计量经济学(第四版)习题参考答案
计量经济学精要习题参考答案(第四版)

计量经济学(第四版)习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2 NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设 120:0=μH备择假设 120:1≠μH 检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即此样本不是取自一个均值为120元、标准差为10元的正态总体。
计量经济学(第四版)习题及参考答案解析详细版

计量经济学(第四版)习题参考答案潘省初第一章 绪论试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
什么是时间序列和横截面数据 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
估计量和估计值有何区别估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间NS S x ==45= 用=,N-1=15个自由度查表得005.0t =,故99%置信限为x S t X 005.0± =174±×=174±也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。
25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体 原假设 120:0=μH备择假设 120:1≠μH 检验统计量()10/2510/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。
第四章练习题及参考解答(第四版)计量经济学

第四章练习题及参考解答4.1 假设在模型i i i i u X X Y +++=33221βββ中,32X X 与之间的相关系数为零,有人建议你分别进行如下回归:1221i i i Y X u αα=++ 1332i i i Y X u γγ=++(1) 是否存在3322ˆˆˆˆβγβα==且?为什么? (2) 1ˆβ会等于1ˆα或1ˆγ或者两者的某个线性组合吗? (3) 是否有()()22ˆˆVar Var βα=且()()33ˆˆVar Var βγ=?【练习题4.1参考解答】(1) 存在2233ˆˆˆˆαβγβ==且 。
因为 ()()()()()()()2233232ˆi iii ii iy x x y x x x-∑∑∑∑资料来源:《中国统计年鉴2017》考虑建立模型: i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。
(2)你认为数据中有多重共线性吗?(3)进行以下回归:121ln ln t t i Y A A GDP v =++ 122ln ln t t i Y B B CPI v =++ 123ln ln t t i GDP C C CPI v =++ 根据这些回归你能对多重共线性的性质有什么认识?(4)假设经检验数据有多重共线性,但模型中32ˆˆββ和在5%水平上显著,并且F 检验也显著,你对此模型的应用有何建议?【练习题4.2参考解答】建立模型: i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。
(2)你认为数据中有多重共线性吗?其中居民消费价格指数CPI 对商品进口额影响为负,与预期不符合,可能存在多重共线性。
(3)分别进行以下回归:1)作回归121ln ln t t i Y A A GDP v =++说明GDP 的确对商品进口额有正的影响,是重要变量。
庞皓计量经济学练习题及参考解答第四版

庞皓计量经济学练习题及参考解答第四版Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】练习题表中是中国历年国内旅游总花费(Y)、国内生产总值(X1)、铁路里程(X2)、公路里程数据(X3)的数据。
表中国历年国内旅游总花费、国内生产总值、铁路里程、公路里程数据资料来源:中国统计年鉴(1)分别建立线性回归模型,分析中国国内旅游总花费与国内生产总值、铁路里程、公路里程数据的数量关系。
(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
【练习题参考解答】(1)分别建立亿元线性回归模型建立y与x1的数量关系如下:ŶY=−3228.02+0.05X1i建立y与x2的数量关系如下:ŶY=−39438.73+6165.25X1i建立y与x3的数量关系如下:ŶY=−9106.17+71.64X1i(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
关于中国国内旅游总花费与国内生产总值模型,由上可知,Y2=0.987,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=21.68>Y(21)=2.08,对斜率系0.025数的显着性检验表明,GDP对中国国内旅游总花费有显着影响。
同理:关于中国国内旅游总花费与铁路里程模型,由上可知,Y2= 0.971,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=26.50>Y(21)=2.08,对斜率系0.025数的显着性检验表明,铁路里程对中国国内旅游总花费有显着影响。
关于中国国内旅游总花费与公路里程模型,由上可知,Y2=0.701,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=7.02>Y(21)=2.08,对斜率系0.025数的显着性检验表明,公路里程对中国国内旅游总花费有显着影响。
为了研究浙江省一般预算总收入与地区生产总值的关系,由浙江省统计年鉴得到如表所示的数据。
计量经济学(第四版)习题及参考答案详细版知识讲解

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NSS x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
计量经济学(第四版)习题参考答案

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2 NSS x ==45=1.25用=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设 120:0=μH备择假设 120:1≠μH 检验统计量()10/2510/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。
计量经济学第四版习题及参考答案解析

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
第四章练习题及参考解答(第四版)计量经济学

第四章练习题及参考解答4.1 假设在模型i i i i u X X Y +++=33221βββ中,32X X 与之间的相关系数为零,有人建议你分别进行如下回归:1221i i i Y X u αα=++ 1332i i i Y X u γγ=++(1) 是否存在3322ˆˆˆˆβγβα==且?为什么? (2) 1ˆβ会等于1ˆα或1ˆγ或者两者的某个线性组合吗? (3) 是否有()()22ˆˆVar Var βα=且()()33ˆˆVar Var βγ=?【练习题4.1参考解答】(1) 存在2233ˆˆˆˆαβγβ==且 。
因为 ()()()()()()()22332322222323ˆi iii ii iiii iy x x y x x x x x x x β-=-∑∑∑∑∑∑∑当23X X 与 之间的相关系数为零时,离差形式的230i ix x =∑有 ()()()()223222222223ˆˆi i ii i iiiy x x y x xx x βα===∑∑∑∑∑∑ 同理有: 33ˆˆγβ= (2)会的。
(3) 存在 ()()()()2233ˆˆˆˆvar var var var βαβγ==且 因为 ()()2222223ˆvar 1ix r σβ=-∑当 230r = 时, ()()()22222222223ˆˆvar var 1iix x r σσβα===-∑∑ 同理,有 ()()33ˆˆvar var βγ=4.2 表4.4给出了1995—2016年中国商品进口额Y 、国生产总值GDP 、居民消费价格指数CPI 的数据。
表4.4 中国商品进口额、国生产总值、居民消费价格指数资料来源:《中国统计年鉴2017》考虑建立模型: i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。
(2)你认为数据中有多重共线性吗?(3)进行以下回归:121ln ln t t i Y A A GDP v =++ 122ln ln t t i Y B B CPI v =++ 123ln ln t t i GDP C C CPI v =++ 根据这些回归你能对多重共线性的性质有什么认识?(4)假设经检验数据有多重共线性,但模型中32ˆˆββ和在5%水平上显著,并且F 检验也显著,你对此模型的应用有何建议?【练习题4.2参考解答】建立模型: i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。
计量经济学第四版习题及参考答案

计量经济学第四版习题及参考答案Document number【AA80KGB-AA98YT-AAT8CB-2A6UT-A18GG】计量经济学(第四版)习题参考答案潘省初第一章 绪论试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
什么是时间序列和横截面数据 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
估计量和估计值有何区别估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间NSS x ==45= 用?=,N-1=15个自由度查表得005.0t =,故99%置信限为 x S t X 005.0± =174±×=174±也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。
计量经济学精要第四版课后习题答案(2020年10月整理).pdf
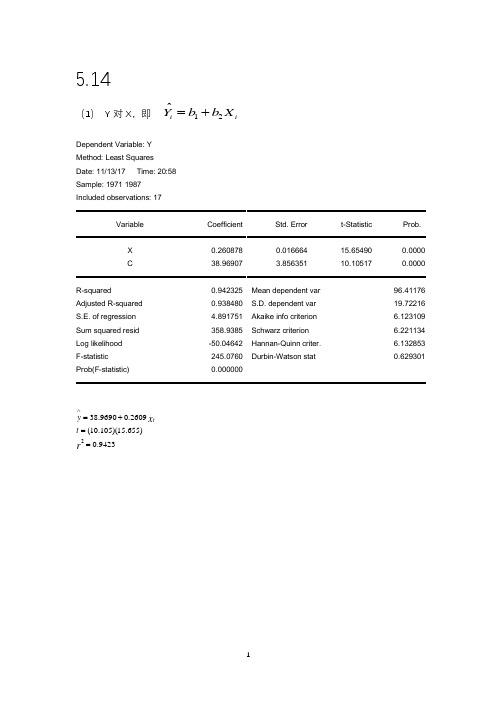
5.14(1) Y 对X ,即12ˆi iY b b X =+Dependent Variable: Y Method: Least Squares Date: 11/13/17 Time: 20:58 Sample: 1971 1987 Included observations: 17Variable Coefficient Std. Error t-Statistic Prob.X 0.260878 0.016664 15.65490 0.0000 C38.969073.85635110.10517 0.0000R-squared0.942325 Mean dependent var 96.41176 Adjusted R-squared 0.938480 S.D. dependent var 19.72216 S.E. of regression 4.891751 Akaike info criterion 6.123109 Sum squared resid 358.9385 Schwarz criterion 6.221134 Log likelihood -50.04642 Hannan-Quinn criter. 6.132853 F-statistic 245.0760 Durbin-Watson stat 0.629301Prob(F-statistic) 0.0000009423.0)655.15)(105.10(2609.09690.382==+=∧r x t y t(2)InY 对InX ,即 12ˆi iInY b b InX =+9642.0)090.20)(954.8(ln 5890.04041.1ln 2==+=∧r x t y tDependent Variable: LNY Method: Least Squares Date: 11/13/17 Time: 21:40 Sample: 1971 1987 Included observations: 17Variable Coefficient Std. Error t-Statistic Prob.C 1.404051 0.156813 8.953649 0.0000 LNX0.5889650.02931720.08981 0.0000R-squared0.964166 Mean dependent var 4.547848 Adjusted R-squared 0.961777 S.D. dependent var 0.213165 S.E. of regression 0.041675 Akaike info criterion -3.407698 Sum squared resid 0.026052 Schwarz criterion -3.309673 Log likelihood 30.96543 Hannan-Quinn criter. -3.397954 F-statistic 403.6007 Durbin-Watson stat 0.734161Prob(F-statistic)0.000000(3),即 12i iDependent Variable: LNY Method: Least Squares Date: 11/13/17 Time: 21:42 Sample: 1971 1987 Included observations: 17Variable Coefficient Std. Error t-Statistic Prob.C 3.931578 0.046430 84.67764 0.0000 X0.0027990.00020113.94972 0.0000R-squared0.928433 Mean dependent var 4.547848 Adjusted R-squared 0.923662 S.D. dependent var 0.213165 S.E. of regression 0.058896 Akaike info criterion -2.715956 Sum squared resid 0.052031 Schwarz criterion -2.617930 Log likelihood 25.08562 Hannan-Quinn criter. -2.706212 F-statistic 194.5946 Durbin-Watson stat 0.529132Prob(F-statistic) 0.0000009284.0)950.13)(678.84(0028.09316.3ln 2==+=∧r X t y t(4),即 12i iDependent Variable: Y Method: Least Squares Date: 11/13/17 Time: 21:43 Sample: 1971 1987 Included observations: 17Variable Coefficient Std. Error t-Statistic Prob.C -192.9661 16.38000 -11.78059 0.0000 LNX54.212573.06227817.70335 0.0000R-squared0.954325 Mean dependent var 96.41176 Adjusted R-squared 0.951280 S.D. dependent var 19.72216 S.E. of regression 4.353186 Akaike info criterion 5.889824 Sum squared resid 284.2535 Schwarz criterion 5.987849 Log likelihood -48.06350 Hannan-Quinn criter. 5.899568 F-statistic 313.4086 Durbin-Watson stat 0.610822Prob(F-statistic) 0.0000009542.0)703.17)(781.11(ln 2126.549661.1922=−=+−=∧r X t Y t解:1.XY∆∆=1ˆβ斜率说明X 每变动一个单位,Y 的绝对变动量;2. E XX Y Y =∆∆=//ˆ1β斜率便是弹性系数; 3. XY Y ∆∆=/ˆ1β斜率表示X 每变动一个单位,Y 的均值的瞬时增长率; 4,. XX Y/ˆ1∆∆=β斜率表示X 的相对变化对Y 的绝对量的影响。
第四章练习题及参考解答(第四版)计量经济学

第四章练习题及参考解答4.1 假设在模型i i i i u X X Y +++=33221βββ中,32X X 与之间的相关系数为零,有人建议你分别进行如下回归:1221i i i Y X u αα=++ 1332i i i Y X u γγ=++(1) 是否存在3322ˆˆˆˆβγβα==且?为什么? (2) 1ˆβ会等于1ˆα或1ˆγ或者两者的某个线性组合吗? (3) 是否有()()22ˆˆVar Var βα=且()()33ˆˆVar Var βγ=?【练习题4.1参考解答】(1) 存在2233ˆˆˆˆαβγβ==且 。
因为 ()()()()()()()22332322222323ˆi iii ii iiii iy x x y x x xx x x x β-=-∑∑∑∑∑∑∑当23X X 与 之间的相关系数为零时,离差形式的230i ixx =∑有 ()()()()223222222223ˆˆi i i i i iiiy x x y x xx x βα===∑∑∑∑∑∑ 同理有: 33ˆˆγβ= (2)会的。
(3) 存在 ()()()()2233ˆˆˆˆvar var var var βαβγ==且 因为 ()()2222223ˆvar 1ix r σβ=-∑当 230r = 时, ()()()22222222223ˆˆvar var 1iix x r σσβα===-∑∑ 同理,有 ()()33ˆˆvar var βγ=4.2 表4.4给出了1995—2016年中国商品进口额Y 、国内生产总值GDP 、居民消费价格指数CPI 的数据。
表4.4 中国商品进口额、国内生产总值、居民消费价格指数资料来源:《中国统计年鉴2017》考虑建立模型: i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。
(2)你认为数据中有多重共线性吗?(3)进行以下回归:121ln ln t t i Y A A GDP v =++ 122ln ln t t i Y B B CPI v =++ 123ln ln t t i GDP C C CPI v =++ 根据这些回归你能对多重共线性的性质有什么认识?(4)假设经检验数据有多重共线性,但模型中32ˆˆββ和在5%水平上显著,并且F 检验也显著,你对此模型的应用有何建议?【练习题4.2参考解答】建立模型: i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。
计量经济学习题及参考答案详细版

计量经济学习题及参考答案详细版(总25页)-本页仅作为预览文档封面,使用时请删除本页-计量经济学(第四版)习题参考答案潘省初第一章 绪论试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
什么是时间序列和横截面数据 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
估计量和估计值有何区别估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间N SS x ==45= 用=,N-1=15个自由度查表得005.0t =,故99%置信限为x S t X 005.0± =174±×=174±也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。
25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体 原假设 120:0=μH备择假设 120:1≠μH 检验统计量()10/2510/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。
计量经济学(第四版)习题及参考问题详解详细版

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
(完整版)伍德里奇计量经济学(第4版)答案

(4)对profmarg的显著性进行T检验:t= 1.087<1.311,因为它在统计上并不显著。
第五章
5.3风险承受能力越强,越愿意投资于股票市场,因此 假设funds 和 risktol正相关,我们使用等式 因此 具有高度不一致(渐进有偏),这表明如果我们在回归方程中省略risktol,并且它和funds高度相关,funds 的估计效应取决于risktol的效应。(省略risktol,回归方程倾向于高估funds的影响)
(4)因为T检验与F检验是建立在同方差假定与其他线性模型假定基础上的,所以如果睡眠方程中含有异方差性,就意味着我们对方程的检验是无效的。
4.11(1)假定profmarg不变,当sales变化10%时, rdinters=(0.321/100)*10=0.0321,j即rdintens变化大约3%。相对于sales的变化,rdintens的变化是个较小的影响。
第六章
6.3(1)当其他要素固定时,我们有
等式两边同除以 得到结果, 是不显著的,尽管 大于0,如果来我们考虑一个孩子多得一年教育,孩子的父母会有更高的学历。
(2)我们选择pareduc的两个具体值来解释交叉项系数,比如父母双方都受过大学教育时pareduc=32或父母都是高中毕业时pareduc=24,educ的估计回报差额是0.00078(32-24)=0.0062,或者说0.62%。
性别差异的证据是相当强烈的。
(2)totwrk的t统计是−0.163/0.018 ≈ −9.06,这是统计性水平是很显著的。这个系数意味着多工作一个小时(60分钟)就会少睡0.163(60) ≈ 9.8分钟。
庞皓计量经济学(第四版)课后答案

第一章导论第一节什么是计量经济学计量经济学是现代经济学的重要分支。
为了深入学习计量经济学的理论与方法,有必要首先从整体上对计量经济学有一些概略性的认识,了解计量经济学的性质、基本思想、基本研究方法以及若干常用的基本概念。
一、计量经济学的产生与发展在对实际经济问题的研究中,经常需要对经济活动及其数量变动规律作定量的分析。
例如,为了研究中国经济的增长,需要分析中国国内生产总值(GDP)变动的状况? 分析有哪些主要因素会影响中国GDP的增长?分析中国的GDP与各种主要影响因素关系的性质是什么?分析各种因素对中国GDP影响的程度和具体数量规律是什么?分析所得到的数量分析结果的可靠性如何?还要分析经济增长的政策效应,或者预测中国GDP发展的趋势。
显然,对这类经济问题的定量分析,需要解决一些共性问题:提出所研究的经济问题及度量方式,确定表现研究对象的经济变量(如用GDP的变动度量经济的增长);分析对研究对象变动有影响的主要因素,选择若干作为影响因素的变量;分析各种影响因素与所研究经济现象相互关系的性质,决定相互联系的数学关系式;运用科学的数量分析方法,确定所研究的经济对象与各种影响因素间具体的数量规律;运用统计方法分析和检验所得数量结论的可靠性;运用数量研究的结果作经济分析和预测。
对社会经济问题数量规律的研究具有普遍性,计量经济学是专门研究这类问题的经济学科。
计量经济学(Econometrics)这个词是挪威经济学家、第一届诺贝尔经济学奖获得者弗瑞希(R.Frisch)在其1926年发表的《论纯经济问题》一文中,按照”生物计量学”(Biometrics)一词的结构仿造出来的。
Econometrics一词的本意是指“经济度量”,研究对经济现象和经济关系的计量方法,因此有时也译为“经济计量学”。
将Econometrics译为计量经济学,是为了强调计量经济学是一门经济学科,不仅要研究经济现象的计量方法,而且要研究经济现象发展变化的数量规律。
经济计量学精要第四版课后练习题含答案

经济计量学精要第四版课后练习题含答案前言经济计量学是运用数学和统计方法研究经济现象及其规律的一门学科。
经济计量学精要第四版是经济计量学的入门教材,本文将为各位读者提供该教材课后练习题及答案,帮助读者更好地掌握该门学科。
第一章经济计量学基础选择题1.什么是偏差?A.衡量回归直线的直角离散程度B.已知均值估计总体标准差C.样本中的观测值与其相应总体值之差D.对称分布的方差答案:C2.在经济计量分析中,线性关系是基本关系之一。
下列哪个假设是错误的?A.线性关系是基本关系之一B.线性关系是在整个取值区间内成立的C.在一些情况下线性关系只在某一特定范围内成立D.线性方程存在可比较的斜率答案:B填空题1.在经验研究中,一般采用______________式估计总体参数。
答案:样本2.如果增加自变量个数,再加上满足一定条件,使得求出的参数估计仍有标准正态分布的概率较大,这就是多元_____________中的问题。
答案:线性回归第二章单一线性回归模型选择题1.在单一线性回归中,为使OLS估计量无偏,必须假定误差项都等于____。
A.正态分布B.泊松分布C.自变量D.零答案:D2.投资量与利息率之间可能存在一种哪种关系?A.负向线性关系B.正向线性关系C.非线性关系D.都不正确答案:B填空题1.在单一线性回归模型中,因变量和自变量之间需要满足线性关系,使散点图大致呈现出一个______________。
答案:直线趋势2.单一线性回归模型的OLS估计量被定义为将所有预测误差的平方之和最小化得来的样本_______________。
答案:回归方程第三章多元线性回归模型选择题1.当模型自变量与因变量的简单相关系数大于0.7时,发生的问题是什么?A.多重共线性B.异方差性C.自相关D.标准误增大答案:A2.关于多解释变量线性回归模型,下列哪个描述是错误的?A.利用OLS估计法估计各个参数的估计值B.OLS含有多个系数,这些系数代表因变量特定解释变量的影响。
(完整版)伍德里奇计量经济学(第4版)答案
(4)较多的教育意味着较少的睡眠时间,但教育对睡眠时间的影响是较小的。如果我们假设大学与高中的差别是4年,那么大学毕业生平均每年要少睡大约45(11.13*4)分钟。
(5)很明显,这3个解释变量只解释了睡眠时间11.3%的变异( =0.113)。其他可能影响花在睡眠上时间的因素包括:健康状况、婚姻状况以及是否有孩子。一般来讲,这3个变量都与工作时间有关。(比如:身体状况较差的人工作时间较少)
7.2(i)如果cigs= 10那么 =0.0044(10) =0.044,意味着每天多抽十根烟,婴儿出生体重下降4.4%。
(2)在第一个方程中,保持其他因素不变,预计一个白人孩子比一个非白人孩子的出生体重高5.5%。而且twhite4.23,这个比普通的临界值高,因此,白人孩子和非白人孩子的差异也是统计显著性的。
(4)85%的妇女怀孕期间不抽烟,即1388个样本中有大约1180个妇女不抽烟。因为我们只用cigs一个变量解释婴儿出生体重,所以当cigs=0时,我们只有一个相对应的出生体重数。在cigs=0时,预计的出生体重数大致位于观测的出生体重数的中间。因此,我们可能会低估较高的出生体重数。
第三章
3.3(1)法学院的排名(rank值)越大,说明学校威望越低:这会降低起薪。例如:rank=100说明有99所学校排在其前面。
(3)因为销售获取除以1 000,得到salesbil,相应的系数乘以1000:(1,000)(0.00030) =0.30。标准错误乘以相同的因子。提示,salesbil2 =销售额/1,000,000,所以对二次系数获取乘以100万:(1,000,000)(.0000000070) =.0070;它的标准误差也获取乘以100万。截距或R2(因为rdintens不其重新缩放)不会发生变化:
计量经济学(第四版)第三章练习题及答案
第三章练习题及参考解答3.1进入21世纪后,中国的家用汽车增长很快。
家用汽车的拥有量受到经济增长、公共服务、市场价格、交通状况、社会环境、政策因素,都会影响中国汽车拥有量。
为了研究一些主要因素与家用汽车拥有量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量,2016年全国各省市区的有关数据如表3.5。
表3.5 2016年各地区的百户拥有家用汽车量等数据资料来源:中国统计年鉴2017.中国统计出版社1)建立百户拥有家用汽车量计量经济模型,估计参数并对模型加以检验,检验结论的依据是什么?。
2)分析模型参数估计结果的经济意义,你如何解读模型估计检验的结果? 3) 你认为模型还可以如何改进?【练习题3.1 参考解答】:1)建立线性回归模型: 1223344t t t t t Y X X X u ββββ=++++ 回归结果如下:由F 统计量为14.69998, P 值为0.000007,可判断模型整体上显著, “人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量联合起来对百户拥有家用汽车量有显著影响。
解释变量参数的t 统计量的绝对值均大于临界值0.025(27) 2.052t =,或P 值均明显小于0.05α=,表明在其他变量不变的情况下,“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”分别对百户拥有家用汽车量都有显著影响。
2)X2的参数估计值为4.8117,表明随着经济的增长,人均地区生产总值每增加1万元,平均说来百户拥有家用汽车量将增加近5辆。
由于城镇公共交通的大力发展,有减少家用汽车的必要性,X3的参数估计值为-0.4449,表明随着城镇化的推进,“城镇人口比重”每增加1%,平均说来百户拥有家用汽车量将减少0.4449辆。
汽车价格和使用费用的提高将抑制家用汽车的使用, X4的参数估计值为-5.7685,表明随着家用汽车使用成本的提高, “居民消费价格指数”每增加1个百分点,平均说来百户拥有家用汽车量将减少5.7685辆。
庞皓计量经济学练习题及参考解答第四版
庞皓计量经济学练习题及参考解答第四版Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】练习题表中是中国历年国内旅游总花费(Y)、国内生产总值(X1)、铁路里程(X2)、公路里程数据(X3)的数据。
表中国历年国内旅游总花费、国内生产总值、铁路里程、公路里程数据资料来源:中国统计年鉴(1)分别建立线性回归模型,分析中国国内旅游总花费与国内生产总值、铁路里程、公路里程数据的数量关系。
(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
【练习题参考解答】(1)分别建立亿元线性回归模型建立y与x1的数量关系如下:ŶY=−3228.02+0.05X1i建立y与x2的数量关系如下:ŶY=−39438.73+6165.25X1i建立y与x3的数量关系如下:ŶY=−9106.17+71.64X1i(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
关于中国国内旅游总花费与国内生产总值模型,由上可知,Y2=0.987,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=21.68>Y(21)=2.08,对斜率系0.025数的显着性检验表明,GDP对中国国内旅游总花费有显着影响。
同理:关于中国国内旅游总花费与铁路里程模型,由上可知,Y2= 0.971,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=26.50>Y(21)=2.08,对斜率系0.025数的显着性检验表明,铁路里程对中国国内旅游总花费有显着影响。
关于中国国内旅游总花费与公路里程模型,由上可知,Y2=0.701,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=7.02>Y(21)=2.08,对斜率系0.025数的显着性检验表明,公路里程对中国国内旅游总花费有显着影响。
为了研究浙江省一般预算总收入与地区生产总值的关系,由浙江省统计年鉴得到如表所示的数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计量经济学(第四版)习题参考答案潘省初编著胡世明整编第一章 绪论1.1试列出计量经济分析的主要步骤。
1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2计量经济模型为何要包括扰动项?1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列数据和横截面数据?试举例说明二者的区别?1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2 NSS x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设 120:0=μH备择假设 120:1≠μH 检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。
2.4 原假设 : 2500:0=μH备择假设 : 2500:1≠μH()100/1200.83ˆX X t μσ-==== 查表得 131.2)116(025.0=-t 因为t = 0.83 < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。
第三章 双变量线性回归模型3.1 判断题(说明对错;如果错误,则予以更正) (1)对 (2)对 (3)错只要线性回归模型满足假设条件(1)~(4),OLS 估计量就是BLUE 。
(4)对 (5)错R 2 =ESS/TSS 。
(6)对(7)错。
我们可以说的是,手头的数据不允许我们拒绝原假设。
(8)错。
因为∑=22)ˆ(tx Var σβ,只有当∑2t x 保持恒定时,上述说法才正确。
3.2 证明:22222222ˆˆ()ˆˆi ii ii i YX XYiiii i YX XYi i x y y x x yxyyx y r x y ββββ===⎛⎫⋅===∑∑∑∑∑∑∑∑∑3.3 (1),得两边除以,=n ˆ0ˆ)ˆ(ˆ∑∑∑∑∑∑∑∑=∴+=⇒+=⇒+=tt t tt t t tt t t t YY e e Y Y e YY e Y YY nY nY ==∑∑ˆ,即Y 的真实值和拟合值有共同的均值。
(2)的拟合值与残差无关。
,=,即因此,(教材中已证明),由于Y 0ˆˆ),ˆ(0ˆ0,0e ˆˆ)ˆˆ(ˆ22t∑∑∑∑∑∑∑∑∑∑====+=+=tttt tttt tt tt ttttt eY e Y e Y Cov e Ye X eX e e X e Y βαβα 3.4 (1)222222222221112222222ˆˆ,ˆˆ()ˆˆˆ2u()()ˆ()2()()()()ˆ2()()ˆ2()iit tti n n n t ii j i ii j i ji j i jtY X Y X u u X u X X u u x uX X nn xu u u x u x u X X nn x uu u x ux x u u X nn x αβαβααββααββββββββββ≠≠=+=++-=---=--+-=-⋅⋅+-++=-⋅+-+++=-⋅+-∑∑∑∑∑∑∑∑∑∑∑()2X2222222222222222()ˆˆ2E()1(()2())()2i i ji i i j i j i j i j t i i j i j i i j i j i i i j i j i jt u u u x u x x u u E E XE X n n x u u u E E u E u u n n n nx u x x u u XE n x ααββσσ≠≠≠≠≠⎛⎫⎡⎤+++ ⎪⎢⎥-=-⎪⎢⎥ ⎪⎢⎥⎝⎭⎣⎦⎛⎫+ ⎪=+==⎪⎪⎝⎭++∑∑∑∑∑∑∑∑∑∑∑∑两边取期望值,有:()-+等式右端三项分别推导如下:22222222222222222222212(()()())200ˆE()()ˆ[]0ii i i j i j ii jt t t t tt tt x Xx E u x x E u u Xx n x n x X X x x nX X X E n x n x n x σσββσσσσαα≠⎛⎫ ⎪ ⎪⎪⎝⎭=++==-=+-=-+==∑∑∑∑∑∑∑∑∑∑∑∑∑(=)因此()∑∑=222)ˆ(tt x n X Var σα即(2)2222ˆˆ,ˆˆ()ˆˆˆˆˆˆ(,)[()][(())()]ˆˆ[(()][()]ˆ0()01ˆ()t Y X Y X u u X Cov E E u X E u XE XE XVar X x αβαβααββαβααβββββββββββββσ=+=++-=--=--=---=---=--=-=-∑()(第一项为的证明见本题())3.5(1)X Y 21ˆˆββ-=,注意到 nx n x x x n x Var x n X Var Y x Y x x X X x ii i i ii i i i 22222221222121)()ˆ()ˆ(ˆˆ,0,0,σσσασβαα==-==-==-=∑∑∑∑∑∑∑==则我们有从而由上述结果,可以看到,无论是两个截距的估计量还是它们的方差都不相同。
(2)∑∑∑∑∑∑∑==---==222222222)ˆ()ˆ()())((ˆ,ˆiiiiiiiiii x Var Var xyx x x Y Y x x xy x σαβαβ=容易验证,这表明,两个斜率的估计量和方差都相同。
3.6(1)斜率的值 -4.318表明,在1980-1994期间,相对价格每上升一个单位,(GM/$)汇率下降约4.32个单位。
也就是说,美元贬值。
截距项6.682的含义是,如果相对价格为0,1美元可兑换6.682马克。
当然,这一解释没有经济意义。
(2)斜率系数为负符合经济理论和常识,因为如果美国价格上升快于德国,则美国消费者将倾向于买德国货,这就增大了对马克的需求,导致马克的升值。
(3)在这种情况下,斜率系数被预期为正数,因为,德国CPI 相对于美国CPI 越高,德国相对的通货膨胀就越高,这将导致美元对马克升值。
3.7(1)78.16982.187*31.126.76ˆ86.13998.164*31.126.76ˆ49.15667.177*31.126.76ˆ=+-==+-==+-=eight Weight Weight W(2)99.481.3*31.1*31.1ˆ==∆=∆height eight W3.8 (1)6.910/96===∑n Y Y t 810/80===∑X X t75.028/21ˆ2===∑∑ttt xy x β 6.38*75.06.9*ˆˆ=-=-=X Y βα估计方程为: tt X Y 75.06.3ˆ+= (2)222ˆˆ(2)()(2)(30.40.75*21)/8 1.83125t t t te n y x y n σβ=-=--=-=∑∑∑934.2ˆˆ)ˆ(/ˆ2===∑txSe t σββββ733.1ˆˆ)ˆ(/ˆ22===∑∑ttx n XSe t σαααα518.0)4.30*28/21()(22222===∑∑∑ttt t y x y x R 回归结果为(括号中数字为t 值):tt X Y 75.06.3ˆ+= R 2=0.518 (1.73) (2.93) 说明:X t 的系数符号为正,符合理论预期,0.75表明劳动工时增加一个单位,产量增加0.75个单位,拟合情况。
R 2为0.518,作为横截面数据,拟合情况还可以.系数的显著性。
斜率系数的t 值为2.93,表明该系数显著异于0,即X t 对Y t 有影响.(3) 原假设 : 0.1:0=βH备择假设 : 0.1:1≠βH检验统计量 ˆˆ( 1.0)/()(0.75 1.0)/0.25560.978t Se ββ=-=-=- 查t 表, 0.025(8) 2.306c t t == ,因为│t │= 0.978 < 2.306 ,故接受原假设:0.1=β。
3.9对于x 0=250 ,点预测值 0ˆy=10+0.90*250=235.0 0ˆy的95%置信区间为: 00.025ˆ(122)*yt σ±-2352350.29=±=±即 234.71 - 235.29。
也就是说,我们有95%的把握预测0y 将位于234.71 至235.29 之间.3.10(1)列表计算如下:35/15===∑n Y Y t 115/55===∑X X t365.074/27ˆ2===∑∑ttt xy x β015.111*365.03*ˆˆ-=-=-=X Y βα我们有:tt X Y 365.0015.1ˆ+-= (2)048.03/)27*365.010()2()ˆ()2222=-=--=-=∑∑∑n y x y n e tt t t βσ 985.0)10*74/27()(22222===∑∑∑ttt t y x y x R (3) 对于0X =10 ,点预测值 0ˆY =-1.015+0.365*10=2.635 0Y 的95%置信区间为:∑-++-±220025.00)(/11ˆ*)25(ˆx X X n t Y σ=770.0635.274/)1110(5/11*048.0*182.3635.22±=-++± 即 1.895 -3.099,也就是说,我们有95%的把握预测0Y 将位于1.865 至3.405 之间.3.11 问题可化为“预测误差是否显著地大?”当X 0 =20时,285.620365.0015.1ˆ0=⨯+-=Y 预测误差 335.1285.662.7ˆ000=-=-=Y Y e原假设0H :0)(0=e E 备择假设1H :0)(0≠e E 检验:若0H 为真,则021.4332.0335.174)1120(511048.00335.1)(11ˆ)(222000==-++-=-++-=∑x X X n e E e t σ对于5-2=3个自由度,查表得5%显著性水平检验的t 临界值为:182.3=c t 结论:由于 4.021 3.182t =>故拒绝原假设0H ,接受备则假设H 1,即新观测值与样本观测值来自不同的总体。