或者⼀个可能为负的开头不为0的数字.让⽤户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下⾯我们要加的是说明可能的⼩数部分:^[0-9]+(.[0-9]+)?$20 5.必须说明的是,⼩数点后⾯⾄少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$21 6.这样我们规定⼩数点后⾯必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$22 7.这样就允许⽤户只写⼀位⼩数.下⾯我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$23 8.1到3个数字,后⾯跟着任意个逗号+3个数字,逗号成为可选,⽽不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$24 备注:这就是最终结果了,别忘了"+"可以⽤"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在⽤函数时去掉去掉那个反斜杠,⼀般的错误都在这⾥25 xml⽂件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$26 中⽂字符的正则表达式:[\u4e00-\u9fa5]27 双字节字符:[^\x00-\xff] (包括汉字在内,可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1))28 空⽩⾏的正则表达式:\n\s*\r (可以⽤来删除空⽩⾏)29 HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (⽹上流传的版本太糟糕,上⾯这个也仅仅能部分,对于复杂的嵌套标记依旧⽆能为⼒)30 ⾸尾空⽩字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式)31 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)32 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字) 33 IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有⽤) 34 IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))20个正则表达式必知(能让你少写1,000⾏代码)正则表达式(regular expression)描述了⼀种字符串匹配的模式,可以⽤来检查⼀个串是否含有某种⼦串、将匹配的⼦串做替换或者从某个串中取出符合某个条件的⼦串等。
整数小数正则

整数小数正则正则表达式在日常生活中有着广泛的应用,尤其是在数据处理中。
在处理数字时,经常需要使用正则表达式匹配整数和小数。
因此,了解整数小数正则表达式的匹配规则是非常重要的。
整数正则表达式:匹配整数可以使用如下的整数正则表达式:^[1-9]d*$该正则表达式由两部分组成:^:代表字符串的开始位置。
[1-9]:代表第一位不能是0,只能是1-9的数字。
d*:代表后面的数字可以是0-9的任意数字。
$:代表字符串的结束位置。
该正则表达式可以匹配所有正整数,但是无法匹配负整数。
小数正则表达式:匹配小数可以使用如下的小数正则表达式:^-?(0|[1-9]d*)(.d+)?$该正则表达式由三部分组成:^-?:先判断是否为负数,如果是负数,第一位为负号“-”。
(0|[1-9]d*):如果是正数,第一位可以是0,也可以是1-9的数字,后面的数字可以是任意数字。
这部分表示整数部分。
(.d+)?:小数部分由小数点“.”和数字组成,小数点前面只能是整数,小数点后面可以是1个或多个数字。
这部分表示小数部分。
$:代表字符串的结束位置。
该正则表达式可以匹配所有数字,包括正数、负数、整数和小数。
综合应用:当需要匹配正整数和小数时,可以使用如下的正则表达式:^[1-9]d*(.d+)?$该正则表达式由两部分组成:^[1-9]d*:匹配正整数,第一位不能是0,后面的数字可以是0-9的任意数字。
(.d+)?:匹配小数,小数点前面必须是正整数,小数点后面可以是1个或多个数字。
$:代表字符串的结束位置。
该正则表达式可以匹配所有正整数和小数,但是无法匹配负数。
如果需要匹配负数,可以在前面加上符号“-”,即可得到匹配负数的正则表达式。
正则表达式在数据处理中是非常重要的工具,学会运用正则表达式可以大大提高数据处理的效率。
掌握整数小数正则表达式的匹配规则,可以更加灵活地处理数据。
1以内小数正则 -回复

1以内小数正则-回复如何使用正则表达式匹配1以内的小数。
正则表达式是一种强大的文本模式匹配工具,它可以用于确定文本中是否存在特定的模式或规律。
在本文中,我们将学习如何使用正则表达式匹配1以内的小数。
1. 理解正则表达式基础知识在开始之前,我们需要了解一些基本的正则表达式语法。
- 点号(.)表示匹配任意字符。
- 星号(*)表示匹配前面的模式零次或多次。
- 加号(+)表示匹配前面的模式一次或多次。
- 问号(?)表示匹配前面的模式零次或一次。
- 方括号([])表示匹配括号内的任一字符。
- 花括号({})用来指定模式的重复次数。
2. 创建正则表达式要匹配1以内的小数,我们可以使用以下正则表达式模式:[0-9]*\.[0-9]+这个模式的意思是:匹配任意数字(0到9)零次或多次,紧接着一个小数点,再匹配一个或多个数字。
3. 测试正则表达式为了验证我们的正则表达式是否正确,让我们使用一个文本编辑器或在线正则表达式测试工具来进行测试。
假设我们有以下文本:0.25 0.5 0.75 1.0我们可以应用我们的正则表达式模式来匹配其中的小数。
选择一种正则表达式测试工具,将正则表达式模式和目标文本输入到相应的字段中。
点击测试按钮。
如果我们的正则表达式正确,测试结果将显示我们想要匹配的小数。
4. 整合正则表达式在实际编程中,我们通常需要将正则表达式与其他方法和函数进行整合。
以下是一个使用Python编程语言的例子。
import repattern = r'[0-9]*\.[0-9]+'text = "0.25 0.5 0.75 1.0"result = re.findall(pattern, text)print(result)这段代码使用Python的re模块,在给定的文本中搜索与正则表达式模式匹配的部分。
它返回一个包含所有匹配项的列表。
5. 注意事项在使用正则表达式时,需要注意以下几点:- 确保正则表达式符合你的需求。
0到999正则表达式

0到999正则表达式
答:我们要找出0到999的正则表达式。
首先,我们需要理解正则表达式的结构和规则。
正则表达式是一种用于匹配字符串的强大工具,它由一系列的字符、元字符和运算符组成。
对于0到999,我们可以使用以下的正则表达式:
^[0-9]{1,3}$
这个正则表达式的含义是:
^ 表示字符串的开始。
[0-9]表示匹配任何一个数字(0-9)。
{1,3} 表示前面的字符(在这里是数字)可以出现1到3次。
$表示字符串的结束。
所以,这个正则表达式会匹配任何由1到3个数字组成的字符串,这些数字可以是0到999之间的任何数。
非0的正则表达式

非0的正则表达式
我们要找出一个非0的正则表达式。
首先,我们需要理解什么是正则表达式。
正则表达式是一种用于匹配字符串的特殊语法。
在这个问题中,我们要找的是一个非0的数字的正则表达式。
一个非0的数字可以表示为:从1到9的任何数字,或者是一个数字后跟一个或多个0。
所以,我们可以使用以下的正则表达式来表示非0的数字:
^[1-9]\d0$
这个正则表达式的含义是:
1. ^ 表示字符串的开始。
2. [1-9] 表示数字1到9中的任何一个。
3. \d 表示0或多个数字。
4. 表示或者。
5. 0$ 表示字符串结束时是0。
所以,这个正则表达式匹配的是任何非0的数字,包括整数和小数。
验证整数的正则表达式

验证整数的正则表达式
验证整数的正则表达式
正则表达式是一种强大的文本匹配工具,它可以用来检查文本是否符合特定的模式或格式。
在实际应用中,我们常常需要用到正则表达式来验证输入的数据是否合法。
当输入参数是整数时,我们可以使用正则表达式来验证其是否合法。
下面是一些常见的整数正则表达式及其说明。
1. 匹配所有整数
- \d+ 匹配1个或多个数字,可以是整数或小数。
2. 匹配正整数
- [1-9]\d* 匹配1个以1-9之间的数字开头的整数。
3. 匹配负整数
- -[1-9]\d* 匹配1个以负号“-”开头的整数。
4. 匹配非负整数
- \d+ 匹配1个或多个数字,可以是整数或小数,包括0。
5. 匹配非正整数
- -?\d+ 匹配1个或多个数字,可以是整数或小数,包括0和负整数。
6. 匹配指定范围的整数
- [m,n] 匹配m到n之间的整数,包括m和n。
比如要匹配1到100之间的整数,可以使用正则表达式:1[0-
9]{0,1}|[1-9][0-9]{0,1}|100
其中,1[0-9]{0,1}表示10到19之间的整数,[1-9][0-9]{0,1}表示20到99之间的整数,100表示100。
总结
以上是一些常见的整数正则表达式及其说明,可以根据实际需求选择合适的正则表达式进行验证。
当然,在实际开发中,还需要根据具体情况进行调整,以确保输入的数据能够满足要求。
正则表达式是一种功能强大的文本匹配工具,掌握好它的使用,可以使开发工作更高效、更精准。
正则匹配数字范围

正则匹配数字范围正则表达式是一种强大的工具,可以用来匹配各种数据类型,包括数字。
在某些情况下,我们可能会需要匹配一定范围内的数字。
下面是一些常用的匹配数字范围的正则表达式:1.匹配0到9之间的数字:[0-9]2.匹配1到9之间的数字:[1-9]3.匹配10到99之间的数字:[1-9][0-9]4.匹配100到199之间的数字:1[0-9]{2}5.匹配200到299之间的数字:2[0-9]{2}6.匹配300到399之间的数字:3[0-9]{2}7.匹配400到499之间的数字:4[0-9]{2}8.匹配500到599之间的数字:5[0-9]{2}9.匹配600到699之间的数字:6[0-9]{2}10.匹配700到799之间的数字:7[0-9]{2}11.匹配800到899之间的数字:8[0-9]{2}12.匹配900到999之间的数字:9[0-9]{2}使用正则表达式可以实现数字范围的匹配,可以帮助我们更快更准确地处理数据。
以下是按照列表划分的中文内容:第一部分:正则匹配数字范围正则表达式可以用来匹配不同类型的数据,其中包括数字。
如果我们想要匹配一定范围内的数字,可以使用特定的正则表达式。
以下是一些常用的匹配数字范围的正则表达式。
第二部分:匹配单个数字要匹配单个数字,我们可以使用方括号。
例如,[0-9]可以匹配0到9之间的任何数字。
如果我们想要匹配1到9之间的数字,可以使用[1-9]。
第三部分:匹配两位数数字如果我们想要匹配两位数字,可以使用\d{2}。
这个正则表达式可以匹配所有两位数字的组合。
但是,这个表达式会匹配0开头的数字,例如01、02等。
如果我们只想匹配10到99之间的数字,可以使用[1-9][0-9]。
第四部分:匹配三位数数字如果我们想要匹配三位数字,可以使用\d{3}。
但是,这个表达式会匹配所有三位数字的组合。
如果我们只想匹配特定范围的数字,可以根据需要使用相应的正则表达式。
第五部分:常用的范围匹配表达式以下是常用的数字范围匹配表达式。
时间的正则表达式(比较简单)

时间的正则表达式(⽐较简单)正则1种: ([0-1]?[0-9]|2[0-9]):([0-5][0-9]):([0-5][0-9]) 可以匹配 23:59:59, 可是当数据为34:59:59 却也⼀样的能通过。
(不够完善)正则2种:测试暂是通过能⽐较完美的匹配时间的正则:([0-1][0-9]|2[0-3]|^[0-9]):([0-5]?[0-9]):([0-5]?[0-9]) 当情况为3:4:7这样的时间格式也能通过,且分别得到时分秒下⾯为 2种做下解释:([0-1][0-9]|2[0-3]|^[0-9]):([0-5]?[0-9]):([0-5]?[0-9]) 为什么能匹配3:4:7 是因为([0-5]?[0-9])之间的?当?字符紧跟在任何⼀个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后⾯时,匹配模式是⾮贪婪的。
⾮贪婪模式尽可能少的匹配所搜索的字符串,⽽默认的贪婪模式则尽可能多的匹配所搜索的字符串。
例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",⽽ 'o+' 将匹配所有 'o'。
现在?跟在[0-5] ,所以是⾮贪婪的那么他可以匹配0 也可以不匹配0.这个就根据⾃⼰的需求。
所以你只要把?去掉分秒就必须匹配09不会出现匹配9这种情况了. /^([0-1][0-9]|2[0-3]):([0-5][0-9]):([0-5][0-9])$/ 前⾯这个[0-1][0-9]|2[0-3] 是⽤来匹配01-09 11-19 20-23的字符串。
JS 代码实现: 1.//⽇期格式为:YYYY|MM|DD|hh|ss. 例如:2010|04|09|12|25 {0:yyyy-MM-dd HH:ss} 2. var pattern = /^(?:20\d{2})\|(?:0[1-9]|1[0-2])\|(?:0[1-9]|[12][0-9]|3[01])\|(?:0[0-9]|1[0-9]|2[0-3])\|(?:[0-5]\d)$/;分钟转换⼩时:例如 new TimeSpan(0,Convert.ToInt32(Eval("数据源(分钟数)")),0).TotalHours.ToString("F2")。
纯数字正则

纯数字正则1. 什么是正则表达式正则表达式是一种强大且灵活的字符串匹配工具,通过定义一种规则来匹配目标字符串。
在计算机编程领域,常常用来处理文本数据和字符串操作。
2. 正则表达式的基本语法正则表达式的基本语法由一系列字符和特殊字符组成,用于构建匹配规则。
其中,纯数字正则主要关注于匹配纯数字的情况。
2.1 匹配单个数字要匹配单个数字,可以使用\d这个元字符。
\d可以匹配任意一个数字字符(0-9)。
示例:正则表达式:\d匹配目标:1匹配结果:匹配成功2.2 匹配多个数字要匹配多个数字,可以使用量词。
常用的量词包括+、*和{n,m}。
•+表示匹配一个或多个前面的元素。
•*表示匹配零个或多个前面的元素。
•{n,m}表示匹配n到m个前面的元素。
示例:正则表达式:\d+匹配目标:123匹配结果:匹配成功正则表达式:\d*匹配目标:0匹配结果:匹配成功正则表达式:\d{2,4}匹配目标:1234匹配结果:匹配成功3. 常用的纯数字正则表达式3.1 匹配整数匹配整数可以使用\d+,表示匹配一个或多个数字字符。
示例:正则表达式:\d+匹配目标:123匹配结果:匹配成功3.2 匹配正整数匹配正整数可以使用[1-9]\d*,表示首位为非零数字,后面可以是任意多个数字。
示例:正则表达式:[1-9]\d*匹配目标:123匹配结果:匹配成功3.3 匹配负整数匹配负整数可以使用-[1-9]\d*,表示首位为负号,后面可以是任意多个数字。
示例:正则表达式:-[1-9]\d*匹配目标:-123匹配结果:匹配成功3.4 匹配小数要匹配小数,可以使用\d+\.?\d*,表示小数点前可以是一个或多个数字,小数点后可以是零个或多个数字。
示例:正则表达式:\d+\.?\d*匹配目标:3.14匹配结果:匹配成功3.5 匹配正小数匹配正小数可以使用[0-9]*\.?[0-9]*[1-9]+[0-9]*,表示首位可以是零个或多个数字,小数点可有可无,小数点后面必须至少有一位非零数字。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
正则表达式
7.1、在JavaScript中,正则表达式是对Perl版的改进和发展。
7.2、^表示一个字符串的开始,$表示一个字符串的结束。
7.3、(?:...)表示一个非捕获型分组(noncapturing group)。
7.4、(...)表示一个捕获型分组(capturing group)。
7.5、[...]表示一个字符类,[^?#]表示一个字符类包含除?和#之外的所有字符。
7.6、有两个方法来创建RegExp对象。
优先采用正则表达式字面量。
如下:
var my_regexp=/"(?:\\.|[^\\\"])*"/g;但如果要使用RegExp构造器创建一个正则表达式,要多加小心,因为反斜杠在正则表达式和在字符串字面量中有不同的含义。
通常需要双写反斜杠及对引号进行转义:
var my_regexp=new RegExp("\"(?:\\.|[^\\\\\\\"])*\"",'g');7.7、在RegExp中,有三个标志:g、i和m。
7.8、RegExp对象的属性
属性用法
global如果标志g被使用,值为true
ignoreCase如果标志i被使用,值为true
lastIndex下一次exec匹配开始的索引。
初始值为0
multiline如果m被使用,值为true
source正则表达式源代码文本
7.9、一个正则表达式因子可以是一个字符、一个由圆括号包围的组、一个字符类,或者是一个转义序列。
除了控制字符和特殊字符以外,所有的字符都将被按照字面处理:\/[](){}?+*|.^$
如果上面列出的字符按字面去【匹配,那么必须要一个\前缀来进行转移。
7.10、正则表达式转义:
\f是换页符,\n是换行符,\r是回车符,\t是制表符,\u允许指定一个Unicode字符来表示一个十六进制的常量
\d等同于[0-9]
\s等同于[\f\n\r\t\u000B\u0020\u00A0\u2028\u2029]。
这是Unicode空白符的一个不完全子集。
\S表示与其相反的:[^\f\n\r\t\u000B\u0020\u00A0\u2028\u2029]
\w等同于[0-9A-Z_a-z]。
\W则表示与其相反。
\b被指定为一个字的边界标志。
\1是指分组1所捕获到的文本的一个引用,\2指向分组2的引用,\3指向分组3的引用,以此类推。
7.11、正则表达式分组共有4种:捕获型、非捕获型、向前正向匹配和向前负向匹配。
7.12、正则表达式字符类内部的转义规则和正则表达式因子相比稍有不同。
[\b]是退格符。
下面是在字符类中需要被转义的特殊字符:
-/[\]^
7.13、正则表达式因子可以用一个正则表达式量词后缀,用来决定这个因子应该被匹配的次数。
包围在一对花括号中的一个数字表示这个因子应该被匹配的次数。
所以,/www/和/w{3}/等价。
{3,6}将【匹配3、4、5或6次。
{3,}匹配3次或更多次。
7.14、?等同于{0,1}。
*等同于{0,}+则等同于{1,}。
7.15、如果只有一个量词,则趋向于进行贪婪性的匹配,即匹配尽可能多的重复直至达到上限。
如果这个量词还有一个额外的后缀?,那么则趋向于进行懒惰性匹配,即试图匹配尽可
能少的必要重复。
总结:本章对正则略感并未深入,关于“捕获分组”即点到为止,也未触及“零宽断言”的概念(一个使用零宽断言的例子——《不包含字符串abc的正则表达式》)。
《正则表达式30分钟入门教程》言简意赅地丰富并弥补了这些不足。