数据库CH (12)
2023年计算机二级《MySQL数据库程序设计》考试历年真题摘选附带答案

2023年计算机二级《MySQL数据库程序设计》考试历年真题摘选附带答案第1卷一.全考点综合测验(共20题)1.【单选题】以下能正确定义二维数组的是( )A.int a[][3];B.int a[][3]={2*3);C.int a[][3]={};D.int a[2][3] 一{{1) ,{2} ,{3,4}};2.【单选题】设有学生表student(sno ,sname,sage,smajor) ,要从student 表中检索sname字段值第 2 个字是" 红" 的所有学生信息。
以下能够按照上述条件进行检索的WHERE表达式是______。
A.sname LIKE "_ 红%"B.sname LIKE "_ 红_"C.sname LIKE "% 红%"D.sname LIKE "% 红_"3.【单选题】模式/ 内模式映像保证数据库系统中的数据能够具有较高的______。
A.逻辑独立性B.物理独立性C.共享性D.结构化4.【单选题】SQL语言具有____的功能。
A.关系规范化、数据操纵、数据控制B.数据定义、数据操纵、数据控制C.数据定义、关系规范化、数据控制D.数据定义、关系规范化、数据操纵5.【单选题】恢复MySQL数据库可使用的命令是______。
A.mysqldumpB.mysqladminC.mysqlD.mysqld6.【单选题】在MySQL数据库中,以下不会受字符集设置影响的数据类型有______。
A.CHARB.INTC.VARCHARD.TEXT7.【单选题】以下关于二进制日志文件的叙述中,错误的是______。
A.使用二进制日志文件能够监视用户对数据库的所有操作B.二进制日志文件记录所有对数据库的更新操作C.启用二进制日志文件,会使系统性能有所降低D.启用二进制日志文件,会浪费一定的存储空间8.【单选题】下列关于触发器的叙述中,错误的是______。
MySQL(二)数据库数据类型详解

MySQL(⼆)数据库数据类型详解 序⾔ 今天去健⾝了,感觉把⾝体练好还是不错的,闲话不多说,把这个数据库所遇到的数据类型今天统统在这⾥讲清楚了,以后在看到什么数据类型,咱度应该认识,下⾯就跟着我的节奏去把这个拿下吧。
---WZY⼀、数据类型 MySQL的数据类型有⼤概可以分为5种,分别是整数类型、浮点数类型和定点数类型、⽇期和时间类型、字符串类型、⼆进制类型。
现在可以来看看你对这5种类型的熟悉程度,哪个看起来懵逼了,那就说明⾃⼰哪个不熟悉,不理解。
注意:整数类型和浮点数类型可以统称为数值数据类型,这不难理解。
数值数据类型 整数类型:TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT 浮点数类型:FLOAT、DOUBLE 定点⼩数:DECIMAL ⽇期/时间类型 YEAR、TIME、DATE、DATETIME、TIMESTAMP 字符串类型 CHAR、VARCHAR、TEXT、ENUM、SET等 ⼆进制类型 BIT、BINARY、VARBINARY、BLOB 1、整数类型 不管你学什么语⾔,在基础⽅⾯,都应该知道 1个字节= 8位⼆进制数。
每个类型的取值范围也就能够知道,⽐如TINYINT占⽤1个字节,也就是8位,2的8次⽅减1等于255,也就是说如果代表没符号的整数,该取值范围为0~255,如果是有符号的,最⾼位为符号号位,也就是2的7次⽅减1,也就是127,取值范围为-128~127,为什么需要减1,这个问题就需要考虑临界值的问题了。
⽽考虑临界值问题⼜有需要讨论原码补码反码的知识,这些度不是我们讨论的重点,所以在这就⾃⾏百度。
给出⼀张范围表,给⼤家做参考。
不同整数类型的取值范围 根据⾃⼰所需去选取不同的类型名称, 例如: CREATE TABLE aaa( id INT(10) PRIMARY KEY, age INT(6) ); 这个例⼦中INT(10)、INT(6) 括号中的数字表⽰的是该数据类型指定的显⽰宽度,指定能够显⽰的数值中数字的个数。
【精】数据库CH(6)(学习资料)

Formal Relational Query LanguagesIn this chapter we study three additional formal relational languages.RelationalAlgebra,tuple relational calculus and domain relational calculus.Of these three formal languages,we suggest placing an emphasis on rela-tional algebra,which is used extensively in the chapters on query processing andoptimization,as well as in several other chapters.The relational calculi generallydo not merit as much emphasis.Our notation for the tuple relational calculus makes it easy to present the concept of a safe query.The concept of safety for the domain relational calcu-lus,though identical to that for the tuple calculus,is much more cumbersomenotationally and requires careful presentation.This consideration may suggestplacing somewhat less emphasis on the domain calculus for classes not focusingon database theory.Exercises6.10Write the following queries in relational algebra,using the universityschema.a.Find the names of all students who have taken at least one Comp.Sci.course.b.Find the ID s and names of all students who have not taken any courseoffering before Spring2009.c.For each department,find the maximum salary of instructors in thatdepartment.You may assume that every department has at least oneinstructor.d.Find the lowest,across all departments,of the per-department maxi-mum salary computed by the preceding query.Answer:4344Chapter6Formal Relational Query Languagesemployee(person name,street,city)works(person name,company name,salary)company(company name,city)manages(person name,manager name)Figure6.22Relational database for Exercises6.2,6.8,6.11,6.13,and6.15a. name(student1takes1 course id(dept name=′Comp.Sci.′(course)))Note that if we join student,takes,and course,only students fromthe Comp.Sci.department would be present in the result;studentsfrom other departments would be eliminated even if they had taken aComp.Sci.course since the attribute dept name appears in both studentand course.b. I D,name(student)− I D,name(year<2009(student1takes)Note thatSpring is thefirst semester of the year,so we do not need to performa comparison on semester.c.dept name G max(salary)(instructor)d.G min(maxsal)(dept name G max(salary)as maxsal(instructor))6.11Consider the relational database of Figure6.22,where the primary keys areunderlined.Give an expression in the relational algebra to express each ofthe following queries:a.Find the names of all employees who work for“First Bank Corpora-tion”.b.Find the names and cities of residence of all employees who work for“First Bank Corporation”.c.Find the names,street addresses,and cities of residence of all em-ployees who work for“First Bank Corporation”and earn more than$10,000.d.Find the names of all employees in this database who live in the samecity as the company for which they work.e.Assume the companies may be located in several cities.Find all com-panies located in every city in which“Small Bank Corporation”islocated.Answer:(w orks))a. person name(company name=“First Bank Corporation”b. person name,city(employee1(w orks)))(company name=“First Bank Corporation”Exercises 45c. person name ,street ,city ((company name =“First Bank Corporation”∧salar y >10000)w orks 1employee )d. person name (employee 1w orks 1company )e.Note:Small Bank Corporation will be included in each answer.company name (company ÷( city (company name =“Small Bank Corporation”(company ))))6.12Using the university example,write relational-algebra queries to find thecourse sections taught by more than one instructor in the following ways:a.Using an aggregate function.b.Without using any aggregate functions.Answer:a.instrcnt >1(course id ,section id ,year ,semester G count (∗)as instrcnt (teaches ))b.course id ,section id ,year ,semester (I D <>ID2(takes 1takes1(ID2,course id ,section id ,year ,semester )(takes )))6.13Consider the relational database of Figure 6.22.Give a relational-algebraexpression for each of the following queries:a.Find the company with the most employees.b.Find the company with the smallest payroll.c.Find those companies whose employees earn a higher salary,on av-erage,than the average salary at First Bank Corporation.Answer:a.t 1←company name G count-distinct (person name )(w orks )t 2←G max (num employees)(company strength (company name ,num employees )(t 1))company name (t 3(company name ,num employees )(t 1)1t 4(num employees )(t 2))b.t 1←company name G sum (salary )(w orks )t 2←G min (payroll )(company payroll (company name ,payroll )(t 1)) company name (t 3(company name ,payroll )(t 1)1t 4(payroll )(t 2))c.t 1←company name G avg (salary )(w orks )t 2←company name =“First Bank Corporation”(t 1) t pany name ((t 3(company name ,a v g salar y )(t 1))1t 3.a v g salar y >f irst bank .a v g salar y (f irst bank (company name ,a v g salar y )(t 2)))6.14Consider the following relational schema for a library:46Chapter6Formal Relational Query Languagesmember(memb no,name,dob)books(isbn,title,authors,publisher)borrowed(memb no,isbn,date)Write the following queries in relational algebra.a.Find the names of members who have borrowed any book publishedby“McGraw-Hill”.b.Find the name of members who have borrowed all books publishedby“McGraw-Hill”.c.Find the name and membership number of members who have bor-rowed more thanfive different books published by“McGraw-Hill”.d.For each publisher,find the name and membership number of mem-bers who have borrowed more thanfive books of that publisher.e.Find the average number of books borrowed per member.Take intoaccount that if an member does not borrow any books,then thatmember does not appear in the borrowed relation at all.Answer:a.t1← isbn(publisher=“McGra w−Hill′′(books))name((member1borro w ed)1t1))b.t1← isbn(publisher=“McGra w−Hill′′(books))name,isbn(member1borro w ed)÷t1c.t1←member1borro w ed1(publisher=“McGra w−Hill′′(books))name(countisbn>5((memb no G count-distinct(isbn)as countisbn(t1))))d.t1←member1borro w ed1bookspublisher,name(countisbn>5((publisher,memb no G count-distinct(isbn)as countisbn(t1)))6.15Consider the employee database of Figure6.22.Give expressions in tuplerelational calculus and domain relational calculus for each of the followingqueries:a.Find the names of all employees who work for“First Bank Corpora-tion”.b.Find the names and cities of residence of all employees who work for“First Bank Corporation”.c.Find the names,street addresses,and cities of residence of all em-ployees who work for“First Bank Corporation”and earn more than$10,000.Exercises47 d.Find all employees who live in the same city as that in which thecompany for which they work is located.e.Find all employees who live in the same city and on the same streetas their managers.f.Find all employees in the database who do not work for“First BankCorporation”.g.Find all employees who earn more than every employee of“SmallBank Corporation”.h.Assume that the companies may be located in several cities.Find allcompanies located in every city in which“Small Bank Corporation”is located.Answer:a.Find the names of all employees who work for First Bank Corporation:i.{t|∃s∈w orks(t[person name]=s[person name]∧s[company name]=“First Bank Corporation”)} ii.{<p>|∃c,s(<p,c,s>∈w orks∧c=“First Bank Corporation”)} b.Find the names and cities of residence of all employees who work forFirst Bank Corporation:i.{t|∃r∈employee∃s∈w orks(t[person name]=r[person name]∧t[city]=r[city]∧r[person name]=s[person name]∧s[company name]=’First Bank Corporation’)} ii.{<p,c>|∃co,sa,st(<p,co,sa>∈w orks∧<p,st,c>∈employee∧co=“First Bank Corporation”)}c.Find the names,street address,and cities of residence of all employeeswho work for First Bank Corporation and earn more than$10,000perannum:i.{t|t∈employee∧(∃s∈w orks(s[person name]=t[person name]∧s[company name]=“First Bank Corporation”∧s[salar y]> 10000))}ii.{<p,s,c>|<p,s,c>∈employee∧∃co,sa(<p,co,sa>∈w orks∧co=’First Bank Corporation’∧sa>10000)}d.Find the names of all employees in this database who live in the samecity as the company for which they work:48Chapter6Formal Relational Query Languagesi.{t|∃e∈employee∃w∈w orks∃c∈company(t[person name]=e[person name]∧e[person name]=w[person name]∧w[company name]=c[company name]∧e[city]=c[city])}ii.{<p>|∃st,c,co,sa(<p,st,c>∈employee∧<p,co,sa>∈w orks∧<co,c>∈company)}e.Find the names of all employees who live in the same city and on thesame street as do their managers:i.{t|∃l∈employee∃m∈manages∃r∈employee(l[person name]=m[person name]∧m[manager name]=r[person name]∧l[street]=r[street]∧l[city]=r[city]∧t[person name]=l[person name])}ii.{<t>|∃s,c,m(<t,s,c>∈employee∧<t,m>∈manages∧<m,s,c>∈employee)}f.Find the names of all employees in this database who do not workfor First Bank Corporation:If one allows people to appear in the database(e.g.in employee)but notappear in works,the problem is more complicated.We give solutionsfor this more realistic case later.i.{t|∃w∈w orks(w[company name]=“First Bank Corporation”∧t[person name]=w[person name])}ii.{<p>|∃c,s(<p,c,s>∈w orks∧c=“First Bank Corporation”)}If people may not work for any company:i.{t|∃e∈employee(t[person name]=e[person name]∧¬∃w∈w orks(w[company name]=“First Bank Corporation”∧w[person name]=t[person name]))}ii.{<p>|∃s,c(<p,s,c>∈employee)∧¬∃x,y(y=“First Bank Corporation”∧<p,y,x>∈w orks)}g.Find the names of all employees who earn more than every employeeof Small Bank Corporation:i.{t|∃w∈w orks(t[person name]=w[person name]∧∀s∈w orks(s[company name]=“Small Bank Corporation”⇒w[salar y]>s[salar y]))}Exercises49 ii.{<p>|∃c,s(<p,c,s>∈w orks∧∀p2,c2,s2(<p2,c2,s2>∈w orks∨c2=“Small Bank Corporation”∨s>s2))}h.Assume the companies may be located in several cities.Find all com-panies located in every city in which Small Bank Corporation is lo-cated.Note:Small Bank Corporation will be included in each answer.i.{t|∀s∈company(s[company name]=“Small Bank Corporation”⇒∃r∈company(t[company name]=r[company name]∧r[city]=s[city]))}ii.{<co>|∀co2,ci2(<co2,ci2>∈company∨co2=“Small Bank Corporation”∨<co,ci2>∈company)} 6.16Let R=(A,B)and S=(A,C),and let r(R)and s(S)be relations.Write relational-algebra expressions equivalent to the following domain-relational-calculus expressions:a.{<a>|∃b(<a,b>∈r∧b=17)}b.{<a,b,c>|<a,b>∈r∧<a,c>∈s}c.{<a>|∃b(<a,b>∈r)∨∀c(∃d(<d,c>∈s)⇒<a,c>∈s)}d.{<a>|∃c(<a,c>∈s∧∃b1,b2(<a,b1>∈r∧<c,b2>∈r∧b1>b2))}Answer:a. A(B=17(r))b.r1sc. A(r)∪(r÷B( C(s)))d. r.A((r1s)1c=r2.A∧r.B>r2.B(r2(r)))It is interesting to note that(d)is an abstraction of the notoriousquery“Find all employees who earn more than their manager.”LetR=(emp,sal),S=(emp,mgr)to observe this.6.17Repeat Exercise6.16,writing SQL queries instead of relational-algebra ex-pressions.Answer:a.select afrom rwhere b=1750Chapter6Formal Relational Query Languagesb.select a,b,cfrom r,swhere r.a=s.ac.(select afrom r)union(select afrom s)d.select afrom r as r1,r as r2,swhere r1.a=s.a and r2.a=s.c and r1.b>r2.b6.18Let R=(A,B)and S=(A,C),and let r(R)and s(S)be relations.Using the special constant null,write tuple-relational-calculus expressionsequivalent to each of the following:a.r1sb.r1sc.r1sAnswer:a.{t|∃r∈R∃s∈S(r[A]=s[A]∧t[A]=r[A]∧t[B]=r[B]∧t[C]=s[C])∨∃s∈S(¬∃r∈R(r[A]=s[A])∧t[A]=s[A]∧t[C]=s[C]∧t[B]=null)}b.{t|∃r∈R∃s∈S(r[A]=s[A]∧t[A]=r[A]∧t[B]=r[B]∧t[C]=s[C])∨∃r∈R(¬∃s∈S(r[A]=s[A])∧t[A]=r[A]∧t[B]=r[B]∧t[C]=null)∨∃s∈S(¬∃r∈R(r[A]=s[A])∧t[A]=s[A]∧t[C]=s[C]∧t[B]=null)}c.{t|∃r∈R∃s∈S(r[A]=s[A]∧t[A]=r[A]∧t[B]=r[B]∧t[C]=s[C])∨∃r∈R(¬∃s∈S(r[A]=s[A])∧t[A]=r[A]∧t[B]=r[B]∧t[C]=null)}6.19Give a tuple-relational-calculus expression tofind the maximum value inrelation r(A).Answer:{<a>|<a>∈r∧∀<b>∈R a>=b}。
数据库系统概论CH11(部分)习题解答

第十一章并发控制事务处理技术主要包括数据库恢复技术和并发控制技术。
本章讨论数据库并发控制的基本概念和实现技术。
本章内容有一定的深度和难度。
读者学习本章一定要做到概念清楚。
一、基本知识点数据库是一个共享资源,当多个用户并发存取数据库时就会产生多个事务同时存取同一个数据的情况。
若对并发操作不加控制就可能会存取和存储不正确的数据,破坏数据库的一致性。
所以DBMS必须提供并发控制机制。
并发控制机制的正确性和高效性是衡量一个DBMS性能的重要标志之一。
①需要了解的: 数据库并发控制技术的必要性,活锁死锁的概念。
②需要牢固掌握的: 并发操作可能产生数据不一致性的情况(丢失修改、不可重复读、读“脏数据”)及其确切含义;封锁的类型;不同封锁类型的(例如X锁,S锁)的性质和定义,相关的相容控制矩阵;封锁协议的概念;封锁粒度的概念;多粒度封锁方法;多粒度封锁协议的相容控制矩阵。
③需要举一反三的:封锁协议与数据一致性的关系;并发调度的可串行性概念;两段锁协议与可串行性的关系;两段锁协议与死锁的关系。
④难点:两段锁协议与串行性的关系;与死锁的关系;具有意向锁的多粒度封锁方法的封锁过程。
二、习题解答和解析1. 在数据库中为什么要并发控制? 并发控制技术能保证事务的哪些特性?答数据库是共享资源,通常有许多个事务同时在运行。
当多个事务并发地存取数据库时就会产生同时读取和/或修改同一数据的情况。
若对并发操作不加控制就可能会存取和存储不正确的数据,破坏事务的一致性和数据库的一致性。
所以数据库管理系统必须提供并发控制机制。
并发控制技术能保证事务的隔离性和一致性。
2. 并发操作可能会产生哪几类数据不一致? 用什么方法能避免各种不一致的情况?答并发操作带来的数据不一致性包括三类:丢失修改、不可重复读和读“脏”数据。
(1) 丢失修改(Lost Update)两个事务T1和T2读入同一数据并修改,T2提交的结果破坏了(覆盖了)T1提交的结果,导致T1的修改被丢失。
2023年计算机二级《MySQL数据库程序设计》考试全真模拟易错、难点汇编叁(带答案)试卷号:43

2023年计算机二级《MySQL数据库程序设计》考试全真模拟易错、难点汇编叁(带答案)(图片大小可自由调整)一.全考点综合测验(共45题)1.【单选题】下列关于SQL的叙述中,正确的是______。
A.SQL是专供MySQL使用的结构化查询语言B.SQL是一种过程化的语言C.SQL是关系数据库的通用查询语言D.SQL只能以交互方式对数据库进行操作正确答案:C2.【单选题】在讨论关系模型时,与“属性”同义的术语是______。
A.元组B..NC.. 表D.关系正确答案:B3.【单选题】下列SQL语句中,创建关系表的是____。
A.ALTERB.CREATEC.UPDATED.INSERT正确答案:B4.【单选题】语句int(*ptr)() 的含义是( )。
A.ptr 是一个返回值为int 的函数B.ptr 是指向int 型数据的指针变量C.ptr 是指向函数的指针,该函数返回一个int 型数据D.ptr 是一个函数名,该函数的返回值是指向int 型数据的指针正确答案:C5.【单选题】对于日期"2013 年10 月21 日",MySQL默认显示的格式是______。
A."2013-10-21"B."2013-21-10"C."10-21-2013"D."21-10-2013"正确答案:A6.【单选题】在使用CREATE INDEX创建索引时,其默认的排序方式是______。
A.升序B.降序C.无序D.聚簇正确答案:A7.【单选题】下列程序的输出结果是( )。
#includevoid p(int*x){ printf("%d ¨,++*x);}void main(){ int y=3;p(&y);}A.3B.4C.2D.5正确答案:B8.【单选题】在使用SHOW GRANTS命令显示用户权限时结果为USAGE,该用户拥有的权限为______。
Oracle实验报告

Oracle数据库实验报告实验一:Oracle 10g安装卸载及相关工具配置一、实验目标:安装Oracle 10g,了解OEM,通过DBCA安装数据库,通过DBCA删除数据库,sqldeveloper连接数据库,卸载oracle 10g。
二、实验学时数2学时三、实验步骤和内容:1、安装Oracle10g(默认安装数据库)双击,选择基本安装,安装目录D:盘,标准版,默认数据库orcl,口令bhbh。
进入先决条件检查界面时:网络配置需求选项不用打勾,直接下一步,是。
直到安装成功。
2、登陆和了解OEM主要是已网页的形式来对数据库进行管理。
- OraDb10g_home1->配置和移植工具->Database Configuration Assistant->删除数据库->……4、通过DBCA安装数据库xscj程序->Oracle - OraDb10g_home1->配置和移植工具->Database Configuration Assistant->创建数据库->……5、sqldeveloper连接数据库打开sqldeveloper,新建连接连接名:system_ora用户名:system口令:bhbh主机名:本机计算机名SID:xscj测试,显示成功,连接,保存。
6、卸载oracle 10gWindows下1>停止所有Oracle服务,点Universal Installer卸载2>删除注册表中的所有关于Oracle项在HKEY_LOCAL_MACHINE\SOFTWARE下,删除Oracle目录3>删除硬盘上所有Oracle文件。
(1)Oracle安装文件(2)系统目录下,在Program files文件夹中的Oracle文件四、上机作业根据实验步骤完成逐个实验目标中的任务。
五、心得体会通过这次的实验,我了解了oracle数据库的情况。
用友GRPr9、u8数据库表结构

R9、u8帐务处理系统主要数据结构一、数据表基本信息:序号物理表名中文名称页号1 GL_Czrz 操作日志 42 GL_Czy操作员 53 GL_Dlzgsml多栏帐格式目录 64 GL_Dlzgsnr多栏帐格式内容75 GL_DmSyzt代码使用状态86 GL_Ffkmgx非法科目对应关系97 GL_Fzsmx辅助说明项108 GL_Fzxlb辅助项类别119 GL_Fzxzl辅助项资料1210 GL_Fzye辅助余额1311 GL_Fzyek辅助余额(预记帐)1412 GL_Fzys辅助预算1513 GL_Gn功能库1614 GL_GnQx功能权限库1715 GL_Jldwxx计量单位库1816 GL_Jsgx结算方式1917 GL_Kjcz会计词组2018 GL_Kmmxfl科目明细分类(预期置)2119 GL_Kmxx科目信息2220 GL_Kmye科目余额2421 GL_Kmyek 科目余额(预记帐)2522 GL_Kmys科目预算2623 GL_Kmznr科目组内容2724 GL_Kmzxx 科目组信息2825 GL_Language提示用语语言翻译库2926 GL_Mails邮件箱3127 GL_MailUsers邮件箱用户3228 GL_Pzflmx凭证分录明细3329 GL_PZHZTemp凭证汇总(取登记簿中的数34据)30 GL_Pzlx凭证类型3531 GL_Pzml凭证目录3632 GL_Pznr凭证内容3833 GL_Pzqx凭证权限4034 GL_Pzzy凭证常用摘要4135 GL_Qxkz数据权限控制4236 GL_Tdgsml套打格式目录4337 GL_Tdgsnr套打格式内容4538 GL_Wlkm往来单位核算科目4639 GL_Wlyw往来业务4740 GL_Xjllxm现金流量项目4941 GL_Xmkm项目核算科目5042 GL_Xmlje项目累计发生额5143 GL_Xmljek项目累计发生额(预记帐)5244 GL_Xmzl 项目资料5345 GL_Yetjb 余额调节表5446 GL_Yhdzd 银行对帐单5547 GL_Yhrjz 银行日记帐5648 GL_Yhzh 银行帐号5749 GL_Zdfl 自动分录5850 GL_Ztcs 帐套参数5951 PubBizh 币种6152 PubBmxx 部门信息6253 PubDqzl 地区资料6354 PubGszl 公司资料6455 PubHlb 浮动汇率表6656 PubHsdw 核算单位6757 PubKjqj 会计期间6858 PubKszl 往来单位资料7059 PubPzly 凭证来源7260 PubZyxx 职员信息7361 GL_Pzflmx_Bk 凭证分录明细临时表7562GL_Pzml_Bk 凭证目录临时表7663 GL_Pznr_Bk 凭证内容临时表7864 Gl_Gnfl 权限功能分类表(新增表)65 PubSZDWZH 指标中新增的表附录:1、Anyi2000账务系统自定义数据类型。
ch12 Project Server 2007的安装

中文版 Project 2007 实用教程
12.3 安装后的设置 安装后的设置
安装完Project 安装完Project Server 2007后,为了确保从另一台计算机访问Access数 2007后,为了确保从另一台计算机访问Access数 据库时不会发生权限问题,或不同的Windows用户帐户都可以对Project 据库时不会发生权限问题,或不同的Windows用户帐户都可以对Project Server 2007进行访问,需要设置允许用户使用不同的Microsoft Windows用 2007进行访问,需要设置允许用户使用不同的Microsoft Windows用 户帐户进行登录.当然,在客户端为了能够访问Project Server,也需要进 户帐户进行登录.当然,在客户端为了能够访问Project Server,也需要进 行相关设置.
中文版 Project 2007 实用教程 第12章 12章 Project Server 2007 的安装
பைடு நூலகம்
为了通过浏览器管理企业内多个同时进行的项目,更好地与项目工作组共 享项目信息以及简化工作组成员之间的协作,可以使用Project 享项目信息以及简化工作组成员之间的协作,可以使用Project Server 2007将 2007将 所有的项目和资源信息存储在一个中心数据库中,只需项目经理安装Project专 所有的项目和资源信息存储在一个中心数据库中,只需项目经理安装Project专 业版,其他工组成员都可以使用基于浏览器的Project 业版,其他工组成员都可以使用基于浏览器的Project Web Access来查看 Access来查看 Project Server中的各项项目数据. Server中的各项项目数据.
中文版 Project 2007 实用教程 教学重点与难点
管家婆数据库字典

字段名称
说明
类型
是否允许空
主外键
1.
TypeID
品牌节点编号
varchar(25)
2.
ParID
品牌父节点编号
varchar(25)
3.
Leveal
品牌级别
int
4.
SonNum
子节点数量
int
5.
SonCount
子节点创建数量
int
6.
UserCode
品牌编号
varchar(26)
1
表1表名称
表名
说明
1
Department
部门表
2
Employee
职员表
3
AreaType
地区表
4
Btype
供应商、客户信息表
5
Stack
仓库表
6
Brandtype
品牌表
7
T_goodsprop
存货核算方法
8
P_type
商品
9
Dlyndxorder
进货订单,销售订单主表
10
Dlyndx
草稿,所有单据主表
2.
parid
父节点编号
varchar(25)
3.
leveal
供应商级别
smallint
4.
soncount
子节点创建数量
int
5.
sonnum
子节点数量
int
6.
UserCode
供应商,客户编号
varchar(26)
7.
FullName
全名
varchar(66)
数据库课程设计(完整版)

HUNAN CITY UNIVERSITY 数据库系统课程设计设计题目:宿舍管理信息系统姓名:学号:专业:信息与计算科学指导教师:20年 12月1日目录引言 3一、人员分配 4二、课程设计目的和要求 4三、课程设计过程1.需求分析阶段1.1应用背景 51.2需求分析目标51.3系统设计概要 51.4软件处理对象 61.5系统可行性分析 61.6系统设计目标及意义7 1.7系统业务流程及具体功能 71.8.1数据流程图82.系统的数据字典113.概念结构设计阶段 134.逻辑结构设计阶段 155.物理结构设计阶段 186.数据库实施 187.数据库的运行和维护 187.1 解决问题方法 197.2 系统维护 197.3 数据库性能评价 19四、课程设计心得. 20参考文献 20引言学生宿舍管理系统对于一个学校来说是必不可少的组成部分。
目前好多学校还停留在宿舍管理人员手工记录数据的最初阶段,手工记录对于规模小的学校来说还勉强可以接受,但对于学生信息量比较庞大,需要记录存档的数据比较多的高校来说,人工记录是相当麻烦的。
而且当查找某条记录时,由于数据量庞大,还只能靠人工去一条一条的查找,这样不但麻烦还浪费了许多时间,效率也比较低。
当今社会是飞速进步的世界,原始的记录方式已经被社会所淘汰了,计算机化管理正是适应时代的产物。
信息世界永远不会是一个平静的世界,当一种技术不能满足需求时,就会有新的技术诞生并取代旧技术。
21世纪的今天,信息社会占着主流地位,计算机在各行各业中的运用已经得到普及,自动化、信息化的管理越来越广泛应用于各个领域。
我们针对如此,设计了一套学生宿舍管理系统。
学生宿舍管理系统采用的是计算机化管理,系统做的尽量人性化,使用者会感到操作非常方便,管理人员需要做的就是将数据输入到系统的数据库中去。
由于数据库存储容量相当大,而且比较稳定,适合较长时间的保存,也不容易丢失。
这无疑是为信息存储量比较大的学校提供了一个方便、快捷的操作方式。
历年计算机二级c++真题及答案

天下盘算机品级测验二级口尝尝卷年夜众根底常识及C++言语次序计划(测验时刻90分钟,总分值100)分)一、抉择题((1)~(35)每题2分,共70分)以下各题A)、B)、C)、D)四个选项中,只要一个选项是准确的,请将准确选项涂写在答题卡响应地位上,答在试卷上不得分。
(1) 下面表白准确的选项是A)算法的履行效力与数据的存储结构有关B)算法的空间庞杂度是指算法次序中指令(或语句)的条数C)算法的有穷性是指算法必需能在履行无限个步调之后停止D)以上三种描绘都过错(2)以下数据结构中不属于线性数据结构的是A)行列B)线性表C)二叉树D)栈(3)在一棵二叉树上第5层的结点数最多是A)8 B)16 C)32 D)15(4)下面描绘中,契合结构化次序计划作风的是A)运用次序、抉择跟反复(轮回)三种全然把持结构表现次序的把持逻辑B)模块只要一个进口,能够有多个出口C)重视进步次序的履行效力D)不运用goto语句(5)下面观点中,不属于面向东西办法的是A)东西B)承继C)类D)进程挪用(6)在结构化办法中,用数据流程图(DFD)作为描绘东西的软件开辟阶段是A)可行性剖析B)需要剖析C)具体计划D)次序编码(7)在软件开辟中,下面义务不属于计划阶段的是A)数据结构计划B)给出零碎模块结构C)界说模块算法D)界说需要并树破零碎模子(8)数据库零碎的中心是A)数据模子C)软件东西B)数据库治理零碎D)数据库(9)以下表白中准确的选项是A)数据库零碎是一个独破的零碎,不需要操纵零碎的支撑B)数据库计划是指计划数据库治理零碎C)数据库技巧的全然目标是要处置数据共享的咨询题D)数据库零碎中,数据的物理结构必需与逻辑结构分歧(10)以下方法中,能够给出数据库物理存储结构与物理存取办法的是A)内方法B)外方法C)观点方法D)逻辑方法(11)对于面向东西的次序计划办法,以下说法准确的选项是A)“封装性〞指的是将差别范例的相干数据组合在一同,作为一个全体进展处置B)“多态性〞指的是东西的形态会依照运转时请求主动变更C)基类的私有成员在派生类的东西中弗成访咨询,也不占内存空间D)在面向东西的次序计划中,结构化次序计划办法仍有着主要感化(12)推断字符型变量ch能否为年夜写英笔墨母,应运用表白式A ) ch>='A' & ch<='Z'B ) ch<='A' ||ch>='Z'C ) 'A'<=ch<='Z'D ) ch>='A' && ch<='Z'(13)曾经明白以下语句中的x跟y基本上int型变量,此中过错的语句A ) x=y++;B ) x=++y;C ) (x+y)++;D ) ++x=y;(14)履行语句序列int n;cin >> n;switch(n){ case 1:case 2: cout << '1';case 3:case 4: cout << '2'; break;default: cout << '3';}时,假设键盘输入1,那么屏幕表现A)1 B)2 C)3 D)12(15)以下次序的输入后果是#include <iostream>using namespace std;int main(){char a[] = "Hello, World";char *ptr = a;while (*ptr){if (*ptr >= 'a' && *ptr <= 'z')cout << char(*ptr + 'A' -'a');else cout << *ptr;ptr++;}return 0;}A ) HELLO, WORLDB ) Hello, WorldC ) hELLO, wORLD D ) hello, world(16)曾经明白:int m=10;在以下界说援用的语句中,准确的选项是A ) int &x=m;B )int y=&m;C )int &z;D ) int &t=&m;(17)以下函数原型申明中过错的选项是A ) void Fun(int x=0, int y=0);B ) void Fun(int x, int y);C ) void Fun(int x, int y=0);D ) void Fun(int x=0, int y);(18)曾经明白次序中曾经界说了函数test,其原型是int test(int, int, int);,那么以下重载方法中准确的选项是A ) char test(int,int,int);B ) double test(int,int,double);C ) int test(int,int,int=0);D ) float test(int,int,float=3.5F);(19)有以下次序#include<iostream>int i = 0;void fun(){ {static int i = 1;std::cout<<i++<<',';}std::cout<<i<<',';}int main(){fun(); fun();return 0;}次序履行后的输入后果是A)1,2,1,2, B)1,2,2,3, C)2,0,3,0, D)1,0,2,0,(20)曾经明白函数f的原型是:void f(int *a, long &b); 变量v1、v2的界说是:int v1;long v2;,准确的挪用语句是A) f(v1, &v2); B) f(v1, v2);C) f(&v1, v2); D) f(&v1, &v2);(21)有以下类界说class MyClass{public:MyClass(){cout<<1;}};那么履行语句MyClass a, b[2], *p[2];后,次序的输入后果是A)11 B)111 C)1111 D)11111(22)对于友元,以下说法过错的选项是A)假如类A是类B的友元,那么类B也是类A的友元B)假如函数fun()被阐明为类A的友元,那么在fun()中能够访咨询类A的私有成员C)友元关联不克不及被承继D)假如类A是类B的友元,那么类A的一切成员函数基本上类B的友元(23)对于静态存储调配,以下说法准确的选项是A)new跟delete是C++言语中专门用于静态内存调配跟开释的函数B)静态调配的内存空间也能够被初始化C)当零碎内存不敷时,会主动接纳不再运用的内存单位,因而次序中不用用delete开释内存空间D)当静态调配内存掉败时,零碎会破即解体,因而必定要慎用new(24)有以下次序#include<iostream>using namespace std;class MyClass{public:MyClass(int n){number = n;}//拷贝结构函数MyClass(MyClass &other){ number=other.number;}~MyClass(){}private:int number;};MyClass fun(MyClass p){MyClass temp(p);return temp;}int main(){MyClass obj1(10), obj2(0);MyClass obj3(obj1);obj2=fun(obj3);return 0;}次序履行时,MyClass类的拷贝结构函数被挪用的次数是A)5 B)4 C)3 D)2(25)在私有派生的状况下,派生类中界说的成员函数只能访咨询原基类的A)私有成员跟私有成员B)私有成员跟爱护成员C)私有成员跟爱护成员D)私有成员、爱护成员跟私有成员(26)在C++顶用来实现运转时多态性的是A)重载函数B)析构函数C)结构函数D)虚函数(27)一个类能够同时承继多个类,称为多承继。
中国湖泊数据库数据字典
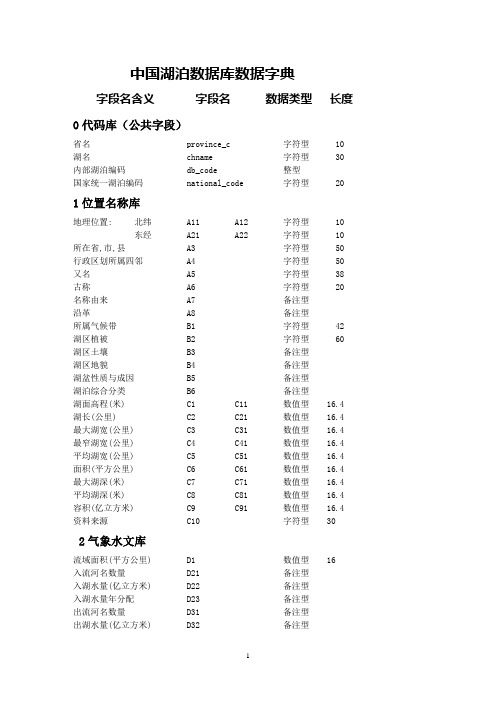
中国湖泊数据库数据字典字段名含义字段名数据类型长度0代码库(公共字段)省名 province_c 字符型 10 湖名 chname 字符型 30 内部湖泊编码 db_code 整型国家统一湖泊编码 national_code 字符型 201位置名称库地理位置: 北纬 A11 A12 字符型 10 东经 A21 A22 字符型 10 所在省,市,县 A3 字符型 50 行政区划所属四邻 A4 字符型 50 又名 A5 字符型 38 古称 A6 字符型 20 名称由来 A7 备注型沿革 A8 备注型所属气候带 B1 字符型 42 湖区植被 B2 字符型 60 湖区土壤 B3 备注型湖区地貌 B4 备注型湖盆性质与成因 B5 备注型湖泊综合分类 B6 备注型湖面高程(米) C1 C11 数值型 16.4 湖长(公里) C2 C21 数值型 16.4 最大湖宽(公里) C3 C31 数值型 16.4 最窄湖宽(公里) C4 C41 数值型 16.4 平均湖宽(公里) C5 C51 数值型 16.4 面积(平方公里) C6 C61 数值型 16.4 最大湖深(米) C7 C71 数值型 16.4 平均湖深(米) C8 C81 数值型 16.4 容积(亿立方米) C9 C91 数值型 16.4 资料来源 C10 字符型 302气象水文库流域面积(平方公里) D1 数值型 16入流河名数量 D21 备注型入湖水量(亿立方米) D22 备注型入湖水量年分配 D23 备注型出流河名数量 D31 备注型出湖水量(亿立方米) D32 备注型出湖水量年分配 D33 备注型地表水 D41 数值型 2 地下水 D42 数值型 2 降水 D43 数值型 2 融水 D44 数值型 2 外流 D51 数值型 2 内流 D52 数值型 2 换水周期(天) D6 字符型 16 备注 D7 备注型多年平均水位(米) E1 数值型 16.2 历年最高水位(米) E2 数值型 16.2 出现时间(年月日) E3 字符型 10 历年最低水位(米) E4 数值型 16.2 出现时间(年月日) E5 字符型 10 年最大变幅(米) E6 数值型 16.2 年最小变幅(米) E7 数值型 16.2 绝对变幅(米) E8 数值型 16.2 资料年限 E9 字符型 16 备注 E10 备注型入湖地表径流(亿立方米) F11 字符型 16 湖面降水(亿立方米) F12 字符型 16 入湖地下径流(亿立方米) F13 字符型 16 湖水变量(亿立方米) F14 字符型 16 合计(亿立方米) F15 字符型 16 出湖地表径流(亿立方米) F21 字符型 16 湖面蒸发(亿立方米) F22 字符型 16 出湖地下径流(亿立方米) F23 字符型 16 湖水变量(亿立方米) F24 字符型 16 合计(亿立方米) F25 字符型 16 备注 F3 备注型水位(米) G1 数值型 16.2 面积(平方公里) G2 数值型 16.2 容积(亿立方米) G3 数值型 16.4 入湖输沙量(立方米) G4 字符型 16 出湖输沙量(立方米) G5 字符型 16 湖盆年淤积量(立方米) G6 字符型 16 年泥沙淤积速率(厘米) G7 数值型 16.2 淤积年限(年) G8 字符型 16 备注 G9 备注型最大风速(m/s) H1 字符型 16 风向与盛行风向 H2 字符型 16 平均风速(m/s) H3 字符型 16 最大流速(cm/s) H4 字符型 16 平均流速(cm/s) H5 字符型 16流型 H7 字符型 30 最大波高(米) H81 字符型 16 波长(米) H82 字符型 16 爬高(米) H83 字符型 16 增减水(米) H91 字符型 16 周期(分钟) H92 字符型 16 风涌水(米) H10 字符型 16 多年平均降水量(mm) I1 数值型 16.2 年最大降水量(mm) I2 数值型 16.2 年份 I3 字符型 10 年最小降水量(mm) I4 数值型 16.2 年份 I5 字符型 10 多年平均蒸发量(mm) I6 数值型 16.2 年最大蒸发量(mm) I7 数值型 16.2 年份 I8 字符型 10 年最小蒸发量(mm) I9 数值型 16.2 年份 I10 字符型 10 蒸发皿型号 I11 字符型 16 时间 J1 字符型 16 湖水含沙量(公斤/立方米) J2 字符型 16 浮游生物数量(毫克/升) J3 字符型 16 日照时数(小时) J4 字符型 16 日照百分率(%) J5 字符型 16 年总辐射量(焦耳/平方厘米) J61 字符型 16 散射辐射(焦耳/平方厘米) J62 字符型 16 直接辐射(焦耳/平方厘米) J63 字符型 16 反射率(%) J7 字符型 16 水色 J8 字符型 16 透明度(米) J9 字符型 16 备注 J10 备注型月平均最高水温(度) K1 字符型 20 极端最高水温(度) K2 字符型 20 月平均最低水温(度) K3 字符型 20 极端最低水温(度) K4 字符型 20 年平均水温(度) K5 字符型 20 月平均最高气温(度) K6 字符型 20 极端最高气温(度) K7 字符型 20 月平均最低气温(度) K8 字符型 20 极端最低气温(度) K9 字符型 20 年平均气温(度) K10 字符型 20 积温>0(度) K111 字符型 20 积温>10(度) K112 字符型 20 储热量(焦耳) K12 字符型 30年份 L1 字符型 16 纬度 L2 字符型 16 湖面海拔(米) L3 字符型 16 结冰期(起始时间) L4 字符型 16 解冰期(结束时间) L5 字符型 16 封冻时间(天数) L6 字符型 16 最大冰厚(米) L7 字符型 16 备注 L8 备注型3化学与污染库年份 M1 字符型 10 PH M2 数值型 16.4 钾离子 M31 数值型 16.4 钠离子 M32 数值型 16.4 钙离子 M33 数值型 16.4 镁离子 M34 数值型 16.4 氯离子 M35 数值型 16.4 硫酸根离子 M36 数值型 16.4 重碳酸根离子 M37 数值型 16.4 碳酸根离子 M38 数值型 16.4 数据单位 M9_UNIT 字符型 8矿化度(Mg/L) M4 数值型 16.4 总硬度(德国度) M5 数值型 16.4 水型 M6 字符型 20 电导率 M7 字符型 16 数据来源 M8 字符型 30 年份 N1 字符型 16 溶解氧 N21 字符型 16 游离二氧化碳 N22 字符型 16 硫化氢 N23 字符型 16 铵态氮 N31 字符型 16 硝态氮 N32 字符型 16 亚硝态氮 N33 字符型 16 无机氮 N34 字符型 16 备注 N4 字符型 20 年份 O1 字符型 10 初级生产率(g.(O2)/m2.d) O2 字符型 16 浮游植物生物量(mg/L) O3 字符型 16 叶绿素a(mg/m3) O4 字符型 16 TN(mg/L) O5 字符型 16 TP(mg/L) O6 字符型 16 备注 O7 备注型酚年均值 P11 字符型 16氰化物年均值 P21 字符型 16 范围值 p22 字符型 16 汞年均值 P31 字符型 16 范围值 p32 字符型 16 六价铬年均值 P41 字符型 16 范围值 p42 字符型 16 总铬年均值 P51 字符型 16 范围值 p52 字符型 16 砷年均值 P61 字符型 16 范围值 p62 字符型 16 铅年均值 P71 字符型 16 范围值 p72 字符型 16 锌年均值 P81 字符型 16 范围值 p82 字符型 16 铜年均值 P91 字符型 16 范围值 p92 字符型 16 油年均值 P101 字符型 16 范围值 p102 字符型 16 DO年均值 P111 字符型 16 范围值 p112 字符型 16 COD年均值 P121 字符型 16 范围值 p122 字符型 16 B0D5年均值 P131 字符型 16 范围值 p132 字符型 16 PH年均值 P141 字符型 16 范围值 p142 字符型 16 水质类别 P151 字符型 16 主要污染物 P152 字符型 204生物生态库蓝藻门生物量(毫克/升) Q111 字符型 16 数量(万个/升) Q112 字符型 16 硅藻门生物量(毫克/升) Q121 字符型 16 数量(万个/升) Q122 字符型 16 绿藻门生物量(毫克/升) Q131 字符型 16 数量(万个/升) Q132 字符型 16 甲藻门生物量(毫克/升) Q141 字符型 16 数量(万个/升) Q142 字符型 16 金藻门生物量(毫克/升) Q151 字符型 16 数量(万个/升) Q152 字符型 16 黄藻门生物量(毫克/升) Q161 字符型 16 数量(万个/升) Q162 字符型 16 裸藻门生物量(毫克/升) Q171 字符型 16数量(万个/升) Q172 字符型 16 轮藻门生物量(毫克/升) Q181 字符型 16 数量(万个/升) Q182 字符型 16 湖泊优势种类 Q2 备注型浮游植物时间变化 Q31 备注型平面变化 Q32 备注型垂直变化 Q33 备注型藻型湖分类 Q4 备注型原生动物生物量(毫克/升) R111 字符型 16 数量(个/升) R112 字符型 16 轮虫生物量(毫克/升) R121 字符型 16 数量(个/升) R122 字符型 16 枝角类生物量(毫克/升) R131 字符型 16 数量(个/升) R132 字符型 16 桡足类生物量(毫克/升) R141 字符型 16 数量(个/升) R142 字符型 16 湖泊优势种类 R2 备注型浮游动物时间变化 R31 备注型平面变化 R32 备注型垂直变化 R33 备注型摇蚊幼虫数量(个/平方米) S11 字符型 8 生物量(克/平方米) S12 字符型 16 寡毛虫数量(个/平方米) S21 字符型 8 生物量(克/平方米) S22 字符型 16 软体动物数量(个/平方米) S31 字符型 8 生物量(克/平方米) S32 字符型 16 环节动物数量(个/平方米) S41 字符型 8 生物量(克/平方米) S42 字符型 16 甲壳动物数量(个/平方米) S51 字符型 8 生物量(克/平方米) S52 字符型 16 底栖动物分布 S6 备注型种群组成 T1 备注型植被类型 T2 备注型生态类型 T3 字符型 20 分布面积(平方公里) T4 字符型 20 生物量(克/平方米) T5 字符型 16 主要经济植物 T6 字符型 16 植被演变 T7 备注型主要经济鱼类组成 U1 备注型多年平均年产量(吨) U2 字符型 16 最高年产量(吨) U3 字符型 16 最低年产量(吨) U4 字符型 16 平均亩产(公斤) U5 字符型 16 资源变动情况 U6 备注型增殖措施 U7 备注型资料年限 U8 字符型 165资源利用库多年平均最高水位(米) V1 数值型 16.4 多年平均最低水位(米) V2 数值型 16.4 滩地面积(平方公里) V3 字符型 20 总围垦面积(平方公里) V4 字符型 20 50年代围垦面积(平方公里) V51 字符型 20 60年代围垦面积(平方公里) V52 字符型 20 70年代围垦面积(平方公里) V53 字符型 20 80年代围垦面积(平方公里) V54 字符型 20 开垦利用方式与存在问题 V6 备注型水利工程控制情况 W1 备注型滞蓄洪水量(万立方米) W21 字符型 16 灌溉面积(公顷) W22 字符型 16 水力发电(千瓦) W23 字符型 16 航线里程(公里) W31 字符型 16 年货运量(万吨) W32 字符型 16 矿产资源 W4 字符型 30 旅游资源 W5 备注型资源利用前景 W6 备注型受灾年份 Z1 字符型 16 洪水位(米) Z2 字符型 16 超警戒水(米) Z3 字符型 16 持续时间(天) Z4 字符型 16 受灾农田 Z51 字符型 16 成灾农田 Z52 字符型 16 损失粮食 Z53 字符型 16 鱼池漫溢 Z6 字符型 16 居民住宅进水 Z7 字符型 16 倒塌房屋 Z8 字符型 16 工矿企业停产 Z9 字符型 16 工农业经济损失 Z10 字符型 16 受灾人口 Z11 字符型 16 死亡人口 Z12 字符型 16 其他 Z13 备注型6风景旅游库风景照片 photo 字符型 20 旅游介绍 travelling 字符型 20 补充说明 note1 备注型7遥感图象库遥感图象 image 字符型 20 补充说明 note2 备注型8湖泊地图库地图 map 字符型 20 补充说明 note3 备注型。
数据库命名规范

数据库命名规范批准人:审核人:编制人:编制日期:目录一、数据库的命名 (3)二、表的命名 (3)(一)表命名概要 (3)(二)表的中文名称 (3)(三)表物理名 (4)三、字段的命名 (5)(一)字段中文名 (5)(二)字段物理名 (5)(三)通用性字段中文名 (6)(四)数据库关键字-不能单独用作物理名 (8)(五)其他字段的命名 (9)数据库命名规范一、数据库的命名二、表的命名(一)表命名概要数据表的物理命名采用英文缩写的形式,多个缩写单词之间用下划线连接,开头部分表示表的分类前缀。
同时,一系列表、或一个风格的表应用较为统一的后缀。
例如:STK_DIV_MAIN表示上市公司及股票分类下的分红主表;STK_DIV_SUB表示上市公司及股票分类下的分红子表;STK_HOLDER_MAIN表示上市公司及股票分类下的股东主表;FND_INV_DETAIL表示基金分类下的投资组合股票投资明细。
一般规则:采用英文缩写的形式,多个缩写单词之间用下划线连接。
命名时要避免不同表间发生同名不同物,也要避免不同表间和相同表内发生同物不同名的命名情况。
(二)表的中文名称➢应尽量统一风格、统一标准。
➢同一个主题下的表中文名应尽量统一,保持同一风险的前缀或后缀。
➢主子表尽量加统一的后缀(主表、子表)(物理名类同)。
➢字段中文名不宜超过15个汉字➢财务类报表命名规范:财务横表:用“报表名称”+“_”+“金融/非金融/通用”+“_”+“新准则/旧准则”+“_”+“最新记录表”财务纵表:“报表名称”+“_”+“金融/非金融/通用”+“_”+“新准则/旧准则”+“_”+“纵表”(三)表物理名➢应按不同的主题,对物理名加统一前缀,便于进行检索。
➢物理名统一前缀与后续英文缩写用下划线连接。
➢物理名统一用大写英文字母。
➢表物理名字符长度不超过20,英文字母大写。
➢表物理名不能用数字开头。
➢参数表一律以“PAR”收尾。
➢必须避免用一个单词作表物理名,至少用两个词节。
chembl 筛选标准

chembl 筛选标准一、概述Chembl(Chemicals and their effects on Biological systems)是一个在线化学物质数据库,它包含了大量化学物质的信息,并可以用于药物研发中的筛选和比对。
在Chembl中,化学物质的筛选标准是其重要的一部分,它决定了哪些物质能够被纳入数据库,以及如何描述和呈现这些物质。
二、筛选标准内容1. 物质类型:Chembl数据库主要收录了小分子化合物、生物碱、天然产物等类型的物质。
物质类型会影响到数据库中物质的收录和分类。
2. 物质来源:物质来源包括实验室合成、天然产物、市场购买等。
不同的物质来源可能会对物质的性质和用途产生影响,因此在收录时需要进行分类和标注。
3. 化合物纯度:化合物纯度是筛选的重要标准之一,它决定了物质的可用性和效果。
数据库需要收录高质量的、纯度稳定的物质,以确保研究结果的准确性和可靠性。
4. 物质描述:物质描述包括物质的名称、分子式、分子量、结构式等信息。
这些信息需要准确、全面,以便于研究者能够快速了解物质的性质和特点。
5. 安全性评估:安全性评估是筛选标准的重要组成部分,它涉及到物质的毒性、刺激性、过敏性等信息。
只有经过安全评估的物质才能被收录到数据库中。
6. 活性评估:活性评估是筛选的另一个重要标准,它涉及到物质对生物系统的效应和作用机制。
只有具有明确活性的物质才能被纳入数据库,并用于药物研发中的筛选和比对。
三、筛选流程Chembl的筛选流程包括物质提交、初步筛选、实验验证、安全性评估、活性评估等步骤。
只有符合所有筛选标准的物质才能被收录到数据库中,并在其中进行共享和比对。
四、总结Chembl筛选标准是数据库收录物质的重要依据,它涉及到物质类型、来源、纯度、描述、安全性和活性等多个方面。
只有符合这些标准的物质才能被收录到数据库中,并用于药物研发中的筛选和比对。
通过严格的筛选流程,Chembl数据库为药物研发提供了重要的数据支持和服务。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
C H A P T E R12Query ProcessingThis chapter describes the process by which queries are executed efficiently bya database system.The chapter starts off with measures of cost,then proceedsto algorithms for evaluation of relational algebra operators and expressions.Thischapter applies concepts from Chapter2,6,10,and11.Query processing algorithms can be covered without tedious and distracting details of size estimation.Although size estimation is covered later,in Chapter13,the presentation there has been simplified by omitting some details.Instructorscan choose to cover query processing but omit query optimization,without lossof continuity with later chapters.Exercises12.10Suppose you need to sort a relation of40gigabytes,with4kilobyte blocks,using a memory size of40megabytes.Suppose the cost of a seek is5milliseconds,while the disk transfer rate is40megabytes per second.a.Find the cost of sorting the relation,in seconds,with b b=1and withb b=100.b.In each case,how many merge passes are required?c.Suppose aflash storage device is used instead of a disk,and it has aseek time of1microsecond,and a transfer rate of40megabytes persecond.Recompute the cost of sorting the relation,in seconds,withb b=1and with b b=100,in this setting.Answer:a.The number of blocks in the main memory buffer available for sort-=104.The number of blocks containing records ofing(M)is40×1063=107.Then the cost of sorting thethe given relation(b r)is40×1093relation is:(Number of disk seeks×Disk seek cost)+(Number of blocktransfers×Block transfer time).Here Disk seek cost is5x10−3seconds103104Chapter12Query Processingand Block transfer time is10−4seconds(4×10340×106).The number of blocktransfers is independent of b b and is equal to25×106.•Case1:b b=1Using the equation in Section12.4,the number of disk seeks is5002×103.Therefore the cost of sorting the relation is:(5002×103)×(5×10−3)+(25×106)×(10−4)=25×103+2500=27500seconds.•Case2:b b=100The number of disk seeks is:52×103.Therefore the cost ofsorting the relation is:(52×103)×(5×10−3)+(25×106)×(10−4)=260+2500=2760seconds.b.Disk storage The number of merge passes required is given by⌈log M−1(b r)⌉.This is independent of b b.Substituting the values above,we get⌈log104−1(1074)⌉which evaluates to1.c.Flash storage:•Case1:b b=1The number of disk seeks is:5002×103.Therefore the cost ofsorting the relation is:(5002×103)×(1×10−6)+(25×106)×(10−4)=5.002+25002506seconds.•Case2:b b=100The number of disk seeks is:52×103.Therefore the cost of sortingthe relation is:(52×103)×(1×10−6)+(25×106)×(10−4)=0.052+2500,which is approx=2500seconds.12.11Consider the following extended relational-algebra operators.Describehow to implement each operation using sorting,and using hashing.a.Semijoin(⋉):r⋉s is defined as R(r1s),where R is the setof attributes in the schema of r;that it selects those tuples r i in r forwhich there is a tuple s j in s such that r i and s j satisfy predicate.b.Anti-semijoin(¯⋉):r¯⋉s is defined as r− R(r1s);that it it selectsthose tuples r i in r for which there is no tuple s j in s such that r i ands j satisfy predicate.Answer:As in the case of join algorithms,semijoin and anti-semijoin can be done efficiently if the join conditions are equijoin conditions.We describe below how to efficiently handle the case of equijoin conditions using sorting and hashing.With arbitrary join conditions,sorting and hashing cannot be used;(block)nested loops join needs to be used instead.a.Semijoin:•Semijoin using Sorting:Sort both r and s on the join attributes in.Perform a scan of both r and s similar to the merge al-Exercises105 gorithm and add tuples of r to the result whenever the joinattributes of the current tuples of r and s match.•Semijoin using Hashing:Create a hash index in s on the join attributes in.Iterate over r,and for each distinct value of thejoin attributes,perform a hash lookup in s.If the hash lookupreturns a value,add the current tuple of r to the result.Note that if r and s are large,they can be partitioned on thejoin attributesfirst,and the above procedure applied on eachpartition.If r is small but s is large,a hash index can be built onr,and probed using s;and if an s tuple matches an r tuple,ther tuple can be output and deleted from the hash index.b.Anti-semijoin:•Anti-Semijoin using Sorting:Sort both r and s on the join attributes in.Perform a scan of both r and s similar to themerge algorithm and add tuples of r to the result if no tuple ofs satisfies the join predicate for the corresponding tuple of r.•Anti-Semijoin using Hashing:Create a hash index in s on the join attributes in.Iterate over r,and for each distinct valueof the join attributes,perform a hash lookup in s.If the hashlookup returns a null value,add the current tuple of r to theresult.As for semijoin,partitioning can be used if r and s are large.Anindex on r can be used instead of an index on s,but then whenan s tuple matches an r tuple,the r tuple is deleted from theindex.After processing all s tuples,all remaining r tuples in theindex are output as the result of the anti-semijoin operation. 12.12Why is it not desirable to force users to make an explicit choice of a query-processing strategy?Are there cases in which it is desirable for users to be aware of the costs of competing query-processing strategies?Explain your answer.Answer:In general it is not desirable to force users to choose a query processing strategy because naive users might select an inefficient strat-egy.The reason users would make poor choices about processing queries is that they would not know how a relation is stored,nor about its indices.It is unreasonable to force users to be aware of these details since ease of use is a major object of database query languages.If users are aware of the costs of different strategies they could write queries efficiently,thus helping performance.This could happen if experts were using the system.12.13Design a variant of the hybrid merge-join algorithm for the case whereboth relations are not physically sorted,but both have a sorted secondary index on the join attributes.Answer:We merge the leaf entries of thefirst sorted secondary index with the leaf entries of the second sorted secondary index.The resultfile contains pairs of addresses,thefirst address in each pair pointing to a106Chapter12Query Processingtuple in thefirst relation,and the second address pointing to a tuple inthe second relation.This resultfile isfirst sorted on thefirst relation’s addresses.The relationis then scanned in physical storage order,and addresses in the resultfileare replaced by the actual tuple values.Then the resultfile is sorted onthe second relation’s addresses,allowing a scan of the second relation inphysical storage order to complete the join.12.14Estimate the number of block transfers and seeks required by your solu-tion to Exercise12.13for r11r2,where r1and r2are as defined in PracticeExercise12.3.Answer:r1occupies800blocks,and r2occupies1500blocks.Let there ben pointers per index leaf block(we assume that both the indices have leafblocks and pointers of equal sizes).Let us assume M pages of memory,M<800.r1’s index will need B1=⌈20000n ⌉leaf blocks,and r2’s indexwill need B2=⌈45000⌉leaf blocks.Therefore the merge join will need B3=B1+B2accesses,without output.The number of output tuplesis estimated as n o=⌈20000∗4500012⌉.Each output tuple will need twopointers,so the number of blocks of join output will be B o1=⌈n o⌉.Hence the join needs B j=B3+B o1disk block accesses.Now we have to replace the pointers by actual tuples.For thefirst sorting,B s1=B o1(2⌈log M−1(B o1/M)⌉+2)disk accesses are needed,including thewriting of output to disk.The number of blocks of r1which have to be accessed in order to replace the pointers with tuple values is min(800,n o).Let n1pairs of the form(r1tuple,pointer to r2)fit in one disk block.Therefore the intermediate result after replacing the r1pointers will occupy B o2=⌈(n o/n1)⌉blocks.Hence thefirst pass of replacing the r1-pointers will costB f=B s1+B o1+min(800,n o)+B o2disk accesses.The second pass for replacing the r2-pointers has a similar analysis.Let n2 tuples of thefinal joinfit in one block.Then the second pass of replacing the r2-pointers will cost B s=B s2+B o2+min(1500,n o)disk accesses,whereB s2=B o2(2⌈log M−1(B o2/M)⌉+2).Hence the total number of disk accesses for the join is B j+B f+B s,and the number of pages of output is⌈n o/n2⌉.12.15The hash-join algorithm as described in Section12.5.5computes the nat-ural join of two relations.Describe how to extend the hash-join algorithm to compute the natural left outer join,the natural right outer join and the natural full outer join.(Hint:Keep extra information with each tuple in the hash index,to detect whether any tuple in the probe relation matches the tuple in the hash index.)Try out your algorithm on the takes and student relations.Answer:For the probe relation tuple t r under consideration,if no matching tuple is found in the build relation’s hash partition,it is padded with nulls and included in the result.This will give us the natural left outer join t r1t s.To get the natural right outer join t r1t s,we can keepExercises107a booleanflag with each tuple in the current build relation partition s iresiding in memory,and set it whenever any probe relation tuple matches with it.When we arefinished with s i,all the tuples in it which do not have theirflag set,are padded with nulls and included in the result.To get the natural full outer join,we do both the above operations together.To try out our algorithm,we use the sample student and takes relations of Figures A.9and A.10.Let us assume that there is enough memory to hold three tuples of the build relation plus a hash index for those three tuples.We use takes as the build relation.We use the simple hashing function which returns the student ID mod10.Taking the partition corresponding to value7,we get r1={(“Snow”)},and s1=.The tuple in the probe relation partition will have no matching tuple,so(“70557”,“Snow”,“Physics”,“0”,null)is outputted.Proceeding in a similar way,we process all the partitions and complete the join.12.16Pipelining is used to avoid writing intermediate results to disk.Supposeyou need to sort relation r using sort–merge and merge-join the result with an already sorted relation s.a.Describe how the output of the sort of r can be pipelined to themerge join without being written back to disk.b.The same idea is applicable even if both inputs to the merge joinare the outputs of sort–merge operations.However,the availablememory has to be shared between the two merge operations(themerge-join algorithm itself needs very little memory).What is theeffect of having to share memory on the cost of each sort–mergeoperation?Answer:ing pipelining,output from the sorting operation on r is writtento a buffer B.When B is full,the merge-join processes tuples from B,joining them with tuples from s until B is empty.At this point,thesorting operation is resumed and B is refilled.This process continuesuntil the merge-join is complete.b.If the sort–merge operations are run in parallel and memory isshared equally between the two,each operation will have only M/2frames for its memory buffer.This may increase the number of runsrequired to merge the data.12.17Write pseudocode for an iterator that implements a version of the sort–merge algorithm where the result of thefinal merge is pipelined to its consumers.Your pseudocode must define the standard iterator functions open(),next(),and close().Show what state information the iterator must maintain between calls.Answer:Let M denote the number of blocks in the main memory buffer available for sorting.For simplicity we assume that there are less than M108Chapter12Query Processingruns created in the run creation phase.The pseudocode for the iteratorfunctions open,next and close are as follows:SortMergeJoin::open()beginrepeatread M blocks of the relation;sort the in-memory part of the relation;write the sorted data to a runfile R iuntil the end of the relationread one block of each of the N runfiles R i,into abuffer block in memorydone r:=false;endSortMergeJoin::close()beginclear all the N runs from main memory and disk;endboolean SortMergeJoin::next()beginif the buffer block of any run R i is empty and not end-of-file(R i)beginread the next block of R i(if any)into the buffer block;endif all buffer blocks are emptyreturn false;choose thefirst tuple(in sort order)among the buffer blocks;write the tuple to the output buffer;delete the tuple from the buffer block and increment its pointer;return true;end12.18Suppose you have to compute A G sum(C)(r)as well as A,B G sum(C)(r).Describehow to compute these together using a single sorting of r.Answer:Run the sorting operation on r,grouping by(A,B),as requiredfor the second result.When evaluating the sum aggregate,keep runningtotals for both the(A,B)grouping as well as for just the A grouping.。