oracle 数据库状态转换
oracle switchover切换原理

oracle switchover切换原理Oracle Switchover 是一种数据库切换技术,用于无需停机的在数据库的主备之间切换角色。
它基于 Oracle Data Guard 技术,保证数据库的高可用性和灾备性能。
下面是 Oracle Switchover 切换的简要原理:1. 数据库配置:首先,需要配置一个主数据库(Primary)和一个备数据库(Standby)。
主数据库用于处理正常的读写操作,备数据库用于持续复制主数据库的变更。
2. 数据复制:主数据库生成归档日志(Archive Log)并将其传输到备数据库。
备数据库通过应用归档日志来保持与主数据库的同步,并反映主数据库的所有更改。
3. 角色切换前的准备:在切换前,需要确保主数据库和备数据库的同步状态,并保证备数据库中的数据与主数据库一致。
可以使用 Data Guard Broker 或手动管理来监视和管理主备数据库之间的同步。
4. 角色切换操作:当需要执行 Switchover 操作时,可以使用 ALTER DATABASE 命令或 Data Guard Broker 进行操作。
在此过程中,主数据库会转换为备数据库(Standby),备数据库会转换为主数据库(Primary)。
5. 角色切换后的操作:在角色切换完成后,原先的主数据库现在成为备数据库,它将继续接收归档日志并保持与新主数据库的同步。
新主数据库将接收读写操作,并继续生成归档日志。
6. 切换完成后的验证:在切换完成后,可以验证新主数据库和原备数据库的角色切换是否成功。
确保新主数据库能够正常处理读写请求,而原备数据库能够正常接收归档日志并与新主数据库同步。
通过 Oracle Switchover 技术,数据库管理员可以实现主备数据库之间的无缝切换,确保业务的连续性和高可用性。
同时,Switchover 还可以用于执行计划的数据库维护和升级操作,以减少对业务的影响。
ORACLE常用数据库类型(转)

ORACLE常⽤数据库类型(转)oracle常⽤数据类型1、Char定长格式字符串,在数据库中存储时不⾜位数填补空格,它的声明⽅式如下CHAR(L),L为字符串长度,缺省为1,作为变量最⼤32767个字符,作为数据存储在ORACLE8中最⼤为2000。
不建议使⽤,会带来不必要的⿇烦a、字符串⽐较的时候,如果不注意(char不⾜位补空格)会带来错误b、字符串⽐较的时候,如果⽤trim函数,这样该字段上的索引就失效(有时候会带来严重性能问题)c、浪费存储空间(⽆法精准计算未来存储⼤⼩,只能留有⾜够的空间;字符串的长度就是其所占⽤空间的⼤⼩)2、Varchar2/varchar⽬前VARCHAR是VARCHAR2的同义词。
⼯业标准的VARCHAR类型可以存储空字符串,但是oracle不这样做,尽管它保留以后这样做的权利。
Oracle⾃⼰开发了⼀个数据类型VARCHAR2,这个类型不是⼀个标准的VARCHAR,它将在数据库中varchar列可以存储空字符串的特性改为存储NULL值。
如果你想有向后兼容的能⼒,Oracle建议使⽤VARCHAR2⽽不是VARCHAR。
不定长格式字符串,它的声明⽅式如下VARCHAR2(L),L为字符串长度,没有缺省值,作为变量最⼤32767个字节,作为数据存储在ORACLE8中最⼤为4000。
在多字节语⾔环境中,实际存储的字符个数可能⼩于L值,例如:当语⾔环境为中⽂(SIMPLIFIED CHINESE_CHINA.ZHS16GBK)时,⼀个VARCHAR2(200)的数据列可以保存200个英⽂字符或者100个汉字字符;对于4000字节以内的字符串,建议都⽤该类型a。
VARCHAR2⽐CHAR节省空间,在效率上⽐CHAR会稍微差⼀些,即要想获得效率,就必须牺牲⼀定的空间,这也就是我们在数据库设计上常说的‘以空间换效率’。
b。
VARCHAR2虽然⽐CHAR节省空间,但是如果⼀个VARCHAR2列经常被修改,⽽且每次被修改的数据的长度不同,这会引起‘⾏迁移’(Row Migration)现象,⽽这造成多余的I/O,是数据库设计和调整中要尽⼒避免的,在这种情况下⽤CHAR代替VARCHAR2会更好⼀些。
ORCLE数据库转换的基本操作流程
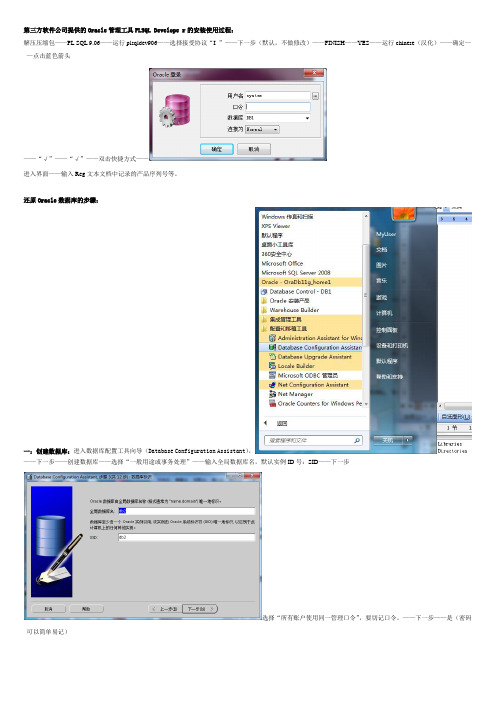
第三方软件公司提供的Oracle管理工具PLSQL Develope r的安装使用过程:解压压缩包——PL SQL 9.06——运行plsqldev906——选择接受协议“I ”——下一步(默认,不做修改)——FINISH——YES——运行chinese(汉化)——确定——点击蓝色箭头——“√”——“√”——双击快捷方式——进入界面——输入Reg文本文档中记录的产品序列号等。
还原Oracle数据库的步骤:一:创建数据库:进入数据库配置工具向导(Database Configuration Assistant),——下一步——创建数据库——选择“一般用途或事务处理”——输入全局数据库名,默认实例ID号:SID——下一步选择“所有账户使用同一管理口令”,要切记口令。
——下一步——是(密码可以简单易记)全部默认下一步,直至完成。
点击退出。
二、测试连接点击Net Manager.点击服务名(此处为db2)——点击测试服务按钮——更改登录——测试成功——关闭。
三、找到源数据(即被审计单位备份数据),进入D OS命令环境下,开始转换数据。
(在转换被审计单位数据时,监听及数据库服务必须启动,才能还原数据库。
计算机(我的电脑)——右击鼠标——管理——服务和应用程序——服务)四、生成日志文件,查找用户名和表空间名:点击所有程序——附件——运行——在对话框中输入:cmd,进入dos命令环境。
输入:CD\,回车;再输入:imp system/123@db1 f ile=d:\ wzxs110711.dmp f ull=y buf fer=10240000 show=y log=d:\db1.log ——回车键。
(注意:IMP为客户端导入工具,与EXP(导出)成对使用,命令格式:IMP <用户名>/<口令>@服务名<参数1> <参数2> …;导入整个dmp文件:IMP <用户名>/<口令>@<数据库> FILE=<文件名> FULL=Y IGNORE=Y BUFFER=<缓冲区大小> LOG=<日志文件名>——参数说明:FILE:输入文件(dmp文件);FULL:导入整个dmp文件(N)(完全还原,还原当前用户的数据库,默认N(NO));BUFFER:数据缓冲区大小(并不是越大越好,建议值:10240000);SHOW:只列出文件内容(N)(第一次测试时用SHOW =Y);LOG:导出日志文件(必须提供,生成日志文件,可以在生成的文件中查找用户名和表空间名)。
Oracle常用函数以及行列转换

常用的函数数值函数➢ABS(N) 返回指定值的绝对值➢CEIL(N) 返回大于或等于给出数字的最小整数➢FLOOR(N) 对给定的数字取整数➢MOD(M,N) 返回一个M除以N的余数➢ROUND( M [,N] ) 按照指定的小数位元数进行四舍五入运算的结果参数:如果N不为整数则截取N整数部分,如果N>0则四舍五入为N位小数,如果N 小于0则四舍五入到小数点向左第N位。
➢TRUNC(M[,N]) 返回M按精度N截取后的值参数:如果N不为整数则截取N整数部分,如果N>0则截取到N位小数,如果N小于0则截取到小数点向左第N位,小数前其它数据用0表示。
转换函数➢TO_CHAR (NUMBER | date,'format')➢TO_NUMBER (char , 'format')➢TO_DATE (char, 'format')分组函数➢MAX➢AVG➢MIN➢COUNT ➢SUM字段为空的判断NULL的概述NULL在Oracle中是很特殊的值,任何类型的值都可以是NULL。
如果在某行中有一列没有值,那么就说慈航中这个列的值是NULL。
NULL是未知的东西,常称它为“UNKNOWN”或空值。
正因为它是未知的,才会有很多值得注意的规则。
NULL可以是任何数据类型的值,也可以不依赖于数据类型单独存在(字面量NULL),任何没有NOT NULL约束或主键约束的列都有可能出现NULL值。
NULL和其他任何值都不相等或相等,包括自身(当然是用IS NULL判断是可以的)。
但是在某些时候,Oracle却把他们当成相等的(指Oracle的一些内部规则),如SQL集合语句、Group by分组、Decode函数等。
NULL的判断和比较运算规则Oracle中判断一个列值或变量值是否是NULL,必须是用IS NULL或IS NOT NULL,而不能使用=NULL或<>NULL。
Oracle11G数据库DataGuard灾备切换方案

Oracle 11G数据库DataGuard灾备切换方案、检查1、确定MRP进程在正常运行real-time apply real-time apply SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT;2、确定有足够的归档进程在所有的主备库实例上查询参数LOG_ARCHIVE_MAX_PROCESSES,确定其值大于等于4, 但不会太大3、确定目标备库的REDO为clear状态虽然在发起SWITCHOVER TO PRIMARY命令时,备库的REDO会自动转换为CLEAR 状态,但依然建议在SWITCHOVER前REDO为CLEAR状态。
确保正确设置了 LOG_FILE_NAME_CONVERT参数。
AND L.STATUS NOT IN (\UNUSED’,、CLEARING’,’CLEARING_CURRENT’);如果如上的查询有结果,4、确定没有大量的GAP5、确定主库以及目标备库的所有文件都为ONLINE主备库分别执行如下SQL,查看tempfile是否正常,如果备库上缺失文件则需要进行处、切换1、检查主库是否可切换至STANDBY如上的SQL查询结果如果为〃TO STANDBY”或者〃SESSIONS ACTIVE〃表示主库可切换至STANDBY,如果不为这两个值,则说明REDO传输存在问题。
2、停止主库第一个节点以外的所有实例(RAC)最好使用shutdown normal或者shutdown immediate方式停止数据库。
如果使用了shutdown abort将其他节点进行了关闭,则需等待RAC reconfig完成,且第一个节点将其余REDO正常前滚或回滚3、切换主库至STANDBY角色如果遇到ORA-16139报错,且V$DATABASE视图中DATABASE_ROLE字段的值已为“ PHYSICAL STANDBY”,则可继续(这种问题的出现其中一个可能是数据库有大量的数据文件)。
数据库的关闭与启动
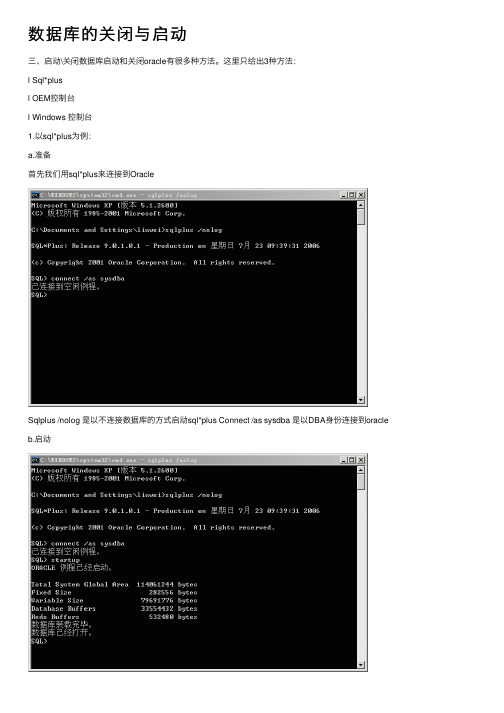
数据库的关闭与启动三、启动\关闭数据库启动和关闭oracle有很多种⽅法。
这⾥只给出3种⽅法:l Sql*plusl OEM控制台l Windows 控制台1.以sql*plus为例:a.准备⾸先我们⽤sql*plus来连接到OracleSqlplus /nolog 是以不连接数据库的⽅式启动sql*plus Connect /as sysdba 是以DBA⾝份连接到oracle b.启动启动还是⽐较简单的Startup就OK了。
不过oracle启动模式有3种:l Startup nomount (nomount模式)启动实例不加载数据库。
l Startup mount (mount模式)启动实例加载数据库但不打开数据库l Startup (open 模式)启动实例加载并打开数据库,就是我们上⾯所⽤的命令Nomount模式中oracle仅为实例创建各种内存结构和服务进程,不会打开任何数据库⽂件,所以说:1)创建新数据库2)重建控制⽂件这2种操作都必须在这个模式下进⾏。
Mount模式中oracle只装载数据库但不打开数据库,所以说:1)重命名数据⽂件2)添加、删除和重命名重做⽇⼦⽂件3)执⾏数据库完全恢复操作4)改变数据库的归档模式这4种操作都必须在这个模式下进⾏Open模式(就是我们上⾯的startup不带任何参数的)呵呵就不多说了,正常启动。
当然这3种模式之间可以转换:Alter database mount(nomount模式)—〉alter database open(mount 模式)—〉(open模式)当然还有其它⼀些情况,在我们open模式下可以将数据库设置为⾮受限状态和受限状态在受限状态下,只有DBA才能访问数据库,所以说:1)执⾏数据导⼊导出2)使⽤sql*loader提取外部数据3)需要暂时拒绝普通⽤户访问数据库4)进⾏数据库移植或者升级操作这4种操作都必须在这个状态下进⾏在打开数据库时使⽤startup restrict命令即进⼊受限状态。
Oracle中的数据类型和数据类型之间的转换

Oracle中的数据类型和数据类型之间的转换Oracle中的数据类型/*ORACLE 中的数据类型;char 长度固定范围:1-2000VARCHAR2 长度可变范围:1-4000LONG 长度可变最⼤的范围2gb 长字符类型number 数字 number(p,s)Date ⽇期类型,精确到秒TIMESTAMP 存储⽇期,时间,时区,妙值,精确到⼩数CLOB 字符数据BLOB 存放⼆进制数据,视频图⽚等BFILE :⽤于将⼆进制数据存储在数据库外部的操作系统⽂件中所谓固定长度:所谓固定长度:是指虽然输⼊的字段值⼩于该字段的限制长度,但是实际存储数据时,会先⾃动向右补⾜空格后,才将字段值的内容存储到数据块中。
这种⽅式虽然⽐较浪费空间,但是存储效率较可变长度类型要好。
同时还能减少数据⾏迁移情况发⽣。
所谓可变长度:是指当输⼊的字段值⼩于该字段的限制长度时,直接将字段值的内容存储到数据块中,⽽不会补上空⽩,这样可以节省数据块空间。
*/--储字节或字符?CREATE TABLE T1(NAME CHAR(4) --默认的是字节);INSERT INTO T1 VALUES('AB');INSERT INTO T1 VALUES('ABCD');INSERT INTO T1 VALUES('我爱中国'); --这个就会报错INSERT INTO T1 VALUES('我爱'); --这样就是正确滴呀SELECT*FROM T1;SELECT LENGTH(ltrim(rtrim(NAME))) FROM T1 WHERE NAME='AB'--2SELECT LENGTH(NAME) FROM T1 WHERE NAME='AB'--4SELECT NAME FROM T1 WHERE NAME=N'AB'; --没有值滴呀;SELECT NAME FROM T1 WHERE NAME='AB';--同样的⽐较;CREATE TABLE T2(NAME CHAR(4CHAR) --默认的是字节);INSERT INTO T2 VALUES('ABCD');INSERT INTO T2 VALUES('ABCDABCD'); --报错INSERT INTO T2 VALUES('我爱中国'); ----正常插⼊SELECT*FROM T2;--⼀个汉字占⼏个字符,具体的还要看编码⽅式/*数据库的NLS_CHARACTERSET 为AL32UTF8,即⼀个汉字占⽤三到四个字节。
oracle主备库切换ora-01507

主备切换(SWITCHOVER)switchover:主库切换为备库:SQL> select database_role ,switchover_status from v$database;DATABASE_ROLE SWITCHOVER_STATUS-------------------------------- ------------------------------------PRIMARY SESSIONS ACTIVESQL> ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY WITH SESSION SHUTDO WN;数据库已更改。
SQL>SQL> select database_role ,switchover_status from v$database;select database_role ,switchover_status from v$database*ERROR 位于第 1 行:ORA-01507: 未安装数据库SQL> startup mount;ORA-01081: 无法启动已在运行的 ORACLE --- 请首先关闭SQL> shutdown immediate;ORA-01507: 未安装数据库ORACLE 例程已经关闭。
SQL> startup mount;ORACLE 例程已经启动。
Total System Global Area 143727516 bytesFixed Size 453532 bytesVariable Size 109051904 bytesDatabase Buffers 33554432 bytesRedo Buffers 667648 bytesORA-01666: ???????????SQL> select database_role ,switchover_status from v$database;select database_role ,switchover_status from v$database*ERROR 位于第 1 行:ORA-01507: ??????SQL> select status from v$instance;STATUS------------------------STARTEDSQL> alter database mount standby database;数据库已更改。
Oracle归档模式和非归档模式的区别

Oracle归档模式和⾮归档模式的区别⼀。
查看oracle数据库是否为归档模式:Sql代码1.select name,log_mode from v$database;NAME LOG_MODE------------------ ------------------------QUERY NOARCHIVELOG2.使⽤ARCHIVE LOG LIST 命令Database log mode No Archive ModeAutomatic archival DisabledArchive destination /data/oracle/product/10.2.0/db_1//dbs/archOldest online log sequence 739Current log sequence 741[sql] view plaincopyprint?1.select name,log_mode from v$database;NAME LOG_MODE------------------ ------------------------QUERY NOARCHIVELOG2.使⽤ARCHIVE LOG LIST 命令Database log mode No Archive ModeAutomatic archival DisabledArchive destination /data/oracle/product/10.2.0/db_1//dbs/archOldest online log sequence 739Current log sequence 7411.select name,log_mode from v$database;NAME LOG_MODE------------------ ------------------------QUERY NOARCHIVELOG2.使⽤ARCHIVE LOG LIST 命令Database log mode No Archive ModeAutomatic archival DisabledArchive destination /data/oracle/product/10.2.0/db_1//dbs/archOldest online log sequence 739Current log sequence 741⼆。
Oracle数据隐式转换规则

Oracle数据隐式转换规则The following rules govern the direction in which Oracle makes implicit data type conversions(在oracle中,如果不同的数据类型之间关联,如果不显式转换数据,则它会根据以下规则对数据进行隐式转换):1)During INSERT and UPDATE operations, Oracle converts the value to the datatypeof the affected column(对于INSERT和UPDATE操作,oracle会把插入值或者更新值隐式转换为字段的数据类型)如:假如id列的数据类型为numberupdate t set id='1'; -> 相当于update t set id=to_number('1');insert into t(id) values('1') -> insert into t values(to_number('1'));2)During SELECT FROM operations, Oracle converts the data from the column tothe type of the target variable(对于SELECT语句,oracle会把字段的数据类型隐式转换为变量的数据类型).如:假设id列的数据类型为varchar2select * from t where id=1; -> select * from t where to_number(id)=1;但如果id列的数据类型为number,则select * from t where id='1'; -> select * from t where id=to_number('1');3)When comparing a character value with a NUMBER value, Oracle converts thecharacter data to NUMBER(当比较一个字符型和数值型的值时,oracle会把字符型的值隐式转换为数值型).如:假设id列的数据类型为numberselect * from t where id='1'; -> select * from t where id=to_number('1');4)When comparing a character value with a DATE value, Oracle converts thecharacter data to DATE(当比较字符型和日期型的数据时,oracle会把字符型转换为日期型).如:假设create_date为字符型,select * from t where create_date>sysdate; -> select * from t where to_date(create_date)>sysdate;(注意,此时session的nls_date_format需要与字符串格式相符)假设create_date为date型select * from t where create_date>'2006-11-11 11:11:11'; -> select * from t where create_date>to_date('2006-11-11 11:11:11'); (注意,此时session的nls_date_format需要与字符串格式相符)5)When you use a SQL function or operator with an argument of a datatype otherthan the one it accepts, Oracle converts the argument to the accepted datatype.(如果调用函数或过程等时,如果输入参数的数据类型与函数或者过程定义的参数数据类型不一直,则oracle会把输入参数的数据类型转换为函数或者过程定义的数据类型)如:假设过程如下定义p(p_1 number)exec p('1'); -> exec p(to_number('1'));6)When making assignments, Oracle converts the value on the right side of theequal sign (=) to the datatype of the target of the assignment on the left side(赋值时,oracle会把等号右边的数据类型转换为左边的数据类型).如:var a numbera:='1'; - > a:=to_number('1');7)During concatenation operations, Oracle converts from noncharacter datatypesto CHAR or NCHAR(用连接操作符(||)时,oracle会把非字符类型的数据转换为字符类型).如:select 1||'2' from dual; -> select to_char(1)||'2' from dual;8)During arithmetic operations on and comparisons between character andnoncharacter datatypes, Oracle converts from any character datatype to a number, date, or rowid, as appropriate. In arithmetic operations between CHAR/VARCHAR2 and NCHAR/NVARCHAR2, Oracle converts to a number.如果字符类型的数据和非字符类型的数据(如number、date、rowid等)作算术运算,则oracle会将字符类型的数据转换为合适的数据类型,这些数据类型可能是number、date、rowid等。
Oracle转换启动模式

Oracle转换启动模式在进行某些特定的管理和维护操作时,需要使用某种特定的启动模式来启动数据库。
但是当管理或维护操作完成后,需要改变数据库的启动模式。
例如,为一个未加载数据库的实例加载数据库,或者将一个处于未打开状态的数据库设置为打开状态等。
在数据库的各种启动模式之间切换需要使用ALTER DATABASE语句。
下面分别介绍在不同的情况下,如何利用ALTER DATABASE语句来改变数据库的启动模式。
1.实例加载数据库在执行一些特殊的管理和维护操作时,需要进入NOMOUNT启动模式。
在完成操作后,可以使用如下语句为实例加载数据库,切换到MOUNT启动模式:SQL> startup nomountORACLE 例程已经启动。
Total System Global Area 376635392 bytesFixed Size 1333312 bytesVariable Size 310380480 bytesDatabase Buffers 58720256 bytesRedo Buffers 6201344 bytesSQL> alter database mount;数据库已更改。
2.打开数据库为实例加载数据库后,数据库可能仍然处于关闭状态。
为了使用户能够访问数据库,可以使用如下语句打开数据库,即切换到OPEN启动模式:SQL> alter database open;数据库已更改。
数据库设置为打开状态后,用户就可以以正常方式访问数据库。
3.切换受限状态在正常启动模式下(OPEN启动模式),可以选择将数据库设置为非受限状态和受限状态。
在受限状态下,只有具有管理权限的用户才能够访问数据库。
当需要进行如下数据库维护操作时,必须将数据库置于受限状态:●执行数据导入或导出操作。
●暂时拒绝普通用户访问数据库。
●进行数据库移植或升级操作。
当打开的数据库被设置为受限状态时,只有同时具有CREATE SESSION和RESTRICTED SESSION系统权限的用户才能够访问。
OracleCBO几种基本的查询转换详解

OracleCBO⼏种基本的查询转换详解在执⾏计划的开发过程中,转换和选择有这个不同的任务;实际上,在⼀个查询进⾏完语法和权限检查后,⾸先发⽣通称为“查询转换”的步骤,这⾥会进⾏⼀系列查询块的转换,然后才是“优选”(优化器为了决定最终的执⾏计划⽽为不同的计划计算成本从⽽选择最终的执⾏计划)。
我们知道查询块是以SELECT关键字区分的,查询的书写⽅式决定了查询块之间的关系,各个查询块通常都是嵌在另⼀个查询块中或者以某种⽅式与其相联结;例如:复制代码代码如下:select * from employees where department_id in (select department_id from departments)就是嵌套的查询块,不过它们的⽬的都是去探索如果改变查询写法会不会提供更好的查询计划。
这种查询转换的步骤对于执⾏⽤户可以说是完全透明的,要知道转换器可能会在不改变查询结果集的情况下完全改写你的SQL 语句结构,因此我们有必要重新评估⾃⼰的查询语句的⼼理预期,尽管这种转换通常来说都是好事,为了获得更好更⾼效的执⾏计划。
我们现在来讨论⼀下⼏种基本的转换:1.视图合并2.⼦查询解嵌套3.谓语前推4.物化视图查询重写⼀、视图合并这种⽅式⽐较容易理解,它会将内嵌的视图展开成⼀个独⽴处理的查询块,或者将其与查询剩余部分合并成⼀个总的执⾏计划,转换后的语句基本上不包含视图了。
视图合并通常发⽣在当外部查询块的谓语包括:1,能够在另⼀个查询块的索引中使⽤的列2,能够在另⼀个查询块的分区截断中所使⽤的列3,在⼀个联结视图能够限制返回⾏数的条件在这种查询器的转换下,视图并不总会有⾃⼰的⼦查询计划,它会被预先分析并通常情况下与查询的其他部分合并以获得性能的提升,如下例。
复制代码代码如下:SQL> set autotrace traceonly explain-- 进⾏视图合并SQL> select * from EMPLOYEES a,2 (select DEPARTMENT_ID from EMPLOYEES) b_view3 where a.DEPARTMENT_ID = b_view.DEPARTMENT_ID(+)4 and a.SALARY > 3000;Execution Plan----------------------------------------------------------Plan hash value: 1634680537----------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |----------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 3161 | 222K| 3 (0)| 00:00:01 || 1 | NESTED LOOPS OUTER| | 3161 | 222K| 3 (0)| 00:00:01 ||* 2 | TABLE ACCESS FULL| EMPLOYEES | 103 | 7107 | 3 (0)| 00:00:01 ||* 3 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 31 | 93 | 0 (0)| 00:00:01 |----------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------2 - filter("A"."SALARY">3000)3 - access("A"."DEPARTMENT_ID"="DEPARTMENT_ID"(+))-- 使⽤NO_MERGE防⽌视图被重写SQL> select * from EMPLOYEES a,2 (select /*+ NO_MERGE */DEPARTMENT_ID from EMPLOYEES) b_view3 where a.DEPARTMENT_ID = b_view.DEPARTMENT_ID(+)4 and a.SALARY > 3000;Execution Plan----------------------------------------------------------Plan hash value: 1526679670-----------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-----------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 3161 | 253K| 7 (15)| 00:00:01 ||* 1 | HASH JOIN RIGHT OUTER| | 3161 | 253K| 7 (15)| 00:00:01 || 2 | VIEW | | 107 | 1391 | 3 (0)| 00:00:01 || 3 | TABLE ACCESS FULL | EMPLOYEES | 107 | 321 | 3 (0)| 00:00:01 ||* 4 | TABLE ACCESS FULL | EMPLOYEES | 103 | 7107 | 3 (0)| 00:00:01 |-----------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - access("A"."DEPARTMENT_ID"="B_VIEW"."DEPARTMENT_ID"(+))4 - filter("A"."SALARY">3000)出于某些情况,视图合并会被禁⽌或限制,如果在⼀个查询块中使⽤了分析函数,聚合函数,,集合运算(如union,intersect,minux),order by⼦句,以及rownum中的任何⼀种,这种情况都会发⽣;尽管如此,我们仍然可以使⽤/*+ MERGE(v) */提⽰来强制使⽤视图合并,不过前提⼀定要保证返回的结果集是⼀致的如下例:复制代码代码如下:SQL> set autotrace on-- 使⽤聚合函数avg导致视图合并失效SQL> SELECT st_name, e1.salary, v.avg_salary2 FROM hr.employees e1,3 (SELECT department_id, avg(salary) avg_salary4 FROM hr.employees e25 GROUP BY department_id) v6 WHERE e1.department_id = v.department_id AND e1.salary > v.avg_salary;Execution Plan----------------------------------------------------------Plan hash value: 2695105989----------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |----------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 17 | 697 | 8 (25)| 00:00:01 ||* 1 | HASH JOIN | | 17 | 697 | 8 (25)| 00:00:01 || 2 | VIEW | | 11 | 286 | 4 (25)| 00:00:01 || 3 | HASH GROUP BY | | 11 | 77 | 4 (25)| 00:00:01 || 4 | TABLE ACCESS FULL| EMPLOYEES | 107 | 749 | 3 (0)| 00:00:01 || 5 | TABLE ACCESS FULL | EMPLOYEES | 107 | 1605 | 3 (0)| 00:00:01 |----------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - access("E1"."DEPARTMENT_ID"="V"."DEPARTMENT_ID")filter("E1"."SALARY">"V"."AVG_SALARY")--使⽤/*+ MERGE(v) */强制进⾏视图合并SQL> SELECT /*+ MERGE(v) */ st_name, e1.salary, v.avg_salary2 FROM hr.employees e1,3 (SELECT department_id, avg(salary) avg_salary4 FROM hr.employees e25 GROUP BY department_id) v6 WHERE e1.department_id = v.department_id AND e1.salary > v.avg_salary;Execution Plan----------------------------------------------------------Plan hash value: 3553954154----------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |----------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 165 | 5610 | 8 (25)| 00:00:01 ||* 1 | FILTER | | | | | || 2 | HASH GROUP BY | | 165 | 5610 | 8 (25)| 00:00:01 ||* 3 | HASH JOIN | | 3296 | 109K| 7 (15)| 00:00:01 || 4 | TABLE ACCESS FULL| EMPLOYEES | 107 | 2889 | 3 (0)| 00:00:01 || 5 | TABLE ACCESS FULL| EMPLOYEES | 107 | 749 | 3 (0)| 00:00:01 |----------------------------------------------------------------------------------⼆、⼦查询解嵌套最典型的就是⼦查询转变为表连接了,它和视图合并的主要区别就在于它的⼦查询位于where⼦句,由转换器进⾏解嵌套的检测。
Oracle数据库归档模式的切换及其相关操作详解

首先我们执行下面的代码:1.SQL> shutdown immediate;2.Database closed.3.Database dismounted.4.ORACLE instance shut down.5.SQL> startup mount;6.ORACLE instance started.Total System Global Area 205520896 bytes7.Fixed Size 1218532 bytes8.Variable Size 71305244 bytes9.Database Buffers 130023424 bytes10.Redo Buffers 2973696 bytes11.Database mounted.12.SQL> alter database archivelog;Database altered.SQL> alter database open;Database altered.SQL> archive log list;13.Database log mode Archive Mode14.Automatic archival Enabled15.Archive destination /oracle/app/oradata/LARRY/arch116.Oldest online log sequence 18417.Next log sequence to archive 18618.Current log sequence 186切换归档模式查看存档模式1.SQL> archive log list;2.数据库日志模式非存档模式此时为非存档模式3.自动存档禁用4.存档终点 c:\oracle\ora92\RDBMS5.最早的概要日志序列 376.当前日志序列 397.SQL> shutdown immediate8.数据库已经关闭。
详解Oracledg三种模式切换

详解Oracledg三种模式切换oracle dg 三⼤模式切换===================================1 最⼤性能模式MAXIMUM PERFORMANCE ------默认模式===================================⼀最⼤性能模式特点192.168.1.181SQL> select database_role,protection_mode,protection_level from v$database;DATABASE_ROLE PROTECTION_MODE PROTECTION_LEVEL---------------- -------------------- --------------------PRIMARY MAXIMUM PERFORMANCE MAXIMUM PERFORMANCESQL> col dest_name for a25SQL> select dest_name,status from v$archive_dest_status;DEST_NAME STATUS------------------------- ---------LOG_ARCHIVE_DEST_1 VALIDLOG_ARCHIVE_DEST_2 VALIDSQL> show parameter log_archiveNAME TYPE VALUE------------------------------------ ----------- ------------------------------log_archive_config string dg_config=(orcl,db01)log_archive_dest_1 string location=/home/oracle/arch_orcl valid_for=(all_logfiles,all_roles) db_unique_name=orcllog_archive_dest_2 string service=db_db01 LGWR ASYNC valid_for=(online_logfiles,primary_roles) db_unique_name=db01SQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_orclOldest online log sequence 31Next log sequence to archive 33Current log sequence 33192.168.1.183SQL> select database_role,protection_mode,protection_level from v$database;DATABASE_ROLE PROTECTION_MODE PROTECTION_LEVEL---------------- -------------------- --------------------PHYSICAL STANDBY MAXIMUM PERFORMANCE MAXIMUM PERFORMANCESQL> col dest_name for a25SQL> select dest_name,status from v$archive_dest_status;DEST_NAME STATUS------------------------- ---------LOG_ARCHIVE_DEST_1 VALIDLOG_ARCHIVE_DEST_2 VALIDSQL> show parameter log_archiveNAME TYPE VALUE------------------------------------ ----------- ------------------------------log_archive_config string dg_config=(db01,orcl)log_archive_dest_1 string location=/home/oracle/arch_db01 valid_for=(all_logfiles,all_roles) db_unique_name=db01log_archive_dest_2 string service=db_orcl LGWR ASYNC valid_for=(online_logfiles,primary_roles) db_unique_name=orclSQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_orclOldest online log sequence 31Next log sequence to archive 33Current log sequence 33192.168.1.181SQL> alter system switch logfile;SQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_orclOldest online log sequence 32Next log sequence to archive 34Current log sequence 34192.168.1.183SQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_db01Oldest online log sequence 32Next log sequence to archive 0Current log sequence 34===================================2 最⼤性能模式--切换到-->最⼤⾼可⽤ (默认是最⼤性能模式---MAXIMUMPERFORMANCE)===================================192.168.1.181SQL> select DATABASE_ROLE,PROTECTION_MODE,PROTECTION_LEVEL from v$database;DATABASE_ROLE PROTECTION_MODE PROTECTION_LEVEL---------------- -------------------- --------------------PRIMARY MAXIMUM PERFORMANCE MAXIMUM PERFORMANCESQL> show parameter log_archive_dest_2NAME TYPE VALUE------------------------------------ ----------- ------------------------------log_archive_dest_2 string service=db_db01 LGWR ASYNC valid_for=(online_logfiles,primary_roles) db_unique_name=db01192.168.1.181SQL> shutdown immediate192.168.1.183SQL> alter database recover managed standby database cancel;SQL> shutdown immediate192.168.1.181SQL> startup mount;SQL> alter database set standby database to maximize availability;SQL> alter system set log_archive_dest_2='service=db_db01 LGWR SYNC valid_for=(online_logfiles,primary_roles) db_unique_name=db01' scope=spfile; 192.168.1.183SQL> startup nomountSQL> alter database mount standby database;SQL> alter system set log_archive_dest_2='service=db_orcl LGWR SYNC valid_for=(online_logfiles,primary_roles) db_unique_name=orcl' scope=spfile; SQL> shutdown immediateSQL> startup nomountSQL> alter database mount standby database;192.168.1.181SQL> startupSQL> col dest_name for a25SQL> select dest_name,status from v$archive_dest_status;DEST_NAME STATUS------------------------- ---------LOG_ARCHIVE_DEST_1 VALIDLOG_ARCHIVE_DEST_2 VALIDSQL> show parameter log_archive_dest_2NAME TYPE VALUE------------------------------------ ----------- ------------------------------log_archive_dest_2 string service=db_db01 LGWR SYNC valid_for=(online_logfiles,primary_roles) db_unique_name=db01SQL> select database_role,protection_level,protection_mode from v$database;DATABASE_ROLE PROTECTION_LEVEL PROTECTION_MODE---------------- -------------------- --------------------PRIMARY MAXIMUM AVAILABILITY MAXIMUM AVAILABILITYSQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_orclOldest online log sequence 34Next log sequence to archive 36Current log sequence 36192.168.1.183SQL> col dest_name for a25SQL> select dest_name,status from v$archive_dest_status;DEST_NAME STATUS------------------------- ---------LOG_ARCHIVE_DEST_1 VALIDLOG_ARCHIVE_DEST_2 VALIDSQL> show parameter log_archive_dest_2NAME TYPE VALUE------------------------------------ ----------- ------------------------------log_archive_dest_2 string service=db_orcl LGWR SYNC valid_for=(online_logfiles,primary_roles) db_unique_name=orclSQL> select database_role,protection_level,protection_mode from v$database; DATABASE_ROLE PROTECTION_LEVEL PROTECTION_MODE---------------- -------------------- --------------------PHYSICAL STANDBY MAXIMUM AVAILABILITY MAXIMUM AVAILABILITY SQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_db01Oldest online log sequence 35Next log sequence to archive 0Current log sequence 36192.168.1.181SQL> alter system switch logfile;SQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_orclOldest online log sequence 35Next log sequence to archive 37Current log sequence 37192.168.1.183SQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_db01Oldest online log sequence 36Next log sequence to archive 0Current log sequence 37===================================3 最⼤⾼可⽤--切换到-->最保护能模式===================================DG最⼤保护模式Maximum protection192.168.1.181SQL> shutdown immediate192.168.1.183SQL> shutdown immediate192.168.1.181SQL> alter database set standby database to maximize protection;SQL> shutdown immediate192.168.1.183SQL> startup nomountSQL> alter database mount standby database;192.168.1.181SQL> startupSQL> col dest_name for a25SQL> select dest_name,status from v$archive_dest_status;DEST_NAME STATUS------------------------- ---------LOG_ARCHIVE_DEST_1 VALIDLOG_ARCHIVE_DEST_2 VALIDSQL> show parameter log_archive_dest_2NAME TYPE VALUE------------------------------------ ----------- ------------------------------log_archive_dest_2 string service=db_db01 LGWR SYNC valid_for=(online_logfiles,primary_roles) db_unique_name=db01SQL> select database_role,protection_level,protection_mode from v$database; DATABASE_ROLE PROTECTION_LEVEL PROTECTION_MODE---------------- -------------------- --------------------PRIMARY MAXIMUM PROTECTION MAXIMUM PROTECTIONSQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_orclOldest online log sequence 37Next log sequence to archive 39Current log sequence 39192.168.1.183SQL> col dest_name for a25SQL> select dest_name,status from v$archive_dest_status;DEST_NAME STATUS------------------------- ---------LOG_ARCHIVE_DEST_1 VALIDLOG_ARCHIVE_DEST_2 VALIDSQL> show parameter log_archive_dest_2NAME TYPE VALUE------------------------------------ ----------- ------------------------------log_archive_dest_2 string service=db_db01 LGWR SYNC valid_for=(online_logfiles,primary_roles) db_unique_name=db01SQL> select database_role,protection_level,protection_mode from v$database;DATABASE_ROLE PROTECTION_LEVEL PROTECTION_MODE---------------- -------------------- --------------------PRIMARY MAXIMUM PROTECTION MAXIMUM PROTECTIONSQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_db01Oldest online log sequence 37Next log sequence to archive 0Current log sequence 39192.168.1.181SQL> alter system switch logfile;SQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_orclOldest online log sequence 38Next log sequence to archive 40Current log sequence 40192.168.1.183SQL> archive log listDatabase log mode Archive ModeAutomatic archival EnabledArchive destination /home/oracle/arch_db01Oldest online log sequence 37Next log sequence to archive 0Current log sequence 40附:Oracle DG管理模式和只读模式相互切换将standby数据库开启⾄只读模式(⽤于primary⾮常忙时,可以在standby跑⼀些报表) $sqlplus “/as sysdba”SQL>startup mountSQL>alter database open read only;[@more@]将只读模式standby数据库切换⾄管理模式$sqlplus “/as sysdba”SQL>alter database recover managed standby database disconnect from session;将管理模式的standby数据库切换⾄只读模式$sqlplus “/as sysdba”SQL>alter database recover managed standby database cancel;SQL>alter database open read only;以上内容给⼤家介绍了Oracle dg 三种模式切换的相关知识,希望⼤家喜欢。
oracle数据库状态转换

oracle数据库状态转换
实验三数据库状态转换
一、实验目的
1、熟练掌握数据库的各种关闭和开启状态的转换方法;
2、掌握数据库态和静默/非静默状态的转换。
二、实验内容
1、数据库启动模式间的转换操作;
3、数据库的读写/只读状态、受限/非受限状态、挂起非挂起状态和静默/非静默状态的转换操作。
三、实验步骤
1、快速关闭数据库;
2、启动数据库到NOMOUNT状态,并指出当前能查看物理存储结构中的哪些文件?
能查看读取初始化参数文件,但是不能访问数据
3、将数据库转换到MOUNT状态,并指出当前能查看物理存储结构中的哪些文件?
去初始化参数文件里读取控制文件的位置及控制文件名称
4、切换数据库到正常打开状态。
5、将数据库转换为挂起状态,再将数据库由挂起状态转换为非挂
起状态;
6、将数据库转换为只读状态,再将数据库由只读状态转换为读写状态;
Alter database open read only;
Alter database open read write;
7、将数据库转换为静默状态,再将数据库由挂起状态转换为非静默状态;
alter system quiesce restricted;
alter system unquiesce;
8、写出利用OEM关闭数据库的操作步骤。
四、思考题
若在关闭数据库时使用了shutdown命令,使得数据库长时间处于正在关闭的状态,这时可以怎样处理以快速关闭数据库?
以sysdba身份登录,用shutdown abort来进行快速关闭
五、实验小结(请列出此次上机中遇到的所有错误代码及其解决方式)。
Oracle数据转换服务

主要内容第18章数据转换服务D T S返回总目录↵ 有关数据转换服务的基本概念↵ 如何使用DTS 向导↵DTS Designer在使用SQL Server 的过程中由于经常需要从多个不同地点将数据集中起来或向多个地点复制数据所以数据的导出导入是极为常见的操作我们可以使用BCP 命令来完成这一任务但是记住BCP 的命令格式是一件令人头痛的苦差事虽然你可以查看帮助文件所以我们需要功能强大操作简单的工具来完成这一任务数据转换服务DTS 提供了这种支持因此本章将介绍DTS 的基本情况讨论DTS 的各个构建组件以及如何完成数据转换服务18.1数据转换服务基本概念18.1.1 数据转换服务简介为了支持企业决策许多组织都需将数据集中起来进行分析但是通常数据总是以不同的格式存储在不同的地方有的可能是文本文件有的虽然具有表结构但不属于同一种数据源这些情况极大地妨碍数据的集中处理SQL Server为我们提供了令人欣慰的组件即Data Transformation Services DTS DTS本身包含多个工具并提供了接口来实现在任何支持OLE DB的数据源间导入导出或传递数据并使这一工作变得简单高效这意味着不仅可以在SQL Server数据源间进行数据的转储而且可以把Sybase Oracle Informix下的数据传递到SQL Server利用Data Transformation Services DTS可能在任何OLE DB ODBC驱动程序的数据源或文本文和SQL Server之间导入导出或传递数据具体表现在数据的导入导出服务通过读写数据在不同应用程序间交换数据例如可将文本文件或Microsoft Access 数据库导入到SQL Server也可以把数据从SQL Server导出到任何OLE DB数据源转换数据所谓传递是指在数据未到达目标数据源前而对数据采取的系列操作比如DTS允许从源数据源的一列或多列计算出新的列值然后将其存储在目标数据库中传递数据库对象在异构数据源情况下DTS的内置工具只能在数据源间传递表定义和数据如果要传递其它数据库对象如索引约束视图时必须定义一个任务从而在目标数据库上执行那些包含在任务中的SQL语句SQL语句是被用来创建这些数据库对象的18.1.2 DTS结构DTS将数据导入导出或传递定义成可存储的对象即包裹或称为包每一个包都是包括一个或具有一定顺序的多个任务的工作流每个任务可以将数据从某一数据源拷贝至目标数据源或使用Active脚本转换数据或执行SQL语句或运行外部程序也可以在SQL Server数据源间传递数据库对象包对象用来创建并存储步骤这些步骤定义了一系列任务执行的顺序以及执行任务的必要细节包对象中还包括源列目标列以及有关在数据传递过程中如何操纵数据的信息包可以存储在DTS COM结构的存储文件中msdb数据库中或Microsoft Repository 中可以通过以下工具来运行包它们是dtsrun工具DTS Designer DTS的导入导出向导SQL Server Agent来运行规划作业使用Execute方法调用DTS包对象的COM应用程序包是顶层对象它包含三种底层对象连接任务步骤1连接连接定义了有关源和目标数据数据源或文件的信息这些信息包括数据格式和位置以及安全认证的密码DTS包可不包含或包含多个连接使用连接的任务有DTS Data Pump任务执行SQL任务数据驱动查询任务定制任务有三种类型的连接对象数据源连接数据源连接定义了有关源和目标OLE DB数据源的信息这些信息包括服务器名称数据格式和位置以及安全认证的密码第一个使用连接的任务负责创建该连接如果使用ODBC的OLE DB提供者则连接也可以定义ODBC数据源信息文件连接文件连接定义了有关源和目标文件的信息这些信息包括文件格式和位置Microsoft 数据连接对象Microsoft数据连接对象或者加载数据连接文件*.udl或者为OLE DB提供者设置数据连接文件的属性2任务每个DTS包都含有一个或多个任务每个任务都是数据转换传递处理的工作项目任务的种类包括执行SQL任务即执行SQL语句Data Pump任务该任务为Data Pump操作定义了源和目标数据源以及数据转换Data Pump从源和目标OLE DB数据源间拷贝并转换数据ActiveX脚本执行ActiveX, VB, Jscript或Perscript脚本凡是脚本支持的操作都可以执行执行处理任务Execute Process task指执行外部程序批量插入指执行SQL Server批拷贝操作发送邮件使用SQL Mail发送寻呼或邮件数据驱动查询执行OLE DB数据源间的高级数据传递转换SQL Server对象即从SQL Server OLE DB数据源向另外的同类数据源复制对象例如表索引视图3步骤步骤对象定义了任务执行的顺序以及某一任务的执行是否依赖于前一个任务的结果如果某一任务不与步骤对象相关联则其将无法被执行可以为某一步骤设定运行条件使其只在一定条件才被执行为了提高执行的性能也可以并行执行多个步骤步骤的一个重要特性是步骤优先权约束步骤优先权约束定义了前一步必须满足哪些条件之后才会执行当前步骤通过步骤优先权约束可以控制任务的执行顺序有三种类型的优先权约束完成表示前一步骤完成后就执行当前步骤而不管其成功与否成功表示前一步骤只有成功执行才执行当前步骤失败表示前一步骤执行失败时才执行当前步骤某一步骤可有多个优先权约束只有前一步满足所有的约束后才能执行当前步骤18.2DTS导入导出向导DTS导入导出向导帮助用户交互式地建立包从而在具有OLE DB和ODBC驱动程序的源和目标数据源间进行数据的导入导出和转换下面将以两个具体例子来讲解如何使用DTS向导同时将对其中涉及的每一个选项进行详细的介绍例18-1使用DTS向导导出pubs数据库中的authors表利用SQL Server Enterprise Manager执行数据导出的步骤为1启动SQL Server Enterprise Manager后登录到指定的服务器右击Data Transformation Services文件夹在弹出菜单中选择All tasks Export data打开DTS Export Wizard 如图18-1所示图18-1 DTS Import/Export Wizard对话框2单击下一步按钮打开Choose a Data Source对话框如图18-2所示首先在Source Server旁的下拉列表中选择数据源在本例中选择MicrosoftOLE DB Provider for SQL Server如果使用SQL Server认证方式则应输入访问数据库的合法用户账号和密码在Database 旁的下拉列表中选择pubs先单击Refresh按钮图18-2 Choose a Data Source对话框3单击下一步按钮打开Choose a Destination对话框如图18-3所示在Destination旁的下拉列表中选择Microsoft OLE DB Provider for SQL Server Database 旁的下拉列表中选择DBA_pubs数据库图18-3 Choose a Destination对话框4单击下一步按钮打开Specify Table Copy or Query对话框如图18-4所示在此处可以指定传递的内容可以传递表或某一查询的数据结果集甚至于数据库对象在本例中选择Copy table s from the source database图18-4 Specify Table Copy or Query对话框5单击下一步打开Select Source Table and View对话框如图18-5所示从中选择一个或多个表或视图进行传递通过Preview按钮可对将要传递的数据进行预览图18-5 Select Source Table and View对话框6如果想定义数据转换时源表和目标表之间列的对应关系则单击Transform 列的方格按钮打开Columns Mapping Transformation and Constrains 对话框如图18-6所示图18-6 Column Mappings, Transformations and Constraints对话框 – Column Mappings标签页其中各选项的含义如下Create destination table在从源表拷贝数据前首先创建目标表在缺省情况下总是假设目标表不存在如果存在则发生错误除非选中了Drop and recreatedestination table if it exists选项Delete rows in destination table在从源表拷贝数据前将目标表的所有行删除仍保留目标表上的约束和索引当然使用该选项的前提是目标表必须存在Append rows to destination table把所有源表数据添加到目标表中目标表中的数据索引约束仍保留但是数据不一定追加到目标表的表尾如果目标表上有聚簇索引则可以决定将数据插入何处Drop and recreate destination table如果目标表存在则在从源表传递来数据前将目标表表中的所有数据索引等删除后重新创建新目标表Enable identity insert允许向表的标识列中插入新值7在进行数据转换时可以通过脚本语言如Jscript Perscript Vbscript对源表中的某一列施加某种运算乘除或将该分割成几列或将几列合并成一列然后再将这种结果复制到目标表此时应选中Columns MappingTransformation and Constrains对话框的 Transformations标签页如图18-7所示图18-7 Column Mappings, Transformations, and Constraints 对话框– Transformations 标签页其中各选项的含义如下Language 表示使用哪种脚本语言Copy the source columns directly to the destination column 表示不对原表进行任何处理Transform information as it is copied to the destination 表示通过脚本语言编写如何改变原始例的程序比如我们假设源表在拷贝到目标表时将源表address列全转为小写则在空白区域的VB 脚本是'**********************************************************************' Visual Basic Transformation Script' Copy each source column to the' destination column'***********************************************************************Function MainDTSDestination "au_id" = DTSSource "au_id"DTSDestination "au_fname" = DTSSource "au_fname"DTSDestination "au_lname"= DTSSource "au_lname"DTSDestination "phone" = DTSSource "phone"DTSDestination "address" = lcase DTSSource "address"DTSDestination "city" = DTSSource "city"DTSDestination "state" = DTSSource "state"DTSDestination "zip" = DTSSource "zip"DTSDestination "contract" = DTSSource "contract"Main = DTSTransformStat_OKEnd Function8应选中Columns Mapping Transformation and Constraints 对话框的Constraints 标签页如图18-8所示图18-8 Columns Mapping, Transformation, and Constraints 对话框– Constraints标签页9返回Select Source Table对话框单击下一步打开Save Schedule andReplicate Package对话框如图18-9所示图18-9 Save Schedule and Replicate Package对话框在When选项区可以选择与包有关的操作Run immediately表示立即运行包Create DTS package for Replication表示让由发布目标来进行复制Schedule DTS package for later execution 表示将包保存之后在以后的某一规划时间运行在Save 选项选中Save DTS Package 则将包进行保存SQL Server 将包存储在msdb 数据库中SQL Server Meta Data Service 将包存储在Repository 中Structured Storage File以DTS COM 结构的文件格式存储容易通过文件服务器进行邮递和分发Visual Basic File 10单击下一步打开Save DTS Package 对话框如图18-10所示在Name 输入该包的名称AuthorsPackage 可以将包保存在本地服务器或其它的远程服务器也可以选择适当的认证方式如果选择SQL Server 认证要提供用户名和密码图18-10 Save DTS Package 对话框11单击下一步在Completing the DTS Import/Export Wizard 对话框中单击完成结束包的创建操作如图18-11所示 在步骤4的Specify Table Copy or Query 对话框中如果选中Use a Query to specify the data to transfer 选项单击下一步之后打开Type SQL Statement 对话框如图18-12 所示在Query statement 下的空白框中输入SELECT 语句则该查询语句的结果集就 是所有转换数据可以通过单击Query Builder 按钮来激活创建查询向导图18-11 Completing the DTS Import/Export Wizard对话框图18-12 Type SQL Statement对话框图18-13 Select Object to Copy 对话框在步骤4的Specify Table Copy or Query 对话框中如果选中Copy object and databetween SQL Server Database 表示在源与目标数据源间传递数据对象包括表视图 存储过程参照完整性索引单击下一步打开Select Objects to Transfer 对话框 如图18-13所示其中各选项的含义为Create destination objects在目标数据源中为所有传递对象创建目标对象Drop destination objects first 在创建新对象之前删除所有与源对象相同的目标对象Include all dependent objects 包括所有的依赖对象比如视图引用的基本表Copy data 选中该复选框表示允许从源向目标数据源拷贝数据Replacing existing data 用指定源数据源的数据覆盖目标数据源中的数据Append data 保留目标数据源中的原有数据并添加从数据源拷贝来的数据Transfer all objects 传递数据源中的所有数据库对象Select objects 只传递被选择的数据库对象Options 设置高级传递选项Script file directory 指定执行传递操作的SQL 语句存储的目录单击下一步继续包创建余下的创建步骤大体雷同例18-2在该例中利用DTS Wizard 向数据库中导入一个文本文件其创建的步骤与例1基本相同下面主要介绍不同的创建步骤1建立源连接在例18-1的Step2的Choose a Data Source 对话框中在Source 旁的下拉列表中选择Text File 选项然后输入文件的存储位置如图18-14所示2设定文件格式单击下一步打开Select File Format 对话框如图18-15所示图18-14 Choose a Data Source对话框图18-15 Select File Format对话框Delimited把文本中的数据分配成不同的字段所有的字段必须以相同的结束符分隔Fixed Field把文本中的数据分配到具有相同宽度的字段中不同的字段宽度可以不同如果选中Delimited选项则应执行第三步如选中Fixed Field则执行第四步3确定分界符单击下一步打开Specify Column Delimiter对话框如图18-16所示在该对话框中确定分界符来将文件中的文件按记录逐条分开成多列这里提供了常见的符号也可以在Other输入框中输入自定义的分界符图18-16 Specify Column Delimiter对话框4定义每一字段的长度5为导入数据输入目标表6定义数据转换要求7执行数据导入18.3DTS DesignerDTS Designer与DTS Wizard一样都是在同构或异构数据源间进行数据的导入导出和转换但是DTS Designer是一个图形工具它使创建和编辑DTS包的工作变得更简单轻松而且提供了比DTS Wizard更为强大的功能DTS Designer中包含几个关键性概念如连接数据传递包优先权约束任务这些概念对于理解DTS Designer是如何工作很有帮助18.3.1 创建DTS Designer包在包中不仅要指明源和目标数据源而且还要定义多个步骤每个步骤执行的任务在某些情况下还包括步骤优先权约束使用DTS Designer创建包首先要添加连接每个包包含目标连接和源连接在连接中指明OLE DB提供者数据源接着定义源和目标连接间的数据转换然后要定义包将执行的任务也可以自定义任务最后决定是否运行包或将其存储以备后用下面以具体地转换authors表为例子来说明如何使用DTS Designer来创建包而且在该例中我们要求将authors的au_fname列和au_lname 列合并成目标表desauthors的au_name列18.3.2 添加连接首先为包添加源与目标连接每个连接中指出了数据源的驱动程序当然不同的OLE DB提供者所提出的要求不同1启动SQL Server Enterprise Manager后登录到指定的服务器右击Data Transformation Services文件夹在弹出菜单中选择New package选项打开DTS Package <New Package>对话框2在主菜单中单击Data菜单项在下拉菜单中选择Microsoft OLE DB Provider for SQL Server选项打开Connection Properties对话框如图18-17所示图18-17 Connection Properties 对话框18.3.3 定义数据转换数据转换任务是将数据从源连接传递到目标连接的主要机制每个数据转换任务都要引用一个DTS Data Dump和OLE DB服务提供者创建完源与目标连接后应创建数据转换其方法是按住<Shift>键不放分别先后选中源连接和目标连接然后右击目标连接在弹出菜单中选择Transform data Task此时在DTS Designer工作区会出现从源连接指向目标连接的箭头以此来指明数据的流向如图18-18所示图18-18 创建数据转换任务18.3.4 数据转换任务属性设置1创建完数据转换接着要进行转换的属性设置右击源和目标连接之间的箭头在弹出菜单中选择Properties选项打开Transform Data Task Properties对话框选中Source 标签页如图18-19所示在Source标签页可以选择来自源连接的数据图18-19 Transformation Data Task Properties对话框 – Source标签页Table name表示来自源连接的一张表SQL Query表示来自源连接的一个查询结果集2选中Destination标签页如图18-20所示在Table name旁的下拉列表中选择目标表或Create New按钮创建新表在此单击Create New按钮在弹出对话框中输入如下内容图18-20 Transform Data Task Properties对话框 – Destination标签页CREATE TABLE [desauthors][au_id] varchar 11 NOT NULL,[au_name] varchar 50 NOT NULL,[phone] char 12 NOT NULL,[address] varchar 40 NULL,[city] varchar 20 NULL,[state] char 2 NULL,[zip] char 5 NULL,[contract] bit NOT NULL3选中Transformations标签页如图18-21所示该对话框允许定义源连接与目标连接列之间的映射关系可以定义以下几个映射关系一对一多对一或一对多在本例中进行映射要执行以下操作如果源列与目标列之间已存在映射则选中两者间的箭头然后按<Del>键删除两者间的映射图18-21 Transform Data Task Properties对话框 – Transformations标签页按下<Ctrl>键不放分别在Source table与Destination table中选择想要映射的列单击New按钮在弹出的Create New Transformation对话框中选择ActiveX script选项单击OK按钮打开Transformation Options对话框如图18-22所示图18-22 Transformation Options对话框4分别选中Source columns和Destination columns标签页从中选择准备转换的列如果源与目标连接的列映射存在多对一或一对多的关系则通过脚本语言可在转换过程中对源数据列进行加工从而让转换结果满足用户的要求再单击Properties按钮打开Active Script Transformation Properties对话框如图18-23所示图18-23 Active Script Transformation Properties对话框在空白区域输入如下VB代码'**********************************************************************' Visual Basic Transformation Script'**********************************************************************' Copy each source column to the destination columnFunction MainDTSDestination"contract" =DTSSource"contract"DTSDestination"zip" =DTSSource"zip"DTSDestination"state" =DTSSource"state"DTSDestination"city" =DTSSource"city"DTSDestination"address" =DTSSource"address"DTSDestination"phone" =DTSSource"phone"DTSDestination"au_name" =DTSSource"au_fname"+ DTSSource"au_lname"DTSDestination"au_id" =DTSSource"au_id"Main = DTSTransformStat_OKEnd Function5选中Lookups标签页如图18-24所示图18-24 Transform Data Task Properties对话框 – Lookup标签页6选中Options标签页如图18-25所示图18-25 Transform Data Task Properties对话框 – Options标签页18.3.5 定义任务在完成数据转换属性设置之后可以向包中添加自定义任务其操作步骤为1从左边的任务栏中将要添加的任务类型拖到DTS Designer工作区然后右击进行属性设置其属性对话框如图18-26所示在本例中所定义的任务是SQL脚本任务图18-26 Execute SQL Task Properties 对话框2添加自定义任务之后则应该在转换数据任务和自定义任务上定义优先级条件其操作顺序为先后选择自定义任务和某个源连接然后选择Workflow 菜单的On Success选项此时如图18-27所示图18-27 定义优先级条件3在完成包的创建之后可以单击工具栏上的Run按钮来运行包在包执行时可以通过暂停和停止按钮来对执行过程进行控制如图18-28所示图18-28 运行包窗口18.4本章小结在本章中我们主要介绍DTS的若干问题重点讨论了如何使用导入/导出向导以及DTS Designer来实现数据或数据库对象的转换。
Oracle到mysql转换的问题总结

Oracle到mysql转换的问题总结Oracle到mysql转换的问题总结常用字段类型区别oracle mysqlnumber(10,0)intnumber(10,2)decimal(10,2)varchar2 varchardate datetimeColb text个别语句写法区别1.oracle里只可以用单引号包起字符串,mysql里可以用双引号和单引号。
2.mysql 在select * from () ....,from后面是一个结果集时,括号后面必须加上别名。
3.mysql在delete数据时不能给表加别名,如:delete from table1 T where....,会报错,但是可以这样写:delete T from table1 T where....。
4.Mysql不支持在同一个表中先查这个表在更新这个表,举个例子说明一下,insert into table1 values(字段1,(select 字段2 from table1 where...)),但是可以在后面那个table1加上别名就没有问题了。
(select T.字段2 from table1T where...))insert into table1 values(字段1,5.MYSQL有自动增长的数据类型,插入记录时不用操作此字段,会自动获得数据值。
ORACLE没有自动增长的数据类型,需要建立一个自动增长的序列号,插入记录时要把序列号的下一个值赋于此字段。
也可以自定义函数实现oracle的nextval。
6.翻页的sql语句处理,MYSQL处理翻页的SQL语句比较简单,用LIMIT 开始位置, 记录个数,例如:select * from table limit m,n,意思是从m+1开始取n条。
常见的函数替换oracle mysql 说明to_char(date,’yyyy-MM-dd hh24:mi:ss’) date_format(date,'%Y-%m-%d %H:%i:%s')注意时间格式的对应to_date(str,’yyyy-MM-dd hh24:mi:ss’) str_to_date(str,'%Y-%m-%d %H:%i:%s')注意时间格式to_date(str,’yyyy-MM-dd hh24:mi:ss’) str_to_date(str,'%Y-%m-%d%T')注意时间格式to_char()、to_number() convert(字段名,类型) 类型转换date + n date_add(date,intervaln day)日期增加n天selectdate_add(sysdate(),INTE RV AL 2 DAY);add_months(date,n) date_add(date,intervaln month)日期增加n个月selectdate_add(sysdate(),INTE RV AL 2 MONTH);date1 - date2 datediff(date1,date2) 日期相减获取天数例子:Oracle:select decode(a,b,c,d) as col1 from table1;Mysql:selectcasewhen a=b then cwhen a!=b then dend as col1from table13.oracle的函数ROW_NUMBER() OVER(PARTITION BY col1 ORDER BY col2),根据col1分组,在分组内根据col2排序,改函数计算的值就表示每组内部排序后的顺序编号。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验三数据库状态转换
一、实验目的
1、熟练掌握数据库的各种关闭和开启状态的转换方法;
2、掌握数据库态和静默/非静默状态的转换。
二、实验内容
1、数据库启动模式间的转换操作;
3、数据库的读写/只读状态、受限/非受限状态、挂起非挂起状态和静默/非静默状态的转换操作。
三、实验步骤
1、快速关闭数据库;
2、启动数据库到NOMOUNT状态,并指出当前能查看物理存储结构中的哪些文件?
能查看读取初始化参数文件,但是不能访问数据
3、将数据库转换到MOUNT状态,并指出当前能查看物理存储结构中的哪些文件?
去初始化参数文件里读取控制文件的位置及控制文件名称
4、切换数据库到正常打开状态。
5、将数据库转换为挂起状态,再将数据库由挂起状态转换为非挂起状态;
6、将数据库转换为只读状态,再将数据库由只读状态转换为读写状态;
Alter database open read only;
Alter database open read write;
7、将数据库转换为静默状态,再将数据库由挂起状态转换为非静默状态;
alter system quiesce restricted;
alter system unquiesce;
8、写出利用OEM关闭数据库的操作步骤。
四、思考题
若在关闭数据库时使用了shutdown命令,使得数据库长时间处于正在关闭的状态,这时可以怎样处理以快速关闭数据库?
以sysdba身份登录,用shutdown abort来进行快速关闭
五、实验小结(请列出此次上机中遇到的所有错误代码及其解决方式)。