基于Ceph的分布式存储节能技术研究
分布式存储系统对比之 Ceph VS MinIO

分布式存储系统对比之 Ceph VS MinIO分布式存储系统对比之Ceph VS MinIO对象存储概述对象存储通常会引用为基于对象的存储,它是能够处理大量非结构化数据的数据存储架构,在众多系统中都有应用。
对于部署在公有云的服务来说,公有云一般都提供对象存储服务,如阿里云的 OSS, 华为云的 OBS ,腾讯云的 COS 。
通过提供的 SDK 就可以访问。
如果不想用公有云的话,也有一些开源方案可以自己搭建。
一些开源的对象存储都会遵循 Amazon s3 协议。
Amazon s3 协议定义了操作对象存储的Resestfull 风格的 API 。
通过在 pom 中引用 aws-java-sdk-s3 可以实现对存储的操作。
开源方案对比存储的方案分成两种:① 一种是可以自定对象名称的;②另一种是系统自动生成对象名称。
不能自定义名称的有领英的 Ambry , MogileFS 。
TFS 是淘宝开源的,但是目前已经很少有人维护它并且也不是很活跃。
Ceph 是一个比较强大的分布式存储,但是它整个系统非常复杂需要大量的人力进行维护。
GlusterFS 为本身是一个非常成熟的对象存储的方案, 2011 年被收购了,原班的人马又做了另外一个存储系统 MinIO 。
其中 Ceph 跟 MinIO 是支持 s3 协议的。
后面对这两种方案做了一个详细的介绍。
对象存储选型①MinIOMinIO 是一个基于 Apache License V2.0 开源协议的对象存储服务,它兼容亚马逊 S3 云存储服务,非常适合于存储大容量非结构化的数据,如图片,视频,日志文件等。
而一个对象文件可以任意大小,从几 KB 到最大的 5T 不等。
它是一个非常轻量级的服务,可以很简单的和其它的应用结合,类似于 NodeJS, Redis 或者 MySQL 。
MinIO 默认不计算 MD5 ,除非传输给客户端的时候,所以很快,支持 windows ,有 web 页进行管理。
ceph存储原理

ceph存储原理ceph是一种开源、分布式的对象存储和文件系统,它能够在大规模的集群中存储和管理海量数据。
在ceph中,数据被分割成对象,并将这些对象存储在不同的存储节点上以实现高可用性和容错性。
这篇文章将介绍ceph存储的原理,包括ceph的架构、数据的存储和调度方式以及ceph如何处理故障。
ceph架构ceph的架构包括三个主要组成部分:客户端、存储集群和元数据服务器。
客户端是使用ceph存储的应用程序,它们通常是通过ceph API或者对象存储接口来访问ceph集群。
存储集群由一个或多个monitors、object storage devices(OSD),以及可能的元数据服务器组成。
monitors是ceph集群的核心组件,它负责管理ceph的全局状态信息、监控OSD 状态,并为客户端提供服务发现和配置信息。
OSD是实际存储数据的存储节点,它负责存储和处理对象,并在节点故障时自动重新平衡数据。
元数据服务器用于管理ceph文件系统中的元数据信息,包括文件和目录的名称、属性和层次关系等。
ceph存储数据的方式ceph将数据分割成对象,并使用CRUSH算法将这些对象分布在集群中的OSD上。
CRUSH 算法是ceph中存储调度的核心算法,它通过一系列计算将对象映射到存储集群中的OSD。
CRUSH将对象映射到OSD的方式是通过建立CRUSH映射表以实现负载均衡和容错。
CRUSH映射表可以根据管理员的需求进行调整,以达到最佳的性能和可扩展性。
ceph的CRUSH算法有以下特点:1. CRUSH将对象映射到可扩展的存储后端,以实现分布式存储和高可用性。
2. CRUSH使用元数据信息来动态调整对象的存储位置,并根据OSD的状态和磁盘使用情况等信息来实现负载均衡。
3. CRUSH允许管理员对存储策略进行调整,以适应不同的应用场景。
ceph的故障处理ceph具有强大的故障处理机制,它能够自动处理节点故障和数据损坏等问题,以确保数据的完整性和可用性。
分布式能源储能技术及关键技术研究

分布式能源储能技术及关键技术研究摘要:进入工业化社会后,对能源的依赖更加严重。
另一方面,传统能源燃烧时产生的CO2、NOX、SO2和烟尘等污染物不仅造成全球温室效应加剧,同时引发了雾霾等环境问题。
传统发展模式造成资源日渐短缺、环境严重污染、生态明显恶化,人类亟待寻求新的清洁能源方式,分布式能源成为能源领域的一个突破。
关键词:分布式能源;储能技术;关键技术;引言分布式能源是指分布在用户端的能源综合利用系统,具有能效利用合理、损耗小、污染少、运行灵活、系统经济性好等特点。
目前,我国高度重视节能减排和能源结构优化工作,正在大力转变能源发展方式,积极调整和优化能源产业结构,实现能源利用的多元化发展。
1分布式能源的特点相比于传统能源方式,分布式能源系统具有了以下方面的优势:(1)能够提高能源利用效率。
能够高效地对冷、热、电能等多种形式的能源实现梯级利用。
(2)实现生态环境效益。
综合分布式能源系统能够对多种清洁能源形式进行有效利用,其中风能、太阳能等更有助于实现生态环保。
(3)创造良好经济效益。
由于分布式能源系统能够减少大型电网和大型热力管网的建设,节约了大量的集中供能成本,实现良好的经济效益。
(4)提高安全可靠性能。
分布式能源减少了远距离传输的环节,可靠性和安全性都得到了较好的保障。
2分布式储能系统分布式储能系统具有很大的灵活性,从几千瓦到数万瓦不等。
多点接入用户端及低功耗的中低压配电网。
分布式储能系统在接入配电网络时,可以与分布式电源并联,也可以与低压配电网络进行单独的连接。
分布式储能系统可以应用于配电网络的各个环节,可以有效地提高系统的安全、稳定,减少大规模风电并网对电网的影响,从而改善电网的供电品质,增强风力发电的容量,为智能电网的发展提供了强有力的保证。
与集中式储能系统相比,它不需要太高的接入环境,也不需要太多的自然条件,而在接入电网时,它具有更大的灵活性。
然而,它的建造和维修费用要比集中式储能系统高得多。
分布式软件定义存储Ceph介绍

•Xfs
•Btrfs
•Ext4
•新版本中将支持更多的后端形式,如直接管理
块设备
•在一个集群中支持3-10000+的OSD
MON
Mon1
Mon2
Mon3
•Monitoring daemon •维护集群的视图和状态 •OSD和monitor之间相互传输节点状态信息,共同得出系统的总体 工作状态,并形成一个全局系统状态记录数据结构,即所谓的集群 视图(cluster map)
Ceph的历史
•2003年项目成立; •2006年作者将其开源; •2009年Inktank公司成立并发布Ceph的第一个稳定版本”Argonaut” ; •2014年红帽公司收购了Inktank,丰富了自己的软件定义存储的产品 线,此次收购使红帽成为领先的开源存储产品供应商,包括对象存储 、块存储和文件存储。
•通过RESTFUL API管理所有的集群和对象存储功能
特性总结-安全
•访问控制列表
•高细腻度的对象存储用户和用户组的安全控制
•配额
•支持对Cephfs设定使用额度
特性总结-可用性
•在集群节点之间条带和复制数据
•保证数据的持久性、高可用和高性能
•动态块设备大小调整
•扩卷缩卷不会导致宕机
•快速数据定位
•扩展的RADOS •RADOS可以横跨2个异地的数据中心并经过优化设计(低网络延时)
归档/冷 存储
CEPH STORAGE CLUSTER
成本
•支持瘦部署
•支持超量分配(block only)
•支持普通硬件设备
•将廉价PC服务器转换成存储设备满足不同负载和大容量、高可用、可扩展 的需求
•Erasure Coding纠删码
Ceph分布式存储中遇到的问题和解决办法

Ceph分布式存储中遇到的问题和解决办法最近有很多朋友拿着一篇关于“ceph运维那些坑”的文章来找我,起初我并没有在意,毕竟对于一个“新物种”来说,存在质疑是再正常不过的。
不过,陆续有更多的合作伙伴甚至圈内同行来问我如何看待这篇文章时,我觉得做为一名Ceph开发和运维的技术者,理应站出来为Ceph说点什么。
首先,原作者分析Ceph运维中遇到的问题是真实存在的,甚至在实际的运维过程中还出现过其他更复杂的问题。
因为最初的Ceph只是社区提供的一套开源版,因而想要实现产品化需要趟过很多次“坑”,就像最早的安卓系统一样。
我想任何产品在一开始都难以做到十全十美,因为技术本身就是在发现问题与解决问题的道路上不断前进发展的。
不过,在这里我想澄清的事实是:连初涉Ceph的运维人员都能发现的问题,研究Ceph多年的资深技术人员们肯定也早已发现。
接下来我就根据那篇文章中提到的坑,来说一说在实际产品化过程中我们是如何解决它们的。
一、扩容问题Ceph本身基于Crush算法,具备了多种数据复制策略,可以选择在磁盘、主机、机柜等等位置附着。
例如:如果采取3副本的数据保护策略,就可以通过复制策略来决定这3个副本是否同时分布在不同的磁盘、不同的主机、不同的隔离域、不同的机柜等位置来保证部分硬件故障后数据安全性和服务运行不中断。
Ceph底层是用资源池(POOL)来实现数据逻辑隔离,往往我们会出现因容量或性能不足需要对资源池进行扩容的问题,但是在容量扩容过程中,势必会带来进行数据重新平衡的要求。
Ceph中数据以PG为单位进行组织,因此当数据池中加入新的存储单元(OSD)时,通过调整OSDMAP会带来数据重平衡。
正如文章所提到的,如果涉及到多个OSD的扩容是可能导致可用PG中OSD小于min_size,从而发生PG不可用、IO阻塞的情况。
为了尽量避免这种情况的出现,只能将扩容粒度变小,比如每次只扩容一个OSD或者一个机器、一个机柜(主要取决于存储隔离策略),但是这样注定会带来极大的运维工作量,甚至连扩容速度可能都赶不上数据增长速度。
基于CEPH—BlueStore与BCACHE应用研究

基于CEPH—BlueStore与BCACHE应用研究作者:沈磊李凯林云来源:《中国科技纵横》2018年第16期摘要:为了实现基于ceph的BlueStore存储引擎在SSD和HDD混合模式场景下有更好的性能,本文提出了基于bcache提升ceph性能的解决方案。
该方案是将bcache技术应用到BlueStore引擎解决方案中。
通过实验验证,使用bcache可以让BlueStore在混合模式下发挥更好的性能。
关键词:CEPH;BlueStore;BCACHE中图分类号:TP333 文献标识码:A 文章编号:1671-2064(2018)16-0038-021 引言在分布式存储CEPH高速发展过程中诞生了filestore和bluestore存储引擎,filestore一开始只是对于机械盘进行设计的,没有专门针对ssd做优化考虑,因此诞生的bluestore初衷就是为了减少写放大,并针对ssd做优化,而且直接管理裸盘,从理论上进一步减少文件系统如ext4/xfs等部分的开销。
然而,使用bluestore存储引擎抛弃了原有的journal机制。
因此,本文提出使用bcache技术来提升bluestore存储引擎下SSD和HDD混合场景的最大性能。
2 BCACHE技术分析bcache是linux内核块层cache。
它使用类似SSD来作为HDD硬盘的cache,从而起到加速作用。
HDD硬盘便宜并且空间更大,SSD速度快但更贵。
bcache设计目标是等同于SSD。
最大程度上去最小化写放大,并避免随机写。
bcache将随机写转换为顺序写,首先写到SSD,然后回写缓存使用SSD缓存大量的写,最后将写有序写到磁盘或者阵列上。
bcache的优势在于可以将SSD资源池化,一块SSD可对应多块HDD,形成一个缓存池。
bcache还支持从缓存池中划出瘦分配的纯flash卷(thin-flash lun)单独使用。
一个cache pool 包含一个journal,缓存所有未完成操作的连续日志。
Ceph分布式存储学习指南

云计算与虚拟化技术丛书Ceph分布式存储学习指南Learning Ceph(芬)卡伦·辛格(Karan Singh) 著Ceph中国社区 译ISBN:978-7-111-56279-5本书纸版由机械工业出版社于2017年出版,电子版由华章分社(北京华章图文信息有限公司,北京奥维博世图书发行有限公司)全球范围内制作与发行。
版权所有,侵权必究客服热线:+ 86-10-68995265客服信箱:service@官方网址:新浪微博 @华章数媒微信公众号 华章电子书(微信号:hzebook)我们喜欢称呼Ceph为“未来的存储”,这是一个能够引起很多不同层的人共鸣的称呼。
对于系统架构师而言,Ceph的系统架构满足了所有人都希望构建的一类系统的需求。
它是模块化和可扩展的,并且有容错设计的。
对于用户来说,Ceph为传统和新兴的工作负载提供了一系列存储接口,可以在商用硬件上运行,并且支持仅以适度的资本投资来部署生产集群。
对于免费软件爱好者来说,Ceph持续推动着这些技术,这些技术的代码库是完全开源的,且允许所有人免费审查、修改并完善这些代码,在存储行业中这些代码仍然成本昂贵且具有专有的使用权限。
Ceph项目始于我在加州大学圣克鲁斯的一个研究计划,这个计划由几个能源部实验室(洛斯·阿拉莫斯、劳伦斯·利弗莫尔和桑迪亚)资助。
这个计划的目标是进一步加强拍字节(PB)级别的扩展、基于对象的存储系统。
在2005年加入该组织的时候,我最初的重点是为文件系统构建可扩展的元数据管理,即如何在多个服务器之间管理文件和目录层次结构,这样,系统就可以响应超级计算机中的100万个处理器,在同一时间将文件写入文件系统的同一目录下。
在接下来的3年里,我们主要研究了这个关键概念,然后构建了一个完整的体系结构并一直致力于这种系统的实现。
2006年当我们将最初描述Ceph的学术论文发表,并将相关代码开源且发布在网上后,我想我的主要工作就已经完成了。
分布式存储基础、Ceph、cinder及华为软件定义的存储方案

块存储与分布式存储块存储,简单来说就是提供了块设备存储的接口。
通过向内核注册块设备信息,在Linux 中通过lsblk可以得到当前主机上块设备信息列表。
本文包括了单机块存储介绍、分布式存储技术Ceph介绍,云中的块存储Cinder,以及华为软件定义的存储解决方案。
单机块存储一个硬盘是一个块设备,内核检测到硬盘然后在/dev/下会看到/dev/sda/。
因为需要利用一个硬盘来得到不同的分区来做不同的事,通过fdisk工具得到/dev/sda1, /dev/sda2等,这种方式通过直接写入分区表来规定和切分硬盘,是最死板的分区方式。
分布式块存储在面对极具弹性的存储需求和性能要求下,单机或者独立的SAN越来越不能满足企业的需要。
如同数据库系统一样,块存储在scale up的瓶颈下也面临着scale out的需要。
分布式块存储系统具有以下特性:分布式块存储可以为任何物理机或者虚拟机提供持久化的块存储设备;分布式块存储系统管理块设备的创建、删除和attach/detach;分布式块存储支持强大的快照功能,快照可以用来恢复或者创建新的块设备;分布式存储系统能够提供不同IO性能要求的块设备。
现下主流的分布式块存储有Ceph、AMS ESB、阿里云磁盘与sheepdog等。
1Ceph1.1Ceph概述Ceph目前是OpenStack支持的开源块存储实现系统(即Cinder项目backend driver之一) 。
Ceph是一种统一的、分布式的存储系统。
“统一的”意味着Ceph可以一套存储系统同时提供对象存储、块存储和文件系统存储三种功能,以便在满足不同应用需求的前提下简化部署和运维。
“分布式”在Ceph系统中则意味着真正的无中心结构和没有理论上限的系统规模可扩展性。
Ceph具有很好的性能、可靠性和可扩展性。
其核心设计思想,概括为八个字—“无需查表,算算就好”。
1.2Ceph系统的层次结构自下向上,可以将Ceph系统分为四个层次:基础存储系统RADOS(Reliable, Autonomic, Distributed Object Store,即可靠的、自动化的、分布式的对象存储);基础库LIBRADOS;高层应用接口:包括了三个部分:RADOS GW(RADOS Gateway)、RBD(Reliable Block Device)和Ceph FS(Ceph File System)。
如何利用Ceph构建高可靠性分布式存储系统

如何利用Ceph构建高可靠性分布式存储系统Ceph是一个免费开源的分布式存储系统,可以轻松地构建高可靠性的分布式存储系统。
Ceph是基于对象存储的,并提供了可伸缩性、高可用性和高性能的特性。
Ceph的体系结构包括Ceph存储集群、Ceph客户端和Ceph Gateway。
Ceph存储集群由一组存储节点组成,这些存储节点可以是笔记本电脑、台式机或服务器。
Ceph客户端是与应用程序交互的组件,提供了文件系统、块存储和对象存储接口。
Ceph Gateway是一个可选组件,提供了S3和Swift接口。
Ceph的存储数据结构是RADOS(可靠自定存储对象),是一个对象存储系统。
RADOS的数据对象是具有唯一标识和可用性功能的二进制对象。
RADOS存储的二进制数据与Ceph存储集群的存储节点分布有关,可以利用Ceph内置的一个分布式文件系统(CephFS)或基于块设备(RBD)来使用存储。
Ceph利用三个关键技术来实现高可靠性分布式存储系统:分布式副本、PG(placement groups)和CRUSH(Controlled Replication Under Scalable Hashing)算法。
分布式副本是Ceph副本管理的核心部分。
每个PG都有多个副本,Ceph在多个存储节点上分别存储这些副本,确保在节点故障的情况下数据的可用性。
PG是Ceph在存储集群上分配桶的方式,它将桶分组为小的计算单位,以便根据负载平衡和其他因素有效地管理设备。
CRUSH算法是一种分布式算法,它能够在存储集群中组织节点和数据副本的散列。
CRUSH算法通过构建一颗基于哈希值的树(称为CRUSH树),将所有的存储节点和副本散列到CRUSH树上的节点上。
这样,每个数据对象都可以存储在CRUSH树上的某个节点上,而这个节点也对应一个存储节点。
当存储节点发生故障时,CRUSH算法可以自动重新映射数据对象的存储位置,以确保数据的可用性。
分布式存储Ceph技术

分布式存储Ceph技术分布式存储介绍⼤规模分布式存储系统的定义如下:“分布式系统是⼤量普通的PC通过⽹络互连,对外提供⼀个整体的存储服务”。
分布式存储系统有以下的特性:可扩展性:分布式存储系统可以扩展到⼏百台的集群规模,⽽且随着集群规模的增长,系统的整体性能呈线性增长;低成本:分布式存储系统的⾃动容错、⾃动负载均衡机制使其可以构建在普通的PC机器上,另外,线性扩展的能⼒也使得增加、减少机器⾮常的⽅便,可以实现⾃动运维;⾼性能:⽆论是针对整个集群还是单台服务器,都要求分布式存储系统具备⾼性能;易⽤:分布式存储系统需要对外提供易⽤的接⼝,另外,也要求具备完善的运维、监控⼯具,并可以⽅便的和系统进⾏集成。
分布式存储系统的主要挑战在于数据、状态信息的持久化,要求在⾃动迁移、⾃动容错、并发读写的过程中保证数据的⼀致性。
分布式存储涉及的技术主要来⾃两个领域:分布式系统以及数据库,如下所⽰:数据分布:如何将数据分布到多台机器上并保证数据分布均匀?数据分布到多台服务器之后如何实现跨服务器读写操作?⼀致性:如何将数据的多个副本复制到多台服务器,即使在异常的清空下,也能够保证数据在不同副本之间的⼀致性容错:如何检测到服务器故障?如何⾃动将出现故障的机器上的数据和服务迁移到别的机器上?负载均衡:新增服务器和集群正常运⾏的过程中如何实现⾃动负载均衡?数据迁移的过程中如何保证不影响已有的服务?事务和并发控制:如何设计对外接⼝使得系统更容易使⽤?如何设计监控系统并将系统的内部系统状态以⽅便的形式暴露给运维⼈员?压缩、解压缩算法:如何根据数据的特点设计合理的压缩和解压缩算法?如何平衡压缩算法节省的空间存储和对CPU资源的消耗?存储分类本地存储系统级⽂件系统 ext4 xfs ntfs⽹络存储⽹络级⽂件系统共享的都是⽂件系统nfs ⽹络⽂件系统hdfs 分布式⽹络⽂件系统glusterfs 分布式⽹络⽂件系统共享的是裸设备块存储 cinder ceph(块存储对象存储⽹络⽂件系统-分布式)SAN(存储区域⽹)分布式集群client|namenode 元数据服务器|------------------------------------| | |datanode datanode datanode分布式存储种类及其对⽐Hadoop HDFS(⼤数据分布式⽂件系统)Hadoop分布式⽂件系统(HDFS)是⼀个分布式⽂件系统,适⽤于商⽤硬件上⾼数据吞吐量对⼤数据集的访问的需求。
ceph ssd cache 最佳实践

ceph ssd cache 最佳实践Ceph是一个开源的分布式存储系统,提供了高性能、高可靠性和可扩展性的存储解决方案。
为了进一步提高系统的性能,我们可以使用SSD缓存来加速访问速度。
本文将介绍一些Ceph SSD缓存的最佳实践,以帮助您优化系统性能。
1. 硬件选择选择适合的SSD驱动器是加速Ceph存储性能的关键。
我们建议选择具有高性能和高耐久性的SSD,例如基于NVMe或者SATA接口的企业级SSD。
另外,选择容量适当的SSD,以满足您的存储需求,并留出一定的空间用于缓存。
2. 部署策略为了最大化SSD缓存的效果,我们建议将SSD驱动器安装在Ceph存储群集的OSD主机上。
在每个主机上安装一个或多个SSD驱动器,并将其配置为OSD 的日志和缓存。
这样可以将存储负载均衡到多个SSD上,提高系统的并发能力。
3. OSD配置对于每个OSD,我们需要配置日志和缓存设备。
可以使用以下命令将SSD驱动器配置为OSD的日志设备:ceph-volume lvm prepare bluestore data [data-dev] block.db [ssd-dev]其中,[data-dev]是HDD设备,[ssd-dev]是SSD设备。
这个命令将创建一个SSD分区,用于OSD的日志。
接下来,我们需要将SSD配置为OSD的缓存设备。
可以使用以下命令将SSD 驱动器配置为OSD的缓存设备:ceph osd tier add [pool-name] [pool-name]-cacheceph osd tier cache-mode [pool-name]-cache writebackceph osd tier set-overlay [pool-name]-cache [pool-name]其中,[pool-name]是要配置缓存的池名称。
4. 调整缓存策略Ceph提供了几种缓存模式,可以根据实际需求选择合适的模式。
NFS CephFS构建基于Ceph的NAS服务

NFS+CephFS构建基于Ceph的NAS服务本文介绍了两种基于CephFS构建NAS的解决方案,并从架构、IO栈与性能方面比较和分析了各自特点,为读者提供参考。
1 Ceph介绍Ceph是统一分布式存储系统,具有优异的性能、可靠性、可扩展性。
Ceph的底层是RADOS(可靠、自动、分布式对象存储),可以通过LIBRADOS直接访问到RADOS的对象存储系统。
Ceph还提供三种标准的访问接口:RBD(块设备接口)、RADOS Gateway(对象存储接口)、Ceph File System(POSIX文件接口)。
对于CephFS主要由三个组件构成:MON、OSD和MDS。
Ceph系统架构图2NFS协议及NAS介绍NFS是Network File System的简写,即网络文件系统,通过使用NFS,用户和程序可以像访问本地文件一样访问远端系统上的文件,而NFS客户端和NFS服务器之间正是通过NFS协议进行通信的。
目前NFS协议版本有NFSv3、NFSv4和NFSv4.1,NFSv3是无状态的,NFSv4是有状态,NFSv3和NFSv4是基于Filelayout驱动的,而NFSv4.1是基于Blocklayout驱动。
本文主要使用NFSv4协议。
NAS(Network Attached Storage)网络存储基于标准网络协议NFSv3/NFSv4实现数据传输,为网络中的Windows / Linux / Mac OS 等各种不同操作系统的计算机提供文件共享和数据备份。
NAS示意图目前市场上的NAS存储是专门的设备,成本较高,且容量不易动态扩展,数据高可用需要底层RAID来保障。
下面将介绍基于CephFS的NAS解决方案,在成本、容量扩展性与高可用方面,较传统NAS有优势。
3CephFS的部署首先介绍部署CephFS的过程,为了展示功能及原理,本文使用linux-fedora24虚拟机建立单点的ceph(V10.2.2)环境,使用一个OSD存储、一个MON和一个MDS。
ceph分布式存储介绍
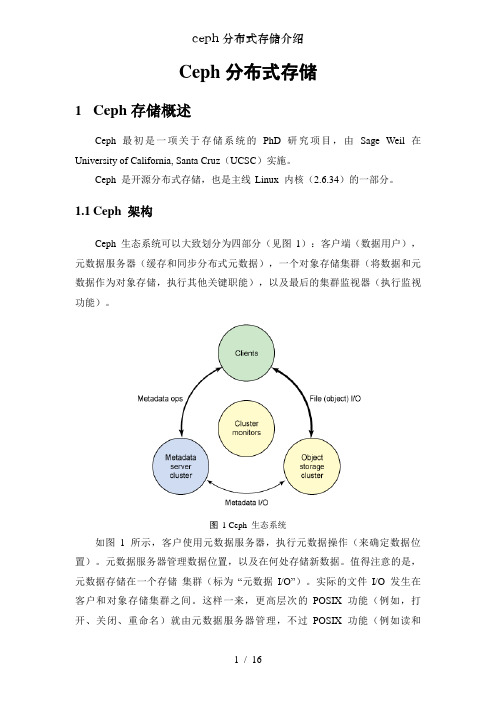
Ceph分布式存储1Ceph存储概述Ceph 最初是一项关于存储系统的PhD 研究项目,由Sage Weil 在University of California, Santa Cruz(UCSC)实施。
Ceph 是开源分布式存储,也是主线Linux 内核(2.6.34)的一部分。
1.1Ceph 架构Ceph 生态系统可以大致划分为四部分(见图1):客户端(数据用户),元数据服务器(缓存和同步分布式元数据),一个对象存储集群(将数据和元数据作为对象存储,执行其他关键职能),以及最后的集群监视器(执行监视功能)。
图1 Ceph 生态系统如图1 所示,客户使用元数据服务器,执行元数据操作(来确定数据位置)。
元数据服务器管理数据位置,以及在何处存储新数据。
值得注意的是,元数据存储在一个存储集群(标为“元数据I/O”)。
实际的文件I/O 发生在客户和对象存储集群之间。
这样一来,更高层次的POSIX 功能(例如,打开、关闭、重命名)就由元数据服务器管理,不过POSIX 功能(例如读和写)则直接由对象存储集群管理。
另一个架构视图由图2 提供。
一系列服务器通过一个客户界面访问Ceph 生态系统,这就明白了元数据服务器和对象级存储器之间的关系。
分布式存储系统可以在一些层中查看,包括一个存储设备的格式(Extent and B-tree-based Object [EBOFS] 或者一个备选),还有一个设计用于管理数据复制,故障检测,恢复,以及随后的数据迁移的覆盖管理层,叫做Reliable Autonomic Distributed Object Storage(RADOS)。
最后,监视器用于识别组件故障,包括随后的通知。
图2 ceph架构视图1.2Ceph 组件了解了Ceph 的概念架构之后,您可以挖掘到另一个层次,了解在Ceph 中实现的主要组件。
Ceph 和传统的文件系统之间的重要差异之一就是,它将智能都用在了生态环境而不是文件系统本身。
ceph集群中的数据分布和负载均衡的实现策略和算法

ceph集裙是一种广泛应用于分布式存储系统中的技术,它的数据分布和负载均衡机制对于整个系统的性能和稳定性至关重要。
在本文中,我们将探讨ceph集裙中数据分布和负载均衡的实现策略和算法。
1. 数据分布策略数据分布是指将数据均匀地分布在整个集裙中的各个存储节点上。
合理的数据分布可以充分利用集裙的各个存储节点,提高整个系统的存储能力和性能。
1.1 数据分布的原则数据分布的原则是保证数据的均匀性和高效性。
具体的原则包括:- 均匀性:保证集裙中每个存储节点上存储的数据量尽量均匀,避免出现存储节点负载不均衡的情况。
- 高效性:尽量减少数据的迁移和复制,减少数据访问的延迟,提高系统的性能。
1.2 数据分布的实现算法数据分布的实现算法包括哈希算法和CRUSH算法。
- 哈希算法:通过对数据的关键属性进行哈希运算,然后根据哈希值的大小将数据分配到不同的存储节点上。
- CRUSH算法:CRUSH是一个具有自适应性的数据分布算法,可以根据存储节点的负载情况和网络拓扑结构来动态地调整数据的分布。
2. 负载均衡策略负载均衡是指将集裙中的数据请求和计算任务均匀地分配给各个存储节点,以避免某些节点过载而导致系统性能下降。
2.1 负载均衡的原则负载均衡的原则是保证集裙中各个存储节点的负载均衡,并提高整个系统的性能。
具体的原则包括:- 负载均衡:保证集裙中存储节点的负载均衡,避免出现某些节点负载过重的情况。
- 性能提升:通过负载均衡策略,提高系统的数据访问性能和计算效率。
2.2 负载均衡的实现算法负载均衡的实现算法包括基于容量的负载均衡和基于请求的负载均衡。
- 基于容量的负载均衡:根据存储节点的容量大小来动态地调整数据的分布,使得各个节点的负载尽量均衡。
- 基于请求的负载均衡:根据数据请求的类型和数量来动态地调整数据的分布,以提高系统的性能和响应速度。
3. 实际应用和优化在实际应用中,数据分布和负载均衡的实现需要考虑集裙的规模、存储节点的性能和网络带宽等因素。
分布式存储Ceph技术架构原理

分布式存储 Ceph 技术架构原理【摘要】本文带你层层深入Ceph的架构原理、读写原理,从而理解Ceph的特性及其应用场景。
1. 什么是Ceph?首先,我们从 Ceph的官方网站上,可以看到:“Ceph is a unified, distributed storage system designed for excellent performance, reliability and scalability.” 从它的定义上我们可以明确它是一种存储系统,而且可以明确它所具备的两点特性:(1)统一性( unified ):意味着可以同时提供对象存储、块存储和文件系统存储三种接口功能。
(2)分布式( distributed ):意味着其内部节点架构是以分布式集群算法为依托的。
接下来,我们从其架构原理以及读写原理上来分析其如何支撑定义当中所提到的各个特性。
2. Ceph的架构原理2.1 Ceph存储功能架构从功能角度来讲,Ceph本身的架构比较清晰明了,主要分应用接口层、存储基础接口层以及存储对象层,接口层主要对客户端的访问负责,分为本地语言绑定接口(C/C++, Java, Python)、RESTful (S3/Swift)、块存储设备接口、文件系统接口。
从这个点上,其完整诠释了“统一性( unified )”的特性。
具体如图2.1所示:图2.1 Ceph存储系统功能图(1)基础存储系统(RADOS)RADOS是理解Ceph的基础与核心。
物理上,RADOS由大量的存储设备节点组层,每个节点拥有自己的硬件资源(CPU、内存、硬盘、网络),并运行着操作系统和文件系统。
逻辑上,RADOS 是一个完整的分布式对象存储系统,数据的组织和存储以及Ceph本身的高可靠、高可扩展、高性能等使命都是依托于这个对象。
(2)基础库(LIBRADOS)LIBRADOS是基于RADOS对象在功能层和开发层进行的抽象和封装。
ceph分布式存储技术参数

ceph分布式存储技术参数
Ceph 是一个开源的分布式存储系统,具有许多参数和特性。
以
下是一些关于 Ceph 分布式存储技术的参数:
1. 可扩展性,Ceph 可以轻松地扩展到数千台服务器,以适应
不断增长的存储需求。
2. 可靠性,Ceph 使用复制和纠删码等技术来确保数据的高可
靠性和容错性。
3. 性能,Ceph 具有良好的性能,能够处理大规模的并发访问,并在不同的硬件环境下提供高性能的存储服务。
4. 对象存储,Ceph 提供对象存储服务,允许用户以对象的形
式存储和访问数据。
5. 块存储,Ceph 也支持块存储,可以作为虚拟化平台的后端
存储使用。
6. 文件系统,Ceph 还提供了分布式文件系统 CephFS,可以为
应用程序提供共享文件系统的访问。
7. 可管理性,Ceph 提供了丰富的管理工具和 API,可以方便地管理和监控存储集群。
以上是关于 Ceph 分布式存储技术的一些参数和特性。
希望这些信息能够帮助您更好地了解 Ceph。
基于开源Ceph的自研分布式存储架构及关键技术分析

I nternet Technology互联网+技术一、业务需求对存储技术的新要求(一)非结构化数据高速增长及对象存储的兴起随着大数据、云计算和物联网技术的迅速发展,手机短视频、基于摄像头的视频监控业务也随之迅猛发展,带来流量爆炸式增长,企业也面临着加密越来越多的大规模、非结构化的数据存储、敏感信息和隐私数据以及AI识别等处理需求。
由于传统的集中式存储系统存在数据规模有限、存储和处理能力瓶颈、单点故障等问题,已经难以满足现阶段的业务需求。
为了更好地满足大规模数据存储和处理的需求,从成本考虑,分布式存储系统的软硬件投资成本相比公有云具有明显优势;从国产化考虑,分布式存储系统自主可控,适配龙芯CPU、麒麟V10和统信UOS操作系统,能够根据业务的个性化需求定制需求支撑。
分布式存储系统将数据分散存储在多个节点上,通过网络进行通信和协作,实现高可用性、高扩展性和高性能的存储和处理。
目前,对自研分布式存储系统的要求进一步提高,应当具备数据迅速增长、多样化存储类型支持、自主可控及成本效益考量等方面的能力,并能够根据具体需求进行设计和优化,以满足企业或组织特定的数据存储和处理需求。
(二)存储虚拟化和容器化的发展存储虚拟化技术和容器化技术的发展使得分布式存储系统能够更高效地在虚拟化环境或容器化环境中部署和管理。
容器化有两个重点,一是控制平面,能够调度服务器资源来运行企业不同类型的应用;二是数据平台,无状态应用的数据要想落到统一存储上,开源Ceph提供的块存储是很好的解决方案,为企业提供了低成本、高可用性和可扩展性,并已经在业界取得了广泛应用。
(三)异地多活灾备和数据复制新要求随着企业全球化业务的增长,异地多活灾备和数据复制成为迫切需求。
分布式存储系统能够跨多个地理位置复制数据,以增加数据的可用性和容灾能力。
对于异地多活,集群在不同的地理位置部署多个存储集群,通过复制数据和具有自动故障转移功能的Monitor来实现数据的跨地理位置访问与同步,即使一个地点的存储集群发生故障,其他地点的集群仍然可以提供服务。
基于Ceph存储产品介绍

基于Ceph存储产品介绍产品特点高性能:a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据。
高可用性:a. 副本数可以灵活控制。
b. 支持故障域分隔,数据强一致性。
c. 多种故障场景自动进行修复自愈。
d. 没有单点故障,自动管理。
高可扩展性:a. 去中心化。
b. 扩展灵活。
c. 随着节点增加而线性增长。
特性丰富:a. 支持三种存储接口:块存储、文件存储、对象存储。
b. 支持自定义接口,支持多种语言驱动。
产品优势专业的应用接口及增强的可靠性●支持基于IP 的iSCSI 接口全系列命令字,并支持专业存储设备最为广泛使用的FC 光纤通道接口;●对关键IO 路径和管理控制模块进行了冗余设计,支持多路径MPIO 或者VIP,实现Active-Active 双活访问,并保证系统高可用,快速切换;●支持即时ROW 快照、克隆、复制、自动精简配置、卷在线扩容与缩容、延展集群、云备份、多种服务质量(QoS)控制等企业级高级功能特性,适应企业存储管理的各种复杂场景需求和流程。
●通过拓扑规划功能对存储集群支持多种安全级别的数据安全保护,如支持服务器级别、机架级别、数据中心级别的故障域。
使存储系统可靠性及持续在线特性得到有效保证。
基于XSKY 最佳实践的性能优化●基于主流的开源分布式存储系统Ceph,在关键环节进行了深度代码优化,包括网络和磁盘处理效率的优化、数据分层与缓存机制的优化等。
使得存储系统能够胜任高并发、高输入输出效率的需求。
●与主流NVMe 闪存技术相结合,并优化IO 路径,单节点可达数万IOPS,提供高性能多级Cache 存储加速引擎,包括RAM、SSD 两级Cache,其中RAMRead Cache 采用具有专利技术的增强型预读算法,提升系统读性能;●SSD R/W Cache 提供智能IO 算法,大大提升OLTP 业务下的系统读写性能;●基于各种企业级虚拟化场景下的交互最佳实践:VMware VAAI 就绪,通过VMware Ready 和Citrix Ready 认证;●基于容器场景的XSKY 最佳实践,提供官方认证的CSI-iSCSI 驱动。
ceph ec实现原理

ceph ec实现原理引言概述:Ceph是一种分布式存储系统,其EC(Erasure Coding)实现原理是其性能和可靠性的重要组成部分。
本文将详细介绍Ceph EC实现原理的六个主要要点,并进行总结。
正文内容:1. EC的基本概念1.1 容错编码容错编码是一种通过将数据分割成多个编码块,并添加冗余信息以实现数据恢复的技术。
Ceph EC使用的是Erasure Coding,将数据分割成多个数据块和校验块,并通过冗余信息实现数据的恢复。
1.2 数据分块Ceph EC将原始数据分割成多个数据块,并通过编码算法生成校验块。
数据分块的大小可以根据需求进行调整,以平衡存储空间和计算开销。
1.3 冗余信息Ceph EC通过添加冗余信息,将原始数据块和校验块进行组合。
冗余信息可以用于恢复数据,即使部分数据块丢失也可以通过冗余信息进行重建。
2. EC的编码算法2.1 Reed-Solomon编码Ceph EC使用Reed-Solomon编码作为其主要的编码算法。
Reed-Solomon编码通过将数据分割成多个块,并生成冗余信息块,实现数据的恢复。
这种编码算法具有高效的纠错能力和低计算开销。
2.2 矩阵运算Reed-Solomon编码通过矩阵运算实现数据的编码和解码。
编码过程中,将数据块和校验块组合成矩阵,并进行矩阵运算生成编码块;解码过程中,通过矩阵运算将丢失的数据块恢复出来。
2.3 编码参数Ceph EC的编码参数包括数据块数量、校验块数量和编码块大小等。
这些参数可以根据系统的需求进行调整,以平衡存储空间和计算开销。
3. EC的数据恢复过程3.1 数据块丢失检测Ceph EC通过检测数据块的丢失情况来触发数据恢复过程。
当检测到数据块丢失时,系统会根据冗余信息进行恢复。
3.2 校验块重建在数据恢复过程中,Ceph EC会通过校验块重建丢失的数据块。
校验块的重建是通过矩阵运算实现的,将丢失的数据块恢复出来。
3.3 数据块重组数据恢复过程中,Ceph EC会将已经恢复的数据块和原始数据块进行重组,以恢复原始数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
【 A b s t r a c t 】D i s t r i b u t e d s t o r a g e s y s t e ms a r e w i d e l y u s e d i n d a t a c e n t e r s , b e c a u s e o f h i g h p e r f o r ma n c e a n d s c a l a b i l i t y , y e t
s a vi n g a nd pr opos es a pow e r gr oup pa r t i t i on a l go r i t hm t O i nc r ea s e t he e ne r gy— s av i ng pr opo r t i on, bui l ds a m ul t i — l e ve l power
第4 1卷 第 8期
VOl | 41
计
算
机
工
程
2 01 5年 8月
Aug u s t 2 01 5
NO. 8
Co mp u t e r En g i n e e r i n g
・ቤተ መጻሕፍቲ ባይዱ
先进计 算 与数据 处理 ・
文章编号 : 1 0 0 0 ・ 3 4 2 8 【 2 0 1 5 ) 0 8 - 0 0 1 3 - 0 5
文献标识码 : A
中图分类号: T P 3 9 1
基于 C e p h的 分 布 式存 储 节 能 技 术研 究
沈 良好 , 吴庆波 , 杨 沙 洲
( 国 防科 学 技术 大 学 计算 机 学 院 , 长沙 4 1 0 0 7 3 )
摘 要 :分 布 式存 储 作 为 目前 流行 的数 据 中心 存 储 系统 , 在具有高性 能 、 高扩展性 的同时 , 面 临 着 系统 能 耗 增 加 的 问题 。为 此 , 基于 C e p h分 布 式 存储 , 分 析其 数 据 布 局 在节 能 方 面 的 不 足 , 提 出划 分 功 耗 组 的节 能 优 化 算 法 , 以 提 升 系统 节 能 比例 。建 立 Ce p h的 多 级 功 耗模 型 并 给 出 管 理 策 略 , 设计 并实现 C e p h系 统 的 多 级 功 耗 管 理 框 架 , 以进 行 Ce p h系 统 功 耗 的 动 态 管理 。实 验 结 果 证 明 , 该框架 能够有 效降低 C e p h分 布 式 存 储 的 能 耗 , 并 保 证 系 统 的 服 务 质
Re s e a r c h o n Di s t r i b ut e d S t o r a g e En e r g y Sa v i ng Te c h no l o g i e s Ba s e d o n Ce p h
S HE N Li a n g h a o. WU Qi n g b o. YANG S h a z h o u
1 3— 1 7.
英文引用格式 : S h e n L i a n g h a o, Wu Qi n g b o, Ya n g S h a o z h o u . Re s e a r c h o n Di s t r i b u t e d S t o r a g e E n e r g y S a v i n g T e c h — n o l o g i e s Ba s e d o n C e p h [ J ] . C o mp u t e r E n g i n e e r i n g , 2 0 1 5 , 4 l ( 8 ): 1 3 — 1 7 .
mo s t o f t h e m a r e n o t e n e r g y— e fi c i e n t .Th i s p a p e r , b a s e d o n Ce p h, a n a l y s e s t h e d a t a l a y o u t ’S d i s a d v a n t a g e i n e n e r g y
( S c h o o l o f C o mp u t e r , Na t i o n a l Un i v e r s i t y o f De f e n c e Te c h n o l o g y, Ch a n g s h a 4 1 0 0 7 3, Ch i n a )
mo d e o f Ce p h a n d p r o p o s e s a mu l t i — l e v e l p o we r ma n a g e me n t s t r a t e g y, b e s i d e s ,i t d e s i g n s a n d i mp l e me n t s a p o we r ma n a g e me n t f r a me wo r k b a s e d o n t h e t wo f o r me r p o i n t s , t o ma n a g e Ce p h’ S p o we r d y n a mi c l y. Ex p e r i me n t a l r e s u l t s s h o w
量 和数 据 可用 性 。
关键 词 :分 布 式 存储 ; 节 能计 算 ; Ce p h存储 ; 功 耗 管理 ; 数 据 布 局 中文引用格式 : 沈 良好 , 吴庆波 , 杨 沙洲 . 基于 C e p h的分布 式 存储 节 能技 术 研究 [ J ] . 计算 机 工程 , 2 0 1 5 , 4 1 ( 8) :