Pandas_talk_baidu_movie_recommendation
人工智能自然语言技术练习(习题卷9)

人工智能自然语言技术练习(习题卷9)第1部分:单项选择题,共45题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]如何理解NNLM这个模型,它是一个什么样的模型A)基于统计的语言模型B)基于神经网络的语言模型C)预训练模型D)编解码模型答案:C解析:2.[单选题]文本文件中存储的其实并不是我们在编辑器里看到的一个个的字符,而是字符的()。
A)内码B)外码C)反码D)补码答案:A解析:3.[单选题]数据可视化data visualization,导入_哪个包?A)A: sklearn.linear_modelB)B: sklearn.model_selectionC)C: matplotlib.pylabD)D: sklearn.metrics答案:D解析:4.[单选题]dropout作为常用的函数,它能起到什么作用A)没有激活函数功能B)一种正则化方式C)一种图像特征处理算法D)一种语音处理算法答案:B解析:5.[单选题]以下四个描述中,哪个选项正确的描述了XGBoost的基本核心思想A)训练出来一个一次函数图像去描述数据B)训练出来一个二次函数图像去描述数据C)不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数f(x),去拟合上次预测的残差。
D)不确定答案:C解析:C)LSTM 神经网络模型使用门结构实现了对序列数据中的遗忘与记忆D)使用大量的文本序列数据对 LSTM 模型训练后,可以捕捉到文本间的依赖关系,训练好的模型就可以根据指定的文本生成后序的内容答案:B解析:7.[单选题]relu函数的作用是可以将小于()的数输出为0A)-1B)0C)1D)x答案:B解析:8.[单选题]以下不是语料库的三点基本认识的是A)语料库中存放的是在语言的实际使用中真实出现出的语言材料。
B)语料库是以电子计算机为载体承载语言知识的基本资源,并不等于语言知识。
C)真实语料需要经过加工(分析和处理),才能成为有用的资源。
基于Python影评数据挖掘与分析 以《你好 李焕英》为例

总结来说,《大家好,李焕英》是一部集娱乐性、艺术性和情感力于一体的优 秀华语电影。通过Python影评数据挖掘与分析,我们可以清晰地看到这部电 影在观众中引发的强烈共鸣。母爱的伟大与无私是电影的核心,也是触动人心 的关键所在。希望未来的华语电影能继续出产更多如《大家好,李焕英》一样 有深度、有情感、有口碑的作品。
参考内容二
基本内容
随着科技的快速发展,大数据分析在许多领域都得到了广泛的应用。其中,基 于文本挖掘的影评数据情感分析是一个重要的研究方向。本次演示以《我和我 的祖国》为例,探讨了这一方法的应用。
ห้องสมุดไป่ตู้
《我和我的祖国》是一部由陈凯歌担任总导演,黄建新担任总制片人,众多导 演联合执导,众多明星主演的剧情片。该片于2019年9月30日在中国大陆上映, 讲述了新中国成立70年间普通百姓与共和国息息相关的故事。
经过分析,我们发现《我和我的祖国》的影评总体上呈现出积极的情感态度。 大部分观众对这部电影持正面评价,认为该片在讲述新中国成立70年间普通百 姓与共和国息息相关的故事方面做得很好,演员的表演也非常出色。然而,也 有一部分观众对该片表达出了消极的情感态度,认为该片在某些情节安排和人 物塑造方面存在问题。
本次演示利用基于文本挖掘的影评数据情感分析方法,对《我和我的祖国》的 影评数据进行了深入的分析。首先,收集了大量的影评数据,包括各大电影评 论网站、社交媒体以及相关新闻报道等。然后,利用自然语言处理技术,对影 评数据进行预处理,包括分词、去停用词、词干化等。接着,利用情感词典和 机器学习算法,对预处理后的数据进行情感分析。
使用Python进行影评数据挖掘和分析,可以更加深入地理解观众对这部电影 的看法。首先,我们可以通过爬虫技术抓取网络上的影评数据。例如,我们可 以使用BeautifulSoup或者Scrapy等Python库,来爬取豆瓣、猫眼等电影评价 网站上的影评。
pandas cut用法

pandas cut用法Pandas是一种快速、强大且灵活的Python数据分析库。
它提供了各种功能和工具来处理和操作数据,使数据分析和数据处理变得更加简单和高效。
Pandas中的cut函数是一个非常有用的工具,用于将连续的数据按照一定的间隔划分成离散的区间,从而方便我们进行数据分析和可视化。
在本篇文章中,我将一步一步地回答关于Pandas cut函数的使用方法和应用场景,帮助您更好地理解和掌握这个功能强大的工具。
第一步:导入必要的库和数据首先,在使用Pandas的cut函数之前,我们需要导入必要的库——Pandas和NumPy,并准备好我们的数据。
假设我们有一个包含身高数据的数据集,如下所示:pythonimport pandas as pdimport numpy as np# 创建一个包含身高数据的数据集data = pd.DataFrame({'height': [165, 170, 160, 175, 180, 155, 165, 185]})第二步:了解cut函数的基本语法和参数接下来,让我们了解一下Pandas cut函数的基本语法和参数。
cut函数的语法如下:pythonpandas.cut(x, bins, labels=None, ...)其中,`x`是要划分的数据,可以是一个Series对象或DataFrame的某一列;`bins`是用于划分的区间,可以是一个整数、一个数组或一个定义区间的字符串;`labels`是可选的,用于对划分后的区间进行标记。
第三步:使用cut函数进行数据划分现在,我们可以使用cut函数来将身高数据划分成几个区间。
假设我们希望将身高划分成三个区间:矮、中等和高。
我们可以使用如下代码来实现:python# 使用cut函数划分身高数据data['height_category'] = pd.cut(data['height'], bins=[0, 165, 175, np.inf], labels=['short', 'medium', 'tall'])在这个例子中,我们使用`bins`参数将身高划分成了三个区间。
使用pytorch框架实现使用MF模型在movielen数据集上的电影评分预测

使用pytorch框架实现使用MF模型在movielen数据集上的电影评分预测使用PyTorch框架实现电影评分预测的MF模型可以帮助我们根据用户的历史评分数据来预测用户对未评分电影的喜好程度。
本文将从数据预处理、模型构建以及训练过程几个方面介绍如何在MovieLens数据集上实现电影评分预测。
1.数据预处理:MovieLens数据集是一个经典的电影评分数据集,其中包含了用户对电影的评分、电影信息等。
我们可以使用pandas库来读取数据集,然后进行预处理。
首先,我们对数据集进行索引重置,并将用户和电影的id 进行映射。
另外,我们可以将数据集分成训练集和测试集,通常可以按照80%的比例划分。
最后,我们计算训练集和测试集中用户和电影的数量。
```pythonimport pandas as pdimport numpy as np#读取数据集ratings = pd.read_csv('ratings.csv')#重置索引ratings = ratings.reset_index(drop=True)# 用户和电影id映射user_ids = ratings['userId'].uniqueuser_to_idx = {old: new for new, old in enumerate(user_ids)} movie_ids = ratings['movieId'].uniquemovie_to_idx = {old: new for new, old inenumerate(movie_ids)}#划分训练集和测试集train_ratio = 0.8np.random.seed(0)mask = np.random.rand(len(ratings)) < train_ratiotrain_ratings = ratings[mask]test_ratings = ratings[~mask]#计算用户和电影数量num_users = train_ratings['userId'].nuniquenum_movies = train_ratings['movieId'].nunique```2.模型构建:在MF模型中,用户的评分由用户特征向量和电影特征向量的内积决定。
基于数据挖掘的电影评分预测研究

基于数据挖掘的电影评分预测研究电影评分是了解观众对电影的态度和喜好的重要指标之一。
在过去的几年中,随着大数据和数据挖掘技术的迅速发展,电影行业也越来越依赖于这些技术来预测和分析观众的评分。
本文将着重研究基于数据挖掘的电影评分预测,并讨论该方法在电影行业中的应用。
首先,我们需要明确数据挖掘在电影评分预测中的作用和重要性。
数据挖掘是从大量的数据中提取出有价值的信息和模式的过程。
对于电影评分预测,数据挖掘可以帮助我们挖掘出观众喜好的关键特征和规律,从而准确预测观众可能给出的评分。
这对电影行业来说具有重要意义,可以帮助制片方更好地了解观众需求,优化电影制作和推广策略。
其次,我们需要介绍数据挖掘在电影评分预测中的具体方法和步骤。
在实际应用中,电影评分预测可以通过以下几个步骤来完成:第一步,数据获取和清洗。
获取电影评分数据是进行预测的前提。
我们可以从电影评价网站、社交媒体等渠道获取相关数据。
然后需要对数据进行清洗,包括去除重复数据、处理缺失值和异常值等。
第二步,特征选择和提取。
在评分预测中,观众的个人信息和电影的特征是非常关键的。
因此,我们需要选择和提取出能够反映观众喜好和电影特征的关键特征。
这可以通过统计学方法、机器学习算法和专家经验等多种手段来完成。
第三步,建模和算法选择。
在电影评分预测中,我们可以使用多种机器学习算法来构建模型,如线性回归、决策树、支持向量机和神经网络等。
选择合适的算法和模型可以提高预测准确度。
第四步,模型训练和验证。
建立模型后,我们需要将数据分为训练集和测试集。
使用训练集对模型进行训练,并使用测试集对模型进行验证。
通过评估模型的准确度和性能指标,可以确定模型的优劣。
第五步,预测和应用。
在完成模型训练和验证后,我们可以使用该模型对新的电影或观众进行评分预测。
这些预测结果可以帮助电影制片方更好地了解观众喜好和需求,从而优化电影制作和推广策略。
接下来,我们需要讨论基于数据挖掘的电影评分预测在电影行业中的应用。
Python案例分析科学计算库练习之电影数据分析

Python案例 --电影数据分析Python案例 --电影数据分析一、课前准备二、课堂主题三、课堂目标四、案例-----电影数据分析1、项目背景2、概览数据3、分析过程,拆解项目3.1、读取数据3.2、数据清洗3.3、数据分析1. 电影发展趋势2. 电影情况分析3. 盈利问题4.电影评分及票房因素五、总结一、课前准备1. 复习之前知识点,特别是Pandas;2. 熟悉数据表;二、课堂主题本小节主要通过前面阶段知识内容, 完成Python案例分析。
三、课堂目标1. 掌握解决项目问题的能力;2. 掌握Python及科学计算的知识点;四、案例-----电影数据分析1、项目背景互联网电影资料库(Internet Movie Database,简称IMDb)是一个关于电影演员、电影、电视节目、电视明星和电影制作的在线数据库。
IMDb的资料中包括了影片的众多信息、演员、片长、内容介绍、分级、评论等。
对于电影的评分目前使用最多的就是IMDb评分。
数据源:movie_metadata.csv字段解释:-----------------------------------------电影描述字段------------------------------------------movie_title 电影题目language 语言country 国家 content_rating 电影分级 title_year 电影年份color 色彩 duration 片长genres 电影体裁/类型 plot_keywords:剧情关键字-----------------------------------------电影描述字段-----------------------------------------------------------------------------------电影制作字段------------------------------------------budget:制作成本gross 总收入 aspect_ratio :画布比例-----------------------------------------电影制作字段-----------------------------------------------------------------------------------电影阵容字段-----------------------------------------facenumber_in_poster海报中的人脸数量director_name 导演director_facebook_likes 导演facebook粉丝数actor_1_name 主演1姓名actor_1_facebook_likes 主演1Facebook粉丝数actor_2_name 主演2姓名actor_2_facebook_likes 演员2 的facebook粉丝数actor_3_name 演员3名字actor_3_facebook_likes 主演3Facebook粉丝数-----------------------------------------电影阵容字段----------------------------------------------------------------------------------电影评论字段-----------------------------------------num_voted_users 投票人数num_user_for_reviews 用户的评论数量num_critic_for_reviews 评论家评论数movie_facebook_likes脸书上被点赞的数量cast_total_facebook_likes Facebook上投喜爱的总数movie_imdb_link 电影数据链接imdb_score:imdb上的评分-----------------------------------------电影评论字段-----------------------------------------2、概览数据查看概览数据,熟悉字段,以及相应格式。
人工智能深度学习技术练习(习题卷5)

人工智能深度学习技术练习(习题卷5)说明:答案和解析在试卷最后第1部分:单项选择题,共50题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]反向传播算法一开始计算什么内容的梯度,之后将其反向传播?A)预测结果与样本标签之间的误差B)各个输入样本的平方差之和C)各个网络权重的平方差之和D)都不对2.[单选题]在典型的Batch归一化运用中需要用什么来估算A)一个指数加权平均B)平均值C)方差D)最大值3.[单选题]pytorch中,LSTM输入尺寸参数为A)input_sizeB)batch_firstC)biasD)hidden_size4.[单选题]学习率的作用是()A)控制参数更新速度B)减少过拟合C)减少偏差D)以上都不是5.[单选题]基于切比雪夫距离的单位园是一个A)圆形B)45度的正方型C)正方形,其边与xy轴平行D)不确定6.[单选题]梯度消失的现象是A)导数为0B)参数不再更新C)达到最优梯度D)到达最优解7.[单选题]一个32X32大小的图像,通过步长为2,尺寸为2X2的池化运算后,尺寸变为A)14X14C)28X28D)16X168.[单选题]什么是卷积?A)缩小图像的技术B)放大图像的技术C)提取图像特征的技术D)过滤掉不需要的图像的技术9.[单选题]在TF框架中,激活函数tf.nn.relu的作用是?A)用于卷积后数据B)用于卷积核C)用于步长D)不能用到全连接层10.[单选题]不是随机梯度下降的特点是:A)批量数值选取为1B)学习率逐渐减小C)可以达到最小值D)在最小值附近波动11.[单选题]百度飞桨中训练过程流程的内层循环是指()。
A)负责整个数据集的二次遍历,采用分批次方式(batch)B)负责整个数据集的一次遍历,采用分批次方式(batch)C)定义遍历数据集的次数,通过参数EPOCH_NUM设置D)负责整个数据集的多次遍历,采用分批次方式(batch)12.[单选题]编码器-解码器模式属于以下哪种模式?A)一对一B)一对多C)多对一D)多对多13.[单选题]双向循环神经网络的英文缩写是?A)RNNB)SRNNC)TRNND)Bi-RNN14.[单选题]如果我们用了一个过大的学习速率会发生什么?()A)神经网络会收敛B)不好说C)都不对D)神经网络不会收敛15.[单选题]动态图处理中,无序开启A)求导B)会话C)自动微分D)反向传播16.[单选题]pandas的常用类不包括()。
python nlp 好莱坞电影 对话内容

《Python在NLP领域的应用:探索好莱坞电影对话内容》一、引言在当今信息爆炸的时代,自然语言处理(Natural Language Processing, NLP)作为人工智能领域的一个重要分支,正在变得越来越重要。
而好莱坞电影作为全球最具影响力的电影产业之一,其对话内容更是具有丰富的语言信息。
本文将深入探讨Python在NLP领域的应用,以及如何通过对好莱坞电影对话内容的分析来理解其中蕴含的文化和情感。
二、Python在NLP领域的应用1. 文本处理Python作为一种高效的编程语言,具有丰富的库和工具,使其成为NLP领域的首选语言之一。
通过使用NLTK(Natural Language Toolkit)等库,可以轻松实现文本的分词、词性标注、命名实体识别等常见任务,为对文本内容进行深度分析提供了强大的支持。
2. 机器学习在NLP领域,机器学习扮演着至关重要的角色。
Python中的机器学习库如scikit-learn和TensorFlow提供了丰富的算法和工具,可用于进行文本分类、情感分析、情感生成等高级NLP任务。
这使得通过Python进行NLP相关研究和应用变得更加便利和高效。
3. 数据可视化除了NLP技术本身,Python还具备强大的数据可视化能力。
使用Matplotlib、Seaborn等库,可以对NLP分析结果进行直观的展示,使得复杂的文本数据变得更加直观和易于理解。
三、好莱坞电影对话内容的深度分析好莱坞电影作为全球最具影响力的电影产业之一,其对话内容包含了丰富的文化内涵和情感表达。
通过对好莱坞电影对话内容的深度分析,可以不仅仅了解其在语言形式上的特点,更可以从中捕捉到人类文化和情感的多维度表达。
1. 词频分析通过Python的文本处理工具,我们可以对好莱坞电影的对话内容进行词频分析。
这可以帮助我们了解哪些词语在对话中出现的频率较高,从而把握到人物之间的关系、情感倾向等信息。
2. 情感分析利用Python的机器学习库,我们可以进行情感分析,从对话内容中挖掘人物的情感倾向。
Python学习-Python大作业电影推荐系统
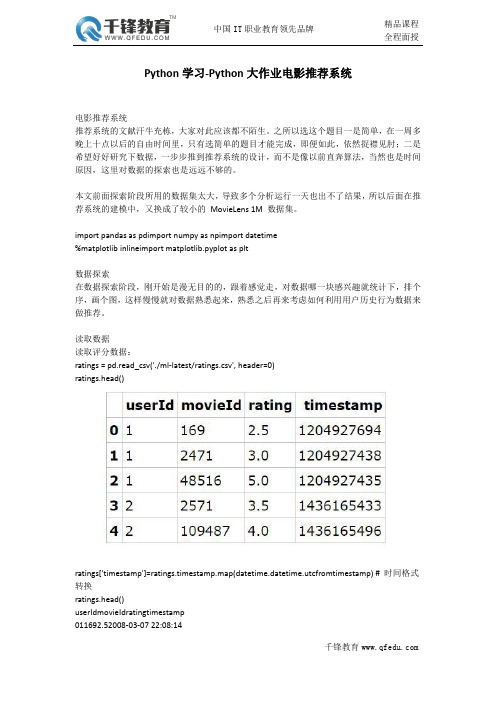
Python学习-Python大作业电影推荐系统电影推荐系统推荐系统的文献汗牛充栋,大家对此应该都不陌生。
之所以选这个题目一是简单,在一周多晚上十点以后的自由时间里,只有选简单的题目才能完成,即便如此,依然捉襟见肘;二是希望好好研究下数据,一步步推到推荐系统的设计,而不是像以前直奔算法,当然也是时间原因,这里对数据的探索也是远远不够的。
本文前面探索阶段所用的数据集太大,导致多个分析运行一天也出不了结果,所以后面在推荐系统的建模中,又换成了较小的MovieLens1M数据集。
import pandas as pdimport numpy as npimport datetime%matplotlib inlineimport matplotlib.pyplot as plt数据探索在数据探索阶段,刚开始是漫无目的的,跟着感觉走,对数据哪一块感兴趣就统计下,排个序,画个图,这样慢慢就对数据熟悉起来,熟悉之后再来考虑如何利用用户历史行为数据来做推荐。
读取数据读取评分数据:ratings=pd.read_csv('./ml-latest/ratings.csv',header=0)ratings.head()ratings['timestamp']=ratings.timestamp.map(datetime.datetime.utcfromtimestamp)#时间格式转换ratings.head()userIdmovieIdratingtimestamp011692.52008-03-0722:08:141124713.02008-03-0722:03:5821485165.02008-03-0722:03:553225713.52015-07-0606:50:33421094874.02015-07-0606:51:36ratings.count()userId22884377movieId22884377rating22884377timestamp22884377dtype:int64读取电影信息数据:movies=pd.read_csv('./ml-latest/movies.csv',header=0)movies.head()movies=movies.set_index("movieId")movies.head()movies.count()title34208genres34208dtype:int64该数据集包含了对34208部电影的22884377个评分数据。
pandas官方教程中文翻译
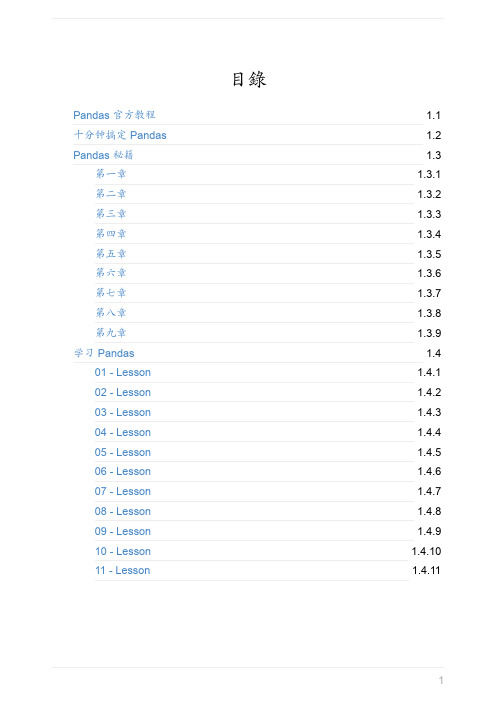
In [6]: dates = pd.date_range('20130101', periods=6)
In [7]: dates Out[7]: DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-0 1-04',
'2013-01-05', '2013-01-06'], dtype='datetime64[ns]', freq='D')
In [17]: df.columns Out[17]: Index([u'A', u'B', u'C', u'D'], dtype='object')
In [18]: df.values Out[18]: array([[ 0.4691, -0.2829, -1.5091, -1.1356],
[ 1.2121, -0.1732, 0.1192, -1.0442], [-0.8618, -2.1046, -0.4949, 1.0718], [ 0.7216, -0.7068, -1.0396, 0.2719], [-0.425 , 0.567 , 0.2762, -1.0874], [-0.6737, 0.1136, -1.4784, 0.525 ]])
2013-01-06 -0.673690 0.113648 -1.478427 0.524988
3、通过传递一个能够被转换成类似序列结构的字典对象来创建一 个 DataFrame :
4
十分钟搞定 Pandas
pythonpandas基本操作练习50题

pythonpandas基本操作练习50题Python Pandas 基本操作练习50题1. 创建一个空的DataFrame对象,名字为df。
```pythonimport pandas as pddf = pd.DataFrame()```2. 从列表创建一个DataFrame。
```pythondata = [['Alice', 25], ['Bob', 30], ['Charlie', 35]]df = pd.DataFrame(data, columns=['Name', 'Age'])```3. 从字典创建一个DataFrame。
```pythondata = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]} df = pd.DataFrame(data)```4. 展示DataFrame的前5行。
```pythonprint(df.head())```5. 查看DataFrame的行数和列数。
```pythonprint("行数:", df.shape[0])print("列数:", df.shape[1])```6. 查看DataFrame每一列的数据类型。
```pythonprint(df.dtypes)```7. 展示DataFrame的统计信息(均值、标准差、最小值、最大值等)。
```pythonprint(df.describe())```8. 展示DataFrame的列名。
```pythonprint(df.columns)```9. 选取DataFrame的某一列。
```pythoncolumn = df['Name']```10. 选取DataFrame的多列。
pandas习题100道

pandas习题100道#1import pandas as pd#2pd.__version__'1.0.5'#3pd.show_versions()INSTALLED VERSIONS------------------commit : Nonepython : 3.8.3.final.0python-bits : 64OS : DarwinOS-release : 19.6.0machine : x86_64processor : i386byteorder : littleLC_ALL : NoneLANG : zh_CN.UTF-8LOCALE : zh_CN.UTF-8pandas : 1.0.5numpy : 1.18.5pytz : 2020.1dateutil : 2.8.1pip : 20.1.1setuptools : 49.2.0.post20200714Cython : 0.29.21pytest : 5.4.3hypothesis : Nonesphinx : 3.1.2blosc : Nonefeather : Nonexlsxwriter : 1.2.9lxml.etree : 4.5.2html5lib : 1.1pymysql : 0.10.1psycopg2 : Nonejinja2 : 2.11.2IPython : 7.16.1pandas_datareader: Nonebs4 : 4.9.1bottleneck : 1.3.2fastparquet : Nonegcsfs : Nonelxml.etree : 4.5.2matplotlib : 3.2.2numexpr : 2.7.1odfpy : Noneopenpyxl : 3.0.4pandas_gbq : Nonepyarrow : Nonepytables : Nonepytest : 5.4.3pyxlsb : Nones3fs : Nonescipy : 1.5.0sqlalchemy : 1.3.18tables : 3.6.1tabulate : Nonexarray : Nonexlrd : 1.2.0xlwt : 1.3.0xlsxwriter : 1.2.9numba : 0.50.1#4创建⼀个DataFrame(df),⽤data做数据,labels做⾏索引import numpy as npdata = {'animal': ['cat', 'cat', 'snake', 'dog', 'dog', 'cat', 'snake', 'cat', 'dog', 'dog'],'age': [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],'visits': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],'priority': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']df = pd.DataFrame(data,index=labels)dfanimal age visits prioritya cat 2.51yesb cat 3.03yesc snake0.52nod dog NaN3yese dog 5.02nof cat 2.03nog snake 4.51noh cat NaN1yesi dog7.02noj dog 3.01no#5显⽰有关此df及其数据的基本信息的摘要()df.describe()<class 'pandas.core.frame.DataFrame'>Index: 10 entries, a to jData columns (total 4 columns):# Column Non-Null Count Dtype--- ------ -------------- -----0 animal 10 non-null object1 age 8 non-null float642 visits 10 non-null int643 priority 10 non-null objectdtypes: float64(1), int64(1), object(2)memory usage: 400.0+ bytesage visitscount8.00000010.000000mean3.4375001.900000std 2.0077970.875595min0.5000001.00000025% 2.3750001.00000050% 3.0000002.00000075% 4.6250002.750000max7.0000003.000000#6查看此df的前三⾏数据df.head(3)animal age visits prioritya cat 2.51yesb cat 3.03yesc snake0.52no#7选择df中列标签为animal和age的数据df1 = df[['animal','age']]df1animal agea cat 2.5b cat 3.0c snake0.5d dog NaNe dog 5.0f cat 2.0g snake 4.5h cat NaNi dog7.0j dog 3.0#8选择⾏为[3, 4, 8],且列为['animal', 'age']中的数据#本题的难点在于当⾏索引被命名为⾮数字时不能再使⽤loc按照数字取值,如果使⽤iloc就不能⽤名称取列,⽽本题的要求是按数字取⾏,按名称取列#解法⼀:分两次取值df2 = df.iloc[[3,4,8],:][['animal', 'age']]#解法⼆:取⾏索引然后按索引取df2 = df.loc[df.index[[3,4,8]],['animal', 'age']]#错误⽤法:# df2 = df.loc[[3,4,8],['animal', 'age']]df2animal aged dog NaNe dog 5.0i dog7.0#9选择visuts⼤于2的动物种类dfbool_s=df.visits>2df[bool_s]['animal']b catd dogf catName: animal, dtype: object#10选择age为缺失值的⾏df[df.age.isnull()]df[df['age'].isnull()]animal age visits priorityd dog NaN3yesh cat NaN1yes#11选择animal为cat,且age⼩于3的⾏df[(df['animal']=='cat') & (df['age']<3)]animal age visits prioritya cat 2.51yesf cat 2.03no#12选择age在2到4之间的数据(包含边界值)df[(df['age']>=2) &(df['age']<=4)]animal age visits prioritya cat 2.51yesb cat 3.03yesf cat 2.03noj dog 3.01no#13将f⾏的age改为1.5# df.loc['f']['age']=1.5 这个操作不规范会警报df.loc['f','age']=1.5#14计算visits列的数据总和res = df['visits'].sum()res19#15计算每种animal的平均agedf.groupby('animal')['age'].mean()animalcat 2.333333dog 5.000000snake 2.500000Name: age, dtype: float64#16追加⼀⾏(k),列的数据⾃定义,然后再删除新追加的k⾏df.loc['k']=df.loc['a'].valuesdf.drop('k',inplace=True) #删除⾏# del df['k'] #删除列dfanimal age visits prioritya cat 2.51yesb cat 3.03yesanimal age visits priorityc snake0.52nod dog NaN3yese dog 5.02nof cat 2.03nog snake 4.51noh cat NaN1yesi dog7.02noj dog 3.01no#17计算每种animal的个数(cat有⼏个,dog⼏个...)df.groupby('animal').size()df['animal'].value_counts()# df['animal'].unique() #查看动物的种类# df['animal'].nunique() #查看动物种类的个数dog 4cat 4snake 2Name: animal, dtype: int64#18先根据age降序排列,再根据visits升序排列df.sort_values(by=['age','visits'],ascending=[False,True])animal age visits priorityi dog7.02noe dog 5.02nog snake 4.51noj dog 3.01nob cat 3.03yesa cat 2.51yesf cat 2.03noc snake0.52noh cat NaN1yesd dog NaN3yes#19将priority列的yes和no⽤True和False替换#这题似乎有点问题,不同类型的数据类型似乎不能相互转换df['priority'] = df['priority'].astype(bool).map({'yes': True, 'no': False}) dfanimal age visits prioritya cat 2.51NaNb cat 3.03NaNc snake0.52NaNd dog NaN3NaNe dog 5.02NaNf cat 2.03NaNg snake 4.51NaNh cat NaN1NaNi dog7.02NaNj dog 3.01NaN#20 将animal列的snake⽤python替换df['animal'].replace('snake','python',inplace=True)dfanimal age visits prioritya cat 2.51NaNb cat 3.03NaNc python0.52NaNd dog NaN3NaNe dog 5.02NaNanimal age visits priorityf cat 2.03NaNg python4.51NaNcat NaN1NaNi dog7.02NaNj dog 3.01NaN#21对于每种动物类型和每种访问次数,求出平均年龄。
基于Python技术电影口碑的研究

基金项目:智慧校园移动微信云平台系统设计与实现(2018A-153)基于Python 技术电影口碑的研究为了解决电影评分体系的打分机制存在诸多不足,提出基于Python 网络爬虫技术的电影口碑研究方法。
以2部电影为例,利用该技术将电影网站上的用户评论提取下来,并对其进行自然语言处理情感分析,通过实验分析得出的情感分数可以表示用户对于电影的态度,作为一种评判电影口碑的重要依据。
1.引言电影口碑对于电影营销的重要性不言而喻,目前国内对于电影口碑的研究很少,除了比较具有代表性的豆瓣电影评分,其他相关机构的数据都很难有参考价值,而豆瓣电影评分体系的打分机制本身也存在诸多不足,因此,提出一种更权威的电影口碑研究方法成为亟待解决的问题。
观众对于一部电影的评论能够真实反映对于该部电影的态度。
详细的文字描述可以表达出观众的主观态度,运用大数据Python 技术,以豆瓣平台亿万观众所发表的文字为研究对象。
实现对电影评论的文本挖掘和情感分析,理论与实际操作相结合进行研究,解决电影营销中遇到的问题,进而对营销人员如何有效应用大数据提供启示,使其可以用于营销决策。
2.信息提取2.1Python 技术与信息提取网络爬虫是一种通过既定规则,可自动地抓取网页信息的计算机程序。
通过Python 技术,可以方便、快捷和高效地对电影评论实现网络数据爬取和网页解析,部分代码如图1所示。
其中Requests 库,可以对豆瓣网页爬取,获取网络页面,Beautiful Soup 库,可以有效地解析HTML 页面的内容,并且提取相关的信息。
图1线程类部分代码2.2情感分析情感分析又称意见挖掘,简而言之,是对带有情感色彩的主观性文本进行分析、处理、推理和归纳的过程,采取基于深度学习的情感分析方法,实现步骤如下:文本预处理包括以下3部分。
①分词:在语言学中,词作为最小的独立情感单元具有丰富的情感内涵。
②词性标注:词性是指根据词的特点用来划分词类的根据。
Python简单电影推荐算法(根据用户看过的电影名和对其打分进行推荐)

Python简单电影推荐算法(根据⽤户看过的电影名和对其打分进⾏推荐)def max_score(film):return data[user2][film]def score_different(use, fil):score = 0for filmName in fil:# sum = abs(data[use][filmName]-user[filmName])# if(sum!=0):# score += 3*1/(abs(data[use][filmName] - user[filmName])**2)# else:# score+=0;score += (abs(data[use][filmName] - user[filmName]))**2return scoredata = {'user' + str(i): {'film' + str(randrange(1, 15)): randrange(1, 6) for j in range(randrange(3, 10))}for i in range(1, 20)}print("各个⽤户的电影打分情况:",data)user = {'film' + str(randrange(1, 15)): randrange(1, 6) for j in range(randrange(3, 10))}print("⽤户本⼈的电影打分情况:",user)film_len = 0user2 = ""Film_Score = 0user_score = dict()for key, value in data.items():film = set(value) & set(user)#推荐电影的各⽤户推荐度分数算法:看过的相同电影数*2+(每部3*1/(看过的相同电影的评分差的平⽅))# 例如我: 1:5 2:5# user2: 1:8 2:8# 课上讲的评分标准为:2*0.5+3*1/(3**2+3**2)# ⽽我的标准为:2*0.5+(3*1/(3**2)+3*1/(3**2))Film_Score = score_different(key, film)if Film_Score !=0:user_score[key] = 3*1/Film_Score+len(film)*0.5else:user_score[key] = len(film)*0.5+5# if len(film) == film_len:# if score_different(key, film) < Film_Score:# film_len = len(film)# user2 = key# Film_Score = score_different(key, film)# if len(film) > film_len:# film_len = len(film)# user2 = key# Film_Score = score_different(key, film)print("输出⽤户的推荐度分数")print(user_score)print("与⽤户本⼈最相似的⽤户:")user3 = max(zip(user_score.values(),user_score.keys()))print(max(zip(user_score.values(),user_score.keys())))# print(user2, data[user2])print(user3[1],data[user3[1]])print("为⽤户推荐电影:")# print(max(set(data[user2]) - set(user), key=max_score))# print(max(set(data[user3[1]])-set(user)))# print(set(data[user3[1]])-set(user))# max_value = max(set(data[user3[1]])-set(user))# for i,j in set(data[user3[1]])-set(user):# user4 = data[user3[1]][1]# print(user3)# print(user3[1])uuu = dict(data[user3[1]])# print(uuu) # print(max(uuu))maxvalue = max(uuu.values())r_commend_film = []for m,n in uuu.items():if n==maxvalue and m not in user:r_commend_film.append(m)print(r_commend_film)def max_score(film):return data[user2][film]def score_different(use, fil):score = 0for filmName in fil:# sum = abs(data[use][filmName]-user[filmName])# if(sum!=0):# score += 3*1/(abs(data[use][filmName] - user[filmName])**2)# else:# score+=0;score += (abs(data[use][filmName] - user[filmName]))**2return scoredata = {'user' + str(i): {'film' + str(randrange(1, 15)): randrange(1, 6) for j in range(randrange(3, 10))}for i in range(1, 20)}print("各个⽤户的电影打分情况:",data)user = {'film' + str(randrange(1, 15)): randrange(1, 6) for j in range(randrange(3, 10))}print("⽤户本⼈的电影打分情况:",user)film_len = 0user2 = ""Film_Score = 0user_score = dict()for key, value in data.items():film = set(value) & set(user)#推荐电影的各⽤户推荐度分数算法:看过的相同电影数*2+(每部3*1/(看过的相同电影的评分差的平⽅))# 例如我: 1:5 2:5# user2: 1:8 2:8# 课上讲的评分标准为:2*0.5+3*1/(3**2+3**2)# ⽽我的标准为:2*0.5+(3*1/(3**2)+3*1/(3**2))Film_Score = score_different(key, film)if Film_Score !=0:user_score[key] = 3*1/Film_Score+len(film)*0.5else:user_score[key] = len(film)*0.5+5# if len(film) == film_len:# if score_different(key, film) < Film_Score:# film_len = len(film)# user2 = key# Film_Score = score_different(key, film)# if len(film) > film_len:# film_len = len(film)# user2 = key# Film_Score = score_different(key, film)print("输出⽤户的推荐度分数")print(user_score)print("与⽤户本⼈最相似的⽤户:")user3 = max(zip(user_score.values(),user_score.keys()))print(max(zip(user_score.values(),user_score.keys())))# print(user2, data[user2])print(user3[1],data[user3[1]])print("为⽤户推荐电影:")# print(max(set(data[user2]) - set(user), key=max_score))# print(max(set(data[user3[1]])-set(user)))# print(set(data[user3[1]])-set(user))# max_value = max(set(data[user3[1]])-set(user))# for i,j in set(data[user3[1]])-set(user):# user4 = data[user3[1]][1]# print(user3)# print(user3[1])uuu = dict(data[user3[1]])# print(uuu) # print(max(uuu))maxvalue = max(uuu.values())r_commend_film = []for m,n in uuu.items():if n==maxvalue and m not in user:r_commend_film.append(m)print(r_commend_film)以上代码的逻辑对于推荐电影来说不是很严格,单纯的使⽤其他⽤户的电影评分数量和评分⾼低与本⽤户的数据做⽐对,并对每个⽤户计算其推荐指数:例如:我看了 {film1:打分5,film2:打分8}。
pandas层次化索引和切片方法_概述及解释说明

pandas层次化索引和切片方法概述及解释说明1. 引言1.1 概述本文将对pandas的层次化索引和切片方法进行概述和解释说明。
随着数据分析领域的不断发展,处理多维数据变得越来越常见和重要。
而pandas作为一种强大的数据分析工具,提供了灵活且高效的层次化索引和切片方法,使得处理多维数据变得更加简单和方便。
1.2 文章结构本文共分为五个部分。
首先,在引言部分我们将对本文的研究对象进行介绍,并给出本文的整体结构。
接着,在第二部分,我们将介绍pandas层次化索引和切片方法的基本概念,包括层次化索引的概述以及切片方法的介绍。
然后,在第三部分,我们将讨论pandas层次化索引和切片方法在实际应用场景中的优势和局限性。
在第四部分,我们将详细介绍如何使用pandas进行层次化索引和切片操作,包括创建层次化索引对象、查询与选择方法介绍以及实际操作示例等内容。
最后,在第五部分中,我们将对全文进行总结,并对未来发展进行展望。
1.3 目的本文的目的在于全面介绍和解释pandas的层次化索引和切片方法,使读者对其原理、应用场景和操作方法有一个清晰的了解。
通过学习本文,读者将能够掌握使用pandas进行多维数据处理、灵活选择数据子集以及实现层次化切片的技巧和方法。
希望本文能够为读者在数据分析领域中利用pandas进行高效处理提供一定的帮助,并为未来pandas发展提供一些启示。
2. pandas层次化索引和切片方法的基本概念:2.1 层次化索引概述在数据分析中,为了处理复杂的多维数据集,pandas提供了层次化索引的功能。
层次化索引可以在一个轴上拥有多个(两个及以上)级别的索引标签,使得我们能够对高维数据进行更加灵活和方便的操作。
在层次化索引中,每个级别都有自己的索引标签,并且可以通过这些标签来选择、过滤和切片数据。
2.2 切片方法介绍在pandas中,切片是指按照一定条件选择数据集中的子集。
通过切片操作,我们可以根据某些条件来获取我们需要的数据。
《基于深度强化学习的电影推荐模型研究》范文

《基于深度强化学习的电影推荐模型研究》篇一一、引言随着互联网技术的快速发展,海量的电影资源为观众带来了丰富多样的选择,同时也增加了用户找到满意电影的难度。
为了解决这个问题,推荐系统在各大电影平台中发挥着越来越重要的作用。
近年来,基于深度学习和强化学习的电影推荐模型逐渐成为研究的热点。
本文将探讨基于深度强化学习的电影推荐模型的研究,旨在提高推荐的准确性和个性化程度。
二、相关研究背景传统的电影推荐模型主要基于协同过滤、内容过滤等方法。
然而,这些方法在处理大规模数据时存在局限性,难以实现精确的推荐。
近年来,深度学习在推荐系统中的应用逐渐受到关注,如基于深度神经网络的推荐模型能够从用户的历史行为和电影内容中提取更丰富的特征信息。
然而,这些模型往往忽略了用户行为的动态变化和长期决策过程。
因此,结合深度学习和强化学习的优势,构建基于深度强化学习的电影推荐模型成为了一个重要的研究方向。
三、深度强化学习在电影推荐中的应用深度强化学习是一种结合了深度学习和强化学习的技术,具有处理大规模数据和动态决策的能力。
在电影推荐中,我们可以利用深度神经网络提取用户和电影的特征信息,然后利用强化学习算法优化推荐策略。
具体而言,我们可以将用户的行为看作是一个决策过程,通过强化学习算法学习用户的偏好和决策规则,从而为用户提供更准确的电影推荐。
四、模型构建与实现(一)数据预处理首先,我们需要收集大量的用户行为数据和电影内容数据。
然后,对数据进行预处理,包括数据清洗、特征提取等步骤。
特征提取是关键的一步,我们需要从用户行为和电影内容中提取出有意义的特征信息,如用户的历史观看记录、电影的类别、演员等。
(二)模型构建在模型构建阶段,我们采用深度神经网络和强化学习算法相结合的方式。
首先,利用深度神经网络提取用户和电影的特征信息。
然后,利用强化学习算法优化推荐策略。
具体而言,我们可以将用户的行为看作是一个马尔可夫决策过程,通过强化学习算法学习用户的偏好和决策规则。
Python基于机器学习方法实现的电影推荐系统实例详解

Python基于机器学习⽅法实现的电影推荐系统实例详解推荐算法在互联⽹⾏业的应⽤⾮常⼴泛,今⽇头条、美团点评等都有个性化推荐,推荐算法抽象来讲,是⼀种对于内容满意度的拟合函数,涉及到⽤户特征和内容特征,作为模型训练所需维度的两⼤来源,⽽点击率,页⾯停留时间,评论或下单等都可以作为⼀个量化的 Y 值,这样就可以进⾏特征⼯程,构建出⼀个数据集,然后选择⼀个合适的监督学习算法进⾏训练,得到模型后,为客户推荐偏好的内容,如头条的话,就是咨询和⽂章,美团的就是⽣活服务内容。
可选择的模型很多,如协同过滤,逻辑斯蒂回归,基于DNN的模型,FM等。
我们使⽤的⽅式是,基于内容相似度计算进⾏召回,之后通过FM模型和逻辑斯蒂回归模型进⾏精排推荐,下⾯就分别说⼀下,我们做这个电影推荐系统过程中,从数据准备,特征⼯程,到模型训练和应⽤的整个过程。
我们实现的这个电影推荐系统,爬取的数据实际上维度是相对少的,特别是⽤户这⼀侧的维度,正常推荐系统涉及的维度,诸如页⾯停留时间,点击频次,收藏等这些维度都是没有的,以及⽤户本⾝的维度也相对要少,没有地址、年龄、性别等这些基本的维度,这样我们爬取的数据只有打分和评论这些信息,所以之后我们⼜从这些信息⾥再拿出⼀些统计维度来⽤。
我们爬取的电影数据(除电影详情和图⽚信息外)是如下这样的形式:这⾥的数据是有冗余的,⼜通过如下的代码,对数据进⾏按维度合并,去除冗余数据条⽬:# 处理主函数,负责将多个冗余数据合并为⼀条电影数据,将地区,导演,主演,类型,特⾊等维度数据合并def mainfunc():try:unable_list = []with connection.cursor() as cursor:sql='select id,name from movie'cout=cursor.execute(sql)print("数量: "+str(cout))for row in cursor.fetchall():#print(row[1])movieinfo = df[df['电影名'] == row[1]]if movieinfo.shape[0] == 0:disable_movie(row[0])print('disable movie ' + str(row[1]))else:g = lambda x:movieinfo[x].iloc[0]types = movieinfo['类型'].tolist()types = reduce(lambda x,y:x+'|'+y,list(set(types)))traits = movieinfo['特⾊'].tolist()traits = reduce(lambda x,y:x+'|'+y,list(set(traits)))update_one_movie_info(type_=types, actors=g('主演'), region=g('地区'), director=g('导演'), trait=traits, rat=g('评分'), id_=row[0])mit()finally:connection.close()之后开始准备⽤户数据,我们从⽤户打分的数据中,统计出每⼀个⽤户的打分的最⼤值,最⼩值,中位数值和平均值等,从⽽作为⽤户的⼀个附加属性,存储于userproex表中:'insert into userproex(userid, rmax, rmin, ravg, rcount, rsum, rmedian) values(\'%s\', %s, %s, %s, %s, %s, %s)' % (userid, rmax, rmin, ravg, rcount, rsum, rmedium) 'update userproex set rmax=%s, rmin=%s, ravg=%s, rmedian=%s, rcount=%s, rsum=%s where userid=\'%s\'' % (rmax, rmin, ravg, rmedium, rcount, rsum, userid)以上两个SQL是最终插⼊表的时候⽤到的,代表准备⽤户数据的最终步骤,其余细节可以参考⽂末的github仓库,不在此赘述,数据处理还⽤到了⼀些SQL,以及其他处理细节。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Item-CF Ridge
Multi-class LR
LDA Preprocess
Movie Topic
CV-based Ensemble
(LR+GBDT+NN) Postprocess
FM Session
FM-GI
Time Bin Implicit Feedback
Features
Test Ensemble
RMSE 0.5972 0.6449 0.6295 0.6526 0.5946
Post Process (trБайду номын сангаасcks)
• User-movie pairs in “Test” also appear in “Train” • Variance of ratings in session is 0 (#ratings per session > 10)
CV Based Ensemble
Rating Meta Features FM FM-GI
……
Linear Regression 0.5994
residual
residual
GBDT 0.5981
NN 0.5972
Test Ensemble
Ridge Regression
Models CV-Ensemble GE ItemCF Multi-class LR Test Ensemble
(Ridge Regression)
PMF
Models
Ensemble
Preprocess
• Remove Redundant Samples • Global Effects
No. 0 1 2 3 Global Effect Overall Mean Movie User User Avg(Movie) RMSE 0.8219 0.7089 0.6463 0.6451 a 0 1 12 29
ID Feature
Topics
Session Time Bin Implicit Feedback
Feature Importance
0.625 uid+mid 0.62 time-bin 0.615 RMSE 0.61 0.605 0.6 0.595 uid, mid RMSE 0.6204 session 0.6174 Time bin 0.6111 topics 0.6082 tags 0.6069 session topics implicit feedback tags meta feature Implicit 0.6046
Meta Features 0.6064
Models
• Factorization Machine(FM) MCMC
• Factorization Machine with Group-wise Interaction(FM-GI)
SGD
• PMF • Multi-Class Logistic Regression • Ridge Regression
Final RMSE:0.5932
Thanks
Informative Boosted Collaborn Contest Pandas Team
Informative Boosted Collaborn Challenge Pandas Team
@严强Justin
Frameworks
Meta Features User, Movie, Tag
User Topic
4
User Support(Movie)
0.6449
1
Features
Cat. Meta Feature Features
#rating of user (Log-scale ,Median-Var Norm, Max-Min Norm) #rating of Movie (Log-scale , Median-Var Norm, Max-Min Norm) Mean/variance of user ratings (Median-Var Norm, Max-Min Norm) Variance of user/movie ratings (Median-Var Norm, Max-Min Norm) UserID MovieID TagID User Topics (Watch History) Movie Topics 1 (Movie Tag) Movie Topics 2 (Movie Tag + Watch History) Watch History Session Watch History Time Bin (500) Watch History