openmp并行程序设计
openmp原子操作

openmp原子操作OpenMP(Open Multi-Processing)是一种并行编程模型,用于编写多线程并行程序。
OpenMP原子操作是指一种并行编程中的技术,用于确保对共享变量的原子性操作,以避免并发访问导致的竞态条件。
在OpenMP中,原子操作可以通过使用#pragma omp atomic指令来实现。
原子操作允许在并行代码中对共享变量执行原子操作,这意味着在执行原子操作期间,不会发生其他线程对同一变量的并发访问。
这有助于避免数据竞争和确保程序的正确性。
在OpenMP中,原子操作可以应用于一些基本的算术运算,比如加法、减法、乘法和除法,以及位操作,比如与、或、异或等。
原子操作的语法如下:c.#pragma omp atomic.x += 1;这个例子中,对变量x的自增操作是一个原子操作,即使在并行环境中也能够保证操作的原子性。
需要注意的是,原子操作虽然可以确保操作的原子性,但在高度并行化的情况下可能会导致性能下降。
因此,在使用原子操作时,需要权衡并行性和原子性之间的关系,以确保程序既能够正确运行,又能够获得良好的性能表现。
除了原子操作外,OpenMP还提供了其他一些机制来处理并发访问共享变量的问题,比如使用临界区(critical section)、使用互斥锁(mutex)、使用重复检测(test-and-set)等。
选择合适的并发控制机制取决于具体的并行算法和应用场景。
总之,OpenMP原子操作是一种重要的并行编程技术,用于确保对共享变量的原子性操作,从而避免数据竞争和确保程序的正确性。
在实际应用中,需要根据具体情况选择合适的并发控制机制,以实现既能够正确运行又能够高效利用并行计算资源的并行程序。
并行程序实验报告

并行程序设计实验报告姓名:学号:一、实验目的通过本次试验,了解使用OpenMP编程的基本方法和MPI的编程方法,通过实践实现的基本程序,掌握基本的线程及进程级并行应用开发技术,能够分析并行性能瓶颈及相应优化方法。
二、实验环境Linux操作系统,mpi库,多核处理器三、实验设计与实现(一)MPI并行程序设计用MPI编写一个greeting程序,编号为0的进程接受其它各进程的“问候”,并在计算机屏幕上显示问候情况。
用MPI编写一个多进程求积分的程序,并通过积分的方法求π的值,结果与π的25位精确值比较。
(二)多线程程序设计用Pthreads或OpenMP编写通过积分的方法求π的程序。
把该程序与相应的MPI程序比较。
用Pthreads或OpenMP编写编写矩阵相乘的程序,观察矩阵增大以及线程个数增减时的情形。
四、实验环境安装(一)MPI环境安装1.安装kylin操作系统的虚拟机(用VirtualBox)2.安装增强功能,使之与windows主机能够文件共享。
3.拷贝mpich-3.0.4.tar.gz到/root/myworkspace/目录下,并解压(tar xzf mpich-3.0.4.tar.gz)4.下面开始安装mkdir /root/myworkspace/mpi./configure --prefix=/root/myworkspace/mpi --disable-f77 --disable-fcmakemake install5.配置环境变量打开/root/.bashrc文件,在文件的末尾加上两行:PATH=$PATH:/root/myworkspace/mpi/binexport PATH保存退出,然后执行命令source /root/.bashrc(二)openMP实验环境安装Visual Studio中修改:项目->属性->c/c++->语言,将“OpenMP支持”改成“是”:五、实验结果及分析(一)MPI并行程序设计实验一:问候发送与接收非零号进程将问候的信息发送给0号进程,0号进程依次接收其它进程发送过来的消息并将其输出。
intelvisualfortran在visualstudio中如何正常的使用openmp并行程序

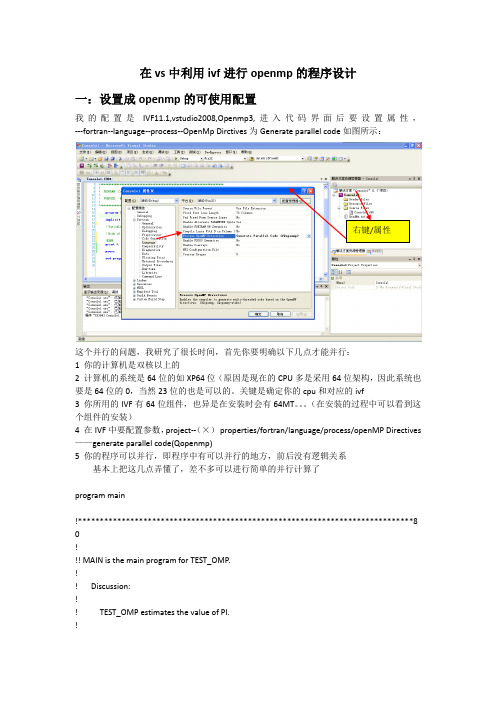
intelvisualfortran在visualstudio中如何正常的使⽤openmp并⾏程序在vs中利⽤ivf进⾏openmp的程序设计⼀:设置成openmp的可使⽤配置我的配置是IVF11.1,vstudio2008,Openmp3,进⼊代码界⾯后要设置属性,---fortran--language--process--OpenMp Dirctives为Generate parallel code如图所⽰:右键/属性这个并⾏的问题,我研究了很长时间,⾸先你要明确以下⼏点才能并⾏:1 你的计算机是双核以上的2 计算机的系统是64位的如XP64位(原因是现在的CPU多是采⽤64位架构,因此系统也要是64位的0,当然23位的也是可以的。
关键是确定你的cpu和对应的ivf3 你所⽤的IVF有64位组件,也异是在安装时会有64MT。
(在安装的过程中可以看到这个组件的安装)4 在IVF中要配置参数,project--(×)properties/fortran/language/process/openMP Directives ——generate parallelcode(Qopenmp)5 你的程序可以并⾏,即程序中有可以并⾏的地⽅,前后没有逻辑关系基本上把这⼏点弄懂了,差不多可以进⾏简单的并⾏计算了program main!*****************************************************************************8 0!!! MAIN is the main program for TEST_OMP.!! Discussion:!! TEST_OMP estimates the value of PI.!! This program uses Open MP parallelization directives.!! It should run properly whether parallelization is used or not.!! However, the parallel version computes the sum in a different! order than the serial version; some of the quantities added are! quite small, and so this will affect the accuracy of the results.!! Modified:! Author:!! John Burkardt!! A FORTRAN 90 module may be available:!! use omp_lib!! A FORTRAN 77 include file may be available:!! include 'omp_lib.h'!implicit noneinteger, parameter :: r4_logn_max = 9integer idinteger nthreadsinteger omp_get_num_procsinteger omp_get_num_threadsinteger omp_get_thread_numcall timestamp ( )write ( *, '(a)' ) ' 'write ( *, '(a)' ) 'TEST_OMP'write ( *, '(a)' ) ' FORTRAN90 version'write ( *, '(a)' ) ' 'write ( *, '(a)' ) ' Estimate the value of PI by summing a series.'write ( *, '(a)' ) ' 'write ( *, '(a)' ) ' This program includes Open MP directives, which' write ( *, '(a)' ) ' may be used to run the program in parallel.' write ( *, '(a)' ) ' 'write ( *, '(a)' ) ' The number of processors available:'write ( *, '(a,i8)' ) ' OMP_GET_NUM_PROCS () = ', omp_get_num_procs ( ) nthreads = 4write ( *, '(a)' ) ' 'write ( *, '(a,i8,a)' ) ' Call OMP_SET_NUM_THREADS, and request ', &nthreads, ' threads.'! Note that the call to OMP_GET_NUM_THREADS will always return 1! if called outside a parallel region!!!$OMP parallel private ( id )id = omp_get_thread_num ( )write ( *, '(a,i3)' ) ' This is process ', idif ( id == 0 ) thenwrite ( *, '(a)' ) ' 'write ( *, '(a)' ) ' Calling OMP_GET_NUM_THREADS inside a 'write ( *, '(a)' ) ' parallel region, we get the number of'write ( *, '(a,i3)' ) ' threads is ', omp_get_num_threads ( )write ( *, '(a)' ) ' 'end if!$OMP end parallelcall r4_test ( r4_logn_max )write ( *, '(a)' ) ' 'write ( *, '(a)' ) 'TEST_OMP'write ( *, '(a)' ) ' Normal end of execution.'write ( *, '(a)' ) ' 'call timestamp ( )stopendsubroutine r4_test ( logn_max )!*****************************************************************************8 0!!! R4_TEST estimates the value of PI using single precision.!! Discussion:!! PI is estimated using N terms. N is increased from 10^2 to 10^LOGN_MAX.! The calculation is repeated using both sequential and Open MP enabled code. ! Wall clock time is measured by calling SYSTEM_CLOCK.!! 06 January 2003!! Author:!! John Burkardt!implicit noneinteger clock_maxinteger clock_rateinteger clock_startinteger clock_stopreal errorreal estimateinteger logninteger logn_maxcharacter ( len = 3 ) modeinteger nreal r4_pireal timewrite ( *, '(a)' ) ' 'write ( *, '(a)' ) 'R4_TEST:'write ( *, '(a)' ) ' Estimate the value of PI,'write ( *, '(a)' ) ' using single precision arithmetic.'write ( *, '(a)' ) ' 'write ( *, '(a)' ) ' N = number of terms computed and added;' write ( *, '(a)' ) ' 'write ( *, '(a)' ) ' ESTIMATE = the computed estimate of PI;' write ( *, '(a)' ) ' 'write ( *, '(a)' ) ' ERROR = ( the computed estimate - PI );'write ( *, '(a)' ) ' 'write ( *, '(a)' ) ' TIME = elapsed wall clock time;'write ( *, '(a)' ) ' 'write ( *, '(a)' ) ' Note that you can''t increase N forever, because:'write ( *, '(a)' ) ' B) maximum integer size is a problem.'write ( *, '(a)' ) ' 'write ( *, '(a,i12)' ) ' The maximum integer:' , huge ( n )write ( *, '(a)' ) ' 'write ( *, '(a)' ) ' 'write ( *, '(a)' ) ' N Mode Estimate Error Time' write ( *, '(a)' ) ' 'n = 1do logn = 2, logn_maxmode = 'OMP'call system_clock ( clock_start, clock_rate, clock_max )call r4_pi_est_omp ( n, estimate )call system_clock ( clock_stop, clock_rate, clock_max )time = real ( clock_stop - clock_start ) / real ( clock_rate )error = abs ( estimate - r4_pi ( ) )write ( *, '( i12, 2x, a3, 2x, f14.10, 2x, g14.6, 2x, g14.6 )' ) &n, mode, estimate, error, timen = n * 10end doreturnendsubroutine r4_pi_est_omp ( n, estimate )!*****************************************************************************8 0 !!! R4_PI_EST_OMP estimates the value of PI, using Open MP.!! Discussion:!! The calculation is based on the formula for the indefinite integral:!! Integral 1 / ( 1 + X**2 ) dx = Arctan ( X )!! Hence, the definite integral!! Integral ( 0 <= X <= 1 ) 1 / ( 1 + X**2 ) dx!! A standard way to approximate an integral uses the midpoint rule.! If we create N equally spaced intervals of width 1/N, then the! midpoint of the I-th interval is!! X(I) = (2*I-1)/(2*N).!! The approximation for the integral is then:!! Sum ( 1 <= I <= N ) (1/N) * 1 / ( 1 + X(I)**2 )!! In order to compute PI, we multiply this by 4; we also can pull out! the factor of 1/N, so that the formula you see in the program looks like: !! ( 4 / N ) * Sum ( 1 <= I <= N ) 1 / ( 1 + X(I)**2 )!! Until roundoff becomes an issue, greater accuracy can be achieved by ! increasing the value of N. !! Modified:!! 06 January 2003!! Author:!! John Burkardt!! Parameters:!! Input, integer N, the number of terms to add up.!! Output, real ESTIMATE, the estimated value of pi.!implicit nonereal hinteger nreal sum2real xh = 1.0E+00 / real ( 2 * n )sum2 = 0.0E+00!!$OMP parallel do private(x) shared(h) reduction(+: sum2)!do i = 1, nx = h * real ( 2 * i - 1 )sum2 = sum2 + 1.0E+00 / ( 1.0E+00 + x**2 )end doestimate = 4.0E+00 * sum2 / real ( n )returnendfunction r4_pi ( )!*****************************************************************************8 0 !!! R4_PI returns the value of pi.!! Modified:!! 02 February 2000!! Author:!! John Burkardt!! Parameters:!! Output, real R4_PI, the value of pi.!implicit noner4_pi = 3.14159265358979323846264338327950288419716939937510E+00 returnendsubroutine timestamp ( )!*****************************************************************************8 0!!! TIMESTAMP prints the current YMDHMS date as a time stamp.!! Example:!! May 31 2001 9:45:54.872 AM!! Modified:!! 31 May 2001!! Author:!! John Burkardt!! Parameters:!! None!implicit nonecharacter ( len = 8 ) ampminteger dcharacter ( len = 8 ) dateinteger hinteger minteger mmcharacter ( len = 9 ), parameter, dimension(12) :: month = (/ &'January ', 'February ', 'March ', 'April ', &'May ', 'June ', 'July ', 'August ', &integer ninteger scharacter ( len = 10 ) timeinteger values(8)integer ycharacter ( len = 5 ) zonecall date_and_time ( date, time, zone, values ) y = values(1)m = values(2)d = values(3)h = values(5)n = values(6)s = values(7)mm = values(8)if ( h < 12 ) thenampm = 'AM'else if ( h == 12 ) thenif ( n == 0 .and. s == 0 ) thenampm = 'Noon'elseampm = 'PM'end ifelseh = h - 12if ( h < 12 ) thenampm = 'PM'else if ( h == 12 ) thenif ( n == 0 .and. s == 0 ) thenampm = 'Midnight'elseampm = 'AM'end ifend ifend iftrim ( month(m) ), d, y, h, ':', n, ':', s, '.', mm, trim ( ampm ) returnend!===================================== COPY上⾯的程序,可以完全运⾏成功,运⾏界⾯如下:。
并行程序设计实验报告-OpenMP 进阶实验

实验2:OpenMP 进阶实验1、实验目的掌握生产者-消费者模型,具备运用OpenMP相关知识进行综合分析,可实现实际工程背景下生产者-消费者模型的线程级负责均衡规划和调优。
2、实验要求1)single与master语句制导语句single 和master 都是指定相关的并行区域只由一个线程执行,区别在于使用master 则由主线程(0 号线程)执行,使用single 则由运行时的具体情况决定。
两者还有一个区别是single 在结束处隐含栅栏同步,而master 没有。
在没有特殊需求时,建议使用single 语句。
程序代码见程序2-12)barrier语句在多线程编程中必须考虑到不同的线程对同一个变量进行读写访问引起的数据竞争问题。
如果线程间没有互斥机制,则不同线程对同一变量的访问顺序是不确定的,有可能导致错误的执行结果。
OpenMP中有两种不同类型的线程同步机制,一种是互斥机制,一种是事件同步机制。
其中事件同步机制的设计思路是控制线程的执行顺序,可以通过设置barrier同步路障实现。
3)atomic、critical与锁通过critical 临界区实现的线程同步机制也可以通过原子(atomic)和锁实现。
后两者功能更具特点,并且使用更为灵活。
程序代码见程序2-2、2-3、2-44)schedule语句在使用parallel 语句进行累加计算时是通过编写代码来划分任务,再将划分后的任务分配给不同的线程去执行。
后来使用paralle for 语句实现是基于OpenMP 的自动划分,如果有n 次循环迭代k 个线程,大致会为每一个线程分配[n/k]各迭代。
由于n/k 不一定是整数,所以存在轻微的负载均衡问题。
我们可以通过子句schedule 来对影响负载的调度划分方式进行设置。
5)循环依赖性检查以对π 的数值估计的方法为例子来探讨OpenMP 中的循环依赖问题。
圆周率π(Pi)是数学中最重要和最奇妙的数字之一,对它的计算方法也是多种多样,其中适合采用计算机编程来计算并且精确度较高的方法是通过使用无穷级数来计算π 值。
OpenMP+MPI混合并行编程

H a r b i n I n s t i t u t e o f T e c h n o l o g y并行处理与体系结构实验报告实验题目: OpenMP+MPI混合并行编程院系:计算机科学与技术姓名:学号:实验日期: 2011-12-25哈尔滨工业大学实验四:OpenMP+MPI混合并行编程一、实验目的1、复习前几次实验的并行机制,即OpenMP与MPI编程模式。
2、掌握OpenMP与MPI混合并行编程模式。
二、实验内容1、使用OpenMP+MPI混合编程并与OpenMP、MPI单独编程的比较。
在OpenMp并行编程中,主要针对细粒度的循环级并行,主要是在循环中将每次循环分配给各个线程执行,主要应用在一台独立的计算机上;在MPI并行编程中,采用粗粒度级别的并行,主要针对分布式计算机进行的,他将任务分配给集群中的所有电脑,来达到并行计算;OpenMp+MPI混合编程,多台机器间采用MPI分布式内存并行且每台机器上只分配一个MPI进程,而各台机器又利用OpenMP进行多线程共享内存并行。
2、分析影响程序性能的主要因素。
在采用OpenMP实现的并行程序中,由于程序受到计算机性能的影响,不能大幅度的提高程序运行速度,采用了集群的MPI并行技术,程序被放到多台电脑上运行,多台计算机协同运行并行程序,但是,在集群中的每台计算机执行程序的过程又是一个执行串行程序的过程,因此提出的OpenMP+MPI技术,在集群内采用MPI技术,减少消息传递的次数以提高速度,在集群的每个成员上又采用OpenMP技术,节省内存的开销,这样综合了两种并行的优势,来提升并行程序的执行效率。
三、实验原理OpenMP编程:使用Fork-Join的并行执行模式。
开始时由一个主线程执行程序,该线程一直串行的执行,直到遇到第一个并行化制导语句后才开始并行执行。
含义如下:①Fork:主线程创建一队线程并行执行并行域中的代码;②Join:当各线程执行完毕后被同步或中断,最后又只有主线程在执行。
在fortran下进行openmp并行计算编程

在fortran下进⾏openmp并⾏计算编程最近写⽔动⼒的程序,体系太⼤,必须⽤并⾏才能算的动,⽆奈只好找了并⾏编程的资料学习了。
我想我没有必要在博客⾥开⼀个什么并⾏编程的教程之类,因为⽹上到处都是,我就随⼿记点重要的笔记吧。
这⾥主要是openmp的~1 临界与归约在涉及到openmp的并⾏时,最需要注意的就是被并⾏的区域中的公共变量,对于需要reduce的变量,尤其要注意,⽐如这段代码:program mainimplicit noneinclude 'omp_lib.h'integer N,M,ireal(kind=8) tN=20000t=0.0!$OMP PARALLEL DOdo i=1,Nt=t+float(i);M=OMP_get_num_threads()enddowrite(*, "('t = ', F20.5, ' running on ', I3, ' threads.')") t,Mpausestopend串⾏代码可以很容易的得到正确结果:t = 200010000.00000 running on 1 threads.不幸的是,如果是并⾏的话,可能每次都得到⼀个不同的结果:t = 54821260.00000 running on 8 threads.t = 54430262.00000 running on 8 threads.....原因很简单,假设do被并⾏了两个线程,A1,A2,则每个线程都可以t,在其中⼀个线程访问t的时候,另⼀个线程修改了t,导致t的某些值“丢了”。
解决⽅法有两种,第⼀种就是“临界”,就是锁定t:!$OMP PARALLEL DOdo i = 1, N!$OMP CRITICALt = t+float(i)!$OMP END CRITICALM = OMP_get_num_threads()enddo这样每个时刻只有⼀个线程能访问这个变量。
openMP(并行计算) 超简单快速上手

openMP(并行计算)超简单快速上手简介:•OpenMp是并已被广泛接受的,用于共享内存并行系统的多处理器程序设计的一套指导性的编译处理方案。
•OpenMP支持的编程语言包括C语言、C++和Fortran;•OpenMp提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。
当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
openMP并行化for循环(只需三步)1.vs等编译器中开启openMP支持2.将 Project 的Properties中C/C++里Language的OpenMP Support开启(参数为 /openmp)3.4.包含头文件5.#include<omp.h>6.7.在需要并行化的for循环前加入pragma指令8.#pragma omp parallel for9.这就三步就够了,是不是非常简单啊,赶快用起来吧。
使用技巧1.2.不是给所有的for都加并行化就会变更快,如果for的次数不是很多,就没必要使用并行了,反而会变慢3.多层for循环的情况#pragma omp parallel for是放在内层还是外层要视情况而定,绝对不能一概而论。
•如果内层的计算复杂度很高,比如循环次数多,每次循环计算量也比较大,放在内层可能效果要大大地好于外层。
•如果内层访问的内存比较多,#pragma omp parallel for放在外层的话,可能导致cache命中率大大降低,计算速度可能会是几十倍的下降。
openmp用法

openmp用法OpenMP是一种支持共享内存多线程编程的标准API。
它提供了一种简单而有效的方法,用于在计算机系统中利用多核和多处理器资源。
本文将逐步介绍OpenMP的用法和基本概念,从简单的并行循环到复杂的并行任务。
让我们一步一步来学习OpenMP吧。
第一步:环境设置要开始使用OpenMP,我们首先需要一个支持OpenMP的编译器。
常见的编译器如GCC、Clang和Intel编译器都支持OpenMP。
我们需要确保在编译时启用OpenMP支持。
例如,在GCC中,可以使用以下命令来编译包含OpenMP指令的程序:gcc -fopenmp program.c -o program第二步:并行循环最简单的OpenMP并行化形式是并行循环。
在循环的前面加上`#pragma omp parallel for`指令,就可以让循环被多个线程并行执行。
例如,下面的代码演示了如何使用OpenMP并行化一个简单的for循环:c#include <stdio.h>#include <omp.h>int main() {int i;#pragma omp parallel forfor (i = 0; i < 10; i++) {printf("Thread d: d\n", omp_get_thread_num(), i);}return 0;}在上面的例子中,`#pragma omp parallel for`指令会告诉编译器将for 循环并行化。
`omp_get_thread_num()`函数可以获取当前线程的编号。
第三步:数据共享与私有变量在并行编程中,多个线程可能会同时访问和修改共享的数据。
为了避免数据竞争和不一致的结果,我们需要显式地指定哪些变量是共享的,哪些变量是私有的。
我们可以使用`shared`和`private`子句来指定。
`shared`子句指定某个变量为共享变量,对所有线程可见。
intel visual fortran 在visual studio中如何正常的使用openmp并行程序
write ( *, '(a)' ) ' '
write ( *, '(a,i8,a)' ) ' Call OMP_SET_NUM_THREADS, and request ', &
nthreads, ' threads.'
call omp_set_num_threads ( nthreads )
在vs中利用ivf进行openmp的程序设计
一:设置成openmp的可使用配置
我的配置是IVF11.1,vstudio2008,Openmp3,进入代码界面后要设置属性,---fortran--language--process--OpenMp Dirctives为Generate parallel code如图所示:
write ( *, '(a)' ) ' N = number of terms computed and added;'
write ( *, '(a)' ) ' '
write ( *, '(a)' ) ' ESTIMATE = the computed estimate of PI;'
write ( *, '(a)' ) ' '
write ( *, '(a,i3)' ) ' This is proபைடு நூலகம்ess ', id
if ( id == 0 ) then
write ( *, '(a)' ) ' '
write ( *, '(a)' ) ' Calling OMP_GET_NUM_THREADS inside a '
linux openmp 例子程序

linux openmp 例子程序标题:Linux OpenMP例子程序1. OpenMP简介OpenMP是一种并行编程模型,可以在共享内存系统上实现并行计算。
它使用指令集和编译器指示来将串行代码转换为并行代码,从而实现更高效的计算。
2. Hello World程序下面是一个简单的OpenMP程序,用于打印“Hello World”:```c#include <stdio.h>#include <omp.h>int main() {#pragma omp parallel{int thread_id = omp_get_thread_num();printf("Hello World from thread %d\n", thread_id);}return 0;}```该程序使用了`#pragma omp parallel`指令来创建线程,并使用`omp_get_thread_num()`函数获取线程ID。
3. 并行for循环OpenMP可以很方便地并行化for循环。
下面是一个计算数组元素和的例子:```c#include <stdio.h>#include <omp.h>int main() {int sum = 0;#pragma omp parallel for reduction(+:sum)for (int i = 0; i < 100; i++) {sum += i;}printf("Sum: %d\n", sum);return 0;}```在上述代码中,`#pragma omp parallel for`指令将for循环并行化,`reduction(+:sum)`指示OpenMP将每个线程的局部和累加到全局和`sum`中。
4. 并行化矩阵乘法OpenMP也可以用于并行化矩阵乘法。
下面是一个简单的矩阵乘法示例:```c#include <stdio.h>#include <omp.h>#define N 100void matrix_multiply(int A[N][N], int B[N][N], int C[N][N]) {#pragma omp parallel forfor (int i = 0; i < N; i++) {for (int j = 0; j < N; j++) {C[i][j] = 0;for (int k = 0; k < N; k++) {C[i][j] += A[i][k] * B[k][j];}}}}int main() {int A[N][N];int B[N][N];int C[N][N];// 初始化A和B矩阵matrix_multiply(A, B, C);// 打印结果return 0;}```在上述代码中,`#pragma omp parallel for`指令将外层循环并行化,从而加快矩阵乘法的计算速度。
并行编程——MPIOPENMP混合编程

并⾏编程——MPIOPENMP混合编程在⼤规模节点间的并⾏时,由于节点间通讯的量是成平⽅项增长的,所以带宽很快就会显得不够。
所以⼀种思路增加程序效率线性的⽅法是⽤MPI/OPENMP混合编写并⾏部分。
这⼀部分其实在了解了MPI和OPENMP以后相对容易解决点。
⼤致思路是每个节点分配1-2个MPI进程后,每个MPI进程执⾏多个OPENMP线程。
OPENMP部分由于不需要进程间通信,直接通过内存共享⽅式交换信息,不⾛⽹络带宽,所以可以显著减少程序所需通讯的信息。
Fortran:Program hellouse mpiuse omp_libImplicit NoneInteger :: myid,numprocs,rc,ierrInteger :: i,j,k,tidCall MPI_INIT(ierr)Call MPI_COMM_RANK(MPI_COMM_WORLD,myid,ierr)Call MPI_COMM_SIZE(MPI_COMM_WORLD,numprocs,ierr)!$OMP Parallel private(tid)tid=OMP_GET_THREAD_NUM()write(*,*) 'hello from',tid,'of process',myid!$OMP END PARALLELCall MPI_FINALIZE(rc)StopEnd Program helloC++:# include <cstdlib># include <iostream># include <ctime># include "mpi.h"# include "omp.h"using namespace std;int main ( int argc, char *argv[] );//****************************************************************************80int main ( int argc, char *argv[] ){int myid;int nprocs;int this_thread;MPI::Init();myid=MPI::COMM_WORLD.Get_rank();nprocs=MPI::COMM_WORLD.Get_size();#pragma omp parallel private(this_thread){this_thread=omp_get_thread_num();cout <<this_thread<<" thread from "<<myid<<" is ok\n";}MPI::Finalize();return0;}这⾥值得要注意的是,似乎直接⽤mpif90/mpicxx编译的库会报错,所以需要⽤icc -openmp hello.cpp -o hello -DMPICH_IGNORE_CXX_SEEK -L/Path/to/mpi/lib/ -lmpi_mt -lmpiic -I/path/to/mpi/include其中-DMPICH_IGNORE_CXX_SEEK为防⽌MPI2协议中⼀个重复定义问题所使⽤的选项,为了保证线程安全,必须使⽤mpi_mt库对于intel的mpirun,必须在mpirun后加上-env I_MPI_PIN_DOMAIN omp使得每个mpi进程会启动openmp线程。
并行计算实验题目(OpenMP)

上机地点:电三楼519机房上机时间分为两组:周六上午9:00~11:30,PB12011班级同学周六晚上6:30~9:00,其他同学【注意事项】1.本次作业分为简单题和中等题,简单题每题3分,共6分,中等题4分。
2.实验请用基于C/C++的OpenMP编程模型最大效度的实现并行。
3.在完成实验后,提交实验报告时请务必给出不同线程数的加速比图或加速比表格,并需要给出你算法的核心思想。
代码请附在实验报告最后的附件中,最后只需要交实验报告即可。
4.请在一周之内提交你的实验报告,命名按照“1_学号_姓名”的格式,如“1_SA13011075_张三”,并发送至pc_2015spring@163aaa 5.实验报告模板和本文档可以到此处下载:bbb://bbb/~xiangbin/pc2015/6.测试时间函数参考。
double time_used;struct timeval tv_start, tv_end;gettimeofday(&tv_start, NULL);function();gettimeofday(&tv_end, NULL);time_used=(tv__sec-tv__sec)*1000000+(tv__usec-tv__ usec);printf("time_used = %lf s\n", time_used/1000000);一.简单题1.针对教材中求PI的实例程序,请给出至少两种不同并行方式的OpenMP实现。
(划分数>= 1, 000, 000)2. 使用OPENMP编写矩阵乘法程序。
二.中等题1. 用OpenMP实现2到1, 000, 000素数的求解,并把最后的结果输出到一个文件中,同时在屏幕中显示寻找到的素数的个数。
(尽量尝试用利于并行的高效的确定性算法实现)。
友情提示:部分文档来自网络整理,供您参考!文档可复制、编制,期待您的好评与关注!。
基于OpenMP的多核系统并行程序设计方法研究

南华 大学学 报( 自然科学版 ) J o u r n a l o f U n i v e r s i t y o f S o u t h C h i n a ( S c i e n c e a n d T e c h n o l o g y )
h o w t o ma k e f ul l u s e o f mu l t i — c o r e c o mp u t i n g p o we r , mi n i n g a pp l i c a t i o n i n p a r a l l e l , t o g i v e
s t a n d a n d ma s t e r . T h i s p a p e r d e s c r i b e s a O p e n MP b a s e d o n mu l t i — c o r e p ra a ll e l p r o g r a m d e — s i g n me t h o d s , a n d p u t s f o r w rd a t wo k i n d s o f n u c l e r a s y s t e m w i h t mu l t i p l e p ra a ll e l p r o ra g m
V0 I . 2 7 No . 1 Ma L 2 0 1 3
文章编号 : 1 6 7 3— 0 0 6 2 ( 2 0 1 3 ) 0 1— 0 0 6 4— 0 5
基于 O p e n MP的多核 系统并行程 序设计 方法研究
龚向 坚, 邹腊 梅 , 胡 义 香
( 南华大学 计算机科学与技术学 院, 湖南 衡 阳 4 2 1 0 0 1 )
DCS11(多核编程OpenMP)

OpenMP并行程序设计OpenMP (Open Multi-Processing,开放多处理)是一种支持多平台共享内存多处理编程的C、C++和Fortran语言API。
它支持许多体系结构,包括Unix和Windows。
它包含一组编译器指令、库程序、和影响运行时行为的环境变量。
支持OpenMP的编译器包括Sun Compiler、GNU Compiler、Intel Compiler和Microsoft Visual C++等。
OpenMP的API规范由OpenMP ARB(Architecture Review Board, 架构评审委员会,网址为:/wp/)公布。
1997年10月推出OpenMP for Fortran 1.0、1998年10月推出OpenMP for C/C++ 1.0、2000年推出OpenMP for Fortran 2.0、2002年10月推出OpenMP for C/C++ 2.0、2008年5月推出OpenMP 3.0、2011年7月9日推出OpenMP 3.1。
多核(Multi-Core)、众核(Many-Core)A multi-core processor is a single computing component with two or more independent actual processors (called "cores"), which are the units that read and execute program instructions. The instructions are ordinary CPU instructions such as add, move data, and branch, but the multiple cores can run multiple instructions at the same time, increasing overall speed for programs amenable to parallel computing. Manufacturers typically integrate the cores onto a single integrated circuit die (known as a chip multiprocessor or CMP), or onto multiple dies in a single chip package.Processors were originally developed with only one core. A many-core processor is a multi-core processor in which the number of cores is large enough that traditional multi-processor techniques are no longer efficient—largely because of issues with congestion in supplying instructions and data to the many processors. The many-core threshold is roughly in the range of several tens of cores; above this threshold network on chip technology is advantageous. Tilera processors feature a switch in each core to route data through an on-chip mesh network to lessen the data congestion, enabling their core count to scale up to 100 cores.OpenMP并行计算模型多核处理器的并行计算模型[1]1. 指令级并行性程序代码本质上是偏序的,这意味着可以同时发射执行多条不相关的指令,这种指令间的可重叠性与无关性就是指令级并行性。
OpenMP并行编程

8
第8页,共60页。
并行化方法
基本并行化方法
相并行(Phase Parallel) 流行线并行(Pipeline Parallel) 主从并行(Master-Slave Parallel) 分而治之并行(Divide and Conquer Parallel) 工作池并行(Work Pool Parallel)
第18页,共60页。
18
Fork-Join
并行域
并行域
串行域 F O
R K
J 串行域 F
O
O
I
R
N
K
J 串行域
O
I
N
Fork:主线程创建一个并行线程队列,然后,并行域中的代码在不同
的线程上并行执行
Join:当并行域执行完之后,它们或被同步,或被中断,最后只有 主线程继续执行
并行域可以嵌套
19
第19页,共60页。
9
第9页,共60页。
并行化方法
相并行
一组超级步(相)
步内各自计算 步间通信同步 方便差错和性能分析 计算和通信不能重叠
C
C ...... C
Synchronous Interaction
C
C ...... C
Synchronous Interaction
流行线并行
将分成一系列子任务 t1, t2, …, tm,一旦 t1 完成,
父进程把负载分割并指派给子进程
重点在于归并 难以负载平衡
第11页,共60页。
11
并行化方法
工作池并行
初始状态:一件工作
进程从池中取任务执行
可产生新任务放回池中
直至任务池为空 易于负载平衡
OpenMP多核并行程序的设计与实现

( 1 , C o l l e g e o f E l e c t r o n i c E n g i n e e r i n g , X i’ a n p e t r o l e u m u n i v e r s i t y , X i’ a n , 7 1 0 0 6 5 , C h i n a :
能, 提 出将单 一任 务 分解 成若 干个 子任 务 , 分 别在 不 同 的节 点 执行 时 , 这 时候 , 主线 程会 派 生 出子线程 或者 启用 系 统原 有线 上运行。 在 多核 处理 机 上 , 研 究并 行算法 的实现 技术 与 并行 后 程 来 并行执 行任 务 。 在 执行 的过 程 中 , 主线程 协 同子 线程 共 同 系 统 的性能 , 具 有非常 重要 的理论 与现实 意义 。
二 次 分配 问题( Q A P ) 是 一种经 典 的组合 优 化 问题 , 易 于描 述而 难于求 解 , 已经 归入 N P - h a r d问题 。Q A P不仅 以各种不 同
a l g o r i t h m b a s e d o n O p e n M P.
Ke y wor d s :m u l t i — c o r e: O p e n M P: p a r t i c l e s w a r m o p t i m i z a t i o n
3 ,C o l l e g e o f E l e c t r o n i c E n g i n e e r i n g , X i’ a n p e t r o l e u m u n i v e r s i t y , X i’ a n 7 1 0 0 6 5 , C h i n a )
OpenMP简易教程

2) 方便性问题
在多核编程时,要求计算均摊到各个 CPU 核上去,所有的程序都需要并行化执行,对计算的负载均衡有很高 要求。这就要求在同一个函数内戒同一个循环中,可能也需要将计算分摊到各个 CPU 核上,需要创建多个线 程。操作系统 API 创建线程时,需要线程入口函数,很难满足这个需求,除非将一个函数内的代码手工拆成多 个线程入口函数,这将大大增加程序员的工作量。使用 OpenMP 创建线程则丌需要入口函数,非常方便,可 以将同一函数内的代码分解成多个线程执行,也可以将一个 for 循环分解成多个线程执行。
OpenMP 创建线程中的锁及原子操作性能比较 ............................................................................................................... 21 OpenMP 程序设计的两个小技巧 ....................................................................................................................................... 25
目录openmp简易教程openmp并行程序设计一openmp并行程序设计二forkjoin并行执行模式的概念openmp指令和库函数介绍parallel指令的用法sections和section指令的用法28openmp中的数据处理子句private子句firstprivate子句lastprivate子句threadprivate子句shared子句default子句reduction子句copyin子句copyprivate子句15openmp中的任务调度schedule子句用法guided调度guidedruntime调度rumtime20openmp创建线程中的锁及原子操作性能比较21openmp程序设计的两个小技巧28openmp并行程序设计一openmp是一个支持共享存储并行设计的库特别适宜多核cpu上的并行程序设计
2024版并行程序设计导论之OpenMP编程指南

OpenMP编程指南•OpenMP 概述•OpenMP 基本原理•OpenMP 编程实践•并行算法设计与优化•多线程并发控制及同步机制•内存访问优化与缓存一致性维护•性能评价与调试技巧分享目录01 OpenMP概述并行计算与OpenMP并行计算定义并行计算是指同时使用多种计算资源解决计算问题的过程,其主要目的是快速解决大型且复杂的计算问题。
OpenMP简介OpenMP是一种用于共享内存并行编程的API,在C/C和Fortran中广泛使用。
它提供了一种简单、灵活的线程并行编程模型,支持多平台和多编译器。
OpenMP与并行计算关系OpenMP通过提供一套编程接口和运行时库,使得程序员能够方便地使用多线程进行并行计算,从而加速程序的执行速度。
OpenMP历史与发展OpenMP起源OpenMP起源于1997年,由一组计算机硬件和软件厂商共同发起,旨在创建一个开放的、标准的并行编程模型。
OpenMP版本演进自1998年发布第一个版本以来,OpenMP不断发展和完善,增加了对任务并行、加速器支持、原子操作、线程同步等功能的支持。
OpenMP现状与未来目前,OpenMP已成为并行编程领域的事实标准之一,广泛应用于科学计算、工程仿真、数据分析等领域。
未来,随着硬件技术的不断发展和应用需求的不断提高,OpenMP将继续发展并完善。
OpenMP 在科学计算领域有着广泛的应用,如天气预报、气候模拟、油藏模拟等。
科学计算在工程仿真领域,OpenMP 可用于加速有限元分析、流体动力学仿真等计算过程。
工程仿真在数据分析领域,OpenMP 可用于加速数据挖掘、机器学习等算法的执行速度。
数据分析此外,OpenMP 还可应用于图像处理、密码学、生物信息学等领域。
其他领域OpenMP 应用领域02 OpenMP基本原理共享内存模型OpenMP基于共享内存模型,多个线程可以访问和修改同一块内存空间,需要解决数据一致性和同步问题。
分布式内存模型与MPI等基于分布式内存的并行计算模型不同,OpenMP不需要显式地进行数据分发和收集。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
OpenMP并行程序设计(一)OpenMP是一个支持共享存储并行设计的库,特别适宜多核CPU上的并行程序设计。
今天在双核CPU机器上试了一下OpenMP并行程序设计,发现效率方面超出想象,因此写出来分享给大家。
在VC8.0中项目的属性对话框中,左边框里的“配置属性”下的“C/C++”下的“语言”页里,将OpenMP支持改为“是/(OpenMP)”就可以支持OpenMP了。
先看一个简单的使用了OpenMP程序int main(int argc, char* argv[]){#pragma omp parallel forfor (int i = 0; i < 10; i++ ){printf("i = %d\n", i);}return 0;}这个程序执行后打印出以下结果:i = 0i = 5i = 1i = 6i = 2i = 7i = 3i = 8i = 4i = 9可见for 循环语句中的内容被并行执行了。
(每次运行的打印结果可能会有区别)这里要说明一下,#pragma omp parallel for 这条语句是用来指定后面的for循环语句变成并行执行的,当然for循环里的内容必须满足可以并行执行,即每次循环互不相干,后一次循环不依赖于前面的循环。
有关#pragma omp parallel for 这条语句的具体含义及相关OpenMP指令和函数的介绍暂时先放一放,只要知道这条语句会将后面的for循环里的内容变成并行执行就行了。
将for循环里的语句变成并行执行后效率会不会提高呢,我想这是我们最关心的内容了。
下面就写一个简单的测试程序来测试一下:void test(){int a = 0;clock_t t1 = clock();for (int i = 0; i < 0; i++){a = i+1;}clock_t t2 = clock();printf("Time = %d\n", t2-t1);}int main(int argc, char* argv[]){clock_t t1 = clock();#pragma omp parallel forfor ( int j = 0; j < 2; j++ ){test();}clock_t t2 = clock();printf("Total time = %d\n", t2-t1);test();return 0;}在test()函数中,执行了1亿次循环,主要是用来执行一个长时间的操作。
在main()函数里,先在一个循环里调用test()函数,只循环2次,我们还是看一下在双核CPU上的运行结果吧:Time = 297Time = 297Total time = 297Time = 297可以看到在for循环里的两次test()函数调用都花费了297ms,但是打印出的总时间却只花费了297ms,后面那个单独执行的test()函数花费的时间也是297ms,可见使用并行计算后效率提高了整整一倍。
下一篇文章中将介绍OpenMP的具体指令和用法。
OpenMP并行程序设计(二)1、fork/join并行执行模式的概念OpenMP是一个编译器指令和库函数的集合,主要是为共享式存储计算机上的并行程序设计使用的。
前面一篇文章中已经试用了OpenMP的一个Parallel for指令。
从上篇文章中我们也可以发现OpenMP并行执行的程序要全部结束后才能执行后面的非并行部分的代码。
这就是标准的并行模式fork/join式并行模式,共享存储式并行程序就是使用fork/join式并行的。
标准并行模式执行代码的基本思想是,程序开始时只有一个主线程,程序中的串行部分都由主线程执行,并行的部分是通过派生其他线程来执行,但是如果并行部分没有结束时是不会执行串行部分的,如上一篇文章中的以下代码:int main(int argc, char* argv[]){clock_t t1 = clock();#pragma omp parallel forfor ( int j = 0; j < 2; j++ ){test();}clock_t t2 = clock();printf("Total time = %d\n", t2-t1);test();return 0;}在没有执行完for循环中的代码之前,后面的clock_t t2 = clock();这行代码是不会执行的,如果和调用线程创建函数相比,它相当于先创建线程,并等待线程执行完,所以这种并行模式中在主线程里创建的线程并没有和主线程并行运行。
2、OpenMP指令和库函数介绍下面来介绍OpenMP的基本指令和常用指令的用法,在C/C++中,OpenMP指令使用的格式为#pragma omp 指令 [子句[子句]…]前面提到的parallel for就是一条指令,有些书中也将OpenMP的“指令”叫做“编译指导语句”,后面的子句是可选的。
例如:#pragma omp parallel private(i, j)parallel 就是指令, private是子句为叙述方便把包含#pragma和OpenMP指令的一行叫做语句,如上面那行叫parallel语句。
OpenMP的指令有以下一些:parallel,用在一个代码段之前,表示这段代码将被多个线程并行执行for,用于for循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性。
parallel for, parallel 和 for语句的结合,也是用在一个for循环之前,表示for循环的代码将被多个线程并行执行。
sections,用在可能会被并行执行的代码段之前parallel sections,parallel和sections两个语句的结合critical,用在一段代码临界区之前single,用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行。
flush,barrier,用于并行区内代码的线程同步,所有线程执行到barrier时要停止,直到所有线程都执行到barrier时才继续往下执行。
atomic,用于指定一块内存区域被制动更新master,用于指定一段代码块由主线程执行ordered,用于指定并行区域的循环按顺序执行threadprivate, 用于指定一个变量是线程私有的。
OpenMP除上述指令外,还有一些库函数,下面列出几个常用的库函数:omp_get_num_procs, 返回运行本线程的多处理机的处理器个数。
omp_get_num_threads, 返回当前并行区域中的活动线程个数。
omp_get_thread_num, 返回线程号omp_set_num_threads, 设置并行执行代码时的线程个数omp_init_lock, 初始化一个简单锁omp_set_lock,上锁操作omp_unset_lock,解锁操作,要和omp_set_lock函数配对使用。
omp_destroy_lock, omp_init_lock函数的配对操作函数,关闭一个锁OpenMP的子句有以下一些private, 指定每个线程都有它自己的变量私有副本。
firstprivate,指定每个线程都有它自己的变量私有副本,并且变量要被继承主线程中的初值。
lastprivate,主要是用来指定将线程中的私有变量的值在并行处理结束后复制回主线程中的对应变量。
reduce,用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的运算。
nowait,忽略指定中暗含的等待num_threads,指定线程的个数schedule,指定如何调度for循环迭代shared,指定一个或多个变量为多个线程间的共享变量ordered,用来指定for循环的执行要按顺序执行copyprivate,用于single指令中的指定变量为多个线程的共享变量copyin,用来指定一个threadprivate的变量的值要用主线程的值进行初始化。
default,用来指定并行处理区域内的变量的使用方式,缺省是shared3、parallel 指令的用法parallel 是用来构造一个并行块的,也可以使用其他指令如for、sections等和它配合使用。
在C/C++中,parallel的使用方法如下:#pragma omp parallel [for | sections] [子句[子句]…]{//代码}parallel语句后面要跟一个大括号对将要并行执行的代码括起来。
void main(int argc, char *argv[]) {#pragma omp parallel{printf(“Hello, World!\n”);}}执行以上代码将会打印出以下结果Hello, World!Hello, World!Hello, World!Hello, World!可以看得出parallel语句中的代码被执行了四次,说明总共创建了4个线程去执行parallel 语句中的代码。
也可以指定使用多少个线程来执行,需要使用num_threads子句:void main(int argc, char *argv[]) {#pragma omp parallel num_threads(8){printf(“Hello, World!, ThreadId=%d\n”, omp_get_thread_num() );}}执行以上代码,将会打印出以下结果:Hello, World!, ThreadId = 2Hello, World!, ThreadId = 6Hello, World!, ThreadId = 4Hello, World!, ThreadId = 0Hello, World!, ThreadId = 5Hello, World!, ThreadId = 7Hello, World!, ThreadId = 1Hello, World!, ThreadId = 3从ThreadId的不同可以看出创建了8个线程来执行以上代码。
所以parallel指令是用来为一段代码创建多个线程来执行它的。
parallel块中的每行代码都被多个线程重复执行。
和传统的创建线程函数比起来,相当于为一个线程入口函数重复调用创建线程函数来创建线程并等待线程执行完。
4、for指令的使用方法for指令则是用来将一个for循环分配到多个线程中执行。
for指令一般可以和parallel 指令合起来形成parallel for指令使用,也可以单独用在parallel语句的并行块中。